A Comprehensive Machine-Learning-Based Software Pipeline to Classify EEG Signals: A Case Study on PNES vs. Control Subjects



 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Protocol and Dataset Description
2.2. EEG Acquisition
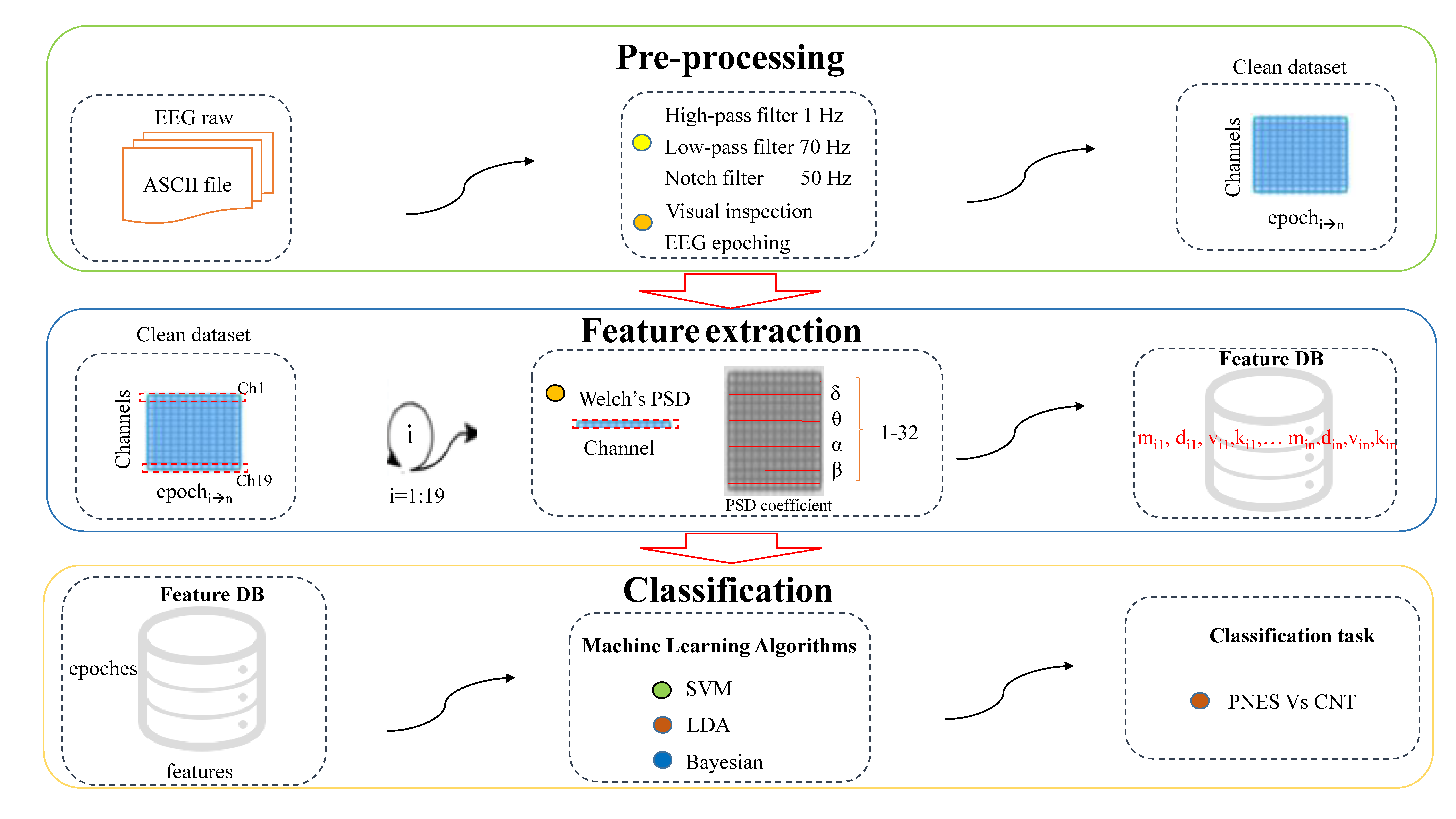
2.3. EEG Software Pipeline
- Artifact rejection: Artifactual EEGs were rejected through visual inspection. At this stage, to avoid imbalances, the dataset size was changed from 20 to 15 min.
