
Abstract
In two experiments, we examined the spatial integration of two viewpoints onto dynamic scenes. We tested the spatial-alignment hypothesis (which predicts integration by alignment along the shortest path) against the spatial-heuristic hypothesis (which predicts integration by observation of the left–right orientation on the screen). The stimuli consisted of film clips comprising two shots, each showing a car driving by. In Experiment 1, the dynamic scenes were ambiguous with regard to their interpretation: The cars could have been driving either in the same or in opposite directions. In line with the spatial-heuristic hypothesis, participants responded with “same direction” if the cars shared a screen direction. In Experiment 2, environmental cues disambiguated the dynamic scenes, and the screen direction of the cars was either congruent or incongruent with the depicted environmental cues. As compared with congruent dynamic scenes, incongruent dynamic scenes elicited prolonged reaction times, thus suggesting that heuristic spatial updating was used with congruent stimuli, whereas spatial-alignment processes were used with incongruent stimuli.
Similar content being viewed by others

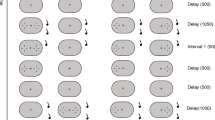
How do humans integrate different views of one scene into one coherent mental representation? As long as proprioceptive and/or visual inputs are continuous, this seems to work effortlessly (Meyerhoff, Huff, Papenmeier, Jahn, & Schwan, 2011; Simons & Wang, 1998). In contrast, several lines of experimental research have shown that the integration of discontinuous views of a given scene, presented in succession, requires computationally demanding spatial-alignment processes. For example, the model of Mou and colleagues (e.g., Mou, Fan, McNamara, & Owen, 2008; Mou, McNamara, Valiquette, & Rump, 2004) assumes that when viewers are presented with a given scene for the first time, they establish an intrinsic reference vector that refers to a prominent scene structure (e.g., the spatial orientation of a wall). If viewers are presented with a new viewpoint of that scene at a later time, they will try to identify the internal reference vector and, on the basis of this common reference, align the current perspective with the former one. Accordingly, in experiments in which researchers have examined spatial memory, visual recognition performance typically decreases with increasing angular distance between the learning and testing viewpoints (Diwadkar & McNamara, 1997; Garsoffky, Schwan, & Hesse, 2002; Garsoffky, Schwan, & Huff, 2009; Simons & Wang, 1998). Furthermore, viewers tend to align a given view with the closest possible view (in terms of angular distance) stored in memory (Diwadkar & McNamara, 1997; see also Shepard & Metzler, 1971). Aligning views is particularly difficult in dynamic scenes (Garsoffky, Huff, & Schwan, 2007), where even minor angular deviations of 20° may lead to severe difficulties (Huff, Jahn, & Schwan, 2009). One explanation for these difficulties may be that the ongoing visual dynamics of the scene interfere with the time course of the mental alignment processes.
On the other hand, people in industrial countries such as Germany spend almost 4 h per day watching TV (AGF/GfK Fernsehforschung, 2011) and are thus regularly confronted with the task of aligning successive views (or shots, respectively). While viewers who are unfamiliar with films do face severe problems with integrating different views of the same scene (Schwan & Ildirar, 2010; R. Smith, Anderson, & Fischer, 1985), regular viewers are able to integrate different views with apparent ease, and often do not even notice that a change of view has taken place (T. J. Smith & Henderson, 2008). Thus, although films and TV mainly provide discontinuous visual input—a typical shot in a Hollywood movie lasts between 2.7 and 5.4 s (Bordwell & Thomson, 2001)—spatial integration of successive shots seems to works effortlessly. Typically, filmmakers argue that certain editing conventions facilitate this process (Arijon, 1978). In particular, the so-called centerline rule (or 180° rule) requires that the camera positions of successive views should be kept on one side of the main axis (centerline) of the portrayed events. In this case, corresponding objects or persons stay on the same side of the screen across shots, and also the direction of moving objects is kept constant. In contrast, if the rule is violated, corresponding objects switch screen positions from left to right—or vice versa—across shots, and the directions of movement are reversed (see Fig. 1).

