
Human activity recognition refers to the classification of activities into known predefined human activity categories based on the temporal data obtained from sensors. With the current rapid development and massive application of wearable devices, the collected data such as human activity and vital signs are becoming more and more accurate, thus making the quality of capturing human activity information and the accuracy of HAR increasingly high [1]. The improvement of HAR accuracy is of great significance for health surveillance systems, remote healthcare, human-computer interaction, rehabilitation medicine and other fields [2]. In the field of intelligent transportation, the behavioral recognition technology can automatically identify traffic violations such as pedestrians/vehicles running red lights and unsafe driving by drivers to ensure people’s travel safety; in the field of medical monitoring, the technology can achieve real-time monitoring of patients and accidental fall detection to ensure that patients can receive timely treatment and assistance; in the field of safety production, real-time monitoring of the whole process of production operations can be achieved, and the detection of accidents occurring in the process of operations and production can be achieved. In the field of safety production, real-time monitoring of the whole process of production operations can be realized, and timely alarms can be provided for actions that may lead to safety hazards in the process of operations and production, ensuring that operations and production are carried out within a safe and controllable range, and safeguarding the personal safety of personnel and property [3].
Although human activity recognition can also be performed through video capture, issues such as privacy protection, capturing blind spots and ethics make this form of information collection flawed and limited in its application. Ke et al. [4] mentioned that wearable health monitoring systems have the advantage of being non-invasive to the human body when performing real-time monitoring, and that HAR ensures the accuracy of the information collected and the safety of the subject while circumventing issues such as privacy protection. Qayyum et al. [5] summarized the application of wearable device data for chronic disease prevention and management, noting that effective data feedback can increase human activity, enhance patient health, improve disease prognosis, reduce healthcare costs and help clinical users make healthcare decisions; Acharya et al. [6] proposed an integrated sensor network, the Care Net and used for remote health care and healthcare; Tsai and Chen [7] summarized the application of wirelessly transmitted sensor networks in rehabilitation medicine, noting that sensor feedback can help in the immediate monitoring of patients undergoing rehabilitation training, and that this information is also of research value at the level of helping to correct rehabilitation postures.
Behavior recognition tasks based on video analysis require the creation of a library of action and pose samples and the training of the designed model to achieve the classification of behavior in video [8]. Traditional methods rely on manual extraction of features, and due to the small amount of data in the early sample library, simple scenes and single actions, traditional methods can meet certain needs [9]. However, with the popularity of video surveillance technology, the application scenes become more and more complex, and the video features extracted using traditional methods can no longer meet the actual needs in terms of recognition accuracy, making it difficult to make full use of the actual value of video surveillance [10].
In this paper, we propose a two-person interaction behavior recognition method based on multi-channel spatiotemporal fusion network for two-person skeleton sequence behavior. Neural networks that have undergone continuous development have unique advantages in solving HAR tasks [11]. The advantages of CNN and RNN in neural networks are considered, and a hybrid CNN-LSTM model is designed and improved in order to automatically extract features from sensor data and incorporate consideration of temporal dependency issues to achieve recognition of basic human states and common rehabilitation and health care activities [12].
Dual-stream CNN has good recognition effect in the field of human body recognition [13]. Its network architecture is shown in Figure 1.
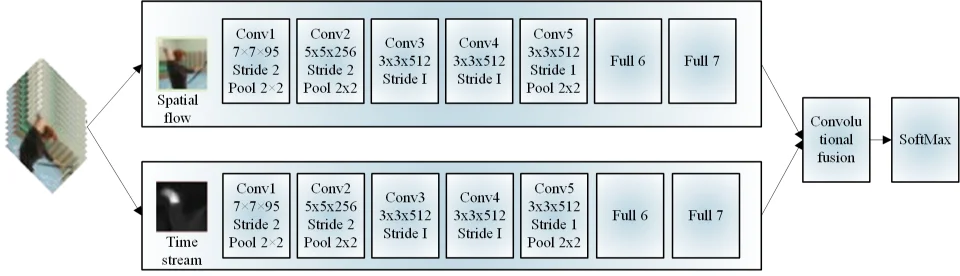
The dual-stream architecture is one of the current benchmarks in the field of human behavior recognition, and scholars at home and abroad have further explored the dual-stream architecture on its basis [14]. The earliest dual-stream convolutional model is based on the VGG-16 convolutional network, and adds residual blocks to the network for the temporal and spatial channels respectively to enhance the network’s ability to extract temporal and spatial features, and finally fuses the feature information of the two channels [15].
