Attentional modulation of neuronal variability in circuit models of cortex
- Carnegie Mellon University and University of Pittsburgh, United States
- University of Pittsburgh, United States
- Center for the Neural Basis of Cognition, United States
- Allen Institute for Brain Science, United States
Abstract
The circuit mechanisms behind shared neural variability (noise correlation) and its dependence on neural state are poorly understood. Visual attention is well-suited to constrain cortical models of response variability because attention both increases firing rates and their stimulus sensitivity, as well as decreases noise correlations. We provide a novel analysis of population recordings in rhesus primate visual area V4 showing that a single biophysical mechanism may underlie these diverse neural correlates of attention. We explore model cortical networks where top-down mediated increases in excitability, distributed across excitatory and inhibitory targets, capture the key neuronal correlates of attention. Our models predict that top-down signals primarily affect inhibitory neurons, whereas excitatory neurons are more sensitive to stimulus specific bottom-up inputs. Accounting for trial variability in models of state dependent modulation of neuronal activity is a critical step in building a mechanistic theory of neuronal cognition.
https://doi.org/10.7554/eLife.23978.001eLife digest
The world around us is complex and our brains need to navigate this complexity. We must focus on relevant inputs from our senses – such as the bus we need to catch – while ignoring distractions – such as the eye-catching displays in the shop windows we pass on the same street. Selective attention is a tool that enables us to filter complex sensory scenes and focus on whatever is most important at the time. But how does selective attention work?
Our sense of vision results from the activity of cells in a region of the brain called visual cortex. Paying attention to an object affects the activity of visual cortex in two ways. First, it causes the average activity of the brain cells in the visual cortex that respond to that object to increase. Second, it reduces spontaneous moment-to-moment fluctuations in the activity of those brain cells, known as noise. Both of these effects make it easier for the brain to process the object in question.
Kanashiro et al. set out to build a mathematical model of visual cortex that captures these two components of selective attention. The cortex contains two types of brain cells: excitatory neurons, which activate other cells, and inhibitory neurons, which suppress other cells. Experiments suggest that excitatory neurons contribute to the flow of activity within the cortex, whereas inhibitory neurons help cancel out noise. The new mathematical model predicts that paying attention affects inhibitory neurons far more than excitatory ones. According to the model, selective attention works mainly by reducing the noise that would otherwise distort the activity of visual cortex.
The next step is to test this prediction directly. This will require measuring the activity of the inhibitory neurons in an animal performing a selective attention task. Such experiments, which should be achievable using existing technologies, will allow scientists to confirm or disprove the current model, and to dissect the mechanisms that underlie visual attention.
https://doi.org/10.7554/eLife.23978.002Introduction
The behavioral state of the brain exerts a powerful influence on the cortical responses. For example, electrophysiological recordings from both rodents and primates show that the level of wakefulness (Steriade et al., 1993), active sensory exploration (Crochet et al., 2011), and attentional focus (Treue, 2001; Reynolds and Chelazzi, 2004; Gilbert and Sigman, 2007; Moore and Zirnsak, 2017) all modulate synaptic and spiking activity. Despite the diversity of behavioral contexts, in all of these cases an overall elevation and desynchronization of cortical activity accompanies heightened states of processing (Harris and Thiele, 2011). Exploration of the neuronal mechanisms that underly such state changes has primarily centered around how various neuromodulators shift the cellular and synaptic properties of cortical circuits (Hasselmo, 1995; Lee and Dan, 2012; Noudoost and Moore, 2011; Moore and Zirnsak, 2017) However, a coherent theory linking the modulation of cortical circuits to an active desynchronization of population activity is lacking. In this study we provide a circuit-based theory for the known attention-guided modulations of neuronal activity in the visual cortex of primates performing a stimulus change detection task.
The investigation of the neuronal correlates of attention has a rich history. Attention increases the firing rates of neurons engaged in feature- and spatial-based processing tasks (McAdams and Maunsell, 2000; Reynolds et al., 1999). Attentional modulation of the stimulus-response sensitivity (gain) of firing rates is more complicated, often depending on stimulus specifics such as the size and contrast of a visual image (Williford and Maunsell, 2006; Reynolds and Heeger, 2009; Sanayei et al., 2015). In recent years there has been increased focus on how brain states affect trial-to-trial spiking variability (Crochet et al., 2011; Lin et al., 2015; Doiron et al., 2016; Stringer et al., 2016). In particular, attention decreases the shared variability (noise correlations) of the firing rates from pairs of neurons (Cohen and Maunsell, 2009; Mitchell et al., 2009; Cohen and Maunsell, 2011; Herrero et al., 2013; Ruff and Cohen, 2014; Engel et al., 2016). The combination of a reduction in noise correlations and an increase in response gain has potentially important functional consequences through an improved population code (Cohen and Maunsell, 2009; Rabinowitz et al., 2015). In total, there is an emerging picture of the impact of attention on the trial-averaged and trial-variable spiking dynamics of cortical populations.
Phenomenological models of attentional modulation have been popular (Reynolds and Heeger, 2009; Navalpakkam and Itti, 2005; Gilbert and Sigman, 2007; Ecker et al., 2016); however, such analyses cannot provide insight into the circuit mechanics of attentional modulation. Biophysical models of attention circuits are difficult to constrain, due in large part to the diversity of mechanisms which control the firing rate and response gain of neurons (Silver, 2010; Sutherland et al., 2009). Nonetheless, several circuit models for attentional modulation have been proposed (Ardid et al., 2007; Deco and Thiele, 2011; Buia and Tiesinga, 2008), but analysis has been mostly confined to trial-averaged responses. Taking inspiration from these studies, mechanistic models of attentional modulation can be broadly grouped along two hypotheses. First, the circuit mechanisms that control trial-averaged responses may be distinct from those that modulate neuronal variability. This hypothesis has support from experiments in primate V1 showing that N-methyl-D-aspartate receptors have no impact on top-down attentional modulation of firing rates, yet have a strong influence of attentional control of noise correlations (Herrero et al., 2013). A second hypothesis is that the modulations of firing rates and noise correlations are reflections of a single biophysical mechanism. Support for this comes from pairs of V4 neurons that each show strong attentional modulation of firing rates, also show a strong attention mediated reductions in noise correlation (Cohen and Maunsell, 2011). In this study we provide novel analysis of the covariability of V4 population activity engaged in an attention-guided detection task (Cohen and Maunsell, 2009) that is consistent with the second hypothesis. Specifically, the modulation of spike count covariance between unattended and attended states has the same dimensionality as the firing rate modulation.
We use the results from our dimensionality analysis to show that an excitatory-inhibitory recurrent circuit model subject to global fluctuations is sufficient to capture both the increase in firing rate and response gain as well as population-wide decrease of noise correlations. Our model makes two predictions regarding neuronal modulation: (1) that attentional modulation favors inhibitory neurons, and (2) that stimulus drive favors excitatory neurons. Finally, we show that our model predicts increased informational content in the excitatory population, which would result in improved readout by potential downstream targets. In total, our study provides a simple, parsimonious, and biologically motivated model of attentional modulation in cortical networks.
Results
Attention decreases noise correlations primarily by decreasing covariance
Two rhesus monkeys (Macaca mulatta) with microelectrode arrays implanted bilaterally in V4 were trained in an orientation change detection task (Figure 1a; see Materials and methods: Data preparation). A display with oriented Gabor gratings on the left and right flashed on and off. The monkey was cued to attend to either the left or right grating before each block of trials, while keeping fixation on a point between the two gratings. After a random number of presentations, one of the gratings changed orientation. The monkey then had to saccade to that side to obtain a reward. The behavioral task and data collection have been previously reported (Cohen and Maunsell, 2009).
Figure 1
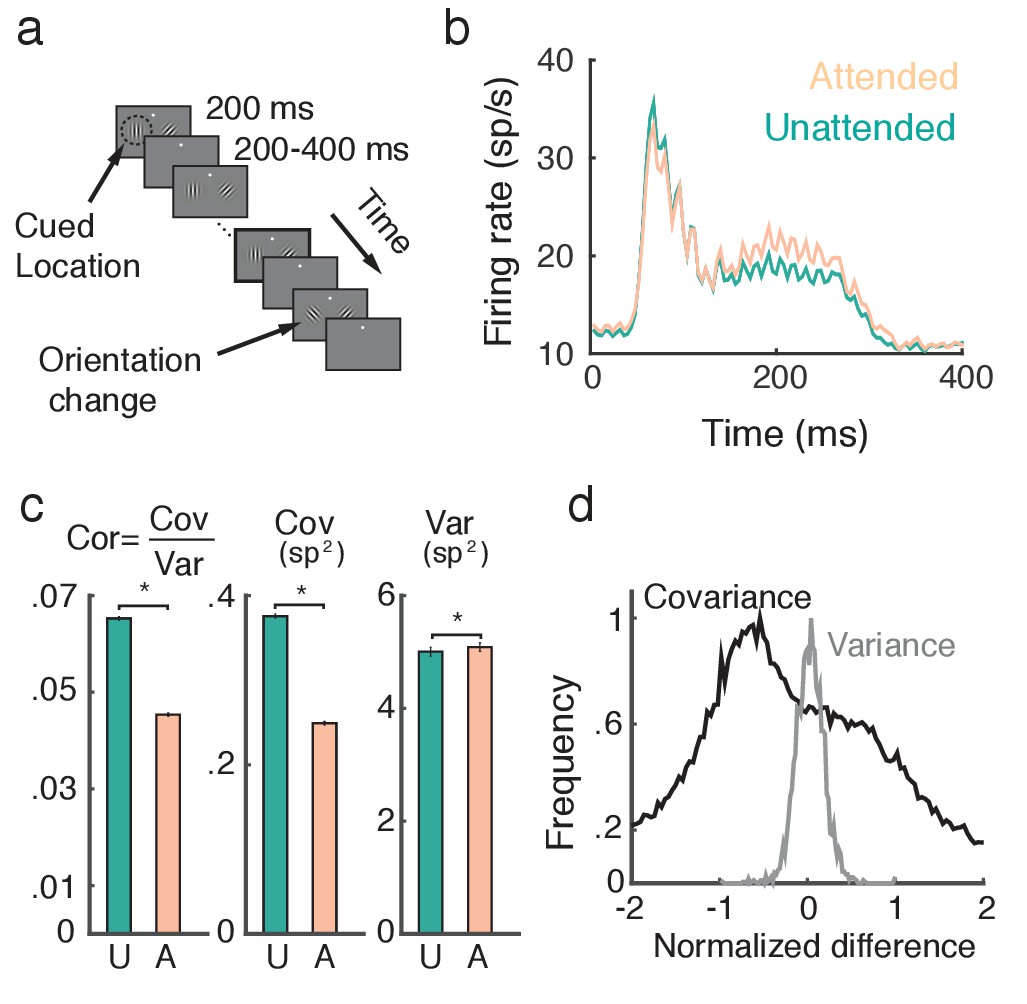
Attention increases firing rates and decreases trial-to-trial covariability of population responses.
(a) Overview of orientation-change detection task; see (Cohen and Maunsell, 2009) for a full description. (b) Firing rates of neurons in the unattended (turquoise) and attended (orange) states, averaged over 3170 units. The slight oscillation in the firing rate was due to the monitor refresh rate. (c) Attention significantly decreased the spike count correlation and covariance and slightly increased variance. Error bars provide the SEM. (d) Histograms of changes in covariance for each unit pair (black) and variance for each unit (gray). In each case we consider the relative change , where is either or . Data was collected from two monkeys over 21 and 16 recording sessions respectively. Signals were analyzed over a ms interval, starting ms after stimulus onset.
A neuron is considered to be in an 'attended state' when the attended stimulus is in the hemifield containing that neuron’s receptive field (contralateral hemifield), and in an 'unattended state' when it is in the other (ipsilateral) hemifield. The trial-averaged firing rates from both attended and unattended neurons displayed a brief transient rise (100 ms after stimulus onset), and eventually settled to an elevated sustained rate before the trial concluded (Figure 1b). During the sustained period the mean firing rate of attended neurons ( sp/s) was greater than that of unattended neurons ( sp/s) ( test, ).
A major finding of Cohen and Maunsell (2009) was that the pairwise trial-to-trial noise correlations of the neuronal responses decreased with attention (Figure 1c, left, mean unattended 0.065, mean attended 0.045, test, ). The noise correlation between neurons and is a normalized measure, , where Cov and Var denote spike count covariance and variance respectively. Both spike count variance and covariance significantly change with attention (, , test, , , test, ), but the decrease in covariance () is much more pronounced than the increase in variance (; Figure 1c, middle and right). We therefore conclude that the attention mediated decrease in noise correlation is primarily due to decreased covariance.
To further validate this observation, we consider the distributions of pairwise changes in covariance (black) and variance (gray) with attention over the entire data set (Figure 1d). Covariance and variance are normalized by their respective maximal unattended or attended values (see Methods: Comparing change in covariance to change in variance). The change in covariance with attention is concentrated below zero with a large spread, whereas the change in variance is centered on zero with a narrower spread. Taken together these results suggest that to understand the mechanism by which noise correlations decrease it is necessary and sufficient to understand how spike count covariance decreases with attention.
Attention is a low-rank modulation of noise covariance
A reasonable simplification of V4 neurons is that they receive a bottom-up stimulus alongside an attention-mediated top-down modulatory input. However, to properly model top-down attention we need to first understand the dimension of attentional modulation on the V4 circuit as a whole. Let denote the attentional modulation of measure from its value in the unattended state, , to its value in the attended state, . For example, the firing rate modulation can be written as , where is an vector of neural firing rates in the attended state, denotes the firing rate vector in the unattended state, is a vector the same size as , and denotes elementwise multiplication. In this case, the entries of are the ratios of the firing rates: (Figure 2a).
