Residual Dense Network Based on Channel-Spatial Attention for the Scene Classification of a High-Resolution Remote Sensing Image


Abstract
:
1. Introduction
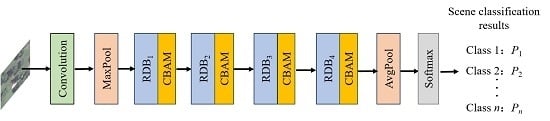
2. Structure of the Proposed Residual Dense Network Based on Channel-Spatial Attention
3. Deep Feature Extraction of a High-Resolution Remote Sensing Image
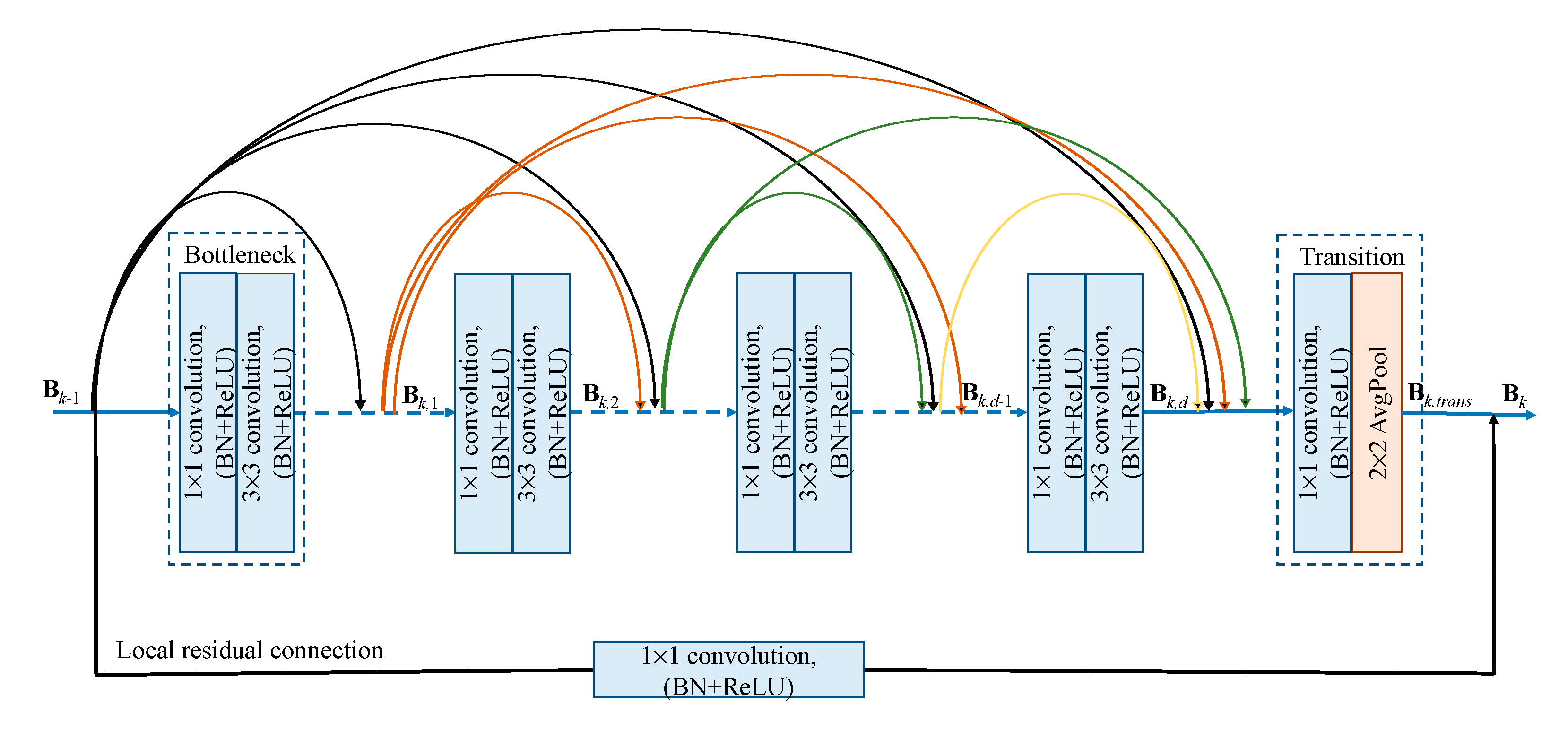
3.1. Residual Dense Blocks for Multilayer Feature Fusion
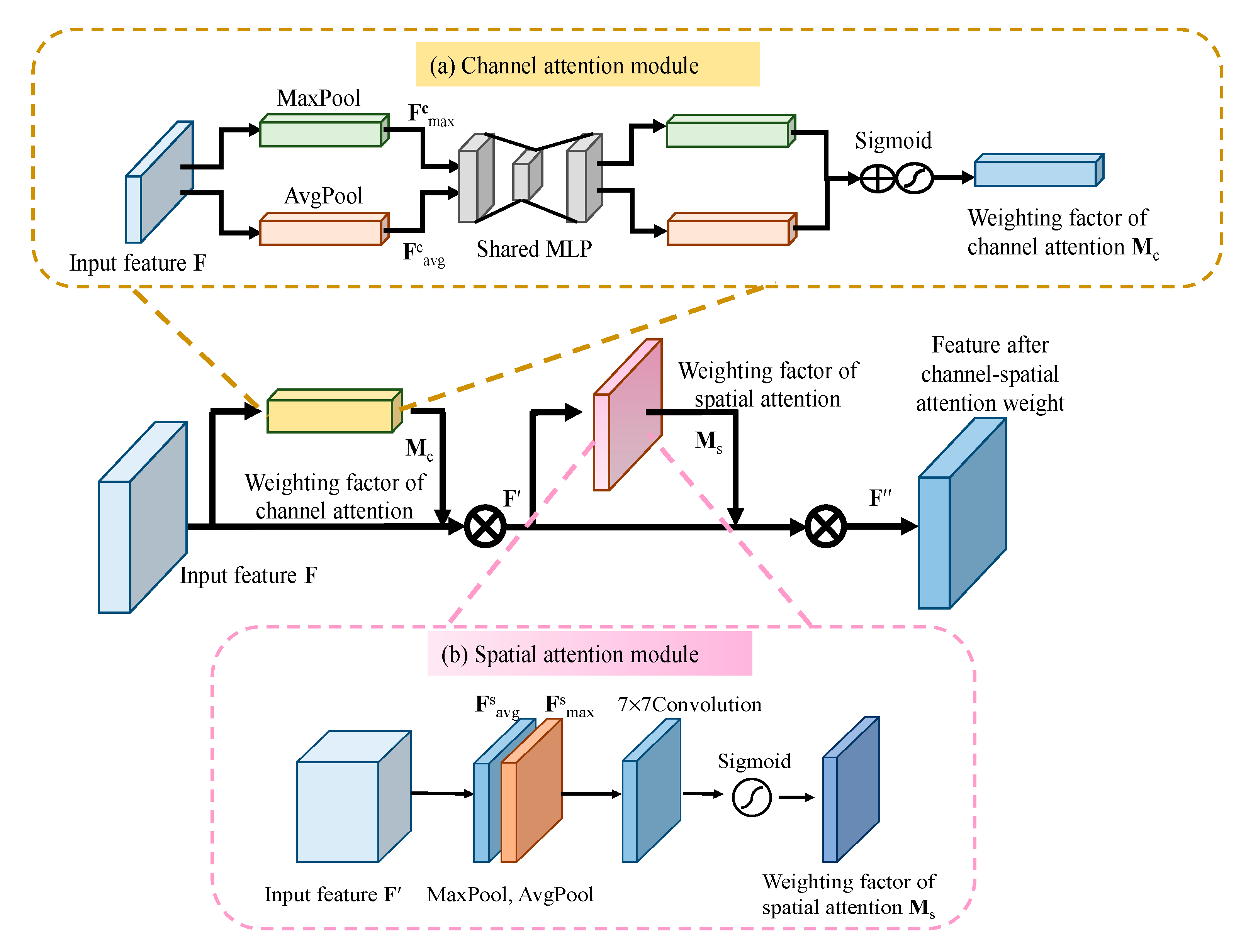
3.2. Channel-Spatial Attention Module for Feature Refinement
4. Scene Classification of High-Resolution Remote Sensing Image
4.1. Data Augmentation
4.2. Scene Classification
5. Experimental Results
5.1. Experiment Details
5.2. Experiment I: Effect of the Combination of Residual Connection and Dense Connection
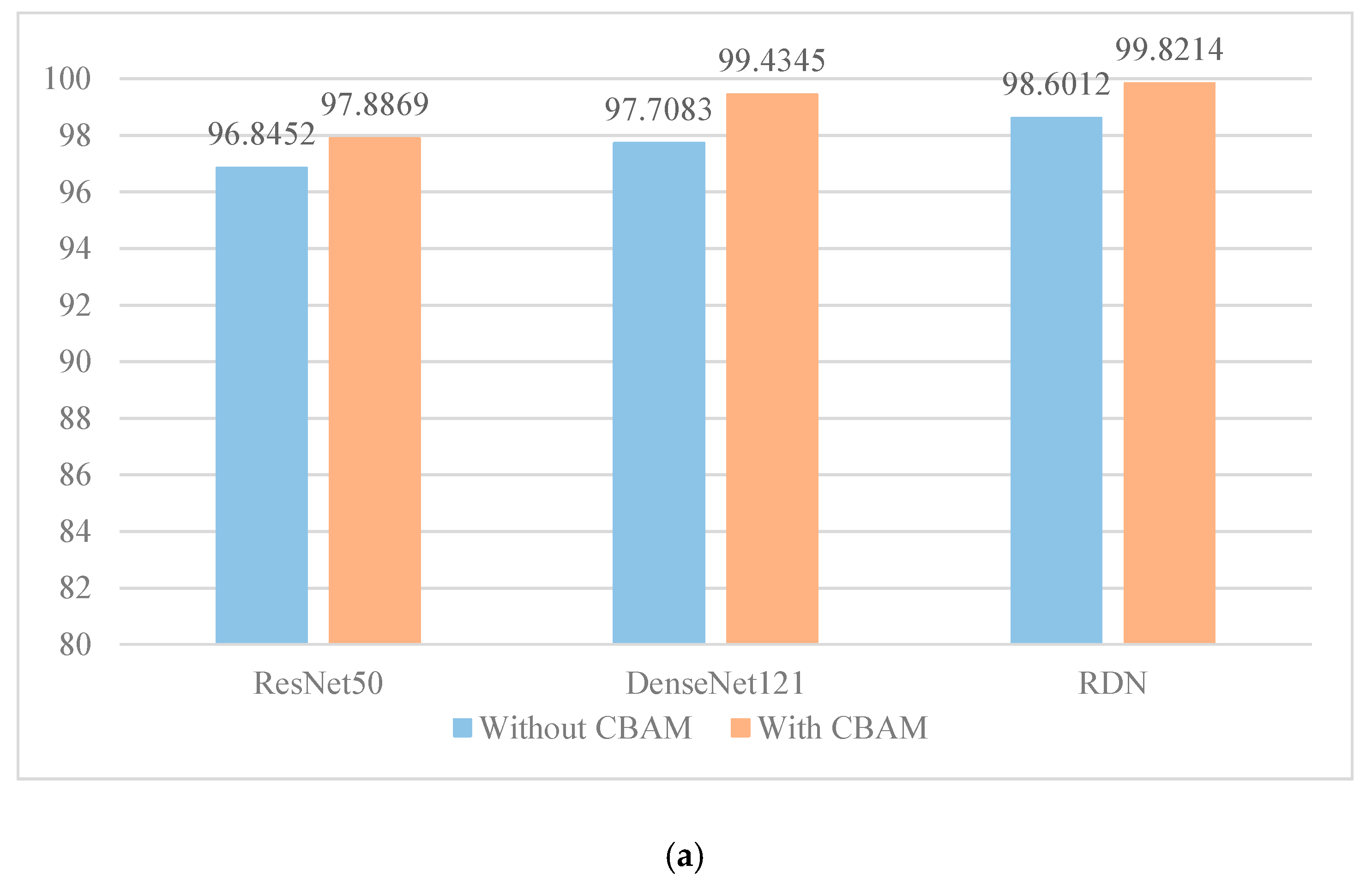
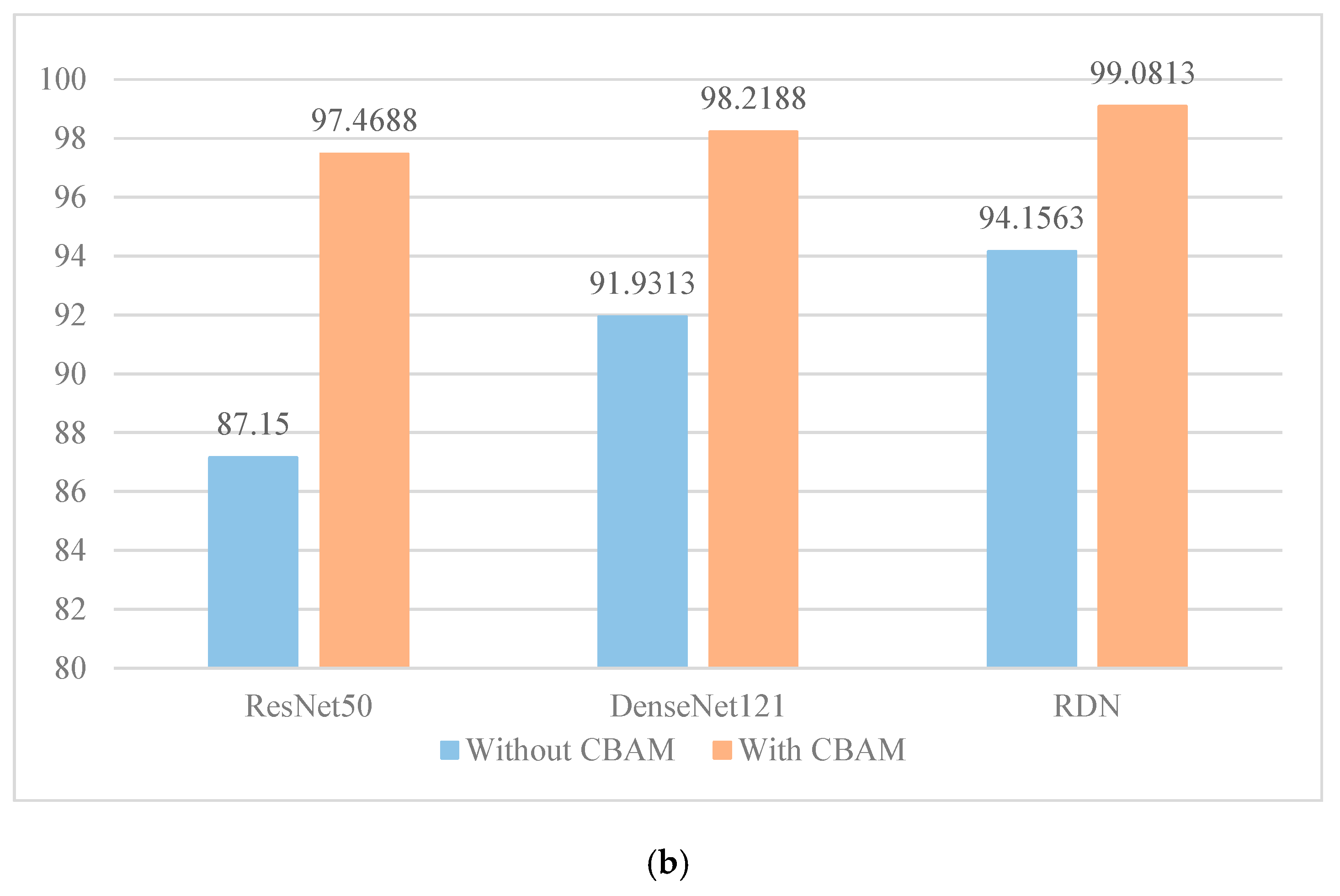
5.3. Experiment II: Effect of the Channel-Spatial Attention Module
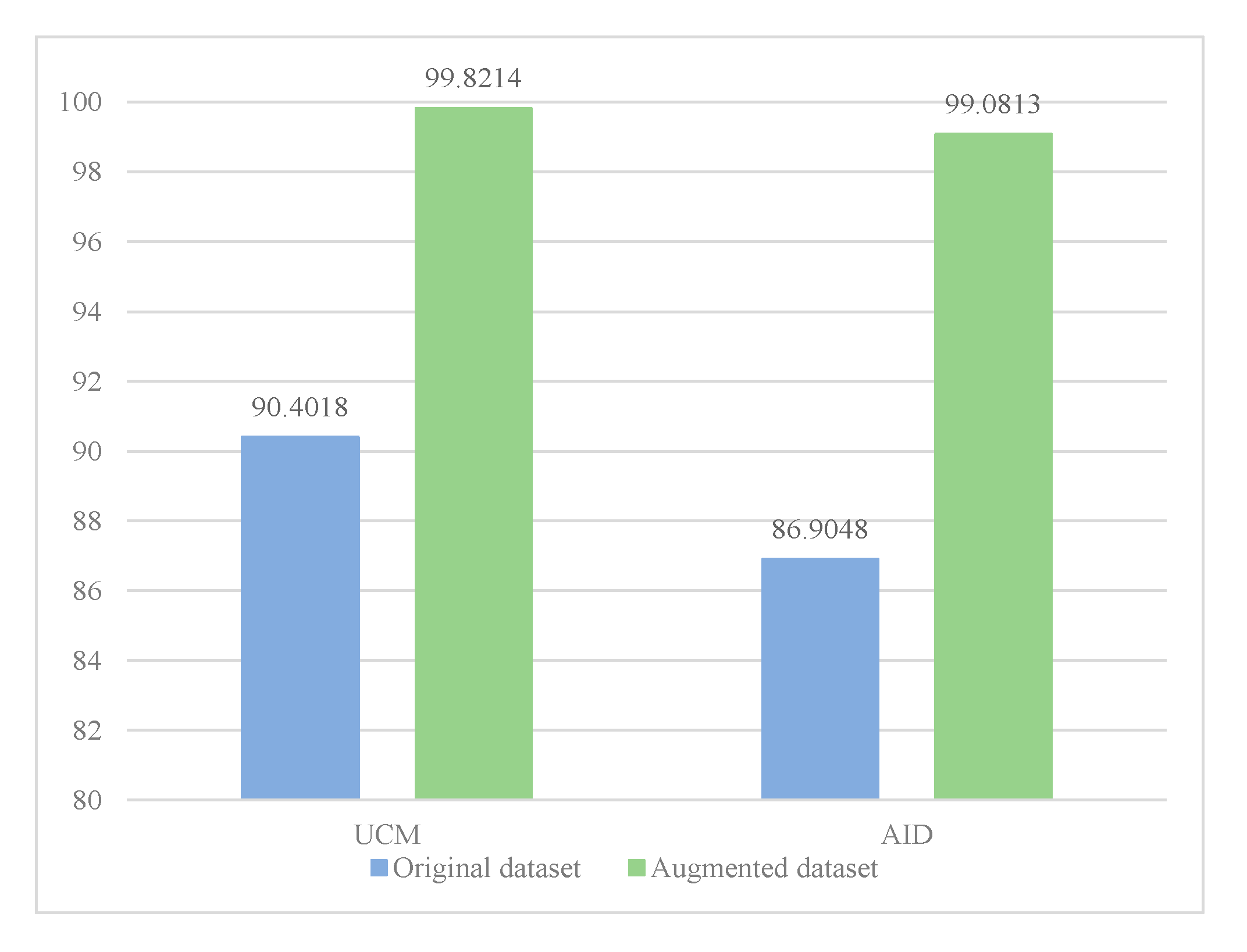
5.4. Experiment III: Effect of Dataset Augmentation
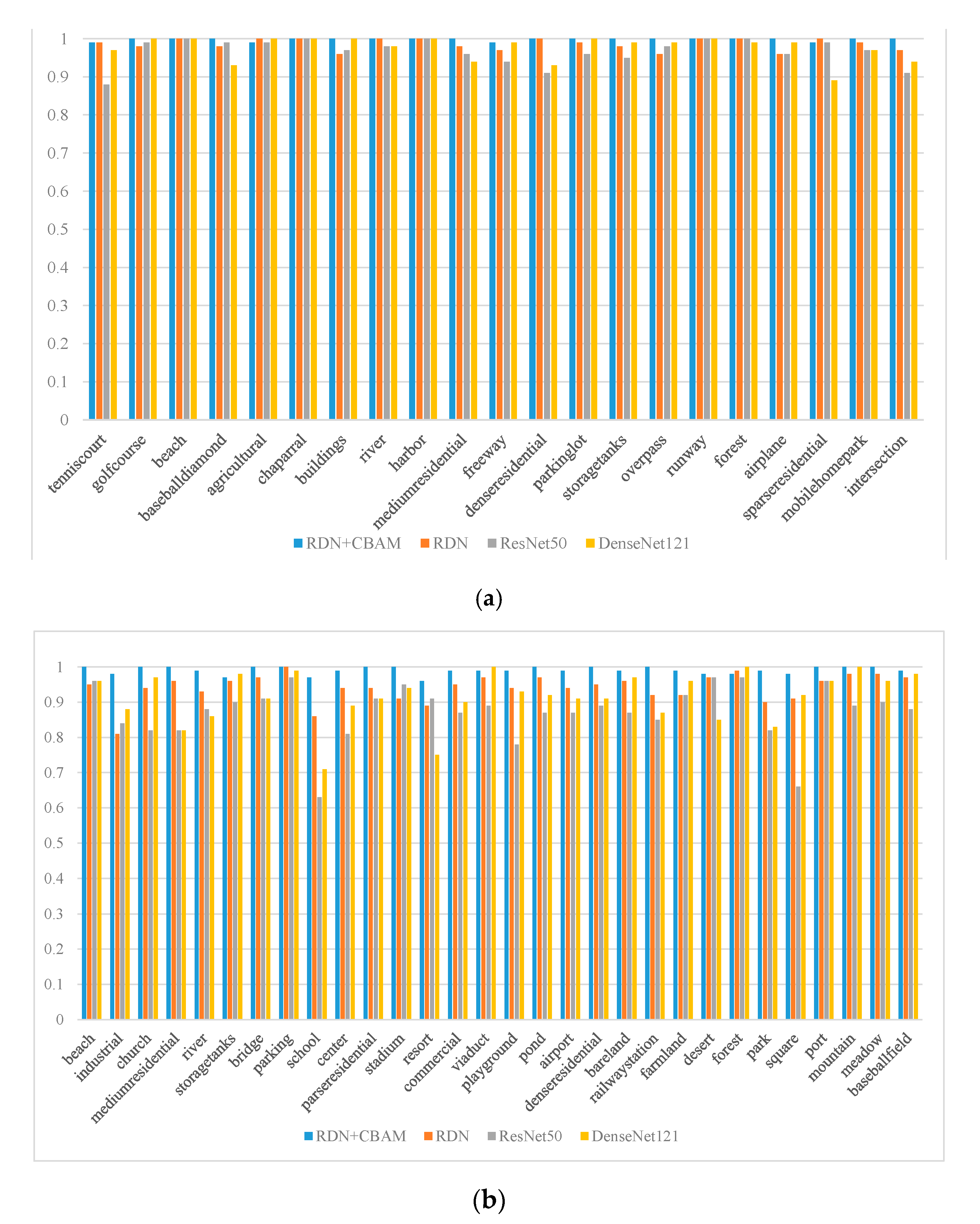
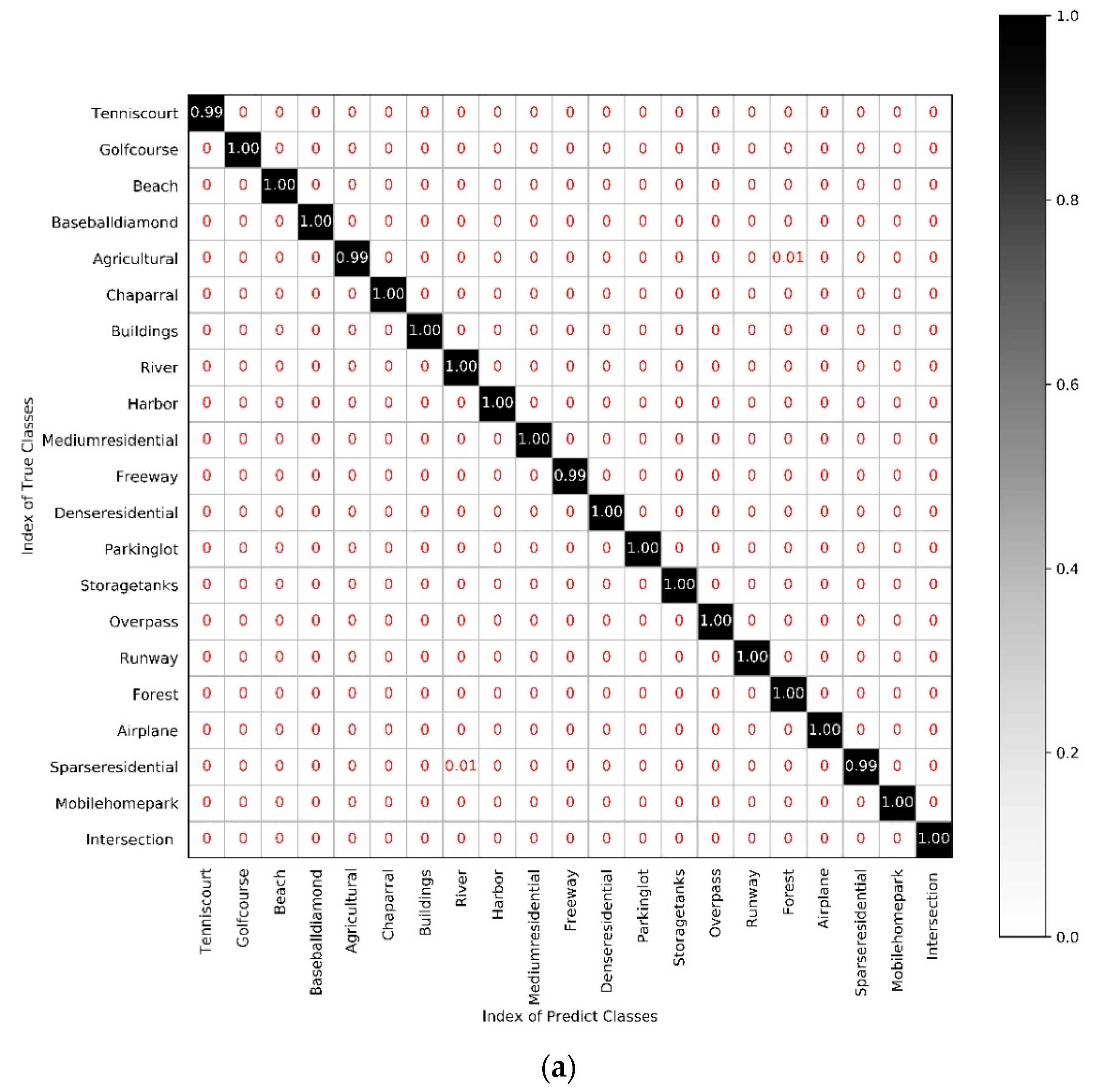
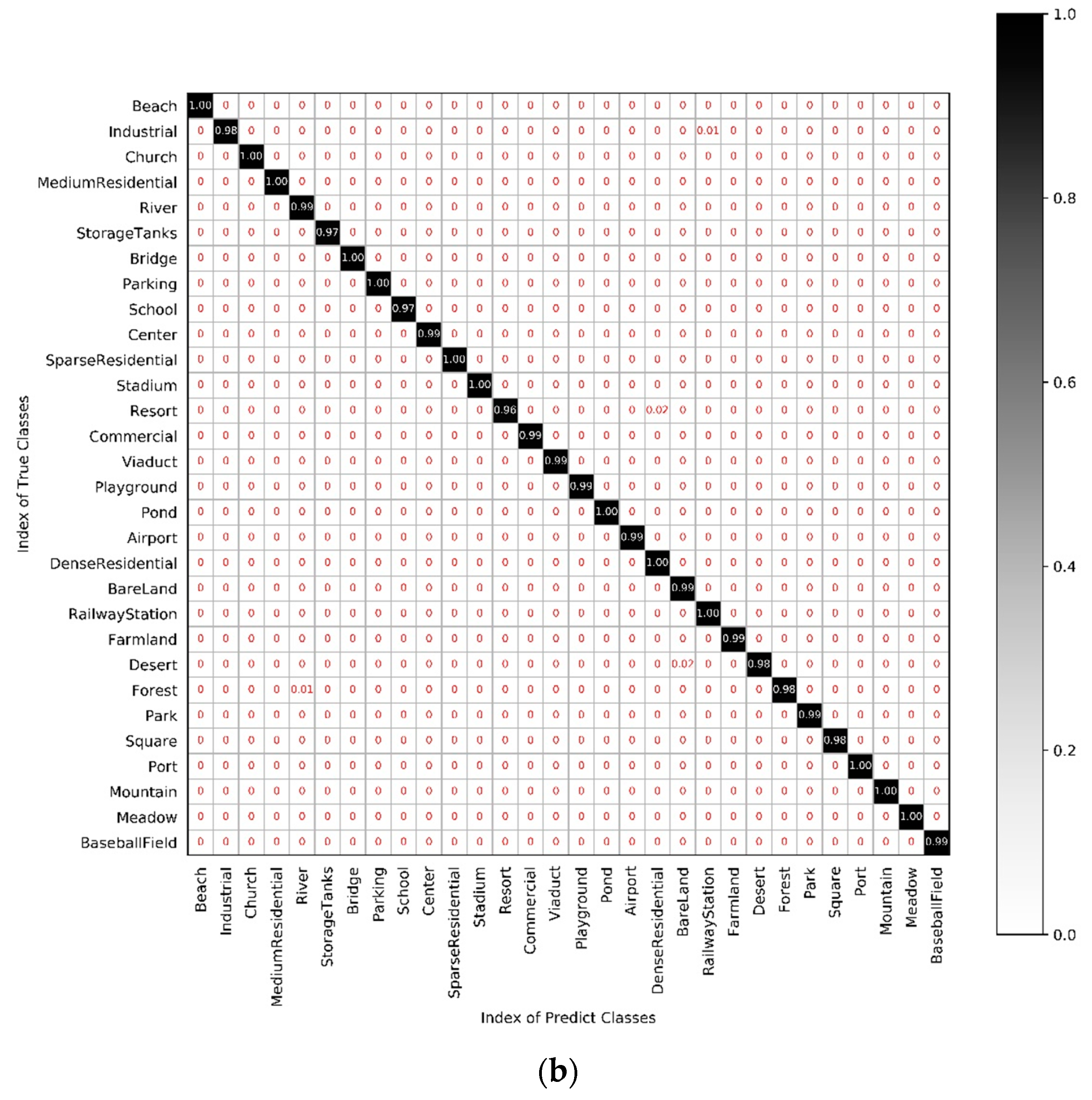
5.5. Experiment IV: Comparison of the Scene Classification Accuracy of Each Category in Different Networks
5.6. Experiment V: Comparison with Other State-of-the-Art Methods
