
Equity Cost Induced Dichotomy for Optimal Dividends with Capital Injections in the Cramér-Lundberg Model


1
Laboratoire de Mathématiques Appliquées, Université de Pau, F-64012 Pau, France
2
School of Mathematics and Statistics, Shandong University (Weihai), Weihai 264209, China
3
LAMA, Univ Gustave Eiffel, UPEM, Univ Paris Est Creteil, Univ Paris Est Creteil, CNRS, F-77447 Marne-la-Vallée, France
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Mathematics 2021, 9(9), 931; https://doi.org/10.3390/math9090931
Submission received: 10 March 2021
/
Revised: 17 April 2021
/
Accepted: 20 April 2021
/
Published: 22 April 2021
(This article belongs to the Special Issue Stochastic Processes Applied to Modelling in Finance: Latest Advances and Prospects)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We investigate a control problem leading to the optimal payment of dividends in a Cramér-Lundberg-type insurance model in which capital injections incur proportional cost, and may be used or not, the latter resulting in bankruptcy. For general claims, we provide verification results, using the absolute continuity of super-solutions of a convenient Hamilton-Jacobi variational inequality. As a by-product, for exponential claims, we prove the optimality of bounded buffer capital injections policies. These policies consist in stopping at the first time when the size of the overshoot below 0 exceeds a certain limit a, and only pay dividends when the reserve reaches an upper barrier b. An exhaustive and explicit characterization of optimal couples buffer/barrier is given via comprehensive structure equations. The optimal buffer is shown never to be of de Finetti () or Shreve-Lehoczy-Gaver () type. The study results in a dichotomy between cheap and expensive equity, based on the cost-of-borrowing parameter, thus providing a non-trivial generalization of the Lokka-Zervos phase-transition Løkka-Zervos (2008). In the first case, companies start paying dividends at the barrier , while in the second they must wait for reserves to build up to some (fully determined) before paying dividends.
1. Introduction
Motivation. Keeping shareholders satisfied while maintaining the company liquid enough constitutes the core of the control activity of reserves/risk processes. The rough idea is that one should intelligently balance return over invested capital (dividends) and replenishment by capital injections to insure the company’s robustness against claims. The easiest way to conceive such balance can roughly be stated as follows: when below low levels (a acting as a maximally-admitted severity of ruin), reserve processes should be replenished by capital injections at some cost (hereafter, the unitary cost is denoted by ), and when above high levels , they should be taken out of the reserves as dividends–see for example [1,2] and the comprehensive book [3].
Historical overview. The first results tackling a related problem, due to de Finetti [4], concerned maximizing the expected value of the discounted cumulative dividends until the time of passage below a given level, called ruin. This can be seen as a particular case of the above-mentioned setting in which the cost of “borrowing” money is (or, equivalently, in which the maximal-targeted severity of ruin is .
Next, Shreve, Lehoczky and Gaver (1984) [5] (with extra help from Coffman and Karatzas), introduced, for a state-dependent diffusion process, the dividends problem for the reflected process (RP). This consists in maximizing the functional
where
- x is the initial surplus;
- q is a discount factor;
- are the cumulative dividends;
- are the cumulative forced capital injections each time the process attempts to cross into , and is a proportional cost for injecting capital;
- is the process modified by capital injections and dividends, and .
They studied this objective (roughly corresponding to unrestricted maximal severity of ruin ), as well as the classic de Finetti dividends with absorption problem (AP), separately (and left many outstanding open problems behind). A complete solution for both of these problems (AP) and (RP) for spectrally negative Lévy processes was given in [6]—see also [7,8,9,10,11] for further developments. Note though that all these papers deal with forced bailouts. To our best knowledge, our paper hereafter seems to be the first to quantify the optimal buffer (severity of ruin) when bankruptcy should replace individual bailouts (to be fair, this possibility has been considered before, but without studying optimality—see for example [12]). For a different approach, quantifying the optimal policy under an expected total bailouts constraint, see [13].
The next important step was taken in [14] who compared the problems (AP), (RP) in a Brownian setting. The first was incorporated into the latter by adding the possibility of bankruptcy at ruin, i.e., of not systematically using capital injections. Their objective is to maximize, under the state constraint ,
where denotes a policy-dependent random time (which may be ∞) when the controlled process goes below the ruin threshold. This objective is fundamentally different from that adopted in the “Shreve, Lehoczky and Gaver literature” cited before. Now, capital injections will not only modify the dividend barrier level, but may also provoke bankruptcy; this happens only when k is big enough—the so called Lokka-Zervos alternative.
More precisely, let , denote the value functions of the (AP) and (RP) problems. [14] showed, by analyzing the corresponding HJB equation, that for Brownian motion surpluses there exists a critical cost such that one of the following strategies is optimal:
- ; the optimal policy is (RP), i.e., pay dividends at an upper barrier and always inject capital at 0, implying that bankruptcy never occurs;
- ; the optimal policy is (AP), i.e., pay dividends in order to reflect the surplus process at some upper barrier , and never inject capital.
We wish to emphasize that the analysis conducted strongly relies on an heuristic step in [14] (first paragraph on page 959 leading to the boundary condition ([14], 5.2)), used when formulating the HJB. Roughly speaking, by invoking the Markovian structure at , it is argued that the value functions must either be 0, or have a derivative equal to k. Both these conditions fail to hold when one deals with Exponential Jumps—see Remark 14; this means that the Lokka-Zervos alternative holds for Brownian motion only because of the absence of jumps. Note that subsequently, ref. [15] showed that a similar Lokka-Zervos alternative holds for the Cramér-Lundberg process with exponential jumps, provided that one restricts from the start to either de Finetti or Shreve, Lehoczky and Gaver policies; as we know now, these are locally the worst possible policies.
