
Machine Learning Undercounts Reproductive Organs on Herbarium Specimens but Accurately Derives Their Quantitative Phenological Status: A Case Study of Streptanthus tortuosus


Abstract
:1. Introduction
- Can machine learning be used to obtain counts of reproductive organs on herbarium specimens that match those recorded by human observers?
- Do distinct organ types (e.g., flower buds, open flowers, or fruits) differ with respect to the degree to which machine-learned counts match those recorded by human observers?
- When counts obtained via machine learning are used to estimate the phenological index (PI)—a quantitative metric of the phenological status of an herbarium specimen that reflects the proportions of different types of reproductive organs (Love et al., 2019)—does the machine-generated PI match the PI calculated from counts reported by human observers?
- Does the year of specimen collection affect counting error or estimation of the phenological status? For example, does the fading of floral pigments over time make it more difficult for machine learning algorithms to distinguish between buds and open flowers as herbarium specimens age?
- When the phenological status (PI) of specimens generated by machine learning is used to construct models that provide estimates of the rate of temporal shifts in flowering date, the sensitivity to climate, and the rate of phenological progression, do these estimates match those based on data derived from human observers?
2. Results
2.1. Herbarium Data
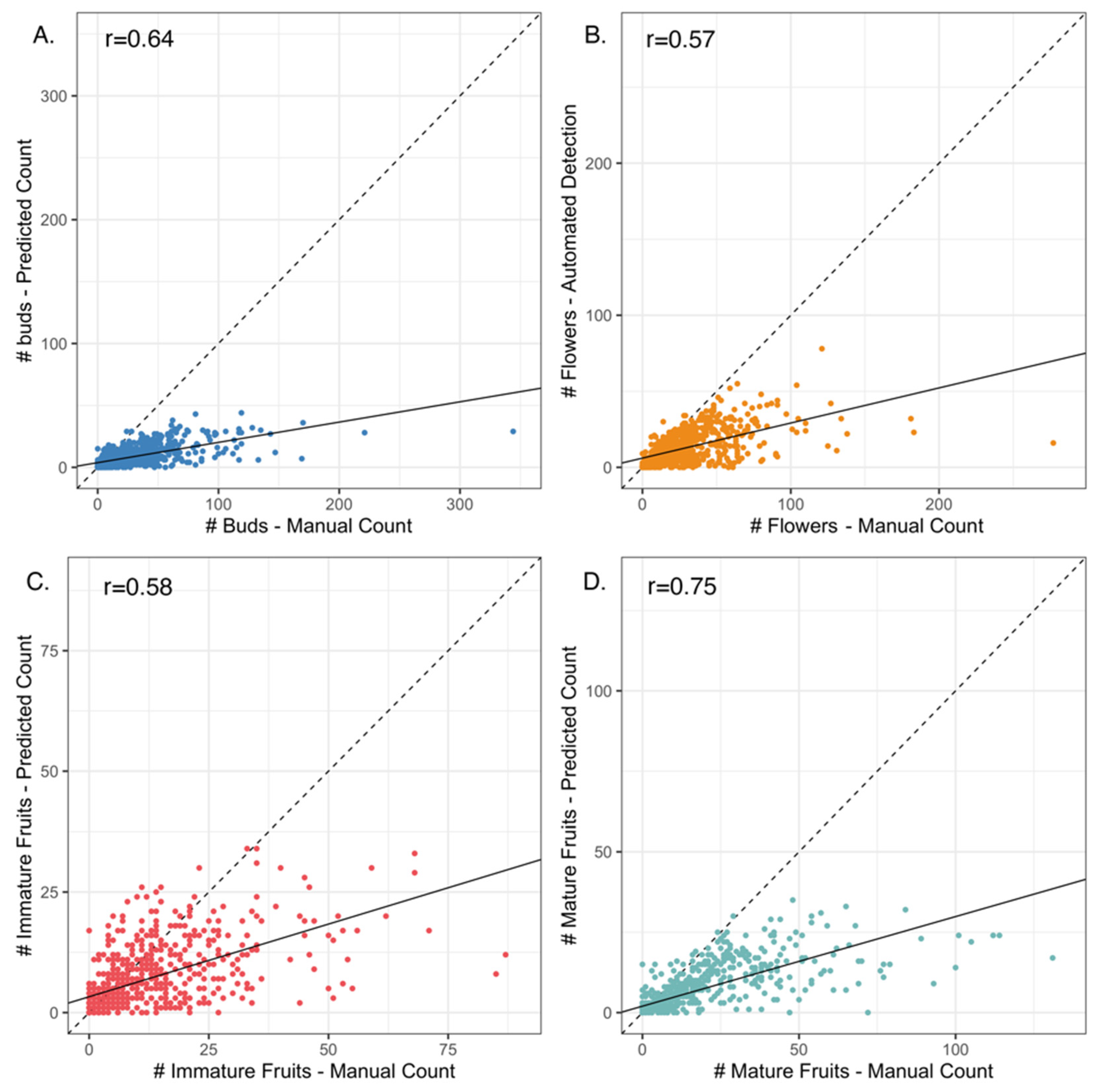
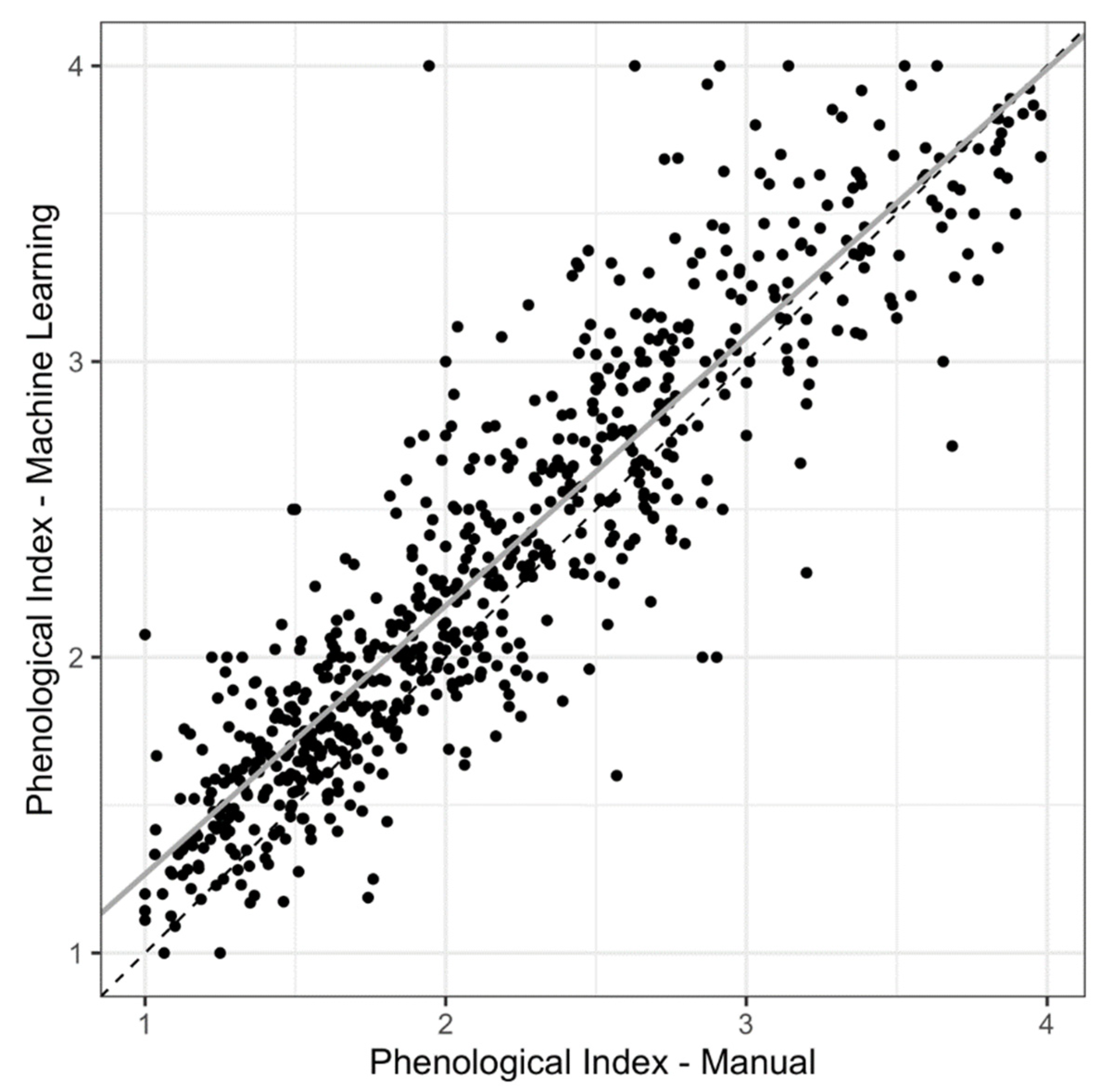
2.2. Phenological Scoring: Manual vs. Machine Learning
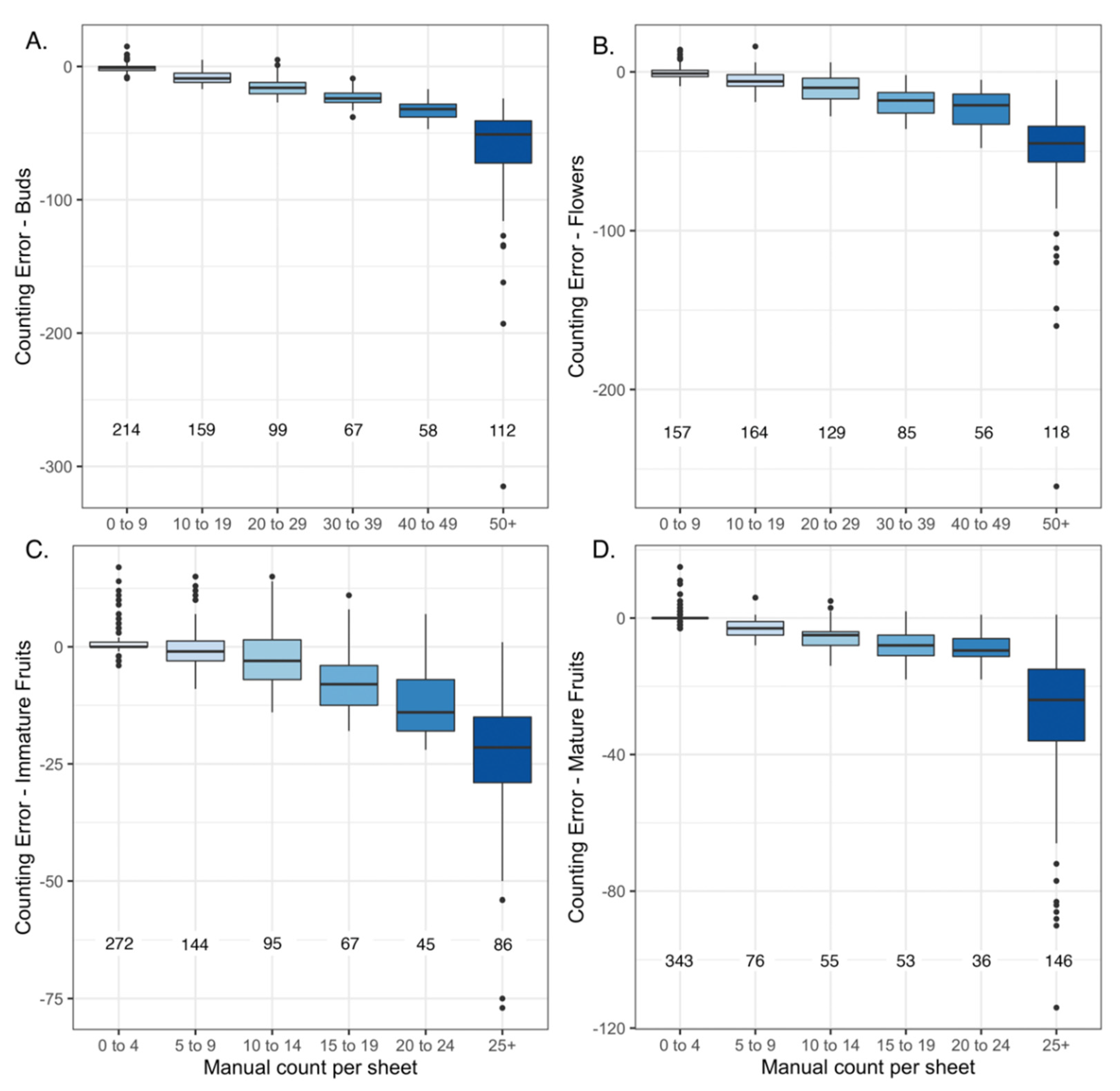
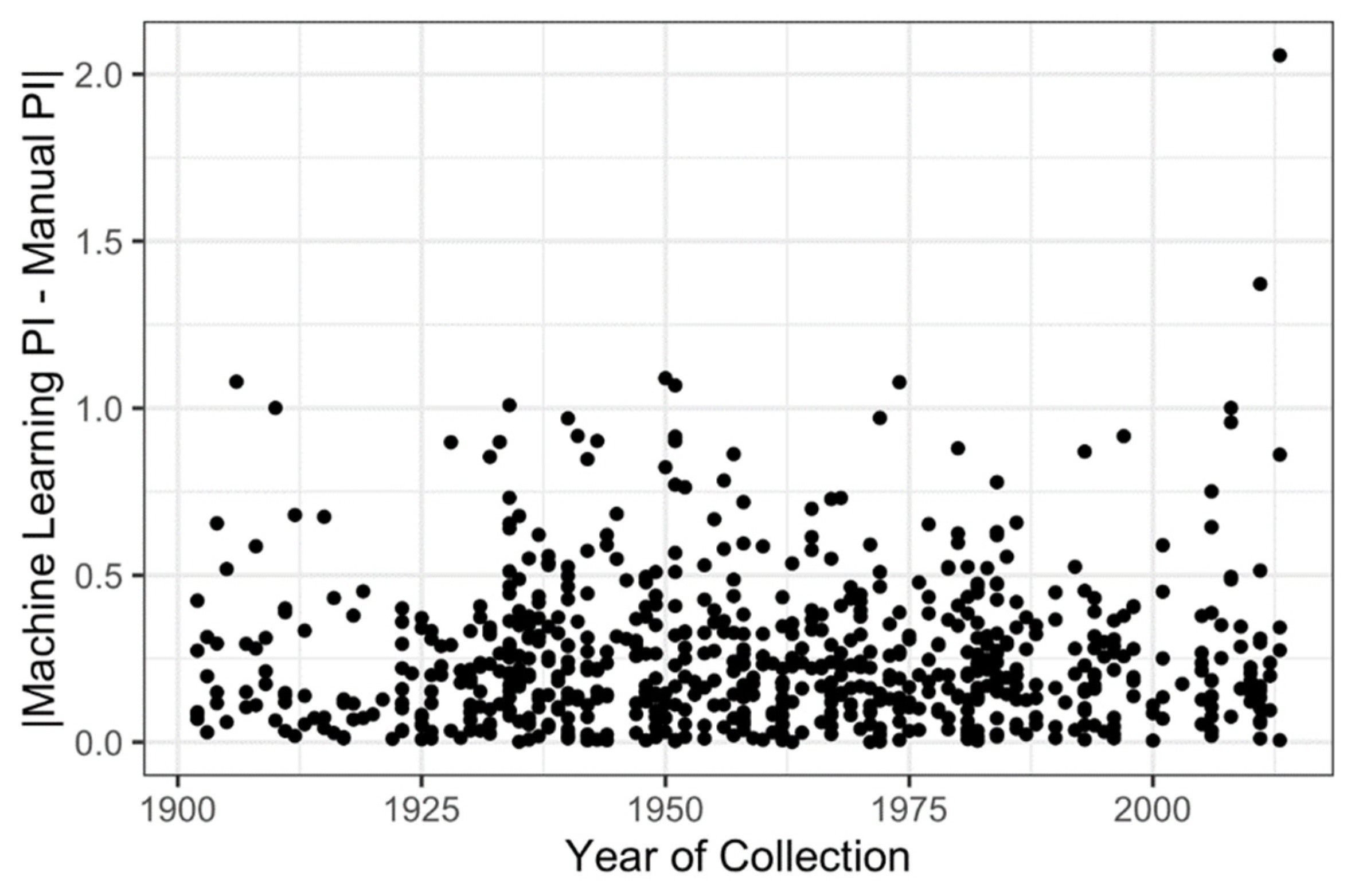
2.3. Effect of Year of Specimen Collection on Counting Error
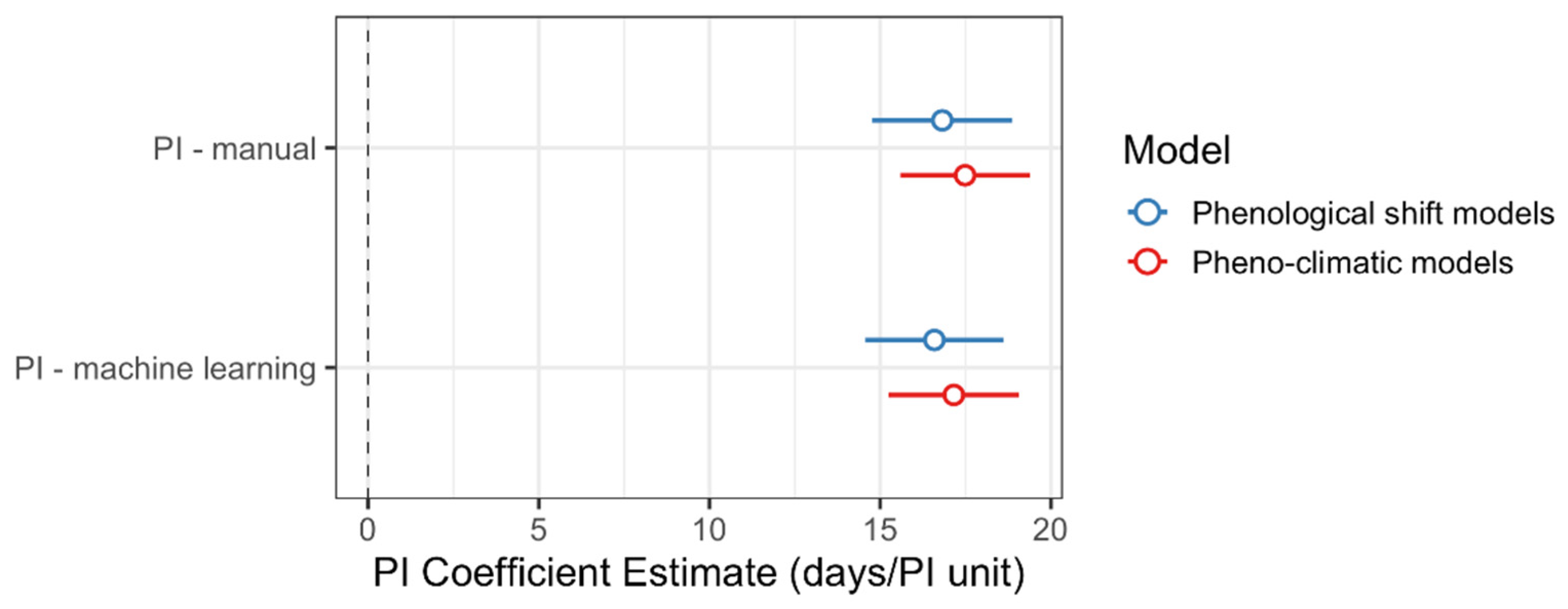