Schematic illustration of the centerline rule. If two cameras are on the same side of the centerline (cameras a and b), the left–right orientation of the car and the movement direction are preserved. If the cameras are on different sides of the centerline (cameras a and d), the left–right orientations and movement directions change
In two experiments, we present first evidence that the intuition of filmmakers that adhering to the centerline rule facilitates spatial processing has some validity. In particular, we show that, as long as a film conforms to the centerline rule, viewers cut short the process of aligning two successive views by applying simple spatial heuristics: Namely, across two shots with different viewpoints, objects on the same side of the screen correspond to each other in the depicted scene, and across two shots, objects moving in the same screen direction also move in the same direction in the depicted scene.
Experiment 1
We asked participants to judge whether two cars of different colors driving on a road in two successive shots moved in the same or in opposite directions. Due to the lack of environmental background information (e.g., trees alongside the road), and in contrast to previous studies on spatial updating (Simons & Wang, 1998) and on the centerline rule (Germeys & d’Ydewalle, 2007), every combination of the two successive views was ambiguous with regard to their spatial relations. Hence, for each pair of successive views, both answers (“the cars are moving in the same direction” vs. “the cars are moving in opposite directions”) were equally valid. However, depending on the strategy of the viewers, we expected varying judgment patterns. In the case of spatial alignment, as specified in models of spatial updating, viewers should align the two views along their shortest path (Diwadkar & McNamara, 1997), regardless of whether this implies crossing the centerline (Table 1). In contrast, in the case of applying the spatial heuristic, viewers should base their judgments on screen direction, thereby implicitly aligning the two views in such a manner that crossing the centerline is avoided, regardless of the amount of angular difference between the views (Table 1). More specifically, when the two cars share a screen direction (to the left or to the right), viewers should answer “same direction.” When the two cars do not share a screen direction, the viewers should answer “opposite directions.” Furthermore, in the case of heuristic processing, reaction times should be independent of the actual viewpoint deviation between the shots. For half of the pairs of views, alignment and the centerline heuristic made similar predictions, while for the other, critical trials, they made opposite predictions (Table 1).
Method
Participants
The participants were 23 students at the University of Tübingen, Germany. They were paid for their participation.
Apparatus, stimulus materials, and design
The videos consisted of two shots, each showing a car driving by. The cars’ colors were red and yellow. Both cars were recorded from four possible perspectives, each with a 30° angle relative to the road (see Fig. 2). This resulted in angular deviations of 60° between adjacent cameras on opposite sides of the road and of 120° between adjacent cameras on the same side of the road. Combining two shots resulted in 16 combinations, which could be reduced to four types (see Table 1). In Type I stimuli, both the viewpoints and directions of the two cars were similar across the two shots. This sequence could either be interpreted as two cars being filmed from the same camera position—hence, driving in the same direction—or alternatively, as two cars being filmed from opposite camera positions, thus driving in opposite directions. In Type II stimuli, the viewpoints were similar across shots, but the two cars moved in opposite directions on the screen. This sequence could either be interpreted as two cars being filmed from the same camera position—hence, driving in opposite directions—or alternatively, as two cars being filmed from opposite camera positions, and thus driving in the same direction. In Type III stimuli, the viewpoint changed across shots, and the two cars moved in opposite directions on the screen. This sequence could be interpreted as two cars being filmed from two cameras positioned on the same side of the road (centerline), with an angular difference of 120°—hence, as cars driving in opposite directions. Alternatively, it could be interpreted as two cars being filmed from two cameras positioned on opposing sides of the road (centerline), with an angular difference of 60°—hence, as cars driving in the same direction. Finally, in Type IV stimuli, the viewpoint changed across shots, and the two cars moved in the same direction on the screen. This sequence could be interpreted as two cars being filmed from two cameras positioned on the same side of the road (centerline), with an angular difference of 120°—hence, as two cars driving in the same direction. Alternatively, it could be interpreted as two cars being filmed from two cameras positioned on opposing sides of the road (centerline), with an angular difference of 60°—hence, as cars driving in opposite directions. We counterbalanced the serial order of the cameras and car colors. Each clip lasted 10 s (5 s per shot) and was presented twice in a randomized order, thus resulting in 32 experimental trials. In addition, we presented four practice trials that were discarded from the analysis.

