



Abstract
The current and upcoming large data volume galaxy surveys require the use of machine-learning techniques to maximize their scientific return. This study explores the use of Self-Organizing Maps (SOMs) to estimate galaxy parameters with a focus on handling cases of missing data and providing realistic probability distribution functions for the parameters. We train an SOM with a simulated mass-limited lightcone assuming a ugrizYJHKs+IRAC data set, mimicking the Hyper Suprime-Cam Deep joint data set. For parameter estimation, we derive SOM likelihood surfaces considering photometric errors to derive total (statistical and systematic) uncertainties. We explore the effects of missing data, including which bands are particularly critical to the accuracy of the derived parameters. We demonstrate that the parameter recovery is significantly better when the missing bands are "filled in" rather than if they are completely omitted. We propose a practical method for such recovery of missing data.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The study of the physical mechanisms that drive galaxy formation and evolution (see Somerville & Davé 2015, for a review) starts with our ability to derive galaxy properties such as their distance, stellar mass, and star formation activity. We also need to do so for large enough galaxy populations that span all potential evolutionary stages, environments, and cosmic epochs. In the past few decades, increasingly large multi-band imaging and spectroscopic surveys have been constructed to address this need (e.g., SDSS; York et al. 2000; COSMOS; Scoville et al. 2007; CANDELS; Grogin et al. 2011). Set to start in 2025, the Rubin Observatory Legacy Survey of Space and Time (LSST) will cover 18,000 deg2 in six filters (ugrizy) and reach a 5σ depth of 27.5 in r (LSST Science Collaboration et al. 2009). In many respects, the three-tiered Subaru Hyper Suprime-Cam (HSC) survey (Aihara et al. 2017) is a precursor of the Rubin LSST survey using nearly all the same filters and reaching comparable depth in its middle (HSC-Deep) tier, which covers 27 deg2. Large photometric surveys are complemented by spectroscopic surveys (e.g., VVDS; Le Fèvre et al. 2013) although spectroscopic samples have been observationally expensive and therefore limited in the past.
Next-generation spectrographs will allow for thousands of spectra to be taken simultaneously within wide fields of view, allowing for dramatic increases in spectroscopic data samples (Greene et al. 2022; Wang et al. 2022; Jin et al. 2023). Survey planning with these upcoming spectrographs, as well as fully contextualizing the results thereof, critically depends on our understanding of the selection functions of the parent photometric samples as well as of the spectroscopic data sets themselves.
Techniques employed for determining galaxy parameters from such multi-band data can be classified as physically motivated or data-driven methods (Salvato et al. 2019). The first techniques, already widely used for decades, rely on physical models that have been improved by integrating all the physical knowledge acquired over the years. The estimation is carried out through template Spectral Energy Distribution (SED) fitting to the observed photometry. This method helps us derive parameters such as zphot, stellar mass, stellar population age, metallicity, star formation history, etc. (Gallazzi et al. 2005). This approach works because each physical parameters leaves specific marks on the SED, determining its shape and amplitude. Template libraries, spanning a range of physical parameters, are constructed ahead of time or on the go in the process of exploring the parameter space. Then, stellar population parameters are assigned to the galaxy based on the properties corresponding to the SED model that best fits the observed photometry (e.g., Sawicki & Yee 1998; Walcher et al. 2010; Conroy 2013; Leja et al. 2017). The more sophisticated, and hence realistic, the modeling (e.g., treating the Star Formation History SFH as nonparametric in Leja et al. 2017), the more computationally expensive the SED fitting becomes. Multiplying this by millions and soon billions of galaxies makes this traditional approach largely unfeasible. The necessity of speeding up the process of galaxy parameter estimation from observed photometry or spectroscopy is one of the reasons for the widespread applications of machine learning (ML) in astronomy (Ball & Brunner 2010; Acquaviva 2015; Baron 2019). Machine-learning methods are data-driven, since they learn directly from the data used to train the algorithm. Techniques include data compression, dimensionality reduction, visualization techniques, etc., which all help to manage and process large amounts of information. Machine-learning methods not only offer significant speed-up over traditional SED fitting, but also, as they learn complex connections among multidimensional data, can help us make additional inferences from them.
As stated above, ML is already widely used in astrophysics and cosmology (Baron 2019; Longo et al. 2019). Salvato et al. (2019) provides a comprehensive review of different ML methods that can be applied to estimate zphot. Star Formation Rate SFR and stellar mass M* are predicted by training deep neural networks for the Galaxy And Mass Assembly (GAMA) survey (Surana et al. 2020). Lovell et al. (2019) derive SFHs by training convolutional neural networks (CNN) with simulated galaxy spectra from Illustris and EAGLE. Acquaviva (2015) applies a range of supervised ML methods (regularized ridge regression, extremely randomized trees (ERT), boosted decision trees (AdaBoost), and support vector machines) to predict galaxy metallicity from five-band SDSS photometry. The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project (Villaescusa-Navarro et al. 2021) was created to offer a large, state-of-the-art hydrodynamic simulation that can serve as a training data set for a variety of ML methods. One such application involved using neural networks to estimate cosmological and astrophysical parameters from 17 simulated galaxy properties, revealing significant correlations between Ωm and galaxy properties (Villaescusa-Navarro et al. 2022).
The Self-Organizing Map (SOM; Kohonen 1982) is an unsupervised ML algorithm that projects high-dimensional data onto a 2D map that nevertheless preserves the topology. In the case of galaxy surveys, inputting for example a catalog of 10+ observed colors results in galaxies with similar colors being grouped closely on the 2D map. This makes SOMs a powerful tool for visualizing large astronomical surveys (Geach 2012; Longo et al. 2019). Because observed colors depend on the redshift and stellar population parameters of galaxies, this effective grouping by multidimensional colors can also be used for accurate and computationally very efficient derivation of said parameters. SOMs have been used in the literature to classify stellar spectra (Mahdi 2011), classify galaxy morphology (Galvin et al. 2019), estimate photometric redshifts and other galaxy parameters (Masters et al. 2015; Davidzon et al. 2019; Hemmati et al. 2019; Davidzon et al. 2022), or for target selection (to have spectroscopic samples that are more representative of the photometric ones; Hemmati et al. 2019; Masters et al. 2019).
The goal of this paper is to investigate the use of SOMs for parameter estimation, including the effects of photometric errors and missing data, a common scenario in real astronomical data sets that is not adequately handled within SOM applications. To achieve this, we employ a fiducial Ks -magnitude limited sample to mimic the joint HSC-Deep photometric data set. This analysis lays the groundwork for future work involving training an SOM with real data from the HSC-Deep+ survey.
This paper is organized as follows. The employed simulated mass-limited and magnitude-limited data sets are described in detail in Section 2. In Section 3, we describe the setup, training, labeling, and visualization of our SOM. In Section 4.1, we present the visualization of the observed-like sample and the lessons learned therefrom. In Sections 4.2–4.7, we present parameter estimation results, with further investigation into how derivations are influenced by realistic cases like noise and gaps in the photometric coverage. In Section 5, we discuss the implications of our findings as well as compare them with the literature. In Section 6, we present our summary and conclusions. In an Appendix, we compare an SOM trained on a simulated versus an observed data set. Throughout this paper, all the magnitudes are expressed in the AB system (Oke & Gunn 1983), and we adopt ΛCDM cosmology with H0 = 70 km s−1 Mpc−1, ΩM = 0.3, and ΩΛ = 0.7.
2. Data
We start with a mass-limited simulated data set that we color-calibrate with real galaxy data to provide realistic color–parameter correlations. We then generate a fiducial magnitude-limited simulated data set that is modeled after the HSC-Deep survey with ancillary data. Below, we present the details of our mass-limited initial data set, its color calibrations, and finally the observations-like simulated data set.
2.1. Simulated Lightcone
Our analysis is based on two publicly available mock catalogs (described in Laigle et al. 2019) with observed-frame photometry extracted from the Horizon-AGN lightcone
5
(Dubois et al. 2014). Horizon-AGN is a cosmological hydrodynamic simulation that contains 10243 dark matter particles in a box of Lbox
= 100 h−1 Mpc, corresponding to a dark matter mass resolution of 8 × 107
M⊙. The simulation is run with the adaptive mesh refinement code ramses (Teyssier 2002), following the evolution of the gas, including the effects of gravity, hydrodynamics, gas cooling and heating processes, star formation and stellar feedback, and feedback from black holes (see Kaviraj et al. 2017, for details). Gas is heated from an uniform UV background after the reionization epoch, according to Haardt & Madau (1996), and it cools down to 104 K via H, He, and metals, per Sutherland & Dopita (1993). Star formation is activated only in regions with gas number density n > 0.1 H cm−3, and according to the Schmidt law (Schmidt 1959),  , where
, where  is the SFR mass density,
is the SFR mass density,  is the star formation efficiency, ρgas is the gas mass density, and τff
is the freefall time of the collapsing gas cloud. Stellar feedback is provided by stellar winds and type Ia and II supernovae, and AGN feedback is a combination of the radio or quasar mode based on the black hole accretion rate.
is the star formation efficiency, ρgas is the gas mass density, and τff
is the freefall time of the collapsing gas cloud. Stellar feedback is provided by stellar winds and type Ia and II supernovae, and AGN feedback is a combination of the radio or quasar mode based on the black hole accretion rate.
In Laigle et al. (2019), the 1 deg2 lightcone is built by running the AdaptaHOP halo finder (Aubert et al. 2004) on the Horizon-AGN lightcone over 0 < z < 4 and selecting structures with a density threshold 178 times the average matter density at that redshift, and then considering the total stellar mass within each halo. The extracted lightcone contains 789,354 galaxies with stellar masses >109 M⊙ in a redshift range z = 0–4. For each galaxy, Laigle et al. (2019) compute its SED by adopting single stellar population models from Bruzual & Charlot (2003) and a Chabrier IMF (Chabrier 2003). They adopt an empirical conversion relation from the gas-phase metals to dust and estimate the spatial distribution of that dust from the gas density in each cell. Integrated along the line of sight, this provides the column density of dust. Dust attenuation is then applied to the spectra by assuming the dust follows the RV = 3.1 Milky Way dust model of Weingartner & Draine (2001). They do not take into account scattering in or out of the line of sight, but only dust absorption. This results, for example, in higher (by ≈0.8dex) estimated magnitudes in the UV (Laigle et al. 2019). They also account for absorption by the IGM, but not for foreground extinction by the Milky Way, which is expected to be corrected for in any observed survey that would be compared with this simulated data set.
Apparent magnitudes are obtained by convolving the thus-computed galaxy spectra with the desired filter profiles. Of the two mock catalogs 6 we use, one is the COSMOS-like mock where the photometry matches the Laigle et al. (2016) COSMOS2015 catalog. Specifically, this catalog includes the u* band from MegaCam on the Canada–Hawaii–France Telescope CHFT (Boulade et al. 2003), 6 broad optical bands (B, V , r, i+, z++), 12 median, and 2 narrow bands from the Suprime-Cam on the Subaru telescope (Taniguchi et al. 2007, 2015), as well as the Y band from the Hyper Suprime-Cam/Subaru (Miyazaki et al. 2012), which is slightly bluer than the Y filter from VIRCAM. The COSMOS2015 also includes near-IR YJHKs band from VIRCAM on the VISTA telescope (Beard et al. 2004; McCrackene et al. 2012), and the H and Ks bands from WIRCam/CFHT (Puget et al. 2004; McCracken et al. 2010). Finally, the catalog includes the mid-IR Spitzer IRAC channels centered at 3.6 and 4.5 μm (ch1 and ch2, respectively; Fazio et al. 2004). For our analysis, we need a simulated mock of the HSC-Deep survey (Aihara et al. 2017) and its ancillary surveys, as described in more detail in Section 2.2. To provide a similar photometric coverage, we use the u, r, i, z, Y, J, H, Ks , ch1, and ch2 photometric data points from the Horizon-AGN COSMOS-like mock. However, the COSMOS-like mock is missing the g band. Therefore, we also use the public Euclid+LSST-like mock that includes the LSST g filter, which is very close to the HSC g filter. From these simulated photometric catalogs, we use only the photometry without any photometric errors applied, since we add photometric errors ourselves for the specific surveys we are considering (see Section 4.3). In cross-matching the two mocks, ≈100 objects are lost, leaving us with 789,292 galaxies. In the simulation, the u band exhibits a tail that extends to highly unrealistic values (corresponding to this band dropping shortward of the Lyman break). To mitigate this issue, we consider only galaxies with mu < 28, leaving us with 691,486 objects. This cut limits the redshifts to z ∼ 3.4, as shown in Figure 1 (top), but has no other effects on the data set.