2.4. Summary and Comparison of Models Constructed with Manually vs. Machine Learning-Derived Phenological Indices
3. Discussion
3.1. Mask R-CNN Model Underestimates Organ Counts but Results in High Concordance between Manual- vs. Machine-Learning-Derived Phenological Indices (PIs)
3.2. Low Impact of the Specimen Age on Counting Error
3.3. Machine-Learning-Derived Estimates of the Phenological Status Can Be Used to Assess Ecological Patterns
3.4. Future Directions
4. Materials and Methods
4.1. Assembling Herbarium Records and Manual Phenological Scoring
Extracting Climate Data
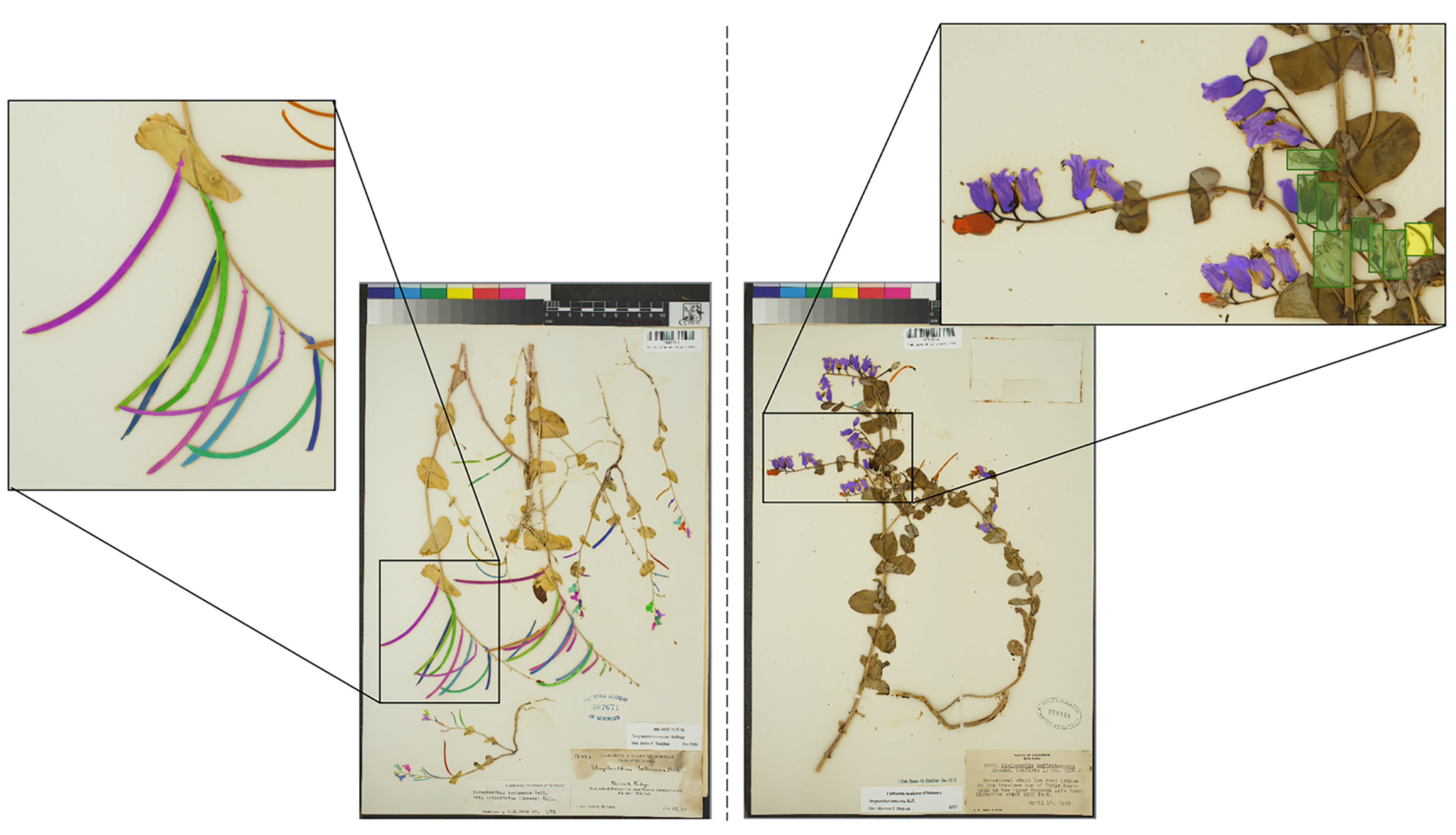
4.2. Machine Learning Methods
4.2.1. Training Dataset
4.2.2. CNN Training and Prediction
4.3. Model Evaluation and Statistical Analyses
4.3.1. Evaluation of Machine Learning Model Predictions
4.3.2. Statistical Analysis
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Input image size: Images are resized such that the longest edge is 2048 pixels and the shorter one is 1024 pixels, in order to have sufficient pixels related to small objects such as the buds (by default the mask R-CNN implementation used here considers a longest edge of 1024 pixels and a shorter one of 600 pixels).
