
Abstract
Recent studies of visual search suggest that learning about valued outcomes (rewards and punishments) influences the likelihood that distractors will capture spatial attention and slow search for a target, even when those value-related distractors have never themselves been the targets of search. In the present study, we demonstrated a related effect in the context of temporal, rather than spatial, selection. Participants were presented with a temporal stream of pictures in a fixed central location and had to identify the orientation of a rotated target picture. Response accuracy was reduced if the rotated target was preceded by a “valued” distractor picture that signaled that a correct response to the target would be rewarded (and an incorrect response punished), relative to a distractor picture that did not signal reward or punishment. This effect of signal value on response accuracy was short-lived, being most prominent with a short lag between distractor and target. Impairment caused by a valued distractor was observed if participants were explicitly instructed regarding its relation to reward/punishment (Exps. 1, 3, and 4), or if they could learn this relationship only via trial-by-trial experience (Exp. 2). These findings show that the influence of signal value on attentional capture extends to temporal selection, and also demonstrate that value-related distractors can interfere with the conscious perception of subsequent target information.
Similar content being viewed by others
A traditional and influential view of attention distinguishes between two different types of attentional control: one that is volitional and goal-directed (top-down control) and another that is automatic and stimulus-driven, based on the physical features of stimuli (Corbetta & Shulman, 2002; Yantis, 2000). A recent body of research, however, has made a case for a third category of influence on attentional selection that is neither goal-directed nor stimulus-driven. Specifically, this research has shown that attention is influenced by what we have previously learned about stimuli, particularly in terms of how they relate to rewards and punishments, which we term learned value (for reviews, see Anderson, 2016; Awh, Belopolsky, & Theeuwes, 2012; Le Pelley, Mitchell, Beesley, George, & Wills, 2016). Notably, many of these studies have shown an influence of learned value on attentional capture that operates independently of both the physical features of stimuli and an observer’s goals, suggesting that capture can be modulated by previous experience.
Most of the research on learned value has examined its effect on spatial selection, typically using visual search procedures. For example, in one study (Le Pelley, Pearson, Griffiths, & Beesley, 2015), participants had to move their eyes as quickly as possible to a diamond-shaped target among circles on each trial. A distractor circle could appear in either a high-value color or a low-value color (red or blue, counterbalanced); all other stimuli were grey. On trials with a distractor circle in the high-value color, rapid saccades to the diamond earned a large reward. On trials with a low-value distractor, rapid saccades to the diamond earned a small reward. Thus, although the distractor predicted the reward value, it was never the stimulus to which people were required to respond (or direct their attention) to obtain that reward. Crucially, if at any point participants looked at the distractor circle, the reward on that trial was cancelled; these were termed omission trials. Attending to the distractor was thus counterproductive to participants’ goal of maximizing their payoff; in particular, looking at a high-value distractor was most counterproductive, since this resulted in the loss of a high-value reward. Nevertheless, high-value distractors produced significantly more omission trials than did low-value distractors. That is, people were more likely to look at high-value than at low-value distractors, even though doing so lost them the large reward that they would otherwise have obtained. The implication is that learning that a stimulus signals a high-value reward increases the likelihood that it will automatically capture spatial attention, independently of its physical salience. This effect has been termed value-modulated attentional capture (Pearson, Donkin, Tran, Most, & Le Pelley, 2015; Pearson et al., 2016).Footnote 1
Other studies using visual search have shown that the influence of learned value on attentional capture is not restricted to the effect of reward: Stimuli associated with high punishment (e.g., large loss of money, or electric shock) are also more likely to capture spatial attention than stimuli associated with lower or no punishment (e.g., small loss of money or no shock: Wang, Yu, & Zhou, 2013; Wentura, Müller, & Rothermund, 2014). These findings suggest that the crucial determinant of value-modulated attentional capture is the motivational significance of the outcome that is signaled by a stimulus, rather than the prospect of reward per se.
However, spatial attention is only one aspect of attentional selection. We can also prioritize the detection of events that will occur at a known location—for instance, an impatient driver at an intersection knows where the green light will appear, but not when. The problem here is one of temporal selection. Whereas the spatial studies described above suggested that value-related distractors can slow down spatial selection of a target stimulus, studies using temporal selection tasks have suggested that value-related stimuli can interfere with people’s conscious perception of a target—that is, their awareness of whether a target was presented at all, even when the target was the focus of spatial attention (e.g., Della Libera & Chelazzi, 2009; Failing & Theeuwes, 2015; Most & Wang, 2011; O’Brien & Raymond, 2012; Raymond & O’Brien, 2009; Smith, Most, Newsome, & Zald, 2006: for a systematic review, see Le Pelley et al., 2016).
Of particular interest are studies of temporal selection in which attention to the critical, reward-related stimuli was assessed while the stimuli acted as task-irrelevant distractors, since under these conditions it is unlikely that attentional prioritization would reflect the operation of explicit goal-directed processes (Della Libera & Chelazzi, 2009; Failing & Theeuwes, 2015; Smith et al., 2006). Studies have shown that graphic pictures with positive or negative emotional content spontaneously impair the perception of subsequent targets in a rapid serial visual presentation (RSVP) detection task (e.g., Most, Chun, Widders, & Zald, 2005; Most, Laurenceau, Graber, Belcher, & Smith, 2010; Most, Smith, Cooter, Levy, & Zald, 2007; Wang, Kennedy, & Most, 2012), and similar effects seem to arise in the wake of distractors that have accrued value through learning. In one study by Failing and Theeuwes (2015), each trial of an initial phase presented two pictures from different semantic categories (e.g., forests and mountains) side by side. Participants had to choose one of the pictures: Choice of a picture from one category typically yielded a large reward, choosing the other typically yielded a small reward. Participants learned these relationships, becoming more likely to choose pictures from the high-reward category. Following this training came a test phase, which used an RSVP task. On each trial, a stream of pictures appeared rapidly (100 ms per picture) in the center of the screen. Participants’ task was to detect a target picture belonging to a category that had never been rewarded during training (e.g., a field). The key finding was that target detection was significantly poorer if the target was shortly preceded by a distractor picture from the high-reward category than a picture from the low-reward category. This suggests that high-reward pictures were more likely to capture attention and hence reduce perceptual processing of a subsequent target. This capture effect could not be attributed to shifts of spatial attention, since all stimuli (distractors and targets) were presented centrally, at the focus of participants’ spatial attention. Following Folk, Leber, and Egeth (2008), we refer to this erroneous temporal selection of a task-irrelevant stimulus as nonspatial attentional capture.
This finding is consistent with the idea that learned value modulates temporal, as well as spatial, attentional capture. An important caveat, however, is that the difference in reward history of the different categories during the test phase of Failing and Theeuwes’s (2015) study was confounded with a difference in their selection history: Pictures from the high-reward category were selected more frequently as targets during the training phase, and it may be that this greater selection history (as opposed to learned value) drives the greater capture by these pictures in the test phase (cf. Kyllingsbaek, Schneider, & Bundesen, 2001; see Awh et al., 2012; Le Pelley et al., 2016).
In a related study using aversive outcomes (Smith et al., 2006), participants experienced an initial training phase in which a single picture was presented on each trial. Pictures belonging to a particular category (e.g., birds) were consistently paired with delivery of an aversive loud noise; pictures belonging to another category (e.g., cars) were never paired with the noise. When these pictures were subsequently used as distractors in an RSVP task, responses to the target were significantly less accurate when it was preceded by a picture from the noise-paired category. This finding is again consistent with the idea that learned value (here with regard to an aversive event) influences nonspatial attentional capture. However, a caveat is also necessary here. Rather than reflecting a change in the attention-grabbing properties of the noise-paired picture, the increased distraction caused by this picture may reflect participants’ expectation of the noise itself. That is, perhaps the noise-paired stimulus does not capture attention but instead elicits some sort of strategic, preparatory response to protect against the aversive outcome, which then results in disengagement from the RSVP task. Notably in this regard, Smith et al. continued to deliver occasional picture–noise pairings during the RSVP test phase, to maintain participants’ expectancy of an aversive outcome.
So we have two studies using RSVP tasks to measure changes in nonspatial attentional capture by value-related distractors, but in both cases the interpretation is somewhat equivocal. Both of these studies used a “training phase–test phase” procedure (see also Della Libera & Chelazzi, 2009): in an initial training phase, the value-related stimuli were task-relevant—in effect they were the targets that participants needed to identify (in order to obtain reward or prepare for punishment)—and the subsequent test phase assessed the extent to which these stimuli continued to capture attention when they were task-irrelevant distractors. Le Pelley et al. (2016; see also Le Pelley et al., 2015) noted that, under these conditions, the capture by value-related stimuli observed during the test phase may reflect a carryover of a conditioned attentional response that is automatically reenacted whenever the relevant conditioned stimulus appears—that is, an “attentional habit” (see also Anderson, 2016; Luque et al., 2017). We can contrast this with the situation in Le Pelley et al.’s (2015) visual search task, described earlier, in which the reward-related stimuli were only ever presented as distractors. Under these conditions, the influence of learned value on attentional capture cannot reflect a carryover of a conditioned attentional orienting response; it suggests that value-modulated attentional capture is a function of the value of the outcome that is signaled by a stimulus, rather than the value of responding to that stimulus.
