1. Introduction
Over the next decades, climate change combined with demographic and environmental pressures are expected to have significant effects on livelihoods and food systems, particularly in developing countries where less adaptable, small rainfed agricultural systems are dominant [
1]. Nevertheless, such forms of agriculture account for about 50% of rural populations and contribute to roughly 90% of staple food production in developing countries [
2]. A sustainable improvement of food security for these farmers and populations requires better monitoring of agricultural systems and of their production at regional and global scales. However, satellite observations of these systems are subject to several constraints such as small field sizes, landscape fragmentation, vast within plot and cultivation practices heterogeneity, cloudy conditions, synchronized agro-system and ecosystem phenologies related to rainfall, etc.
Many attempts have been made to use remote sensing to objectively characterize and monitor agricultural systems at different scales. Remote sensing approaches have been developed to identify cropping systems and practices, such as crop type and cropping intensity, across large spatial and temporal scales [
3,
4,
5,
6]. Given their ability to observe cultivated areas on a uniform timescale and cover large areas, time series composed of low spatial resolution (LSR) satellite images that record phenological changes in crop reflectance characteristics have been identified as a particularly appropriate source of information for the estimation of such data [
7]. However, existing satellite sources may not be appropriate for mapping cropping practices of smallholder farms, in which fields are typically smaller than the spatial resolution of readily available LSR satellite data, such as MODIS (Moderate Resolution Imaging Spectroradiometer, 250 m resolution) and even medium spatial resolution (MSR) Landsat data (30 m resolution). Using the Pareto Boundary method [
8], one study analyzed the optimal accuracy of cropland maps that could theoretically be reached for a broad range of West African agricultural systems [
9]. The authors quantified the expected accuracy of different spatial resolutions (from 500 m to 10 m) and showed that a resolution of 10 m allows one to produce very accurate cropland maps, even in smallholder agriculture regions.
After the launch of the second Sentinel-2B satellite in March 2017, the Sentinel-2 mission proposed by the European Space Agency will provide significant improvements from existing Landsat-type sensors with an unprecedented combination of spectral (13 bands), spatial (from 10 to 60 m) and temporal (five day) resolutions over a swath of 290 km (see [
10] for more information on the mission). The mission may spur major advances in the mapping of agricultural systems, particularly when methods involve the use of Landsat 8 to increase acquisition frequency levels, which may be needed in countries characterized by frequent cloud coverage. However, such high spatial resolution time series with multiple bands and possible derivations constitute a large volume of data that remains a significant challenge for the automated mapping of agricultural land [
11]. An emerging machine learning technique based on the use of ensemble methods (e.g., neural network ensembles, random forests, bagging and boosting) is currently receiving increasing interest [
12]. Ensemble classifiers are based on the theory that a set of classifiers gives a more robust outcome than an individual classifier [
12]. The ensemble learning technique referred to as Random Forests (RF) [
13] is increasingly being applied in land-cover classification using multispectral and hyperspectral satellite sensor imagery [
14,
15,
16,
17,
18,
19,
20]. The approach presents many advantages in its application to remote sensing: it is non-parametric, it can manage a large volume of data and variables (even those that are highly correlated), it can measure degrees of variable importance, etc. [
12].
A preparatory work of the Sentinel-2 mission based on such a technique was carried out for the crop type classification of 12 contrasting agricultural sites of the JECAM network (Joint Experiment for Crop Assessment and Monitoring,
www.jecam.org), including the Antsirabe site in Madagascar [
21,
22]. The project was based on a Random Forest analysis of a set of reflectances and spectral indices (Normalized Difference Vegetation Index (NDVI), Normalized Difference Water Index (NDWI) and brightness) extracted at the pixel level, mainly from HRS SPOT4 times series (from the SPOT4 Take5 experiment [
23] simulating Sentinel-2). This study highlights the difficulties associated with mapping smallholder agriculture. For sites of intensive farming (France, China, Argentina, Ukraine, etc.), the overall accuracy of classifications of main crop types were always higher than 80%, whereas for sites characterized by smallholder agriculture (JECAM sites in Burkina Faso and Madagascar), the overall accuracies were found to be approximately 50%.
