
Abstract
When responding to the identity of a visual target, nearby stimuli (flankers) that are associated with the same response as the target cause faster and more accurate responding than flankers that are associated with different responses. Because this flanker-congruence effect (FCE) decreases with increasing target-flanker separation, it was thought to reflect limited precision of spatial selection mechanisms. Later studies, however, showed that FCEs are larger when the target and flankers are the same color compared to when they are different colors. This led to the group selection hypothesis, which states that flankers are perceptually grouped with the target and are obligatorily selected along with it, regardless of spatial separation. An alternative hypothesis, the image segmentation hypothesis, states that feature differences facilitate the segmentation of visual information into relevant and irrelevant parts, thereby mitigating the limitations of spatial precision of selection mechanisms. We test between these hypotheses using a design in which targets and flankers are grouped or not grouped, while holding feature differences in the stimulus constant. Contrary to earlier results, we found that same-colored flankers do not yield larger FCEs than different-colored flankers when feature differences are held constant. We conclude that similarity effects on the FCE reflect differential support for image segmentation, on which selection depends, rather than the obligatory selection of perceptually grouped flankers and targets.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Nearly a half century ago, C. W. Eriksen, together with many students and colleagues, published a series of papers investigating properties of spatial selective attention using what is now referred to as the flankers task (e.g., B. A. Eriksen & Eriksen, 1974; Eriksen & Hoffman, 1972, 1973; Eriksen & St. James, 1986; Eriksen & Schultz, 1979; Eriksen & Yeh, 1985). The base observation – the flanker congruence effect (FCE) – is that responses to the identity of target stimuli that are presented at a known location (often fixation) are influenced by the identity of nearby flanking stimuli. Specifically, responses tend to be faster and/or more accurate when flankers are associated with the same response as the target (congruent) compared to when they are associated with different responses (incongruent). This is true even when the target and flankers are different stimuli that are associated with the same response, suggesting that the interference impacts response-related stages of processing in particular. Notably, when the target and flankers are sufficiently separated in space, the FCE is nearly eliminated (Eriksen & Hoffman, 1972; Eriksen & Eriksen, 1974)
Eriksen and colleagues suggested that the FCE, and its dependence on spatial separation, indicates that “…visual attention is not capable of infinitely fine selectivity. Rather, there is a minimal channel size…” such that if “…there are other letters or stimuli present, they will be processed simultaneously along with the target” with the consequence that “…2, 3, or perhaps 4 or more letters … begin the process of evoking responses” (Eriksen & Eriksen, 1974, p. 144). In light of this interpretation and related findings (e.g., Posner, 1980; Posner, Snyder, & Davidson, 1980), selective attention was discussed using the now familiar metaphor of a spotlight, whereby selection processes are focused on a small region of space in anticipation of prioritizing the processing of stimuli that appear in that location. Within this metaphor, the limitation suggested by Eriksen and Eriksen’s account is that there is a limit to how small the spotlight can be narrowed. The modified metaphor of a zoom lens was suggested later, capturing the idea that observers can adopt a small focus that is highly selective or a wider focus that captures a broader range, but is less selective (Eriksen & St. James, 1986; Eriksen & Yeh, 1985; LaBerge, 1983; LaBerge & Brown, 1986). For current purposes, the defining characteristic of these explanations is that selectivity is defined on the basis of regions of space, and that the FCE reflects a limit in how narrow the selected region can be, or as others later characterized it, attentional resolution (He, Cavanagh, & Intriligator, 1996; Intriligator & Cavanagh, 2001).
Since the publication of the original wave of papers, there has been an enormous amount of work on the FCE, ranging from exploring it as evidence of deep processing of task-irrelevant stimuli (a.k.a. late selection; e.g., Flowers & Wilcox, 1982; Hagenaar & van der Heijden, 1986; Lavie & Tsal, 1994; Miller, 1987; but see Lachter, Forster, & Ruthruff, 2004), identification of the neural substrate of the effect (e.g., Botvinick, Nystrom, Fissell, Carter, & Cohen, 1999; Fan, Flombaum, McCandliss, Thomas, & Posner, 2003; Geißler, Hofmann, & Frings, 2020; Hazeltine, Poldrack, & Gabrieli, 2000), to the use of the FCE as a metric of individual differences in selective attention and inhibitory control (e.g., Fan, McCandliss, Sommer, Raz, & Posner, 2002; Liu-Ambrose, Nagamatsu, Voss, Kahn, & Handy, 2012; Jones et al., 2016; McDermott, Pérez-Edgar, & Fox, 2007).
In the current study, we are concerned with the early observation that FCEs are larger when the target and flankers are the same color compared to when they are different colors (e.g., Harms & Bundesen, 1983; Schneider, 2018; see also Kahneman & Henik, 1981; see Fig. 1a). This is often attributed to perceptual organization of the stimuli, such as through grouping-by-similarity processes, and is cited as evidence that “[a]ttention can only be directed to preattentively defined perceptual objects, [which] facilitates all the responses associated with properties or elements of the selected object,” as originally articulated by Kahneman and Henik (1981, p. 181). Under this view, when flankers are grouped with the target, they are obligatorily selected along with it, allowing their identity to influence response processes. In contrast, if flankers are not grouped with the target, then they will not be selected with it, allowing the target to determine the response uncontaminated by flanker identities. We refer to this as the group selection hypothesis.

(a) Illustration of flanker displays in which the target (T) and flankers (F) are either similar (top) or different (bottom) (b) Illustration of conditions used in Driver and Baylis (1989). They are examples of incongruent displays in which the target (X) indicates one response, two of the flankers (C) are associated with the alternative response and two (H) are neutral, associated with no response. In one condition, the incongruent flankers are designed to group by common fate with the target (top), whereas in the other condition, the neutral flankers are designed to group by common fate with the target (bottom). (c) Illustration of the grouping-by-similarity version of the linear-display design used in Baylis and Driver (1992, Experiment 2) and Experiments 1, 2, and 4c of the current study. (d) Illustration of the X-display design used by Baylis and Driver (1992, Experiment 1) and Experiments 3b and 4b of the current study. (e) Illustration of the control conditions used in Experiments 3a and 4a of the current study
An alternative explanation for why FCEs are larger when target and flankers are the same color compared to when they are different colors concerns the relative quality of the image within which selection occurs under those different conditions. Specifically, when target and flankers are different colors, there are feature discontinuities that support segmentation of the image into relevant and irrelevant parts that are not there when target and flankers are the same color. Under this view, target-flanker similarity effects reflect what is essentially better visual input when target and flankers are different compared to when they are the same. Rather than being about differences in how perceptual elements (i.e., the individual letters in flankers displays) are organized into groups under same-color versus different-color conditions, it is about differences in how well separate representations of the units themselves are established. Selection processes have limited spatial precision, both in the spatial extent of the selection channel (e.g., Eriksen & Eriksen, 1974; Eriksen & Hoffman, 1972; Intriligator & Cavanagh, 2001; Palmer & Moore, 2009; Yiğit -Elliot, Palmer, & Moore, 2011) and in the degree of control over spatial targeting of selection mechanisms (e.g., Bahcall & Kowler, 1999; Palmer & Moore, 2009; Yiğit-Elliot et al., 2011), and the traditional understanding of the FCE is that it reflects these limitations; stimuli that are too close cannot be separately selected. In addition to the spatial limitations of selection mechanisms themselves, however, the initial representation of stimuli is limited in its spatial precision (e.g., Levi & Tripathy, 1996). The success of any spatial selection mechanism, therefore, will be determined both by its own spatial limitations and the quality of the input, in terms of its spatial precision, to that mechanism. We refer to this alternative explanation of similarity effects on FCEs as the image segmentation hypothesis.
Eriksen and Eriksen’s (1974) original account of the spatial proximity effect on the FCE is consistent with the image segmentation hypothesis. They pointed out that the longer it takes to discriminate the target from the flankers, the longer it will take to reach the selective stage of processing, and therefore the greater the opportunity there will be for flankers to influence responses. Explaining the spatial proximity effect on the FCE, they noted that “…selection is more rapid if the spatial discrimination is easy.” Here, we add the more general assertion that selection will be more rapid (and effective) if discrimination, for any reason, is easier. Color differences between target and flankers, like spatial separation between target and flankers, facilitate the segmentation of the image into relevant and irrelevant parts, and can thereby reduce the FCE by facilitating target-flanker discrimination.
These two alternative hypotheses – group selection and image segmentation – offer different explanations for similarity effects on FCEs because they begin with different underlying explanations for why FCEs occur under standard conditions (i.e., closely spaced, identically colored stimuli). Distinguishing between them, therefore, involves not only an understanding of similarity effects on FCEs, but also of the underlying cause of FCEs in the first place. To be clear, the group selection hypothesis is based on the assertion that flankers are obligatorily selected along with the target because they are represented as part of the same perceptual group as the target, and selection mechanisms act on group representations. Under standard conditions, flankers may be grouped with targets on the basis of proximity and color similarity, and perhaps other attributes as well (e.g., common onset and/or alignment). In contrast, the image segmentation hypothesis is based on the assertion that information from the flankers is selected along with the target when stimulus conditions are beyond the spatial precision of selection mechanisms. Under standard conditions, spatial proximity and uniformity of stimulus attributes give rise to a relatively indistinct representation of the target separate from the flankers compared to when there are additional image-level differences between target and flankers, and therefore constitute a greater challenge to the limited precision of spatial selection mechanisms than when there are differences.
