
Using Artificial Intelligence for Assistance Systems to Bring Motor Learning Principles into Real World Motor Tasks

 ,
,
Abstract
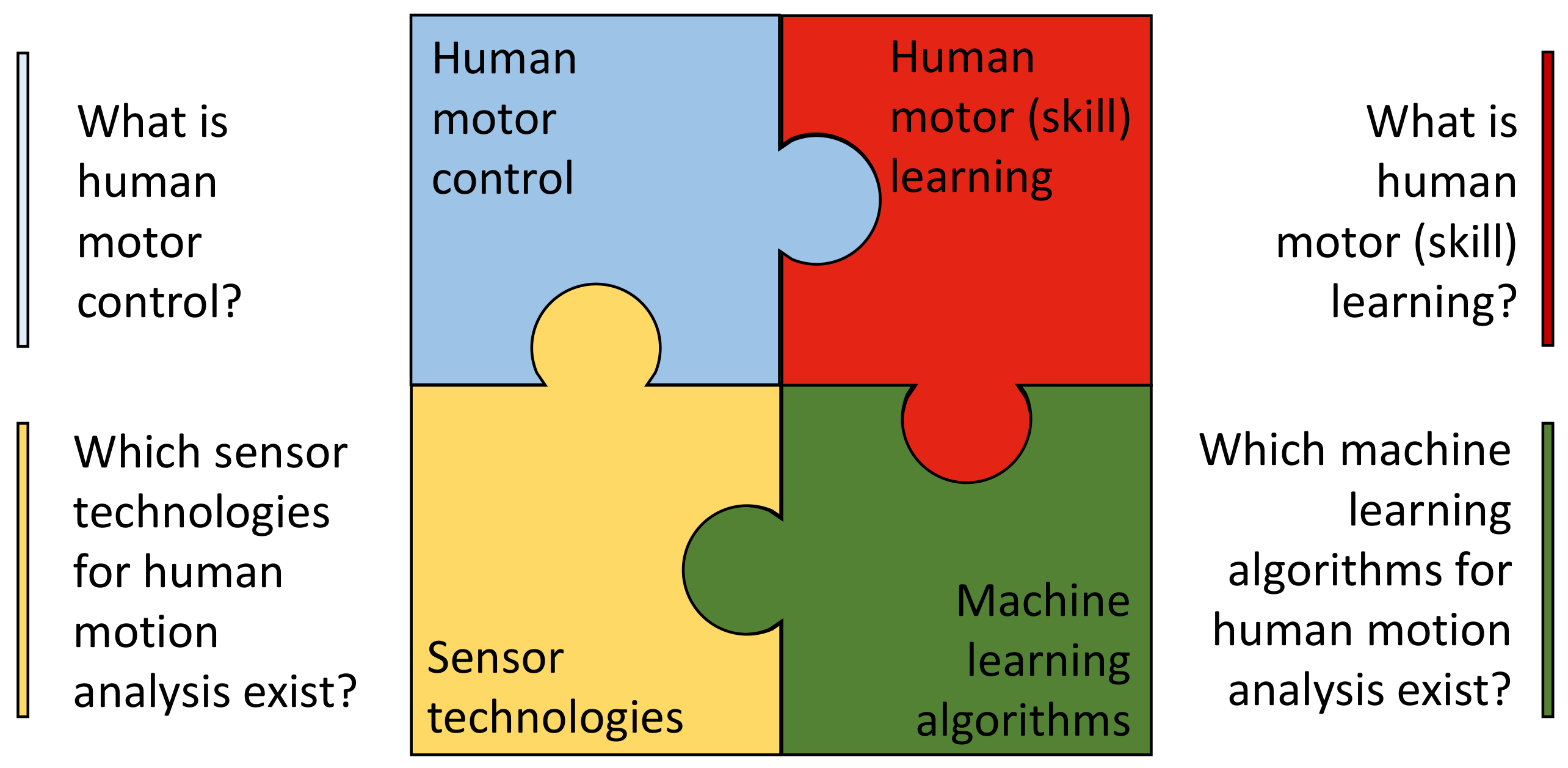
:1. Introduction
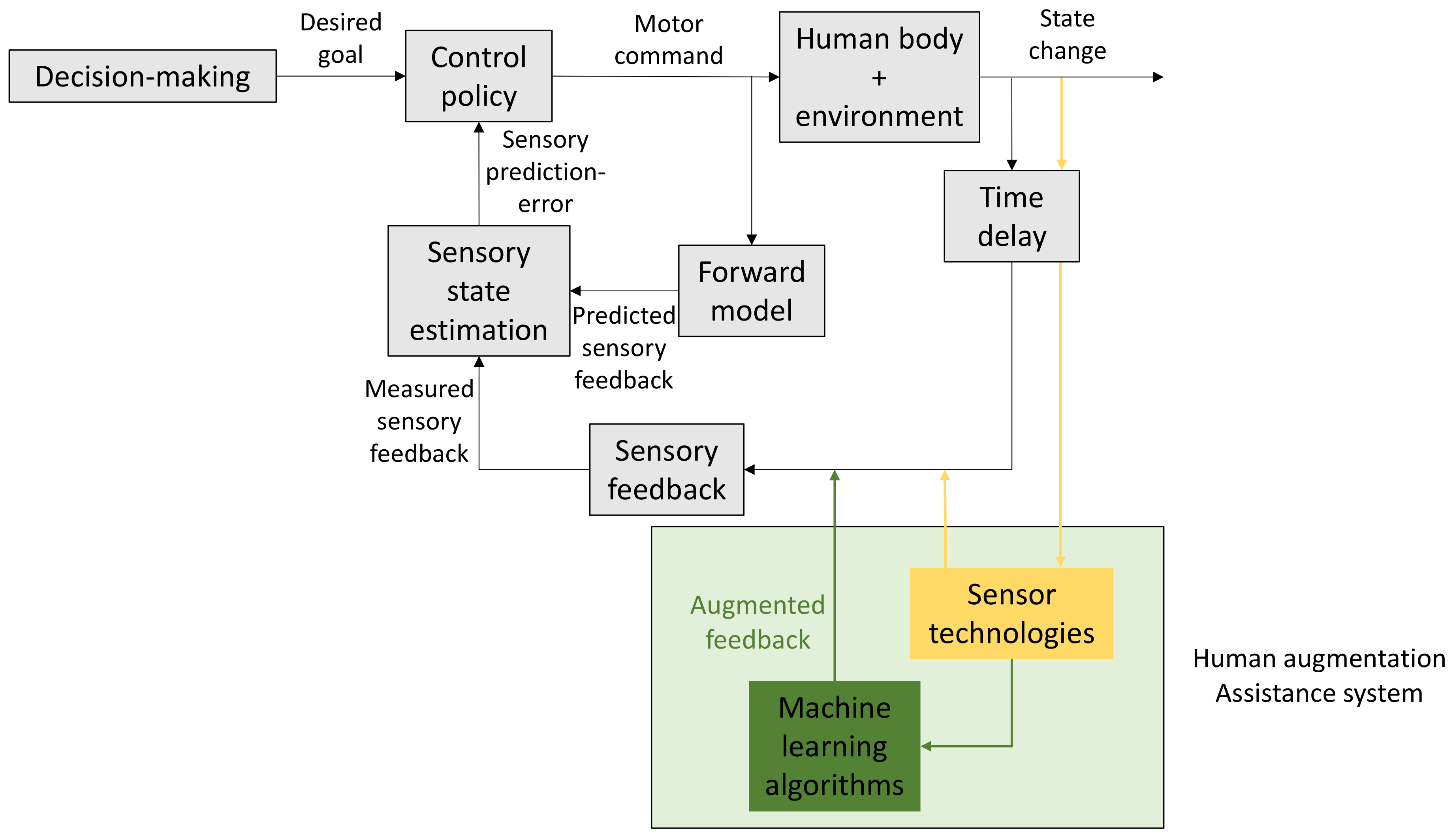
2. Human Motor Control
3. Human Motor Learning
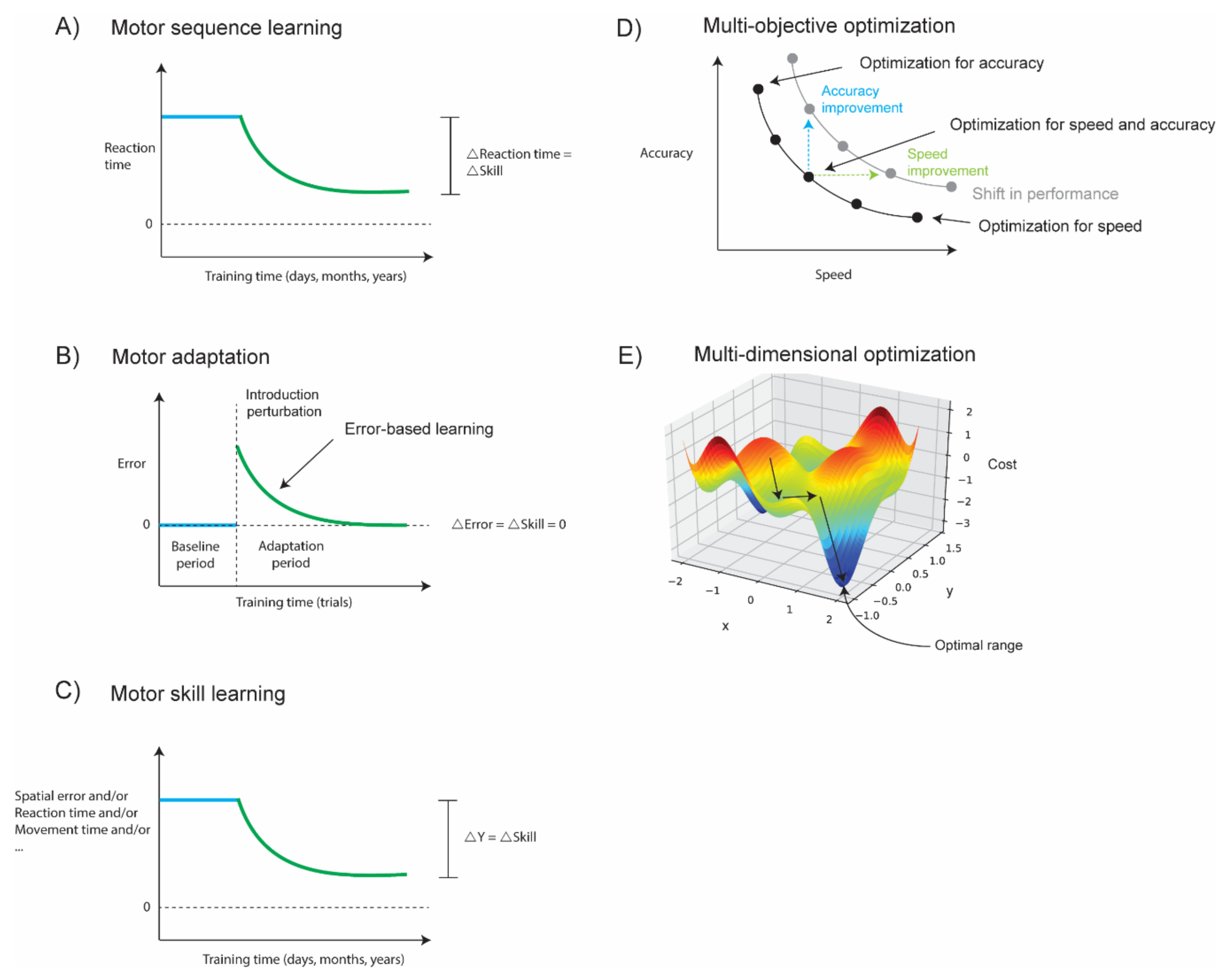
3.1. Motor Sequence Learning
3.2. Motor Adaptation
