1. Introduction
In the design phase of various large-scale construction projects (highways, roads, high rise buildings) and geotechnical structures (earth dams, retaining walls), shear strength is an important factor used to define the capability of soil foundations [
1]. The shear strength of soil is determined using Mohr–Coulomb criteria through two parameters, namely unit cohesion (c) and internal friction angle (
) in the case of normal soil or only unit cohesion (c) in the case of sandy soil [
1]. However, to determine these parameters, the consuming time and costly experiments are often carried out in the laboratory, including direct shear test, triaxial compression tests, or unconfined compression tests which might increase the cost and prolong the time of completing the projects. Moreover, the test accuracy depends significantly on the instruments, the meticulous procedures, and the expertise of the experimenters [
1]. Therefore, the development of new advanced techniques for quick and accurate prediction of shear strength of soil is essential and practical.
Traditionally, the shear strength of soil is often predicted by using traditional formula-based methods. Garven and Vanapalli [
2] summarized and evaluated nineteen empirical techniques that are available for the prediction of the shear strength of unsaturated soils. Out of these, six techniques used tool of the soil-water retention curve (SWRC) and the remainder thirteen procedures are based on mathematical formulations. In these empirical techniques, various parameters of soil were used to correlate with the shear strength in unsaturated soils such as the texture of soil surface, pore size distribution, residual suction. In another study, Sheng et al. [
3] proposed different empirical equations for the prediction of shear strength of unsaturated soils using different approaches, which are based on the independent stress, Bishop’s stress, and constitutive models. Vanapalli and Fredlund [
4] compared different empirical approaches for the prediction of shear strength of unsaturated soils. Various parameters used for forming the correlation equations such as particle gain distribution, liquid limit, plasticity indices, water content. Al Aqtash and Bandini [
5] used the soil-water characteristic curve to predict the unsaturated shear strength of an adobe soil. In general, these studies show the suitability of these approaches for predictions of the shear strength of soil. However, these approaches might not produce predictive results with satisfactory accuracy as they are based on the linear assumption of the factors used and non-multivariate models [
1].
More recently, advanced data-driven methods based on computational algorithms, like machine learning (ML) approaches, have been developed and applied for the construction of soil shear strength prediction models. They are known as excellent models with high predictive capability as they are useful in discovering the nonlinear relationship inside the data and are capable of considering many input variables in the prediction of shear strength of soil [
1]. These models are also flexible as they can adjust their model structures to be suitable with the changes in the data. Tien Bui et al. [
1] developed a swarm intelligence-based ML approach (LSSVM-CSO) to predict soil shear strength for road construction. A number of geotechnical factors were used in the model, such as sample depth, sand percentage, loam percentage, clay percentage, moisture content, wet density, of soil, specific gravity, liquid limit, plastic limit, plastic index, and liquid index. The results of this study showed that the proposed model has a good predictive capability in the prediction of soil shear strength. This model outperformed other benchmark ML models, namely least squares support vector machine (LSSVM), artificial neural network (ANN), and regression tree (RT). Pham et al. [
6] developed two hybrid advanced ML techniques, namely GANFIS and PANFIS, for prediction of soil shear strength and compared these hybrid models with two other benchmark models, namely ANN and Support Vector Regression (SVR). The results showed that the proposed hybrid models outperformed benchmark models with outstanding predictive accuracy. Prediction of shear strength using ML approaches is also an interesting topic of many studies [
7,
8].
Although advanced ML approaches are good compared with traditional approaches, these models are very sensitive to the selection of input parameters used in the modeling. Das et al. [
9] investigated the performance of two popular ML methods, namely SVM and ANN, for prediction of soil shear strength under the effects of different input properties and stated that the performance of SVM and ANN are good but very different under the effects of different input properties. The study also suggested to carry out the sensitivity analysis to select the best suitable factors for developing and applying the ML models. The same observation has been pointed out in other studies of Nguyen et al. [
10] and Pham et al. [
11]. However, these studies used a trial-manual process for sensitivity analysis, which might not cover all the cases of variation of input parameters. Therefore, in this study, the main objective is to use two advanced computational statistical methods such as Monte Carlo simulation and Feature Backward Elimination for evaluation of the sensitivity analysis of an advance ML technique, namely Extreme Learning Machine (ELM) algorithm for prediction of soil shear strength. The main contribution of this study to the knowledge body is that (i) it proposes a soft computing technique (ELM) for quick and accurate prediction of soil shear strength considering more input parameters, which is limited or not easy to be done by using the empirical correlation equation, (ii) it evaluates for the first time the performance of ELM under different combination of input parameters using Monte Carlo simulation and Feature Backward Elimination, which will help in suitable selection of parameters for prediction of soil shear strength using soft computing techniques. For this aim, data of 538 soil samples collected from the Long Phu 1 power plant project, Long Phu district, Soc Trang province, Vietnam were used for generating the datasets used in the modeling. Well-known statistical indicators, such as the correlation coefficient (R), root mean squared error (RMSE), and mean absolute error (MAE), were utilized to evaluate the performance of the ELM algorithm under sensitivity analysis.
2. Methodology
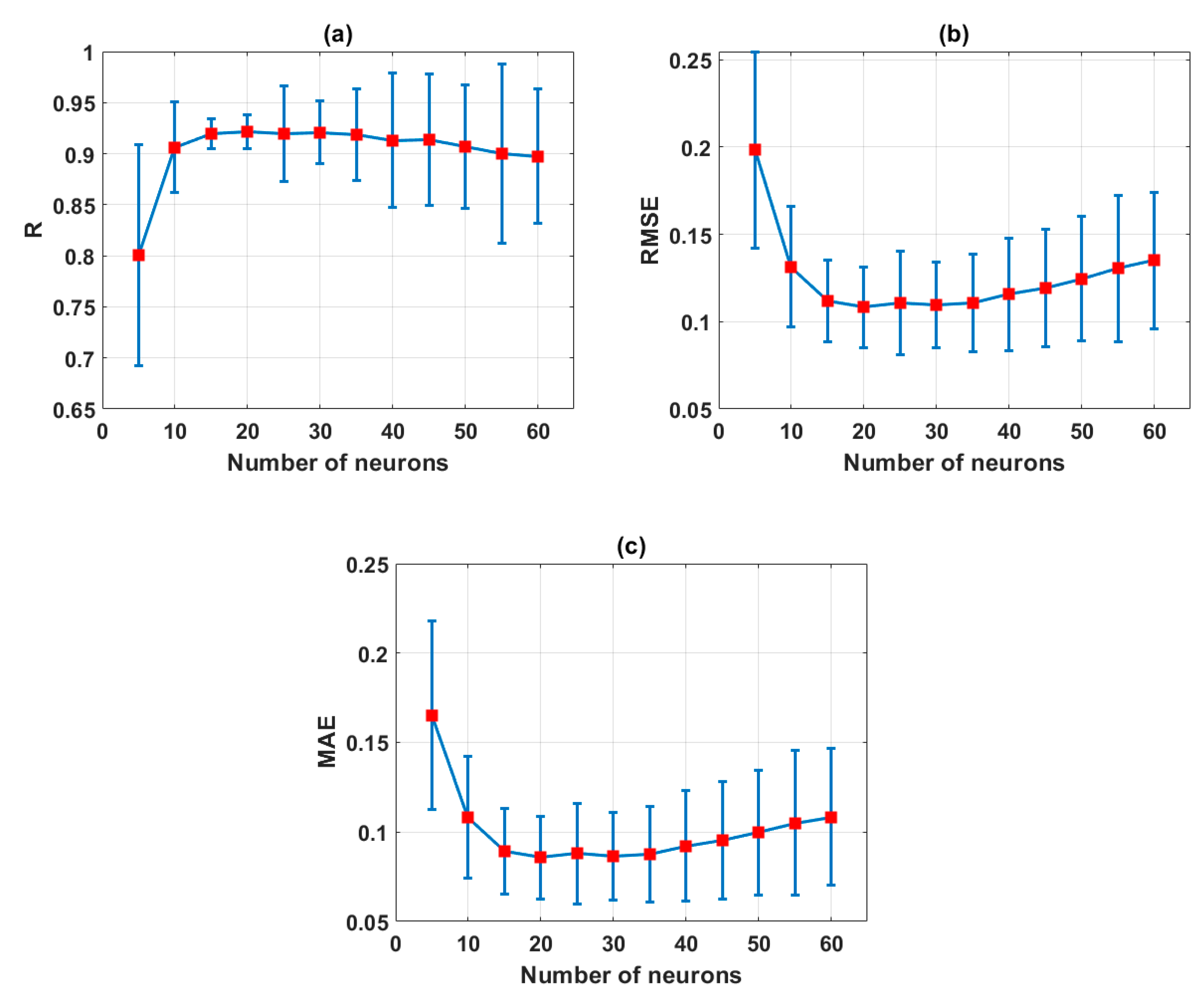
In order to address this problem, the methodology of the present study contains several main steps such as (1) construction of the database: Input parameters, namely the clay content, moisture content, specific gravity, void ratio, liquid limit, and plastic limit were gathered from technical reports. The considered output variable of this work is the shear strength of soil, (2) ELM algorithm was firstly optimized by an analysis concerning the number of neurons used in the model, (3) after the optimal number of neurons of ELM successfully found, it was used to perform the backward elimination in combination with Monte Carlo simulation, (4) using six types of criteria, namely the maximum value of R, minimum values of RMSE and MAE, average values of R, RMSE and MAE, the elimination of input variables was decided by majority vote.
