
Abstract
Previous evidence demonstrated that individuals can recall a target’s location in a search display even if location information is completely task-irrelevant. This finding raises the question: does this ability to automatically encode a single item’s location into a reportable memory trace extend to other aspects of spatial information as well? We tested this question using a paradigm designed to elicit attribute amnesia (Chen & Wyble, Psychological Science, 26(2) 203-210, 2015a). Participants were initially asked to report the location of a target letter among digits with stimuli arranged to form one of two or four spatial configurations varying randomly across trials. After completing numerous trials that matched their expectations, participants were surprised with a series of unexpected questions probing their memory for various aspects of the display they had just viewed. Participants had a profound inability to report which spatial configuration they had just perceived when the target’s location was not unique to a specific configuration (i.e., orthogonal). Despite being unable to report the most recent configuration, answer choices on the surprise trial were focused around previously seen configurations, rather than novel configurations. Thus, there were clear memories of the set of configurations that had been viewed during the experiment but not of the specific configuration from the most recent trial. This finding helps to set boundary conditions on previous findings regarding the automatic encoding of location information into memory.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
For decades, an object’s location has been posited as the first stage of visual processing, serving as an anchor to which other features and information can be bound (Kahneman et al., 1992; Marr, 1976; Marr, 1982). Recent evidence has shown that the location of this anchor persists, regardless of its task relevance. Specifically, the location information of a single stimulus can be explicitly reported even if task-irrelevant (Chen & Wyble, 2015b), implying that these spatial tokens may play a key role in explicit memory formation as well. However, the theoretical importance of location processing in explicit memory formation has been directed toward that related to targets or task-relevant stimuli, both of which fall under the focus of attention. Because the deployment of attention has been shown to greatly impact both explicit and implicit memory formation (Logan, 1988; Palmeri, 1997; Isingrini et al., 1995; Mulligan, 1998; Schmitter-Edgecombe, 1996), a gap in our understanding remains: is the entire display configuration, which contains the location of multiple spatial tokens, automatically stored in memory in a similar manner as a selected target’s spatial token? Here, we set out to answer this question using the surprise trial paradigm utilized by Chen and Wyble (2015a) to assess for a participant’s ability to explicitly report all spatial information presented via identifying the spatial configuration of targets and distractors in a visual search display.
Previous studies have utilized the surprise trial paradigm to test the explicit reportability of multiple attributes of the target, including location information (Born et al., 2020; Chen et al., 2016; Chen et al., 2019; Chen & Howe, 2017; Chen & Wyble, 2015a; Chen & Wyble, 2016). In these studies, a participant is tasked with finding a target through one of its attributes, termed the key attribute (e.g., a letter among digits), in order to report another of the target’s attributes (e.g., its location). Participants can complete this task with ease; however, after numerous trials transpire, they are surprised with a new question asking them to identify the target’s key attribute (e.g., which letter had been shown) and exhibit a poor ability to report that attribute. Poor recall of the key attribute is only present on the surprise trial itself, as memory improves dramatically on the very next control trial when participants have an expectation to report the key attribute. This phenomenon has been termed attribute amnesia (AA; Chen & Wyble, 2015a; Wyble & Chen, 2017). Importantly, memory for the location of a target item does not greatly suffer from attribute amnesia. Chen and Wyble (2015b, 2018) demonstrated that participants could report a cue’s location quite accurately in a surprise trial even if that cue was completely task-irrelevant before surprise onset. Despite being able to report its location, other attributes of the cue, such as its color or shape, were poorly remembered. In other words, there was AA for all tested attributes of the cue except its location, providing evidence that an explicit memory for the location of a salient visual event is automatically encoded (Logan, 1988; Palmeri, 1997).
Beyond AA studies, there exists ample evidence that visuospatial information may experience privileged memory encoding (Hasher & Zacks, 1979). Williams et al. (2013) highlighted the ability to remember multiple object locations in a display. During the blank retention interval of a change detection experiment, participants were more likely to saccade to locations in a configuration where to-be-remembered items were presented compared to item-absent locations, demonstrating clear knowledge of where objects were and were not present. Moreover, Rajsic and Wilson (2014) showed that not only is location easily remembered, but it can also be reported with greater precision relative to the other features of the located object. Beyond memory for location information itself, studies have shown that participants often cannot identify featural components of targets without first demonstrating knowledge of the target’s location (Johnston & Pashler, 1990; Nissen, 1985; but see Allen et al., 2015; Woodman et al., 2012). Moreover, object-feature mis-bindings are more likely to occur when multiple objects are presented in the same location compared to different locations (Cave & Pashler, 1995; Golomb et al., 2014; Pertzov & Husain, 2014). Specifically, Pertzov and Husain (2014) demonstrated that presenting multiple targets of varying colors and orientations in the same location within an RSVP format led to greater feature binding errors compared to when targets were presented in different locations. Golomb et al. (2014) also showed that participants were more likely to report complex objects as being similar to one another (regardless of report veridicality) when presented in the same location compared to different locations. Thus, presenting objects to different locations aids in individuation, overall supporting the critical role of location in memory encoding.
Memory for non-target item locations
What is the mnemonic representation for non-target spatial locations? As is true for the spatial information of a target or salient singleton, is this spatial information automatically encoded? Previous work has examined the influence of display configurations, or the holistic representation of multiple object locations, on memory encoding and behavioral performance. Lassaline and Logan (1993) provided evidence that changing the structural configuration of a display after multiple training sessions disrupted automatic processing during a numerosity task, implying that the structural regularities of the visual display were represented in memory (Logan, 1988). Other studies have found deficits in remembering feature bindings when display configurations and/or object locations were changed between study and test (Elsley & Parmentier, 2009; Jiang, Olson, & Chun, 2000; Toh et al., 2020; Treisman & Zhang, 2006; Vidal et al., 2005; but see Udale et al., 2018). Finally, recent work studying priming of popout (Maljkovic & Nakayama, 1994), in which the ability of a popout stimulus to attract attention is affected by whether that stimulus is located in the same position as the previous trial, has found that this effect is not just linked to retinotopic position but is also affected by the visuospatial context of the surrounding items (Geyer et al., 2011; Gokce et al., 2013; Gokce et al., 2015).
While the above evidence suggests that configural information affects performance implicitly, it is not clear if this information is encoded in an explicitly retrievable form. Contextual cuing research has provided some distinction as to whether display configurations are stored implicitly or explicitly. In contextual cuing (Chun & Jiang, 1998) participants search for a target among an array of distractors, with the added nuance that some displays are repeatedly presented while others are only shown once. Participants find targets faster within repeated displays compared to novel displays, suggesting that participants learn where to search for targets across repetitions (i.e., the search configuration cues participants to the target location; Chun & Jiang, 1998; Jiang & Wagner, 2004). However, recognition tests administered to assess awareness of the repetition manipulation have revealed essentially chance level performance, implying that the configurations guiding search were remembered implicitly rather than explicitly. Results following the original contextual cuing study have been mixed regarding a participant’s ability to explicitly recall which displays repeated and which have not. Though multiple studies have replicated the original awareness results (Chun & Jiang, 2003; Chun & Phelps, 1999; Howard et al., 2004; Manns & Squire, 2001; Park et al., 2004), Smyth and Shanks (2008) found participants could recognize repeated displays compared to non-repeated foils if there were an increased number of trials during the recognition test or if recognition tests were administered at multiple points throughout the experiment. Schlagbauer et al. (2012) also found that only some repeated displays could be remembered, but the specific configurations which were recognized as being repeated seemed to be drivers of the contextual cuing effect. Finally, other researchers (Brockmole et al., 2006; Brockmole & Henderson, 2006a; Brockmole & Henderson, 2006b; Ehinger & Brockmole, 2008; Rosenbaum & Jiang, 2013) have found a distinction in explicit awareness of repeating displays between an array-based cuing paradigm and a scene-based cuing paradigm, such that there was a strong ability to recognize repeated displays that were superimposed onto natural scenes or if participants searched for targets within a scene. Thus, while there exists some evidence that configurations can be explicitly recallable, the nature of the contextual information seems to be critical as to if the configuration is encoded into a reportable memory trace.
