
Normalized Metadata Generation for Human Retrieval Using Multiple Video Surveillance Cameras


Abstract
:
1. Introduction
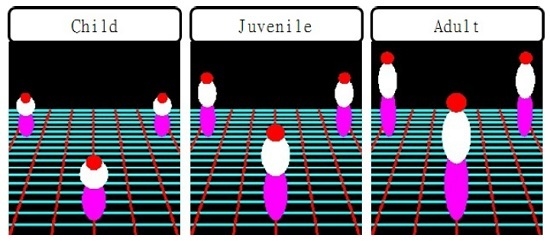
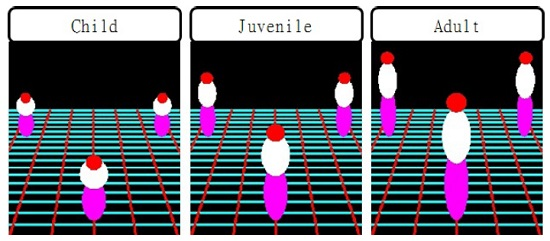
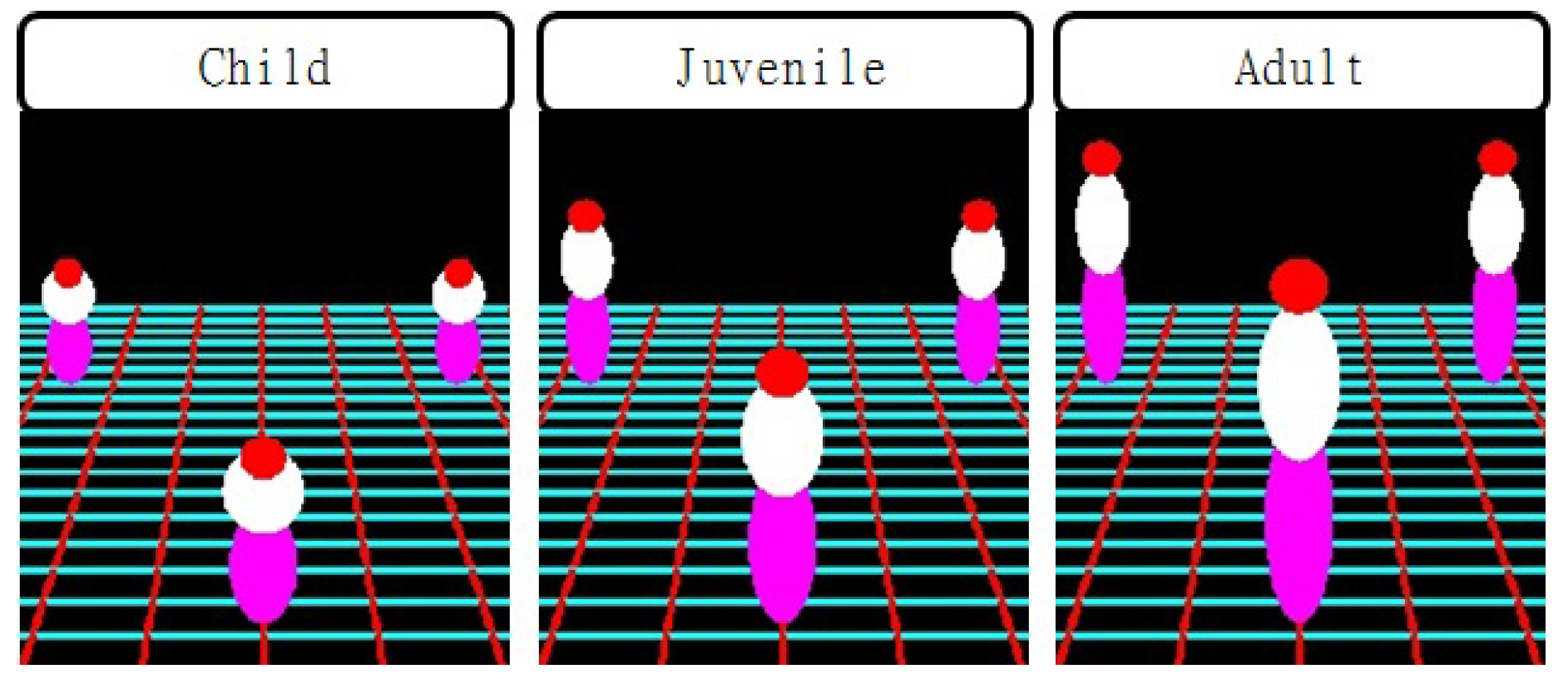
2. Modeling Human Body Using Three Ellipsoids
3. Human Model-Based Automatic Scene Calibration
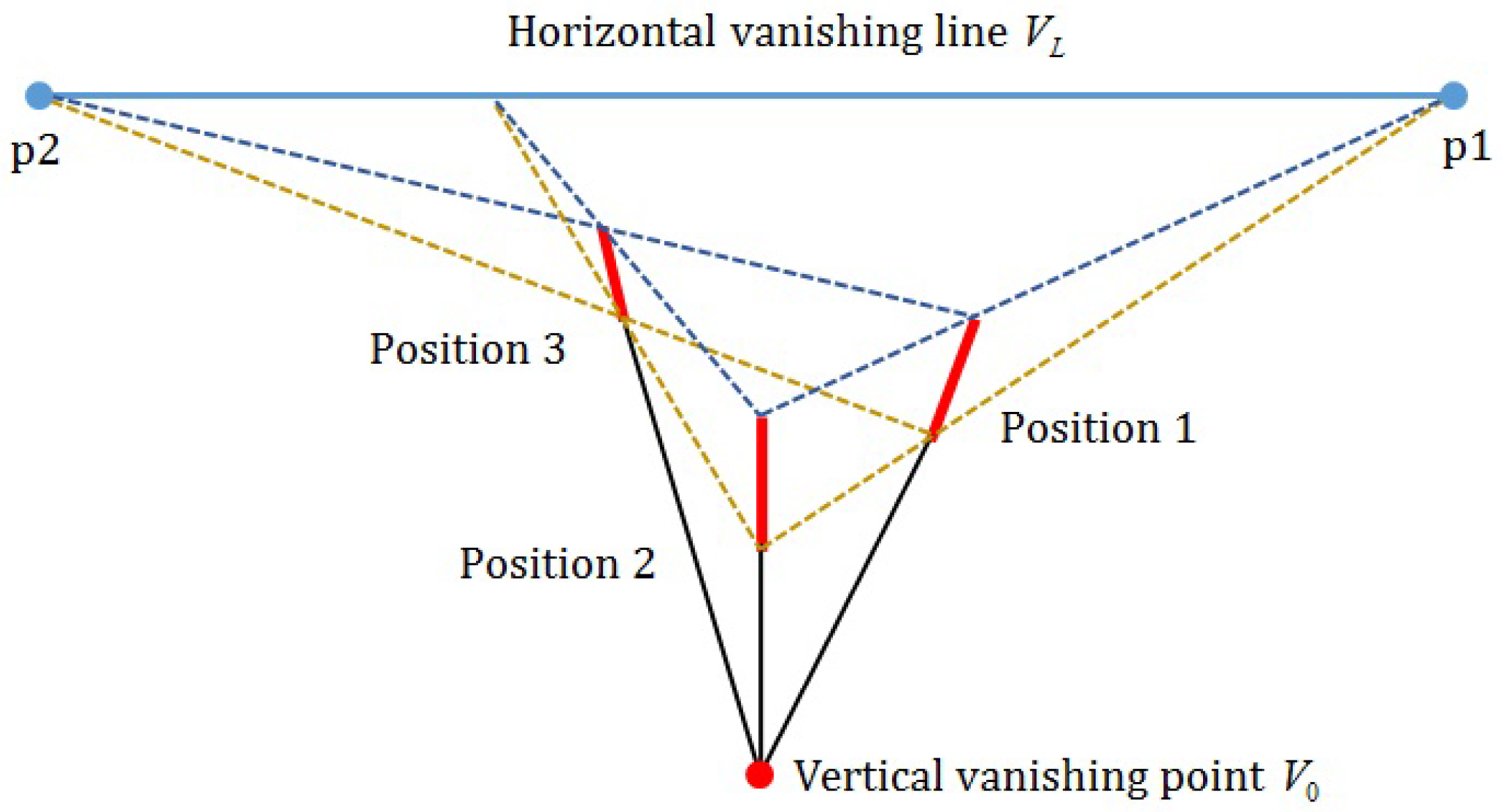
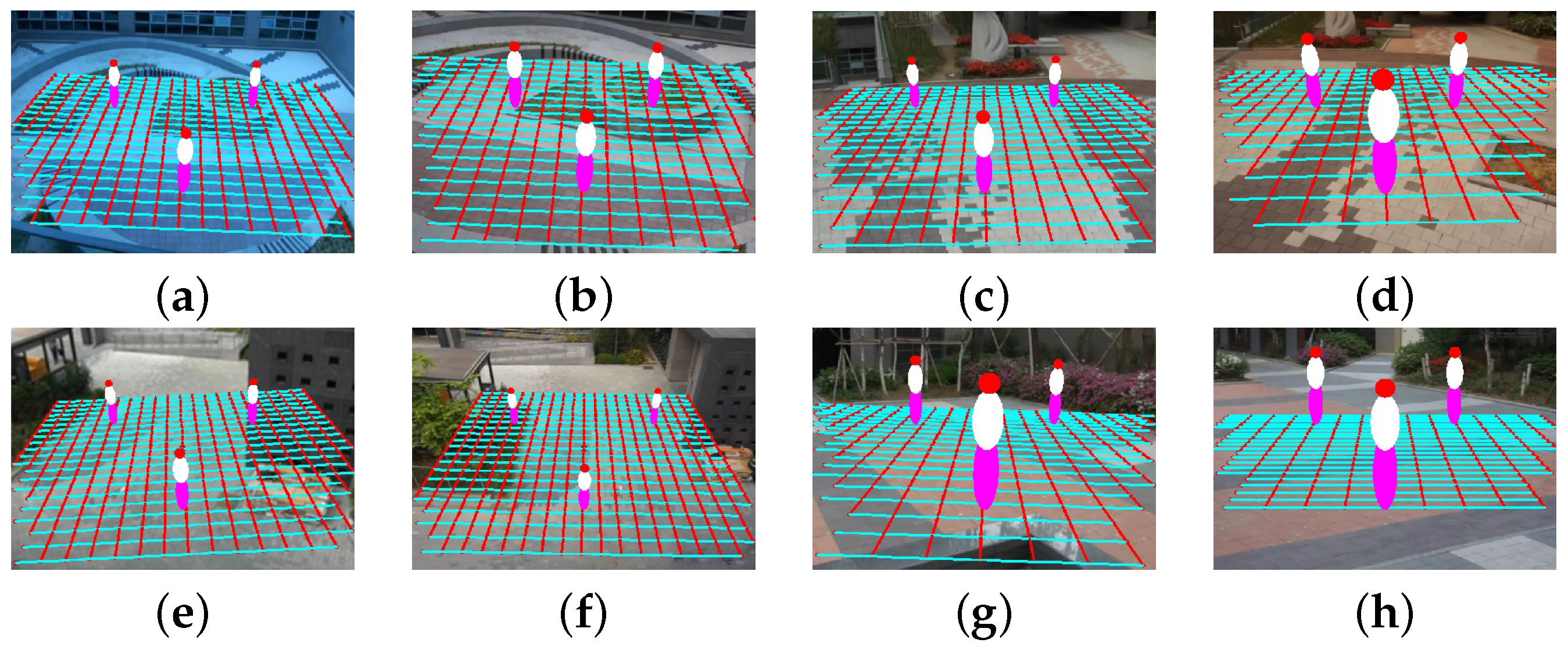