For such complex landscapes, methods could benefit from the addition of very high spatial resolution (VHSR) imagery [
24] or from any other satellite-derived environmental information, such as elevation data [
20]. Very high spatial resolution images allow one to retrieve field boundaries using segmentation processes [
25], thus paving the way for Objects Based Image Analysis (OBIA) [
26]. Because per-pixel methods can be affected by mixed pixels, spectral similarities between different crops, and crop pattern variability [
27], the OBIA approach already showed many advantages over per-pixel methods, including over agricultural areas [
28]. The level of detail provided by VHSR images can also be mobilized in OBIA approaches to calculate textural indices that provide information on the spatial organization of pixels (within a field or between fields, depending on the calculation window size) that is complementary to spectral information [
27,
29]. Concerning the classification algorithm to be used in an object-based approach for agricultural mapping, a recent study showed the relevance and stability of the RF approach over other supervised classifiers [
30].
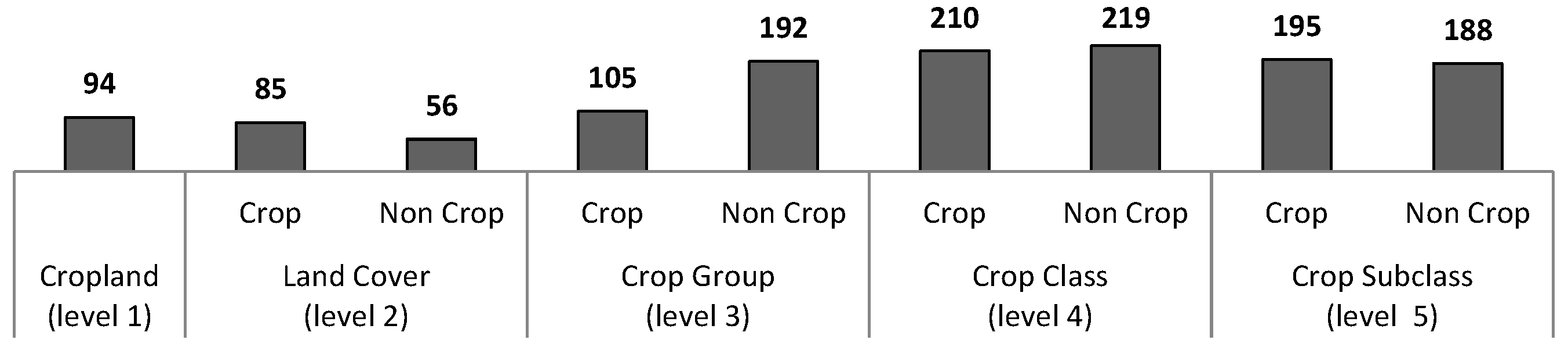
To effectively address the challenges associated with mapping tropical smallholder agricultural systems at a regional scale, the present study aimed at testing the potential of coupling Sentinel-2 data with VHSR and ancillary data (including a Digital Elevation Model—DEM) to map land use, with a focus on agricultural land in the central highlands of Madagascar. The simulation of Sentinel-2 images was based on existing 2014–2015 SPOT 5 and Landsat 8 satellite time series associated with VHSR PLEIADES image coverage. A mixed Random Forest and OBIA classification scheme was developed to combine the HRS time series, VHSR data and ancillary (DEM) data and to achieve a land-use classification at different levels (cropland, land cover, crop group, crop type, and crop subclass). After optimizing the classification approach by reducing the number of features used, we conducted experiments to (i) test cropland masking prior to the classification of more detailed nomenclature levels, (ii) analyze the importance of each data source (HSR, VHRS and DEM) and type (spectral, textural or other), and (iii) quantify their contribution to the classification accuracy. Finally, recommendations are given on ways to perform multisource classifications for mapping smallholder agriculture at different nomenclature levels from cropland to crop subclasses.