To summarize, the existing literature has shown that attended location information is privileged in memory encoding (Hasher & Zacks, 1979; Rajsic & Wilson, 2014), and that manipulating this spatial information leads to binding errors and other memory failures of non-spatial features (Pertzov & Husain, 2014; Treisman & Gelade, 1980; Treisman & Zhang, 2006; Wheeler & Treisman, 2002). Moreover, from the work of Chen and Wyble (2015b), there is evidence that the location of a recently perceived cue or target can be explicitly reported during an unexpected memory test. Furthermore, a large body of evidence has demonstrated that display configuration information is represented in memory at the bare minimum as a summary statistic, including information such as which configurations have appeared (Chun & Jiang, 1998; Gokce et al., 2013; Lassaline & Logan, 1993;) and the individual arrangement of items within a configuration (Gokce et al., 2013; Gokce et al., 2015; Williams et al., 2013). However, theories of spatial location hypothesize that place-tokens individuate objects when a complex display is first perceived (Kahneman et al., 1992; Marr, 1976; Marr, 1982). Thus, a question remains: if a single item’s location is automatically encoded into an explicit memory trace, is the entire display configuration, which contains the location information for multiple objects, automatically stored in memory in a similar manner?
The present study
To test this question, we ran multiple experiments in which participants reported the location of targets within display configurations that alternated randomly between one of two forms throughout an experiment (Fig. 1), and were then given a series of surprise questions asking them to report the identity of both the target and, critically, the display configuration. In the first experiment, participants were able to report some aspects of the display configuration on the surprise trial. However, because our task required participants to report the target’s specific location, which was correlated with the display configuration, participants could have inferred the configuration based on the target’s location. In the following three experiments, in which the target location and display configuration were orthogonal, participants had very poor memory of the display configuration seen on the surprise trial. A final experiment demonstrated that participants had some memory trace for the set of previously seen configurations despite being unable to explicitly report the specific configuration identity seen during the surprise trial.

Visualization of the ten possible display combinations used in these experiments. Displays are enlarged for clarity and not drawn to scale. The background shape could appear as either red or green in Experiment 1. The letters ‘A’ through ‘D’ were shown to participants in Experiments 1 and 3, ‘A,’ ‘B’ ‘D’ and ‘E’ in Experiment 2c, and only ‘A’ and ‘B’ were used as targets in Experiments 2a and 2b
Experiment 1: Diamond/Square
To test whether the configuration of the display on each trial is automatically encoded in an explicitly reportable form, participants first located a target letter among distractor digits presented in displays which randomly varied between diamond and square configurations. Participants were then surprised with a series of questions asking them to identify the target letter as well as the display configuration’s structure. A task-irrelevant background frame of either a square or a circle was also presented on each trial and probed at surprise. This additional component of the display was added to assess the extent of an individual’s ability to explicitly report on background elements of a display that are completely irrelevant.
Methods
The experimental scripts and analysis codes are posted at: https://osf.io/8kgfh
The pre-registration for the crucial analyses is listed at: https://osf.io/byx6c/register/5771ca429ad5a1020de2872e
Participants
Eighty undergraduate participants at Pennsylvania State University (mean age 18.78 years, ranged 18–22; 91.25% female; 92.5% right-handed) were included after passing our pre-registered inclusion criteria (see Analysis section of this experiment; 21 excluded). This study was approved by the Pennsylvania State University Internal Review Board, and all participants gave written consent before taking part in the study. Participants were pseudorandomly divided into two groups of 40 participants, determining whether a previously before seen (A, B, C, or D) or novel letter (G, M, R, or T) was shown during the surprise trial. This manipulation addressed a separate research question, and the analysis is included for completeness despite being tangential to the main focus of this paper.
Apparatus and stimuli
The experiment was presented on a 17-in. CRT computer monitor at 1,024 × 768 resolution and a 75-Hz refresh rate running MATLAB 2012 and Psychtoolbox 3.0.12 (Kleiner et al., 2007) on Windows XP. Participants sat approximately 61 cm away from the screen in a chinrest. Stimuli were black letters (A, B, C, D, G, M, R, and T) and numbers (1–9) which were 0.94o visual angle tall and presented on a grey background. The four stimuli (three digits, one letter) formed a square or a diamond, each subtending 5.16o × 5.16o (Fig. 1). Furthermore, a background outline of a red or green square or circle was presented, subtending 16.51o × 16.51o.
Procedure
On each trial (Fig. 2A), a fixation cross was presented for a random interval of 800–1,800 ms before the target display appeared, lasting for 250 ms. A blank display followed lasting for 1,500 ms before the questions of that trial appeared. Participants completed 60 pre-surprise trials in which they located the target (A, B, C, or D) within the display, using buttons ‘1’ through ‘4’ for a square configuration and ‘5’ through ‘8’ for a diamond. Feedback was provided for 2,000 ms. The exact location the target appeared was chosen at random on each trial.

Experimental protocols for Experiments 1, 2a, 2b, 2c, and 3. A An example trial from Experiment 1 in which a square was shown as the display configuration. B An example trial of Experiment 2a where a triangle was shown as the display configuration, and the identity of the configuration was probed first. Experiment 2b used the same procedure as Experiment 2a but with face displays. Experiment 2c and Experiment 3 also used a similar procedure, but with 4 display structures (either 4 right triangles for Expt. 2b or vertical or horizontal face displays for Expt. 3), and a 4-alternative forced choice (afc) surprise configuration question. Note: these displays are drawn to scale, and all screenshots can be found in full in Supplement 3 (OSM) of this paper and on our OSF repository for this study: https://osf.io/8kgfh
On trial 61, participants were surprised with three questions about the target’s identity and the display.Footnote 1 First, a free-recall question asked about the target letter’s identity. Next, a two-alternative-forced choice (afc) recognition question asked participants to identify the background shape as a square or a circle by pressing the ‘left’ or ‘right’ arrow key, respectively. Third, participants used the ‘up’ and ‘down’ arrow keys to choose whether the display configuration formed a square or a diamond, respectively. Finally, participants completed the surprise trial by answering the same target location question that they had been answering during the pre-surprise trials. This question order was fixed for all participants. Answer options for all questions were presented in the appropriate location of the screen to reflect these button presses (Fig. 2A). Half of the participants saw one of four novel letters (G, M, R, or T) on the surprise trial while the other half saw one of the four previously presented letters. Following the surprise trial, participants completed 11 control trials containing those same questions, using only the letters A, B, C, or D as targets regardless of group. The following variables were counterbalanced across participants on the surprise trial: the presence of a novel letter, the display configuration, and the background shape. The two display configurations and background shapes were presented an equal number of times across the entirety of trials. Eye movements were not controlled for in any of the experiments.
Analysis
Participants were excluded if they scored less than 60% (i.e., less than three of five correct location reports) in either of two separate sets of pre-surprise trials (6–10 and 51–55) or less than 66% (i.e., less than two of three) on any set of the four questions on the final three control trials.Footnote 2 Attribute amnesia was assessed using analyses first reported in Chen and Wyble (2015a). Chi-square analyses compared surprise trial accuracy to the first control trial accuracy, with an attribute amnesia effect deemed significant if there is diminished performance on the surprise trial relative to the first control trial. This analysis was completed separately for each question type. To assess the influence of a novel target on surprise trial performance, chi-square analyses compared accuracy on reports given during the surprise trial between participant groups shown either a repeated or novel target. These comparisons were again completed separately for each surprise question type. Response times (RTs) were also recorded, and the median RT for each trial type is listed in Supplement 1 (Online Supplemental Material, OSM) of this paper. A description of which analyses were pre-registered can be found in Supplement 2 (OSM).
Results
Accuracy scores for Experiment 1 are listed in Table 1. To better understand the table: previous work on AA effects compared surprise trial performance to the first control trial of the same question types. Control trials 2 and 3 are provided to demonstrate that performance on the first control trial is consistent. In a similar vein, the pre-surprise column, which shows location accuracy (the only question asked during these trials), provides support that participants were paying attention during this portion of the experiment. Moreover, for this experiment novelty effects compare surprise trial performance of the same question type, but across groups (novel vs. familiar).
