1. Introduction
The derivation of reliable quantitative traits (QTs), such as morphological and developmental features, became the method of choice by investigation of the effects of biotic and abiotic factors on plant growth and grain yield [
1]. However, the high variability of optical setups and plant appearance turned out to render a non-trivial task for image-based phenotyping, which represents one of the major bottlenecks of quantitative plant science [
2,
3]. In addition to assessment of the overall plant biomass and structure, the detection and quantification of plant organs, such as wheat ears and spikes, is of particular interest for biologists and breeders.
The predominant majority of previous works were focused on the analysis of spikes visible on the top of plants grown under field conditions, where researchers were primarily interested in assessing spike counts and density per square area [
3,
4,
5]. In contrast to field images, where spikes are only visible on the top of grain crops, greenhouse images of single plants acquired from different rotational angles in side view potentially enable to assess the amount and phenotype of all spikes, including spikes that emerge not only on the top, but also within the mass of plant leaves, as is often the case for many European wheat cultivars. In general, the high-throughput phenotyping of plants in a controlled greenhouse environment is used for the investigation of effects of environmental conditions, such as drought stress, temperature, light intensity as well as their fluctuations [
6,
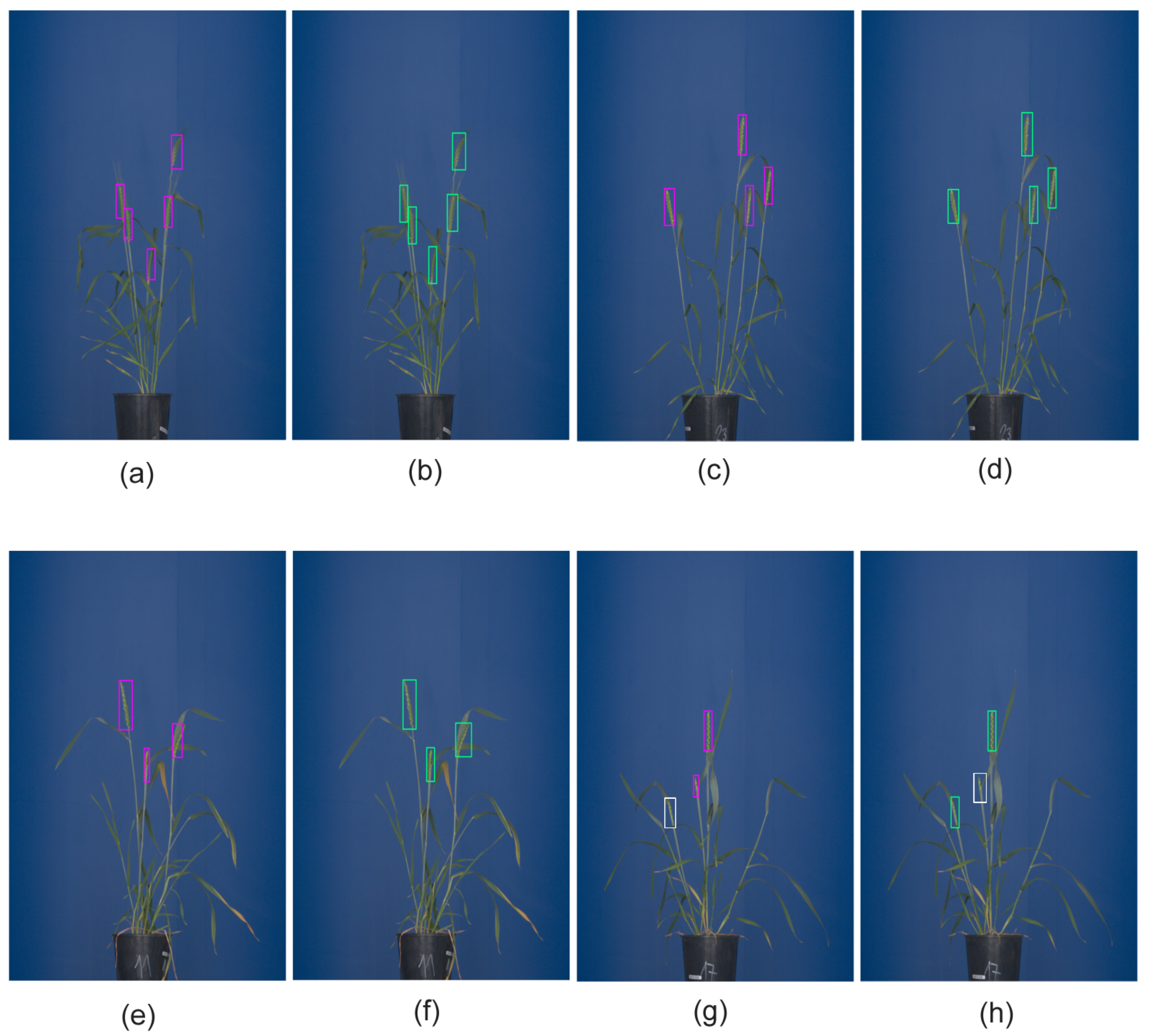
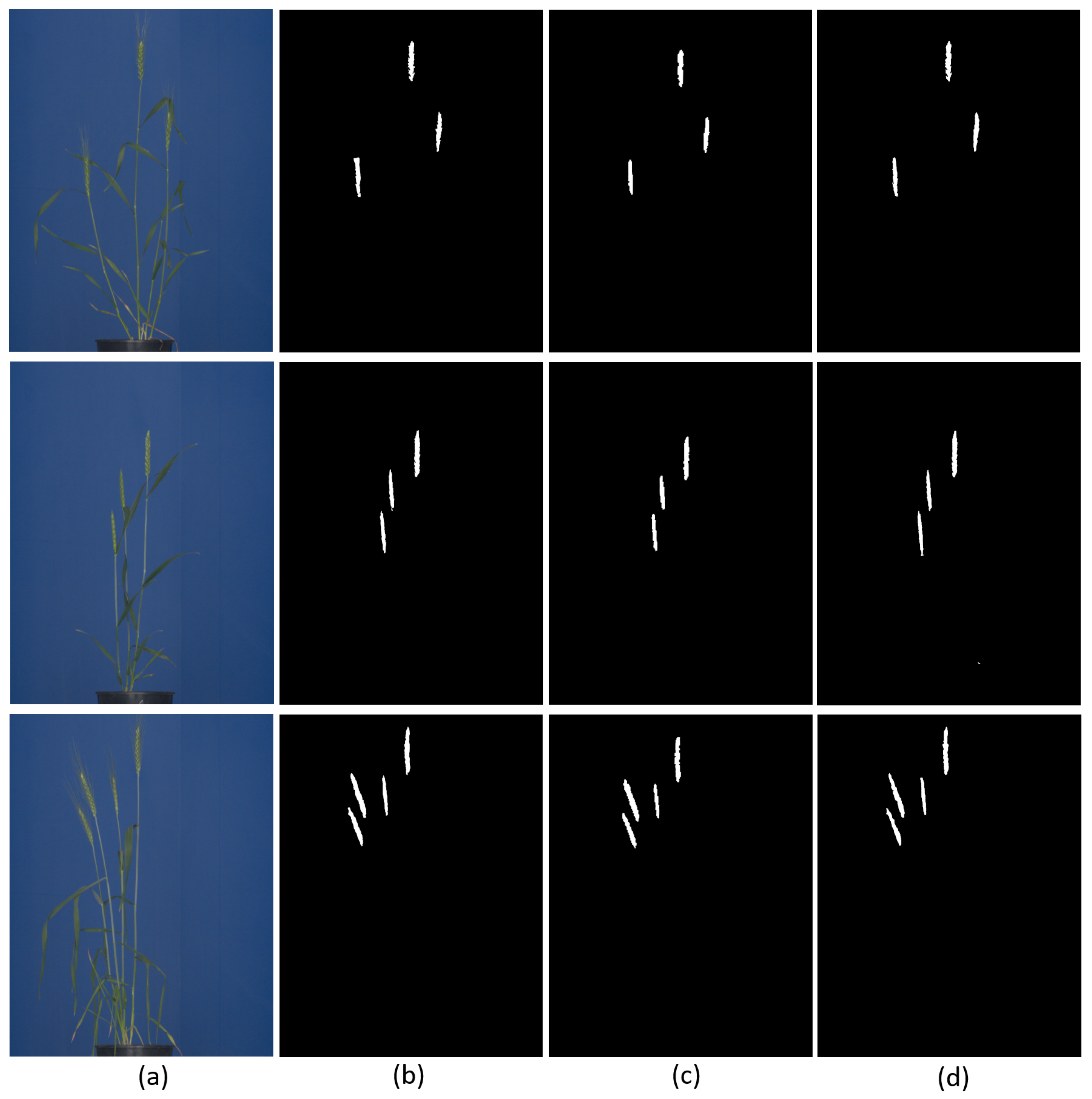
7]. Furthermore, detection of spikes in images of greenhouse-grown plants is of interest for subsequent remote screening of grain yield and development, using X-ray imaging, which requires the precise location of spikes in the image. However, even in a controlled greenhouse environment, spikes can be partially covered by leaves and/or occluded together, which hampers their straightforward detection and phenotyping. Depending on the particular research goals, biologists are, in general, interested in automation of two major tasks: (i) detection/localization/counting and (ii) pixel-wise segmentation of spikes. See examples in
Figure 1.
