
Lightweight Anomaly Detection Scheme Using Incremental Principal Component Analysis and Support Vector Machine

 , , and
, , and
Abstract
:1. Introduction
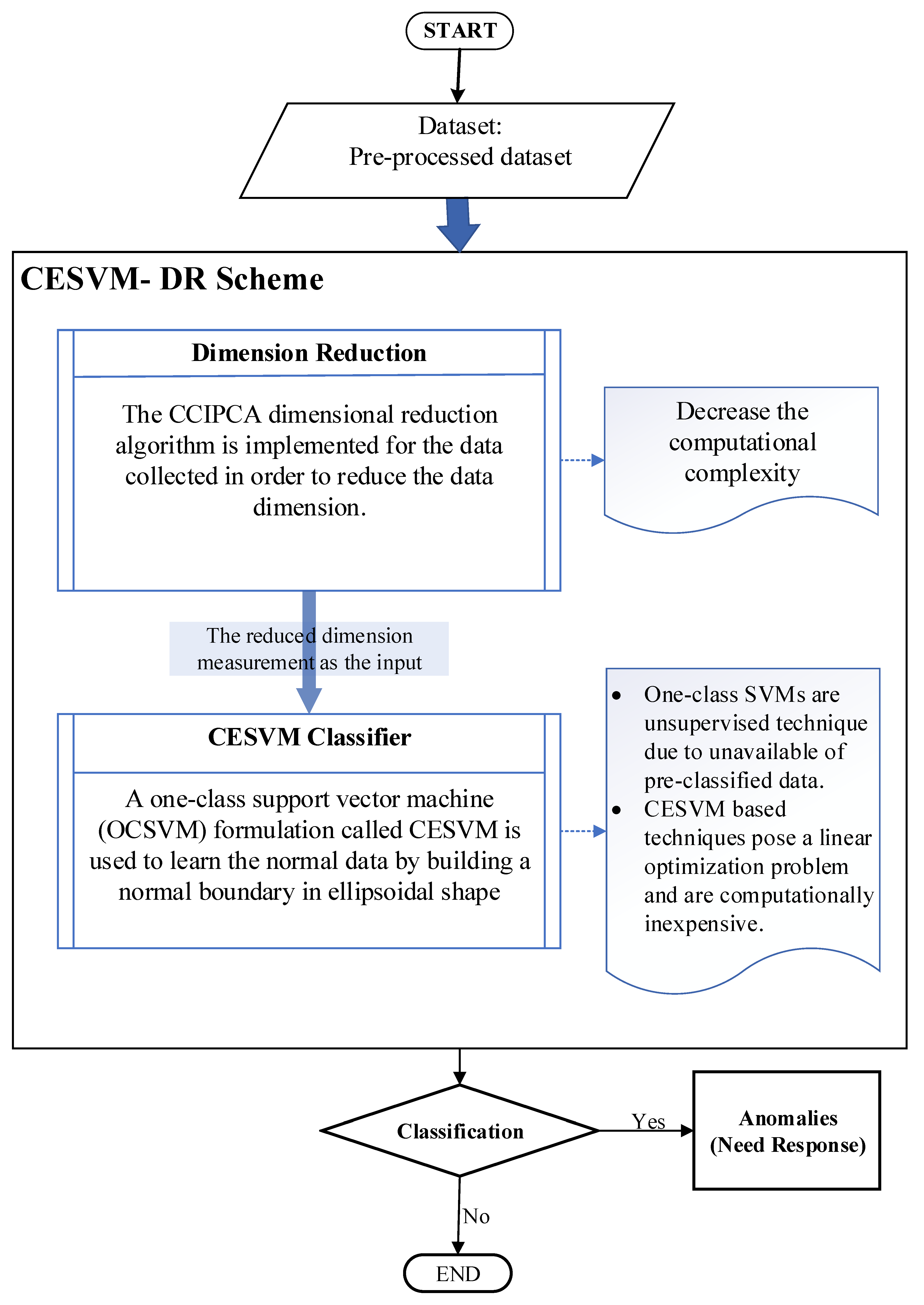
- An effective and efficient anomaly detection scheme is designed and developed by combining the unsupervised One-Class Support Vector Machine (OCSVM) with the Candid Covariance-Free Incremental Principal Component Analysis (CCIPCA) to decrease the computational complexity and improve memory utilization while increasing the detection accuracy.
- Various OCSVM formulations have been investigated such as a hyper-plane, hyper-sphere, Quarter-sphere, Hyper-Ellipsoid, and Centred-Ellipsoid (CESVM) to improve the detection accuracy for multivariate data.
- The Candid Covariance-Free Incremental Principal Component Analysis (CCIPCA) has been incorporated in the design to reduce the data dimension and thus decrease the computational complexity and improve memory utilization.
- Extensive experiments have been conducted to evaluate and validate the effectiveness and efficiency of the proposed scheme.