Figure 2
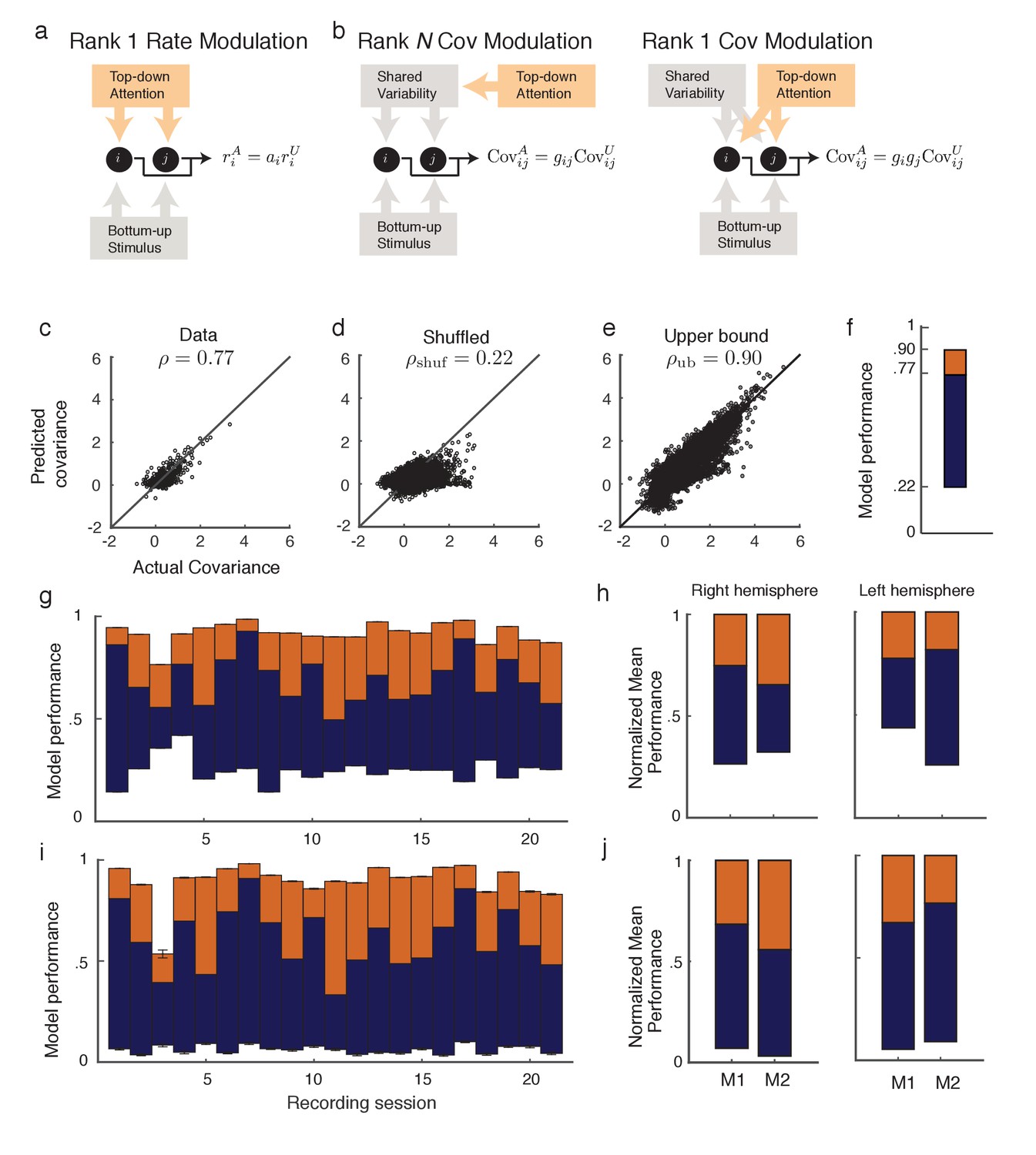
Rank one structure of attentional modulation of spike count covariance.
(a) Attentional modulation of firing rate. Firing rates of neurons and (black circles are modulated by bottom-up stimulus and top-down attention. (b) Two possible models of attentional modulation of covariance. Left: High-rank covariance modulation, in which attention modulates the shared variability of each pair of neurons. Right: Low-rank covariance modulation, in which attention modulates each neuron individually rather than in a pairwise manner. (c–e) The measured covariance values plotted against those predicted by the rank-1 model for data collected in one recording session, for c, the actual data (), d, shuffled data (, 100 shuffles), and (e) artificial upper-bound data (, 10 realizations of the upper bound model). (f) Synthesis of c-e in a bar plot. The orange area represents the loss of model performance compared to the upper bound model, and the blue area represents the increase in model performance compared to model applied to shuffled data. (g) Rank-1 model performance reported for recording sessions from one monkey. Each bar represents one recording session. Recordings from a mean of units in the right-hemisphere were analyzed, with maximum and minimum of and , respectively. Error bars denote standard error of the mean. (h) Mean normalized performance (relative to ) for both hemispheres of two monkeys (M1 and M2). (i), Analysis as in (g), using leave-one-out cross-validation to test the predictive power of the model. (j) Mean normalized performance of the cross-validated data.
A less trivial aspect of attentional modulation is the modulation of covariance matrices:
(1)
Here is the attended spike count covariance matrix, the unattended spike count covariance matrix, and is a matrix the same size as , consisting of entries , which we will call covariance gains. Unlike firing rates, the transformation matrix can be of varying rank. On the one hand could be constructed from the ratios of the individual elements: , with each pair of neurons receiving an individualized attentional modulation of their shared variability (Figure 2b, left). Under this modulation is a rank matrix. A rank will always perfectly (and trivially) capture the matrix mapping in Equation (1). However, it is difficult to conceive of a top-down circuit mechanism that would allow attention to modulate each pair individually. On the other hand, could depend not on the specific pair , but on the individual neurons of the pairing: (Figure 2b, right). In this case, only values are needed to characterize , where is a column vector, meaning has rank of . This is a more parsimonious and biophysically plausible scenario for attentional modulation, since in this case the covariance gain of neurons and is simply emergent from the attentional modulation of the individual neurons. To test whether is low rank we analyzed the V4 population recordings during the visual attention task (Figure 1), specifically measuring under the assumption that is rank 1:
(2)
Equation (2) is a system of equations of the form in unknowns (we only consider to exclude variance modulation from our analysis). For this is an overdetermined system, and we solve for using a nonlinear equation solver. Let be the optimal solution obtained by the solver (measured as a minimization of the -norm of the error; see Methods: objfxn). Then provides an approximation to the attended covariance matrix. In an example data set from a single recording session with units, the correlation coefficient of the actual attended covariance values from versus the approximated attended covariance values from was (Figure 2c). A shuffled matrix provides a reasonable null model, and the example data set produces the lower bound correlation (Figure 2d; see Materials and methods: Shuffled covariance matrices). Finally, a Poisson model that perfectly decomposes as Equation (2), yet sampled with the same number of trials as in the experiment, gives an upper bound for the rank one structure, the example data yields (Figure 2e; see Materials and methods: Upper bound covariance matrices). In total, the combination of , , and (Figure 2f) suggests that the rank one model of attention modulation of covariance is well justified.
We applied this analysis to 21 recording sessions from the right hemisphere of one monkey (Figure 2g). For most of the recording sessions is closer to than . The averaged performance of all sessions for both hemispheres of two monkeys generally agreed with this trend (Figure 2h). We normalized and by for each session to better compare different sessions that were subject to day-to-day variations outside of the experimenter’s control, such as the task performance or the internal state of the monkey. To further validate our model we show the distribution of s computed from the entire data set (Figure 3a). The majority of values are less than one, consistent with (Figure 1c). Further, there was little relation between the attentional modulation of firing rates, measured by , and the attentional modulation of covariance through (Figure 3b). This indicates that the circuit modulation of firing rates and covariance are not trivially related to one another (Doiron et al., 2016).
Figure 3
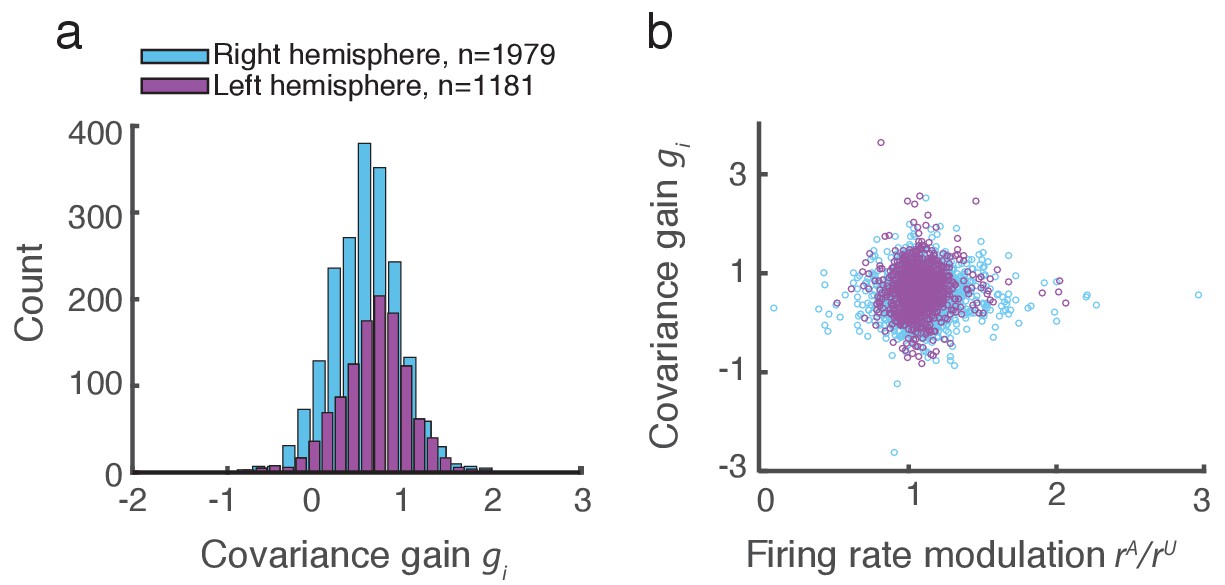
Covariance gain shows the attenuation of population-wide fluctuations with attention.
(a) Distribution of covariance gains computed from the entire data set. (b) The relation between covariance and the attention mediated modulation of firing rates . The correlation coefficients between the data sets were and for the right and left hemispheres, respectively.
We additionally tested the validity of our model in Equation (2) with a leave-one-out cross-validation analysis (see Materials and methods: Leave-one-out cross-validation). We accurately predicted an omitted covariance (Figure 2i and j), consistent with our original analysis (Figure 2g and h). The individual session-by-session performance values for both the standard and leave-one-out setups are provided (Appendix: Model performance for all monkeys and hemispheres).
Finally, we investigated to what extent the actual value of the covariance gain of neuron depends on the population of neurons in which it was computed. We solved the system of equations using covariance matrices computed from recordings from distinct sets of neurons, overlapping only by neuron . This gives two estimates of , that nevertheless agreed largely with one another (Appendix: Low-dimensional modulation is intrinsic to neurons). This supported the hypothesis that covariance gain is an intrinsic property of neuron .
The standard and cross-validation tests verify that the low-rank model of attentional modulation defined in Equation (2) explains between and (standard), or and (cross-validation) of the data. Taking this to be a positive result, we conclude that the covariance gain modulation depends largely on the modulation of individual neurons.
Network requirements for attentional modulation
Having described attentional modulation statistically our next goal is to develop a circuit model to understand the process mechanistically. Consider a network of coupled neurons, and let the spike count from neuron on a given trial be . The network output has the covariance matrix with elements . In this section we identify the minimal circuit elements so that the attentional mapping satisfies the following two conditions (on average):
C1: ; attentional modulation of covariance is rank one (Figure 2).
C2: ; spike count covariance decreases with attention (Figure 1).
What follows is only a sketch of our derivation (a complete treatment is given in Appendix: Network requirements for attentional modulation).
If inputs are weak then can be described by a linear perturbation about a background state (Ginzburg and Sompolinsky, 1994; Doiron et al., 2004; Trousdale et al., 2012):
(3)
Here is the background activity of neuron , is the coupling strength from neuron to , and is the input-to-output gain of neuron . In addition to internal coupling we assume a source of external fluctuations to neuron . Here , , and are random variables that vary across trials. The trial-averaged firing rate of neuron is (where denotes averaging over trials of length ). The background state has variability which we assume to be independent across neurons, meaning the background network covariance is . Finally, the external fluctuations have covariance matrix with element .
Motivated by our analysis of population recordings (Figure 2) we study attentional modulations that target individual neurons. This amounts to considering only and . Additionally, we assume that any model of attentional modulation must result in (Figure 1b). A widespread property of both cortical pyramidal cells and interneurons is that an increase of firing rate causes an increase of input-output gain (Cardin et al., 2007), thus we will also require .
Spiking covariability in recurrent networks can be due to internal interactions (through ) or external fluctuations (through ), or both (Ocker et al., 2017). Networks with unstructured connectivity have internally generated covariability that vanishes as grows. This is true if the connectivity is sparse (van Vreeswijk and Sompolinsky, 1998), or dense having weak synapses where (Trousdale et al., 2012) or strong synapses where combined with a balance between excitation and inhibition (Renart et al., 2010; Rosenbaum et al., 2017). In these cases spiking covariability requires external fluctuations to be applied and subsequently filtered by the network. We follow this second scenario and choose so as to provide external covariability to our network.
Recent analysis of cortical population recordings show that the shared spiking variability across the population can be well approximated by a rank one model of covariability (Kelly et al., 2010; Ecker et al., 2014; Lin et al., 2015; Ecker et al., 2016; Rabinowitz et al., 2015; Whiteway and Butts, 2017) (we remark that Rabinowitz et al., 2015 analyzed the same data set that we have in Figures 1 and 2). Thus motivated we take the external fluctuations to be rank one with , reflecting a single source of global external variability with unit variance (neuron receives ). Combining this assumption with the linear ansatz in Equation (3) yields:
(4)
where matrix has element and . We have also defined the vectors and with . In total, the output covariability will simply inherit the rank of the input covariability . Attentional modulation affects through and and we easily satisfy condition with .
What remains is to find constraints on and the attentional modulation of that satisfy condition . Let us consider the case where so that condition is satisfied when . For the sake of mathematical simplicity let us separate the population into excitatory neurons and inhibitory neurons (). Let all excitatory (inhibitory) neurons project with synaptic strength (), have gain (), and receive the external inputs of strength (). Finally, let the probability for all connections be , and consider only weak connections ( and large) so that we can ignore the influence of polysynaptic paths in the network (Pernice et al., 2011; Trousdale et al., 2012). Then the attentional modulation of an excitatory neuron decomposes into:
(5)
The first term is the direct transfer of the external fluctuations, and the second and third terms are indirect transfer of external fluctuations via the excitatory and inhibitory populations, respectively. Recall that , meaning that for to be satisfied we require the third term to outweigh the combination of the first and second terms. In other words, the inhibitory population must experience a sizable attentional modulation. A similar cancelation of correlations by recurrent inhibition has been recently studied in a variety of cortical models (Renart et al., 2010; Tetzlaff et al., 2012; Ly et al., 2012; Doiron et al., 2016; Rosenbaum et al., 2017).
In the above we considered weak synaptic connections where . Rather, if we scale , as would be the case for classical balanced networks (van Vreeswijk and Sompolinsky, 1998), then for very large the solution no longer depends upon the gain . Finite or the inclusion of synaptic nonlinearities through short term plasticity (Mongillo et al., 2012) may be necessary to satisfy condition with large synapses. Furthermore, the large synaptic weights associated with do not allows us to neglect polysynaptic paths, as is needed for Equation (5). Extending our analysis to networks with balanced scaling will be the focus of future work.
In summary our analysis has identified two circuit features that allow recurrent networks to capture conditions and for attentional modulation. First, the network must be subject to a global source of external fluctuations that dominates network covariability (). Second, the network must have recurrent inhibitory connections that are subject to a large attentional modulation ().
Mean field model of attention
We next apply the intuition gained in the preceding section to propose a cortical model that captures key neural correlates of attentional modulation. We model V4 as a recurrently coupled network of excitatory and inhibitory leaky integrate-and-fire model neurons (Tetzlaff et al., 2012; Ledoux and Brunel, 2011; Trousdale et al., 2012; Doiron et al., 2004) (Figure 4a). In addition to recurrent synaptic inputs, each neuron receives private and global sources of external fluctuating input (Figure 4b). The global noise is an attention-independent source of input correlation that the network filters and transforms into network-wide output spiking correlations (Figure 4c).
