A Central Edge Selection Based Overlapping Community Detection Algorithm for the Detection of Overlapping Structures in Protein–Protein Interaction Networks

 , ,
, ,
Abstract
:1. Introduction
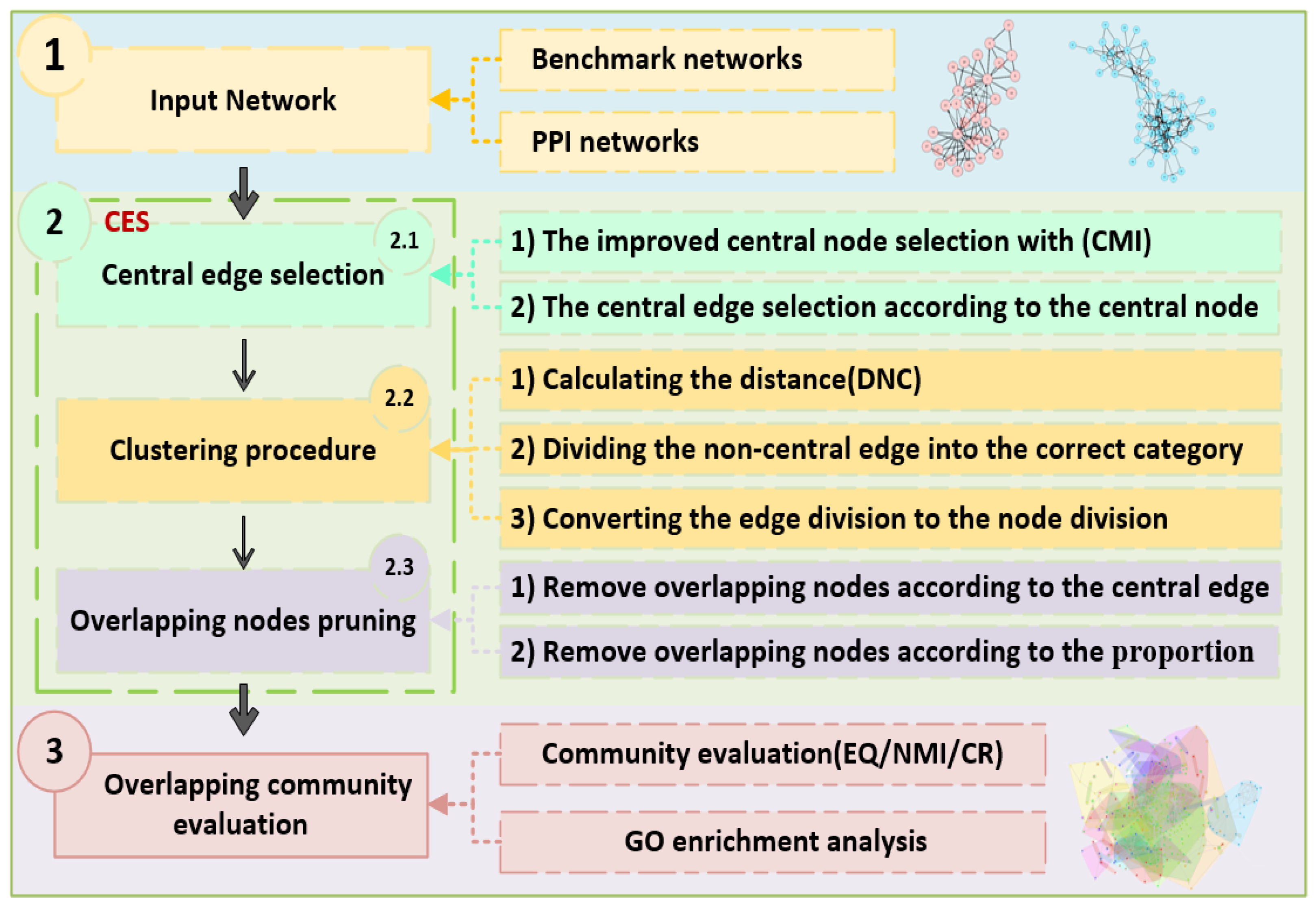
2. Materials and Methods
2.1. Data Source
2.2. OCD Algorithm Based on Central Node Selection (CNS)
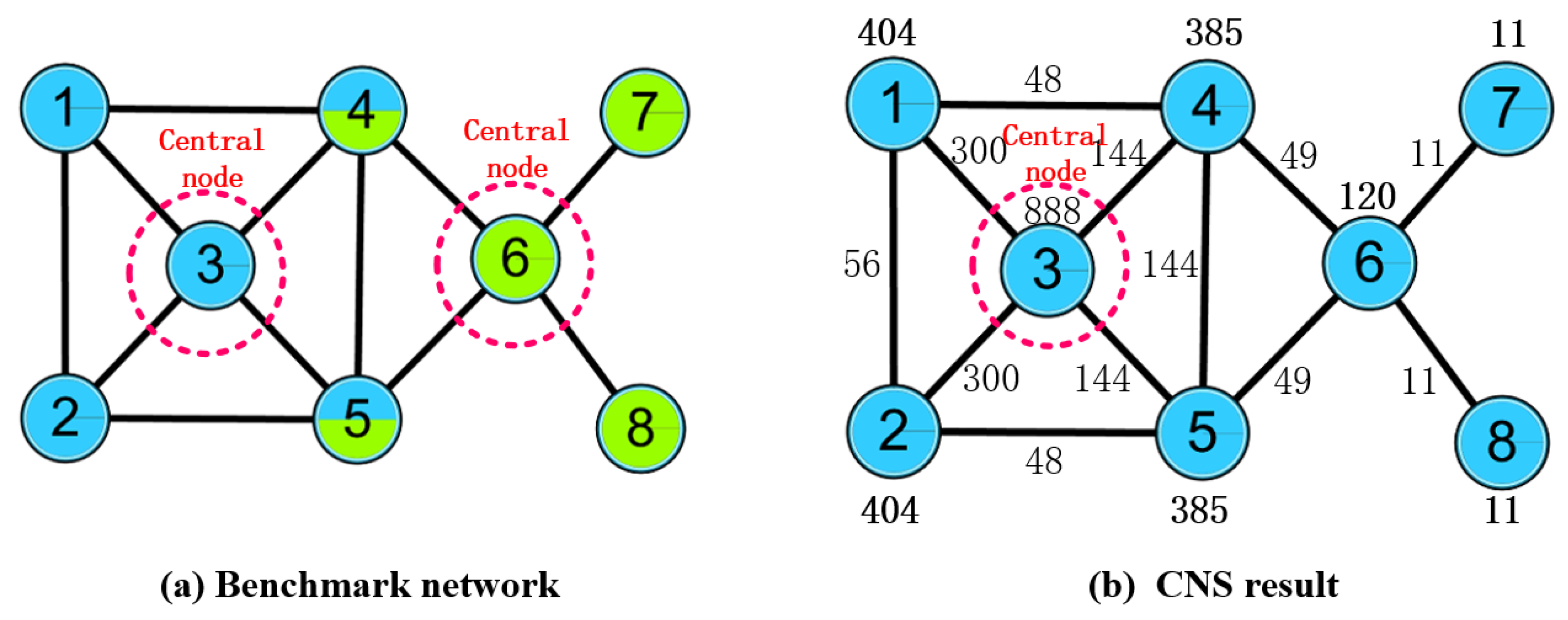
2.2.1. Procedure of the CNS
2.2.2. Limitation of CNS
2.3. OCD Algorithm Based on Central Edge Selection (CES)
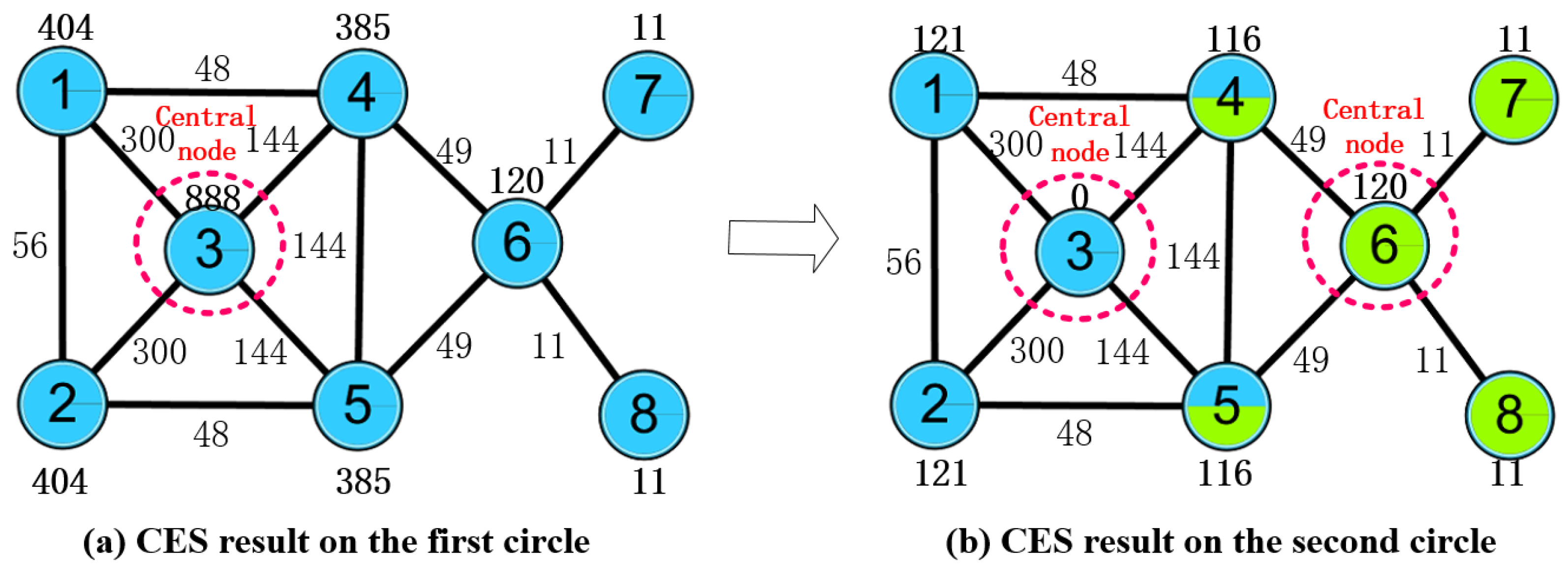
2.3.1. Central Edge Selection
| Algorithm 1. Improved central node selection. |
| 1 Calculate the all influence of nodes |
| 2 For each do |
| 3 |
| 4 End for |
| 5 Central node selection with CMI |
| 6 For each do |
| 7 Central node selection |
| 8 If and |
| 9 Then |
| 10 |
| 11 |
| 12 Revise according to the CMI |
| 13 For each do |
| 14 |
| 15 End for |
| 16 End for |
2.3.2. Clustering Procedure
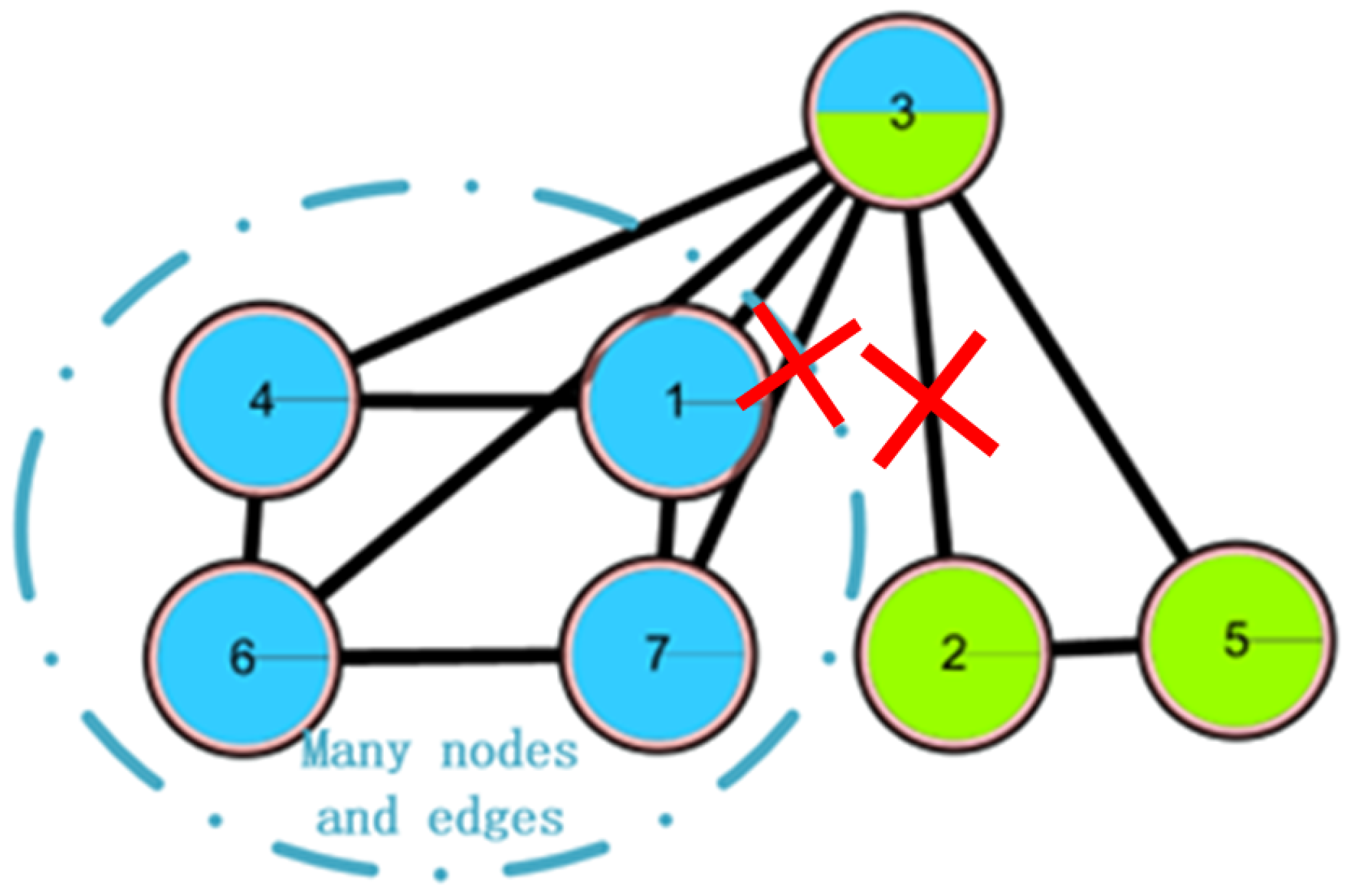
2.3.3. ONP Procedure
2.3.4. Time Complexity Analysis
2.4. CPM Algorithm
2.5. LC Algorithm
2.6. Evaluation
2.6.1. EQ Algorithm
2.6.2. NMI Algorithm
2.6.3. CR Algorithm
2.6.4. GO Enrichment Analysis
3. Results and Discussion
3.1. Benchmark Network
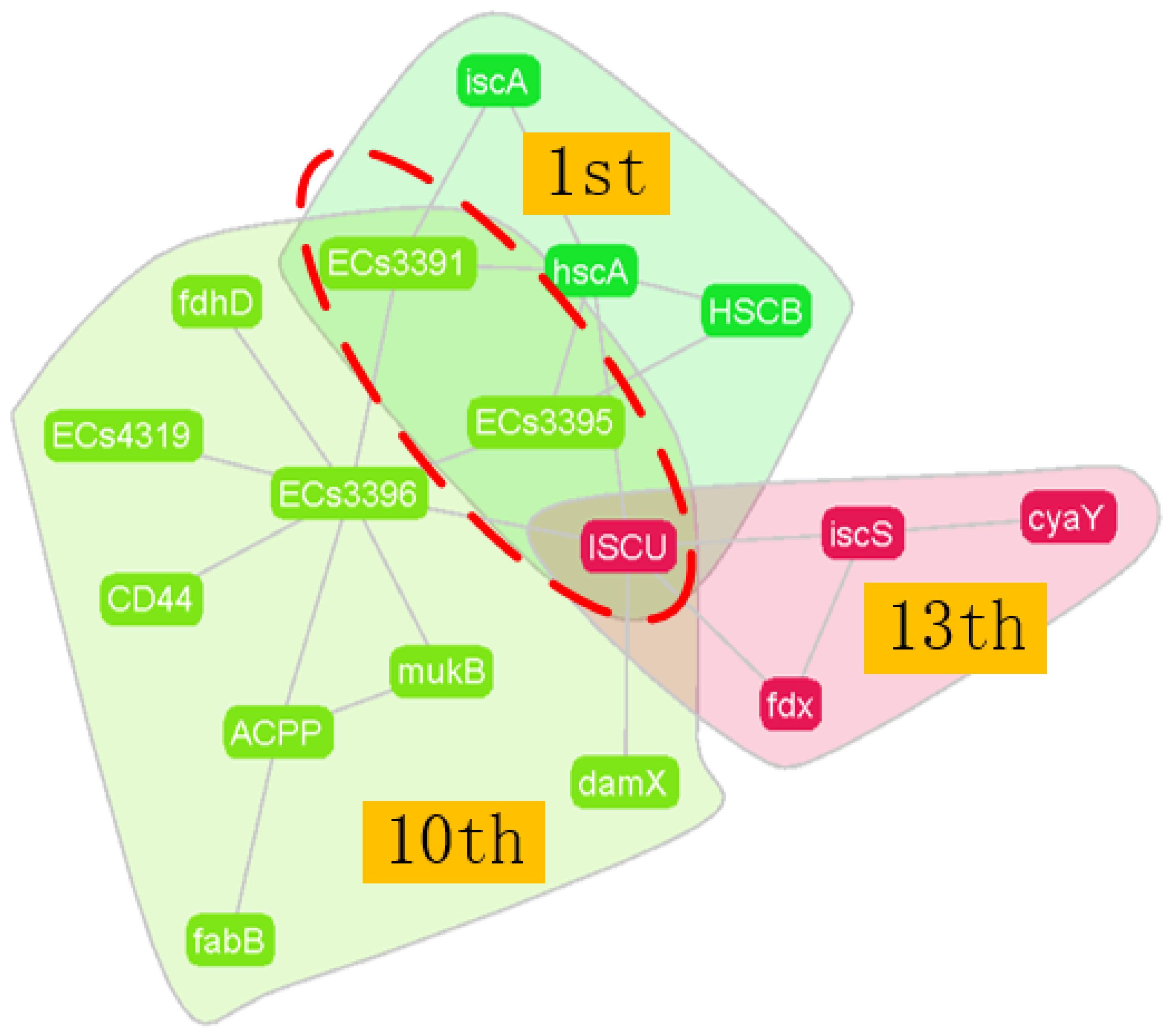
3.2. PPI Network
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cui, G.; Shrestha, R.; Han, K. ModuleSearch: Finding functional modules in a protein—Protein interaction network. Comput. Methods Biomech. Biomed. Eng. 2012, 15, 691. [Google Scholar] [CrossRef] [PubMed]
