
A Machine Learning Approach to Determine Airport Asphalt Concrete Layer Moduli Using Heavy Weight Deflectometer Data





1
Polytechnic Department of Engineering and Architecture (DPIA), University of Udine, Via del Cotonificio 114, 33100 Udine, Italy
2
Department of Engineering, University of Palermo, Viale delle Scienze, Ed. 8, 90128 Palermo, Italy
*
Author to whom correspondence should be addressed.
Sustainability 2021, 13(16), 8831; https://doi.org/10.3390/su13168831
Submission received: 1 July 2021
/
Revised: 30 July 2021
/
Accepted: 3 August 2021
/
Published: 6 August 2021
(This article belongs to the Special Issue Transportation Safety and Pavement Management)
Abstract
:An integrated approach based on machine learning and data augmentation techniques has been developed in order to predict the stiffness modulus of the asphalt concrete layer of an airport runway, from data acquired with a heavy weight deflectometer (HWD). The predictive model relies on a shallow neural network (SNN) trained with the results of a backcalculation, by means of a data augmentation method and can produce estimations of the stiffness modulus even at runway points not yet sampled. The Bayesian regularization algorithm was used for training of the feedforward backpropagation SNN, and a k-fold cross-validation procedure was implemented for a fair performance evaluation. The testing phase result concerning the stiffness modulus prediction was characterized by a coefficient of correlation equal to 0.9864 demonstrating that the proposed neural approach is fully reliable for performance evaluation of airfield pavements or any other paved area. Such a performance prediction model can play a crucial role in airport pavement management systems (APMS), allowing the maintenance budget to be optimized.
1. Introduction
Road networks and airport areas are key assets [1] for both developed and developing countries [2]. Maintenance work costs are more significant for developed countries, while first construction work costs are more relevant for developing ones [3]. However, both maintenance and construction work require huge natural resource consumption in terms of aggregates and bituminous binder. In fact, such transport infrastructures have a great impact on energy consumption for the industrial productions involved and the related emissions, given that their service life fixed is in several tens of years [4]. In this regard, the prediction of long-term performance is fundamental, particularly the mechanical strength (stiffness modulus) from repeated investigations over time, in order to properly implement maintenance and rehabilitation (M&R) strategies to achieve sustainable technical, economic, and environmental solutions [5]. It is widely recognized that efficient airport management has positive environmental effects both in reducing major airport congestion and in minimizing land consumption by making a better use of existing infrastructures [6], thus improving the sustainability of airport construction.
The runway is the most important airport infrastructure as it has to ensure adequate operability whatever the traffic and weather conditions. However, there are many causes that can lead to its deterioration such as aging, increased traffic demand, and lack of adequate investment [7]. It is therefore necessary to employ the most suitable and reliable investigation techniques [8] to assess its structural integrity, compliant with the limits of budget constraints [9]. The structural assessment of airport pavements provides valuable information about their expected behavior [10]. It is very useful for estimating their current technical suitability as well as their remaining service life. Moreover, it helps in deciding what rehabilitation strategies to adopt if the frame of a proper airport pavement management system (APMS).
An APMS is based on the concept of preventive maintenance [11,12]: namely, intervening before emergency conditions occur and pavement functionality is compromised. The main purpose of an APMS is to support the managing authority in identifying reliable and cost-effective strategies for preserving the pavement’s proper condition over time. In order to optimize available resources, it is necessary to identify the sections of the pavement that require maintenance, the suitable maintenance solution, the intervention time, and the budget required.
To identify the sections that require structural rehabilitation, pavement structural data is typically obtained through destructive tests on pavement samples, which requires borings, cores, and excavation pits on an existing pavement [13]. These procedures were usually very expensive as they involved subsequent repair of the test pit and could cause the survey area to be closed for several days [14]. Fortunately, hardware and software technology progress has made it possible to replace these procedures with others that are faster and less intrusive, and do not compromise the structural integrity of the pavement. These new approaches, also known as non-destructive tests (NDT) still make it possible to determine the physical and mechanical properties of airport pavement but in a non-destructive manner [15]. For this reason, in recent years, there has been massive use of such tests in the fields of highway and airport pavement evaluation and design [16,17,18,19,20,21,22,23]. Among these NDT methods, the most commonly used for airfield infrastructure condition assessment is the heavy weight deflectometer (HWD) [24]. Similar to the falling weight deflectometer (FWD) which employs smaller loads for highway pavements, the HWD simulates greater aircraft wheel loads [25] and allows for rapid testing of the entire airport pavement so that maintenance and rehabilitation programs can be defined. The deflection basin resulting from the application of the load and measured by means of geophones placed at several distances from the load axis represents an overall system response, namely a good indicator of the pavement’s mechanical behavior. It is also common practice to post-process the deflections measured in order to obtain a significant combination of the deflection basin parameters (DBPs) [26] that even better characterize the structural degradation of the airport pavement [27]. In the literature, the most traditional method to process F/HWD deflections is backcalculation, for pavement layer modulus estimation. Backcalculation is also known as the parameter identification problem, and is basically an optimization process performed to obtain inverse mapping of a known constitutive relationship using discrete or continuous data points [28]. It therefore consists in a numerical analysis of the measured deflections in order to estimate the pavement layer moduli. To achieve this, the measured deflections are matched with the calculated ones. The latter are computed based on the multi-layer elastic (MLE) theory in which stresses and strains are characterized with fourth-order differential equations [29]. In practice, starting from the thickness of the layers, the magnitude of the load and some synthetic moduli (assuming values based on experience and best engineering practices), it is possible to calculate the deflections. Using different sets of moduli, the matching process is iteratively performed until the best match between computed and measured deflections is achieved [30,31,32]. Due to the simplifications introduced by the MLE theory, some studies have observed that the results produced by backcalculation are only acceptable for the pavement surface layer while base and subgrade moduli are often underestimated or overestimated [33]. The fact is that traditional backcalculation software neglect the dynamic effects of F/HWD loadings which, and in order to be implemented would require major model complexity, with consequent huge computational costs [34].
In recent years, several optimization techniques such as genetic algorithms, data mining, heuristic algorithms, and artificial neural networks (ANNs) have been increasingly used to solve similar issues [35,36]. These functional abstractions of the biological neural structure are particularly suited for hard-to-learn problems without a well-established formal theory for their solution [37]. Although ANNs work on the basis of a non-physically based approach, they are characterized by high computational efficiency and small prediction errors [38]. It is also worth pointing out that with such neural models data processing is very fast, allowing the routine F/HWD deflection analysis to be performed even in the field [39]. However, artificial neural networks usually require a large dataset to be successfully trained. For this reason, starting from multiple finite element simulations, synthetic databases are often prepared and subsequently used as input for the neural models in order to allow its proper training [40]. In this study, the goal was to develop a predictive model which can enhance the conventional backcalculation by means of advanced machine learning features. The result is an innovative soft computing tool that, using state-of-the-art data augmentation techniques and the computational effectiveness of artificial neural networks, can predict reliable values of the runway asphalt concrete modulus (), even in points not yet sampled. Since with the proposed approach, it is possible to predict the stiffness modulus by providing as input the deflections and the spatial distribution of the sampling points only, the functional relationship between such variables is respected. Compared to the traditional use of ANNs in the field of pavement engineering, the proposed approach avoids preliminary long finite element simulations for training the model. Therefore, this fast and reliable approach could be used in APMS as a support tool for the planning of intervention priorities.
By providing a numerical estimation of the modulus in an arbitrary location on the runway, the proposed pavement performance prediction model could allow us to identify the areas that most require maintenance interventions thus reducing the costs of instrumental monitoring and consequently allowing active and efficient management [41].
