



Abstract
We address the turbulent fragmentation scenario for the origin of the stellar initial mass function (IMF), using a large set of numerical simulations of randomly driven supersonic MHD turbulence. The turbulent fragmentation model successfully predicts the main features of the observed stellar IMF assuming an isothermal equation of state without any stellar feedback. As a test of the model, we focus on the case of a magnetized isothermal gas, neglecting stellar feedback, while pursuing a large dynamic range in both space and timescales covering the full spectrum of stellar masses from brown dwarfs to massive stars. Our simulations represent a generic 4 pc region within a typical Galactic molecular cloud, with a mass of 3000 M⊙ and an rms velocity 10 times the isothermal sound speed and 5 times the average Alfvén velocity, in agreement with observations. We achieve a maximum resolution of 50 au and a maximum duration of star formation of 4.0 Myr, forming up to a thousand sink particles whose mass distribution closely matches the observed stellar IMF. A large set of medium-size simulations is used to test the sink particle algorithm, while larger simulations are used to test the numerical convergence of the IMF and the dependence of the IMF turnover on physical parameters predicted by the turbulent fragmentation model. We find a clear trend toward numerical convergence and strong support for the model predictions, including the initial time evolution of the IMF. We conclude that the physics of isothermal MHD turbulence is sufficient to explain the origin of the IMF.
Export citation and abstract BibTeX RIS
1. Introduction
The origin of the stellar initial mass function (IMF) is still not fully understood. Many processes, such as magnetic support, radiative and mechanical feedbacks from young stars, density enhancements or pressure support from supersonic turbulence, dynamical interactions between accreting stars, or competitive accretion, may affect the mass distribution of stars. Their relative importance varies with environment and is still disputed. Numerical simulations of star formation have started to reveal the mechanisms controlling the star formation rate (SFR), thanks to systematic parameter studies based on large sets of simulations with a modest dynamic range of scales (e.g., Padoan & Nordlund 2011a; Federrath & Klessen 2012; Padoan et al. 2012), or, more recently, with large-scale simulations where many star-forming regions are formed ab initio and the time evolution and scatter of the SFR can also be investigated (Padoan et al. 2017). While the SFR is already converged in these simulations, a much larger dynamic range is needed to achieve a numerically converged IMF covering the whole spectrum of stellar masses, from brown dwarfs to massive stars. The computational cost of such experiments is beyond the reach of most studies of star formation, so stellar IMFs from numerical simulations are scarce and generally of low statistical significance. Typically limited to ∼100 stars, these simulations barely constrain the IMF turnover and do not yield enough massive stars to probe the Salpeter range. Unable to pursue the necessary range in space and timescales, numerical studies often opt for increasing the physical complexity, for example, including radiative and mechanical feedbacks, in the hope of discerning the effect of new processes on the IMF, despite the small sample size and dubious numerical convergence.
The first numerical IMF with a large enough number of sink particles to probe both the IMF turnover, including brown dwarfs, and the Salpeter range was presented in Padoan et al. (2014b), where we simulated randomly driven, supersonic MHD turbulence in a 4 pc region with a total mass of 3000 M⊙ and a maximum resolution of 50 au. After a long initialization phase without self-gravity, the simulation was evolved with self-gravity, generating 1288 sink particles over a period of 3.2 Myr (2.7 free-fall times). The mass distribution of the sink particles was consistent with a Chabrier IMF (Chabrier 2005) at low masses and a power law with Salpeter's slope (Salpeter 1955) above 1–2 M⊙. In previous numerical studies, the size of the simulated region, L, the duration of star formation (between the first and the last sink particles), tSF, and the total number of sink particles, N*, were respectively ∼10, ∼100, and ∼10 times smaller than in Padoan et al. (2014b). The radiation hydrodynamic (HD) smoothed particle hydrodynamics (SPH) simulations by Bate (2012) and Bate (2014) described a 500 M⊙ region with L = 0.4 pc and yielded at most N* = 183 over a time tSF ∼ 0.09 Myr. The HD grid-based simulations by Krumholz et al. (2012), representing a 1000 M⊙ region, had L = 0.46 pc, N* = 158, and an even shorter star formation time, tSF ∼ 0.02 Myr. The more recent MHD simulations by Myers et al. (2014), modeling a region of the same size and mass, yielded at most N* = 92 over a time tSF ∼ 0.05 Myr.
The earlier barotropic SPH simulations by Bate (2009), with 500 M⊙ in a region with L = 0.4 pc, achieved a large number of sink particles, N* = 1254, and a slightly longer star formation time, tSF ∼ 0.15 Myr. However, that IMF peaked at 0.02 M⊙, an order of magnitude below the peak of the Chabrier IMF, so most of the sink particles had very low masses, which are created only in the absence of a magnetic field or radiation feedback (Bate 2012), and would not exist in nature. An even earlier SPH simulation by Bonnell et al. (2003), modeling 1000 M⊙ in a region with L = 1 pc, reached N* ≈ 400 and tSF ∼ 0.35 Myr. This IMF peaked around 0.3 M⊙ and produced a realistic Salpeter range. However, lacking both magnetic field and radiation feedback, the realistic peak was almost certainly the result of the very limited number of SPH particles, 5 × 105 compared with 3.5 × 107 in Bate (2009). With such a low number of SPH particles, the IMF was incomplete just below its peak and, more importantly, the turbulent velocity field could not be resolved well enough to describe the smallest scales of the turbulent fragmentation process responsible for the IMF turnover. Similar considerations apply to the more recent SPH simulations by Ballesteros-Paredes et al. (2015), modeling a region of the same size, same mass, and similar duration of star formation as in Bonnell et al. (2003).
SPH and grid-based simulations without a magnetic field have been used to claim that the radiative feedback from accreting protostars (perhaps even the mechanical feedback from stellar outflows) is necessary to reproduce the observed IMF (Bate 2009, 2012, 2014; Krumholz et al. 2012). MHD simulations focusing on the effect of the magnetic field strength on star formation have included the radiative feedback as well, without exploring the isothermal case (Myers et al. 2014) and thus could not establish the relative importance of the magnetic field and radiation feedback in controlling the IMF. According to the turbulent fragmentation models (Padoan et al. 1997; Padoan & Nordlund 2002, 2011b; Hennebelle & Chabrier 2008, 2009; Hopkins 2012), the IMF originates primarily as the consequence of supersonic turbulence and can be reproduced under an isothermal gas approximation. Thus, it is important to carefully test the case of supersonic MHD turbulence of an isothermal gas, using as realistic as possible initial conditions and pursuing a large dynamic range in space and timescales in order to probe the whole IMF with a large statistical sample.
As mentioned above, in Padoan et al. (2014b) we already succeeded in reproducing the observed IMF with a simulation of isothermal MHD turbulence that represented a significant step forward in terms of the size of the simulated region, the length of the star formation time, and the number of sink particles. This model has since been refined with slightly better hydrodynamics and more optimal parameters for the sink particle model (Frimann et al. 2016b; Jensen & Haugbølle 2017). In this work, we carry out a more systematic study of the isothermal MHD case, using a large number of simulations to test the dependence of the results on the numerical parameters of the sink particle model (Sections 2 and 3 and Appendix C), to verify the numerical convergence of the IMF (see Section 4), and to test the predicted variability of the IMF due to variations of physical parameters (virial parameter or mean density) or resulting from the early time evolution of the IMF (see Section 5). We also use observed properties of molecular clouds (MCs) to constrain the environmental dependence of the IMF peak (Section 5.2) and stress that the IMF time evolution predicted by our turbulent fragmentation model (Padoan & Nordlund 2002, hereafter PN02), a consequence of the relatively long timescale of massive star formation (Padoan & Nordlund 2011b; Padoan et al. 2014b), is not necessarily predicted by other turbulent fragmentation models (Hennebelle & Chabrier 2008, 2009; Hopkins 2012), where massive stars result from the collapse of massive cores, in line with the scenario of massive star formation by McKee & Tan (2002, 2003). However, we do not see an accelerated accretion rate as the stars gain mass, so the results of our simulations are also at odds with the predictions of the competitive accretion scenario (Bonnell et al. 2001; Bonnell & Bate 2006).
This work focuses on star formation under physical conditions typical of Galactic MCs, i.e., turbulent regions of cold molecular gas following the observed velocity–size relation (with a large scatter). Different conditions in more extreme environments may require a careful consideration of detailed processes that are neglected here, such as radiation and mechanical feedbacks.
2. Numerical Methods
The simulations are carried out with a locally developed version of the public adaptive mesh refinement (AMR) code ramses (Teyssier 2002) that includes random turbulence driving and a robust algorithm for sink particles. Compared to the public version, it has been heavily modified to scale better on supercomputers with large number of cores per node, using an OpenMP/MPI hybrid parallelization, improved MPI load balancing, and with special attention to minimizing and bundling MPI communication. We have also improved the stability of the HLLD in high Mach number flows (see Appendix A), optimized the conjugate gradient method used for solving self-gravity, and improved the consistency of gravitational forces and the stability of sink particle orbits when using subcycling in time (see Appendix B). For the models considered in this paper we use periodic boundary conditions and an isothermal equation of state.
To initialize the turbulent state, we first run without self-gravity for ∼20 dynamical times, starting with uniform density and magnetic fields and a random acceleration with power only at wavenumbers 1 ≤ k ≤ 2 (k = 1 corresponds to the computational box size). The driving force keeps the rms sonic Mach number,  , at an approximate constant value, where σv is the three-dimensional rms velocity and cs is the isothermal speed of sound.
, at an approximate constant value, where σv is the three-dimensional rms velocity and cs is the isothermal speed of sound.
The driving is implemented as in Padoan & Nordlund (2004, 2011a) and Padoan et al. (2012). We use purely solenoidal driving, because of the large separation between the typical driving scale of supernovae (∼70 pc) and the size of the simulated region (4 pc). In Pan et al. (2016) we showed that, in supernova-driven turbulence, the compressive ratio (compressive over solenoid power) at MC scales is consistent with that obtained in the inertial range of randomly driven turbulence with purely solenoidal driving.
The refinement strategy is based on the overdensity. We refine the root grid when the density reaches a certain level, typically 10 times the average density, and then refine using a Truelove refinement criterion (Truelove et al. 1997), where the grid is refined every time the density increases by a factor of four. This refinement strategy is retained when self-gravity is turned on, though the number of AMR levels is increased to better resolve the gravitational collapse. Additionally, we expand the most refined grid so that it is at least eight cells across, to counteract the creation of many small island grids around density peaks. In contrast to Kritsuk et al. (2006) and Schmidt et al. (2009), we do not refine based on velocity or pressure gradients. However, we verified that the tails of the density probability density functions (pdf's) are sufficiently converged in the turbulence simulations used as initial conditions (see Figure 1).
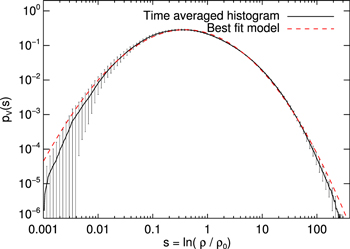
Figure 1. Volume-weighted log-density probability distribution. The dashed red line is a best fit using the model proposed by Hopkins (2013). The histogram is time averaged over 10 snapshots taken from 6 to 24 turnover times, sampling the fully developed turbulence, and is calculated from the initial run with  ,
,  , solenoidal driving, no self-gravity, and a uniform resolution. Error bars indicate the standard deviation of variations between different snapshots.
, solenoidal driving, no self-gravity, and a uniform resolution. Error bars indicate the standard deviation of variations between different snapshots.
Download figure:
Standard image High-resolution imageGravitational collapse is central to simulations of star formation. As cloud cores in the turbulent flow become unstable and start to collapse, the density rises by many orders of magnitude. With current computational capabilities it is very challenging to capture the collapse to stellar densities even with very deep AMR hierarchies, and the correspondingly small time step would lead to prohibitively expensive simulations (though see Nordlund et al. 2014; Kuffmeier et al. 2017, for examples where stellar densities are almost reached). In this work, we are not interested in the detailed stellar physics, and to correctly capture the physics at larger scales of tens of astronomical units, we use sink particles to represent collapsed-gas regions. These should be formed robustly where the gas has unequivocally started to collapse gravitationally, but the conversion from gas in a grid cell to a sink particle representation cannot happen at an arbitrarily high density. An isothermal gas will fragment while collapsing, and if the Jeans length is not sufficiently resolved, the gas can undergo numerical fragmentation (Truelove et al. 1997, 1998). The normalized Jeans length at a given density and numerical resolution, the Jeans number, is
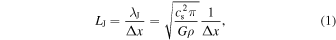
and it has been argued that one should have LJ ≥ 4 (Truelove et al. 1997) everywhere.
To detect gravitational collapse in the gas and to convert the gas into a sink particle, we use a number of criteria:
- 1.Sink particles can only be created in cells where the gas density is above a threshold value ρs. We generally make sure that this only happens at the highest AMR level and that the Jeans length is resolved. In most of the presented runs the Jeans length is resolved with at least two cells at ρs (LJ,s = 2), though tests have shown that even if the Jeans length is slightly under resolved we do not generate artificially a higher amount of sinks (in accordance with Gong & Ostriker 2013). This is likely because even if the gas has started to fragment a bit, the different fragments will afterward be accreted by the sink particle. A typical value for ρs in the runs presented here is 105–106 times the average density.
- 2.The gravitational potential is required to have a local minimum at the cell where the sink particle will be created. This is evaluated by smoothing with a 2 × 2 × 2 average and comparing with the potential in the 26 neighboring smoothed cells.
- 3.The velocity field has to be converging in the cell, ∇ · v < 0.
- 4.No other previously created sink particle can be present within an exclusion radius, rex, of the cell where the new particle is created.
- 5.In runs with an active energy equation, we also disallow creation of sinks from very warm gas. This can otherwise spur the creation of sink particles in, e.g., the high-density expanding shell of a supernova.
This sink particle recipe has already been used in a number of papers (Padoan et al. 2012, 2014b, 2016a, 2016b, 2017; Vasileiadis et al. 2013; Nordlund et al. 2014; Frimann et al. 2016a, 2016b; Kuffmeier et al. 2016, 2017; Pan et al. 2016; Jensen & Haugbølle 2017). In the past, we had used a simpler recipe based only on density criteria in lower-dynamic-range simulations aimed at deriving the SFR (Padoan & Nordlund 2011a). Due to the much larger resolution in following works and the added goal of predicting robustly the stellar IMF, we have switched to using all the above criteria. The individual conditions are similar to what has been used by Federrath et al. (2010), Bate et al. (1995), Krumholz et al. (2004), Gong & Ostriker (2013), and Bleuler & Teyssier (2014). A major difference between our models and many of the cloud-scale models in the literature is the very deep AMR grids we can afford. This makes it possible to use a high-density threshold, ρs, while still resolving the Jeans length and ensures that the gas is already undergoing a physical collapse, at the point where the sink particle is created.
A sink particle is born without any mass but will immediately acquire mass by accretion. Sink particles can accrete gas from cells that are within the accretion radius, racc, if the gas density is higher than a threshold value, ρacc. In the runs presented below we are using two different accretion recipes. A simple recipe is used for the test runs, while a more complicated recipe, capable of tracing the accretion down to very low densities, is used for the convergence runs. The stellar masses obtained with the two recipes are practically identical (see Figure 14 in Appendix C), and the only difference is that the second recipe allows us to get a more precise picture of the accretion history at accretion rates down to 10−9 M⊙ yr−1.