The stimuli in this study comprised two shots depicting a car each, which were concatenated by means of a filmic cut
Procedure
Each participant was tested individually in a within-subjects design. We presented the video clips using E-Prime 2.0 (Psychology Software Tools, Inc.; Schneider, Eschman, & Zuccolotto, 2002). The participants were asked to judge the movement directions of the cars. Specifically, they were asked to respond spontaneously “whether the cars were driving in the same or in opposite directions on the road” by pressing one of the two outer keys on a DirectIN Button-Box with horizontally aligned buttons (www.empirisoft.com). We counterbalanced the assignment of direction judgments (“same direction,” “opposite directions”) to the response keys (left, right) across participants, and recorded reaction times from the beginning of the second shot.
Results and discussion
We analyzed the proportions of answers that were in line with the heuristic-processing hypothesis (proportions of heuristic-processing answers), the reaction times of the heuristic answers, and the reaction times of nonheuristic answers for Types III and IV (see Table 1). We analyzed the data with linear mixed-effects models (lme; Baayen, 2008; Pinheiro, Bates, DebRoy, Sarkar, & R Development Core Team, 2011). We fitted separate lme models with random intercepts for the participant effect for each dependent variable.
Proportion of heuristic-processing answers
We compared a first—saturated—lme model with four fixed parameters (Types I, II, III, and IV; Akaike information criterion [AIC; Akaike, 1974] = 23.65) with a second lme model with two fixed parameters. For the second lme model, we pooled data across the conditions in which alignment and heuristic processing resulted in similar judgments of driving directions (Types I and II), and across the conditions in which alignment and heuristic processing resulted in different judgments of driving direction (Types III and IV). This resulted in an lme model with two fixed effects (AIC = 20.89). A likelihood-ratio test revealed no significant differences between these lme models, χ 2(2) = 1.23, p = .539. Thus, we retained the simpler lme model, with two fixed effects only. The results for this lme model are presented in Table 2. The intercept (.97) indicates the average proportion of heuristic answers in the “no-alignment” condition (Types I and II). The estimate of the “alignment” condition (Types III and IV) is significantly lower than the intercept. Critically, the proportion of heuristic responses in the alignment condition is well above chance level (defined as .5), t(45) = 2.46, p = .018.
Reaction time analysis
We analyzed reaction times on heuristic responses. We fitted a saturated model with four fixed effects (Types I, II, III, and IV; AIC = 1,287.41) and a second model with only the intercept as a fixed effect (AIC = 1,268.69). A likelihood-ratio test showed no significant difference between the two lme models, χ 2(3) = 5.28, p = .153. Thus, we retained the simpler model, with intercept as a fixed effect, which suggests that reaction times were independent of the angular deviation between the two shots. The results of this model are presented Table 2.
Taken together, analyses of the viewers’ judgments of driving directions suggest that when faced with spatially ambiguous pairs of shots of dynamic scenes, viewers preferably interpreted them in terms of the centerline rule instead of aligning them along their shortest path. In particular, in the case of conflicts between heuristic processing and alignment, viewers chose the heuristic-processing outcome to a significantly higher degree. Also, viewers showed no increase in reaction times with increasing angular difference, which again argues for heuristic processing instead of alignment processes.
