
Mapping Daily Air Temperature for Antarctica Based on MODIS LST

Abstract
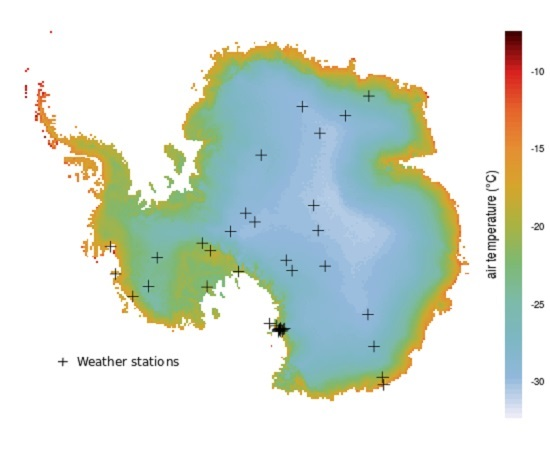
:
1. Introduction
2. Methods
2.1. Data and Preprocessing
2.1.1. MODIS LST
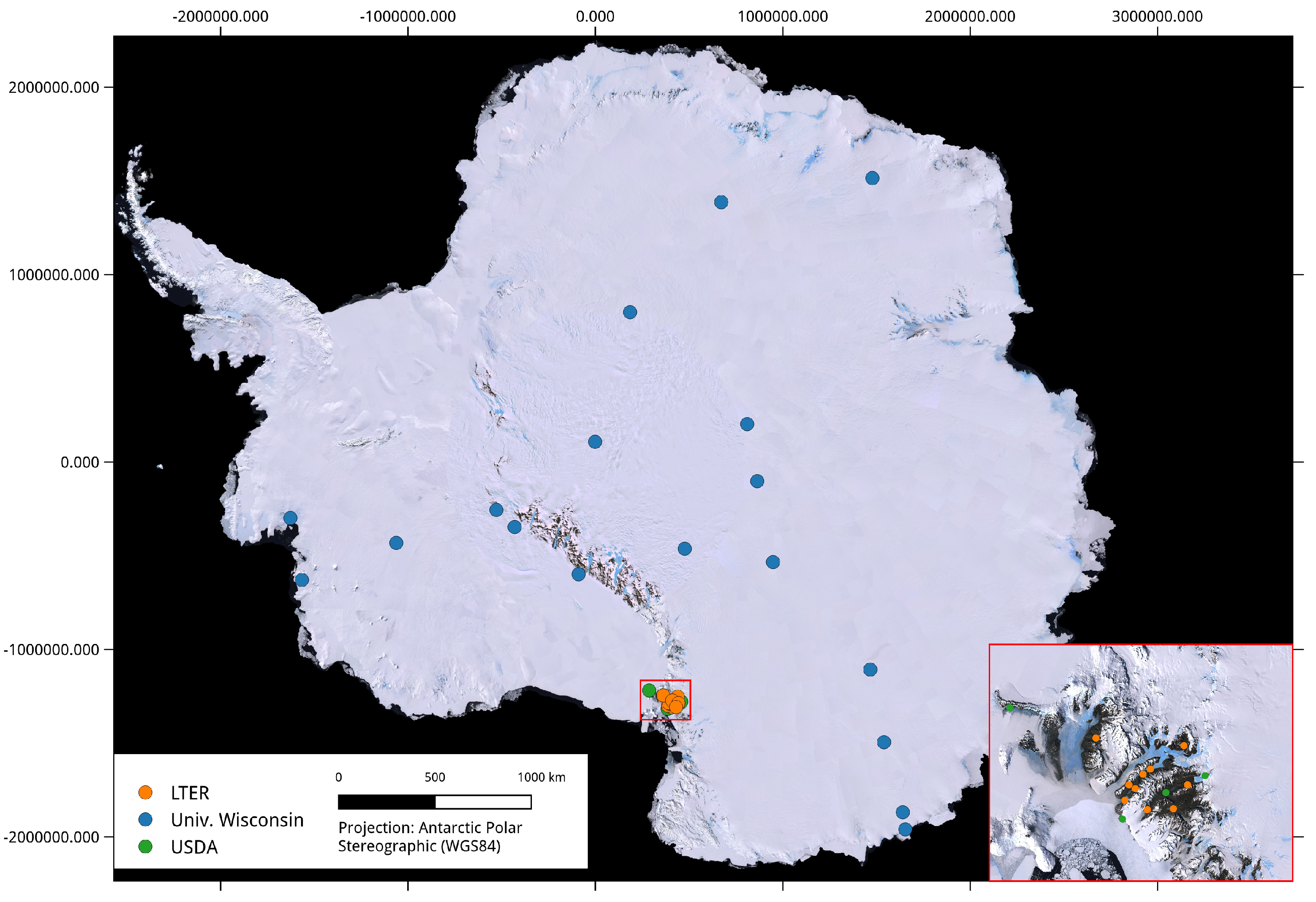
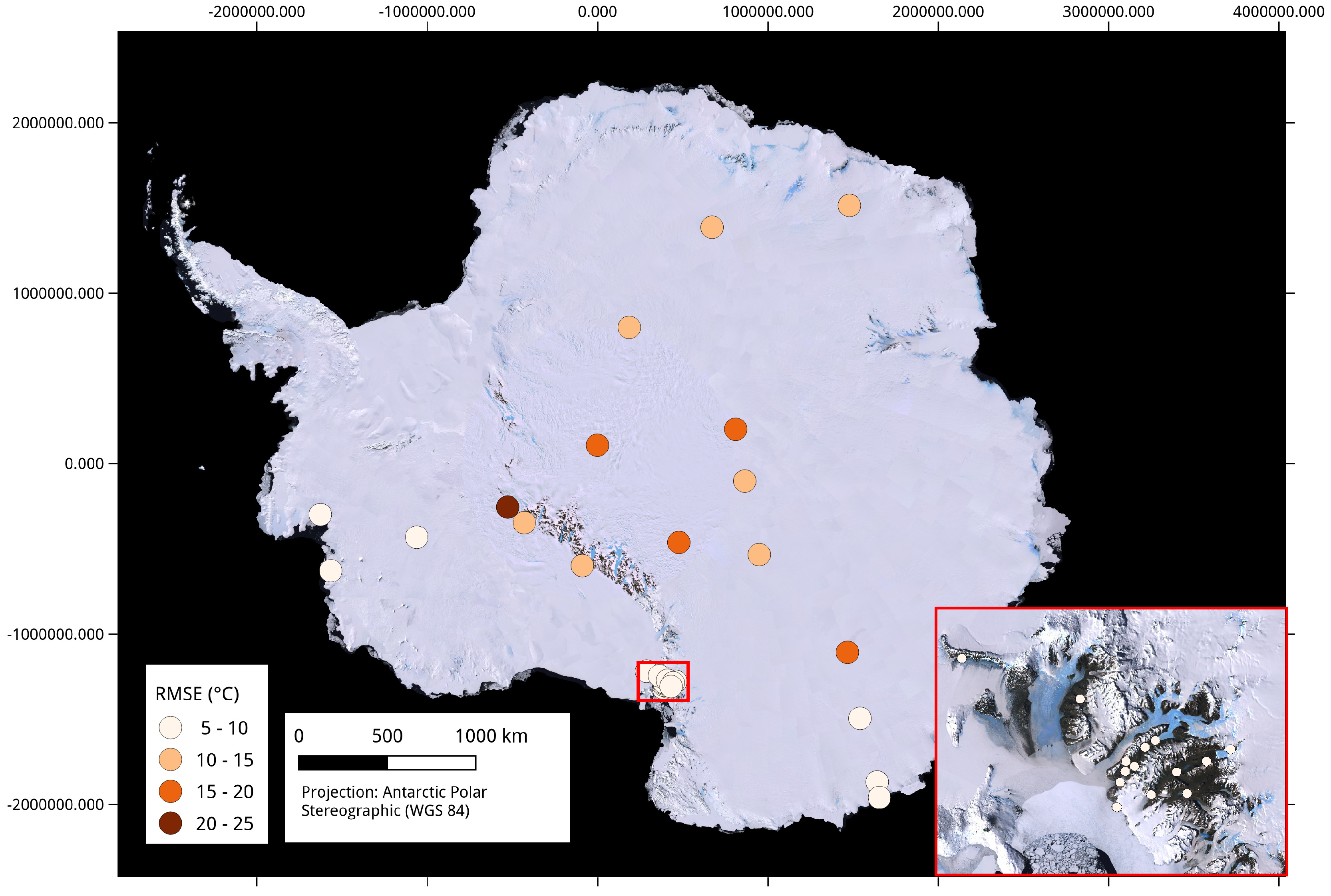
2.1.2. Station Records
2.1.3. Auxiliary Data
2.1.4. Compilation of Model Training and Testing Data
2.2. Modelling
2.2.1. Algorithms
2.2.2. Cross-Validation Strategies and Feature Selection to Minimize Overfitting
2.2.3. Final Model Training, Evaluation and Prediction
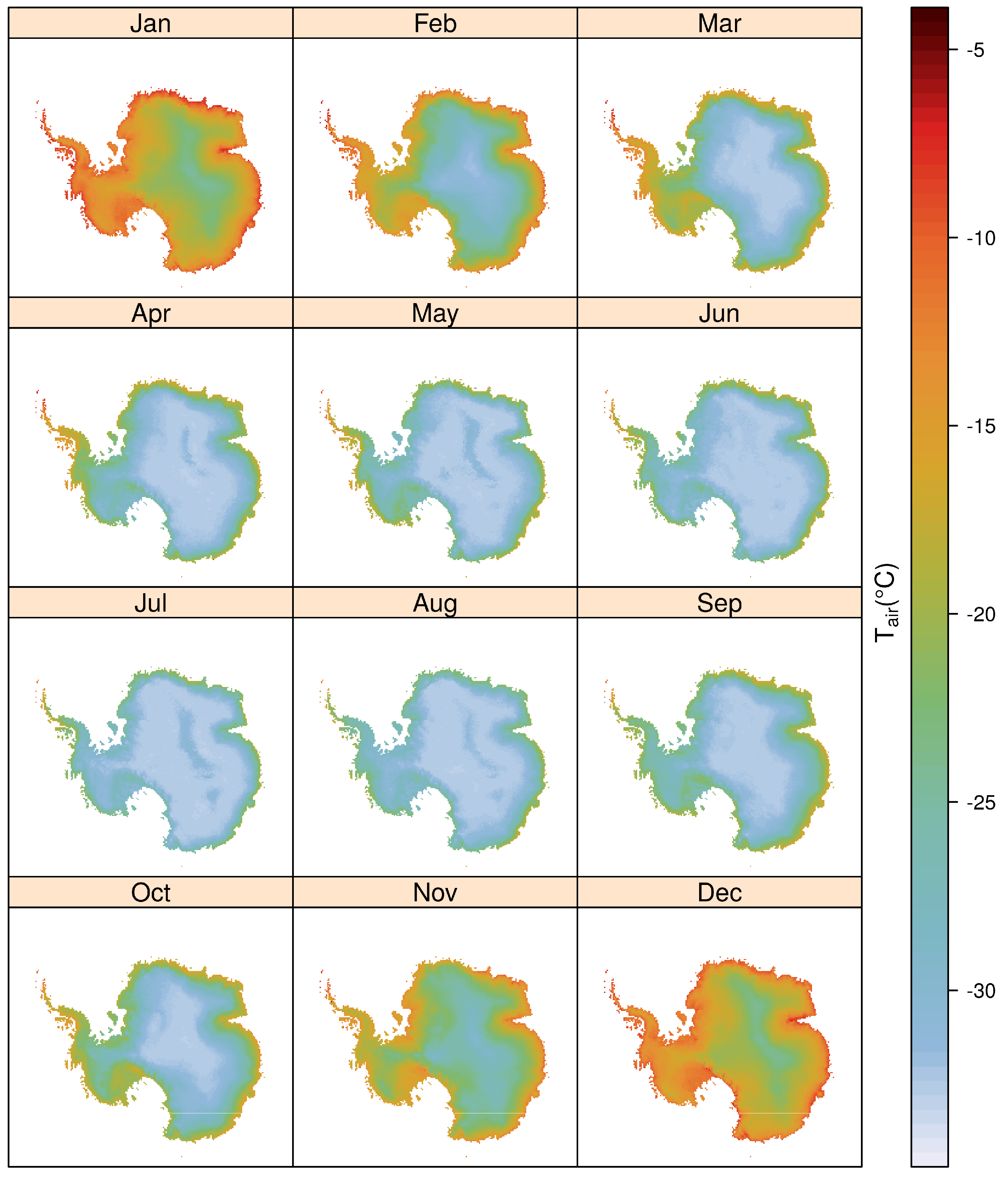
3. Results
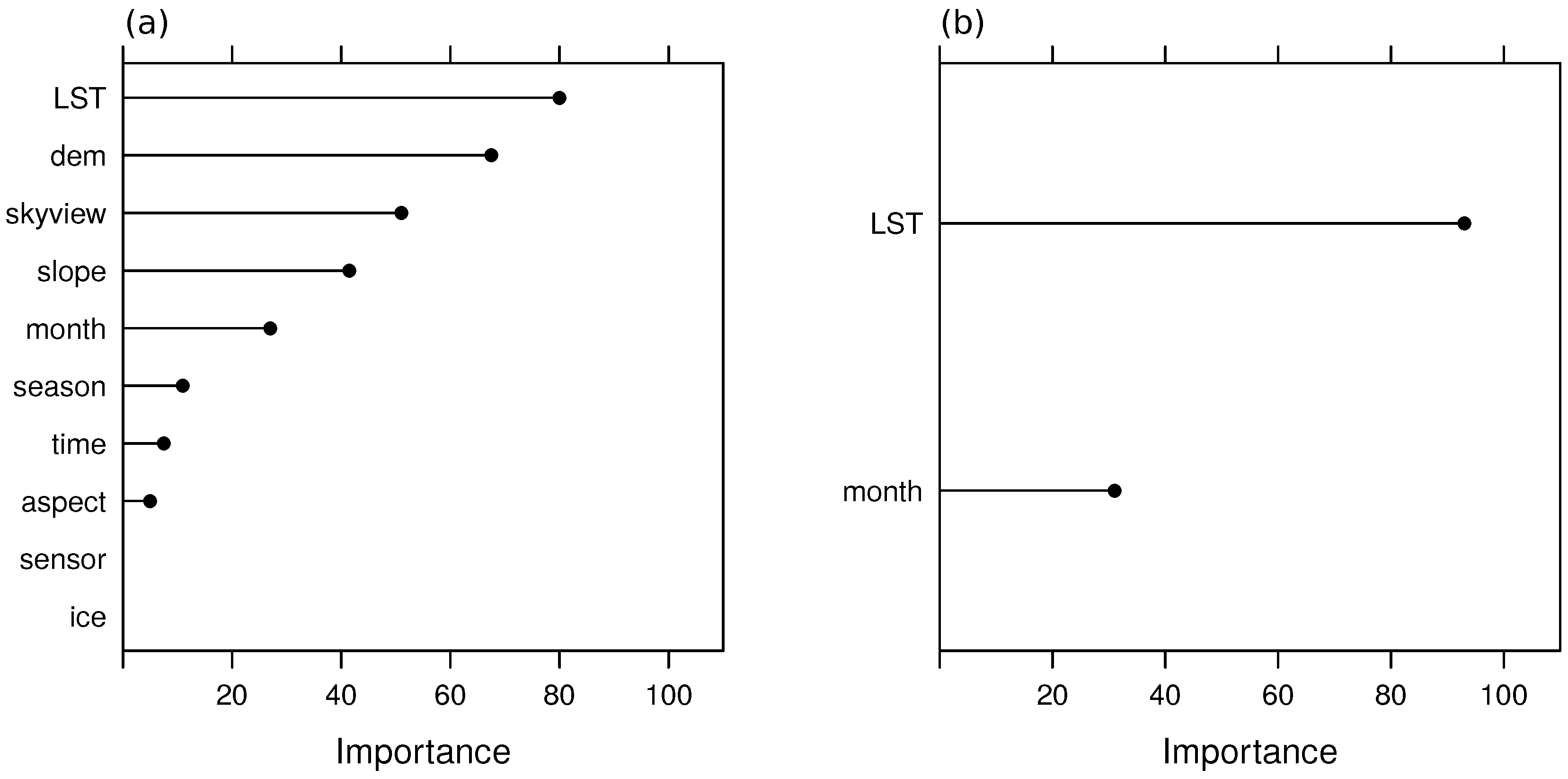
3.1. Selected Features
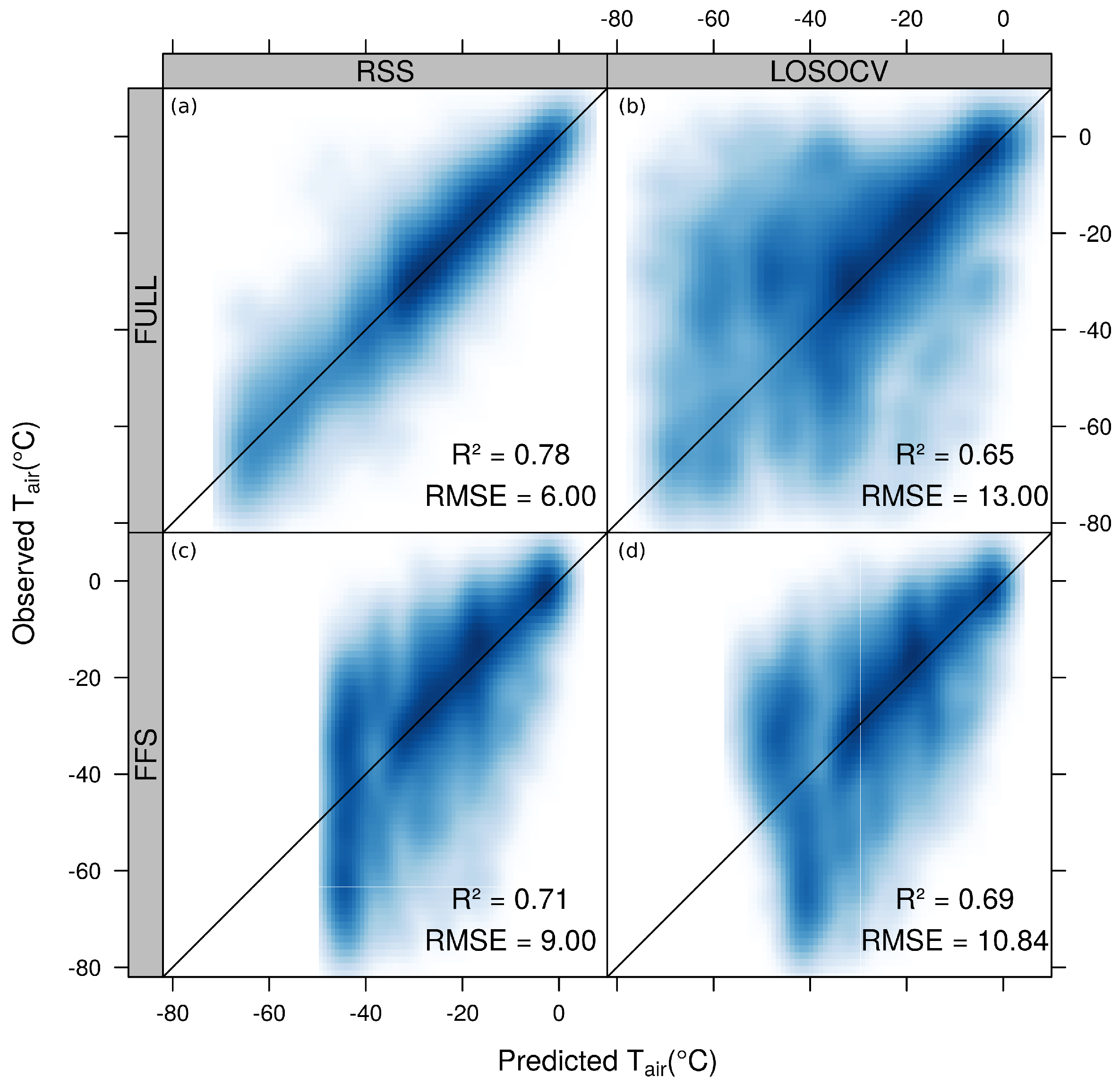
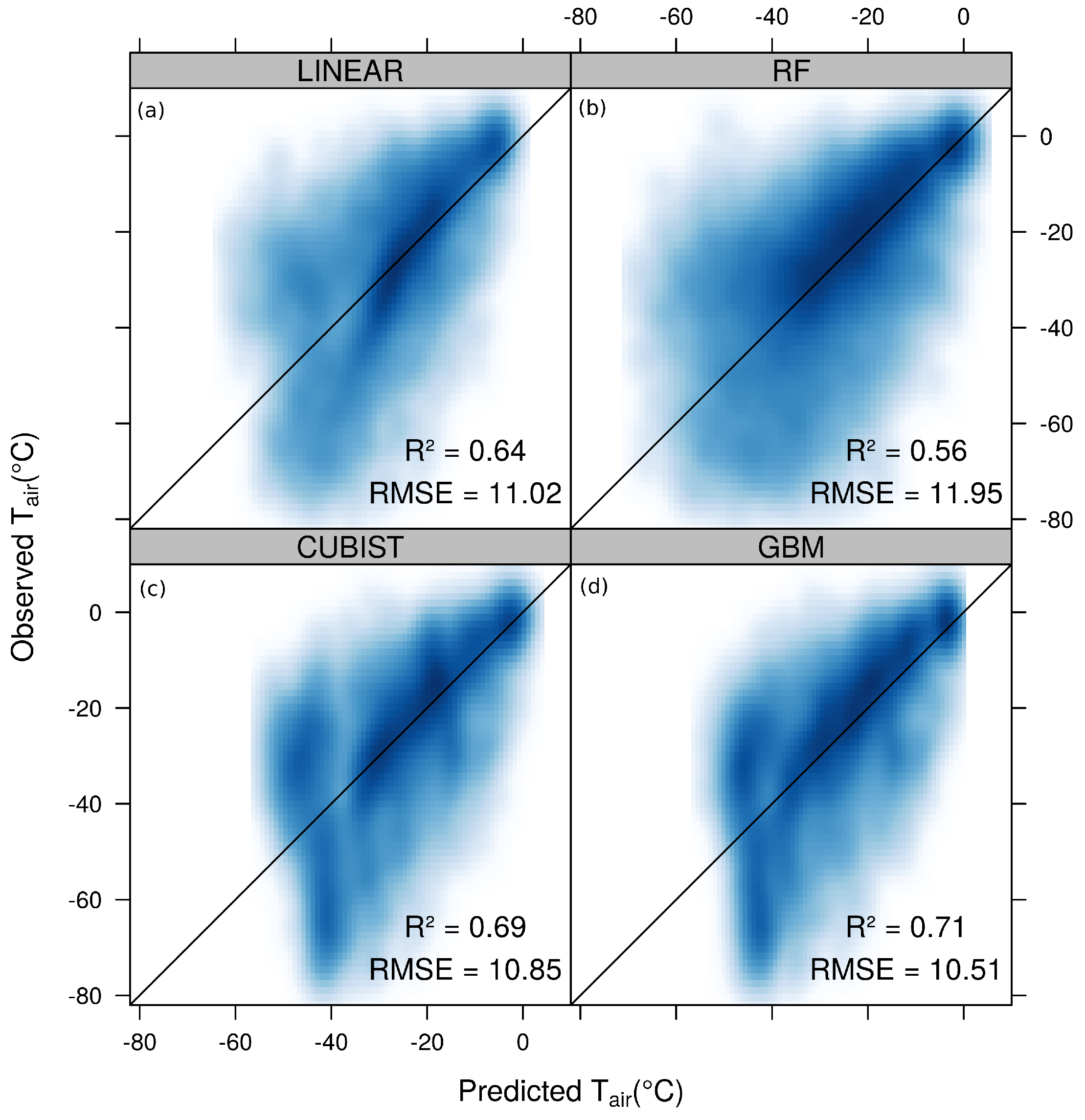
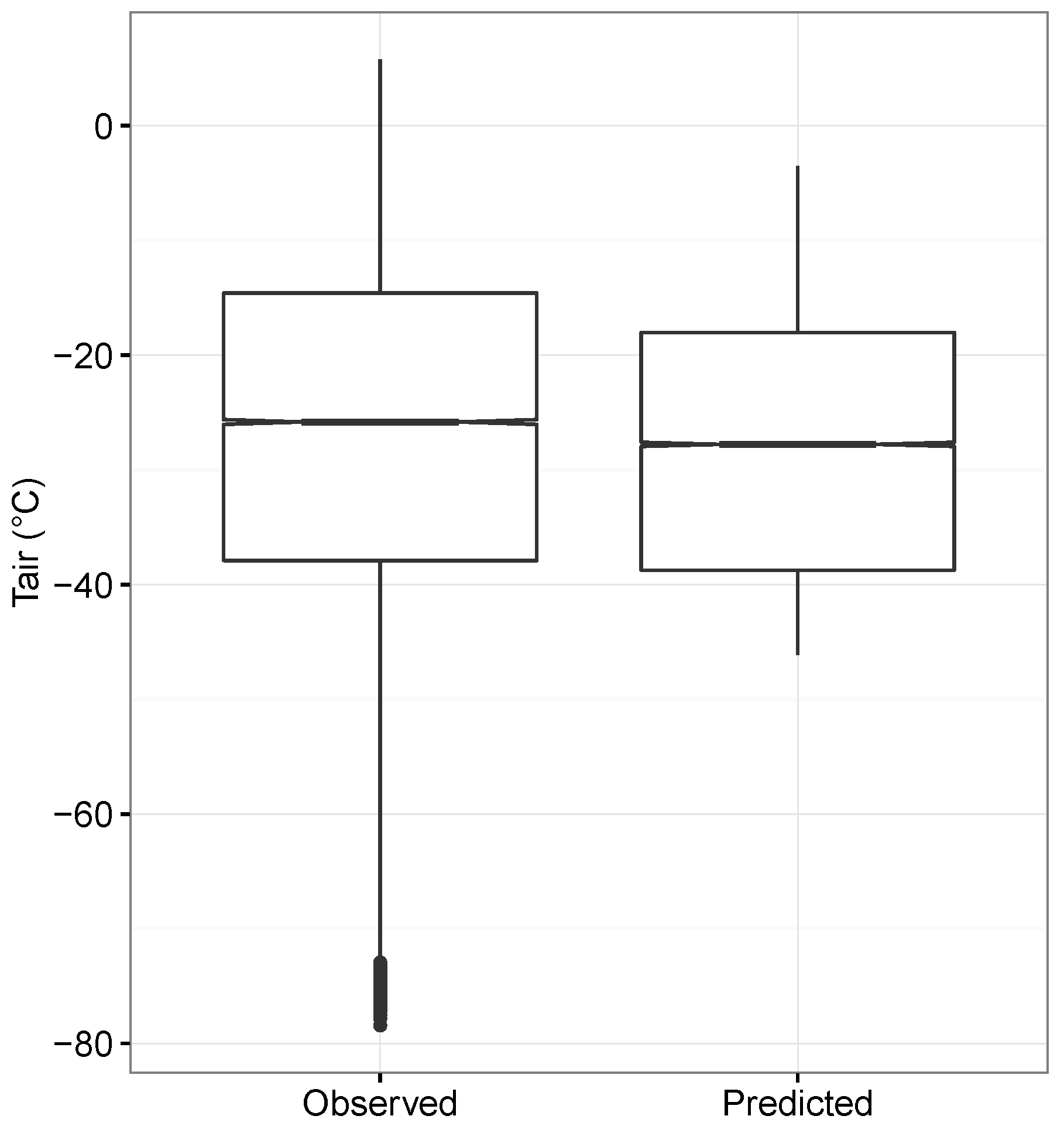
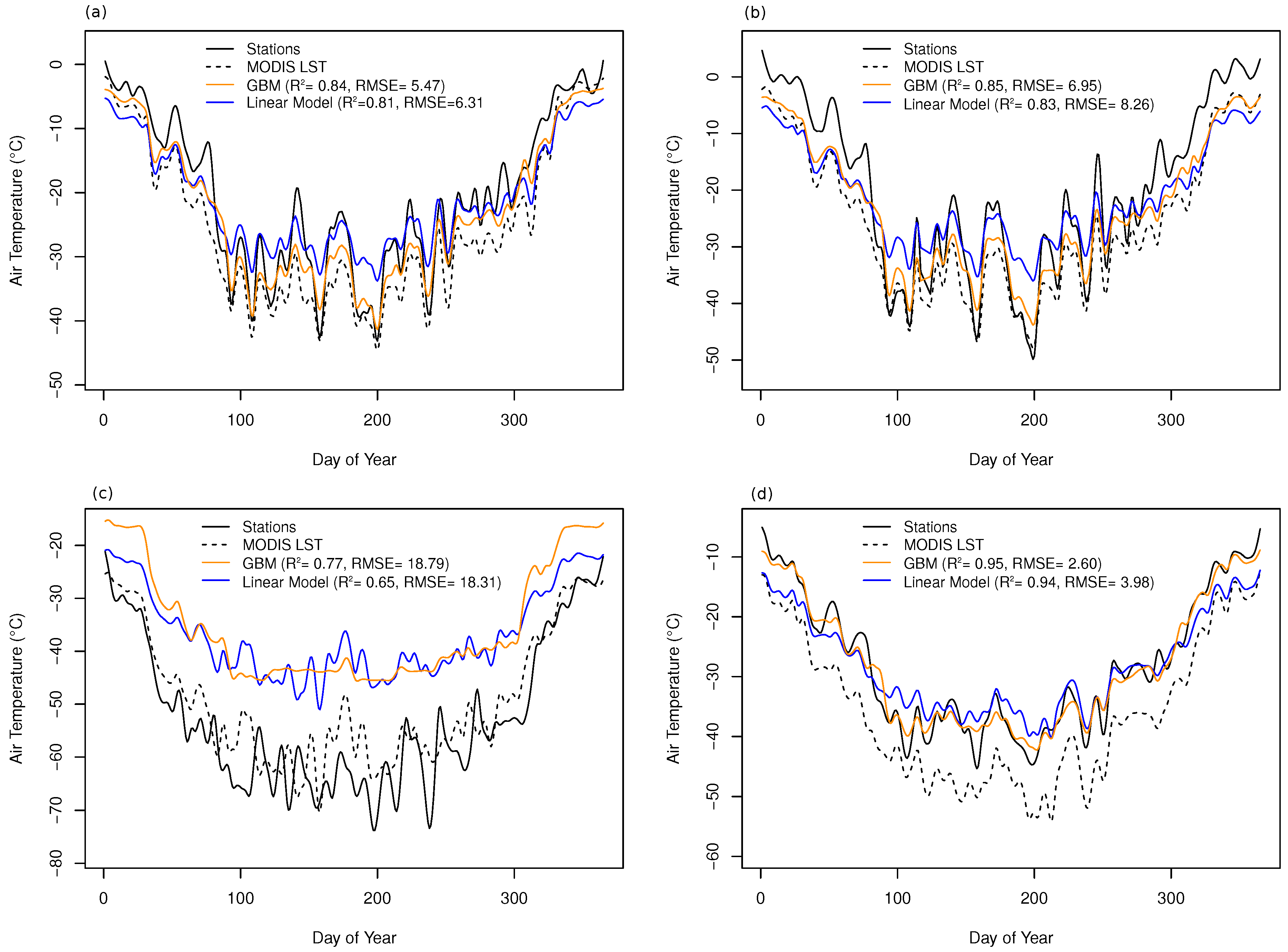
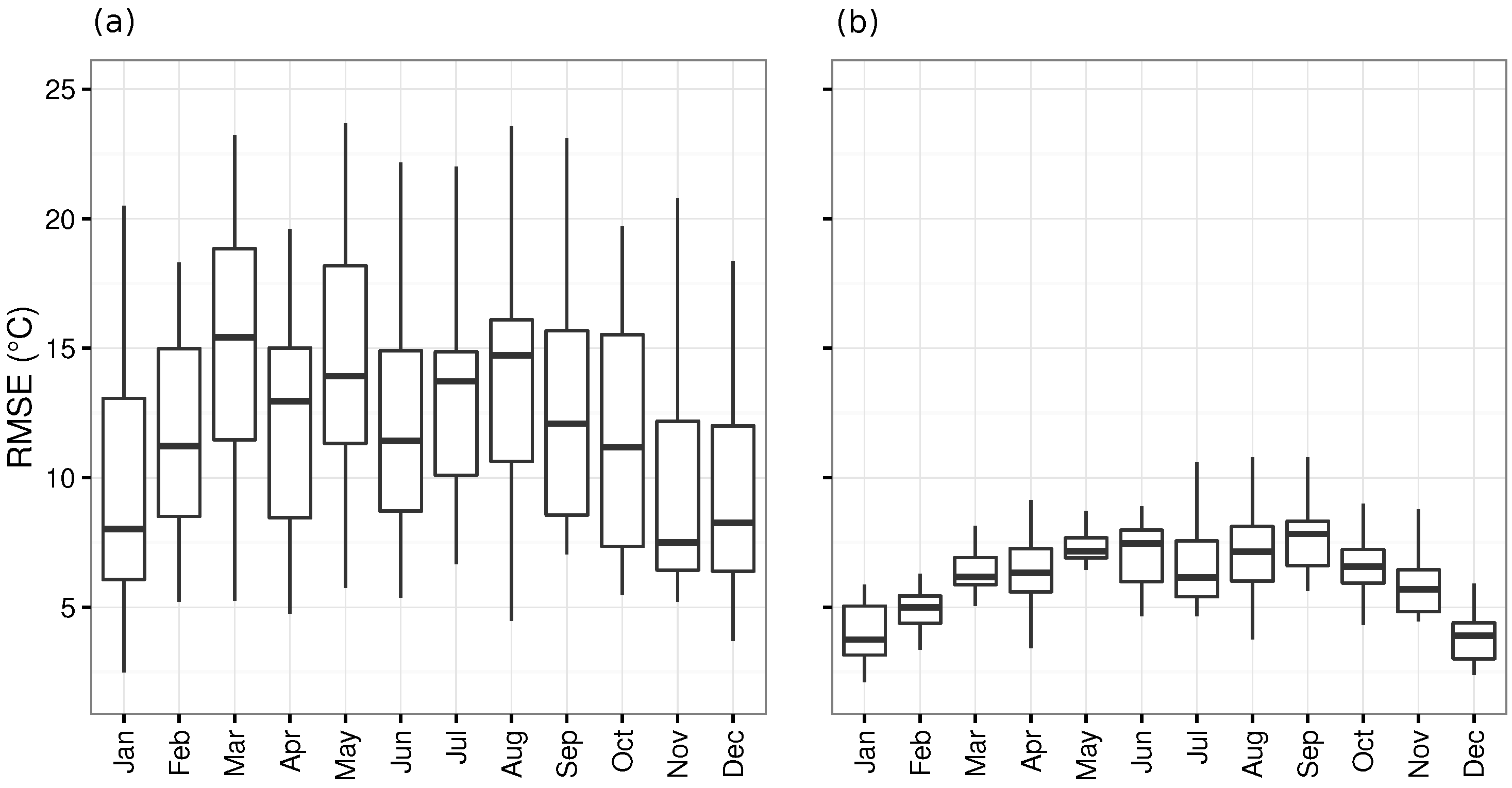
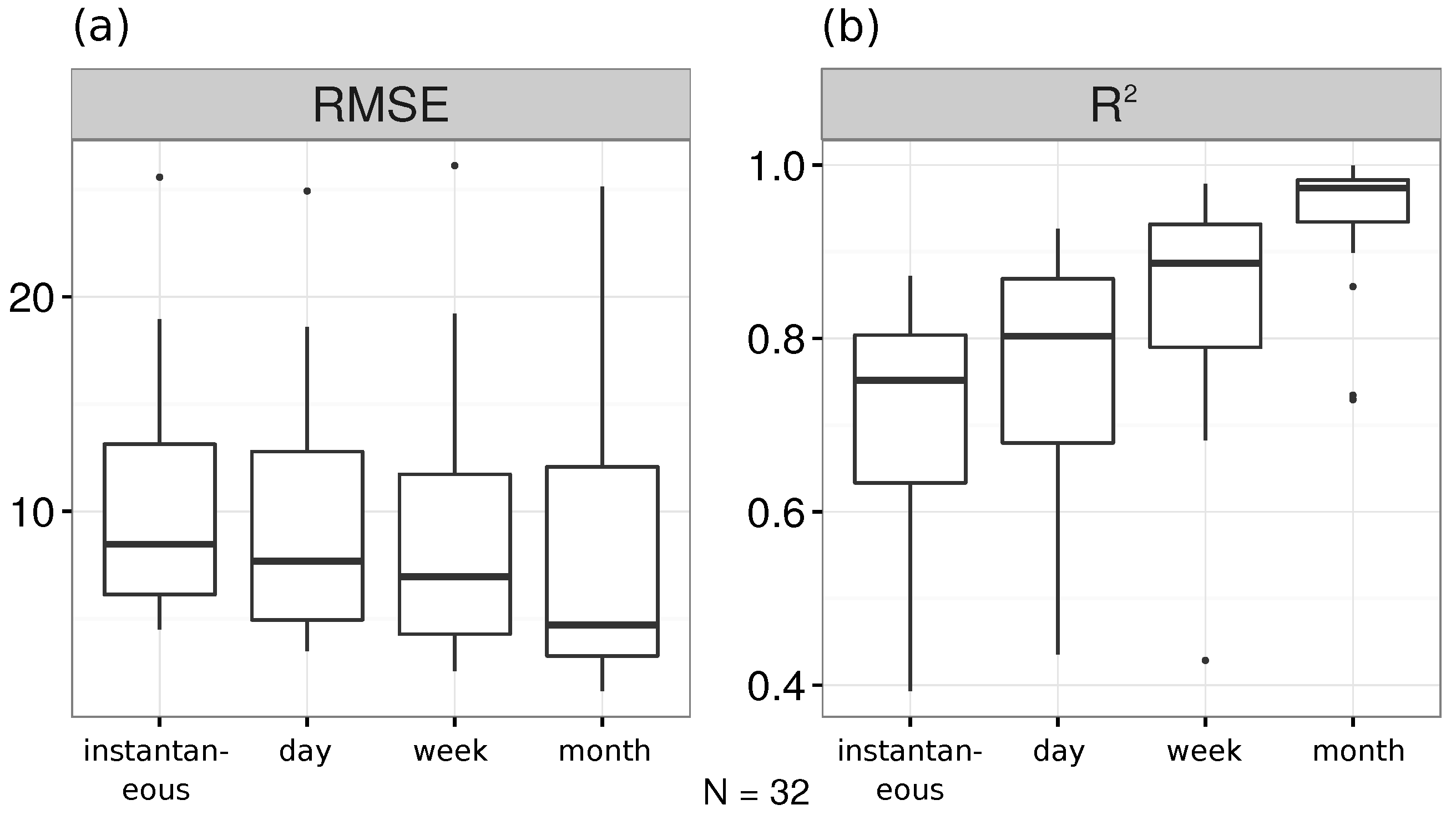
3.2. Model Comparison and Evaluation