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2012, 34, 45–59. [Google Scholar] [CrossRef]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic Annotation of High-Resolution Satellite Images via Weakly Supervised Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Tong, X.; Zhang, L.; Zhang, Z.; Liu, H.; Xing, X.; Mathiopoulos, P.T. A Three-Layered Graph-Based Learning Approach for Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6020–6034. [Google Scholar] [CrossRef]
- Plaza, J.; Plaza, J.; Paz, A.; Sanchez, S. Parallel Hyperspectral Image and Signal Processing [Applications Corner]. IEEE Signal Process. Mag. 2011, 28, 119–126. [Google Scholar] [CrossRef]
- Hubert, M.J.; Carole, E. Airborne SAR-efficient signal processing for very high resolution. Proc. IEEE. 2013, 101, 784–797. [Google Scholar]
- Cheriyadat, A.M. Unsupervised Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2013, 52, 439–451. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.-S. Extreme value theory-based calibration for the fusion of multiple features in high-resolution satellite scene classification. Int. J. Remote Sens. 2013, 34, 8588–8602. [Google Scholar] [CrossRef]
- Estoque, R.C.; Murayama, Y.; Akiyama, C.M. Pixel-based and object-based classifications using high- and medium-spatial-resolution imageries in the urban and suburban landscapes. Geocarto Int. 2015, 30, 1113–1129. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wang, Q.; Chen, G.; Dai, F.; Zhu, K.; Gong, Y.; Xie, Y. An object-based supervised classification framework for very-high-resolution remote sensing images using convolutional neural networks. Remote Sens. Lett. 2018, 9, 373–382. [Google Scholar] [CrossRef]
- Pham, M.-T.; Mercier, G.; Regniers, O.; Michel, J. Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection. Remote Sens. 2016, 8, 368. [Google Scholar] [CrossRef] [Green Version]
- Napoletano, P. Visual descriptors for content-based retrieval of remote-sensing images. Int. J. Remote Sens. 2017, 39, 1343–1376. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Geographic Image Retrieval Using Local Invariant Features. IEEE Trans. Geosci. Remote Sens. 2012, 51, 818–832. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Wang, S.; Guan, Y.; Shao, L. Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fang, J.; Yuan, Y.; Lu, X.; Feng, Y. Robust Space–Frequency Joint Representation for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7492–7502. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, J. Remote Sensing Scene Classification Using Multilayer Stacked Covariance Pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Khan, N.; Chaudhuri, U.; Banerjee, B.; Chaudhuri, S. Graph convolutional network for multi-label VHR remote sensing scene recognition. Neurocomputing 2019, 357, 36–46. [Google Scholar] [CrossRef]