Aim. Our paper focuses on the optimization of a criterion of type (2) in a Cramér-Lundberg framework without further assumptions on behavior of the value function at . We seek a related dichotomy (hereafter referred to as Lokka-Zervos alternative) of optimal policies following the expensiveness of capital injections. Three points are of particular interest
- we prove the optimality of policies such as those described at the very beginning for which, in general, (i.e., de Finetti and Shreve, Lehoczky and Gaver policies fail to be optimal);
- the resulting value function is not of class at 0 (in the sense that its derivative does not exist at and, more, the right-hand derivative at 0 is not k as assumed, for Brownian claims, in [14], 5.2). This can be found in Remark 14 and it implies, in particular, that the verification Theorem 4 has to be given for absolutely-continuous functions. Working with super-solutions also explains the particular form of the Equation (8) on .
- the optimal parameters and are completely characterized by non-trivial equations and so is the alternative-inducing cost .
Method. We have organized our paper around the classical guess and verify procedure for solving stochastic control problems:
- Guess a family of policies which yields the optimum for all possible values of the parameters, and compute its expected net present value (EPV) in terms of the scale functions.
Our paper shows that optimality is achieved here via “bounded buffer capital injections” policies, consisting in stopping at the first time when the size of the overshoot below 0 exceeds the limit a defined in Theorem 12. These policies turn out to work better than both the de Finetti and the Shreve, Lehoczky and Gaver policies, which are locally the worst possible choices!
For example—see Figure 1, with a special choice (see [15]) which ensures that the Shreve, Lehoczky and Gaver and de Finetti values coincide (with Exponential Jumps), the de Finetti and Shreve, Lehoczky and Gaver values are equal and globally the worst ones
This illustrates the fact that the critical feature of our control problem is that capital injections should be allowed only when they are smaller than a critical size.
- 2.
- Identify the optimal arguments with respect to the parameters of our policies. This step forced us to restrict to the case of exponential jumps, where the independence of ruin and ruin overshoots leads to simplifying factorizations related to the memoryless property of this distribution.
- 3.
- In the final step, confirm the optimality of the selected candidate optimal policy via a verification theorem (sufficient condition for optimality). If the conjectured value function were sufficiently smooth (this means in our problem), this would require only verifying that it satisfies an associated HJB equation (system of variational inequalities).
This is however not the case in our problem—see Remark 14 showing the value function to have a discontinuous derivative at 0—and made us turn to the minimality of the value functions among absolutely continuous super-solutions—see also the book [16] for a similar study (of the Cramér-Lundberg processwithout injections).
The model. We focus here on the classic Cramér-Lundberg model
with being a family of i.i.d.r.v. distributed according to a distribution function F, and N being an independent Poisson process of intensity .
For optimization reasons, in the computations starting from Section 3 onward, F will be corresponding to the exponential law , for some . We restrict to this process since the independence of ruin and ruin overshoots leads to simpler formulae. Also, we take advantage of explicit computations in this case, which involve the two roots of the Cramér-Lundberg equation (where is the Laplace exponent ).
Remark 1.
The results in Section 2 may be modified to work for a considerably more general model of reserves with reinsurance
where the premium p is (claim and) level-dependent in a Lipschitz manner and r is a further (continuous) control specifying the retention level for each claim. More precisely, we envisage , where y specifies the realised value of the claim C, the retention level () and F describes the distribution of claims C. The premium p is allowed to depend on the reserve x (e.g., in a linear way to recover Segerdahl’s model). However, for simplicity and consistency with the rest of the paper, only the Cramér-Lundberg case is presented below.
Related literature. Among other papers dealing with similar topics like [17,18,19], the most related to ours is [20], which was brought to our attention only after completion of our paper. Ref. [20] deals with the spectrally negative Lévy model, and the expressions for the cost functions provided in [20] are more general than ours. However, we prefer to offer here direct proofs adapted to the exponential case, for the sake of completeness.
Concerning optimality, the proof in [20] seems unclear to us, and we wrote two messages with no answer on this point to the authors. We believe that optimality is the hardest issue in our problem, and we have provided a full (and by no means easy) proof of that. In fact, this is precisely why we restricted to the exponential case; while the extension of the expected cost function to the matrix exponential case for example is standard—see (Section 7 in [21]), extending the optimality proof to the matrix exponential case seems very difficult and is for us still an open problem.
Note also (see Remark 1) that our approach in Section 2 may be modified to apply to more general spectrally negative processes, for example to the Segerdahl process [22], which is currently under study. Also importantly, for the Lévy case, our results are more explicit, and lead to algorithms presented in [21]. In fact, the algorithms (but not the optimality) are easily generalizable to the matrix-exponential case.
We end this literature review by mentioning a few related works on the dual spectrally positive Lévy model, where the situation is however much simpler, since capital injections occur without overshoot. A Lokka-Zervos alternative for the compound Poison model with exponential jumps and mixtures of exponential jumps was established in [23], and the first works on the general spectrally positive Lévy model were due to [24,25,26]. Note that in all these works the “overshoot dilemma” is absent: the dividends barrier may be overshot, but since we want to maximize dividends, in this case we do not need to distinguish between small and large overshoots.
Finally, we draw the attention to recent works concerning the diffusion approximation of the Cramér-Lundberg process, which further incorporate more sophisticated features like reinsurance [27,28,29]. It would be very interesting to investigate whether such sophisticated results can still be obtained while keeping the jumps.
Contents. The paper is organized as follows. Section 2 gives the necessary framework, mathematically formulates the admissible policies, the targeted cost and the value function. Section 2.2 turns to a structural study of the value function for arbitrarily distributed claims. This is achieved by making precise the regularity of the value function (Lipschitz-continuity, upper and lower-bounds in Proposition 2). Furthermore, the value function is characterized, among a class of linear-growth functions, as the smallest absolutely-continuous super-solution of the associated variational inequality of Hamilton-Jacobi integro-differential type. As it is by now standard, this characterization implies a verification result as to the optimality of policies (cf. Theorem 4).