- Sriganesh, S.; Chern, H.Y.; Limsoon, W. Computational Prediction of Protein Complexes from Protein Interaction Networks; ACM Books and Morgan and Claypool: New York, NY, USA, 2017. [Google Scholar]
- Li, M.; Wang, J.; Chen, J. A Graph-Theoretic Method for Mining Overlapping Functional Modules in Protein Interaction Networks. Bioinf. Res. Appl. 2008, 4983, 208–219. [Google Scholar]
- Diez, D.; Hutchins, A.P.; Miranda-Saavedra, D. Systematic identification of transcriptional regulatory modules from protein–protein interaction networks. Nucleic Acids Res. 2014, 42, e6. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, G.; Meng, D.; Huang, L.; Cui, J.; Blanzieri, E. A Markov Clustering Based Link Clustering Method for Overlapping Module Identification in Yeast Protein-Protein Interaction Networks. Bioinform. Res. Appl. 2014, 8492, 28–30. [Google Scholar]
- Vinayagam, A.; Zirin, J.; Roesel, C.; Hu, Y.; Yilmazel, B.; Samsonova, A.A. Integrating protein-protein interaction networks with phenotypes reveals signs of interactions. Nat. Methods 2013, 11, 94–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jonsson, P.F.; Cavanna, T.; Zicha, D.; Bates, P.A. Cluster analysis of networks generated through homology: Automatic identification of important protein communities involved in cancer metastasis. BMC Bioinform. 2006, 7, 2. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; He, W. Special Protein Molecules Computational Identification. Int. J. Mol. Sci. 2018, 19, 536. [Google Scholar] [Green Version]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lancichinetti, A.; Fortunato, S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities. Phys. Rev. E 2009, 80, 016118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lancichinetti, A.; Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E 2009, 80, 056117. [Google Scholar] [CrossRef] [PubMed]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Kelley, S.; Szymanski, B.K. Overlapping Community Detection in Networks: The State-of-the-Art and Comparative Study. ACM Comput. Surv. 2013, 45, 43. [Google Scholar] [CrossRef]
- Enright, A.J.; Van, D.S.; Ouzounis, C.A. An efficient algorithm for large-scale detection of protein families. Nucleic Acids Res. 2002, 30, 1575–1584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srihari, S.; Kang, N.; Hon, L. MCL-CAw: A refinement of MCL for detecting yeast complexes from weighted PPI networks by incorporating core-attachment structure. BMC Bioinform. 2010, 11, 504. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, M.; Li, X.; Kwoh, C.K.; Ng, S.K. A core-attachment based method to detect protein complexes in PPI networks. BMC Bioinform. 2009, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Palla, G.; Derenyi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, Y.; Jeong, H. Map equation for link communities. Phys. Rev. E 2011, 84, 026110. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Qi, J.; Liang, X.; Yi, W. Overlapping community detection algorithm based on selection of seed nodes. Appl. Res. Comput. 2017, 34, 3534–3537. [Google Scholar]
- Evans, T.S.; Lambiotte, R. Line graphs, link partitions, and overlapping communities. Phys. Rev. E 2009, 80, 016105. [Google Scholar] [CrossRef] [PubMed]
- Ahn, Y.-Y.; Bagrow, J.P.; Lehmann, S. Link communities reveal multiscale complexity in networks. Nature 2010, 466, 761. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Wang, G.; Wang, Y.; Blanzieri, E.; Su, C. Link Clustering with Extended Link Similarity and EQ Evaluation Division. PLoS ONE 2013, 8, e66005. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Huang, L.; Wang, Y.; Pang, W.; Ma, Q. Link community detection based on line graphs with a novel link similarity measure. Int. J. Modern Phys. B 2016, 30, 1650023. [Google Scholar] [CrossRef]
- Deng, X.; Li, G.; Dong, M.; Ota, K. Finding overlapping communities based on Markov chain and link clustering. Peer-to-Peer Netw. Appl. 2017, 10, 411–420. [Google Scholar] [CrossRef]
- Angiulli, F. Fast condensed nearest neighbor rule. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 25–32. [Google Scholar]
- Wu, Z.; Lin, Y.; Wan, H.; Tian, S. A fast and reasonable method for community detection with adjustable extent of overlapping. In Proceedings of the International Conference on Intelligent Systems and Knowledge Engineering, Hangzhou, China, 15–16 November 2010; pp. 376–379. [Google Scholar]