In the simple recipe, the amount of gas accreted is such that the density in the cell is left to be just below ρacc. Typically, we set ρacc to be ρs/2. The sink particles only accrete mass, momentum, and, if present, passive scalars. Thermal energy is removed from the gas in proportion to the amount of mass removed, while magnetic field cannot be deposited on the sink particles. To avoid a pileup of high-density gas just outside the accretion radius, racc, it is necessary to have ρacc ≤ ρs. The accretion distance is typically set to one to two Jeans' lengths at racc around the sink particle. This simple accretion recipe of removing gas to bring it below a critical density is similar to what we have used in the past (Padoan & Nordlund 2011a; Padoan et al. 2012, 2014b; Vasileiadis et al. 2013; Nordlund et al. 2014) and what is used by Federrath et al. (2010). At the very high densities and small racc we are considering, due to the deep AMR hierarchy, the Bondi–Hoyle accretion radius is larger than racc for most of the lifetime of a sink particle, and correct accretion rates are therefore naturally enforced, and we do not need the more complicated accretion recipes employed by other groups (e.g., Krumholz et al. 2004; Gong & Ostriker 2013).
In the more complicated recipe, we set ρacc to a much lower value, allowing for accretion from gas at lower densities, but we also add the condition that the relative speed between the sink particle and the cell is lower than  the Kepler velocity, to avoid artificial accretion of unbound gas. We also taper off the efficiency of the accretion depending on how bound the gas in a cell is to the sink particle. In a simple picture where a sink particle has an effective geometric cross section of πR2, the accretion rate should be
the Kepler velocity, to avoid artificial accretion of unbound gas. We also taper off the efficiency of the accretion depending on how bound the gas in a cell is to the sink particle. In a simple picture where a sink particle has an effective geometric cross section of πR2, the accretion rate should be  , where v is the relative speed between the gas and the sink particle. This formula is our starting point, but we modify it to take into account that unless R is the grid spacing in our code this would correspond to accretion at a distance. Let d be the distance between the center of the cell and the nearest sink particle and vK = (Gmsink/d)1/2 be the Kepler velocity. The mass accretion rate in a single time step Δt from a cell with density ρ is then
, where v is the relative speed between the gas and the sink particle. This formula is our starting point, but we modify it to take into account that unless R is the grid spacing in our code this would correspond to accretion at a distance. Let d be the distance between the center of the cell and the nearest sink particle and vK = (Gmsink/d)1/2 be the Kepler velocity. The mass accretion rate in a single time step Δt from a cell with density ρ is then
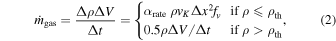
where Δρ is the change in the gas density in the cell volume ΔV, and ρth is a threshold density that we normally set to 2ρs as a safety valve to avoid a large amount of gas piling up faster than it is accreted inside the accretion radius. αrate = 0.2 controls how efficient accretion proceeds compared to rotation. In the unrealistic case of spherical accretion with zero rotation αrate = 1. fv is a tapering function that limits the rate depending on how far the cell is from the sink and how large the relative speed is,
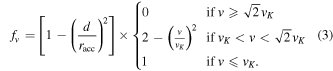
An optimal accretion algorithm should work as a transparent boundary condition such that no discontinuity is seen across the accretion radius. We have tested the formula both in the low-resolution limit, where a sink particle is streaming through a low-density gas, and in the opposite limit with very high resolution, where the sink is accreting from an accretion disk. In both cases, the above numerical parameters, αrate = 0.2 and ρth = 2 ρs, result in a smooth transition between gas inside and outside the accretion radius, racc.
A large fraction of the mass in protostellar systems is lost through winds and jets (Matzner & McKee 2000; Alves et al. 2007; Könyves et al. 2010), launched from small scales not resolved in the current simulations. To account for this mass loss, we apply an efficiency factor,  acc = 0.5, to the accreted mass and momentum of the sink particles in the simulation, so that only
acc = 0.5, to the accreted mass and momentum of the sink particles in the simulation, so that only  of the mass is accreted to a given sink particle in a time interval dt (the nonaccreted gas fraction is simply removed from the simulation). Without a more detailed knowledge of the typical mass loss in outflows, we prefer to stay with a single value of acc, rather than expand the parameter space with yet another dimension. In an older version of the code, used for some of the smaller runs in Appendix C, we accreted the full amount of mass (acc = 1), and the accretion rates and sink particle masses were readjusted after the simulation had finished running. Since this overestimates the gravitational pull of the individual stars, one cannot simply rescale after the fact with the same factor. Two otherwise-identical test runs have shown that to rescale from a run with acc = 1 to one with acc = 0.5 the appropriate factor is 2.4 (see Figure 14 in Appendix C). As discussed by Kuffmeier et al. (2017) in the context of deep zoom-in simulations and by Federrath et al. (2014) in the context of jet and outflow models as a function of resolution, acc depends on the maximum resolution in the model. In our case with a maximum resolution of 50 au for the high model, we do not resolve disks, except for the most massive stars, and we are therefore not accounting for outflows. Thus, it is appropriate to use acc = 0.5 in all runs.
of the mass is accreted to a given sink particle in a time interval dt (the nonaccreted gas fraction is simply removed from the simulation). Without a more detailed knowledge of the typical mass loss in outflows, we prefer to stay with a single value of acc, rather than expand the parameter space with yet another dimension. In an older version of the code, used for some of the smaller runs in Appendix C, we accreted the full amount of mass (acc = 1), and the accretion rates and sink particle masses were readjusted after the simulation had finished running. Since this overestimates the gravitational pull of the individual stars, one cannot simply rescale after the fact with the same factor. Two otherwise-identical test runs have shown that to rescale from a run with acc = 1 to one with acc = 0.5 the appropriate factor is 2.4 (see Figure 14 in Appendix C). As discussed by Kuffmeier et al. (2017) in the context of deep zoom-in simulations and by Federrath et al. (2014) in the context of jet and outflow models as a function of resolution, acc depends on the maximum resolution in the model. In our case with a maximum resolution of 50 au for the high model, we do not resolve disks, except for the most massive stars, and we are therefore not accounting for outflows. Thus, it is appropriate to use acc = 0.5 in all runs.
3. Numerical Model
This paper is based on a large suite of simulations that describe the evolution of a generic MC piece of size Lbox = 4 pc, using isothermal supersonic turbulence, self-gravity, magnetic field, and a subgrid sink particle model for the gravitational collapse of the gas. The simulations are characterized by three nondimensional numbers: the sonic Mach number,  , the Alfvénic Mach number,
, the Alfvénic Mach number,  , and the virial number,
, and the virial number,  , which measure the relative strength of kinetic energy to thermal, magnetic, and gravitational energies, respectively. In the expression for the Alfvénic Mach number, va is the Alfvén speed corresponding to the mean magnetic field and the mean density in the computational domain. R is a characteristic size we use to define the virial number of a simulation, which we take to be R = Lbox/2, and M is the total mass in the simulation, M = Mbox.
, which measure the relative strength of kinetic energy to thermal, magnetic, and gravitational energies, respectively. In the expression for the Alfvénic Mach number, va is the Alfvén speed corresponding to the mean magnetic field and the mean density in the computational domain. R is a characteristic size we use to define the virial number of a simulation, which we take to be R = Lbox/2, and M is the total mass in the simulation, M = Mbox.
The basic parameters of our simulations cannot be chosen arbitrarily. They are constrained by observations and the physical conditions in the interstellar medium (ISM), and by what is feasible with current computational capabilities. At large scales of hundreds of parsecs, the ISM has a complex thermal structure. On parsec scales, high-density cold molecular gas is shielded from UV radiation and cooled by dust and atomic lines balanced by cosmic-ray and shock heating, forming an effectively isothermal medium from where stars are born. Thus, to be realistic, our model should have a size smaller than ∼10 pc. On the other hand, because we aim at studying the emergence of the IMF including the high-mass Salpeter range, the model should contain at least several thousand solar masses of gas. Numerically, the resolution needed to properly characterize the density fluctuations induced by supersonic turbulence limits the sonic Mach number corresponding to the rms velocity and therefore the size of the box we can consider (because of the velocity–size relation followed by MCs (Larson 1981), albeit with a significant scatter). Another constraint is the desire to resolve small enough scales that we marginally resolve large disks around the sink particles. In summary, the approximation of an isothermal gas sets an ultimate upper limit for a realistic box size, while numerical constraints set a more stringent limit. The requirement of sufficient mass sets a lower limit.
Taking the above constraints into consideration, we have chosen  ,
,  , and αvir = 0.83 for the reference simulations. To convert to physical units, we assume an isothermal sound speed of 0.18 km s−1, corresponding to a temperature of T ≈ 10 K, and a mean molecular weight μ = 2.37, appropriate for cold MCs. Given the nondimensional parameters, the rest depends on the physical box size. Choosing Lbox = 4 pc (in line with a characteristic velocity–size relation in MCs) corresponds to setting a total mass Mbox = 3000 M⊙, a mean density of 795 cm−3, and a mean magnetic field strength of 7.2 μG. The resulting mean column density is consistent with MC observations (e.g., Heyer et al. 2001; Roman-Duval et al. 2010), and the magnetic field strength with OH Zeeman splitting measurements (e.g., Crutcher 2012), once density and magnetic fluctuations arising in the super-Alfvénic turbulence are properly modeled (Lunttila et al. 2008, 2009). This gives a free-fall time,
, and αvir = 0.83 for the reference simulations. To convert to physical units, we assume an isothermal sound speed of 0.18 km s−1, corresponding to a temperature of T ≈ 10 K, and a mean molecular weight μ = 2.37, appropriate for cold MCs. Given the nondimensional parameters, the rest depends on the physical box size. Choosing Lbox = 4 pc (in line with a characteristic velocity–size relation in MCs) corresponds to setting a total mass Mbox = 3000 M⊙, a mean density of 795 cm−3, and a mean magnetic field strength of 7.2 μG. The resulting mean column density is consistent with MC observations (e.g., Heyer et al. 2001; Roman-Duval et al. 2010), and the magnetic field strength with OH Zeeman splitting measurements (e.g., Crutcher 2012), once density and magnetic fluctuations arising in the super-Alfvénic turbulence are properly modeled (Lunttila et al. 2008, 2009). This gives a free-fall time,  , of 1.18 Myr and a dynamical or crossing time of tdyn = 1.08 Myr. The virial parameter is known to control the SFR (Krumholz & McKee 2005; Padoan et al. 2012, 2014a, 2017) and is expected to influence the peak of the IMF (see Section 5.2). Thus, we complement our base model, high, with three additional models, light, heavy, and massive, with Mbox = 1500 M⊙, Mbox = 6000 M⊙, and Mbox = 12,000 M⊙ respectively.
, of 1.18 Myr and a dynamical or crossing time of tdyn = 1.08 Myr. The virial parameter is known to control the SFR (Krumholz & McKee 2005; Padoan et al. 2012, 2014a, 2017) and is expected to influence the peak of the IMF (see Section 5.2). Thus, we complement our base model, high, with three additional models, light, heavy, and massive, with Mbox = 1500 M⊙, Mbox = 6000 M⊙, and Mbox = 12,000 M⊙ respectively.
The main properties of the five convergence models with a total mass of 3000 M⊙ and the three models light, heavy, and massive are listed in Table 1. All models use six levels of refinement on top of the root grid. These are the reference models discussed in the main sections of the paper. An additional 36 models are discussed in Appendix C, where we explore the model dependence on the numerical parameters of our sink particle implementation. Computationally, the project has required more than 50 million CPUh at four different HPC centers and has resulted in ∼100 TB of data.
Table 1. Numerical Parameters of the Large-scale Runs Exploring Convergence and the Dependence on αvir
| Run Parameters | Creation of Sinks | Accretion to Sinks | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Run | Root | NAMR | Δx | LJ | ρref | Mbox | αvir | tend | SFE | Nsink | LJ,s | ρs | ρs | rex | ρacc | ρacc | ρth | racc | acc |
| Grid | au |
|
M⊙ | Myr | cm−3 |
|
Δx | cm−3 |
|
ρs | Δx | ||||||||
| 16 | 163 | 6 | 800 | 2.0 | 2 | 3000 | 0.83 | 1.6 | 13% | 108 | 2 | 6.6 × 106 | 8.3 × 103 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| 32 | 323 | 6 | 400 | 2.5 | 5 | 3000 | 0.83 | 1.8 | 13% | 169 | 2 | 2.6 × 107 | 3.3 × 104 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| low | 643 | 6 | 200 | 3.6 | 10 | 3000 | 0.83 | 2.4 | 13% | 279 | 2 | 1.1 × 108 | 1.3 × 105 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| med | 1283 | 6 | 100 | 7.2 | 10 | 3000 | 0.83 | 2.5 | 13% | 363 | 2 | 4.2 × 108 | 5.3 × 105 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| high | 2563 | 6 | 50 | 14.4 | 10 | 3000 | 0.83 | 2.5 | 13% | 410 | 2 | 1.7 × 109 | 2.1 × 106 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| light | 2563 | 6 | 50 | 14.4 | 20 | 1500 | 1.67 | 4.0 | 5% | 86 | 2 | 1.7 × 109 | 4.3 × 106 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| heavy | 2563 | 6 | 50 | 14.4 | 5 | 6000 | 0.42 | 0.7 | 5% | 614 | 2 | 1.7 × 109 | 1.1 × 106 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
| massive | 2563 | 6 | 50 | 14.4 | 2.5 | 12,000 | 0.21 | 0.3 | 3% | 1223 | 2 | 1.7 × 109 | 5.3 × 106 | 8 | 4227 | 5.3 | 2 | 4 | 0.5 |
Download table as: ASCIITypeset image
The results from running the numerical tests discussed in Appendix C have guided us toward a definitive set of parameters for the sink particle model. We require a density threshold for sink particle creation corresponding to resolving the Jeans length with at least two grid cells, LJ,s = 2. Very close to a sink particle the flow will be artificially disturbed and we require an exclusion radius of rex = 8 cells to avoid the creation of spurious sink particles, the occurrence of which can be tested with a very powerful method, the nearest-neighbor histogram (see Appendix C.5). In addition, it is important that the density at sink formation ρs is significantly above the highest densities reached by the turbulence alone, which sets a minimum requirement of ≈105 for the gas overdensity at the highest AMR level, which in this case requires six levels of refinement and a gas density of ≈108 cm−3 (in our reference model high, we actually have ρs = 1.7 × 109 cm−3 and a minimum cell size of Δx = 50 au). Finally, the model needs to have a high enough resolution that small-scale high-density cores, which are the progenitors of low-mass stars, are resolved and can collapse; otherwise, a numerical IMF turnover would be created, dictated by the resolution. This requires both that the turbulence is sufficiently well resolved to sample well the high-density tail of the gas density pdf and that the Jeans length is sufficiently resolved to allow the gravitational collapse and suppress numerical fragmentation (Truelove et al. 1997).