2. Experimental Campaign
2.1. In Situ Investigation
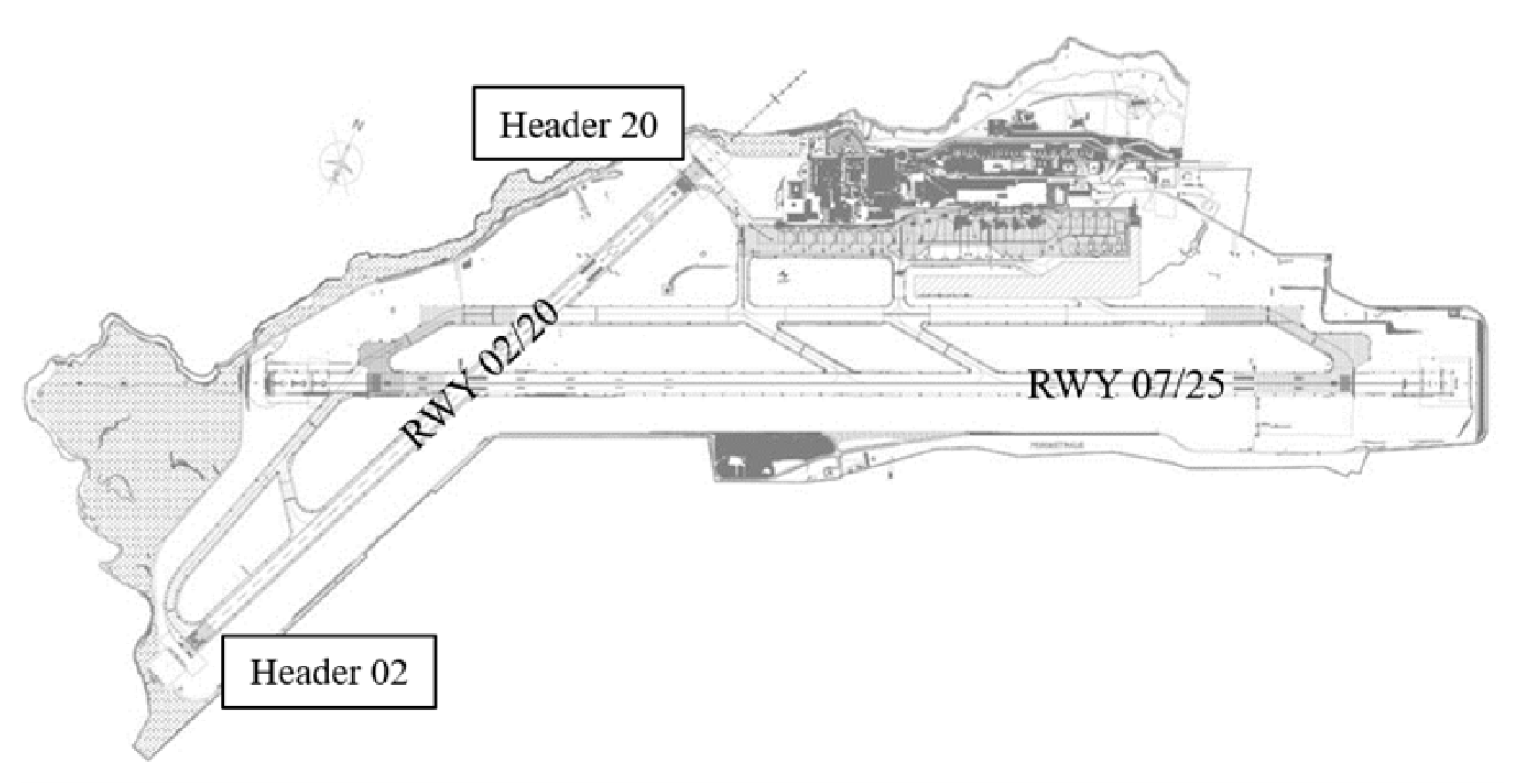
The experimental campaign took place at the “Falcone e Borsellino” airport of Palermo-Punta Raisi in the period between 9 and 29 February 2012. The Italian international airport is located 35 km west of Palermo. This infrastructure consists of two intersecting runways: the main one named Runway 07/25 and the secondary one named Runway 02/20. On the latter, deflection measurements were collected by means of a heavy weight deflectometer.
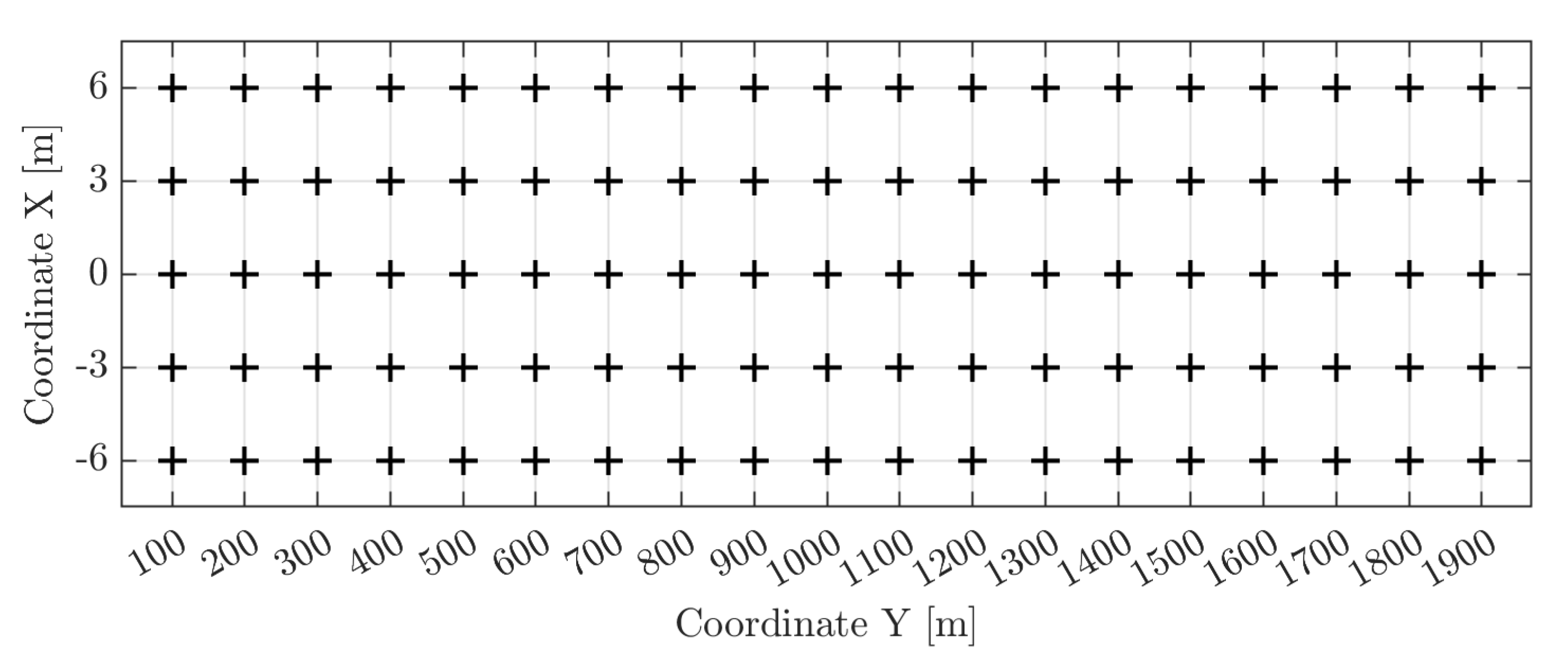
Five measurement lines were established: the central axis of the runway (0 m) and other axes ±3 m and ±6 m away from it. The portion of the runway considered, starting from header 02 in the south and arriving at header 20 in the north, was 1800 m long (Figure 1). The experiments were carried out at regular 100 m intervals, thus obtaining 19 impact points for each longitudinal axis. Since there were 5 measurement lines, the total number of measuring points was 95 (Figure 2).