2.1. Data Collection and Preparation
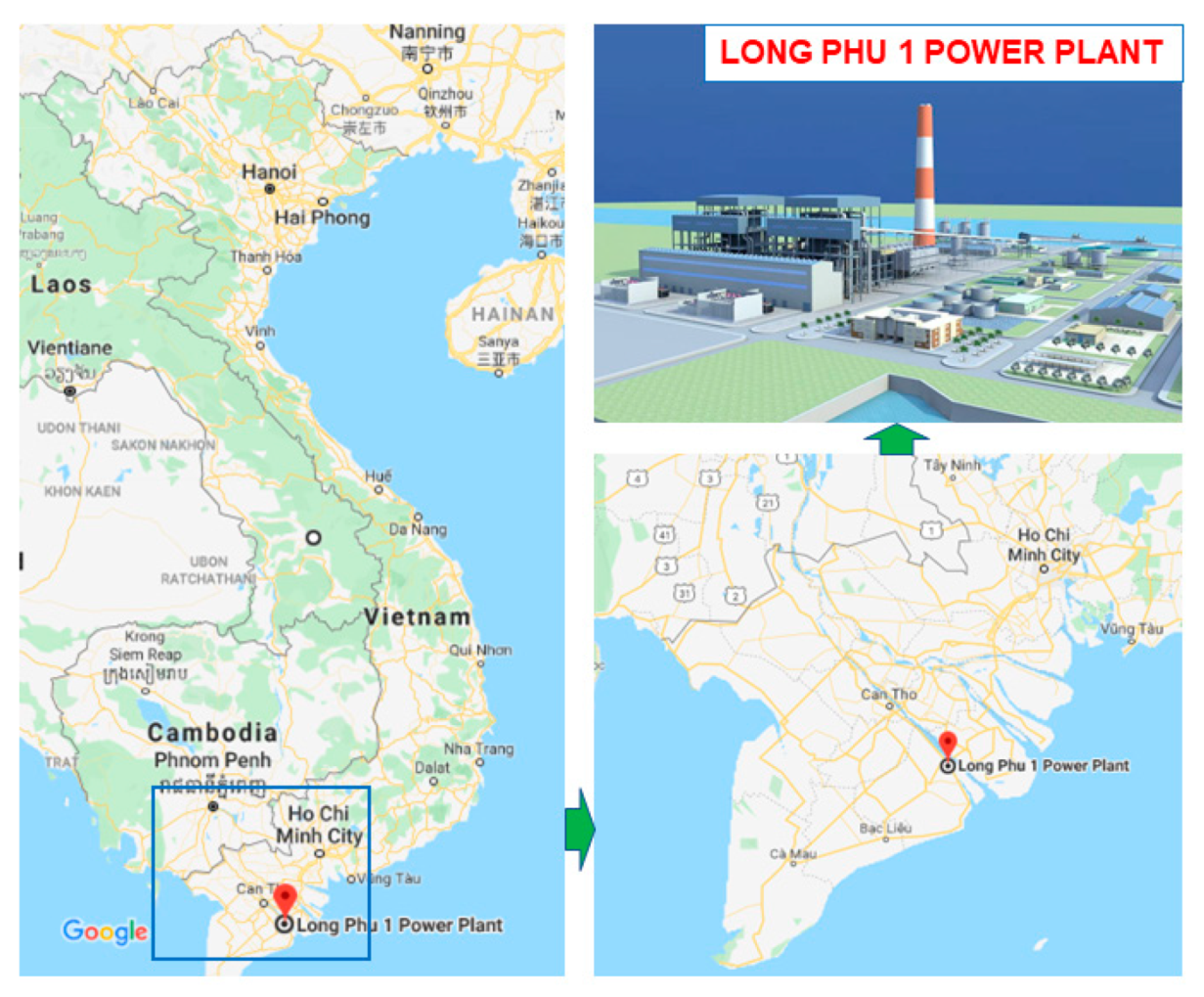
Data used in this study were collected from the Long Phu 1 power plant project (longitude of 9°59′07.3″N and latitude of 106°04′48″E) located at the southern side of the Hau river, Long Duc commune, Long Phu district, Soc Trang province, Vietnam (
Figure 1). Union of Engineering Geology, Construction and Environment (UGCE) was in charge of the soil investigation works. In addition, a program of the additional soil investigation was carried out by UGCE in April and August 2011, including exploratory borings, field testing, and soil laboratory testing to provide the information relating to the soil conditions of foundation design and construction of the project, and these data were extracted to generate the datasets for the modeling of soil shear strength prediction in this study.
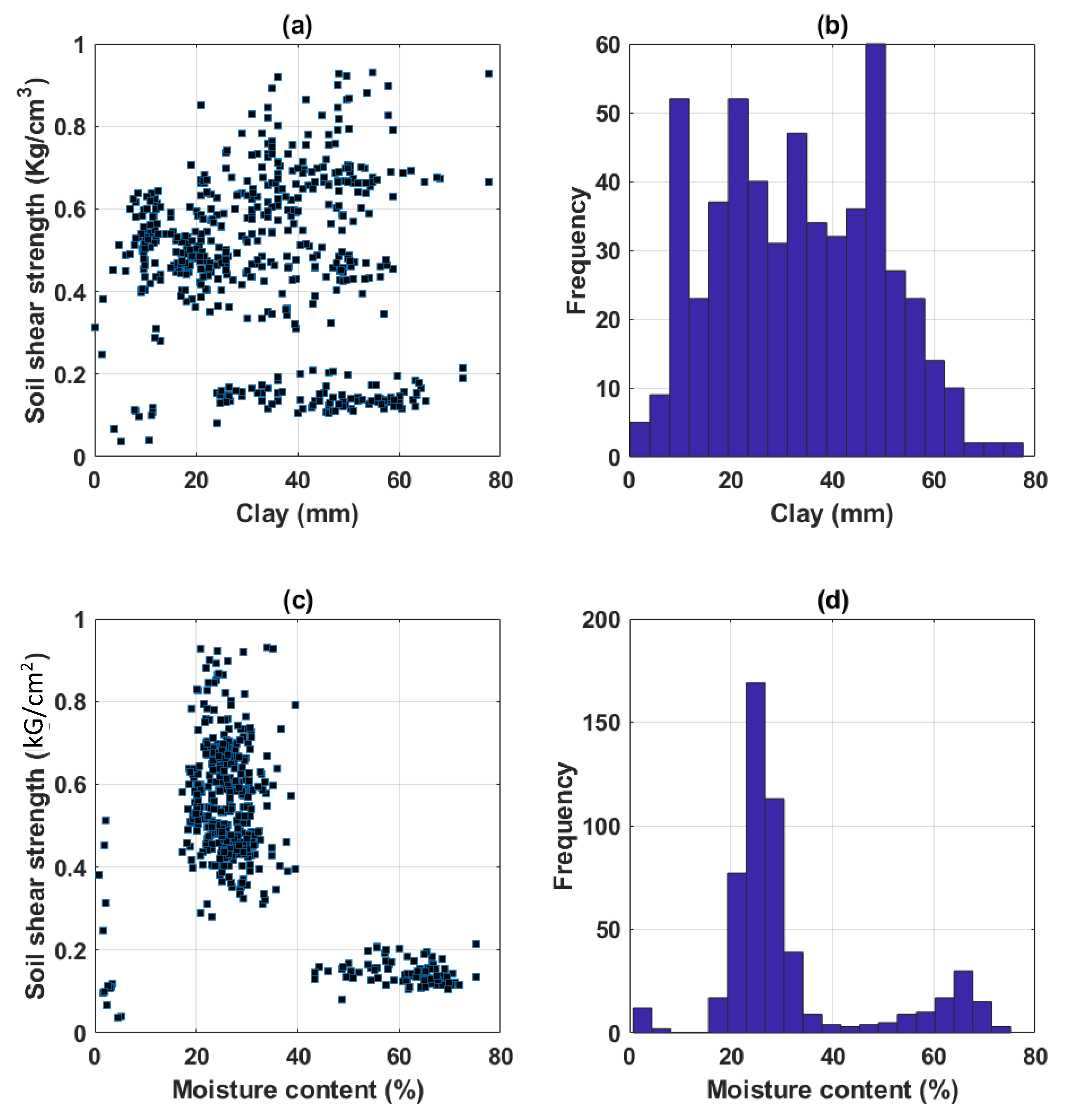
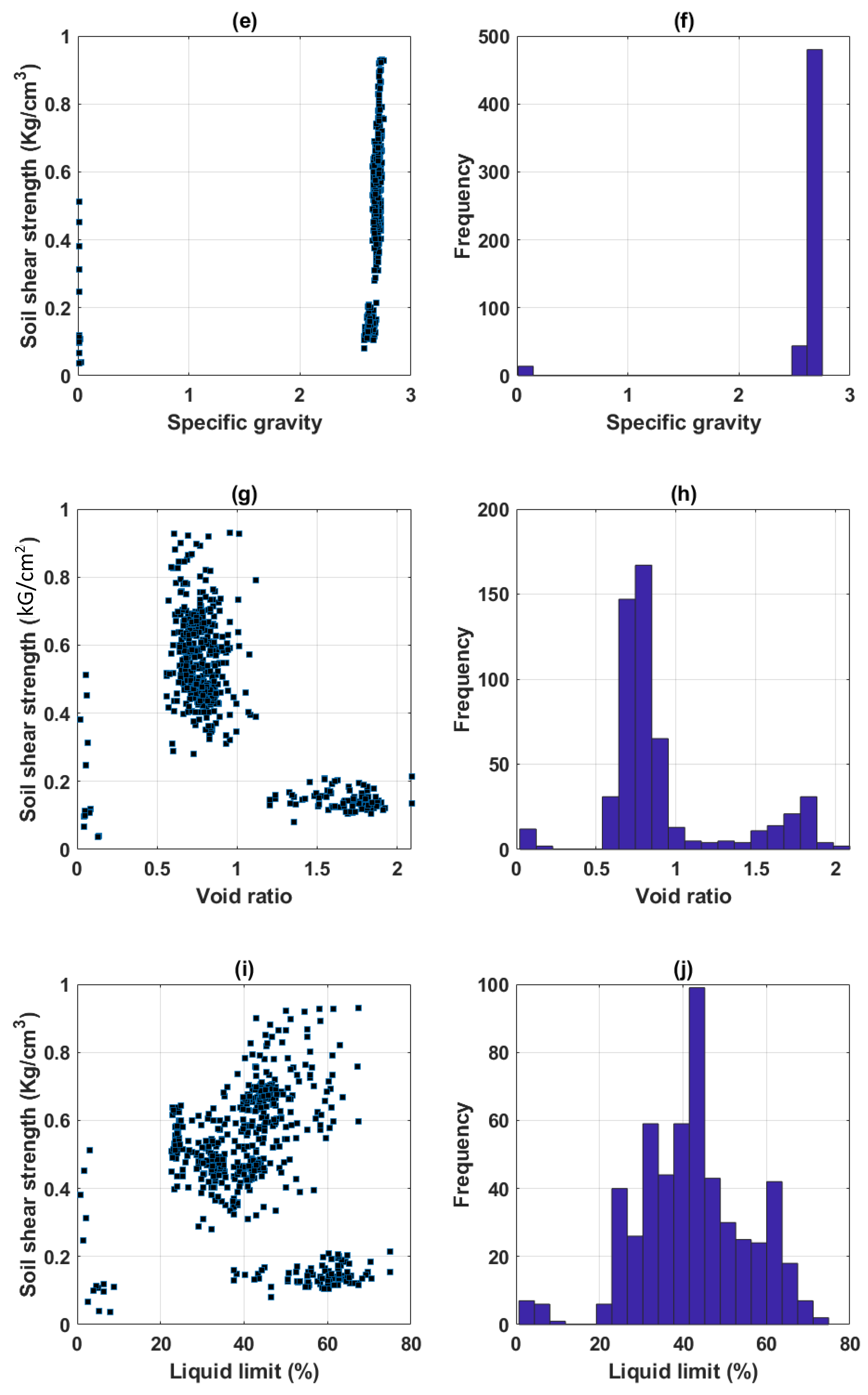
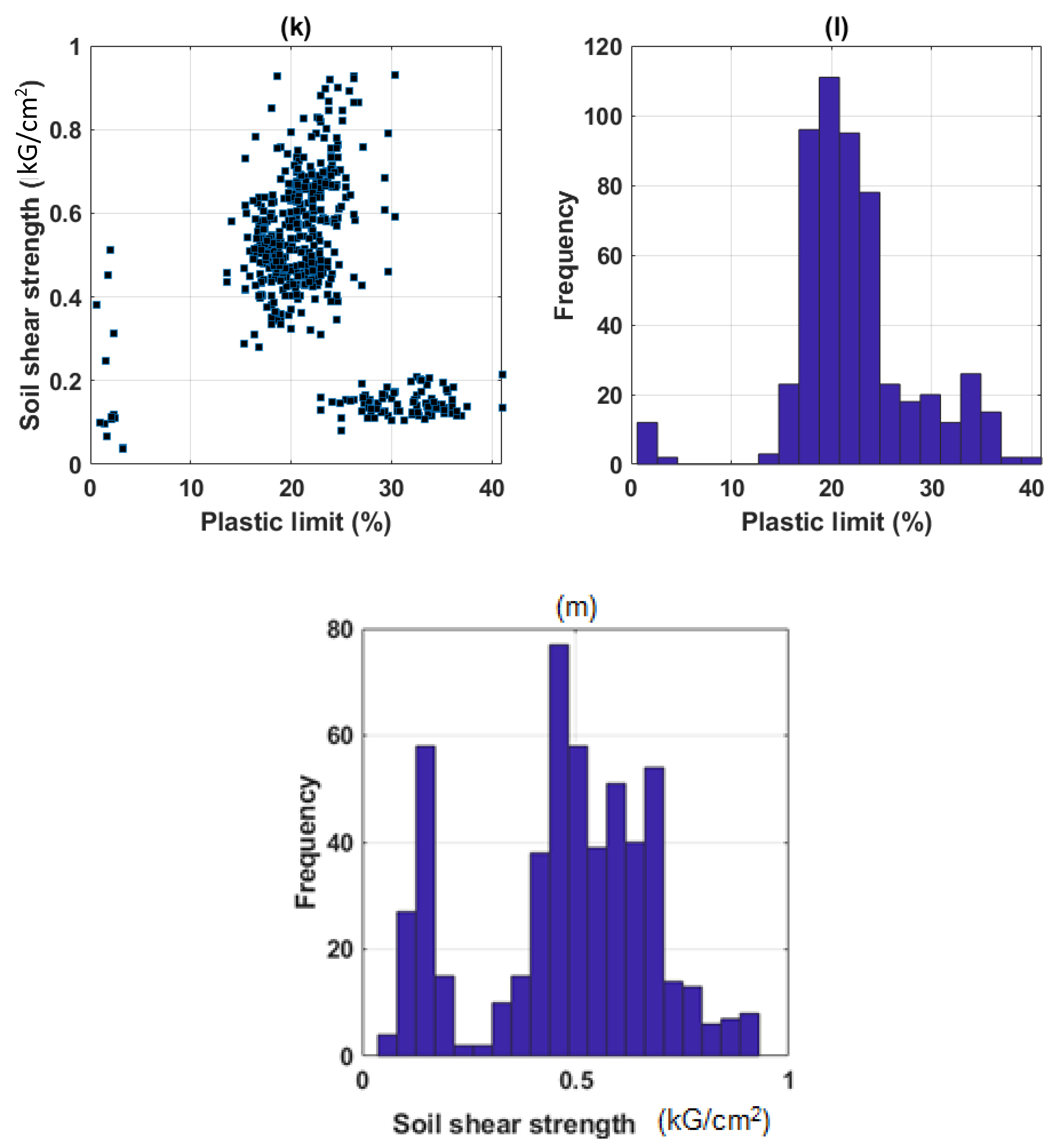
Datasets of 538 soil samples were extracted from the project and used in this study. In datasets, variables, such as moisture content (%), clay content (%), void ratio, plastic limit (%), liquid limit (%), and specific gravity, were used as inputs, and shear strength was used as output.
Table 1 shows the initial statistical analysis of the dataset, including the unit and coding of each variable. It is seen that statistical information, such as average, standard deviation, and quantiles of all variables, is fully exposed. For illustration purposes,
Figure 2 presents the corresponding histograms of all variables used in this study, as well as the scatter plot between input variables and output response. It can be observed that the distribution of clay covered a wide range between 0 and 65 (mm), the liquid limit from 20 to 65 (%), and the plastic limit from 15 to 35 (%) with a high concentration around 20 (%). Most of the specific gravity values were in the 2.6–2.7 range, whereas the void ratio covered between the 0.5–1.0 range and a low concentration of values was around the 1.75 range. It can also be observed that there is no direct relationship between inputs and output response. Thus, it can be stated that the choice of variables in this study is relevant and suitable [
12].