Attribute amnesia analyses
Among individuals who saw a familiar letter during the surprise trial, AA effects were present for the letter identity question, (Msurprise = 67.5% vs. Mcontrol = 90%)Footnote 3, χ2(1,N = 80) = 6.05, p = .013, and background shape question, (Msurprise = 42.5% vs. Mcontrol = 65%), χ2(1,N = 80) = 4.07, p = .04. Critically, there was no AA effect present for the display configuration question, (Msurprise = 90% vs. Mcontrol = 85%), χ2(1,N = 80) = 0.46, p = .50. Among individuals who saw a novel letter on the surprise trial, there was no AA effect present for any question (all ps > .36).
Benefit from novelty analyses
Chi-square analyses between surprise trial question types of each letter group (familiar ABCD vs. novel GMRT) showed no significant effect of presenting a novel letter for any question type: surprise letter identity, χ2(1,N = 80) = 3.38, p = .07; surprise background identity , χ2(1,N = 80) = 1.80, p = .18, surprise display configuration, χ2(1,N = 80) = 0.12, p = .72, or location, χ2(1,N = 80) = 0.95, p = .33.
Discussion
The key results of this experiment are that on the surprise trial participants could not report the background shape framing the display, but they could report the configuration of the four stimuli in the display, which is similar to the automatic processing of single-item location information reported by Chen and Wyble (2015b). However, since the target location was fully predictive of the spatial configuration, the spatial configuration was to some degree task-relevant, which may have caused it to be better remembered. Moreover, the spatial configuration could be deduced via the planned response for the target location question. Experiments 2a, 2band 2c eliminated this confound by keeping target location information orthogonal from display configuration information, such that the target location of a trial could be plausibly attributed to any configuration presented throughout the experiment.
Though unrelated to the main focus of this paper, a discussion of the novelty manipulation is included here. According to our confirmatory analysis, the novel letter manipulation had no statistically significant effect on report of the spatial configuration or background frame, nor did it significantly improve performance on the identity question when comparing surprise trial performance between groups.Footnote 4 This latter effect was surprising given previous evidence that presenting a novel stimulus reduces AA (Chen & Howe, 2017). However, performance in the novel letter condition was quite good at 85%, and the lack of an effect is likely due to unusually high accuracy in the non-novel condition (67.5%) relative to most AA studies. One possibility for this increased accuracy could be the use of a free recall question instead of an alternative-forced choice recognition question, as the recognition response requires an extra level of response mapping (i.e., generating a response of ‘1’ rather than ‘A’). Another possibility could be that our delay time, which is longer than that of other AA studies, allowed more time for memory consolidation, thereby reducing the AA effect (Chen & Wyble, 2016).
Experiment 2a: Triangles
To make the reportability of target location and display configuration orthogonal, two new experiments were run utilizing display configurations in which the target’s location could occur in either configuration with equal probability. If participants still exhibit an ability to report the surprise display configuration, this would imply that the spatial configuration of a search array is encoded and reportable on each trial. The background frame was removed from this – and future – experiments, as participants were no better than chance at reporting the shape of the frame and still struggled even on the control trials, implying that this question was quite difficult and likely would not change in future experiments.
Methods
The experimental scripts and analysis codes (for Experiments 2a and 2b) are posted at: https://osf.io/8kgfh
The pre-registration for the crucial analyses (of Experiments 2a and 2b) is listed at: https://osf.io/k7h9u/register/5771ca429ad5a1020de2872e
Experiment 2a was similar to Experiment 1 except for the following.
Participants
Eighty undergraduate participants at the Pennsylvania State University (mean age 19.19 years, range 18–23; 68.75% female; 90% right-handed) were included after passing our pre-registered inclusion criteria, which required a score of 60% or higher on five pre-surprise trials (Trials 41–45; one excluded).
Apparatus and stimuli
The target location question was changed such that participants only had to report what side of the screen the letter was on by using the ‘left’ and ‘right’ arrow keys. Similarly, the number of target letters was reduced to two (A or B) and the target identity question was changed to a recognition question (participants responded by typing ‘1’ for A and ‘2’ for B). These changes were made so that all reports came from 2-afc recognition questions, allowing for direct comparisons of accuracy between questions. To ensure that the display configuration was orthogonal to the target’s location, the configuration of the display was designed to form a right triangle comprised of one letter and two numbers presented in either of two orientations (Fig. 1). Importantly, targets were only presented in the bottom two locations of the triangles because these locations were identical between configurations. This made the spatial configuration of the display orthogonal to the location of the target, similar to how the cue location was orthogonal to the target location in Chen and Wyble (2015b). The target’s location was counterbalanced across trials such that it equally occurred to the left or right of fixation. The two display configurations occurred equally often across trials. However, the specific letter shown on each trial was randomly selected.
Procedure
Participants completed 50 pre-surprise trials which asked about target location. Following the pre-surprise portion of the experiment, one surprise trial and nine control trials were completed containing two additional questions which asked about the letter and display configuration identities (Fig. 2B).Footnote 5 These additional questions preceded the location question and were counterbalanced in order of presentation between participants. Whether the participant saw a leftward or rightward pointing triangle at surprise was also counterbalanced. Thus, a 2 × 2 between-subject design, with factors of question order and triangle orientation, was utilized.
Analysis
Along with using chi-square analyses to assess for AA, chi-squares were used to assess for question order effects via two different comparisons. First, chi-squares compared accuracy between display configuration questions across groups to assess whether seeing the display configuration question first or second significantly altered accuracy. Second, chi-square analyses compared accuracy between display configuration and letter identity accuracy within order groups to assess whether the specific order of questions altered accuracy.
Results
Accuracy scores for Experiment 2a are listed in Table 2. Interpretation of this table is similar to that of Table 1, though note that the order of questions changes between the two question-order groups to reflect the order in which the questions were asked.
Attribute amnesia analyses
A statistically significant AA effect for letter identity was found both when the letter identity question was asked first, (Msurprise = 67.5% vs. Mcontrol = 95%), χ2(1,N = 80) = 9.93, p = .002, and second, (Msurprise = 67.5% vs. Mcontrol = 90%), χ2(1,N = 80) = 6.05, p = .013. Furthermore, and crucial to the framework of this study, a statistically significant AA effect for display configuration was found both when the display configuration question was asked first, (Msurprise = 70% vs. Mcontrol = 90%), χ2(1,N = 80) = 5.00, p = .03, and second, (Msurprise = 55% vs. Mcontrol = 90%), χ2(1,N = 80) = 12.29, p < .001.
Order effect analyses
There was no statistically significant order effect for the surprise display configuration question, as accuracy was no lower when the question came second on the surprise trial (M = 55%) compared to first (M = 70%), χ2(1,N = 80) = 1.92, p = .17. There was also no significant difference in surprise trial accuracy between letter identity and display configuration questions regardless of the order in which the questions were asked (both ps > .25).
Discussion of Experiment 2a follows the description of Experiment 2b.
Experiment 2b: Faces
Experiment 2b explored the same question as Experiment 2a but with a different configural arrangement of the array. Instead of forming right triangles the arrays now formed a visual Gestalt resembling a smiley face. Along with changing the structure of the display configuration, in this experiment the target could appear in the top and bottom portions of the display configuration. This eliminated the possibility that poor display configuration memory for Experiment 2a was caused by the target appearing only on the bottom of the array, thereby allowing participants to ignore the top half of the display.
Methods
This experimental procedure (including all randomization and counterbalancing) was identical to that of Experiment 2a except for the following changes.
Participants
Eighty undergraduate participants at the Pennsylvania State University (mean age 19.08 years, range 18–25; 78.75% female; 88.75% right-handed) were included after passing our inclusion criteria (one excluded).