The latter enables the assessment of such important traits as spike area (biomass), shape, color, and texture, which is otherwise not accessible by means of pattern detection methods.
A plethora of conventional and modern methods for spike image analysis in different optical and environmental setups for different biological tasks was developed in the past. From the summary of existing approaches to spike image analysis in
Table 1, it is evident that the majority of previous works focused on spike image analysis under field conditions. Furthermore, different measures were used in different studies, including average precision (AP), accuracy of the confusion matrix (A) and F1-score (also known as the Dice coefficient).
Grillo et al. applied image analysis techniques to identify wheat landraces based on glume phenotypes by statistical analysis of morpho-colorimetric descriptors [
8]. Alharbi et al. [
5] detected wheat ears by transforming raw plant images, using the color index of vegetation extraction (CIVE) and performed the clustering of pixel features extracted in the CIVE domain, using k-means. CIVE uses principal component analysis for the estimation of biomass. Tan et al. applied support vector machine (SVM) and k-nearest neighborhood for wheat spike recognition on pre-segmented spike regions and super-pixels that were generated by simple linear iterative clustering. Bi et al. designed different architectures of a 3-layer neural network based on the number of hidden layer nodes to classify four wheat varieties of a sole-spike image to extract the spike traits, such as the awn number, the average awn length, and the spike length [
9]. Misra et al. presented SpikeSegNet, which performs spike detection with two cascaded feature networks: local patch extraction and a global mask refinement network [
10]. Hasan et al. achieved spike detection and counting with R-CNN obtaining a F1 score of 0.95 on 20 wheat field images, having an average of 70–80 spikes per image [
3]. Pound et al. implemented a deep neural network (DNN) for the identification of spikelets and their counting [
11]. Most of the above methods were developed for field image analysis and restricted to a particular subset of image data and imaging modalities. The source code of the algorithmic implementations or deployed tools are rarely provided for reproducing the results and routine application.
Only a few works are known to deal with detailed analysis of spikes images acquired from greenhouse plant phenotyping experiments. Qiongyan et al. presented a spike segmentation framework based on artificial (shallow) neural networks (ANNs), which was trained and evaluated only on images of wheat species exhibiting spikes on the top of the plant (further termed ‘top spikes’) and almost no leaf-covered (‘inner’) or occluded spikes [
12]. In our previous work, we extended the ANN approach to the detection of more difficult bushy European wheat phenotypes [
13]. Improvements introduced to the shallow ANN architecture, such as Frangi line filters, could enhance the final segmentation results; however, this ANN framework still requires substantial efforts, such as parameter adjustment by application to new image data. In particular, the improved ANN performed well on detecting spikes in crops with relatively low biomass and low yielding but showed limitations when applied to high biomass and high yielding wheat images. In these phenotypes, spikes emerge within the mass of leaves. In such cases, the Frangi filters did not suffice for filtering out spike regions from wrongly segmented leave and tiller edges. Further, this method also employed a morphological reconstruction step to compensate for the reduced area prediction as a result of pure performance on the spike boundaries. This step can be mitigated if the neural network architecture is deployed to reconstruct or upsample the feature samples, such as in the case of a encoder–decoder architecture.