Figure 4
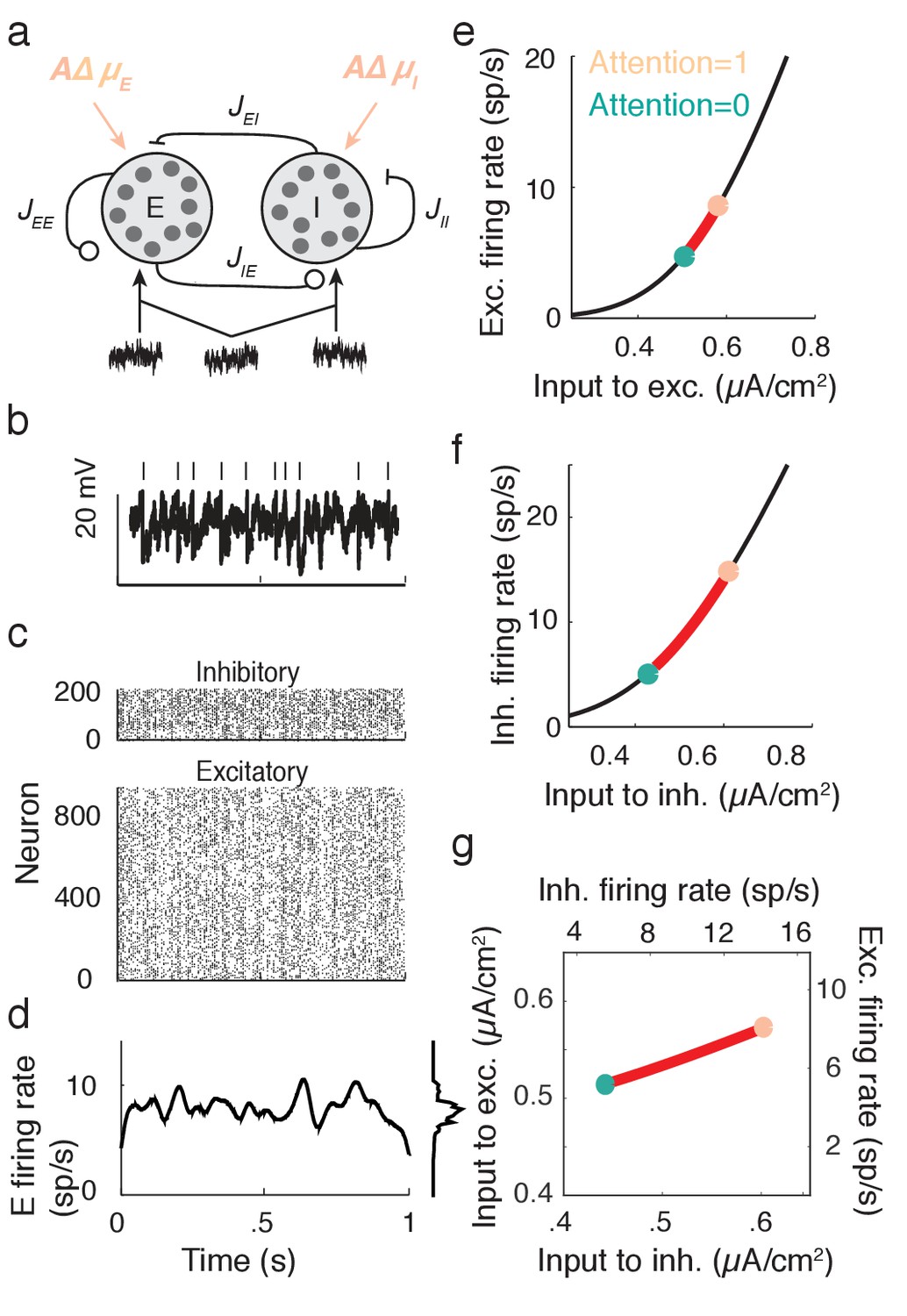
Excitatory-inhibitory network model.
(a) Recurrent excitatory-inhibitory network subject to private and shared fluctuations as well as top-down attentional modulation. (b) Example voltage trace from a LIF model neuron in the network. Top tick marks denote spike times. (c) Spike time raster plot of the spiking activity from the model network. (d) Population-averaged firing rate of the excitatory population. Left: frequency distribution of population-averaged firing rate. (e) Transfer function between the effective input and the firing rate for a model excitatory neuron. The red segment represents the attentional shift in effective input and hence firing rate. (f), Same as e, but for the inhibitory population. (g) Attention as a path through (,) space, and equivalently through (, space.
While the linear response theory introduced in Equation (3) is well suited to study large networks of integrate-and-fire neurons driven by weakly correlated inputs (Tetzlaff et al., 2012; Ledoux and Brunel, 2011; Trousdale et al., 2012; Doiron et al., 2004), the analysis offers little analytic insight. Instead, we consider the instantaneous activity across population , where is the spike train from neuron of population and is the population size ( or ). This approach reduces the model to just the two dynamic variables, the excitatory population rate and the inhibitory population rate ( is shown in Figure 4d). Despite this severe reduction the model retains the key ingredients for attentional modulation identified in the previous section – recurrent excitation and inhibition combined with a source of global fluctuations.
We take the population sizes to be large and consider a phenomenological dynamic mean field (Tetzlaff et al., 2012; Ledoux and Brunel, 2011) of the cortical network (see Materials and methods: Mean field model):
(6)
The function is the input-output transfer of population , taken to be the mean firing rate for a fixed input (Figure 4e for the population and Figure 4f for the population). The parameter is the coupling strength from population to population . Finally, and are the respective strengths of the mean input and the global fluctuation to population (throughout has a zero mean). To simplify our exposition we take symmetric coupling and and symmetric timescales . We set the recurrent coupling so that the model has a stationary mean firing rate (), about which induces fluctuations in and .
Attention is modeled as a top-down influence on the static input: . Here is a background input, the parameter models attention with denoting the unattended state and the fully attended state, and is the increase in due to attention. We note that the choice of representing the unattended state by and the attended state by is only due to convenience, and is not meant to make any statement about particular bounds on these states. In this model attention simply increases the excitability of all of the neurons in the network (Figure 4a). This modulation is consistent with the rank one structure of attentional modulation in the data (Figure 2), since is a single neuron property. The attention-induced increase in causes an increase in the mean firing rates (red paths in Figure 4e,f), consistent with recordings from putative excitatory (McAdams and Maunsell, 2000; Reynolds et al., 1999) and inhibitory neurons (Mitchell et al., 2007) in visual area V4. Since is a simple rising function then there is a unique mapping of an attentional path in space to a path in space (Figure 4g).
In total, our population model has the core features required to satisfy Conditions C1 and C2 of the previous section. We next use our mean field model to investigate how attentional paths in space affect population spiking variability.
Attention modulates population variability
The global input causes fluctuations about the network stationary state: . The fluctuations are directly related to coordinated spiking activity in population . In particular, in the limit of large we have that , where the expectation is over pairs in the spiking network. Thus, in our mean field network we require attentional modulation to decrease population variance .
For sufficiently small the fluctuations and obey linearized mean field equations (see Materials and methods: Mean field model, Equation (17)). The linear system is readily analyzed and we obtain the population variance computed over long time windows (see Materials and methods: Computing ):
(7)
Here is the response gain of neurons in population . Equation (7) shows that depends directly on , and we recall that changes with attention (the slope of in Figure 4e,f). Thus, while the derivation of requires linear fluctuations about a steady state, attentional modulation samples the nonlinearity in the transfer by changing the state about which we linearize. Any attention-mediated change in is not obvious since both and , meaning that both the numerator and denominator in Equation (7) will change with attention.
We explore by sweeping over (, ) space (Figure 5a). When the network has high and low then is large, while is low for the opposite case of high and low . Along our attention path increases while decreases (Figure 5b), satisfying our requirements for attentional modulation. The attention path that we highlight is just one potential path that reduces population variability, however all paths which reduce share a large attention-mediated recruitment of inhibition. If we start with the unattended state (turquoise dot in Figure 5c) we can label all () points that have a smaller population variance than the unattended point (light green region in Figure 5c). These modulations all share that (Figure 5c, green region is below the line). While the absolute comparison between and may depend on model parameters, a robust necessary feature of top-down attentional modulation is that it must significantly recruit the inhibitory population. This observation is a major circuit prediction of our model.
Figure 5
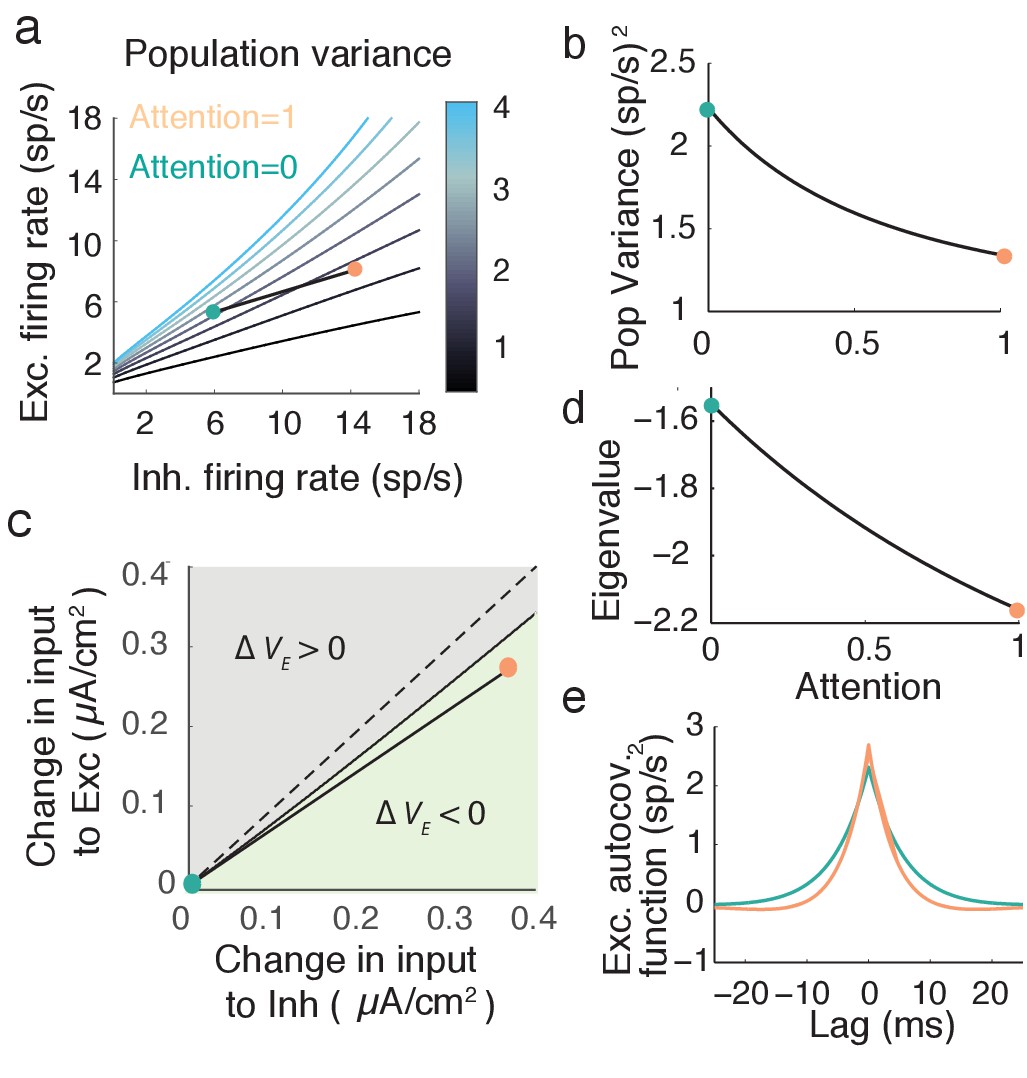
Mean field model shows an attention mediated decrease in population variance.
(a) An attentional path in excitatory-inhibitory firing rate space for which the population variance decreases. Colored contours define iso-lines of population variance in increments of (sp/s). The attentional path links the unattended state (; turquoise point) to the attended state (, orange point). (b) Variance values as a function of the attentional path defined in a. (c) The modulation from an unattended state (origin) to an attended state over the input space (). Solid black line marks where remains unchanged, and the green region where is less than zero. (d) The eigenvalue along the attentional path. With increased attention it becomes more negative, indicating that the state , is more stable. e, Autocovariance function of the excitatory population rate in the attended and unattended state (computed using Equation (19)).
An intuitive way to understand inhibition’s role in the decrease in population variance is through the stability analysis of the mean field equations. The eigenvalues of the linearized system are and (see Materials and methods: Mean field model, Equation (18)). Note that the denominator of the population variance (Equation 7) equals the square of the eigenvalue product . The stability of the network activity is determined by ; the more negative , the more stable the point , and the better the network dampens the perturbations about the point due to input fluctuations . The decrease of along the example attention path is clear (Figure 5d), and overcomes the increase in the numerator of due to increases in and . The enhanced damping is why decreases, explicitly seen in the steeper decline of the excitatory population autocovariance function in the attended compared to the unattended state (Figure 5e).
This enhanced stability due to recurrent inhibition is a reflection of inhibition canceling population variability provided by external fluctuations and recurrent excitation (Renart et al., 2010; Tetzlaff et al., 2012; Ozeki et al., 2009). Indeed, taking the coupling to be weak allows the expansion in Equation (7), so that the attention mediated increase in reduces population variance through cancellation, as in Equation (5). However, this expansion is not formally required to compute the eigenvalues and , and these measure the stability of the firing rate dynamics. We mention the expansion only to compare to the original motivation for inhibition.
The expression for given above (Equation 7) assumes a symmetry in the network coupling, namely that and . This allowed to be compactly written, facilitating the analysis of how attention affects both the numerator and denominator of Equation (7). However, the linearization of the mean field equations and the subsequent analysis of population variability do not require this assumption (see Materials and methods: Mean field model Equations (18–20)). To explore the robustness of our main result we let and , thereby breaking the coupling symmetry for . The reduction in with attention is robust over a large region of () (Figure 6a, green region). Focusing on selected pairings within the region where decreases shows that the attentional path identified for the network with coupling symmetry produces qualitatively similar behavior in the more general network (compare Figure 5c to Figure 6b–e). In total, the inhibitory mechanism for attention mediated reduction in population variability is robust to changes in the recurrent coupling with the network.