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Schneider, D.P.; Reusch, D.B. Antarctic and southern ocean surface temperatures in CMIP5 Models in the context of the surface energy budget. J. Clim. 2016, 29, 1689–1716. [Google Scholar] [CrossRef]
- Appelhans, T.; Mwangomo, E.; Hardy, D.R.; Hemp, A.; Nauss, T. Evaluating machine learning approaches for the interpolation of monthly air temperature at Mt. Kilimanjaro, Tanzania. Spat. Stat. 2015, 14A, 91–113. [Google Scholar] [CrossRef]
- Hofstra, N.; Haylock, M.; New, M.; Jones, P.; Frei, C. Comparison of six methods for the interpolation of daily, European climate data. J. Geophys. Res.-Atmos. 2008, 113, D21110. [Google Scholar] [CrossRef]
- Jarvis, C.H.; Stuart, N. A Comparison among strategies for interpolating maximum and minimum daily air temperatures. Part II: The interaction between number of guiding variables and the type of interpolation method. J. Appl. Meteor. 2001, 40, 1075–1084. [Google Scholar] [CrossRef]
- Stahl, K.; Moore, R.; Floyer, J.; Asplin, M.; McKendry, I. Comparison of approaches for spatial interpolation of daily air temperature in a large region with complex topography and highly variable station density. Agric. For. Meteorol. 2006, 139, 224–236. [Google Scholar] [CrossRef]
- Lazzara, M.A.; Weidner, G.A.; Keller, L.M.; Thom, J.E.; Cassano, J.J. Antarctic automatic weather station program: 30 years of polar observation. Bull. Amer. Meteor. Soc. 2012, 93, 1519–1537. [Google Scholar] [CrossRef]
- Wang, Y.; Hou, S. A new interpolation method for Antarctic surface temperature. Prog. Nat. Sci. 2009, 19, 1843–1849. [Google Scholar] [CrossRef]
- Rhee, J.; Im, J. Estimating high spatial resolution air temperature for regions with limited in situ data using MODIS products. Remote Sens. 2014, 6, 7360–7378. [Google Scholar] [CrossRef]