2. Related Work
3. The Proposed CESVM-DR Scheme
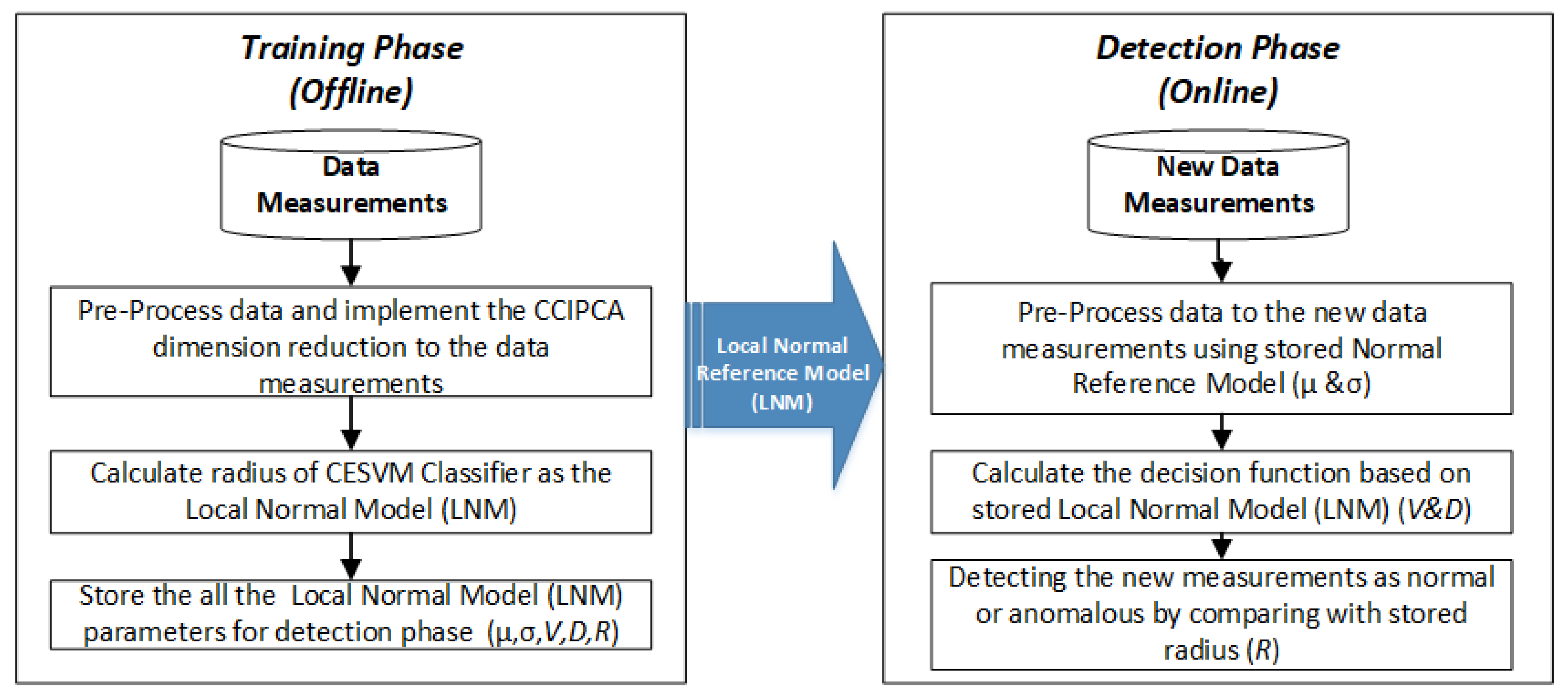
3.1. Description of Proposed CESVM-DR Scheme
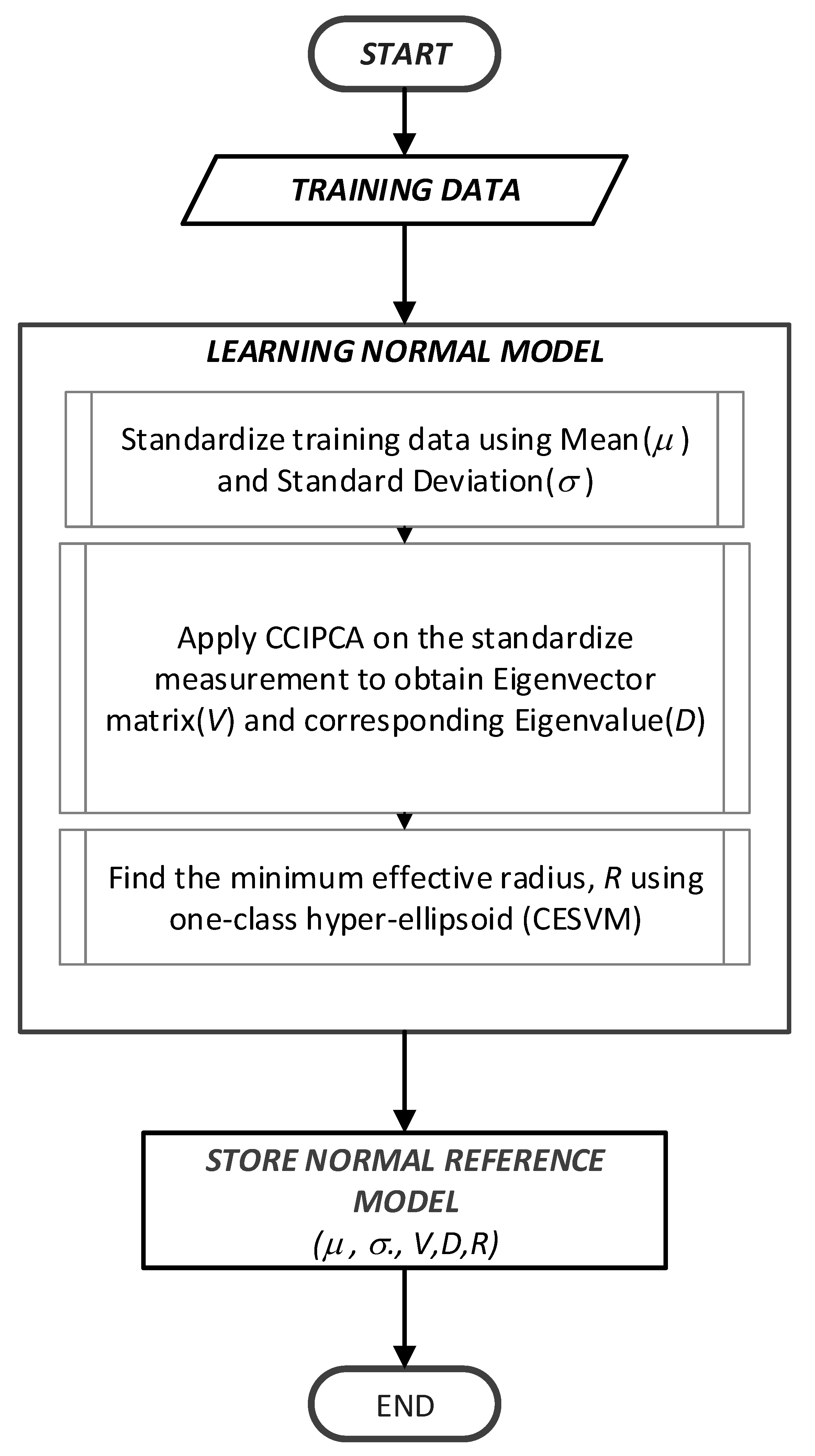
3.1.1. Training Phase (Offline)
- Raw data measurements are collected at each of the sensor nodes to build the normal reference model.