3.3. Motor Skill Learning

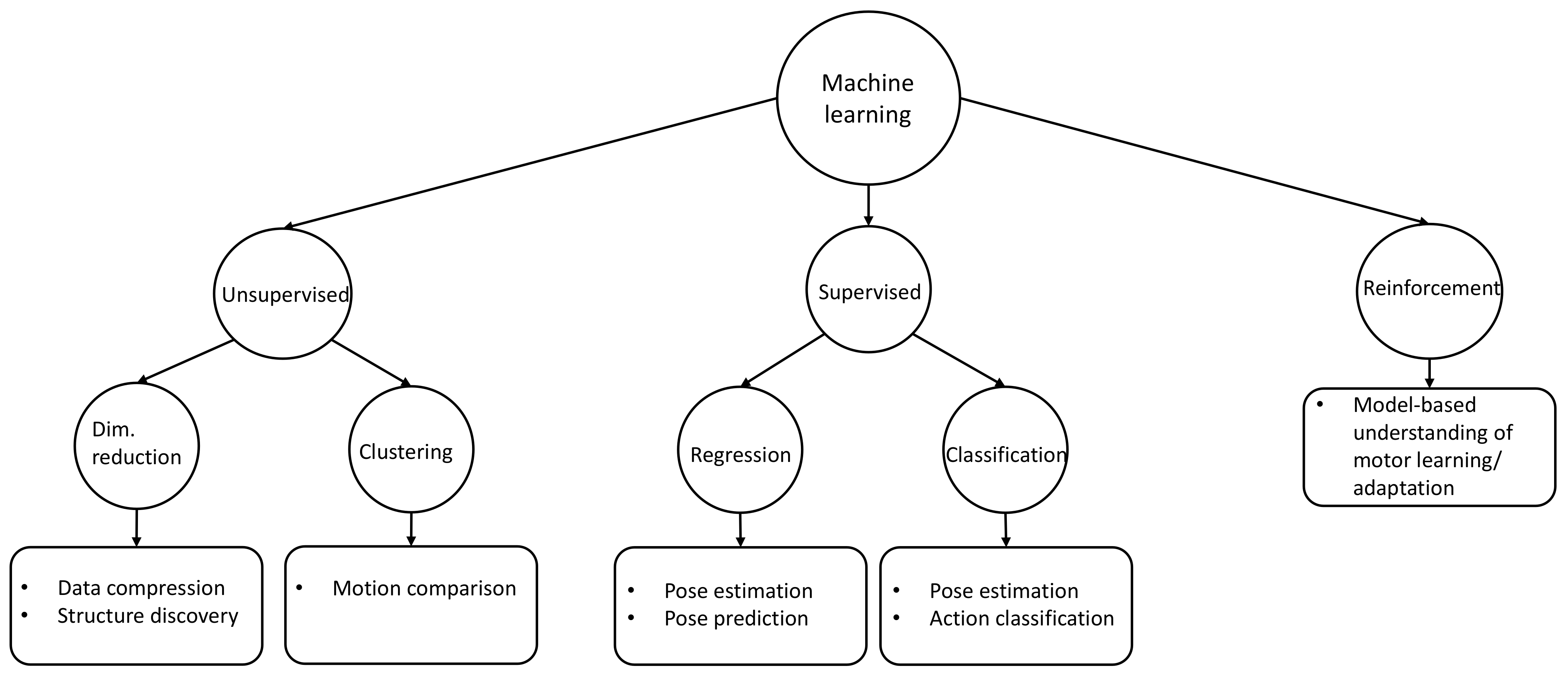
4. Machine Learning Algorithms for Human Motion Analysis
4.1. Structure Discovery and Data Compression by Using Dimensionality Reduction Techniques
4.2. Motion Comparison with Clustering
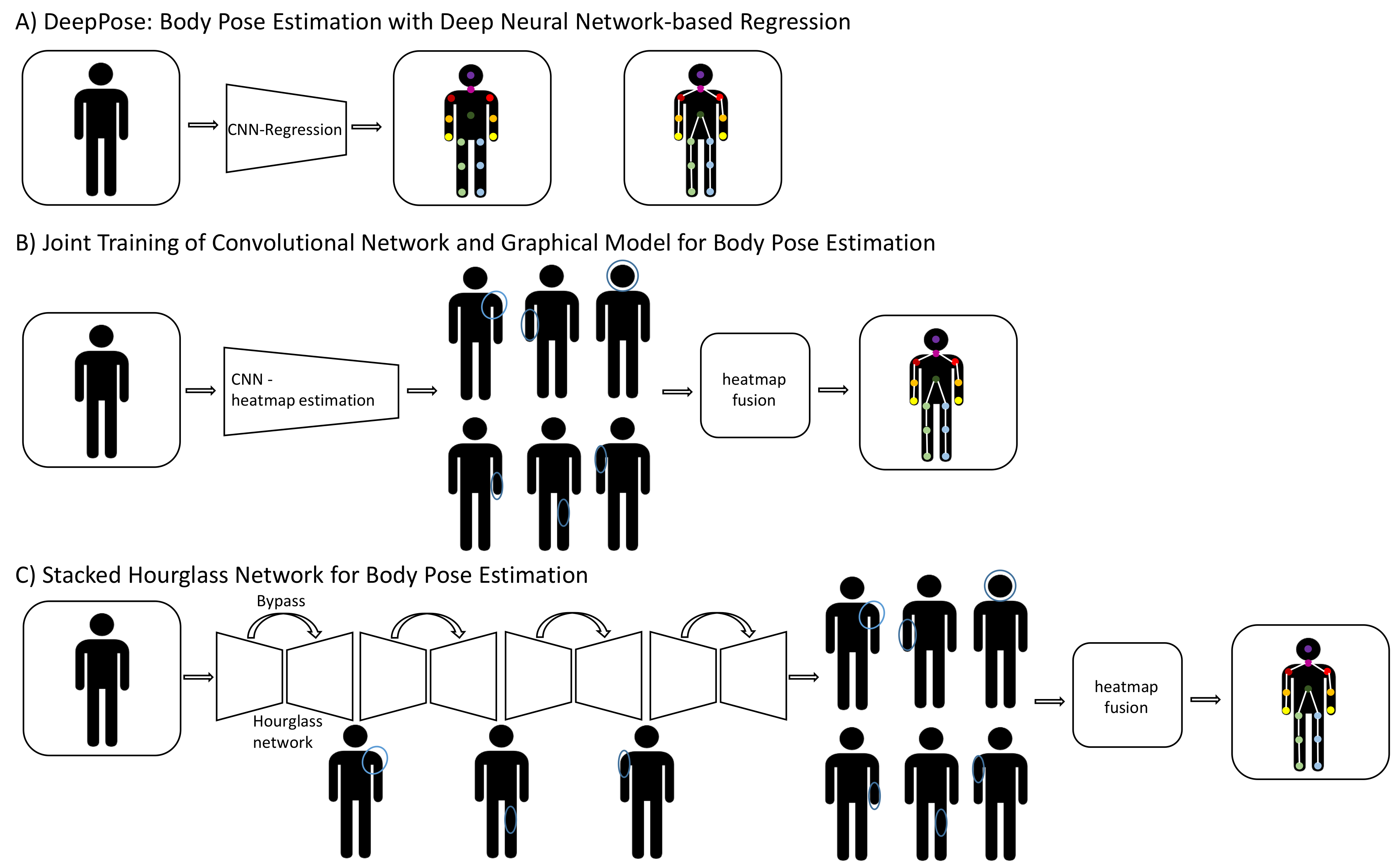
4.3. Pose Estimation
4.3.1. Pose Estimation in Two Dimensions