- Gallo, K.; Hale, R.; Tarpley, D.; Yu, Y. Evaluation of the relationship between air and land surface temperature under clear- and cloudy-sky conditions. J. Appl. Meteor. Climatol. 2011, 50, 767–775. [Google Scholar] [CrossRef]
- Vancutsem, C.; Ceccato, P.; Dinku, T.; Connor, S.J. Evaluation of MODIS land surface temperature data to estimate air temperature in different ecosystems over Africa. Remote Sens. Environ. 2010, 114, 449–465. [Google Scholar] [CrossRef]
- Colombi, A.; De Michele, C.; Pepe, M.; Rampini, A. Estimation of daily mean air temperature from MODIS LST in alpine areas. EARSeL eProced. 2007, 6, 38–46. [Google Scholar]
- Zhu, W.; Lü, A.; Jia, S. Estimation of daily maximum and minimum air temperature using MODIS land surface temperature products. Remote Sens. Environ. 2013, 130, 62–73. [Google Scholar] [CrossRef]
- Sohrabinia, M.; Zawar-Reza, P.; Rack, W. Spatio-temporal analysis of the relationship between LST from MODIS and air temperature in New Zealand. Theor. Appl. Climatol. 2014, 119, 567–583. [Google Scholar] [CrossRef]
- Mostovoy, G.V.; King, R.L.; Reddy, K.R.; Kakani, V.G.; Filippova, M.G. Statistical estimation of daily maximum and minimum air temperatures from MODIS LST data over the state of Mississippi. GISci. Remote Sens. 2006, 43, 78–110. [Google Scholar] [CrossRef]
- Benali, A.; Carvalho, A.; Nunes, J.; Carvalhais, N.; Santos, A. Estimating air surface temperature in Portugal using MODIS LST data. Remote Sens. Environ. 2012, 124, 108–121. [Google Scholar] [CrossRef]
- Neteler, M. Estimating daily land surface temperatures in mountainous environments by reconstructed MODIS LST Data. Remote Sens. 2010, 2, 333–351. [Google Scholar] [CrossRef]
- Huang, R.; Zhang, C.; Huang, J.; Zhu, D.; Wang, L.; Liu, J. Mapping of daily mean air temperature in agricultural regions using daytime and nighttime land surface temperatures derived from TERRA and AQUA MODIS data. Remote Sens. 2015, 7, 8728–8756. [Google Scholar] [CrossRef]