Experiment 2
In Experiment 1, the dynamic scenes were ambiguous because no environmental cues were available, such as trees alongside the road. The participants’ interpretations were in line with predictions of the spatial-heuristic hypothesis. In Experiment 2, we tested spatial-integration processes with nonambiguous dynamic scenes. We resolved the ambiguity by introducing explicit environmental cues and designed dynamic scenes that either conformed to the centerline rule or violated it. As a consequence, there was always a correct answer to the question “In which direction are the cars driving?” Thus, from the stance of the spatial-alignment hypothesis, we would expect that two clips that required the same amount of angular alignment should be processed similarly, irrespective of their adherence to the centerline rule. More specifically, we would expect no difference with regard to proportion correct scores and reaction times. In contrast, from the stance of the spatial-heuristic hypothesis, we would expect that clips conforming to the centerline rule should be processed more quickly than clips that violate the rule—even if the required angular alignment was the same.
Method
Participants
The participants were 25 students at the University of Tübingen, Germany. They were paid for their participation.
Stimulus materials, design, and apparatus
The stimulus materials were identical to those of Experiment 1, with the following exceptions: First, we added explicit environmental cues by coloring one shoulder of the road red and the other green (see Fig. 3). In half of the clips, the shoulders of the road were colored in a way that the two shots conformed to the centerline rule—the foreground and background colors were identical across the filmic cut (see Types I–IV in Table 3). In the other half of the clips, the foreground and background colors were switched across the cut. Thus, the centerline rule was violated (see Types V–VIII in Table 3). Second, the cars were recorded with an angular deviation of 45° relative to the road. This resulted in a horizontal deviation between two adjacent cameras of 90° in either direction (different and same side of the road). Third, the colors of the cars were altered: One was yellow, but the other was now gray. The serial order of the two shots, including all colors (environment and cars), was counterbalanced.

In addition to the movement information of the cars, the stimuli in Experiment 2 also depicted environmental information. All colors were counterbalanced
Results and discussion
Proportions of correct responses and reaction times on correct responses are plotted in Table 3. On the basis of the results of Experiment 1—in which the best fit of the data was provided by a model that aggregated across Type I and II stimuli and across Type III and IV stimuli—we aggregated the data across conditions requiring 0° alignment (Types I and II), 90° alignment conforming to centerline (Types III and IV), 90° alignment violating the centerline (Types V and VI), and 180° alignment (Types VII and VIII).
The proportions correct were high across all conditions (M = .85, SD = .29). We fitted two lme models—with a random intercept for the participant effect and proportion correct as the dependent variable. The first, saturated, lme model treated each alignment condition separately (AIC = –0.46). The second lme model included only two fixed parameters: conditions conforming to the centerline rule and centerline-violated conditions (as predicted by the heuristic hypothesis; AIC = –2.89). A likelihood-ratio test revealed no significant differences between the two lme models, χ 2(2) = 1.57, p = .457. Thus, the reduced model was retained. The results of this model are presented in Table 4. The intercept (.96) indicates the average proportion correct in the conditions conforming to the centerline rule. The estimate for the centerline-violated conditions is significantly lower than the intercept. Taken together, the proportion correct data show significant influences of the centerline on processes of spatial integration of two viewpoints onto dynamic scenes.
For the reaction time analysis, we fitted the same two lme models from the proportion correct analysis. The saturated model (AIC = 2,724.20) provided a significantly better fit than the reduced model (AIC = 2,729.07), as shown by a likelihood ratio test, χ 2(1) = 6.87, p = .008. The results of the saturated model are shown in Table 4. The intercept (1,566) indicates the average reaction time in the 0° condition. The estimates of the 90°-conforming-to-centerline, 90°-centerline-violated, and 180° conditions are all significantly higher than the intercept. Multiple comparisons based on adjusted p values (single-step method, Tukey) showed that reaction times were shortest in the 0° and longest in the 90°-centerline-violated conditions, as compared to the other conditions (ps < .049 and .048, respectively). Most importantly, reaction times in the 90°-conforming-to-centerline condition were significantly shorter than those in the 90°-centerline-violated condition (p = .040). We observed longer reaction times in the 180° than in the 0° condition. However, the difference between the 90°-conforming-to-centerline and 180° conditions was not significant (p = .999).