The second part of the paper, starting with Section 3, is devoted to specifying the optimal policies in the exponential Cramér-Lundberg setting. We consider the costs associated to severity-constrained double barrier policies in Section 3.1. The explicit dependency on severity and upper barrier is made explicit in Propositon 7. The rigorous optimization on the two parameters is pursued in Section 4. The main result detailing the regions of optimality of the underlying parameters (cost of capital injections, severity of ruin and upper barrier) make the object of the main result Theorem 12. Finally, all the proofs are relegated to Section 6.
2. Optimizing Dividends and Capital Injections with Proportional Costs
2.1. The Framework
We will work with the process (3), living on a probability space rich enough to support the family of i.i.d.r.v. and the independent Poisson process N. The space is then endowed with the natural right-continuous, completed filtration . The surplus process will be modified by dividendsand capital injections (equity issuance), which are intended to maintain nonnegative.
- given a couple : describing dividends and capital injection, the modified surplus process is defined (under the ) by setting
- the cumulative dividend strategy L is adapted, non-decreasing and càdlàg (right-continuous, left-limits), ;
- the cumulative capital injection process I is adapted, non-decreasing and càdlàg, ;
- the triplet satisfying the previous conditions is referred to as (general) strategy and the family of all such strategies is denoted by .
- (prior to ruin) for every , the dividends should satisfy
- (after the ruin time ), we set (The reader is invited to note that in this case one of the jumping times for N such that remain adapted, non-decreasing and càdlàg).
- the satisfying the dividends restriction is called an admissible strategy and the family of all such strategies is denoted by .
- for an admissible strategy ,
- (a)
- we consider the ruin time (if a “very large” claim occurs, bankruptcy is declared; as we will see in the main result, it is never optimal to take and modify the equity I accordingly).
- (b)
- the associated cost is
- (c)
- Every strategy can be replaced with by modifying if such that and improving the associated cost . From now on, whenever a policy is considered, we identify it with and reason accordingly.
- (d)
- In connection to this type of policies and the related cost, we set
2.2. The Value Function
We turn now to establishing a verification-type result for the stochastic control problem (7). Roughly speaking, we present the following program:
- First, we focus on the regularity properties of the value function (lower and upper-bound and Lipschitz-continuity) in Proposition 2.
- Second, we prove the connection between this value function and the associated partial-integral differential system (of HJB-type) in Proposition 3.
- Third, we show in Theorem 4 that the value function is the lowest absolutely-continuous super-solution of the associated equation and, as a verification result, give the optimality condition for candidate policies.
All the results in this section are valid for general laws of the claims C. To emphasize this, we consider that this law of C is given by its distribution function denoted by F.
2.3. Some Elementary Properties of the Value Function
We start with gathering some elementary properties of the value function
Proposition 2.
- For every , the set of admissible strategies is non-empty. If , then and, for every , .
- For every and every , one has .
- If , then, for every and every policy , one has .
- For every and every , .
The proof, relying on rather standard arguments, will be postponed to Section 6.
2.4. The HJB System
In connection to the value function , we consider the following equation
where the Hamiltonian is given by
On , it is expected that the value function satisfy the first equation. The lower bound on the derivative (1) is linked to the possibility of lump-sum dividend payments, and the k upper bound is linked to the possibility of lump-sum, instant reserves replenishment. The second equation is written in prevision of a super-solution formulation. Indeed, a (non-negative) super-solution is expected to comply to the inequality ≤. In particular, either the derivative belongs to , or the sub-solution has reached 0. As anticipated, here is the simplest link to our stochastic control problem:
The proof—postponed to Section 6—relies, as it usually does, on the dynamic programming principle. The absolute continuity of allows to obtain the desired properties on the derivative almost surely.
2.5. The Value Function as Smallest Super-Solution
In this section, we strive to characterize the value function as the smallest super-solution in the class of regular ( i.e., absolutely continuous) functions with linear growth. We begin with the following (standard) approximating result. Let us point out that whenever is a non-negative super-solution of (8), there exists a (unique) point such that
As a consequence, we get the following result.
Theorem 4.
- The value function is non-negative, for and .
- Every non-negative -regular of growth viscosity super-solution of (8), where α is introduced in Proposition 15, is greater than or equal to on .
- If is a family of admissible strategies such that the associated costs is an super-solution for (8), then is optimal and .
The proof, again postponed to Section 6, is obtained in two steps. First, in order to prove the second assertion, we provide convenient approximations of by a sequence of convoluted (mollified) functions. Second, we conclude by proving that are, up to an -controlled error, super-solutions of . The verification part (assertion 3) is a mere consequence of the previous comparison and the definition of .
Remark 5.
Without any changes it can be shown that if ϕ is an super-solution of (8) on , then, for every and every admissible policy π keeping , the associated cost .
3. The Value Function for the Cramér-Lundberg Model
3.1. The Guess Step: Severity-Constrained Double Barrier Policies, for the Cramér-Lundberg Process with Exponential Jumps
Now, we turn to the guess step of the “guess-and-verify” method, by computing the value function associated to policies consisting in injecting capital up till the level 0, provided that the severity of ruin does not exceed and paying dividends as soon as the process reaches some upper level .
We recall that the modern control theory of spectrally negative Lévy processes uses intensively the so-called and scale functions, defined respectively for as:
- the inverse Laplace transform of , where is the Laplace exponent, and
- .
The reader is referred to the papers [30,31,32] for the first appearance of these functions, and to [2,33,34] for extensive reviews. A further important role in the results below will be played by the functions
and
Here,
denotes the mean function of our claims cut at level .