- The collected data are standardized using mean, µ and standard deviations, σ using mean-centered value.
- The dimension reduction based on the CCIPCA algorithm is applied to reduce the data dimension and a suitable number of the principal component is chosen.
- The minimum effective radius, R is calculated based on a calculation of R = . This parameter is known as the normal reference model to be used in the detection phase.
- All calculated parameters including σ, µ, V, D, and R are stored in the node. The Eigenvector (V) and Eigenvalue (D) are calculations taken from calculating the centered kernel matrix of the training data.
| Algorithm 1: Pseudocode algorithm for the training phase of proposed CESVM-DR Scheme |
| Input: // ) of sensor measurements collected from specific time period Output: are mean , standard deviations , Eigenvector Eigenvalue and minimum effective radius
|
3.1.2. Detection Phase (Online)
| Algorithm 2: Pseudocode algorithm for the detection phase of proposed CESVM-DR Scheme |
| Input: and // of real time sensor measurements Output: Normal or Anomalous type of class WSN data
If > then Class = Anomaly Else, Class = Normal
|
- New data observations of m size collected from the sensor nodes are standardized to the calculation in the training phase using mean (µ) and standard deviation (σ) of the normal reference model.
- The distance of each new measurement is calculated as described in Equation (1), using the stored normal reference parameters which are Eigenvector (V) and Eigenvalue (D). The measure similarity between data is based on decision function
- These new data measurements are classified as normal or anomalous using the decision function in Equation (2).
4. Experimental Design
4.1. Preprocessing
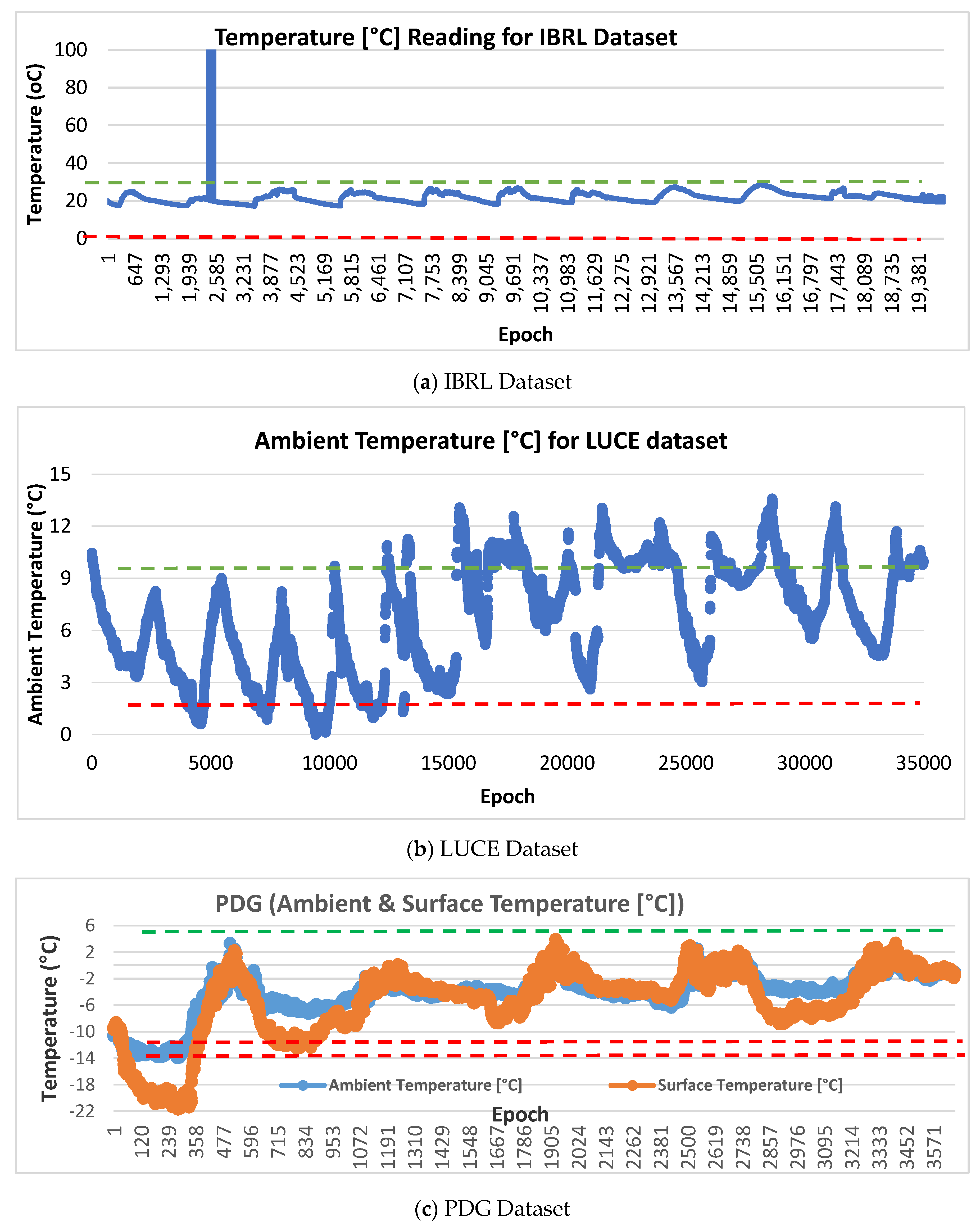
4.2. Datasets and Data Labeling
- The normal data measurements are collected from a real-life dataset with the size of where 𝑚 and 𝑛 represent the number of data measurements and the number of variables respectively. The mean and standard deviation of the collected data measurements are calculated with .
- The new µ and σ values to generate artificial anomalies are selected by adding and with the preferred amount of deviation to produce slightly different mean and standard deviation from normal values.
- Based on the selected new µ and σ values, the artificial anomalies are produced based on normal random distribution function, f as follow: Artificial anomalies = f ( µ, σ, m, n).
4.3. Testing Procedures
- Linear function:
- 2.
- Radial basis function (RBF)
- 3.
- Polynomial function
4.4. Performance Evaluation
5. Results and Analysis
5.1. Effectiveness Evaluation
5.1.1. Accuracy Evaluation Using the Simulated-Based Data Labelling
5.1.2. Accuracy Performance Result Using Histogram-Based Dataset
5.2. Efficiency Evaluation
5.2.1. Memory Utilization
5.2.2. Computational Complexity
5.2.3. Communication Overhead
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
- GSB, Grand-St-Bernard (GSB) dataset, 2007. http://lcav.epfl.ch/cms/lang/en/pid/86035, Accessed date (20 April 2018)
- IBRL, Intel Berkeley Research Lab Dataset, 2004. http://db.csail.mit.edu/labdata/ labdata.html, Accessed date (26 September 2017)
- PDG, Patrouille des Glaciers dataset, 2008. http://lcav.epfl.ch/cms/lang/en/pid/86035, Accessed date (23 April 2016)
