
A regularized stochastic configuration network based on weighted mean of vectors for regression
- Published
- Accepted
- Received
- Academic Editor
- Carlos Fernandez-Lozano
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Data Mining and Machine Learning, Neural Networks
- Keywords
- Stochastic configuration networks, Swarm intelligence optimization, Weighted mean of vectors, Residual error feedback
- Copyright
- © 2023 Wang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. A regularized stochastic configuration network based on weighted mean of vectors for regression. PeerJ Computer Science 9:e1382 https://doi.org/10.7717/peerj-cs.1382
Abstract
The stochastic configuration network (SCN) randomly configures the input weights and biases of hidden layers under a set of inequality constraints to guarantee its universal approximation property. The SCN has demonstrated great potential for fast and efficient data modeling. However, the prediction accuracy and convergence rate of SCN are frequently impacted by the parameter settings of the model. The weighted mean of vectors (INFO) is an innovative swarm intelligence optimization algorithm, with an optimization procedure consisting of three phases: updating rule, vector combining, and a local search. This article aimed at establishing a new regularized SCN based on the weighted mean of vectors (RSCN-INFO) to optimize its parameter selection and network structure. The regularization term that combines the ridge method with the residual error feedback was introduced into the objective function in order to dynamically adjust the training parameters. Meanwhile, INFO was employed to automatically explore an appropriate four-dimensional parameter vector for RSCN. The selected parameters may lead to a compact network architecture with a faster reduction of the network residual error. Simulation results over some benchmark datasets demonstrated that the proposed RSCN-INFO showed superior performance with respect to parameter setting, fast convergence, and network compactness compared with other contrast algorithms.
Introduction
Neural networks have shown superiority over data modeling because of their powerful representation learning ability to learn patterns with multiple levels of abstraction that make sense to the data (Bengio, Courville & Vincent, 2013). However, the gradient-based iterative training process of neural networks is time-consuming and computationally intensive (Wang & Li, 2017b). Feed-forward neural networks (FNNs) with random parameters have drawn widespread attention due to their faster training speed and lower computational cost (Scardapane & Wang, 2017). Igelnik & Pao (1995) found that any continuous function can be approximated by a random vector functional link (RVFL) network with probability one under appropriate parameters. The hidden parameters of RVFL were assigned randomly in a preset scope and the output weights were calculated based on the least squares method (Cao et al., 2021). However, determining the preset scope of randomized learning models is challenging, and the widely used scope of random parameters (e.g., [−1,1]) is not always feasible (Li & Wang, 2017).
To resolve the infeasibility of using RVFL networks for data modeling with a fixed scope (i.e., [−1,1]), Wang & Li (2017b) proposed a novel randomized learning framework, termed SCN. The hidden parameters (input weights and biases) of SCN are randomly assigned under a supervisory mechanism and adaptively select their ranges, which indicate prominent merits on human intervention of network structure, range adaptation of hidden layer parameters, and sound generalization (Dai et al., 2019a).
Many efforts have been made to enhance the performance of SCN since it was developed in 2017. SCN with kernel density estimation (RSC-KDE) and maximum correntropy criterion (RSC-MCC) were presented to weaken the negative influences of noise and outliers, respectively, on modeling performance (Wang & Li, 2017a; Li, Huang & Wang, 2019). Zhu et al. (2019) delved deeper into the inequality constraint used in SCN and presented two new inequalities to increase the probability of satisfying the constraint condition. As deep neural networks (DNNs) with multiple levels of feature extraction can learn more abstract representations of the data, a deep version of SCN (DeepSCN) with multi-hidden layer network structure was proposed by Wang & Li (2018). For image data analysis with matrix inputs, a two-dimensional version of SCN (2DSCN) was proposed by Li & Wang (2019). For SCN ensembles, Wang & Cui (2017) adopted the negative correlation learning (NCL) ensemble learning technique to reduce the covariance among the base SCN for large-scale data analysis. Huang, Li & Wang (2021) designed a novel indicator that contained some key factors to explore appropriate base learner models from a set of SCN to generate an effective ensemble model. Zhang et al. (2021) developed a parallel SCN (PSCN) by introducing the beetle antennae search (BAS) optimization algorithm and fuzzy evidence theory for large-scale data regression. For finding the optimal parameter settings, Zhang & Ding (2021) utilized the chaotic sparrow search algorithm to optimize the contractive factor in the inequality and the scale factor λ of random parameters to enhance the effectiveness of SCN. In addition, various extensions of SCN were applied to data modeling in real-world applications, such as molten iron quality (MIQ) modeling in blast furnace ironmaking (BFI) (Xie & Zhou, 2020), particle size estimation of hematite grinding process (Dai et al., 2019b), traffic state prediction across geo-distributed data centers of the China Southern Power Grid (CSG) (Huang, Huang & Wang, 2019), and prediction of asphaltene and total nitrogen in crude oil (Lu & Ding, 2019; Lu et al., 2020).
SCN starts with a small-sized network structure and gradually adds new hidden nodes into the network until the residual error of SCN is smaller than the tolerance threshold. With the increasing number of hidden nodes, the constructive SCN model is prone to overfitting and thus poor performance (Wang et al., 2021). Meanwhile, the performance of SCN is frequently impacted by the parameter settings of the model, such as λ (the scale factor of weights and bias) and (the contractive factor in the inequality). Seeking better model parameters is vital for SCN. It is well known that the regularization technique, which adds the “squared magnitude” of the coefficient to the loss function, can prevent the problem of overfitting effectively. In the famous Residual Network (ResNet), He et al. (2016) let the stacked nonlinear layers fit a residual mapping of . Inspired by the idea of residual learning in ResNet, we used the current network residual error feedback to dynamically adjust the parameters of SCN.
Therefore, the objective of this study was to automatically obtain better parameters for SCN and get a more compact architecture. First, the regularization item combined with network residual error was introduced to improve the generalization performance of SCN. In addition, a regularized SCN based on INFO was developed to optimize the parameter selection of SCN. INFO is a relatively new swarm intelligence optimization method published in 2022. Updating rule, vector combining, and a local search were the three core phases of INFO (Ahmadianfar et al., 2022). It is a promising tool for the parameter optimization of the regularized stochastic configuration network (RSCN). To summarize, the key contributions of this article are as follows:
Introduce the regularization term that combines the ridge method with the network residual error into the objective function to dynamically adjust the training parameters of SCN.