Figure 6
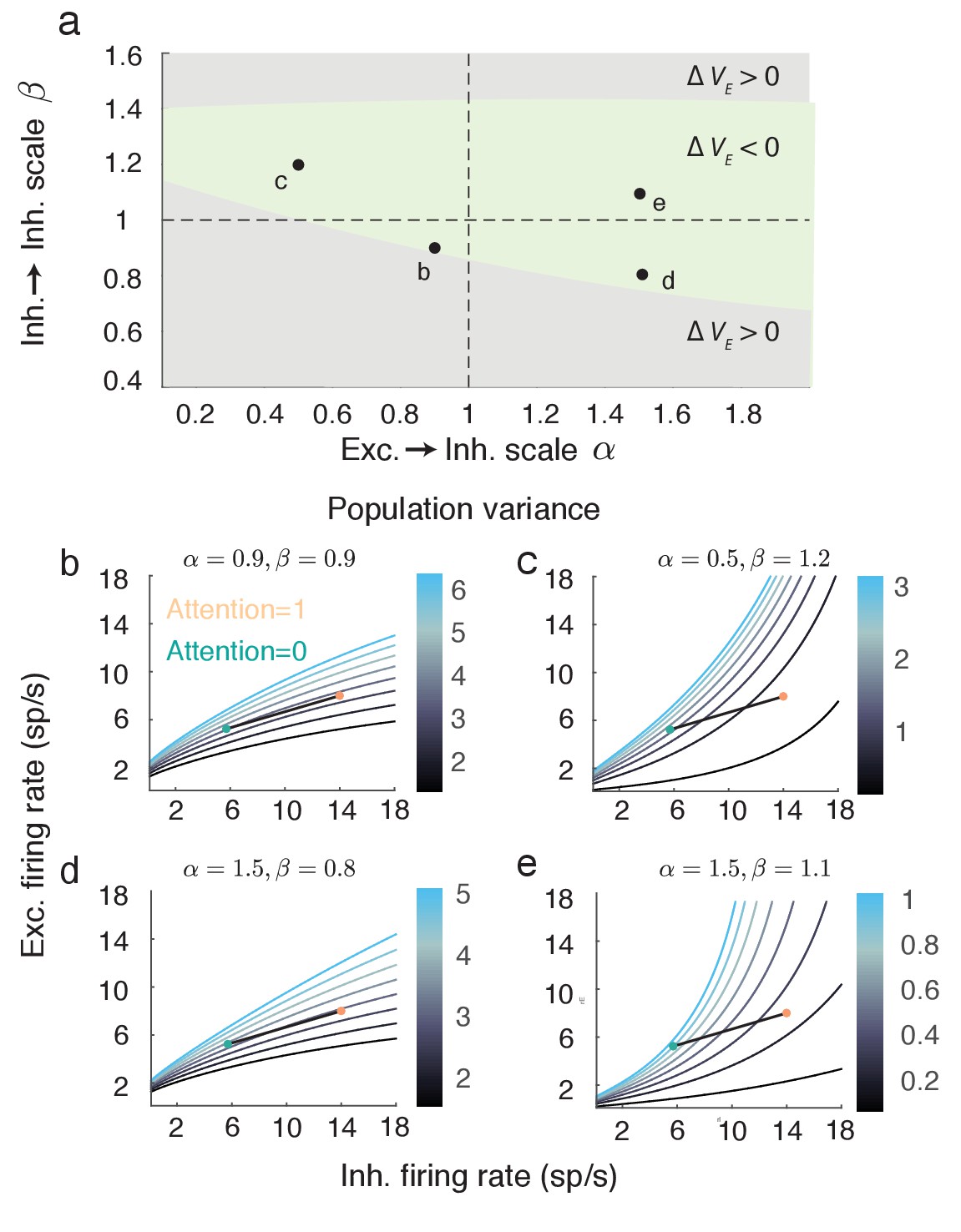
The attention mediated reduction in population variance is robust to changes in strength of recurrent connectivity.
(a) Sweep over and space (with and fixed) labeling the region where is positive (grey) and negative (green). (b–e) Attentional path in excitatory-inhibitory firing rate space. The colored contours are as in Figure 5a. All calculations are done using Equations (18–20).
While the reduced mean field equations are straightforward to analyze, a similar attenuation of pairwise covariance along the same attentional path occurs in the LIF model network (Appendix: Spiking network). Using linear response analysis for the spiking network we can relate the effect of inhibition to previous work in spiking networks (Renart et al., 2010; Tetzlaff et al., 2012; Ly et al., 2012; Doiron et al., 2016). In particular, the attention-mediated decrease of occurs for a wide range of timescale, ranging as low as 20 ms. However, for short timescales that match the higher gamma frequency range (approximately 60–70 Hz) this attentional modulation increases (Appendix 1—figure 6). This finding is consistent with reports of attention-mediated increases of neuronal synchrony on gamma frequency timescales(Fries et al., 2001; Buia and Tiesinga, 2008), particularly when inhibitory circuits are engaged (Kim et al., 2016).
Attention can simultaneously increase stimulus gain and decrease noise covariance
An important neural correlate of attention is enhanced stimulus response gain (McAdams and Maunsell, 2000). The previous section outlines how the recruitment of recurrent inhibitory feedback by attention reduces response variability. However, inhibitory feedback is also a common gain control mechanism, and increased inhibition reduces response gain through the same mechanism that dampens population variability (Sutherland et al., 2009). Thus it is possible that the decorrelating effect of attention in our model may also reduce stimulus response gain as well, which would make the model inconsistent with experimental data.
To insert a bottom-up stimulus in our model we let the attention-independent background input have a stimulus term: . Here is the feedforward stimulus gain to population and is the background input that is both attention and stimulus independent. Our model captures a bulk firing rate rather than a population model with distributed tuning. Because of this the stimulus should either be conceived as the contrast of an input, or the population conceived as a collection of identically-tuned neurons (i.e a single cortical column).
Straightforward analysis shows that the stimulus response gain of the excitatory population can be written as (Materials and methods: Computing stimulus response gain):
(8)
If then , and thus any attentional modulation that reduces population variability will necessarily reduce population stimulus sensitivity. However, for the second term in Equation (8) can counteract this effect and decouple stimulus sensitivity and variability modulations.
Consider the example attentional path (Figure 4g) with the extreme choice of and . In this case attention causes an increase in (Figure 7a,b), while simultaneously causing a decrease in (Figure 5a,b). This is a robust effect, as seen by the region in () space for which the change in from the unattended state is negative, and the change in is positive (green region, Figure 7c). Further, for fixed the proportion of the gray rectangle that the green region occupies increases with (Figure 7d). Thus, the decoupling of attentional effects on population variability and stimulus sensitivity is robust to both attentional path () and feedforward gain () choices. The condition that implies that feedforward stimuli must directly target excitatory neurons to a larger degree than inhibitory neurons (or at least the inhibitory neurons subject to attentional modulation). This gives us a complementary prediction to the one from the previous section: while top-down attention favors inhibitory neurons, the bottom-up stimulus favors excitatory neurons.
Figure 7

Attention model can capture increase in stimulus response gain despite decrease in population variance .
(a) Attentional path through () space shows an increase in stimulus response gain. The shown path is the same path as in Figure 5. (b) Values of along the path depicted in a. (c) The green region in () space denotes where and . Black lines are iso-lines of covariance and gain, along which those quantities do not change. (d) Percent area of the green region in c out of a constant rectangle, as the feedforward stimulus gain increases, with held constant.
In total, our model of attentional modulation in recurrently coupled excitatory and inhibitory cortical networks subject to global fluctuations satisfies three main neural correlates of attention: (1) increase in excitatory firing rates and in (2) stimulus-response gain, with a (3) decrease in pairwise excitatory neuron co-variability.
Impact of attentional modulation on neural coding
Attention serves to enhance cognitive performance, especially on discrimination tasks that are difficult (Moore and Zirnsak, 2017). Thus, it is expected that the attention-mediated reduction in population variability and increase in stimulus response gain subserve an enhanced stimulus estimation (Cohen and Maunsell, 2009; Ruff and Cohen, 2014). In this section we investigate how the attentional modulation outlined in the previous sections affects stimulus coding by the population.
As mentioned above our simplified mean field model (Equation 6) considers only a bulk response, where any individual neuron tuning is lost. As such a proper analysis of population coding is not possible. Nonetheless, our model has two basic features often associated with enhanced coding, decreased population variability (Figure 5) and increased stimulus-response gain (Figure 7).
Fisher information (Averbeck et al., 2006; Beck et al., 2011) gives a lower bound on the variance of a stimulus estimate constructed from noisy population responses, and is an often used metric for population coding. The linear Fisher information (Beck et al., 2011) computed from our two-dimensional recurrent network is:
(9)
Here , , and . The important result is that is invariant with attention, meaning that attention does not increase the network’s capacity to estimate the stimulus .
While the proof of Equation (9) is straightforward and applies to our recurrent excitatory-inhibitory population (see Materials and methods: Fisher information), the invariance of the total information with attention is most easily understood by analogy with an uncoupled, one-dimensional excitatory population (Figure 8a). Without coupling, the input to the population is simply , which is then passed through the firing rate nonlinearity . In this case the gain is , and assuming a linear transfer the population variance is . In total the linear Fisher information from the uncoupled population is then:
(10)
Figure 8
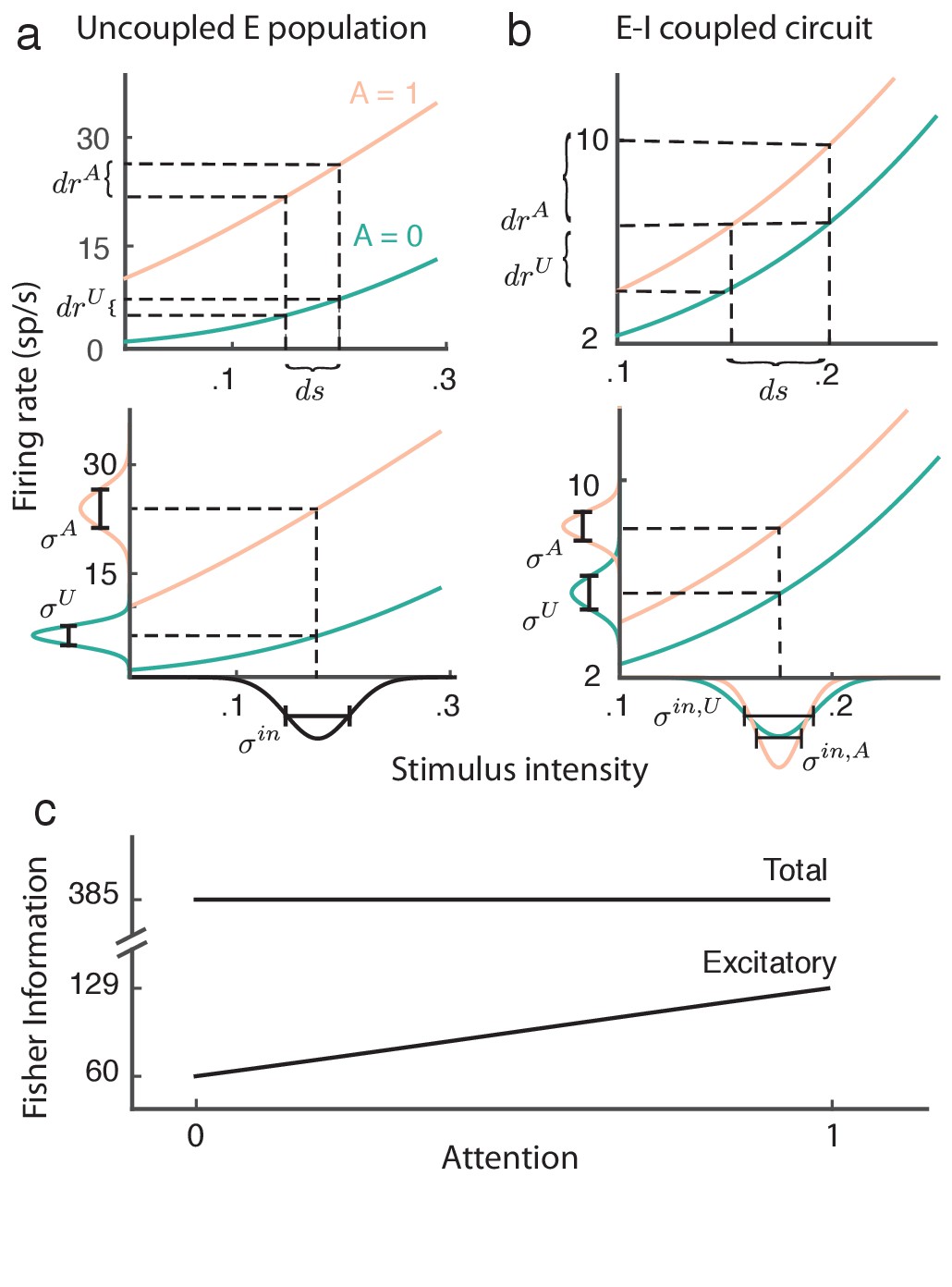
Attention improves stimulus estimation by the excitatory population embedded within excitatory ()-inhibitory () network.
(a) Top: For a uncoupled excitatory population, the stimulus response gain increases with attention. Turquoise: unattended state; orange: attended state. Bottom: Population variance increases with attention. Stimulus-response curves same as above. Input variance is computed from all input to a population, including external noise and recurrent coupling. The Fisher information for the uncoupled population is constant with attention because the squared gain and variance increase proportionally (b) Same as (a) but for the population within the network. Top: increases with attention. Bottom: decreases with attention, because the net input variance of the population decreases with attention. (c) Total Fisher information for coupled E-I populations is constant with attention. By contrast, the Fisher information of the excitatory component increases with attention.
The proportion by which attention increases the squared gain (Figure 8a, top) is exactly matched by the attention related increase in population variance (Figure 8a, bottom), resulting in cancellation of any attention-dependent terms in .
The majority of projection neurons in the neocortex are excitatory, so we now consider the stimulus estimation from a readout of only the excitatory population. Combining our previous results we obtain:
(11)
Restricting the readout to be from only the excitatory population drastically reduces the total information (compare to in Figure 8c). As with the uncoupled population the response gain of the excitatory neurons in the coupled population increases with attention (Figure 8b, top). Yet unlike the uncoupled population the net input variability to the population is reduced by attention through a cancelation of the external variability via inhibition (Figure 8b, bottom). These two components combine so that despite , we have that does increase with attention (Figure 8c). In sum, even though the total stimulus information in the network does not change with attention, the amount of information extractable from the excitatory population increases, which could lead to improved downstream stimulus estimation in the attended state.
Discussion
Using population recordings from visual area V4 we identified rank one structure in the mapping of population spike count covariability between unattended and attended states. We used this finding to motivate an excitatory-inhibitory cortical circuit model that captures both the attention-mediated increases in the firing rate and stimulus response gain, as well as decreases in noise correlations. Our model accomplishes this with only an attention dependent shift in the overall excitability of the cortical population, in contrast to a scheme where distinct biophysical mechanisms would be responsible for respective firing rate and noise correlations modulations. The model makes two key predictions about how stimulus and modulatory inputs are distributed over the excitatory-inhibitory cortical circuit. First, top-down attentional signals must affect inhibitory neurons more than excitatory neurons to allow a better damping of global fluctuations in the attended state. Second, bottom-up stimulus information must be biased towards excitatory cells to permit higher gain in the attended state. In total, the increased response gain and decreased correlations enhance the flow of information when the readout is confined to the excitatory population.