- LUCE, Lausanne Urban Canopy Experiment, 2007. http://lcav.epfl.ch/cms/lang/en/pid/86035, Accessed date (24 January 2018)
- NAMOS, Networked Aquatic Microbial Observing System Dataset, 2006. http://robotics.usc.edu/~namos/data/, Accessed date (12 October 2017).
Acknowledgments
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Obeid, A.M.; Abid, M. Outlier detection approaches for wireless sensor networks: A survey. Comput. Netw. 2017, 129, 319–333. [Google Scholar] [CrossRef]
- Gao, C.; Chen, Y.; Wang, Z.; Xia, H.; Lv, N. Anomaly detection frameworks for outlier and pattern anomaly of time series in wireless sensor networks. In Proceedings of the 2020 International Conference on Networking and Network Applications (NaNA), Haikou, China, 10–13 December 2020; Volume 10, pp. 229–232. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–72. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Rajasegarar, S.; Bezdek, J.C.; Leckie, C.; Palaniswami, M. Analysis of Anomalies in IBRL Data from a Wireless Sensor Network Deployment. In Proceedings of the 2007 International Conference on Sensor Technologies and Applications (SENSORCOMM 2007), Valencia, Spain, 14–20 October 2007; Volume 29, pp. 158–163. [Google Scholar] [CrossRef]
- Rassam, M.A.; Maarof, M.A.; Zainal, A. Adaptive and online data anomaly detection for wireless sensor systems. Knowl.-Based Syst. 2014, 60, 44–57. [Google Scholar] [CrossRef]
- Rassam, M.A.; Zainal, A. Principal Component Analysis-Based Data Reduction Model for Wireless Sensor Networks. Int. J. Ad Hoc Ubiquitous Comput. 2015, 18, 85–101. [Google Scholar] [CrossRef]
- Randhawa, S.; Jain, S. Data Aggregation in Wireless Sensor Networks: Previous Research, Current Status and Future Directions. Wirel. Pers. Commun. 2017, 97, 3355–3425. [Google Scholar] [CrossRef]
- Xue, Y.; Jia, W.; Zhao, X.; Pang, W. An Evolutionary Computation Based Feature Selection Method for Intrusion Detection. Secur. Commun. Netw. 2018, 2018, 2492956. [Google Scholar] [CrossRef]
- Aldweesh, A.; Derhab, A.; Emam, A. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl.-Based Syst. 2020, 189, 105124. [Google Scholar] [CrossRef]
- Safaei, M.; Ismail, A.S.; Chizari, H.; Driss, M.; Boulila, W.; Asadi, S.; Safaei, M. Standalone noise and anomaly detection in wireless sensor networks: A novel time-series and adaptive Bayesian-network-based approach. Softw. Pract. Exp. 2019, 50, 428–446. [Google Scholar] [CrossRef]
- Davahli, A.; Shamsi, M.; Abaei, G. A Lightweight Anomaly Detection Model using SVM for WSNs in IoT through a Hybrid Feature Selection Algorithm based on GA and GWO. J. Comput. Secur. 2020, 7, 63–79. [Google Scholar]
- Chen, Y.; Li, S. A Lightweight Anomaly Detection Method Based on SVDD for Wireless Sensor Networks. Wirel. Pers. Commun. 2019, 105, 1235–1256. [Google Scholar] [CrossRef] [Green Version]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M. CESVM: Centered Hyperellipsoidal Support Vector Machine Based Anomaly Detection. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 1610–1614. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P.J. Distributed online outlier detection in wireless sensor networks using ellipsoidal support vector machine. Ad Hoc Netw. 2013, 11, 1062–1074. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Qaisar, S.B. Quarter-Sphere SVM: Attribute and Spatio-Temporal Correlations based Outlier & Event Detection in Wireless Sensor Networks. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 2048–2053. [Google Scholar]