Optimize the scope setting of the input weights and biases λ, contractive factor in the inequality, regularization coefficient , and positive scale factor of feedback residual error of RSCN by INFO, which in turn achieves a better RSCN model with respect to fast convergence and structure compactness.
Illustrate the merits of RSCN-INFO on one function approximation and three benchmark regression datasets. The evaluation results justify the effectiveness of the proposed RSCN-INFO.
Preliminaries
This section briefly reviews the classical SCN framework and the newer INFO algorithm.
SCN
SCN is a novel randomized incremental learner framework with a supervisory mechanism. The universal approximation property of SCN is guaranteed by its innovative inequality constraint. The network structure of SCN is depicted in Fig. 1.
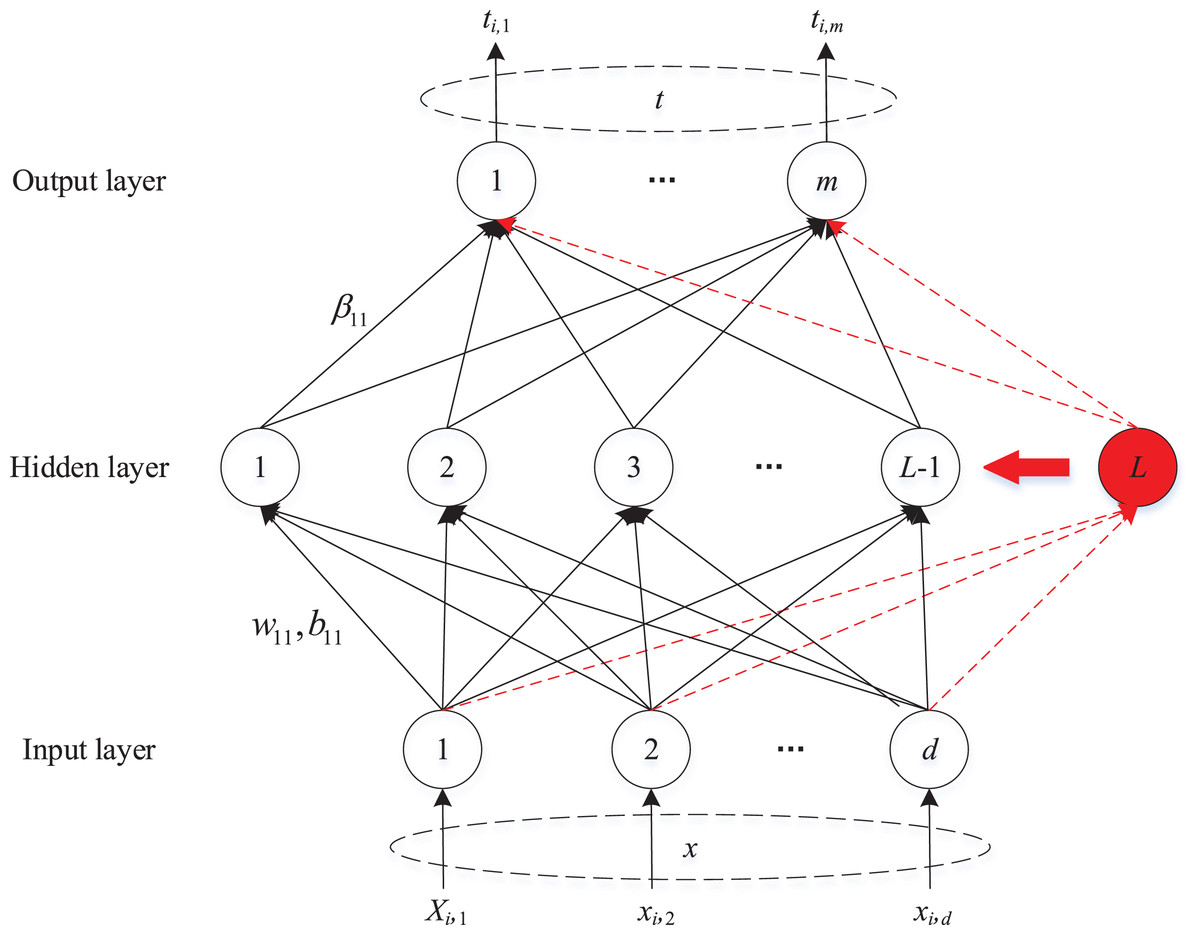
Figure 1: The network structure of SCN.
{kind=link}
Let be a set of real-valued functions, span( ) denotes a function space spanned by , and represents the space of all Lebesgue measurable functions on a set . represents the output of a single layer feed-forward network with hidden nodes, where and denote the parameters of the th hidden node, and is the activation function of the th hidden node. The inner product of and is:
(1)
Given a training dataset , and , suppose that an established SCN model contains hidden nodes. The network residual error is:
(2) where is the given target function, and represents the output of the network with hidden nodes. The residual error of SCN gradually decreased as the number of hidden neurons increased. If the value of was larger than the tolerance threshold , SCN added a new hidden node into the network until was smaller than . The parameters of the added hidden node were assigned randomly under a set of inequalities.
(3) where is the inner product of and , represents a nonnegative real number sequence with , and . indicates a non-linear activation function. (span( ) is dense in space), ( ). determines the strictness of the inequality constraint, and . The output weights were evaluated by:
(4) where represents the Moore-Penrose inverse of and is the output matrix of the hidden layer. Readers may refer to Wang & Li (2017b) for more details on the SCN framework and associated algorithms.
INFO
INFO is a new population-based optimization algorithm that employs updating rule, vector combining, and local search to move the population’s position in D dimensional search domains. Given a population with vectors, .
Updating rule
INFO randomly selected three differential vectors ( ) to calculate the weighted mean of vectors. To increase the diversity of the population, the best, better, and worst solutions were employed to define the MeanRule (mean-based rule).
(5)
(6) where
(7)
(8)
(9)
(10)
(11) where
(12)
(13)
(14)
(15)
The weighted mean of vectors was used to generate two new vectors.
(16) where was defined as the objective function, three different integers ( ) were randomly chosen from , and were two new vectors, and was the scaling rate of a vector.
Vector combining
The two new vectors and were combined with vector to generate a new vector .