- Signal filtering: EEG was high-pass filtered at 1 Hz and low-pass filtered at 70 Hz plus notch at 50 Hz.
- EEG epoching: The artifact-free epoch EEG recordings were segmented in nonoverlapping T = 5 s epochs.
- Power spectrum analysis: The spectral structure of a sliding window of length L = 5 s was extracted. We used the Welch method and sliding Hamming window with 50% overlap on 1280 samples for the segment.
- Feature extraction: The power spectral density (PSD) of the epochs was split into five submaps corresponding to the five main EEG sub-bands: delta (1–4 Hz), theta (4–8 Hz), alpha (8–13 Hz), beta (13–32 Hz), and the whole band (1–32 Hz). After that, given the PSD submap of the EEG band under analysis, four features were extracted: mean (m), standard deviation (d), skewness (v), and kurtosis (k). Hence, 5 (sub-bands) × 4 (features) = 20 PSD features were extracted for each EEG epoch.
- Dataset preparation: A stacked feature vector XT was the result of concatenating contiguous W feature vectors in nonoverlapping PSD sliding windows. Therefore µ, σ, v, and k extracted from four frequency sub-bands and µ, σ, k, and v of the whole PSD map were concatenated in XT. The feature vector output size for each subject was of 4 (features) × 5 (frequency bands) × 19 (electrodes) × 120 (epochs) = 45,600 elements.
- Classification algorithm: The framework implemented three different ML approaches, namely, SVM, BN, and LDA, in order to discriminate EEG time series of PNES patients from the CNT ones.
2.3.1. EEG Preprocessing
2.3.2. EEG Feature Extraction
2.3.3. EEG Feature Classification
Support Vector Machine
Bayesian Networks
Linear Discrimination Analysis
2.4. Use of Classifiers for the Discrimination between CNT and PNES
3. Results
4. Discussion and Conclusion
Author Contributions
Funding
Conflicts of Interest
References
- Bodde, N.M.G.; Brooks, J.L.; Baker, G.A.; Boon, P.A.J.M.; Hendriksen, J.G.M.; Mulder, O.G.; Aldenkamp, A.P. Psychogenic non-epileptic seizures: Definition, etiology, treatment and prognostic issues: A critical review. Seizure 2009, 8, 543–553. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cianci, V.; Ferlazzo, E.; Condino, F.; Mauvais, H.S.; Farnarier, G.; Labate, A.; Latella, M.A.; Gasparini, S.; Branca, D.; Pucci, F.; et al. Rating scale for psychogenic nonepileptic seizures: Scale development and clinimetric testing. Epilepsy Behav. 2011, 21, 128–131. [Google Scholar] [CrossRef]