Figure 1. Top: The density of galaxies in the stellar mass vs. redshift plane from the mass-limited 1 deg2 simulated Horizon-AGN lightcone, after applying a u-magnitude cut of mu < 28 (Section 2.1). Bottom: The same simulated data set after color calibration and applying a Ks -magnitude cut of Ks < 23.5 (Section 2.2).
Download figure:
Standard image High-resolution image2.1.1. Color Calibration
We expect the magnitude and color distributions of this lightcone to not be quite right, because of the simplicity of the dust attenuation treatment, as well as the fact that this idealized photometry does not take into account all the systematic effects that one would have from extracting photometry from an image (Laigle et al. 2019). We correct for this systematic offsets in the photometry following the method of Pearl et al. (2022). This method adjusts simulated magnitudes to match the correlation between M/Lν,obs ratios and sSFRUV,obs, ensuring consistency between simulations and observations.
We performed the color calibration using the UltraVISTA catalog (UVISTA; Muzzin et al. 2013), which has similar photometric coverage as well as all necessary derived quantities including redshift. To ensure maximum reliability for our color calibration, we selected galaxies from the UltraVISTA catalog based on the following criteria: 0.2 < z _peak < 4.0, 5  [M⊙], star=0, contamination=0, nan _contam < 3, use=1, Ks
< 23.5 AB. This results in a Ks
-limited catalog with only ∼100 objects at z > 3.
[M⊙], star=0, contamination=0, nan _contam < 3, use=1, Ks
< 23.5 AB. This results in a Ks
-limited catalog with only ∼100 objects at z > 3.
We derived the SFRUV for both the simulated data set and UVISTA following the Kennicutt & Evans (2012) conversion relation from LNUV, which was available for both data sets. For the sake of the calibration, we excluded simulated galaxies with log(sSFRUV) < −13 and log(sSFR) < −13, as such values are not typically observed.
We perform the color calibration in 70 redshift bins. The first 69 bins cover the range 0 < z ≤ 2.5, each with ≈8 K simulated galaxies, making k correction negligible within these narrow redshift bins. The remaining 132,281 simulated galaxies at z > 2.5 are all grouped in the final bin. The choice of this binning is motivated by the use of the Ks -selected UVISTA catalog for the calibration, indicating that there are few observed objects at z > 2.5. Consequently, dividing this redshift range into smaller bins would yield too few objects for a reliable fit in the log(M/Lν )–log(sSFRUV) plane. Figure 2 shows as an example the M/Lν,u ratio for the u band versus the sSFRUV for the redshift bin 0.8 < z < 0.9. We chose the u band as an example because the necessary calibration is by far the strongest in this band. As shown in Figure 2, prior to color calibration, the slopes of the fitted lines in the log(M*/Lu )–log(sSFRUV) plane differ between the Horizon-AGN mock and UVISTA data. To align the simulated fitted line with the observations, we perform linear fits to both distributions and calculate Δm (slope difference) and Δb (y-intercept difference). The new luminosity in each band and redshift bin is derived as

where Lν,old is the old luminosity in a specific band ν. We then derive new apparent magnitudes from