(17) where was the composite vector of the th generation.
Local search
The local search operator used the global position ( ) and the MeanRule to help INFO convergence to global optima.
(18) in which
(19)
(20) where and were two random values within [0,1] and (0,1) respectively. The random value and increased the best position’s influence on the vector. INFO updated the best vector ( ) and returned as the final solution. For more details about the INFO algorithm, refer to Ahmadianfar et al. (2022).
Rscn-info
RSCN
Given a training dataset , the objective function of the SCN with -norm penalty term could be expressed as:
(21) where stands for the hidden output for the input , is a non-negative real number, and the regularization coefficient balances the residual error and norm of the output weights ( ).
SCN added new hidden neuron incrementally leading to . After dynamically adjusting the output weights during the training process, the current residual error was added to the regularization term. After adding the Lth new hidden node into an established SCN model with hidden nodes, a new objective function was introduced. (22) where is the positive scale factor of feedback residual error. The derivative of function Eq. (22) with respect to is:
(23)
Letting Eq. (23) be equal to 0, The output weights of the L-th hidden node was obtained by:
(24)
Theorem 1. Assume that is dense in space. Given , , , and a nonnegative real number sequence , with and . , for some . For and , the random basis function is generated by Eq. (25), and the output weights of the Lth hidden neuron are obtained by Eq. (26). Then, the SCN has .
(25)
(26)
Proof. First, the monotonically decreasing property of will be proved.
(27)
The monotonically decreasing property of has been proven. From Eqs. (25)–(27):
(28)
According to Eq. (25):
(29)
Therefore:
(30)
Theorem 1 has given , which means . Based on Eq. (30), . Therefore, .
Remark 1. In theorem 1, the output weights are evaluated by Eq. (26) and kept fixed. This may cause a slow convergence rate. To cope with this problem, the output weights of all hidden neurons are updated by the least squares method after the new hidden node has been added. Let , where , , , ‘ ’ denotes the Hadamard product (element-wise multiplication) and .
The output weights are calculated by:
(31)
The output weights are recalculated in accordance with Eq. (31) as the newly added hidden neuron is generated to satisfy Eq. (25). The inequality constraint guarantees the universal approximation capability of RSCN. The process of proof is similar to theorem 1, so the detailed proof procedure is omitted.
Remark 2. In Eq. (22), the residual error is added into the regularization term. The reason why is used instead of is that the value of the residual error is equal to the output of training samples before adding hidden neurons into the network ( ). So the residual error is relatively larger at the beginning of the construction process. It gradually decreases as the constructive process proceeds. Meanwhile, due to the randomness of SCN, is randomly generated under a set of inequality constraints. The scale factor makes it possible for the feedback residual error to adjust dynamically in pace with the change of the hidden output ( ).
RSCN-INFO algorithm
INFO is a very competitive new optimization algorithm. In this section, INFO is applied to optimize the parameter λ, the contractive factor , the regularization coefficient , and the positive scale factor for RSCN. The widely-used root mean square error (RMSE) is employed as the fitness function.
(32)
For convenience’s sake, is defined to describe the algorithm. The pseudo-code of RSCN-INFO is summarized in Algorithm 1.
| Training dataset: , . |
| Parameters: the population size , maximum number of generations , dimensional search domain D, upper bounds ub and lower bounds lb of λ, r, η and γ, maximum number of hidden layer neurons , residual error threshold τ, maximum number of random assignment . |
| Output: , , |
| 1: STEP 1: Initialization |
| 2: Initialize |
| 3: Produce an initial population where ; |
| 4: Calculate by Eq. (32); |
| 5: STEP 2: Parameter optimization by INFO |
| 6: for to do |
| 7: for to do |
| 8: Randomly choose three vectors ( ), and calculate w by Eqs. (7)–(9) and (12)–(14); |
| 9: Create two new vectors using Eq. (16); |
| 10: The two new vectors are combined by Eq. (17); |
| 11: Execute local search using Eqs. (18)–(20); |
| 12: Update the Vector ; |
| 13: while AND do |
| 14: STEP 3: Hidden parameter configuration (Step 15–28) |
| 15: for , , and do |
| 16: for do |
| 17: Randomly select and from and λ; |
| 18: Compute and by Eqs. (33) and (34) |
| 19: if and satisfy constraint inequality then |
| 20: Save the random parameters in W, in Ω; |
| 21: end if |
| 22: end for |
| 23: if W is not empty then |
| 24: Choose and corresponding to the maximize in Ω, set and ; |
| 25: Break (go to Step 30); |
| 26: else Return to Step 7; |
| 27: end if |
| 28: end for |
| 29: STEP 4: Output weight determination (Step 30–32) |
| 30: Calculate ; |
| 31: Calculate ; |
| 32: Renew ; |
| 33: end while |
| 34: Determine and ; |
| 35: Calculate the fitness function according to Eq. (32). |
| 36: if then |
| 37: end if |
| 38: end for |
| 39: Update the best vector ; |
| 40: end for |
| 41: Return |
(33) where
(34)
The calculation complexity
The computational complexity of the INFO algorithm depends on the size of the population , the times of iterations , and the dimensional search domain D. The complexity of INFO is . For SCN, assume that a set of datasets with N inputs , and the maximum number of hidden layer neurons of SCN is . The main cost of SCN is caused by computing Moore-Penrose pseudo-inverse . A rough estimate of the computational complexity of can be expressed as (Li & Wang, 2017). Note that the cost of is calculated by the widely-used singular value decomposition. Hence, the total complexity of RSCN-INFO is .
Experiments
The effectiveness of RSCN-INFO was evaluated on a function approximation and three benchmark datasets from the Knowledge Extraction based on Evolutionary Learning (KEEL, http://www.keel.es) dataset repository supported by the Spanish Ministry of Science and Technology. The approximation function is a conventional high nonlinear compound function that is widely used to evaluate randomized neural networks. The KEEL dataset contains classification, regression, unsupervised, and time series datasets. To verify the effectiveness of RSCN-INFO, it was compared with classical IRVFL, SCN (Wang & Li, 2017b), RSCN (Wang et al., 2021), and DASCN-II (Wang et al., 2020). All the experiments were implemented with MATLAB R2019b on a PC with AMD Ryzen 7 3.20 GHz CPU, NVIDIA GeForce MX450 GPU, and 16 GB RAM.