3.1. Foot-To-Head Homology
3.2. Automatic Scene Calibration
3.3. Camera Parameter Estimation
4. Indexing of Object Characteristics
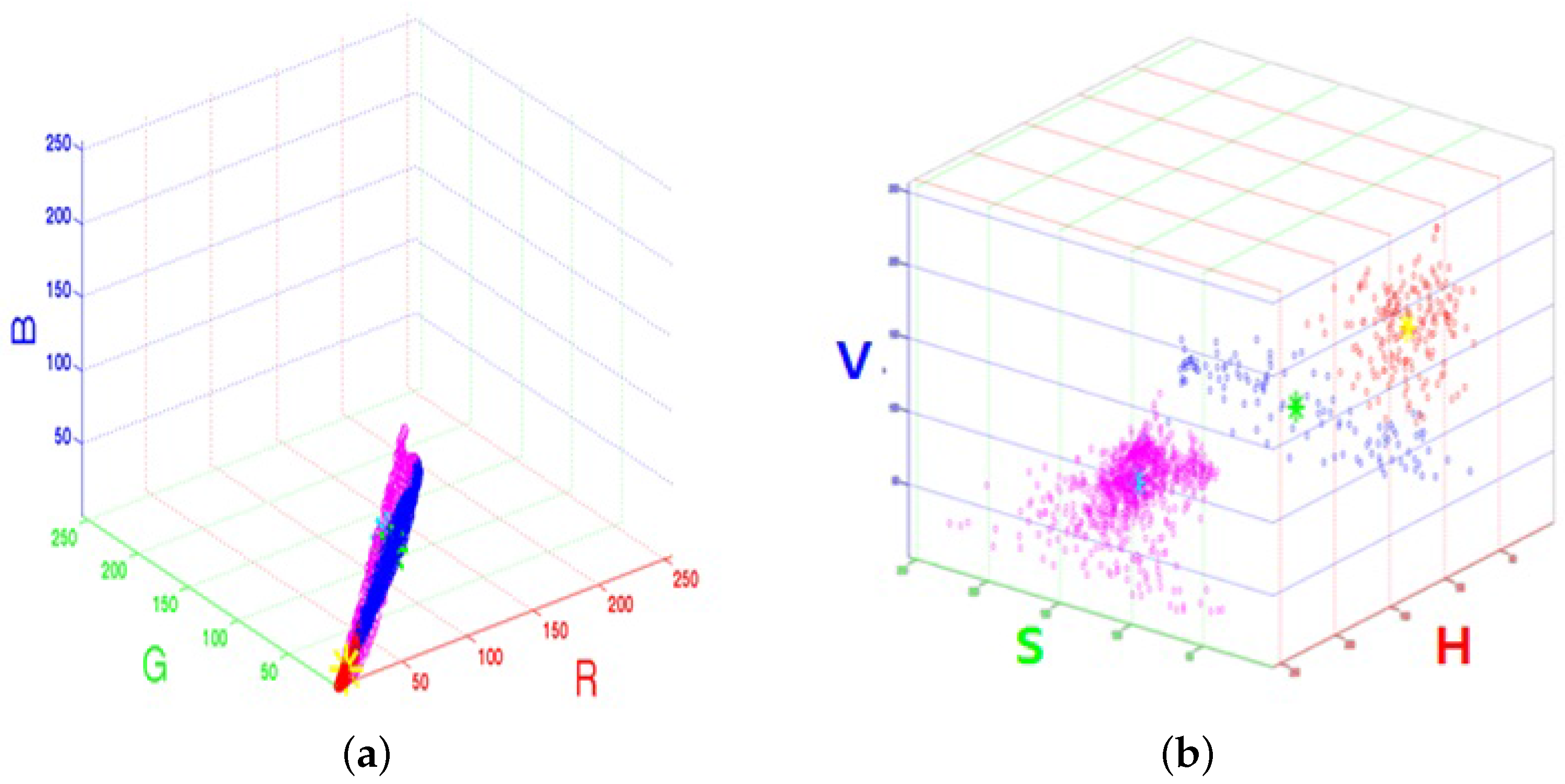
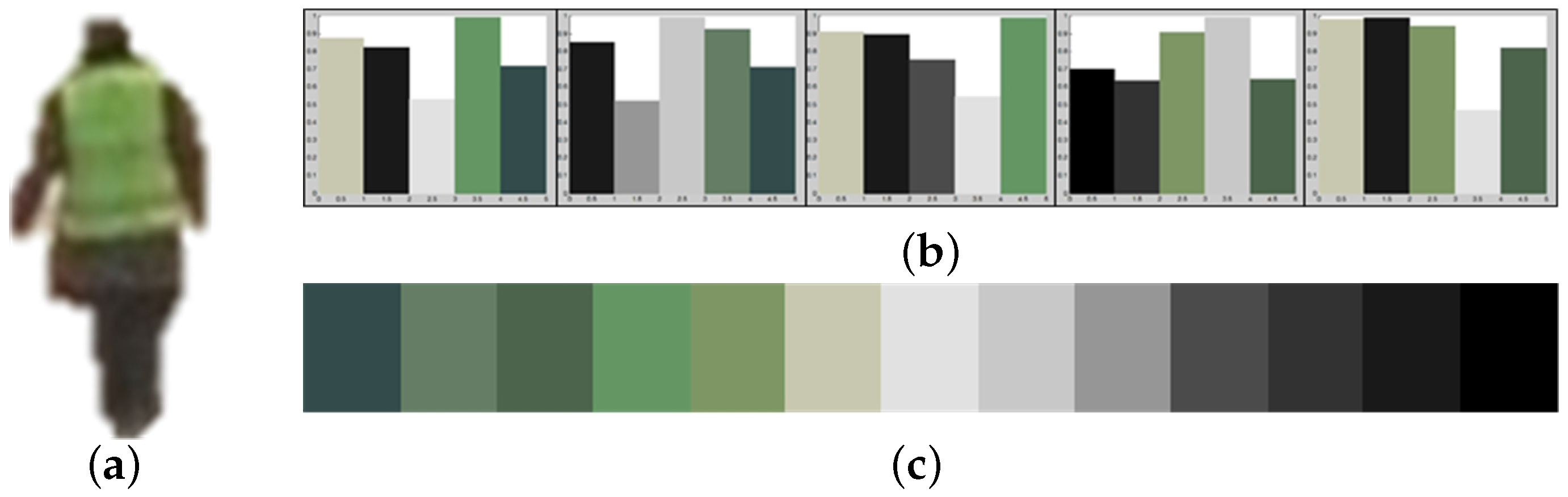