The instrumentation used was the Dynatest 8000, a device capable of performing non-destructive tests and widely used to determine physical and mechanical properties of airport pavements. The principle is to induce small surface deflections of the pavement by applying an impulsive load in a controlled manner. This is done in order to better simulate the effects of an aircraft’s moving wheel [42]. The load is obtained by dropping a suspended mass from a predetermined height on a 30 cm diameter plate resting on the pavement surface. The magnitude of the impulse load transmitted by the device to the pavement can be varied from 30 kN to 240 kN by changing the weight and height of the fall. A magnitude of around 140 kN was adopted. Together with the plate, a set of accelerometric transducers is placed in contact with the pavement and is able to measure the deflections induced at several distances from the loading axis such as 0 (), 200 (), 300 (), 450 (), 600 (), 900 (), 1200 (), 1500 (), and 1800 mm () from the center of the load. This method is preferred among other methods because it is simpler, more reliable, and cheaper [43]. In fact, the costs that would be associated with reconstructing the area of operation if destructive testing were adopted are avoided [44]. A preliminary contour map of the values measured just below the loading plate (Figure 3) immediately shows that the highest deflections are located near the central axis of the pavement. This makes it possible to identify the so-called touchdown zones (TDZs), i.e., those portions of a runway, beyond the threshold, where landing airplanes are first intended to meet the runway [45]. In these areas, values exceed 900 and are more than twice or sometimes three times higher than the deflections measured moving away toward the ends of the runway. This provides a preliminary evaluation of which runway areas could require maintenance interventions.
2.2. Deflection Basin Parameters
Deflection basin parameters (DBPs) are obtained by processing the results produced by a HWD investigation and sometimes can be used to monitor the structural integrity of in-service pavements [46]. Based on a comprehensive literature review, the most widely used are:
- Surface curvature index (SCI) which provides information on changes in the near-surface layer’s relative strength.
SCI is an accurate indicator of the AC layer conditions and, for certain thicknesses, and SCI tend to show an approximately linear behavior in a log-log scale [47].
- Deflection ratio (DR) which takes into account the type and quality of materials by relating them to the ratio of two deflections.
- Area under deflection basin curve (AREA) which relates the stiffness of the pavement structure to a shape factor. In fact, it is the partial area under the deflection basin curve normalized with respect to using Simpson’s rule [48].
This is the definition of the AREA when the deflections are given in millimeters.
2.3. Backcalculation Process
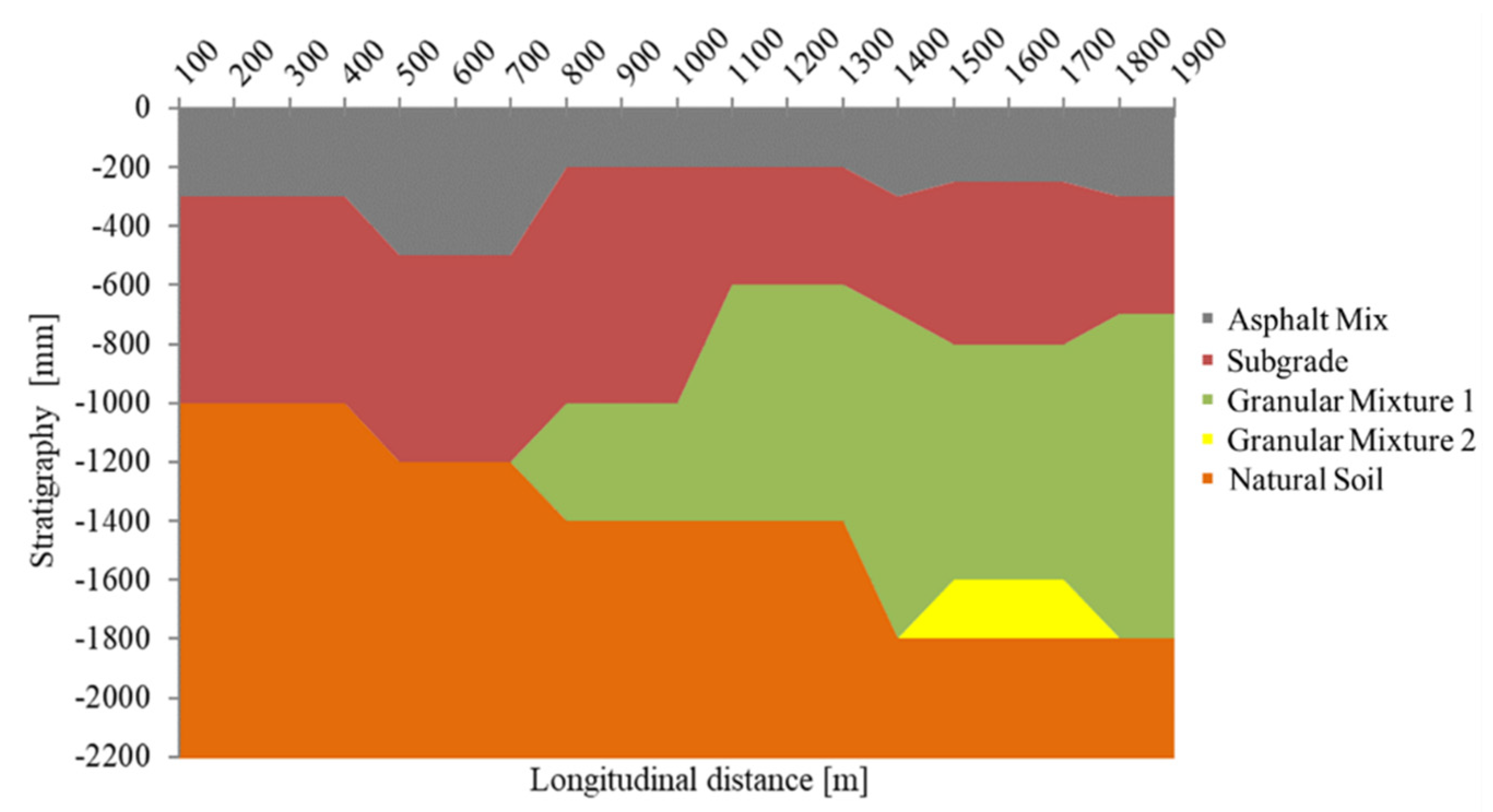
The Road Moduli Evaluation (RO.M.E.) method was used to determine the elastic moduli of the surface layer impact points. This procedure refers to the multi-layer elastic theory, the Boussinesq-Odemark equation, and the equivalent thickness (E.T.) method. In fact, starting from the thickness measurements of the layers composing the track (obtained from cores and radargrams (Figure 4)) as well as from the FWD results obtained during the experimental campaign, the RO.M.E. method makes it possible to determine the stress/deformation state of each point of the bituminous layer assumed as homogeneous, isotropic, and of semi-infinite thickness. Subsequently, using an iterative procedure, the RO.M.E. method makes the theoretical deflection basin congruent with the experimentally measured one so the pavement layers’ moduli can be estimated. For a complete and comprehensive description of RO.M.E. method operations, please refer to the work of Battiato et al. [51].
Moduli thus backcalculated in Figure 5 make it clear that those areas characterized by the highest deflections (TDZs) show lower modulus values. Similarly, lower deflections are related to higher modulus values. Moreover, the prior determination of the different pavement layers’ thicknesses allowed the identification of homogeneous sections, i.e., those sections of the runway which show the same stratigraphy. A categorical variable that takes into account the homogeneous sections will hereafter be referred to as HS. Backcalculated moduli together with HS have therefore been associated, for each impact point, with the corresponding measured deflections and DBPs. These data will become part of the Input/Target table needed to implement the following supervised learning strategy.
3. Theory and Calculation
3.1. Neural Modeling
An artificial neural network (ANN) is a soft computing technique that takes inspiration from biological neural networks. In this connection, similar to the biological nervous system, such model is constituted by a group of artificial neurons and more or less reinforced interconnections among them. Thus, the artificial neural network is an adaptive system that progressively adapts according to the internal and/or external information learned during the so-called training phase. Its structure, however, does not change over time [52]. Such models are often used to simulate complex relationships between inputs and outputs that other analytic functions cannot represent. Typically, an artificial neural network is organized as a series of layers [53]. Each of them is a collection of neurons and plays a different role. A layer that represents the known data is called the input layer. A layer that produces the network output is called the output layer. All other layers between the input and the output ones are called hidden layers and it is where the computational processing takes place. Here it is necessary to define the activation function, which modulates the amplitude of the output and defines whether or not it should be transmitted to subsequent layers. It is advisable to add more hidden layers as the complexity of the problem to be investigated increases. However, to solve most input–output fitting problems, a single hidden layer with a sufficient number of neurons is adequate [54]. This kind of structure is often called shallow neural network (SNN).