Function approximation
Let the real-valued function be defined as follows (Tyukin & Prokhorov, 2009):
(35)
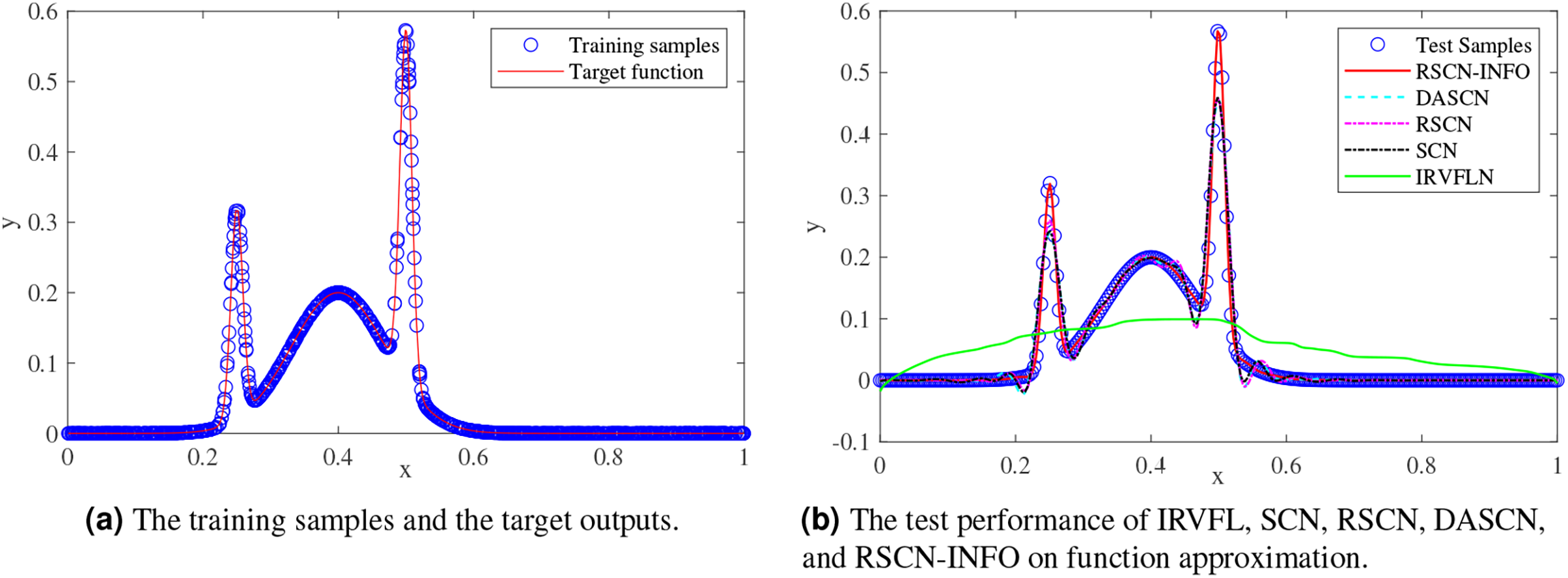
We randomly generated 1,000 training samples and 300 test samples from the uniform distribution, and a regularly spaced grid over (0,1). Figure 2 compares the function approximation performance of RSCN-INFO with IRVFL, SCN, RSCN, and DASCN-II. Since our proposed RSCN-INFO could achieve reliable and accurate performance with the lower number of hidden neurons, the value of was set to 25. In the simulations, the value of RMSE remained virtually unchanged when the widely used setting [−1,1] was set for IRVFL. So the scope of random parameters for IRVFL was set as (−250, 250). For SCN, the value of was set to 100, λ and were selected from the set and . In RSCN-INFO, the population size and the maximum generations were set to 30 and 10, respectively. The lower bounds and upper bounds of λ, , , and were set to , , , and . As seen in Fig. 2B, the IRVFL showed far worse performance than that of SCNs, while the performance of our proposed RSCN-INFO was the best.
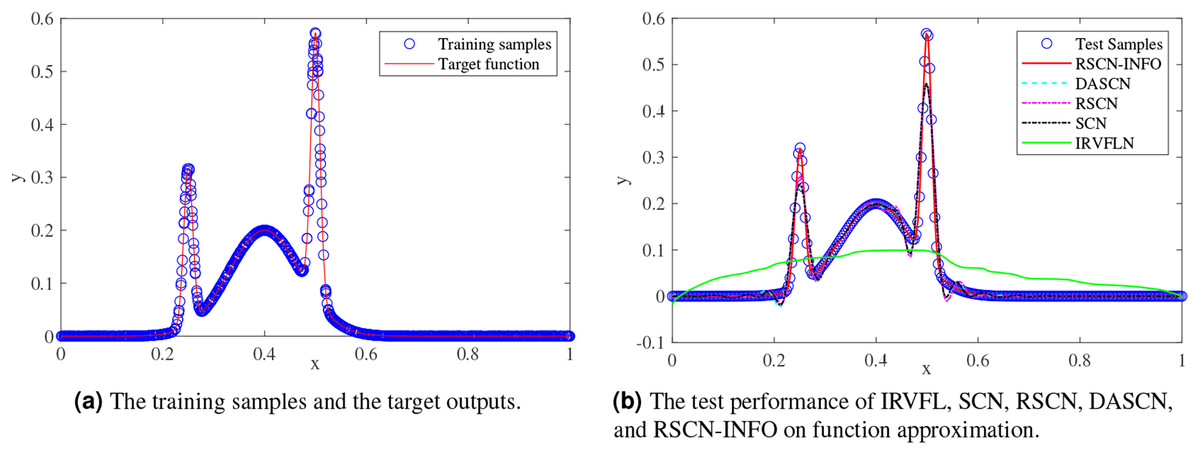
Figure 2: Performance comparisons on function approximation.
{kind=link}
Figures 3 and 4 display the training and test results of the real-value function with 25 and 50 hidden nodes, respectively. The average training RMSE was obtained from 20 independent experiments. For IRVFL, Figs. 3 and 4 clearly show that the training RMSE was unacceptable. Furthermore, the convergence rate of RSCN-INFO is faster than that of SCN, RSCN, and DASCN-II, which verifies the efficiency of RSCN-INFO. In addition, Table 1 reports the average RMSE and standard deviation results of different models. It is evident that RSCN-INFO achieved more favorable results than the other algorithms.