- Baslet, G.; Roiko, A.; Prensky, E. Heterogeneity in psychogenic nonepileptic seizures: Understanding the role of psychiatric and neurological factors. Epilepsy Behav. 2010, 17, 236–241. [Google Scholar] [CrossRef]
- Uliaszek, A.A.; Prensky, E.; Baslet, G. Emotion regulation profiles in psychogenic non-epileptic seizures. Epilepsy Behav. 2012, 23, 364–369. [Google Scholar] [CrossRef]
- Leis, A.A.; Ross, M.A.; Summers, A.K. Psychogenic seizures: Ictal characteristics and diagnostic pitfalls. Neurology 1992, 42, 95–99. [Google Scholar] [CrossRef] [PubMed]
- Perez, D.L.; LaFrance, W.C., Jr. Nonepileptic seizures: An updated review. CNS Spectr. 2016, 21, 239–246. [Google Scholar] [CrossRef] [Green Version]
- Martin, R.; Burneo, J.G.; Prasad, A.; Powell, T.; Faught, E.; Knowlton, R.; Mendez, M.; Kuzniecky, R. Frequency of epilepsy in patients with psychogenic seizures monitored by video-EEG. Neurology 2003, 61, 1791–1792. [Google Scholar] [CrossRef] [PubMed]
- Sigurdardottir, K.R.; Olafsson, E. Incidence of psychogenic seizures in adults: A Population-Based study in Iceland. Epilepsia 1998, 39, 749–752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LaFrance, W.C., Jr.; Benbadis, S.R. Avoiding the costs of unrecognized psychological nonepileptic seizures. Neurology 2006, 66, 1620–1621. [Google Scholar] [CrossRef] [PubMed]
- Gasparini, S.; Beghi, E.; Ferlazzo, E.; Beghi, M.; Belcastro, V.; Biermann, K.P.; Bottini, G.; Capovilla, G.; Cervellione, R.A.; Cianci, V.; et al. Management of psychogenic non-epileptic seizures: A multidisciplinary approach. Eur. J. Neurol. 2019, 26, 205-e15. [Google Scholar] [CrossRef] [PubMed]
- Benbadis, S.R. Nonepileptic behavioral disorders: Diagnosis and treatment. Continuum (Minneap Minn) 2013, 19, 715–729. [Google Scholar] [CrossRef] [PubMed]
- Subasi, A.; Kevric, J.; Abdullah Canbaz, M. Epileptic seizure detection using hybrid machine learning methods. Neural. Comput. Applic. 2019, 31, 317–325. [Google Scholar]
