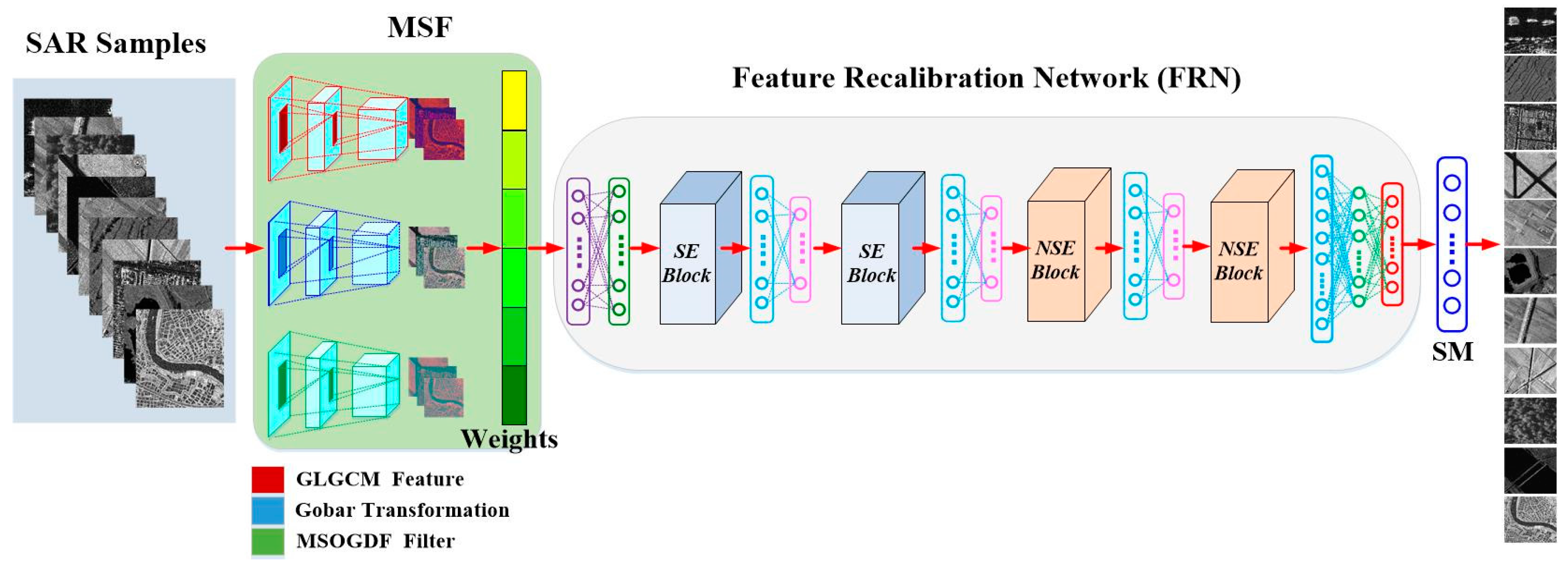
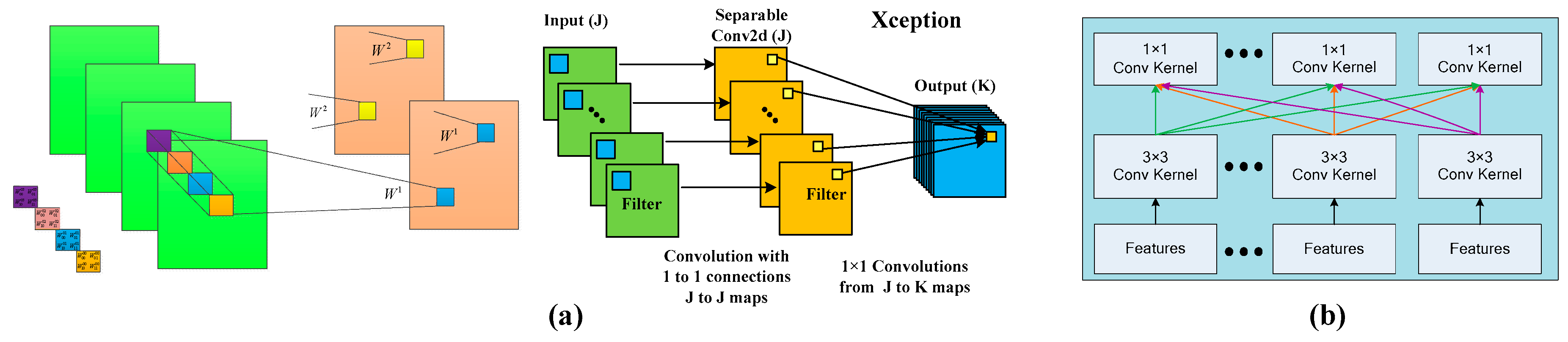
4.3.1. Multi-Scale Feature Extraction and Fusion
In this paper, three feature extraction methods were used, including GLGCM, Gabor transformation and MSOGDF. For a SAR scene, we could compute 15 digital feature maps by GLGCM. After analyzing the effects of texture features for the 11 types of scene, the correlation and inertia features were selected.