To summarize, the results of the reaction time analysis complement those of the proportion correct analysis. Although the dynamic scenes in the 90°-conforming-to-centerline and the 90°-centerline-violated conditions required the same amount of angular alignment, integration processes were more difficult (lower proportions correct and longer reaction times) when the centerline rule was violated.
General discussion
Current theories of spatial updating propose that humans use alignment processes to integrate different viewpoints of a given scene (e.g., Mou et al., 2004). Outside the laboratory, the most frequent occurrences of discontinuous viewpoints of scenes, by far, are found in films and on TV. Additionally, people in industrial countries such as Germany spent almost 4 h per day watching TV (AGF/GfK Fernsehforschung, 2011), and are thus frequently confronted with the task of aligning successive views (or shots, respectively). In the present study, we have presented initial evidence that spatial updating may cut short this alignment by applying a simple spatial heuristic—namely, that screen direction equals movement direction. This spatial heuristic presupposes that the presentation of successive pairs of viewpoints is designed according to the centerline rule, which is widely used in films and on TV (Arijon, 1978).
The spatial-alignment hypothesis, which is derived from current theories of spatial updating (e.g., Mou et al., 2004), fails to predict viewers’ perceptions when the dynamic scenes were ambiguous (Exp. 1). Furthermore, the alignment hypothesis also fails to explain the lower performance and longer reaction times to centerline-rule-violating stimuli than to stimuli that conformed to the centerline rule in Experiment 2, when both types of stimuli required a 90° realignment. Thus, we propose that heuristic processes are used to integrate spatial information across discontinuities if there is no environmental information or if the environment is consistent across shots. When the centerline rule was violated in dynamic scenes (Exp. 2, Types V–VII), we observed lower proportion correct scores and longer reaction times, indicating processes of spatial alignment.
Thus, in order to be able to account for the viewing conditions portrayed on television, a model of spatial updating across discontinuities should entail two processes. First, a heuristic process is triggered if there is only movement information (i.e., for ambiguous dynamic scenes). Second, if salient environmental information resolves the ambiguity of dynamic scenes, alignment processes are triggered. This second process aims at aligning the new viewpoint and the viewpoint of the previous shot, which is stored in memory, by considering both movement information and environmental cues. This is a time-consuming and error-prone process. Evidence for this conclusion comes from research on trans-saccadic integration that has shown that the spatial configuration after a saccade is important for establishing spatial coherence (Deubel, 2004). Thus, if the environment—here, in the form of color information on the road—changes across shots, alignment processes are triggered. The finding that performance (proportions correct and reaction times) in the 180°-alignment condition in Experiment 2 was not lower (lower proportions correct and longer reaction times) than in the 90° conditions seems to be incompatible with the proposed model. However, this finding is in line with the findings of Diwadkar and McNamara (1997), who observed a similar result pattern and suggested that the higher self-similarity between views is responsible for shorter reaction times in conditions with 180° viewpoint deviations.
In this study, we show – to our knowledge for the first time – that spatial updating across discontinuities is facilitated if films conform to the centerline rule. In light of a recent study with film-illiterate viewers, which demonstrated that comprehending spatial relations between adjacent shots requires sufficient familiarity with films (Schwan & Ildirar, 2010), the interplay of the centerline rule and the spatial heuristic may be interpreted as a convention or as a kind of “contract” between filmmaker and viewer. We also speculate that the applicability of this heuristic instead of computationally demanding realignment is one of the reasons why sequences of shots in films are often experienced as continuous and film cuts often go unnoticed by the viewers (T. J. Smith & Henderson, 2008).
References
AGF/GfK Fernsehforschung. (2011). TV Scope. Retrieved November 29, 2011, from www.agf.de/daten/zuschauermarkt/sehdauer/
Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, AC-19, 716–723. doi:10.1109/TAC.1974.1100705
Arijon, D. (1978). Grammar of the film language. Los Angeles: Silman-James Press.