4. IMF Convergence
To test the numerical convergence of the IMF, we have carried out five runs, 16, 32, low, med, and high, with a varying root grid size of 163, 323, 643, 1283, and 2563, respectively, and six levels of refinement (reaching a minimum cell size Δx = 50 au in the reference simulation high). The corresponding minimum numerical values of the Jeans length (in units of Δx of each simulation) are LJ = 2, 2.5, 3.6, 7.2, and 14.4, while the parameters in the sink particle model are identical in all five runs (see Table 1). Notice that instead of using the same overdensity threshold  for refinement for all the runs, giving a factor of two increase in LJ between runs when the spatial resolution is doubled, we have adopted a slightly more generous refinement strategy (lower density thresholds) for the runs 16 and 32 to avoid resolving the Jeans length with less than two cells (see column with ρref in Table 1). However, the threshold density for sink creation, ρs, does increase by a factor of four between runs with increasing resolution by a factor of two, in order to keep the numerical value of the Jeans length at the density of sink creation, LJ,s, independent of resolution (as all other sink particle model parameters), LJ,s = 2. In these simulations, we have also imposed a small maximum time step size of 80 days at the highest level of refinement. The small time step size facilitates an accurate integration of sink particle orbits over the long integration time of most of these runs.
for refinement for all the runs, giving a factor of two increase in LJ between runs when the spatial resolution is doubled, we have adopted a slightly more generous refinement strategy (lower density thresholds) for the runs 16 and 32 to avoid resolving the Jeans length with less than two cells (see column with ρref in Table 1). However, the threshold density for sink creation, ρs, does increase by a factor of four between runs with increasing resolution by a factor of two, in order to keep the numerical value of the Jeans length at the density of sink creation, LJ,s, independent of resolution (as all other sink particle model parameters), LJ,s = 2. In these simulations, we have also imposed a small maximum time step size of 80 days at the highest level of refinement. The small time step size facilitates an accurate integration of sink particle orbits over the long integration time of most of these runs.
To illustrate the general evolution of the simulations, in Figure 2 we show the column density in the high run at different times. At the time when gravity is turned on, the density field is well mixed and well described by a lognormal pdf (see Figure 1). At later times, the densest gas decouples from the turbulent flow and starts to collapse. Some effect of self-gravity can also be seen at larger scales, such as the formation of a large (∼1 pc), elongated dense region that has assembled most of the high-density gas and most of the sink particles by the end of the simulation. This region is itself embedded in a looser, but still discernible, overdense structure that stretches the full width of the computational volume (see the bottom right panel of Figure 2).
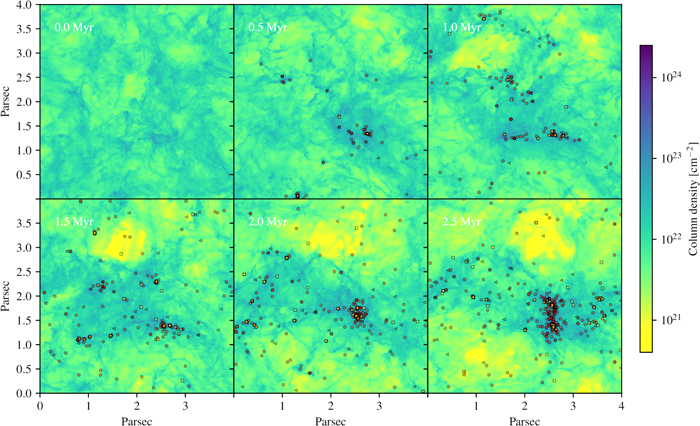
Figure 2. Column density from left to right and top to bottom at 0.5 Myr time intervals after the formation of the first star. The red circles mark the positions of stars with masses m < 0.5 M☉, brown triangles are stars with 0.5 M☉ < m < 1.5 M☉, and orange squares indicate stars with m > 1.5 M☉.
Download figure:
Standard image High-resolution imageThe star formation efficiency (SFE) is the fraction of mass turned into stars at a given time t: SFE(t) = Msink(t)/Mbox, where Msink(t) is the total mass in sink particles at time t. The SFR is the time derivative of SFE and can be expressed in nondimensional units if multiplied by a characteristic timescale. We follow the convention introduced by Krumholz & McKee (2005) to adopt the free-fall time of the mean density as the characteristic time, so the nondimensional SFR is defined as SFRff(t) = dSFE(t)/d (t/tff). Figure 3 shows the time evolution of SFE and SFRff in the convergence runs. The time dependence is well fitted by a power law, SFRff ≈ 0.06 (t/tff)0.5, a slow increase of SFRff from 0.04 at 0.5 Myr (0.4 tff) to 0.08 at 2.4 Myr (2 tff). This increase in SFRff is probably related to the formation of a dominant dense cluster toward the end of the run (see Figure 2). The increasing density in the cluster-forming region decreases the local virial parameter, increasing the SFR (Padoan et al. 2012, 2017).

Figure 3. Evolution of the SFE (top) and SFR per free-fall time (bottom) as a function of time, measured in free-fall times for the convergence runs. The dashed line is a power-law fit SFE = 0.04 (t/tff)1.5 corresponding to SFRff = 0.06 (t/tff)0.5. The free-fall time of the runs is tff = 1.18 Myr. The SFRff is highly intermittent on the very fine cadence of 80 days, which we use to record the sink particle properties, and has been low-pass filtered to aid readability.
Download figure:
Standard image High-resolution imageWe do not expect this trend of increasing SFRff to continue for a much longer time under more realistic conditions. To keep the evolution realistic for a longer timescale, past SFE = 0.13, external forcing from scales beyond the 4 pc box size would be needed to properly account for the interaction of larger-scale turbulence with the cluster-forming region, as observed in larger-scale simulations with supernova driving (Padoan et al. 2017). With supernova driving, the typical disruption time of a MC is ≈2 tdyn (Padoan et al. 2016b), equivalent to ∼2.5 Myr in the simulations of this work, meaning that external feedback from larger scales should play an important role in the evolution of a 4 pc region after approximately 2 Myr. Protostellar feedback from the high-mass stars in the dense cluster could also become important as a local feedback agent at that stage, but it is neglected here.
Compared to the high run, SFRff is converged in the med run and nearly converged in the low run, while at lower resolutions the runs are clearly not converged, and possibly also affected by numerical fragmentation, given the low minimum Jeans number of LJ = 2. There is a period between 0.7tff and 1.2tff where the low run has a higher SFRff, but otherwise the three runs low, med, and high show converged SFRff. This result is in agreement with previous studies of the SFR (e.g., Padoan & Nordlund 2011a; Padoan et al. 2012; Federrath & Klessen 2012), where it was found that SFRff converges at a relatively low numerical resolution, which allowed those works to explore a broad parameter space with many relatively low resolution simulations. On the other hand, the numerical convergence of the stellar IMF is much more demanding and, in our opinion, has never been convincingly achieved. It has not even been tried, so far, in the case of isothermal MHD turbulence, which is the main goal of this work.
The convergence test of our numerical IMFs is shown in Figures 4 and 5. It has been carried out for a single snapshot of each simulation, near the end of each run, to take advantage of the highest value reached by SFE and thus the larger statistical sample. All five runs are compared at SFE = 0.13, corresponding to a time of 1.61, 1.91, 2.46, 2.62, and 2.64 Myr after the formation of the first star, in order of increasing resolution (SFEff is higher in the low-resolution runs, so the same value of SFE is reached in a shorter time). The IMF histograms computed at those times are plotted in Figure 4. To avoid the confusion generated by noisy overlapping histograms, the IMFs have been vertically shifted, except in the case of the reference run high, where N(m) is indeed the number of sink particles in each logarithmic mass interval of the histogram.
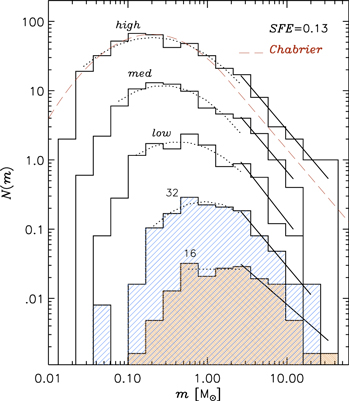
Figure 4. Dependence of the IMF on numerical resolution. The five histograms correspond to the IMFs for the runs 16, 32, low, med, and high (bottom to top), all sampled at SFE = 0.13, corresponding to a time of 1.61, 1.91, 2.46, 2.62, and 2.64 Myr, respectively, after the formation of the first star. Except for the top one, the histograms are shifted vertically by a factor of 1/5 (med), 1/25 (low), 1/125 (32), and 1/625 (16). The dotted lines are lognormal fits between the smallest mass bin where the IMF appears to be complete (based on a sharp cutoff at lower masses, more apparent in histograms with narrower bins) and 2 M⊙. The solid lines are power-law fits above 2 M⊙. The dashed line corresponds to Chabrier's IMF (Chabrier 2005) up to 2 M⊙ and Salpeter's IMF (Salpeter 1955) above that mass.
Download figure:
Standard image High-resolution image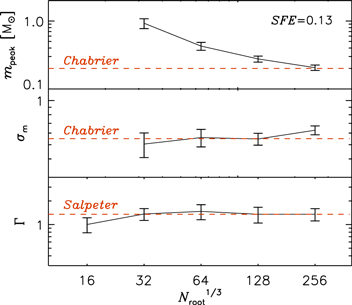
Figure 5. Parameters of the lognormal fits (top and middle panels) and the power-law fits (bottom panel) shown in the previous figure, plotted as a function of the numerical resolution, expressed as the linear size of the root grid in number of computational cells. The error bars show the 1σ uncertainty of the parameters. The top panel shows that the IMF peak tends to converge with resolution, although a full convergence would probably require an even larger root grid size of at least 5123 cells.
Download figure:
Standard image High-resolution imageThe figure shows a clear shift of mpeak toward lower values as the resolution increases, although the shift is quite small between the two highest-resolution runs. To quantify the result of this comparison, we have fitted all the IMFs with a lognormal function for sink masses m ≲ 2 M⊙ (dotted lines), and with a single power law for masses m > 2 M⊙ (solid straight lines). Both models clearly provide very good representations, in their respective mass ranges, of the shape of the IMFs. In the case of the reference run high, the IMF is complete over more than three orders of magnitude in mass, with two orders of magnitude covered by the lognormal fit, and over one order of magnitude by the power-law fit. The smallest mass bin where the IMF is assumed to be complete is taken to be the one just above a sharp drop in N(m), at approximately 0.02 M⊙ in the case of the run high (and larger values by approximately a factor of two for each consecutive step of decreasing resolution). The cutoff is much more apparent when the histograms are computed with narrower mass bins, which is what we have done in order to determine these approximate completeness limits.
The dashed line in Figure 4 shows the Chabrier IMF for single stars (Chabrier 2005) below 2 M⊙, continued by the Salpeter IMF (Salpeter 1955) at larger masses. It fits almost exactly our highest-resolution IMF, except that the Salpeter range is slightly higher in the case of the simulation, partly because the turnover region has a slightly larger width than in the Chabrier IMF. The values of the best-fit parameters are plotted in Figure 5, showing that all IMFs above 16 have a width, σm, consistent with that of the Chabrier IMF, except for the slight increase in the case of the run high, and a power-law slope, Γ, consistent with the Salpeter value. In the case of the lowest-resolution run, 16, σm cannot be measured and Γ is slightly smaller than Salpeter's value. The IMF peak, mpeak, shows a clear dependence on resolution (top panel of Figure 6), but also a trend toward numerical convergence (which may or may not have been already reached at the resolution of the run high).
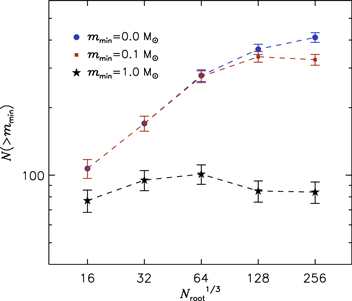
Figure 6. Convergence plots for the total number of stars (circles), the number of stars with mass m > 0.1 M⊙ (squares), and the number of stars with mass m > 1.0 M⊙ (stars), at SFE = 0.13 in all the runs. Within the  uncertainty shown by the error bars, all runs have essentially the same number of intermediate- and high-mass stars, while convergence is achieved at the resolution of the run med in the case of m > 0.1 M⊙. Even the total number of stars (mmin = 0 M⊙) shows a clear trend toward numerical convergence, although it may still slightly increase at a resolution even higher than that of the run high.
uncertainty shown by the error bars, all runs have essentially the same number of intermediate- and high-mass stars, while convergence is achieved at the resolution of the run med in the case of m > 0.1 M⊙. Even the total number of stars (mmin = 0 M⊙) shows a clear trend toward numerical convergence, although it may still slightly increase at a resolution even higher than that of the run high.
Download figure:
Standard image High-resolution imageAn alternative way to test for numerical convergence of the IMFs with increasing resolution is to use the cumulative IMFs. Although the value of mpeak is best defined by a lognormal fit to the IMF, as we did above, the procedure has some dependence on the choice of bin size and location, while the cumulative IMF is immune to such choices. In Figure 7, we show the cumulative IMFs of the convergence-test simulations at SFE = 0.13, expressed as the number of sink particles above the mass m as a function of m. The figure shows a clear tendency toward numerical convergence. The two highest-resolution runs, med and high, have essentially the same cumulative IMF down to a mass of order 0.1 M⊙, lower than the IMF peak. The rate of convergence is illustrated in Figure 6, where we plot the number of stars above a given mass, mmin, as a function of the root grid size of the simulation. Even in the case of the total number of stars, mmin = 0 M⊙, the cumulative IMFs are clearly converging with increasing resolution, consistent with the convergence of mpeak in the top panel of Figure 5. For stars with m > 0.1 M⊙, the convergence is achieved at the resolution of the run med, and all runs have essentially the same number of intermediate- and high-mass stars (mmin = 1.0 M⊙).

Figure 7. Cumulative IMFs of the convergence-test simulations at SFE = 0.13, as in Figure 4. The curves show the number of sink particles above the mass m as a function of m. There is a clear tendency toward convergence, with the two highest-resolution runs, med and high, having essentially the same cumulative IMF down to a mass of order 0.1 M⊙, lower than the IMF peak.
Download figure:
Standard image High-resolution imageBased on the above convergence tests, we can conclude that we have found, for the first time, clear evidence of the convergence of the IMF turnover (with a nearly converged value of mpeak in agreement with the observations) in the case of isothermal MHD turbulence, as predicted by the turbulent fragmentation models of the IMF (PN02; Padoan et al. 1997; Hennebelle & Chabrier 2008, 2009; Padoan & Nordlund 2011b; Hopkins 2012).
5. IMF Variability
The universality of the stellar IMF is hotly debated. While most works emphasize the apparent invariance of the IMF (e.g., Chabrier 2005; Bastian et al. 2010; Massey 2011; Offner et al. 2014; Weisz et al. 2015), some stress compelling evidence of IMF variability (e.g., Kroupa 2001; Dib et al. 2010, 2017; Marks et al. 2012; Kroupa et al. 2013; Scholz et al. 2013; Dib 2014). Observational determinations of the stellar IMF have been approximated with different models, such as a multicomponent power-law function (Kroupa 2001, 2002), a tapered power-law function (Parravano et al. 2011), or a lognormal function below 1 M⊙ continued by a power law at larger masses (Chabrier 2005). The slope of the power law at large masses is usually assumed to be Γ = 1.35, as first estimated by Salpeter (1955), or slightly shallower (e.g., Γ = 1.3 in Kroupa's and Chabrier's IMFs). However, in the most complete and homogeneous study to date, based on 85 resolved clusters in M31, the IMF is actually found to be somewhat steeper, with  (Weisz et al. 2015). Besides this well-defined mean value, the value of Γ exhibits variations from cluster to cluster that are found to be within the error bars, with only a few outliers (e.g., Weisz et al. 2015), or interpreted as indications of intrinsic IMF variations (e.g., Dib et al. 2017). The IMF peak is found to be at approximately 0.2 M⊙, but statistically significant variations from cluster to cluster are suggested by Dib (2014). These variations, if confirmed, may reflect both the environment and the age of the observed stellar populations.
(Weisz et al. 2015). Besides this well-defined mean value, the value of Γ exhibits variations from cluster to cluster that are found to be within the error bars, with only a few outliers (e.g., Weisz et al. 2015), or interpreted as indications of intrinsic IMF variations (e.g., Dib et al. 2017). The IMF peak is found to be at approximately 0.2 M⊙, but statistically significant variations from cluster to cluster are suggested by Dib (2014). These variations, if confirmed, may reflect both the environment and the age of the observed stellar populations.