The basic observation that dissimilar flankers and targets yield smaller FCEs than similar flankers and targets is insufficient to distinguish between the group selection hypothesis and the image segmentation hypothesis because it is predicted by both. In 1989, however, Driver and Baylis published a critical test that could distinguish between them. The innovation was to measure the effects of two different, simultaneously present, sets of flankers on target processing separately, one that was designed to perceptually group with the target and another that was designed to perceptually group away from the target. The grouped flankers were spatially farther from the target than the ungrouped flankers were, and, therefore, the design directly contrasted the possible consequences of grouping by similarity with the possible consequences of limited spatial precision. They used the motion cue of common fate to group the two outer flankers with the target, separate from the two inner flankers (Fig. 1b). On some of the trials, the identities of the outer flankers were congruent or incongruent with the target, while the inner flankers were neutral (associated with no response). On other trials, the reverse was true. This design provided separate measures of FCEs for ungrouped (inner) and grouped (outer) flankers. The results were consistent with the group selection hypothesis and inconsistent with the image segmentation hypothesis. Specifically, the grouped flankers, which were farther from the target, yielded larger FCEs than the ungrouped flankers, which were closer to the target. These results are inconsistent with the image segmentation explanation of similarity effects on FCEs because all of the displays were identical as far as feature discontinuities were concerned. They differed only in regard to the identities of individual stimuli (i.e., which were neutral and which were associated with a response).
In a later study, Baylis and Driver (1992) replicated their original findings using grouping by color similarity instead of grouping by common fate (Fig. 1c). They also introduced an elegant variation of the design that equated both the spatial separation from the target for the two sets of flankers and the eccentricity of the two sets of flankers (Fig. 1d). In this new X-display design, central targets were flanked by two diagonals of flankers – one with flankers that were the same color as the target and one with flankers that were a different color from the target. On some trials, the same-color flankers were congruent or incongruent while the different-color flankers were neutral. On other trials, the reverse was true. As with the linear-display design, they found that same-color flankers yielded larger FCEs than different-color flankers, a result that is consistent with the group selection hypothesis and inconsistent with the image segmentation hypothesis.
The finding that similar flankers yielded larger FCEs than dissimilar flankers, even when image-level differences are controlled, is critical evidence. Specifically, it is consistent with the group-selection hypothesis and inconsistent with the image segmentation hypothesis. A complication, however, is that soon after the first study (Driver & Baylis, 1989) was published, two failures to replicate it appeared in the literature (Berry & Klein, 1994; Kramer, Tham, & Yeh, 1991). And unlike the original studies, which according to Google Scholar at the time of this writing have been cited 911 times with an additional 482 citations of two theoretical reviews that were based on that work, the failures to replicate the findings have been cited only 64 times. The relative neglect of these other studies may be attributed to the fact that they were focused on the original common-fate version (Driver & Baylis, 1989), which was followed up on with the color-similarity version, and, moreover, was extended to include the X-display design (Baylis & Driver, 1992). Addressing the Kramer et al. (1991) failure to replicate, for example, Baylis and Driver (1998) suggested that with small changes to the display, grouping by proximity may come to dominate grouping by common fate, causing grouping by proximity to determine the FCE.
In the current study, we report seven experiments investigating the effect of target-flanker color-similarity on the FCE. Target-flanker similarity affected the FCE only when there were feature discontinuities in the different-color conditions and not the same-color conditions. When image-level differences were controlled, same-color flankers had no greater impact on target processing than did different-color flankers. These results are not what is predicted by the group selection hypothesis, but are what is predicted by the image segmentation hypothesis. These findings are discussed in the context of a broader set of related studies investigating the relationship between object structure and attention in the General discussion.
General method
Subjects
All subjects were University of Iowa undergraduate students who received course credit toward a research-experience requirement in an introductory psychology course. All reported normal or corrected-to-normal visual acuity and color vision. No individual participated in more than one of the experiments.
Apparatus
Experiments were run on a Mac Mini computer (Mac OS X, Versions 10.9.5) driving a 23-in. EIZO FS2434-LCD monitor with spatial resolution of 1,920 × 1,080 and a frame rate of 16.67 ms. Viewing distance was fixed at 57 cm using a chin rest. Responses were entered on a standard QWERTY keyboard. Experiments were programmed in MATLAB (version R2013b, 8.2, The Mathworks Inc., Natick, MA, USA) with the Psychtoolbox extension (version 3.0.11; Brainard, 1997; Pelli, 1997). Experiments were conducted in individual testing rooms with standard room lights on.
Stimuli
Stimuli were green and purple letters presented at the center of a dark background (1.5° cd/m2). The colors were set so that they were approximately photometrically equiluminant with each other at approximately ~23 cd/m2. The color choices were made to match the original Baylis and Driver (1992) studies as closely as possible. A white (~82 cd/m2) fixation cross was presented at the center of the screen. Stimulus sizes differed across experiments. Targets were× and Y, assigned to one response (left or right), and C and S assigned to the other response. Neutral Flankers differed across experiments. Target color was fixed for a given subject, but counter-balanced across subjects.
Task
For all experiments, the task was to respond to the identity of the center letter by pressing the ‘F’ or ‘J’ key with the left or right index fingers as quickly and accurately as possible. Two letters were assigned to each of the two responses (left or right). Half of the subjects responded with a left key press if the center letter was× or Y and with a right key press if the central letter was C or S. For the other half of the subjects, the stimulus-response mapping was reversed. Instructions emphasized that responses should be made as quickly as possible without making too many errors.
Procedure
Subjects were tested in single individual sessions, which took approximately 1 h to complete. Following the consent process, a set of written instructions was provided on the monitor, which the experimenter read aloud as the subject followed along. Subjects then completed a single block of practice trials to learn the stimulus-response mapping without an emphasis on speed. This was followed by a second practice block in which subjects were asked to make their responses as quickly as possible, and following each correct response, the response time in milliseconds (ms) for that trial was displayed visually.
Following the second practice block, the experimenter left the room and subjects completed a set of blocks on their own. Trial-by-trial feedback was limited to indicating when an error was made. Mean response time and accuracy for the preceding block was provided at the end of each block. Subjects could rest as long as they liked between blocks before self-initiating the next one. If fewer than two errors were made across two consecutive blocks, an additional message was provided during the between-block period to encourage faster responding: “You are doing great but have made very few errors over the past two blocks. Please try going a bit faster. It is okay to make a few errors. Thank you!” If accuracy was less then 90% across two consecutive blocks, an additional message was provided during the between-block period to encourage more accurate responding: “You are doing great, but you made a fair number of errors over the last two blocks. Please try to slow down a little bit to make fewer errors. Thank you!” At the end of the experiment, a message indicated that the experiment was complete and that the subject could go out to the main lab. The experimenter then asked the subject if he/she had any questions and provided a brief explanation of the experiment.
Individual trial events varied slightly across experiments. But trials always began with the presentation of a white cross at the center of the screen that subjects were asked to fixate. A short while later, the stimulus display was presented and a response was recorded. Following an intertrial interval during which the screen was blank, the fixation cross for the next trial was presented. Specific timing of these events differed across experiments. Incorrect responses were followed by a beep (200 ms, 450 Hz) and a visual feedback message for 1 s. If the error was an incorrect response, the message was “error.” If the error was a button other than the two response alternatives, the message was “not a response key.” If the error was a time-out (no response after 2.5 s), the message was “no response.”
Design and analyses
Specific designs differed across experiments, but some details were common. Following Baylis and Driver (1992), target color was fixed for a given subject but counterbalanced across subjects. Stimulus response mapping was also counter-balanced across subjects. The dependent measures were mean response time and percent error. Analyses of error rates were conducted on their arcsin transformations. Alpha was set at .05 throughout. Effect sizes are reported as adjusted partial eta-squared (\( adj\ {\hat{\eta}}_p^2 \)), which is an estimate of partial eta-squared that adjusts for the positive bias of partial eta-squared (Mordkoff, 2019). Initial choice of number of subjects was based on the Baylis and Driver studies. They did not provide sufficient information to conduct actual power analyses, but we conducted analyses based on our initial experiments as best as we could; however, we were limited to basing it mainly on the FCE itself as the interaction effects critical to the Baylis and Driver findings were consistently non-significant. We generally tested substantially more subjects than those in the original studies, and we conducted multiple experiments as well.
Experiment 1
Experiment 1 tested the effect of grouping by color similarity on the FCE using the linear-display design (see Fig. 1c) used in Experiment 2 of Baylis and Driver (1992). In addition to displays in which flankers alternated color and the relevant flanker set was either the inner (ungrouped) or outer (grouped) set, where “ungrouped” means the target and flankers were different colors and “grouped” means the target and flankers were the same color. On half of the trials the letters were all the target color. These homogenous displays were not included in the original experiment (Baylis & Driver 1992, Experiment 2).