The reader is invited to note that
and that are non-decreasing functions (for all ).
The Laplace exponent of the Cramér-Lundberg process with exponential jumps is , and
where are the two roots of the second-order equation
The following proposition gathers a few results useful for explicit root computations (when ).
Proposition 6.
The following assertions hold true simultaneously.
- ;
- ;
- ;
- , for all ;
Again, the essential elements of the (rather immediate) proof are postponed to Section 6.
Proposition 7.
For a perturbed Cramér-Lundberg process with exponential jumps, we let
denote the expected discounted dividends and capital injections associated to policies consisting in capital injections with proportionality cost , provided that the severity of ruin is smaller than (and declaring bankruptcy for larger severity), and paying dividends as soon as the process reaches some upper level b. We set
- The cost function satisfies, for ,In particular, if we setthen
- Moreover, the cost can be explicitly written asand
The proof is postponed to Section 6. The first assertion follows by applying, to the reserve process starting at , the strong Markov property at the time the process reaches either 0 or the upper barrier b. A second expression for can be obtained by looking at the behavior at the time of the first claim. As a consequence, we get the dependency .
Remark 8.
- The first step of the previous proposition applies also to the perturbed Cramér-Lundberg process obtained by adding a Brownian term to (3). The second and third however use specific features available only if (in particular that ).
- Note thatwhere the last identity as well as the notation appear in [15]. Our formula interpolates between the de Finetti and Shreve, Lehoczky and Gaver cases:(Again, for details, the reader is guided to [15] and references therein).
- The Equation (20) may also be expressed asand making shows that the expected discounted dividends are . It follows that the expected capital injections when are .
Remark 9.
Looking at the last case of the result (20) for our functional , we notice formal similarities with the known particular cases (recalled in Remark 8).
To explain this, and to relate to other similar “case by case observations”, note first that our functional could be studied at three related levels: (A) stopping at ; (B) computing expected capital injections with reflection at T; (C) reflecting and getting dividends at T. The corresponding boundary conditions are , and they will yield different formulas for . We recall that the final corresponding results when are
Notice they are all decompositions into
- a term depending on b, which is multiplied by the scale function , and
- a term independent of b, , which has been called sometimes “smooth Gerber-Shiu function”—see for example [35], and also “smooth harmonic extension of , see [2]. It is striking that the scale function and the Gerber-Shiu function are the same for these three problems. This begs for a formula for the Gerber-Shiu function which does not depend on the problem, and such a candidate is offered by the “LRZ harmonic extension” obtained in [36,37]. However, this has only been rigorously proved in particular examples – see for example [12].
This informal discussion motivates us to call the functions the scale function and Gerber-Shiu function for our problem. For a more down to earth reason for this name, recall that interpolate between the de Finetti and Shreve, Lehoczky and Gaver scale function and Gerber-Shiu function, cf. (23).
4. The Optimal for the Cramér-Lundberg Model with Exponential Claims
In the previous arguments, we found it convenient to express the cost in terms of the functions S and G to illustrate computations starting from the fundamental scale functions and . From now on, however, instead of using this basis, we will switch to the fundamental exponentials (see Proposition 6). With the notations
(which lead to a separation of the variables ), the initial datum satisfies
4.1. Preliminary Remarks
We note first that , and, thus, can never be optimal. For this purpose, one notes that . It follows that either or it is a critical point of .
We start with a preparatory result, obtained by differentiating (21) with respect to a. For the complete proof, the reader is referred to Section 6.
Lemma 10.
The partial derivative ofwith respect to a (on (0, ∞)) is given by
- As a consequence, picking can never be optimal.
- For fixed and , there exists a unique critical point satisfying
This is equivalent to
Furthermore, (27) implies that at our objective simplifies to
Thus, the optimal policy can neither be of Shreve-Lehoczky-Gaver type (i.e., systematic injection to keep the reserve positive independently of the severity of the ruin), nor of De Finetti type.
We discover thus that our solution of the Lokka-Zervos problem provided in [15], where we restricted to these two types of policies, is irrelevant to the global optimization problem!
4.2. Determining the Candidate Maximal Arguments
Relying on the previous Lemma 10, we prove (see Section 6) the following characterization of overall optimal buffer and barrier.
Proposition 11.
If realizes the maximum of the quantity , then
- either , in which case (27) implies that satisfies
- or satisfiesand
5. From Guess to Optimality
The main result in this paper is based on the verification Theorem 4. Using the guess step developed in the previous sections, we completely characterize the parameters k for which , leading to a “take the money and run’ behavior at 0 and the remaining configurations, for which . For each case, we show that the )-policies (described in the guess step) induce an absolutely-continuous cost that is a super-solution of (8), thus being optimal.
Theorem 12.
- A.
- If , then, we have the following dichotomy.
- A1.
- The “cheap” equity regime, with , holds for , where is the unique solution ofHere the strategy consists in injecting capital to take reserve to 0 (for levels above satisfying (28)) and paying dividends with the barrier 0 (i.e., “take the money and run”) is optimal, and the optimal value function is
- A2.
- For “expensive” equity i.e., ,
- B.
- In the remaining case , independently of , and the value function is got as in A1:with given by the Equation (28).
Remark 13.
In preparation of the proof, the reader may want to note that (34) can be rewritten with the use of Proposition 6 (fourth assertion) as
As before, the proof is postponed to Section 6.
Remark 14.
- A careful look at the upper-bound in 2.2.2 (in the proof) shows that . As a consequence:
- the heuristic intuition in ([14], 5.2) no longer holds true for our case ( and fails to hold true);
- is only absolutely continuous (but not ) such that the comparison in Theorem 4 must be given among absolutely continuous super-solutions.