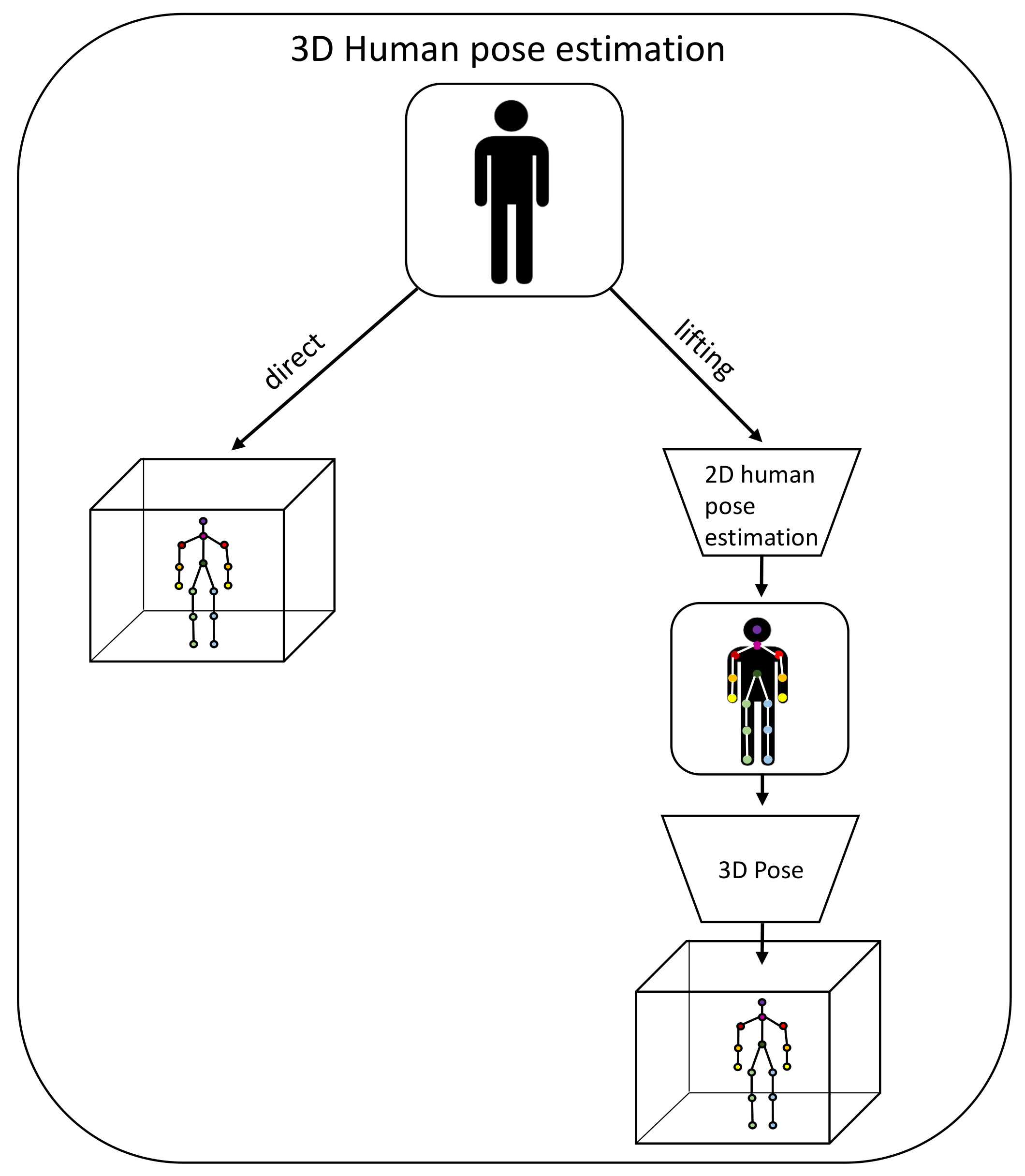
4.3.2. Pose Estimation in Three Dimensions
4.4. Action Recognition
4.4.1. Graph-Based Neural Networks
4.4.2. Learning Directly from Video
4.5. Motion Prediction
4.6. Robot Motor Learning for Understanding Human Motor Learning
5. Sensor Technologies for Human Motion Analysis
5.1. RGB Camera
5.2. Depth Camera
5.3. Inertial Measurement Unit
5.4. Sensor Fusion
5.5. Virtual and Augmented Reality Devices
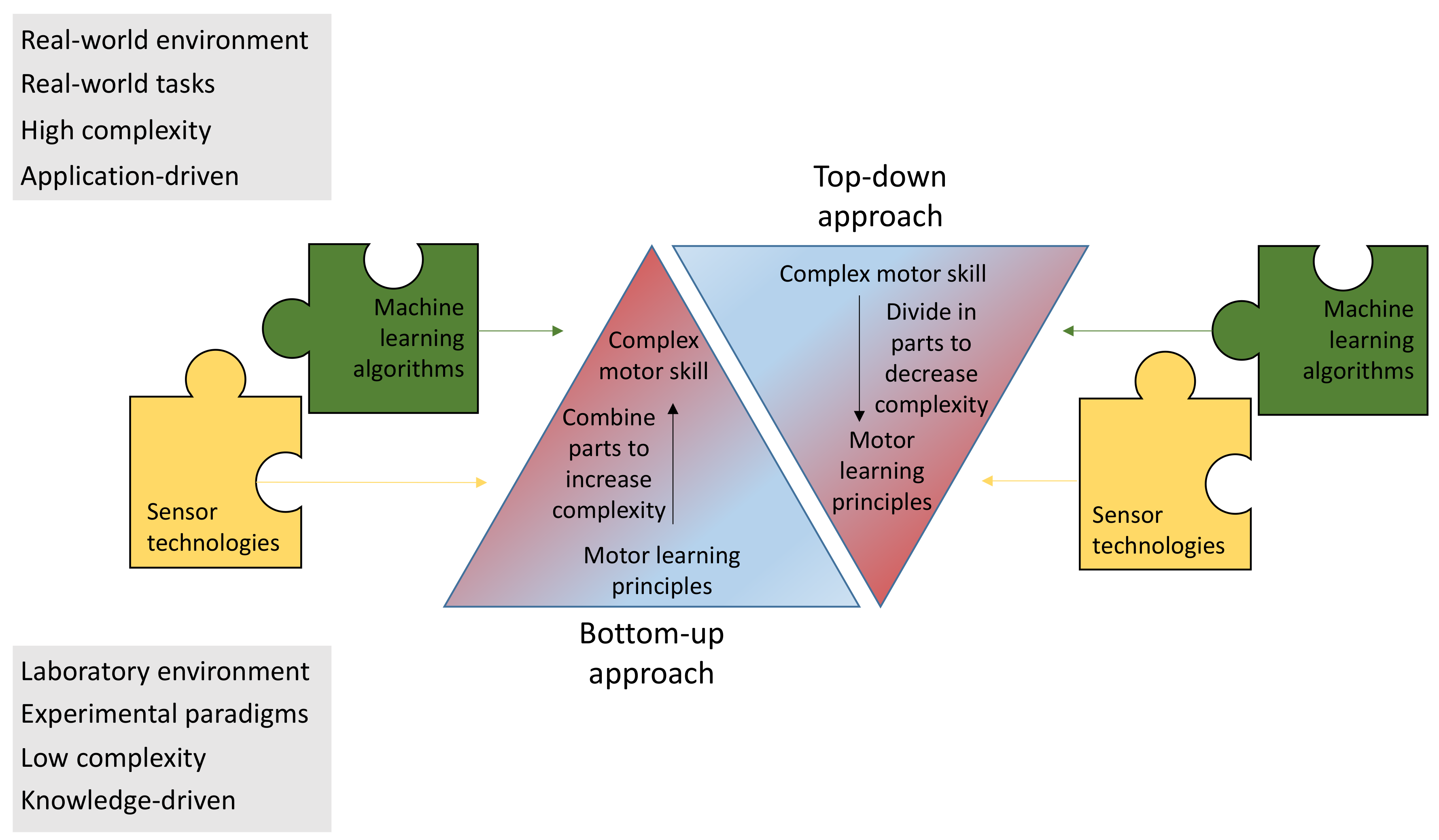
6. How to Transfer Motor Learning Principles to Complex Real World Environments?
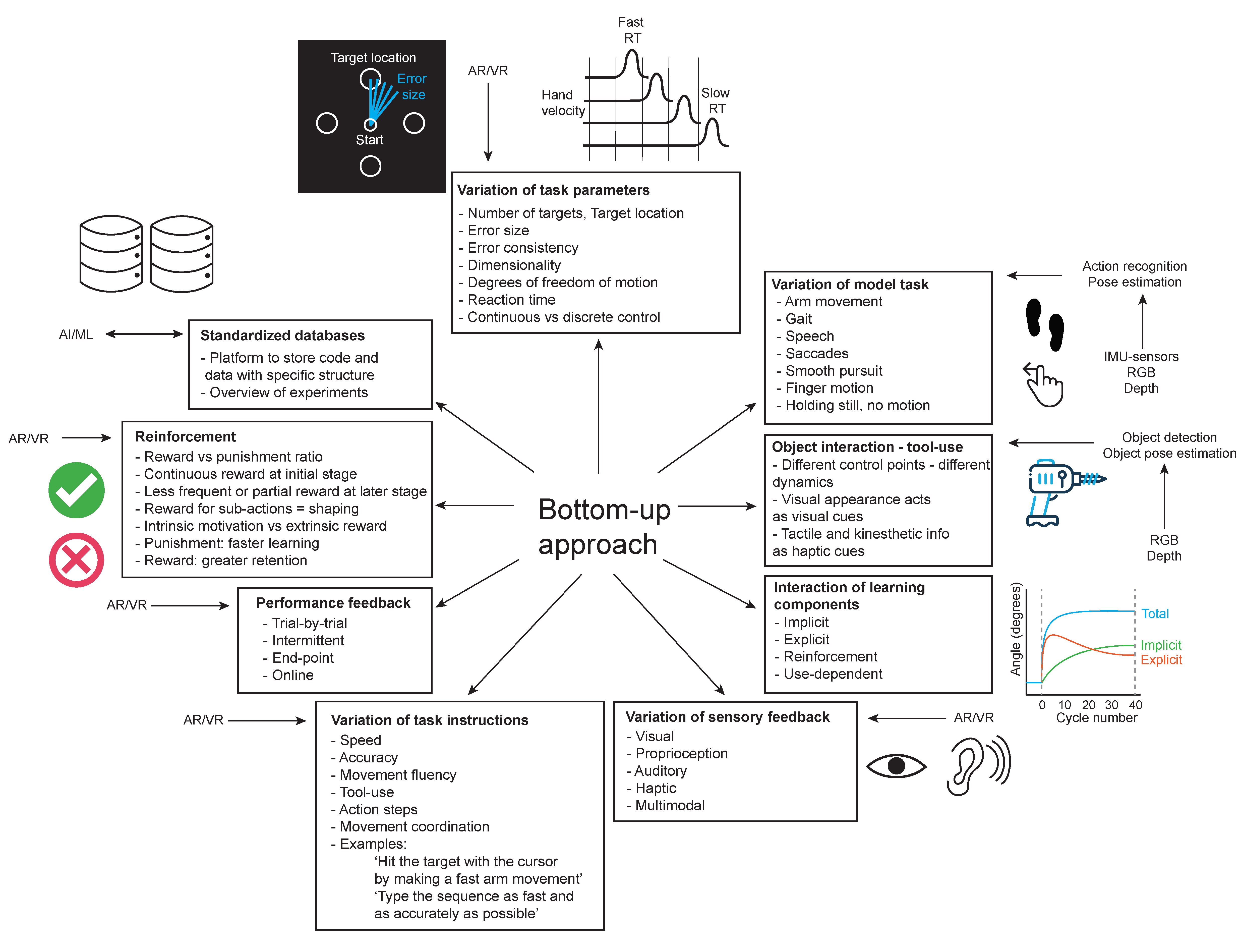
6.1. Bottom-Up Approach: Improve Understanding of Motor Learning Principles That Are Relevant for Motor Skill Learning
- Variation of task parameters
- 2.
- Investigate a variety of model task paradigms
- 3.
- Investigate object interaction and tool use
- 4.
- Investigate interaction of motor adaptation components
- 5.
- Investigate how different sensory feedback can modulate motor learning
- 6.
- Investigate how different task instructions can modulate motor learning
- 7.
- Investigate how (sub)task performance feedback can modulate motor learning
- 8.
- Investigate how reinforcement can modulate motor learning
- 9.
- Create standardized collaborative database of motor learning experiments
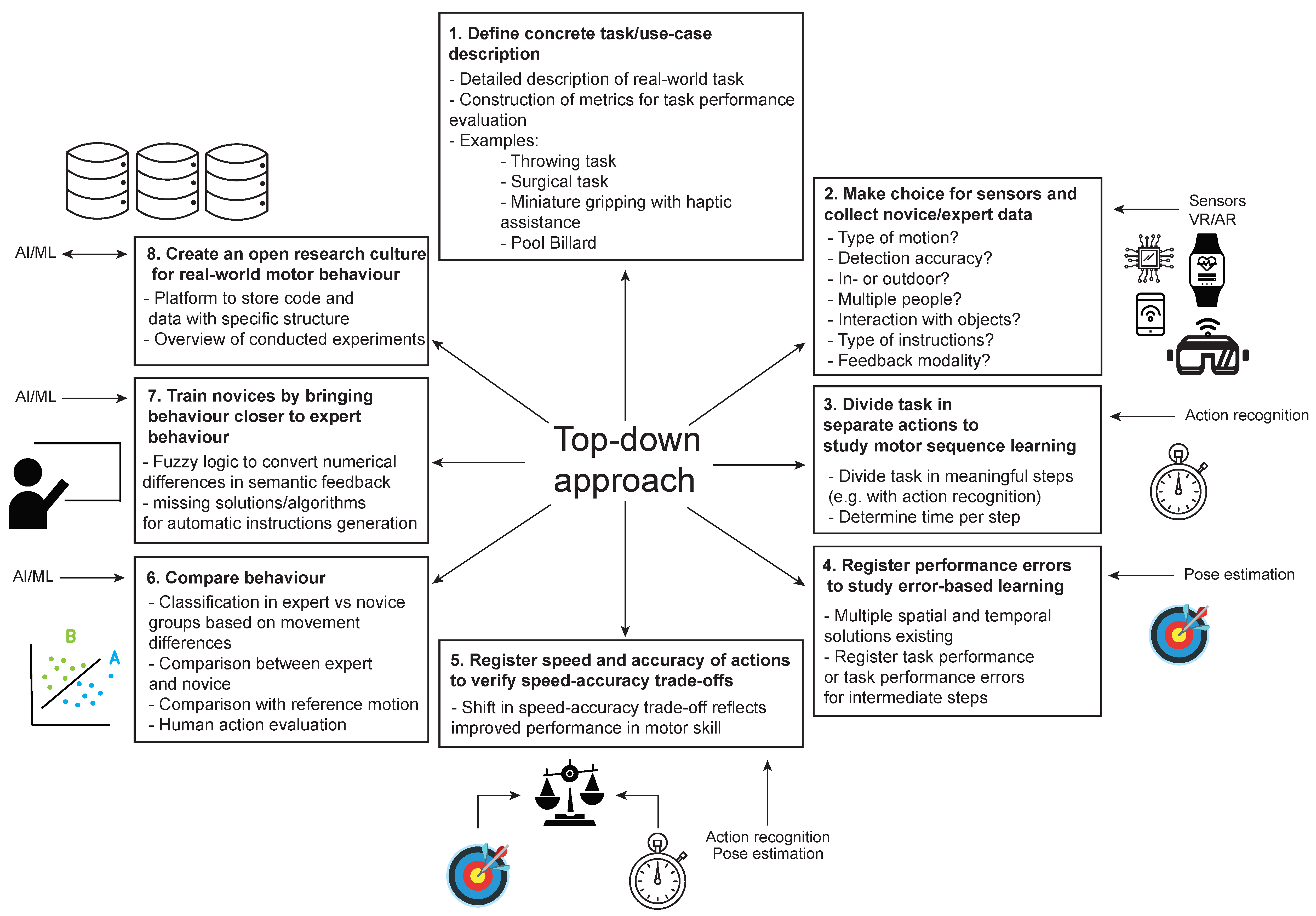
6.2. Top-Down Approach: Develop AI-Guided Assistance System for Motor Skill Training
- Define concrete task/use–case description
- 2.
- Make choice for sensors and collect novice/expert data
- 3.
- Divide motor behavior in separate actions to study motor sequence learning
- 4.
- Register performance error to study error-based learning
- 5.
- Assess speed–accuracy trade-offs of motor actions
- 6.
- Compare behavior between experts and novices during skilled tasks
- 7.
- Train novices by bringing behavior closer to expert behavior
- 8.