Figure 2. M/Lν,u ratio for the observed u band vs. the sSFRUV in the redshift bin 0.8 < z < 0.9, before and after color calibration in the upper and lower panels, respectively. The black data points and their relative best fits (black solid lines) represent the simulations. The red dashed line represents the best fit to the observed UVISTA catalog (Muzzin et al. 2013). These best fits are used to adjust the simulated photometry to match the observed relation. We perform such color calibration for all bands in all redshift bins.
Download figure:
Standard image High-resolution imageIn this way, we obtain the color-calibrated version of the mock data set. For the rest of this paper, we refer to this mass-limited, color-calibrated mock as the mass-limited simulated data set, and it is what we use to train the SOM (see Section 3) as well as to generate the observations-like sample as described in the next subsection.
2.2. The Ks -limited Data Set
From the mass-limited simulated data set described above, we construct a simple Ks -limited sample that is meant to mimic the Hyper Supreme-Cam (HSC) Deep survey and ancillary data.
The HSC Deep survey is one of the three layers of the HSC survey (Aihara et al. 2017). The HSC is a 1.8 deg2 field-of-view imaging camera (Miyazaki et al. 2017) mounted on the 8.2 m Subaru telescope on the summit of Maunakea in Hawaii, operated by the National Astronomical Observatory of Japan (NAOJ). The product of its wide field of view and the large collecting area of the telescope makes HSC second only to the anticipated LSST Camera (Aihara et al. 2017). The Deep layer, which is our focus, covers 27 deg2 spread across four well-studied extragalactic fields (XMM-LSS, COSMOS, ELAIS_N1, and DEEP2-3). The HSC photometry includes five broad bands (g, r, i, z, and Y) and three narrowband filters (NB387, NB816, and NB921).
The HSC Deep joint data set augments the above through the addition of several complementary surveys. The u-band coverage is provided by the CLAUDS survey (Sawicki et al. 2019), which uses the Megaprime camera on the CFHT telescope. The near-IR J, H, and Ks bands are supplied from a variety of surveys, including UKIDSS/DXS and UDS (Lawrence et al. 2007), VIDEO (Jarvis et al. 2012), UltraVISTA (Muzzin et al. 2013), and DUNES 7 (in preparation). Spitzer IRAC imaging in channels 1 and 2 (3.6 and 4.5 μm) is supplied from the DeepDrill survey (Lacy et al. 2020), the SHIRAZ survey (Annunziatella et al. 2023), as well as a number of surveys within COSMOS (e.g., Sanders et al. 2007).
At the time of writing this paper, the precise properties of the multi-band photometric catalog for this HSC-Deep joint data set had not been determined. To test the degree to which our HSC-like mock catalog depends on the precise catalog construction method, we explored two extremes in such a catalog construction. The first extreme, which results in the smallest number of galaxies included, required a 5σ detection in each band from the u band through to IRAC ch2. Our second extreme simulates a scenario where one uses a reference image for source detection and performs forced photometry on all other images, thus producing a photometry value regardless of whether the brightness of any given source exceed 5σ in these other bands or not (e.g., McCrackene et al. 2012). This method would result in simpler selection function (a single magnitude cut) and a larger number of galaxies than the first method. For this method, we chose to make a simple Ks cut of Ks < 23.5 without any additional cuts. We find that 75% of the Ks -limited sample are also within the first HSC-like mock where we required a 5σ cut in all bands. Thus, for the bulk of the galaxies, our results are independent of the specifics of the catalog construction. While we ran our analysis on both HSC-like mocks, we only show in this paper the results of the runs with the Ks -limited mock, because of its more extended redshift and mass coverage. There was no significant difference in our findings on parameter estimation accuracy or effects of missing data between the two HSC-like mocks. Our adopted HSC-like Ks -limited data set contains 232,118 galaxies, and its stellar mass versus redshift distribution is shown in the bottom panel of Figure 1.
The bottom panel of Figure 1 shows that the Ks -magnitude cut introduces an incompleteness in stellar mass as a function of redshift, with the stellar mass limit increasing with increasing redshift. As a result, low-mass galaxies are excluded from the sample at z ≳ 1, in particular those with log(M*/M⊙) < 10 are entirely absent by z ∼ 3. We caution that the simulated lightcone we started with represents 1 deg2, whereas the HSC-Deep survey covers 27 deg2. Rarer populations such as log(M*/M⊙)>11 galaxies at z > 3 can be present in the real data even though they are largely missing here.
3. Method
3.1. Self-organizing Maps
A Self-Organizing Map (SOM; Kohonen 1982) is an unsupervised artificial neural network that performs a dimensional reduction of a multidimensional parameter space to a lower-dimensional space, while preserving the topology of the data. It thus consists of a lower-dimensional grid where each pixel is characterized by a weight vector that represents the mapping from the higher-dimensional to the lower-dimensional space. The training involves determining these "weights" so that objects that are similar in the high-dimensional parameter space are grouped together, maintaining the intrinsic structure of input data. For this reason, the SOM is a powerful visualization tool, especially for a final 2D grid, as considered in this work. We use the Python library SomPY 8 (Moosavi et al. 2014) for constructing and training our SOM. Below, we describe in more detail how the algorithm works.