Physical models for the origin of the IMF predict a dependence on the average physical parameters of the star-forming environment, which may in principle result in a larger IMF variability than observed. One may explore extra processes that would keep the predicted IMF invariant, such as the radiative feedback from the accretion luminosity of protostars (Krumholz et al. 2016), which appears to be crucial in simulations neglecting the magnetic field (e.g., Bate 2012; Krumholz et al. 2012). However, it is also possible that the variability predicted by the theory does not violate the observational constraints. In this section, we consider the turbulent fragmentation model by PN02 and use our simulations to test its prediction for the dependence of the IMF turnover on physical parameters. We then apply the model to the physical parameters of MCs derived from large MC surveys, showing that the predicted IMF variations are within the observational constraints. The PN02 model also implies an early time evolution of the IMF, which we show to be qualitatively confirmed by the simulations.
5.1. The IMF Turnover from Turbulent Fragmentation
The origin of the characteristic stellar mass, essentially the turnover and peak of the IMF, is arguably the most fundamental question in star formation. Padoan et al. (1997) proposed that the IMF turnover is the direct result of the pdf of gas density in a turbulent MC and modeled the turnover as a probability distribution of Jeans masses in the isothermal gas with a lognormal density pdf. Although that early model did not account for the power-law tail of the IMF at large masses, its original explanation for the origin of the IMF turnover has been essentially retained in following turbulent fragmentation models that can predict the full IMF (PN02; Hennebelle & Chabrier 2008, 2009; Hopkins 2012).
A numerical derivation of the turnover mass from the PN02 model yields  , where
, where  is the Bonnor–Ebert (BE) mass with the external density equal to the average density of the star-forming region and
is the Bonnor–Ebert (BE) mass with the external density equal to the average density of the star-forming region and  is the rms Mach number of the turbulent flow (Equation (7) in Padoan et al. 2007). This result can be easily derived as the characteristic BE mass in the turbulent flow, meaning the BE mass with external density equal to the characteristic post-shock density, or, equivalently, the BE mass with external pressure equal to the characteristic dynamic pressure of the turbulent flow. The standard BE mass confined by a thermal pressure
is the rms Mach number of the turbulent flow (Equation (7) in Padoan et al. 2007). This result can be easily derived as the characteristic BE mass in the turbulent flow, meaning the BE mass with external density equal to the characteristic post-shock density, or, equivalently, the BE mass with external pressure equal to the characteristic dynamic pressure of the turbulent flow. The standard BE mass confined by a thermal pressure  is given by
is given by
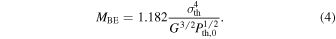
Including the dynamic pressure of the turbulence, the external pressure is given by  . Substituting into the previous expression of MBE, we get a modified turbulent BE mass:
. Substituting into the previous expression of MBE, we get a modified turbulent BE mass:
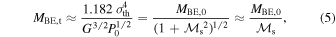
which is a good approximation to the turnover mass in the turbulent fragmentation models mentioned above, providing an intuitive explanation of the origin of the IMF peak. To test the validity of this prediction, we express the IMF peak as
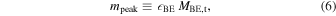
where BE is a local efficiency parameter analogous to acc in the sink particle accretion model, and use the simulations to verify whether it provides a good fit to the numerical IMFs.
For this purpose, we use the four simulations light, high, heavy, and massive with a root grid of 2563 cells and six AMR levels, with four different values of the virial parameter (see Table 1). The virial parameter is varied by leaving the rms velocity constant and increasing or decreasing the mean density (total mass) in the computational volume by a factor of two or four relative to the reference run high (see Section 3 and Table 1). The overdensity threshold at which the root grid is refined is changed from  in run high to
in run high to  in light, heavy, and massive, respectively, to keep the minimum Jeans number constant, at 14.4. The IMFs from these four simulations are shown in Figure 8, where the histograms are shifted vertically by a factor of four between consecutive runs, except for the top histogram, to minimize the confusion of overlapping plots. The IMFs are all sampled at SFE = 0.024, corresponding to a time of 2.07, 0.83, 0.46, and 0.23 Myr after the formation of the first star, for the runs light, high, heavy, and massive, respectively. We have chosen a rather low SFE for this comparison because the run light has a very low SFRff, such that to reach a much higher SFE the simulation should be integrated for much longer than 2 Myr. As commented above, on a scale of 4 pc the influence of larger-scale feedbacks should become quite significant after approximately 2 Myr, making this idealized setup driven by a random force somewhat questionable at later times. Despite the short timescale of the higher αvir runs at SFE = 0.024, we have found that the value of mpeak (and the ratios of its values from different runs) is already reasonably stable to allow this comparison.
in light, heavy, and massive, respectively, to keep the minimum Jeans number constant, at 14.4. The IMFs from these four simulations are shown in Figure 8, where the histograms are shifted vertically by a factor of four between consecutive runs, except for the top histogram, to minimize the confusion of overlapping plots. The IMFs are all sampled at SFE = 0.024, corresponding to a time of 2.07, 0.83, 0.46, and 0.23 Myr after the formation of the first star, for the runs light, high, heavy, and massive, respectively. We have chosen a rather low SFE for this comparison because the run light has a very low SFRff, such that to reach a much higher SFE the simulation should be integrated for much longer than 2 Myr. As commented above, on a scale of 4 pc the influence of larger-scale feedbacks should become quite significant after approximately 2 Myr, making this idealized setup driven by a random force somewhat questionable at later times. Despite the short timescale of the higher αvir runs at SFE = 0.024, we have found that the value of mpeak (and the ratios of its values from different runs) is already reasonably stable to allow this comparison.
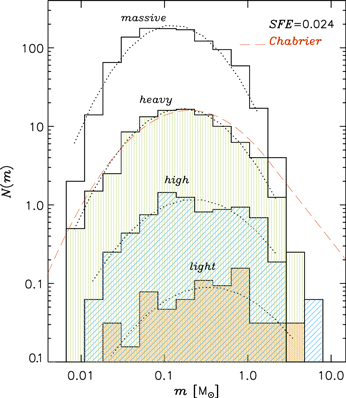
Figure 8. Dependence of the IMF turnover on virial parameter (or mean density, equivalently), from the four simulations with a 2563 root grid, light, high, heavy, and massive, from bottom to top. The IMFs are all sampled at SFE = 0.024, corresponding to a time of 2.07, 0.83, 0.46, and 0.23 Myr, respectively, after the formation of the first star. Except for the top one, the histograms are shifted vertically by a factor of 1/4 (heavy), 1/16 (high), and 1/64 (light). The dotted lines are lognormal fits between the smallest mass bin where the IMF appears to be complete and approximately 10 × mpeak. The IMF peak clearly shifts toward smaller values as the mean density increases.
Download figure:
Standard image High-resolution imageThe dotted lines in Figure 8 are lognormal fits of the IMFs (the power-law fit at larger masses is not possible in this case because the high-mass tail is not developed yet at this early time). The lowest-mass bin for the fit is based on the approximate IMF completeness limit judged as in the numerical convergence test, while the highest-mass bin is approximately 10 × mpeak, assuming that the beginning of the power-law tail is also shifted to higher masses as the mean density decreases. The IMF peak clearly shifts toward smaller values as the mean density increases, as predicted by the isothermal turbulent fragmentation model of the IMF. The best-fit values of the lognormal peaks are shown in Figure 9, plotted as a function of the αvir value of each run (a proxy for the inverse of the mean density at a fixed rms velocity and size). The prediction of Equation (6) is shown by the open circles, after normalizing the relation by the measured value of mpeak in the run high. The normalization corresponds to the choice BE = 0.64, quite close to the related local efficiency parameter set in the sink particle accretion model, acc = 0.5.

Figure 9. Values of the IMF peak, mpeak, from the lognormal fits of the previous figure, plotted as a function of the virial parameter of each simulation (a proxy for the inverse of the mean gas density at constant rms velocity and size). The filled circle shows the value predicted by Equation (6) for the simulation high, assuming an efficiency factor BE = 0.64, in order to match exactly mpeak measured from the simulation. Assuming this fixed value of BE, the open circles show the prediction of Equation (6) for the other three simulations. The measured value for the highest-density run is larger than the prediction, possibly because of a decreasing numerical convergence of the value of mpeak as this becomes smaller with increasing mean density.
Download figure:
Standard image High-resolution imageFigure 9 shows that the measured variation of mpeak with the mean density is approximately consistent with the prediction of Equation (6). Although the slight discrepancy in the case of the run massive may seem significant, it is not significant if one takes into account the uncertainty in the measured value for the run high. Furthermore, because we have established that the value of mpeak in the run high may not be fully converged (see Figure 5), it is also possible that the value of mpeak in the run massive is even less converged, as the total mass in this run is larger and the peak smaller than in the run high. The increasingly higher lack of numerical convergence with increasing mean density could then explain the observed deviation from the prediction of Equation (6).
We set the system rms velocity assuming a temperature of 10 K and the system size (or total mass) based on a standard Larson velocity–size relation (see Section 3). If we chose not to follow the observed Larson relation, both the rms velocity and the size (or total mass) of the system could be rescaled, as long as the nondimensional parameters of the simulation,  and αvir, were not changed. Thus, one may suspect that the predicted IMF peak is consistent with the numerical IMFs only for specific values of gas temperature or system size, but it can be easily shown that this agreement is immune to the rescaling of the simulation. The virial parameter can be expressed as
and αvir, were not changed. Thus, one may suspect that the predicted IMF peak is consistent with the numerical IMFs only for specific values of gas temperature or system size, but it can be easily shown that this agreement is immune to the rescaling of the simulation. The virial parameter can be expressed as
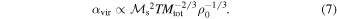
Because both  and αvir are fixed in the simulation, the mass can only be scaled according to
and αvir are fixed in the simulation, the mass can only be scaled according to  . This shows that imposing a value for both
. This shows that imposing a value for both  and αvir in the simulation implies a fixed value of the ratio
and αvir in the simulation implies a fixed value of the ratio  , and thus a fixed value of
, and thus a fixed value of  . Thus, rescaling the temperature or size (or total mass) of the system does not affect our comparison of the predicted IMF peak with the IMF peak from the simulations.
. Thus, rescaling the temperature or size (or total mass) of the system does not affect our comparison of the predicted IMF peak with the IMF peak from the simulations.
To fully test the prediction of the turbulent fragmentation model with respect to the IMF turnover (and the width of the IMF as well), we should also consider the dependence of mpeak on the sonic and Alfvénic rms Mach number. Because all the simulations of this work have the same Mach number, this important test will be addressed in a separate study.
5.2. Variability of the IMF Turnover with Environment
The theoretical and numerical prediction that the IMF peak scales with  implies an environmental dependence of the IMF. In previous works, we have already stressed that if the virial parameter does not vary significantly in star-forming regions, and assuming standard velocity–size and mass-size relations, the predicted IMF peak should have only mild variations (Padoan et al. 2007). Here, we try to quantify the expected scatter of mpeak based on the scatter in the observed properties of star-forming regions. We can express mpeak as a function of the nondimensional parameters of the simulation and the total mass:
implies an environmental dependence of the IMF. In previous works, we have already stressed that if the virial parameter does not vary significantly in star-forming regions, and assuming standard velocity–size and mass-size relations, the predicted IMF peak should have only mild variations (Padoan et al. 2007). Here, we try to quantify the expected scatter of mpeak based on the scatter in the observed properties of star-forming regions. We can express mpeak as a function of the nondimensional parameters of the simulation and the total mass:
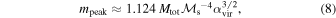
which shows that for constant αvir and for standard Larson relations, Mtot ∝ L2 and σv ∝ L1/2, mpeak is constant. However, observed MCs have a range of values of αvir and yield Larson relations with a significant scatter and with exponents in general different from those standard values. Thus, our IMF model should predict non-negligible IMF peak variations from cloud to cloud.
In order to quantify the observational scatter in mpeak predicted by the model, we consider two of the largest Galactic MC samples available: the MC catalog by Heyer et al. (2001), extracted from a decomposition of the 12CO FCRAO Outer Galaxy Survey (Heyer et al. 1998), and the MC catalog by Roman-Duval et al. (2010), extracted from the UB–FCRAO Galactic Ring Survey (Jackson et al. 2006). To limit the distance and mass uncertainties, Heyer et al. (2001) consider only MCs with circular velocity <−20 km s−1, which yield a sample of 3901 clouds. Roman-Duval et al. (2010) provide an estimate of the error in the mass determination of each of the 750 MCs in their catalog. We select a subsample of their clouds with a mass error <20%, in order to minimize the scatter in cloud properties due to observational errors instead of intrinsic cloud differences. Finally, we retain only MCs with mass >103 M⊙ (smaller clouds would not yield a well-sampled IMF), resulting in 720 MCs from the Outer Galaxy Survey and 174 MCs from the Galactic Ring Survey.
Figure 10 shows the estimated value of mpeak for the clouds in the two observational samples. In the case of the Outer Galaxy, mpeak shows a tendency to decrease with increasing cloud mass, while mpeak is essentially independent of cloud mass in the case of the Galactic Ring. On the average, the expected IMF peak is more than twice larger for clouds in the Outer Galaxy than for those in the Galactic Ring, because of the larger values of αvir in the Outer Galaxy clouds. For the most massive clouds (few ×105 M⊙), where αvir is relatively low also in the case of the Outer Galaxy Survey, the two samples give approximately the same value, mpeak ≈ 0.25, consistent with the peak of the Chabrier IMF. In order to estimate a characteristic value of the peak, we consider the clouds with αvir < 3.0, because of the strong suppression of star formation at larger values of the virial parameter (e.g., Padoan & Nordlund 2011a; Padoan et al. 2012, 2017), and with mass Mcl > 104 M⊙, because most of the mass is in the most massive clouds, based on the cloud mass distribution. With these subsets of clouds from the two surveys, the mean and standard deviations are mpeak = 0.6 ± 0.25 M⊙ and mpeak = 0.26 ± 0.09 M⊙ for the outer and inner Galaxy, respectively, with over 90% of these star-forming clouds yielding values in the range 0.1 M⊙ < mpeak < 1.0 M⊙.

Figure 10. Predicted IMF peak according to Equation (6) vs. cloud mass, for Outer Galaxy Survey clouds from Heyer et al. (1998) and the Galactic Ring Survey clouds from Roman-Duval et al. (2010), more massive than 103 M⊙ (see main text for details about the cloud selection). The error bars give the mean and standard deviation of mpeak in six logarithmic bins of Mcl.
Download figure:
Standard image High-resolution imageThis scatter in the peak of the stellar IMF predicted for different MCs is the consequence of the scatter in the velocity–size and mass-size relations, or, equivalently, the scatter in the relation between virial parameter and mass (see Figures 31, 33, 34, and 35 in Padoan et al. 2016b and Figures 5–7 in Padoan et al. 2016a). We have recently shown that supernova-driven turbulence generates MCs with properties consistent with the observations (Padoan et al. 2016a, 2016b; Pan et al. 2016). Because of this successful comparison between MCs selected from our simulation and the observations, we can use the simulation to infer that most of the scatter in the observational Larson relations may originate from true physical variations from cloud to cloud, rather than be dominated by statistical uncertainties in the observational measurements. Thus, we conclude that the predicted variations of the IMF peak from cloud to cloud, illustrated by Figure 10, are realistic. This result is consistent with the recent finding that the IMFs of young nearby stellar clusters show significant variations from region to region. Using a Bayesian analysis of the IMFs of eight young Galactic clusters, Dib (2014) has demonstrated that the posterior probability distribution functions of the IMF parameters of different clusters do not generally overlap within the 1σ uncertainty level. In the case of the Chabrier plus power-law fit, he derives IMF peak values in the range 0.29–0.69 M⊙; in the case of the fit with Parravano's tapered power law, the range is even larger, 0.14–0.80 M⊙.4
These observed IMF peak values are consistent with the ones predicted by our model applied to the star formation conditions of typical Galactic MCs. Thus, their scatter is consistent with that expected as a consequence of cloud-to-cloud variations in  and αvir at fixed cloud mass (essentially the scatter in the Larson relations).
and αvir at fixed cloud mass (essentially the scatter in the Larson relations).