4. Discussion
4.1. Relevance of the Approach
Faced with the challenge of mapping smallholder agriculture and given the opportunities created through the recent Sentinel-2 mission, we have developed a classification workflow based on multisource data. We tested ways to couple a Sentinel-2 time series (allowing for crop development monitoring and identification) with VHSR images (providing access to field delineation and texture analysis) and other auxiliary data (DEM, enabling the constraint of classifications through land cover drivers) to map land use at different nomenclature levels with a focus on agriculture classes (from cropland to crop subclasses). The method developed involves the use of Random Forest, which has already proven to be efficient over a broad range of agricultural landscapes [
20], applied to a vast set of satellite variables extracted at the object level over an agricultural site in the Madagascar highlands.
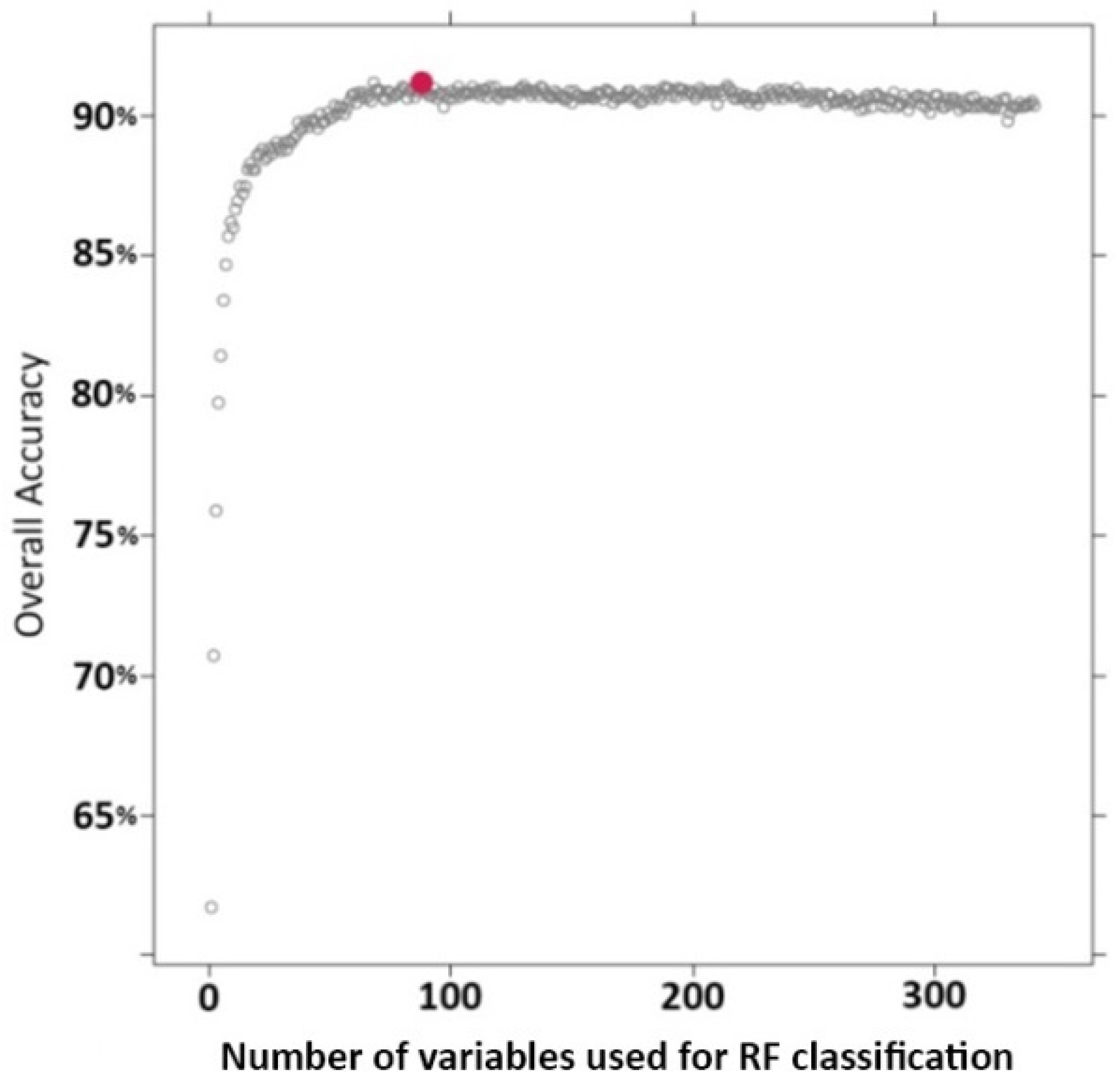
We first optimized the classifier by reducing the number of features to be extracted for an implementation facility. The results of the optimization phase show that the number of features to be extracted before applying the optimized classifiers to an entire study zone could be significantly reduced from 1.5- to 6-fold, depending on the nomenclature level, with no significant effects on classification accuracy. This could lead to significant gains in computation time for generating object features given that, for the 60 km × 60 km site, the segmentation process for the whole area produced more than 6 million objects for which features must be extracted.