- The equality in (50) gives a way to characterize when is known.
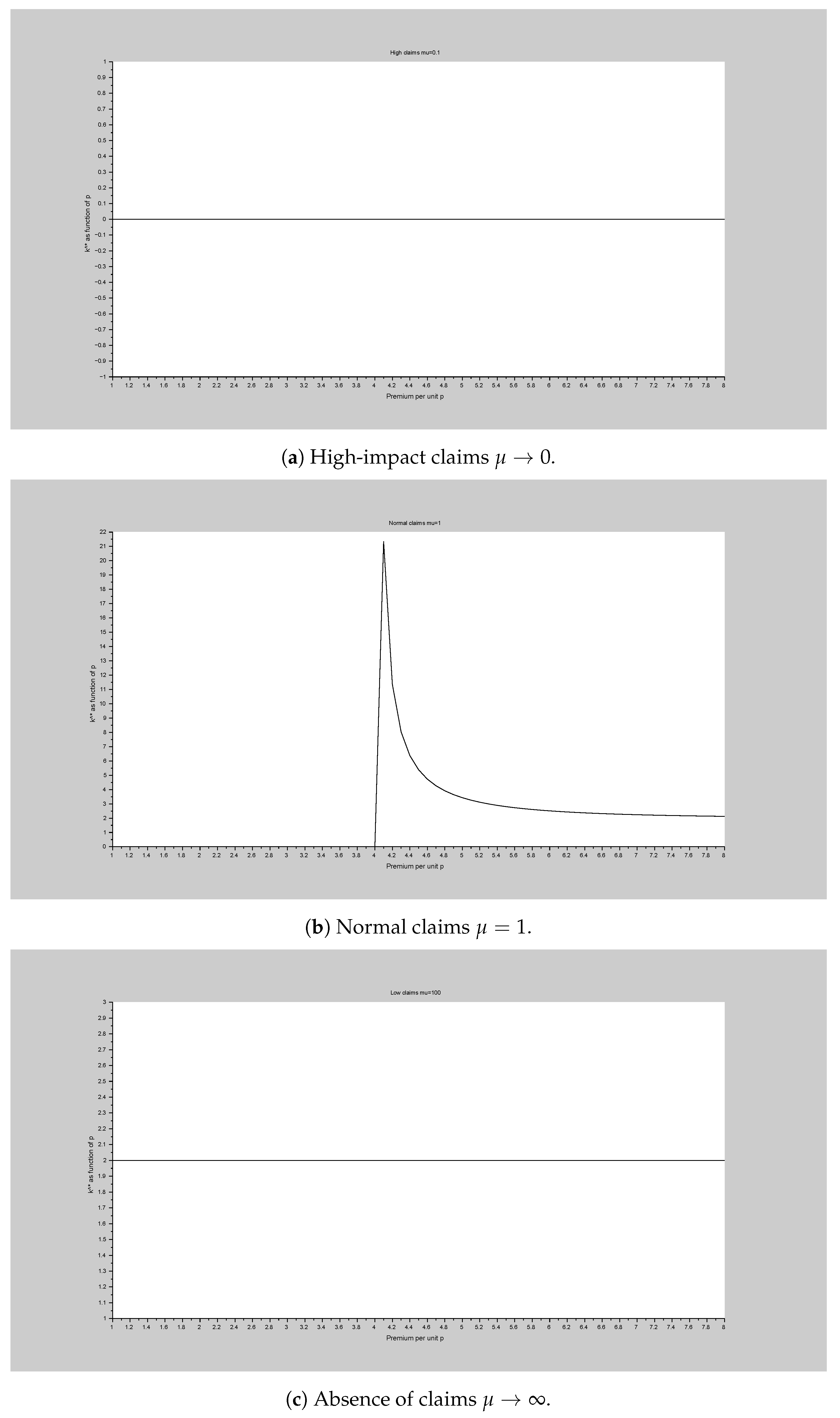
We illustrate the dependency of the discriminating equity level of and q in Figure 2.
- As , the claims approach ∞ average. In a highly impacted market, the notion of equity expensiveness vanishes and it is not optimal to wait for any amount of time (Figure 2a).