Apparatus and stimuli
The number ‘8’ was removed from the distractor set because of its perceptual similarity to the target letter ‘B’ and the increased perceptual load of the display. The displays were arranged to form an upright or inverted smiley face comprised of one letter and seven numbers, which subtended 7.50o × 7.50o (Fig. 1). Targets only appeared in four locations which could plausibly occur in either display: the locations which formed the “eyes” of the display and the two points on the “mouth” vertically aligned with the “eyes.”
Analysis
The analysis was the same as that conducted in Experiment 2a, with the addition of comparing performance on surprise trials in which participants saw the upright or inverted display configuration. Moreover, a between-configuration chi-square compared display structure accuracy between the face and triangle configuration experiments.
Results
Accuracy scores for Experiment 2b are listed in Table 3.
Attribute amnesia analyses
No statistically significant AA effect for letter identity was found either when the letter identity question was asked first, (Msurprise = 80% vs. Mcontrol = 80%), χ2(1,N = 80) < .001, p > .9, or second, (Msurprise = 52.5% vs. Mcontrol = 70%), χ2(1,N = 80) = 2.58, p = .11. Conversely and critically, a statistically significant AA effect for display configuration was found both when the display configuration question was asked first (Msurprise = 52.5% vs. Mcontrol = 87.5%), χ2(1,N = 80) = 11.67, p < .001, and second (Msurprise = 55% vs. Mcontrol = 82.5%), χ2(1,N = 80) = 7.04, p = .008.
Between-configuration analyses
Participants were more accurate when they saw an upright face (M = 65%) on the surprise trial compared to an inverted (M = 42.5%), χ2(1,N = 80) = 4.07, p = .043. However, a follow-up exploratory analysis within the two question-order groups demonstrated that this effect only occurred when the display configuration question was asked first, 80% for upright versus 25% for inverted, χ2(1,N = 40) = 12.13, p < .001, not second, 50% for upright vs. 60% for invert, χ2(1,N = 40) = .404, p = .53.
Between-experiment analyses
There was no difference in surprise trial accuracy between whether a triangle or a face was used as the display configuration, χ2(1, N = 160) = 1.26, p = .26. A follow-up analysis affirmed that this non-significant finding occurred regardless of when the display question was asked on the surprise trial.
Order effect analyses
There was no statistically significant order effect in accuracy scores for the surprise display configuration question when it was asked either first (M = 52.5%) or second (M = 55%), χ2(1,N = 80) = .05, p = .82. There was no statistically significant within-group difference between surprise trial accuracy for letter identity and display configuration when the display question was asked first, χ2(1,N = 80) < .001, p > .99; however, there was a significant difference when the letter identity question was asked first, 80% for Letter Identity versus 55% for Display Configuration, χ2(1,N = 80) = 5.7, p = .017.
Discussion
The results of Experiments 2a and 2b demonstrate that if target location information is orthogonal to the display configuration information, participants cannot reliably report the spatial configuration of the search array, regardless of the configuration gestalt used. Thus, it appears spatial configuration information is not available for explicit report in the same manner as target location and can only be explicitly reported if doing so is relevant to the original task.
Note that Experiment 2b failed to replicate an AA effect for letter identity, which is surprising as AA for letter identity has been found in previous papers (e.g., Chen & Wyble, 2015a, 2016) and previous experiments of this study. The failure to replicate AA in this one case could be caused in part by an amalgamation of methodology choices made in this study. First, the reduction in answer options in the surprise trials of both 2a and 2b raises the floor of accuracy performance, making it more difficult to observe statistical differences between surprise and control trials. Second, which letter appeared on the surprise trial was selected at random rather than being counterbalanced, allowing for the possibility of one letter to appear more frequently. Third, in both conditions of Experiment 2b there was a bias to select answer option ‘A’. This bias benefited accuracy when the letter identity was probed first, as the letter ‘A’ appeared for more than half of the participants due to randomization, biasing accuracy in the positive direction. This imbalance of target presentations did not occur when the identity question was probed second in this experiment, providing further evidence that accuracy only increased on the surprise trial when the letter ‘A’ was both presented and guessed with greater frequency. Thus, we believe the failed replication of AA for letter identity in this study is largely the result of type 2 error.
Experiment 2c
Though both Experiments 2a and 2b demonstrated that participants could not reliably report the configuration of the item locations in the display, these results could be due in part to the manner in which attention was distributed across the study display. In both experiments, the target could only appear in a subset of locations, potentially encouraging participants to only attend to possible target locations. To test this narrowed attention hypothesis, the target was allowed to appear in any of the four locations of the square configuration used in Experiment 1; however, one location of the square was removed to generate four different right triangle displays. This allowed all possible target locations to be utilized during the pre-surprise portion of the experiment, while also preventing participants from using the target’s location to surmise the structure. If distributing their attention across the display aids in display structure memory, then no AA for the display structure should be observed.
Methods
The experimental scripts and analysis code can be found at: https://osf.io/8kgfh.
The methods are very similar to Experiment 2a except for the following changes.
Participants
Forty undergraduate participants at the Pennsylvania State University (mean age 19.2 years, range 18–26; 72.5% female; 92.5% right-handed) were included after passing our inclusion criteria (0 excluded).
Apparatus and stimuli
The experiment was conducted online via PsychoJS code housed on Pavlovia (Peirce et al., 2019). Four target letters (‘A’,’B’,’D’,’E’) were used in this experiment, and could appear in any of four locations on the screen (the same used in the square structure of Experiment 1). Which target appeared on a given trial was counterbalanced across pre-surprise trials. Targets and distractors could appear in one of four right triangle display structures, generated by removing one of the four locations from the square structure used in Experiment 1. These four structures were counterbalanced across the pre-surprise portion of the experiment, and the specific location in which the target appeared was also counterbalanced to ensure that targets were equally likely to appear in any location within a structure. On the surprise and control trials, the specific letter, display structure, and target location utilized was selected at random for each trial.
Procedure
Participants completed 50 pre-surprise trials which asked about target location, one surprise trial, and nine control trials. On the surprise and control trials, participants were first asked to identify the display’s structure, then the target’s identity, and finally the target’s location.Footnote 6 The surprise questions were asked in only this order to minimize any interference or forgetting effects on the display configuration question that might occur from answering previous questions. The location question consisted of a 4-afc in which participants pressed the number that corresponded to the target’s location (1–4). The surprise display structure and target identity questions were also 4-afcs in which the participant made a numeric response (5–8) that corresponded to their answer choice. Unlike in Experiments 2a and 2b, on the target identity question the response options were randomly assigned to each letter presented at test.
Analysis
Chi-square tests assessed the presence of AA for all tested target attributes. No analyses were pre-registered for this study.
Results
Accuracy scores for this experiment can be found in Table 4.
A statistically significant AA effect for display configuration was observed, (Msurprise = 45% vs. Mcontrol = 70%), χ2(1,N = 80) = 5.12, p = .024. A statistically significant AA effect for letter identity was also observed, (Msurprise = 32.5% vs. Mcontrol = 82.5%), χ2(1,N = 80) = 20.46, p < .001.
Discussion
Though the target could appear in any location of the display structure, participants were not reliably able to report the spatial structure on the surprise trial. This result rules out the hypothesis that an inability to report the display’s structure is due to a narrowing of attention to the task relevant locations of the structure, as all locations were relevant in this experiment.
Experiment 3
We have demonstrated that participants cannot reliably recall the configuration of a display when they do not expect to report such information. We next evaluated to what extent participants are building an accessible memory representation of the set of configurations appearing in the experiment. In Experiment 3, we addressed this question by having participants view one of two orientations of face displays during the experiment, either two vertically orientated displays or two horizontally oriented configurations. Then, when asked to identify the configuration of the display on the surprise trial, participants were shown four configuration options to choose from, the two displays which they had seen on previous trials, and the two never-before shown configurations.
Methods
The experimental scripts and analysis codes are posted at: https://osf.io/8kgfh.
The pre-registration for the crucial analyses is listed at: https://osf.io/bqaek
The methods are very similar to Experiment 2b except for the following changes.
Participants
Eighty undergraduate participants at the Pennsylvania State University (mean age 18.36 years, range 18–22; 76.25 % female; 91.25 % right-handed) were included after passing our inclusion criteria (two excluded).