With this classification scheme, the first level of the nomenclature (cropland) was classified very well (OA of 91.7%). The “crop” class was better classified than the “non-crop” class (f1-scores of 0.93 and 0.89, respectively) due to the relative homogeneity of the “crop” class (only composed of crops) compared to the heterogeneity of the “non-crop” class (composed of forests, water bodies, built-up surfaces, etc.).
The hierarchical approach (first isolating “crop” and “non-crop” domains at level 1, then performing classifications within each domain at following nomenclature levels) improved significantly the accuracy of the classifications for the majority of classes from levels 2 (land cover) to 5 (crop subclass) when compared to the classical approach. However, as expected, rainfed crops were difficult to classify even for major crops such as “maize” and “rainfed rice” (f1-scores of 0.61 and 0.65 at level 5, respectively). This can be attributed to the very small size (often lower than the size of one or two 10 m pixels) of cropped objects within the rainfed area, precluding a pure crop signal at the Sentinel-2 spatial resolution. The configuration of the rainfed cultivated domain composed of a patchwork of small agricultural fields and natural vegetation patches and the frequent practice of mixed cropping also complicated the correct classification of rainfed crops. The presence of mixed pixels in the HRS time series did not affect the classification of cropland (level 1 of the nomenclature) for which accuracy was good, as expected by the study of [
9] which showed that a 10 m spatial resolution was adapted for cropland classification, even in the typical fragmented landscapes of smallholder agricultural areas. However, it seemed to be a major source of error in the classification of more detailed levels (crop group, crop type, crop subclass). The same limits can be observed on more intensive agriculture, for crop type classification of large and regular shaped fields with LSR sensors [
46], as the likelihood of finding mixed pixels is a function of the spatial resolution of the image, the thematic detail to be mapped, and the size and spatial pattern of land cover patches [
47].
By contrast, the classification scheme was shown to be accurate at classifying crops within the irrigated domain, as only irrigated rice occupied this area, resulting in larger patches of the same crop with a specific spectral response due to the presence of a surface water layer. Consequently, “irrigated rice” was classified with a high f1-score of 0.82, allowing for classification of this key crop in terms of food security, with a high level of confidence. All of these results should, however, be interpreted with in mind the fact that the training set represented only 0.038% of the total number of objects in the study area (more the 6 million), whereas studies like [
48] recommend a training set of 0.25% of the whole study area, meaning more than 15,000 training samples in our case. Such maps could be validated according to the method provided by [
49] for area-based and location-based validation of the classified images using OBIA, in order to spatially identify where there is error or uncertainty.
In terms of performance, it is very difficult to compare our results with those of previous studies or even with those of studies performed in the same area or with equivalent agricultural systems since satellite time series (with key dates of data acquisition), ground truth data, and/or nomenclature are rarely the same. For instance, [
22] performed classifications of major crop types of the same site in Madagascar based only on HSR time series (mainly from SPOT4 Take5 experiments), and an RF classifier applied at the pixel level to a reduced set of variables (reflectances and three spectral indices) within a cropland mask. While the authors achieved a classification accuracy of 50.2% for the discrimination of four main crops, we achieved a value of 64.1% at an equivalent nomenclature level for the discrimination of 14 crop classes. As noted above, simple comparisons should be made only with caution.