- Create an open research culture for real world motor behavior
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Krakauer, J.W.; Hadjiosif, A.M.; Xu, J.; Wong, A.L.; Haith, A.M. Motor Learning. Compr. Physiol. 2019, 9, 613–663. [Google Scholar] [CrossRef] [PubMed]
- Nissen, M.J.; Bullemer, P. Attentional requirements of learning: Evidence from performance measures. Cogn. Psychol. 1987, 19, 1–32. [Google Scholar] [CrossRef]
- Shadmehr, R.; Mussa-Ivaldi, F.A. Adaptive representation of dynamics during learning of a motor task. J. Neurosci. 1994, 14, 3208–3224. [Google Scholar] [CrossRef] [PubMed]
- Diedrichsen, J.; Kornysheva, K. Motor skill learning between selection and execution. Trends Cogn. Sci. 2015, 19, 227–233. [Google Scholar] [CrossRef] [Green Version]
- Haith, A.M.; Krakauer, J.W. The multiple effects of practice: Skill, habit and reduced cognitive load. Curr. Opin. Behav. Sci. 2018, 20, 196–201. [Google Scholar] [CrossRef]
- Shadmehr, R.; Krakauer, J.W. A computational neuroanatomy for motor control. Exp. Brain Res. 2008, 185, 359–381. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.E.; Avraham, G.; Ivry, R.B. The Psychology of Reaching: Action Selection, Movement Implementation, and Sensorimotor Learning. Annu. Rev. Psychol. 2021, 72, 61–95. [Google Scholar] [CrossRef]
- Lepetit, V. Recent Advances in 3D Object and Hand Pose Estimation. arXiv 2020, arXiv:2006.05927. [Google Scholar]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Insafutdinov, B.E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. DeeperCut: A Deeper, Stronger, and Faster Multi-person Pose Estimation Model. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 1, pp. 34–50. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar] [CrossRef] [Green Version]
- Seethapathi, N.; Wang, S.; Kording, K.P. Movement science needs different pose tracking algorithms. arXiv 2019, arXiv:1907.10226. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hampali, S.; Rad, M.; Oberweger, M.; Lepetit, V.; Page, P. Honnotate: A method for 3D Annotation of Hand and Object Poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, J.; Li, W.; Ogunbona, P.O.; Wang, P.; Tang, C. RGB-D-based action recognition datasets: A survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef] [Green Version]
- Patrona, F.; Chatzitofis, A.; Zarpalas, D.; Daras, P. Motion analysis: Action detection, recognition and evaluation based on motion capture data. Pattern Recognit. 2018, 76, 612–622. [Google Scholar] [CrossRef]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar] [CrossRef]
- Camomilla, V.; Bergamini, E.; Fantozzi, S.; Vannozzi, G. Trends supporting the in-field use of wearable inertial sensors for sport performance evaluation: A systematic review. Sensors 2018, 18, 873. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Serafin, S.; Adjorlu, A.; Nilsson, N.; Thomsen, L.; Nordahl, R. Considerations on the use of virtual and augmented reality technologies in music education. In Proceedings of the 2017 IEEE Virtual Reality Workshop on K-12 Embodied Learning through Virtual & Augmented Reality (KELVAR), Los Angeles, CA, USA, 19 March 2017. [Google Scholar] [CrossRef]
- Yoon, J.W.; Chen, R.E.; Kim, E.J.; Akinduro, O.O.; Kerezoudis, P.; Han, P.K.; Si, P.; Freeman, W.D.; Diaz, R.J.; Komotar, R.J.; et al. Augmented reality for the surgeon: Systematic review. Int. J. Med. Robot. Comput. Assist. Surg. 2018, 14, e1914. [Google Scholar] [CrossRef] [PubMed]
- Kärcher, S.; Cuk, E.; Denner, T.; Görzig, D.; Günther, L.C.; Hansmersmann, A.; Riexinger, G.; Bauernhansl, T. Sensor-driven Analysis of Manual Assembly Systems. Procedia CIRP 2018, 72, 1142–1147. [Google Scholar] [CrossRef]
- Webel, S.; Bockholt, U.; Engelke, T.; Gavish, N.; Olbrich, M.; Preusche, C. An augmented reality training platform for assembly and maintenance skills. Robot. Auton. Syst. 2013, 61, 398–403. [Google Scholar] [CrossRef]
- Kärcher, S.; Bauernhansl, T. Approach to generate optimized assembly sequences from sensor data. Procedia CIRP 2019, 81, 276–281. [Google Scholar] [CrossRef]
- Al-Amin, M.; Tao, W.; Doell, D.; Lingard, R.; Yin, Z.; Leu, M.C.; Qin, R. Action recognition in manufacturing assembly using multimodal sensor fusion. Procedia Manuf. 2019, 39, 158–167. [Google Scholar] [CrossRef]
- Wei, K.; Kording, K.P. Behavioral tracking gets real. Nat. Neurosci. 2018, 21, 1146–1147. [Google Scholar] [CrossRef] [PubMed]
- Shadmehr, R.; Smith, M.; Krakauer, J.W. Error correction, sensory prediction, and adaptation in motor control. Annu. Rev. Neurosci. 2010, 33, 89–108. [Google Scholar] [CrossRef] [Green Version]
- Morehead, J.R.; Orban de Xivry, J.-J. A Synthesis of the Many Errors and Learning Processes of Visuomotor Adaptation. BioRxiv 2021. [Google Scholar] [CrossRef]
- Wolpert, D.M.; Diedrichsen, J.; Flanagan, J.R. Principles of sensorimotor learning. Nat. Rev. Neurosci. 2011, 12, 739–751. [Google Scholar] [CrossRef] [PubMed]
- Doyon, J.; Gabitov, E.; Vahdat, S.; Lungu, O.; Boutin, A. Current issues related to motor sequence learning in humans. Curr. Opin. Behav. Sci. 2018, 20, 89–97. [Google Scholar] [CrossRef]
- King, B.R.; Fogel, S.M.; Albouy, G.; Doyon, J. Neural correlates of the age-related changes in motor sequence learning and motor adaptation in older adults. Front. Hum. Neurosci 2013, 7, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Korman, M.; Raz, N.; Flash, T.; Karni, A. Multiple shifts in the representation of a motor sequence during the acquisition of skilled performance. Proc. Natl. Acad. Sci. USA 2003, 100, 12492–12497. [Google Scholar] [CrossRef] [Green Version]
- Press, D.Z.; Casement, M.D.; Pascual-Leone, A.; Robertson, E.M. The time course of off-line motor sequence learning. Cogn. Brain Res. 2005, 25, 375–378. [Google Scholar] [CrossRef]
- Bo, J.; Seidler, R.D. Visuospatial Working Memory Capacity Predicts the Organization of Acquired Explicit Motor Sequences. J. Neurophysiol. 2009, 101, 3116–3125. [Google Scholar] [CrossRef] [Green Version]
- Keele, S.W.; Jennings, P.; Jones, S.; Caulton, D.; Cohen, A. On the modularity of sequence representation. J. Mot. Behav. 1995, 27, 17–30. [Google Scholar] [CrossRef]
- Wong, A.L.; Lindquist, M.A.; Haith, A.M.; Krakauer, J.W. Explicit knowledge enhances motor vigor and performance: Motivation versus practice in sequence tasks. J. Neurophysiol. 2015, 114, 219–232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, A.; Fu, Z.; Pathak, D.; Malik, J. RMA: Rapid Motor Adaptation for Legged Robots. arXiv 2021, arXiv:2107.04034. [Google Scholar]
- Flanagan, J.R.; Bowman, M.C.; Johansson, R.S. Control strategies in object manipulation tasks. Curr. Opin. Neurobiol. 2006, 16, 650–659. [Google Scholar] [CrossRef] [PubMed]
- Johansson, R.S.; Westling, G. Programmed and triggered actions to rapid load changes during precision grip. Exp. Brain Res. 1988, 71, 72–86. [Google Scholar] [CrossRef]
- Salimi, I.; Hollender, I.; Frazier, W.; Gordon, A.M. Specificity of internal representations underlying grasping. J. Neurophysiol. 2000, 84, 2390–2397. [Google Scholar] [CrossRef]
- Malone, L.A.; Bastian, A.J. Thinking about walking: Effects of conscious correction versus distraction on locomotor adaptation. J. Neurophysiol. 2010, 103, 1954–1962. [Google Scholar] [CrossRef] [Green Version]
- Torres-Oviedo, G.; Vasudevan, E.; Malone, L.; Bastian, A.J. Locomotor adaptation. Prog. Brain Res. 2011, 191, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Malone, L.A.; Bastian, A.J.; Torres-Oviedo, G. How does the motor system correct for errors in time and space during locomotor adaptation? J. Neurophysiol. 2012, 108, 672–683. [Google Scholar] [CrossRef] [Green Version]
- Lametti, X.D.R.; Neufeld, E.; Shiller, D.M.; Ostry, D.J. Plasticity in the Human Speech Motor System Drives Changes in Speech Perception. J. Neurosci. 2014, 34, 10339–10346. [Google Scholar] [CrossRef]
- Lametti, D.R.; Nasir, S.M.; Ostry, D.J. Sensory Preference in Speech Production Revealed by Simultaneous Alteration of Auditory and Somatosensory Feedback. J. Neurosci. 2012, 32, 9351–9358. [Google Scholar] [CrossRef]
- Parrell, B.; Ramanarayanan, V.; Nagarajan, S.; Houde, J. The FACTS model of speech motor control: Fusing state estimation and task-based control. PLoS Comput. Biol. 2019, 15, e1007321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sedaghat-Nejad, E.; Herzfeld, D.J.; Shadmehr, R. Reward prediction error modulates saccade vigor. J. Neurosci. 2019, 39, 5010–5017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoon, T.; Jaleel, A.; Ahmed, A.A.; Shadmehr, R. Saccade vigor and the subjective economic value of visual stimuli. J. Neurophysiol. 2020, 123, 2161–2172. [Google Scholar] [CrossRef] [PubMed]
- Orozco, S.; Albert, S.; Shadmehr, R. Spontaneous recovery and the multiple timescales of human motor memory. bioRxiv 2020, 1–30. [Google Scholar] [CrossRef]
- Kowler, E.; Rubinstein, J.F.; Santos, E.M.; Wang, J. Predictive Smooth Pursuit Eye Movements. Annu. Rev. Vis. Sci. 2019, 5, 223–246. [Google Scholar] [CrossRef]
- Orban De Xivry, J.J.; Bennett, S.J.; Lefèvre, P.; Barnes, G.R. Evidence for synergy between saccades and smooth pursuit during transient target disappearance. J. Neurophysiol. 2006, 95, 418–427. [Google Scholar] [CrossRef]
- Orban De Xivry, J.J.; Lefèvre, P. Saccades and pursuit: Two outcomes of a single sensorimotor process. J. Physiol. 2007, 584, 11–23. [Google Scholar] [CrossRef]
- Taylor, J.; Krakauer, J.W.; Ivry, R.B. Explicit and Implicit Contributions to Learning in a Sensorimotor Adaptation Task. J. Neurosci. 2014, 34, 3023–3032. [Google Scholar] [CrossRef] [Green Version]
- Morehead, J.R.; Qasim, S.E.; Crossley, M.J.; Ivry, R. Savings upon Re-Aiming in Visuomotor Adaptation. J. Neurosci. 2015, 35, 14386–14396. [Google Scholar] [CrossRef] [Green Version]
- Werner, S.; Van Aken, B.C.; Hulst, T.; Frens, M.A.; Van Der Geest, J.N.; Strüder, H.K.; Donchin, O. Awareness of sensorimotor adaptation to visual rotations of different size. PLoS ONE 2015, 10, e0123321. [Google Scholar] [CrossRef] [Green Version]
- Bond, K.M.; Taylor, J.A. Flexible explicit but rigid implicit learning in a visuomotor adaptation task. J. Neurophysiol. 2015, 113, 3836–3849. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McDougle, S.D.; Bond, K.M.; Taylor, J.A. Explicit and Implicit Processes Constitute the Fast and Slow Processes of Sensorimotor Learning. J. Neurosci. 2015, 35, 9568–9579. [Google Scholar] [CrossRef] [PubMed]
- Haith, A.M.; Huberdeau, D.M.; Krakauer, J.W. The Influence of Movement Preparation Time on the Expression of Visuomotor Learning and Savings. J. Neurosci. 2015, 35, 5109–5117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leow, L.; Gunn, R.; Marinovic, W.; Carroll, T.J. Control of Movement Estimating the implicit component of visuomotor rotation learning by constraining movement preparation time. J. Neurophysiol. 2017, 118, 666–676. [Google Scholar] [CrossRef] [Green Version]
- Shmuelof, L.; Huang, V.S.; Haith, A.M.; Delnicki, R.J.; Mazzoni, P.; Krakauer, J.W. Overcoming Motor “Forgetting” Through Reinforcement of Learned Actions. J. Neurosci. 2012, 32, 14617–14621. [Google Scholar] [CrossRef] [Green Version]
- Galea, J.M.; Mallia, E.; Rothwell, J.; Diedrichsen, J. The dissociable effects of punishment and reward on motor learning. Nat. Neurosci. 2015, 18, 597–602. [Google Scholar] [CrossRef]
- Cashaback, J.G.A.; Mcgregor, H.R.; Mohatarem, A.; Gribble, L. Dissociating error-based and reinforcement- based loss functions during sensorimotor learning. PLoS Comput. Biol. 2017, 13, e1005623. [Google Scholar] [CrossRef]
- Codol, O.; Holland, P.J.; Galea, J.M. The relationship between reinforcement and explicit control during visuomotor adaptation. Sci. Rep. 2018, 8, 9121. [Google Scholar] [CrossRef]