- Kilibarda, M.; Hengl, T.; Heuvelink, G.B.M.; Gräler, B.; Pebesma, E.; Perčec Tadić, M.; Bajat, B. Spatio-temporal interpolation of daily temperatures for global land areas at 1 km resolution. J. Geophys. Res.-Atmos. 2014, 119, 2294–2313. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, M.; Zhao, J. A comparison of MODIS LST retrievals with in situ observations from AWS over the lambert glacier basin, East Antarctica. Int. J. Geosci. 2013, 4, 611–617. [Google Scholar] [CrossRef]
- Xu, Y.; Qin, Z.; Shen, Y. Study on the estimation of near-surface air temperature from MODIS data by statistical methods. Int. J. Remote Sens. 2012, 33, 7629–7643. [Google Scholar] [CrossRef]
- Janatian, N.; Sadeghi, M.; Sanaeinejad, S.H.; Bakhshian, E.; Farid, A.; Hasheminia, S.M.; Ghazanfari, S. A statistical framework for estimating air temperature using MODIS land surface temperature data. Int. J. Climatol. 2016. [Google Scholar] [CrossRef]
- Emamifar, S.; Rahimikhoob, A.; Noroozi, A.A. Daily mean air temperature estimation from MODIS land surface temperature products based on M5 model tree. Int. J. Climatol. 2013, 33, 3174–3181. [Google Scholar] [CrossRef]
- Xu, Y.; Knudby, A.; Ho, H.C. Estimating daily maximum air temperature from MODIS in British Columbia, Canada. Int. J. Remote Sens. 2014, 35, 8108–8121. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Wan, Z. New refinements and validation of the MODIS Land-Surface Temperature/Emissivity products. Remote Sens. Environ. 2008, 112, 59–74. [Google Scholar] [CrossRef]
- Land Processes Distributed Active Archive Center (LP DAAC). MODIS Level 3 Land Surface Temperature and Emissivity; Version 3; Land Processes DAAC: Sioux Falls, SD, USA, 2013.