In order to validate the efficiency of the developed ML model, a sub-dataset calling testing part was made, exhibiting 30% (161 samples) of the total 538 configurations. It is worth noticing that such a rate of testing/training was recommended in the literature when developing ML-based models [
13,
14,
15,
16,
17]. On the other hand, in order to reduce fluctuations within the dataset in training the ML model, as the variables have different ranges of values, all variables were scaled into the range of [0, 1] in order to avoid an unexpected jump in optimizing weight parameters of the models [
13,
18,
19,
20]. The scaling process of a variable
x is expressed by Equation (1), and it involves two parameters,
α and
β, as indicated in
Table 1. Precisely,
α is the minimum value of the dataset and
β is the maximum value.
2.2. Extreme ML-Based Modeling
Extreme Learning Machine (ELM) is a single hidden layer feedforward neural network (SLFN). The performance of SLFN should be suitable for the system, which can be modeled for data such as critical value, weight, activation function. Therefore, higher learning can be done. In gradient-based learning approaches, all of these parameters are reiteratively modified for each appropriate value. Unlike feedforward neural networks (FNN), which are renewed based on the gradient, in the ELM process, the output weights are analytically built while the input weights are randomly chosen. For an analytic learning process, success rate increases thanks to a strong reduction of the resolution time and the error value. ELM can be introduced to choose a linear function for activating cells in a hidden layer, maybe use non-linear (such as sigmoid and sinusoidal), non-derivatized, or intermittent activation functions [
21,
22]. ELM algorithm can be shown in the following equations:
where α
i is the weights between the input layer and the hidden layer and α
j is the weights between the output layer and the hidden layer, a
j is the critical value of the neurons in the hidden layer, g(.) activation function. Input layer weights (w
i,j) and bias (a
j) are randomly selected. At the beginning of the input layer neuron number (n) and hidden-layer neuron number (m), the activation function (g(.)) is selected. To construct the ELM algorithm, the database was split into a training dataset (70% data) and the remaining data (30%) for building and validation of the ELM model.