5.3. Variability of the IMF from Time Evolution
As explained in Padoan & Nordlund (2011b), the PN02 turbulent fragmentation model implies a time evolution of the IMF, because more massive stars are the result of converging motions from larger scales in the turbulent flow, requiring larger time to assemble the stellar mass (the turnover time of turbulent eddies increases with their size) than lower-mass stars. Therefore, at very early times, massive stars are still not fully formed, as they require a timescale comparable to the turnover time of the largest turbulent scales in the flow, of order of 1 Myr in typical MCs. This is much longer than the formation time of 100 kyr in the model of massive star formation of McKee & Tan (2002, 2003).
It should be stressed that the mechanism of massive star formation (and thus the origin of the Salpeter slope of the IMF tail) in the turbulent fragmentation models of Hennebelle & Chabrier (2008) and Hopkins (2012) is quite different than in PN02 and, unlike PN02, may lead to the McKee and Tan scenario of massive star formation. In these models, massive stars originate from massive cores that manage to exceed their Jeans mass. The reason why a large mass is needed to exceed the Jean mass is that the turbulence is included as a source of pressure support defining the Jeans mass, despite the fact that such a generalization of the Jeans mass is actually valid only in the case in which the turbulent outer scale is much smaller than the core size and the turbulent velocity is much smaller than the speed of sound (Chandrasekhar 1951), both conditions being largely violated in the context of these models. The collapse of such a massive core cannot occur until it is fully formed, meaning until it has exceeded this turbulent Jeans mass. Once that happens, the core collapses and forms a massive star essentially in a free-fall time, similarly to the scenario of the McKee and Tan model. However, massive prestellar cores as predicted by these turbulent fragmentation models may have too low gas density (too large sizes), on average, compared with observed cores, or even with the initial conditions of the McKee and Tan model, because they only need to be mild density fluctuations in the turbulent flow, rather than post-shock regions.
Turbulent pressure support against self-gravity plays no role in PN02, where the turbulence is only viewed as a source of density enhancement through shocks. Prestellar cores are assumed to emerge in the post-shock gas, where the turbulence has been largely dissipated. The inertial converging flows feeding such post-shock cores can accumulate enough mass to form a massive star, over a characteristic turnover time on the scale of such flows, much longer than the free-fall time in the post-shock gas. At the post-shock density, such mass would be many times larger than the Jeans mass (excluding support from turbulent motions that is not important in the post-shock gas), so the core cannot be supported against collapse for the whole time necessary to gather all the available mass. As soon as the critical mass for collapse in the post-shock gas has been reached, a protostar of intermediate mass is formed by the collapse of the core, and the rest of the mass has to be accreted through a circumstellar disk fed by the same converging flows that had assembled the prestellar core. In other words, the stellar mass predicted by the PN02 model should be seen as the total mass available to form a star, while the actual mass of a prestellar core (prior to its collapse into a protostar) could be significantly smaller, at least in the case of massive stars (see Figure 1 in Padoan & Nordlund 2011b). This results in a difference between the prestellar core mass function (MF) and the stellar IMF, with the prestellar core MF having a steeper high-mass tail than the Salpeter IMF (Padoan & Nordlund 2011b). In the case of low-mass stars, the stellar mass is not much larger than the characteristic BE mass in the post-shock gas, so most of the core mass is assembled before the core collapses.
Earlier turbulence simulations without self-gravity and sink particles have already demonstrated the post-shock origin of prestellar cores as assumed in PN02 (Padoan et al. 2001, 2007), at odds with the scenario of Hennebelle & Chabrier (2008) and Hopkins (2012). Using a clump-find algorithm (instead of sink particles), Padoan et al. (2007) identified dense post-shock cores containing many Jeans masses (and not supported against self-gravity by their turbulent pressure) in very large simulations of supersonic MHD turbulence without self-gravity. They also found that the core mass distribution was consistent with a power law with the Salpeter slope, proving that such cores could contain the mass reservoir responsible for the formation of massive stars. Evidently, if self-gravity had been present in the simulations, those massive cores would have collapsed much before gathering their total mass, and the rest of their mass would have been accumulated over many free-fall times, as indeed shown by more recent simulations with self-gravity and sink particles, such as in the work by Padoan et al. (2014b). In Padoan et al. (2014b), using a simulation with almost identical physical and numerical parameters as the model high in this work, we obtained nearly 1300 sink particles over a time of 3.2 Myr, with a mass function closely following a Chabrier IMF at small masses and a Salpeter IMF at masses larger than 1–2 M⊙. We used that simulation to argue that the large-scale infall from the turbulent inertial flows feeding the protostars through an accretion disk could explain the observed luminosity distribution of protostars. We also showed that, on average, the time to gather 95% of the final stellar mass, t95, increases with increasing final stellar mass, Mf, according to t95 = 0.45 Myr × (Mf/1 M⊙)0.56, so it takes on average over 1 Myr to form a 10 M⊙ star (see Figure 13 in Padoan et al. 2014b). However, we did not see an accelerated accretion rate as the stars gain mass, so our results are at odds with the predictions of the competitive accretion scenario (Bonnell et al. 2001; Bonnell & Bate 2006).
The dependence of the formation time on the final stellar mass is confirmed by the simulations of this work. Figure 11 shows the dependence of t95 on Mf, for our reference simulation high with 2563 root grid. Only stars that have practically stopped accreting by the end of the simulation are included in the plot, to ensure that the value of t95 is not artificially truncated by the finite integration time. This is enforced by selecting only the sink particles whose accretion rate averaged over the final 100 kyr of the simulation is less than 10% of their accretion rate averaged from their birth time to the time they reach 95% of their final mass. This selection retains 72.5% of the sink particles. We have verified that a much more stringent selection, where the accretion rate in the last 100 kyr has dropped to less than 0.005% of its lifetime average, retains only 28% of the sink particles but yields the exact same power-law fit given below, albeit with larger uncertainties of the slope and intercept. Even the power-law fit obtained by retaining all the sink particles yields the same parameters as in Equation (9) below, within the 1σ uncertainties, as long as the two stars more massive than 20 M⊙ (and still actively accreting) are excluded from the fit. The apparent insensitivity of the relation between t95 and Mf is due to the long integration time of the simulation relative to the t95 values of even the most massive stars.
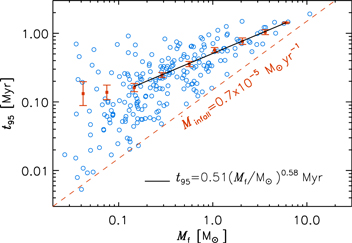
Figure 11. Formation time of sink particles when 95% of their final mass has been assembled, vs. sink particle final mass, defined as the sink particle mass at the end of the simulation high, at t = 2.5 Myr. The squared symbols and the error bars show the average and standard deviation of t95 computed inside logarithmic intervals of the final mass. The solid black line is a linear fit to the logarithmic values of t95 vs. final mass, giving t95 = 0.51 Myr (Mf/M⊙)0.58, and the dashed line is an approximate lower envelope of the plot, corresponding to a constant infall rate of 0.7 × 10−5 M⊙ yr−1.
Download figure:
Standard image High-resolution imageFigure 11 shows that the values of t95 increase with increasing Mf, with a lower envelope approximately consistent with a constant infall rate of approximately 0.7 × 10−5 M⊙ yr−1. A power-law fit of the average values of t95 in logarithmic bins of Mf gives
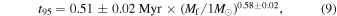
consistent with our previous result in Padoan et al. (2014b). Although the fit would be barely affected by including the two lowest-mass bins, those bins were excluded because the relation seems to flatten at the lowest masses. Furthermore, we do not expect t95, as we measure it, to scale with Mf for masses below the IMF peak, as such stars (mainly brown dwarfs) do not result from characteristic turbulent compressions at a certain (small) scale, but from very rare compression events biased toward very large density (necessary for the BE mass to reach brown-dwarf values; Padoan & Nordlund 2004).
The relatively long formation timescale should result in a time dependence of the IMF. Using the same simulation high, we quantify this time evolution through a lognormal fit of the IMF between 0.03 and 1.5 M⊙ and a power-law fit of the IMF above 1.5 M⊙. Figure 12 shows the IMF and the two fits at seven select times. Every time includes stars of ages between 0 and Δt, so it is equivalent to observe a star-forming region of age Δt. At very early times, only a few stars have been formed, so the IMF would be poorly defined. To increase the statistical sample, for every value of Δt we consider all the adjacent time intervals of size Δt included between the beginning and the end of the star formation process (2.5 Myr in total) and measure the mass of all the sink particles formed in each of those intervals (hence with age between 0 and Δt). In this way, the stellar sample is always of the order of the total number of sink particles at the end of the simulation, for every value of Δt. Under the reasonable assumption that the average physical conditions in the simulated star-forming region are stationary, this procedure should provide the correct IMF also for very small values of Δt. For clarity, the IMF histograms in Figure 12 have been shifted vertically by an arbitrary value, except for the case of 0.03 Myr, which shows the actual number of stars in each mass bin.

Figure 12. Time evolution of the mass distribution of sink particles in the reference simulation high. The time of each IMF since the formation of the first sink particle is given next to each histogram. The histograms are shifted vertically by an arbitrary value, except for the case of 0.03 Myr, which shows the actual number of stars in each mass bin. The dotted lines are lognormal fits between the smallest mass bin where the IMF appears to be complete (based on a sharp cutoff at lower masses, more apparent in histograms with narrower bins and corresponding to late times) and 2 M⊙. The solid lines are power-law fits above 2 M⊙.
Download figure:
Standard image High-resolution imageFigure 12 shows a clear time evolution of the IMF, with the lognormal part at low masses becoming gradually broader over the first megayear of evolution, and a gradual buildup of the power-law tail. The time dependences of the best-fit parameters are plotted in Figure 13, where the horizontal dashed lines mark the value of mean and standard deviation of the observational IMF from Chabrier (2005) (middle and top panels) and the Salpeter IMF slope (bottom panel). Both the peak and the width, σm, of the IMF grow with time and settle after approximately 1 Myr.

Figure 13. Time evolution of the IMF parameters derived from the fits shown in the previous figure. The IMF peak is already established after less than 1 Myr from the creation of the first sink particles, although it is a bit larger around 1.5 Myr (top panel). The power-law tail at large masses takes approximately 2 Myr to develop beyond 10 M⊙ and achieve a stable slope, Γ, consistent with Salpeter's value (bottom panel). The progressive buildup of the tail and the decreasing value of Γ are reflected by a gradual increase in the width of the IMF, σm, during the initial 1.7 Myr (middle panel).
Download figure:
Standard image High-resolution imageWhile σm settles at a value indistinguishable from the observational one, mpeak remains a bit larger than Chabrier's value. The time-averaged value of the IMF peak after the first 1 Myr is  . The exponent of the power-law tail has a rather large uncertainty, due to the limited number of intermediate- and high-mass stars in the simulation. However, it is clearly decreasing over time as the high-mass tail of the IMF develops. The gradual buildup of the IMF tail takes nearly 2 Myr, after which its power-law slope, Γ, is essentially constant and consistent with Salpeter's value.
. The exponent of the power-law tail has a rather large uncertainty, due to the limited number of intermediate- and high-mass stars in the simulation. However, it is clearly decreasing over time as the high-mass tail of the IMF develops. The gradual buildup of the IMF tail takes nearly 2 Myr, after which its power-law slope, Γ, is essentially constant and consistent with Salpeter's value.
This time dependence of the IMF is very hard to constrain observationally, because a very young star-forming region, say, less than 0.5 Myr, would typically have very few stars and thus a poorly defined IMF (we cannot generate many Δt intervals as we have done with the simulation). Furthermore, the variations of mpeak due to variations in the physical parameters of the star-forming regions according to Equation (8) may be difficult to disentangle from the effect of time evolution, particularly if the physical parameters of a given region also vary with time.
6. Conclusions
We have presented results from a large set of simulations of randomly driven supersonic MHD turbulence, meant to represent a characteristic MC region of 4 pc and 3000 M⊙. To match the assumptions of the turbulent fragmentation model of the IMF, we have adopted an isothermal equation of state, neglecting both radiative and mechanical feedbacks from protostars. Our main results are as follows:
- 1.Thanks to a large number of test runs, we have found a definitive set of optimal parameters of our sink particle model: number of cells per Jeans' length at the sink particle creation density LJ,s = 2, exclusion radius for creation rex = 8 Δx, ratio of accretion threshold density to sink creation density ρth/ρs = 2, and accretion radius racc = 4 Δx.
- 2.We have found clear trends toward a numerical convergence of the IMF and have shown that isothermal MHD turbulence can reproduce both the IMF turnover, consistent with the Chabrier IMF, and the power-law tail at high masses, consistent with the Salpeter slope.
- 3.The dependence of the IMF peak on the mean gas density predicted by the turbulent fragmentation model has been confirmed using three simulations with different values of the mean density.
- 4.We have estimated the expected variations of the IMF peak due to variations of virial parameter and Mach number in MCs, based on observed cloud properties derived from large Galactic MC surveys. The predicted variations are in line with the observational evidence of IMF variations in young stellar clusters.
- 5.The timescale of star formation increases with stellar mass, with 10 M⊙ stars requiring on average over 1 Myr to reach 95% of their final mass. This results in a time dependence of the IMF. It takes of order 1 Myr for the width and peak of the IMF to grow to their final values, and nearly 2 Myr for the power-law high-mass tail to get established and for the slope to settle to the Salpeter value.
- 6.The time evolution of the IMF is expected from the turbulent fragmentation model of PN02, but not necessarily from other turbulent fragmentation models. It is also in contradiction to the idea that massive stars form from the rapid collapse of massive cores, as well as to the idea that the growth of massive stars is controlled primarily by their own mass through competitive accretion.
We conclude that isothermal MHD turbulence yields a stellar IMF consistent with the observations. Other physical processes, such as radiation and outflows from protostars, competitive accretion, or dynamical interactions, may not play a dominant role. Because we have focused on typical star-forming conditions in Galactic MCs, it is still possible that these other processes become dominant in more extreme environments, such as near the Galactic center or in starburst galaxies. The important implications for the formation of massive stars mentioned in this work will be addressed in detail in a separate work.
T.H. is supported by a Sapere Aude Starting Grant from the Danish Council for Independent Research. P.P. is supported by the Spanish MINECO under project AYA2014-57134-P. Å.N. is supported by a large framework grant from the Danish Council for Independent Research. Research at the Centre for Star and Planet Formation is funded by the Danish National Research Foundation (DNRF97). Computing resources for this work were partly provided by the NASA High-End Computing (HEC) Program through the NASA Advanced Supercomputing (NAS) Division at Ames Research Center. We acknowledge PRACE for awarding us access to the computing resource JUQUEEN based in Germany at Forschungszentrum Jülich and access to the computing resource CURIE based in France at CEA, where part of the simulations where carried out. The astrophysics HPC facility at the University of Copenhagen, which is supported by a research grant (VKR023406) from VILLUM FONDEN, was used for carrying out part of the simulations, the analysis, and long-term storage of the results.