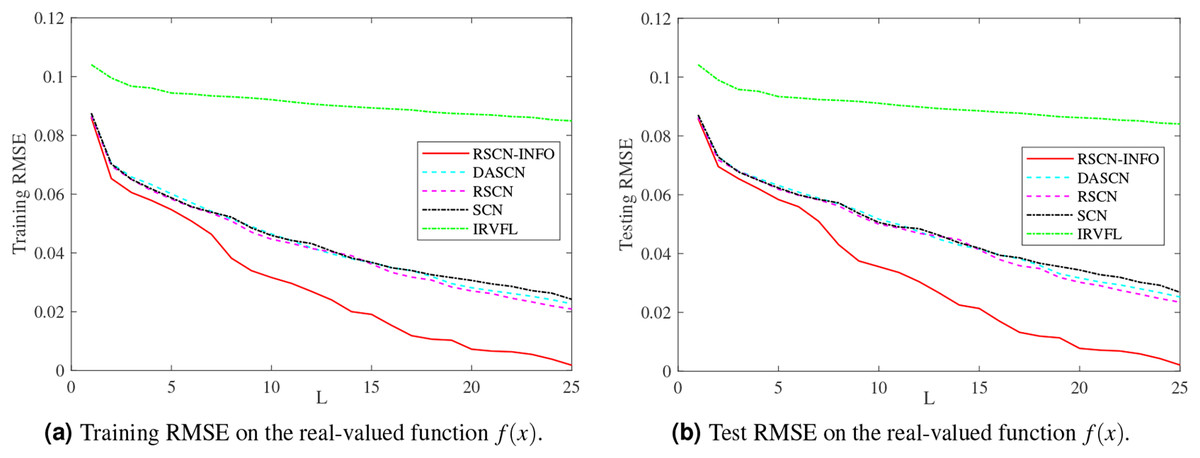
Figure 3: Average RMSE on the real-valued function .
{kind=link}

Figure 4: Average RMSE on the real-valued function .
{kind=link}
| Methods | Training results | Test results | ||
|---|---|---|---|---|
| IRVFL | 0.08493 0.00548 | 0.08389 0.00426 | 0.08405 0.00524 | 0.06756 0.00559 |
| SCN | 0.02421 0.00479 | 0.00535 0.00342 | 0.02681 0.00535 | 0.00570 0.00364 |
| RSCN | 0.02090 0.00448 | 0.00477 0.00222 | 0.02344 0.00499 | 0.00506 0.00252 |
| DASCN-II | 0.02267 0.00345 | 0.00512 0.00268 | 0.02523 0.00368 | 0.00553 0.00285 |
| RSCN-INFO | 0.00179 0.00025 | 0.00015 0.00008 | 0.00209 0.00031 | 0.00016 0.00009 |
Benchmark datasets
Three real-world benchmark datasets for regression from KEEL were employed as experimental datasets. Specifications of these datasets are given in Table 2.
| Dataset | Attributes | Instances | |
|---|---|---|---|
| Features | Output | ||
| Concrete | 8 | 1 | 1,030 |
