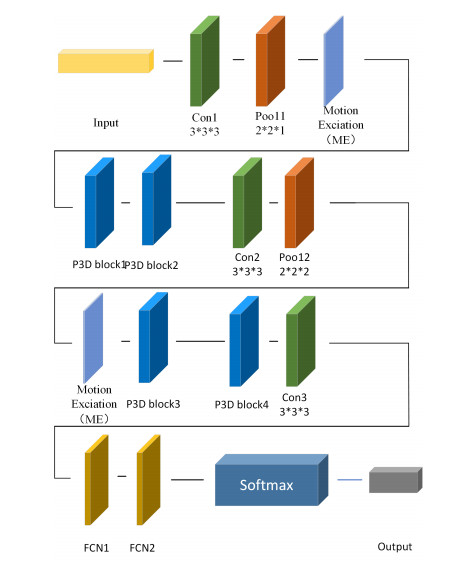
A Multiscale-Motion Embedding Pseudo-3D (MME-P3D) gesture recognition algorithm has been proposed to tackle the issues of excessive parameters and high computational complexity encountered by existing gesture recognition algorithms deployed in mobile and embedded devices. The algorithm initially takes into account the characteristics of gesture motion information, integrating the channel attention (CE) mechanism into the pseudo-3D (P3D) module, thereby constructing a P3D-C feature extraction network that can efficiently extract spatio-temporal feature information while reducing the complexity of the algorithmic model. To further enhance the understanding and learning of the global gesture movement's dynamic information, a Multiscale Motion Embedding (MME) mechanism is subsequently designed. The experimental findings reveal that the MME-P3D model achieves recognition accuracies reaching up to 91.12% and 83.06% on the self-constructed conference gesture dataset and the publicly available Chalearn 2013 dataset, respectively. In comparison with the conventional 3D convolutional neural network, the MME-P3D model demonstrates a significant advantage in terms of parameter count and computational requirements, which are reduced by as much as 82% and 83%, respectively. This effectively addresses the limitations of the original algorithms, making them more suitable for deployment on embedded and mobile devices and providing a more effective means for the practical application of hand gesture recognition technology.
Citation: Hongmei Jin, Ning He, Boyu Liu, Zhanli Li. Research on gesture recognition algorithm based on MME-P3D[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3594-3617. doi: 10.3934/mbe.2024158
A Multiscale-Motion Embedding Pseudo-3D (MME-P3D) gesture recognition algorithm has been proposed to tackle the issues of excessive parameters and high computational complexity encountered by existing gesture recognition algorithms deployed in mobile and embedded devices. The algorithm initially takes into account the characteristics of gesture motion information, integrating the channel attention (CE) mechanism into the pseudo-3D (P3D) module, thereby constructing a P3D-C feature extraction network that can efficiently extract spatio-temporal feature information while reducing the complexity of the algorithmic model. To further enhance the understanding and learning of the global gesture movement's dynamic information, a Multiscale Motion Embedding (MME) mechanism is subsequently designed. The experimental findings reveal that the MME-P3D model achieves recognition accuracies reaching up to 91.12% and 83.06% on the self-constructed conference gesture dataset and the publicly available Chalearn 2013 dataset, respectively. In comparison with the conventional 3D convolutional neural network, the MME-P3D model demonstrates a significant advantage in terms of parameter count and computational requirements, which are reduced by as much as 82% and 83%, respectively. This effectively addresses the limitations of the original algorithms, making them more suitable for deployment on embedded and mobile devices and providing a more effective means for the practical application of hand gesture recognition technology.

| [1] |
Y. Zhang, J. Wang, X. Wang, H. Jing, Z. Sun, Y. Cai, Static hand gesture recognition method based on the vision transformer, Multimedia Tools Appl., 82 (2023), 1–20. https://doi.org/10.1007/s11042-023-14732-3 doi: 10.1007/s11042-023-14732-3