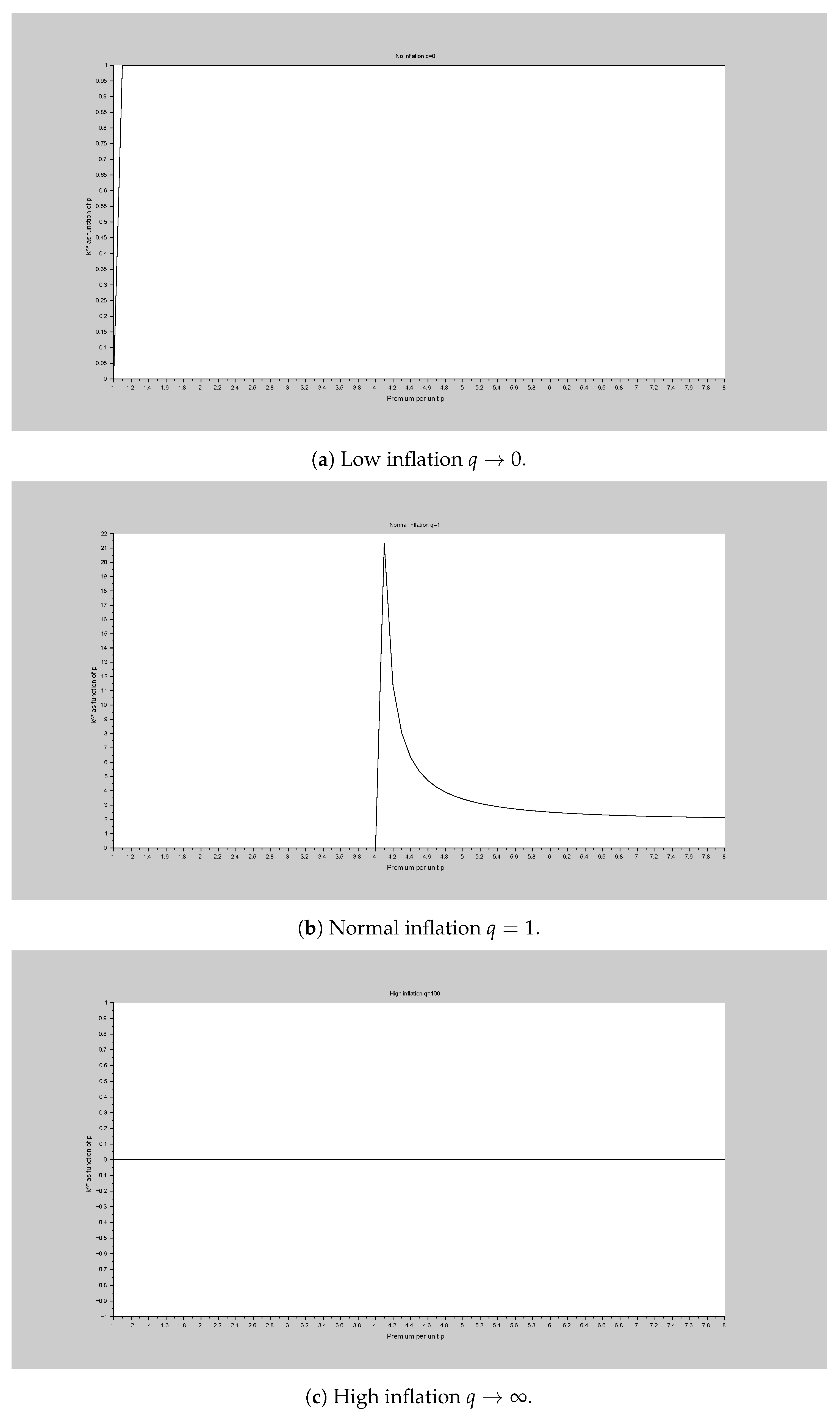
- On the other hand (Figure 3a), as the discount parameter , for all p that may give a dichotomy (cf. A), such that the Equation (31) leads to . In other words, absence of inflation makes every equity expensive. Conversely (Figure 3c), high inflation (large q) makes the notion of equity expensiveness vanish.
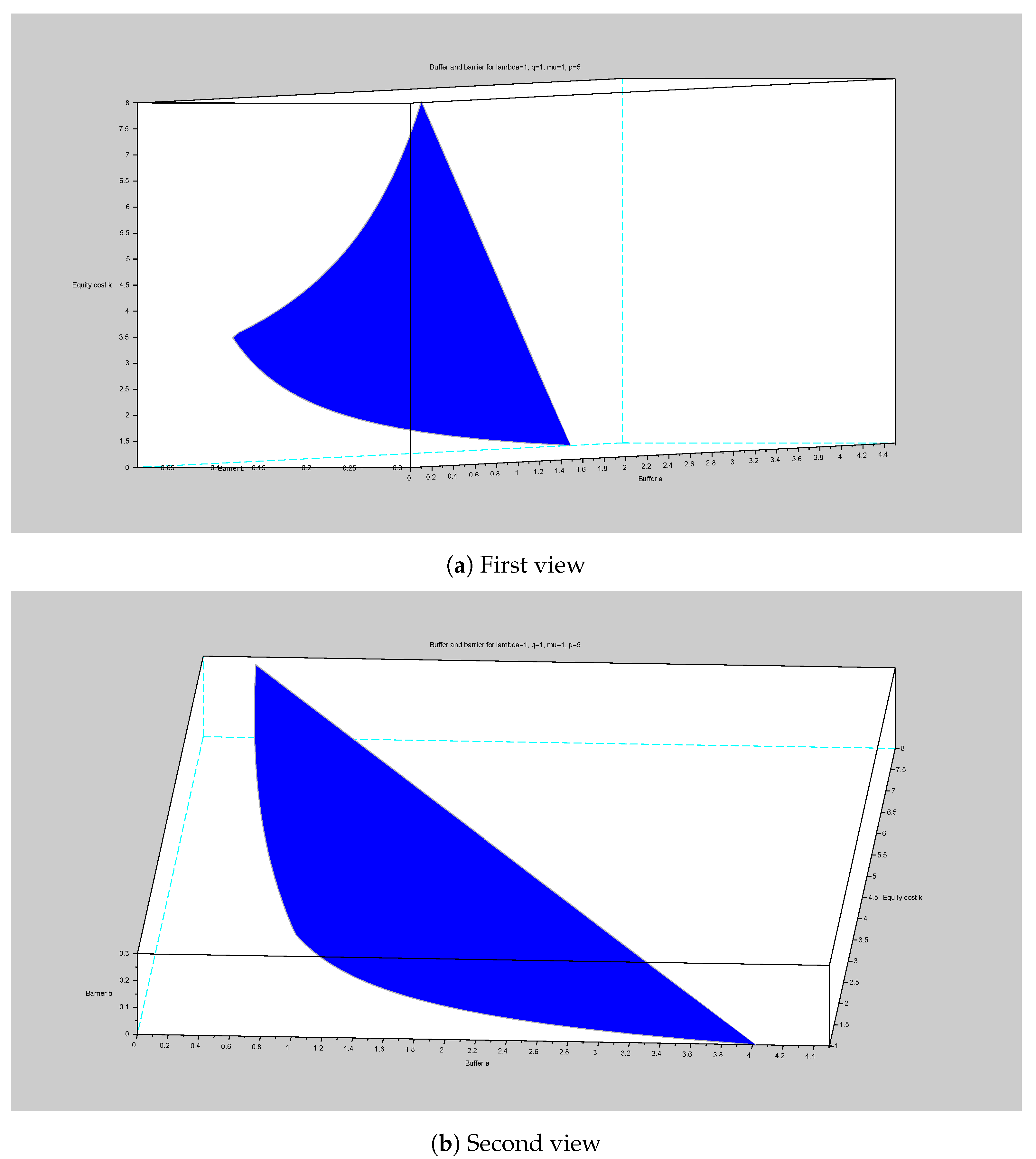
We end the section with a numerical illustration of the surface as the equity cost evolves in a compact interval in Figure 4.