On the other hand, the deep network model is optimized by adding an attention module to the residual network, and most attention models today are based on the Encoder-Decoder framework, which can be understood as the process of first transforming a given sequence X into a fixed-length vector by encoding it and then decoding it into a target output sequence \(Y.\) The Encoder-Decoder framework is shown in Figure 2.
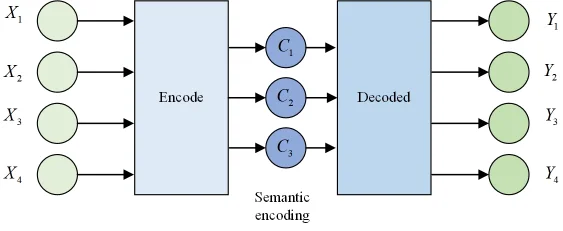
The Encoder-Decoder framework was proposed to lay the foundation for building network models that can selectively extract feature information.
Through the efforts of many scholars, research based on dual-stream CNN models has become more and more mature, and many achievements have been made in the field of human behavior recognition [16]. Although the dual-stream network can well combine the static and dynamic feature information of human behavior and has the characteristics of strong stability and high recognition accuracy, it is undeniable that its high performance is based on the training of a large number of data samples, and in practical applications, many scenarios are due to the inability to collect enough sample information for training, which will make the dual-stream CNN appear in the training process overfitting. This also leads to the problem that in practice it cannot achieve the theoretical recognition accuracy [17].
The spatiotemporal feature fusion network uses a two-layer cascade structure, with the first layer learning spatial features, the second layer learning temporal features, and finally outputting spatiotemporal fusion features.
The spatial feature learning network layer is shown in Figure 3, which learns the spatial relationship features of the skeleton at \(t,t\in \left(1,…,T\right)\) time. To maintain the temporality of the sequence, a \(M\) one-dimensional CNN filter \(\omega\) is used to filter the sequence \(F\) of length \(T\)and dimension \(N\), and a one-dimensional maximum pooling layer extracts the maximum features in the neigh bour hood to obtain a \(M\) feature map \(f_{m}\) of scale \(\left(T,P\right)\), see Eq. [1]: \[\label{GrindEQ__1_} f_{m} =\sigma \left(\omega _{\left(1,I\right)} *F+b\right),m=\left(1,2,…,M\right).\tag{1}\]
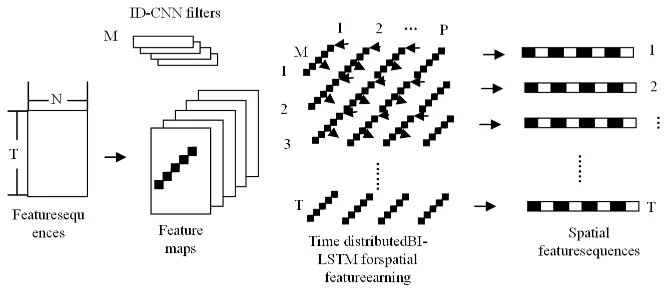