- Liu, N.; Wan, L.; Zhang, Y.; Zhou, T.; Huo, H.; Fang, T. Exploiting Convolutional Neural Networks With Deeply Local Description for Remote Sensing Image Classification. IEEE Access 2018, 6, 11215–11228. [Google Scholar] [CrossRef]
- Jin, P.; Xia, G.-S.; Hu, F.; Lu, Q.; Zhang, L. AID++: An Updated Version of AID on Scene Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4721–4724. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.S.; Yang, W.; Zhang, L.P. Recent advances and opportunities in scene classification of aerial images with deep models. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 4371–4374. [Google Scholar]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1349–1362. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Liu, F. Dense Connectivity Based Two-Stream Deep Feature Fusion Framework for Aerial Scene Classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef] [Green Version]
- Luo, B.; Jiang, S.; Zhang, L. Indexing of Remote Sensing Images with Different Resolutions by Multiple Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.-S.; Zhang, L. Bag-of-Visual-Words Scene Classifier With Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical Coding Vectors for Scene Level Land-Use Classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and gabor texture features for classification of remote sensed imagery. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1522–4880. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.; Zhang, L. The bag-of-visual-words scene classifier combining local and global features for high spatial resolution imagery. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Ohio, CO, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. GISci. Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Yuan, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral Image Denoising Employing a Spatial–Spectral Deep Residual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Fei, F.; Zhang, L. Large patch convolutional neural networks for the scene classification of high spatial resolution imagery. J. Appl. Remote Sens. 2016, 10, 25006. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Jian, L.; Gao, F.; Ren, P.; Song, Y.; Luo, S. A Noise-Resilient Online Learning Algorithm for Scene Classification. Remote Sens. 2018, 10, 1836. [Google Scholar] [CrossRef] [Green Version]
- Scott, G.J.; Hagan, K.C.; Marcum, R.A.; Hurt, J.; Anderson, D.T.; Davis, C. Enhanced Fusion of Deep Neural Networks for Classification of Benchmark High-Resolution Image Data Sets. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1451–1455. [Google Scholar] [CrossRef]