4.1. Extraction of Representative Color
4.1.1. Color Constancy
4.1.2. Representative Color Extraction
4.2. Non-Color Metadata: Size, Speed, Aspect Ratio and Trajectory
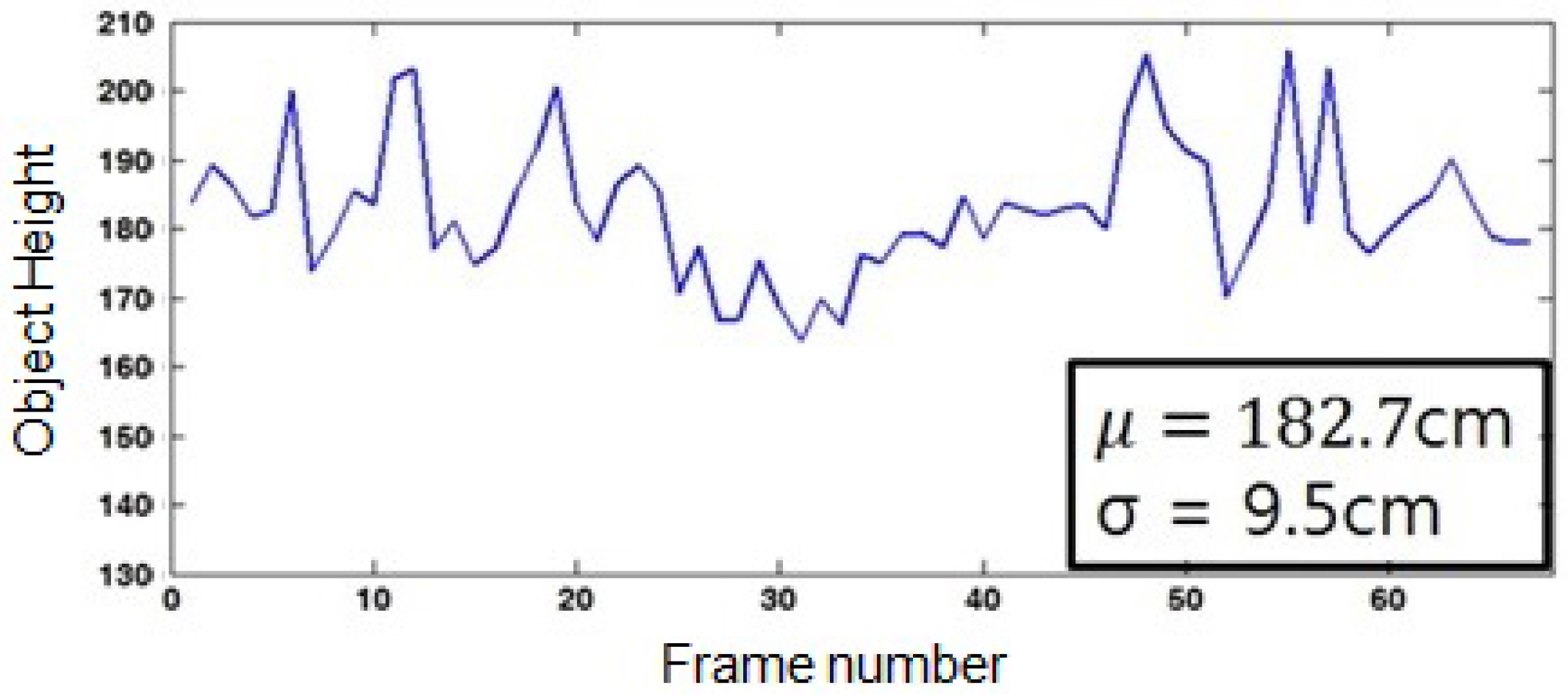