In the present experiments, we used a related approach to investigate value-modulated attentional capture in the context of temporal, rather than spatial, selection. We used an RSVP task in which the critical value-related stimuli were only ever presented as distractors, to investigate whether differences in the learned signal value of stimuli can influence temporal selection. In Experiment 1 participants were explicitly informed at the outset regarding the relationship between the distractors and the possibility of reward (or punishment). In Experiment 2, participants could learn this relationship only through trial-by-trial experience. Within the RSVP task, we varied the delay between distractor and target (referred to as lag) in order to investigate the temporal characteristics of attentional capture by the value-related distractor: either 200, 400, or 1,000 ms separated the onset of the distractor and target. The shortest lag (200 ms) provided an index of the early impact of the distractor; at the longest lag (1,000 ms), the target occurred outside what would typically be considered the window of nonspatial attentional capture (Folk, Leber, & Egeth, 2002; Raymond, Shapiro, & Arnell, 1992). The intermediate lag (400 ms) provided a proxy measure of the rate of recovery from capture by a salient distractor.
Experiment 1
Method
Participants
Previous studies of value-modulated capture of spatial attention by task-irrelevant distractors (Failing, Nissens, Pearson, Le Pelley, & Theeuwes, 2015; Le Pelley et al., 2015; Pearson et al., 2015; Pearson et al., 2016) have revealed medium to very large effect sizes (Cohen’s d z = 0.41 to 2.2). We therefore ran each of Experiments 1–3 for as many days as required to test 44 participants, which would yield a power of .90 to detect a medium effect size of d z = 0.5. In total, 52 UNSW Sydney students (mean age = 22.0 years; 33 females, 19 males) participated in Experiment 1, either for course credit (n = 38) or for payment of AU $15 (n = 14). All participants received an additional monetary bonus dependent on their performance (M = $11.11, SEM = $0.10). All research reported in this article was approved by the Human Research Ethics Advisory Panel (Psychology) of UNSW Sydney.
Apparatus and stimuli
Participants were tested individually; they viewed stimuli on a 23-in. monitor (1,920 × 1,080 resolution, 120-Hz refresh) positioned ~60 cm away. Auditory stimuli were played over headphones, and all responses were made using the keyboard. Stimulus presentation was controlled by MATLAB using the Psychophysics Toolbox extensions (Kleiner, Brainard, & Pelli, 2007).
The visual stimuli were color photographs presented centrally on a black background; the pictures subtended 8.1° × 6.1° of visual angle. The target pictures were drawn from a pool of 244 landscape/architectural pictures, half of which had been rotated 90° to the left, and the other half 90° to the right (while maintaining the same dimensions as the nonrotated pictures). The critical distractors (see the Design section) were ten pictures of birds and ten pictures of cars. Filler items were drawn from a pool of 251 upright landscape/architectural pictures.
Design
Unlike previous studies of value-modulated attentional capture in nonspatial attention (Della Libera & Chelazzi, 2009; Failing & Theeuwes, 2015; Smith et al., 2006), the present study did not include separate training and test phases. Instead, the experiment involved only a single phase, using an RSVP task (Fig. 1a). On each trial, a stream of 18 pictures were presented for 100 ms each. Each stream contained one rotated target picture; once all items in the stream had been presented, participants responded according to whether they thought the target picture had been rotated left or right, by using the left and right arrow keys, respectively. Feedback was then provided for 900 ms, depending on the type of distractor that had preceded the target and the accuracy of the participant’s response (see below).

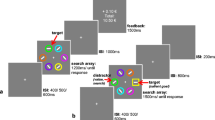
(a) Schematic of a trial from the rapid serial visual presentation (RSVP) task. The actual RSVP streams comprised 18 pictures in Experiments 1 and 2, and 12 pictures in Experiments 3 and 4. Participants responded to the orientation of a rotated target picture. This could be preceded by a critical distractor picture of a bird or car: One of these categories (valued distractors) signaled that correct/incorrect responses to the target would be rewarded/punished by gain/loss of points; the other distractor category (neutral distractors) signaled that responses would not be rewarded or punished. On baseline trials, no bird/car distractor was presented. (b) Accuracy of responses to the target in Experiment 1. Lag refers to the difference in the serial positions of the critical distractor and target in the RSVP stream (or between the filler item that substituted for the distractor and the target on baseline trials). (c) Accuracy of responses to the target in Experiment 2, averaged across all participants. (d) Accuracy of responses to the target for lag 2 trials in Experiment 2, for subgroups of participants who showed independent evidence of having learned the value of the valued distractor (Learners), and those who did not (Non-learners; see the text for details of the subgroup assignments). Error bars show within-subjects standard errors of the means (Cousineau, 2005). ns: p ≥ .10, +p < .10, *p < .05, ***p < .001. (e) Scatterplot of learned-value scores against contingency belief scores for the participants of Experiment 2 (see the text for definitions of each variable). The solid line shows the line of best fit
The experiment had three trial types: valued, neutral, and baseline trials. For half of participants, pictures of birds were the valued distractors and pictures of cars were the neutral distractors; for the remaining participants, this mapping was reversed. On valued and neutral trials, the critical distractor was drawn randomly from the appropriate pool of pictures (birds or cars). On baseline trials, the RSVP stream did not contain a bird or a car; instead, an architectural/landscape picture drawn from the same pool as the filler items was used in place of the critical distractor.
On valued trials, a correct response to the orientation of the target yielded reward feedback: The message “CORRECT: WIN 50 POINTS!!” appeared centrally in green, 42-point text, accompanied by a rising-pitch “victory” sound. An incorrect response to the target on valued trials yielded loss feedback: the message “ERROR: LOSE 50 POINTS” in red, 42-point text, accompanied by a buzzer. Consequently, distractors from the valued category signaled the potential for both reward and loss, but critically, they were never the stimuli that participants responded to in order to obtain valued outcomes: From the participant’s perspective, they were task-irrelevant throughout the experiment (we consider the issue of task irrelevance in more detail in Exp. 3). On neutral and baseline trials, the feedback simply displayed either “correct” or “incorrect” (as appropriate) in white, 40-point text, with no gain or loss of points. Hence, the neutral distractors were never paired with valued outcomes.
The distractor (or the additional filler item, on baseline trials) appeared randomly as the third, fourth, fifth, or sixth item in the stream. The target appeared either as the second item (lag 2), the fourth item (lag 4), or the tenth item (lag 10) after the distractor; thus, either 200, 400, or 1,000 ms separated the onset of the distractor and target. One-third of trials for each distractor type (valued, neutral, and baseline) in every block were at each of the different lags. Even though baseline trials did not feature a critical distractor, controlling the “lag” on these trials in the same way as for the valued and neutral trials was important, since it controlled for the serial position of the target in the RSVP stream; the target tended to occur later on long-lag than on short-lag trials.
The nondistractor and nontarget items in the RSVP stream on each trial were drawn randomly, and without replacement, from the pool of filler items. The target item was drawn randomly from the pool of target pictures, such that the target rotation (left or right) was random on each trial.
Procedure
The experiment began with a short, six-trial practice session, with RSVP rates starting at five pictures per second and increasing to the experimental presentation rate of ten pictures per second. The practice session did not include distractors, and no points were won or lost.
Following practice, participants were informed that they could now win points for correct responses, that the number of points they earned would determine their monetary bonus at the end of the experiment, and that most participants could earn between $8 and $12 (no specific information on the conversion rate from points to money was provided). They were also explicitly informed that if the stream included a picture of a [bird/car] (whichever was the valued distractor for that participant), they would win 50 points for making a correct response to the target and lose 50 points for an incorrect response, and that on all other trials they would not win points for correct responses or lose them for incorrect responses. Finally, participants were told that the bird/car would never be the target stimulus, so they would do better at the task by trying to ignore it.
Participants then began the main experiment, which comprised 14 blocks of 45 trials. Each block contained 18 valued trials, 18 neutral trials, and 9 baseline trials. The intertrial interval was 500 ms. Participants took a short break after each block, during which they were told their running total of points. At the end of the experiment, participants received a bonus based on their final point total, calculated as bonus (AUD) = 8 + (points – 3,780)/1,890, capped at $12.10.