In the current study, three SNNs were examined. The first presents a architecture, the second an , whereas the third a . The first number represents the neurons composing the input layer (a neuron for every input feature). stands for the number of neurons in the hidden layer with being an integer in the range . Once the first model has been trained and tested (i.e., starting from ), a model with neurons in the hidden layer was iteratively generated until the 30-hidden neurons architecture was obtained. The best hidden activation function for every model was also investigated within a group of four different functions: the exponential linear (ELU), the rectified linear (ReLU), the hyperbolic tangent (TanH), and the logistic sigmoid (LogS). Their analytical expressions together with the resulting graphs are shown in Figure 6. This resulted in a grid-search procedure aimed at identifying the best combination of hidden neurons function guaranteeing the best network performances within the search intervals. Finally, the output layer always consisted of neuron, and it was associated with a linear activation function.
Each model presented as its input the homogeneous sections (HS) and spatial coordinates of the impact points along the runway . In addition, the first model added to the feature vector the deflections, , collected. The second one considered both the and all deflections between and . The third one considered the DBPs defined in Section 2.2 instead of individual deflections. The only output was the elastic modulus of the bituminous layer (). Even before being assigned to the network, for both inputs and outputs a standardization procedure was provided. This means that each data item was subtracted from its respective mean and divided by its respective standard deviation. This was done because the algorithm chosen to train the network (Bayesian regularization) works best when the inputs and targets are scaled so that they fall approximately in the range of [−1,1] [55].
3.2. Bayesian Regularization
The training process of a neural network consists of applying the sequential steps required to fine-tune synaptic weights and biases in order to generalize the solutions produced by its outputs [56]. In the current study, it started from the Input/Target table mentioned in Section 2.3 and for this reason it is called supervised. The process involves two fundamental steps: a forward and a backward one [57]. The former consists in assigning the feature vector (i.e., the set of known data) to the network and computing the corresponding output . The latter consists in comparing the generated output with the desired target . The difference between and will define the so-called loss function used to determine the corrections to the weights and biases matrix . There are several analytical expressions that define how to update according to the value assumed by the loss function for a fixed number of iterations , thus differentiating the several learning algorithms. Usually, the mean squared error (MSE) is used as loss function . Its analytical expression is presented in Equation (5).
The gradient of the loss function with respect to , calculated applying a backpropagation algorithm [58], allows one to update network weights in order to minimize the loss value. Equation (6) shows that the weights at the next iteration are calculated starting from those used at the previous one :
Combining this with the Levenberg–Marquardt (LM) backpropagation algorithm [59] results in:
where is the matrix of weights and biases, is the Jacobian matrix of the training loss function with respect to , is the identity matrix, whereas is the vector of the network errors obtained through the expression:
The scalar (also known as “learning rate”) defines the algorithm convergence rate. As is increased, the LM algorithm moves toward a small step in the direction of steepest descent . Instead, if is decreased, convergence will be faster with the possibility that the algorithm may jump over the minimum. For this reason, during the training phase, the value is modified to reach convergence as quickly as possible avoiding undesirable local minima. An initial value of is set for the first step. Subsequently it increases (or decreases) being multiplied by a factor (or ) if the previous iteration led to worse (or better) results in terms of the loss function F. In this way, the loss function tends to gradually decrease step by step. Finally, it is necessary to set a maximum value of (indicated by ) in order to interrupt the training if it is exceeded. When has been reached (or alternatively at the end of the iterations) the best weights and biases are identified and kept fixed. Then the test feature vector is assigned as input making the network work only in the forward manner thus determining the model’s loss index on some data never processed before. However, working this way, it is possible to run into a phenomenon known in machine learning as “overfitting”. Overfitting occurs when the model performs very well with the given training set of observations but cannot generalize correctly beyond it and consequently performs very poorly with test data or different sets of observations [60]. This often occurs when the connection weights’ values are too high. For this reason, in the current study, it was decided to use a regularization technique considering the matrix values. This technique consists in no longer rewriting the loss function as MSE but as follows:
The operator represents the 2-norm, and it is applied first to the errors and then to network parameters . For this reason, the first term is also known as the sum squared error (SSE) while the second term represents a correction that considers the complexity of the network through its weights (also known as “penalty”). In addition, both terms are pre-multiplied by parameters indicated as and whose ratio defines the smoothness of the loss function. The larger the ratio is, the smoother the network response will be. This concept was first introduced by Tikhonov [61]. The penalty term (also referred to as “regularization”) forces the resulting loss function to be smooth. When the weights are large, the loss function can have large slopes and is therefore more likely to overfit the training data. On the other hand, if the weights are forced to be small, the loss function will smoothly interpolate the training data, thus achieving good performance even beyond the training set. The correct choice of the regularization ratio is essential in producing a network that generalizes properly. In this study, it was decided to use David MacKay’s approach [62] to correctly define the regularization terms. This approach involves an early initialization of the and parameters (as well as the network weights). Using Bayesian statistical and optimization techniques, and values are varied at each iteration thus changing the loss function and obviously its minimum point. Generally, each time a new minimum is set, the regularization parameters are more accurate. Eventually, the precision will be high enough that the objective function will no longer significantly change with every subsequent iteration and convergence will therefore have been achieved. The default values of the hyperparameters implemented in the MATLAB® Toolbox LM algorithm ( and ) were used, namely the initial was set equal to 0.001, to 10, to 0.1, to , whereas the maximum number of training epochs was 1000. As explained in Section 3.1, the size of the hidden layer together with its activation function were identified by performing a grid search. Moreover, one last parameter, , was defined. It represented the number of re-trainings performed for each iteration and was set equal to 10. This was done in order to obtain the best network among the 10 fitted networks for every combination of neurons function as a result of a k-fold cross-validation partitioning.
3.3. K-Fold Cross-Validation
Together with the standardization procedure explained in Section 3.1, a further data pre-processing step was implemented. Usually, the dataset is simply split into two partitions: one for training and the other for testing. This method, also known as “hold-out”, produces errors in the test phase with very variable results depending on which observations have ended up in one partition or another [63]. This undesirable effect is even more pronounced when the dataset is particularly limited so, to overcome this problem, the -fold cross-validation (CV) was adopted [64]. This technique depends on a single parameter , an index of the number of partitions into which the dataset must be divided. After randomly mixing the known data, a value of is established and consequently the dataset is divided into groups each containing the same number of elements. In this way, groups are used to build the model and the left-out sample to validate it Figure 7. This is an iterative procedure that is repeated -times so that each of the -folds is successively assigned as validation data [65].
For each iteration, a validation score is tracked and recorded before moving on to the next iteration. The average of the obtained -validation scores is assumed as the general performance of the model [66]:
A review of model validation methods recommends -fold cross-validation, particularly five or ten-fold [67]. The value of has therefore been set equal to five, to remain consistent with the relevant literature [68]. Because of the five-fold CV, the dataset is split as follows: 80% of the available data for the training set and 20% for the test set.
3.4. Data Augmentation
In the context of machine learning, whenever a certain technique is used to expand the size of the starting dataset, a data augmentation technique is used. This is a generation of synthetic data that comes from data processing and not from a new experimental campaign. In this sense, increasing the amount of data available to the network increases its predictive capabilities by improving its generalization. Data augmentation techniques are particularly popular in the field of image classification because rotating, zooming, cropping, or changing the brightness does not mean changing the information stored in an image. Similarly, in the case of time-series data augmentation it is necessary to use techniques that do not disturb the information collected during the experimental campaign but, at the same time, allow one to increase the sample size. Since collecting new data can be very expensive and time-consuming, multiple interpolation techniques are progressively emerging in data augmentation. Interpolation is a method of estimating unknown values using known data. More precisely, if the function of the real variable is unknown and the function value for the value of two or more variables with a certain interval is known, estimating a function value for any in between is called interpolation [69]. As suggested by Oh et al. [70], the known dataset should never be shorter but rather longer than the one obtained through interpolation. For this reason, it was decided to nearly double the initial dataset by interpolating the unknown bidimensional function at a midpoint between two successive impact points of the same measuring line (Figure 8).