A glance at the first point of view shows that until the critical value and then it increases with . The second point of view shows a to be decreasing with the equity cost . Then, it continues decreasing, although somewhat slower with .
6. Proofs of the Results
6.1. Proofs for the Value Function: Estimates, Dynamic Programming, Solution
Although following rather classical arguments, for our readers’ sake, we provide the proof of the basic properties of the value function .
Proof of Proposition 2.
- The classical (no dividend, no injection) policy is an admissible strategy. The second result is a mere consequence of the definition of .
- For , we consider the strategy consisting in no capital injection (), then paying and (continuously) the premium and declare bankruptcy at the first (positive) claim. For this admissible strategy , the ruin time (the first jumping time except on the 0-probability event ). We have
- One merely notes that, for every ,on . Then,
The conclusion follows by computing the average under .
- 4.
- The first inequality follows by modifying an arbitrary strategy into on to get . For the last inequality, one modifies (on ) an admissible strategy into .
□
Let us now turn to the proof of the super-solution behavior of .
Proof of Proposition 3.
Let .
As it is by now standard, the arguments rely on the dynamic programming principle (The proof of this principle is skipped in this paper. It is quite similar to the one without injections, e.g., in [16] with the only supplementary difficulty that is not bounded, due to the presence of the injection term I. However, this is overcome by restricting to 1-optimal policies as we did in the proof of Theorem 4 in order to obtain convenient bounds on the expected value of injections, hence of reserves. A paper on level-depending premiums and reinsurance is ongoing and the DPP is proven in this much more general framework) stating that, given a stopping time ,
We consider the admissible strategy (no dividends, no capital injection). We begin with the remark that, in this case,
The dynamic programming principle (using the time of the first claim and , i.e., ) with the particular choice of yields
by passing on the right and dividing by t, it follows that
Passing , one gets
The Lipschitz estimates on take care of the bounds on the derivative.
For negative reserves , only two strategies are possible: either declare immediate bankruptcy s.t. or inject capital at unitary cost k leading to . The super-solution condition follows. □
Before providing the proof of Theorem 4, we need the following approximation result.
Proposition 15.
Let ϕ be a non-negative super-solution of (8) s.t. , for all and some . Then, there exists a sequence of functions s.t.
- on ;
- on ;
- (pointwise a.e. on ).
Proof.
The proof is a mere modification of (Lemma 4.1 in [16]). Let us consider, for a sequence of standard mollifiers based on a non-negative continuously differentiable function supported on i.e, by setting , the convoluted function
It is clear that are of class , as are the convergence assertions. Since is , on which implies the same bounds on the . □
We proceed with the proof of the minimality of and the verification result for policies.
Proof of Theorem 4.
We fix . If is a non-negative, super-solution of (8), then, using introduced before and Itô’s formula, we get
where
If the strategy is 1-optimal for , then, owing to (35), one has
It follows that
To pass and/or in (40), one has to guarantee that the integrands are dominated (then apply Lebesgue dominated convergence). This follows from the previous inequality, the estimates on the trajectory (cf. 3. in Proposition 2), the growth condition and by noting that
This bounds are also valid for . By passing in (40) and recalling that is non-negative, we get
Let us set
where is the domain of differentiability of . Due to the convolution definition of , it follows that . Moreover, since , we are able to find some point such that . Using the mononicity of as well as the choice of and the super-solution condition for at , we get
Going back to (43), letting and taking the supremum over , it follows that as claimed.
The third assertion follows from the admissibility of , the definition of and from the second assertion. □
6.2. Proofs for the Guess Step
We begin with the tools in Proposition 6.
Proof of Proposition 6.
The assertions are quite forward. For our readers’ comfort, we hint at the proof of the fourth assertion. Owing to the first assertion, one gets
We now focus on the fifth assertion and write . We compute (using the previous assertions),
which implies the desired result. The proof for is quite similar. □
Now we are ready to provide the proof of the expression of the cost .
Proof of Lemma 7.
1. This statement follows by applying the strong Markov property at the stopping time . It follows that, for ,
where (and the random times are understood to be applied to the controlled reserve starting at y). The term can be explicitly computed (using the Gerber-Shiu measure).
It follows easily that
Our first assertion follows by plugging into (44). The second assertion (19) is a mere consequence of the first.
2. Putting in (18) yields , such that
Using this and together with (19) simplifies (18) to
for all . We will use a third equation for , obtained by conditioning at the time of the first claim when starting from b, and applying the first Equation (18), with eliminated using (45):
where the convolution terms were computed using the last assertion in Proposition 6. As a consequence, by recalling that as well as the definitions of w and z, it follows that we can isolate the terms containing
or, again,
6.3. Proofs for the Optimal Couple
We proceed with the proof of Lemma 10 showing that the optimal parameter a should be a critical one and the uniqueness of such maximizers for a fixed upper barrier
Proof of Lemma 10.
The first assertion is a mere computation starting from (26).
1. To see that cannot provide the maximal value for , one notes that
Similarly, for every as a is large enough, , thus proving that the supremum (w.r.t a, hence, due to the considerations in the beginning of the subsection, w.r.t ) is a maximum (attained for some ).