The correlation and inertia GLGCM features were further combined as a fused feature for SAR scene classification. The correlation describes the grayscale similarity between rows and columns in a matrix, which is a measure of the relationship between gray level and gray gradient in GLGCM. The greater the similarity, the higher the correlation coefficient is. While the inertia reflects the smoothness of the texture. The coarser the texture is, the smaller the inertia value is. Fusing the two features together with SAR image by concatenation [
52], we could obtain the enhanced texture feature, as depicted in
Figure 6.
The Gabor function is like the biological function of the human eye, which is frequently used to recognize a texture and achieves good results. Through the analysis for four angles of feature extraction with Gabor transformation in the experiments, we found that the 45° and 135° transformation features were clearer. We could get the fusion map in
Figure 7 after fusing the 45° and 135° features together. From which, we could see much better local texture features, especially the edge information. It is much more useful for us to classify the different types of scene.
According to Equation (10), we analyzed the feature effects of the different directions for by 30° spacing with the scale of is 1 or 2 respectively. Finally, we selected three directions (45°, 90° and 135°) with two scales (), considering the characteristic of the targets in different directions and the demand of the three channels in the concatenation method. Therefore, we could generate the six features of a SAR image.
MSOGDF can extract multi-directional gray-scale change information, which is frequently applied to identify edges and corners. It can capture detailed spatial information with different directions in the image. Thus, it is widely employed to classify various objects [
44].
Figure 8 delineates the fusion map of two feature maps of MSOGDF in 90° direction with scale
and
. The fusion map presents more detailed information about targets.
4.3.2. Performance Assessment
(1) Feature Fusion Method
In this paper, we use three methods to extract different features of the targets: GLGCM, Gabor and MSOGDF. For GLGCM, we fused the correlation and inertia feature maps with the SAR image into a three-channel matrix as the output. As Gabor transformation is concerned, we combined the feature maps of 45° and 135° with the SAR image into a new three-channel feature map. For MSOGDF, we select three directions, namely 45°, 90°and 135°. For each direction, we chose two observation scales, and . The feature maps were grouped by angle, within each group two different scale feature maps were integrated to form a three-channel matrix as the new feature map.
For MSOGDF, the three groups of fusion features were separately experimented for classification with the proposed algorithm. From
Table 3, we find that the 45° group presented the best classification results. Therefore, we selected this group as the input for further analysis.