The first step is selecting a representative training data, which is then normalized by SomPY to the unit variance with a mean of zero. The weight vector of each SOM pixel, or neural network, in SomPY is initialized using principal component analysis (PCA; Chatfield & Collins 1980) to bring the initial weights closer to the input data (SomPY also allows for random initialization, but it extends the training duration). At this point, the Euclidean distance between each neurons and input data is calculated. The neuron with the smallest distance to an input data becomes the Best Match Unit (BMU). The latter is thus dragged closer to the data point, and neurons around the BMU, specifically those within a "neighborhood radius," are also dragged in the same direction. This process is repeated in an iterative way until all neurons are as close as possible to the input data. This process is unsupervised, as it does not require any a priori labeling of input data, unlike, for example, traditional neural networks where the weights are optimized to match some particular outputs vector. After this optimization, similar objects in the high-dimensional parameter space will be grouped together in the final lower-dimensional (usually 2D) space, maintaining the intrinsic topology of input data.
3.2. The SOM Trained with Galaxy Colors
In this work, the input parameter space has 10 dimensions representing observed-frame colors for galaxies. These colors, based on the expected photometry available for the HSC-Deep joint data set (see Section 2.2) are: u − g, g − Y, g − J, r − i, r − z, r − Y, i − z, J − H, K − ch2, and ch1 − ch2. We select these colors for their sensitivity to galaxy parameters such as redshift, normalized M* and SFR, and sSFR. To do so, we computed the distance correlation for all possible two-color combinations (55 in total) between the 11 available bands. This analysis identified the 10 colors with the strongest nonlinear relationships with our target parameters. While we initially explored using adjacent colors for SOM training, our final selection minimized parameter spread within SOM pixels (Section 3.4), leading to more accurate parameter estimations, in particular for M* and SFR.
For our training set, we selected a random subset from the mass-limited data set. The training set consists of 228,524 galaxies or about 1/3 of the total. The performance of SOM depends on the user set map's size and geometry, which need to be verified by the user depending on their specific case (see Davidzon et al. 2019). The choices of size and geometry of the map should represent a compromise between good sampling of the data and a high resolution (less quantization error). We achieve this, following the Davidzon et al. (2019) procedure, by training different SOMs, starting with a square 20 × 20 map and gradually increasing the size by adding 10 cells in both dimensions. We kept track of sampling versus error, finding that an 80 × 80 SOM represents a good compromise, similar to the findings of Davidzon et al. (2019). We also tested the effect of different aspect ratios, but found that a square map gave the best performance. Finally, in our final 80 × 80 SOM, we verified that the 10-color distributions in the input data set and across SOM pixels are consistent. This ensures that an SOM trained via this method is representative of the input data. 9
3.3. Visualization
Figure 3 shows the distribution of each of the 10 normalized colors across the map. The distribution is typically smooth except for a sharp discontinuity, in the middle of the SOM, that is more evident for some of the colors such as u − g or ch1 − ch2. This is because, in this case, the algorithm organized the input data in a ring-like structure, which causes the colors to change in a counterclockwise direction. The point where the loop closes marks the discontinuity. However, this discontinuity is not random, but rather it has a physical meaning, denoting the transition between galaxies with low and high redshift and other stellar population properties. For instance, for ch1 − ch2 we expect redder colors at z > 1.7 when both IRAC channels sample blueward of the 1.6 μm bump. This means that lower values of ch1 − ch2 on the map would correspond to z < 1.7 and vice versa. The u − g colors also switch from low to high across the same discontinuity, likely due to the effects of redshift and SFR. Lower redshifts correspond to lower-mass, passive galaxies, while higher redshifts correspond to redder colors, indicating more massive, star-forming galaxies.
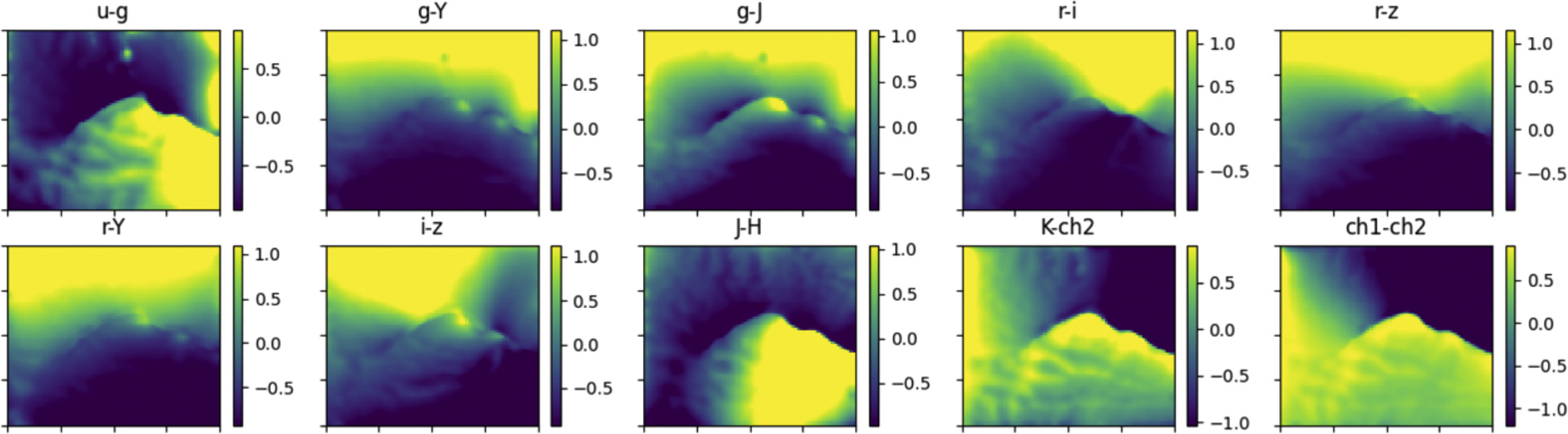
Figure 3. Component maps showing each of the 10 input normalized colors across our trained SOM. The color bar indicates the normalized color values.
Download figure:
Standard image High-resolution imageAt z > 1.7, the u − g colors redden further as a result of the Lyman break, which enters the u filter at z > 2.2. In general, both redshift and galaxy stellar population properties affect these distributions. Figure 3 clearly demonstrates that galaxies with similar 10-color sets are grouped together in the trained SOM.
Considering our ultimate goal is to replicate the methodology presented in this work with observed data, we conduct an additional sanity check, shown in the Appendix. This check involves verifying the similarity of the component maps of two different SOMs, one trained with an observed data set (UVISTA) and the other with simulated data where we match as closely as possible the selection function of the observed data set. We find encouragingly consistent component maps.
3.4. SOM Pixel Labeling
The color distributions across the SOM (Figure 3) already allowed us to identify trends with redshift and stellar population parameters. To quantify these trends and use SOM for parameter estimation, we need to label each SOM pixel with the galaxy properties based on its corresponding 10-dimensional color combination. There are multiple ways to approach this task. Masters et al. (2015) use the subset of their galaxies with spectroscopic redshifts to label each pixel by the expected redshift. Hemmati et al. (2019) use simple empirical template libraries covering a range of parameters such as age of the stellar population and dustiness. In our case, following the approach of Davidzon et al. (2019), we label SOM pixels with the median of each parameter. The latter are the Horizon-AGN parameters from the training set galaxies falling within a given pixel. This works for redshifts and sSFRs, which only depend on the observed-frame colors. Stellar mass M* and SFR, however, require information about the overall amplitude of a galaxy's spectrum, which is not modeled in our color-trained SOM. To account for this amplitude dependence, we normalize M* and SFR values from our simulated data set to a reference magnitude J = 23 mag:

