
A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery

Abstract
:
1. Introduction
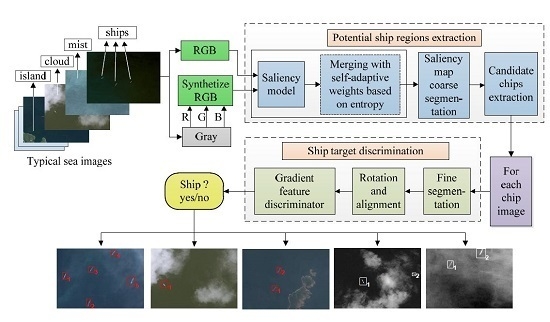
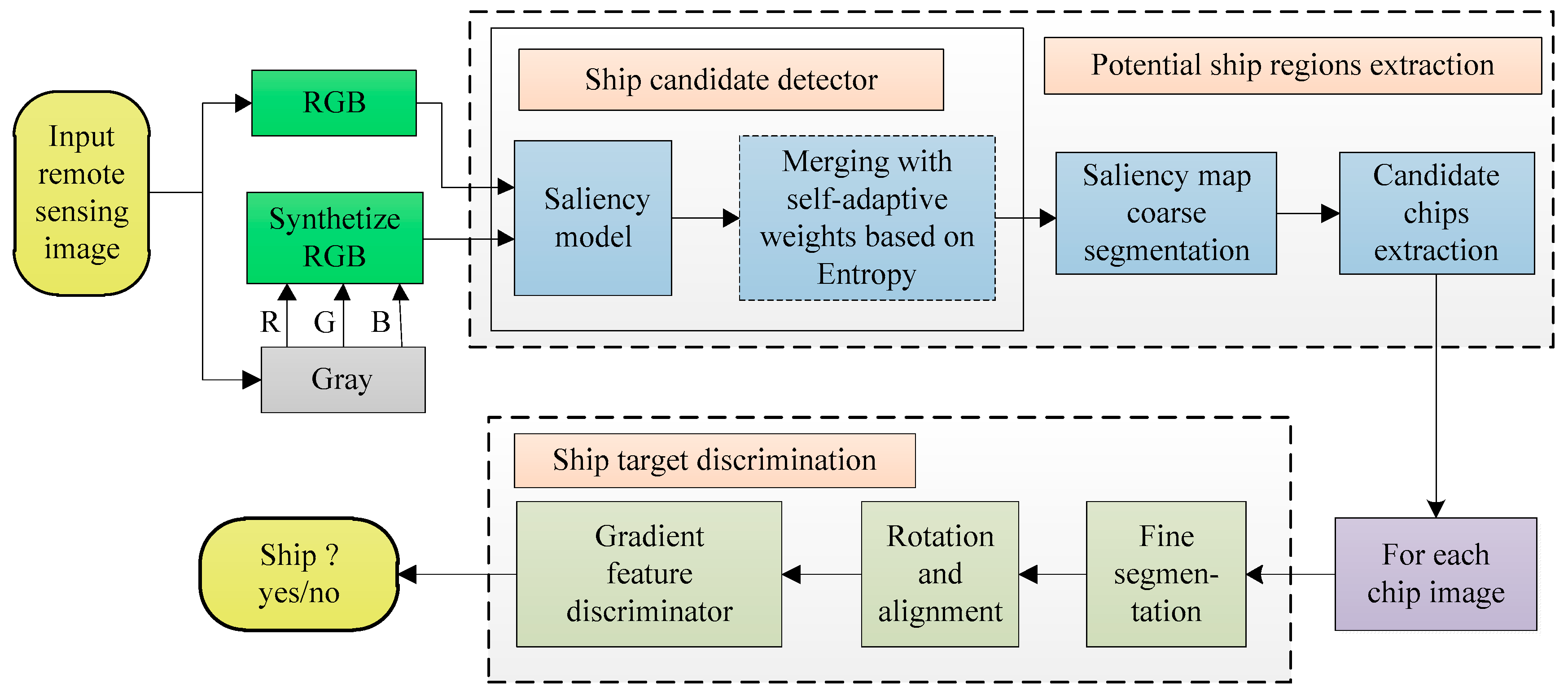
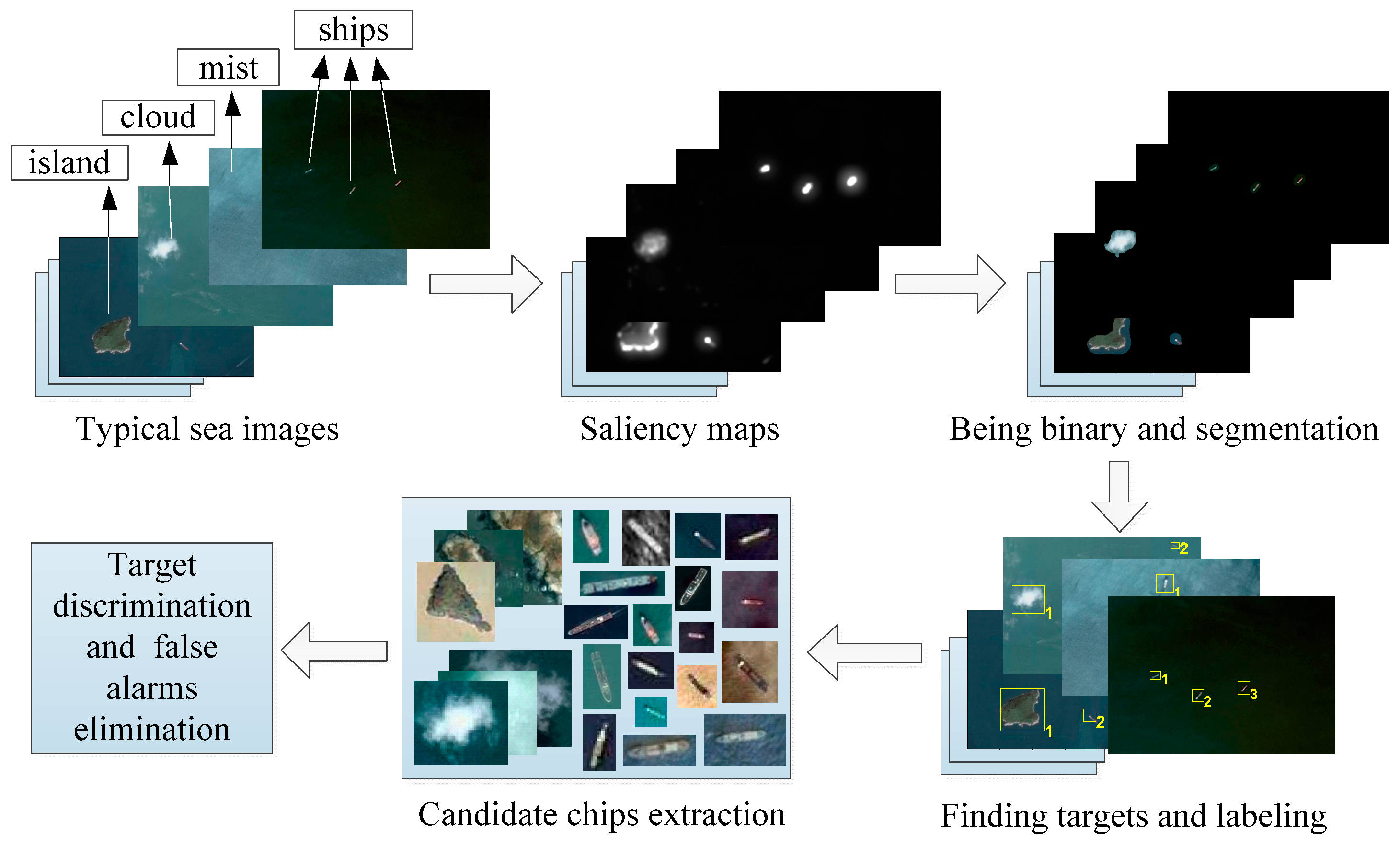
2. Ship Candidates Extraction Based on Visual Saliency
2.1. Overall Framework
2.2. Saliency Detection Model
- Include complete salient objects.
- Uniformly highlight the entire target regions.
- Disregard high frequencies introduced by clouds, islands, ship wakes and sea clutters.
- Efficiently output the saliency maps with full resolution.
2.3. Saliency Map Modification Based on Entropy Information
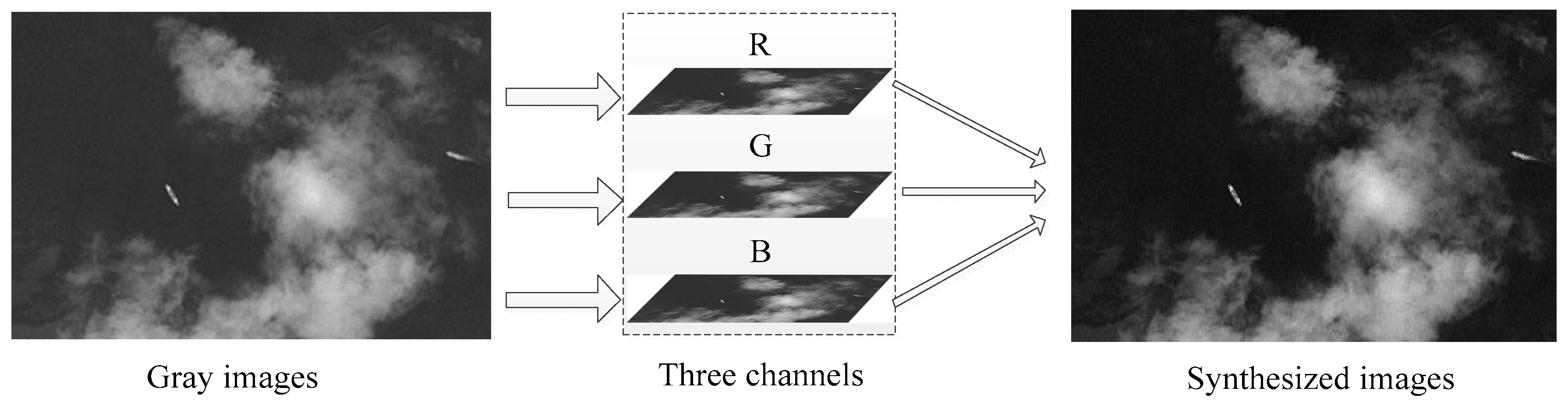
2.4. Gray Image Processing
2.5. Target Candidate Extraction
3. Ship Discrimination
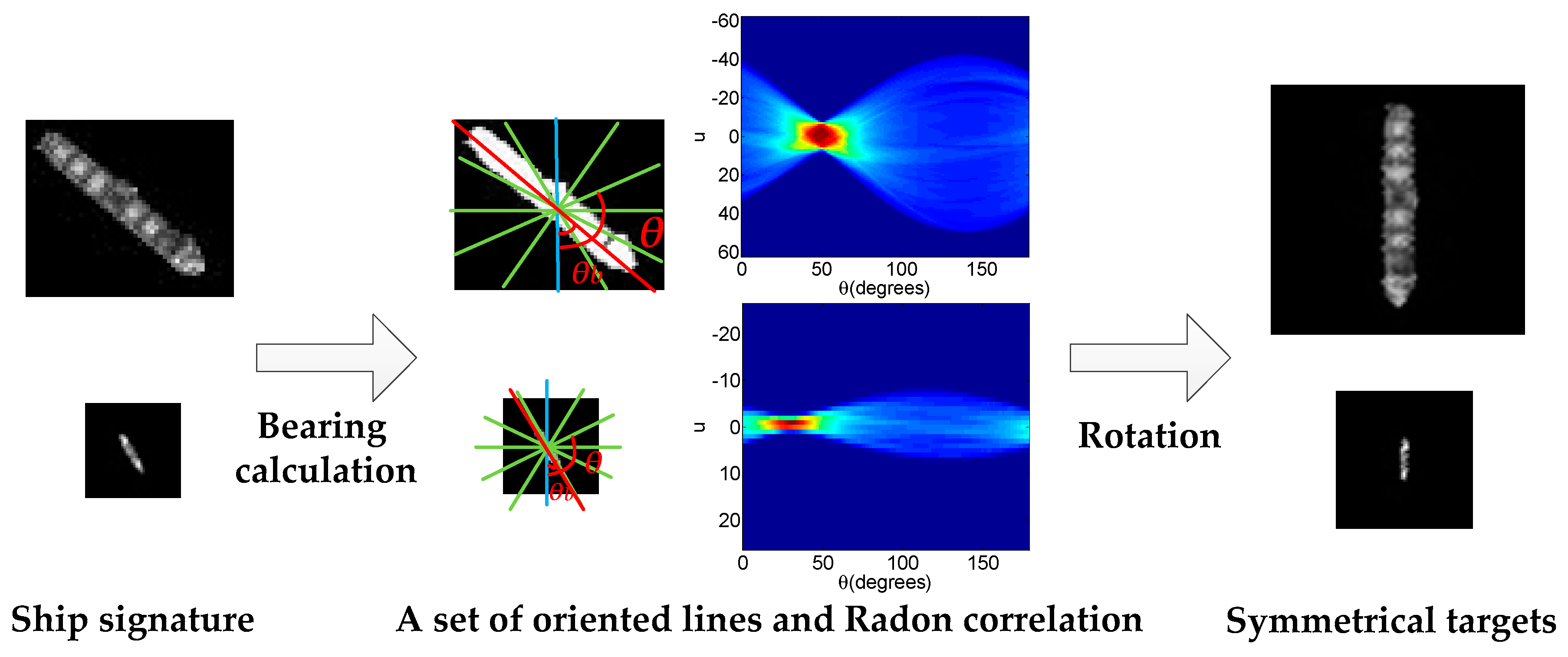
3.1. Fine Segmentation and Symmetry
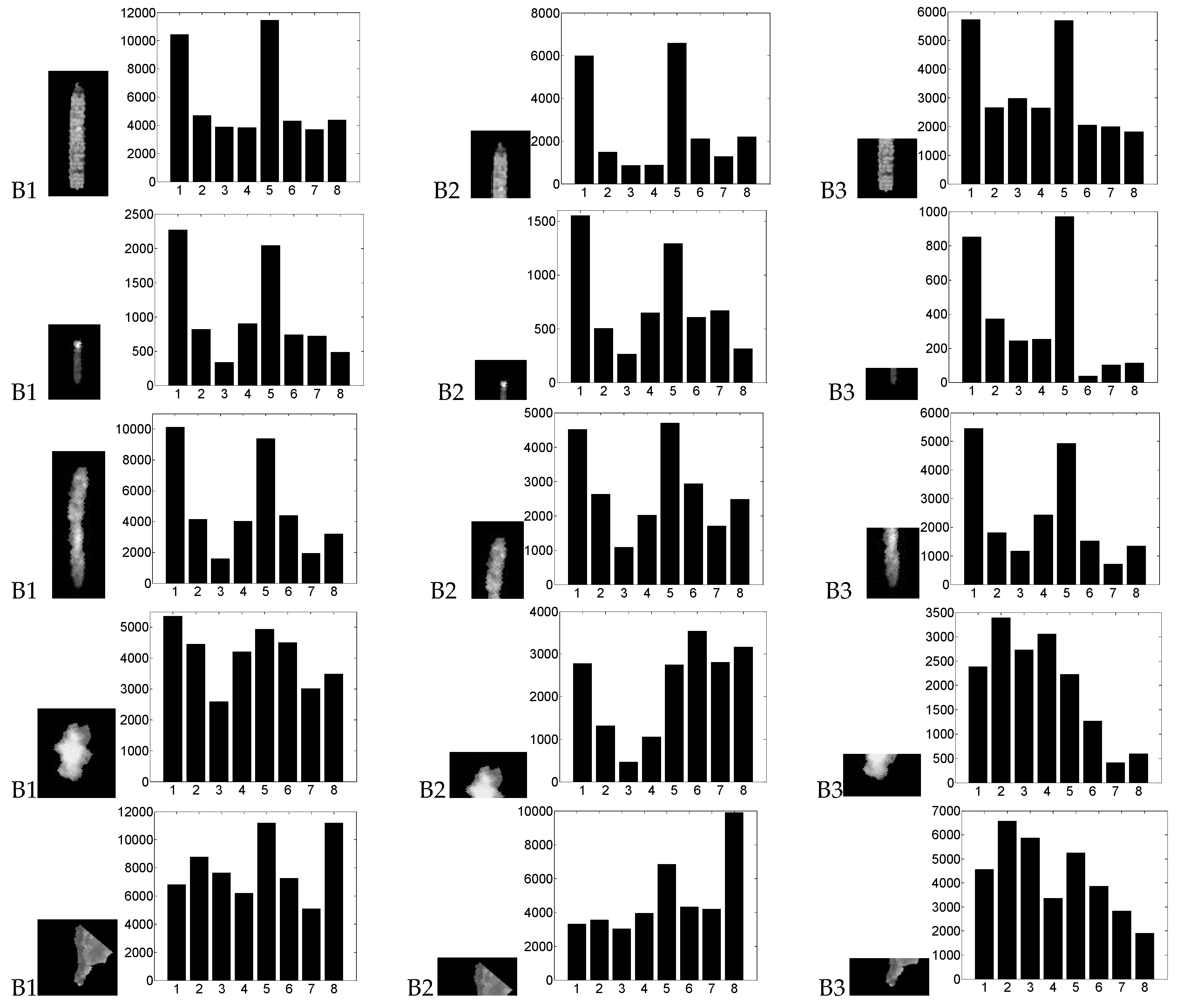
3.2. Gradient Features
3.3. Discrimination Principles
4. Experimental Results and Discussion
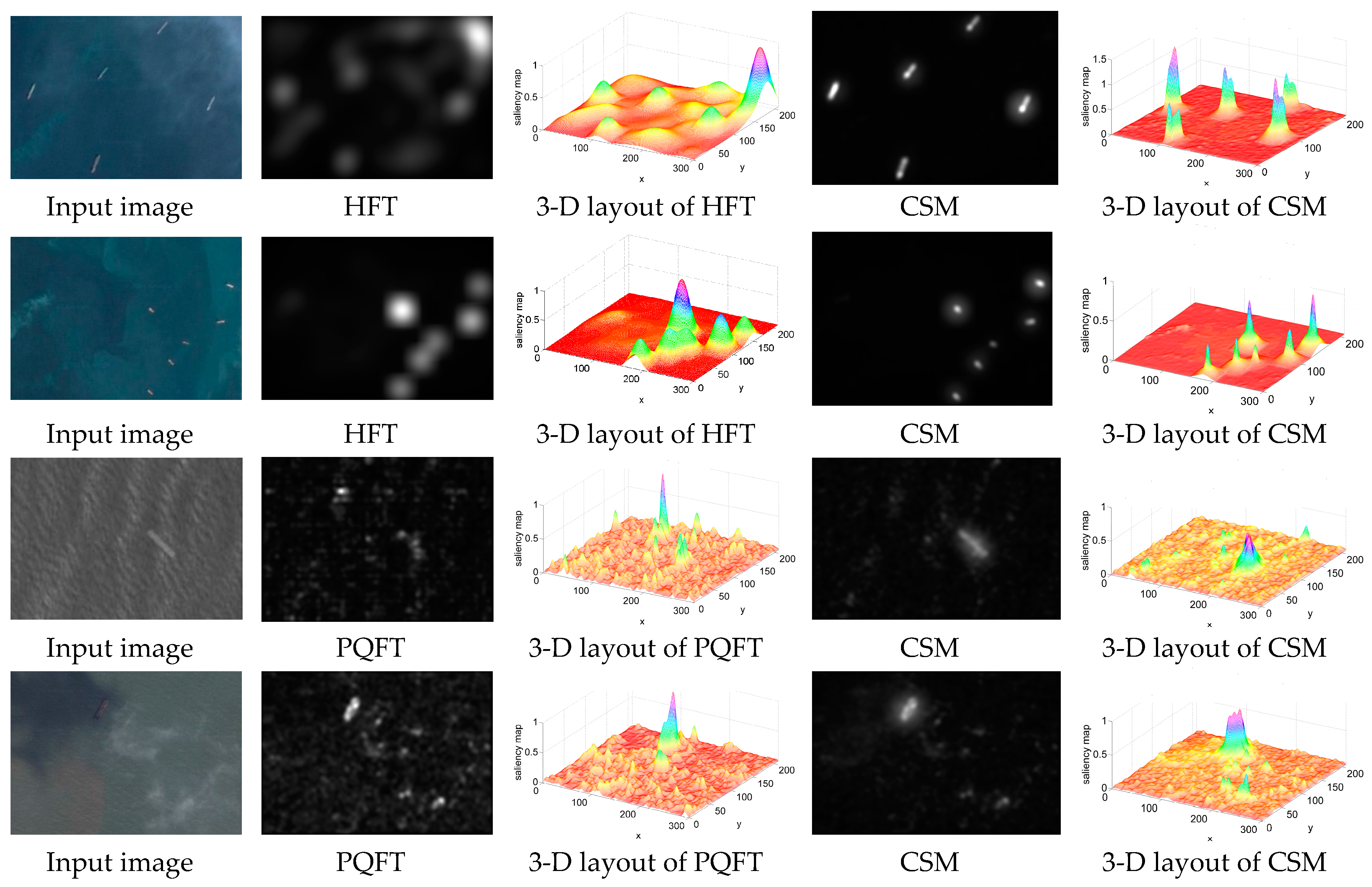
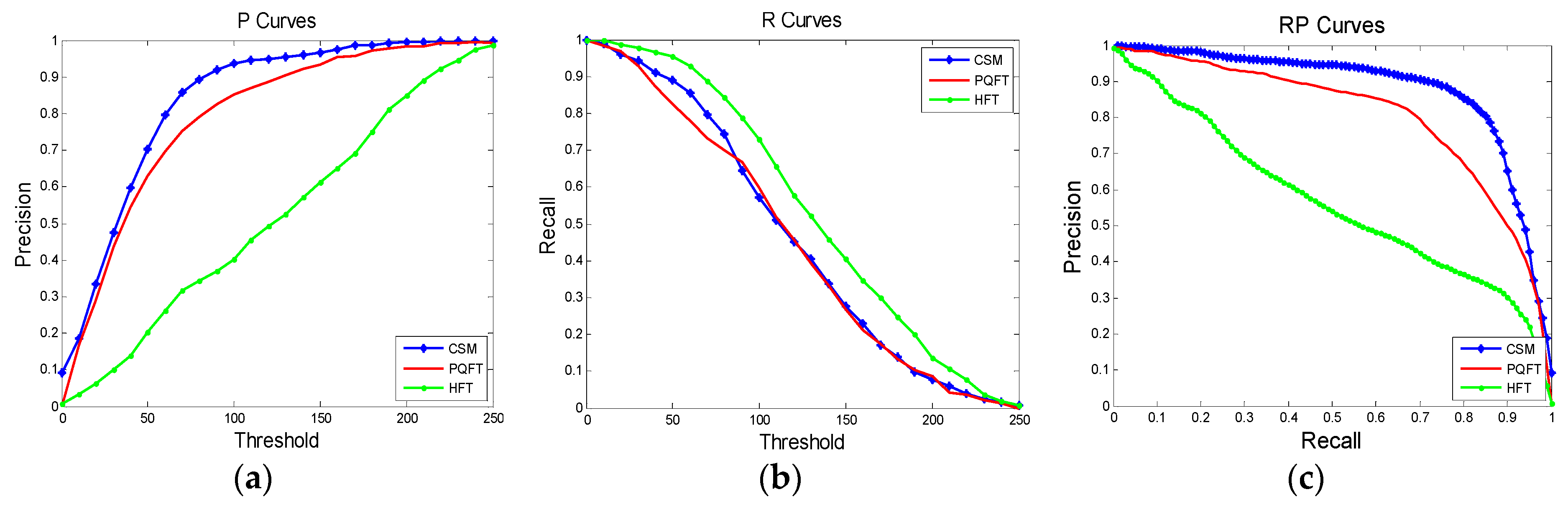
4.1. Comparisons of Different Saliency Models
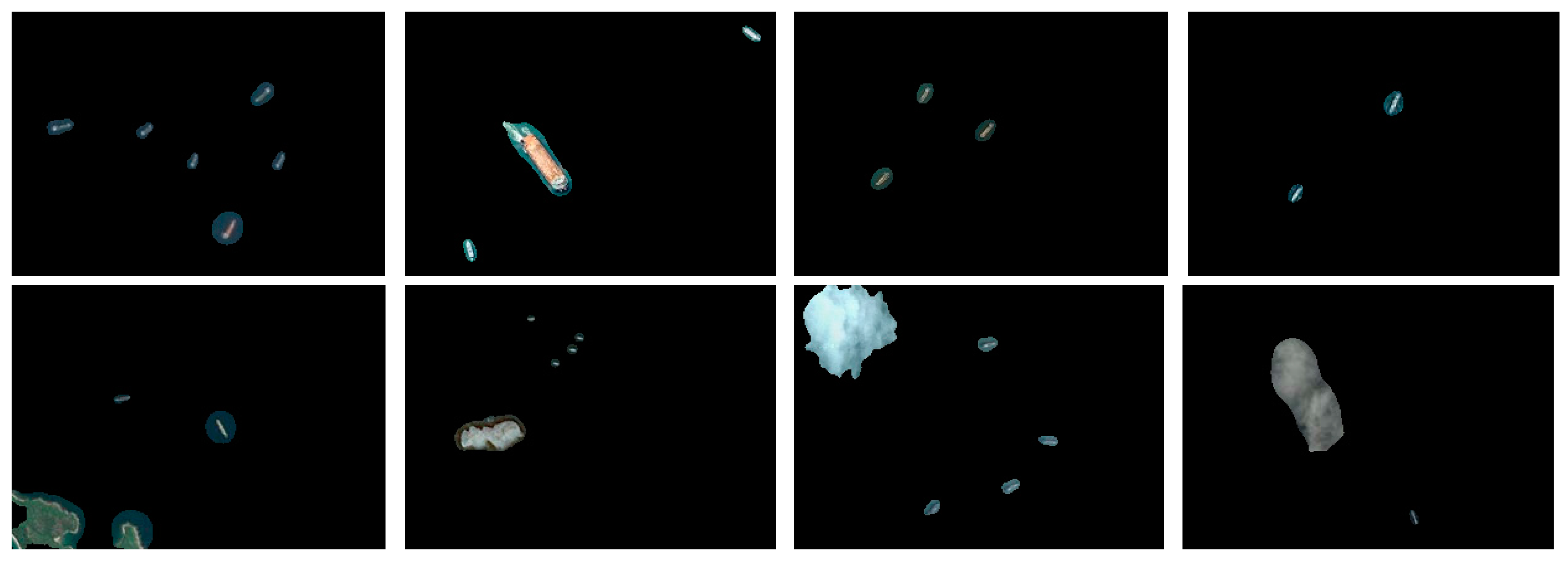
4.2. Discrimination Results
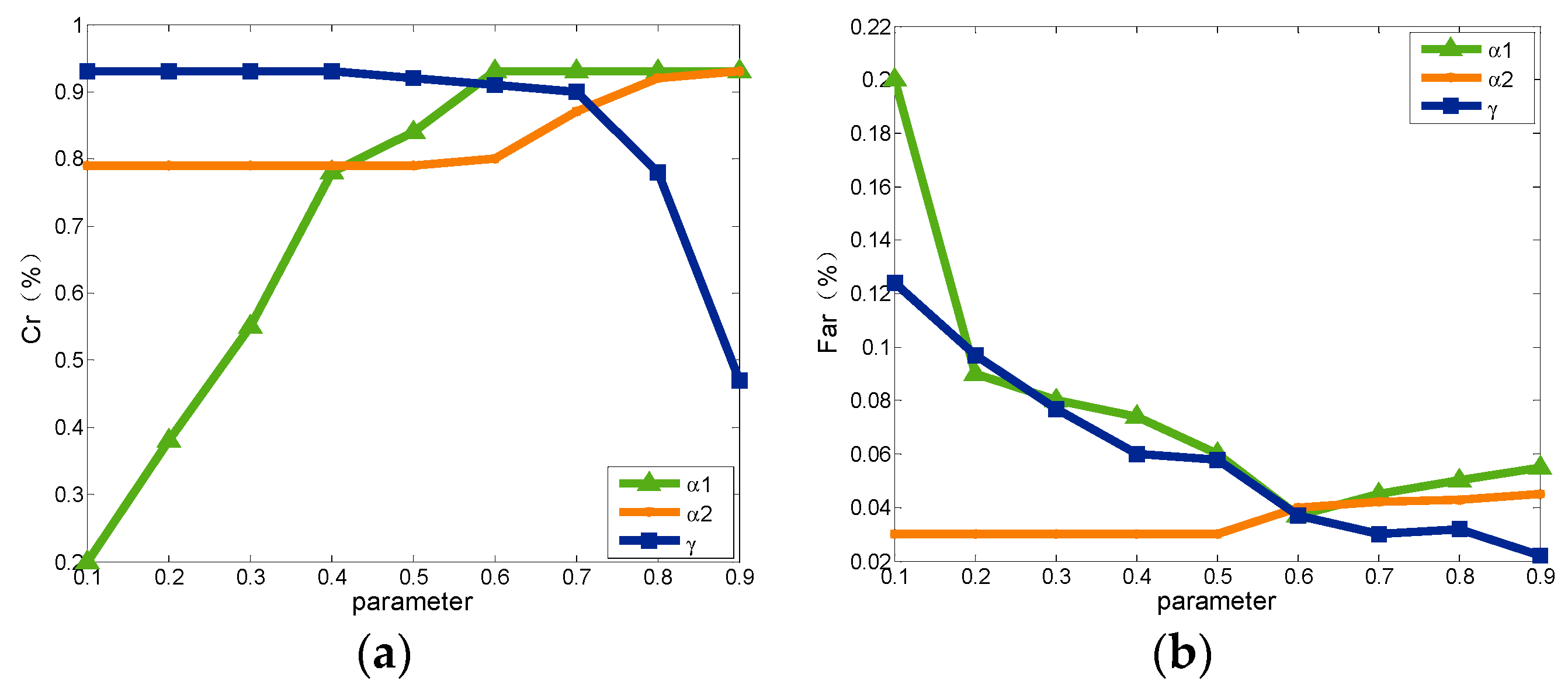
4.3. Selection of Relaxation Parameters