- Moshtaghi, M.; Leckie, C.; Karunasekera, S.; Rajasegarar, S. An adaptive elliptical anomaly detection model for wireless sensor networks. Comput. Netw. 2014, 64, 195–207. [Google Scholar] [CrossRef]
- Ghorbel, O.; Ayadi, A.; Loukil, K. Classification Data using Outlier Detection Method in Wireless Sensor Networks. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference, Valencia, Spain, 26–30 June 2017; pp. 699–704. [Google Scholar] [CrossRef]
- Xie, M.; Han, S.; Tian, B.; Parvin, S. Anomaly detection in wireless sensor networks: A survey. J. Netw. Comput. Appl. 2011, 34, 1302–1325. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P. Outlier Detection Techniques for Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2010, 12, 159–170. [Google Scholar] [CrossRef] [Green Version]
- Ifzarne, S.; Tabbaa, H.; Hafidi, I.; Lamghari, N. Anomaly Detection using Machine Learning Techniques in Wireless Sensor Networks. J. Phys. Conf. Ser. 2021, 1743, 12021. [Google Scholar] [CrossRef]
- Poornima, I.G.A.; Paramasivan, B. Anomaly detection in wireless sensor network using machine learning algorithm. Comput. Commun. 2020, 151, 331–337. [Google Scholar] [CrossRef]
- Kim, T.; Vecchietti, L.F.; Choi, K.; Lee, S.; Har, D. Machine Learning for Advanced Wireless Sensor Networks: A Review. IEEE Sens. J. 2021, 21, 12379–12397. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M. Anomaly Detection in Wireless Sensor Networks. IEEE Wirel. Commun. 2008, 15, 34–40. [Google Scholar] [CrossRef]
- Safaei, M.; Asadi, S.; Driss, M.; Boulila, W.; Alsaeedi, A.; Chizari, H.; Abdullah, R.; Safaei, M. A Systematic Literature Review on Outlier Detection in Wireless Sensor Networks. Symmetry 2020, 12, 328. [Google Scholar] [CrossRef] [Green Version]
- Erfani, S.M.; Baktashmotlagh, M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. R1SVM: A randomised nonlinear approach to large-scale anomaly detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 1, pp. 432–438. [Google Scholar]
- Zhang, Y.; Meratnia, N.; Havinga, P. Hyperellipsoidal SVM-Based Outlier Detection Technique for Geosensor Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 31–41. [Google Scholar]
- Liu, W.; Hua, G.; Smith, J.R. Unsupervised One-Class Learning for Automatic Outlier Removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Volume 48, pp. 3826–3833. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Castillo, E.; Peteiro-Barral, D.; Berdiñas, B.G.; Fontenla-Romero, O. Distributed One-Class Support Vector Machine. Int. J. Neural Syst. 2015, 25, 1550029. [Google Scholar] [CrossRef]
- He, Q.; Zhang, Q.; Wang, H.; Zhang, C. Local Similarity-Based Fuzzy Multiple Kernel One-Class Support Vector Machine. Complex 2020, 2020, 8853277. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Leckie, C.; Palaniswami, M. Hyperspherical cluster based distributed anomaly detection in wireless sensor networks. J. Parallel Distrib. Comput. 2014, 74, 1833–1847. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.J.; Duin, R.P.W. Support vector domain description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Laskov, P.; Schäfer, C.; Kotenko, I.; Muller, K.