The function chosen as interpolator becomes a kind of model hyperparameter. The proposed method used the modified Akima interpolation, often known as the “makima” technique. In general, the Akima algorithm performs cubic interpolation to produce piecewise polynomials with continuous first-order derivatives [71]. Unlike 3rd degree polynomial or cubic spline interpolation, the Akima algorithm avoids excessive local undulations while still being able to deal with oscillatory data. The modified Akima algorithm (i.e., “makima”) is an extension of the method just mentioned and it is designed for interpolating values given at points of a rectangular grid in a plane by a smooth bivariate function . The interpolating function is therefore a bicubic polynomial in each cell of the rectangular grid [72]. The main purpose is still to produce fewer undulations between given grid points. Data obtained through makima interpolation (85 augmented points) were used exclusively during the model training phase and were added to the -fold partitioning for a total of 161 training points.
Assuming as current state-of-practice (CSP) the ANN model implemented in MATLAB® Toolbox, the comparison between this simplified model and the one proposed by the authors has been considered. Such comparison allows one to evaluate the improvement of stiffness values estimation given by the proposed model. Moreover, assuming that data augmentation implementation is nearly equivalent to a denser experimental campaign, it can be understood how the change of the HWD measurements resolution affects the modeling result.
4. Results and Discussion
Although the starting dataset is highly variable both in terms of measured deflections and backcalculated moduli along the runway (due to the pronounced differences in mechanical behavior), the proposed neural model returns very satisfactory results (Table 1, Table 2 and Table 3). The performance of the model is expressed in terms of Pearson coefficient , mean squared error , and adjusted coefficient of determination . The first one expresses, if any, a linear correlation between the backcalculated moduli and those predicted by the neural model :
where and are the mean and the standard deviation of the variables, respectively. Values of exceeding 0.8 are typical of a satisfactory correlation [73,74]. The second provides an accurate estimation of the model generalization capability by averaging the squares of the differences between backcalculated and predicted moduli:
The third one represents in what percentage the input variables can explain a variation of the output variable:
where is the sum of squared error, is the sum of squared total, is the number of observations, and is the number of model inputs. Its formulation allows one to understand whether adding more independent variables will improve the goodness-of-fit for the regression model. In fact, the adjusted -squared score increases when new terms improve the model fit while decreases when this improvement is not appreciable.
For what concerns the grid search approach, among the possible combinations of hidden neurons-activation function, the one that maximized the was chosen. The intention was to produce a network that would make small errors and, at the same time, make the best use of the parameters provided as input. From this point of view, the model that produced the best results is the third one. The architecture with logistic sigmoid activation function (hereafter referred to as LogS-SNN) has produced a value equal to 0.9516, confirming that the DBPs, together with the homogeneous sections and the spatial coordinates of the impact points, are very suitable starting data to make modulus predictions. The graphical trend of and is shown in Figure 9a for a clearer appreciation of the learning process. It is important to notice how the former increases up to the best value and then settles around constant values. Similarly, the latter decreases down to the best value and then settles around constant values. This is the representation of the happened learning process. Adding more hidden neurons beyond the threshold of the best value would computationally weigh down the model without leading to any benefit in predictive terms.
As further evidence of the network efficiency from the computational cost point of view, another parameter was kept under observation: the effective number of parameters (). It provides a measure of how many parameters (weights and biases) in the neural model are effectively used in reducing the loss function [59]. The is expressed by:
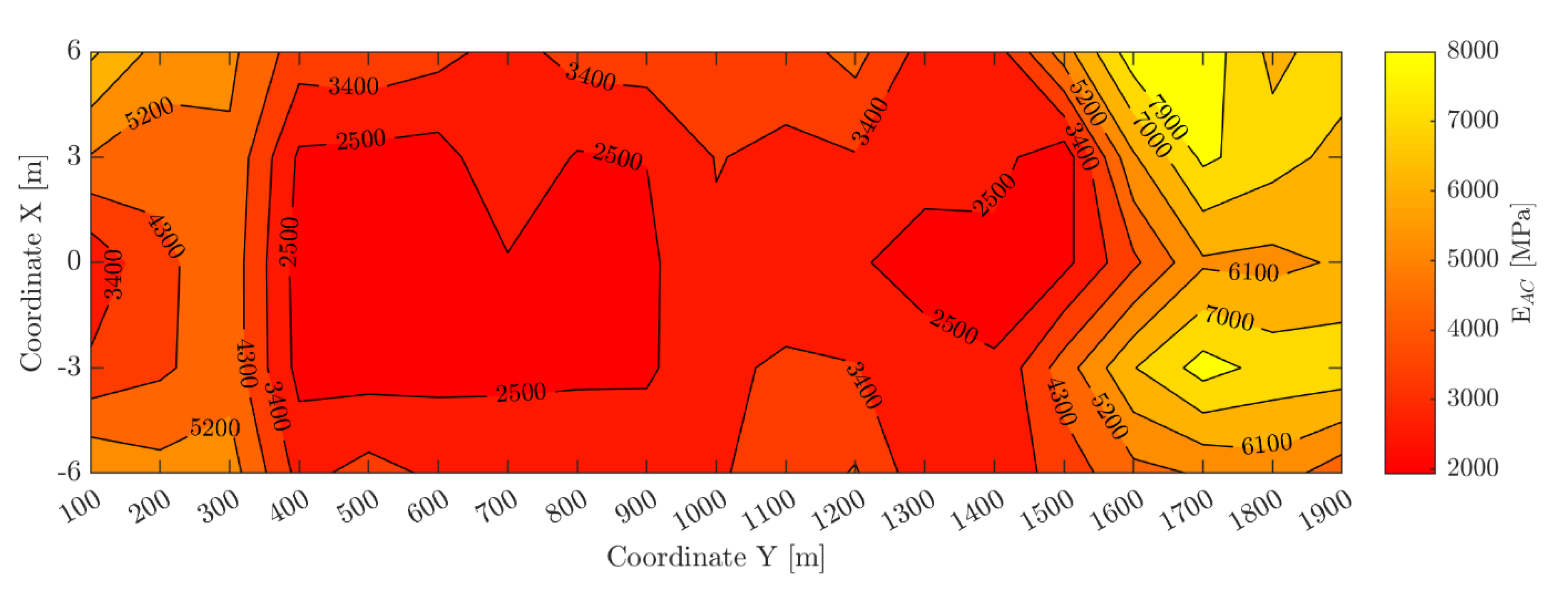
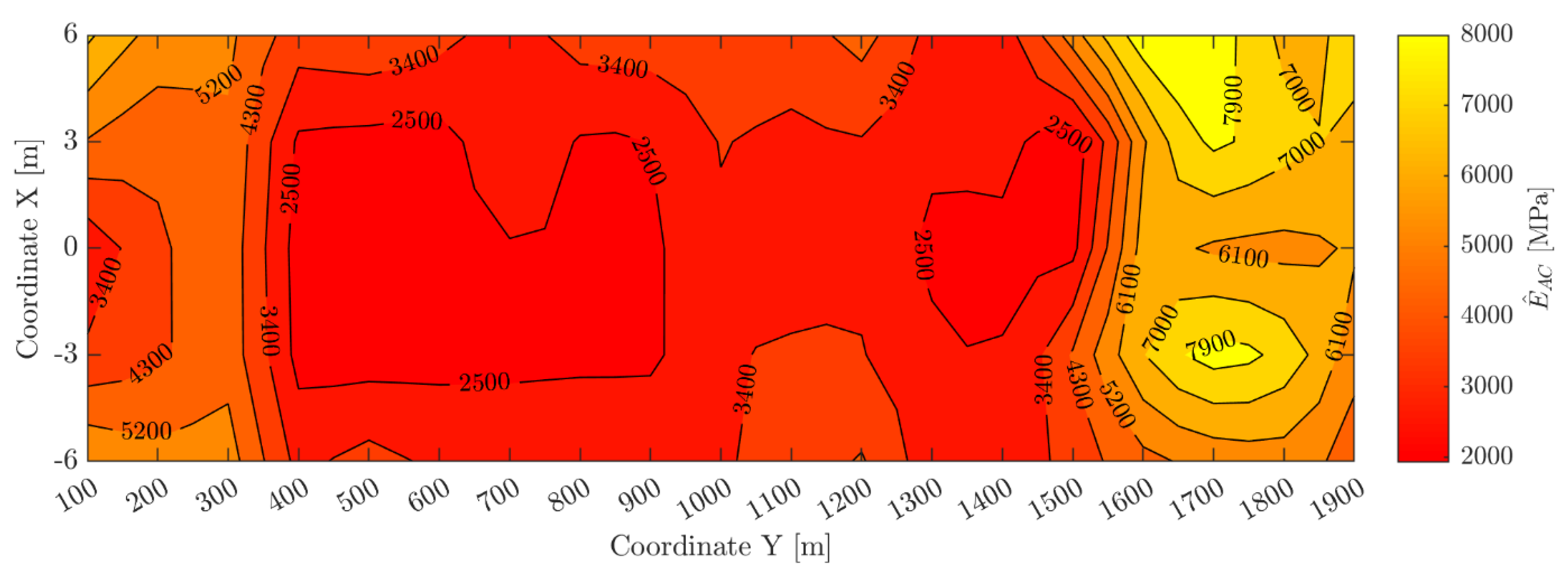
where is the matrix of weights and biases of the -th SNN model trained during the -fold cross-validation procedure and is the total number of parameters of the same -th SNN. The trace of the Hessian matrix can be computed starting from the Jacobian matrix of the training set errors and the parameters and , as explained by Hagan et al. [59]. With a ratio of 185/254, the LogS-SNN shows that, despite the large number of neurons within the hidden layer, more than 70% of the model’s parameters are used to reduce the loss function. It is probably the ideal combination of computational efficiency and accuracy in the predictions as also highlighted by the value of mean squared error equal to 0.0321. For a complete illustration of the results, the performance of the LogS-SNN model for each of the five folds has been graphically represented Figure 9b. As explained in Section 3.3, averaging the results over the five folds, the predictive capabilities of the model can be evaluated resulting in a equal to 0.9864. Using a VivoBookProN580GD-FI018T with Intel(R) core(TM) i7-8750H CPU @2.20 GHz and 16 GB RAM, this model takes 13 s to process the data. The LogS-SNN model finally made it possible to predict the modulus value at each point of the runway thus generating a contour map (Figure 10). From a comparison with the map in Section 2.3, it can be concluded that the neural modeling procedure followed was successful in fitting the presented experimental data. The contour map provides a quantitative estimation of the pavement mechanical performance at the time of the HWD experimental investigations.
It is worth pointing out that a simple interpolation of the backcalculated modulus data can certainly estimate the value of at any point on the runway, but it would predict the stiffness without any phenomenological relationship being considered. On the other hand, the proposed neural model predicts the AC modulus value at any point on the pavement but requires the measured deflections, their coordinates along the runway, and the stratigraphy as input. This approach preserves the fundamental relationship between the modulus and the mentioned variables, from a logical point of view.