- Anchor size and stride: Anchors are the raw regions of interest used by the region proposal network to select the candidate bounding boxes for object detection. We chose their size to guarantee that the targeted objects have their size covered. The anchor size values were set to [32; 64; 128; 256; 512], the anchor stride values to [4; 8; 16; 32; 64], and the anchor ratios to [0.5; 1; 2].
- Non-maximal suppression: The non-maximal suppression (NMS) quantifies the degree of overlap tolerated between two distinct objects (set to 0.5, the default value in the mask R-CNN implementation used here).
References
- Ettinger, A.K.; Chamberlain, C.J.; Morales-Castilla, I.; Buonaiuto, D.M.; Flynn, D.F.B.; Savas, T.; Samaha, J.A.; Wolkovich, E.M. Winter Temperatures Predominate in Spring Phenological Responses to Warming. Nat. Clim. Chang. 2020, 10, 1137–1142. [Google Scholar] [CrossRef]
- Cook, B.I.; Wolkovich, E.M.; Parmesan, C. Divergent Responses to Spring and Winter Warming Drive Community Level Flowering Trends. Proc. Natl. Acad. Sci. USA 2012, 109, 9000–9005. [Google Scholar] [CrossRef] [Green Version]
- Wolkovich, E.M.; Davies, T.J.; Schaefer, H.; Cleland, E.E.; Cook, B.I.; Travers, S.E.; Willis, C.G.; Davis, C.C. Temperature-Dependent Shifts in Phenology Contribute to the Success of Exotic Species with Climate Change. Am. J. Bot. 2013, 100, 1407–1421. [Google Scholar] [CrossRef]
- Kudo, G.; Cooper, E.J. When Spring Ephemerals Fail to Meet Pollinators: Mechanism of Phenological Mismatch and Its Impact on Plant Reproduction. Proc. R. Soc. B Biol. Sci. 2019, 286, 20190573. [Google Scholar] [CrossRef] [Green Version]
- Meineke, E.K.; Davies, T.J. Museum Specimens Provide Novel Insights into Changing Plant–Herbivore Interactions. Philos. Trans. R. Soc. B Biol. Sci. 2019, 374, 20170393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Willis, C.G.; Ellwood, E.R.; Primack, R.B.; Davis, C.C.; Pearson, K.D.; Gallinat, A.S.; Yost, J.M.; Nelson, G.; Mazer, S.J.; Rossington, N.L.; et al. Old Plants, New Tricks: Phenological Research Using Herbarium Specimens. Trends Ecol. Evol. 2017, 32, 531–546. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jones, C.A.; Daehler, C.C. Herbarium Specimens Can Reveal Impacts of Climate Change on Plant Phenology; a Review of Methods and Applications. PeerJ 2018, 6, e4576. [Google Scholar] [CrossRef] [PubMed]
- Pau, S.; Wolkovich, E.M.; Cook, B.I.; Davies, T.J.; Kraft, N.J.B.; Bolmgren, K.; Betancourt, J.L.; Cleland, E.E. Predicting Phenology by Integrating Ecology, Evolution and Climate Science. Glob. Chang. Biol. 2011, 17, 3633–3643. [Google Scholar] [CrossRef]
- Wolkovich, E.M.; Cook, B.I.; Davies, T.J. Progress towards an Interdisciplinary Science of Plant Phenology: Building Predictions across Space, Time and Species Diversity. New Phytol. 2014, 201, 1156–1162. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Robbirt, K.M.; Davy, A.J.; Hutchings, M.J.; Roberts, D.L. Validation of Biological Collections as a Source of Phenological Data for Use in Climate Change Studies: A Case Study with the Orchid Ophrys sphegodes: Herbarium Specimens for Climate Change Studies. J. Ecol. 2011, 99, 235–241. [Google Scholar] [CrossRef]
- Davis, C.C.; Willis, C.G.; Connolly, B.; Kelly, C.; Ellison, A.M. Herbarium Records Are Reliable Sources of Phenological Change Driven by Climate and Provide Novel Insights into Species’ Phenological Cueing Mechanisms. Am. J. Bot. 2015, 102, 1599–1609. [Google Scholar] [CrossRef]
- Meineke, E.K.; Davis, C.C.; Davies, T.J. The Unrealized Potential of Herbaria for Global Change Biology. Ecol. Monogr. 2018, 88, 505–525. [Google Scholar] [CrossRef]