-R. Intrusion Detection in Unlabeled Data with Quarter-sphere Support Vector Machines. PIK-Prax. Der Inf. Und Kommun. 2004, 27, 228–236. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Yeung, D.S.; Tsang, E.C.C. Structured one-class classification. IEEE Trans. Syst. Man Cybern. Part B 2006, 36, 1283–1295. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Bin Qaisar, S. One-class support vector machines: Analysis of outlier detection for wireless sensor networks in harsh environments. Artif. Intell. Rev. 2015, 43, 515–563. [Google Scholar] [CrossRef]
- Li, P.H.; Lee, T.; Youn, H.Y. Dimensionality Reduction with Sparse Locality for Principal Component Analysis. Math. Probl. Eng. 2020, 2020, 9723279. [Google Scholar] [CrossRef]
- Rault, T.; Bouabdallah, A.; Challal, Y. Energy efficiency in wireless sensor networks: A top-down survey. Comput. Netw. 2014, 67, 104–122. [Google Scholar] [CrossRef] [Green Version]
- Ejaz, W.; Anpalagan, A. Dimension Reduction for Big Data Analytics in Internet of Things. In Internet of Things for Smart Cities; Springer: Singapore, 2018; pp. 31–37. [Google Scholar]
- Shi, F.; Li, Q.; Zhu, T.; Ning, H. A Survey of Data Semantization in Internet of Things. Sensors 2018, 18, 313. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mashere, M.P.; Barve, S.S.; Ganjewar, P.D. Data Reduction in Wireless Sensor Network: A Survey. Int. J. Comput. Sci. Technol. 2015, 8491, 86–88. [Google Scholar]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 914. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Wen, F.; Jia, H. Algorithm of data compression based on multiple principal component analysis over the WSN. In Proceedings of the 2010 International Conference on Computational Intelligence and Software Engineering, Chengdu, China, 23–25 September 2010; pp. 2–5. [Google Scholar] [CrossRef]
- Rooshenas, A.; Rabiee, H.R.; Movaghar, A.; Naderi, M.Y. Reducing the data transmission in Wireless Sensor Networks using the Principal Component Analysis. In Proceedings of the 2010 Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, QLD, Australia, 7–10 December 2010; pp. 133–138. [Google Scholar] [CrossRef] [Green Version]
- Seo, S.; Kang, J.; Ryu, K.H. Multivariate Stream Data Reduction in Sensor Network Applications. In Proceedings of the International Conference on Embedded and Ubiquitous Computing, Nagasaki, Japan, 6–9 December 2005; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; Volume 3823, pp. 198–207. [Google Scholar] [CrossRef] [Green Version]
- da Silva, A.P.R.; Martins, M.H.T.; Rocha, B.P.S.; Loureiro, A.A.F.; Ruiz, L.B.; Wong, H.C. Decentralized intrusion detection in wireless sensor networks. In Proceedings of the 1st ACM International Workshop on Quality of Service & Security in Wireless and Mobile Networks, Montreal, QC, Canada, 13 October 2005; Volume 11, pp. 16–23. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, C.; Gomes, D.G.; Agoulmine, N.; De Souza, J.N. Improving Prediction Accuracy for WSN Data Reduction by Applying Multivariate Spatio-Temporal Correlation. Sensors 2011, 11, 10010–10037. [Google Scholar] [CrossRef] [Green Version]
- Matos, T.B.; Brayner, A.; Maia, J. Towards in-network data prediction in wireless sensor networks. ACM Symp. Appl. Comput. 2010, 12, 592–596. [Google Scholar] [CrossRef]