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mirghasemi, S.; Yazdi, H.S.; Lotfizad, M. A target-based on color space for sea target detection. Appl. Intell. 2012, 36, 960–978. [Google Scholar] [CrossRef]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; Schie, B.V. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1092–1101. [Google Scholar] [CrossRef]
- Wei, J.J.; Zhang, J.X.; Huang, G.M.; Zhao, Z. On the use of cross-correlation between volume scattering and helix scattering from polarimetric SAR data for the improvement of ship detection. Remote Sens. 2016, 8, 74. [Google Scholar] [CrossRef]
- Wang, W.G.; Ji, Y.; Liu, X.X. A novel fusion-based ship detection method from Pol-SAR images. Sensors 2015, 15, 25072–25089. [Google Scholar] [CrossRef] [PubMed]
- Fan, F.Y.; Luo, F.; Li, M.; Hu, C.; Chen, S.L. Fractal properties of autoregressive spectrum and its application on weak target detection in sea clutter background. IET Radar Sonar Navig. 2015, 9, 1070–1077. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. A novel algorithm for ship detection in SAR imagery based on the wavelet transform. IEEE Trans. Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Gómez-Enri, J.; Scozzari, A.; Soldovieri, F.; Coca, J.; Vignudelli, S. Detection and characterization of ship targets using CryoSat-2 altimeter waveforms. Remote Sens. 2016, 8, 193. [Google Scholar] [CrossRef]