5. Conclusions
This paper was focused on prediction of the stiffness modulus of a runway pavement AC layer, a critical element in pavement management, by means of an innovative methodological approach based on soft computing techniques, namely machine learning and data augmentation. Specifically, shallow neural networks, characterized by a three-layer architecture, and the modified Akima algorithm were adopted. The results of an experimental trial carried out on Runway 02/20 at Palermo airport by means of HWD, were used to develop three different predictive SNN models.
The spatial coordinates of the impact points and a categorical variable representative of the pavement section type were always included in the model’s input vector. In addition to such variables, the first SNN model considered the measure . In the second predictive model, all deflections between and were also included. In the third and last neural model, the deflection measurements were replaced by the deflection basin parameters.
To optimize the number of hidden neurons and to select the best suited type of activation function, a grid search was carried out. Bayesian regularization algorithms and a k-fold cross-validation procedure was implemented in order to identify the model characterized by the best predictive performance.
The results showed that the best performing SNN model is the third one, characterized by 23 neurons in the hidden layer and a logistic sigmoid activation function. This model can produce very accurate stiffness modulus predictions with and values equal to 0.9864 and 0.0321, respectively. Moreover, in order to consider both the size of the available dataset and the number of parameters, the evaluation metric has been used; its value, equal to 0.9516, has fully confirmed the good performance of the predictive model.
The elaboration of the data by means of CSP ANN model produced a Pearson correlation coefficient equal to 0.9460. Conversely, thanks to the implementation of a data augmentation technique, the proposed model produces more accurate predictions. The R-value is equal to 0.9864, resulting in a 4% increase in the correlation coefficient.
The proposed soft computing approach, which is proven to be able to predict the stiffness modulus at any point on the runway, can become a crucial element in APMS, thus allowing optimization of the available maintenance budget, in order to improve safety and sustainability of airport infrastructures.
The proposed approach has been developed with respect to the Palermo runway, but it could be easily adopted to analyze any runway or paved area such as parking lots. So far, the study does not consider historical series of deflections: it would be interesting to implement this additional information in order to evaluate if the presented methodology is suitable not only for evaluating the current pavement deterioration state, but for predicting its evolution and scheduling intervention priorities over time as well.
Author Contributions
Conceptualization, N.B., M.M., F.R. and C.C.; Methodology, N.B., M.M., F.R. and C.C.; Software, M.M. and F.R.; Validation, N.B., M.M., F.R. and C.C.; Formal Analysis, N.B., M.M., F.R. and C.C.; Investigation, N.B., M.M., F.R. and C.C.; Resources, N.B., M.M., F.R. and C.C.; Data Curation, N.B., M.M., F.R. and C.C.; Writing—Original Draft Preparation, N.B., M.M., F.R. and C.C.; Writing—Review & Editing, N.B., M.M., F.R. and C.C.; Visualization, N.B., M.M., F.R. and C.C.; Supervision, N.B., M.M., F.R. and C.C.; Project Administration, N.B. and C.C.; Funding Acquisition, C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received funding from the ERDF Regional Operational Programme Sicily 2014–2020 (POR FESR Sicilia 2014–2020), Action 1.1.5—“SMARTEP”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding authors upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Moteff, J.; Parfomak, P. Critical Infrastructure and Key Assets: Definition and Identification; Library of Congress Washington DC Congressional Research Service: Washington, DC, USA, 2004. [Google Scholar]
- Schweikert, A.; Chinowsky, P.; Espinet, X.; Tarbert, M. Climate change and infrastructure impacts: Comparing the impact on roads in ten countries through 2100. Procedia Eng. 2014, 78, 306–316. [Google Scholar] [CrossRef] [Green Version]
- Makovšek, D.; Tominc, P.; Logožar, K. A cost performance analysis of transport infrastructure construction in Slovenia. Transportation 2012, 39, 197–214. [Google Scholar] [CrossRef]
- Navneet, G.; Guo, E.; McQueen, R. Operational Life of Airport Pavements; Federal Aviation Administration: Washington, DC, USA, 2004. [Google Scholar]
- Ashtiani, A.Z.; Murrell, S.; Brill, D.R. Machine Learning Approach to Identifying Key Environmental Factors for Airfield Asphalt Pavement Performance. In Airfield and Highway Pavements 2021, Virtual Conference, 8–10 June 2021; American Society of Civil Engineers: Reston, VA, USA, 2021; pp. 328–337. [Google Scholar]
- Carlucci, F.; Cirà, A.; Coccorese, P. Measuring and explaining airport efficiency and sustainability: Evidence from Italy. Sustainability 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Rix, G.J.; Baker, N.C.; Jacobs, L.J.; Vanegas, J.; Zureick, A.H. Infrastructure assessment, rehabilitation, and reconstruction. In Proceedings of the Frontiers in Education 1995 25th Annual Conference. Engineering Education for the 21st Century, Atlanta, GA, USA, 1–4 November 1995; IEEE: New York, NY, USA, 1995; Volume 2, pp. 4c1–11. [Google Scholar]
- Zou, L.; Yi, L.; Sato, M. On the use of lateral wave for the interlayer debonding detecting in an asphalt airport pavement using a multistatic GPR system. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4215–4224. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; He, X.; Peeta, S.; Weiss, W.J. Internal curing for concrete bridge decks: Integration of a social cost analysis in evaluation of long-term benefit. Transp. Res. Rec. 2016, 2577, 25–34. [Google Scholar] [CrossRef]
- Haas, R.; Hudson, W.R.; Zaniewski, J.P. Modern Pavement Management; Krieger Publishing Company: Melbourne, FL, USA, 1994. [Google Scholar]
- Zheng, M.; Chen, W.; Ding, X.; Zhang, W.; Yu, S. Comprehensive life cycle environmental assessment of preventive maintenance techniques for asphalt pavement. Sustainability 2021, 13, 4887. [Google Scholar] [CrossRef]
- De Souza, N.M.; De Almeida Filho, A.T. A systematic airport runway maintenance and inspection policy based on a delay time modeling approach. Autom. Constr. 2020, 110, 103039. [Google Scholar] [CrossRef]