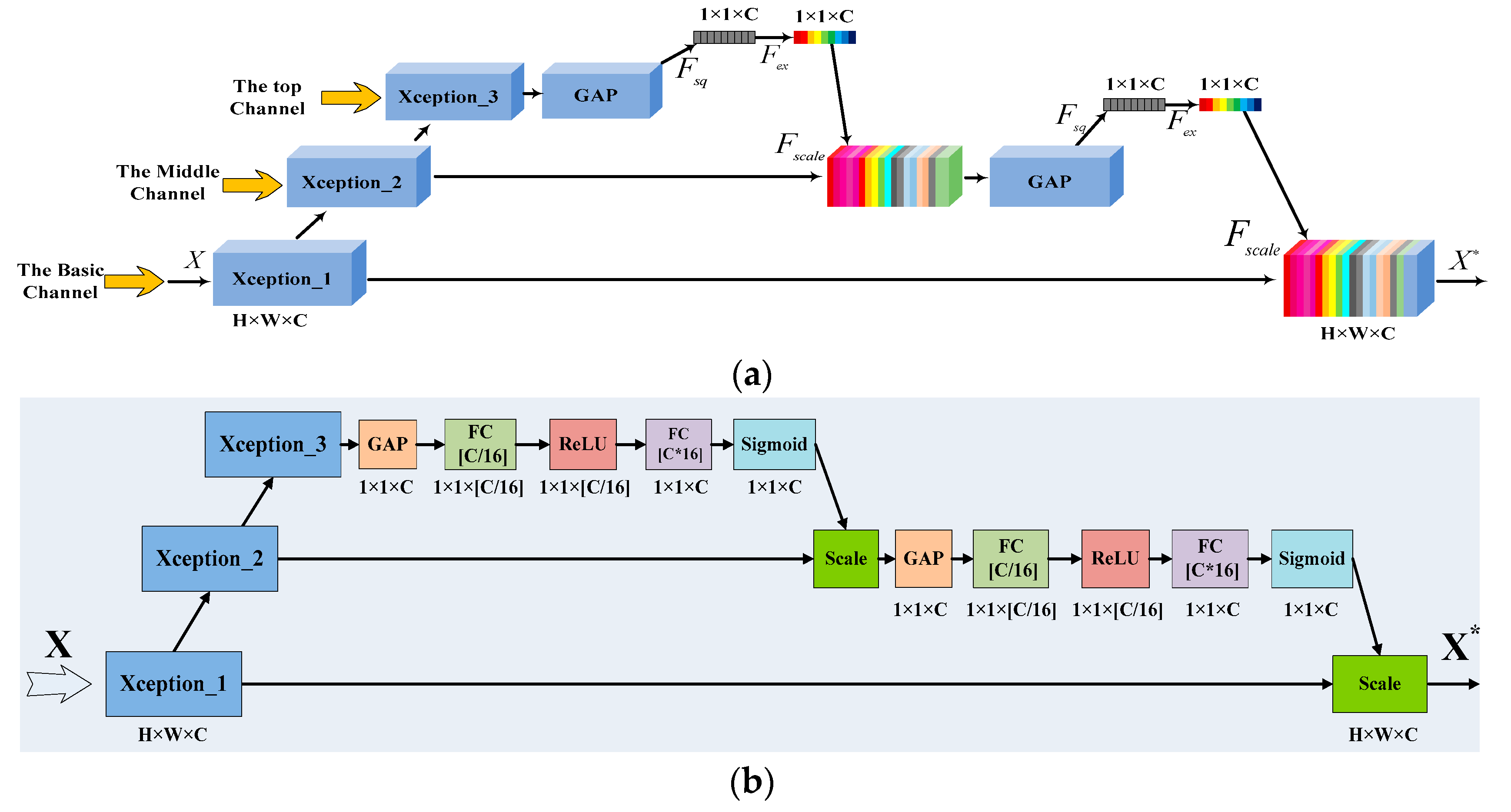
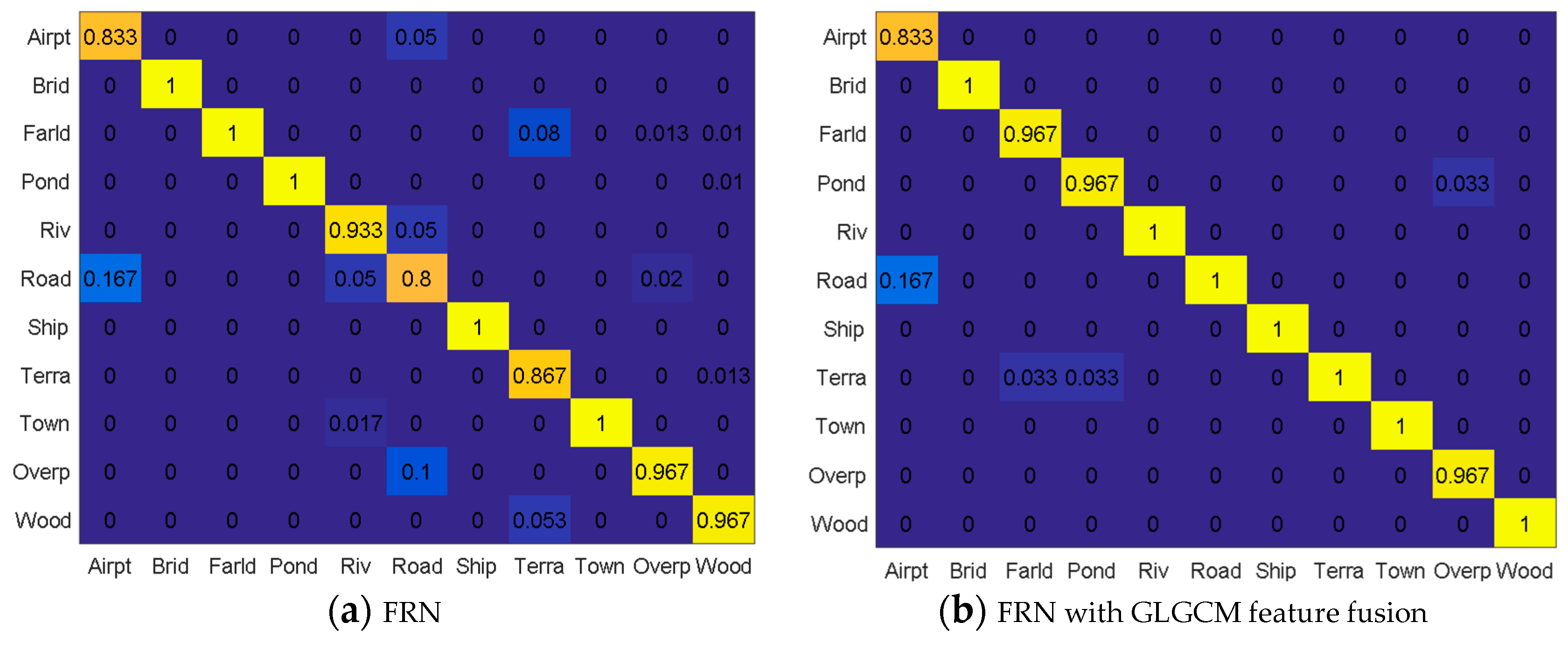
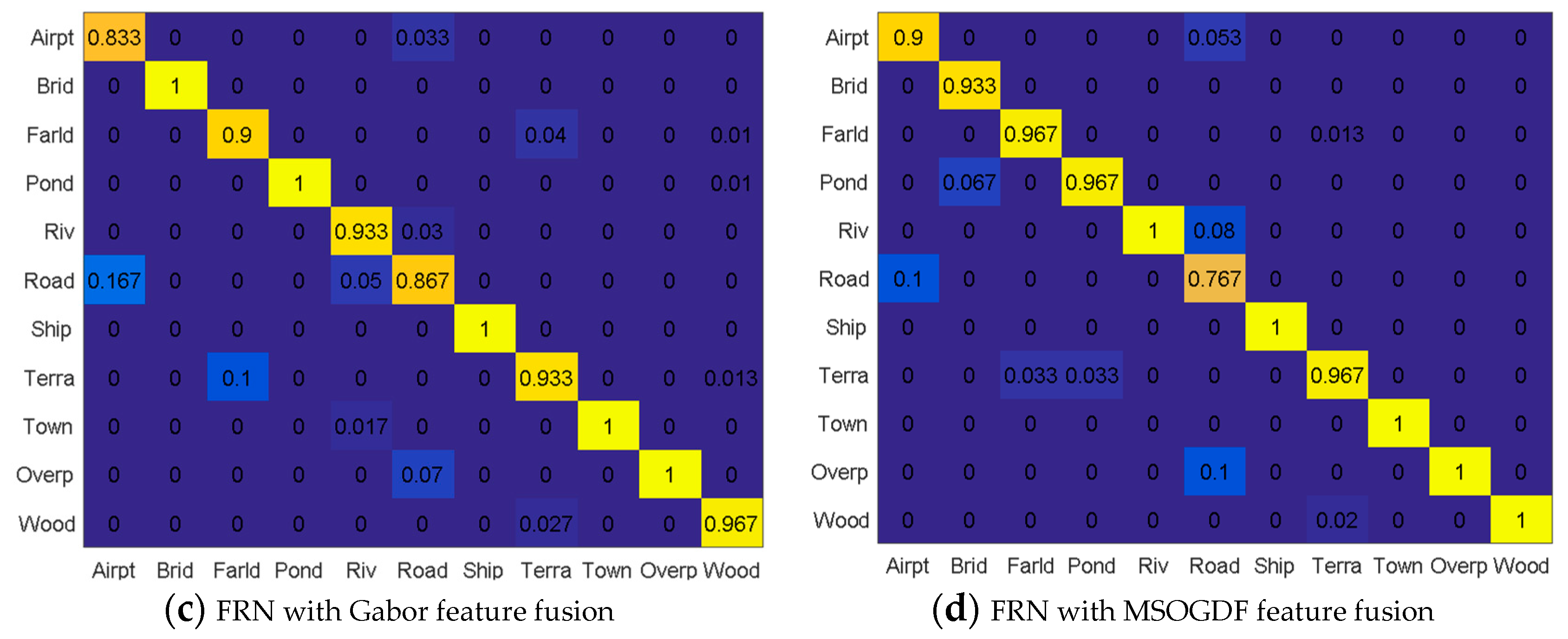
Four classification methods were tested based on the fused feature maps. They are FRN without feature extraction, FRN with the GLGCM feature, FRN with the Gabor feature, and FRN with the MSOGDF feature. The confusion matrices are shown in
Figure 9. The abscissa axis shows the real 11 types of scene, while the ordinate shows the classified results of the 11 types. Compared with the standard FRN method, the remaining three methods presented better classification accuracy.