- Liu, Y.; Suen, C.Y.; Liu, Y.; Ding, L. Scene Classification Using Hierarchical Wasserstein CNN. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2494–2509. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Wang, Q.; Liu, S.T.; Chanussot, J. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Xu, K. Combing Triple-Part Features of Convolutional Neural Networks for Scene Classification in Remote Sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epoch | Learning Rate | Batch Size | Weight Decay |
|---|---|---|---|
| 300(UCM) | 0.01 (0–200 epoch) | 64 | 0.0002 |
| 400(AID) | 0.001 (200–400 epoch) |
| Network | UCM (%) | AID (%) |
|---|---|---|
| ResNet50 | 96.8452 | 87.1500 |
| DenseNet121 | 97.7083 | 91.9313 |
| RDN (ours) | 98.6012 | 94.1563 |
| Class | RDN + CBAM | RDN | ResNet50 | DenseNet121 |
|---|---|---|---|---|
| Tenniscourt | 0.99 | 0.99 | 0.88 | 0.97 |
| Golfcourse | 1 | 0.98 | 0.99 | 1 |
| Beach | 1 | 1 | 1 | 1 |
| Baseballdiamond | 1 | 0.98 | 0.99 | 0.93 |
| Agricultural | 0.99 | 1 | 0.99 | 1 |
| Chaparral | 1 | 1 | 1 | 1 |
| Buildings | 1 | 0.96 | 0.97 | 1 |
| River | 1 | 1 | 0.98 | 0.98 |
| Harbor | 1 | 1 | 1 | 1 |
| Mediumresidential | 1 | 0.98 | 0.96 | 0.94 |
| Freeway | 0.99 | 0.97 | 0.94 | 0.99 |