Method
Subjects
Twelve subjects (11 female, one male; mean age = 18.9 years) participated in Experiment 1.
Stimuli
Stimuli were five letters (Courier font) presented equally spaced in a horizontally aligned array at the center of the screen. The entire array subtended 3.2° × 0.5° (degrees of visual angle). Letters were 0.4° × 0.5° and the center-to-center separation between them was 0.6°. The target color was purple for half of the subjects and green for the other half. For half of the trials in a block, all of the letters were presented in the target color. For the other half, the target and the two outer flankers were presented in the target color and the two inner flankers were presented in the other color. Neutral letters were H and T.
Design
A 2 (Display: grouped, homogenous) × 5 (Congruence: inner congruent, inner incongruent, outer congruent, outer incongruent, all neutral) within-subject design was used. All conditions were mixed within blocks of trials. For grouped displays, the outer flankers were the same color as the target and the inner flankers were the other color. For the homogenous displays, all stimuli were the target color. The target was equally likely to be X, Y, C, or S (two of which indicated a left response and two a right response; see General method). When the inner or outer flankers were congruent, they were the other letter that indicated the same response as the target. When they were incongruent, they were equally often one of the two letters that indicated the other response. Neutral flankers were H for half the trials and T for the other half. For neutral trials, all of the flankers were neutral (all Ts or all Hs, equally often across trials). Subjects completed 11 blocks of 80 trials each. The first three blocks were considered practice and were not included in the analyses. This resulted in 64 observations per condition for each subject.
Procedure
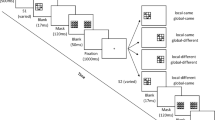
Trial events are illustrated in Fig. 2. Each trial began with a 250-ms fixation display that included a cross at the center of the screen, followed by a 250-ms blank screen, and then the array of letters for 200 ms. Subjects responded with a key press. If the response was correct, it was followed by an 800-ms intertrial interval (ITI) after which the fixation cross for the next trial was presented. If it was incorrect, it was followed by a beep and a written “error” message for 1,000 ms before the 800-ms ITI. If no response was detected after 2,500 ms, the trial ended with a “no response” message followed by the 800 ms ITI.

Illustration of trial events in Experiment 1. The other experiments were the same except that specific timing varied slightly
Results and discussion
Mean Response Time (RT) Error Rates (ER) are shown in Fig. 3. Subjects’ mean RTs were submitted to a 2 (Display: grouped, homogenous) × 2 (Relevant Flanker: inner, outer) × 2 (Congruence: congruent incongruent) repeated-measures analysis of variance (ANOVA). Relevant Flanker refers to whether the inner or outer flankers had identities that were associated with a response, rather than being neutral. The only significant effect was the main effect of Congruence, mean difference of 14 ± 3.8 ms, F(1, 11) = 15.28, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .543. Neither the main effect of Display, F(1, 11) = 3.68, p = .081, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .183, nor the main effect of Relevant Flanker, F(1, 11) = 1.27, p = .284, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .022, was reliable, and none of the interactions reached significance.

This pattern of results is not what was predicted by the group selection hypothesis. Outer flankers, which were the same color as the target, did not yield larger FCEs than inner flankers, which were a different color. If anything, inner flankers yielded larger FCEs than outer flankers for both grouped and homogenous displays, although this pattern was not confirmed statistically as the Relevant Flanker × Congruence interaction did not reach significance, F(1, 11) = 3.08, p = .108, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .147. There was also no evidence of any differences in FCEs between the grouped and homogenous displays, as one would expect there to be if grouping were a key determinant of the FCE; neither the Display × Relevant Flanker × Congruence interaction, F(1, 11) = .049, p = .830, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.086 nor the Display × Relevant Flanker interaction, F(1, 11) = .511, p = .108, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.042Footnote 1 was significant.
Finally, RTs on neutral trials did not differ across the grouped and homogenous conditions, t(11) = 1.45, ns, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .084.
We conducted all of the same analyses on the arcsin transformations of the error rates and found no significant effects that were different from what was obtained for the RTs.
The results of this modified version of Baylis and Driver (1992, Experiment 2) did not yield results consistent with the group selection hypothesis as their study did. In contrast, the results are what is predicted by the image segmentation hypothesis. Because the target was no better defined in terms of the stimulus when the outer flankers were relevant compared to when the inner flankers were relevant – every display consisted of letters in alternating colors – no difference in FCE due to color match is expected under the image segmentation hypothesis. The design of the current experiment, however, was different from that of Baylis and Driver (1992, Experiment 2) in that it included homogeneous displays mixed in with grouped displays, and they only included grouped displays. It is possible that the inclusion of homogenous displays somehow diluted the impact of color grouping.
Before turning to Experiment 2 in which we test the possibility that it was the addition of homogeneous displays that altered the results, we offer a comment on the magnitude of the FCEs observed in this experiment, which may appear small. They are, however, nearly identical to those reported by Baylis and Driver (1992, Experiment 2), suggesting that our conditions are generally well matched. Whereas they reported an FCE of 23 ms for far (grouped) flankers and 11 ms for near (ungrouped) flankers, we found nearly the same effects, but in the reverse direction: an FCE of 8 ms for far (grouped) flankers and 22 ms FCE for near (ungrouped) flankers. FCEs are probably small in general because in each congruent and incongruent display, half of the flankers were neutral.
Experiment 2
Experiment 2 tested the possibility that the inclusion of homogenous displays in Experiment 1 disrupted the influence of grouping by color similarity on the FCE. If this is the case, then it is something that needs to be incorporated into our understanding of grouping effects on FCEs. We therefore designed Experiment 2 such that the first half of the blocks included only grouped displays (pure blocks), and the second half included both grouped and homogenous displays like Experiment 1 (mixed blocks). This allowed us to test a more direct replication of Baylis and Driver (1992, Experiment 2) and, at the same time, test the effect of mixing in homogenous displays with grouped displays.
Method
Subjects
Twenty-four subjects (seven female, 17 male; mean age = 18.9 years) completed Experiment 2. Two additional subjects were tested, but their data were lost due to experimenter error.
Stimuli
Stimuli were five letters (Lucida font) presented equally spaced in a horizontally aligned array at the center of the screen. The sizes of the stimuli were slightly different for the first 16 and the last 10 subjects tested. For the first 16 subjects, the stimulus and array sizes were identical to Experiment 1. For the last 10 subjects tested, the array subtended 6.2° × 1.0° (degrees of visual angle). Letters were 0.7° × 1.0° and the center-to-center separation between them was by 1.2°. Size was included as a between-subject variable in preliminary analyses to confirm that it had no impact on the pattern of results, which it did not. Otherwise, the stimuli were the same as in Experiment 1. For grouped displays, the outer flankers were the same color as the target (purple or green) and the inner flankers were the other color. For homogenous displays, all of the flankers were the same color as the target. Neutral letters were again H and T.
Design
A nested design was used. For the first six blocks of trials, all trials were grouped displays (pure blocks). For the last six blocks, a random half of the trials were grouped displays and the other half were homogenous displays (mixed blocks). The first pure block and the first mixed block were considered practice and were not included in the analyses. For the pure blocks, Congruence (inner congruent, inner incongruent, outer congruent, outer incongruent, all neutral) was the only variable. For the mixed block, a 2 (Display: grouped, homogenous) × 5 (Congruence: inner congruent, inner incongruent, outer congruent, outer incongruent, all neutral) design was used. Blocks were 80 trials each, which resulted in a total of 80 observations per condition in the pure design and a total of 40 observations per condition in the mixed design.
Procedure
The session structure and trials events were identical to those in Experiment 1.
Results and discussion
Mean RTs and ERs are shown in Fig. 4. Figure 4a shows the results from pure blocks that included only Grouped displays. Figure 4b and c shows the results from the grouped and homogenous displays, respectively, from the mixed blocks.

Comparing blocked versus mixed conditions for grouped displays
We first consider just grouped displays. We conducted an initial 2 (Size: small, large) × 2 (Mixing: pure, mixed) × 2 (Relevant Flanker: inner, outer) × 2 (Congruence: congruent incongruent) repeated-measures mixed ANOVA, with size as a between-subject variable and the others within-subject variables. Mixing refers to whether the trials, which were all grouped displays, occurred within the context of pure blocks or mixed blocks. Size was included to confirm that the small size difference in stimuli across subjects had no impact on the pattern of results. There was no main effect of Size, F < 1, nor were any of the interactions with Size significant. Size is not considered further.