where X is the galaxy parameter that needs to be normalized and J is the J magnitude for each particular galaxy.
The left panels of Figure 4 show how redshift (z), normalized stellar mass (n M*), normalized star formation rate (nSFR), and sSFR vary across the SOM. Consistent with our initial visual inspection, the considered parameters increase in a counterclockwise trend. Specifically, more distant galaxies at z > 2.5 are also more massive and active. Note that the SOM's morphology is not universal; it varies depending on the specific colors and data set used for training. However, its ability to reveal trends remains consistent. For instance, comparing these plots with Figure 3, it is evident that redder galaxies are the farther, more massive ones.

Figure 4. Left panels: SOM with cells color-coded according to the median of galaxy redshift, normalized stellar mass, normalized SFR, and specific SFR, respectively, from the top to the bottom panel. Right panels: SOM with cells color-coded according to the distribution width 〈δ〉 = 〈84%–16%〉 of the corresponding galaxy parameters on the left side.
Download figure:
Standard image High-resolution imageThe right panels of Figure 4 show the distribution width δ for each parameter. The width is quantified by the difference between the 84th and 16th percentiles among galaxies within each pixel. The δ/2 represents the systematic uncertainties σsys of the derived redshifts and stellar population pararameters using SOMs. Large parameter spread within a pixel can be due to degeneracies, although the use of 10 different colors tends to mitigate this to a large degree. We also notice that large spreads in our SOM tend to concentrate the edges. This could be due to (1) boundary effects, as Davidzon et al. (2019) explains, arising from galaxies with extreme colors being placed on the borders of the map by the algorithm; or (2) poorly defined areas, where there are not enough objects to properly train a cell.
4. Results
Now that we have a trained and calibrated SOM, we use it both to explore the selection functions for our observations-like simulated data set (Section 4.1), as well as to derive the redshift and stellar population parameters (Section 4.2). Specifically, for the latter we account for photometric errors (Sections 4.3 and 4.4) and cases of missing data (Section 4.5).
4.1. Visualization of Sample
One of the main strengths of SOMs is its ability to provide interpretable visualization of high-dimensional data. In particular, once an SOM is trained using the mass-limited data set, it is possible to project on the map different samples derived by applying different cuts. Figure 5 shows the projection of the Ks -limited sample, or HSC-Deep joint-like sample, reaffirming the conclusion of Figure 1. Indeed, a lack of objects at z ≳ 2.5 with log(M*/M⊙)<10 is present on the SOM. This is due to the stellar mass incompleteness introduced by the Ks -magnitude cut. Additionally, we notice that the "missing" galaxies in the HSC-Deep joint-like sample are predominantly higher sSFR galaxies with log(sSFR)≳−9.2 yr−1. In observed terms, these are galaxies with blue optical (e.g., g − Y and r − i), but red near/mid-IR (e.g., J − H and ch1 − ch2) colors. This projection of the Ks -limited sample highlights the effectiveness of SOMs in visualizing the impact of both magnitude and color cuts.

Figure 5. The dark region represents the log of the number of galaxies projected on the SOM when Ks < 23.5 is applied to the data set. The Ks -limited sample contains 232,118 objects. The rainbow contours represent levels of values of redshift (Figure 4), with redder colors representing higher redshift.
Download figure:
Standard image High-resolution image4.2. Deriving Redshift and Stellar Population Parameters from SOM
We test the use of SOMs in deriving redshift and stellar population parameters by projecting the Ks -limited data set onto the SOM. For each galaxy, we assign the median of z, log(n M*), log(nSFR), and log(sSFR) of the SOM pixel in which it resides. To denormalize M* and SFR, we use Equation (3) and the observed J-band magnitude for each galaxy. Note that, while we employ the Ks -limited sample for predictions, the SOM was trained and its pixels labeled with a different data set, specifically the training data set, which was randomly drawn from the mass-limited data set. Although the distributions of these two data sets, in terms of z, M*, and SFR may differ, we expect the relation between the mapping color space and physical parameter space to be consistent.
Figure 6 shows the comparison between the true (in values from the HorizonAGN simulation) and the SOM-derived values for z, M*, SFR, and sSFR. For each parameter, we also show four statistics: normalized median absolute deviation (σNMAD), outlier fraction η, root mean squared error (RMSE), and bias. The outlier fraction η is the percentage of objects that satisfy  in the case of zphot, and
in the case of zphot, and  in the case of the other properties X. Here, σ is the standard deviation of the difference log(predicted) – log(true).
in the case of the other properties X. Here, σ is the standard deviation of the difference log(predicted) – log(true).

Figure 6. The true simulated vs. SOM-derived parameter values in the ideal case with no photometric errors. These are based on the Ks -limited test data set. The solid red line represents the bisection line; the red dashed lines indicate the boundaries of the outlier. The number of objects is 232,111.
Download figure:
Standard image High-resolution imageWe find that redshift outperforms other statistics, with σNMAD and RMSE of 0.01 and 0.03, respectively. Stellar mass estimation is also accurate, with σNMAD and RMSE of 0.06 and 0.07, respectively. As is typical of all parameter estimation methods, the estimation of SFR and sSFR has higher uncertainties. The spread between the true and SOM-derived parameters in Figure 6 is due to the intrinsic spread δ in these parameters within an SOM pixel as shown in Figure 4. This spread does not include the effect of photometric errors. Therefore, the performance statistics presented here represents the ideal scenario.
4.3. Accounting for Photometric Uncertainties
To consider photometric uncertainties, we adopted relative errors per magnitude derived from the HSC DR2 preliminary u2K catalog 10 for the u through Ks bands (Aihara et al. 2019). We focused on the XMM-LSS field, since its IRAC ch1 and ch2 fluxes and uncertainties were available from Krefting et al. (2020) and Nyland et al. (2023). We computed the relative photometric errors σν in each band by fitting a line between log(σν /fν ) and magnitude in that band. This approach accounts for larger relative errors for the more abundant faint objects and vice versa.
For each galaxy in our simulated HSC-like data set, we drew a new random flux value from a Gaussian distribution centered at the true flux and a width given by the photometric error. We projected these new perturbed data onto the SOM trained with noiseless colors. Afterward, we repeated the procedure to estimate parameters as described in Section 4.2. Note that, to denormalized M* and SFR, we used the J-band magnitudes with added noise.
Figure 7 shows the comparison of true and SOM-derived parameters, accounting for photometric uncertainties. As expected, parameter uncertainties increase with photometric errors, but the estimations remain reasonably accurate. For instance, the new redshift σNMAD is 0.026 with only a 1.2% outlier fraction. The true versus SOM-derived zphot distribution in Figure 7, however, shows horizontal stripes where the zphot derivation is less reliable, with increased numbers of outliers, at specific redshift ranges. The most evident stripe is at zSOM ∼ 1–2. We investigated the primary cause of these effects by examining the position on SOM of these outliers. The latter are all located near the area of the abrupt change in K − ch2 and ch1 − ch2 (Figure 3), as a result of the move across the 1.6 μm bump. The larger photometric errors in the IRAC channels can cause galaxies to fall into neighboring SOM pixels associated with different redshift values. We validated this hypothesis by repeating the same analysis of this section but removing the IRAC photometric errors. As a result, the horizontal stripes visible in the upper right panel in Figure 7 disappeared, confirming that the colors associated with the IRAC-channels were indeed the primary contributors. This illustrates how photometric noise in specific bands impacts derived parameter uncertainties.

Figure 7. The true simulated vs. SOM-derived parameter values in the more realistic case including photometric errors. These are based on the Ks -selected test data set. The solid red line indicates the bisection line; the red dashed lines show the boundaries of the outlier. The number of objects is 227,365. Approximately 2% of objects are lost because of invalid values from the log.
Download figure:
Standard image High-resolution imageDue to the degeneracies between photometric redshift and shape of the SED, the outliers of the horizontal stripes are also responsible for the outliers in mass and SFR derivation visible in Figure 7. For example, if objects at somewhat higher z are incorrectly placed at lower z (right side of the stripe), their redder colors are associated with more quiescent galaxies, leading to an underestimation of SFR, and vice versa. Similarly, if an object is placed at a redshift lower than its true value, the observed J band suggests a lower stellar mass than in reality. This results in stripes below the 1:1 relation in M* (see Figure 7). Since sSFR is the ratio of SFR and M*, these effects are canceled out. This explains why our estimates for sSFR changed the least between the no-error and error cases (Figures 6 versus 7). We tested this interpretation by running the analysis without any IRAC channel errors, and as a result, the horizontal stripes in zphot, in M* ( ), and in SFR (log(SFR)SOM ∼ 0) disappeared.
), and in SFR (log(SFR)SOM ∼ 0) disappeared.
4.4. Uncertainty Estimation for Individual Galaxies
Figure 7 gives an overall sense of parameter uncertainties when photometric errors are considered. These parameter uncertainties can be statistical, resulting from photometric errors, and systematic, resulting from parameter value distribution within a single SOM pixel. Below, we explain how we compute both statistical and systematic parameter uncertainties for individual galaxies.
For any galaxy, the likelihood  of it occupying an SOM pixel with coordinates [x, y] is computed as
of it occupying an SOM pixel with coordinates [x, y] is computed as