Apparatus and stimuli
Participants were divided into two groups. In one group, participants saw the two display configurations shown in Experiment 2b, here referred to as vertical displays, whereas the other group saw horizontal rotations of the face display configurations subtending 7.50o × 7.50o, referred to as horizontal displays (Fig. 1). Within the two configuration groups, participants were also evenly subdivided into groups specifying which letters were presented as targets during the experiment, either seeing ‘A’ and ‘B’ or ‘C’ and ‘D.’
Procedure
To minimize the ability to utilize the “eye” locations as a means of easily answering the pre-surprise location questions, participants in the horizontal displays group were asked to locate whether the target letter was above or below the fixation cross while participants in the vertical displays group made left-right judgements as in previous experiments. After 50 pre-surprise trials, participants were surprised with two additional questions on the surprise trial which preceded the location question asked in the following order: (1) a 4-afc display configuration question using two horizontal and two vertical displays as options, and (2) a 4-afc target identity question which included all letters A through D (due to a bug in the experimental code, the data from this question was not able to be analyzed). This question order did not change across participants. Critically, in both questions, only two of the options were previously seen during the pre-surprise phase while the other two served as novel response options.Footnote 7 Participants then completed nine additional control trials identical in presentation to the surprise trial. Across trials, the target’s location was counterbalanced to occur equally often to the left or right (or up or down in the horizontal orientation condition) of the fixation cross. Which configuration appeared was also counterbalanced across trials.
Analysis
Two pre-registered analyses were conducted. The first assessed the presence of attribute amnesia within the display configuration question via a chi-square test comparing surprise trial accuracy to first control trial accuracy. This analysis was conducted separately within the horizontal and vertical display groups. The second analysis assessed answer choices on the surprise trial, where answers were separated into “Chose Horizontal” or “Chose Vertical” and compared between horizontal (“Saw Horizontal”) and vertical (“Saw Vertical”) display conditions.
Results
Accuracy scores for Experiment 3 are listed in Table 5.
Attribute amnesia analyses
There was a statistically significant AA effect for the display configuration question in both the vertical display, χ2(1, N = 80) = 22.75, p < .001, and horizontal display conditions, χ2(1, N = 80) = 7.04, p = .008.
Display orientation analyses
There was a statistically significant effect of exposure to display configurations on answer choice on the surprise question (Table 6). If participants were in the horizontal display condition, they were more likely to choose a horizontal display as their answer choice (regardless of accuracy), while participants in the vertical display condition were more likely to choose vertical displays, χ2(1, N = 80) = 36.47, p < .001.
A follow-up analysis provided evidence that this effect was not solely driven by correctly reporting the configuration. A probability estimate of reporting the correct orientation given an incorrect response, P(report same orientation | incorrect response), revealed that in both groups people were more likely to pick the correct orientation of the display structure even when incorrect about the specific structure observed on that trial, horizontal group: P(report same orientation | incorrect response) = .785; vertical group: P(report same orientation | incorrect response) = .74.
Discussion
The results of this experiment demonstrate that though participants are unable to explicitly report the exact display they saw on the surprise trial, they are able to select one of the two displays they had seen throughout the experiment. Thus, the characteristics of experienced display configurations are stored in an accessible memory format in summary form, but the individual display shown on a given trial cannot be recalled. Though participants experienced AA for the specific display configuration despite being capable of selecting the correct display configuration group, this does not mean they were more likely to pick the wrong display on the surprise trial. In fact, the accuracy for correctly picking the exact display configuration among individuals who selected the correct display orientation flipped across conditions. Specifically, in the vertical orientation group, participants who picked the correct orientation were slightly more likely to pick the correct structure (~65% accurate), but individuals in the horizontal orientation group were slightly less likely to do so (~39% accurate). Because this pattern flipped between conditions, and we had no a priori reason to believe one orientation should lead to better performance, we are hesitant to interpret this result any further other than to reaffirm that participants are aware of the overall structure of the configurations they see but cannot recall the exact configuration they saw on that trial.
General Discussion
As reviewed in the introduction, there has been considerable interest in determining the extent to which the spatial configuration of stimuli is stored in memory, and the findings have provided strong evidence that statistical regularities of such spatial information are stored in some form of memory that is encoded incidentally and can be measured with implicit memory tests (Chun & Jiang, 1998; Gokce et al., 2013; Lassaline & Logan 1993; Jiang, Olson, & Chun, 2000; Treisman & Zhang, 2006; Vidal et al., 2005) and under the right conditions with explicit tests (Brockmole et al., 2006; Brockmole & Henderson, 2006a; Brockmole & Henderson, 2006b; Schlagbauer et al., 2012; Smyth & Shanks, 2008).
The focus of the experiments here is whether those statistical regularities of spatial information form representations that support declarative memory retrieval from the just-studied display of the current trial. Previous work has shown that it is possible to retrieve the location of a highly salient cue or visual target on a surprise trial (Chen & Wyble, 2015b; Chen & Wyble, 2018), but it was not known whether the location of all the stimuli in a complex display were also retrievable. This question is interesting insofar as it helps us to understand the fate of spatial information that is not in the focus of attention, thereby assessing the true extent of privileged memory encoding of location. The results reported here demonstrate that even when location of the target was a task-relevant attribute there was no appreciable ability to automatically remember the spatial configuration of the non-target elements in the just-studied display. These findings suggest that spatial information for non-target stimuli contribute to location memory formation in a statistical sense (i.e., contextual cueing; Chun & Jiang, 1998) but not in a way that allows for immediate, declarative memory retrieval. The findings and conclusions are elaborated in the following paragraphs.
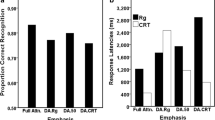
In Experiment 1, participants were able to report the configuration of the array (Fig. 3), although they had poor memory for the shape of a surrounding geometric frame (circle vs. square). However, the correlation between target location and display configuration report may have supported the ability to report the configuration. After eliminating this confound in Experiments 2a, 2b, and 2c by changing the configurations such that the target item can be equally likely to occur in any display configuration, participants had difficulty reporting the spatial configuration of the display during a surprise trial (Fig. 3). Finally, Experiment 3 demonstrated that though participants had difficulty reporting the identity of the surprise display configuration without an expectation to do so, the answers they provided on the surprise trial were largely confined to the two previously seen displays. Therefore, it appears that spatial configurations do not form memorable representations on an individual trial basis, in contrast to the locations of targets or salient cues (Chen &Wyble, 2015b; Chen & Wyble, 2018).

Comparison of Display Configuration Question accuracy across experiments. Regardless of question order, so long as target location information of the target is kept orthogonal from display configuration information (Experiments 2a, 2b, 2c, and 3), participants have poor memory for the display configuration. However, they can answer this question when prepared to do so. All differences in the red circle are statistically significant comparisons between surprise and control trial. Color version of this figure can be found in the online version of the article
Though participants exhibited poor accuracy in explicitly reporting a display configuration without expectation, previous studies showed that violating the expected configuration of a display disrupts performance in automatic processing of numerosity (Lassaline & Logan, 1993) or change detection for a different feature (Jiang, Olson, & Chun, 2000; Treisman & Zhang, 2006; Vidal et al., 2005). Taken together, these results suggest that the spatial configuration from each individual trial is not obligatorily converted into an episodic, explicitly reportable memory representation. However, there is strong evidence that a statistical representation of the average spatial configuration may be constructed gradually over trials to form an implicit representation of display configurations. Indeed, the results from Experiment 3 could be used to support this claim, as answers given by participants on the surprise trial matched choices that would be plausible within the statistical representation a participant may form or the retrieval of previously seen configurations from long-term memory.