From the FRN confusion matrix, we found that the classification accuracies of bridge, farmland, pond, ship and town were all 100%, because their features are relatively distinctive. While for the airport scene, 16.7% of the samples were classified as road due to their high similarity, which is illustrated in
Figure 10c. For the river scene, there were 5% and 1.7% misclassifications as road and town, respectively. Possible reasons include the river might be embedded in a town, or the small river is very straight like a road, as samples depicted in
Figure 10a. For the road scene, there were 10%, 5% and 5% misclassifications as overpass, airport and river. It might be because the road looks like a straight small river or overpass, or the road locates in the airport, such as the samples in
Figure 10a,c,d. For the terraced field scene, there were 8% and 5.3% misclassifications as farmland and woods, because of their similar texture delineated in
Figure 10b. For the overpass scene, there were 2% and 1.3% misclassifications as farmland and road; while the woods scene results in 1.3%, 1% and 1% misclassification as terraced field, farmland and pond, as shown in
Figure 10b.
Compared with the FRN algorithm, the FRN with GLGCM feature fusion method improved the accuracies of river, road, terraced field and woods to 100% in our case study, which verifies the advantage of GLGCM considering the local gray level and gray gradient, which provides a better way to encode a scenes’ texture. However, we find the accuracies of farmland and pond were both reduced by 3.3%. They were misclassified as terraced field, and GLGCM feature maps of some farmland and pond samples are quite like features of terraced field samples. According to
Figure 9c, the accuracies of road, terraced field and overpass increased by 6.7%, 6.6% and 3.3%, respectively, compared to FRN, but the accuracy of farmland decreased by 10%. After the MSOGDF feature fusion, the accuracies of airport, river, terraced field, overpass and woods were improved by 6.7%, 6.7%, 10%, 3.3% and 3.3% compared with FRN. However, the accuracies of bridge, farmland, pond and road decreased by 6.7%, 3.3%, 3.3% and 3.3%, respectively.
From the above analysis, we conclude that the proposed framework using three methods of feature extraction and fusion are not suitable for every scene. Therefore, we should select an optimal method for different scenes according to the confusion matrix in
Figure 9. The selected feature extraction methods for the 11 types of scene from Gabor, GLGCM, MSOGDF are presented in
Table 4. In this table, 1 denotes the feature is selected for the scene classification, and 0 denotes the opposite. For the airport, the MSOGDF feature was selected, since it is the only feature that could improve the classification according to the experiment performance. For the bridge classification, Gabor and GLGCM features were selected with an identical weight, because the MSOGDF feature will increase the risk of misclassification into ponds. For the farmland, none of the features were selected, because they will all reduce the classification accuracy at least by 3.3%. For the pond, the Gabor feature was selected. For the river, the GLGCM feature and MSOGDF outperform. For the road, we prefer the GLGCM feature. Ships are very distinctive thus we do not need to employ feature extraction and fusion. For the terraced field, the GLGCM feature was the best. According to
Figure 9, we found that the town’s classification accuracies were all 100% in the four confusion matrices, but there were some river samples which were misclassified as town samples, as show in
Figure 9a,c. Therefore, GLGCM feature and MSOGDF features were selected for the town. For the overpass, Gabor and MSOGDF features were chosen. For the woods, GLGCM and MSOGDF features were adopted.