Appendix A: MHD in Highly Supersonic Flows
Performing simulations of magnetized and highly supersonic flows is a challenge for Godunov solvers, which is only amplified when coupled with self-gravity, sink particles, and fine-coarse transitions of an adaptive mesh. The average Mach number in the presented simulations is 10, but at exceptional points in the flow the combined advection and fast-mode speed can be more than 500 times the sound speed. To stabilize the solver in these extreme conditions, we have made several changes to the public MHD solver included in ramses. First of all, we have contributed a small bug fix to how the magnetic fluxes are updated at fine–coarse interfaces that occasionally would result in nonphysical solutions. Second, we have made a modification of how states in the HLLD solver are computed when in principle a "0/0" situation arises (Miyoshi & Kusano 2005) in the computation of the transverse velocities and magnetic fields in the Riemann fan. The equations for the intermediate states are
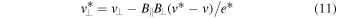
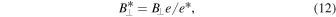
where ρ, v, B, e, and S are the density, velocity, magnetic field, internal energy, and combined advection and fast-mode speed, respectively. Here ∥ and ⊥ indicate the parallel and perpendicular components, respectively, with respect to the normal of the interface over which the Riemann problem is solved. This is indeterminate when e* = 0. Instead, the limiting expressions (Miyoshi & Kusano 2005)
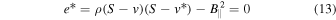
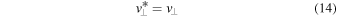
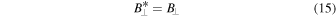
should be used. In practice, numerical round-off introduce large errors when e* is close to 0, compared to the quantities involved. We have therefore modified the condition, such that we use the limiting expressions already when  . This has removed cases where the solver crashed immediately from one time step to the next. Both fixes have been propagated to the public version of ramses.
. This has removed cases where the solver crashed immediately from one time step to the next. Both fixes have been propagated to the public version of ramses.
In a finite-volume code, unphysical ringing and striping in the solution can arise near strong shocks. The principle mechanism to counteract the problem is using a slope-limiting procedure that lowers the order of interpolation from centered to interface values in the vicinity of the shocks introducing diffusion. If the slope-limiting procedure is only based on variations in variables across the interface, in a dimensionally split MHD code plane-parallel shock fronts can trigger the so-called carbuncle instability (Sutherland et al. 2003). To counteract this, we have introduced a new three-dimensional slope-limiting procedure, which has the added benefit that it introduces diffusion isotropically close to shocks irrespective of the direction of propagation maintaining, e.g., spherical symmetry in supernova-driven shock fronts. Letting f(i, j, k) be the variable that is to be slope limited, we then compute all 26 slopes
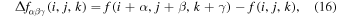
where α, β, γ = −1, 0, +1, and also the face-aligned slopes
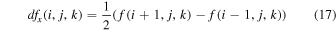
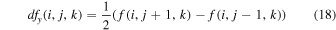
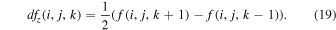
This is used to construct an isotropic slope limiter
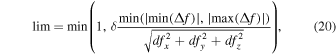
where 1 ≤ δ ≤ 2 is an input parameter that smoothly interpolates the slope limiter between behaving as a min-mod and a monotonized-central limiter. The limiter is then applied to the final slopes equally in all directions:  . We have typically used a value of δ = 1.5 for the simulations presented in this paper.
. We have typically used a value of δ = 1.5 for the simulations presented in this paper.
With the above modifications the HLLD solver in ramses has turned out to be exceptionally stable. Even though the solution is stable, sometimes the time step will decrease dramatically owing to cells with strong magnetic fields and low densities typically in the vicinity of sink particles. To finish the runs in a reasonable time, we calculate the combined advection and fast-mode speed, cB, at all cell centers. If  we use a diffusive Lax-Friedrichs (LLF) solver on all connecting edges and interfaces of the cell to calculate the Riemann problem. This is effective in diffusing the solution sufficiently for the time step to stabilize at reasonable values. Typically we have used
we use a diffusive Lax-Friedrichs (LLF) solver on all connecting edges and interfaces of the cell to calculate the Riemann problem. This is effective in diffusing the solution sufficiently for the time step to stabilize at reasonable values. Typically we have used  , which activates LLF in approximately 1 out of 104 cells.
, which activates LLF in approximately 1 out of 104 cells.
Appendix B: Gravity
In ramses the Poisson equation is solved on the adaptive mesh using a combination of multigrid and conjugate gradient methods (Guillet & Teyssier 2011). The code can use not only spatial but also temporal subcycling, with a factor of two resolution difference between each AMR level. The latter is required when using 10 or more AMR levels for efficient evolution of the model. The code is structured such that the gravitational potential is calculated on the coarse levels first, with a recursive call midway through the time step to the time evolution routine on the finer level. The time evolution of the cells is done after this recursive call, resulting in the finest AMR levels to be evolved forward first in a W-like evolution cycle for the different AMR levels. Therefore, the boundary conditions on individual patches in the AMR hierarchy, computed by interpolating the potential at coarser levels to boundary cells constructed on the fly, can be out of temporal sync at the second step in a subcycle. If two sink particles are placed inside individual patches with coarser grid cells in between, this will lead to a delayed transmission of the gravitational force and a complete decay of, e.g., binary systems in less than 10 orbits. In a periodic box, tests with a few particles show that the delayed transmission of gravity through lower levels subjects moving particles to self-interaction and will slow them down on relatively short timescales. Notice that self-interaction is in practice not a problem in our simulation since a single particle will not dominate the potential. While these effects are most obvious for the particles (both sink and dark matter), similar effects happen for the gas dynamics. Fortunately, the gravitational potential is the second integral of the density, and as such in general smooth, both spatially and in time. In the case of time subcycling we have implemented extrapolation forward in time in the boundary cells between different levels. Letting Δtc be the past time step at the coarse level and Δtf be the current time step at the fine level, the gravitational potential at the boundary then becomes  . This extrapolation has effectively removed the decaying orbits and self-interaction induced by time subcycling and is now also integrated in the public version of the ramses code.
. This extrapolation has effectively removed the decaying orbits and self-interaction induced by time subcycling and is now also integrated in the public version of the ramses code.
Federrath et al. (2010) use a combination of a grid-based potential for the gas and a direct computation of the gravitational forces of the sink particles, which has a cost that is proportional to (Ncell + Nsink) × Nsink. They also subcycle the sink particles in time to resolve the orbits of individual sink orbits. While this method is arguably very precise in evolving in particular multiple stars in close orbits, it rapidly becomes prohibitively expensive when considering large-scale simulations, such as those presented in this paper, with up to 1000 sink particles. Gong & Ostriker (2013) present an alternative implementation where the combined gravitational potential of the gas and sink particles is computed on the grid, and the force on individual particles is found through interpolation of the forces on the nearest grid cell centers. While this method is scalable, it is not precise at the subcell scale, and long-term stable orbits require binaries to be separated by at least 10 grid cells at all times, and even then the orbits are prone to precession and some level of decay.
To couple gas and sink particles gravitationally, we have developed two methods for evaluating the force on individual particles. We use either CIC (eight neighbors) or TSC (27 neighbors) interpolation from the sink particle position to deposit the mass on the grid. The combined density of the gas and the sink particles is used as input to the Poisson equation, and the resulting gravitational potential  is used for finding the gravitational acceleration of the gas.
is used for finding the gravitational acceleration of the gas.
In the first method to calculate the gravitational acceleration on the sink particles we use a matching CIC or TSC interpolation of the gradients of ϕsink+gas to the sink particle position. This corresponds closely to the method described in Gong & Ostriker (2013). In the second method, which is the default for the runs presented here, only the gas is updated by calculating the gravitational acceleration from  . To find the gravitational acceleration of the sink particles, we solve the Poisson equation again, but this time for the gas only. The gravitational acceleration of the gas on the sink particles can then be computed from ϕgas, while the gravitational force of the sink particles instead is evaluated by direct summation of the forces from individual particles. We use a cubic spline softening of the gravitational force (Federrath et al. 2010) with a typical softening length of 0.3Δx when directly computing the forces between different sink particles.
. To find the gravitational acceleration of the sink particles, we solve the Poisson equation again, but this time for the gas only. The gravitational acceleration of the gas on the sink particles can then be computed from ϕgas, while the gravitational force of the sink particles instead is evaluated by direct summation of the forces from individual particles. We use a cubic spline softening of the gravitational force (Federrath et al. 2010) with a typical softening length of 0.3Δx when directly computing the forces between different sink particles.
Both of the methods are scalable to thousands of sink particles, and the second method gives as precise orbits in multiple-star systems as the method of Federrath et al. (2010) at the added cost of requiring an additional solution to the Poisson equation.
The smaller-scale 643 root grid test models in Appendix C, RUN1–RUN27, are using the first method, while all other runs have been evolved with the second method. We have performed test runs at  with both the first and the second method. Even though individual binary systems are much better described by the second method, the overall impact on the IMF in the test runs is negligible and significantly smaller than the Poisson scatter in the IMF distribution.
with both the first and the second method. Even though individual binary systems are much better described by the second method, the overall impact on the IMF in the test runs is negligible and significantly smaller than the Poisson scatter in the IMF distribution.
To move the sink particles through the volume, we use a simple leapfrog Kick–Drift–Kick algorithm, identical to the method used to integrate the orbits of dark matter particles in ramses. The global Courant condition is modified to take into account both the velocity vx,y,z and acceleration ax,y,z of the sink particles. Let Δxs be the minimum of the distances between sink particles and the softening length
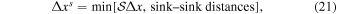
where  is the cell size at refinement level ℓ and
is the cell size at refinement level ℓ and  is the softening number. Then the limit on the time step imposed by each sink particle i is
is the softening number. Then the limit on the time step imposed by each sink particle i is
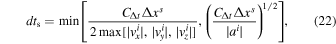
where  is the Courant factor, which is set to 0.5 in the runs.
is the Courant factor, which is set to 0.5 in the runs.
Appendix C: Testing the Sink Particle Algorithm
The sink particle algorithm contains a number of density and distance thresholds for creation and accretion of gas to the sink particles, and it is important to understand the impact of different choices, and in particular the impact on the SFR, and the IMF. To test the algorithm, we have created a large grid of models that enables us to study the dependence of the IMF on all parameters. The test runs are prepared using the same physical parameters and driving as the convergence runs and are listed in Table 2. Our grid of models mainly affects three aspects of the simulation.
Table 2. Numerical Parameters of the Test Runs
| Run Parameters | Creation of Sinks | Accretion to Sinks | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Run | Root | NAMR | Δx | LJ | Mass | αvir | tend | SFE | LJ,s | ρs | ρs | rex | ρacc | ρacc | Nbody | racc | acc |
| Grid | (au) | (M⊙) | (Myr) | (cm−3) | ( ) ) |
(Δx) | (cm−3) | (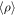 ) ) |
(Δx) | ||||||||
| RUN1 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 8 | 6.6 × 106 | 8.3 × 103 | 16 | 3.3 × 106 | 4.1 × 103 | no | 2 | 1.0 |
| RUN2 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 6.6 × 106 | 8.3 × 103 | 32 | 3.3 × 106 | 4.1 × 103 | no | 2 | 1.0 |
| RUN3 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 6.6 × 106 | 8.3 × 103 | 64 | 3.3 × 106 | 4.1 × 103 | no | 2 | 1.0 |
| RUN4 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 4 | 2.6 × 107 | 3.3 × 104 | 32 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN5 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 4 | 2.6 × 107 | 3.3 × 104 | 32 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN6 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 2.6 × 107 | 3.3 × 104 | 64 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN7 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 16 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN8 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 32 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN9 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 64 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN10 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 8 | 2.6 × 107 | 3.3 × 104 | 16 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN11 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 2.6 × 107 | 3.3 × 104 | 32 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN12 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 8 | 2.6 × 107 | 3.3 × 104 | 64 | 1.3 × 107 | 1.6 × 104 | no | 2 | 1.0 |
| RUN13 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 1.0 × 108 | 1.3 × 105 | 16 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN14 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 1.0 × 108 | 1.3 × 105 | 32 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN15 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 4 | 1.0 × 108 | 1.3 × 105 | 64 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN16 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 4.2 × 108 | 5.2 × 105 | 16 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN17 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 4.2 × 108 | 5.2 × 105 | 32 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN18 | 643 | 7 | 100 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 4.2 × 108 | 5.2 × 105 | 64 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN19 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 1.0 × 108 | 1.3 × 105 | 16 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN20 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 1.0 × 108 | 1.3 × 105 | 32 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN21 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 8 | 1.0 × 108 | 1.3 × 105 | 64 | 5.2 × 107 | 6.6 × 104 | no | 2 | 1.0 |
| RUN22 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 4.2 × 108 | 5.2 × 105 | 16 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN23 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 4.2 × 108 | 5.2 × 105 | 32 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN24 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 4 | 4.2 × 108 | 5.2 × 105 | 64 | 2.1 × 108 | 2.6 × 105 | no | 2 | 1.0 |
| RUN25 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 2 | 1.7 × 109 | 2.1 × 106 | 16 | 8.3 × 108 | 1.0 × 106 | no | 2 | 1.0 |
| RUN26 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 1.7 × 109 | 2.1 × 106 | 32 | 8.3 × 108 | 1.0 × 106 | no | 2 | 1.0 |
| RUN27 | 643 | 8 | 50 | 8.0 | 3000 | 0.83 | 1.6 | 25% | 2 | 1.7 × 109 | 2.1 × 106 | 64 | 8.3 × 108 | 1.0 × 106 | no | 2 | 1.0 |
| RUN28 | 5123 | 3 | 200 | 8.0 | 3000 | 0.83 | 2.0 | 25% | 1 | 4.2 × 108 | 5.2 × 105 | 8 | 2.1 × 108 | 2.6 × 105 | yes | 2 | 1.0 |
| RUN29 | 5123 | 3 | 200 | 8.0 | 3000 | 0.83 | 2.0 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 4 | 5.2 × 107 | 6.6 × 104 | yes | 2 | 1.0 |
| RUN30 | 5123 | 3 | 200 | 8.0 | 3000 | 0.83 | 1.9 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 8 | 5.2 × 107 | 6.6 × 104 | yes | 2 | 1.0 |
| RUN31 | 5123 | 3 | 200 | 8.0 | 3000 | 0.83 | 2.0 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 16 | 5.2 × 107 | 6.6 × 104 | yes | 2 | 1.0 |
| RUN32 | 5123 | 3 | 200 | 8.0 | 3000 | 0.83 | 2.0 | 25% | 4 | 2.6 × 107 | 3.3 × 104 | 8 | 1.3 × 107 | 1.6 × 104 | yes | 2 | 1.0 |
| RUN33 | 643 | 6 | 200 | 8.0 | 3000 | 0.83 | 1.5 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 8 | 5.2 × 107 | 6.6 × 104 | yes | 2 | 1.0 |
| RUN34 | 10243 | 2 | 200 | 8.0 | 3000 | 0.83 | 2.1 | 25% | 2 | 1.0 × 108 | 1.3 × 105 | 4 | 5.2 × 107 | 6.6 × 104 | yes | 2 | 1.0 |
| test | 1283 | 6 | 100 | 7.2 | 3000 | 0.83 | 2.5 | 13% | 2 | 4.2 × 108 | 5.3 × 105 | 8 | 2. 1 × 108 | 2.6 × 105 | yes | 4 | 1.0 |
| acc | 1283 | 6 | 100 | 7.2 | 3000 | 0.83 | 2.5 | 13% | 2 | 4.2 × 108 | 5.3 × 105 | 8 | 4227 | 5.3 | yes | 4 | 1.0 |
Note. the Test and acc runs are identical to the med run, except that the acc run is using an accretion efficiency acc = 1 and the test run, in addition to that, is only using a density threshold for accretion like the rest of the test runs. We have set in boldface the main parameters that are explored in each set of runs.