Overall, our results have implications for theories of contextual cueing. In combination with prior work (Chen & Wyble, 2015b), we show that only target-relevant spatial tokens are encoded into an explicitly reportable memory trace. However, the spatial relationships between targets and proximal distractors are key for contextual cueing effects to occur (Brady & Chun, 2007). This is consistent with our finding from Experiment 3 that participants are building a more gradual memory of the distribution of locations over time. Combining our results with those of contextual cueing, we conclude that knowledge of the layout of a display structure may prove important for guiding behaviors such as search (Chun & Jiang, 1998; Lassaline & Logan, 1993; Schlagbauer et al., 2018), despite the fact that accessible memory traces of structures on individual trials are not created. Thus, memories of the average configurations of trials are constructed, and these can guide search, but the memories of the configuration of individual trials (even the most recent one) are not readily remembered. This combination suggests that summary statistics of configurations are created without necessarily building individual episodic traces of those configurations.
It has also been shown that eye movements are predictive of AA for certain attributes and under specific viewing conditions (Born et al., 2020). Future work could use eye tracking to determine how the pattern of eye movements during a given trial predicts the ability to remember a display.
Is attribute amnesia driven by proactive interference?
An alternative explanation for the memory failures in this experiment is that episodic memories of the configuration are formed but inaccessible due to proactive interference (Greenberg & Underwood, 1950; Keppel & Underwood, 1962; Postman & Underwood, 1973). In this account, the display configurations presented before the surprise trial interfere with the retrieval of the configuration on the surprise trial. It could be argued that the results of Experiment 3 serve as evidence of a proactive interference, as participants who were incorrect typically reported the other configuration that they had seen on previous trials. A collection of results provides some evidence against an explanation that AA is primarily driven by proactive interference, although the evidence is not entirely conclusive.
The possibility that failures to retrieve information in a surprise trial are due to proactive interference has been addressed and discussed in previous work (Chen et al., 2016; Chen et al., 2019; Chen & Wyble, 2016; Wyble et al., 2019). In particular, Wyble et al. (2019) included a manipulation within their experiment to rule out the idea that proactive interference was leading to a lower accuracy on the surprise trial. Participants underwent a standard surprise paradigm, only instead of presenting previously seen letters on the surprise trial (occurring at trial 50) and preceding three trials, novel letters were presented. Thus, the letter presented at the surprise trial would have no previous presentations and should have been difficult to confuse with repeated letters. However, despite this manipulation, attribute amnesia still occurred at levels equivalent to a companion experiment in which the stimuli were not novel (30% surprise identity accuracy in both experiments). This is a result that cannot be readily explained by proactive interference, since the novel letter would have been easier to retrieve if that was the primary factor.
Another finding that is inconsistent with proactive interference as the primary cause of observed AA effects is the common finding that performance remains consistently near ceiling on the following control trials. If proactive interference was the sole determinant in observed retrieval failures, then we assume that performance on the subsequent control trials should equally suffer from the effects of proactive interference, leading to diminishing accuracy on the control trials over time. However, accuracy on these trials increases to near ceiling performance and remains consistently high, suggesting that it is quite easy to store and retrieve this information when it is expected to be needed. Therefore, the general simplicity of this task is such that proactive interference does not seem to harm retrieval when a robust memory has been formed.
One could also argue that proactive interference makes retrieval more difficult, and when coupled with the additional interference of reading the surprise question for the first time (Swan et al., 2017), proactive interference becomes responsible for the memory impairment. However, this same combination of factors was present in the previous results of Chen and Wyble (2015b), which showed that people could easily remember the location of a visual stimulus on a surprise trial. Moreover, in Chen and Wyble (2018, Experiment 9) location was reported correctly 80% of the time despite subjects experiencing 322 pre-surprise trials, in comparison to the 50–60 trials used in this study. By contrasting the results of those experiments (no AA on surprise trial for location) with these (AA on surprise trial for display configuration), which used essentially the same method, it is hard to explain the complete pattern of results as a consequence of proactive interference. Thus, the alternative account, that there is a clear advantage in the ability to remember the location of a single attended or salient stimulus compared to the configurational information, is favored. Future experiments that more directly contrast the predictions of attribute amnesia and proactive interference would also help to dissociate the two mechanisms.
Is attribute amnesia caused by forgetting or a lack of encoding?
We have interpreted the low accuracy on the surprise trial for reporting configuration as indicating a lack of memory encoding in line with previous conclusions from the AA paradigm (Chen & Wyble, 2016; Chen & Wyble, 2018; Swan et al., 2016; Swan et al., 2017). However, another possible interpretation of AA effects in these studies (and indeed all of the findings on AA) is that the surprise trial requires additional cognitive processing compared to the following control trials where the same question is no longer a surprise. On the surprise trial, participants read the surprise question for the first time which produces cognitive interference (Swan et al., 2017; Wessel, 2018; Wessel et al., 2016) and also lengthens response times considerably (see Supplement 1, OSM). One would expect that such interference would diminish accuracy on a question due to a combination of forgetting and interference even if that information was known to be important for report. For example, in the studies here, location accuracy is lower than ceiling on the surprise trial presumably because it is always the last question to be asked, and the previous questions on that trial would have induced retrieval-induced forgetting (Anderson et al., 2000).
In prior work we investigated the impact of a surprise question on information that is known to be important and found a cost from a surprising event (Swan et al., 2017). However, the patterns that we observe are not consistent with the possibility that surprise trial interference is the sole cause of participants’ profound inability to report the configuration. In Chen and Wyble (2015a) participants were able to report target location on the surprise trial very accurately despite the use of a very similar surprise trial. Moreover, in the experiments here, participants are able to report the target location at above-chance levels on the surprise trial even though the location question occurs after two or three surprise questions. Therefore, episodic information about the most recent trial can survive the interference caused by reading the surprise question. Furthermore, in Chen and Wyble (2016) it was demonstrated that an encoding manipulation causes the AA effect to largely disappear (i.e., Experiments 3a and 3b vs. 3c) despite the fact that participants must still comprehend a surprise trial with a similar verbal complexity as used here. RTs from experiments in Chen and Wyble (2016) that showed improved surprise trial performance from encoding benefits were similarly long compared to experiments in which AA was observed (~8 s in all three experiments). Therefore, it seems unlikely that surprise-question interference is able to account for the pattern of results we observe here.
Conclusion
The results of this study chart the fate of unattended spatial tokens that are hypothesized to be the first stage of processing a visual scene (Kahneman et al., 1992; Marr, 1976; Marr, 1982). Previously, Chen and Wyble (2015b) demonstrated that the location of a highly salient cued stimulus could be accurately reported even when participants were asked to ignore it, and/or it was task-irrelevant. The high accuracy in response to that unexpected location is a stark contrast to the general inability to report the configuration of unattended stimuli in a display, even when that configuration forms an easily discernable configuration such as a triangle or a face. Therefore, it seems our ability to explicitly recall an object’s location in a surprise trial is limited to those of an attended stimulus or one presented in isolation, and also does not include the specific holistic representation of all objects present on that trial. Though non-target location information cannot be easily recalled without an expectation to do so, it is reflected in the overall statistics of an experiment, guiding task-relevant behaviors. These results have implications for our understanding of how memories of display configurations are created in phenomena like contextual cueing.
Notes
The exact wording of the surprise question was as follows (note ellipses denote the beginning of the wording for the next surprise question): “This is a surprise memory test! Try to remember the display you just saw. What was the identity of the letter you just saw? Type in your answer…What was the identity of the background shape? Press left arrow for square and right arrow for circle…Which of the following was the correct display orientation? Press up arrow for the top display or down arrow for the bottom.”
We chose the pre-surprise exclusion criteria as a means of ensuring that participants were attending at both the beginning and end of the pre-surprise trial phase. We did not use accuracy across all trials as an exclusion criterion because we wanted to avoid using pre-surprise accuracy as both an exclusion criterion and a data point. For the control trial criterion, based on previous experiments we believed participants would be capable of performing at a minimum of 66% accuracy for all control trials. However, the combination of asking a large number of control trial questions and probing for a completely task-irrelevant object (the background frame) made these trials harder than expected. Thus, a majority of our exclusions (17) came from this one criterion. Because it was far too strict, we removed it from subsequent experiments but kept it for Experiment 1 as it was a pre-registered decision. The overall pattern of significance remains unchanged if we analyze results without excluding any participants.