4.2.1. Normalized Object Size and Speed
4.2.2. Aspect Ratio and Trajectory
4.3. Unified Model of Metadata
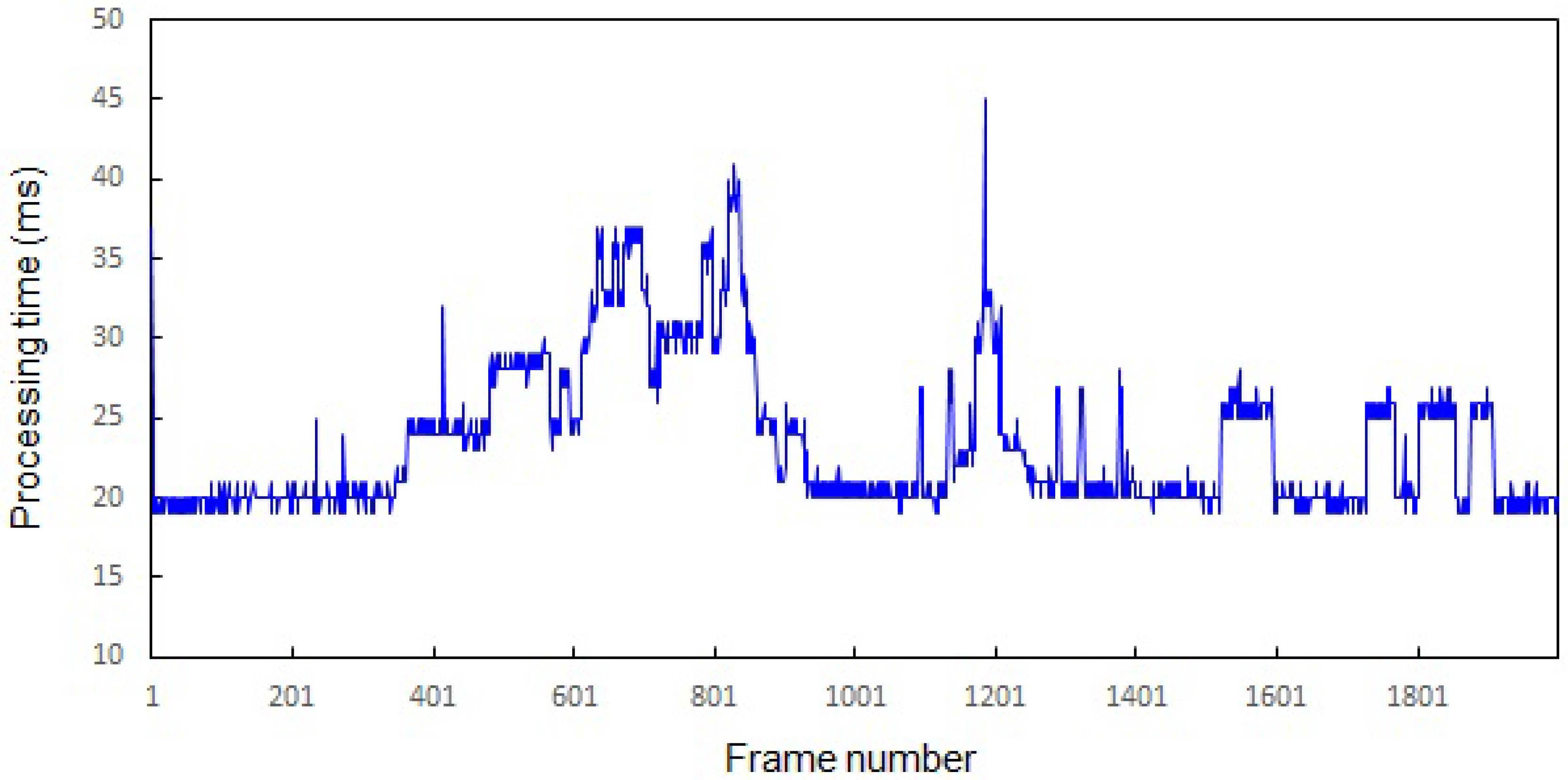
5. Experimental Results
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hampapur, A.; Brown, L.; Feris, R.; Senior, A.; Shu, C.F.; Tian, Y.; Zhai, Y.; Lu, M. Searching surveillance video. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, AVSS 2007, London, UK, 5–7 September 2007; pp. 75–80.