with

where, in the pixel [x, y], Ci
are the 10 colors of the test galaxy,  are the 10 median colors in that pixel, and
are the 10 median colors in that pixel, and  represent the uncertainties of Ci
. The likelihood surface is normalized by dividing
represent the uncertainties of Ci
. The likelihood surface is normalized by dividing ![${{ \mathcal L }}_{[x,y]}$](https://content.cld.iop.org/journals/1538-3881/167/6/261/revision1/ajad3821ieqn10.gif) by its sum. Figure 8 (left panels) shows the likelihood surfaces for two test galaxies. These test galaxies are of similar redshift (z ∼ 1.2) and were chosen to represent a high-S/N (signal-to-noise ratio) galaxy (pixel = [61, 21], S/N = 82.3 in g band, mg
= 23.4) and a low-S/N galaxy (pixel = [71, 29], S/N = 4.0 in g band, mg
= 27.7). The likelihood surface of the high-S/N test galaxy is very concentrated around its true position on the SOM, while for the low-S/N test galaxy it is more spread out.
by its sum. Figure 8 (left panels) shows the likelihood surfaces for two test galaxies. These test galaxies are of similar redshift (z ∼ 1.2) and were chosen to represent a high-S/N (signal-to-noise ratio) galaxy (pixel = [61, 21], S/N = 82.3 in g band, mg
= 23.4) and a low-S/N galaxy (pixel = [71, 29], S/N = 4.0 in g band, mg
= 27.7). The likelihood surface of the high-S/N test galaxy is very concentrated around its true position on the SOM, while for the low-S/N test galaxy it is more spread out.

Figure 8. The panels on the left show the normalized likelihood surfaces for two test galaxies: a high-S/N (= 82.3 in g band, mg = 23.4) example on top, and a low-S/N (= 4.0 in g band, mg = 27.7) example on the bottom, both with true redshifts around z ∼ 1.1–1.2. The rainbow colors correspond to the redshift levels as in Figure 5. The panels on the right show the redshift probability distribution based on these likelihood surfaces. The blue solid line represents the most likely redshift value, zpeak , from the 2D surface. The red solid line represents the true redshift, zsim, while the red dotted line corresponds to the median of redshift, zmed, used to label the pixel in which the test galaxy is located. Note that the standard deviation σstd of the distribution is smaller for an higher-S/N test galaxy.
Download figure:
Standard image High-resolution imageFrom these likelihood surfaces, combined with the pixel labels for a given parameter, we can derive probability distribution functions for any of our parameters. For example, the right-hand panels of Figure 8 show the redshift probability distribution functions P(z) derived from these likelihood surfaces. The P(z) of the low-S/N test galaxy exhibits a larger spread compared to the high-S/N test galaxy. This confirms the idea that the accuracy of parameter estimation with SOMs depends on a galaxy's S/Ns, as indeed is the case for all methods used in deriving galaxy parameters.
We define the statistical uncertainty for the given parameter, σstat,param, for any individual galaxy as the standard deviation of the probability distribution function, such as the P(z) functions discussed above. To estimate the parameter systematic uncertainty σsys,param, we take half of the 〈δ〉 = 84%–16%, the dispersion of galaxy parameter within the best-fit pixel for that galaxy (see right panels of Figure 4). The total uncertainty is

For example, to derive the uncertainties in the redshift estimation for the high-S/N test galaxy, we look at its pixel [61, 21], which has a redshift spread 〈δ〉 = 0.057, hence σsys = 0.029, leading to a total redshift uncertainty of  . To compare this with the nominal σNMAD in Figure 7, we need σtot,z
/(1 + 1.2) = 0.02, which is consistent with the σNMAD of 0.026.
. To compare this with the nominal σNMAD in Figure 7, we need σtot,z
/(1 + 1.2) = 0.02, which is consistent with the σNMAD of 0.026.
4.5. Handling Missing Data
The previous section's analysis assumes flux measurements are available across all bands. In reality, the surveys making up the HSC-Deep joint data set do not perfectly overlap. Several square degrees of the HSC-Deep joint survey in fact will have no data outside the core bands of grizY. Additionally, even in overlapping areas, there can be instances of missing data in individual bands, due to issues such as bad data arising from image artifacts. The simplest approach would be to train an SOM excluding any missing bands. We tested this scenario for multiple individual missing bands or sets of missing bands. Figure 9 shows the zphot σNMAD in a case where the u band, J band, H band, Ks band, JHKs , Ks +IRAC, and uJHK+IRAC are missing. The σNMAD gets worse compared to the baseline of complete data (dashed line) with σNMAD = 0.026. Note that this analysis takes into account photometric uncertainties in the same manner as done in Section 4.3, where each flux is perturbed by Gaussian noise based on the given flux uncertainty.

Figure 9. The σNMAD for estimated zphot as a function of missing bands. Stars represent the cases when the missing bands are omitted from the SOM training. Squares represent the cases when the SOM is trained on the complete data, and data sets with missing data are projected onto it using the missing color recovery method described in Section 4.5. The horizontal dashed line indicates the σNMAD = 0.026 achieved using all bands (see Figure 7).
Download figure:
Standard image High-resolution imageThe degradation in parameter estimation seen in Figure 9 is due to the loss of information resulting from the missing bands. To address this, we assume that galaxies with missing data fall within the same color distribution as the training sample. This is justifiable when the missing data is simply due to the inhomogeneous coverage of the various multiband surveys. To recover the colors involved with missing bands, we perform 500 random draws from the color distribution of these same colors, as defined in the training set. Our color distribution again includes photometric uncertainties as discussed above. The random draws involve either 1D, 2D, or 3D color distributions, depending on whether the missing band is on the edge (e.g., u band) or in the middle (e.g., H band), or if a set of adjacent bands is missing (e.g., JHK). With our 500 random draws for the "missing band" colors combined with the existing colors for each galaxy, we are able to essentially build an SOM likelihood surface for that galaxy in a manner similar to that discussed in Section 4.4. The adopted parameter value is then simply based on the maximum-likelihood SOM pixel. The resulting redshift σNMAD values for each of our missing data scenarios are shown in Figure 9. We note that, in most cases, this band recovery procedure allows us to achieve significantly better σNMAD values than by simply training the SOM without the missing data. We emphasize that this improvement is based on the assumption that the color distributions determined from the data with complete coverage are representative of the data with incomplete coverage as well.
The only cases where our recovered data perform worse than the SOM trained by omitting the missing data are those involving IRAC channels. We tested that this worsening does not depend on the adopted photometric error. This effect is likely due to a more uncertain extrapolation when more than one color needs to be recovered right on the edge of the wavelength coverage, as is the case when the IRAC channels are missing.
4.6. Parameter Recovery versus Wavelength Coverage
The missing-data analysis also provides us with information on the relative importance of having particular bands present for the recovery of our parameters. Table 1 goes beyond zphot, shown in Figure 9, to explore how the σNMAD for zphot, M*, and SFR all vary depending on which bands are missing and filled in with our recovery method (Section 4.5). We reach reasonably good accuracy for when only a single band is missing. As more bands are missing and filled in, the values of σNMAD increase. For example, the worst parameter estimation occurs when all ancillary bands outside the HSC-Deep core bands (grizY), namely uJHK+IRAC, are missing and filled in with our method. If at least the u band, among the ancillary bands, is not missing (i.e., in the case of recovered missing JHK+IRAC) the parameter σNMAD improves, especially for zphot estimation, with a decrease in σNMAD of ∼32%. These findings show the critical importance of the ancillary surveys providing the u-band, the near-IR, and the Spitzer IRAC ch1 and ch2 coverage.
Table 1. Effect of Parameter Recovery for Different Missing Bands "Filled in" as Described in Section 4.5
| σNMAD | |||
|---|---|---|---|
| All Bands | zphot | M* | SFR |
| 0.026 | 0.090 | 0.169 | |
| Missing Bands | zphot | M* | SFR |
| u | 0.034 | 0.102 | 0.240 |
| uJ/uJH | 0.041 | 0.158 | 0.276 |
| uJK/uJHK | 0.056 | 0.224 | 0.321 |
| uJHK+IRAC/uJK+IRAC | 0.105 | 0.336 | 0.484 |
| uH | 0.040 | 0.145 | 0.279 |
| uHK | 0.053 | 0.244 | 0.336 |
| uHK+IRAC | 0.090 | 0.318 | 0.480 |
| uK | 0.043 | 0.156 | 0.278 |
| uKIRAC | 0.068 | 0.290 | 0.383 |
| J/JH | 0.030 | 0.141 | 0.208 |
| JHK | 0.037 | 0.172 | 0.226 |
| JK+IRAC/JHK+IRAC | 0.071 | 0.305 | 0.399 |
| JK | 0.037 | 0.171 | 0.226 |
| H | 0.030 | 0.127 | 0.202 |
| HK | 0.042 | 0.181 | 0.218 |
| HK+IRAC | 0.066 | 0.292 | 0.349 |
| K | 0.035 | 0.144 | 0.189 |
| IRAC-ch1 | 0.035 | 0.117 | 0.208 |
| K+IRAC | 0.050 | 0.237 | 0.304 |
Download table as: ASCIITypeset image
The variation of parameter σNMAD with specific bands depends on their different sensitivities to galaxy parameters at different ranges. Figure 10 illustrates this for the cases when u-band (top panel), H-band (middle panel), and all ancillary to HSC-Deep data are missing (bottom panel). We chose these specific cases because the u band is crucial for accurate zphot estimation at z ≳ 2.5 (as this filter enters the Lyman break) and traces the rest-frame ultraviolet, hence it is relevant for the SFR estimation. The top panel in Figure 10 shows that indeed, when the u band is missing, our redshift recovery gets worse beyond z ∼ 2.5, and the SFR recovery is poor. As seen in Table 1, the SFR recovery here is the worst compared to any other single (or couple of) missing-band cases.