The N used in AA chi-squares reflects the number of trials used in the analysis (both surprise and control), not the number of participants (as count data N includes the total count sampled, not just the total number of participants). Our reporting of the chi-square's N in this paper is identical to the chi-squares in the original AA paper (Chen & Wyble, 2015a).
The disappearance of the AA effect in the novel condition could serve as support that novelty reduced AA. However, in their experiment Chen and Howe (2017) demonstrated both the disappearance of an AA effect (via comparison between surprise and first control trials) as well as a significant difference in surprise trial accuracy between novel and non-novel conditions. Because we do not see both differences, we do not wish to claim that novelty reduces AA within the context of our current study.
The exact wording of the surprise question was as follows: “This is a surprise memory test! Try to remember the display you just saw. Which of the following was the correct display structure? Press the number within the correct structure…What was the identity of the letter you just saw? Type in the number that corresponds to the letter.” This wording was identical if the letter identity question came first (but exchanging the exact wording of the identity question with the display structure question). This wording was identical in Experiment 2b.
The exact wording of the surprise trial was as follows: “This is a surprise memory test! Try to remember the display you just saw. What was the configuration of the letters and numbers you just saw? Type the number in the same box as the display structure you remember…What was the identity of the letter you were locating? Type in the number that is next to the letter you remember seeing.”
The exact wording of the surprise questions read: “This is a surprise memory test! Try to remember the display you just saw. Which of the following was the correct display structure? Press the number within one of the boxes to choose. Now, what was the identity of the letter you last saw? Type in the number next to the letter you choose.”
References
Allen, R. J., Castellà, J., Ueno, T., Hitch, G. J., & Baddeley, A. D. (2015). What does visual suffix interference tell us about spatial location in working memory? Memory & Cognition, 43(1), 133–142. https://doi.org/10.3758/s13421-014-0448-4
Anderson, M. C., Bjork, E. L., & Bjork, R. A. (2000). Retrieval-induced forgetting: Evidence for a recall-specific mechanism. Psychonomic Bulletin & Review, 7(3), 522-530. https://doi.org/10.3758/BF03214366
Born, S., Jordan, D., & Kerzel, D. (2020). Attribute amnesia can be modulated by foveal presentation and the pre-allocation of endogenous spatial attention. Attention, Perception, & Psychophysics, 1-13. https://doi.org/10.3758/s13414-020-01983-7
Brady, T. F., & Chun, M. M. (2007). Spatial constraints on learning in visual search: Modeling contextual cuing. Journal of Experimental Psychology: Human Perception and Performance, 33(4), 798–815. https://doi.org/10.1037/0096-1523.33.4.798
Brockmole, J. R., Castelhano, M. S., & Henderson, J. M. (2006). Contextual cueing in naturalistic scenes: Global and local contexts. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 699–706. https://doi.org/10.1037/0278-7393.32.4.699
Brockmole, J. R., & Henderson, J. M. (2006a). Recognition and attention guidance during contextual cueing in real-world scenes: Evidence from eye movements. Quarterly Journal of Experimental Psychology, 59, 1177–1187. https://doi.org/10.1080/17470210600665996
Brockmole, J. R., & Henderson, J. M. (2006b). Using real-world scenes as contextual cues during search. Visual Cognition, 13, 99–108. https://doi.org/10.1080/13506280500165188
Cave, K. R., & Pashler, H. (1995). Visual selection mediated by location: Selecting successive visual objects. Perception & Psychophysics, 57, 421–432. https://doi.org/10.3758/BF03213068
Chen, H., Swan, G., & Wyble, B. (2016). Prolonged focal attention without binding: Tracking a ball for half a minute without remembering its color. Cognition, 147, 144-148. https://doi.org/10.1016/j.cognition.2015.11.014
Chen, H., & Wyble, B. (2015a). Amnesia for object attributes: Failure to report attended information that had just reached conscious awareness. Psychological Science, 26(2) 203-210. https://doi.org/10.1177/0956797614560648
Chen, H., & Wyble, B. (2015b). The location but not the features of visual cues are automatically encoded into working memory. Vision research, 26(2), 203-210. https://doi.org/10.1016/j.visres.2014.11.010
Chen, H., & Wyble, B. (2016). Attribute amnesia reflects a lack of memory consolidation for attended information. Journal of Experimental Psychology: Human Perception and Performance, 42(2), 225-234. https://doi.org/10.1037/xhp0000133
Chen, H., & Wyble, B. (2018). The neglected contribution of memory encoding in spatial cueing: A new theory of costs and benefits. Psychological Review, 125(6), 936-968. https://doi.org/10.1037/rev0000116
Chen, H., Yu, J., Fu, Y., Zhu, P., Li, W., Zhou, J., & Shen, M. (2019). Does attribute amnesia occur with the presentation of complex, meaningful stimuli? The answer is, “it depends”. Memory & Cognition, 47(6), 1133–1144. https://doi.org/10.3758/s13421-019-00923-7
Chen, W., & Howe, P. D. L. (2017). Attribute amnesia is greatly reduced with novel stimuli. PeerJ, 5, e4016. https://doi.org/10.7717/peerj.4016
Chun, M. M. & Jiang, Y. (1998). Contextual Cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28-71. https://doi.org/10.1006/cogp.1998.0681
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 224–234. https://doi.org/10.1037/0278-7393.29.2.224
Chun, M. M., & Phelps, E. A. (1999). Memory deficits for implicit contextual information in amnesic subjects with hippocampal damage. Nature Neuroscience, 2, 844–847. https://doi.org/10.1038/12222
Ehinger, K. A., & Brockmole, J. R. (2008). The role of color in visual search in real-world scenes: Evidence from contextual cuing. Perception & Psychophysics, 70, 1366–1378. https://doi.org/10.3758/PP.70.7.1366
Elsley, J. V., & Parmentier, F. B. R. (2009). Is verbal–spatial binding in working memory impaired by a concurrent memory load? Quarterly Journal of Experimental Psychology, 62(9), 1696–1705. https://doi.org/10.1080/17470210902811231.
Geyer, T., Gokce, A., & Muller, H. J. (2011). Reinforcement of inhibitory positional priming by spatial working memory contents. Acta Psychologica, 137, 235-242. https://doi.org/10.1016/j.actpsy.2010.06.009
Gokce, A., Muller, H. J., & Geyer, T. (2013). Positional priming of pop-out is nested in visuospatial context. Journal of Vision, 13(3), 32–32. https://doi.org/10.1167/13.3.32
Gokce, A., Müller, H. J., & Geyer, T. (2015). Positional priming of visual pop-out search is supported by multiple spatial reference frames. Frontiers in Psychology, 6, 838. https://doi.org/10.3389/fpsyg.2015.00838
Golomb, J. D., Kupitz, C. N., & Thiemann, C. T. (2014). The influence of object location on identity: a “spatial congruency bias”. Journal of Experimental Psychology: General, 143(6), 2262-2278. https://doi.org/10.1037/xge0000017.
Greenberg, R., & Underwood, B. J. (1950). Retention as a function of stage of practice. Journal of Experimental Psychology, 40, 452-457. https://doi.org/10.1037/h0062147
Hasher, L., & Zacks, R. T. (1979). Automatic and effortful processes in memory. Journal of Experimental Psychology: General, 108(3), 356-388. https://doi.org/10.1037/0096-3445.108.3.356
Howard, J. H., Howard, D. V., Dennis, N. A., Yankovich, H., & Vaidya, C. J. (2004). Implicit Spatial Contextual Learning in Healthy Aging. Neuropsychology, 18(1), 124–134. https://doi.org/10.1037/0894-4105.18.1.124
Isingrini, M., Vazou, F., & Leroy, P. (1995). Dissociation of implicit and explicit memory tests: Effect of age and divided attention on category exemplar generation and cued recall. Memory & Cognition, 23(4), 462-467. https://doi.org/10.3758/BF03197247
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3), 683-702. https://doi.org/10.1037/0278-7393.26.3.683
Jiang, Y., & Wagner, L. C. (2004). What is learned in spatial contextual cuing— configuration or individual locations? Perception & Psychophysics, 66(3), 454–463. https://doi.org/10.3758/bf03194893
Johnston, J. C., & Pashler, H. (1990). Close binding of identity and location in visual feature perception. Journal of Experimental Psychology: Human Perception and Performance, 16, 843–856. https://doi.org/10.1037/0096-1523.16.4.843
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24, 175–219. https://doi.org/10.1016/0010-0285(92)90007-O
Keppel, G., & Underwood, B. J. (1962). Proactive inhibition in short-term retention of single items. Journal of Verbal Learning and Verbal Behavior, 1, 153-161. https://doi.org/10.1016/s0022-5371(62)80023-1
Kleiner, M., Brainard, D., Pelli, D., Ingling, A., Murray, R., & Broussard, C. (2007). What’s new in Psychtoolbox-3. Perception, 36(14), 1-16.