Baayen, R. H. (2008). Analyzing linguistic data: A practical introduction to statistics using R. Cambridge: Cambridge University Press.
Bordwell, D., & Thompson, K. (2001) Film Art: An introduction (6th ed.,). New York, USA: Mc Graw Hill.
Deubel, H. (2004). Localization of targets across saccades: Role of landmark objects. Visual Cognition, 11, 173–202.
Diwadkar, V. A., & McNamara, T. P. (1997). Viewpoint dependence in scene recognition. Psychological Science, 8, 302–307. doi:10.1111/j.1467-9280.1997.tb00442.x
Garsoffky, B., Huff, M., & Schwan, S. (2007). Changing viewpoints during dynamic events. Perception, 36, 366–374. doi:10.1068/p5645
Garsoffky, B., Schwan, S., & Hesse, F. W. (2002). Viewpoint dependency in the recognition of dynamic scenes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 1035–1050.
Garsoffky, B., Schwan, S., & Huff, M. (2009). Canonical views of dynamic scenes. Journal of Experimental Psychology: Human Perception and Performance, 35, 17–27.
Germeys, F., & d’Ydewalle, G. (2007). The psychology of film: Perceiving beyond the cut. Psychological Research, 71, 458–466.
Huff, M., Jahn, G., & Schwan, S. (2009). Tracking multiple objects across abrupt viewpoint changes. Visual Cognition, 17, 297–306. doi:10.1080/13506280802061838
Meyerhoff, H. S., Huff, M., Papenmeier, F., Jahn, G., & Schwan, S. (2011). Continuous visual cues trigger automatic spatial target updating in dynamic scenes. Cognition, 121, 73–82. doi:10.1016/j.cognition.2011.06.001
Mou, W., Fan, Y., McNamara, T. P., & Owen, C. B. (2008). Intrinsic frames of reference and egocentric viewpoints in scene recognition. Cognition, 106, 750–769. doi:10.1016/j.cognition.2007.04.009
Mou, W., McNamara, T. P., Valiquette, C. M., & Rump, B. (2004). Allocentric and egocentric updating of spatial memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 142–157. doi:10.1037/0278-7393.30.1.142
Pinheiro, J., Bates, D., DebRoy, S., Sarkar, D., & R Development Core Team. (2011). nlme: Linear and nonlinear mixed effects models. R package version, 3, 1–102.
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime user’s guide. Pittsburgh: Psychology Software Tools.
Schwan, S., & Ildirar, S. (2010). Watching film for the first time: How adult viewers interpret perceptual discontinuities in film. Psychological Science, 21, 970–976. doi:10.1177/0956797610372632
Shepard, R. N., & Metzler, J. (1971). Mental rotation of three-dimensional objects. Science, 171, 701–703. doi:10.1126/science.171.3972.701
Simons, D. J., & Wang, R. F. (1998). Perceiving real-world viewpoint changes. Psychological Science, 9, 315–320. doi:10.1111/1467-9280.00062
Smith, R., Anderson, D. R., & Fischer, C. (1985). Young children’s comprehension of montage. Child Development, 56, 962–971.
Smith, T. J., & Henderson, J. M. (2008). Edit blindness: The relationship between attention and global change blindness in dynamic scenes. Journal of Eye Movement Research, 2, 1–17.
Author Note
Markus Huff, University of Tübingen, Germany; Stephan Schwan, Knowledge Media Research Center, Tübingen, Germany.
Correspondence concerning this article should be addressed to Markus Huff, University of Tübingen, Department of Psychology, Schleichstr. 4, D-72076 Tübingen, Germany. E-mail: markus.huff@uni-tuebingen.de
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Huff, M., Schwan, S. Do not cross the line: Heuristic spatial updating in dynamic scenes. Psychon Bull Rev 19, 1065–1072 (2012). https://doi.org/10.3758/s13423-012-0293-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-012-0293-z