The bi-directional long and short term memory network (Bi-LSTM) is used to learn the correlation of the nodes in the feature map \(f_{m}\) space. The LSTM network is defined as shown in [2] and contains input gate \(i_{t}\), output gate \(o_{t}\), forgetting gate \(f_{t}\) and memory gate \(c_{t}\), which can avoid the gradient disappearance caused by RNN [18]. The Bi-LSTM network consists of a combination of a forward LSTM and a backward LSTM. Point \(t,t\in \left(1,…,P\right)\), the values on feature map \(\left(1,…,M\right)\) form a \(M\)dimensional feature vector \(f\overrightarrow{s}\left(i,t\right)=\left[f_{1} \left(i,t\right),f_{2} \left(i,t\right),…,f_{M} \left(i,t\right)\right]\). Inputting \(f\overrightarrow{s}\left(i,t\right),i\in \left(1,…,P\right)\) into the Bi-LSTM network, the output is a spatial feature representation \(fsr\left(t\right)\) of node correlations at the moment \(t\), see [3]:
\[\label{e2} \begin{cases}{i_{t} =\sigma \left(W_{iy} y_{t} +W_{ih} h_{t-1} +b_{i} \right)}, \\ {f_{t} =\sigma \left(W_{fy} y_{t} +W_{fh} h_{t-1} +b_{f} \right)} ,\\ {o_{t} =\sigma \left(W_{oy} y_{t} +W_{oh} h_{t-1} +b_{o} \right)}, \tag{2}\\ {c_{t} =f_{t} \cdot c_{t-1} +i_{t} \cdot \tanh \left(W_{cy} y_{t} +W_{ch} h_{t-1} +b_{c} \right)}, \\ {h_{t} =o_{t} \cdot \tanh \left(c_{t} \right)}.\end{cases}\]
\[\label{e3} \begin{cases}{hs_{i}^{{\rm forward\; }} (t)=LSTM^{{\rm forward\; }} \left(h_{i-1} ,fs(i,t),c_{i-1} \right)}, \\ {hs_{i}^{{\rm backward\; }} (t)=LSTM^{{\rm backward\; }} \left(h_{i-1} ,fs(i,t),c_{i-1} \right)}, \tag{3}\\ {fsr(t)=\left\{hs_{i}^{{\rm forward\; }} (t),hs_{i}^{{\rm backward\; }} (t)\right\}}.\end{cases}\]
The time-domain LSTM network layer learns the temporal features of the sequence, inputting the spatial features \(fsr\left(t\right)\) at time \(t\) into the time-domain LSTM network, and learning the temporal correlation of the sequence at time \(1\sim T\), to obtain vector \(fsr\) , which represents the temporal fusion features of the behavioral sequence, see Eq. [4]: \[\label{GrindEQ__4_} fsr=LSTM\left(fsr(t)\right).\tag{4}\]
A multi-channel feature fusion network based on distance features was designed to learn single and double association features respectively, as shown in Figure 4. The features input to each channel of this network belong to the distance features of the skeleton and have the same physical meaning. Therefore, a multi-channel weight-sharing spatiotemporal feature fusion network structure is used. Multiple convolutional kernels are used to extract features in a single channel, and the remaining channels use the same structure with shared convolutional kernel weights [19]. The multi-channel weight sharing spatiotemporal fusion network structure has two advantages, one is to reduce the network parameters, and the other is to avoid the gradient dispersion during the training process of the multi-channel structure.