- Khorasgani, R.R.; Chen, J.; Zaiane, O.R. Top leaders community detection approach in information networks. In Proceedings of the SNA-KDD, Washington, DC, USA, 10 July 2010. [Google Scholar]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 2005, 09008. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Kertész, J. Detecting the overlapping and hierarchical community structure in complex networks. New J. Phys. 2009, 11, 033015. [Google Scholar] [CrossRef] [Green Version]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Guerriero, V. Power law distribution: Method of multi-scale inferential statistics. J. Modern Math. Front. 2012, 1, 21–28. [Google Scholar]
- Bollobás Be Riordan, O.; Spencer, J.; Tusnády, G. The degree sequence of a scale-free random graph process. Random Struct. Algorithms 2001, 18, 279–290. [Google Scholar] [CrossRef]
- Yu, G.; Wang, L.-G.; Han, Y.; He, Q.-Y. clusterProfiler: An R Package for Comparing Biological Themes Among Gene Clusters. OMICS J. Integrat. Biol. 2012, 16, 284–287. [Google Scholar] [CrossRef] [PubMed]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D. Cytoscape: A Software Environment for Integrated Models of Biomolecular Interaction Networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Sample Availability: Samples of the compounds are not available from the authors. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nodes | Edges | BCN |
|---|---|---|---|
| Karate | 34 | 78 | 2 |
| Dolphin | 62 | 158 | 2 |
| Football | 115 | 612 | 12 |
| E. coli | 1396 | 2092 | - |
| M. musculus | 1883 | 2597 | - |
| Cerevisiae | 2172 | 5124 | - |
| Methods | Karate | Dolphin | Football | E. coli | M. musculus | Cerevisiae | ||
|---|---|---|---|---|---|---|---|---|
| RT(s) | ||||||||
| Datasets | ||||||||
| CES | 0.02 | 0.105 | 0.413 | 1.742 | 58.746 | 863.617 | ||
| CNS | 0.124 | 0.609 | 2.809 | 67.487 | 1395.1 | 15,780 | ||
| CPM | 0.01 | 0.3 | 0.8 | 1 | 5 | 7 | ||
| LC | 0.636 | 1.841 | 7.331 | 20.988 | 187 | 1682.22 | ||
| Dataset | Karate | Dolphin | Football | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Evaluation | EQ | NMI | CR | BCN | ECN | EQ | NMI | CR | BCN | ECN | EQ | NMI | CR | BCN | ECN |
| CES | 0.37 | 0.92 | 100% | 2 | 2 | 0.38 | 0.76 | 100% | 2 | 2 | 0.40 | 0.52 | 99% | 12 | 12 |
| CNS | 0.35 | 0.69 | 100% | 2 | 2 | 0.46 | 0.41 | 100% | 2 | 3 | 0.28 | 0.62 | 44% | 12 | 5 |
| CPM | 0.19 | 0.18 | 94% | 2 | 3 | 0.36 | 0.32 | 74% | 2 | 4 | 0.19 | 0.26 | 100% | 12 | 4 |
| LC | 0.17 | 0.06 | 97% | 2 | 12 | 0.18 | 1 × 10−16 | 87% | 2 | 22 | 0.16 | 5.5 × 10−17 | 100% | 2 | 46 |
| Algorithms | CES | CNS | CPM | |
|---|---|---|---|---|
| Datasets | ||||
| Karate Network |  |  |  | |
| Dolphin Network |  |  |  | |
| Football Network |  |  |  | |
| Dataset | M. musculus | E. coli | Cerevisiae | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Evaluation | EQ | CR | ECN | EQ | CR | ECN | EQ | CR | ECN |