| Compactiv | 21 | 1 | 8,192 |
| Pole | 26 | 1 | 14,998 |
Figures 5–7 and Tables 3–5 depict the average training and test results on these benchmark datasets. Each test’s statistical results for the 20 run times and the average value of RMSE were selected to evaluate the performance of the different algorithms. The IRVFL could not reach the preset tolerance threshold, so it was omitted here. In this case, the scope of random parameters λ in SCN was selected from the set and the lower and upper bounds of λ in RSCN-INFO were set to . All the other parameters were set the same as the function approximation.

Figure 5: Average training and test results on concrete.
{kind=link}
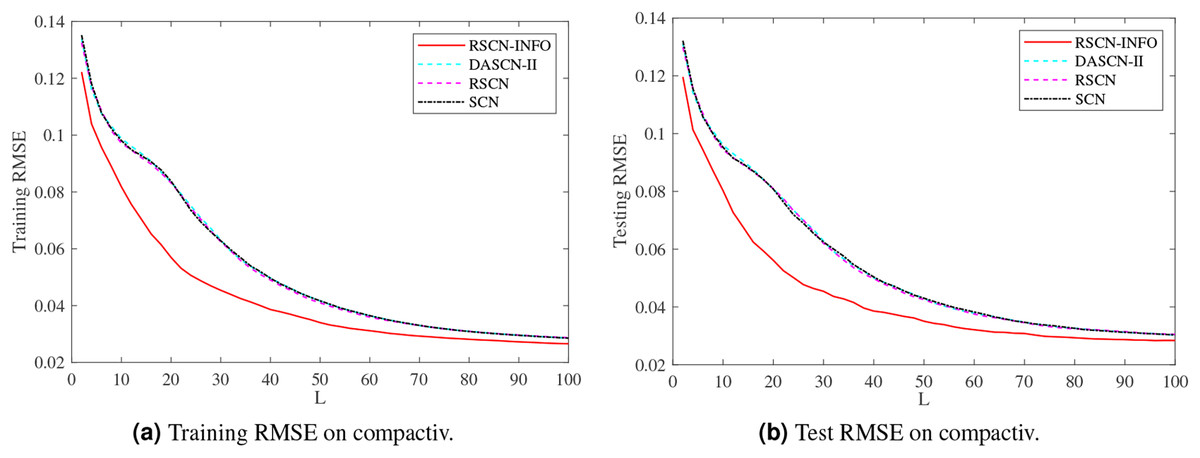
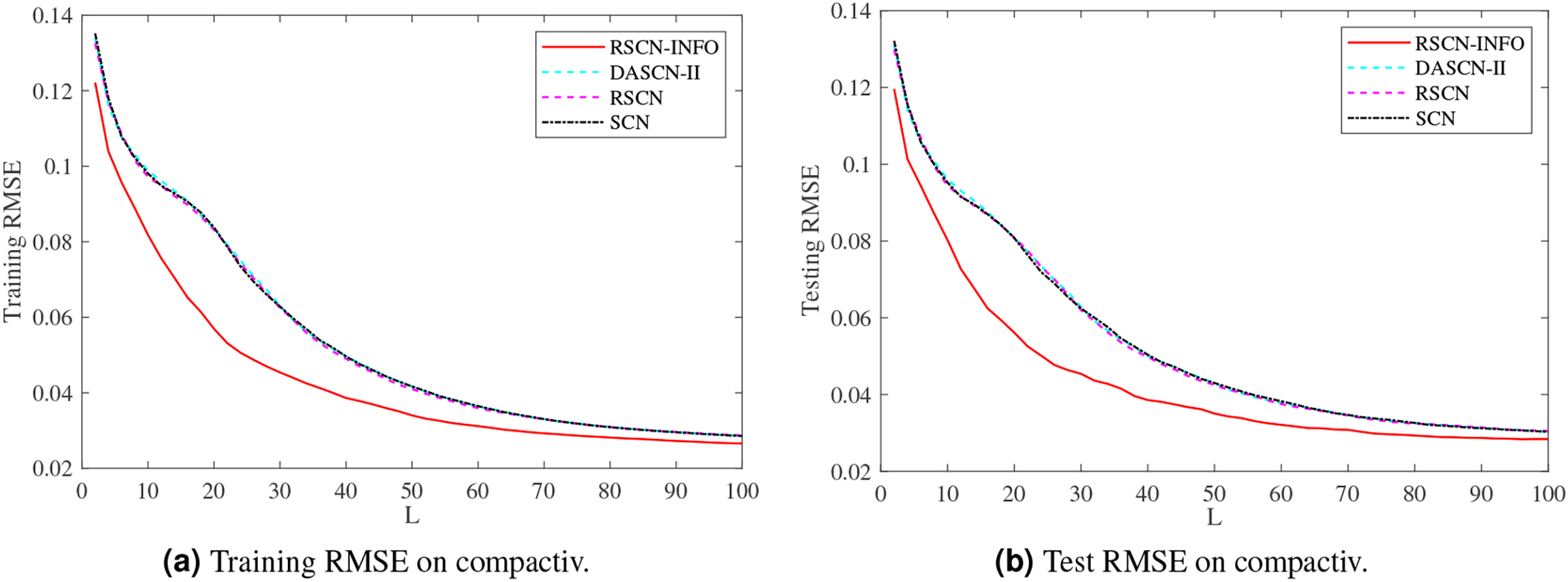
Figure 6: Average training and test results on compactiv.
{kind=link}

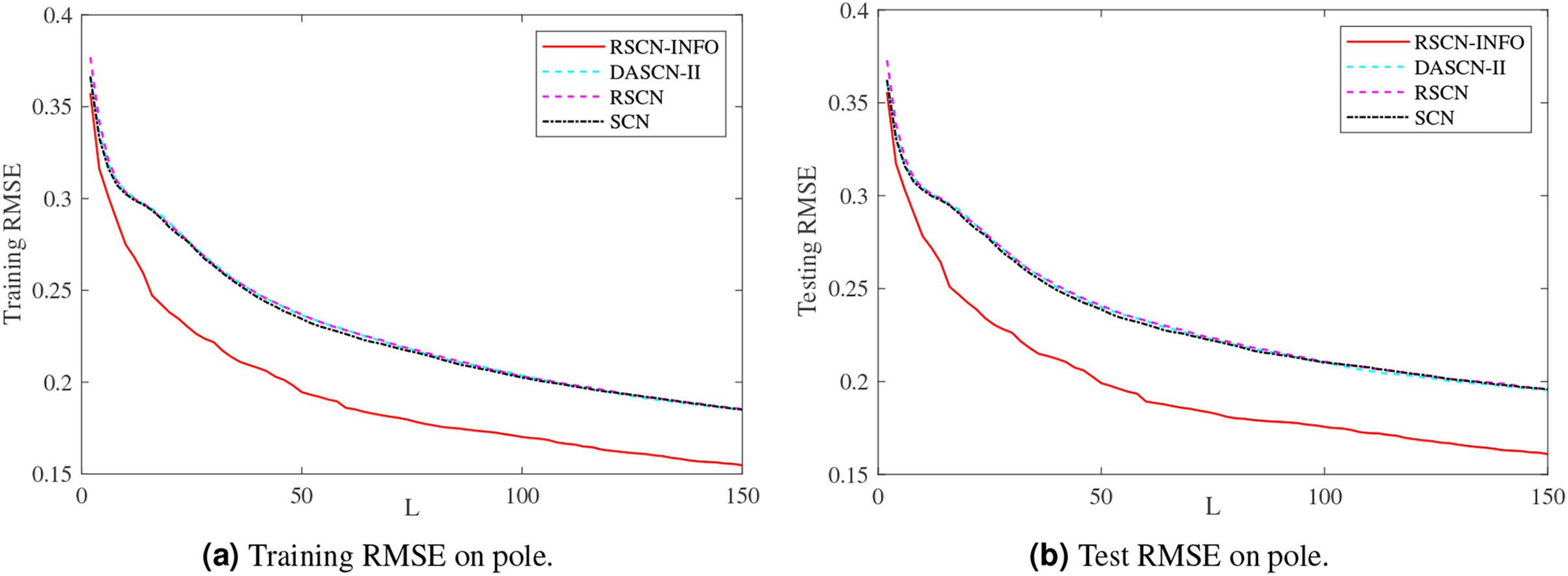
Figure 7: Average training and test results on pole.