Lassaline, M. E., & Logan, G. D. (1993). Memory-based automaticity in the discrimination of visual numerosity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(3), 561-581. https://doi.org/10.1037/0278-7393.19.3.561
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95(4), 492-527. https://doi.org/10.1037/0033-295x.95.4.37
Maljkovic, V., & Nakayama, K. (1994) Priming of pop-out: I. Role of features. Memory & Cognition, 22(6), 657-672. https://doi.org/10.3758/bf03209251
Manns, J. R., & Squire, L. R. (2001). Perceptual learning, awareness, and the hippocampus. Hippocampus, 11, 776-782. https://doi.org/10.1002/hipo.1093
Marr, D. (1976). Early processing of visual information. Philosophical Translations of the Royal Society London B. 275, 483-524.
Marr, D. (1982). Vision. W.H. Freeman.
Mulligan, N. W. (1998). The role of attention during encoding in implicit and explicit memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(1), 27-47. https://doi.org/10.1037/0278-7393.24.1.27
Nissen, M. J. (1985). Accessing features and objects: Is location special? In: M. I. Posner & O. S. M. Marin (Eds.), Attention and performance XI (pp. 205–219). Erlbaum.
Palmeri, T. J. (1997). Exemplar similarity and the development of automaticity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(2), 324-354. https://doi.org/10.1037/0278-7393.23.2.324
Park, H., Quinlan, J., Thornton, E., & Reder, L. M. (2004). The effect of midazolam on visual search: Implications for understanding amnesia. Proceedings of the National Academy of Sciences, 101, 17879-17883. https://doi.org/10.1073/pnas.0408075101
Peirce, J. W., Gray, J. R., Simpson, S., MacAskill, M. R., Höchenberger, R., Sogo, H., Kastman, E., Lindeløv, J. (2019). PsychoPy2: experiments in behavior made easy. Behavior Research Methods, 51, 195-203. https://doi.org/10.3758/s13428-018-01193-y.
Pertzov, Y., & Husain, M. (2014). The privileged role of location in visual working memory. Attention, Perception, & Psychophysics, 76(7), 1914–1924. https://doi.org/10.3758/s13414-013-0541-y
Postman, L., & Underwood, B. J. (1973). Critical issues in interference theory. Memory & Cognition, 1, 19-40. https://doi.org/10.3758/bf03198064
Rajsic, J. & Wilson, D. E. (2014). Asymmetrical access to color and location in visual working memory. Attention, Perception & Psychophysics. 76, 1902-1913. https://doi.org/10.3758/s13414-014-0723-2
Rosenbaum, G. M., & Jiang, Y. V. (2013). Interaction between scene-based and array-based contextual cueing. Attention, Perception, & Psychophysics, 75(5), 888–899. https://doi.org/10.3758/s13414-013-0446-9
Schlagbauer, B., Muller, H. J., Zehetleitner, M., & Geyer, T. (2012). Awareness in contextual cueing of visual search as measured with concurrent access- and phenomenal-consciousness tasks. Journal of Vision, 12(11), 25–25. https://doi.org/10.1167/12.11.25
Schlagbauer, B., Rausch, M., Zehetleitner, M., Müller, H. J., & Geyer, T. (2018). Contextual cueing of visual search is associated with greater subjective experience of the search display configuration. Neuroscience of Consciousness, 2018(1), niy001.
Schmitter-Edgecombe, M. (1996). The effects of divided attention on implicit and explicit memory performance. Journal of the International Neuropsychological Society, 2(2), 111-125. https://doi.org/10.1017/S1355617700000965
Smyth, A. C., & Shanks, D. R. (2008). Awareness in contextual cuing with extended and concurrent explicit tests. Memory & Cognition, 36(2), 403–415. https://doi.org/10.3758/mc.36.2.403
Swan, G., Collins, J., & Wyble, B. (2016). Memory for a single object has differently variable precisions for relevant and irrelevant features. Journal of Vision, 16(3), 32. https://doi.org/10.1167/16.3.32.
Swan, G., Wyble, B., & Chen, H. (2017). Working memory representations persist in the face of unexpected task alterations. Attention, Perception, & Psychophysics, 79(5), 1408-1414. https://doi.org/10.3758/s13414-017-1318-5
Toh, Y. N., Sisk, C. A., & Jiang, Y. V. (2020). Effects of changing object identity on location working memory. Attention, Perception, & Psychophysics, 82(1), 294–311. https://doi.org/10.3758/s13414-019-01738-z
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97–136. https://doi.org/10.1016/0010-0285(80)90005-5
Treisman, A. M., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34(8), 1704-1719. https://doi.org/10.3758/bf03195932
Udale, R., Farrell, S., & Kent, C. (2018). No evidence of binding items to spatial configuration representations in visual working memory. Memory & Cognition, 46(6), 955-968. https://doi.org/10.3758/s13421-018-0814-8
Vidal, J. R., Gauchou, H. L., Tallon-Baudry, C., & O’Regan, J. K. (2005). Relational information in visual short-term memory: The structural gist. Journal of Vision, 5(8), 619-619. https://doi.org/10.1167/5.3.8
Wessel, J. R. (2018). A Neural Mechanism for Surprise-related Interruptions of Visuospatial Working Memory. Cerebral Cortex, 28(1), 199-212. https://doi.org/10.1093/cercor/bhw367
Wessel, J. R., Jenkinson, N., Brittain, J. S., Voets, S., Aziz, T. Z., & Aron, A. R. (2016). Surprise disrupts cognition via a fronto-basal ganglia suppressive mechanism. Nature Communications, 7. https://doi.org/10.1038/ncomms11195
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131(1), 48–64. https://doi.org/10.1037/0096-3445.131.1.48
Williams, M., Pouget, P., Boucher, L., & Woodman, G. F. (2013). Visual–spatial attention aids the maintenance of object representations in visual working memory. Memory & Cognition, 41(5), 698–715. https://doi.org/10.3758/s13421-013-0296-7
Woodman, G. F., Vogel, E. K., & Luck, S. J. (2012). Flexibility in visual working memory: Accurate change detection in the face of irrelevant variations in position. Visual Cognition, 20(1), 1– 28. https://doi.org/10.1080/13506285.2011.630694
Wyble, B., & Chen, H. (2017). Memory consolidation of attended information is optional: Comment on Jiang et al. (2016). Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(6), 997-1000. https://doi.org/10.1037/xlm0000333
Wyble, B., Hess, M., O’Donnell, R. E., Chen, H., & Eitam, B. (2019). Learning how to exploit sources of information. Memory & Cognition, 47, 696-705. https://doi.org/10.3758/s13421-018-0881-x
Acknowledgements
We thank Chloe Callahan-Flintoft, Shekoofeh Hedayati, Rick O. Gilmore, Baruch Eitam, and undergraduates of the Wyble lab for their helpful comments and suggestions. This work was supported by BSF grant 2015299, NNSF (No.31771201), and National Science Foundation for Distinguished Young Scholars of Zhejiang Province, China (No. LR19C090002).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 416 kb)
Rights and permissions
About this article

Cite this article
O’Donnell, R.E., Chen, H. & Wyble, B. No explicit memory for individual trial display configurations in a visual search task. Mem Cogn 49, 1705–1721 (2021). https://doi.org/10.3758/s13421-021-01185-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-021-01185-y