- Scozzari, A.; Gómez-Enri, J.; Vignudelli, S.; Soldovieri, F. Understanding target-like signals in coastal altimetry: Experimentation of a tomographic imaging technique. Geophys. Res. Lett. 2012. [Google Scholar] [CrossRef]
- Bai, X.Z.; Liu, M.M.; Wang, T.; Chen, Z.G.; Wang, P.; Zhang, Y. Feature based on fuzzy inference system for segmentation of low-contrast infrared ship images. Appl. Soft Comput. 2016, 46, 128–142. [Google Scholar] [CrossRef]
- Tao, W.B.; Jin, H.; Liu, J. Unified mean shift segmentation and graph region merging algorithm for infrared ship target segmentation. Opt. Eng. 2007. [Google Scholar] [CrossRef]
- Wu, J.W.; Mao, S.Y.; Wang, X.P.; Zhang, T.X. Ship target detection and tracking in cluttered infrared imagery. Opt. Eng. 2011. [Google Scholar] [CrossRef]
- Liu, Z.Y.; Bai, X.Z.; Sun, C.M.; Zhou, F.G.; Li, Y.J. Infrared ship target segmentation through integration of multiple feature maps. Image Vis. Comput. 2016, 48, 14–25. [Google Scholar] [CrossRef]