{kind=link}
| Methods | Training, Test results | ||||
|---|---|---|---|---|---|
| SCN | 0.09842, 0.10212 | 0.09122, 0.09786 | 0.08626, 0.09655 | 0.08098, 0.09381 | 0.07566, 0.09114 |
| RSCN | 0.09912, 0.10187 | 0.09156, 0.09831 | 0.08613, 0.09724 | 0.08113, 0.09438 | 0.07594, 0.09190 |
| DASCN-II | 0.09840, 0.10109 | 0.09175, 0.09769 | 0.08626, 0.09613 | 0.08066, 0.09405 | 0.07566, 0.09239 |
| RSCN-INFO | 0.09957, 0.10391 | 0.08933, 0.09684 | 0.08097, 0.09427 | 0.07545, 0.09596 | 0.06944, 0.09439 |
| Methods | Training, Test results | ||||
|---|---|---|---|---|---|
| SCN | 0.08380, 0.08076 | 0.04963, 0.05035 | 0.03646, 0.03823 | 0.03090, 0.03264 | 0.02855, 0.03032 |
| RSCN | 0.08317, 0.08091 | 0.04902, 0.04981 | 0.03595, 0.03752 | 0.03093, 0.03243 | 0.02872, 0.03049 |
| DASCN-II | 0.08345, 0.08081 | 0.04972, 0.05003 | 0.03638, 0.03781 | 0.03096, 0.03263 | 0.02858, 0.03028 |
| RSCN-INFO | 0.05695, 0.05613 | 0.03863, 0.03856 | 0.03117, 0.03211 | 0.02815, 0.02932 | 0.02658, 0.02839 |
| Methods | Training, Test results | ||||
|---|---|---|---|---|---|
| SCN | 0.26345, 0.26582 | 0.22619, 0.23069 | 0.20756, 0.21426 | 0.19464, 0.20406 | 0.18507, 0.19572 |
| RSCN | 0.26411, 0.26746 | 0.22831, 0.23278 | 0.20871, 0.21545 | 0.19524, 0.20409 | 0.18542, 0.19602 |
| DASCN-II | 0.26462, 0.26741 | 0.22856, 0.23264 | 0.20895, 0.21497 | 0.1945, 0.20299 | 0.18478, 0.19538 |
| RSCN-INFO | 0.22182, 0.22629 | 0.18604, 0.18925 | 0.17349, 0.17836 | 0.16272, 0.16904 | 0.15479, 0.16099 |
Figure 5 shows similar performance between RSCN-INFO and the competitor algorithms on concrete. The reason for this phenomenon is that the concrete dataset contained smaller features and instances. For the compactiv and pole datasets, Figs. 6 and 7 clearly show that RSCN-INFO can achieve lower RMSE in terms of both training and test results. Intuitively and obviously, the RMSE of RSCN was used as the fitness function of INFO. In essence, INFO explored a global optimum solution that minimizes the fitness function in a four-dimensional search domain ( ) over several successive generations.
To verify the effectiveness of RSCN-INFO, Table 6 lists the computational time among SCN, RSCN, DASCN-II, and RSCN-INFO on benchmark datasets. We found that the training time of RSCN-INFO was significantly shorter than the other methods on the three benchmark datasets. Table 6 indicates that RSCN-INFO which employed optimized parameters and could achieve better efficiency. It should be noted that we did not take the parameter optimization process into account in this experiment. The optimization process may consume additional time. However, the improvement of regression accuracy and network structure may be worth the time that is spent on the parameter optimization.
| Datasets | Algorithms | Error tolerance | Training time (Mean STD) |
|---|---|---|---|
| Concrete | SCN | 0.08 | 0.1977 0.00379 |
| RSCN | 0.2083 0.03008 | ||
| DASCN-II | 0.2275 0.02442 | ||
| RSCN-INFO | 0.1021 0.01095 | ||
| Compactiv | SCN | 0.03 | 2.1405 0.25356 |
| RSCN | 2.1773 0.16212 | ||
| DASCN-II | 2.5231 0.22985 | ||
| RSCN-INFO | 1.2148 0.22618 | ||
| Pole | SCN | 0.20 | 6.5387 0.94180 |
| RSCN | 6.2857 0.68270 | ||
| DASCN-II | 7.9776 1.52610 | ||
| RSCN-INFO | 1.7529 0.28892 |
To further illustrate the network compactness of RSCN-INFO, we investigated how many hidden nodes were required to meet a preset error tolerance. As shown in Fig. 8, RSCN-INFO requires fewer hidden nodes compared with other methods. It can be deduced that given a preset , RSCN-INFO can reach the error tolerance using fewer hidden neurons. This is due to RSCN-INFO using optimized parameters that can achieve a higher residual error reduction. Therefore, the network structure is more compact. It should be pointed out that DASCN-II can also construct a relatively compact SCN. However, the tunable value in DASCN-II is a fixed value. It is selected empirically and difficult to adjust. Moreover, an inappropriate will seriously affect the accuracy of the model.
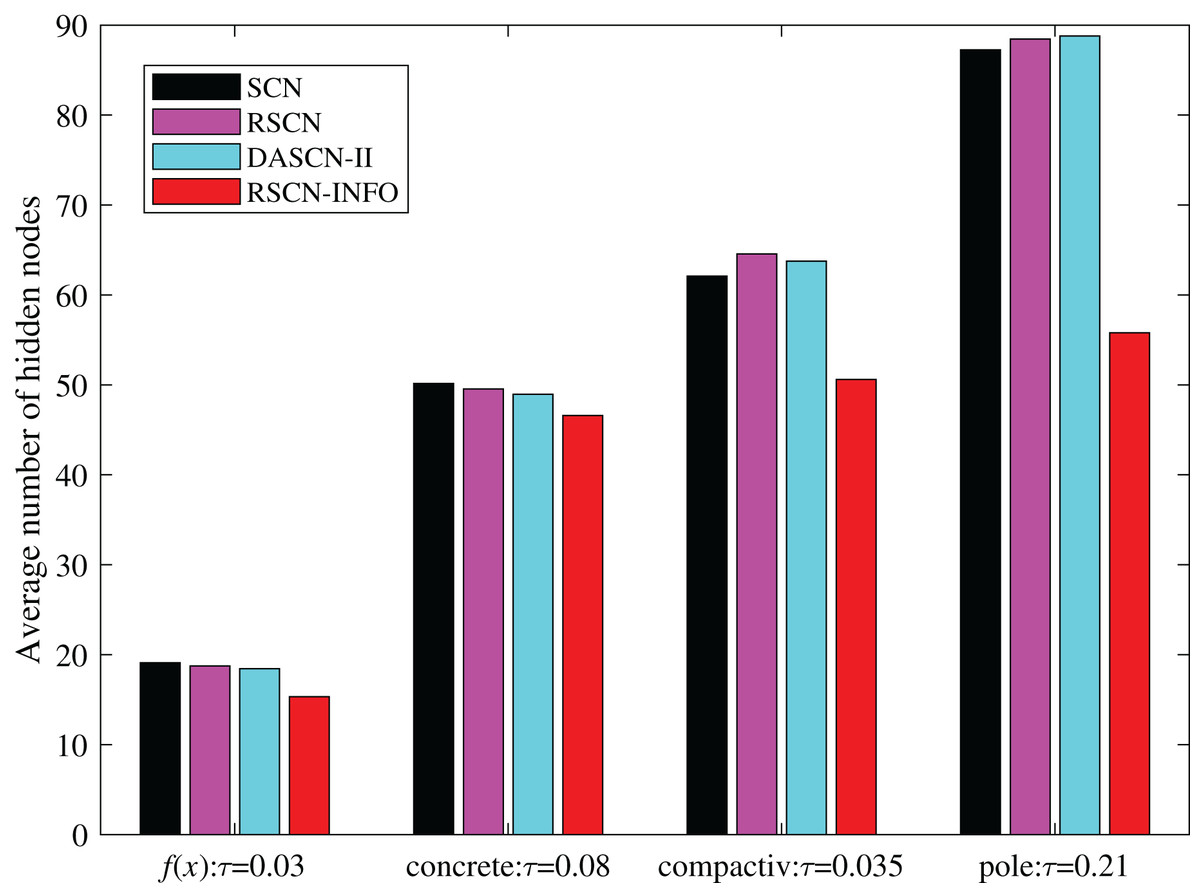
Figure 8: Average number of hidden nodes on and benchmark datasets.