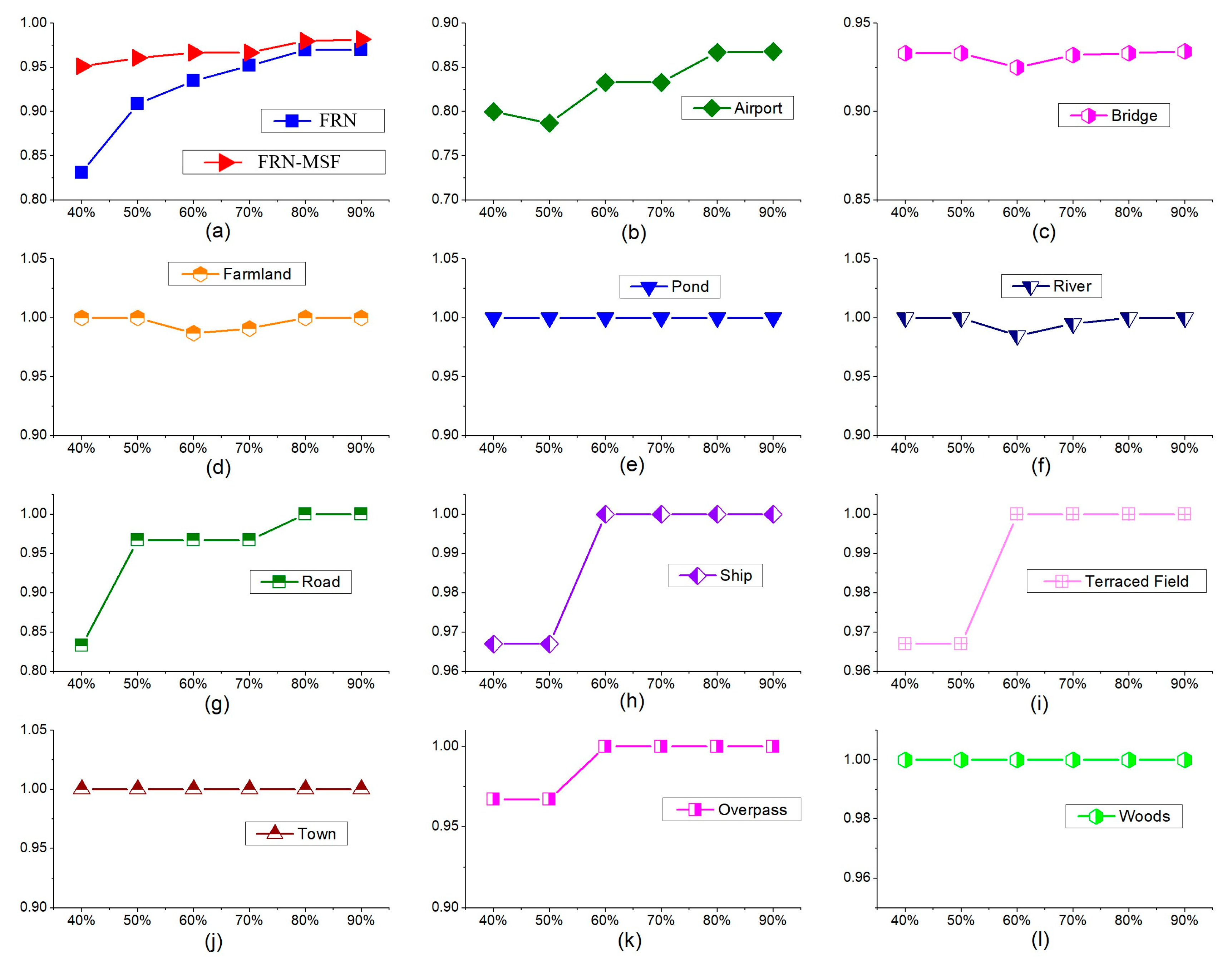
Using the features fusion method in
Table 4 and the proposed framework FRN, the final classified accuracies for the 11 types are shown in
Figure 11b.