Finally, participants completed three questionnaires: the Attentional Control Scale (Derryberry & Reed, 2002), the BIS/BAS scales (Carver & White, 1994), and the Barratt Impulsiveness Scale Version 11 (Patton, Stanford, & Barratt, 1995). Analyses related to the data from these questionnaires were inconclusive and are not pursued further here, but for the sake of completeness are discussed further in the accompanying supplementary materials.
Results
Data from all experiments reported in this article are publically available via the Open Science Framework at https://osf.io/xm845/.
Figure 1b shows accuracy of responses to the target, averaged across all blocks. These data were analyzed using a 3 (distractor: valued, neutral, and baseline) × 3 (lag: 2, 4, and 10) analysis of variance (ANOVA). This revealed significant main effects of distractor, F(2, 102) = 49.9, p < .001, η p 2 = .49, and lag, F(2, 102) = 46.2, p < .001, η p 2 = .48, and a significant interaction, F(4, 204) = 60.0, p < .001, η p 2 = .54. The simple effect of lag was significant for each type of distractor, smallest F(2, 102) = 5.00, p < .008, η p 2 = .09. For valued and neutral distractors, this effect reflected an increase in accuracy as lag increased; for baseline trials, it reflected a decrease in accuracy as lag increased.
Planned pairwise t tests were used to analyze the effect of distractor at each lag. At lag 2, accuracy was significantly lower for valued than for neutral or baseline trials, t(51) = 10.0, p < .001, d z = 1.39, and accuracy was lower for neutral than for baseline trials, t(51) = 3.50, p < .001, d z = 0.48. At lag 4, we observed a trend toward lower accuracy for valued than for neutral trials, t(51) = 1.77, p = .082, d z = 0.25. The accuracy on baseline trials did not differ significantly from that on either valued trials, t(51) = 1.60, p = .115, d z = 0.22, or neutral trials, t < 1. At lag 10, the accuracies on valued and neutral trials did not differ significantly, t < 1. However, accuracy was significantly higher on valued and neutral trials than on baseline trials, t(51) = 2.27, p = .027, d z = 0.31.
We were particularly interested in the difference in accuracy on valued versus neutral trials: These both featured a critical distractor (bird or car), with the only difference being that one category of distractor had a high learned value, and the other did not. We therefore analyzed the data from these trial types using a 2 (distractor: valued vs. neutral) × 3 (lag) ANOVA. This revealed significant main effects of distractor and lag, F(1, 51) = 76.2, p < .001, η p 2 = .60. Most importantly, we found a significant Distractor × Lag interaction, F(2, 102) = 60.1, p < .001, η p 2 = .54; Fig. 1b shows that the pattern of lower accuracy on valued than on neutral trials was particularly pronounced at the shortest lag and decreased as the lag increased.
Discussion
The key finding of Experiment 1 was that accuracy of responding to the target was significantly lower when the target was preceded by a valued rather than a neutral distractor. This is noteworthy, because it means that accuracy was lower on trials that influenced participants’ final monetary payment than on trials that “didn’t matter”—that is, trials on which the response could have no effect on payment. This impairment in accuracy caused by the presence of a valued distractor was short-lived, being particularly pronounced at the short lag but absent at the longest lag tested.
The implication is that the valued distractor was more likely to capture attention, and hence to reduce perceptual processing of the target. That is, a stimulus signaling the potential for reward or loss produced a greater impairment in conscious perception of the target than did a stimulus that had never been paired with reward or loss. This shows that learned value can influence the capture of nonspatial attention, even when the value-related stimulus has never been a task-relevant target.
Although value-related distractors produced the greatest impairment in performance, accuracy was also significantly lower on neutral than on baseline trials at the shortest lag. That is, identification of the target was impaired when it was shortly preceded by a critical distractor (i.e., a picture that was categorically distinct from the other items in the RSVP stream), even when that distractor did not indicate the availability of reward, as compared to when the stream did not contain a critical distractor. This impairment caused by neutral distractors is most likely a consequence of their physical features; perhaps their categorical distinctiveness from other items in the stream drives occasional capture by these distractors (Kennedy & Most, 2015a), or perhaps their pictorial properties (color, brightness, etc.) are such as to cause a short-lived interference with target perception.
On baseline trials, accuracy decreased as the “lag” increased. Since no critical distractor was presented on baseline trials, the lag variable here corresponds to the serial position of the target in the RSVP stream: the longer the lag, the later the target tended to occur in the stream. The decrease in accuracy with lag on baseline trials may therefore reflect a decline in vigilance for the target over the course of each stream. The finding that, at the longest distractor–target lag (1,000 ms), accuracy was significantly higher for trials with a critical distractor (either valued or neutral) than on baseline trials in turn suggests that the occurrence of a distractor relatively early in the stream acts to reduce this longer-term decline in vigilance. However, the learned value of the distractor had no effect on accuracy at the longest lag; we return to this issue in the General Discussion.
Experiment 2
In Experiment 1, participants were explicitly informed of the relationship between the valued distractor and the potential for reward/loss at the outset. In Experiment 2 we investigated whether a similar effect of learned value could be observed in the absence of such explicit instruction—that is, when learning of the reward relationships must be based on trial-by-trial experience.
Method
Participants
Fifty-three UNSW Sydney students (mean age = 20.1 years; 27 females, 26 males) participated for course credit; they also received a monetary bonus dependent on performance (M = AU $11.14, SEM = $0.14).
Apparatus, stimuli, and design
The apparatus, stimuli, and design of the RSVP task were as in Experiment 1.
Procedure
The procedure for the RSVP task was as in Experiment 1, except that the initial instructions did not inform participants that one category of distractor (birds or cars) signaled that points could be won or lost. Instead, they were told simply that on some trials they could win/lose points for correct/incorrect responses, whereas on other trials they would not win or lose points, and they would not be told before each trial whether or not it was one on which they could win points. Participants completed 18 blocks of 45 trials each; this was slightly longer than Experiment 1 (14 blocks), since we thought it might take some time for participants to learn the relationship between the valued distractor and the outcome values that it signaled.
Despite this opportunity for contingency learning, some participants may not have learned the distractor–value association. As a step toward identifying such “nonlearners,” following the RSVP task all participants completed a learning test. They were told that, during the previous task, certain pictures that had appeared in the stream of images had signaled whether they could win or lose points for correct or incorrect responses, and other pictures signaled that they could not win or lose points on that trial. Participants were then shown each of the ten bird and ten car distractors in random order. For each picture they were asked whether, if they made a correct response for a stream containing that picture, they would receive no points or would win 50 points. Participants made their choice by clicking on the appropriate on-screen button using the mouse. They then rated their confidence in that choice, from 1 (not at all confident) to 5 (very confident).
At the end of the experiment, participants’ bonus was calculated as bonus (AUD) = 8 + (points – 4,860)/2,430, capped at $12.10.
Results
Figure 1c shows response accuracy averaged across all participants. A 3 (distractor) × 3 (lag) ANOVA revealed main effects of distractor, F(2, 104) = 15.8, p < .001, η p 2 = .23, and lag, F(2, 104) = 21.9, p < .001, η p 2 = .30, as well as a significant interaction, F(4, 208) = 10.6, p < .001, η p 2 = .17. The simple effect of lag was significant for both valued and neutral trials, F(2, 104) > 18.7, p < .001, η p 2 > .26, with higher accuracy at longer lags. There was no significant effect of lag for baseline trials, F < 1, η p 2 = .002. Pairwise t tests were used to analyze the effect of distractor at each lag. At lag 2, accuracy was highest for baseline trials: valued versus baseline, t(52) = 6.79, p < .001, d z = 0.93; neutral versus baseline, t(52) = 5.79, p < .001, d z = 0.80. Although there was a numerical trend toward lower accuracy for valued than for neutral trials, this difference did not reach significance, t(52) = 1.39, p = .17, d z = 0.19. At lag 4 and lag 10, no pairwise comparisons were significant, ts < 1.52, ps > .13, d z s < 0.21.
Although the lag 2 data showed that distinctive distractors (a bird or a car among architectural/landscape pictures) impaired response accuracy, across all participants we found little evidence of an influence of learned value on accuracy—that is, a difference between valued and neutral distractors. However, as we noted earlier, it is possible that some participants failed to learn the relationship between the valued distractor category and the potential to win or lose points. Responses from the learning test were used to identify nonlearners. Following Pearson et al. (2015), if a participant correctly responded that a picture from the valued category signaled the potential to win points, their contingency belief score for that picture was given by multiplying their confidence rating by 1; if they incorrectly stated that it did not signal potential for reward, their confidence rating was multiplied by –1. Contingency belief scores were averaged across all ten pictures from the valued category, giving a mean score that ranged from 5 (high confidence that valued pictures signaled potential for reward) to –5 (high confidence that valued pictures did not signal potential for reward).