Download table as: ASCIITypeset image
C.1. Creation
The creation of sink particles is controlled by threshold density and the exclusion radius. The higher the density threshold, the more probable it is that we have identified a genuinely collapsing region. It is not clear, though, how much numerical fragmentation due to underresolving of the Jeans length on the grid will affect the creation of sink particles, given that fragments very close to a newborn sink particle can end up being accreted. Gong & Ostriker (2013) find that using a threshold density ρs, where the Jeans length is only resolved by a single cell (LJ ∼ 1), gives consistent results compared to using lower-density floors. In the smallest test runs with a 643 root grid, where we can make a systematic set of models, our runs have LJ ≥ 8 everywhere until the final AMR level. On the final level we use three different ρs, corresponding to Jeans lengths of LJ,s = 2, 4, and 8. The exclusion radius rex controls how close we allow a new sink particle to be formed to existing sinks. Very close to the sink particle the gas flow is disturbed by the sink particle itself, accretion, and the accumulation of magnetic fields. It is not a priori clear how well the MHD dynamics is described in the vicinity of a sink particle, and pileup of gas can lead to the artificial creation of sink particles very close to rex. To test the effect of rex, we use rex between 4 and 64 in our models, measured in units of Δx of the finest AMR level.
C.2. Accretion
A protostar is initially formed in a gravitational free-fall collapse of the gas, while afterward the star grows through accretion. As discussed in Section 2, we use two different accretion methods: either a combination of velocity and density thresholds that makes it possible to describe accretion at low densities, or only a density threshold. Except for the acc model, which is used to compare the two methods, we use the second method for all test runs and let the star accrete when the density reaches ρacc = ρs/2 and the cell is closer than the accretion radius to a sink particle. The accretion radius is kept at racc = 2Δx for runs using a pure density threshold, while when using a combination of velocity and density threshold methods it is possible to relax this, due to a tapering function (Equation (3)), and use a larger accretion radius. We have run a number of control experiments to probe the impact of having larger accretion radius and accretion density, and we do not find significant differences as long as ρacc < ρs, and racc < rex/2. Even though a smaller ρacc and larger racc effectively lower the gas density around the sink particles, avoiding kinks in the gas density distribution close to the star and thus artificial creation of sink particles, it also disturbs the gas dynamics at larger distances from the sink particle. We find the above compromise, ρacc = ρs/2 and racc = 2Δx, to be a good solution for the test runs, while for the main runs with a combined velocity and density criterion we use racc = rex/2 (see also Kuffmeier et al. 2017, for a discussion of the accretion parameters).
C.3. Numerical Resolution
The bulk of the models are evolved with a 643 root grid. To ensure LJ ≥ 8 everywhere, the root grid is refined at an overdensity of 2, while subsequently the adaptive mesh is refined where the density has grown with a factor of four, to have the same minimum Jeans length at all AMR levels, except possibly at the finest level of refinement. This Truelove refinement is different from Lagrangian codes, such as SPH, and corresponds to having increasing mass resolution in the finer cells. To test the impact of numerical resolution, we also run a number of models with a 5123 and 10243 root grid. This has a significant impact on the resolution of the fragmentation, due to the turbulent cascade (the sonic point is expected to be at  ).
).
Besides studying the effect of increasing the root grid size, we also vary the resolution by changing the number of AMR levels above the root grid, NAMR. The supersonic turbulence creates a filamentary self-similar gas structure with a lognormal density distribution. To avoid the creation of spurious sink particles, it is important to achieve a significant separation (at least by a factor of 14, which is the density contrast of a critical BE sphere) between the density threshold for sink creation, ρs, and the highest density reached purely through the turbulent compression of the gas. To test the effect of NAMR, we evolve models with NAMR = 6, 7, and 8.
Varying ρs, rex, and NAMR gives a regular grid of 27 models with a 643 root grid. To further test the impact of resolving the turbulence, we have also evolved five models with a 5123 root grid and a single model with a 10243 root grid. Finally, two runs that are similar to the med convergence run are included to compare the different settings for the gas accretion.
In Table 2, we list 36 models, all simulating the same physical problem and thoroughly testing numerical aspects of our model, and in particular the impact on the SFR and the stellar IMF. In addition, more than 20 other models with variations of root grid resolution, Jeans length, and auxiliary parameters, such as the hydro solver, the coupling of gravity for the sink particles, and the relative size of racc compared to rex, have been run during the course of this project, but to keep the table manageable, we only include runs that are directly referenced and used in the paper.
C.4. Star Formation Efficiency and Average Stellar Mass
The models have run with self-gravity and sink particles for up to 1.5 free-fall times or 1.8 Myr, similar to the lifetimes of nearby star-forming regions. At the end of the runs, the SFE reaches 25%. Notice that since these models have an accretion efficiency acc = 1, their SFEs have to be rescaled with a factor of 2.4, corresponding to a rescaled SFE of 10%, to compare them with the convergence runs as shown in Figure 14 and discussed in Section 2. Figure 15 shows that the overall SFE is extremely robust between runs, which is a consequence of gravitational collapse: if gas reaches a certain threshold density, it will almost unavoidably collapse. Depending on the details of the sink recipe, this will result in either accretion to an existing sink particle or creation of a new sink particle, but the total accreted mass remains nearly constant.

Figure 14. Comparing different acc and accretion algorithms. This compares med, test, and acc. For the first two panels the runs are sampled at an SFE of 4.5%, 10.8%, and 10.8%, respectively. The first panel shows the IMF, and the second panel the cumulative IMF. In the third and fourth panels are shown the SFE and SFR per free-fall time as a function of time. In all panels the masses for the second and third run are rescaled by a factor of 2.4 to show the correspondence between acc = 0.5 and acc = 1.
Download figure:
Standard image High-resolution image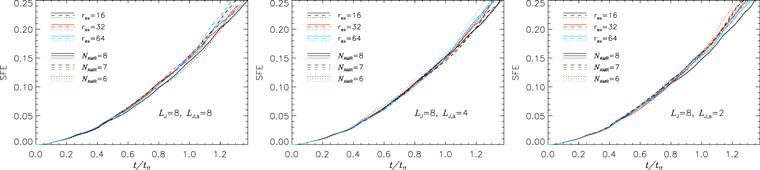
Figure 15. SFE vs. time from all the test runs with 643 root grid and LJ = 8. The three panels corresponds to LJ,s = 8 (left), LJ,s = 4 (middle), and LJ,s = 2 (right).
Download figure:
Standard image High-resolution imageThe average mass of the sink particles produced in each run is shown in Figure 16. We have grouped the runs in terms of the Jeans number at the threshold density for sink particle creation, LJ,s. There are both common trends and a significant dependence on the numerical details of the average mass: there is a clear dependence on the exclusion radius, the number of AMR levels, and the density threshold at which sink particles are created. Given that the SFE is very similar for all runs, a smaller average mass corresponds to a higher number of sink particles and vice versa. A smaller exclusion radius, a higher number of AMR levels, and a lower threshold for sink particle creation all result in a lower average mass and therefore a higher number of sink particles. The difference between different models diminishes with increasing threshold for sink creation, showing convergence at the highest resolution. The parameter with the smallest effect on the average mass is the exclusion radius. Whether adding a higher number of AMR levels, or changing the sink threshold, both have a larger impact.
Figure 16. Average stellar mass vs. time from all the test runs with 643 root grid and LJ = 8. The three panels corresponds to LJ,s = 8 (left), LJ,s = 4 (middle), and LJ,s = 2 (right).
Download figure:
Standard image High-resolution imageAs we will see below, the reasons for the significant dependence of the average stellar mass on the sink particle creation parameters and NAMR may be numerical: with a small root grid of 643 cells, the threshold for sink creation is too low, resulting in the spurious creation of extra particles. Thus, besides being a clear illustration of the effect of numerical parameters, Figure 16 is also a clear indication that the resolution of these test runs is too low to study the stellar IMF, though probably sufficient to study the SFR (as indicated by Figure 15). Although we cannot afford a similar systematic set of test simulations with a much larger root grid size, we expect that the dependence on numerical parameters shown in Figure 16 would be significantly weaker in simulations with a root grid size of 2563 cells or larger. The higher-resolution runs can resolve an increasing number of close binaries, which should not be confused with the artificial creation of spurious sink particles. Finally, another important effect that is explored below is how well the turbulent fragmentation and the smallest collapsing cores are resolved.
A common feature of all models is that the average sink particle mass becomes nearly stationary after roughly 0.8 free-fall times. This can be understood in terms of the time it takes for the most massive stars in a cluster to accrete. Only after ∼0.8 free-fall times is enough of the high-mass Salpeter slope developed to keep the average mass essentially constant, as demonstrated by Figures 12 and 13 in Section 5.3, which are based on our highest-resolution simulations.
C.5. Nearest-neighbor Separation at Formation
To investigate the effects of different parameter choices, a higher-order statistics than the SFE or the average stellar mass is needed. In this section we will introduce the nearest-neighbor separation at formation, and we use it below, together with the IMFs of the different runs, to better understand the differences between the test runs. The nearest-neighbor separation at formation,  , or "neighbor statistics" for brevity, is the histogram of distances from a set of sink particles, at the time of their formation, to the nearest other particle in the simulation volume. It is both very simple to extract from a numerical simulation and a powerful statistic to judge the fidelity of a sink particle distribution, if we have prior knowledge about how it should behave.
, or "neighbor statistics" for brevity, is the histogram of distances from a set of sink particles, at the time of their formation, to the nearest other particle in the simulation volume. It is both very simple to extract from a numerical simulation and a powerful statistic to judge the fidelity of a sink particle distribution, if we have prior knowledge about how it should behave.
In this subsection we will argue that  should increase as a function of distance for reasonable assumptions about the stellar distributions. This can then be used to detect when models are polluted by sink particles generated as a consequence of nonphysical fluctuations close to other sink particles.
should increase as a function of distance for reasonable assumptions about the stellar distributions. This can then be used to detect when models are polluted by sink particles generated as a consequence of nonphysical fluctuations close to other sink particles.
Assume that there is no difference between the statistical distribution of newly formed stars and more evolved stars. Then  can be defined in terms of the nearest-neighbor function of a point-particle set. For a point-particle set with N particles the probability of finding another point at a distance r of a given point is
can be defined in terms of the nearest-neighbor function of a point-particle set. For a point-particle set with N particles the probability of finding another point at a distance r of a given point is
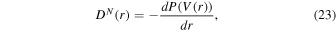
where P(V(r)) is the conditional probability (averaged over all points) that there is another point inside the volume V centered on a given point, and the derivative gives the probability that the nearest neighbor is in the interval [r, r + dr]. Since in a star-forming region stars are formed one at a time,  can then be found by forming the cumulative sum
can then be found by forming the cumulative sum
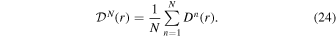
This is a highly nontrivial distribution related to the n-point correlation functions. As an example, if the neighbor diagram has a strong peak close to the exclusion radius for creation of new particles, rex, it could indicate that
- 1.the overall spatial resolution is so low that clumps that should fragment into many stars are not well resolved;
- 2.the minimum density for sink formation, ρs, is low enough that disturbances in the fluid dynamics around other sink particles are sufficient to induce the formation of new sink particles; and
- 3.the Jeans length is not sufficiently resolved, and therefore numerical fragmentation results in a large number of artificial "multiple systems."
To elucidate the properties of this function, we may consider the simplest theoretical example of a stationary Poisson process with a volume point density of n, where we have

If we assume a starting density of one star per unit volume appropriate for our periodic box, we can then write the neighbor statistics for N stars as
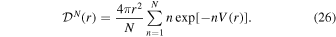
To test for numerical artifacts, the solutions at small distances are most relevant, where NV(r) < 1. There we have  with a binning in terms of
with a binning in terms of  , as done in the histograms from the numerical simulations. At larger scales the function has a relatively well-defined peak close to the point where all terms in the sum in Equation (26) still contribute to the total histogram, i.e., where NV(r) ∼ 1, corresponding to the average separation between particles of the final point set.
, as done in the histograms from the numerical simulations. At larger scales the function has a relatively well-defined peak close to the point where all terms in the sum in Equation (26) still contribute to the total histogram, i.e., where NV(r) ∼ 1, corresponding to the average separation between particles of the final point set.
Define the two-point correlation function, ξ(r), as the excess probability, compared to a homogeneous point set, of finding another particle at distance r from a given point
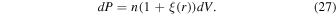
Assuming for a general distribution that all higher-order correlation functions are negligible, we can then repeat the analysis above to find that
where ![${V}_{\xi }(r)\equiv {\int }_{V}[1+\xi (r)]{dV}$](https://content.cld.iop.org/journals/0004-637X/854/1/35/revision1/apjaaa432ieqn55.gif) . For large N,
. For large N,
For a clustered distribution such as those observed in young stellar clusters, and assuming a power law ξ(r) ∝ rβ, we find that at small separations, where ξ(r) ≫ 1,
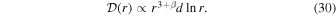
Observationally, the two-point correlation functions in the nearby Taurus, ρ Oph, and Orion regions are found to be a power law with exponents in the range −2 < β < −1 (Gomez et al. 1993; Larson 1995; Gomez & Lada 1998). This corresponds to a slowly increasing trend for  as a function of distance, but with some uncertainty. In the numerical models we are applying the statistics at the birth of the star, while observationally we see a time-evolved distribution. Spectroscopic multiple systems formed through, e.g., disk fragmentation may eject stellar companions to the field, and tight multiple stellar systems may have formed dynamically from systems with larger separations. In a clustered system,
as a function of distance, but with some uncertainty. In the numerical models we are applying the statistics at the birth of the star, while observationally we see a time-evolved distribution. Spectroscopic multiple systems formed through, e.g., disk fragmentation may eject stellar companions to the field, and tight multiple stellar systems may have formed dynamically from systems with larger separations. In a clustered system,  may also have contributions from higher-order correlation functions. Thus, the observational evidence seems to favor a constant or weakly increasing nearest-neighbor separation at formation as a function of the logarithmic distance binning, though there is a considerable uncertainty for the innermost scales, below ∼1000 au. A decreasing
may also have contributions from higher-order correlation functions. Thus, the observational evidence seems to favor a constant or weakly increasing nearest-neighbor separation at formation as a function of the logarithmic distance binning, though there is a considerable uncertainty for the innermost scales, below ∼1000 au. A decreasing  would require a highly peaked two-point correlation function with a slope less than ≈−3, which seems to be at odds with the observations.
would require a highly peaked two-point correlation function with a slope less than ≈−3, which seems to be at odds with the observations.
Because  should increase as a function of distance (up to the mean particle separation), we do not expect it to peak at the smallest possible distance in the simulation, that is, at the exclusion radius, rex (see below). Thus, a sharp peak in
should increase as a function of distance (up to the mean particle separation), we do not expect it to peak at the smallest possible distance in the simulation, that is, at the exclusion radius, rex (see below). Thus, a sharp peak in  at rex is to be interpreted as clear evidence of spurious sink particles emerging from numerical artifacts (e.g., unphysical density fluctuations near the accretion radius).
at rex is to be interpreted as clear evidence of spurious sink particles emerging from numerical artifacts (e.g., unphysical density fluctuations near the accretion radius).
C.6. Impact of Sink Formation Parameters
In this subsection we discuss how the different numerical parameters in the sink formation model impact the IMF and the neighbor statistics,  , discussed above.