| CES | 0.719 | 100% | 85 | 0.519 | 100% | 77 | 0.562 | 100% | 105 |
| CNS | 0.534 | 65% | 43 | 0.49 | 72% | 18 | 0.438 | 55% | 46 |
| CPM | 0.191 | 18% | 41 | 0.226 | 23% | 19 | 0.467 | 53% | 161 |
| LC | 0.19 | 78% | 149 | 0.10 | 60% | 47 | 0.06 | 92% | 580 |
| Datasets | CES | CNS | CPM | LC |
|---|---|---|---|---|
| M. musculus | 66/85 | 33/43 | 40/41 | 118/149 |
| E. coli | 44/77 | 17/18 | 15/19 | 10/47 |
| Cerevisiae | 79/105 | 44/46 | 159/161 | 344/580 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Ma, A.; Wang, Z.; Ma, Q.; Liu, B.; Huang, L.; Wang, Y. A Central Edge Selection Based Overlapping Community Detection Algorithm for the Detection of Overlapping Structures in Protein–Protein Interaction Networks. Molecules 2018, 23, 2633. https://doi.org/10.3390/molecules23102633
Zhang F, Ma A, Wang Z, Ma Q, Liu B, Huang L, Wang Y. A Central Edge Selection Based Overlapping Community Detection Algorithm for the Detection of Overlapping Structures in Protein–Protein Interaction Networks. Molecules. 2018; 23(10):2633. https://doi.org/10.3390/molecules23102633
Chicago/Turabian StyleZhang, Fang, Anjun Ma, Zhao Wang, Qin Ma, Bingqiang Liu, Lan Huang, and Yan Wang. 2018. "A Central Edge Selection Based Overlapping Community Detection Algorithm for the Detection of Overlapping Structures in Protein–Protein Interaction Networks" Molecules 23, no. 10: 2633. https://doi.org/10.3390/molecules23102633