Candidate physiological mechanisms for attentional modulation
Our model does not consider a specific type of inhibitory neuron, and rather models a generic recurrent excitatory-inhibitory circuit. However, inhibitory circuits in cortex are complex, with at least three distinct interneuron types being prominent in many areas: parvalbumin- (PV), somatostatin- (SOM), and vasointestinal peptide-expressing (VIP) interneurons (Rudy et al., 2011; Pfeffer et al., 2013; Kepecs and Fishell, 2014). In mouse visual cortex, both SOM and PV cells form recurrent circuits with pyramidal cells, with PV cells having stronger inhibitory projections to pyramidal cells than those of SOM cells (Pfeffer et al., 2013). Furthermore, PV and SOM neurons directly inhibit one another, with the SOM to PV connection being stronger than the PV to SOM connection (Pfeffer et al., 2013). Finally, VIP cells project strongly to SOM cells (Pfeffer et al., 2013) and are activated from inputs outside of the circuit (Lee et al., 2013; Fu et al., 2014), making them an attractive target for modulation. Recent studies in visual, auditory, and somatosensory cortical circuits show that VIP cell activation provides an active disinhibition of pyramidal cells via a suppression of SOM cells (Kepecs and Fishell, 2014). Basal forebrain (BF) stimulation modulates both muscarinic and nicotinic ACh receptors (mAChRs and nAChRs respectively) in a fashion that mimics attentional modulation (Alitto and Dan, 2012). In particular, the recruitment of VIP cell activity in vivo through BF stimulation is strongly dependent on both the muscarinic and nicotinic cholinergic pathways (Alitto and Dan, 2012; Kuchibhotla et al., 2017; Fu et al., 2014), and it has thus been hypothesized VIP cells activation could be an important component of attentional modulation (Alitto and Dan, 2012; Poorthuis et al., 2014).
If we consider the inhibitory population in our model to be PV interneurons then the recruitment of VIP cell activity via top-down cholinergic pathways is consistent with our attentional model in two ways. First, activation of the VIP SOM pyramidal cell pathway provides a disinhibition to pyramidal cells, modeled simply as an overall depolarization to pyramidal cells in the attended state (Figure 4). Second, the activation of the VIP SOM PV cell pathway disinhibits PV cells, and the strong SOM PV projection would suggest that the disinhibition is sizable as required by our model (Figure 5c). Finally, a recent study in mouse medial prefrontal cortex reports that identified PV interneurons show an attention related increase in activity, and that optogenetic silencing of PV neurons impairs attentional processing (Kim et al., 2016).
However, our logic is perhaps overly simplistic and neglects the direct modulation of SOM cells via muscarinic and nicotinic cholinergic pathways (Alitto and Dan, 2012; Kuchibhotla et al., 2017) that could compromise the disinhibitory pathways. Further, there is evidence of a direct ACh modulation of PV cells (Disney et al., 2014) as opposed to through a disinhibitory pathway. Finally, there may be important differences across both species (mouse vs. primate) and visual area (V1 vs. V4) that fundamentally change the pyramidal, PV, SOM, and VIP circuit that is understood from mouse V1 (Pfeffer et al., 2013). Future studies in the inhibitory to excitatory circuitry of primate visual cortex, and its attentional modulation via neuromodulation, are required to navigate these issues.
Finally, the simultaneous increase in response gain and decrease in noise correlations with attention requires excitatory neurons to be more sensitive to bottom-up visual stimulus than inhibitory neurons (, Figure 7). In mouse visual cortex, GABAergic interneurons show overall less stimulus selectivity than pyramidal neurons (Sohya et al., 2007), however this involves both direct feedforward and recurrent contributions to stimulus tuning. While our model simplified the feedforward stimulus gain and to be constant with attention, it is known that attention also modulates feedforward gain through presynaptic nACh receptors (Disney et al., 2007). Notably, nAChRs are found at thalamocortical synapses onto layer 4 excitatory cells and not onto inhibitory neurons, suggesting that would increase with attention while would not. Thus, should also increase with attention while should not, further supporting that .
Modeling global network fluctuations and their modulation
Our model considered the source of global fluctuations as external to the network. This choice was due in part to difficulties in producing global, long timescale fluctuations through strictly internal coupling (Renart et al., 2010; Rosenbaum et al., 2017). Our model assumed that the intensity of these external input fluctuation were independent of attention. Rather, attention shifted the operating point of the network such that the transfer of input variability to population-wide output activity was attenuated in the attended state.
Recent analysis of population recordings show that generative models of spike trains that consider gain fluctuations in conjunction with standard spike emission variability capture much of the variability of cortical dynamics (Rabinowitz et al., 2015; Lin et al., 2015). Further, these gain fluctuations are well approximated by a one-dimensional, global stochastic process affecting all neurons in the population (Ecker et al., 2014; Rabinowitz et al., 2015; Lin et al., 2015; Ecker et al., 2016; Engel et al., 2016; Whiteway and Butts, 2017). When these techniques are applied to population recordings subject to attentional modulation, the global gain fluctuations are considerably reduced in the attended state (Rabinowitz et al., 2015; Ecker et al., 2016). Our assumption that external input fluctuations to our network are attention-invariant is consistent with this statistical analysis since it is necessarily constructed from only output activity. Nevertheless, another potential model is that the reduction in population variability is simply inherited from an attention-mediated suppression of the global input fluctuations. Unfortunately, it is difficult to distinguish between these two mechanisms when restricted to only output spiking activity.
However, a model where output variability reductions are simply inherited from external inputs suffers from two criticisms. First, it begs the question: what is the mechanism behind the shift in input variability? Second, our model requires only an increase in the external depolarization to excitatory and inhibitory populations to account for all attentional correlates. An inheritance model would necessarily decouple the attentional mechanisms behind increases in network firing rate (still requiring a depolarization) and the decrease in global input variability. Thus, our model offers a parsimonious and biologically motivated explanation of these neural correlates of attention. Further work dissecting the various external and internal sources of variability to cortical networks, and their attentional modulation, is needed to properly validate or refute these different models.
Attentional modulation of neural coding through inhibition
Our network model assumed attention-invariant external fluctuations and weak recurrent inputs, permitting a linear analysis of network activity. As a consequence the linear information transfer by the entire population was attention-invariant (Figure 8), because attention modulated the network’s transfer of signal and noise equivalently. However, this invariance was only apparent if the decoder had access to both the excitatory and inhibitory populations. However, most of the neurons in cortex that project between areas are excitatory. When the decoder was restricted to only the activity of the excitatory population then our analysis uncovered two main results. First, the excitatory population carried less information than the combined excitatory-inhibitory activity, suggesting an inherently suboptimal coding scheme used by the cortex. Second, the attention-mediated modulation of the inhibitory neurons increased the information carried by the excitatory population. This agrees with the wealth of studies that show that attention improves behavioral performance on stimulus discrimination tasks.
Determining the impact of population-wide spiking variability on neural coding is complicated (Averbeck et al., 2006; Kohn et al., 2016). A recent theoretical study has shown that noise correlations that limit stimulus information must be parallel to the direction in which population activity encodes the stimulus (Moreno-Bote et al., 2014). The fluctuations in our network satisfy this criteria, albeit trivially since all neurons share the same stimulus input. Indeed, in our network the external inputs appear to the network as , meaning that fluctuations from the noise source are indistinguishable from fluctuations in the stimulus . This is an oversimplified view and assumes that the decoder treats the neurons as indistinguishable from one another, at odds with classic work in population coding (Pouget et al., 2000). Extending our network to include distributed tuning and feature-based recurrent connectivity is a natural next step (Ben-Yishai et al., 1995; Rubin et al., 2015). To do this the spatial scales of feedforward tuning, recurrent projections, external fluctuations, as well as attention modulation must all be specified. It is not clear how noise correlations will depend on these choices yet work in spatially distributed balanced networks shows that solutions can be complex (Rosenbaum et al., 2017).
The role of inhibition in shaping cortical function is a longstanding topic of study (Isaacson and Scanziani, 2011), including recent work showing inhibition can actively decorrelate cortical responses (Renart et al., 2010; Tetzlaff et al., 2012; Ly et al., 2012). Our work gives a concrete example of how this decorrelation can be gated and used to control the flow of information. Of interest are tasks that probe a distributed population where attention again decreases noise correlations between neurons with similar stimulus preference, yet increases noise correlations between cells with dissimilar stimulus preference (Ruff and Cohen, 2014). The circuit mechanisms underlying this neural correlate of attention are unclear. However, there is ample work in understanding how recurrent inhibition shapes cortical activity in distributed populations (Isaacson and Scanziani, 2011), including in models of attentional circuits (Ardid et al., 2007; Buia and Tiesinga, 2008). Adapting our model to include distributed tuning is an important next step and will be a better framework to discuss the coding consequences of the attentional modulation circuits proposed in our study.
Methods and materials
Data preparation
Request a detailed protocolData was collected by from two rhesus monkeys with microelectrode arrays implanted bilaterally in V4 as they performed an orientation-change detection task (Figure 1a) (Cohen and Maunsell, 2009). All animal procedures were in accordance with the Institutional Animal Care and Use Committee of Harvard Medical School. Two oriented Gabor stimuli flashed on and off several times, until one of them changed orientation. The task of the monkey was to then saccade to the stimulus that changed. Each recording session consisted of at least four blocks of trials in which the monkey’s attention was cued to the left or right. We excluded from the analysis instruction trials which occurred at the start of each block to cue the monkey to one side to attend to, catch trials in which the monkey was rewarded just for fixating, and trials in which the monkey did not perform the task correctly. Moreover, the first and last stimulus presentations in each trial were not analyzed, to prevent transients due to stimulus appearance or change from affecting the results. The total number of trials included in the analysis from all the recording sessions was . Each trial consisted of between and stimulus presentations, of which all but the first and last were analyzed.
Recordings from the left and right hemispheres of each monkey were analyzed separately because the activities of the neurons in opposite hemispheres had near-zero correlations (Cohen and Maunsell, 2009). Neurons in the right hemisphere were considered to be in the attended state when the attentional cue was on the left, and vice-versa. We note that because our criteria for choosing which trials and units to analyze were based on different needs for data analysis compared to the original study (Cohen and Maunsell, 2009) the specific firing rates and covariances differ quantitatively from those previously reported.
In monkey 1, an average of (min , max ) units were analyzed from the right hemisphere, and an average of (min , max ) units were analyzed from the left hemisphere. From monkey 2, an average of (min , max ) units from the right hemisphere, and an average of (min , max ) units from the left hemisphere were analyzed. From each recording, spikes falling between and ms from stimulus onset were considered for the firing rate analysis, to account for the latency of neuronal responses in V4.
Comparing change in covariance to change in variance
Request a detailed protocolLet be the matrix containing spike counts of the neurons on trials in which they are in the unattended state, and the matrix containing spike counts of the neurons on trials in which they are in the attended state. Denote the unattended spike count covariance matrix by , and the attended one by . Attentional changes in covariance and variance were measured both on average (Figure 1c) and as distributions (Figure 1d). The distributions of the normalized differences
(12)
reveal a concentration of negative covariance changes, and a distribution of variance changes symmetric about zero. Here, and ( and ) are vectors containing covariance (variance) values of the entire data set. Note that the distributions are bounded between and by construction.
Solving systems of equations by error minimization
Request a detailed protocolWhen solving systems of the form of Equation (2) in order to quantify the fit of the model, a nonlinear equation solver (fminunc) in MATLAB was used. The solver found minima of an objective function which we defined as the Euclidean norm of the difference of the approximation of the attended covariance matrix and the original attended covariance matrix, in other words, the error of the approximation:
(13)
Shuffled covariance matrices
Request a detailed protocolFor finite population sizes () we expect our algorithm to extract some low-rank structure between arbitrary covariance matrices. Let be the principal square root of the attended covariance matrix, the unique positive-semidefinite square root of a positive-semidefinite matrix. Consider the symmetric matrix computed from the a random permutation of the upper-triangular entries of . Finally, let . The square root-permutation-squaring procedure guarantees a positive-semidefinite matrix, as the square of any matrix is positive-semidefinite. Shuffling removes any relation between and , and any remaining detected structure would be due to finite sampling. The shuffled covariance gain provides the prediction , and measures the relation between and . Synthetic data shows that as population size becomes large the coefficient approaches 0 (Appendix: Detected structure in random covariance matrices is a finite-size effect).
Upper bound covariance matrices
Request a detailed protocolThe covariance matrices and are estimates obtained from a finite number of trials, and any estimation error will compromise the ability to detect rank one structure of . Here we outline an upper bound for the model performance based on a finite number of trials over which the covariance matrices were originally estimated. Let with minimizing the norm of . We remark that perfectly decomposes according to the statistical model in Equation (2). We used to generate an artificial set of correlated Poisson spike counts, using an algorithm based on a latent multivariate gaussian model (Macke et al., 2009). We sampled these population spike counts with a fixed number of trials () with be the resulting matrix of Poisson samples for each process. Let be the 'upper bound' covariance matrix: a finite trial sampling approximation to the perfectly decomposable matrix . Finally, we employ our algorithm to give , where the vector minimizes the norm of the error.
Since is perfectly decomposable then for we have . Thus in the large limit the coefficient between elements of and converges to 1 (Appendix: Performance limited by available number of trials). However, for finite we have that , solely due to inaccuracies in estimating with . To account for the possibility of particular strings of realizations introducing random biases into , we performed the following analysis on independently generated upper-bound covariance matrices .
Leave-one-out cross-validation
Request a detailed protocolInstead of solving the system consisting of all Equations (2), we remove one of them. Denote the complete set of equations by , an individual equation as and the set of equations with one of them removed as . We then solve the system . Denote the solution by . We can then compare and . We do this for possible systems . The of the vector of resulting vs values is a measure of how well the system can predict one of its elements, or in other words, how well the structure holds together when one element is taken out. This leave-one-out cross-validation was performed for the shuffled and the upper-bound cases as well.
Mean field model
The mean spiking activity over the population is
(14)
where is the spike train of excitatory neuron of population , is the number of spikes from that neuron, and is the time of spike . We follow previous studies (Tetzlaff et al., 2012; Ozeki et al., 2009; Ledoux and Brunel, 2011) and consider the firing rate dynamics of the and populations given by the system in Equations (6):
Here is the attention independent drive to population , is the attention variable, and is the maximal drive to population due to attention. The parameter is the coupling from population to populations . The stochastic processes , , and are the global fluctuations applied to the network. The excitatory and inhibitory populations have private fluctuations and also common fluctuations given to both populations; the parameter scales the degree of private versus common fluctuations. We perform calculations for arbitrary and then take to match the system given in Equations (6). The total intensity of fluctuations to population is set by . These simplified rate equations give an accurate picture of the long-timescale dynamics of networks of coupled spiking neuron models that are in the fluctuation driven regime (Ledoux and Brunel, 2011). The operative timescale reflects a combination of synaptic and membrane integration; since we are interested in spiking covariance over time windows that are much longer than these, we take them to be unity for simplicity.
To give a quantitative match between the equilibrium statistics of the rate equations and the leaky integrate-and-fire (LIF) network simulations we take the transfer function to be the inverse first passage time of an LIF neuron driven by white noise (Ledoux and Brunel, 2011):
(15)
The parameter is the intensity of the external fluctuations given to the LIF neurons (Appendix: Spiking model). The membrane timescale gives the dimensions of 1/s to the firing rate . The parameter denotes spike threshold while is the reset potential. Model parameters are given in Table 1.
Table 1
Model Parameters.
| Parameter | Description | Value |
|---|---|---|
| Time constants for membrane dynamics | 0.01 s | |
| Spike Threshold | 1 | |
| Spike Reset | 0 | |
| Excitatory baseline bias | 0.6089 | |
| Inhibitory baseline bias | 0.5388 | |
| Attentional modulation of excitatory bias | 0.2624 | |
| Attentional modulation of inhibitory bias | 0.3608 | |
| Excitatory coupling constant | 1.5 | |
| Inhibitory coupling constant | 3 | |
| Amplitude of external noise to E population | 0.3 | |
| Amplitude of external noise to I population | 0.35 | |
| Proportion of common noise to E and I populations | 1 | |
| Sensitivity of E population to stimulus input | 1 | |
| Sensitivity of I population to stimulus input | 0 |
If the input fluctuations, , , and are white noise processes then the nonlinearity in makes the stochastic dynamics of and complicated (non-diffusive). To simply the analysis we consider as the limiting process from:
for , with and . This makes sufficiently smooth in time (the same is true for and ).
We restrict the coupling such that for the equilibrium point is stable and given by:
For sufficiently small the fluctuations in population activity about the equilibrium firing rate, , obey the linearized stochastic system:
Here is the slope of the transfer function evaluated at the equilibrium point . Equation (17) is a two dimensional Ornstein-Uhlenbeck process (Gardiner, 2004) that is readily amenable to analysis.
Computing
Request a detailed protocolIn matrix form the system Equation(17) is written as:
(18)
Here , , and
and .
The stationary autocovariance function is computed as:
(19)
where is a time lag and is the variance matrix (Det and Tr denote the determinant and trace operations, respectively). Here, is the identity matrix.
The covariance between populations and over long time scales is given by
(20)
where the integration is performed over the appropriate element of the matrix . In particular, the long timescale variance of the excitatory population is given by (after some algebra):
(21)
We remark that the long timescale covariance matrix can alternatively be computed from (Gardiner, 2004). To obtain the compact expression for we have assumed symmetric coupling: , , and . These are not required for the main results of our study and merely ease the analysis of equations.
Computing stimulus response gain
Request a detailed protocolWe decompose and define the gain of population to stimulus as . The term is obtained by differentiating Equations (16)) with respect to :
Solving the system of two equations for yields:
(22)
For the sake of compactness we set to obtain the result in Equation (8).
Fisher information
Request a detailed protocolLinear Fisher Information depends on the stimulus response gains and covariance matrix of the excitatory and inhibitory populations:
When the input correlation we have:
(24)
(25)
and
(26)
Inserting these expressions and those for and into Equation (23) and simplifying yields:
(27)
We remark that is independent of and and thus independent of attentional modulation.
Notice that we have re-introduced the correlation constant into the equations, rather than only considering the limit . If , the excitatory and inhibitory populations are receiving completely identical noise. If this is the case, the correlation cancellation would be perfect, leading to infinite informational content, as can be seen in Equation (27).
Appendix 1
Detected structure in random covariance matrices is a finite-size effect
Here we show that any prediction of rank one structure in our shuffled covariance matrix (non-zero in Figure 2 of the main text) is a finite-data effect. The trial-by-trial covariance matrices of the experimental data are computed from the spike counts recorded from a set number of units. To explore the effect of population size on the detected structure in the shuffled covariance matrices we must rely on synthetic data.
We construct the synthetic covariance matrices by generating Gaussian random numbers with the same mean and standard deviation as the actual covariance matrices from the data. This construction serves as a substitute for the shuffled covariance matrices, and allows for arbitrarily large populations. As we increase the number of units from near to , decreases accordingly, indicating that any positive is due to the finite population size, rather than any inherent structure in the data (Appendix 1—figure 1).
Appendix 1—figure 1
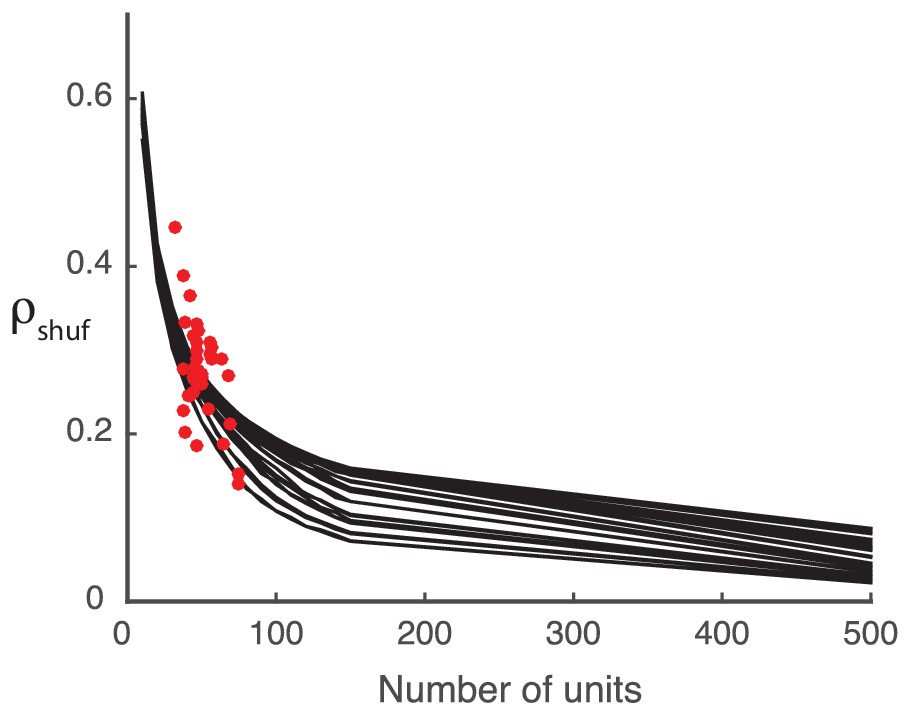
Detected structure in randomly generated covariance matrices is a finite-size effect.
The model performance () decreases with increasing system size (black curves). The computed from the shuffled neural data (red dots) falls in the same area as the synthetic data performance, suggesting that the synthetic data is a reasonable stand-in.
Model performance is limited by number of trials in data
The upper bound for our model did not saturate 1 (see Figure 2 of the main text). Here, we show that this is also due the finite data available. If infinitely many trials were available to compute the spike count covariance matrices from the data, and the data obeyed by the low-rank statistical model, the performance of the model () should tend to one. To test this, we generate synthetic data from correlated Poisson processes as in the upper bound computation of the main text but do not limit the number of samples to the number of trials in the original data. As the number of samples increases we find that (Appendix 1—figure 2).
Appendix 1—figure 2

The performance of the model (black curves) on synthetic data using increasing numbers of Poisson realizations approaches .
The Poisson model computed with the same number of trials as the data is shown for comparison (red dots).
Model performance for all monkeys and hemispheres
The model performance for individual recording sessions are given here for transparency (Appendix 1—figure 3 for the full data and Appendix 1—figure 4 for the leave-one-out cross validation).
Appendix 1—figure 3
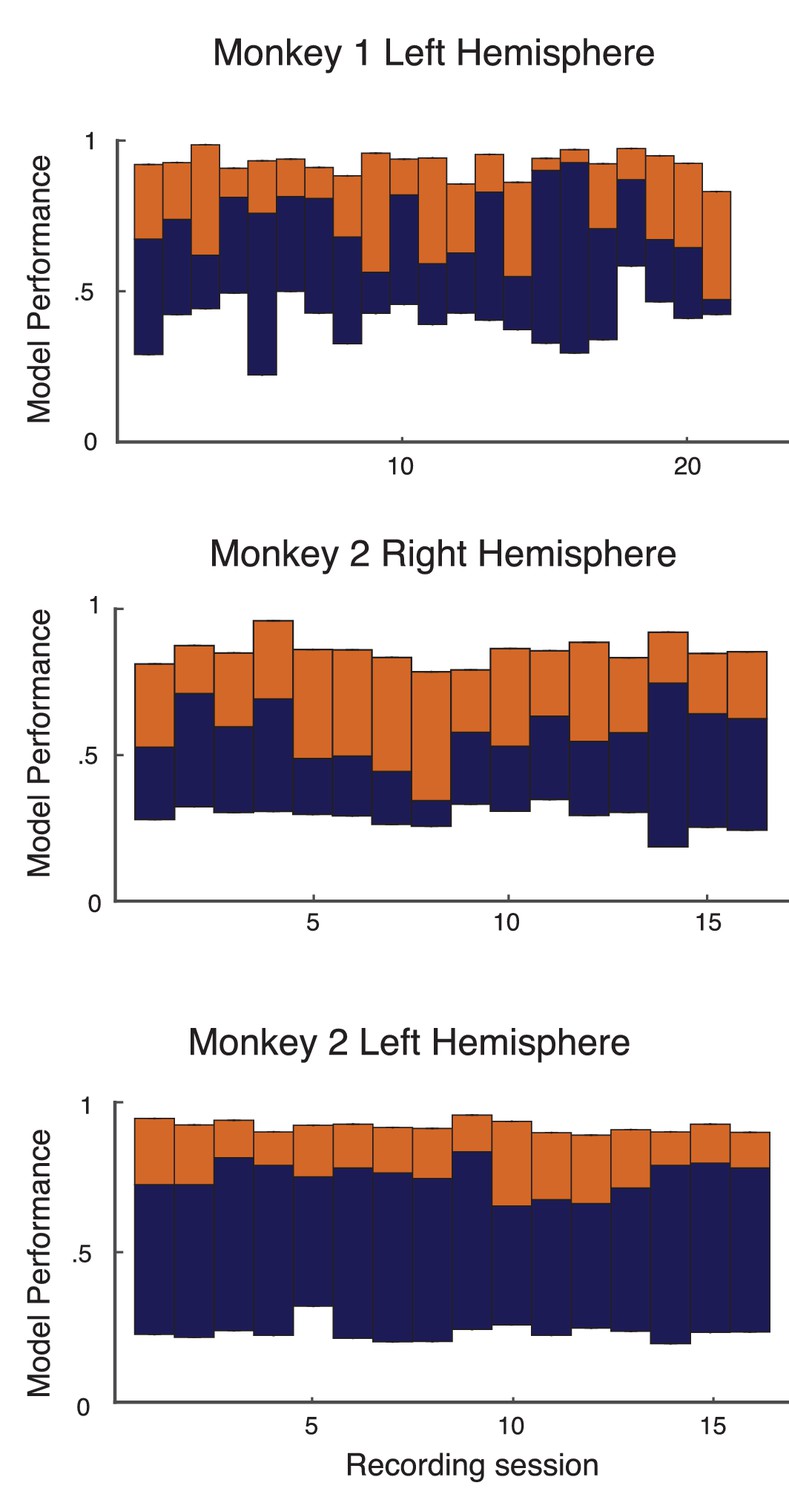
Performance of basic analysis on model on individual recording sessions from left hemisphere of monkey 1, and both hemispheres of monkey 2.
The format and colors match that described in Figure 2 of the main text.
Low-dimensional modulation is intrinsic to neurons
In order to further test our model, we asked to what extent the actual value of the covariance gain of neuron depends on the neural population whose covariance matrix was estimated from. If we had solved the system of equations using covariance matrices computed from recordings from a different set of neurons (including neuron ), would the value of be different? If not, this would be further indication of the independence of the attentional modulation of neuron from the particular set of other neurons it is analyzed with.
We tackle this question by dividing a set of neurons into sets of neurons each that all contain the neuron ( if is originally even). As an example take and consider the set of neurons partitioned into two subsets and (Appendix 1—figure 5a). We solve Equation (1) using the systems of equations obtained from and , and obtain two solutions and . We take the variance of the -estimations as a metric for how closely the different subsets can estimate an intrinsic value of . A higher variance would indicate a poorer convergence, and therefore a lower degree of independence from other neurons. Appendix 1—figure 5b shows the spread of -estimates from one dataset for the data, as well as the upper (UB) and lower (shuf) bounds. This spread includes estimates for all -values for all neurons. The spread in the shuffled case (SEM) is largest by two orders of magnitude, and the spread of the upper bound (SEM) is only one order of magnitude tighter than that of the data (SEM), so this case is close to ideal.
Appendix 1—figure 4
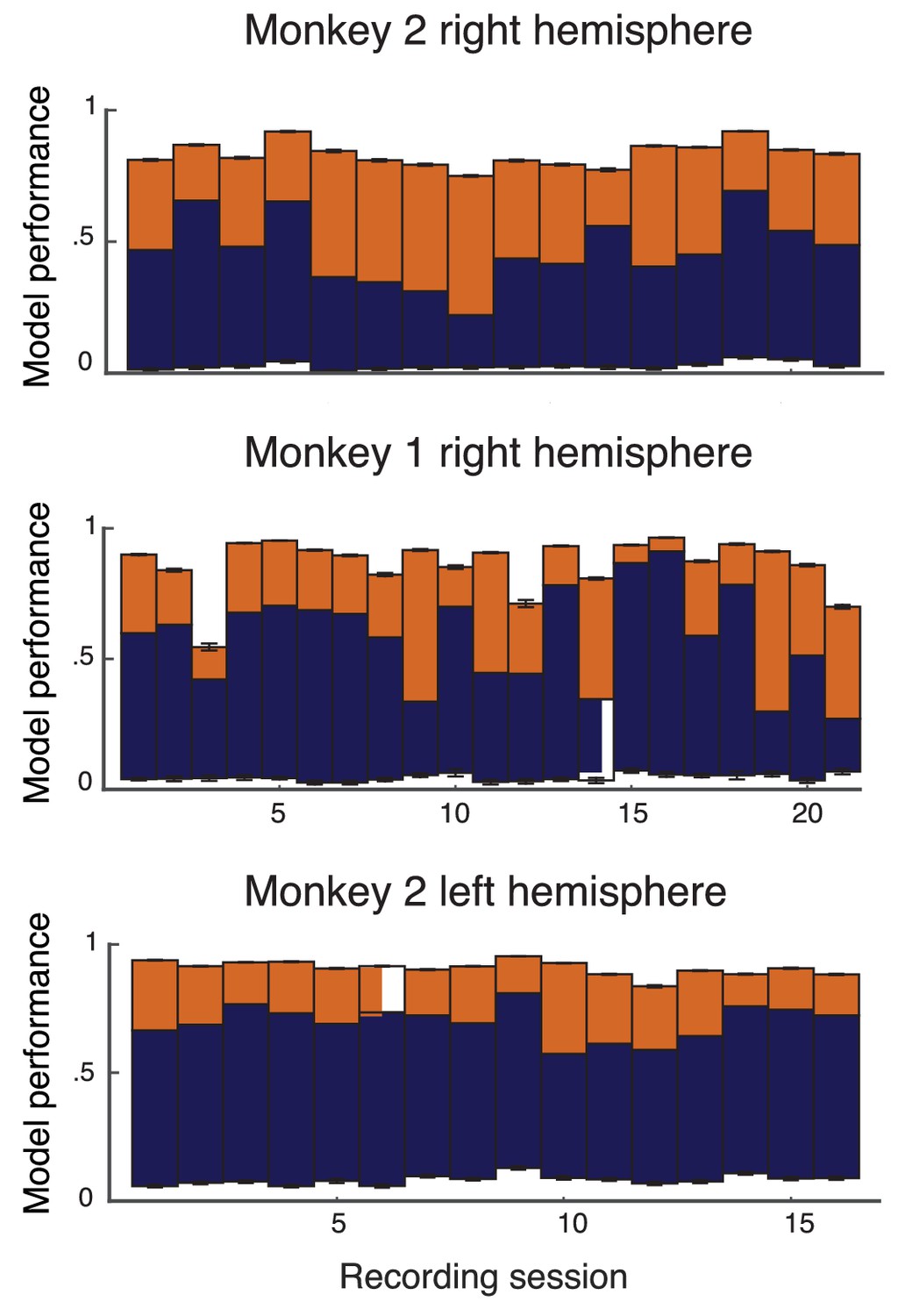
Performance of leave-one-out cross-validation on model on data from individual recording sessions from the left hemisphere of Monkey 1, and both hemispheres of Monkey 2.
The format and colors match that described in Figure 2 of the main text.
Appendix 1—figure 5
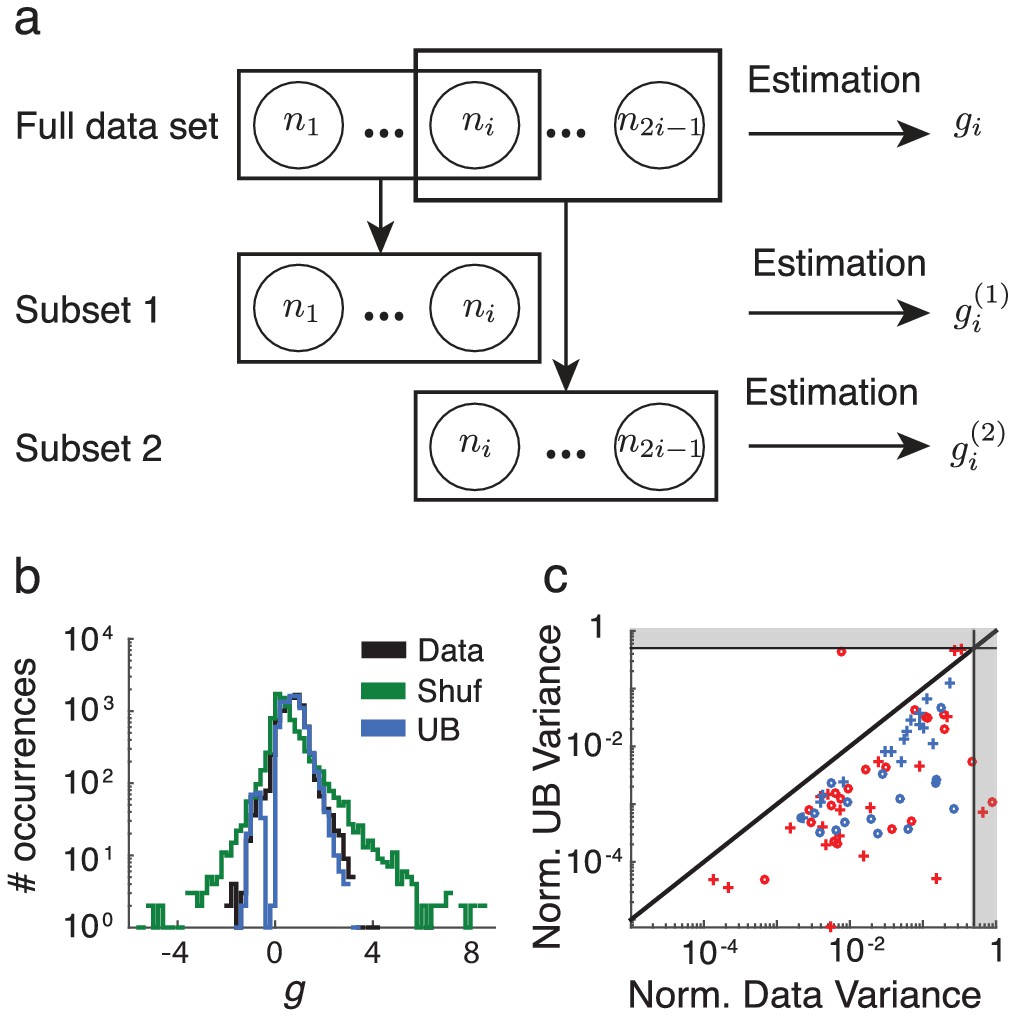
Overlap analysis of gain parameters.
(a) Schematic of overlap analysis. A set of neurons is divided into two sets and of , which overlap by exactly one neuron, indexed without loss of generality as neuron . Parameter is computed using and , resulting in two estimates and . (b) Spread of estimates for the data (black), as well as the upper (blue) and lower (green) bounds, from one day of recordings in one monkey. (c) Mean variance of the estimates computed from the data (abscissa) vs from the upper bound (ordinate), normalized by the mean shuffled variance. Each color denotes one of the monkeys, circles denote the right hemisphere recordings, and plusses denote the left hemisphere recordings. The gray regions consist of those points that are beyond , and therefore closer to the lower bound than the upper bound.
For each data set, the analysis is done for each neuron for different permutations of the neurons to generate , . For shuffled and upper-bound analysis, shuffles or Poisson realizations, and permutations were used. In all cases there was a total of points. Appendix 1—figure 5c shows an overview of the performance for all datasets. The abscissa is the mean variance of the -estimates computed from the data, normalized by the mean variance computed from the shuffled data: . The 'shuf' subscript denotes averaging over each shuffle. The ordinate is the mean variance of the -estimates computed from the upper bound, with the same normalization: . The 'poiss' subscript denotes averaging over each Poisson realization of the upper bound covariance matrix. We chose to normalize the mean data and upper-bound variances by the mean shuffled variance so that a value of would mean equality to the lower bound, meaning the only detected structure comes from finite-size effects, and a value of would mean perfect convergence of the -estimates. The gray regions are a visualization for the points which are closer to than (values above ) on the log-axes. Most of the data unsurprisingly falls below the diagonal, so the variance is greater for the data than the upper bound. Less trivially, most of the data falls outside of the gray regions, and are much closer to than , indicating excellent performance. This implies a structure in the modulation of the (unshuffled) covariance matrices that is preserved over analysis in the contexts of different groups of other neurons. In other words, attention modulates the individual neurons to a large extent independently, in a low-dimensional manner.
Network requirements for attentional modulation
In this section we study a network of neurons with the spike train output from neuron being where is the spike time from neuron . We consider multiple trials of the discrimination experiment and model the spike train only over a time period , where we assume that the spike trains to have have reached equilibrium statistics. We abuse notation and take the spike count from neuron over a trial as . The trial-to-trial covariance matrix of the network response is with element .
To analyze the network activity we first assume that each spike train is simply perturbed about a background state and employ the linear response ansatz (Ginzburg and Sompolinsky, 1994; Doiron et al., 2004; Trousdale et al., 2012) :
(28)
Here, is the synaptic coupling from neuron to neuron (proportional to the synaptic weight), and is a fluctuating external input given to neuron . The background state of neuron is , and it represents the stochastic output of a neuron that is not due to the recurrence from the network or the external input (). Finally, is the input to output gain of a neuron . In this framework, , , and are random variables, while and are parameters that describe the intrinsic and network properties of the system. Without loss of generality we take , , making a solution for the mean activity. We remark that formally Equation (28) is incorrect as written; is a random integer while, for instance, need not be an integer. Equation (28) is only correct upon taking an expectation (over trials) of .
Here we derive the requirements for external fluctuations and internal coupling for network covariability to satisfy the following two conditions (on average):
C1: ; attentional modulation of covariance is rank one.
C2: ; spike count covariance decreases with attention.
It is convenient to write Equation (28) in matrix form and isolate for the population response:
(29)
Here with similar notation for and . The matrix has element , while and is the identity matrix. Using Equation (29) we can express the covariance matrix as:
(30)
where denotes the transpose operation. Here is the background covariance, which we take to be simply . The input covariance matrix is with elements . In the above we assumed that , meaning that the background state is uncorrelated with the external noisy input.
It is clear that naturally decomposes into two terms. The first term represents the correlations that are internally generated within the network, via the direct synaptic coupling acting upon the background state . The second term is how the direct synaptic coupling filters the externally applied correlations .
Satisfying C1
The background matrix is a diagonal matrix and is hence rank . The high rank combined with attentional modulations of both and make it impossible to satisfy condition . If the spectral radius of is less than 1, then we can expand (Pernice et al., 2011; Trousdale et al., 2012). Inserting this expansion into the expression for the internally generated covariability yields:
Extracting the covariance between neuron and () due to internal coupling within the network gives:
If we take and the network connectivity to be dense (meaning the connection probability is ) then each term is . So long as the spectral radius of is less than one then the series converges and as we have that vanishes (Pernice et al., 2011; Trousdale et al., 2012; Helias et al., 2014).
This argument can be extended to networks with when combined with a balance condition between recurrent excitation and inhibition. Such networks also produce an asynchronous state where , vanishing in the large limit (Renart et al., 2010). However, formally balanced networks in the asynchronous state with have solutions that do not depend on the firing rate transfer . The attention dependent modulation is a critical component of our model and care must be taken in ensuring that
In contrast, the external covariance is not a diagonal matrix, so that the contributions from external fluctuations to scale as . This is for . Thus, while the terms in must be weak for the linear approximation in Equation (28) to hold, they need not vanish for large . Indeed, for moderate and large network size it is reasonable to ignore the contribution of internally generated fluctuations to . Recent analysis of cortical population recordings show that the shared spiking variability across the population can be well approximated by a rank one model of covariability (Ecker et al., 2014; Lin et al., 2015; Ecker et al., 2015; Rabinowitz et al., 2015). Thus motivated, we take the external fluctuations where . In total, we have for large the approximation:
(31)
Hence is rank one matrix with . It is trivial to satisfy condition with .
Satisfying C2
We again use the expansion . Truncating this expansion at yields an approximation considering only synaptic paths of length one in the network, and neglecting higher order paths. This is appropriate for sufficiently small. Truncating after inserting the expansion into Equation (30) yields the following approximation for :
(32)
The analysis in the main text begins with this approximation to derive Equation (5) of the main text.
Spiking network
Spiking network description
We implement a network of leaky integrate-and-fire neurons (LIF) with excitatory neurons and inhibitory neurons. Individual neurons were modeled as integrate-and-fire units whose voltages obeyed
(33)
for neuron . When the voltage reached a threshold , a spike was recorded and the voltage reset to . Time was measured in units of the membrane time constant, for all neurons. The bias depended on neuron type and attentional state. In the unattended state, the bias for excitatory neurons was and . In the attended state, and . The recurrent input to neuron was
(34)
where is the strength of the connection from neuron to neuron , is the synaptic filter for the projection from neuron to neuron , denotes convolution and is neuron ’s spike train – a series of -functions centered at spike times. The synaptic filters were taken to be alpha functions,
(35)
with of the passive membrane time constant for all synapses. The connection probability from neurons in population to population was , with and . Synaptic weights for connections between excitatory neurons were and , , . These parameters, and the bias voltages , were chosen so that the mean field theory derived above was valid for the spiking network’s firing rates.
The excitatory neurons were divided into four clusters, each excitatory neuron receiving half of its inputs from neurons in the same cluster and half from others. Projections to and from inhibitory neurons were unclustered.
External input from outside the network was contained in . We modeled this as a partially correlated Gaussian white noise process: . was Gaussian white noise private to neuron and was shared between all neurons. denoted the fraction of common input and the noise intensity for excitatory neurons was and for inhibitory neurons .
The firing rate of neuron in a trial of length is given by its spike count in that trial , where denotes averaging over trials. The spike train covariance between neurons and describes the above-change likelihood that action potentials occur in each spike train separated by a time lag :
(36)
For simulations, we measure the population-averaged spike train cross-covariance function by average a randomly chosen subsample of 100 spike train cross-covariances from pairs of neurons in the same cluster.
In order to calculate the covariance of neuron and ’s spike counts in windows of length , and , we use the relation
(37)
The cross-correlation of input currents was averaged over the same random subsample of the network as the spike train covariances. Current cross-correlations were normalized so that each current’s autocorrelation at zero lag was 1.
Spiking network analysis
The LIF model simulates voltages and produces spike trains, from which we can compute firing rates and covariances. Appendix 1—figure 6a,b show example voltage traces of individual excitatory neurons, with the spikes they produce shown above. Note that in the attended state, more spikes are produced, corresponding to a higher firing rate. Appendix 1—figure 6c,d show rasters for all the neurons in the unattended (c) and attended (d) states. Higher firing rates can be observed, especially for the inhibitory neurons. Averaging the spike trains over the excitatory population gives us the PSTH of the excitatory neurons. Appendix 1—figure 6e, left shows the unattended (turquoise) and attended (orange) PSTH smoothed with a sliding Gaussian window with width (std dev) ms. The histograms on the right demonstrate the decrease in population variance with attention.
Appendix 1—figure 6
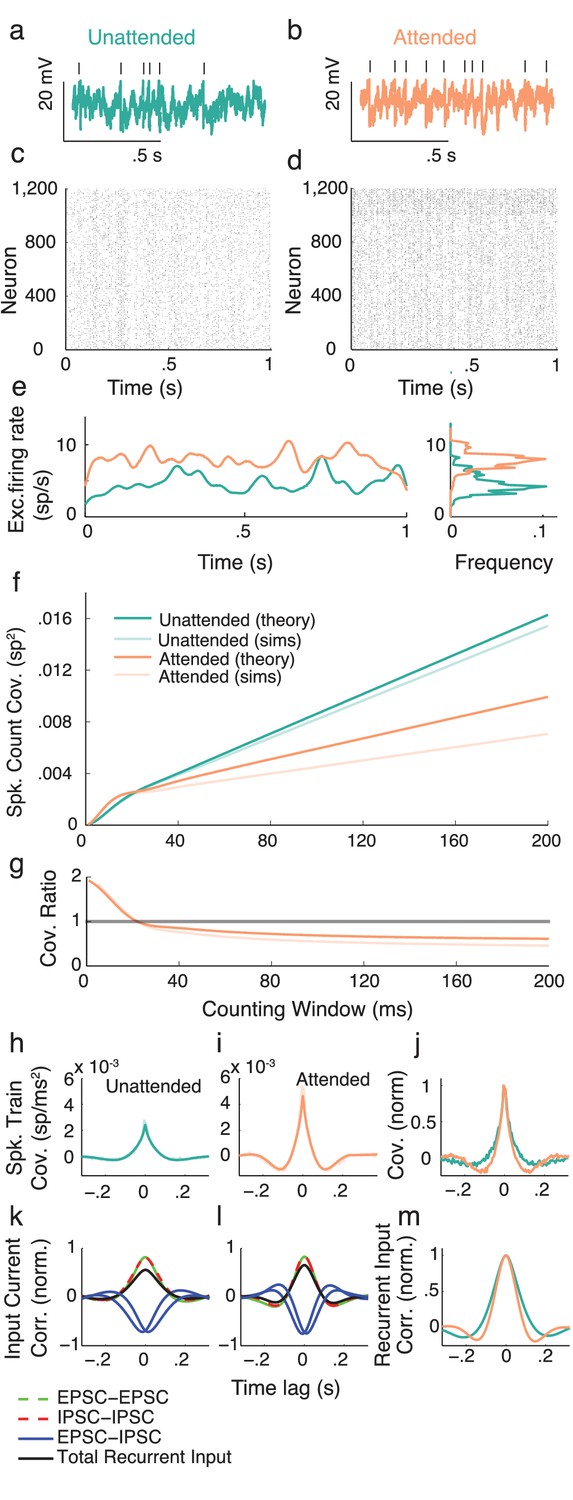
Spiking model and simulations.