The results were again not what is predicted by the group selection hypothesis. The only significant main effect was of Congruence, mean difference of 12 ± 3.7 ms, F(1, 23) = 13.0, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .333. The main effect of Relevant Flanker was not significant, F(1, 23) = .049, p = .826, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.04, nor was the main effect of Mixing, F(1, 22) = .005, p = .942, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .043. The interaction between Relevant Flanker and Congruence was significant, F(1, 23) = 5.81, p < .05, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .167. However, the direction of the difference was in the opposite direction of that predicted by the group selection hypothesis. Specifically, collapsing across blocked and mixed contexts, the FCE for inner (i.e., different color) flankers, 19 ± 5.2 ms, t(23) = 3.74, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .351, was larger than the FCE for outer (i.e., same color) flankers, which was not reliably different from 0, 6 ± 3.6 ms, t(23) = 1.83, p = .08, , \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .089. This finding is consistent with a spatial limitation on selection. Finally, the three-way interaction, Mixing × Relevant Flanker × Congruence was not significant, F(1, 23) = 2.98, p = .097, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .076, meaning that there is no evidence that mixing grouped trials in with homogenous trials caused an effect of grouping to be diluted or eliminated. In order to compare our results more directly to those of the original study (Baylis & Driver, 1992, Experiment 2) however, we nonetheless conducted a post hoc analysis that was limited to just the blocked grouped displays, because this is the condition that most closely matches that experiment. Again, only the main effect of congruence was significant, with a mean difference of 14 ± 4.6 ms, F(1, 23) = 14.31, p = < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .357. Neither the main effect of Relevant Flanker, F(1, 23) = 0.53, p = .475, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.020 nor, critically, the interaction between Relevant Flanker and Congruence, F(1, 23) = 0.463, p = .503, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.023, was significant.
We conducted all of the same analyses on the arcsin transforms of the error rates. There were no significant patterns that were different from what was found in the RTs, except that the main effect of mixing was significant, mean difference 1.4 ± 0.59 percentage points, F(1, 23) = 5.12, p < .05, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .147. This could reflect a practice effect, rather than an effect of mixing per se, because the blocked condition had to be run before the mixed condition, and it did not interact with either Relevant Flanker or Congruence.
Grouped versus homogenous displays under mixed conditions
We next analyzed the data from the mixed blocks. Subjects’ mean RTs were submitted to an initial 2 (Size: small, large) × 2 (Display: grouped, homogenous) × 2 (Relevant Flanker: inner, outer) × 2 (Congruence: congruent, incongruent) mixed ANOVA, with Size as a between-subject variable and the others as within-subject variables. The main effect of Size was not significant, F < 1, nor did Size interact significantly with any of the other variables in any way that would impact the hypotheses being tested. Size is not considered further.
The results from the main design showed the same pattern as Experiment 1. The only significant effect was the main effect of Congruence, mean difference of 12 ± 3.7 ms, F(1, 23) = 11.01, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .294. Neither the main effect of Display, F(1, 23) = .623, p = .438, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.016, nor the main effect of Relevant Flanker, F(1, 23) = 1.52, p = .231, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .021, was reliable. The Relevant Flanker × Congruence interaction, approached significance F(1, 23) = 4.24, p = .051, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .119. Collapsed across grouped and homogenous displays, the FCE was numerically larger for inner flankers, mean difference 18 ± 4.3 ms than for outer flankers, 6 ± 4.9 ms. The Display Type × Relevant Flanker × Congruence interaction was not significant, F(1, 23) = 1.87, p = .185, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .035, meaning that there was no evidence that the pattern of influence for inner and outer flankers was different for the grouped displays than for homogenous displays, as would be expected under the group selection hypothesis.
We conducted the same analyses on the arcsin transformations of the ERs. The only effect that was different from the pattern observed in the RTs was that the Display × Relevant Flanker × Congruence effect was significant, F(1, 23) = 4.561, p < .05, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .129. The form of the interaction, however, is contrary to the predictions of the group selection hypothesis, as can be seen in Fig. 4b.
Finally, we conducted a one-way repeated-measures ANOVA on the neutral conditions (Neutral Context: Pure Grouped, Mixed Grouped, Mixed Homogenous). There were no significant differences between the three neutral conditions across experimental context for either the RTs, F(2, 46) = .991, p = .379, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .000, or the ERs, F(2, 46) = .437, p = .648, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.024.
In summary, the results of Experiment 2 were not what was predicted by the group selection hypothesis, but were what is predicted by the image segmentation hypothesis. Same-color flankers did not impact target processing any more than different color flankers did, regardless of whether they were mixed within blocks with homogenous displays or not. In contrast, spatial separation did impact the FCE. Inner flankers yielded larger FCEs than outer flankers. This pattern of results is what is expected under the image segmentation hypothesis. Flankers that are closer to the target present a greater challenge to the limitations of spatial selection mechanisms, and therefore yield larger FCEs. But because same-color and different-color displays were matched in terms of image-level characteristics, color match had no additional impact on the FCE.
Experiment 3
The linear-display design is especially conservative with regard to testing the group selection hypothesis because it puts grouping by color similarity in competition with target-flanker proximity. The X-display design (Fig. 1d) is a more balanced test in that target-flanker proximity is held constant while still providing a separate measure of the influence of grouping. In Experiment 3, we sought evidence that grouped flankers influence targets more than ungrouped flankers using the X-display design as reported by Baylis and Driver (1992, Experiment 1). We first confirmed that we would obtain the base effect of color similarity on the FCE (e.g., Harms & Bundesen, 1983) using our stimuli in diagonally configured displays (Experiment 3a). These displays are illustrated in Fig. 1e. Notice that there are feature discontinuities in the different-color display (lower) that define the target relative to the distractor that are not present in the same-color display (upper). The image segmentation hypothesis, like the group selection hypothesis, therefore predicts larger FCEs for same-color than different-color flankers for these displays. We then added flankers to the second diagonal to form the X displays (Fig. 1d) in order to test the effect of grouping by similarity separate from differential feature discontinuities (Experiment 3b).
Method
Subjects
Twenty-six subjects participated in Experiment 3a (11 female, 15 male; mean age = 18.8 years) and 26 different subjects (four female, 22 male; mean age = 18.3 years) participated in Experiment 3b.
Stimuli
Stimuli were arrays of letters arranged in an X pattern with a target letter (C S X or Y) in the middle position, flanked by two letters each along the positive and negative diagonal. Letters were 0.7° × 1.0° and the center-to-center separation between them, both vertically and horizontally, was 1.2°. This resulted in a center-to-center separation between target and flankers along the diagonal of 1.7°. The target was centered within the array, which was presented at the center of the screen. Neutral letters were H, T, N, E, D, V, L, or P. In Experiment 3a, the letters along one of the two diagonals were drawn in the background color so that it was analogous to a standard flanker task (one target with two flankers) arranged along a diagonal across fixation.
Design
A 2 (Relevant Diagonal: positive, negative) × 2 (Group: same color, different color) × 3 (Congruence: congruent, neutral, incongruent) within-subject design was used in both experiments. Relevant Diagonal referred to whether the flankers in the positive (right tilted) or negative (left tilted) diagonal were ones that were relevant to measuring the FCE. In Experiment 3a, this was the only visible diagonal. For analyses, data were collapsed across positive and negative diagonal conditions. Congruence was defined by the identity of the flankers in the relevant diagonal. They could be congruent, in which case they were the other stimulus that indicated the same response as the target. They could be incongruent, in which case they were (equally often) one of the two letters that indicated the opposite response from the target. Or they could be neutral, in which case they were (equally often) H or T, which were not associated with a response. Flankers in the other diagonal were also neutral, but were selected from among one set (N E D) for one of the two targets that indicated a given response (e.g., left) and from a second set (V L P) for the other target that indicated that response. Group referred to whether the flankers in the relevant diagonal were the same color as the target or a different color. In Experiment 3a, there were no flankers in the non-relevant diagonal. In Experiment 3b, the flankers along the non-relevant diagonal were the opposite color to those in the relevant diagonal such that every display had one diagonal with same-color flankers and one with different-color flankers.
Subjects completed 15 blocks of 48 trials each, the first five of which were considered practice and not included in the analyses. Collapsing over the positive and negative Relevant Diagonal conditions, this resulted in 80 observations per condition of the main design for each subject.
Procedure
The session structure and trial events were identical to those in Experiments 1 and 2 except that the fixation display was 300 ms, followed by a 200-ms blank interval, and then by the stimulus display for 200 ms.
Results and discussion
Mean RTs and ERs for Experiments 3a and 3b are shown in Fig. 5a and b, respectively.

Experiment 3a
There was a standard FCE in Experiment 3a that was modulated by target-flanker color similarity as previous work has shown (Harms & Bundesen, 1983). Mean RTs were submitted to a 2 (Color: same, different) × 3 (Congruence: congruent, neutral, incongruent) repeated-measures ANOVA. The main effect of Congruence was significant, F(2, 50) = 14.59, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .343, as was the interaction between Color and Congruence, F(2, 46) = 3.60, p < .05, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .091. The main effect of Color was not significant, F(1, 23) = 1.90, p = .181, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .033. The same analyses were conducted on the arcsin transformation of the ERs and no significant effects that differed from those in the RTs were found. These results confirm that our stimuli and the diagonal configuration are sufficient to generate a standard FCE, and to show the effect of similarity on the FCE that has been reported in previous work. Specifically, when the target was defined not only by its location and position within the string, but also by an additional feature discontinuity, the FCE was reduced.