- Holland, P.; Codol, O.; Galea, J.M. Contribution of explicit processes to reinforcement-based motor learning. J. Neurophysiol. 2018, 119, 2241–2255. [Google Scholar] [CrossRef]
- Huberdeau, D.M.; Haith, A.M.; Krakauer, J.W. Formation of a long-term memory for visuomotor adaptation following only a few trials of practice. J. Neurophysiol. 2015, 114, 969–977. [Google Scholar] [CrossRef] [Green Version]
- Crevecoeur, F.; Thonnard, J.L.; Lefèvre, P. A very fast time scale of human motor adaptation: Within movement adjustments of internal representations during reaching. bioRxiv 2018, 7, 269134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Holland, P.; Galea, J.M. The effects of reward and punishment on motor skill learning. Curr. Opin. Behav. Sci. 2018, 20, 83–88. [Google Scholar] [CrossRef]
- Shmuelof, L.; Krakauer, J.W. Are We Ready for a Natural History of Motor Learning? Neuron 2011, 72, 469–476. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, A.M.; Ford, P.R. Expertise and expert performance in sport. Int. Rev. Sport Exerc. Psychol. 2008, 1, 4–18. [Google Scholar] [CrossRef]
- Ericsson, K.A. Deliberate practice and acquisition of expert performance: A general overview. Acad. Emerg. Med. 2008, 15, 988–994. [Google Scholar] [CrossRef] [PubMed]
- Homayounfar, S.Z.; Andrew, T.L. Wearable Sensors for Monitoring Human Motion: A Review on Mechanisms, Materials, and Challenges. SLAS Technol. Transl. Life Sci. Innov. 2020, 25, 9–24. [Google Scholar] [CrossRef]
- Deb, K. Multi-objective optimization. In Search Methodologies; Springer: Boston, MA, USA, 2014; pp. 403–449. [Google Scholar]
- Sternad, D. It’s not (only) the mean that matters: Variability, noise and exploration in skill learning. Curr. Opin. Behav. Sci. 2018, 20, 183–195. [Google Scholar] [CrossRef]
- Shmuelof, L.; Krakauer, J.W.; Mazzoni, P. How is a motor skill learned? Change and invariance at the levels of task success and trajectory control. J. Neurophysiol. 2012, 108, 578–594. [Google Scholar] [CrossRef]
- Schaal, S. Is imitation learning the route to humanoid robots? Trends Cogn. Sci. 1999, 3, 233–242. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Romero, J. Embodied Hands: Modeling and Capturing Hands and Bodies Together. ACM Trans. Graph. 2017, 36, 245. [Google Scholar] [CrossRef] [Green Version]
- Mandery, C.; Terlemez, Ö.; Do, M.; Vahrenkamp, N.; Asfour, T. The KIT whole-body human motion database. In Proceedings of the 2015 International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 329–336. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Geissinger, J.H.; Asbeck, A.T. Motion inference using sparse inertial sensors, self-supervised learning, and a new dataset of unscripted human motion. Sensors 2020, 20, 6330. [Google Scholar] [CrossRef] [PubMed]
- Tenorth, M.; Bandouch, J.; Beetz, M. The TUM kitchen data set of everyday manipulation activities for motion tracking and action recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1089–1096. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning, and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar] [CrossRef] [Green Version]
- Chao, Y.W.; Wang, Z.; He, Y.; Wang, J.; Deng, J. HICO: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1017–1025. [Google Scholar] [CrossRef]
- Johnson, R.E.; Linderman, S.; Panier, T.; Wee, C.L.; Song, E.; Herrera, K.J.; Miller, A.; Engert, F. Probabilistic Models of Larval Zebrafish Behavior Reveal Structure on Many Scales. Curr. Biol. 2020, 30, 70–82.e4. [Google Scholar] [CrossRef]
- DeAngelis, B.D.; Zavatone-Veth, J.A.; Clark, D.A. The manifold structure of limb coordination in walking Drosophila. eLife 2019, 8, e46409. [Google Scholar] [CrossRef]
- Marques, J.C.; Lackner, S.; Félix, R.; Orger, M.B. Structure of the Zebrafish Locomotor Repertoire Revealed with Unsupervised Behavioral Clustering. Curr. Biol. 2018, 28, 181–195.e5. [Google Scholar] [CrossRef] [Green Version]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy image compression with compressive autoencoders. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017; pp. 1–19. [Google Scholar]
- Gisbrecht, A.; Hammer, B. Data visualization by nonlinear dimensionality reduction. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 51–73. [Google Scholar] [CrossRef]
- Hausmann, S.B.; Marin, A.; Mathis, A.; Mathis, M.W. Measuring and modeling the motor system with machine learning. Curr. Opin. Neurobiol. 2021, 70, 11–23. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Holmes, S. Ten quick tips for effective dimensionality reduction. PLoS Comput. Biol. 2019, 15, e1006907. [Google Scholar] [CrossRef] [Green Version]
- Van Der Maaten, L.J.P.; Postma, E.O.; Van Den Herik, H.J. Dimensionality Reduction: A Comparative Review. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Federolf, P.; Reid, R.; Gilgien, M.; Haugen, P.; Smith, G. The application of principal component analysis to quantify technique in sports. Scand. J. Med. Sci. Sport. 2014, 24, 491–499. [Google Scholar] [CrossRef]
- Gløersen, Ø.; Myklebust, H.; Hallén, J.; Federolf, P. Technique analysis in elite athletes using principal component analysis. J. Sports Sci. 2018, 36, 229–237. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Wu, Y.; Huang, T.S. Modeling the constraints of human hand motion. In Proceedings of the Workshop on Human Motion, Austin, TX, USA, 7–8 December 2000; pp. 121–126. [Google Scholar] [CrossRef] [Green Version]
- Donà, G.; Preatoni, E.; Cobelli, C.; Rodano, R.; Harrison, A.J. Application of functional principal component analysis in race walking: An emerging methodology. Sport. Biomech. 2009, 8, 284–301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadler, E.M.; Graham, R.B.; Stevenson, J.M. The personal lift-assist device and lifting technique: A principal component analysis. Ergonomics 2011, 54, 392–402. [Google Scholar] [CrossRef] [PubMed]
- Lopes, A.M.; Tenreiro Machado, J.A. Uniform Manifold Approximation and Projection Analysis of Soccer Players. Entropy 2021, 23, 793. [Google Scholar] [CrossRef]
- Chen, N.; Bayer, J.; Urban, S.; Van Der Smagt, P. Efficient movement representation by embedding Dynamic Movement Primitives in deep autoencoders. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 434–440. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models formotor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef] [Green Version]
- Xu, R.; Wunsch, D. Clustering; John Wiley Sons: Hoboken, NJ, USA, 2008; Volume 10. [Google Scholar]
- Ghasemzadeh, H.; Jafari, R. Coordination analysis of human movements with body sensor networks: A signal processing model to evaluate baseball swings. IEEE Sens. J. 2011, 11, 603–610. [Google Scholar] [CrossRef]
- Zia, A.; Zhang, C.; Xiong, X.; Jarc, A.M. Temporal clustering of surgical activities in robot-assisted surgery. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1171–1178. [Google Scholar] [CrossRef] [Green Version]
- Bribiesca, E. A chain code for representing 3D curves. Pattern Recognit. 2000, 33, 755–765. [Google Scholar] [CrossRef]
- Piórek, M.; Jabłoński, B. A quaternion clustering framework. Int. J. Appl. Math. Comput. Sci. 2020, 30, 133–147. [Google Scholar]
- Park, J.; Cho, S.; Kim, D.; Bailo Oleksandr and Park, H.; Hong, S.; Park, J. A Body Part Embedding Model with Datasets for Measuring 2D Human Motion Similarity. IEEE Access 2021, 9, 36547–36558. [Google Scholar] [CrossRef]
- Coskun, H.; Tan, D.J.; Conjeti, S.; Navab, N.; Tombari, F. Human Motion Analysis with Deep Metric Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 693–710. [Google Scholar]
- Guo, M.; Wang, Z. Segmentation and recognition of human motion sequences using wearable inertial sensors. Multimed. Tools Appl. 2018, 77, 21201–21220. [Google Scholar] [CrossRef]
- Li, R.; Liu, Z.; Tan, J. Human motion segmentation using collaborative representations of 3D skeletal sequences. IET Comput. Vis. 2018, 12, 434–442. [Google Scholar] [CrossRef]
- Park, J.W.; Kim, D.Y. Standard Time Estimation of Manual Tasks via Similarity Measure of Unequal Scale Time Series. IEEE Trans. Hum.-Mach. Syst. 2018, 48, 241–251. [Google Scholar] [CrossRef]
- Pham, T.H.N.; Hochin, T.; Nomiya, H. Evaluation of Similarity Measuring Method of Human Body Movement Based on 3D Chain Code. In Intelligent Information and Database Systems; Nguyen, N., Hoang, D., Hong, T.P., Pham, H., Trawiński, B., Eds.; Springer: Cham, Switzerland, 2018; Volume 10752, pp. 459–471. [Google Scholar]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Effective and efficient similarity searching in motion capture data. Multimed. Tools Appl. 2018, 77, 12073–12094. [Google Scholar] [CrossRef]
- Xia, G.; Sun, H.; Feng, L.; Zhang, G.; Liu, Y. Human Motion Segmentation via Robust Kernel Sparse Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 135–150. [Google Scholar] [CrossRef]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Searching for variable-speed motions in long sequences of motion capture data. Inf. Syst. 2019, 80, 148–158. [Google Scholar] [CrossRef]
- Pham, T.H.N.; Hochin, T.; Nomiya, H. Obtaining the Similarity Value of Human Body Motions Through Their Sub Motions. Int. J. Softw. Innov. 2020, 8, 59–77. [Google Scholar] [CrossRef]
- Aouaidjia, K.; Sheng, B.; Li, P.; Kim, J.; Feng, D.D. Efficient Body Motion Quantification and Similarity Evaluation Using 3-D Joints Skeleton Coordinates. IEEE Trans. Syst. Man Cybern. 2021, 51, 2774–2788. [Google Scholar] [CrossRef] [Green Version]
- Moeslund, T.B.; Hilton, A.; Krüger, V. A survey of advances in vision-based human motion capture and analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision BT-Advances in Computer Vision; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; ISBN 978-3-030-17795-9. [Google Scholar]
- Desmarais, Y.; Mottet, D.; Slangen, P.; Montesinos, P. A review of 3D human pose estimation algorithms for markerless motion capture. Comput. Vis. Image Underst. 2021, 212, 103275. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7745–7754. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Tompson, J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 2, 1799–1807. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. Eur. Conf. Comput. Vis. 2016, 1, 262–277. [Google Scholar] [CrossRef]
- Li, S.; Chan, A.B. 3D human pose estimation from monocular images with deep convolutional neural network. In Computer Vision—ACCV 2014; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9004, pp. 332–347. [Google Scholar] [CrossRef]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1263–1272. [Google Scholar] [CrossRef] [Green Version]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple Yet Effective Baseline for 3d Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2659–2668. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.R.I.; Little, J.J. Exploiting temporal information for 3D human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 69–86. [Google Scholar] [CrossRef] [Green Version]
- Sigal, L.; Balan, A.O.; Black, M.J. HumanEva: Synchronized Video and Motion Capture Dataset and Baseline Algorithm for Evaluation of Articulated Human Motion. Int. J. Comput. Vis. 2010, 87, 4–27. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Bernt, S. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Johnson, S.; Everingham, M. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. Proc. Br. Mach. Vis. Conf. 2010, 2, 5. [Google Scholar]
- Pavlakos, G.; Zhu, L.; Zhou, X.; Daniilidis, K. Learning to Estimate 3D Human Pose and Shape from a Single Color Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D human pose estimation = 2D pose estimation + matching. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 5759–5767. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on Multi-Stage Networks for Human Pose Estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 3711–3719. [Google Scholar] [CrossRef] [Green Version]