- Ackerman, S.A.; Strabala, K.I.; Menzel, W.P.; Frey, R.A.; Moeller, C.C.; Gumley, L.E. Discriminating clear sky from clouds with MODIS. J. Geophys. Res.-Atmos. 1998, 103, 32141–32157. [Google Scholar] [CrossRef]
- Westermann, S.; Langer, M.; Boike, J. Systematic bias of average winter-time land surface temperatures inferred from MODIS at a site on Svalbard, Norway. Remote Sens. Environ. 2012, 118, 162–167. [Google Scholar] [CrossRef] [Green Version]
- Doran, P.T.; Dana, G.; Hastings, J.T.; Wharton, R.A. McMurdo Dry Valleys Long-Term Ecological Research (LTER): LTER automatic weather network (LAWN). Antarc. J. US 1995, 30, 276–280. [Google Scholar]
- Seybold, C.A.; Harms, D.S.; Balks, M.; Aislabie, J.; Paetzold, R.F.; Kimble, J.; Sletten, R. Soil climate monitoring projectin the ross island region of Antarctica. Soil Surv. Horiz. 2009, 50, 52–57. [Google Scholar] [CrossRef]
- US Geological Survey. Landsat Image Mosaic of Antarctica (LIMA): U.S Geological Survey Fact Sheet 2007–3116; US Geological Survey: Reston, VA, USA, 2007.
- Liu, H.; Jezek, K.C.; Li, B.; Zhao, Z. Radarsat Antarctic Mapping Project Digital Elevation Model; Version 2; National Snow and Ice Data Center: Boulder, CO, USA, 2015. [Google Scholar]
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef]
- Fretwell, P.; Pritchard, H.D.; Vaughan, D.G.; Bamber, J.L.; Barrand, N.E.; Bell, R.; Bianchi, C.; Bingham, R.G.; Blankenship, D.D.; Casassa, G.; et al. Bedmap2: Improved ice bed, surface and thickness datasets for Antarctica. The Cryosphere 2013, 7, 375–393. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M. Caret: Classification and Regression Training, R package version 6.0-29; CRAN: Wien, Austria, 2014.
- Ridgeway, G. gbm: Generalized Boosted Regression Models, R package version 2.1.1; CRAN: Wien, Austria, 2015.
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Kuhn, M.; Weston, S.; Keefer, C.; Coulter, N.; Quinlan, R. Cubist: Rule- and Instance-Based Regression Modeling, R package version 0.0.18; CRAN: Wien, Austria, 2014.
- Revolution Analytics.; Weston, S. doParallel: Foreach Parallel Adaptor for the Parallel Package, R package version 1.0.8; CRAN: Wien, Austria, 2014.
- Gasch, C.K.; Hengl, T.; Gräler, B.; Meyer, H.; Magney, T.S.; Brown, D.J. Spatio-temporal interpolation of soil water, temperature, and electrical conductivity in 3D + T: The Cook Agronomy Farm data set. Spat. Stat. 2015, 14A, 70–90. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Hengl, T.; Heuvelink, G.B.M.; Perčec Tadić, M.; Pebesma, E.J. Spatio-temporal prediction of daily temperatures using time-series of MODIS LST images. Theor. Appl. Climatol. 2011, 107, 265–277. [Google Scholar] [CrossRef]
- Shi, L.; Liu, P.; Kloog, I.; Lee, M.; Kosheleva, A.; Schwartz, J. Estimating daily air temperature across the Southeastern United States using high-resolution satellite data: A statistical modeling study. Environ. Res. 2016, 146, 51–58. [Google Scholar] [CrossRef] [PubMed]
- Bromwich, D.H.; Nicolas, J.P.; Monaghan, A.J.; Lazzara, M.A.; Keller, L.M.; Weidner, G.A.; Wilson, A.B. Central West Antarctica among the most rapidly warming regions on Earth. Nat. Geosci. 2013, 6, 139–145. [Google Scholar] [CrossRef]
- Allen, R., Jr.; Durkee, P.A.; Wash, C.H. Snow/Cloud Discrimination with Multispectral Satellite Measurements. J. Appl. Meteorol. 1990, 29, 994–1004. [Google Scholar] [CrossRef]
- Jin, M.; Dickinson, R.E. Interpolation of surface radiative temperature measured from polar orbiting satellites to a diurnal cycle: 1. Without clouds. J. Geophys. Res.-Atmos. 1999, 104, 2105–2116. [Google Scholar] [CrossRef]
- Convey, P.; Chown, S.L.; Clarke, A.; Barnes, D.K.A.; Bokhorst, S.; Cummings, V.; Ducklow, H.W.; Frati, F.; Green, T.G.A.; Gordon, S.; et al. The spatial structure of Antarctic biodiversity. Ecol. Monogr. 2014, 84, 203–244. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Hyperparameter | Tested Values | Optimal Value |
|---|---|---|---|
| Random Forest | mtry | 2 to N with increment 1 | 2 |
| Cubist | committees | 1 to 50 with increment 5 | 31 |
| neighbors | 0 to 9 with increment 1 | 0 | |
| GBM | number of trees | 25 to 500 with increment 25 | 75 |
| max depth of interactions | 1 to N with increment 1 | 1 | |
| shrinkage | 0.01, 0.1 | 0.01 | |
| min observations in terminal nodes | 10 | 10 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meyer, H.; Katurji, M.; Appelhans, T.; Müller, M.U.; Nauss, T.; Roudier, P.; Zawar-Reza, P. Mapping Daily Air Temperature for Antarctica Based on MODIS LST. Remote Sens. 2016, 8, 732. https://doi.org/10.3390/rs8090732
Meyer H, Katurji M, Appelhans T, Müller MU, Nauss T, Roudier P, Zawar-Reza P. Mapping Daily Air Temperature for Antarctica Based on MODIS LST. Remote Sensing. 2016; 8(9):732. https://doi.org/10.3390/rs8090732
Chicago/Turabian StyleMeyer, Hanna, Marwan Katurji, Tim Appelhans, Markus U. Müller, Thomas Nauss, Pierre Roudier, and Peyman Zawar-Reza. 2016. "Mapping Daily Air Temperature for Antarctica Based on MODIS LST" Remote Sensing 8, no. 9: 732. https://doi.org/10.3390/rs8090732