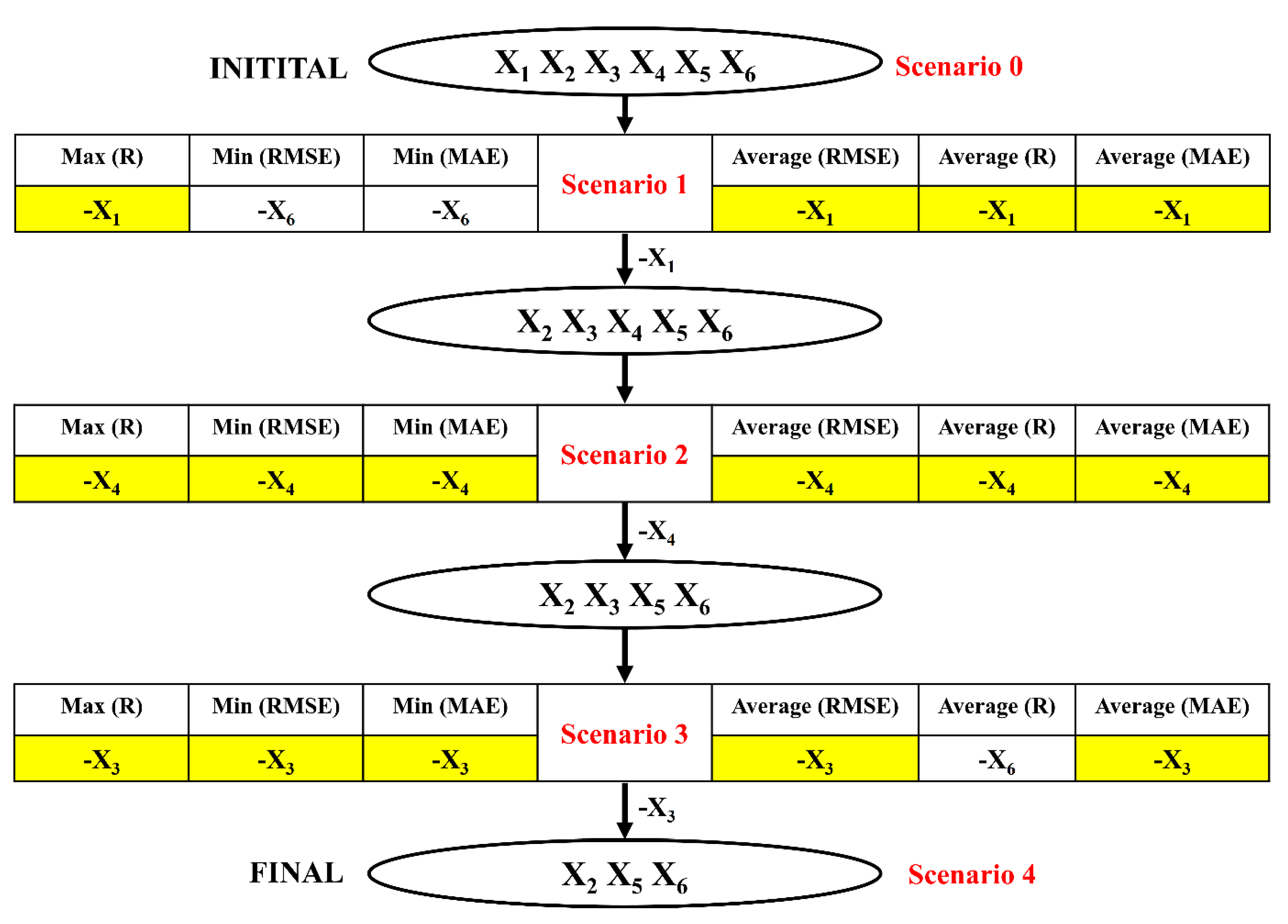
2.3. Backward Elimination-Based Sensitivity Analysis
Backward elimination, belonging to the wrapper methods, is basically the opposite of the forward selection approach [
23]. Precisely, all input variables are firstly chosen, then the most unimportant of the variables are removed one by one in this case [
24]. For strategic choices of the process, relative importance of an input variable can be obtained by eliminating an input variable and assessing the influence on the model to be retrained without it or by examining the effect of each input variable on the output by the sensitivity analysis method. In the filtering strategies, the least relevant candidates will be deleted repeatedly until the optimal criteria are satisfied. The process of backward elimination can be summarized in
Figure 3.
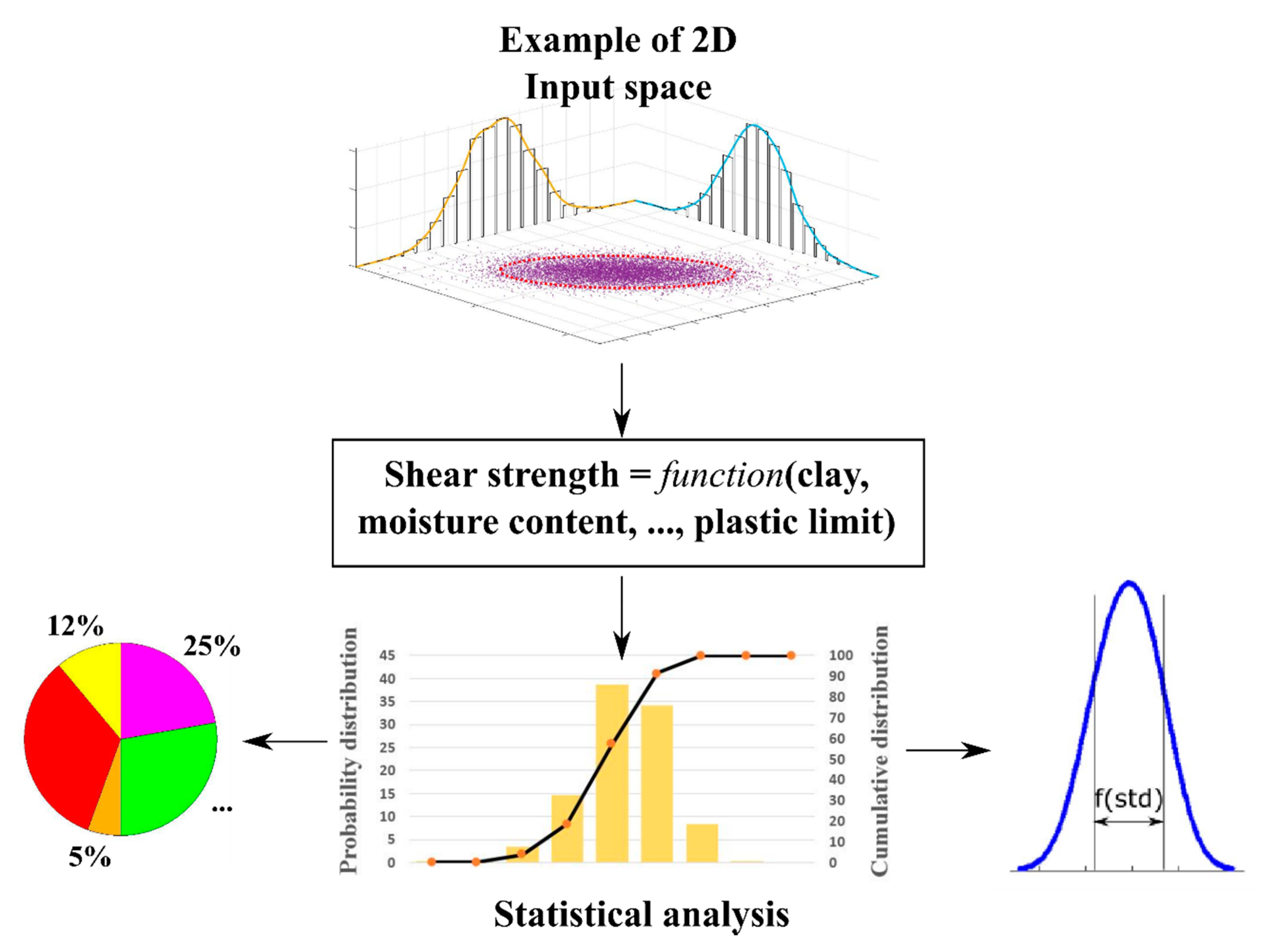
2.4. Monte Carlo Simulations
Monte Carlo method is one of the most widely used techniques for propagating the input variability on the output results [
25,
26,
27,
28,
29]. Regarding, for instance, the field of geotechnical engineering, Pham et al. [
11] applied the Monte Carlo method for accounting variability of various content properties of soil on the prediction of its mechanical behavior under compression during a highway project. In another attempt for steel structures, the Monte Carlo technique was employed by Le et al. [
15] in order to quantify the robustness of hybrid ML models for predicting the critical buckling load of structural members. For typical construction and building materials, such as concrete, many studies involving Monte Carlo technique were introduced in the literature, taking into account the variability in the input space. For instance, Wang et al. [
30] quantified the size effect of random aggregates and pores on the mechanical properties of concrete. Jaskulski et al. [
31] proposed a probabilistic analysis for concrete subjected to shear. So far, numerical prediction models involving Monte Carlo method could strongly explain the variation of the output results through statistical analysis.
Monte Carlo method is extremely robust and efficient for calculating the propagation of the input variability on the output results, especially using ML models [
11,
32]. The main idea of the Monte Carlo method is to repeat realizations randomly in the input space and then calculate the corresponding output through the simulation model [
33,
34]. Therefore, this numerical technique exhibits a high ability in parallel computing [
35,
36,
37,
38]. A concept of using the Monte Carlo method is presented in
Figure 4, involving a two-dimensional input space with a typical probability distribution.
In this work, the statistical convergence of Monte Carlo simulations has been investigated using the following equation [
18,
32,
39,
40]:
where
is the mean value of the considered random variable
G and
nMC is the number of Monte Carlo runs. This convergence function provides efficient information related to the computational time, reliability results for further statistical analysis.
2.5. Performance Evaluation
To validate the predictive capability of the models, Mean Absolute Error (MAE), the Pearson correlation coefficient (R), and Root Mean Squared Error (RMSE) were selected and used, as these validation criteria are popular in evaluating the ML models. Basically, R indicates the statistical relationship between the actual values of experiments and the predicted values of the models [
41]. Its absolute values range from 0 to 1 where 0 shows an inaccurate correct model and 1 indicates an accurate model. Higher R values indicate better performance of the models. RMSE indicates the average squared difference between the actual and predicted values [
42]. In the case of MAE, it shows the average of absolute difference between predicted and actual values [
43]. In general, RMSE and MAE show the error evaluation of the models. Thus, lower RMSE and MAE values indicate better performance of the models. Calculation of these values (R, RMSE, and MAE) can be carried out using the following equations:
where m is defined as the number of samples,
ri and
t are defined as the values and means of the predicted shear strength, respectively, and
ti and
t are the values and mean of the actual shear strength, respectively.