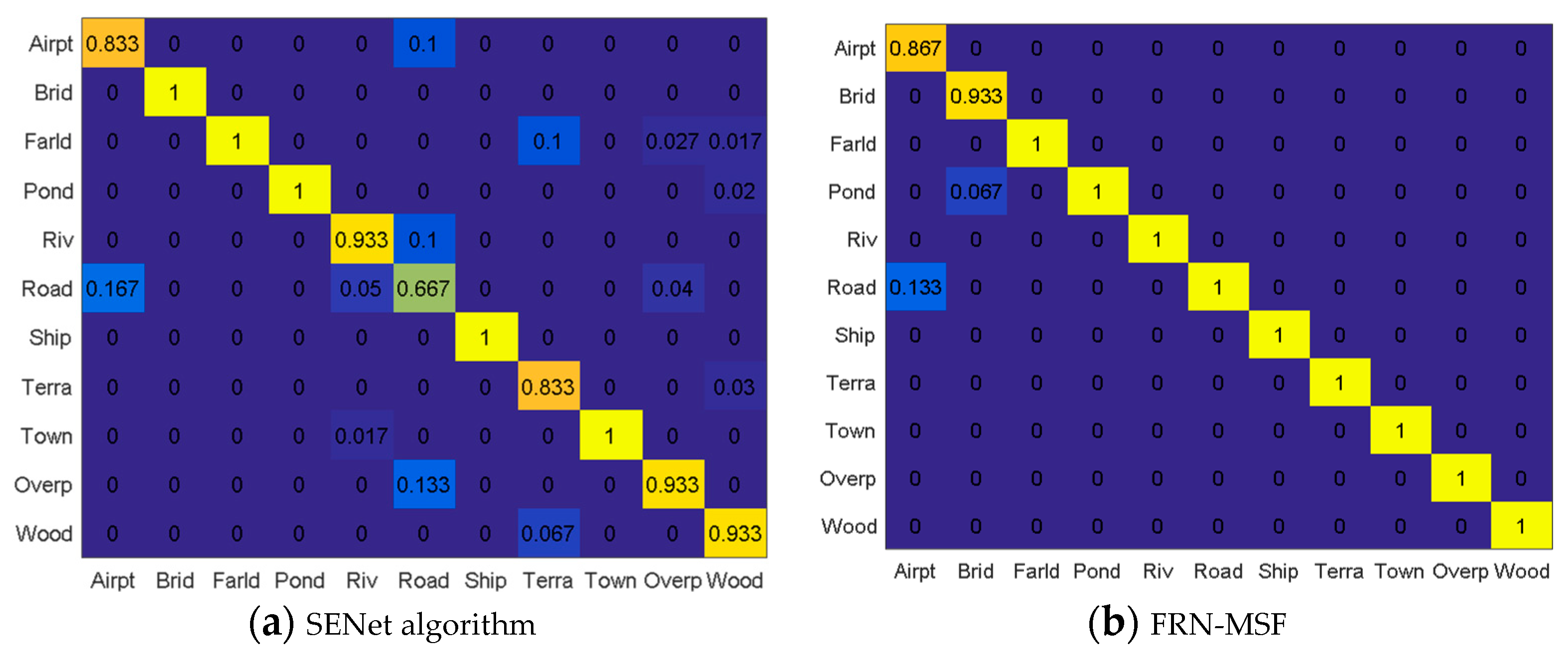
Figure 11a lists the classified accuracy by using the SENet algorithm [
36] without feature fusion, which achieved a better scene classification result than many new deep learning networks, such as ResNet-200 [
53], Inception-V4 [
54], ResNetXt-101 [
55], DenseNet-264 [
56] and PyramidNet-200 [
57].
Compared with the SENet algorithm, the classification accuracy of the proposed framework outperformed. Our framework achieved 100% accuracy in 9 types of scene, and the accuracy of airport was improved by 3.4% as well. Only the accuracy of bridge was reduced by 6.7%. It is likely our fused features make some bridges samples more like pond samples. According to the classification results of FRN-MSF, some airport samples were classified as road.
Table 5 gives the classification Mean Accuracy (MA) of different algorithms. FRN-Gabor denotes the FRN with Gabor feature, FRN-GLGCM means the FRN with GLGCM features, FRN-MSOGDF stands for FRN with MSOGDF features, and FRN-MSF is the proposed framework, which is FRN with multi-scale spatial statistical features. From
Table 5 we can see that the proposed framework has achieved the best accuracy, which was improved by 6.07% in the whole compared with the SENet algorithm.