Experiment 3b
The same analyses were conducted on the data from Experiment 3b in which flankers were present in both diagonals, one with flankers the same color as the target and one with flankers a different color, thereby controlling for differences in feature discontinuities across the same-color and different-color conditions. This experiment yielded a very different pattern of results. Although the main effect of Congruence was significant for the ERs, mean difference 1.5 ± 0.54 percentage points, F(2, 50) = 6.06, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .195, it was not reliable in RT, F(2, 50) = 1.76, p = .182, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .028. Moreover, for neither dependent measure was the main effect of Color, RT: F(1, 25) = 2.41, p = .088, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .051, ER: F(1, 25) = 1.91, p = .179, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .034, or critically the Color × Congruence interaction, RT: F(2, 50) = .795, p = .457, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.008, ER: F(2, 46) = .322, p = .726, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.027, significant .
These results are not what is predicted by the group selection hypothesis, but they are what is predicted by the image segmentation hypothesis. Same-color flankers yielded no larger FCEs than different-color flankers when differential feature discontinuities were controlled for.
While the FCEs in Experiment 3b were small in magnitude and reliable only in the ERs, the FCEs in Experiment 3a were nearly exactly the same magnitudes as those reported for the corresponding experiment in Baylis and Driver (1992, Experiment 1). Whereas they found an FCE of 20 ms for same-color flankers and 4 ms for different-color flankers, we found an FCE of 24 ms for same-color flankers and 7 ms for different-color flankers. Critically, however, we found this difference only when there was no additional diagonal of flankers controlling for the feature discontinuity created by the color difference.
Experiment 4
We have sought evidence for the group selection hypothesis in three experiments by testing whether same color flankers yield larger FCEs than different color flankers when image-level characteristics of the displays are controlled for, and we have consistently failed to find it. In contrast, consistent with the image segmentation hypothesis, when additional feature discontinuities define the target relative to the flanker, different-color flankers did yield smaller FCEs than same-color flankers. To confirm these findings, given contrary results in the literature (Baylis & Driver, 1992; Driver & Baylis, 1989), we re-ran each of the main designs – the control single-diagonal (Experiment 4a), the X-display design (Experiment 4b), and the linear-display design (Experiment 4c) – in a set of matched experiments with new groups of subjects. By way of preview, the same pattern of results as the previous versions of these experiments attained. There was a clear impact of target-flanker color match on the FCE when there were differential feature discontinuities across conditions (Experiment 4a), but no impact of target-flanker color match on the FCE when stimulus differences were controlled using the X-display design (Experiment 4b) or the linear-display design (Experiment 4c).
Method
Subjects
Thirty subjects participated in each of the three experiments, 4a (19 female, 11 male; mean age = 19.4 years), 4b (22 female, eight male; mean age = 18.9 years), 4c (18 female, 12 male; mean age = 19.1 years). No individual participated in more than one experiment.
Stimuli
Stimuli in Experiments 4a and 4b were identical to those of Experiments 3a and 3b, respectively. Stimuli in Experiment 4c were created using the same letter stimuli (size, font, and colors) as those in Experiments 4a and 4b. However, they were instead aligned linearly, as in the grouped conditions of Experiments 1 and 2, with the target letter (C, S, X, or Y) at the center, and an outer set of flankers in the same color as the target and an inner set of flankers in the other color. The entire array subtended 6.2° × 1.0°. Letters were 0.7° × 1.0° and the center-to-center separation between them was by 1.2°. Neutral letters were H and T.
Design
The designs of Experiments 4a and 4b were the same as Experiments 3a and 3b, respectively, except that subjects completed a total of 13 blocks of 48 trials each, the first four of which were considered practice and not included in analyses, resulting in a total of 72 observations per condition. The design of Experiment 4c was the same as the pure blocks of Experiment 2 except that subjects completed a total of 13 blocks of 40 trials each, the first four of which were treated as practice, for a total of 72 observations per condition.
Procedure
The session structure and trial events were identical to those in previous experiments except that the fixation display was 500 ms, and was followed immediately by the stimulus display for 200 ms.
Results and discussion
Mean RTs and ERs from Experiments 4a–4c are shown in Fig. 6a–c, respectively. Generally, the three experiments yielded the same pattern of results as each of their respective previous versions did. The control experiment (4a) yielded an FCE that was reduced when a single set of flankers was a different color than the target compared to when all the stimuli were the same color. However, when the second diagonal was added such that all displays included one diagonal of same-colored flankers and one diagonal of different-colored flankers, thereby controlling for differences in feature discontinuities across conditions, the FCE was unaffected by the color-match of the relevant flankers (Experiment 4b). Finally, controlling for differences in feature discontinuities across conditions using the line-display design also eliminated the effect of color match on the magnitude of the FCE (Experiment 4c).

Experiment 4a
Mean RTs were submitted to a 2 (Color: same, different) × 3 (Congruence: congruent, neutral, incongruent) repeated-measures ANOVA. The main effect of Congruence was significant, F(2, 58) = 10.02, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .231. And although the main effect of Color was not significant, F(1, 29) = .915, p = .347, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.003, the Color × Congruence interaction was, F(2, 58) = 7.00, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .167. Separate one-way ANOVAs with Congruence as the factor for the same-color and different-color conditions, respectively, confirmed that the main effect of Congruence was significant when the target and flanker were the same color, F(2, 58) = 13.12, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .288, but not when they were different colors, F(2, 58) = 1.82, p = .172, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .027. The same analyses conducted on the arcsin transforms of the ERs yielded no significant effects that were different from those observed in the RTs. This is the same pattern of results obtained in Experiment 3a, and confirms that our stimuli and color differences were sufficient to yield a standard FCE that is modulated by color similarity when it gives rise to a feature discontinuity that provides for better target definition.
Experiment 4b
Subject mean RTs were submitted to a 2 (Color: same, different) × 3 (Congruence: congruent, neutral, incongruent) repeated-measures ANOVA. The main effect of Congruence was significant, F(2, 58) = 7.97, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .189, but neither Color, F(1, 29) = .065, p = .347, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.032, nor the Color × Congruence interaction, F(2, 58) = .050, p = .951, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.033, was significant. The same analysis conducted on the ERs showed the identical pattern. As in Experiment 3b, when feature discontinuities were held constant across conditions, the FCE, which was reliable in both RT and ER, was unaffected by whether flankers were the same or a different color to the target.
Experiment 4c
Subject mean RTs were submitted to a 2 (Relevant Flanker: inner, outer) × 2 (Congruence: congruent incongruent) repeated-measures ANOVA. The main effect of Congruence was reliable, F(1, 29) = 16.63, p < .01, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .343 with a mean difference of 15.16 ± 3.78 ms. Although the main effect of Relevant Flanker approached significance, F(1, 29) = 3.88, p = .059, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = .088, the Relevant Flanker × Congruence interaction did not, F(1, 29) = .949, p = .338, \( \mathrm{adj}\ {\hat{\eta}}_p^2 \) = -.002. The same analysis conducted on the arcsin transforms of the ERs yielded the same pattern of results. Once again, when feature discontinuities were held constant across conditions, in this case using the line-display design, the FCE was unaffected by whether flankers were the same or a different color to the target.
In summary, this matched-set of experiments confirmed the findings from the previous experiments reported here. A reliable FCE was modulated by target-flanker color similarity when color provided a feature discontinuity that better defined the target (Experiment 4a). When stimulus-level factors were controlled using either the X-display design (Experiment 4b) or the line-display design (Experiment 4b), however, there was no difference in FCE for same-color and different-color flankers.
General discussion
We have presented results from seven separate experiments collectively aimed at testing whether target-flanker similarity effects on the FCE reflects an impact of perceptual grouping on selection (group selection hypothesis) or a consequence of differential image quality (image segmentation hypothesis). We found no evidence for the group selection hypothesis, and all of the results were consistent with predictions of the image segmentation hypothesis.
Rather than perceptual grouping of targets and flankers that are similar forcing an obligatory selection of grouped flankers along with the target, we conclude that displays in which targets are differently colored (or otherwise featurely dissimilar) from some flankers constitute better input to spatially limited selection mechanisms. Specifically, it is input that is more easily segmented into relevant and irrelevant parts. Non-target stimuli that share attributes of target stimuli could further impact selection through guidance processes that prioritize stimuli with attributes that match current task goals (e.g., Egeth, Virzi, & Garbart, 1984; Folk, Remington, & Johnston, 1992; Kaptein, Theeuwes, & van der Heijden, 1995; Kim & Cave, 2001; Moore & Egeth,1998; Treisman, 1982). But even prior to such attentional guidance, we argue, featural discontinuities can mitigate the effects of limited spatial precision of selection mechanisms (Intriligator & Cavanagh, 2001) by providing better defined input representations to those mechanisms.
The results of the present study are reminiscent of findings from the attentional walk task, which was introduced by Intriligator and Cavanagh (2001) as a method of measuring what they referred to as attentional resolution (see also He, Cavanagh, & Intriligator, 1996). In the version of the attentional walk task that we have used in our lab, displays consisted of circular arrays of disks with varying densities (Fig. 7a). Subjects were asked to fixate a point at the center of the array, and remain fixated throughout a trial as eye position was monitored. Once fixation was established, a single disk changed color, cueing observers to covertly attend to that disk. A series of high and low tones then indicated to subjects to covertly shift their attention by one disk in a clockwise or counterclockwise direction, respectively, so that they were covertly navigating through the array. At the end of the “attentional walk,” observers indicated on which disk they ended. Attentional walks varied from five to seven “steps.” We also included a “zero-step” condition in which immediately after the colored cue disappeared, observers were asked to indicate where the cue was. This provided confirmation that the beginning of the walk was reliable. The consistent finding from this task is that performance decreases as the density of the disk array increases. But the densities at which performance reaches chance levels are still sufficiently low that observers can easily perceive that there are separate disks. That is, they can see the individual items, they just cannot reliably select individual items. It is in this sense that attentional resolution was characterized as being a distinct limitation from perceptual resolution (He et al., 1996; Intriligator & Cavanagh, 2001).