- Chern, S.G.; Lee, Y.S.; Hu, R.F.; Chang, Y.J. A research combines nondestructive testing and a neuro-fuzzy system for evaluating rigid pavement failure potential. J. Mar. Sci. Technol. 2005, 13, 133–147. [Google Scholar]
- Huang, Y.H. Pavement Analysis and Design; Prentice-Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Hoffman, M. Comparative study of selected nondestructive testing devices. Transp. Res. Rec. 1982, 852, 32–41. [Google Scholar]
- ASTM. ASTM D4695. Standard Test Method for Deflections with A Falling Weight-Type Impulse Load Device; ASTM: West Conshohocken, PA, USA, 1996. [Google Scholar]
- ASTM. ASTM D5340. Standard Test Method for Airport Pavement Condition Index Survey; ASTM: West Conshohocken, PA, USA, 1996. [Google Scholar]
- ASTM. ASTM D4695-96. Standard Guide for General Pavement Deflection Measurement; ASTM: West Conshohocken, PA, USA, 1996. [Google Scholar]
- Sebaaly, B.E.; Mamlouk, M.S.; Davies, T.G. Dynamic analysis of falling weight deflectometer data. Transp. Res. Rec. 1986, 1070, 63–68. [Google Scholar]
- Bush III, A.J.; Alexander, D.R. Pavement evaluation using deflection basin measurements and layered theory. Transp. Res. Rec. 1985, 1022, 16–29. [Google Scholar]
- Chang, D.W.; Kang, Y.V.; Roesset, J.M.; Stokoe, K. Effect of depth to bedrock on deflection basins obtained with Dynaflect and falling weight deflectometer tests. Transp. Res. Rec. 1992, 1355, 8–16. [Google Scholar]
- Ullidtz, P.; Coetzee, N. Analytical procedures in nondestructive testing pavement evaluation. Transp. Res. Rec. 1995, 1482, 61–66. [Google Scholar]
- Weil, G.J. Non-destructive testing of bridge, highway and airport pavements. In Proceedings of the Fourth International Conference of Ground Penetrating Radar, Rovaniemi, Finland, 8–13 June 1992; European Association of Geoscientists & Engineers: Utrecht, The Netherlands, 1992; pp. 259–266. [Google Scholar]
- Gopalakrishnan, K. Instantaneous pavement condition evaluation using non-destructive neuro-evolutionary approach. Struct. Infrastruct. Eng. 2012, 8, 857–872. [Google Scholar] [CrossRef]
- FAA. USDOT Advisory Circular 150/5370-11B. Use of Nondestructive Testing in the Evaluation of Airport Pavements; FAA: Washington, DC, USA, 2011. [Google Scholar]
- Talvik, O.; Aavik, A. Use of FWD deflection basin parameters (SCI, BDI, BCI) for pavement condition assessment. Transformation 2009, 7, 260. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Thompson, M.R. Use of nondestructive test deflection data for predicting airport pavement performance. J. Transp. Eng. 2007, 133, 389–395. [Google Scholar] [CrossRef]
- Goktepe, A.B.; Agar, E.; Lav, A.H. Advances in backcalculating the mechanical properties of flexible pavements. Adv. Eng. Softw. 2006, 37, 421–431. [Google Scholar] [CrossRef]
- Burmister, D.M. The general theory of stresses and displacements in layered soil systems. III. J. Appl. Phys. 1945, 16, 296–302. [Google Scholar] [CrossRef]
- Ullidtz, P. Will Nonlinear Backcalculation Help? In Nondestructive Testing of Pavements and Backcalculation of Moduli; American Society for Testing and Materials: West Conshohocken, PA, USA, 2000; pp. 14–22. [Google Scholar]
- Lytton, R.L. Backcalculation of layer moduli, state of the art. In Nondestructive Testing of Pavements and Backcalculation of Moduli; ASTM International: West Conshohocken, PA, USA, 1989; pp. 7–38. [Google Scholar]
- Uzan, J. Advanced backcalculation techniques. In Nondestructive Testing of Pavements and Backcalculation of Moduli: Second Volume; ASTM International: West Conshohocken, PA, USA, 1994; pp. 3–37. [Google Scholar]
- Siddharthan, R.; Norris, G.M.; Epps, J.A. Use of FWD data for pavement material characterization and performance. J. Transp. Eng. 1991, 117, 660–678. [Google Scholar] [CrossRef]
- Goel, A.; Das, A. Nondestructive testing of asphalt pavements for structural condition evaluation: A state of the art. Nondestruct. Test. Eval. 2008, 23, 121–140. [Google Scholar] [CrossRef]
- Scimemi, G.F.; Turetta, T.; Celauro, C. Backcalculation of airport pavement moduli and thickness using the Lévy Ant Colony Optimization Algorithm. Constr. Build. Mater. 2016, 119, 288–295. [Google Scholar] [CrossRef]
- Lei, T.; Claudel, C. Inertial Measurement Units-based probe vehicles: Path reconstruction and map matching. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: New York, NY, USA, 2018; pp. 2899–2904. [Google Scholar]
- Adeli, H. Neural networks in civil engineering: 1989–2000. Comput. Aided Civ. Infrastruct. Eng. 2001, 16, 126–142. [Google Scholar] [CrossRef]
- Li, M.; Wang, H. Development of ANN-GA program for backcalculation of pavement moduli under FWD testing with viscoelastic and nonlinear parameters. Int. J. Pavement Eng. 2019, 20, 490–498. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Ceylan, H.; Guclu, A. Airfield pavement deterioration assessment using stress-dependent neural network models. Struct. Infrastruct. Eng. 2009, 5, 487–496. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Xie, P.; Ji, R.; Gagnon, J. Prediction of airfield pavement responses from surface deflections: Comparison between the traditional backcalculation approach and the ANN model. Road Mater. Pavement Des. 2020, 1–16. [Google Scholar] [CrossRef]
- Justo-Silva, R.; Ferreira, A.; Flintsch, G. Review on machine learning techniques for developing pavement performance prediction models. Sustainability 2021, 13, 5248. [Google Scholar] [CrossRef]
- Crovetti, J.A.; Shahin, M.; Touma, B.E. Comparison of two falling weight deflectometer devices, Dynatest 8000 and KUAB 2M-FWD. In Nondestructive Testing of Pavements and Backcalculation of Moduli; ASTM International: West Conshohocken, PA, USA, 1989. [Google Scholar]
- Claessen, A.; Valkering, C.; Ditmarsch, R. Pavement evaluation with the falling weight deflectometer. Assoc. Asph. Paving Technol. Proc. 1976, 45, 122–157. [Google Scholar]
- Chen, D.H.; Bilyeu, J.; Scullion, T.; Lin, D.F.; Zhou, F. Forensic evaluation of premature failures of Texas specific pavement study-1 sections. J. Perform. Constr. Facil. 2003, 17, 67–74. [Google Scholar] [CrossRef]
- ICAO. Annex 14: Aerodromes, Volume I–Aerodrome Design and Operations, 7th ed.; ICAO: Montréal, QC, Canada, 2016. [Google Scholar]
- Hossain, A.; Zaniewski, J.P. Characterization of falling weight deflectometer deflection basin. Transp. Res. Rec. 1991, 1293, 1–11. [Google Scholar]
- Xu, B.; Ranjithan, S.R.; Kim, Y.R. New relationships between falling weight deflectometer deflections and asphalt pavement layer condition indicators. Transp. Res. Rec. 2002, 1806, 48–56. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Thompson, M.R. Use of deflection basin parameters to characterize structural degradation of airport flexible pavements. In Advances in Pavement Engineering; ASCE Library: Austin, TX, USA, 2005; pp. 1–15. [Google Scholar]