- Yuk, J.S.; Wong, K.Y.K.; Chung, R.H.; Chow, K.; Chin, F.Y.; Tsang, K.S. Object-based surveillance video retrieval system with real-time indexing methodology. In Image Analysis and Recognition; Springer: Berlin, Germany, 2007; pp. 626–637. [Google Scholar]
- Hu, W.; Xie, D.; Fu, Z.; Zeng, W.; Maybank, S. Semantic-based surveillance video retrieval. IEEE Trans. Image Process. 2007, 16, 1168–1181. [Google Scholar] [CrossRef] [PubMed]
- Le, T.L.; Boucher, A.; Thonnat, M.; Bremond, F. A framework for surveillance video indexing and retrieval. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, CBMI 2008, London, UK, 18–20 June 2008; pp. 338–345.
- Ma, X.; Bashir, F.; Khokhar, A.A.; Schonfeld, D. Event analysis based on multiple interactive motion trajectories. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 397–406. [Google Scholar]
- Choe, T.E.; Lee, M.W.; Guo, F.; Taylor, G.; Yu, L.; Haering, N. Semantic video event search for surveillance video. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1963–1970.
- Thornton, J.; Baran-Gale, J.; Butler, D.; Chan, M.; Zwahlen, H. Person attribute search for large-area video surveillance. In Proceedings of the 2011 IEEE International Conference on Technologies for Homeland Security (HST), Waltham, MA, USA, 15–17 November 2011; pp. 55–61.
- Ge, W.; Collins, R.T.; Ruback, R.B. Vision-based analysis of small groups in pedestrian crowds. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1003–1016. [Google Scholar] [PubMed]
- Yun, S.; Yun, K.; Kim, S.W.; Yoo, Y.; Jeong, J. Visual surveillance briefing system: Event-based video retrieval and summarization. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 204–209.
- Gerónimo, D.; Kjellstrom, H. Unsupervised Surveillance Video Retrieval based on Human Action and Appearance. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 4630–4635.
- Lai, Y.H.; Yang, C.K. Video object retrieval by trajectory and appearance. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1026–1037. [Google Scholar]
- Zhengyou, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Zhao, T.; Nevatia, R.; Wu, B. Segmentation and tracking of multiple humans in crowded environments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1198–1211. [Google Scholar] [CrossRef] [PubMed]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2.
- Lv, F.; Zhao, T.; Nevatia, R. Camera calibration from video of a walking human. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1513–1518. [Google Scholar] [PubMed]
- Krahnstoever, N.; Mendonca, P.R. Bayesian autocalibration for surveillance. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1858–1865.
- Liu, J.; Collins, R.T.; Liu, Y. Surveillance camera autocalibration based on pedestrian height distributions. In Proceedings of the British Machine Vision Conference, Scotland, UK, 29 August–2 September 2011; p. 144.
- Cipolla, R.; Drummond, T.; Robertson, D.P. Camera Calibration from Vanishing Points in Image of Architectural Scenes. In Proceedings of the British Machine Vision Conference (BMVC), Citeseer, Nottingham, UK, 13–16 September 1999; Volume 99, pp. 382–391.
- Liebowitz, D.; Zisserman, A. Combining scene and auto-calibration constraints. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greek, 20–27 September 1999; Volume 1, pp. 293–300.
- Zivkovic, Z.; van der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Bradski, G.R. Computer vision face tracking for use in a perceptual user interface. In Proceedings of the Workshop Applications of Computer Vision, Kerkyra, Greek, 19–21 October 1998; pp. 214–219.
- Fischler, M.A.; Bolles, R.C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Liebowitz, D.; Criminisi, A.; Zisserman, A. Creating architectural models from images. Comput. Graph. Forum 1999, 18, 39–50. [Google Scholar] [CrossRef]
- Finlayson, G.D.; Trezzi, E. Shades of gray and colour constancy. In Proceedings of the 12th Color and Imaging Conference, Scottsdale, AZ, USA, 9–12 November 2004; pp. 37–41.