The majority of previous works is typically evaluated on a particular, typically limited, set of images such that the generalizability of one or other method by application to a new experimental setup is difficult to assess. In fact, spikes may exhibit different shape, colors and textures depending on the plant species, developmental stage and experimental environment, which makes the generalization of spike detection/segmentation, especially using conventional methods, a challenging problem. In the absence of unique and robust features for the classification of fore- and background regions, already the very first task of appropriate feature definition is not trivial and has to be approached in a very general manner. Deep learning methods allow to address this task by performing the automated search and selection of features. With the success of AlexNet [
14], significantly more robust and accurate results of image segmentation were achieved in a widely automated manner as compared to traditional classification techniques based on a pre-defined set of features. The top performance of DNNs on a benchmark data set, i.e., VOC 2007-12 (visual object classes) and MS COCO (common objects in context), is attributed to the automated feature extraction of classifier and pixel-wise segmentation [
15,
16]. Meanwhile, numerous DNN architectures were reported for the frequently demanded tasks of pattern detection and image segmentation. However, studies demonstrating the performance of different DNNs in application to plants, plant organs and, in particular, spike detection/segmentation are quite rare. In view of the generally known challenges by analysis of small and optically variable structures, here, we decided to approach the problem of detection/segmentation of diverse (‘top’, ‘leaf-covered’, and ‘occluded’) spikes of different cereal plants (wheat, barley, and rye) by investigating and comparing the performance of six different machine learning frameworks, including three detection deep neural networks (DNNs), such as single shot multibox detector (SSD), faster-RCNN, and YOLOv3/v4, as well as two segmentation DNNs (U-Net, DeepLabv3+) and one conventional shallow ANN.
The optical appearance of spikes changes through the life cycle of cereal plants from vegetative to reproductive stage. The detection of emergent spikes provides important quantitative traits of plant development and yield to plant breeders and biologists. The localization of spikes in the mass of leaves is particularly difficult in the early reproductive stage as well as during the harvesting period when both spikes and leaves exhibit similar color fingerprints. The multi-view imaging systems in greenhouse photo chambers provide not only side, but also top view images, where spikes often exhibit a similar profile as in the side view images but with arbitrary spatial orientation. Consequently, we were interested in evaluating whether spike detection models trained on the majority of side view images can also be applied to the detection of differently oriented spike patterns in top view images. Furthermore, this study investigates the generalizability of detection/segmentation models trained on a particular crop cultivar (e.g., wheat) by application to other crop species (e.g., barley and rye).
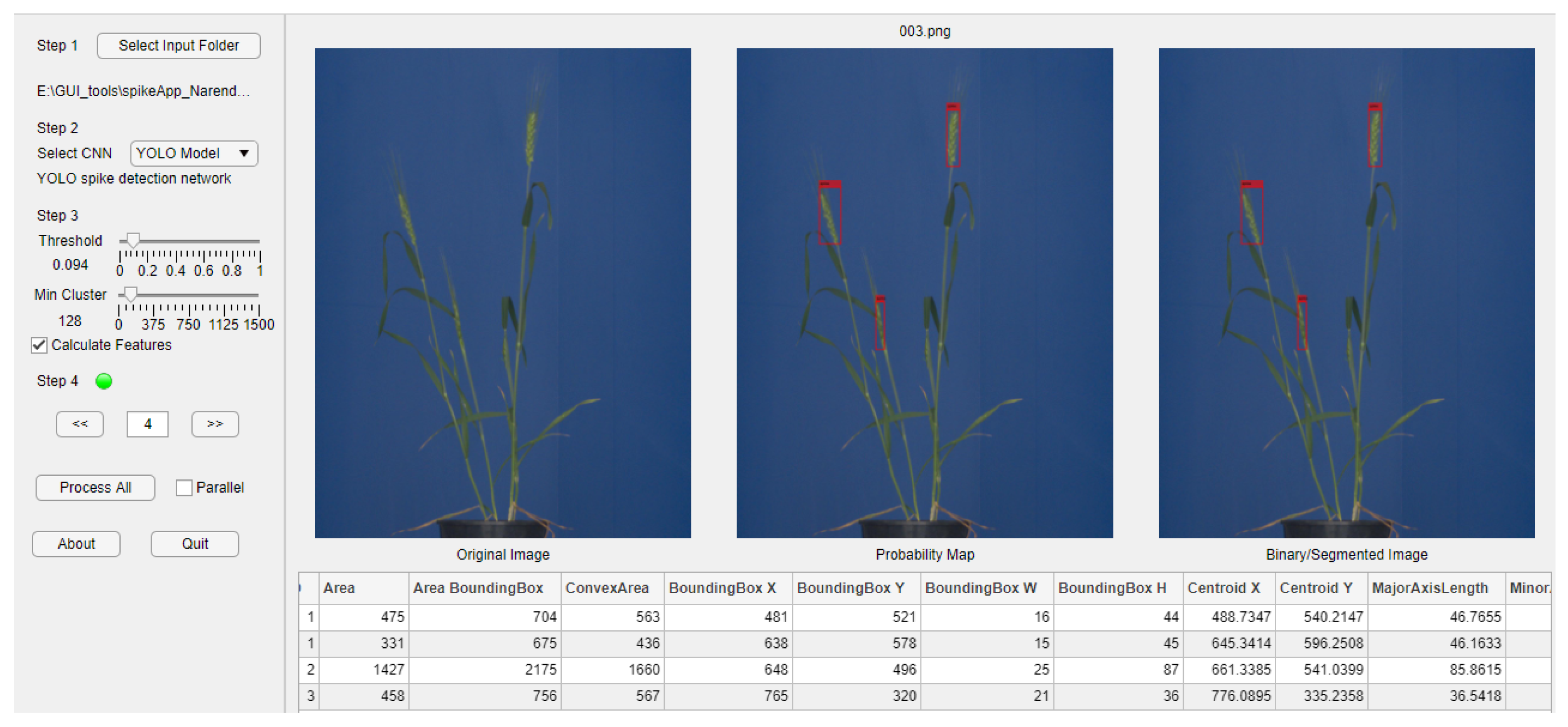
Our work provides comprehensive insights into the entire process of data preparation, model training, and evaluation, and addresses the central question what can be achieved with the above state-of-the-art NN methods, using a typically limited amount of manually annotated ground truth images in terms of accuracy and generalizability. In addition to the experimental investigations, we provide potential end users with a GUI-based tool (SpikeApp) that demonstrates the automated detection, segmentation and phenotyping of spikes in greenhouse-grown plants, using three pre-trained neural network models, including U-Net, YOLOv3 and shallow ANN.
4. Discussion
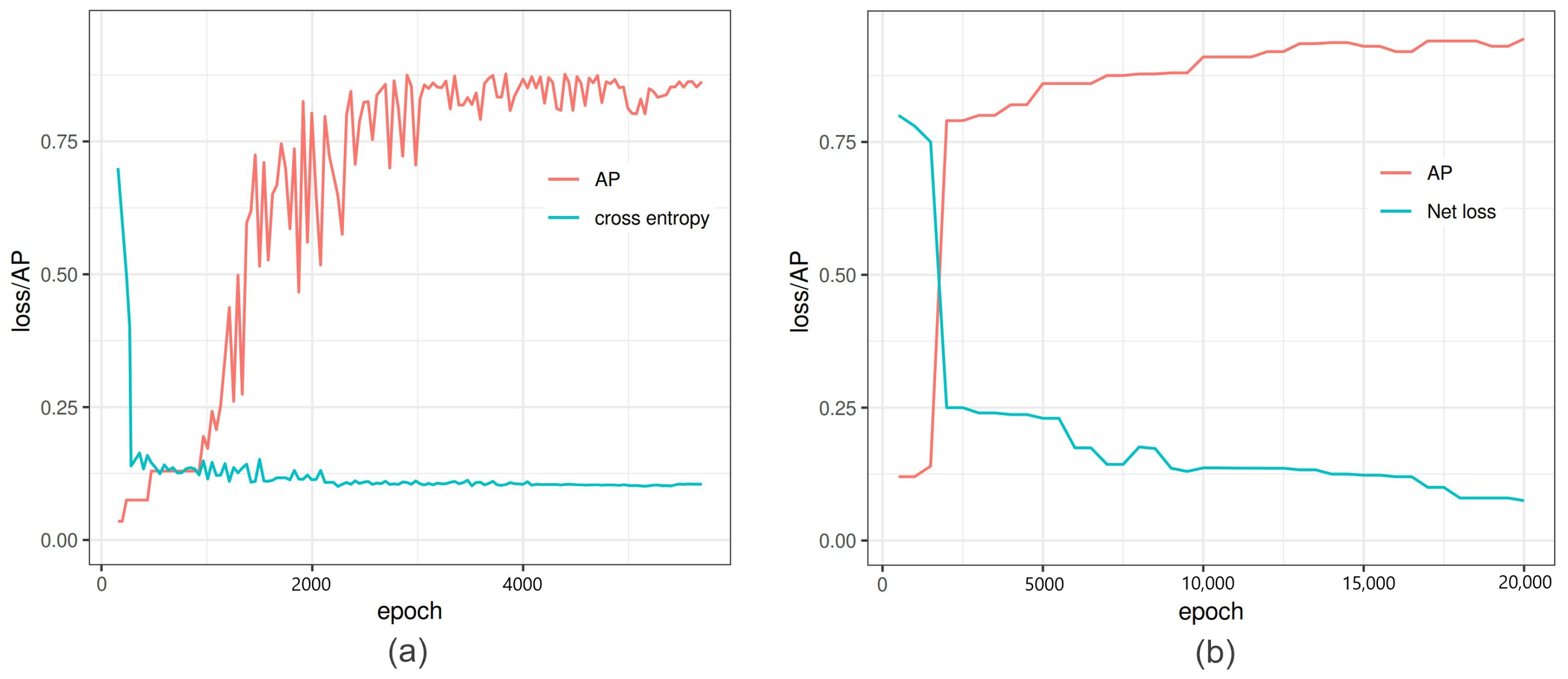
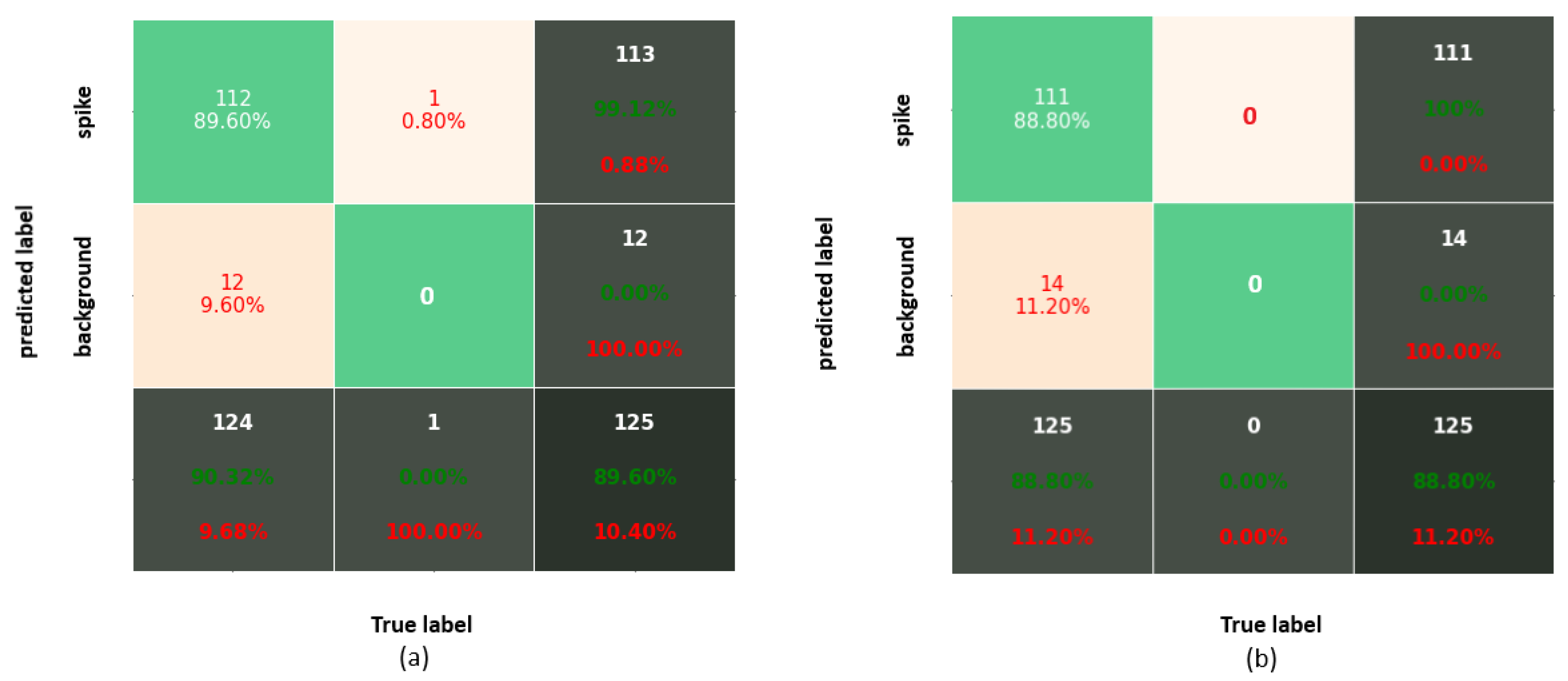
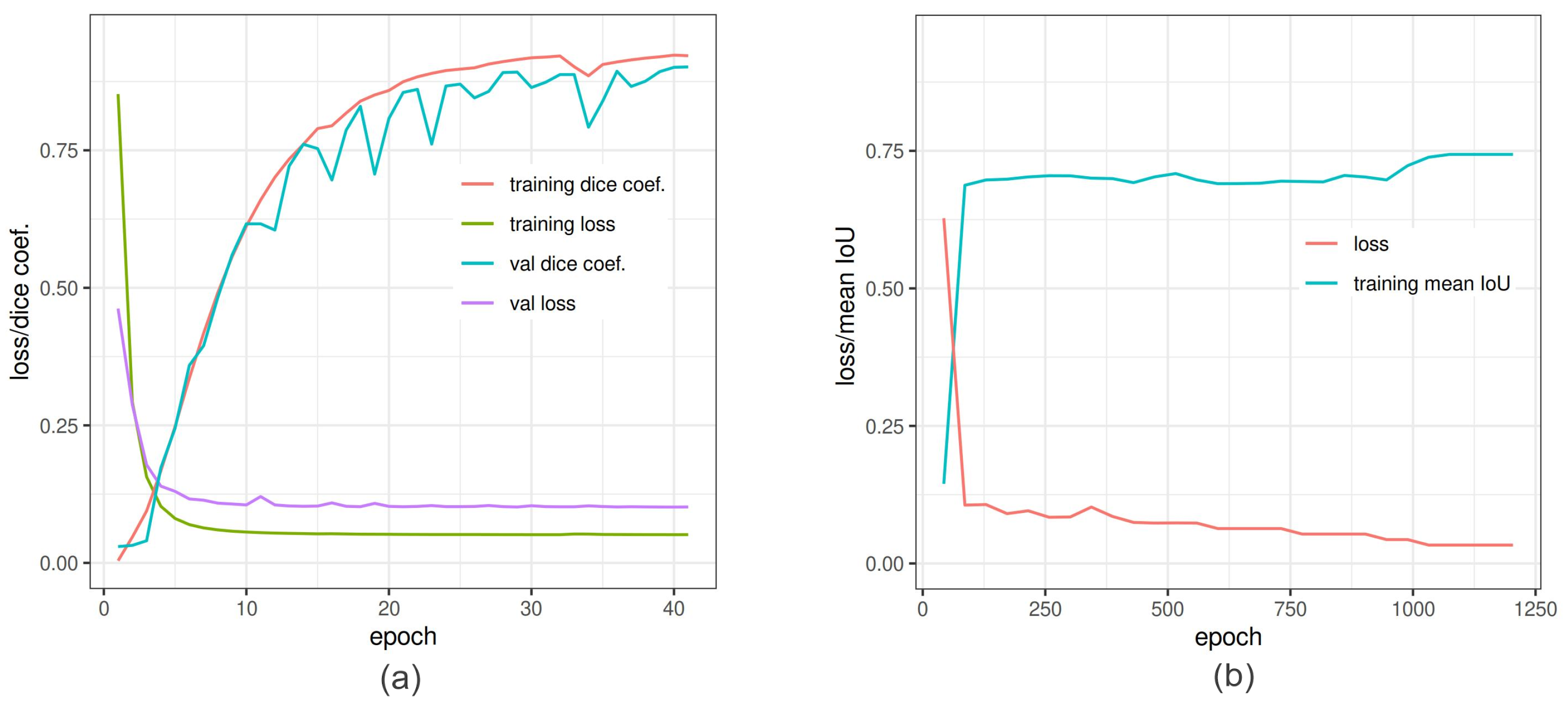
This study aimed to quantitatively compare the performance of different neural network models trained on a particular set of images for the detection and segmentation of grain spikes in visible light greenhouse images acquired from the same as well as different phenotyping facilities. Therefore, the following observations were made. The predictive power of trained detection models certainly depends on optical properties of spike patterns and their position within the plant. Occluded/emergent as well as inner spikes appearing in the middle of a mass of leaves, present a more challenging problem for DNN models, compared to matured top spikes that were predominantly used in this and also previous works for model training. On images of reduced resolution, the accuracy of the DNNs decreased because of the loss in textural and geometric information. In particular, the best performing detection DNNs (YOLOv3/v4 and Faster-RCNN) achieved higher accuracy on matured top spikes, while for the group of inner and occluded/emergent spikes, the performance of Faster-RCNN was reduced. The application of DNN models trained on a particular set of side view wheat images to another crop cultivars (barley and rye acquired from the same phenotyping facility was associated with a relatively moderate reduction in the accuracy of spike detection. For improved performance of DNNs detection, the inclusion of different spike phenotypes in the training set is generally desirable. On the other hand, spikes from the YSYC test set were detected with 100% accuracy despite the fact that they have similar colors as the remaining plant biomass. In barley and rye, the most inaccuracies resulted from occluding/overlapping spikes. This problem likely cannot be solved by expanding the feature pool and requires separate handling. In contrast to images acquired from the same screening facility, the performance of detection models on phenotypically quite distant crop cultivars imaged in another facility was considerable worse. Therefore, side view spikes could be detected slightly better than spikes in the top view; however, this is not surprising in view of the larger differences between the optical appearance of spikes from side and top views. As a general conclusion from the above tests, the consideration of a significantly larger amount of manually annotated images, including different spike phenotypes, appears to be required in order to significantly improve the generalizability of DNN model predictions. Additionally, appropriate augmentation of existing ground truth data can be expected to improve the model performance. In this regard, it is remarkable that YOLOv4, which has the built-in image augmentation methods of Random Erase, CutMix and MixUp, showed the most robust performance by detection of occluded/emergent spikes. Summarizing the results of the spike detection tests, SSD shows the poorest performance, due to the lack of downscale feature extraction in small objects, as also observed in another study [