5. Conclusions
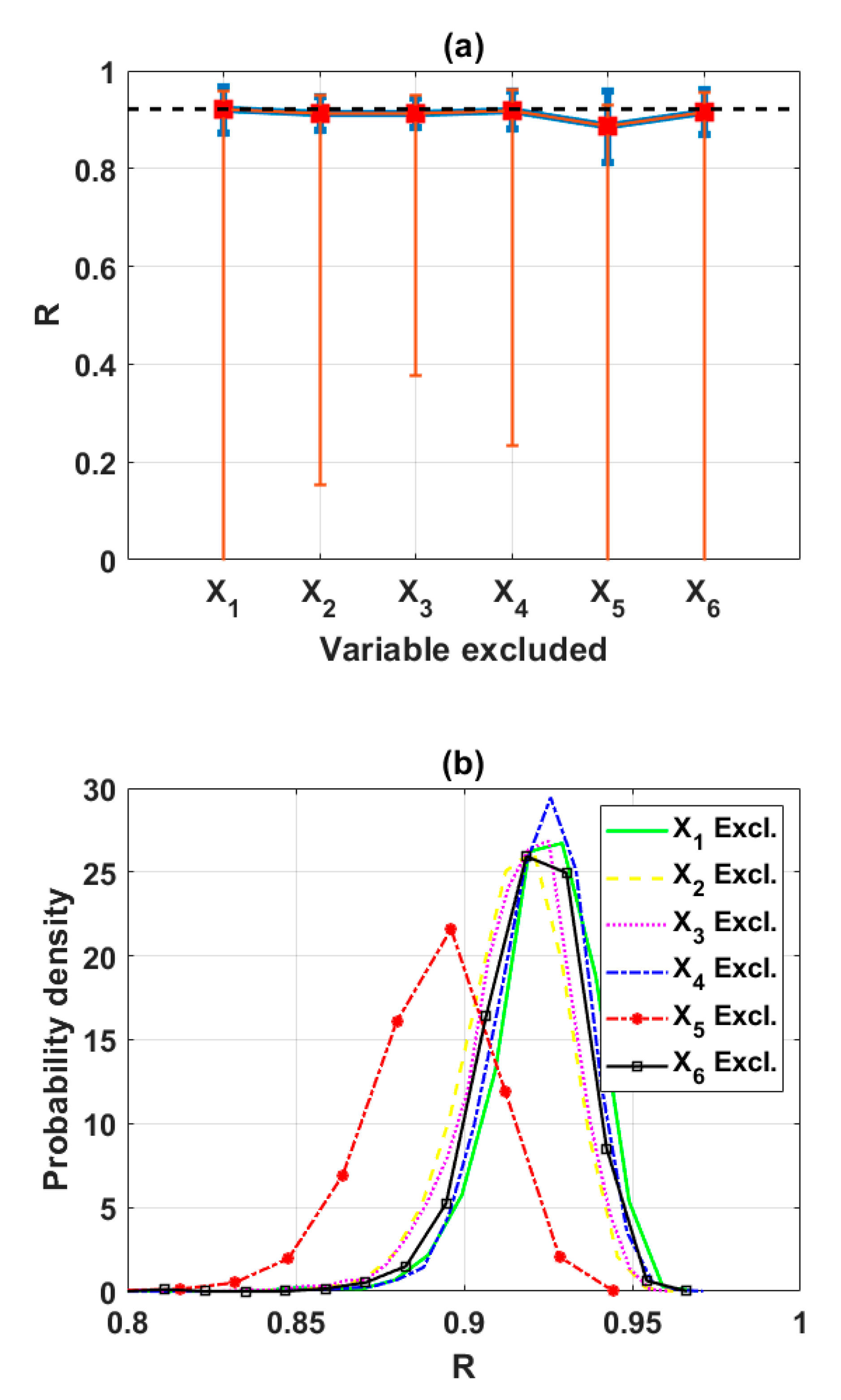
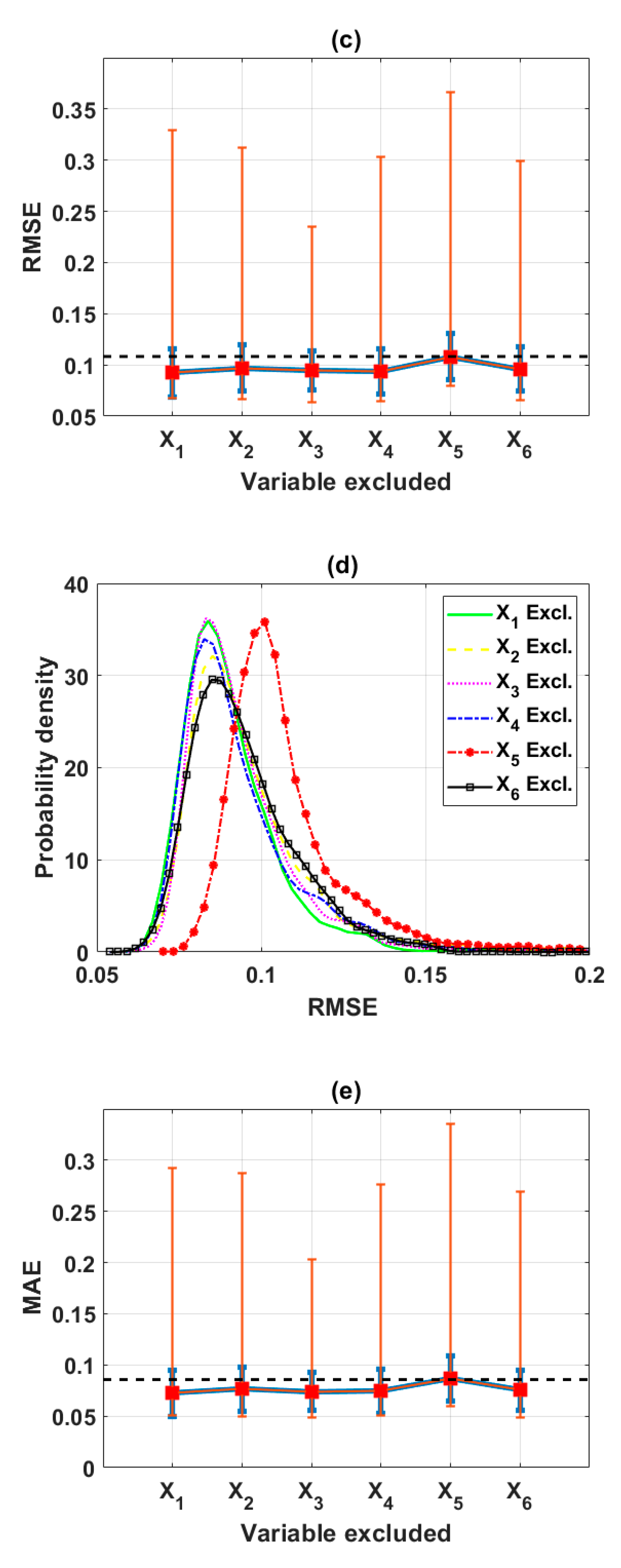
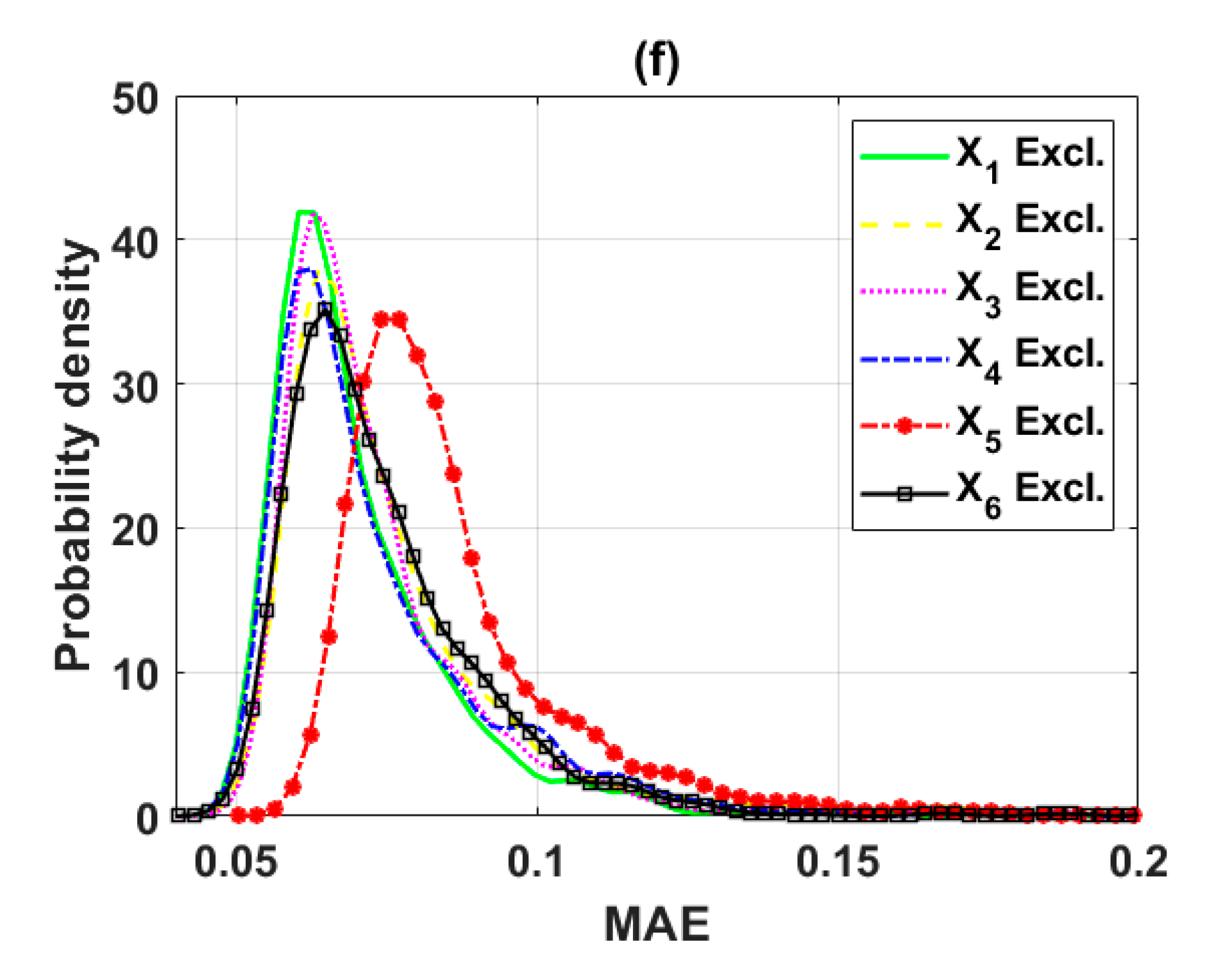
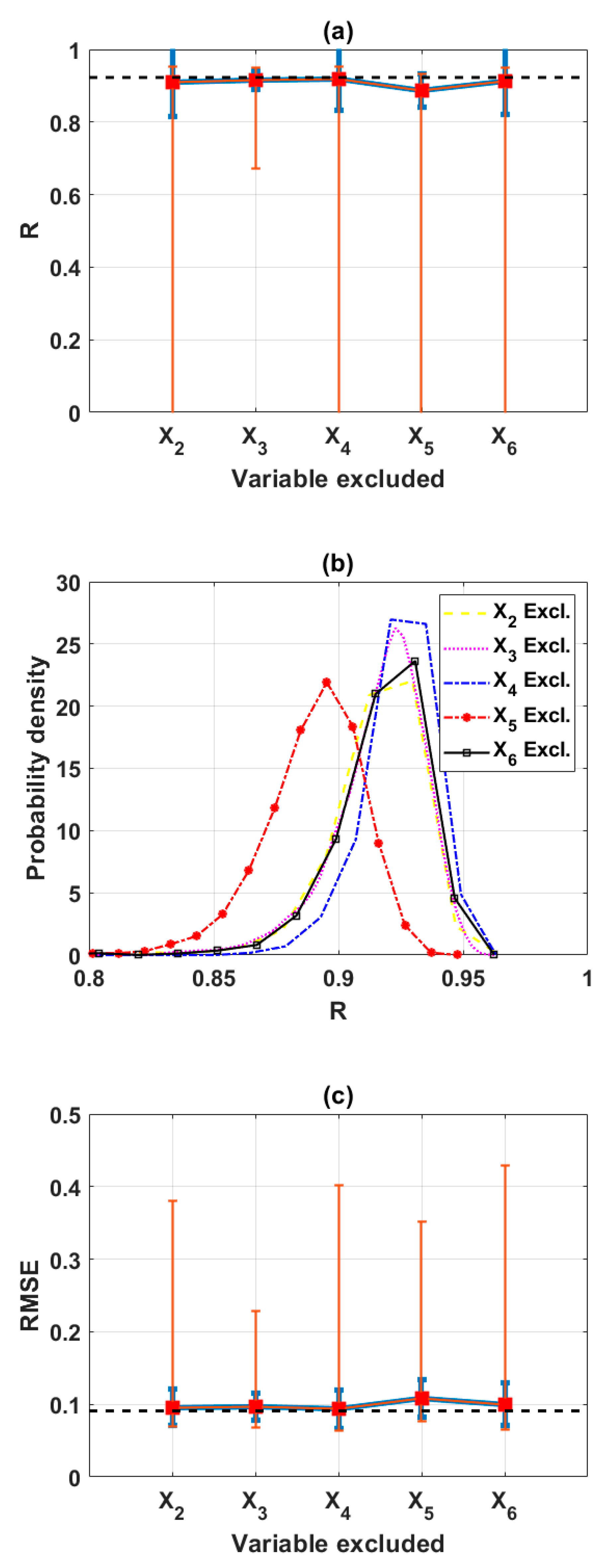
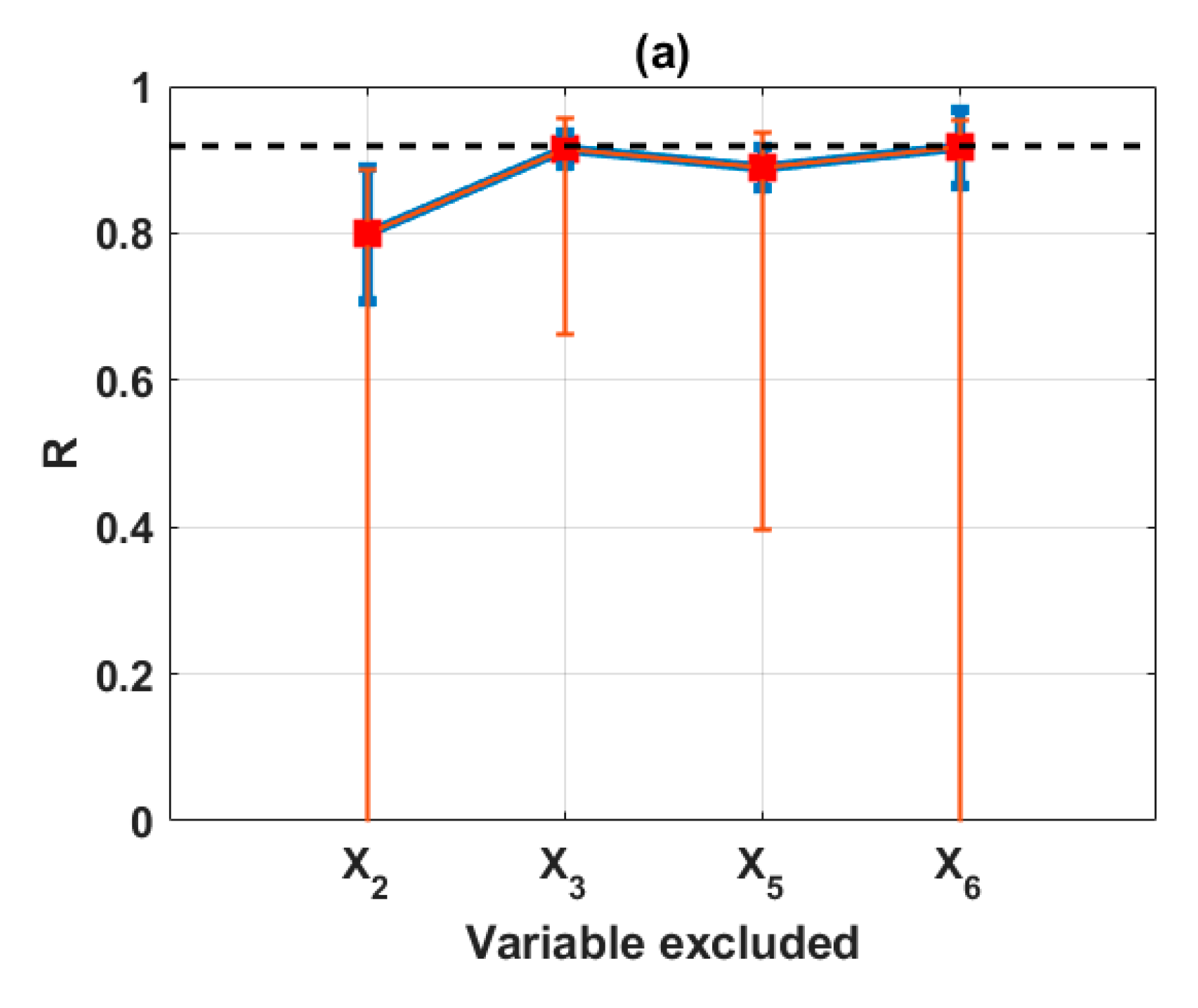
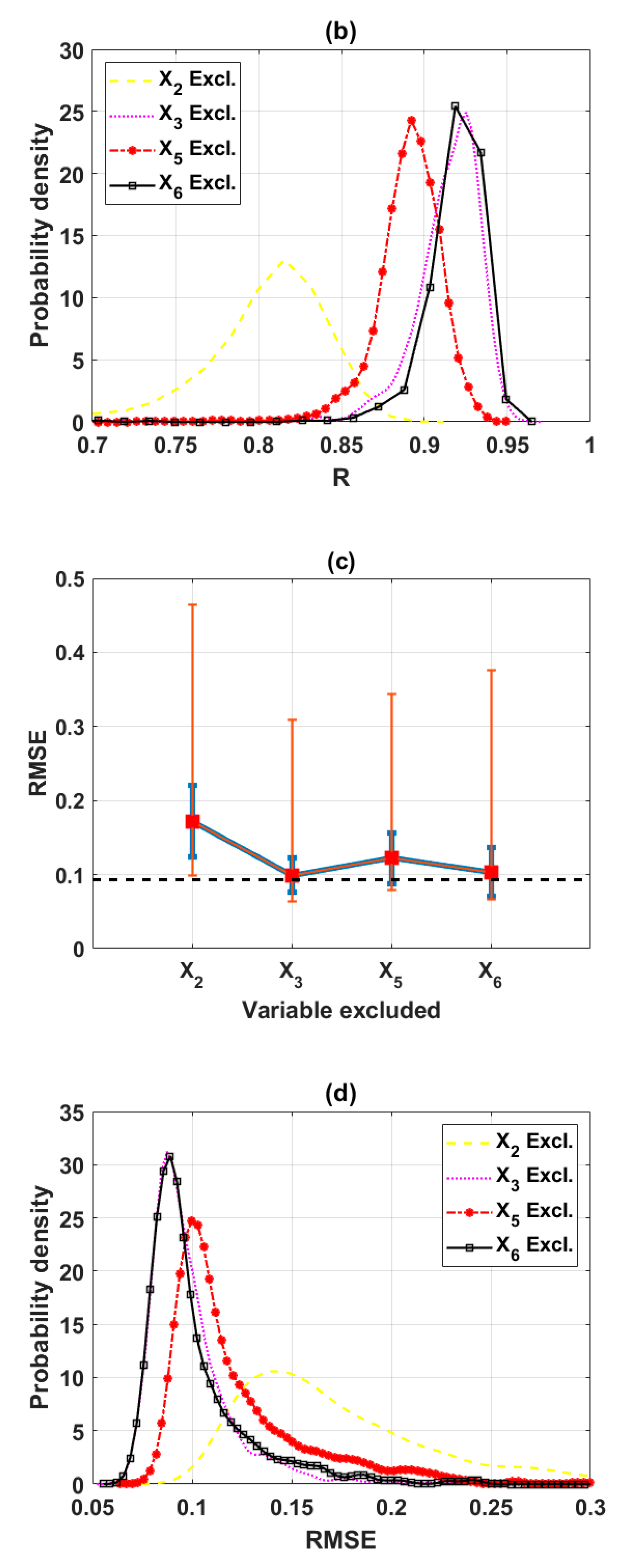
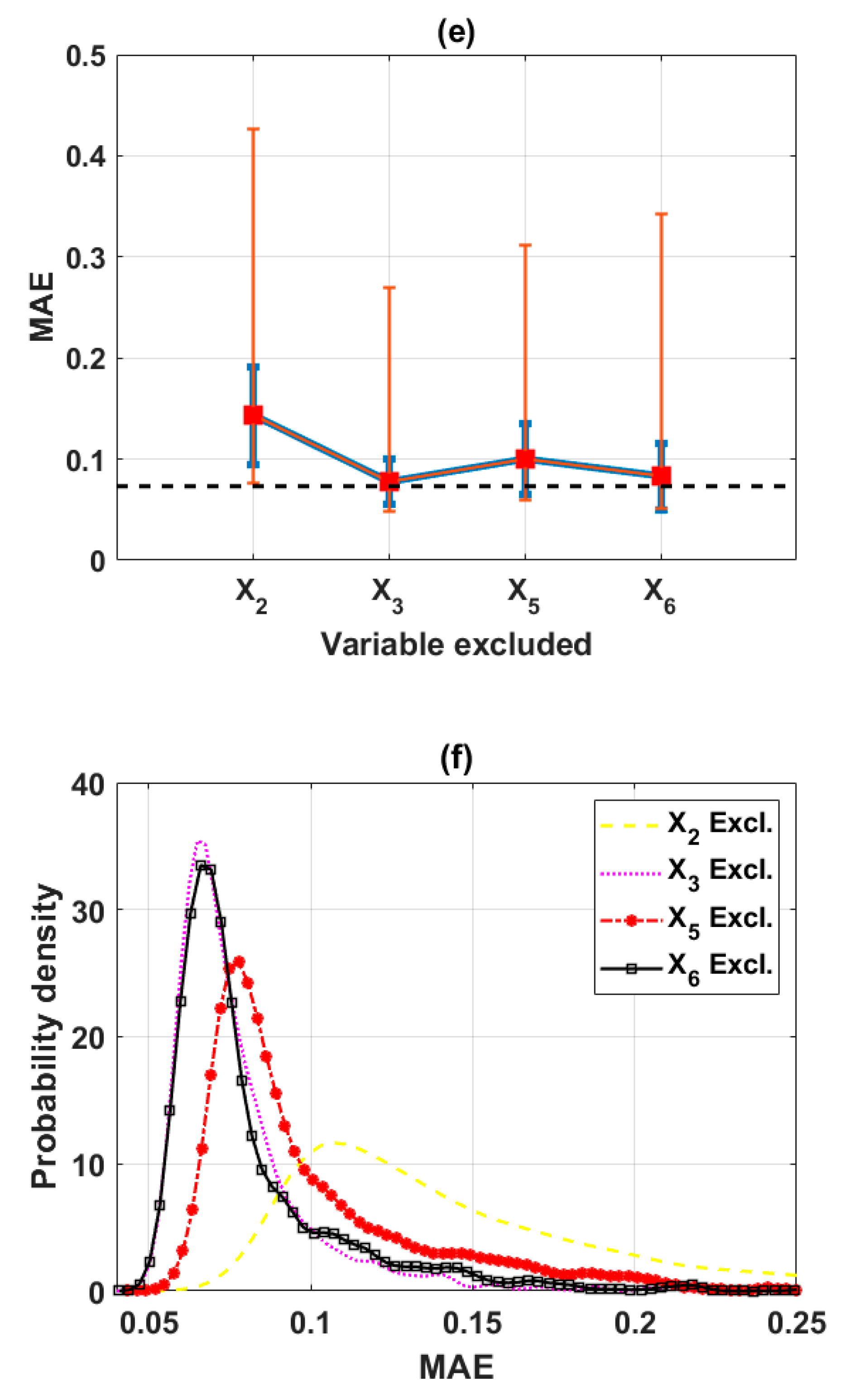
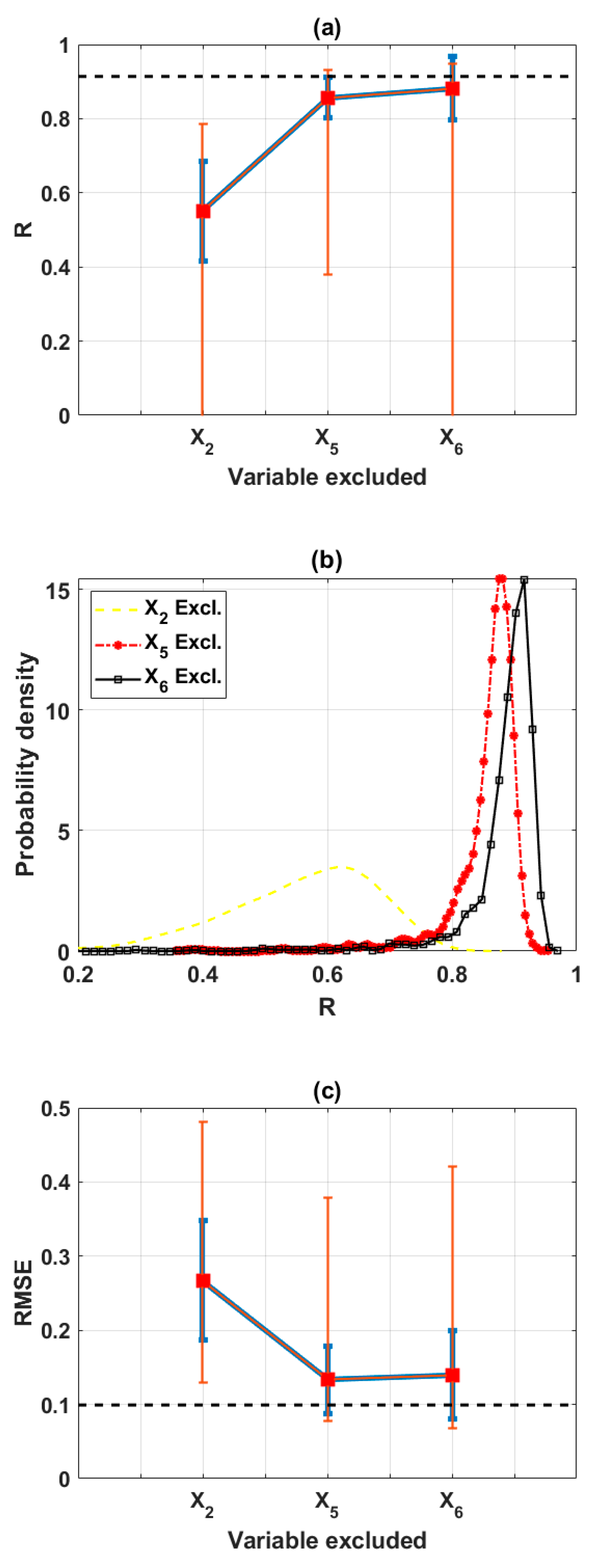
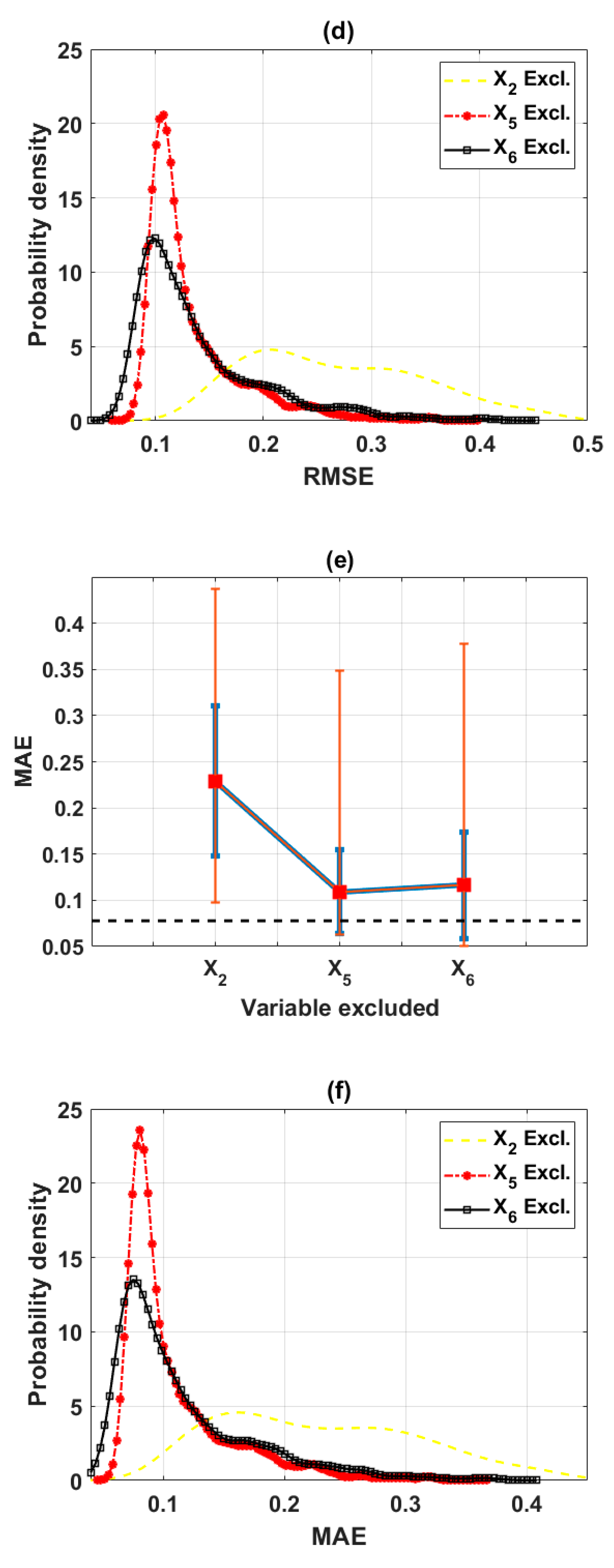
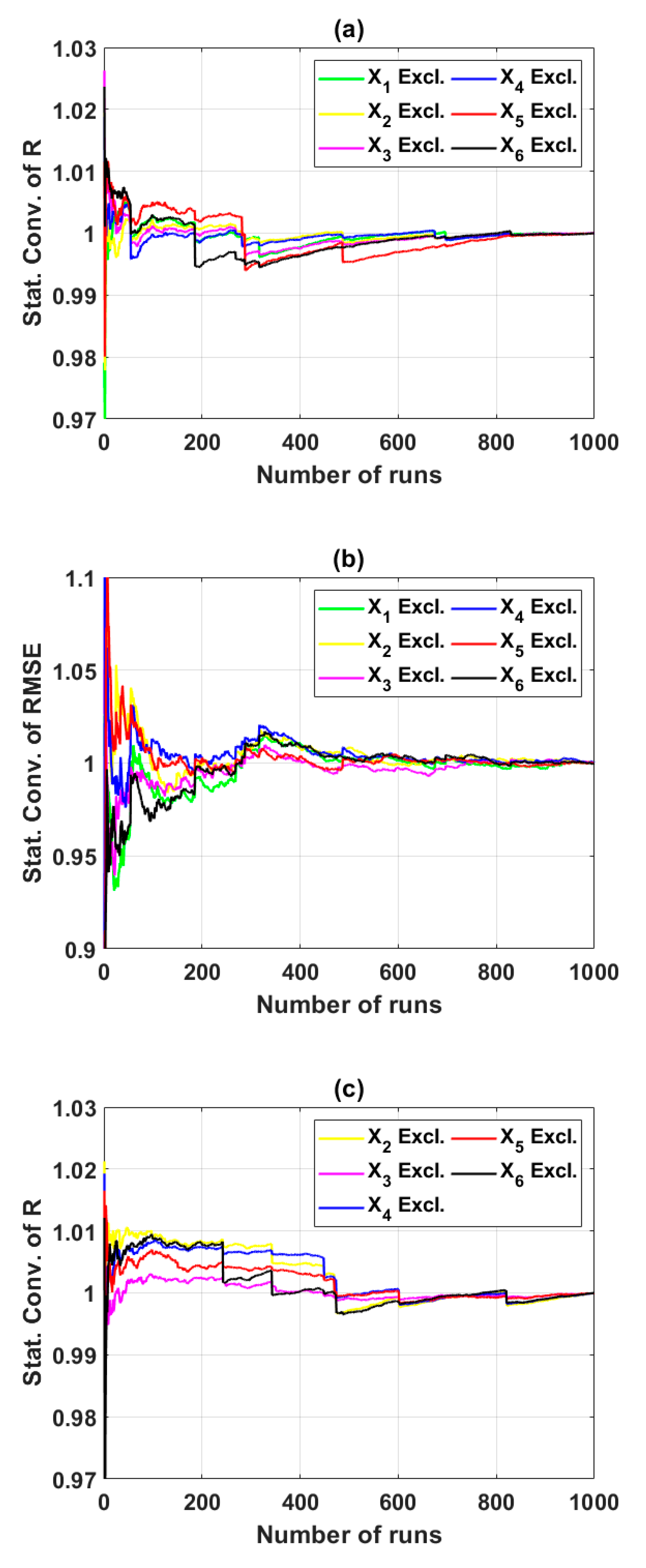
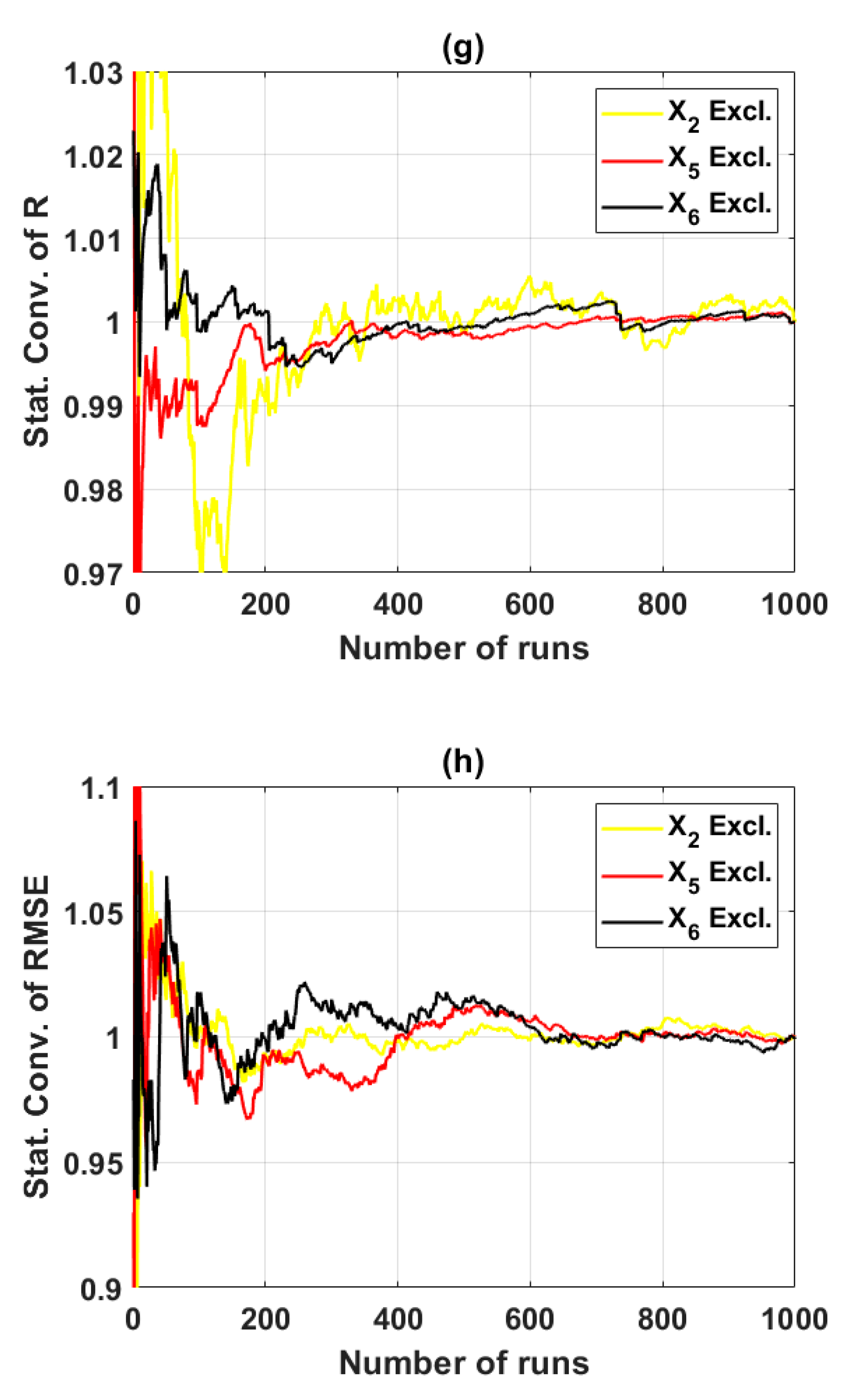
In this study, the sensitivity of an advanced ML method, namely the ELM algorithm under different feature selection scenarios for prediction of shear strength of soil was carried out. Feature backward elimination and Monte Carlo simulations were applied to evaluate the importance of factors used for the modeling. A database including input variables (moisture content (%), clay content (%), void ratio, plastic limit (%), liquid limit (%), and specific gravity) and output variable (shear strength of soil) constructed from 538 samples collected from Long Phu 1 power plant project was used for analysis. Well-known statistical indicators such as R, RMSE, and MAE were utilized to evaluate the performance of ELM algorithm. In each elimination step, the majority vote was selected to decide the variable to be excluded.
The results show that the performance of ELM is good but very different under different combinations of input factors for the prediction of shear strength of soil. The moisture content, liquid limit, and plastic limit were found as the most important variables, and other factors are less important for prediction of shear strength of soil using the ML model. This study might help to select the suitable factors for more quickly and accurately prediction of shear strength of soil using ML models.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}