|
| [2] |
T. Zhang, Application of AI-based real-time gesture recognition and embedded system in the design of English major teaching, Wireless Netw., 2021 (2021), 1–13. https://doi.org/10.1007/s11276-021-02693-0 doi: 10.1007/s11276-021-02693-0
|
| [3] |
Y. Xue, Y. Yu, K. Yin, P. Li, S. Xie, Z. Ju, Human in-hand motion recognition based on multi-modal perception information fusion, IEEE Sens. J., 22 (2022), 6793–6805. https://doi.org/10.1109/JSEN.2022.3148992 doi: 10.1109/JSEN.2022.3148992
|
| [4] |
M. S. Amin, S. T. H. Rizvi, M. M. Hossain, A comparative review on applications of different sensors for sign language recognition, J. Imaging, 8 (2022), 1–48. https://doi.org/10.3390/jimaging8040098 doi: 10.3390/jimaging8040098
|
| [5] |
Y. Zhang, Y. Huang, X. Sun, Y. Zhao, X. Guo, P. Liu, et al., Static and dynamic human arm/hand gesture capturing and recognition via multiinformation fusion of flexible strain sensors, IEEE Sens. J., 20 (2020), 6450–6459. https://doi.org/10.1109/JSEN.2020.2965580 doi: 10.1109/JSEN.2020.2965580
|
| [6] |
N. H. Dardas, N. D. Georganas, Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques, IEEE Trans. Instrum. Meas., 60 (2011), 3592–3607. https://doi.org/10.1109/TIM.2011.2161140 doi: 10.1109/TIM.2011.2161140
|
| [7] |
B. Qiang, Y. Zhai, M. Zhou, X. Yang, B. Peng, Y. Wang, et al., SqueezeNet and fusion network-based accurate fast fully convolutional network for hand detection and gesture recognition, IEEE Access, 9 (2021), 77661–77674. https://doi.org/10.1109/ACCESS.2021.3079337 doi: 10.1109/ACCESS.2021.3079337
|
| [8] | P. Barros, S. Magg, C. Weber, S. Wermter, A multichannel convolutional neural network for hand posture recognition, in Artificial Neural Networks and Machine Learning–ICANN 2014: 24th International Conference on Artificial Neural Networks, Hamburg, Germany, September 15–19, 2014. Proceedings 24, (2014), 403–410. https://doi.org/10.1007/978-3-319-11179-7_51 |
| [9] |
S. Gnanapriya, K. Rahimunnisa, A hybrid deep learning model for real time hand gestures recognition, Intell. Autom. Soft Comput., 36 (2023), 763–767. https://doi.org/10.32604/iasc.2023.032832 doi: 10.32604/iasc.2023.032832
|
| [10] | Q. Miao, Y. Li, W. Ouyang, Z. Ma, X. Xu, W. Shi, et al., Multimodal gesture recognition based on the resc3d network, in 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), (2017), 3047–3055. https://doi.org/10.1109/ICCVW.2017.360 |
| [11] | D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri, Learning spatiotemporal features with 3D convolutional networks, in 2015 IEEE International Conference on Computer Vision (ICCV), (2015), 4489–4497. https://doi.org/10.1109/TIP.2021.3092828 |
| [12] | J. Wan, S. Escalera, G. Anbarjafari, H. Jair Escalante, X. Baró, I. Guyon, et al., Results and analysis of chalearn lap multi-modal isolated and continuous gesture recognition, and real versus fake expressed emotions challenges, in Proceedings of the IEEE International Conference on Computer Vision Workshops, (2017), 3189–3197. https://doi.org/10.1109/ICCVW.2017.377 |
| [13] |
Z. Z. Wang, Automatic and robust hand gesture recognition by SDD features based model matching, Appl. Intell., 52 (2022), 11288–11299. https://doi.org/10.1007/s10489-021-02933-y doi: 10.1007/s10489-021-02933-y
|
| [14] |
Q. Gao, Y. Chen, Z. Ju, Y. Liang, Dynamic hand gesture recognition based on 3D hand pose estimation for human–robot interaction, IEEE Sens. J., 18 (2021), 17421–17430. https://doi.org/10.1109/JSEN.2021.3059685 doi: 10.1109/JSEN.2021.3059685
|
| [15] |
Y. Li, D. Zhang, J. Chen, J. Wan, D. Zhang, Y. Hu, et al., Towards domain-independent and real-time gesture recognition using mmwave signal, IEEE Trans. Mob. Comput., 22 (2022), 7355–7369. https://doi.org/10.1109/TMC.2022.3207570 doi: 10.1109/TMC.2022.3207570
|
| [16] |