, discussed above.
Exclusion radius (rex). The purpose of the exclusion volume is to avoid the formation of spurious sink particles near the accretion radius of a previously created sink particle. However, secondary density peaks may have a physical origin and lead to the formation of bona fide stellar companions, so the exclusion radius should be kept as small as possible in order to resolve as many physical companions as possible. We use the neighbor statistics,  , as our tool of choice to detect spurious sink particles. As rex is a purely numerical radius, the physics of star formation should not yield any special feature in
, as our tool of choice to detect spurious sink particles. As rex is a purely numerical radius, the physics of star formation should not yield any special feature in  at a distance equal to rex. A sharp peak at rex, for example, is certainly not expected, because
at a distance equal to rex. A sharp peak at rex, for example, is certainly not expected, because  is predicted to slowly decrease with decreasing distance, as concluded in the previous subsection. On the other hand, the numerical models for sink creation and accretion may easily cause a peak in
is predicted to slowly decrease with decreasing distance, as concluded in the previous subsection. On the other hand, the numerical models for sink creation and accretion may easily cause a peak in  at rex (for example, if the gas reservoir within racc is depleted too rapidly, the density may temporarily peak at a distance around rex, if rex ∼ racc). Thus, we assume that a peak in the neighbor statistics at a distance equal to rex is evidence for spurious sink particles and hence too small rex; conversely, we assume that if no obvious peak is present at a distance equal to rex, the value of rex is large enough and the contamination from spurious sink particles is small.
at rex (for example, if the gas reservoir within racc is depleted too rapidly, the density may temporarily peak at a distance around rex, if rex ∼ racc). Thus, we assume that a peak in the neighbor statistics at a distance equal to rex is evidence for spurious sink particles and hence too small rex; conversely, we assume that if no obvious peak is present at a distance equal to rex, the value of rex is large enough and the contamination from spurious sink particles is small.
Figure 17 shows  for several test runs with 643 root grid and six to eight levels of refinement (top to bottom rows of panels). Each panel shows the histogram for three different values of rex, with the smallest value, rex = 16Δx, indicated by the vertical dashed line. The panels show the expected behavior: small values of rex may result in a peak of
for several test runs with 643 root grid and six to eight levels of refinement (top to bottom rows of panels). Each panel shows the histogram for three different values of rex, with the smallest value, rex = 16Δx, indicated by the vertical dashed line. The panels show the expected behavior: small values of rex may result in a peak of  at a distance equal to rex, while the peak decreases and even disappears as the value of rex is increased. The effect of rex clearly depends on the parameter LJ,s and hence on the density threshold where sink particles are created, ρs, which is discussed below. One can see that with LJ,s = 4, shown in the middle column of Figure 17, only the largest value of rex is marginally successful at removing the unphysical peak (one remains at the intermediate resolution with seven refinement levels, shown in the central panel), while with LJ,s = 2 the peak is completely removed, also for the smallest value of rex.
at a distance equal to rex, while the peak decreases and even disappears as the value of rex is increased. The effect of rex clearly depends on the parameter LJ,s and hence on the density threshold where sink particles are created, ρs, which is discussed below. One can see that with LJ,s = 4, shown in the middle column of Figure 17, only the largest value of rex is marginally successful at removing the unphysical peak (one remains at the intermediate resolution with seven refinement levels, shown in the central panel), while with LJ,s = 2 the peak is completely removed, also for the smallest value of rex.

Figure 17. Neighbor statistics for RUN1–RUN27 with 643 root grid and LJ = 8. Each row shows the neighbor statistics for runs with a constant number of levels of refinement, NAMR = 6 (RUN1–RUN9; top), 7 (RUN10–RUN18; middle), and 8 (RUN19–RUN27; bottom). From left to right, LJ,s = 8, 4, and 2. Each panel shows three different values of the exclusion radius, rex = 16Δx, 32Δx, and 64Δx, as black, red, and blue histograms, respectively. The dashed vertical lines mark the distance equal to the smallest rex.
Download figure:
Standard image High-resolution imageThe panels in Figure 18 show the corresponding IMFs, where it is clear that the spurious sink particles corresponding to the peaks in the neighbor statistics are almost exclusively low-mass ones. At masses larger than their peak mass, the IMFs are essentially insensitive to the choice of rex. Furthermore, as for the neighbor histogram, the IMF is practically independent of rex when the lowest value of LJ,s is adopted, as shown in the right column of Figure 18.
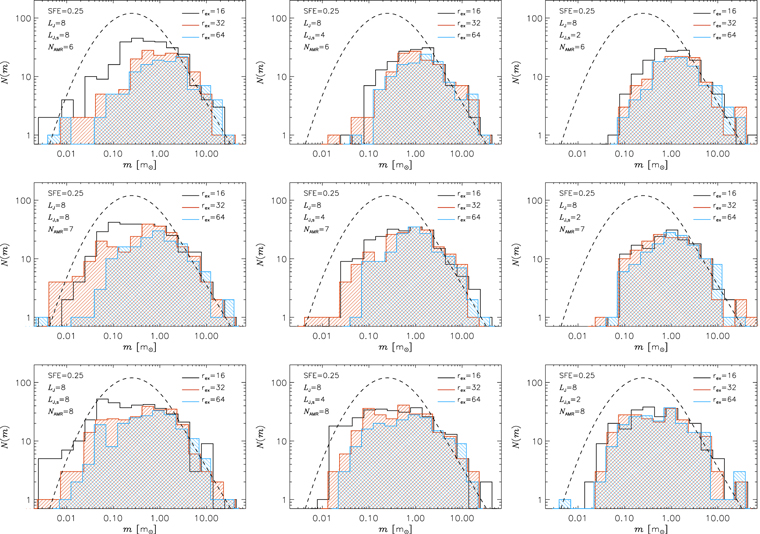
Figure 18. IMF for RUN1–RUN27 with 643 root grid and LJ = 8. Each row shows the IMF for runs with a constant number of levels of refinement NAMR of 6 (RUN1–RUN9; top), 7 (RUN10–RUN18; middle), and 8 (RUN19–RUN27; bottom). From left to right LJ,s = 8, 4, and 2. Each panel shows three different values of the exclusion radius, rex = 16Δx, 32Δx, and 64Δx, as black, red, and blue histograms, respectively.
Download figure:
Standard image High-resolution imageAs discussed below, LJ,s = 2 is the optimal value of the numerical Jeans length at the density of sink creation, so we can conclude that, in these test runs, values of rex as small as rex = 16Δx do not result in significant numbers of spurious sink particles. In principle, we could adopt an exclusion radius as small as rex = 2 racc (a smaller value, comparable to racc, is guaranteed to generate spurious sinks). To test whether this is acceptable, and also to test whether the evidence collected from the low-resolution test runs holds true at higher resolution, we also consider three runs with a 5123 root grid and three levels of refinement and three different values of rex (RUN29, RUN30, and RUN31). The dependence of the IMF and  of these runs on rex is shown in Figure 19. The neighbor statistics does not show any peak at rex, not even at the smallest value, rex = 2racc = 4Δx, and the IMFs are barely affected by the choice of rex. Thus, we conclude that, as long as LJ,s = 2 (see below), we can adopt the smallest possible value of rex, that is, rex = 2racc. In our convergence-test runs, where racc = 4Δx, we have adopted rex = 8Δx.
of these runs on rex is shown in Figure 19. The neighbor statistics does not show any peak at rex, not even at the smallest value, rex = 2racc = 4Δx, and the IMFs are barely affected by the choice of rex. Thus, we conclude that, as long as LJ,s = 2 (see below), we can adopt the smallest possible value of rex, that is, rex = 2racc. In our convergence-test runs, where racc = 4Δx, we have adopted rex = 8Δx.
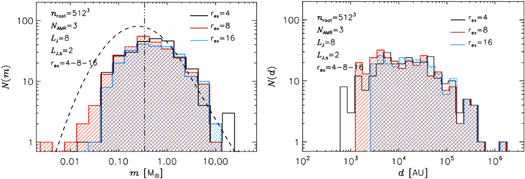
Figure 19. IMF and neighbor statistics dependence on the exclusion radius for otherwise well-resolved RUN29, RUN30, and RUN31. The test runs have a 5123 root grid, LJ = 8, and LJ,s = 2. The number of AMR levels above the root grid is NAMR = 3. Each panel shows three different values of the exclusion radius, rex = 4Δx, 8Δx, and 16Δx, as black, red, and blue histograms, respectively. To the left is shown the IMF, and to the right is the neighbor statistics.
Download figure:
Standard image High-resolution imageDensity at sink formation (LJ,s). The density at sink formation, ρs, has to be as high as possible, so that only bona fide collapsing regions are chosen, but not so high that the Jeans length is not resolved at the available spatial resolution. Because the turbulence alone can generate very large densities that are not necessarily collapsing regions, ρs must be at least several times larger than the highest post-shock density in the absence of self-gravity at the spatial resolution of the simulation. In our case, a turbulent flow with a sonic Mach number of 10, a characteristic high density without self-gravity, is roughly ∼105 times the average density (depending on spatial resolution). However, a very large value of ρs is not a sufficient condition to avoid spurious sink particles. In the converging flow in the vicinity of an already-formed sink particle, the gas may reach densities higher than ρs owing to the gravitational potential around the sink, possibly triggering the formation of spurious sinks. To address this concern, we parameterize the dependence of the IMF on the density at sink formation through the value of the numerical Jeans length at the density of sink formation, LJ,s. As ρs is increased (with constant Δx), the value of LJ,s decreases.
The ideal value of LJ,s is a compromise between the requirement of spatially resolving the Jeans length at the end of the AMR hierarchy (high LJ,s) and the need to adopt a large value of ρs to avoid the creation of spurious sink particles in secondary density peaks that should not collapse into separate stars (low LJ,s). Too low values of LJ,s would cause overmerging of density fluctuations, meaning that a single star would emerge out of a fragmented region that should have yielded a multiple system (in our experience, this outcome is more likely than the risk of artificial fragmentation due to a violation of Truelove's condition). Too high values of LJ,s may result in spurious sink particles.
The dependence of the neighbor statistics and the IMF on LJ,s is shown in Figures 17 and 18. Each column of panels in those figures has a constant value of LJ,s, with LJ,s = 8 on the left, LJ,s = 4 in the middle, and LJ,s = 2 on the right. Figure 17 shows that an artificial peak of spurious sinks at a distance equal to rex is always present for the largest values of LJ,s, at any value of rex. As LJ,s is decreased, the peak decreases, particularly for larger values of rex. It is only with LJ,s = 2 that the peak is completely gone, independent of rex. As mentioned above in relation to the dependence on rex, the peak in the neighbor diagram is reflected by an increase in the number of low-mass stars, as shown by the IMFs of Figure 18.
To make sure that these results hold true at higher resolution, we consider again the simulations with a 5123 root grid, specifically RUN28, RUN30, and RUN32, where LJ,s = 1, 2, and 4, respectively. Figure 20 shows that the neighbor histogram yields a peak at rex when LJ,s = 4. The largest value where the peak is suppressed is LJ,s = 2, as in the lower-resolution runs. Thus, in order to resolve the Jeans length while also avoiding spurious sink particles, the best choice is LJ,s = 2, which is the value we have adopted in the main simulations of this work. A similar conclusion was reached by Gong & Ostriker (2013).
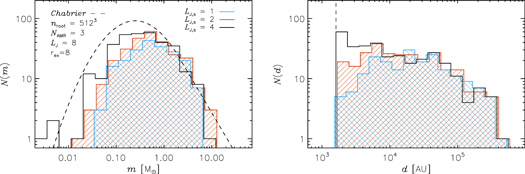
Figure 20. IMF and neighbor statistics as a function of the density threshold for creation, quantified by the corresponding Jeans number for otherwise well-resolved RUN28, RUN30, and RUN32. The test runs have a 5123 root grid, LJ = 8, and rex = 8Δx. The number of AMR levels above the root grid is NAMR = 3. Each panel shows three different values of the Jeans number at sink creation, LJ,s = 4, 2, and 1, as black, red, and blue histograms, respectively. To the left is shown the IMF, and to the right is the neighbor statistics.
Download figure:
Standard image High-resolution imageC.7. Impact of Numerical Resolution
In this subsection we discuss how the numerical resolution impacts the IMF and the nearest-neighbor statistics.
Root grid size. The impact of changing the root grid size while keeping all other parameters fixed can be seen in Figure 21. The root grid resolution impacts how well the turbulence is resolved throughout the volume, but if the number of cells on the refined levels is determined by the same Jeans number, the resulting neighbor statistics and IMF are almost identical. We only see a minor difference with a slight increase in the number of low-mass stars when using a higher-resolution root grid. This makes sense, since a better resolution of the turbulence facilitates the creation of rare peaks with both high density and low mass.
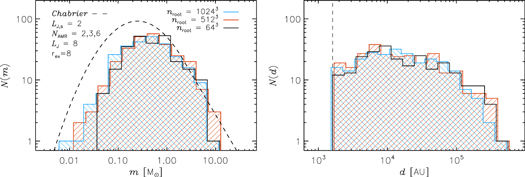
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 21. IMF and neighbor statistics as a function of the root grid resolution for RUN33, RUN31, and RUN34. The test runs have LJ = 8, rex = 8Δx, and LJ,s = 2. Each panel shows three different values of the root grid resolution, Nroot = 643, 5123, and 10243, and number of AMR levels, NAMR = 6, 3, and 2, as black, red, and blue histograms, respectively. To the left is shown the IMF, and to the right is the neighbor statistics. The dashed vertical line marks the distance equal to rex.
Download figure:
Standard image High-resolution image{kind=link}
Number of refinement levels. The number of refinement levels controls the minimum cell size, and correspondingly the maximum density that can be reached, if everything else is kept fixed. The most realistic cases for our test runs are shown in the right column of Figure 18, corresponding to RUN7–RUN9 (NAMR = 6), RUN16–RUN18 (NAMR = 7), and RUN25–RUN27 (NAMR = 8), where in all cases relatively high densities are reached with a Jeans number at sink formation of LJ,s = 2. The increase in the number of levels of refinement results in a better resolution of low-mass stars. This is because higher densities are reached before sink formation, as required for small cores to start collapsing. However, the turbulence is not well sampled in these runs because of a too-small root grid resolution.
As found with the convergence runs in Table 1, by simultaneously increasing the root grid size and the maximal resolution, we can properly populate the low-mass end of the IMF. A very high number of AMR levels is in itself not enough to do it.
To summarize this section, we list a guiding set of rules that we have established for setting the numerical parameters of the sink particle model and the numerical resolution:
- 1.The numerical Jeans length at sink formation should be as high as possible, but in practice it is limited to a rather low ideal value, LJ,s = 2, to avoid the creation of spurious sink particles.
- 2.The exclusion radius should be kept as small as possible. As long as LJ,s = 2, the exclusion radius can be set equal to twice the accretion radius, rex = 2racc (rex = 8Δx in our main simulations where racc = 4Δx).
- 3.A sufficiently high resolution root grid and a large enough minimum Jeans number LJ are needed to resolve both the turbulence and the gravitational collapse. A high number of levels of refinement makes it possible to resolve small, high-density cores that are the natal sites of low-mass stars. Therefore, to populate the IMF toward the low-mass end, it is necessary to increase all three quantities, Nroot, NAMR, and LJ, simultaneously.
These principles have been followed to design the convergence runs listed in Table 1, and they have made it possible to demonstrate the trend toward a convergence of the numerical model.
Footnotes
- 4
We are neglecting the case of NGC 2024 that has only 69 stars.