Across participants, the mean contingency belief score was near zero (M = –0.48, SEM = 0.24), indicating that many participants did not learn the relationship between the valued distractor and valued outcomes. Nevertheless, a subset of participants had positive contingency belief scores, suggesting they may have learned the value of the valued distractors. As a conservative measure, we labeled any participant with a mean contingency belief score greater than zero as a learner (n = 22) and those with scores of zero or below as nonlearners (n = 31).Footnote 2
Analyses of the RSVP data from learners and nonlearners focused on lag 2, since this was where the most pronounced effect of learned value had been observed in Experiment 1. Figure 1d shows accuracy for lag 2 trials separately for learners and nonlearners. Nonlearners were less accurate on trials featuring a critical distractor than on baseline trials, but they showed no effect of learned value (no difference between trials with a valued vs. neutral distractor). In contrast, learners showed evidence of an effect of learned value, with lower accuracy for valued than for neutral trials. Statistical support for a difference in the effects of learned value between the two subgroups came from a 2 (subgroup: learners vs. nonlearners) × 2 (distractor: valued vs. neutral) analysis of covariance (ANCOVA), controlling for participants’ picture assignment conditions (birds vs. cars as valued distractors). This covariate was included because the two counterbalance conditions were not equally represented in the two subgroups (64% of nonlearners were in the “birds valued” condition, and only 32% of learners were in this condition). This ANCOVA revealed a significant main effect of distractor, F(1, 50) = 4.024, p = .050, η p 2 = .074,Footnote 3 but no main effect of subgroup, F(1, 50) = 0.05, p = .82, η p 2 = .001. Importantly, the Subgroup × Distractor interaction was significant, F(1, 50) = 4.21, p = .046, η p 2 = .078, indicating a significant difference in the effects of learned value in learners versus nonlearners. This interaction does not rely on inclusion of picture assignment condition as a covariate, in that it remains significant if the covariate is omitted, F(1, 51) = 6.26, p = .016 , η p 2 = .11.
The effect of distractor for each subgroup was analyzed further using one-way ANCOVAs to compare pairs of distractor types while controlling for picture assignment condition. For learners, accuracy was significantly lower for trials featuring a critical distractor than for those with no distractor: valued versus baseline, F(1, 20) = 18.9, p < .001, η p 2 = .49; neutral versus baseline, F(1, 20) = 5.66, p = .027, η p 2 = .22. Critically, accuracy was significantly lower for valued than for neutral trials, F(1, 20) = 6.18, p = .022, η p 2 = .24, revealing an effect of learned value among the subgroup of learners. For nonlearners, accuracy was significantly lower for trials featuring a critical distractor than for those with no distractor: valued versus baseline, F(1, 29) = 5.74, p = .023, η p 2 = .17; neutral versus baseline, F(1, 29) = 4.75, p = .038, η p 2 = .14. However, for these nonlearners there was no significant effect of learned value: valued versus neutral, F(1, 29) = 0.16, p = .69, η p 2 = .006. None of the results of these pairwise comparisons relied on the inclusion of picture assignment condition as a covariate; the pattern of significant results was unchanged if this covariate was omitted.
An alternative analysis treats contingency belief scores as a continuous variable. For each participant, we calculated a learned value score for lag 2 trials by subtracting the accuracy on valued trials from the accuracy on neutral trials (so that high scores indicated a greater impairment caused by the valued distractor). There was a significant positive correlation between this learned-value score and participants’ contingency belief scores (Fig. 1e), both as a bivariate correlation, Pearson’s r(51) = .343, p = .012, and when controlling for picture assignment condition, r(50) = .295, p = .034.
Discussion
In Experiment 2, participants were not explicitly informed of the relationship between the valued distractor category and the potential to win/lose points, but instead could learn this relationship incidentally through trial-by-trial experience. Across all participants, this incidental learning was rather weak—the majority of participants did not seem to have learned the status of the valued distractor (as revealed by a judgment test following the RSVP task). Presumably as a result of this weak learning, there was little evidence of an influence of learned value on RSVP task performance when data were averaged over all participants. However, the subset of participants who did show evidence of learning also exhibited a significant influence of learned value on RSVP task performance, which was similar in nature to that seen following explicit instructions in Experiment 1. That is, for the shortest distractor–target lag, valued distractors produced a significantly greater impairment in accuracy than did neutral distractors.
As in Experiment 1, accuracy was lower on neutral trials (i.e., trials with a critical distractor that did not signal reward) than on baseline trials (no critical distractor). This difference was significant in both learners and nonlearners in Experiment 2. The finding of an effect for nonlearners—that is, participants who showed no evidence of having learned the relation between the valued distractor and the potential for reward/loss—supports the suggestion raised in the Discussion of Exp. 1 that the impairment caused by neutral distractors is a consequence of the physical features of these distractors, independent of any effect of reward learning.
Finally, Experiment 2 did not replicate the reduction in accuracy with increasing “lag” on baseline trials that was observed in Experiment 1, or the advantage for critical distractor trials over baseline trials at lag 10. Although the reason for this null result is unclear, we note that the overall accuracy on baseline trials was somewhat lower in Experiment 2 (M = 90.4%, SEM = 1.08%) than in Experiment 1 (M = 92.8%, SEM = 0.80%), and this difference approached significance, t(103) = 1.82, p = .072, d = 0.36. This could be taken to suggest that, for some reason (due either to a difference in the participant sample or to the procedural differences between experiments), target vigilance was generally at a lower level in Experiment 2, rather than being reduced as a function of position in the RSVP stream.
Experiment 3
In Experiments 1 and 2, the value-related stimuli (birds/cars) were never the rotated target pictures that participants were required to identify on each trial. Hence, participants could complete the task without ever needing to select these value-related stimuli; in fact, attentional selection of the bird/car on each trial would typically make the task harder, by impairing identification of a target following shortly afterward. This impairment in target identification caused by value-related stimuli is clear in the data of Experiments 1 and 2 for short lags (particularly lag 2), where accuracy was lower for trials containing a distractor than for baseline trials. Given that participants never needed to identify the value-related stimuli to perform the task, and that doing so generally impaired task performance, it could be argued that these stimuli constituted task-irrelevant distractors. It is (in part) on the basis of this task irrelevance that we have argued, up to this point, that the impairment in accuracy caused by value-related distractors reflected involuntary attentional capture by these stimuli.
However, although the value-related stimuli are unrelated to the response that participants must make on each trial, they do provide information on the consequences of that response: They predict whether or not the response will result in reward. As such, the value-related stimuli have informational value (see Gottlieb, Hayhoe, Hikosaka, & Rangel, 2014). This raises the possibility that participants may attempt to use the value-related stimuli strategically, to identify which trials will be rewarded. In fact, this is a poor strategy to use, since (as noted above) attending to the value-related stimuli in this task tends to reduce participants’ monetary benefit; they would actually maximize their overall payoff by ignoring these stimuli altogether. However, participants may nevertheless have believed that they ought to use the value-related stimuli in a goal-directed fashion, to identify trials that would be rewarded.
Experiment 3 tested whether the influence of value-related stimuli on accuracy at short distractor–target lags reflected participants’ strategic selection of reward-informative distractors, or whether it instead resulted from a relatively early and involuntary capture of nonspatial attention. The procedure was based on that of Experiment 1, but with two key differences.
The first difference was that in Experiment 3 we went to greater lengths to clarify to participants that the optimal strategy to maximize their payoff was to ignore the bird/car on each trial. In Experiment 1 the participants had been informed that the bird/car would never be the rotated target stimulus and that they should try to ignore it; in Experiment 3 this instruction was expanded to explain why participants ought to ignore the value-related stimuli (see the Procedure section below). If the influence of value-related distractors on accuracy were to persist despite these clear instructions, this would support the claim that this influence is not mediated by strategic, goal-directed selection of the distractor, but instead reflected a more automatic process of attentional capture.
The second, and perhaps more important, change in Experiment 3 was that we included a final extinction phase. In this final phase, participants were informed that they could no longer win or lose points on any trial; other than this, the task then carried on as before. If selection of the value-related stimuli in the earlier, rewarded phase reflected a strategic process of information gathering, it should be abolished in this extinction phase. This is because participants already knew that no reward was available on each trial, so the (previously) value-related distractors no longer provided any information. If, in contrast, selection of the valued distractor was involuntary and based on its history of association with reward/loss, the selection of this distractor might persist even when participants were explicitly aware that rewards were no longer available.