Figure 10. From left to right, zphot, M*, and SFR predicted vs. true in the cases of recovered missing data for the u band (top) and the H band (middle). The procedure for handling missing data is described in Section 4.5. Bottom: predicted vs. true in the case where only HSC-Deep grizY bands are available and the missing bands are not recovered. Red lines as in Figures 6, 7.
Download figure:
Standard image High-resolution imageThe H band, in our redshift range, traces the rest-frame optical to near-IR, therefore it is sensitive to the stellar mass. It also affects the zphot determination, since that is sensitive to the 1.6 μm bump at lower z, as well as to the 4000 Å break at z > 3. The middle panel in Figure 10 shows that indeed, when the H band is missing, our redshift recovery is much worse at z > 2. The underestimated redshifts in this regime also lead to a pronounced bulge of underestimated stellar masses—and corresponding underestimated SFRs.
The last case we explored in more detail was the worst-case scenario (see Table 1), which was the missing uJHK+IRAC scenario, or when we have no data outside the HSC-Deep core bands (grizY). In this case, we use the scenario where the missing data are simply omitted rather than recovered, since the latter shows worse parameter recovery (see Figure 9). We see, in the bottom panel of Figure 10, that the redshift estimation is still reasonable at z < 1–1.5, where the optical bands trace the 4000 Å break, but there is essentially no handle on the redshift beyond that (up to the z ∼ 3 regime explored here). The longer-wavelength (J+) bands are critical for the z ∼ 1.5–3 estimation, due to their sampling both the Balmer break and the 1.6 μm stellar bump.
4.7. Handling Upper Limits
Besides cases of missing data, we can also have upper limits if the source is too faint relative to the noise in a given image. The naive first approach to handle such upper limits is to draw random fluxes from uniform distributions representing the upper limit. However, this method can lead to unrealistic colors that place the galaxy outside the SOM surface, which only represents the 10D color space present in the training set. Dealing with upper limits is, in general, a significant challenge for machine-learning methods, as it requires extrapolating outside the training set.
While a more comprehensive treatment of upper limits in SOMs is beyond the scope of the present work, we can adapt our missing data approach for one particular scenario involving upper limits. This is the case where upper limits are a result of some part of the survey having significantly shallower coverage in some band relative to another deeper portion of the survey. In this case, we can train the model using the full color set from the deep portion of the survey. The assumption is that the deeper-data training set contains realistic colors for sources with upper limits in the shallower portion. In this case, we can implement a modification of the missing data approach described in the previous section. Instead of drawing from the full color distribution, we draw from a truncated color distribution that accounts for the detection limit in the shallower data. Figure 11 illustrates this approach with an example of a test galaxy having only an upper limit in the H band. The test galaxy is drawn from a fiducial data set with H-band coverage two orders of magnitude shallower coverage than in the training set. In this case, the recovered colors are realistic and fall within the panchromatic space used to train our SOM, as shown by the gray region in Figure 11. Note that the tightness of the SOM likelihood survey of this upper limit galaxy is due to the fact that each SOM pixel involves 10 colors, which helps compensate to a large degree for any missing/upper limit data.