- Hill, H.J. Early Life Study of the FA409 Full-Depth Asphalt Concrete Pavement Sections. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana-Champaign, IL, USA, 1988. [Google Scholar]
- Thompson, M.; Garg, N. Mechanistic-Empirical Evaluation of the Mn/ROAD Low Volume Road Test Sections; Project IHR-535; University of Illinois at Urbana-Champaign: Urbana-Champaign, IL, USA, 1997. [Google Scholar]
- Battiato, G.; Ame, E.; Wagner, T. Description and implementation of RO.MA. for urban road and highway network maintenance. In Proceedings of the 3rd International Conference on Managing Pavement, San Antonio, TX, USA, 22–26 May 1994. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Otuoze, S.H.; Hunt, D.V.L.; Jefferson, I. Neural network approach to modelling transport system resilience for major cities: Case studies of Lagos and Kano (Nigeria). Sustainability 2021, 13, 1371. [Google Scholar] [CrossRef]
- Demuth, H.B.; Beale, M.H.; De Jesús, O.; Hagan, M.T. Neural Network Design, 2nd ed.; Martin Hagan: Boston, MA, USA, 2014; Chapter 11; pp. 4–7. [Google Scholar]
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural Network Toolbox. User’s Guide; MathWorks: Natick, MA, USA, 2010. [Google Scholar]
- Da Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.H.B.; dos Reis Alves, S.F. Artificial neural network architectures and training processes. In Artificial Neural Networks; Springer: Cham, Switzerland, 2017; pp. 21–28. [Google Scholar]
- Baldo, N.; Manthos, E.; Pasetto, M. Analysis of the mechanical behaviour of asphalt concretes using artificial neural networks. Adv. Civ. Eng. 2018, 2018, 1650945. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representation by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef]
- Padhi, S.; Millstein, T.; Nori, A.; Sharma, R. Overfitting in synthesis: Theory and practice. In Proceedings of the International Conference on Computer Aided Verification, New York, NY, USA, 15–18 July 2019; Springer: Cham, Switzerland, 2019; pp. 315–334. [Google Scholar]
- Tikhonov, A.N. On the solution of ill-posed problems and the method of regularization. In Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1963; pp. 501–504. [Google Scholar]
- MacKay, D.J. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Chapter 5; pp. 175–201. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Jung, Y. Multiple prediction K-fold cross-validation for model selection. J. Nonparametr. Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Baldo, N.; Manthos, E.; Miani, M. Stiffness modulus and marshall parameters of hot mix asphalts: Laboratory data modeling by artificial neural networks characterized by cross-validation. Appl. Sci. 2019, 9, 3502. [Google Scholar] [CrossRef] [Green Version]
- Li, J. A critical review of spatial predictive modeling process in environmental sciences with reproducible examples in R. Appl. Sci. 2019, 9, 2048. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M.; Johnson, J. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Chapter 4; pp. 61–92. [Google Scholar]
- Lunardi, A. Interpolation Theory; Edizioni della Normale: Pisa, Italy, 2018. [Google Scholar]
- Oh, C.; Han, S.; Jeong, J. Time-series data augmentation based on interpolation. Procedia Comput. Sci. 2020, 175, 64–71. [Google Scholar] [CrossRef]
- Akima, H. A new method of interpolation and smooth curve fitting based on local procedures. J. ACM 1970, 17, 589–602. [Google Scholar] [CrossRef]
- Akima, H. A method of bivariate interpolation and smooth surface fitting based on local procedures. Commun. ACM 1974, 17, 18–20. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Tang, T.; Guo, Y.; Zhou, X.; Labi, S.; Zhu, S. Understanding electric bike riders’ intention to violate traffic rules and accident proneness in China. Travel Behav. Soc. 2021, 23, 25–38. [Google Scholar] [CrossRef]
Figure 1.
Layout of Palermo Airport.

Figure 2.
Experimental impact points (black plus sign marker) on the Runway 02/20.

Figure 3.
Contour map of the deflections measured at the impact points.

Figure 4.
Thickness of the pavement layers resulting from the coring performed.

Figure 5.
Contour map of the backcalculated elastic asphalt concrete moduli.

Figure 6.
Activation functions. (a) ELU; (b) TanH; (c) ReLU; (d) LogS.


Figure 7.
Schematic representation of the k-fold cross-validation procedure.

Figure 8.
Augmented impact points (red cross marker) on the Runway 02/20.

Figure 9.
(a) Performance metrics of the Log-SNN model; (b) summary of the LogS-SNN performance.

Figure 10.
Contour map of the elastic asphalt concrete moduli predicted by the LogS-SNN model.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary results of the first model.
| Inputs | Output | Activation Fun. | Best Architecture | |||
|---|---|---|---|---|---|---|
| δ0, HS, X, Y | ELU | 4-12-1 | 0.9673 | 0.0682 | 0.9231 | |
| ReLU | 4-27-1 | 0.9408 | 0.1309 | 0.8627 | ||
| TanH | 4-25-1 | 0.9780 | 0.0494 | 0.9477 | ||
| LogS | 4-22-1 | 0.9772 | 0.0474 | 0.9461 |
Table 2.
Summary results of the second model.
| Inputs | Output | Activation Fun. | Best Architecture | |||
|---|---|---|---|---|---|---|
| δ0, δ2, δ3, δ4, δ5, HS, X, Y | ELU | 8-27-1 | 0.9805 | 0.0423 | 0.9368 | |
| ReLU | 8-3-1 | 0.9455 | 0.1217 | 0.8277 | ||
| TanH | 8-9-1 | 0.9806 | 0.0437 | 0.9370 | ||
| LogS | 8-13-1 | 0.9844 | 0.0370 | 0.9493 |
Table 3.
Summary results of the third model.
| Inputs | Output | Activation Fun. | Best Architecture | |||
|---|---|---|---|---|---|---|
| SCI1, SCI2, SCI3, DR, AUPP, AREA, HS, X, Y | ELU | 9-18-1 | 0.9804 | 0.0501 | 0.9303 | |
| ReLU | 9-14-1 | 0.9555 | 0.0963 | 0.8441 | ||
| TanH | 9-26-1 | 0.9807 | 0.0439 | 0.9312 | ||
| LogS | 9-23-1 | 0.9864 | 0.0321 | 0.9516 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Baldo, N.; Miani, M.; Rondinella, F.; Celauro, C. A Machine Learning Approach to Determine Airport Asphalt Concrete Layer Moduli Using Heavy Weight Deflectometer Data. Sustainability 2021, 13, 8831. https://doi.org/10.3390/su13168831
AMA Style
Baldo N, Miani M, Rondinella F, Celauro C. A Machine Learning Approach to Determine Airport Asphalt Concrete Layer Moduli Using Heavy Weight Deflectometer Data. Sustainability. 2021; 13(16):8831. https://doi.org/10.3390/su13168831
Chicago/Turabian StyleBaldo, Nicola, Matteo Miani, Fabio Rondinella, and Clara Celauro. 2021. "A Machine Learning Approach to Determine Airport Asphalt Concrete Layer Moduli Using Heavy Weight Deflectometer Data" Sustainability 13, no. 16: 8831. https://doi.org/10.3390/su13168831
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.