Results from the attentional walk task reveal limitations of the spatial precision of selection mechanisms. Notice, however, that even with the highest density arrays, for which walk performance was at chance levels, observers could reliably report the location of the uniquely colored cue in the zero-step condition. We found this to be true across many different experiments and variations of the task (Hein & Moore, 2009, 2010; Moore, Hein, Grosjean, & Rinkenauer, 2009; Moore, Lanagan-Leitzel, Chen, Halterman, & Fine, 2007; Moore, Lanagan-Leitzel, & Fine, 2008). The uniquely colored-disk cue constitutes a strong feature discontinuity that, we contend here, mitigates limitations of spatial precision of selection mechanisms by providing input in which the target of selection is better defined than when there are no feature discontinuities. Consistent with this conclusion, one of the first findings that we reported with the attentional walk task was that threshold density for successful attentional walks was reduced when the arrays in which the walk was executed were heterogeneously colored rather than homogenous (Moore et al., 2007).
While the limitations of selection revealed in the attentional walk task can be mitigated by providing better defined input, we looked for but found no evidence that perceptual organization of the display can be used to mitigate the limited spatial precision of selection mechanisms (Moore et al., 2009). Inspired by the results reported by Driver and Baylis (1989) and Baylis and Driver (1992), we tested the hypothesis that observers would be able to functionally reduce the density of displays within which they attentionally navigated if they were grouped into separate subsets of items. Figure 7b illustrates the logic. Homogenous displays that were beyond the limits of spatial resolution were adapted so that every other disc was one color and the rest another color, and observers were instructed to shift their attention between disks of the same color. If observers could establish grouped representations and navigate within a group, then the effective density of the array within which they were navigating should have been reduced by half. Contrary to this prediction, however, subjects were no better with the grouped arrays than they were with the homogenous arrays. This finding is consistent with the observations and conclusions drawn from the work reported in the current paper. Feature discontinuities can facilitate selection by mitigating the limited spatial precision of those mechanisms through better defined input to them, but when the discontinuities are controlled or minimized, there are no further advantages (or disadvantages) afforded by potential organization of the image into grouped representations.
While there is consistency across these different lines of work, it is important to be clear about what we are not arguing here. First, we are not suggesting that grouping by similarity and other forms of perceptual organization do not occur. They clearly do, and they lead to critical mid-level visual representations of the structure of scenes (e.g., see Kimchi, Behrmann, & Olson, 2003; Palmer & Rock, 1994; Pomerantz & Portillo, 2011; Wagemans et al., 2012, for reviews). Rather, we are suggesting that the same attributes of the proximal stimulus (i.e., the retinal image), such as color similarity/dissimilarity, that support the perceptual organization of it into representations of the objects in the world that produced it can also, separately, impact selection by presenting less of a challenge to selection mechanisms in the first place. In this case in particular, we assert that a color difference between target and flankers creates an image-level discontinuity that for a task that requires responding to one part of the image rather than another, essentially constitutes a better input stimulus than when target and flankers are the same color. In terms of perceptual organization, we suggest that the color-similarity effect on FCEs is one of differential image segmentation, rather than an effect of target and flankers being grouped together followed by an obligatory selection of everything in a group. This distinction matters because the two alternatives – better input versus group selection – are very different assertions about what the relationship between perceptual organization and selection here is. Starting with Kahneman and Henik’s (1981) original demonstration, these color-similarity effects have been interpreted as evidence of obligatory group selection; but as argued here, there are simpler explanations. Chen and Cave (2019) made a similar argument concerning the two-rectangles paradigm of Egly, Driver, and Rafal (1994), another source of canonical results in the object-based attention literature. They argue that what appear to be object-specific effects may, more simply, reflect a set interacting spatial biases.
A second point that we want to make clear is that we are not arguing that object and scene structure do not impact selection. They clearly do. For example, there is compelling evidence that multiple attributes of stimuli are selected more efficiently when they are instantiated in a single object than when they appear in different objects (e.g., Duncan, 1984; Duncan & Nimmo-Smith, 1996; O’Craven, Downing, & Kanwisher, 1999; but see Brummerloh, Gundlach, & Müller, 2019; Han, Dosher, & Lu, 2003; Xu, 2010, for qualifications). Moreover, identical, and nearly identical, stimuli that are perceptually organized differently can lead to different effects of selection (e.g., Baylis & Driver, 1993; Behrmann, Zemel, & Mozer, 1998; Chen, 1998; He & Nakayama, 1992; Mitroff, Scholl, & Wynn, 2005; Moore & Fulton, 2005; Mordkoff & Danek, 2011). A full understanding of attention, object based or otherwise, however, requires that we distinguish the level of impact of different effects, recognizing that while some may reflect perceptually organized object structure, others may reflect simpler influences on the success or failure of selection processes.
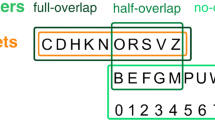
Finally, the findings and conclusions from the present work may help to understand some mixed results in the literature regarding the role of object structure (distinct from group structure) on flanker interference. For some displays, presenting a target on a different object to the flankers reduces the FCE (e.g., Cosman & Vecera, 2012; Kramer & Jacobson, 1991; Luo & Proctor, 2016; Richard, Lee, & Vecera, 2008), and for others there is little or no effect of object structure on the FCE (e.g., Ho, 2011; Luo & Proctor, 2016; Richard et al., 2008; Shomstein & Yantis, 2002; Zhao, Kong, & Wang, 2013). Two competing hypotheses are the spreading activation hypothesis, according to which selecting one part of an object causes the impact of selection to spread within the boundaries of that object (e.g., Richard et al., 2008), and the spatial prioritization hypothesis, according to which under conditions of spatial uncertainty, locations within an object that shares an initially attended location are prioritized over locations in other objects (e.g., Shomstein & Yantis, 2002). We believe that at least some of the inconsistencies in results in this literature may be attributed to displays differing in the extent to which they provide image-based support for distinguishing targets from flankers. Generally, those displays with the greatest image-level differences defining targets and distractors are the ones that yielded an effect on the FCE. It would be right to point out that image-structure is what the system uses to define object structure. However, the best test of the hypothesis that it is the mid-level object representations, in particular – i.e., those that have been abstracted from the image to represent the structure of the scene that produced the image – that mediate the influence of selection, is one that minimizes image differences while retaining object-structure differences. Figure 8 illustrates examples of displays from a set of experiments that are closely matched in the logic that they used to measure the effect of object structure on the FCE, and yet obtained different results. The same- versus different-object displays shown in Fig. 8b are only minimally different at an image level, and they have consistently yielded little or no effect of object-structure on the FCE (Ho, 2011; Shomstein & Yantis, 2002; Zhao et al., 2013). The same-object and different-object displays shown in Fig. 8a include large image-level differences, and yielded a large effect on the FCE (Kramer & Jakobson, 1991). The different-object displays shown in Fig. 8f, which did not reduce the FCE relative to the same-object condition, lack the shape discontinuity that is present in the different-object displays shown in Fig. 8g, which did reduce the FCE (Luo & Proctor, 2016). Similarly, the different-object displays in Fig. 8c and e, which yielded no reduction of the FCE, lack the shape discontinuity that is present in Fig. 8d, which did reduce the FCE (Richard et al., 2008). A strong case regarding this pattern of effects in these terms would depend on comparing quantifications of image-feature discontinuities output by an image analysis, but informally, and in combination with the results reported in the current study, it seems clear that image-level differences can impact the FCE, and therefore, must be taken into account when drawing conclusions about the impact of mid-level representations of scene structure.

Illustration of displays used in a set of studies that used similar logic for measuring the effect of object structure on the FCE and yielded different answers. In each case, a forced choice response was made to an attribute of the stimulus in the center most position. For panels B, C, F, and G, “T” and “F” to indicate letter targets and flankers. For panel A, the task was to report the quality of the pen stroke of the central line (dotted or dashed), and for Panels in D and E, the task was to report the shape of the central notch or patch (square or round)
In summary, we have presented evidence that target-flanker similarity effects on the FCE reflect differential image-level support for segmentation of the image into relevant and irrelevant parts, rather than obligatory selection of flankers that have been perceptually grouped with the target. When image-level differences that could differentially support image segmentation were controlled, same-color and different-color flankers had similar effects on target processing. Visual processing absolutely includes the perceptual organization of stimuli on the basis of feature similarity and other attributes. However, feature similarity versus dissimilarity also gives rise to image-level differences that can affect processing separately from any downstream consequences of perceptual grouping there may be. And in the case of the FCE, we conclude that target-feature dissimilarity mitigates the impact of limitations in the precision of selection mechanisms by providing better input to those mechanisms.