31]. YOLOv4 deploys the feature extraction at three different scales, which improves spike detection compared to Faster-RCNN. In contrast to detection DNNs, segmentation models turned out to be more sensitive to phenotypic variations in plant and spike appearance. In previous works, conventional ANN approaches to spike segmentation were reported to achieve a relatively high accuracy of aDc > 0.95. However, in this study, the ANN framework from
Narisetti et al. exhibited a rather moderate accuracy of aDC=0.76. We traced the reduced accuracy of the ANN framework back to differences between image sets used in previous and our studies. With aDC of 0.906 and 0.935, both U-Net and DeepLabv3+ models clearly outperformed the shallow ANN model by a direct comparison on the same image set, and exhibited relatively high segmentation accuracy by evaluation on both side view wheat images. However, when applied to other crop cultivars, the performance dropped to more than half, compared to the training data set. This indicates that significantly more variable ground truth data are required to achieve a more robust performance of spike segmentation models. Future improvements of segmentation DNNs can include the introduction of more classes for annotation of different background structures (photo chamber, plant canopy), which may improve accuracy of spike detection, particularly in cases where spikes exhibit similar color and texture fingerprints as the background. To mitigate the performance drop of segmentation DNNs on boundary regions of spike in unseen data, the neural network should have a broad feature map to accommodate the fine texture in the edge as well as the central part of a spike. In recent studies, to make DNNs more robust, one improvement was the introduction of weighting each channel (attention) in several layers to emphasize more on the informative channel and scale relevant feature of the object [
34].
5. Conclusions