- Love, N.L.R.; Park, I.W.; Mazer, S.J. A New Phenological Metric for Use in Pheno-climatic Models: A Case Study Using Herbarium Specimens of Streptanthus tortuosus. Appl. Plant Sci. 2019, 7, e11276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Love, N.L.R.; Mazer, S.J. Region-Specific Phenological Sensitivities and Rates of Climate Warming Generate Divergent Shifts in Flowering Date across a Species’ Range. Am. J. Bot. 2021, 108, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Mazer, S.J.; Love, N.L.R.; Park, I.M.; Tadeo, R.P.; Elizabeth, R.M. Phenological Sensitivities to Climate Are Similar in Two Clarkia Congeners: Indirect Evidence for Facilitation, Convergence, Niche Conservatism, or Genetic Constraints. Madroño 2022, in press. [Google Scholar]
- Willis, C.G.; Law, E.; Williams, A.C.; Franzone, B.F.; Bernardos, R.; Bruno, L.; Hopkins, C.; Schorn, C.; Weber, E.; Park, D.S.; et al. CrowdCurio: An Online Crowdsourcing Platform to Facilitate Climate Change Studies Using Herbarium Specimens. New Phytol. 2017, 215, 479–488. [Google Scholar] [CrossRef] [Green Version]
- Lorieul, T.; Pearson, K.D.; Ellwood, E.R.; Goëau, H.; Molino, J.-F.; Sweeney, P.W.; Yost, J.M.; Sachs, J.; Mata-Montero, E.; Nelson, G.; et al. Toward a Large-Scale and Deep Phenological Stage Annotation of Herbarium Specimens: Case Studies from Temperate, Tropical, and Equatorial Floras. Appl. Plant Sci. 2019, 7, e01233. [Google Scholar] [CrossRef] [Green Version]
- Davis, C.C.; Champ, J.; Park, D.S.; Breckheimer, I.; Lyra, G.M.; Xie, J.; Joly, A.; Tarapore, D.; Ellison, A.M.; Bonnet, P. A New Method for Counting Reproductive Structures in Digitized Herbarium Specimens Using Mask R-CNN. Front. Plant Sci. 2020, 11, 1129. [Google Scholar] [CrossRef] [PubMed]
- Goëau, H.; Mora-Fallas, A.; Champ, J.; Love, N.L.R.; Mazer, S.J.; Mata-Montero, E.; Joly, A.; Bonnet, P. A New Fine-grained Method for Automated Visual Analysis of Herbarium Specimens: A Case Study for Phenological Data Extraction. Appl. Plant Sci. 2020, 8, e11368. [Google Scholar] [CrossRef]
- Pearson, K.D.; Nelson, G.; Aronson, M.F.J.; Bonnet, P.; Brenskelle, L.; Davis, C.C.; Denny, E.G.; Ellwood, E.R.; Goëau, H.; Heberling, J.M.; et al. Machine Learning Using Digitized Herbarium Specimens to Advance Phenological Research. BioScience 2020, 70, 610–620. [Google Scholar] [CrossRef]
- Yost, J.M.; Sweeney, P.W.; Gilbert, E.; Nelson, G.; Guralnick, R.; Gallinat, A.S.; Ellwood, E.R.; Rossington, N.; Willis, C.G.; Blum, S.D.; et al. Digitization Protocol for Scoring Reproductive Phenology from Herbarium Specimens of Seed Plants. Appl. Plant Sci. 2018, 6, e1022. [Google Scholar] [CrossRef] [PubMed]
- Pearson, K.D. A New Method and Insights for Estimating Phenological Events from Herbarium Specimens. Appl. Plant Sci. 2019, 7, e01224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weaver, W.N.; Ng, J.; Laport, R.G. LeafMachine: Using Machine Learning to Automate Leaf Trait Extraction from Digitized Herbarium Specimens. Appl. Plant Sci. 2020, 8, e11367. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Hamann, A.; Spittlehouse, D.; Carroll, C. Locally Downscaled and Spatially Customizable Climate Data for Historical and Future Periods for North America. PLoS ONE 2016, 11, e0156720. [Google Scholar] [CrossRef]
- Goëau, H.; Mora-Fallas, A.; Champ, J.; Love, N.L.R.; Mazer, S.; Mata-Montero, E.; Joly, A.; Bonnet, P. Fine-Grained Automated Visual Analysis of Herbarium Specimens for Phenological Data Extraction: An Annotated Dataset of Reproductive Organs in Strepanthus Herbarium Specimens. 2020. Available online: https://zenodo.org/record/3865263#.YZMUt7oRVPY (accessed on 10 November 2021).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Massa, F.; Girshick, R. Maskrcnn-Benchmark: Fast, Modular Reference Implementation of Instance Segmentation and Object Detection Algorithms in PyTorch. 2018. Available online: https://github.com/facebookresearch/maskrcnn-benchmark (accessed on 2 February 2019).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A.; et al. Automatic Differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reproductive Structure | Number per Sheet (Range) | Mean ± SD per Sheet | MAE |