M. Wang, X. Li, S. Chen, X. Zhang, L. Ma, Y. Zhang, Learning representations by contrastive spatio-temporal clustering for skeleton-based action recognition, IEEE Trans. Multimedia, 2023 (2023), 1–14. https://doi.org/10.1109/TMM.2023.3307933 doi: 10.1109/TMM.2023.3307933
|
| [17] |
C. Pang, X. Gao, Z. Chen, L. Lyu, Self-adaptive graph with nonlocal attention network for skeleton-based action recognition, IEEE Trans. Neural Networks Learn. Syst., 2023 (2023), 1–13. https://doi.org/10.1109/TNNLS.2023.3298950 doi: 10.1109/TNNLS.2023.3298950
|
| [18] |
P. Geng, X. Lu, C. Hu, H. Liu, L. Lyu, Focusing fine-grained action by self-attention-enhanced graph neural networks with contrastive learning, IEEE Trans. Circuits Syst. Video Technol., 33 (2023), 4754–4768. https://doi.org/10.1109/TCSVT.2023.3248782 doi: 10.1109/TCSVT.2023.3248782
|
| [19] |
W. Song, T. Chu, S. Li, N. Li, A. Hao, H. Qin, Joints-centered spatial-temporal features fused skeleton convolution network for action recognition, IEEE Trans. Multimedia, 2023 (2023), 1–15. https://doi.org/10.1109/TMM.2023.3324835 doi: 10.1109/TMM.2023.3324835
|
| [20] |
C. Pang, X. Lu, L. Lyu, Skeleton-based action recognition through contrasting two-stream spatial-temporal networks, IEEE Trans. Multimedia, 25 (2023), 8699–8711. https://doi.org/10.1109/TMM.2023.3239751 doi: 10.1109/TMM.2023.3239751
|
| [21] |
C. Xu, X. Wu, M. Wang, F. Qiu, Y. Liu, J. Ren, Improving dynamic gesture recognition in untrimmed videos by an online lightweight framework and a new gesture dataset ZJUGesture, Neurocomputing, 523 (2023), 58–68. https://doi.org/10.1016/j.neucom.2022.12.022 doi: 10.1016/j.neucom.2022.12.022
|
| [22] | Z. Qiu, T. Yao, T. Mei, Learning spatio-temporal representation with pseudo-3D residual networks, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 5533–5541. https://doi.org/10.1109/ICCV.2017.590 |
| [23] | D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, M. Paluri, A closer look at spatiotemporal convolutions for action recognition, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 6450–6459. https://doi.org/10.1109/CVPR.2018.00675 |
| [24] | S. Xie, C. Sun, J. Huang, Z. Tu, K. Murphy, Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 318–335. https://doi.org/10.1007/978-3-030-01267-0_19 |
| [25] | Z. Huang, X. Shi, C. Zhang, Q. Wang, K. C. Cheung, Flowformer: A transformer architecture for optical flow, in European Conference on Computer Vision, (2022), 668–685. https://doi.org/10.1007/978-3-031-19790-1_40 |
| [26] |
J. Wang, X. Li, J. Li, Q. Sun, H. Wang, NGCU: A new RNN model for time-series data prediction, Big Data Res., 27 (2022), 100296. https://doi.org/10.1016/j.bdr.2021.100296 doi: 10.1016/j.bdr.2021.100296
|
| [27] |
T. Huynh-The, C. H. Hua, N. A. Tu, D. S. Kim, Learning 3D spatiotemporal gait feature by convolutional network for person identification, Neurocomputing, 397 (2020), 192–202. https://doi.org/10.1016/j.neucom.2020.02.048 doi: 10.1016/j.neucom.2020.02.048
|
| [28] |
B. Zhou, C. Han, T. Guo, Convergence of stochastic gradient descent in deep neural network, Acta Math. Appl. Sin., 37 (2021), 126–136. https://doi.org/10.1007/s10255-021-0991-2 doi: 10.1007/s10255-021-0991-2
|
| [29] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. https://doi.org/10.48550/arXiv.1704.04861 |
| [30] | J. Carreira, A. Zisserman, Quo vadis, action recognition? a new model and the kinetics dataset, preprint, arXiv: 1705.07750. https://doi.org/10.48550/arXiv.1705.07750 |
| [31] | H. Kataoka, T. Wakamiya, K. Hara, Y. Satoh, Would mega-scale datasets further enhance spatiotemporal 3D CNNs, preprint, arXiv: 2004.04968. https://doi.org/10.48550/arXiv.2004.04968 |















Figures(16) / Tables(4)

Hongmei Jin, Ning He, Boyu Liu, Zhanli Li. Research on gesture recognition algorithm based on MME-P3D[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3594-3617. doi: 10.3934/mbe.2024158







 DownLoad:
DownLoad: