
Influenza NA and PB1 Gene Segments Interact during the Formation of Viral Progeny: Localization of the Binding Region within the PB1 Gene

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Cells and Media
2.2. Construction of Reverse-Engineered Influenza Viruses
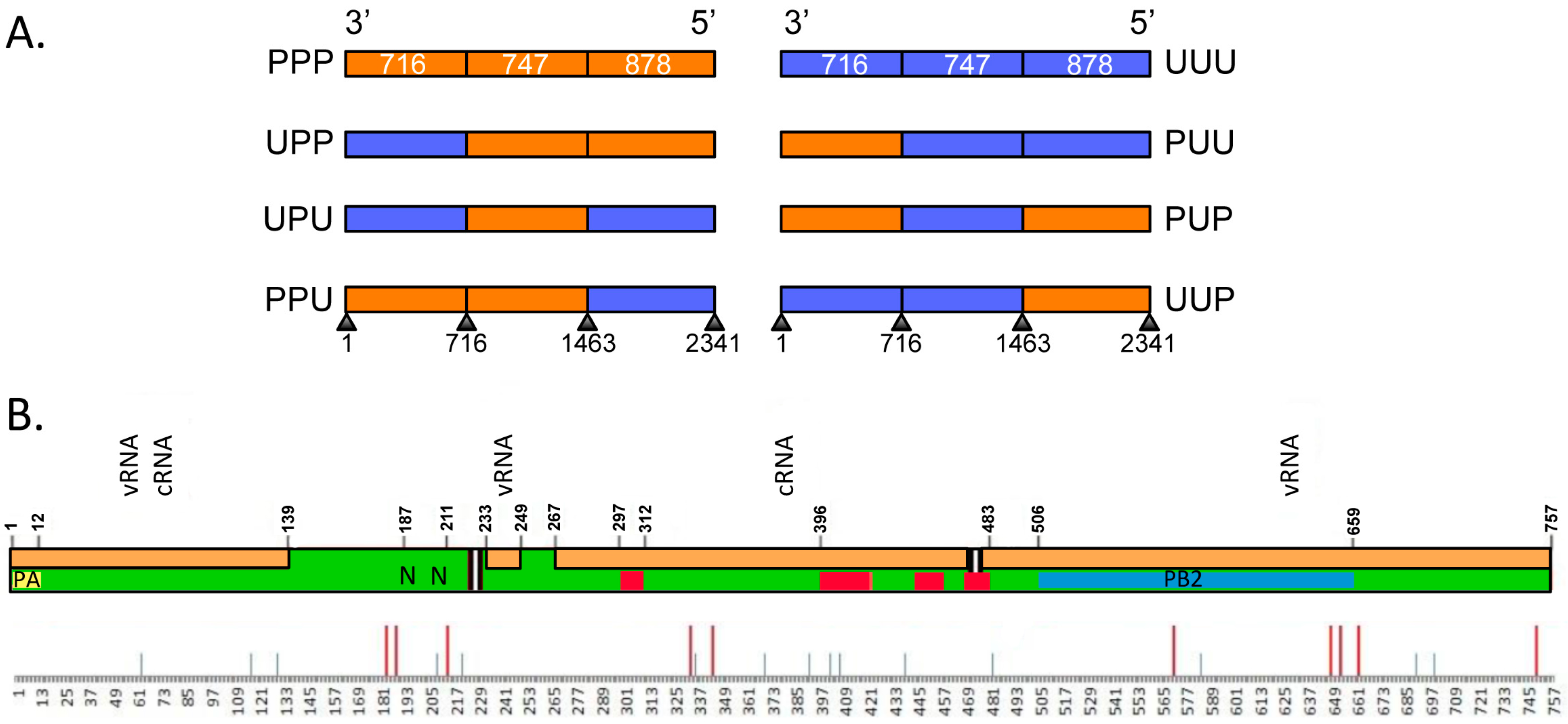
2.3. Construction of Plasmids Expressing Chimeric PB1 Gene Segments
2.4. Minigenome Assay for Polymerase Activity
2.5. Determination of Viral Replication Kinetics
2.6. Nine-Plasmid Competitive Transfections
2.7. Gene-Specific RT-PCR
2.8. In Vitro Transcription and Electrophoretic Mobility Assay
3. Results
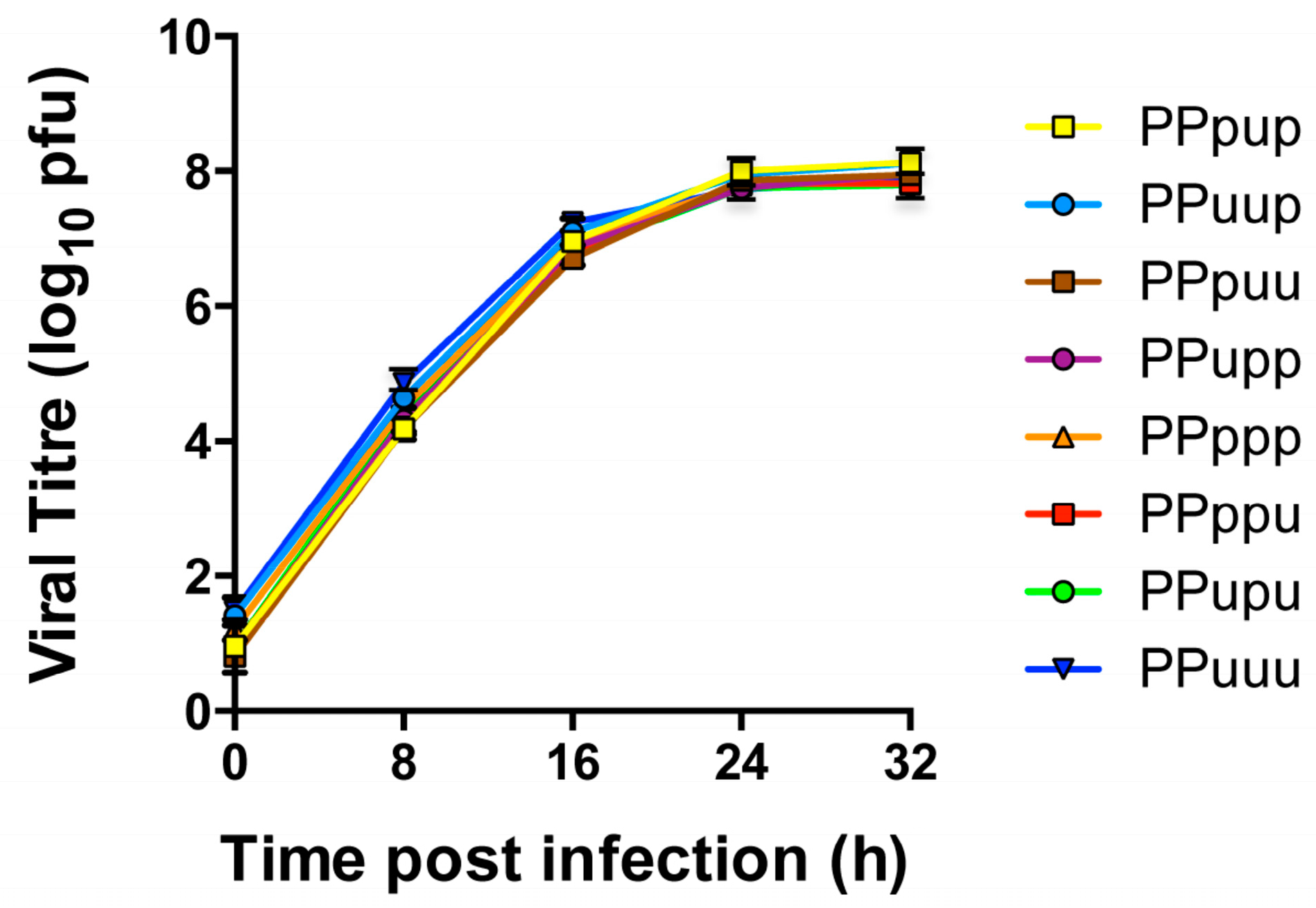
3.1. Viruses Expressing Chimeric PB1 Genes Show No Major Differences in Replication in Vitro
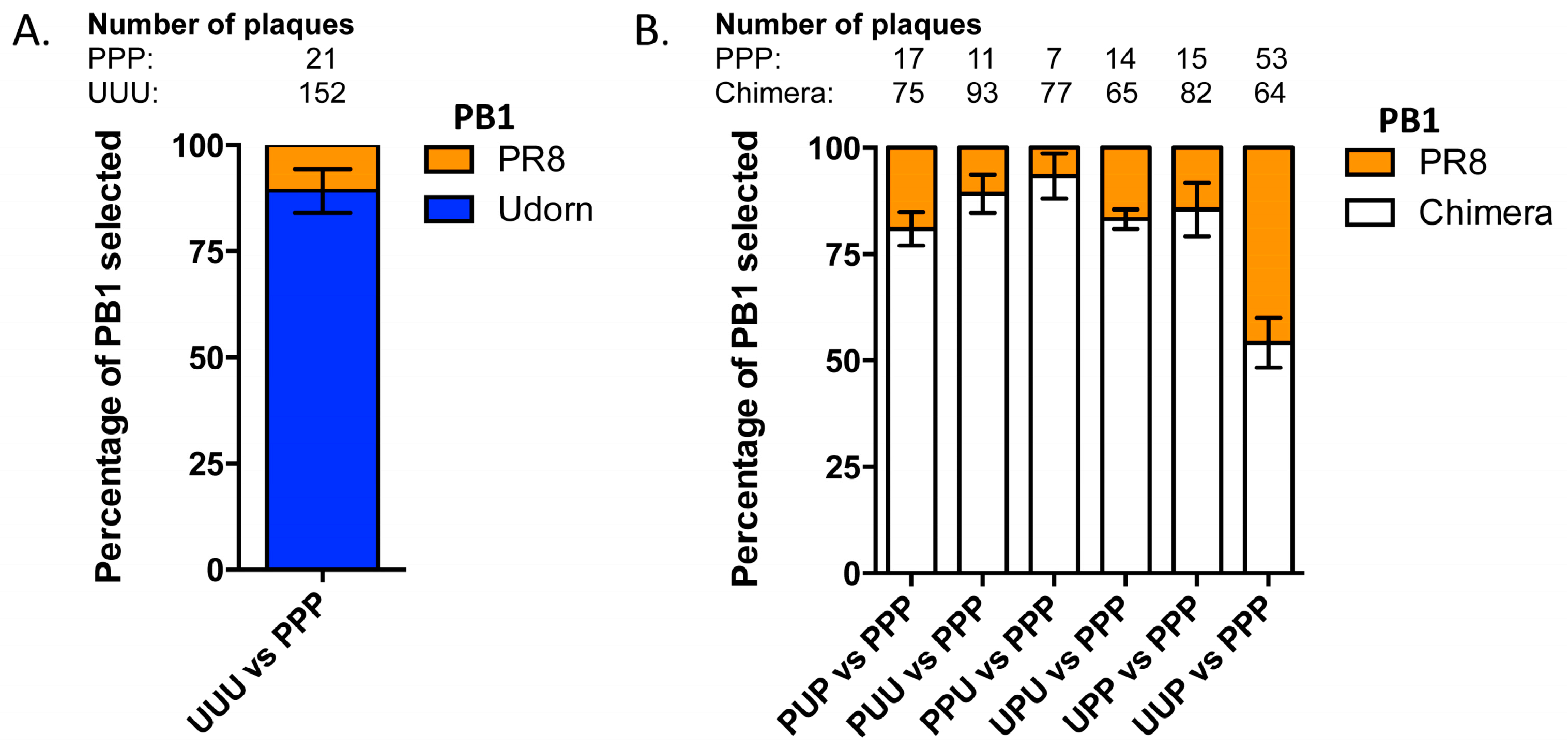
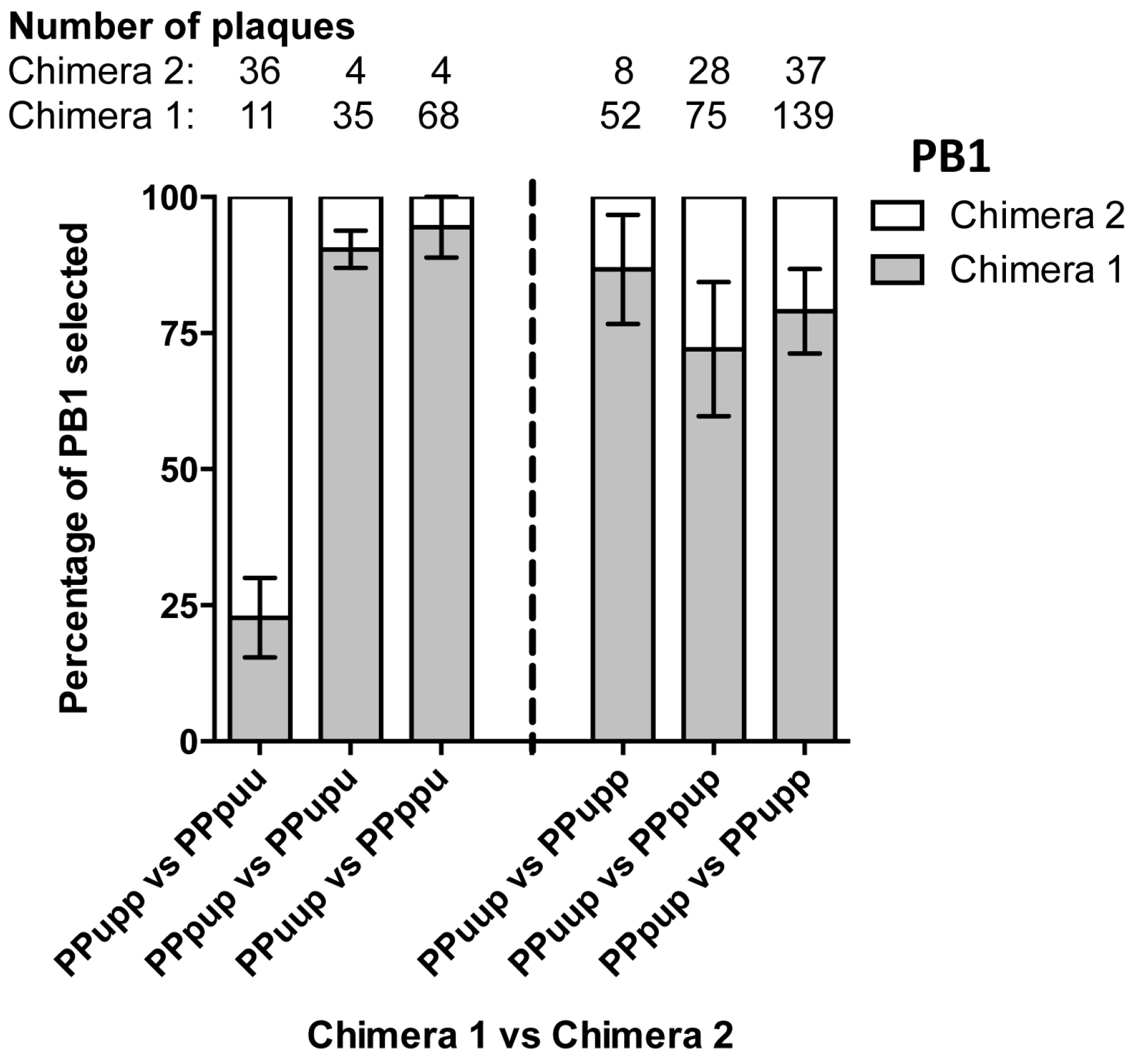
3.2. Nine Plasmid Competitive Transfections Reveal Chimeras Expressing Any Section of Udorn PB1 Are Preferentially Selected Over PR8 PB1 in Progeny Virus
3.3. The Last Third of PB1 RNA Is Driving Preferential Co-Selection of Udorn PB1 and Udorn NA
3.4. Viruses Expressing 5′ Chimeric PB1 Genes Show No Major Differences in Replication in Vitro
3.5. The PB1 RNA Segment Containing Nucleotides 1776–2070 Is Driving Preferential Coselection of Udorn PB1 and Udorn NA
3.6. RNA-RNA Binding Studies Recapitulate Strong and Weak Interactions Predicted by Nine-Plasmid Competitive Transfections
4. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hsu, M.T.; Parvin, J.D.; Gupta, S.; Krystal, M.; Palese, P. Genomic RNAs of influenza viruses are held in a circular conformation in virions and in infected cells by a terminal panhandle. Proc. Natl. Acad. Sci. USA 1987, 84, 8140–8144. [Google Scholar] [CrossRef] [PubMed]
- Compans, R.W.; Content, J.; Duesberg, P.H. Structure of the ribonucleoprotein of influenza virus. J. Virol. 1972, 10, 795–800. [Google Scholar] [PubMed]
- Pons, M.W.; Schulze, I.T.; Hirst, G.K.; Hauser, R. Isolation and characterization of the ribonucleoprotein of influenza virus. Virology 1969, 39, 250–259. [Google Scholar] [CrossRef]
- Pflug, A.; Guilligay, D.; Reich, S.; Cusack, S. Structure of influenza A polymerase bound to the viral RNA promoter. Nature 2014, 516, 355–360. [Google Scholar] [CrossRef] [PubMed]
- Eisfeld, A.J.; Neumann, G.; Kawaoka, Y. At the centre: Influenza A virus ribonucleoproteins. Nat. Rev. Microbiol. 2015, 13, 28–41. [Google Scholar] [CrossRef] [PubMed]
- Harris, A.; Cardone, G.; Winkler, D.C.; Heymann, J.B.; Brecher, M.; White, J.M.; Steven, A.C. Influenza virus pleiomorphy characterized by cryoelectron tomography. Proc. Natl. Acad. Sci. USA 2006, 103, 19123–19127. [Google Scholar] [CrossRef] [PubMed]
- Noda, T.; Sagara, H.; Yen, A.; Takada, A.; Kida, H.; Cheng, R.H.; Kawaoka, Y. Architecture of ribonucleoprotein complexes in influenza A virus particles. Nature 2006, 439, 490–492. [Google Scholar] [CrossRef] [PubMed]
- Noda, T.; Sugita, Y.; Aoyama, K.; Hirase, A.; Kawakami, E.; Miyazawa, A.; Sagara, H.; Kawaoka, Y. Three-dimensional analysis of ribonucleoprotein complexes in influenza A virus. Nat. Commun. 2012, 3, 639. [Google Scholar] [CrossRef] [PubMed]
- Fournier, E.; Moules, V.; Essere, B.; Paillart, J.C.; Sirbat, J.D.; Isel, C.; Cavalier, A.; Rolland, J.P.; Thomas, D.; Lina, B.; Marquet, R. A supramolecular assembly formed by influenza A virus genomic RNA segments. Nucleic Acids Res. 2012, 40, 2197–2209. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chou, Y.Y.; Vafabakhsh, R.; Doganay, S.; Gao, Q.; Ha, T.; Palese, P. One influenza virus particle packages eight unique viral RNAs as shown by FISH analysis. Proc. Natl. Acad. Sci. USA 2012, 109, 9101–9106. [Google Scholar] [CrossRef] [PubMed]
- Inagaki, A.; Goto, H.; Kakugawa, S.; Ozawa, M.; Kawaoka, Y. Competitive incorporation of homologous gene segments of influenza A virus into virions. J. Virol. 2012, 86, 10200–10202. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, E.C.; von Kirchbach, J.C.; Gog, J.R.; Digard, P. Genome packaging in influenza A virus. J. Gen. Virol. 2010, 91, 313–328. [Google Scholar] [CrossRef] [PubMed]
- Gerber, M.; Isel, C.; Moules, V.; Marquet, R. Selective packaging of the influenza A genome and consequences for genetic reassortment. Trends Microbiol. 2014, 22, 446–455. [Google Scholar] [CrossRef] [PubMed]
- Marsh, G.A.; Hatami, R.; Palese, P. Specific residues of the influenza A virus hemagglutinin viral RNA are important for efficient packaging into budding virions. J. Virol. 2007, 81, 9727–9736. [Google Scholar] [CrossRef] [PubMed]
- Marsh, G.A.; Rabadan, R.; Levine, A.J.; Palese, P. Highly conserved regions of influenza A virus polymerase gene segments are critical for efficient viral RNA packaging. J. Virol. 2008, 82, 2295–2304. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, E.C.; Curran, M.D.; Read, E.K.; Gog, J.R.; Digard, P. Mutational analysis of cis-acting RNA signals in segment 7 of influenza A virus. J. Virol. 2008, 82, 11869–11879. [Google Scholar] [CrossRef] [PubMed]
- Fournier, E.; Moules, V.; Essere, B.; Paillart, J.C.; Sirbat, J.D.; Cavalier, A.; Rolland, J.P.; Thomas, D.; Lina, B.; Isel, C.; et al. Interaction network linking the human H3N2 influenza A virus genomic RNA segments. Vaccine 2012, 30, 7359–7367. [Google Scholar] [CrossRef] [PubMed]
- Gavazzi, C.; Isel, C.; Fournier, E.; Moules, V.; Cavalier, A.; Thomas, D.; Lina, B.; Marquet, R. An in vitro network of intermolecular interactions between viral RNA segments of an avian H5N2 influenza A virus: comparison with a human H3N2 virus. Nucleic Acids Res. 2013, 41, 1241–1254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hatta, M.; Halfmann, P.; Wells, K.; Kawaoka, Y. Human influenza A viral genes responsible for the restriction of its replication in duck intestine. Virology 2002, 295, 250–255. [Google Scholar] [CrossRef] [PubMed]
- Jackson, S.; Van Hoeven, N.; Chen, L.M.; Maines, T.R.; Cox, N.J.; Katz, J.M.; Donis, R.O. Reassortment between avian H5N1 and human H3N2 influenza viruses in ferrets: A public health risk assessment. J. Virol. 2009, 83, 8131–8140. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Hatta, M.; Watanabe, S.; Neumann, G.; Kawaoka, Y. Compatibility among polymerase subunit proteins is a restricting factor in reassortment between equine H7N7 and human H3N2 influenza viruses. J. Virol. 2008, 82, 11880–11888. [Google Scholar] [CrossRef] [PubMed]
- Essere, B.; Yver, M.; Gavazzi, C.; Terrier, O.; Isel, C.; Fournier, E.; Giroux, F.; Textoris, J.; Julien, T.; Socratous, C.; et al. Critical role of segment-specific packaging signals in genetic reassortment of influenza A viruses. Proc. Natl. Acad. Sci. USA 2013, 110, E3840–E3848. [Google Scholar] [CrossRef] [PubMed]
- Octaviani, C.P.; Ozawa, M.; Yamada, S.; Goto, H.; Kawaoka, Y. High level of genetic compatibility between swine-origin H1N1 and highly pathogenic avian H5N1 influenza viruses. J. Virol. 2010, 84, 10918–10922. [Google Scholar] [CrossRef] [PubMed]
- Cobbin, J.C.; Ong, C.; Verity, E.; Gilbertson, B.P.; Rockman, S.P.; Brown, L.E. Influenza virus PB1 and neuraminidase gene segments can cosegregate during vaccine reassortment driven by interactions in the PB1 coding region. J. Virol. 2014, 88, 8971–8980. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.M.; Davis, C.T.; Zhou, H.; Cox, N.J.; Donis, R.O. Genetic compatibility and virulence of reassortants derived from contemporary avian H5N1 and human H3N2 influenza A viruses. PLoS Pathog. 2008, 4, e1000072. [Google Scholar] [CrossRef] [PubMed]
- Hara, K.; Nakazono, Y.; Kashiwagi, T.; Hamada, N.; Watanabe, H. Co-incorporation of the PB2 and PA polymerase subunits from human H3N2 influenza virus is a critical determinant of the replication of reassortant ribonucleoprotein complexes. J. Gen. Virol. 2013, 94, 2406–2416. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Hatta, M.; Nidom, C.A.; Muramoto, Y.; Watanabe, S.; Neumann, G.; Kawaoka, Y. Reassortment between avian H5N1 and human H3N2 influenza viruses creates hybrid viruses with substantial virulence. Proc. Natl. Acad. Sci. USA 2010, 107, 4687–4692. [Google Scholar] [CrossRef] [PubMed]
- Octaviani, C.P.; Goto, H.; Kawaoka, Y. Reassortment between seasonal H1N1 and pandemic (H1N1) 2009 influenza viruses is restricted by limited compatibility among polymerase subunits. J. Virol. 2011, 85, 8449–8452. [Google Scholar] [CrossRef] [PubMed]
- Marshall, N.; Priyamvada, L.; Ende, Z.; Steel, J.; Lowen, A.C. Influenza virus reassortment occurs with high frequency in the absence of segment mismatch. PLoS Pathog. 2013, 9, e1003421. [Google Scholar] [CrossRef] [PubMed]
- Bergeron, C.; Valette, M.; Lina, B.; Ottmann, M. Genetic content of Influenza H3N2 vaccine seeds. PLoS Curr. 2010, 2, RRN1165. [Google Scholar] [CrossRef]
- Fulvini, A.A.; Ramanunninair, M.; Le, J.; Pokorny, B.A.; Arroyo, J.M.; Silverman, J.; Devis, R.; Bucher, D. Gene constellation of influenza A virus reassortants with high growth phenotype prepared as seed candidates for vaccine production. PLoS ONE 2011, 6, e20823. [Google Scholar] [CrossRef] [PubMed]
- Cobbin, J.C.; Verity, E.E.; Gilbertson, B.P.; Rockman, S.P.; Brown, L.E. The source of the PB1 gene in influenza vaccine reassortants selectively alters the hemagglutinin content of the resulting seed virus. J. Virol. 2013, 87, 5577–5585. [Google Scholar] [CrossRef] [PubMed]
- Hoffmann, E.; Neumann, G.; Kawaoka, Y.; Hobom, G.; Webster, R.G. A DNA transfection system for generation of influenza A virus from eight plasmids. Proc. Natl. Acad. Sci. USA 2000, 97, 6108–6113. [Google Scholar] [CrossRef] [PubMed]
- Tannock, G.A.; Paul, J.A.; Barry, R.D. Relative immunogenicity of the cold-adapted influenza virus A/Ann Arbor/6/60 (A/AA/6/60-ca), recombinants of A/AA/6/60-ca, and parental strains with similar surface antigens. Infect. Immun. 1984, 43, 457–462. [Google Scholar] [PubMed]
- Hoffmann, E.; Stech, J.; Guan, Y.; Webster, R.G.; Perez, D.R. Universal primer set for the full-length amplification of all influenza A viruses. Arch. Virol. 2001, 146, 2275–2289. [Google Scholar] [CrossRef] [PubMed]
- Cavrois, M.; De Noronha, C.; Greene, W.C. A sensitive and specific enzyme-based assay detecting HIV-1 virion fusion in primary T lymphocytes. Nat. Biotechnol. 2002, 20, 1151–1154. [Google Scholar] [CrossRef] [PubMed]
- Naffakh, N.; Tomoiu, A.; Rameix-Welti, M.A.; van der Werf, S. Host restriction of avian influenza viruses at the level of the ribonucleoproteins. Annu. Rev. Microbiol. 2008, 62, 403–424. [Google Scholar] [CrossRef] [PubMed]
- Nath, S.T.; Nayak, D.P. Function of two discrete regions is required for nuclear localization of polymerase basic protein 1 of A/WSN/33 influenza virus (H1N1). Mol. Cell. Biol. 1990, 10, 4139–4145. [Google Scholar] [CrossRef] [PubMed]
- Biswas, S.K.; Nayak, D.P. Mutational analysis of the conserved motifs of influenza A virus polymerase basic protein 1. J. Virol. 1994, 68, 1819–1826. [Google Scholar] [PubMed]
- Poch, O.; Sauvaget, I.; Delarue, M.; Tordo, N. Identification of four conserved motifs among the RNA-dependent polymerase encoding elements. EMBO J. 1989, 8, 3867–3874. [Google Scholar] [PubMed]
- Gonzalez, S.; Ortin, J. Distinct regions of influenza virus PB1 polymerase subunit recognize vRNA and cRNA templates. EMBO J. 1999, 18, 3767–3775. [Google Scholar] [CrossRef] [PubMed]
- Fujii, K.; Fujii, Y.; Noda, T.; Muramoto, Y.; Watanabe, T.; Takada, A.; Goto, H.; Horimoto, T.; Kawaoka, Y. Importance of both the coding and the segment-specific noncoding regions of the influenza A virus NS segment for its efficient incorporation into virions. J. Virol. 2005, 79, 3766–3774. [Google Scholar] [CrossRef] [PubMed]
- Kingsford, C.; Nagarajan, N.; Salzberg, S.L. 2009 Swine-origin influenza A (H1N1) resembles previous influenza isolates. PLoS ONE 2009, 4, e6402. [Google Scholar] [CrossRef] [PubMed]
- Kawaoka, Y.; Krauss, S.; Webster, R.G. Avian-to-human transmission of the PB1 gene of influenza A viruses in the 1957 and 1968 pandemics. J. Virol. 1989, 63, 4603–4608. [Google Scholar] [PubMed]
- Scholtissek, C.; Rohde, W.; Von Hoyningen, V.; Rott, R. On the origin of the human influenza virus subtypes H2N2 and H3N2. Virology 1978, 87, 13–20. [Google Scholar] [CrossRef]
- Chen, W.; Calvo, P.A.; Malide, D.; Gibbs, J.; Schubert, U.; Bacik, I.; Basta, S.; O‘Neill, R.; Schickli, J.; Palese, P.; et al. A novel influenza A virus mitochondrial protein that induces cell death. Nat. Med. 2001, 7, 1306–1312. [Google Scholar] [CrossRef] [PubMed]