Author Notes
The work reported here was supported in part by NIH grant R21 EY029432. We thank John Palmer for his input on the manuscript and to the members of the Iowa Attention and Perception Lab for helpful discussions and data collection.
Open practices statement
The data and materials for the experiments reported here are available upon request. This study was not preregistered.
Notes
Adjusted partial eta squared will be negative whenever the value of F is less than 1 and should not be rounded up to 0 (Okada, 2017).
References
Bahcall, D. O., & Kowler, E. (1999). Attentional interference at small spatial separations. Vision Research, 39(1), 71-86. https://doi.org/10.1016/S0042-6989(98)00090-X
Baylis, G. C., & Driver, J. (1992). Visual parsing and response competition: The effect of grouping factors. Perception & Psychophysics, 51(2), 145-162. https://doi.org/10.3758/BF03212239
Baylis, G. C., & Driver, J. (1993). Visual attention and objects: Evidence for hierarchical coding of location. Journal of Experimental Psychology: Human Perception & Performance, 19(3), 451-470. https://doi.org/10.1037/0096-1523.19.3.451
Baylis, G. C., & Driver, J. (1998). Attention and visual object segmentation. In R. Parasuraman (Ed.), The Attentive Brain. Cambridge, MA: M IT Press.
Behrmann, M., Zemel, R. S., Mozer, M. C. (1998). Object-based attention and occlusion: Evidence from normal participants and a computational model. Journal of Experimental Psychology: Human Perception & Performance, 24(4), 1011-1036. https://doi.org/10.1037/0096-1523.24.4.1011
Berry, G., & Klein, R. (1994). Does motion-induced grouping modulate the flanker compatibility effect?: A failure to replicate Driver & Baylis, Canadian Journal of Experimental Psychology, 47(4), 714-729. https://doi.org/10.1037/h0078867
Botvinick, M., Nystrom, L. E., Fissell, K., Carter, C. S., & Cohen, J. D. (1999). Conflict monitoring versus selection-for-action in anterior cingulate cortex. Nature, 402(6758), 179-181. https://doi.org/10.1038/46035
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433-436. https://doi.org/10.1163/156856897X00357
Brummerloh, B., Gundlach, C., & Müller, M. M. (2019). Attentional facilitation of constituent features of an object does not spread automatically along object-defining boundaries. Journal of Cognitive Neuroscience, 31(2), 278-287. https://doi.org/10.1162/jocn_a_01350
Chen, Z. (1998). Switching attention within and between objects: The role of subjective organization. Canadian Journal of Experimental Psychology, 52(1), 7-17. https://doi.org/10.1037/h0087274
Chen, Z. & Cave, K. R. (2019). When is object-based attention not based on objects? Journal of Experimental Psychology: Human Perception and Psychophysics, 45(8), 1062-1082. https://doi.org/10.1037/xhp0000657
Cosman, J. D., & Vecera, S. P. (2012). Object-based attention overrides perceptual load to modulate visual distraction. Journal of Experimental Psychology: Human Perception & Performance, 38(3), 576-579. https://doi.org/10.1037/a0027406
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorials in Quantitative Methods for Psychology, 1(1), 42-45. https://doi.org/10.20982/tqmp.01.1.p042
Driver, J., & Baylis, G. C. (1989). Movement and visual attention: The spotlight metaphor breaks down. Journal of Experimental Psychology: Human Perception & Performance, 15(3), 448-456. https://doi.org/10.1037/0096-1523.15.3.448
Duncan, J. (1984). Selective Attention and the Organization of Visual Information. Journal of Experimental Psychology: General, 113(4), 501-517. https://doi.org/10.1037/0096-3445.113.4.501
Duncan, J., & Nimmo-Smith, I. (1996). Objects and attributes in divided attention: Surface and boundary systems. Perception & Psychophysics, 58(7), 1076-1084. https://doi.org/10.3758/BF03206834
Egeth, H. E., Virzi, R. A., & Garbart, H. (1984). Searching for conjunctively defined targets. Journal of Experimental Psychology: Human Perception & Performance, 10(1), 32-39. https://doi.org/10.1037/0096-1523.10.1.32
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention between objects and locations: Evidence from normal and parietal lesion subjects. Journal of Experimental Psychology. General, 123(2), 161-177. https://doi.org/10.1037/0096-3445.123.2.161
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & Psychophysics, 16(1), 143-149. https://doi.org/10.3758/BF03203267
Eriksen, C. W., & Hoffman, J. E. (1972). Temporal and spatial characteristics of selective encoding from visual displays. Perception & Psychophysics, 12(2), 201-204. https://doi.org/10.3758/BF03212870
Eriksen, C. W., & Hoffman, J. E. (1973). The extent of processing of noise elements during selective encoding from visual displays. Perception & Psychophysics, 14(1), 155-160. https://doi.org/10.3758/BF03198630
Eriksen, C. W., & Schultz, D. W. (1979). Information processing in visual search: A continuous flow conception and experimental results. Perception & Psychophysics, 25(4), 249-263. https://doi.org/10.3758/BF03198804
Eriksen, C. W., & St. James, J. D. (1986). Visual attention within and around the field of focal attention: A zoom lens model. Perception & Psychophysics, 40(4), 225-240. https://doi.org/10.3758/BF03211502
Eriksen, C. W., & Yeh, Y.-Y. (1985). Allocation of attention in the visual field. Journal of Experimental Psychology: Human Perception & Performance, 11(5), 583-597. https://doi.org/10.1037/0096-1523.11.5.583
Fan, J., McCandliss, B. D., Sommer, T., Raz, A., & Posner, M. I. (2002). Testing the efficiency and independence of attentional networks. Journal of Cognitive Neuroscience, 14(3), 340-347. https://doi.org/10.1162/089892902317361886
Fan, J., Flombaum, J. I., McCandliss, B. D., Thomas, K. M., & Posner, M. I. (2003). Cognitive and brain consequences of conflict. NeuroImage, 18(1), 42-57. https://doi.org/10.1006/nimg.2002.1319
Flowers, J. H., & Wilcox, N. (1982). The effect of flanking context on visual classification: The joint contribution of interactions at different processing levels. Perception & Psychophysics, 32(6), 581-591. https://doi.org/10.3758/BF03204214
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orientating is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception & Performance, 18(4), 1030-1044. https://doi.org/10.1037/0096-1523.18.4.1030
Geißler, C. F., Hofmann, M. J., & Frings, C. (2020). It is more than interference: Examining the neurohemodynamic correlates of the flanker task with functional near-infrared spectroscopy, European Journal of Neuroscience. https://doi.org/10.1111/ejn.14708
Hagenaar, R., & van der Heijden, A. H. C. (1986). Target-noise separation in visual selective attention. Acta Psychologica, 62(2), 161-176. https://doi.org/10.1016/0001-6918(86)90066-1
Han, S., Dosher, B. A., Lu, Z-L (2003). Object attention revisited: Identifying mechanisms and boundary conditions. Psychological Science, 14(6), 598-604. https://doi.org/10.1046/j.0956-7976.2003.psci_1471.x
Harms, L., & Bundesen, C. (1983). Color segregation and selective attention in a nonsearch task. Perception & Psychophysics, 33(1), 11-19. https://doi.org/10.3758/BF03205861
Hazeltine, E., Poldrack, R., & Gabrieli, J. D. E. (2000). Neural activation during response competition. Journal of Cognitive Neuroscience, 12(2), 118-129. https://doi.org/10.1162/089892900563984
He, S., Cavanagh, P., & Intriligator, J. (1996). Attentional resolution and the locus of visual awareness. Nature, 383(6598), 334-337. https://doi.org/10.1038/383334a0
He, Z., & Nakayama, K. (1992) Surfaces versus features in visual search. Nature, 359(6392), 231-233. https://doi.org/10.1038/359231a0
Hein, E. & Moore, C. M. (2009). Explicit eye movements failed to facilitate the precision of subsequent attentional localization. Experimental Brain Research, 197(4), 387-393. https://doi.org/10.1007/s00221-009-1927-x
Hein, E., & Moore, C. M. (2010). Investigating temporal properties of covert shifts of visual attention using the attentional walk task. Psychonomic Bulletin & Review, 17(1), 41-46. https://doi.org/10.3758/PBR.17.1.41
Ho, M-C. (2011). Object-based attention: Sensory enhancement or scanning prioritization. Acta Psychologica, 138(1), 45-51. https://doi.org/10.1016/j.actpsy.2011.05.004
Intriligator, J., & Cavanagh, P. (2001). The spatial resolution of visual attention. Cognitive Psychology, 43(3), 171-216. https://doi.org/10.1006/cogp.2001.0755
Jones, S. A. H., Butler, B. C., Kintzel, F., Johnson, A., Klein, R. M., Eskes, G. A. (2016). Measuring the performance of attention networks with the Dalhousie Computerized Attention Battery (DalCAB): Methodology and reliability in healthy adults. Frontiers in Psychology, 7, 823-838. https://doi.org/10.3389/fpsyg.2016.00823
Kahneman, D., & Henik, A. (1981). Perceptual organization and attention. In M. Kubovy & J. R. Pomerantz (Eds.), Perceptual organization. Hillsdale, NJ: Erlbaum.