- Graziano, M.D.; D’Errico, M.; Rufino, G. Wake component detection in X-band SAR images for ship heading and velocity estimation. Remote Sens. 2016, 8, 498. [Google Scholar] [CrossRef]
- Heiselberg, H. A direct and fast methodology for ship recognition in Sentinel-2 multispectral imagery. Remote Sens. 2016, 8, 1033. [Google Scholar] [CrossRef]
- Jeong, S.; Ban, W.S.; Choi, S.; Lee, D.H.; Lee, M. Surface ship-wake detection using active sonar and one-class support vector machine. IEEE J. Ocean. Eng. 2012, 37, 456–466. [Google Scholar] [CrossRef]
- Burgess, D.W. Automatic ship detection in optical satellite multispectral imagery. Photogramm. Eng. Remote Sens. 1993, 59, 229–237. [Google Scholar]
- Corbane, C.; Najman, L.; Pecoul, E.; Demagistri, L.; Petit, M. A complete processing chain for ship detection using optical satellite imagery. Int. J. Remote Sens. 2010, 31, 5837–5854. [Google Scholar] [CrossRef]
- Proia, N.; Pagé, V. Characterization of a Bayesian ship detection method in optical satellite images. IEEE Trans. Geosci. Remote Sens. 2010, 7, 226–230. [Google Scholar] [CrossRef]
- Yang, G.; Li, B.; Ji, S.F.; Gao, F.; Xu, Q.Z. Ship detection from optical satellite images based on sea surface analysis. IEEE Trans. Geosci. Remote Sens. 2014, 11, 641–645. [Google Scholar] [CrossRef]