- McAuley, J.L.; Tate, M.D.; MacKenzie-Kludas, C.J.; Pinar, A.; Zeng, W.; Stutz, A.; Latz, E.; Brown, L.E.; Mansell, A. Activation of the NLRP3 inflammasome by IAV virulence protein PB1-F2 contributes to severe pathophysiology and disease. PLoS Pathog. 2013, 9, e1003392. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region of PB1 | Nucleotides | Length (nt) | Nucleotide Homology | Amino Acid Differences |
|---|---|---|---|---|
| Overall | 1–2341 | 2341 | 83.7% | 25 |
| First third | 1–716 | 716 | 85.2% | 8 |
| Middle third | 717–1463 | 747 | 82.6% | 9 |
| Last third | 1464–2341 | 878 | 83.7% | 8 |
| Region within the Last (5′) Third of PB1 | Nucleotides | Length (nt) | Nucleotide Homology | Amino Acid Differences |
|---|---|---|---|---|
| Last 5′ third overall | 1464–2341 | 878 | 83.7% | 8 |
| First third of 5′ | 1464–1775 | 312 | 83.9% | 2 |
| Middle third of 5′ | 1776–2070 | 295 | 79.5% | 4 |
| Last third of 5′ | 2071–2341 | 271 | 86.6% | 2 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gilbertson, B.; Zheng, T.; Gerber, M.; Printz-Schweigert, A.; Ong, C.; Marquet, R.; Isel, C.; Rockman, S.; Brown, L. Influenza NA and PB1 Gene Segments Interact during the Formation of Viral Progeny: Localization of the Binding Region within the PB1 Gene. Viruses 2016, 8, 238. https://doi.org/10.3390/v8080238
Gilbertson B, Zheng T, Gerber M, Printz-Schweigert A, Ong C, Marquet R, Isel C, Rockman S, Brown L. Influenza NA and PB1 Gene Segments Interact during the Formation of Viral Progeny: Localization of the Binding Region within the PB1 Gene. Viruses. 2016; 8(8):238. https://doi.org/10.3390/v8080238
Chicago/Turabian StyleGilbertson, Brad, Tian Zheng, Marie Gerber, Anne Printz-Schweigert, Chi Ong, Roland Marquet, Catherine Isel, Steven Rockman, and Lorena Brown. 2016. "Influenza NA and PB1 Gene Segments Interact during the Formation of Viral Progeny: Localization of the Binding Region within the PB1 Gene" Viruses 8, no. 8: 238. https://doi.org/10.3390/v8080238