Kaptein, N. A., Theeuwes, J., & van der Heijden, A. H. C. (1995). Search for a conjunctively defined target can be selectively limited to a color-defined subset of elements. Journal of Experimental Psychology: Human Perception and Performance, 21(5), 1053-1069. https://doi.org/10.1037/0096-1523.21.5.1053
Kim, M-S., & Cave, K. R. (2001). Perceptual grouping via spatial selection in a focused-attention task. Vision Research, 41(5), 611-624. https://doi.org/10.1016/S0042-6989(00)00285-6
Kimchi, R., Behrmann, M., & Olson, C. R. (Eds.). (2003). Perceptual Organization in Vision: Behavioral and Neural Perspectives. Hillsdale, NJ: Lawrence Erlbaum Associates.
Kramer, A. F., & Jacobson, A. (1991). Perceptual organization and focused attention: The role of objects and proximity in visual processing. Perception & Psychophysics, 50(3), 267-284. https://doi.org/10.3758/BF03206750
Kramer, A. F., Tham, M-P. & Yeh, Y-Y. (1991). Movement and focused attention: A failure to replicate. Perception & Psychophysics, 50(6), 537-546. https://doi.org/10.3758/BF03207537
LaBerge, D. (1983). Spatial extent of attention to letters and words. Journal of Experimental Psychology: Human Perception and Performance, 9(3), 371-379. https://doi.org/10.1037/0096-1523.9.3.371
LaBerge, D., & Brown, V. (1986). Variations in size of the visual field in which targets are presented: An attentional range effect. Perception & Psychophysics, 40(3), 188-200. https://doi.org/10.3758/BF03203016
Lachter, J., Forster, K. I., & Ruthruff, E. (2004). Forty-five years after Broadbent (1958): Still no identification without attention. Psychological Review, 111(4), 880-913. https://doi.org/10.1037/0033-295X.111.4.880
Lavie, N., & Tsal, Y. (1994). Perceptual load as a major determinant of the locus of selection in visual attention. Perception & Psychophysics, 56(2), 183-197. https://doi.org/10.3758/BF03213897
Levi, D. M., & Tripathy, S. P. (1996). Localization of a peripheral patch: The role of blur and spatial frequency. Vision Research, 36(23), 3785-3803. https://doi.org/10.1016/0042-6989(95)00343-6
Liu-Ambrose, T., Nagamatsu, L. S., Voss, M. W., Kahn, K. M., Handy, T. C. (2012). Resistance training and functional plasticity of the aging brain: A 12-month randomized controlled trial. Neurobiology of Aging, 33(8), 1690-1698. https://doi.org/10.1016/j.neurobiolaging.2011.05.010
Luo, C., & Proctor, R. W. (2016). Perceptual grouping of objects occupied by target and flankers affects target-flanker interference. Attention Perception & Psychophysics, 78(1), 251-263. https://doi.org/10.3758/s13414-015-0986-2
McDermott, J. M., Pérez-Edgar, K., & Fox, N. A. (2007). Variations of the flanker paradigm: Assessing selective attention in young children. Behavior Research Methods, 39(1), 62-70. https://doi.org/10.3758/BF03192844
Miller, J. (1987). Priming is not necessary for selective-attention failures: Semantic effects of unattended, unprimed letters. Perception & Psychophysics, 41(5), 419-434. https://doi.org/10.3758/BF03203035
Mitroff, S. R., Scholl, B. J., & Wynn, K. (2005). The relationship between object files and conscious perception. Cognition, 96(1), 67-92. https://doi.org/10.1016/j.cognition.2004.03.008
Moore, C. M., & Egeth, H. (1998). How does feature-based attention affect visual processing? Journal of Experimental Psychology: Human Perception & Performance, 24(4), 1296-1310. https://doi.org/10.1037/0096-1523.24.4.1296
Moore, C. M., & Fulton, C. (2005). The spread of attention to hidden portions of occluded surfaces. Psychonomic Bulletin & Review, 12(2), 301-306. https://doi.org/10.3758/BF03196376
Moore, C. M., Lanagan-Leitzel, L. K., Chen, P., Halterman, R., & Fine, E. M. (2007). Nonspatial attributes of stimuli can influence spatial limitations of attentional control. Perception & Psychophysics, 69(3), 363-371. https://doi.org/10.3758/BF03193757
Moore, C. M., Lanagan-Leitzel, L. K., & Fine, E. M. (2008). Distinguishing between the precision of attentional localization and attentional resolution. Perception & Psychophysics, 70(4), 573-582. https://doi.org/10.3758/PP.70.4.573
Moore, C. M., Hein, E., Grosjean, M., Rinkenauer, G. (2009). Limited influence of perceptual organization on the precision of attentional control. Attention, Perception & Psychophysics, 71(4), 971-983. https://doi.org/10.3758/APP.71.4.971
Mordkoff, J. T. (2019). A simple method for removing bias from a popular measure of standardized effect size: Adjusted partial eta squared (\( adj\ {\hat{\eta}}_p^2 \)). Advances in Methods and Practices in Psychological Science, 2(3), 228-232. https://doi.org/10.1177/2515245919855053
Mordkoff, J. T., & Danek, R. H. (2011). Dividing attention between color and shape revisited: Redundant targets coactivate only when parts of the same perceptual object. Attention, Perception & Psychophysics, 73(1), 103-112. https://doi.org/10.3758/s13414-010-0025-2
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorials in Quantitative Methods for Psychology, 4(2), 61-64. https://doi.org/10.20982/tqmp.04.2.p061
O’Craven, K. M., Downing, P. E., Kanwisher, N. (1999). fMRI evidence for objects as the units of attentional selection. Nature, 410(6753), 584-587. https://doi.org/10.1038/44134
Okada, K. (2017). Negative estimate of variance-accounted-for effect size: How often it is obtained, and what happens if it is treated as zero. Behavior Research Methods, 49, 979-987. https://doi.org/10.3758/s13428-016-0760-y
Palmer, J., & Moore, C. M. (2009). Using a filtering task to measure the spatial extent of selective attention. Vision Research, 49(10), 1045-1064. https://doi.org/10.1016/j.visres.2008.02.022
Palmer, S., & Rock, I. (1994). Rethinking perceptual organization: The role of uniform connectedness. Psychonomic Bulletin & Review, 1(1), 29-55. https://doi.org/10.3758/BF03200760
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10(4), 437-442. https://doi.org/10.1163/156856897X00366
Pomerantz, J. R., & Portillo, M. C. (2011). Grouping and emergent features in vision: Toward a theory of basic Gestalts. Journal of Experimental Psychology: Human Perception and Performance, 37(5), 1331-1349. https://doi.org/10.1037/a0024330
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32(1), 3-25. https://doi.org/10.1080/00335558008248231
Posner, M. I., Snyder, C. R., & Davidson, B. J. (1980). Attention and the detection of signals. Journal of Experimental Psychology: General, 109(2), 160-174. https://doi.org/10.1037/0096-3445.109.2.160
Richard, A. M., Lee, H., & Vecera, S. P. (2008). Attentional spreading in object-based attention. Journal of Experimental Psychology: Human Perception and Performance, 34(4), 842- 853. https://doi.org/10.1037/0096-1523.34.4.842
Schneider, D. W. (2018). Alertness and cognitive control: Toward a spatial grouping hypothesis. Attention, Perception, & Psychophysics, 80(4), 913-928. https://doi.org/10.3758/s13414-018-1491-1
Shomstein, S., & Yantis, S. (2002). Object-based attention: Sensory modulation or priority setting? Perception & Psychophysics, 64(1), 41-51. https://doi.org/10.3758/BF03194556
Treisman, A. (1982). Perceptual grouping and attention in visual search for features and for objects. Journal of Experimental Psychology: Human Perception and Performance, 8(2), 194-214. https://doi.org/10.1037/0096-1523.8.2.194
Wagemans, J., Elder, J. H., Kubovy, M., Palmer, S. E., Peterson, M. A., Singh, M., & von der Heydt, R. (2012). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure-ground organization, Psychological Bulletin, 138(6), 1172-1217. https://doi.org/10.1037/a0029333
Xu, Y. (2010). The neural fate of task-irrelevant features in object-based processing. The Journal of Neuroscience, 30(42), 14020-14028. https://doi.org/10.1523/JNEUROSCI.3011-10.2010
Yiğit-Elliott, S., Palmer, J., & Moore, C. M. (2011). Distinguishing blocking from attenuation in visual selective attention. Psychological Science, 22(6), 771-780. https://doi.org/10.1177/0956797611407927
Zhao, J., Kong, F., & Wang, Y. (2013). Attentional spreading in object-based attention: The roles of target-object integration and target presentation time. Attention, Perception, & Psychophysics, 75(5), 876-887. https://doi.org/10.3758/s13414-013-0445-x
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Moore, C.M., He, S., Zheng, Q. et al. Target-flanker similarity effects reflect image segmentation not perceptual grouping. Atten Percept Psychophys 83, 658–675 (2021). https://doi.org/10.3758/s13414-020-02094-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-020-02094-z