- Petrov, I.; Shakhuro, V.; Konushin, A. Deep probabilistic human pose estimation. IET Comput. Vis. 2018, 12, 578–585. [Google Scholar] [CrossRef]
- Yiannakides, A.; Aristidou, A.; Chrysanthou, Y. Real-time 3D human pose and motion reconstruction from monocular RGB videos. Comput. Animat. Virtual Worlds 2019, 30, e1887. [Google Scholar] [CrossRef]
- Chang, J. DR-Net: Denoising and reconstruction network for 3D human pose estimation from monocular RGB videos. Electron. Lett. 2018, 54, 70–72. [Google Scholar] [CrossRef]
- Hu, T.; Xiao, C.; Min, G.; Najjari, N. An adaptive stacked hourglass network with Kalman filter for estimating 2D human pose in video. Expert Syst. 2021, 38, e12552. [Google Scholar] [CrossRef]
- Wang, X.; Feng, R.; Chen, H.; Zimmermann, R.; Liu, Z.; Liu, H. Personalized motion kernel learning for human pose estimation. Int. J. Intell. Syst. 2022. [Google Scholar] [CrossRef]
- He, Y.; Yan, R.; Fragkiadaki, K.; Yu, S.-I. Epipolar Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Reddy, N.; Guigues, L.; Pischulini, L.; Eledath, J.; Narasimhan, S. TesseTrack: End-to-End Learnable Multi-Person Articulated 3D Pose Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Iskakov, K.; Burkov, E.; Lempitsky, V.; Malkov, Y. Learnable Triangulation of Human Pose. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-point regression pointnet for 3D hand pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 489–505. [Google Scholar] [CrossRef]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Dense 3D Regression for Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5147–5156. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Xu, G.; Li, M.; Chen, L.; Zhang, X.; Xie, J. Human pose estimation method based on single depth image. IET Comput. Vis. 2018, 12, 919–924. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-temporal graph routing for skeleton-based action recognition. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, the 31st Conference on Innovative Applications of Artificial Intelligence, the 9th Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8561–8568. [Google Scholar] [CrossRef] [Green Version]
- Heidari, N.; Iosifidis, A. Progressive spatio-temporal graph convolutional network for skeleton-based human action recognition. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3220–3224. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar] [CrossRef] [Green Version]
- Cho, S.; Maqbool, M.H.; Liu, F.; Foroosh, H. Self-Attention Network for Skeleton-based Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 624–633. [Google Scholar]
- Zhang, D.Y.; Gao, H.W.; Dai, H.L.; Shi, X.B. Human Skeleton Graph Attention Convolutional for Video Action Recognition. In Proceedings of the 2020 5th International Conference on Information Science, Computer Technology and Transportation (ISCTT), Shenyang, China, 13–15 November 2020; pp. 183–187. [Google Scholar]
- Thakkar, K.; Narayanan, P.J. Part-based graph convolutional network for action recognition. arXiv 2018, arXiv:1809.04983. [Google Scholar]
- Ding, W.W.; Li, X.; Li, G.; Wei, Y.S. Global relational reasoning with spatial temporal graph interaction networks for skeleton-based action recognition. Signal Process. Image Commun. 2020, 83, 115776. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Müller, M.; Röder, T.; Clausen, M.; Eberhardt, B.; Krüger, B.; Weber, A. Documentation Mocap Database HDM05; Technical Report; Department of Computer Science II, University of Bonn: Bonn, Germany, 2007. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Kalfaoglu, M.E.; Kalkan, S.; Alatan, A.A. Late temporal modeling in 3d cnn architectures with bert for action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 731–747. [Google Scholar]
- Li, C.; Chen, C.; Zhang, B.; Ye, Q.; Han, J.; Ji, R. Deep Spatio-temporal Manifold Network for Action Recognition. arXiv 2017, arXiv:1705.03148. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 1, 568–576. [Google Scholar]
- Wu, Z.; Jiang, Y.-G.; Wang, X.; Ye, H.; Xue, X.; Wang, J. Fusing Multi-Stream Deep Networks for Video Classification. arXiv 2015, arXiv:1509.06086. [Google Scholar]
- Guo, J.; Shi, M.; Zhu, X.W.; Huang, W.; He, Y.; Zhang, W.W.; Tang, Z.Y. Improving human action recognition by jointly exploiting video and WiFi clues. Neurocomputing 2021, 458, 14–23. [Google Scholar] [CrossRef]
- Srihari, D.; Kishore, P.V.V.; Kumar, E.K.; Kumar, D.A.; Kumar, M.T.K.; Prase, M.V.D.; Prasd, C.R. A four-stream ConvNet based on spatial and depth flow for human action classification using RGB-D data. Multimed. Tools Appl. 2020, 79, 11723–11746. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P.; Zisserman, A. What have We Learned from Deep Representations for Action Recognition? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7844–7853. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Wang, Z.Y.; Dai, H.D.; Shen, T.L.; Qiao, P.; Niu, X.; Jiang, J.; Li, D.S.; Dou, Y. Attentional fused temporal transformation network for video action recognition. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4377–4381. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar] [CrossRef] [Green Version]
- Crasto, N.; Weinzaepfel, P.; Alahari, K.; Schmid, C.; Labs Europe, N. MARS: Motion-Augmented RGB Stream for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7874–7883. [Google Scholar] [CrossRef]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7082–7092. [Google Scholar] [CrossRef] [Green Version]
- Leng, C.J.; Ding, Q.C.; Wu, C.D.; Chen, A.G. Augmented two stream network for robust action recognition adaptive to various action videos. J. Vis. Commun. Image Represent. 2021, 81, 103344. [Google Scholar] [CrossRef]
- Chang, Y.L.; Chan, C.S.; Remagnino, P. Action recognition on continuous video. Neural Comput. Appl. 2021, 33, 1233–1243. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef] [Green Version]
- Shah, D.; Falco, P.; Saveriano, M.; Lee, D. Encoding human actions with a frequency domain approach. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 5304–5311. [Google Scholar] [CrossRef] [Green Version]
- Dong, R.; Cai, D.; Ikuno, S. Motion capture data analysis in the instantaneous frequency-domain using hilbert-huang transform. Sensors 2020, 20, 6534. [Google Scholar] [CrossRef]
- Hu, G.; Cui, B.; Yu, S. Joint Learning in the Spatio-Temporal and Frequency Domains for Skeleton-Based Action Recognition. IEEE Trans. Multimed. 2020, 22, 2207–2220. [Google Scholar] [CrossRef]
- Dos Santos, S.F.; Almeida, J. Faster and Accurate Compressed Video Action Recognition Straight from the Frequency Domain. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 62–68. [Google Scholar] [CrossRef]
- Dong, R.; Chang, Q.; Ikuno, S. A deep learning framework for realistic robot motion generation. Neural Comput. Appl. 2021, 3, 1–14. [Google Scholar] [CrossRef]
- Lebailly, T.; Kiciroglu, S.; Salzmann, M.; Fua, P.; Wang, W. Motion Prediction Using Temporal Inception Module. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar] [CrossRef]
- Liu, R.X.; Liu, C.L. Human Motion Prediction Using Adaptable Recurrent Neural Networks and Inverse Kinematics. IEEE Control Syst. Lett. 2021, 5, 1651–1656. [Google Scholar] [CrossRef]
- Bütepage, J.; Black, M.J.; Kragic, D.; Kjellström, H. Deep representation learning for human motion prediction and classification. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6158–6166. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Shu, X.; Yan, R.; Zhang, J.; Song, Y. Skip-attention encoder–decoder framework for human motion prediction. Multimed. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-abadie, J.; Mirza, M.; Xu, B.; Warde-farley, D. Generative Adversarial Nets. Adv. Neural Inf. Processing Syst. 2014, 27, 1–9. [Google Scholar]
- Barsoum, E.; Kender, J.; Liu, Z. HP-GAN: Probabilistic 3D human motion prediction via GAN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Martinez, J.; Black, M.J.; Romero, J. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2891–2900. [Google Scholar]
- Liu, Z.G.; Lyu, K.D.; Wu, S.; Chen, H.P.; Hao, Y.B.; Ji, S.L.; Intelligence, A.A.A. Aggregated Multi-GANs for Controlled 3D Human Motion Prediction. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 2225–2232. [Google Scholar]
- Caramiaux, B.; Françoise, J.; Liu, W.; Sanchez, T.; Bevilacqua, F. Machine Learning Approaches for Motor Learning: A Short Review. Front. Comput. Sci. 2020, 2, 16. [Google Scholar] [CrossRef]
- Hua, J.; Zeng, L.; Li, G.; Ju, Z. Learning for a robot: Deep reinforcement learning, imitation learning, transfer learning. Sensors 2021, 21, 1278. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Wang, Z.; Merel, J.; Rusu, A.; Erez, T.; Cabi, S.; Tunyasuvunakool, S.; Kramár, J.; Hadsell, R.; de Freitas, N.; et al. Reinforcement and Imitation Learning for Diverse Visuomotor Skills. arXiv 2018, arXiv:1802.09564. [Google Scholar] [CrossRef]
- Hussein, A.; MOHAMED MEDHAT GABER, E.E.; JAYNE, C. Imitation learning: A Survey of Learning Methods AHMED. Deep Reinf. Learn. Fundam. Res. Appl. 2017, 50, 273–306. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Do, M.; Azad, P.; Asfour, T.; Dillmann, R. Imitation of human motion on a humanoid robot using non-linear optimization. In Proceedings of the Humanoids 2008-8th IEEE-RAS International Conference on Humanoid Robots, Daejeon, Korea, 1–3 December 2008; pp. 545–552. [Google Scholar] [CrossRef]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.; Schiele, B. DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Erol, A.; Bebis, G.; Nicolescu, M.; Boyle, R.D.; Twombly, X. Vision-based hand pose estimation: A review. Comput. Vis. Image Underst. 2007, 108, 52–73. [Google Scholar] [CrossRef]
- Cai, M.; Kitani, K.M.; Sato, Y. Understanding hand-object manipulation with grasp types and object attributes. Robot. Sci. Syst. 2016, 12, 1–10. [Google Scholar] [CrossRef]
- Kjellström, H.; Romero, J.; Kragić, D. Visual object-action recognition: Inferring object affordances from human demonstration. Comput. Vis. Image Underst. 2011, 115, 81–90. [Google Scholar] [CrossRef]
- Nagarajan, T.; Feichtenhofer, C.; Grauman, K. Grounded human-object interaction hotspots from video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8687–8696. [Google Scholar] [CrossRef] [Green Version]
- Stergiou, A. Understanding human-human interactions: A survey Understanding human-human interactions: A survey. arXiv 2018, arXiv:1808.00022. [Google Scholar]
- Wang, C.; Shi, F.; Xia, S.; Chai, J. Realtime 3D eye gaze animation using a single RGB camera. ACM Trans. Graph. 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Osoba, O.; Welser, W. An Intelligence in Our Image: The Risks of Bias and Errors in Artificial Intelligence; Rand Corporation: Santa Monica, CA, USA, 2017; ISBN 9780833097637. [Google Scholar]
- Cornman, H.L.; Stenum, J.; Roemmich, R.T. Video-based quantification of human movement frequency using pose estimation. bioRxiv 2021. [Google Scholar] [CrossRef]
- Chambers, C.; Kong, G.; Wei, K.; Kording, K. Pose estimates from online videos show that side-by-side walkers synchronize movement under naturalistic conditions. PLoS ONE 2019, 14, e0217861. [Google Scholar] [CrossRef]
- Sato, K.; Nagashima, Y.; Mano, T.; Iwata, A.; Toda, T. Quantifying normal and parkinsonian gait features from home movies: Practical application of a deep learning–based 2D pose estimator. PLoS ONE 2019, 14, e0223549. [Google Scholar] [CrossRef] [Green Version]
- Zago, M.; Luzzago, M.; Marangoni, T.; De Cecco, M.; Tarabini, M.; Galli, M. 3D Tracking of Human Motion Using Visual Skeletonization and Stereoscopic Vision. Front. Bioeng. Biotechnol. 2020, 8, 181. [Google Scholar] [CrossRef]
- Stenum, J.; Rossi, C.; Roemmich, R.T. Two-dimensional video-based analysis of human gait using pose estimation. PLoS Comput. Biol. 2021, 17, e1008935. [Google Scholar] [CrossRef]