Figure 11. The log of the normalized likelihood for a test galaxy (hot diamond) with an upper limit for the H band, in the scenario where the SOM is trained with complete deeper data. The rainbow contours represent levels of redshift values, as in Figure 5.
Download figure:
Standard image High-resolution image5. Discussion
5.1. Comparison with Davidzon et al.
This paper was originally inspired by Davidzon et al. (2019), who also explored the derivation of zphot and SFR using SomPY on the Horizon-AGN simulated lightcone. They added photometric errors corresponding to the COSMOS photometry. Their training color set excluded g-band colors and colors from nonadjacent bands (e.g., g − Y, r − z). In this paper, we expand on this work, first by applying it to a different photometric set (the HSC-Deep ones). Next, we explore the effect of different color choices for training the SOM, and consider the effects of missing data and how to handle them. Fundamentally, we achieve a photo-z σNMAD of 0.026 and an outlier fraction of 1.2%, while Davidzon et al. (2019) reported a σNMAD of 0.044 and an outlier fraction of 6.1%. While the approach is very similar, this is a significant improvement in performance. Our tests suggests that the key aspect behind this improvement is the specific choice of colors. We use more widely separated colors, such as r − z, which is sensitive to the redshift, and we also add the g band (which is omitted in Davidzon et al. (2019)), which also improves performance, especially in redshift regimes where it helps pinpoint the Balmer break. In addition, our improved performance is aided by our uncertainties being ≈0.2 mag lower in the u band, comparable in the visible bands, and ≈0.1 mag lower in the NIR, although our IRAC channels errors are worse by ≈0.2 mag. Davidzon et al. (2019) do not quote detailed statistics for SFR, but they quote σNMAD < 0.2, which is consistent with our results.
In a more recent paper, Davidzon et al. (2022) used their SOM method to derive M* from the observed COSMOS data and compare their SOM-derived values with traditional SED-fitting. Their results indicate that this method works equally well as traditional SED fitting, but it is computationally much faster, making it suitable for large data sets. Their distribution of SOM-derived versus SED-fitting-derived stellar masses appears visually wider than our SOM-derived versus true stellar mass. However, this is not a fair comparison, since there are uncertainties associated with the SED-fitting-derived values as well.
5.2. The Handling of Missing Data
In this paper, we explore for the first time in the astronomical context the handling of missing data in SOMs. This issue has been explored in SED template fitting codes, e.g., by modifying the χ2 method, usually at the expense of increased computational cost (Sawicki 2012; Boquien et al. 2019). A recent paper by Rejeb et al. (2023) does discuss how to train SOMs with incomplete data; however, this paper did not appear until the final stages of our current work, therefore we have not had a chance to implement it. In future works, we plan to explore the possible use of their algorithm through their publicly available code. 11 One needs to be cautious, however, about including incomplete data in the training, especially in cases of large variance, as discussed in Cottrell & Letrémy (2007). They argue that, when a sufficient amount of data are available to build a robust model, it is preferable to train on the complete data and only afterward consider the effects of missing data. Indeed, this is the approach we adopted in our study. In our paper, we outline a method to train the SOM on the complete data set and "recover" the missing data where the data are incomplete by assuming the SOM training set is otherwise representative of the galaxies with missing bands. In line with our finding that it is better to fill in the missing data rather than simply omit it, Chartab et al. (2023) achieved better results in SED fitting after first using a random forest model to fill in any missing data.
6. Summary and Conclusions
SOMs are an efficient means of grouping galaxies based on their colors, providing a powerful means for visualizing multidimensional galaxy data sets as well as estimate any SED-based parameters. In this study, we train an SOM on a mass-limited lightcone from the Horizon-AGN simulation that has been color-calibrated on real data. Our training color set is based on a fiducial ugrizYJ HKs +IRAC photometric coverage characteristic of the HSC-Deep survey plus ancillary data (the HSC-Deep joint survey). We also examine an observations-like magnitude-limited sample with Ks < 23.5. We assess the quality of the SOM-derived photometric redshifts, stellar masses, SFRs, and sSFRs while considering realistic photometric errors for the HSC-Deep joint survey. Finally, we investigate the effects on the derived parameters in cases of missing data. Our key findings are as follows:
- 1.The set of colors used for SOM training should be those most sensitive to the parameters we intend to estimate. For example, u − g, J − H, and ch1 − ch2 are all colors that are critical to accurate redshift estimation, each of which is particularly sensitive to a different redshift range.
- 2.SOMs can be used to interpret visualization of high-dimensional data. For example, the projection of the Ks -limited sample onto the SOM (Figure 5) shows that this selection is similar to the mass-limited sample up to z ∼ 1, but loses galaxies with higher sSFR (log(sSFR) > −9) and lower stellar mass (log(M*/M⊙)<10), beyond that.
- 3.With the HSC-Deep joint survey photometric uncertainties, the derived zphot parameters have σNMAD = 0.026. For M*, SFR, and sSFR, we have σNMAD < 0.2. The IRAC channels uncertainties are particularly critical in the z ∼ 1–2 range, where the K − ch2 and ch1 − ch2 colors trace the 1.6μm bump.
- 4.We consider both the systematic and statistical uncertainties in the derived parameters for individual galaxies. In particular, the probability distribution function is derived from the likelihood surface of a galaxy within the SOM, which is strongly dependent on the signal-to-noise ratio of the particular galaxy.
- 5.We discuss how to recover and project cases of missing photometric bands onto an SOM trained with the full data set. This leads to improved parameter estimations compared to simply omitting missing data from the training. In limited cases, this approach can be applied to upper limits as well.
- 6.The quality of the derived parameters is strongly dependent on the overall wavelength coverage included in training the SOM. We provide a table for comparison of achieved σNMAD for estimated zphot, M*, and SFR when different (sets of) missing bands are recovered.
We stress that the findings presented in this study are based on simulations, despite our efforts to make the simulations more realistic through the color-calibration process. Our next step will be to use the methods outlined here to use SOMs for parameter estimation for the upcoming HSC-Deep joint catalog. Finally, in a companion paper (V. La Torre et al. 2024b, in preparation), we conduct a performance comparison of SOM with three supervised ML methods: extreme gradient boosting, fully connected neural networks, and random forests. For comprehensive information on the training process and our findings, we refer the reader to that paper.
Acknowledgments
A.S. is grateful for fruitful discussions with Peter Capak, Iari Davidzon, and Shoubaneh Hemmati during a sabbatical leave at Caltech in 2019 that originally brought SOMs and their use in parameter estimation to her attention. We are grateful to Jenny Greene, ChangHoon Hanh, and Tom Loredo for helpful discussions. This work is support by NASA under award number 80NSSC21K0630, issued through the Astrophysics Data Analysis Program (ADAP). L.S.J. acknowledges support from the Brazilian agencies CNPq (308994/2021-3) and FAPESP (2011/51680-6). The authors acknowledge the Tufts University High Performance Computing Cluster (https://it.tufts.edu/high-performance-computing), which was utilized for the research reported in this paper. The authors are grateful to the anonymous reviewers for their insightful feedback and constructive comments, which contributed to the improvement of this paper.
Software: Astropy (Astropy Collaboration et al. 2013, 2018, 2022), SomPY(Moosavi et al. 2014).
Appendix: Comparison of SOMs Trained with Simulated and Observed Datasets
We test if two SOMs trained with a simulated or an observed data set yield similar component maps. This is important, as our final goal is to employ SOM to estimate galaxy parameters for the large HSC Deep joint survey. For this test, we compare two SOMs, one trained with the mass-limited simulation and the other trained with observed galaxies from UltraVISTA catalog (Muzzin et al. 2013). The training colors of these two data sets should be similar if we want to check that simulated and observed galaxies with the same colors are placed in the same regions of the map after the training. To this effect, for this test we select only simulated and observed galaxies brighter than the peak of the observed magnitude's distribution in each band. Thus, the resulting simulated and observed color distributions are similar, as shown in the top panel of Figure 12, and so they can be used to train two SOMs. Note that these component maps differ from Figure 3, due to variations in the magnitude distribution utilized for color computation. In the analysis of this work, we exclusively apply Ks -magnitude cuts, whereas in this test, the cuts are made at the peak of the observed magnitude distributions. The middle and bottom panels in Figure 12 illustrate the two SOMs color-coded by two of the training colors, showing that they yield similar component maps (more details in the figure caption). This means that if the two training data sets have same color distributions, then even the SOMs will be similar. Consequently, with the aim of using this analysis with similar observed color distributions, we can trust, within some limits, the analysis we are performing in this work with simulations.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 12. The top panel shows the comparison of distribution of simulated and UVISTA colors, obtained from magnitudes brighter than the peak of the observed magnitude's distribution in each band. The colors g − r on the left and Y − J on the right are shown as an example of two similar color distributions. The middle and bottom panels show the comparison of component maps obtained from training SOM with simulated galaxy colors (middle) and UVISTA (bottom). A comparison between the middle and the bottom panels shows that the two data sets yield the same component maps, meaning that if the input objects have the same color distribution, as in the top panel, then even the SOMs will be similar. For this test, we trained the two SOMs with the same color set considered in this paper.
Download figure:
Standard image High-resolution image{kind=link}
Footnotes
- 5
- 6
- 7
- 8
- 9
For this test, one needs to denormalize the SOM component pixel values, since SomPY normalizes the input data by the variance in order to keep the data ranges comparable.
- 10
- 11