(a,b) Example voltage trace from an excitatory model neuron in the unattended (a) and attended (b) states. Top tick marks denote spike times. (c) Raster plot of neurons in the unattended state. Neurons 1 to 1000 are excitatory, and 1001 to 1200 are inhibitory. (d) Raster plot of neurons in the attended state. (e) Excitatory population-averaged firing rates for the unattended (turquoise) and attended (orange) states. Right: frequency distributions of population-averaged firing rates. (f) Mean pairwise spike count covariance for different counting windows. Other than an increase in synchrony on very small timescales due to gamma oscillations, the spike count covariance decreases with attention regardless of counting window. (g) Ratio of attended and unattended spike count covariance, as a function of counting window. (h, i) Derived (solid turquoise) and simulated (muted turquoise) spike train cross-covariance functions of excitatory neurons in the unattended (h) and attended (i) states, averaged over pairs. (j) Spike train cross-covariance functions of excitatory neurons in the unattended and attended states, normalized to peak at . (k, l) Normalized input current cross-correlation functions of excitatory inputs to pairs of neurons (dashed green), inhibitory inputs to pairs of neurons (dashed red), excitatory and inhibitory inputs to pairs of neurons (blue), and summed excitatory and inhibitory recurrent inputs to pairs of neurons (black), in the unattended (k) and attended (l) states. (m) Attended (orange) vs unattended (turquoise) recurrent input cross-correlation functions. The excitatory cross-correlation function is narrower, just as for the output cross-covariance function, so the effects are happening on the level of inputs.
The spiking model provides the opportunity to directly compute the pairwise spiking covariance, in addition to the population variance. Appendix 1—figure 6f shows the pairwise spike count covariance computed over counting windows from to ms. For small counting windows, corresponding to high-frequency correlations, neurons in the attended state have slightly higher spike count covariance. This is consistent with the slightly higher peak in the attended autocovariance function from the mean-field theory (Figure 4e, main text), as well as experimental results (Fries et al., 2001). For counting windows greater than ms, the spike count covariance notably decreases with attention. The experiments we are modeling (Cohen and Maunsell, 2009) measure spike count correlations over ms counting windows, corresponding to the right-most points in Appendix 1—figure 6f. The proportional changes in the spike count covariance are expressed in the covariance ratio , shown in Appendix 1—figure 6g. Values of greater than one indicate increased spike count covariance with attention, and values of less than one indicate decreased spike count covariance with attention. The crossing of the line is apparent at counting windows of approximately ms. The theoretical values were computed using linear response theory (Trousdale et al., 2012).
To dissect the spike count covariance by different time lags, we consider the spike train covariance function (Equation 36), which is the pairwise-neuron analogue of the autocovariance function of the population-averaged activity (Figure 5e, main text). Appendix 1—figure 6h,i show the spike train covariance functions of excitatory neurons in the unattended and attended states. To compare the two, Appendix 1—figure 6j shows them normalized so that their maximum values are . In accordance with our mean-field results, the attended spike train covariance decays faster than the unattended spike train covariance, indicating increased stability in the attended state.
The spiking model also provides the opportunity to investigate the inputs to individual neurons, something that is difficult to do experimentally, and does not apply to mean-field models. Appendix 1—figure 6k,l shows the correlation functions of different types of inputs to a pair of excitatory neurons, averaged over pairs of excitatory neurons, in the unattended (k) and attended (l) states. Computing the correlation functions of the total recurrent input (black curves) reveals that correlations between excitatory inputs (EPSC-EPSC, dashed green), and correlations between inhibitory inputs (IPSC-IPSC, dashed red), are canceled by anti-correlations between excitatory and inhibitory inputs (EPSC-IPSC, blue). This is consistent with the idea of correlation cancellation by inhibitory tracking of excitatory activity (Renart et al., 2010; Tetzlaff et al., 2012; Ly et al., 2012). Attention, by shifting the system into a more stable state, allows this cancellation to occur more efficiently, thereby reducing the pairwise covariance. Appendix 1—figure 6m shows the input current correlation functions of the total recurrent inputs to pairs of excitatory neurons, normalized to peak at . We conclude that the correlation cancellation brought about by recurrent inhibitory feedback suppresses correlations of the total recurrent input, which in turn decreases the output correlations.
References
-
Cell-type-specific modulation of neocortical activity by basal forebrain inputFrontiers in Systems Neuroscience 6:79.https://doi.org/10.3389/fnsys.2012.00079
-
An integrated microcircuit model of attentional processing in the neocortexJournal of Neuroscience 27:8486–8495.https://doi.org/10.1523/JNEUROSCI.1145-07.2007
-
Neural correlations, population coding and computationNature Reviews Neuroscience 7:358–366.https://doi.org/10.1038/nrn1888
-
Role of interneuron diversity in the cortical microcircuit for attentionJournal of Neurophysiology 99:2158–2182.https://doi.org/10.1152/jn.01004.2007
-
Stimulus feature selectivity in excitatory and inhibitory neurons in primary visual cortexJournal of Neuroscience 27:10333–10344.https://doi.org/10.1523/JNEUROSCI.1692-07.2007
-
Attention improves performance primarily by reducing interneuronal correlationsNature Neuroscience 12:1594–1600.https://doi.org/10.1038/nn.2439
-
Cholinergic control of cortical network interactions enables feedback-mediated attentional modulationEuropean Journal of Neuroscience 34:146–157.https://doi.org/10.1111/j.1460-9568.2011.07749.x
-
The mechanics of state-dependent neural correlationsNature Neuroscience 19:383–393.https://doi.org/10.1038/nn.4242
-
On the structure of neuronal population activity under fluctuations in attentional stateJournal of Neuroscience 36:1775–1789.https://doi.org/10.1523/JNEUROSCI.2044-15.2016
-
BookHandbook of Stochastic Methods for Physics, Chemistry and the Natural Sciences (3rd edn)Springer-Verlag.
-
Theory of correlations in stochastic neural networksPhysical Review E 50:3171–3191.https://doi.org/10.1103/PhysRevE.50.3171
-
Cortical state and attentionNature Reviews Neuroscience 12:509–523.https://doi.org/10.1038/nrn3084
-
Neuromodulation and cortical function: modeling the physiological basis of behaviorBehavioural Brain Research 67:1–27.https://doi.org/10.1016/0166-4328(94)00113-T
-
The correlation structure of local neuronal networks intrinsically results from recurrent dynamicsPLoS Computational Biology 10:e1003428.https://doi.org/10.1371/journal.pcbi.1003428
-
Local field potentials indicate network state and account for neuronal response variabilityJournal of Computational Neuroscience 29:567–579.https://doi.org/10.1007/s10827-009-0208-9
-
Correlations and Neuronal Population InformationAnnual Review of Neuroscience 39:237–256.https://doi.org/10.1146/annurev-neuro-070815-013851
-
Parallel processing by cortical inhibition enables context-dependent behaviorNature Neuroscience 20:62–71.https://doi.org/10.1038/nn.4436
-
Dynamics of networks of excitatory and inhibitory neurons in response to time-dependent inputsFrontiers in Computational Neuroscience 5:25.https://doi.org/10.3389/fncom.2011.00025
-
A disinhibitory circuit mediates motor integration in the somatosensory cortexNature Neuroscience 16:1662–1670.https://doi.org/10.1038/nn.3544
-
Cellular and circuit mechanisms maintain low spike co-variability and enhance population coding in somatosensory cortexFrontiers in Computational Neuroscience 6:7.https://doi.org/10.3389/fncom.2012.00007
-
Generating spike trains with specified correlation coefficientsNeural Computation 21:397–423.https://doi.org/10.1162/neco.2008.02-08-713
-
Attention to both space and feature modulates neuronal responses in macaque area V4Journal of Neurophysiology 83:1751–1755.
-
Neural mechanisms of selective visual attentionAnnual Review of Psychology 68:47–72.https://doi.org/10.1146/annurev-psych-122414-033400
-
Modeling the influence of task on attentionVision Research 45:205–231.https://doi.org/10.1016/j.visres.2004.07.042
-
The role of neuromodulators in selective attentionTrends in Cognitive Sciences 15:585–591.https://doi.org/10.1016/j.tics.2011.10.006
-
How structure determines correlations in neuronal networksPLoS Computational Biology 7:e1002059.https://doi.org/10.1371/journal.pcbi.1002059
-
Information processing with population codesNature Reviews Neuroscience 1:125–132.https://doi.org/10.1038/35039062
-
Competitive mechanisms subserve attention in macaque areas V2 and V4Journal of Neuroscience 19:1736–1753.
-
Attentional modulation of visual processingAnnual Review of Neuroscience 27:611–647.https://doi.org/10.1146/annurev.neuro.26.041002.131039
-
The spatial structure of correlated neuronal variabilityNature Neuroscience 20:107–114.https://doi.org/10.1038/nn.4433
-
Three groups of interneurons account for nearly 100% of neocortical GABAergic neuronsDevelopmental Neurobiology 71:45–61.https://doi.org/10.1002/dneu.20853
-
Attention can either increase or decrease spike count correlations in visual cortexNature Neuroscience 17:1591–1597.https://doi.org/10.1038/nn.3835
-
Attention and normalization circuits in macaque V1European Journal of Neuroscience 41:949–964.https://doi.org/10.1111/ejn.12857
-
Feedback-induced gain control in stochastic spiking networksBiological Cybernetics 100:475–489.https://doi.org/10.1007/s00422-009-0298-5
-
Decorrelation of neural-network activity by inhibitory feedbackPLoS Computational Biology 8:e1002596.https://doi.org/10.1371/journal.pcbi.1002596
-
Neural correlates of attention in primate visual cortexTrends in Neurosciences 24:295–300.https://doi.org/10.1016/S0166-2236(00)01814-2
-
Impact of network structure and cellular response on spike time correlationsPLoS Computational Biology 8:e1002408.https://doi.org/10.1371/journal.pcbi.1002408
-
Chaotic balanced state in a model of cortical circuitsNeural Computation 10:1321–1371.https://doi.org/10.1162/089976698300017214
-
Effects of spatial attention on contrast response functions in macaque area V4Journal of Neurophysiology 96:40–54.https://doi.org/10.1152/jn.01207.2005
Article and author information
Author details
Funding
National Science Foundation (DMS-1313225)
- Tatjana Kanashiro
- Gabriel Koch Ocker
- Brent Doiron
National Science Foundation (DMS-1517082)
- Gabriel Koch Ocker
- Brent Doiron
Simons Foundation (Simons Collaboration on the Global Brain)
- Marlene R Cohen
- Brent Doiron
National Institutes of Health (R01 EY022930)
- Marlene R Cohen
National Institutes of Health (CRCNS-R01DC015139)
- Brent Doiron
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The research was supported by National Science Foundation grants NSF-DMS-1313225 (BD), NSF DMS-1517082 (BD), a grant from the Simons Foundation collaboration on the global brain (SCGB #325293MC;BD), NIH grants 4R00EY020844-03 and R01 EY022930 (MRC), a Whitehall Foundation Grant (MRC), Klingenstein-Simons Fellowship (MRC), a Sloan Research Fellowship (MRC), and a McKnight Scholar Award (MRC). We thank John Maunsell for the generous use of the data, and Kenneth Miller, Ashok Litwin-Kumar, Douglas Ruff, and Robert Rosenbaum for useful discussions.
Ethics
Animal experimentation: All animal procedures were in accordance with the Institutional Animal Care and Use Committee of Harvard Medical School (Harvard IACUC protocol number: 04214).
Version history
- Received: December 8, 2016
- Accepted: May 20, 2017
- Accepted Manuscript published: June 7, 2017 (version 1)
- Accepted Manuscript updated: June 8, 2017 (version 2)
- Version of Record published: June 19, 2017 (version 3)
Copyright
© 2017, Kanashiro et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,457
- views
-
- 763
- downloads
-
- 70
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Attentional modulation of neuronal variability in circuit models of cortex
eLife 6:e23978.
https://doi.org/10.7554/eLife.23978
Further reading
-
- Neuroscience
Pavlovian fear conditioning has been extensively used to study the behavioral and neural basis of defensive systems. In a typical procedure, a cue is paired with foot shock, and subsequent cue presentation elicits freezing, a behavior theoretically linked to predator detection. Studies have since shown a fear conditioned cue can elicit locomotion, a behavior that - in addition to jumping, and rearing - is theoretically linked to imminent or occurring predation. A criticism of studies observing fear conditioned cue-elicited locomotion is that responding is non-associative. We gave rats Pavlovian fear discrimination over a baseline of reward seeking. TTL-triggered cameras captured 5 behavior frames/s around cue presentation. Experiment 1 examined the emergence of danger-specific behaviors over fear acquisition. Experiment 2 examined the expression of danger-specific behaviors in fear extinction. In total, we scored 112,000 frames for nine discrete behavior categories. Temporal ethograms show that during acquisition, a fear conditioned cue suppresses reward seeking and elicits freezing, but also elicits locomotion, jumping, and rearing - all of which are maximal when foot shock is imminent. During extinction, a fear conditioned cue most prominently suppresses reward seeking, and elicits locomotion that is timed to shock delivery. The independent expression of these behaviors in both experiments reveal a fear conditioned cue to orchestrate a temporally organized suite of behaviors.
-
- Neuroscience
The fragile X syndrome (FXS) represents the most prevalent form of inherited intellectual disability and is the first monogenic cause of autism spectrum disorder. FXS results from the absence of the RNA-binding protein FMRP (fragile X messenger ribonucleoprotein). Neuronal migration is an essential step of brain development allowing displacement of neurons from their germinal niches to their final integration site. The precise role of FMRP in neuronal migration remains largely unexplored. Using live imaging of postnatal rostral migratory stream (RMS) neurons in Fmr1-null mice, we observed that the absence of FMRP leads to delayed neuronal migration and altered trajectory, associated with defects of centrosomal movement. RNA-interference-induced knockdown of Fmr1 shows that these migratory defects are cell-autonomous. Notably, the primary Fmrp mRNA target implicated in these migratory defects is microtubule-associated protein 1B (MAP1B). Knocking down MAP1B expression effectively rescued most of the observed migratory defects. Finally, we elucidate the molecular mechanisms at play by demonstrating that the absence of FMRP induces defects in the cage of microtubules surrounding the nucleus of migrating neurons, which is rescued by MAP1B knockdown. Our findings reveal a novel neurodevelopmental role for FMRP in collaboration with MAP1B, jointly orchestrating neuronal migration by influencing the microtubular cytoskeleton.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}