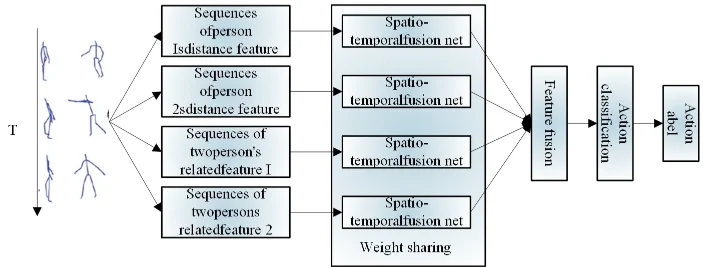
The four sequences of \(D_{1} ,D_{2} ,D_{c1} ,D_{c2}\) are fed into the structure 1DCNN-LSTM LSTM spatiotemporal feature fusion model, which is set to implement the function \(F_{SPT}\), with the same structure of the four branches and shared weights, as shown in [5]: \[\label{GrindEQ__5_} \begin{cases} {fsr_{d1} } {=F_{SPT} \left(D_{1} \right)}, \\ {fsr_{d2} } {=F_{SPT} \left(D_{2} \right)}, \\ {fsr_{dc1} } {=F_{SPT} \left(D_{c1} \right)}, \\ {fsr_{dc2} } {=F_{SPT} \left(D_{c2} \right)}. \end{cases}\tag{5}\]
The outputs are fused together to form a multi-branch fusion feature \(f_{fusion}\), see Eq. [6]:
\[\label{e6}f_{fusion} =\left[fsr_{d1} ,fsr_{d2} ,fsr_{dc1} ,fsr_{dc2} \right].\tag{6}\]
The interaction behavior labels were obtained by learning fusion features using the fully connected network, see Eq. [7]: \[\label{GrindEQ__7_} L=soft\max \left(W*f_{fusion} \right).\tag{7}\]
Experiments were conducted on an Ubuntu 16.04 system with an RTX2070 graphics card using TensorFlow as the back-end and Keras as framework. The hyperparameters of the entire network were: maximum number of iterations 16, batch size 12, input image dimensions (112, 112, 16, 3) for height, width, number of consecutive frames and channels respectively, initial learning rate 0.005, learning rate reduced to one-tenth of the original rate after every 4 rounds, optimizer is stochastic gradient descent, using Nesterov momentum with a momentum value of 0.9. In the test, the input video was time-domain segmented into 3 segments, 16 consecutive RGB images were taken from each segment as network input, and for video frames less than the required number, they were replicated in a loop, and the average of the scores of the 3 video segments was used as the final classification result [20].
Table 1 shows the accuracy of the Inflated VGGNet-16 network designed in this paper compared with the C3D network and other mainstream networks by center-cutting the data as input. Figure 5 shows the data curves of the corresponding experiments in Table 1, where IVGG-16, 19 and IRes-18, 34, 50 represent the corresponding Inflated versions of VGG-16, 19 and Res-18, 34, 50 respectively.
| Method | Accuracy/% |
|---|---|
| C3D | 63.2 |
| VGGNET-6(3D) | 49.8 |
| Inflated Resnet -18 | 43.3 |
| Inflated Res Net-34 | 57.7 |
| Inflated Resnet-50 | 61.9 |
| Inflated VGGNET-16 | 72.4 |
| Inflated VGGNET-19 | 71.0 |
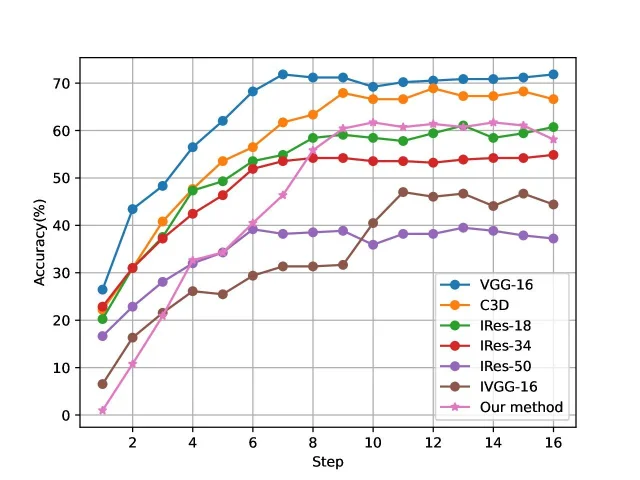
It can be seen from Table 1 and Figure 5 that the small dataset could not satisfy the training of the deep network model of VGGNet-19, while for the relatively shallow residual networks ResNet-18 and ResNet-34 could not model the behavioral actions well, among the VGGNet-16, VGGNet-19, Res-Net-18, ResNet-34 and ResNet-50 of each extended 3D network, this paper models the network with the best recognition performance and the highest accuracy rate [21]. It can also be seen that simply extending the VGGNet-16 network from 2D to 3D is less accurate than the C3D network and converges slowly when trained from scratch, partly because of the insufficient amount of data and partly because the network is initialized from scratch. However, after extending the pre-trained model on the ImageNet dataset to 3D and initializing it, the network converged with improved speed and 72.3% accuracy [22].