|---|---|---|---|
| Buds | 0–344 | 27.4 ± 30.6 | 19.7 |
| lFowers | 0–227 | 28.5 ± 26.4 | 16.6 |
| Immature fruits | 0–87 | 11.0 ± 12.7 | 6.5 |
| Mature fruits | 0–131 | 12.5 ± 19.3 | 8.3 |
| Reproductive Structure | Slope Estimate ± SE | p-Value | R2 |
|---|---|---|---|
| Buds | −0.0015 ± 0.002 | 0.3699 | 0.001 |
| Flowers | −0.0036 ± 0.001 | 0.0204 | 0.008 |
| Immature fruits | −0.0037 ± 0.001 | 0.0095 | 0.008 |
| Mature fruits | −0.0045 ± 0.002 | 0.0083 | 0.008 |
| phenological index | 0.00024 ± 0.0003 | 0.3979 | 0.001 |
| a. | ||||||
|---|---|---|---|---|---|---|
| Independent Variable | Estimate | SE | 95% CI | t-Ratio | p-Value | Partial R2 |
| Intercept | 216.77 | 133.67 | - | 1.62 | 0.1053 | - |
| Year of collection | −0.1 | 0.027 | −0.15 to −0.048 | −3.73 | 0.0002 | 0.02 |
| PI (manual) | 16.82 | 1.04 | 14.77 to 18.87 | 16.11 | <0.0001 | 0.27 |
| Elevation | 0.03 | 0.0011 | 0.027 to 0.032 | 27.33 | <0.0001 | 0.52 |
| Latitude | 5.18 | 1.14 | 2.94 to 7.41 | 4.54 | <0.0001 | 0.03 |
| Longitude | 1.06 | 1.29 | - | 0.82 | 0.412 | <0.01 |
| Full Model R2 | 0.7 | |||||
| b. | ||||||
| Independent Variable | Estimate | SE | 95% CI | t-Ratio | p-Value | Partial R2 |
| Intercept | 134.36 | 133.13 | - | 1.01 | 0.3132 | - |
| Year of collection | −0.11 | 0.027 | −0.16 to −0.058 | −4.14 | <0.0001 | 0.02 |
| PI (machine learning) | 16.59 | 1.03 | 14.56 to 18.6 | 16.1 | <0.0001 | 0.27 |
| Elevation | 0.031 | 0.0011 | 0.028 to 0.033 | 28.54 | <0.0001 | 0.54 |
| Latitude | 4.29 | 1.14 | 2.06 to 6.51 | 3.78 | 0.0002 | 0.02 |
| Longitude | −0.056 | 1.28 | - | −0.043 | 0.9654 | <0.01 |
| Full Model R2 | 0.7 |
| a. | ||||||
|---|---|---|---|---|---|---|
| Independent Variable | Estimate | SE | 95% CI | t-Ratio | p-Value | Partial R2 |
| Intercept | 205.58 | 3.33 | - | 61.65 | <0.0001 | - |
| PI (manual) | 17.49 | 0.97 | 15.59 to 19.38 | 18.09 | <0.0001 | 0.32 |
| Winter PPT | 0.0072 | 0.0019 | 0.0034 to 0.011 | 3.74 | 0.0002 | 0.02 |
| Spring Tmax | −5.28 | 0.14 | −5.56 to −5.00 | −36.71 | <0.0001 | 0.66 |
| Full Model R2 | 0.73 | |||||
| b. | ||||||
| Independent Variable | Estimate | SE | 95% CI | t-Ratio | p-Value | Partial R2 |
| Intercept | 204.75 | 3.41 | - | 59.96 | <0.0001 | - |
| PI (machine learning) | 17.16 | 0.97 | 15.25 to 19.06 | 17.7 | <0.0001 | 0.31 |
| Winter PPT | 0.0072 | 0.0019 | 0.0034 to 0.011 | 3.74 | 0.0002 | 0.02 |
| Spring Tmax | −5.38 | 0.14 | −5.66 to −5.09 | −37.27 | <0.0001 | 0.66 |
| Full Model R2 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Love, N.L.R.; Bonnet, P.; Goëau, H.; Joly, A.; Mazer, S.J. Machine Learning Undercounts Reproductive Organs on Herbarium Specimens but Accurately Derives Their Quantitative Phenological Status: A Case Study of Streptanthus tortuosus. Plants 2021, 10, 2471. https://doi.org/10.3390/plants10112471
Love NLR, Bonnet P, Goëau H, Joly A, Mazer SJ. Machine Learning Undercounts Reproductive Organs on Herbarium Specimens but Accurately Derives Their Quantitative Phenological Status: A Case Study of Streptanthus tortuosus. Plants. 2021; 10(11):2471. https://doi.org/10.3390/plants10112471
Chicago/Turabian StyleLove, Natalie L. R., Pierre Bonnet, Hervé Goëau, Alexis Joly, and Susan J. Mazer. 2021. "Machine Learning Undercounts Reproductive Organs on Herbarium Specimens but Accurately Derives Their Quantitative Phenological Status: A Case Study of Streptanthus tortuosus" Plants 10, no. 11: 2471. https://doi.org/10.3390/plants10112471