4.2. Recommendations and Outlooks for the Operational Mapping of Smallholder Agricultural Systems
In our approach, features were extracted from satellite images to build the learning database based on the following assumptions: (i) crops’ spectral and temporal behaviors can be captured through a set of attributes extracted from time series of multispectral images; (ii) the boundaries of structuring objects in a landscape and inside object heterogeneity (texture) can be extracted from VHSR data; and (iii) ancillary environmental data such as the topography extracted from a DEM can be used to discriminate between different land use types in constrained environments (e.g., water available for irrigation in lowlands).
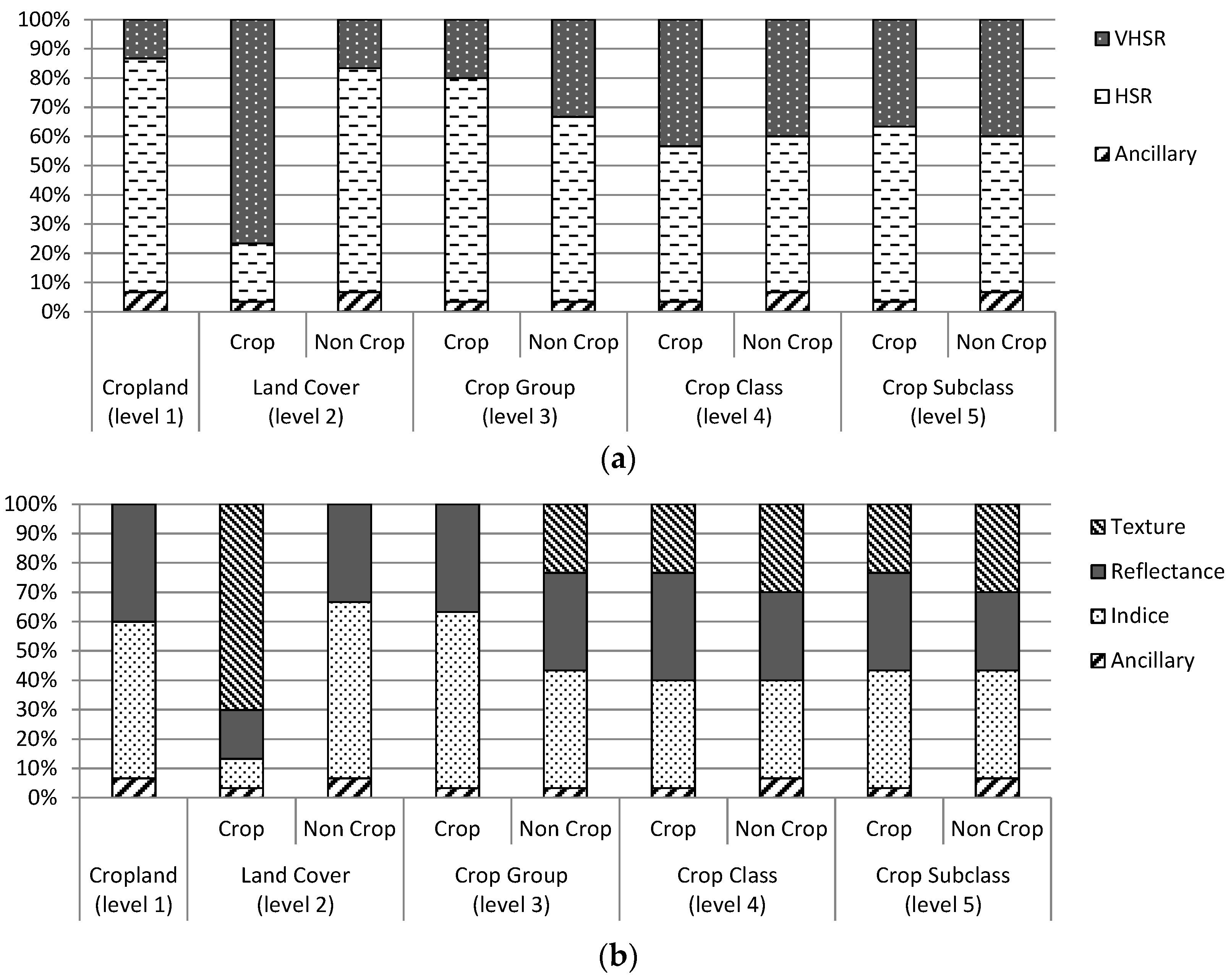
The analysis of the sources of important variables, which were ranked using the MDA measure, showed that the variables derived from the HSR time series were much more informative than the variables derived from VHSR or ancillary data (with the exception of the “ligneous crop”/“annual crop” discrimination, which clearly benefits from the VHSR textural indices). When focusing on types of variables, spectral indices were shown to be the more relevant variables, followed closely by reflectances. This was confirmed through our analysis of the contributions of the different variables to classification accuracy, which showed that eliminating VHSR spectral, textural or ancillary data did not significantly impact the classification results and that spectral indices extracted from the HSR time series were the most discriminant. These results were obtained from an unbalanced small training set, and some studies warn of discrepancies that can be observed in variable importance for such sampling designs [
50]. Despite this fact, our results are consistent with the conclusions of [
27], who used OBIA and decision trees for crop identification with ASTER (Advanced Spaceborne Thermal Emission and Reflection Radiometer) data and showed that textural indices are secondary variables. In conclusion, in this approach, VHSR data are critical for segmentation but are not necessary for classification. In light of this, considerable gains in computation time can be achieved by eliminating VHSR texture calculation and feature extraction tasks.