- Cooper, G.F.; Herskovits, E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Subasi, A.; Kiymik, M.K.; Alkan, A.; Kokluukaya, E. Neural network classification of EEG signals by using AR with MLE preprocessing for epileptic seizure detection. Math. Comput. Appl. 2005, 10, 57–70. [Google Scholar]
- Gasparini, S.; Campolo, M.; Ieracitano, C.; Mammone, N.; Ferlazzo, E.; Sueri, C.; Tripodi, G.G.; Aguglia, U.; Morabito, F.C. Information Theoretic-Based Interpretation of a Deep Neural Network Approach in Diagnosing Psychogenic Non-Epileptic Seizures. Entropy 2018, 20, 43–54. [Google Scholar] [CrossRef] [Green Version]
- Faust, O.; Acharya, R.U.; Allen, A.R.; Lin, C.M. Analysis of EEG signals during epileptic and alcoholic states using AR modeling techniques. IRBM 2008, 29, 44–52. [Google Scholar] [CrossRef]
- Morabito, F.C.; Campolo, M.; Mammone, N.; Versaci, M.; Franceschetti, S.; Tagliavini, F.V.; Sofia, D.; Fatuzzo, A.; Gambardella, A.; Labate, L.; et al. Deep learning representation from electroencephalography of early-stage Creutzfeldt-Jakob disease and features for differentiation from rapidly progressive dementia. Int. J. Neural Syst. 2017, 27, 1650039. [Google Scholar] [CrossRef] [PubMed]
- Ieracitano, C.; Mammone, N.; Barmanti, A.; Morabito, F.C. A convolutional neural network approach for classification of dementia stages based on 2d-spectral representation of EEG recordings. Neurocomputing 2019, 323, 96–107. [Google Scholar] [CrossRef]
- Shoka, A.; Dessouky, M.; El-Sherbeny, A.; El-Sayed, A. Literature Review on EEG Preprocessing, Feature Extraction, and Classifications Techniques. Menoufia J. Electron. Eng. Res. 2019, 28, 292–299. [Google Scholar] [CrossRef]
- Meyer, D.; Leisch, F.; Hornik, K. The support vector machine under 791 test. Neurocomputing 2003, 55, 169–186. [Google Scholar] [CrossRef]
- Bishop, C. Bayesian Tchniques in Neural Networks for Pattern Recognition, 1st ed.; Oxford University Press: New York, NY, USA, 1995; pp. 385–439. [Google Scholar]
- Cherkassky, V.S.; Mulier, F. Methods for data reduction and Dimensionality Reduction. In Learning from Data: Concepts, Theory, and Methods, 2nd ed.; IEEE Press: Hoboken, NJ, USA, 2007. [Google Scholar]



{kind=link}
{kind=link}
| Class | SVM Classifier (LOO) | ||
| Precision | Recall | F1 score | |
| CNT | 1.00 | 0.98 | 0.99 |