Finally, Experiment 3 included trials on which the rotated target followed immediately after the value-related distractor (i.e., a lag 1 condition). These trials allowed us to further probe the temporal dynamics of the effect observed in our previous experiments, by establishing whether reward-related distractors cause an impairment in target identification even when there are no intervening items in the RSVP stream. An alternative possibility is that the distracting effects of reward-related stimuli might be reduced when they immediately precede the target; this pattern is sometimes observed in studies of the closely related attentional blink phenomenon, where it is known as lag 1 sparing (Dell’Acqua, Pierre, Pascali, & Pluchino, 2007; Raymond et al., 1992; Visser, Bischof, & Di Lollo, 1999).
Method
Participants
Forty-four UNSW Sydney students (mean age = 19.1 years; 36 females, eight males) participated for course credit; they also received a monetary bonus dependent on performance (M = AU $9.83, SEM = $0.10).
Apparatus, stimuli, and design
The apparatus and stimuli were as in Experiment 1. The design of the RSVP task was similar to that of Experiment 1. The main differences were that (1) each RSVP trial now contained 12 pictures, and (2) the rotated target appeared as the first (lag 1), second (lag 2), or fourth (lag 4) item after the distractor (or additional filler item on baseline trials); thus, either 100, 200, or 400 ms separated the onsets of the distractor and target.
Procedure
As in Experiment 1, instructions following the brief initial practice phase informed participants that if the stream included a picture of a [bird/car] (whichever was the valued distractor for that participant), the participant would win 50 points for making a correct response to the target and lose 50 points for an incorrect response, and that if the stream contained a [car/bird] (whichever was the neutral distractor), the participant would not win points for correct responses or lose them for incorrect responses. It was then explained that the bird or car would never be the rotated target. To illustrate this, participants were shown an example sequence of pictures in which a bird or car preceded the target by two positions (i.e., lag 2). They were told that, “In fact, you will do better at this task (you will earn more points, and therefore more money) if you IGNORE the bird/car altogether. Sometimes the target will be presented shortly after the bird/car: you will find that if you are paying attention to the bird/car, you will often miss the target that follows it. The best strategy in this task is to ignore the bird/car completely and just try to identify the target as accurately as possible on each trial. On average you will win around $5 to $6 more if you use this strategy. The bird/car is just there to distract you and make the task harder!” These instructions were clarified by the experimenter with reference to the example of the lag 2 sequence shown onscreen, to ensure that all participants understood that they would earn points by responding to the target, and not to the bird/car, so that the best strategy was to ignore the bird/car altogether.
The rewarded phase then began. This comprised 12 blocks of 45 trials, which were structured exactly like the blocks in Experiment 1 (though the three lags used were now lags 1, 2, and 4 rather than 2, 4, and 10). The feedback on each trial was exactly as in Experiment 1.
On completion of the rewarded phase, the following message appeared in yellow, 48-point font: “FROM NOW ON, YOU WILL NOT BE ABLE TO WIN OR LOSE ANY POINTS IN THIS TASK, REGARDLESS OF THE PICTURES PRESENTED IN THE STREAM. Nevertheless, you should carry on responding to the rotated target as accurately as you can on each trial.” This message remained onscreen for at least 12 s. The extinction phase then began. This comprised two blocks of 45 trials, structured as in the reward phase—the only difference being that feedback on every trial was restricted to either “correct” or “incorrect”; the feedback no longer referred to points won or lost, and all auditory feedback was omitted. During the break between the two trial blocks, participants were reminded that they would not be able to win or lose any points in the next block.
At the end of the experiment, participants received a bonus based on how many points they had earned during the rewarded phase, calculated so that correct responses on 100% of valued trials in this phase gave a bonus of $12, and 50% accuracy (i.e., chance performance) gave a bonus of $6.
Results
Figure 2 shows the accuracy of responses to the target, averaged across all blocks of each phase. A 2 (phase: rewarded, extinction) × 3 (distractor: valued, neutral, baseline) × 3 (lag: 1, 2, 4) ANOVA revealed significant main effects of distractor, F(2, 86) = 56.9, p < .001, η p 2 = .57, and lag, F(2, 86) = 56.3, p < .001, η p 2 = .57, as well as a Distractor × Lag interaction, F(4, 172) = 24.8, p < .001, η p 2 = .37. Phase did not exert a significant main effect or interact with any other factors, Fs < 1.40, ps > .23, η p 2 < .03. This suggests that participants’ performance in the task did not critically depend on whether rewards/punishments were currently available (in the rewarded phase) or not (in the extinction phase).

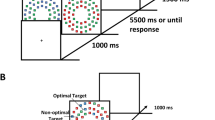
Accuracies of responses to the target in the reward phase (a) and the extinction phase (b) of Experiment 2 as a function of distractor type and lag (see the caption of Fig. 1 for details). Error bars show within-subjects standard errors of the means (Cousineau, 2005). ns: p ≥ .10, +p < .10, **p < .01, ***p < .001
To examine the more specific question of whether the effect of learned value differed between phases, we repeated this ANOVA but omitted the data from baseline trials; that is, the distractor factor now compared valued and neutral trials, which (across participants) differed only in terms of the learned value of the distractor. The main effect of distractor was significant, F(1, 43) = 26.9, p < .001, η p 2 = .38, with lower accuracy on valued than on neutral trials, demonstrating an influence of learned value. The magnitude of this effect of learned value depended on lag, with a significant Distractor × Lag interaction, F(2, 86) = 11.9, p < .001, η p 2 = .22. Once again, however, phase did not have a main effect or interact with any other factors, Fs < 2.46, ps > .09, η p 2 < .055. That is, the effects of learned value did not differ significantly between the rewarded and extinction phases.
Planned t tests were used to analyze the effect of learned distractor value at each lag. In the rewarded phase, accuracy was significantly lower on valued trials than on neutral trials at lag 1, t(43) = 3.70, p < .001, d z = 0.56, and lag 2, t(43) = 10.1, p < .001, d z = 1.53, but not at lag 4, t < 1. In the extinction phase, accuracy was significantly lower on valued trials than on neutral trials at lag 2, t(43) = 4.98, p < .001, d z = 0.75, but not at lag 1, t < 1, or lag 4, t(43) = 1.13, p = .26, d z = 0.17. Although the effect of learned value at lag 1 was significant in the rewarded phase but not in the extinction phase, the size of this effect (given by the accuracy on neutral trials minus valued trials) did not differ significantly between the two phases, t(43) = 1.41, p = .17, d z = 0.21.
Discussion
Experiment 3 replicated the influence of learned value on accuracy of responding to the target at short distractor–target lags that we had observed in Experiments 1 and 2: Once again, accuracy was lower when the target was shortly preceded by a valued distractor than when it was preceded by a neutral distractor. Notably, this counterproductive effect of learned value was observed even though we went to pains in Experiment 3 to explain to participants that deliberately attending to the distractors was a poor strategy, since it would result in a reduced payoff. Indeed, during informal debriefing after the experiment, most participants complained of being unable to help seeing the distractors, despite their best efforts.
Perhaps most importantly, the effect of learned distractor value persisted during the extinction phase, when participants were explicitly informed that they could no longer win or lose points on any trial. Hence, during this extinction phase, the critical distractors no longer carried any information regarding reward availability. The persistence of an influence of learned value under these conditions suggests that attention to value-related distractors does not reflect a strategic search for information in this procedure, but instead reflects involuntary attentional capture driven by past experience of the relationship between distractors and valued outcomes.
Finally, during the rewarded phase of Experiment 3 we observed a significant effect of learned value on performance at lag 1—that is, when 100 ms separated the onsets of the distractor and target, and there were no intervening items. Thus, the impairment in target detection caused by the presence of a reward-related distractor was not subject to lag 1 sparing. This performance impairment at lag 1 is similar to that previously reported for the case in which distractors have intrinsic emotion-related content (e.g., pictures of violence or threat; Kennedy & Most, 2015b).
Experiment 4
Experiment 3 demonstrated an influence of learned distractor value on response accuracy during an extinction phase when participants were fully aware that no rewards would be delivered, and hence the distractors carried no strategically useful information. We argued above that this suggests that the influence of distractors during the extinction phase is not mediated by a strategic search for information regarding reward availability. There is an alternative possibility, however. The distractors did provide valid information on reward availability during the (rather long) rewarded phase that preceded the extinction phase. It is possible that participants developed a strategy of attending to the distractors during the rewarded phase and then persisted in using this strategy during the extinction phase, even though it was no longer necessary (or indeed useful) during the latter period. This possibility is interesting in its own right, since it suggests that strategic attentional responses can persist in influencing behavior even when participants are aware that these responses are no longer appropriate and will only impair performance; in effect, this account proposes that strategic attentional responses can become “attentional habits” (cf. Anderson, 2016; Luque et al., 2017). However, it is still somewhat different from our claim that reward can induce biases in temporal attention that are not under strategic control—that is, that reward can produce capture of nonspatial attention.