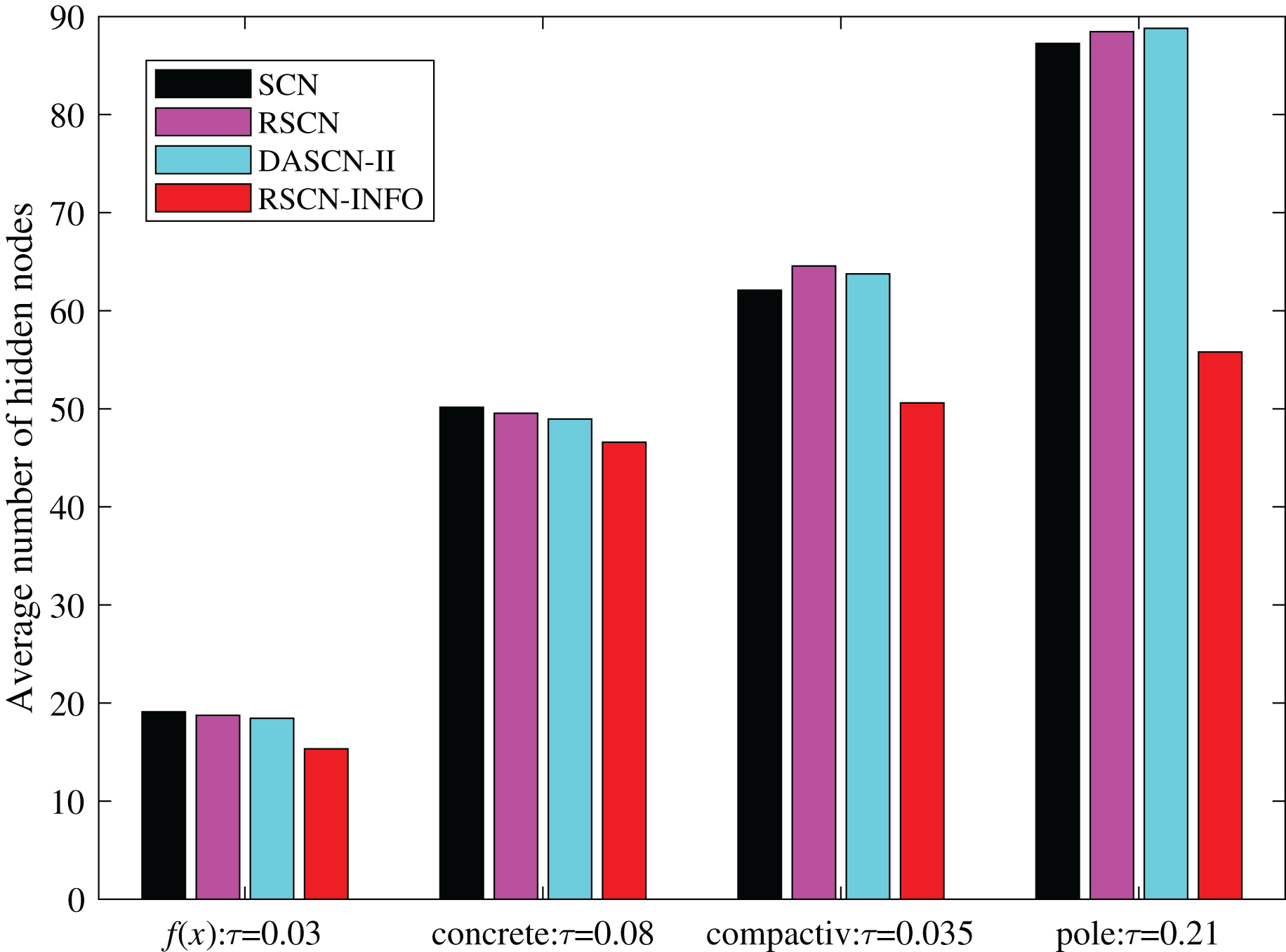{kind=link}
In classical SCN and its various variants, λ tends to set a relatively larger value in complex problems. The parameter is unfixed and set based on an increasing sequence from 0.9 to 1. The other parameters are selected empirically in connection with practical applications. Therefore, the conclusion may be drawn that RSCN-INFO is not only helpful in adaptively selecting parameters of SCN, but also beneficial for constructing a compact network.
Conclusion
This article developed a new regularized SCN based on the INFO optimization algorithm, named RSCN-INFO. On one hand, the added regularization term combines the ridge method with the residual error feedback, contributing to the balance of the structural (output weights) and empirical (network residual error) losses of SCN. On the other hand, RMSE was selected as the fitness function of INFO to assist SCN to locate up-and-coming areas in multi-dimensional search space. A higher residual error decreasing rate is impacted by the parameter selection of RSCN-INFO. The experimental results on a function approximation and three benchmark regression datasets from KEEL indicated that the proposed RSCN-INFO algorithm exhibits considerable advantages in parameter optimization and network structure compactness compared with other algorithms.
In almost all practical modeling tasks, the presence of noise and outliers is inevitable. This optimization strategy will accelerate the degradation of the learning performance of SCN that are subjected to noise or outliers. The robust skills used to weaken the negative influences of noise and outliers will be further discussed.