4.3.4. Generalization
To further validate the generalization ability of the proposed framework, we selected the two unused SAR images, Foshan SAR image from TerraSAR-X and an airport image (Carstensen airport) from Gaofen-3, which are shown in
Figure 13. We designated five types of scene in total, which were river, town, bridge, airport and woods. Some of the samples are shown in
Figure 13b,d. For each type, we collected 200 samples. Then, we use the model trained by the proposed framework to classify the 1000 samples for the five types.
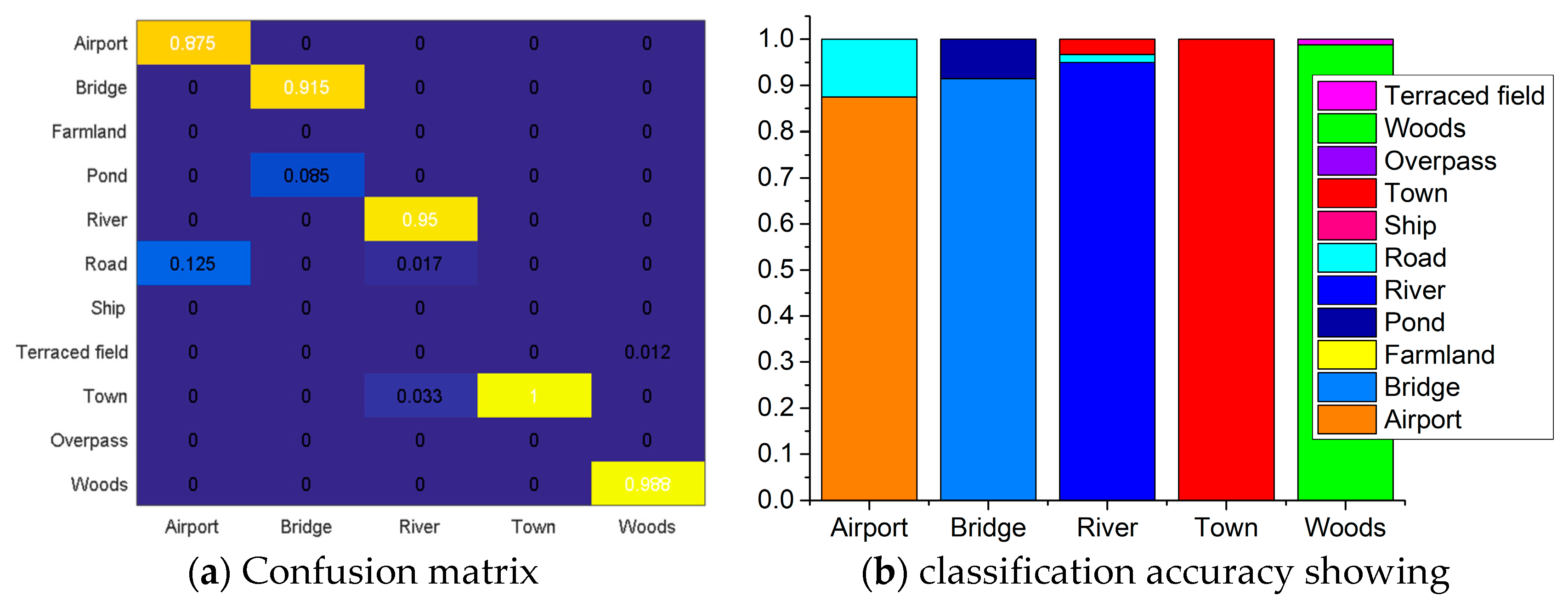
Figure 14 delineates classification results for the five types of scene. From the figure, we found that the classification accuracy for the airport was 87.5%, and the remaining 12.5% was classified as road. For the bridge, the achieved accuracy is 91.5%, with 8.5% pond misclassification. The classification accuracy of rivers reached 95%, and the remaining 3.3% and 1.7% were classified as town and road, respectively. Fortunately, samples of town were all classified correctly, and 98.8% of the wood’s samples were classified correctly. The mean classification accuracy of the five types of scene was 94.56%, which was a little lower than the tested accuracy of 98.18% with the 11 types of scene in
Table 6. When we recalculated the tested accuracy for the same five types of scene using the classification results in
Figure 11b, we got a mean accuracy of 96%. Because the airport and bridge scenes are more challenging than the other types. Therefore, the mean classification accuracy of the validation data was 1.44% lower than the tested data, which is negligible considering the size of data. Consequently, the proposed framework FRN-MSF presented an excellent generalization ability for SAR scenes classification.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}