Experiment 4 provided a final, stringent test of the latter claim of nonstrategic capture. In this experiment, prior to every RSVP trial, participants were explicitly and validly informed of whether reward would be available on that trial, in a pretrial instruction display. Each RSVP stream also contained a distractor from a category that was typically, but not always, associated with the availability of reward, or from a category that was typically associated with a lack of reward. Under these conditions, the critical distractors were entirely redundant from a strategic perspective throughout the experiment: They carried no additional information on reward availability, and were in fact less valid as predictors of reward than was the preinstruction. Consequently, there was no reason for participants to strategically allocate attention to these distractors at any point.
We were interested in whether the reward-related distractors would nevertheless capture attention and impair target detection in the RSVP task. Unlike in previous experiments, the distractor categories were not perfectly correlated with reward (non)availability in Experiment 4: 80% of reward-available trials featured a valued distractor, and 20% featured a neutral distractor; 80% of reward-unavailable trials featured a neutral distractor, and 20% featured a valued distractor. This allowed us to examine the influence of distractors on performance independently of any effect of the preinstruction regarding reward availability.
Method
Participants
Sixty-two UNSW Sydney students participated, either for course credit (n = 30) or for payment of AU $15 (n = 32). All participants also received a monetary bonus dependent on performance. Following exclusions (see the Results), the final sample contained 46 participants (37 females, nine males; age M = 22.6 years, SEM = 1.1; performance bonus M = $10.52, SEM = $0.10).
Apparatus, stimuli, and design
The apparatus and stimuli were as in Experiment 1. The design of the RSVP task was similar to that of Experiment 1, with certain key differences. Each RSVP stream was now preceded by an instruction display that stated, with 100% validity, whether the upcoming trial would be a reward trial or a nonreward trial (Fig. 3a). This instruction display consisted of a white rectangle outline of the same size as the RSVP pictures, presented centrally, and containing the text “REWARD trial” (in yellow) or “nonreward trial” (in white) as appropriate, in 48-point font.

(a) Schematic of a trial in Experiment 4. (b) Accuracies of responses to the target in Experiment 4 as a function of whether participants were preinstructed that the trial would be a reward trial (Instruct reward) or a nonreward trial (Instruct non-reward), and whether the RSVP stream contained a distractor that was typically associated with the availability of reward (valued) or was not typically associated with the availability of reward (neutral). Error bars show within-subjects standard errors of the means (Cousineau, 2005)
Participants completed 18 blocks of 20 trials, each comprising ten reward trials and ten nonreward trials. Of the ten reward trials in each block, eight featured a distractor from the valued distractor category (birds or cars, counterbalanced over participants), and two featured a distractor from the neutral distractor category (cars or birds, as appropriate). Of the ten nonreward trials in each block, eight featured a neutral distractor, and two featured a valued distractor. Note that in Experiment 4, the terms “valued” and “neutral” with regard to distractors refer to probabilistic rather than deterministic relationships: Valued distractors now signaled the availability of a valued outcome (reward/punishment) with 80% validity, and neutral distractors signaled the absence of reward/punishment with 80% validity.
Experiments 1–3 had shown that the cost of attending to the valued distractor was greatest at lag 2 (i.e., when 200 ms separated the onset of distractor and target). To create a situation in which strategic selection of the distractor was most disadvantageous, we therefore used lag 2 for all trials in Experiment 4. Finally, there were no baseline trials (i.e., trials with no distractor); these trials did not relate directly to the central issue of how reward affected performance, and removing them allowed us to include more of the critical trial types.
Procedure
The instructions following the brief initial practice phase were similar to those of Experiment 3. Participants were informed that if the stream included a picture of a [bird/car] (whichever was the valued distractor for that participant), it would typically be a “reward trial,” on which they would win or lose points for making a correct or incorrect response to the target; if the stream included a [car/bird] (neutral distractor), it would typically be a “nonreward trial,” on which they would not win or lose points regardless of their response. The word “typically” was inserted in these instructions in Experiment 4 to reflect the fact that the valued/neutral distractors signaled reward/nonreward trials with only 80% validity. As in Experiment 3, participants were shown an example sequence of pictures in which a bird or car preceded the target by two positions (i.e., lag 2), to illustrate that the bird/car would never be the rotated target, and were informed that “The bird/car is just there to distract you and make the task harder.” Finally, participants were told that an instruction display immediately before each trial would reveal whether the upcoming trial would be a reward or a nonreward trial.
Each trial began with an instruction display shown for 1,500 ms (see Fig. 3a), indicated by a gray “countdown” bar positioned just below the instruction that gradually disappeared over this interval. The screen then blanked, and after 800 ms the RSVP stream began. All other procedural aspects of the RSVP task were as in Experiment 1.
Following the RSVP task, we included a manipulation check to ensure that participants had understood the initial instructions about the reward relationships in the task. The question “Which type of picture was more likely to appear in the stream of images on REWARD TRIALS (i.e., trials on which you could win or lose points)?” appeared above the options “BIRD” and “CAR.” Participants were told that they would receive an additional 500 points for answering this question correctly.
Results
Sixteen participants answered the manipulation check question incorrectly: Despite explicit instruction and extensive experience over the course of the RSVP task, these participants incorrectly identified the distractor category that was more likely to appear on reward trials. The data from these participants were excluded; the analyses below relate to the remaining 46 participants, though we note that the pattern of significant and nonsignificant findings was unaffected by this exclusion.
Figure 3b shows the accuracy of responses to the target, as a function of whether the instruction display preinformed participants that the trial would be a reward or a nonreward trial and whether the RSVP stream contained a valued or a neutral distractor. These data were analyzed using a 2 (instruction: reward, nonreward) × 2 (distractor: valued, neutral) ANOVA. This revealed a significant main effect of instruction, F(1, 45) = 5.65, p = .022, η p 2 = .11, with higher accuracy when participants were instructed that reward would be available on the upcoming trial. Critically, there was also a main effect of distractor, F(1, 45) = 7.20, p = .010, η p 2 = .14, with lower accuracy on trials with a valued distractor than on trials with a neutral distractor. We found no significant interaction, F(1, 45) = 1.67, p = .20, η p 2 = .04.
Discussion
Accuracy was higher in Experiment 4 when participants were prewarned that their response on the upcoming trial would win or lose points than when they were informed that they could not win or lose points. This is unsurprising; presumably, participants were more motivated to engage with the task when the accuracy of their response would have consequences for their monetary payoff. More importantly, performance was influenced by the type of distractor that was presented in the RSVP stream. As in previous experiments, accuracy was impaired when the target was shortly preceded by a valued rather than a neutral distractor. This is notable because, in Experiment 4, participants already knew on every trial whether or not reward would be available—consequently, the distractors provided no further information regarding reward availability, so there was no strategic reason to attend to them (in fact, the distractors, which signaled reward/nonreward with only 80% validity, were less informative than was the instruction display, which signaled with 100% validity). This suggests that reward relationships influenced the extent to which the critical distractors captured participants’ attention, independently of participants’ strategic goals or intentions.
Although statistically significant, the influence of distractor type was numerically somewhat smaller in Experiment 4 than in Experiments 1 and 3; this may reflect the fact that the distractors were weaker signals of reward (or lack of reward) in Experiment 4 (where distractors had 80% validity) than in the prior experiments (100% validity).
General discussion
In four experiments we used an RSVP task to investigate the effect of value learning on nonspatial attentional capture. When a picture from the valued category (birds or cars, counterbalanced across participants) appeared as a distractor in the RSVP stream, it signaled that a correct response to the target would be rewarded and an incorrect response would be punished. A picture from the other, neutral category instead signaled that the response on this trial would not be rewarded or punished. Importantly, these valued and neutral stimuli were never the targets to which participants responded in order to gain reward or avoid punishment; these pictures were only ever presented as task-irrelevant distractors. Nevertheless, we observed an influence of the learned value of these stimuli on the extent to which they impaired processing of the subsequent target. Specifically, valued distractors produced a greater impairment in accuracy than did neutral distractors, both when the value relationship was explicitly described to participants at the outset of the study (Exps. 1, 3 and 4) and when participants learned this relationship incidentally over the course of trial-by-trial experience (Exp. 2, learners subgroup). This influence of the critical distractors on response accuracy was short-lived, being most pronounced when the target followed shortly after the distractor.