| Denseresidential | 1 | 1 | 0.91 | 0.93 |
| Parkinglot | 1 | 0.99 | 0.96 | 1 |
| Storagetanks | 1 | 0.98 | 0.95 | 0.99 |
| Overpass | 1 | 0.96 | 0.98 | 0.99 |
| Runway | 1 | 1 | 1 | 1 |
| Forest | 1 | 1 | 1 | 0.99 |
| Airplane | 1 | 0.96 | 0.96 | 0.99 |
| Sparseresidential | 0.99 | 1 | 0.99 | 0.89 |
| Mbilehomepark | 1 | 0.99 | 0.97 | 0.97 |
| Intersection | 1 | 0.97 | 0.91 | 0.94 |
| Class | RDN +CBAM | RDN | ResNet50 | DenseNet121 |
|---|---|---|---|---|
| Beach | 1 | 0.95 | 0.96 | 0.96 |
| Industrial | 0.98 | 0.81 | 0.84 | 0.88 |
| Church | 1 | 0.94 | 0.82 | 0.97 |
| Mediumresidential | 1 | 0.96 | 0.82 | 0.82 |
| River | 0.99 | 0.93 | 0.88 | 0.86 |
| Storagetanks | 0.97 | 0.96 | 0.9 | 0.98 |
| Bridge | 1 | 0.97 | 0.91 | 0.91 |
| Parking | 1 | 1 | 0.97 | 0.99 |
| School | 0.97 | 0.86 | 0.63 | 0.71 |
| Center | 0.99 | 0.94 | 0.81 | 0.89 |
| Parseresidential | 1 | 0.94 | 0.91 | 0.91 |
| Stadium | 1 | 0.91 | 0.95 | 0.94 |
| Resort | 0.96 | 0.89 | 0.91 | 0.75 |
| Commercial | 0.99 | 0.95 | 0.87 | 0.9 |
| Viaduct | 0.99 | 0.97 | 0.89 | 1 |
| Playground | 0.99 | 0.94 | 0.78 | 0.93 |
| Pond | 1 | 0.97 | 0.87 | 0.92 |
| Airport | 0.99 | 0.94 | 0.87 | 0.91 |
| Denseresidential | 1 | 0.95 | 0.89 | 0.91 |
| Bareland | 0.99 | 0.96 | 0.87 | 0.97 |
| Railwaystation | 1 | 0.92 | 0.85 | 0.87 |
| Farmland | 0.99 | 0.92 | 0.92 | 0.96 |
| Desert | 0.98 | 0.97 | 0.97 | 0.85 |