In this experiment, we also analyzed the performances of our classification approach at different levels of nomenclature, from cropland (two classes) to crop subclass (25 classes). Not surprisingly, the more complex the nomenclature was, the less performing was the approach, especially for classes belonging to cropland. This allowed for identifying the land uses that could be classified with an acceptable accuracy (≥75%) at each nomenclature level. Inside cropland, important crop groups (cereals, fruit crops) and types (rice, fodder crops) were well classified with a class accuracy level above 75%, while for other minor crops, such as leguminous, vegetable, root and tuber crops, accuracy levels between 50% and 60% were achieved. For rice, the dominant crop in the area, our classification approach allowed us to separate rainfed areas from irrigated areas with 82% accuracy (for irrigated rice).
Our results also showed that even when the spatial resolution of a time series is too coarse to obtain a pure signal, temporal information is essential for characterization and discrimination of land uses in such complex small-scale agricultural areas. Improvements in classification accuracy could also be achieved by accounting for the chronology of the time series in Random Forest through the calculation of new variables linked to the phenology, as proposed in [
51,
52] for the MODIS time series, even though [
51] found that phenological variables are less important than reflectances or spectral indices.
Finally, we are aware that the quality of classifications can fluctuate depending on the number and period of clear image acquisition dates. However, the upcoming availability of Sentinel-2 data with a five-day acquisition frequency is expected to improve the probability of obtaining clear images in such tropical and cloudy environments.
5. Conclusions
This paper presents an in-depth study on the use of multisource data for classifying tropical smallholder agriculture at different nomenclature levels using a combined OBIA–Random Forest classification scheme. Our results show that, even for smallholder agricultural systems, maps separating cropland from non-cropland can be produced from a high spatial resolution time series and a very high spatial resolution image with an overall accuracy level above 90% and can be made available for agricultural public policy makers. This type of information is particularly essential for countries that are frequently affected by food crises and where information on acreage and locations of cultivated areas are sorely lacking.
Concerning the characterization of the land use inside the cropland, the major crop group (cereals) and crop type (rice) of the study area were classified well with a class accuracy level close to 80%. For rice, the dominant crop in the area, our classification approach allowed us to separate rainfed areas from irrigated areas with 82% accuracy (for irrigated rice). This information is particularly useful for food security monitoring, as irrigated systems are more productive than rainfed ones, and their relative proportions impact food supply forecasting.
Regarding the availability of data for applying this approach to larger areas, Sentinel-2 time series are now provided on a 10-day basis and will soon be available every five days for the whole country at no charge. This gain in acquisition frequency is particularly important in tropical cloudy areas and is expected to help improving crop classification accuracy thanks to a better description of crop growth. Very high spatial resolution images that are essential in this approach for segmentation of the area into objects remain costly to acquire annually at a regional scale. However, recent initiatives promoting nanosatellites (e.g., Planet®) announce the availability of very high spatial resolution images, with high revisit frequency at reasonable cost.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}