Notably, the pattern of poorer performance following a valued distractor than a neutral distractor was directly counterproductive to participants’ goal of maximizing their payoff. Only trials with valued distractors contributed to this payoff, so poor accuracy on these trials translated into reduced earnings. Put another way, participants showed more accurate performance on (neutral) trials that “didn’t matter” than on (valued) trials that did. This counterproductive effect suggests that the influence of learned value observed in these experiments reflects a mechanism over which participants have little control. Evidence in support of this idea comes from Experiment 3, in which the value-related distractors continued to impair performance even after we had carefully explained to participants why attending to these distractors was a bad idea, and (most notably) in an extinction phase in which participants knew that no rewards/punishments were available. Taking this idea further, Experiment 4 demonstrated that valued distractors impaired performance even when participants knew in advance on every trial of the experiment whether or not reward would be available, such that the distractors carried no useful further information about reward availability at any point. This suggests that attentional selection of value-related distractors does not reflect a goal-directed, strategic process of information gathering in this task (see Gottlieb et al., 2014). Instead, it implies a more automatic process of attentional capture. That is, despite the explicit knowledge that pictures from the value-related category will never be the target, and so should be ignored, participants implicitly continue to monitor for value-related stimuli—with such stimuli being particularly difficult to suppress once detected (cf. Wegner, 1994), reducing the availability of processing resources for subsequent perceptual processing of the target.
The effect of learned value on attentional capture observed in the present experiments is not confounded with a potential influence of selection history (cf. Failing & Theeuwes, 2015), since participants never selected the critical bird/car pictures as targets. Moreover, the fact that these critical stimuli were task-irrelevant throughout the procedure means that the effect of learned value is unlikely to have been a carryover of a conditioned “attentional habit” (Anderson, 2016; Le Pelley et al., 2016; Le Pelley et al., 2015; Luque et al., 2017). In previous nonspatial studies of learned value, the critical stimuli were task-relevant in an initial training phase: Identifying these stimuli allowed participants to obtain reward (Della Libera & Chelazzi, 2009; Failing & Theeuwes, 2015) or prepare for punishment (Smith et al., 2006). This reinforcement could drive the conditioning of attentional processes to allow rapid identification of value-related stimuli, and this conditioned attentional response may continue to be automatically re-enacted whenever the relevant conditioned stimuli appear, even when they are presented as task-irrelevant distractors in a subsequent test phase. In contrast, attentional selection of value-related stimuli in the present experiments did not allow participants to gain reward or avoid punishment. The present findings therefore suggest that the signal value of stimuli is the critical determinant of attention: the valued distractor signals the availability of valued outcomes, and it is this signaling relationship (or Pavlovian relationship, in conditioning terminology) that drives greater capture.
In the present experiments, valued distractors signaled both that correct responses to the target would be rewarded, and incorrect responses would be punished. Under these conditions we cannot be sure whether the influence of learned value on attentional capture reflects an effect of learning about the stimulus’s relationship with reward, with punishment, or both. On the basis of prior findings from studies using “training phase–test phase” procedures, it seems likely that both have an effect—that the critical issue is the motivational significance of the outcome that is paired with a stimulus, rather than the valence (positive vs. negative) of that outcome (Wang et al., 2013; Wentura et al., 2014). Future research could investigate this hypothesis in the present context by examining the likelihood of nonspatial capture by “reward distractors” (which signal that a correct response to the target will be rewarded but an incorrect response will not be punished) and “punishment distractors” (which signal that an incorrect response will be punished but a correct response will not be rewarded).
The influence of learned value on accuracy was rapid, being observed at a distractor–target onset asynchrony of just 100 ms (Exp. 3). It was also short-lived: The effect of value decreased across lags in all experiments, and no difference in accuracy on valued versus neutral trials was observed at the longest lag (ten items, 1,000 ms) in Experiments 1 and 2. Prior to these experiments, we had speculated that, with a long distractor–target lag, we might observe a reversal of the effect of learned value that occurred at short lag, with participants now performing better on valued than on neutral trials. Our rationale was that, by the time the target occurred on long-lag trials, any short-lived capture caused by the valued distractor might have dissipated, but a more controlled, goal-directed influence of this distractor might persist (cf. Bocanegra & Zeelenberg, 2009; Ciesielski, Armstrong, Zald, & Olatunji, 2010). The valued distractor signals that reward is available, and so acts as a warning to participants to try their best to identify the target on these trials (Bucker & Theeuwes, 2014; Engelmann & Pessoa, 2007; Pessoa & Engelmann, 2010). However, no effect of learned value was observed at lag 10, with similar accuracies for valued and neutral trials. It is unclear how best to interpret this null finding (especially given that accuracy for all trials at lag 10 was near ceiling, which may have reduced our sensitivity to observe differences). One possibility is that 1,000 ms was not long enough for the capture by the valued distractor to fully dissipate, counteracting any goal-directed advantage for valued trials. Alternatively, it may be the case that—for some reason—the valued distractor did not exert a goal-directed influence on participants’ vigilance. Future experiments could decide between these alternatives by using even longer distractor–target lags to further reduce any lingering impact of capture by the distractor on target identification.
Conclusion
In summary, we have shown that learning about the “signaling” (Pavlovian) relationship between stimuli and valued outcomes (rewards and punishments) influences the likelihood that those stimuli will capture attention, even when value-related stimuli have never been the target that participants are required to identify or respond to. The crucial role of signal value in modulating attentional capture, illustrated by the present experiments, echoes recent demonstrations of its importance in modulating the capture of spatial attention (Bucker, Belopolsky, & Theeuwes, 2015; Failing et al., 2015; Hopf et al., 2015; Le Pelley et al., 2015; Mine & Saiki, 2015; Pearson et al., 2015). Our data extend this earlier work in two (related) ways. First, they demonstrate an influence of signal value on temporal, rather than spatial, selection. This suggests that the learned signal value of a stimulus results in prioritization of this stimulus in multiple ways: both through spatial orienting of attention and through enhanced recruitment of nonspatial processing resources. Second, our data show that the effect of value-related distractors is not restricted to slowing search for a target; such distractors can also interfere with conscious perception of the target—that is, awareness of whether a target was even presented—even when that target was the focus of spatial attention.
Notes
Since the critical distractors in this study were physically salient color singletons, we would expect them to capture attention on the basis of this physical salience in a stimulus-driven fashion (Theeuwes, 1992). The important finding is that the likelihood of capture was also influenced by the learned value of the distractors, independently of their physical salience; hence, our description of value-modulated capture (as opposed to value-driven capture, which refers to a case in which the reward drives capture by a non-physically-salient stimulus that would not otherwise capture attention; see, e.g., Anderson, Laurent, & Yantis, 2011).
This procedure for identifying “learners” is conservative because, if a group of participants have not learned the value of valued distractors, we would expect their contingency belief scores to be randomly distributed around a mean of zero. Hence, some of these participants would achieve a positive score (and so be allocated to the “learners” subgroup) by chance, even though they did not actually learn the key relationship. Overall, then, the data from the “learners” subgroup are likely to provide an underestimate of the true influence of learning in this task. In line with this idea, the results of a correlational analysis reported later suggest that participants whose contingency belief scores provided stronger evidence of learning also tended to show a larger influence of learned value on performance in the RSVP task.
This ANCOVA finding of a main effect of distractor was unexpected. It suggests that overall, participants were less accurate on valued than on neutral trials (p = .05)—that is, an overall effect of learned value. However, the t test comparing valued and neutral trials across all participants (reported earlier) was nonsignificant (p = .17). These two tests used the same data but produced different results. The lower p value for the ANCOVA finding seems to result from both the inclusion of the between-subjects subgroup factor and the inclusion of picture assignment as a covariate. The contribution of the covariate is shown in that the ANCOVA gives a main effect of distractor at p = .033 even if the between-subjects subgroup factor is omitted. The contribution of the subgroup factor is shown in that a Subgroup × Distractor ANOVA (i.e., omitting the covariate) gives a main effect of distractor that approaches significance (p = .069).
References
Anderson, B. A. (2016). The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences, 1369, 24–39. doi:10.1111/nyas.12957
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108, 10367–10371.
Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16, 437–443. doi:10.1016/j.tics.2012.06.010
Bocanegra, B. R., & Zeelenberg, R. (2009). Dissociating emotion-induced blindness and hypervision. Emotion, 9, 865–873. doi:10.1037/a0017749
Bucker, B., Belopolsky, A. V., & Theeuwes, J. (2015). Distractors that signal reward attract the eyes. Visual Cognition, 23, 1–24. doi:10.1080/13506285.2014.980483
Bucker, B., & Theeuwes, J. (2014). The effect of reward on orienting and reorienting in exogenous cuing. Cognitive, Affective, & Behavioral Neuroscience, 14, 635–646. doi:10.3758/s13415-014-0278-7
Carver, C. S., & White, T. L. (1994). Behavioral inhibition, behavioral activation, and affective responses to impending reward and punishment: The BIS/BAS scales. Journal of Personality and Social Psychology, 67, 319–333. doi:10.1037/0022-3514.67.2.319
Ciesielski, B. G., Armstrong, T., Zald, D. H., & Olatunji, B. O. (2010). Emotion modulation of visual attention: Categorical and temporal characteristics. PLoS ONE, 5(e13860), 1–6. doi:10.1371/journal.pone.0013860
Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience, 3, 201–215. doi:10.1038/nrn755
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorial in Quantitative Methods for Psychology, 1, 42–45.