| PNES | 0.98 | 1.00 | 0.99 |
| Class | LDA Classifier (LOO) | ||
| Precision | Recall | F1 score | |
| CNT | 1.00 | 0.98 | 0.99 |
| PNES | 0.98 | 1.00 | 0.99 |
| Class | NB Classifier (LOO) | ||
| Precision | Recall | F1 score | |
| CNT | 0.87 | 0.75 | 0.81 |
| PNES | 0.78 | 0.89 | 0.83 |
| Class | SVM Classifier (Random Split) | ||
| Precision | Recall | F1 score | |
| CNT | 0.95 | 0.99 | 0.97 |
| PNES | 0.99 | 0.95 | 0.97 |
| Class | LDA Classifier (Random Split) | ||
| Precision | Recall | F1 score | |
| CNT | 1.00 | 1.00 | 1.00 |
| PNES | 1.00 | 1.00 | 1.00 |
| Class | NB Classifier (Random Split) | ||
| Precision | Recall | F1 score | |
| CNT | 0.89 | 0.76 | 0.82 |
| PNES | 0.78 | 0.90 | 0.83 |
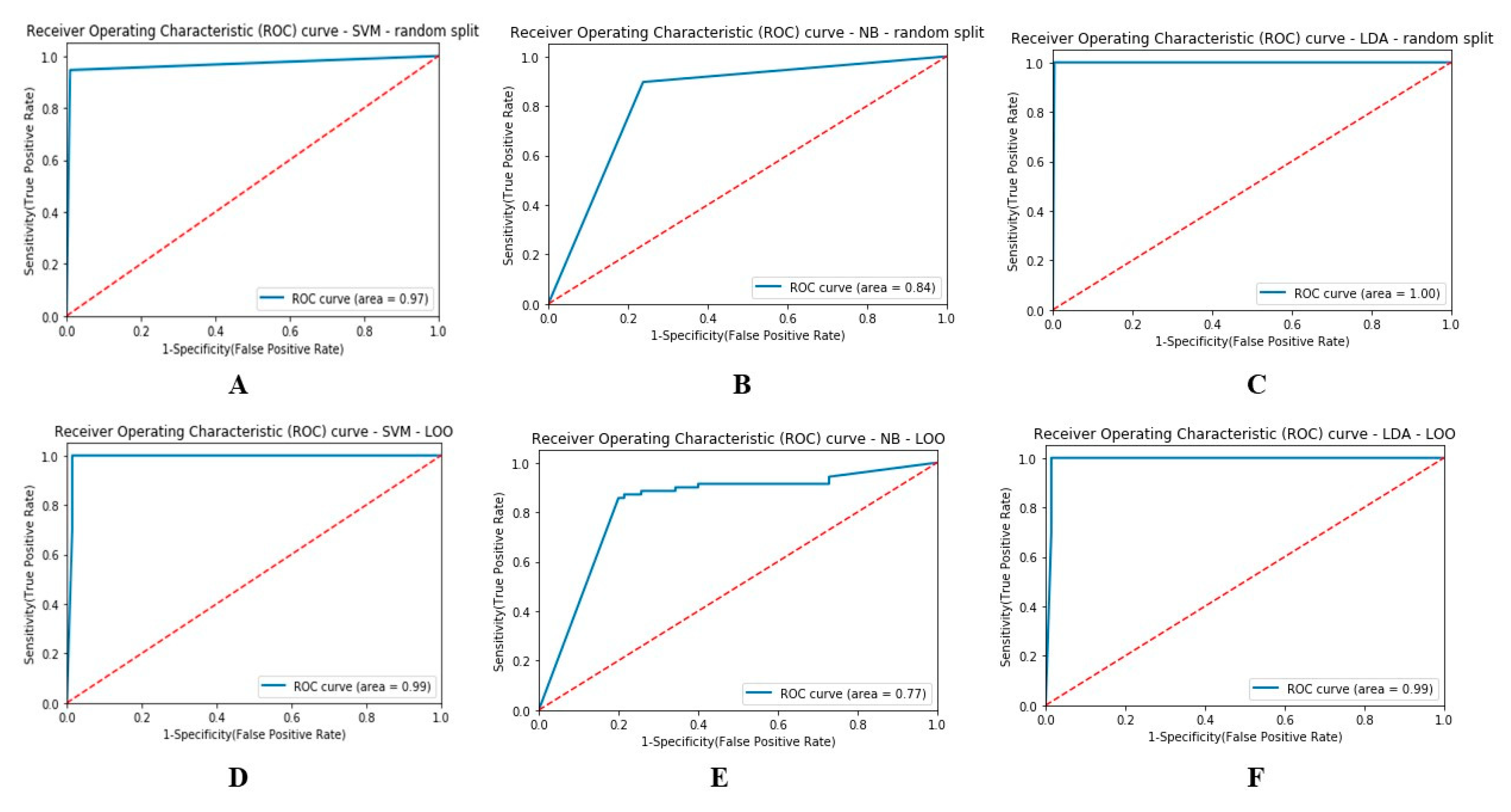
| Classifier | Random Split Evaluation | ||
| Accuracy (ACC) | Precision (PR) | Recall (RC) | |
| SVM | 0.97 ± 0.013 | 0.95 ± 0.03 | 0.99 ± 0.001 |
| LDA | 0.99 ± 0.02 | 0.99 ± 0.30 | 0.99 ± 0.053 |
| NB | 0.82 ± 0.109 | 0.83 ± 0.027 | 0.87 ± 0.163 |
| Classifier | LOO Evaluation | ||
| Accuracy | Precision | Recall | |
| SVM | 0.98 ± 0.0233 | 0.98 ± 0.061 | 0.98 ± 0.126 |
| LDA | 0.98 ± 0.124 | 0.98 ± 0.012 | 0.98 ± 0.002 |
| NB | 0.81 ± 0.109 | 0.81 ± 0.032 | 0.81 ± 0.142 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varone, G.; Gasparini, S.; Ferlazzo, E.; Ascoli, M.; Tripodi, G.G.; Zucco, C.; Calabrese, B.; Cannataro, M.; Aguglia, U. A Comprehensive Machine-Learning-Based Software Pipeline to Classify EEG Signals: A Case Study on PNES vs. Control Subjects. Sensors 2020, 20, 1235. https://doi.org/10.3390/s20041235
Varone G, Gasparini S, Ferlazzo E, Ascoli M, Tripodi GG, Zucco C, Calabrese B, Cannataro M, Aguglia U. A Comprehensive Machine-Learning-Based Software Pipeline to Classify EEG Signals: A Case Study on PNES vs. Control Subjects. Sensors. 2020; 20(4):1235. https://doi.org/10.3390/s20041235
Chicago/Turabian StyleVarone, Giuseppe, Sara Gasparini, Edoardo Ferlazzo, Michele Ascoli, Giovanbattista Gaspare Tripodi, Chiara Zucco, Barbara Calabrese, Mario Cannataro, and Umberto Aguglia. 2020. "A Comprehensive Machine-Learning-Based Software Pipeline to Classify EEG Signals: A Case Study on PNES vs. Control Subjects" Sensors 20, no. 4: 1235. https://doi.org/10.3390/s20041235