Table [2] shows the accuracy of the algorithm in this paper on three standard training-test set grouping schemes (Split1, Split2, Split3) for two datasets with 10-fold enhancement of the input data and a batch normalization layer added to the network, and the final accuracy of the algorithm is averaged over the three components.
| Data set | Accuracy/% | |||
| Split1 | Split2 | Split3 | Average | |
| UCF101 | 88.9 | 90.8 | 89.4 | 89.7 |
| HMDB-51 | 62.4 | 61.0 | 62.0 | 61.8 |
Figures 6 and 7 show the corresponding test accuracy curves for the 3 scenarios on UCF101 and HMDB-51 respectively. The batch size was 32 at the time of testing, and 16 batches were randomly selected for testing on both datasets and the average was taken as the final accuracy.
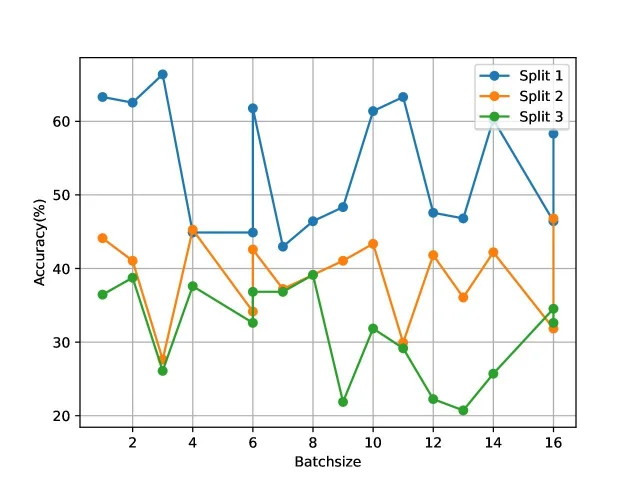
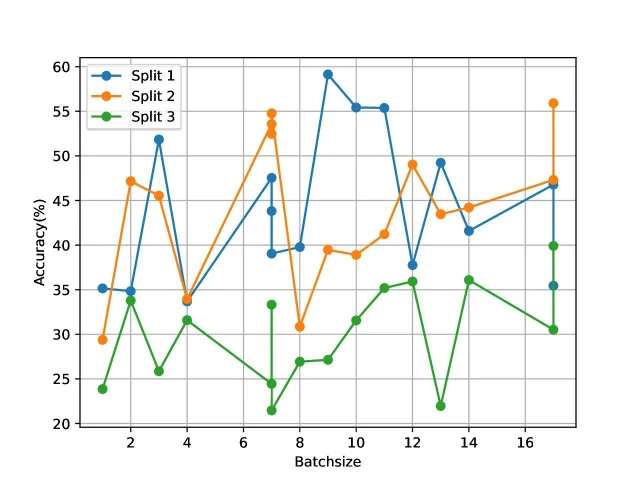
Table [3] shows the accuracy comparison with several classical behavior recognition algorithms as well as algorithms with different data forms as input, it can be seen that the model in this paper is able to achieve a higher recognition accuracy than the classical i DT, two-stream and C3D networks in both cases. The use of the Kinetics dataset to pretrain the network and the combination of different network structures such as two-stream CNN with 3D convolution can all improve the recognition accuracy on small datasets such as UCF101 [23]. It can also be seen that the improvement of the designed network is greater on the HMDB-51 dataset compared to the two-stream algorithm, indicating that the 3D network structure is more favorable for modelling in the temporal dimension and for extracting motion information compared to the 2D network.