- Ghorbel, O.; Ayedi, W.; Snoussi, H.; Abid, M. Fast and Efficient Outlier Detection Method in Wireless Sensor Networks. IEEE Sens. J. 2015, 15, 3403–3411. [Google Scholar] [CrossRef]
- Weng, J.; Zhang, Y.; Hwang, W.-S. Candid covariance-free incremental principal component analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1034–1040. [Google Scholar] [CrossRef] [Green Version]
- Rajasegarar, S.; Leckie, C.; Bezdek, J.C. Centered Hyperspherical and Hyperellipsoidal One-Class Support Vector Machines for Anomaly Detection in Sensor Networks. IEEE Trans. Inf. Forensics Secur. 2010, 5, 518–533. [Google Scholar] [CrossRef]
- Rassam, M.; Zainal, A.; Maarof, M.A. Advancements of Data Anomaly Detection Research in Wireless Sensor Networks: A Survey and Open Issues. Sensors 2013, 13, 10087–10122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghorbel, O.; Abid, M.; Snoussi, H. A Novel Outlier Detection Model Based on One Class Principal Component Classifier in Wireless Sensor Networks. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications, Gwangju, Korea, 24–27 March 2015; pp. 70–76. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; Bensaleh, M.S.; Obeid, A.; Abid, M. Performance of outlier detection techniques based classification in Wireless Sensor Networks. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 687–692. [Google Scholar]
- Rassam, M.; Maarof, M.A.; Zainal, A. A distributed anomaly detection model for wireless sensor networks based on the one-class principal component classifier. Int. J. Sens. Netw. 2018, 27, 200. [Google Scholar] [CrossRef]
- Takianngam, S.; Usaha, W. Discrete Wavelet Transform and One-Class Support Vector Machines for Anomaly Detection in Wireless Sensor Networks. In Proceedings of the International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Chiang Mai, Thailand, 7–9 December 2011. [Google Scholar]
- Siripanadorn, S.; Hattagam, W.; Teaumroong, N. Anomaly detection using self-organizing map and wavelets in Wireless Sensor Networks. In Proceedings of the 10th WSEAS International Conference on Applied Computer Science (ACS’10), Takizawa, Japan, 4–6 October 2010; Volume 4, pp. 291–297. [Google Scholar]
- Alshammari, H.; Ghorbel, O.; Aseeri, M.; Abid, M. Non-Negative Matrix Factorization (NMF) for outlier detection in Wireless Sensor Networks. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 506–511. [Google Scholar] [CrossRef]
- Ayadi, A.; Ghorbel, O.; BenSalah, M.; Abid, M. Spatio-temporal correlations for damages identification and localization in water pipeline systems based on WSNs. Comput. Netw. 2020, 171, 107134. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Variable | Normal | Anomalies | ||
|---|---|---|---|---|---|
| Mean | Std. Dev | Mean | Std. Dev | ||
| D1 | Ambient temperature Relative humidity | 5.26 25.43 | 8.28 0.99 | 7.75 33.83 | 9.90 0.86 |
| D2 | Ambient temperature Relative humidity | 3.61 14.24 | 7.44 1.97 | 5.39 20.88 | 9.00 4.11 |
| D3 | Ambient temperature Relative humidity | 3.29 20.27 | 6.86 0.74 | 5.33 27.52 | 9.77 1.00 |
| D4 | Ambient temperature Relative humidity | 4.56 10.22 | 8.15 2.94 | 7.69 15.14 | 10.02 5.09 |
| D5 | Ambient temperature Relative humidity | 3.37 24.71 | 7.92 1.29 | 10.65 33.08 | 11.60 1.34 |
| Measure | Scheme | D1 | D2 | D3 | D4 | D5 | Average |