- Xu, Q.Z.; Li, B.; He, Z.F.; Ma, C. Multiscale contour extraction using level set method in optical satellite images. IEEE Trans. Geosci. Remote Sens. Lett. 2011, 8, 854–858. [Google Scholar] [CrossRef]
- Corbane, C.; Marre, F.; Petit, M. Using SPOT-5 data in panchromatic mode for operational detection of small ships in tropical area. Sensors 2008, 8, 2959–2973. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.R.; Zhou, H.; Wang, R.S.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Xia, Y.; Wan, S.H.; Yue, L.H. A novel algorithm for ship detection based on dynamic fusion model of multi-feature and support vector machine. In Proceedings of the 6th International Conference on Image and Graph (ICIG 2011), Hefei, China, 12–15 August 2011.
- Kumar, S.S.; Selvi, M.U. Sea object detection using colour and texture classification. Int. J. Comp. Appl. Eng. Sci. 2011, 1, 59–63. [Google Scholar]
- Shi, Z.W.; Yu, X.R.; Jiang, Z.G.; Li, B. Ship detection in high-resolution optical imagery based on anomaly detector and local shape feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Duan, H.B.; Gan, L. Elitist chemical reaction optimization for contour-based target recognition in aerial images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2845–2859. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.Q.; Li, Y.; Li, X.J. Automatic target detection in high-resolution panchromatic satellite imagery based on supervised image segmentation. IEEE Trans. Geosci. Remote Sens. Lett. 2012, 9, 109–113. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.W.; Zhou, P.C.; Guo, L. Multi-class geospatial object detection and geosgraphic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.W.; Guo, L.; Qian, X.L.; Zhou, P.C.; Yao, X.W.; Hu, X.T. Object detection in remote sensing imagery using a discriminatively trained mixture model. ISPRS J. Photogramm. Remote Sens. 2013, 85, 32–43. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.W. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Han, J.W.; Zhou, P.C.; Zhang, D.W.; Cheng, G.; Guo, L.; Liu, Z.B.; Bu, S.H.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Yokoya, N.; Iwasaki, A. Object detection based on sparse representation and Hough voting foroptical remote sensing imagery. IEEE J. Sel. Top. Appl. Obs. Remote Sens. 2015, 8, 2053–2062. [Google Scholar] [CrossRef]