- Van de Weijer, J.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. 2007, 16, 2207–2214. [Google Scholar] [CrossRef] [PubMed]
- Person Re-Identification in the Wild Dataset. Available online: http://robustsystems.coe.neu.edu/sites/robustsystems.coe.neu.edu/files/systems/projectpages/reiddataset.html (accessed on 17 June 2016).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | |
|---|---|---|
| ID | Object number | |
| File name | Occurrence video file name | |
| Frame | Start frame | Start frame, end frame and duration of the frame |
| End frame | ||
| Duration | ||
| Trajectory | First position | First position, 1/3 position, 2/3 position, last position and moving distance |
| Second position | ||
| Third position | ||
| Last position | ||
| Moving distance | ||
| Height (mm) | Min height | Minimum, median and maximum height of the object |
| Median height | ||
| Max height | ||
| Width (mm) | Min width | Minimum, median and maximum width of the object |
| Median width | ||
| Max width | ||
| Speed (m/s) | Min speed | Minimum, median and maximum speed of the object |
| Median speed | ||
| Max speed | ||
| Aspect ratio | Min aspect ratio | Minimum, median and maximum aspect ration of the object |
| Median aspect ratio | ||
| Max aspect ratio | ||
| Color | First color | First, second and third HSV color value |
| Second color | ||
| Third color | ||
| Area size | Min area | Minimum, median and maximum size of the area |
| Median area | ||
| Max area | ||
| Input Scenes | Estimated and Corrected Camera Parameters | Scenes with A | Number of Appearances |
|---|---|---|---|
 <Scene_1> |  | 25 | |
 <Scene_2> |  | 9 | |
 <Scene_3> |  | 2 | |
 <Scene_4> |  | 3 | |
 <Scene_5> |  | 15 | |
 <Scene_6> |  | 10 | |
 <Scene_7> |  | 3 |
| Red | Green | Blue | Yellow | Orange | Purple | Pink | White | Gray | Black | Total Object | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Red | 112 | 0 | 0 | 0 | 2 | 0 | 4 | 0 | 0 | 0 | 129 (95%) |
| Green | 0 | 6 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 (86%) |
| Blue | 0 | 1 | 96 | 0 | 0 | 0 | 0 | 0 | 4 | 3 | 104 (92%) |
| Yellow | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 1 | 0 | 0 | 8 (88%) |
| Orange | 2 | 0 | 0 | 3 | 88 | 0 | 0 | 1 | 0 | 0 | 94 (94%) |
| Purple | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 2 (100%) |
| Pink | 1 | 0 | 0 | 0 | 1 | 0 | 12 | 0 | 0 | 0 | 14 (86%) |
| White | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 79 | 5 | 0 | 84 (94%) |
| Gray | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 93 | 2 | 96 (97%) |
| Black | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 23 | 1237 | 129 (98%) |
| Small | Medium | Large | Total Object | |
|---|---|---|---|---|
| Small | 35 | 11 | 3 | 49 (71%) |
| Medium | 6 | 185 | 21 | 212 (87%) |
| Large | 0 | 17 | 993 | 1010 (98%) |
| Horizontal | Normal | Vertical | Total Object | |
|---|---|---|---|---|
| Horizontal | 38 | 3 | 5 | 46 (83%) |
| Normal | 1 | 54 | 7 | 62 (87%) |
| Vertical | 2 | 21 | 1140 | 1163 (98%) |
| Slow | Normal | Fast | Total Object | |
|---|---|---|---|---|
| Slow | 96 | 37 | 0 | 133 (72%) |
| Normal | 2 | 976 | 5 | 983 (99%) |
| Fast | 0 | 9 | 146 | 155 (94%) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J.; Yoon, I.; Lee, S.; Paik, J. Normalized Metadata Generation for Human Retrieval Using Multiple Video Surveillance Cameras. Sensors 2016, 16, 963. https://doi.org/10.3390/s16070963
Jung J, Yoon I, Lee S, Paik J. Normalized Metadata Generation for Human Retrieval Using Multiple Video Surveillance Cameras. Sensors. 2016; 16(7):963. https://doi.org/10.3390/s16070963
Chicago/Turabian StyleJung, Jaehoon, Inhye Yoon, Seungwon Lee, and Joonki Paik. 2016. "Normalized Metadata Generation for Human Retrieval Using Multiple Video Surveillance Cameras" Sensors 16, no. 7: 963. https://doi.org/10.3390/s16070963