Dell’Acqua, R., Pierre, J., Pascali, A., & Pluchino, P. (2007). Short-term consolidation of individual identities leads to Lag-1 sparing. Journal of Experimental Psychology: Human Perception and Performance, 33, 593–609. doi:10.1037/0096-1523.33.3.593
Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychological Science, 20, 778–784. doi:10.1111/j.1467-9280.2009.02360.x
Derryberry, D., & Reed, M. A. (2002). Anxiety-related attentional biases and their regulation by attentional control. Journal of Abnormal Psychology, 111, 225–236. doi:10.1037/0021-843x.111.2.225
Engelmann, J. B., & Pessoa, L. (2007). Motivation sharpens exogenous spatial attention. Emotion, 7, 668–674. doi:10.1037/1528-3542.7.3.668
Failing, M. F., Nissens, T., Pearson, D., Le Pelley, M. E., & Theeuwes, J. (2015). Oculomotor capture by stimuli that signal the availability of reward. Journal of Neurophysiology, 114, 2316–2327. doi:10.1152/jn.00441.2015
Failing, M. F., & Theeuwes, J. (2015). Nonspatial attentional capture by previously rewarded scene semantics. Visual Cognition, 23, 82–104. doi:10.1080/13506285.2014.990546
Folk, C. L., Leber, A. B., & Egeth, H. E. (2002). Made you blink! Contingent attentional capture produces a spatial blink. Perception & Psychophysics, 64, 741–753. doi:10.3758/BF03194741
Folk, C. L., Leber, A. B., & Egeth, H. E. (2008). Top-down control settings and the attentional blink: Evidence for nonspatial contingent capture. Visual Cognition, 16, 616–642. doi:10.1080/13506280601134018
Gottlieb, J., Hayhoe, M., Hikosaka, O., & Rangel, A. (2014). Attention, reward, and information seeking. Journal of Neuroscience, 34, 15497–15504. doi:10.1523/JNEUROSCI.3270-14.2014
Hopf, J. M., Schoenfeld, M. A., Buschschulte, A., Rautzenberg, A., Krebs, R. M., & Boehler, C. N. (2015). The modulatory impact of reward and attention on global feature selection in human visual cortex. Visual Cognition, 23, 229–248. doi:10.1080/13506285.2015.1011252
Kennedy, B. L., & Most, S. B. (2015a). Affective stimuli capture attention regardless of categorical distinctiveness: An emotion-induced blindness study. Visual Cognition, 23, 105–117.
Kennedy, B. L., & Most, S. B. (2015b). The rapid perceptual impact of emotional distractors. PLoS ONE, 10, e0129320. doi:10.1371/journal.pone.0129320
Kleiner, M., Brainard, D., Pelli, D., & ECVP Abstract Supplement. (2007). What’s new in Psychtoolbox-3? Perception, 36, 14.
Kyllingsbaek, S., Schneider, W. X., & Bundesen, C. (2001). Automatic attraction of attention to former targets in visual displays of letters. Perception & Psychophysics, 63, 85–98. doi:10.3758/Bf03200505
Le Pelley, M. E., Mitchell, C. J., Beesley, T., George, D. N., & Wills, A. J. (2016). Attention and associative learning in humans: An integrative review. Psychological Bulletin, 142, 1111–1140. doi:10.1037/bul0000064
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158–171. doi:10.1037/xge0000037
Luque, D., Beesley, T., Morris, R. W., Jack, B. N., Griffiths, O., Whitford, T. J., & Le Pelley, M. E. (2017). Goal-directed and habit-like modulations of stimulus processing during reinforcement learning. Journal of Neuroscience, 37, 3009–3017. doi:10.1523/JNEUROSCI.3205-16.2017
Mine, C., & Saiki, J. (2015). Task-irrelevant stimulus-reward association induces value-driven attentional capture. Attention, Perception, & Psychophysics.. doi:10.3758/s13414-015-0894-5
Most, S. B., Chun, M. M., Widders, D. M., & Zald, D. H. (2005). Attentional rubbernecking: Cognitive control and personality in emotion-induced blindness. Psychonomic Bulletin & Review, 12, 654–661. doi:10.3758/Bf03196754
Most, S. B., Laurenceau, J. P., Graber, E., Belcher, A., & Smith, C. V. (2010). Blind jealousy? Romantic insecurity increases emotion-induced failures of visual perception. Emotion, 10, 250–256. doi:10.1037/a0019007
Most, S. B., Smith, S. D., Cooter, A. B., Levy, B. N., & Zald, D. H. (2007). The naked truth: Positive, arousing distractors impair rapid target perception. Cognition and Emotion, 21, 964–981. doi:10.1080/0269993060959340
Most, S. B., & Wang, L. L. (2011). Dissociating spatial attention and awareness in emotion-induced blindness. Psychological Science, 22, 300–305. doi:10.1177/0956797610397665
O’Brien, J. L., & Raymond, J. E. (2012). Learned predictiveness speeds visual processing. Psychological Science, 23, 359–363. doi:10.1177/0956797611429800
Patton, J. H., Stanford, M. S., & Barratt, E. S. (1995). Factor structure of the Barratt Impulsiveness Scale. Journal of Clinical Psychology, 51, 768–774. doi:10.1002/1097-4679(199511)51:6<768::Aid-Jclp2270510607>3.0.Co;2-1
Pearson, D., Donkin, C., Tran, S. C., Most, S. B., & Le Pelley, M. E. (2015). Cognitive control and counterproductive oculomotor capture by reward-related stimuli. Visual Cognition, 23, 41–66. doi:10.1080/13506285.2014.994252
Pearson, D., Osborn, R., Whitford, T. J., Failing, M., Theeuwes, J., & Le Pelley, M. E. (2016). Value-modulated oculomotor capture by task-irrelevant stimuli is a consequence of early competition on the saccade map. Attention, Perception, & Psychophysics, 78, 2226–2240. doi:10.3758/s13414-016-1135-2
Pessoa, L., & Engelmann, J. B. (2010). Embedding reward signals into perception and cognition. Frontiers in Neuroscience, 4. doi:10.3389/fnins.2010.00017
Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation: The consequences of value learning in an attentional blink task. Psychological Science, 20, 981–988. doi:10.1111/j.1467-9280.2009.02391.x
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18, 849–860. doi:10.1037/0096-1523.18.3.849
Smith, S. D., Most, S. B., Newsome, L. A., & Zald, D. H. (2006). An emotion-induced attentional blink elicited by aversively conditioned stimuli. Emotion, 6, 523–527. doi:10.1037/1528-3542.6.3.523
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606. doi:10.3758/Bf03211656
Visser, T. A. W., Bischof, W. F., & Di Lollo, V. (1999). Attentional switching in spatial and nonspatial domains: Evidence from the attentional blink. Psychological Bulletin, 125, 458–469. doi:10.1037/0033-2909.125.4.458
Wang, L., Kennedy, B. L., & Most, S. B. (2012). When emotion blinds: A spatiotemporal competition account of emotion-induced blindness. Frontiers in Psychology, 3, 438. doi:10.3389/fpsyg.2012.00438
Wang, L., Yu, H., & Zhou, X. (2013). Interaction between value and perceptual salience in value-driven attentional capture. Journal of Vision, 13(3), 1–13. doi:10.1167/13.3.5
Wegner, D. M. (1994). Ironic processes of mental control. Psychological Review, 101, 34–52. doi:10.1037/0033-295x.101.1.34
Wentura, D., Müller, P., & Rothermund, K. (2014). Attentional capture by evaluative stimuli: Gain- and loss-connoting colors boost the additional-singleton effect. Psychonomic Bulletin & Review, 21, 701–707. doi:10.3758/s13423-013-0531-z
Yantis, S. (2000). Goal-directed and stimulus-driven determinants of attentional control. In S. Monsell & J. Driver (Eds.), Attention and performance XVIII (pp. 73–103). Cambridge: MIT Press.
Author note
We thank Michel Failing for helpful comments on a draft of the manuscript, Lucy Hudson for assistance with data collection, and Clayton Hickey for suggesting the design that formed the basis of Experiment 4. This research was supported by Australian Research Council Grants FT100100260, FT120100707, and DP170101715.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
ESM 1
(DOC 32.8 kb)
Rights and permissions
About this article

Cite this article
Le Pelley, M.E., Seabrooke, T., Kennedy, B.L. et al. Miss it and miss out: Counterproductive nonspatial attentional capture by task-irrelevant, value-related stimuli. Atten Percept Psychophys 79, 1628–1642 (2017). https://doi.org/10.3758/s13414-017-1346-1
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-017-1346-1