- Wang, X.; Shen, S.Q.; Ning, C.; Huang, F.C.; Gao, H.M. Multi-class remote sensing object recognition based on discriminative sparse representation. Appl. Opt. 2016, 55, 1381–1394. [Google Scholar] [CrossRef] [PubMed]
- Bi, F.K.; Zhu, B.C.; Gao, L.N.; Bian, M. A visual search inspired computational model for ship detection in optical satellite images. IEEE Trans. Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar]
- Zhu, J.; Qiu, Y.; Zhang, R.; Huang, J.; Zhang, W. Top-down saliency detection via contextual pooling. J. Sign. Process. Syst. 2014, 74, 33–46. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Patt. Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Bruce, N.D.; Tsotsos, J.K. Saliency based on information maximization. Adv. Neural Inf. Process Syst. 2006, 18, 155–162. [Google Scholar]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. Adv. Neural Inf. Process Syst. 2006, 19, 545–552. [Google Scholar]
- Stas, G.; Lihi, Z.M.; Ayellet, T. Context-aware saliency detection. IEEE Trans. Patt. Anal. Mach. Intell. 2012, 34, 1915–1926. [Google Scholar]
- Zhai, Y.; Shah, M. Visual attention detection in video sequences using spatiotemporal cues. In Proceedings of the 14th ACM international conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2006.