- Viswakumar, A.; Rajagopalan, V.; Ray, T.; Parimi, C. Human Gait Analysis Using OpenPose. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 310–314. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. High-accuracy stereo depth maps using structured light. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 1. [Google Scholar] [CrossRef]
- Gokturk, S.B.; Yalcin, H.; Bamji, C. A time-of-flight depth sensor-System description, issues and solutions. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar] [CrossRef]
- Levin, A.; Fergus, R.; Durand, F.; Freeman, W.T. Image and depth from a conventional camera with a coded aperture. ACM Trans. Graph. 2007, 26, 70. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar] [CrossRef] [Green Version]
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Data, methods, and challenges. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1868–1876. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K.E.N. Real-Time Continuous Pose Recovery of Human Hands Using Convolutional Networks. ACM Trans. Graph. 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Li, M.; Hashimoto, K. Accurate object pose estimation using depth only. Sensors 2018, 18, 1045. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, B.; Tan, K.H.; Jiang, N.; Tai, H.S.; Treffer, D.; Nguyen, T. Hand segmentation for hand-object interaction from depth map. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 259–263. [Google Scholar] [CrossRef] [Green Version]
- Rahmani, H.; Bennamoun, M. Learning Action Recognition Model from Depth and Skeleton Videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5833–5842. [Google Scholar] [CrossRef] [Green Version]
- Van der Kruk, E.; Reijne, M.M. Accuracy of human motion capture systems for sport applications; state-of-the-art review. Eur. J. Sport Sci. 2018, 18, 806–819. [Google Scholar] [CrossRef] [PubMed]
- Von Marcard, T.; Pons-Moll, G.; Rosenhahn, B. Human Pose Estimation from Video and IMUs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1533–1547. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Zeng, A.; Liu, M.; Lai, Q.; Xu, Q. DeepFuse: An IMU-Aware network for real-time 3D human pose estimation from multi-view image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 418–427. [Google Scholar] [CrossRef]
- Clay, V.; König, P.; König, S. Eye tracking in virtual reality. J. Eye Mov. Res. 2019, 12, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Chang, E.; Kim, H.T.; Yoo, B. Virtual Reality Sickness: A Review of Causes and Measurements. Int. J. Hum. Comput. Interact. 2020, 36, 1658–1682. [Google Scholar] [CrossRef]
- Shibata, T.; Kim, J.; Hoffman, D.M.; Banks, M.S. The zone of comfort: Predicting visual discomfort with stereo displays. J. Vis. 2011, 11, 1–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Butt, A.L.; Kardong-Edgren, S.; Ellertson, A. Using Game-Based Virtual Reality with Haptics for Skill Acquisition. Clin. Simul. Nurs. 2018, 16, 25–32. [Google Scholar] [CrossRef] [Green Version]
- Meyer, B.; Stratmann, T.C.; Gruppe, P.; Gruenefeld, U.; Cornelsen, B.; Boll, S. Juggling 4.0: Learning complex motor skills with augmented reality through the example of juggling. In Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology Adjunct Proceedings, Berlin, Germany, 14 October 2018; pp. 54–56. [Google Scholar] [CrossRef]
- Sharma, A.; Niu, W.; Hunt, C.L.; Levay, G.; Kaliki, R.; Thakor, N.V. Augmented Reality Prosthesis Training Setup for Motor Skill Enhancement. arXiv 2019, arXiv:1903.01968. [Google Scholar]
- Haar, S.; van Assel, C.M.; Faisal, A.A. Motor learning in real-world pool billiards. Sci. Rep. 2020, 10, 20046. [Google Scholar] [CrossRef]
- Bahar, L.; Sharon, Y.; Nisky, I. Surgeon-centered analysis of robot-assisted needle driving under different force feedback conditions. Front. Neurorobot. 2020, 13, 108. [Google Scholar] [CrossRef] [Green Version]
- Yao, K.; Billard, A. An inverse optimization approach to understand human acquisition of kinematic coordination in bimanual fine manipulation tasks. Biol. Cybern. 2020, 114, 63–82. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harris, D.J.; Buckingham, G.; Wilson, M.R.; Brookes, J.; Mushtaq, F.; Mon-Williams, M.; Vine, S.J. The effect of a virtual reality environment on gaze behaviour and motor skill learning. Psychol. Sport Exerc. 2020, 50, 101721. [Google Scholar] [CrossRef]
- Vanneste, P.; Huang, Y.; Park, J.Y.; Cornillie, F.; Decloedt, B.; Van den Noortgate, W. Cognitive support for assembly operations by means of augmented reality: An exploratory study. Int. J. Hum. Comput. Stud. 2020, 143, 102480. [Google Scholar] [CrossRef]
- Ropelato, S.; Menozzi, M.; Michel, D.; Siegrist, M. Augmented Reality Microsurgery: A Tool for Training Micromanipulations in Ophthalmic Surgery Using Augmented Reality. Simul. Healthc. 2020, 15, 122–127. [Google Scholar] [CrossRef]
- Lilija, K.; Kyllingsbaek, S.; Hornbaek, K. Correction of avatar hand movements supports learning of a motor skill. In Proceedings of the 2021 IEEE Virtual Reality and 3D User Interfaces (VR), Lisboa, Portugal, 27 March–1 April 2021; pp. 455–462. [Google Scholar] [CrossRef]
- Tommasino, P.; Maselli, A.; Campolo, D.; Lacquaniti, F.; d’Avella, A. A Hessian-based decomposition characterizes how performance in complex motor skills depends on individual strategy and variability. PLoS ONE 2021, 16, e0253626. [Google Scholar] [CrossRef]
- Haar, S.; Sundar, G.; Faisal, A.A. Embodied virtual reality for the study of real-world motor learning. PLoS ONE 2021, 16, e0245717. [Google Scholar] [CrossRef]
- Campagnoli, C.; Domini, F.; Taylor, J.A. Taking aim at the perceptual side of motor learning: Exploring how explicit and implicit learning encode perceptual error information through depth vision. J. Neurophysiol. 2021, 126, 413–426. [Google Scholar] [CrossRef]
- Zhang, Z.; Sternad, D. Back to reality: Differences in learning strategy in a simplified virtual and a real throwing task. J. Neurophysiol. 2021, 125, 43–62. [Google Scholar] [CrossRef]
- Russo, M.; Ozeri-Engelhard, N.; Hupfeld, K.; Nettekoven, C.; Thibault, S.; Sedaghat-Nejad, E.; Buchwald, D.; Xing, D.; Zobeiri, O.; Kilteni, K.; et al. Highlights from the 30th Annual Meeting of the Society for the Neural Control of Movement. J. Neurophysiol. 2021, 126, 967–975. [Google Scholar] [CrossRef]
- Levac, D.E.; Huber, M.E.; Sternad, D. Learning and transfer of complex motor skills in virtual reality: A perspective review. J. Neuroeng. Rehabil. 2019, 16, 121. [Google Scholar] [CrossRef]
- Ingram, J.N.; Wolpert, D.M. Naturalistic Approaches to Sensorimotor Control, 1st ed.; Elsevier B.V.: Amsterdam, The Netherlands, 2011; Volume 191, ISBN 9780444537522. [Google Scholar]
- Krakauer, J.W.; Ghazanfar, A.A.; Gomez-Marin, A.; Maciver, M.A.; Poeppel, D. Neuron Perspective Neuroscience Needs Behavior: Correcting a Reductionist Bias. Neuron 2017, 93, 480–490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haar, S.; Faisal, A.A. Brain Activity Reveals Multiple Motor-Learning Mechanisms in a Real-World Task. Front. Hum. Neurosci. 2020, 14, 354. [Google Scholar] [CrossRef]
- Liu, L.; Johnson, L.; Zohar, O.; Ballard, D.H. Humans Use Similar Posture Sequences in a Whole-Body Tracing Task. iScience 2019, 19, 860–871. [Google Scholar] [CrossRef] [Green Version]
- Heald, J.B.; Ingram, J.N.; Flanagan, J.R.; Wolpert, D.M. Multiple motor memories are learned to control different points on a tool. Nat. Hum. Behav. 2018, 2, 300–311. [Google Scholar] [CrossRef] [PubMed]
- Proud, K.; Heald, J.B.; Ingram, J.N.; Gallivan, J.P.; Wolpert, D.M.; Flanagan, J.R. Separate motor memories are formed when controlling different implicitly specified locations on a tool. J. Neurophysiol. 2019, 121, 1342–1351. [Google Scholar] [CrossRef]
- Listman, J.B.; Tsay, J.S.; Kim, H.E.; Mackey, W.E.; David, J. Long-term Motor Learning in the Wild with High Volume Video Game Data. Front. Hum. Neurosci. 2021, 15, 777779. [Google Scholar] [CrossRef]
- Avraham, G.; Pakzad, S.; Ivry, R. Revisiting sensitivity of implicit visuomotor adaptation to errors of varying magnitude. Soc. Neural Control Mov. Annu. Meet. 2021. [Google Scholar]
- Albert, S.T.; Jang, J.; Haith, A.M.; Lerner, G.; Della-Maggiore, V.; Shadmehr, R.; Albert, S.; Building, T.; Hopkins, J. Competition between parallel sensorimotor learning systems. eLife 2022, 11, e65361. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Morehead, J.R.; Parvin, D.E.; Moazzezi, R.; Ivry, R.B. Invariant errors reveal limitations in motor correction rather than constraints on error sensitivity. Nat. Commun. Biol. 2018, 1, 19. [Google Scholar] [CrossRef]
- Morehead, J.R.; Taylor, J.A.; Parvin, D.; Ivry, R.B. Characteristics of Implicit Sensorimotor Adaptation Revealed by Task-irrelevant Clamped Feedback. J. Cogn. Neurosci. 2017, 26, 194–198. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.G.; Miyamoto, Y.R.; Castro, L.N.G.; Ölveczky, B.P.; Smith, M.A. Temporal structure of motor variability is dynamically regulated and predicts motor learning ability. Nat. Neurosci. 2014, 17, 312–321. [Google Scholar] [CrossRef] [Green Version]
- Albert, S.T.; Jang, J.; Sheahan, H.R.; Teunissen, L.; Vandevoorde, K.; Herzfeld, D.J.; Shadmehr, R. An implicit memory of errors limits human sensorimotor adaptation. Nat. Hum. Behav. 2021, 5, 920–934. [Google Scholar] [CrossRef] [PubMed]
- Schween, R.; Hegele, M. Feedback delay attenuates implicit but facilitates explicit adjustments to a visuomotor rotation. Neurobiol. Learn. Mem. 2017, 140, 124–133. [Google Scholar] [CrossRef] [PubMed]
- Schween, R.; Taube, W.; Gollhofer, A.; Leukel, C. Online and post-trial feedback differentially affect implicit adaptation to a visuomotor rotation. Exp. Brain Res. 2014, 232, 3007–3013. [Google Scholar] [CrossRef]
- Todorov, E.; Jordan, M.I. Optimal feedback control as a theory of motor coordination. Nat. Neurosci. 2002, 5, 1226–1235. [Google Scholar] [CrossRef] [PubMed]
- McDougle, S.D.; Taylor, J.A. Dissociable cognitive strategies for sensorimotor learning. Nat. Commun. 2019, 10, 40. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Cowan, N.; Haith, A. De novo learning and adaptation of continuous control in a manual tracking task. eLife 2021, 10, e62578. [Google Scholar] [CrossRef] [PubMed]
- Danziger, Z.; Mussa-Ivaldi, F.A. The influence of visual motion on motor learning. J. Neurosci. 2012, 32, 9859–9869. [Google Scholar] [CrossRef] [Green Version]
- Albert, S.T.; Hadjiosif, A.M.; Jang, J.; Zimnik, A.J.; Soteropoulos, D.S.; Baker, S.N.; Churchland, M.M.; Krakauer, J.W.; Shadmehr, R. Postural control of arm and fingers through integration of movement commands. eLife 2020, 9, e52507. [Google Scholar] [CrossRef]
- Sadeghi, M.; Sheahan, H.R.; Ingram, J.N.; Wolpert, D.M. The visual geometry of a tool modulates generalization during adaptation. Sci. Rep. 2019, 9, 2731. [Google Scholar] [CrossRef]
- Mon-Williams, M.; Murray, A.H. The size of the visual size cue used for programming manipulative forces during precision grip. Exp. Brain Res. 2000, 135, 405–410. [Google Scholar] [CrossRef]
- Gordon, A.M.; Forssberg, H.; Johansson, R.S.; Westling, G. Visual size cues in the programming of manipulative forces during precision grip. Exp. Brain Res. 1991, 83, 477–482. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Maresch, J. Methods matter: Your measures of explicit and implicit processes in visuomotor adaptation affect your results. Eur. J. Neurosci. 2021, 53, 504–518. [Google Scholar] [CrossRef] [PubMed]
- Tsay, J.S.; Haith, A.M.; Ivry, R.B.; Kim, H.E. Distinct Processing of Sensory Prediction Error and Task Error during Motor Learning. BioRxiv 2021. [Google Scholar] [CrossRef]
- Sigrist, R.; Rauter, G.; Riener, R.; Wolf, P. Augmented visual, auditory, haptic, and multimodal feedback in motor learning: A review. Psychon. Bull. Rev. 2013, 20, 21–53. [Google Scholar] [CrossRef] [Green Version]