|---|---|---|---|---|---|---|---|
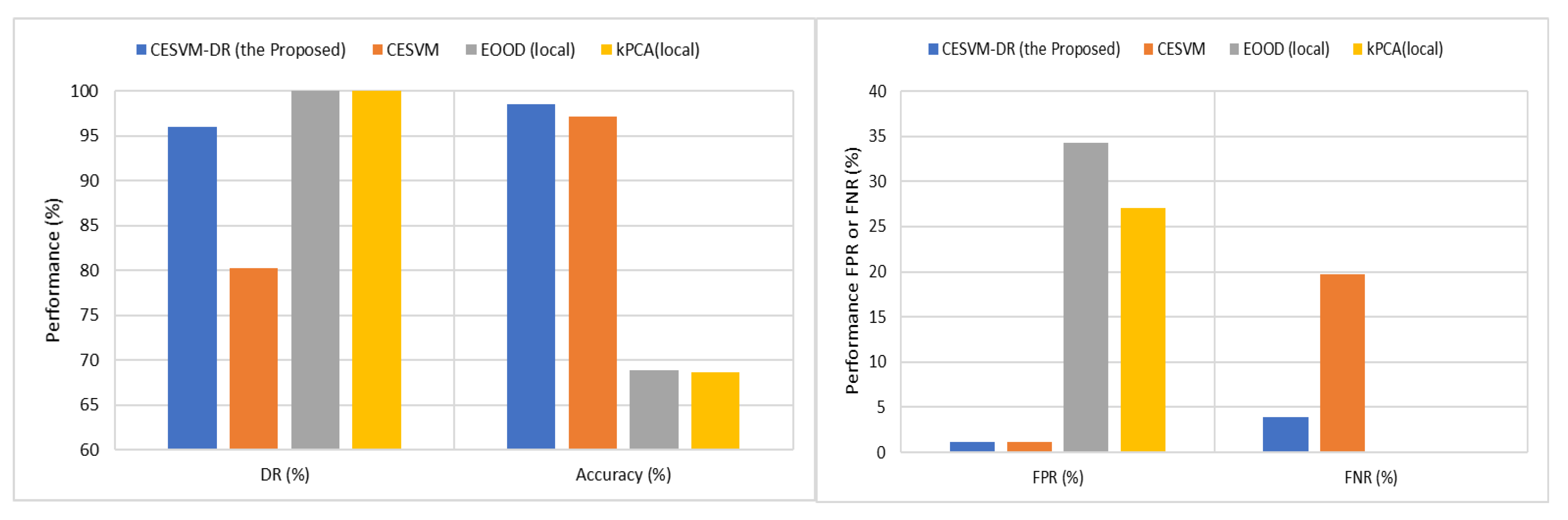
| DR (%) | CESVM-DR | 96.4 | 92 | 92 | 100 | 100 | 96.08 |
| CESVM | 74.8 | 85.2 | 82 | 78.8 | 80.8 | 80.32 | |
| EOOD (local) | 100 | 100 | 100 | 100 | 100 | 100 | |
| kPCA(local) | 100 | 100 | 100 | 100 | 100 | 100 | |
| FPR (%) | CESVM-DR | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| CESVM | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | |
| EOOD (local) | 32.7 | 32.7 | 40.9 | 34.5 | 30.5 | 34.26 | |
| kPCA(local) | 7.4 | 37.6 | 47.2 | 35.4 | 7.4 | 27 | |
| FNR (%) | CESVM-DR | 3.6 | 8 | 8 | 0 | 0 | 3.92 |
| CESVM | 25.2 | 14.8 | 18 | 21.2 | 19.2 | 19.68 | |
| EOOD (local) | 0 | 0 | 0 | 0 | 0 | 0 | |
| kPCA(local) | 0 | 0 | 0 | 0 | 0 | 0 | |
| Accuracy (%) | CESVM-DR | 98.6 | 98.2 | 98.2 | 98.9 | 98.9 | 98.56 |
| CESVM | 96.6 | 97.6 | 97.3 | 97 | 97.2 | 97.14 | |
| EOOD (local) | 70.3 | 70.3 | 62.8 | 68.6 | 72.3 | 68.86 | |
| kPCA(local) | 93.3 | 65.3 | 57.1 | 64 | 63.6 | 68.66 |
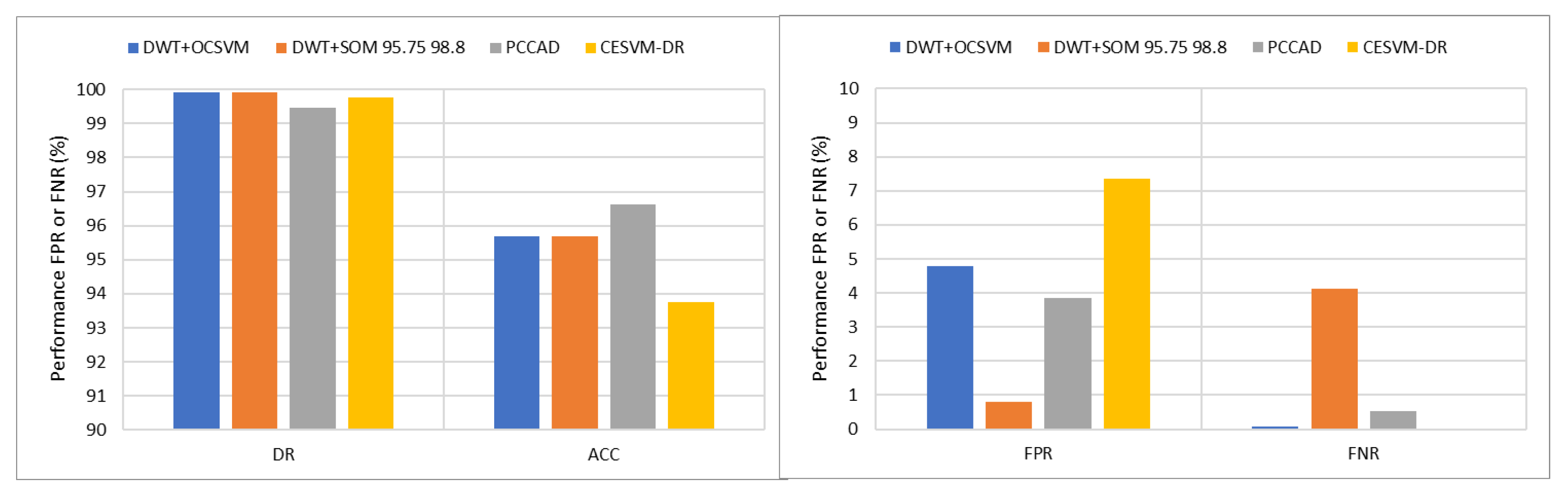
| Dataset | Model | DR | ACC | FPR | FNR |
|---|---|---|---|---|---|
| IBRL | DWT + OCSVM | 100 | 98.3 | 1.9 | 0 |
| DWT + SOM | 100 | 99 | 1.09 | 0 | |
| PCCAD | 100 | 99.7 | 0.3 | 0 | |
| CESVM-DR | 100 | 98.4 | 1.6 | 0 | |
| LUCE | DWT + OCSVM | 100 | 98.3 | 1.9 | 0 |
| DWT + SOM | 100 | 99 | 1.09 | 0 | |
| PCCAD | 100 | 99.9 | 0.09 | 0 | |
| CESVM-DR | 100 | 98 | 2 | 0 | |
| PDG | DWT + OCSVM | 99.7 | 97.6 | 2.6 | 0.3 |
| DWT + SOM | 83 | 97.8 | 0.5 | 16.5 | |
| PCCAD | 97.9 | 96.7 | 3.5 | 2.1 | |
| CESVM-DR | 99.1 | 78.6 | 25.8 | 0.01 | |
| NAMOS | DWT + OCSVM | 100 | 88.6 | 12.8 | 0 |
| DWT + SOM | 100 | 99.4 | 0.5 | 0 | |
| PCCAD | 100 | 90.2 | 11.5 | 0 | |
| CESVM-DR | 100 | 100 | 0 | 0 |
| Scheme | Memory Utilization | Computational Complexity | Communication Overhead |
|---|---|---|---|
| CESVM | |||
| EOOD | - | ||
| PCCAD | - | ||
| kPCA | |||
| DWT + SOM | |||
| DWT + OCSVM | |||
| CESVM-DR | - |
| Legends | Descriptions |
|---|---|
| m | Low-rank approximation of the kernel Gram matrix |
| n | Number of the data observations |
| p | The dimension of the data vector |
| d | The reduced dimension of the data vector |
| P | linear optimization problem calculation |
| N | The calculation of CCIPCA |
| e | applying anomaly detection for DWT |
| s | applying anomaly detection online for OCSVM |
| l | applying anomaly detection for SOM |
| k | communication of wavelet coefficient to the central node |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zamry, N.M.; Zainal, A.; Rassam, M.A.; Alkhammash, E.H.; Ghaleb, F.A.; Saeed, F. Lightweight Anomaly Detection Scheme Using Incremental Principal Component Analysis and Support Vector Machine. Sensors 2021, 21, 8017. https://doi.org/10.3390/s21238017
Zamry NM, Zainal A, Rassam MA, Alkhammash EH, Ghaleb FA, Saeed F. Lightweight Anomaly Detection Scheme Using Incremental Principal Component Analysis and Support Vector Machine. Sensors. 2021; 21(23):8017. https://doi.org/10.3390/s21238017
Chicago/Turabian StyleZamry, Nurfazrina M., Anazida Zainal, Murad A. Rassam, Eman H. Alkhammash, Fuad A. Ghaleb, and Faisal Saeed. 2021. "Lightweight Anomaly Detection Scheme Using Incremental Principal Component Analysis and Support Vector Machine" Sensors 21, no. 23: 8017. https://doi.org/10.3390/s21238017