| Method | Accuracy/% | |
| UCF101 | HMDB-51 | |
| I DT +FV | 86.0 | 57.3 |
| Two- stream | 88.1 | 59.5 |
| Motion Vector +FV | 78.6 | 46.8 |
| RGB +Enhanced Motion vector | 86.5 | |
| RGB+ R GB Diff | 87.4 | |
| two-stream 13 D (Kinetics) | 98.1 | 81.0 |
| C3D + liner SVM | 83.4 | |
| R (2 + 1) D-RGB (Kinetics) | 96.9 | 74.6 |
| T-c3d (Kinetics) | 92.6 | 62.5 |
| MARS + RGB Flow (Kinetics) | 95.9 | |
| our method | 89.7 | 61.8 |
Figure 8 illustrates real-time video prediction utilizing the planned network. The projected action categories and accompanying prediction probabilities are displayed in the two lines of text in the upper left corner. The constructed network has a very high recognition accuracy for actions with modest backdrop changes or obvious moving targets, as shown in the figure, and it continues to have a high recognition accuracy for actions with big background changes and moving targets that are more or less evident [24, 25, 26].
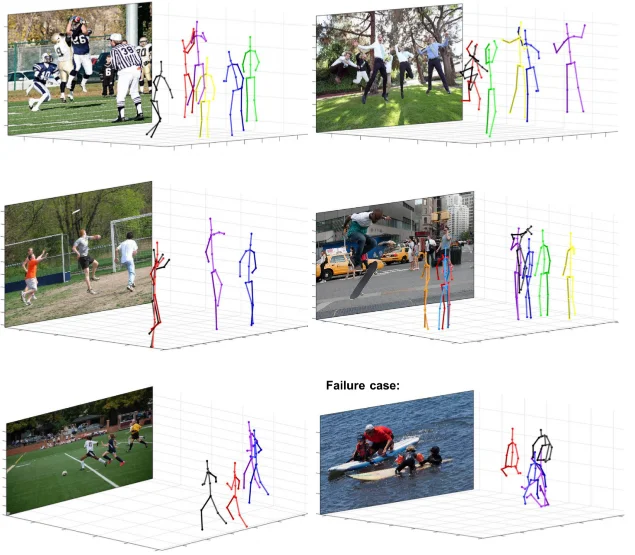
Using a segmented network to separate salient parts of motion and combining attentional mechanisms for the recognition of actions occurring in videos, it is possible to further increase the accuracy of human action recognition by solving the intra-class variability and inter-class similarity problems [25].

The method presented in this paper, which successfully handles the issue of converting 2D portraits to the corresponding 3D models, has the great advantage that it does not require manual feature annotation to achieve good conversion results (although manual gender annotation can produce better results). This is evident from Figure 9. The situation in column 2 also demonstrates that the method in this paper is susceptible to errors due to the complexity of the actual scene: overlapping of different limbs in height, overlapping of different characters in the absence of depth information, and inability to accurately distinguish the orientation of the characters.
A multi-channel spatiotemporal fusion network based on deep learning for two-person interaction behavior recognition method, the experimental results verify that the CNN-LSTM structure can extract the spatiotemporal fusion features of behavior r sequences. A novel two-person behavior representation is designed to obtain a two-person perspective invariant feature representation using four sets of distance features to represent the original skeleton, which improves the perspective invariance of behavior features. A multi-channel weight-sharing spatiotemporal feature fusion network model is designed, using multiple channels to process each group of features separately and sharing the weights among multiple channels to extract multiple groups of spatiotemporal fusion features without increasing the network parameters. The method has a high accuracy rate in two-person behavior recognition, and experimental results comparing with typical algorithms in this field show that the proposed method has obvious advantages in two-person interaction behavior recognition. Multimodal behavior features will be introduced later to achieve behavior analysis of more complex scenes.
No funding is available for this research.
The author declares no conflict of interests.