Our study showed that the performance of DNN models trained on a relatively modest set of ground truth images depends on the optical spike appearance (phenotype) as well as the spatial spike location within the plant in different crop cultivars. Detection DNNs showed an accurate and robust performance crossover of different crop cultivars, including wheat, barley and rye plants. From this observation, we conclude that DNNs trained on a particular set of plant images can, in general, be expected to show comparable performance by spike detection in other phenotypically similar crop cultivars. For the task of pixel-wise spike segmentation, DNN models, such as DeepLabv3+ and U-Net, showed superior performance compared to the conventional shallow ANN. Otherwise, segmentation DNNs showed accurate segmentation results only by application to images of the same cultivar phenotypes as in the training set. A particular challenge for DNN segmentation models seems to represent pixels on the spike boundary, as they exhibit particularly large variations in color and neighborhood properties, depending on the type of grain crops (e.g., grain with spikes emerging on the top of the plant vs. bushy plant phenotype; spike color, texture, size, shape); and scene illumination. From the results of this study, we conclude that a considerably larger set of different plant and spike phenotypes is required to achieve significantly more accurate segmentation of spikes. using DNN models. On the other hand, tested segmentation models (U-Net, DeepLabv3+) appear to be suitable for accurate spike segmentation in large image sets after training on a relatively modest amount of ground truth images. This constitutes them as being suitable tools, especially when processing large amounts of phenotypically similar images is the primary goal. In view of the limitations of different DNN methods, a combination of spike detection and segmentation approaches—in particular, YOLO and DeepLabv3+—appears to be a promising approach for improved analysis and phenotyping of spikes in images of different cereal crops. Finally, it should be stated that the above investigated neural network frameworks are principally not restricted to a particular task. Therefore, they can be expected to exhibit similar performance, advantages and shortcomings by application to the detection and segmentation of other plant structures.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}