- Cheng, M.M.; Zhang, G.X.; Mitra, N.J.; Huang, X.L.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Patt. Anal. Mach. Intell. 2011, 37, 409–416. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Süsstrunk, S. Frequency-tuned Salient Region Detection. IEEE Conf. Comput. Vision Patt. Recogn. 2009. [Google Scholar] [CrossRef]
- Hou, X.D.; Zhang, L. Saliency detection: A spectral residual approach. IEEE Conf. Comput. Vision Patt. Recogn. Minneapolis 2007. [Google Scholar] [CrossRef]
- Guo, C.L.; Ma, Q.; Zhang, L.M. Spatio-temporal saliency detection using phase spectrum of quaternion Fourier transform. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AL, USA, 23–28 June 2008.
- Ding, Z.H.; Yu, Y.; Wang, B.; Zhang, L.M. An approach for visual attention based on biquaternion and its application for ship detection in multispectral imagery. Neurocomputing 2012, 76, 9–17. [Google Scholar] [CrossRef]
- Li, J.; Levine, M.D.; An, X.J.; Xu, X.; He, H.G. Visual saliency based on scale-space analysis in the frequency domain. IEEE Trans. Patt. Anal. Mach. Intell. 2012, 35, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.S.; Lee, B.S.; Lau, C.T.; Lin, C.W. Bottom-up saliency detection model based on human visual sensitivity and amplitude spectrum. IEEE Trans. Multimed. 2012, 14, 187–198. [Google Scholar]
- Haweel, R.T.; El-Kilani, W.S.; Ramadan, H.H. Fast approximate DCT with GPU implementation for image compression. J. Vis. Commun. Image R. 2016, 40, 357–365. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Sys. Man. Cyber. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Qi, S.X.; Ma, J.; Lin, J.; Li, Y.S.; Tian, J.W. Unsupervised ship detection based on saliency and S-HOG descriptor from optical satellite images. IEEE Trans. Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Xu, C.; Zhang, D.P.; Zhang, Z.N.; Feng, Z.Y. BgCut: automatic ship detection from UAV images. Sci. World J. 2014, 171978, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Margarit, G.; Tabasco, A. Ship classification in single-pol SAR images based on fuzzy logic. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3129–3138. [Google Scholar] [CrossRef]
- Song, S.L.; Xu, B.; Yang, J. SAR target recognition via supervised discriminative dictionary learning and sparse representation of the SAR-HOG feature. Remote Sens. 2016, 8, 683. [Google Scholar] [CrossRef]
- Tang, J.X.; Deng, C.W.; Huang, G.B.; Zhao, B.J. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CSM | ITTI | AIM | GBVS | Goferman | LC | HC | FT | SR | PQFT |
|---|---|---|---|---|---|---|---|---|---|---|
| Time(s) | 1.7219 | 0.7301 | 12.6740 | 7.0883 | 32.5659 | 0.0085 | 0.1323 | 0.2181 | 0.1395 | 0.2019 |
| Code | Matlab | Matlab | Matlab | Matlab | Matlab | C++ | C++ | C++ | Matlab | Matlab |
| Model | CSM | ITTI | AIM | GBVS | Goferman | LC | HC | FT | SR |
|---|---|---|---|---|---|---|---|---|---|
| Recall | 0.9506 | 0.5102 | 0.4998 | 0.5718 | 0.5957 | 0.3291 | 0.2952 | 0.1087 | 0.6046 |
| Precision | 0.6173 | 0.1482 | 0.2921 | 0.4327 | 0.4944 | 0.1719 | 0.1257 | 0.1001 | 0.7751 |
| F-Measure | 0.7485 | 0.2297 | 0.3687 | 0.4926 | 0.5403 | 0.2258 | 0.1763 | 0.1042 | 0.6793 |
| Methods | Nt | Ntt | Nfa | Cr | Far | Mr |
|---|---|---|---|---|---|---|
| % | % | % | ||||
| Method [17] | 301 | 239 | 75 | 79.402 | 23.885 | 20.598 |
| Method [18] | 301 | 256 | 94 | 85.049 | 26.857 | 14.951 |
| Method [19] | 301 | 254 | 63 | 84.385 | 19.874 | 15.615 |
| OMWOD | 301 | 288 | 34 | 95.681 | 10.559 | 4.319 |
| OMWD | 301 | 282 | 15 | 93.688 | 5.050 | 6.312 |
| OMWODG | 301 | 280 | 46 | 93.023 | 14.11 | 6.977 |
| OMWDG | 301 | 271 | 21 | 90.033 | 7.192 | 9.967 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Liu, J.; Sun, M.; Zeng, D.; Wang, X. A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery. Remote Sens. 2017, 9, 280. https://doi.org/10.3390/rs9030280
Xu F, Liu J, Sun M, Zeng D, Wang X. A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery. Remote Sensing. 2017; 9(3):280. https://doi.org/10.3390/rs9030280
Chicago/Turabian StyleXu, Fang, Jinghong Liu, Mingchao Sun, Dongdong Zeng, and Xuan Wang. 2017. "A Hierarchical Maritime Target Detection Method for Optical Remote Sensing Imagery" Remote Sensing 9, no. 3: 280. https://doi.org/10.3390/rs9030280