| Forest | 0.98 | 0.99 | 0.97 | 1 |
| Park | 0.99 | 0.9 | 0.82 | 0.83 |
| Square | 0.98 | 0.91 | 0.66 | 0.92 |
| Port | 1 | 0.96 | 0.96 | 0.96 |
| Mountain | 1 | 0.98 | 0.89 | 1 |
| Meadow | 1 | 0.98 | 0.9 | 0.96 |
| Baseballfield | 0.99 | 0.97 | 0.88 | 0.98 |
| Network | UCM (%) | AID (%) |
|---|---|---|
| CaffeNet [46] | 95.02 | 89.53 |
| GoogLeNet [46] | 94.31 | 86.39 |
| VGG-VD-16 [46] | 95.21 | 89.64 |
| CTFCNN [47] | 98.44 | 94.91 |
| VGG-16-CapsNet [48] | 98.81 | 94.74 |
| ARCNet-VGG16 [44] | 99.12 | 93.10 |
| RDN + CBAM (ours) | 99.82 | 99.08 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual Dense Network Based on Channel-Spatial Attention for the Scene Classification of a High-Resolution Remote Sensing Image. Remote Sens. 2020, 12, 1887. https://doi.org/10.3390/rs12111887
Zhao X, Zhang J, Tian J, Zhuo L, Zhang J. Residual Dense Network Based on Channel-Spatial Attention for the Scene Classification of a High-Resolution Remote Sensing Image. Remote Sensing. 2020; 12(11):1887. https://doi.org/10.3390/rs12111887
Chicago/Turabian StyleZhao, Xiaolei, Jing Zhang, Jimiao Tian, Li Zhuo, and Jie Zhang. 2020. "Residual Dense Network Based on Channel-Spatial Attention for the Scene Classification of a High-Resolution Remote Sensing Image" Remote Sensing 12, no. 11: 1887. https://doi.org/10.3390/rs12111887