- Welsher, A.; Grierson, L.E.M. Enhancing technical skill learning through interleaved mixed-model observational practice. Adv. Health Sci. Educ. 2017, 22, 1201–1211. [Google Scholar] [CrossRef]
- Mattar, A.A.G.; Gribble, P.L. Motor learning by observing. Neuron 2005, 46, 153–160. [Google Scholar] [CrossRef] [Green Version]
- Shea, C.H.; Whltacre, C.; Wulf, G. Enhancing Training Efficiency and Effectiveness Through the Use of Dyad Training. J. Mot. Behav. 1999, 31, 119–125. [Google Scholar] [CrossRef] [PubMed]
- Tsay, J.S.; Avraham, G.; Kim, H.E.; Parvin, D.E.; Wang, Z.; Ivry, R.B. The effect of visual uncertainty on implicit motor adaptation. J. Neurophysiol. 2020, 125, 12–22. [Google Scholar] [CrossRef] [PubMed]
- Tsay, J.S.; Kim, H.E.; Parvin, D.; Ivry, R.B. Individual differences in proprioception predict the extent of implicit sensorimotor adaptation. J. Neurophysiol. 2021, 125, 1307–1321. [Google Scholar] [CrossRef]
- Bernier, P.M.; Chua, R.; Inglis, J.T.; Franks, I.M. Sensorimotor adaptation in response to proprioceptive bias. Exp. Brain Res. 2007, 177, 147–156. [Google Scholar] [CrossRef] [PubMed]
- Manzone, D.M.; Tremblay, L. Contributions of exercise-induced fatigue vs. intertrial tendon vibration on visual-proprioceptive weighting for goal-directed movement. J. Neurophysiol. 2020, 124, 802–814. [Google Scholar] [CrossRef] [PubMed]
- Vandevoorde, K.; de Xivry, J.J.O. Why is the explicit component of motor adaptation limited in elderly adults? J. Neurophysiol. 2020, 124, 152–167. [Google Scholar] [CrossRef]
- Ariani, G.; Diedrichsen, J. Sequence learning is driven by improvements in motor planning. J. Neurophysiol. 2019, 121, 2088–2100. [Google Scholar] [CrossRef] [Green Version]
- Vleugels, L.W.E.; Swinnen, S.P.; Hardwick, R.M. Skill acquisition is enhanced by reducing trial-to-trial repetition. J. Neurophysiol. 2020, 123, 1460–1471. [Google Scholar] [CrossRef]
- Dolfen, N.; King, B.R.; Schwabe, L.; Gann, M.A.; Veldman, M.P.; Von Leupoldt, A.; Swinnen, S.P.; Albouy, G. Stress Modulates the Balance between Hippocampal and Motor Networks during Motor Memory Processing. Cereb. Cortex 2021, 31, 1365–1382. [Google Scholar] [CrossRef]
- Heuer, H.; Hegele, M. Constraints on visuo-motor adaptation depend on the type of visual feedback during practice. Exp. Brain Res. 2008, 185, 101–110. [Google Scholar] [CrossRef]
- Brudner, S.N.; Kethidi, N.; Graeupner, D.; Ivry, R.B.; Taylor, J.A. Delayed feedback during sensorimotor learning selectively disrupts adaptation but not strategy use. J. Neurophysiol. 2016, 115, 1499–1511. [Google Scholar] [CrossRef] [Green Version]
- Kitazawa, S.; Kohno, T.; Uka, T. Effects of delayed visual information on the rate and amount of prism adaptation in the human. J. Neurosci. 1995, 15, 7644–7652. [Google Scholar] [CrossRef]
- Warren, W.E. Coaching and Motivation: A Practical Guide to Maximum Athletic Performance; Prentice Hall: Hoboken, NJ, USA, 1983. [Google Scholar]
- Krane, V.; Williams, J.M.; Williams, J.M. Applied Sport Psychology: Personal Growth to Peak Performance; Mcgraw-Hill Education: New York, NY, USA, 2014. [Google Scholar]
- Burton, D.; Raedeke, T.D. Sport Psychology for Coaches; Human Kinetics: Champaign, IL, USA, 2008. [Google Scholar]
- Abe, M.; Schambra, H.; Wassermann, E.M.; Luckenbaugh, D.; Schweighofer, N.; Cohen, L.G. Reward improves long-term retention of a motor memory through induction of offline memory gains. Curr. Biol. 2011, 21, 557–562. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steel, A.; Silson, E.H.; Stagg, C.J.; Baker, C.I. The impact of reward and punishment on skill learning depends on task demands. Sci. Rep. 2016, 6, 36056. [Google Scholar] [CrossRef] [PubMed]
- Dayan, E.; Averbeck, B.B.; Richmond, B.J.; Cohen, L.G. Stochastic reinforcement benefits skill acquisition. Learn. Mem. 2014, 21, 140–142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nisky, I.; Hsieh, M.H.; Okamura, A.M. A framework for analysis of surgeon arm posture variability in robot-assisted surgery. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 245–251. [Google Scholar] [CrossRef]
- Nisky, I.; Okamura, A.M.; Hsieh, M.H. Effects of robotic manipulators on movements of novices and surgeons. Surg. Endosc. 2014, 28, 2145–2158. [Google Scholar] [CrossRef]
- Jarc, A.M.; Nisky, I. Robot-assisted surgery: An emerging platform for human neuroscience research. Front. Hum. Neurosci. 2015, 9, 315. [Google Scholar] [CrossRef]
- Pacchierotti, C.; Ongaro, F.; Van Den Brink, F.; Yoon, C.; Prattichizzo, D.; Gracias, D.H.; Misra, S. Steering and Control of Miniaturized Untethered Soft Magnetic Grippers with Haptic Assistance. IEEE Trans. Autom. Sci. Eng. 2018, 15, 290–306. [Google Scholar] [CrossRef] [Green Version]
- Wickelgren, W. Speed-Accuracy Tradeoff and information processing dynamics. Acta Psychol. 1977, 41, 67–85. [Google Scholar] [CrossRef]
- Heitz, R.P. The speed-accuracy tradeoff: History, physiology, methodology, and behavior. Front. Neurosci. 2014, 8, 150. [Google Scholar] [CrossRef] [Green Version]
- Marko, M.K.; Haith, A.M.; Harran, M.D.; Shadmehr, R. Sensitivity to prediction error in reach adaptation. J. Neurophysiol. 2012, 108, 1752–1763. [Google Scholar] [CrossRef] [Green Version]
- Shmuelof, L.; Yang, J.; Caffo, B.; Mazzoni, P.; Krakauer, J.W. The neural correlates of learned motor acuity. J. Neurophysiol. 2014, 112, 971–980. [Google Scholar] [CrossRef] [Green Version]
- Temprado, J.; Della-Grasta, M.; Farrell, M.; Laurent, M. A novice-expert comparison of (intra-limb) coordination subserving the volleyball serve. Hum. Mov. Sci. 1997, 16, 653–676. [Google Scholar] [CrossRef]
- Lei, Q.; Du, J.-X.; Zhang, H.-B.; Ye, S.; Chen, D.-S. A Survey of Vision-Based Human Action Evaluation Methods. Sensors 2019, 19, 4129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maeda, T.; Fujii, M.; Hayashi, I.; Tasaka, T. Sport skill classification using time series motion picture data. In Proceedings of the IECON 2014-40th Annual Conference of the IEEE Industrial Electronics Society, Dallas, TX, USA, 29 October–1 November 2014; pp. 5272–5277. [Google Scholar] [CrossRef]
- Ahmidi, N.; Hager, G.D.; Ishii, L.; Fichtinger, G.; Gallia, G.L.; Ishii, M. Surgical task and skill classification from eye tracking and tool motion in minimally invasive surgery. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Mirchi, N.; Bissonnette, V.; Yilmaz, R.; Ledwos, N.; Winkler-Schwartz, A.; Del Maestro, R.F. The virtual operative assistant: An explainable artificial intelligence tool for simulation-based training in surgery and medicine. PLoS ONE 2020, 15, e0229596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nosek, B.A.; Alter, G.; Banks, G.C.; Borsboom, D.; Bowman, S.D.; Breckler, S.J.; Buck, S.; Chambers, C.D.; Chin, G.; Christensen, G.; et al. Promoting an open research culture. Science 2015, 348, 1422–1425. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.-Z. XAI—Explainable artificial intelligence David. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Authors | Data Type | Task |
|---|---|---|---|
| 2018 | Coskun, Tan et al. [108] | 3D joint positions | Find better similarity measures between movements suitable for deep learning applications |
| 2018 | Guo and Wang [109] | 3D joint positions | Motion Segmentation |
| 2018 | Li, Liu and Tan [110] | 3D joint positions | Motion Segmentation |
| 2018 | Park and Kim [111] | 3D hand positions | Find start and end of different tasks within a recording |
| 2018 | Pham, Hochin [112] | 3D curves | Similarity between movements considering speed |
| 2018 | Sedmidubsky, Elias et al. [113] | 3D joint positions | Machine learning based searching of large mocap databases |
| 2018 | Xia, Sun et al. [114] | 3D joint positions | Motion Segmentation |
| 2018 | Zia, Zhang et al. [104] | Mixed | Comparison of clustering algorithms for surgical data |
| 2019 | Sedmidubsky, Elias et al. [115] | 3D joint positions | Find subsequence in longer recording |
| 2020 | Pham, Hochin et al. [116] | 3D curves | Compare sub-movements within a sequence |
| 2020 | Piorek, Jablonski [106] | Quaternions | Similarity measure based on rotations |
| 2021 | Aouaidjia, Bin et al. [117] | 3D joint positions | Quantify similarity between movement sequences |
| 2021 | Park, Cho et al. [107] | RGB video | Compare two short video clips |
| Input Datatype | Output Datatype | |
|---|---|---|
| 3D | 2D | |
| RGB images | [127,133,134] | [135,136,137,138] |
| RGB videos | [122,123,139,140] | [9,141,142] |
| Multiview | [143,144,145] | |
| Depth images | [146,147,148] | |
| Year | Author | Method | Accuracy (NTU-RGB+D) |
|---|---|---|---|
| 2018 | Yan, Xiong and Lin [153] | ST-GCN | 81.5% (CS)/88.3% (CV) |
| 2018 | Thakkar and Narayanan [157] | part-based GCN | 87.5% (CS)/93.2% (CV) |
| 2019 | Li et al. [150] | ST-GCN (routing) | 86.9% (CS)/92.3% (CV) |
| 2019 | Si et al. [154] | AGC-LSTM | 89.2% (CS)/95.0% (CV) |
| 2020 | Cho et al. [155] | SAN | 87.2% (CS)/92.7% (CV) |
| 2020 | Zhang et al. [156] | SAN -ST-GCN | 96.9% (CS)/99.1% (CV) |
| Year | Author | Accuracy (UCF-101) | Accuracy (HMDB-51) |
|---|---|---|---|
| 2014 | Simonyan and Zisserman [165] | 88.0% | 59.4% |
| 2015 | Wu et al. [166] | 92.6% | - |
| 2016 | Wang et al. [171] | 94.2% | 69.4% |
| 2017 | Li et al. [163] | 92.5% | 69.7% |
| 2018 | Lin, et al. [173] | 95.5% | 73.5% |
| 2019 | Crasto et al. [172] | 95.8% | 75.0% |
| 2020 | Kalfaoglu, et al. [162] | 98.7% | 85.1% |
| Year | Authors | Motor Task/Motor Learning Principle | Integration of Motor (Skill) Assessment with… |
|---|---|---|---|
| 2018 | Butt et al. [227] | Catheter insertion | Virtual reality, haptics gloves |
| 2018 | Meyer et al. [228] | Juggling | Augmented reality; Ball and hand tracking |
| 2019 | Sharma et al. [229] | Prosthesis training | Augmented reality |
| 2019 | Chambers et al. [207] | Human gait | Pose estimation in YouTube videos |
| 2020 | Stenum et al. [210] | Human gait | Pose estimation (with OpenPose) |
| 2020 | Haar, van Assel, Faisal [230] | Pool billard | IMU motion tracking suit |
| 2020 | Bahar et al. [231] | Robot-assisted needle driving | Haptic feedback in virtual environment |
| 2020 | Yao and Billard [232] | Watchmaking, Bimanual fine manipulation | Hand pose estimation; modeling (inverse optimization) |
| 2020 | Harris et al. [233] | Golf putting | Virtual reality, motion tracker on real golf club |
| 2020 | Vanneste et al. [234] | Product assembly | Augmented reality |
| 2020 | Ropelato et al. [235] | Ophthalmic microsurgery | Augmented reality |
| 2021 | Lilija et al. [236] | Precise hand motion | Virtual reality |
| 2021 | Tommasino et al. [237] | Ball Throwing | Dimensionality reduction techniques |
| 2021 | Haar, Sundar, Faisal [238] | Pool billard | Embodied virtual reality |
| 2021 | Campagnoli et al. [239] | Visuomotor rotation | Virtual reality |
| 2021 | Zhang and Sternad [240] | Ball throwing | Virtual reality |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vandevoorde, K.; Vollenkemper, L.; Schwan, C.; Kohlhase, M.; Schenck, W. Using Artificial Intelligence for Assistance Systems to Bring Motor Learning Principles into Real World Motor Tasks. Sensors 2022, 22, 2481. https://doi.org/10.3390/s22072481
Vandevoorde K, Vollenkemper L, Schwan C, Kohlhase M, Schenck W. Using Artificial Intelligence for Assistance Systems to Bring Motor Learning Principles into Real World Motor Tasks. Sensors. 2022; 22(7):2481. https://doi.org/10.3390/s22072481
Chicago/Turabian StyleVandevoorde, Koenraad, Lukas Vollenkemper, Constanze Schwan, Martin Kohlhase, and Wolfram Schenck. 2022. "Using Artificial Intelligence for Assistance Systems to Bring Motor Learning Principles into Real World Motor Tasks" Sensors 22, no. 7: 2481. https://doi.org/10.3390/s22072481