2. Having fixed , one considers the increasing function . One easily gets (note that ) and the first assertion follows easily. To get the expression of one simply notes that (27) can be written in the equivalent form such that
□
To end the proofs of the section, we give the following.
Proof of Proposition 11.
The assertion in the first case is a direct consequence of Lemma 10.
In the case when , the pair should be a critical point. We write the first-order condition for b.
such that . In particular, using Lemma 10, we get . By plugging this into (27), one gets the first assertion in (29).
Second, we make some remarks on the Hessian matrix at a critical point .
6.4. Proof of the Main Theorem
Proof of Theorem 12.
A1. We compute, for :
If , we have finished our proof. Otherwise, we get
We claim that the last expression is non-positive which amounts to claiming
or, again,
Owing to the fact that , it follows that such that is decreasing. Moreover, and which shows the existence and uniqueness of satisfying (i.e., Equation (31)). Moreover, it follows that, for every ,
The proof is completed owing to the last assertion in Theorem 4 (note that, in this framework, by definition, ).
A2. We now consider the case when . We begin with noting that, in this case,
- if and only if ;
- , for all .
- The continuous function satisfies and . We let denote the first solution of .
- We consider . One notes that . Moreover, such that , for all . In particular, . Owing to the monotonicity of , one deduces that .
It follows that, provided that , the structure equation admits a solution; the first solution is a maximal argument and it gives a better value than . We have proved assertion 2, points (a) and (b).
To complete the assertion (c), one notes that is decreasing in k. It follows that (since is optimal for as we have seen at point 1.), for every
We now prove the remaining assertion (d). As for the assertion 1, we only have to check that the candidate is an super-solution of (8). For later purposes, we note that .
2.1. For , we write down:
The last equality follows from .
2.2. The derivative is explicitly given by
2.2.1. To prove that , one can, alternatively show that The derivative
for all (recall the monotonicity of ). One concludes by recalling that owing to the Equation (32).
2.2.2. We still have to prove that . To this purpose, we consider
and show that . As for the previous argument, is non-increasing such that we only need to show that . Using (c), it follows that
2.3. For , noting that and using the same computations as in A1 (at ), we have
To conclude, we only need to show that
We consider the expression of
Then, proving (49) is equivalent to proving
or, again, by recalling that and are non-negative and increasing,
We now explicitly compute and recall that and satisfy the equation to deduce
It follows that (50) holds (with equality) and, thus, so does (49). The proof of A is now complete. B. One follows the same proof as we did for A1, but (48) is always satisfied. Indeed, as before, this is equivalent to proving
To see this, one writes
and the inequality follows. The proof is now complete. □
Author Contributions
Investigation, J.L. and X.W.; Project administration, F.A. and D.G. All authors have read and agreed to the published version of the manuscript.
Funding
The work of D.G., J.L. and X.W. has been supported by the National Key R and D Program of China (No. 2018YFA0703900) and the NSF of P.R. China (No. 12031009).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Schmidli, H. Stochastic Control in Insurance; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Avram, F.; Grahovac, D.; Vardar-Acar, C. The W,Z scale functions kit for first passage problems of spectrally negative Lévy processes, and applications to the optimization of dividends. arXiv 2019, arXiv:1706.06841. [Google Scholar]
- Albrecher, H.; Asmussen, S. Ruin Probabilities; World Scientific: Singapore, 2010; Volume 14. [Google Scholar]
- De Finetti, B. Su un’impostazione alternativa della teoria collettiva del rischio. In Transactions of the XVth International Congress of Actuaries; International Congress of Actuaries: New York, NY, USA, 1957; Volume 2, pp. 433–443. [Google Scholar]
- Shreve, S.E.; Lehoczky, J.P.; Gaver, D.P. Optimal consumption for general diffusions with absorbing and reflecting barriers. SIAM J. Control Optim. 1984, 22, 55–75. [Google Scholar] [CrossRef]
- Avram, F.; Palmowski, Z.; Pistorius, M.R. On the optimal dividend problem for a spectrally negative Lévy process. Ann. Appl. Probab. 2007, 17, 156–180. [Google Scholar] [CrossRef]
- Kulenko, N.; Schmidli, H. Optimal dividend strategies in a Cramér–Lundberg model with capital injections. Insur. Math. Econ. 2008, 43, 270–278. [Google Scholar] [CrossRef]
- Eisenberg, J.; Schmidli, H. Minimising expected discounted capital injections by reinsurance in a classical risk model. Scand. Actuar. J. 2011, 2011, 155–176. [Google Scholar] [CrossRef]
- Eisenberg, J.; Schmidli, H. Optimal control of capital injections by reinsurance with a constant rate of interest. J. Appl. Probab. 2011, 48, 733–748. [Google Scholar] [CrossRef] [Green Version]
- Pérez, J.L.; Yamazaki, K.; Yu, X. On the bail-out optimal dividend problem. J. Optim. Theory Appl. 2018, 179, 553–568. [Google Scholar] [CrossRef] [Green Version]
- Noba, K.; Pérez, J.L.; Yu, X. On the Bailout Dividend Problem for Spectrally Negative Markov Additive Models. SIAM J. Control Optim. 2020, 58, 1049–1076. [Google Scholar] [CrossRef] [Green Version]
- Avram, F.; Pérez, J.L.; Yamazaki, K. Spectrally negative Lévy processes with Parisian reflection below and classical reflection above. Stoch. Process. Appl. 2018, 128, 255–290. [Google Scholar] [CrossRef] [Green Version]
- Junca, M.; Moreno-Franco, H.A.; Pérez, J.L. Optimal Bail-Out Dividend Problem with Transaction Cost and Capital Injection Constraint. Risks 2019, 7, 13. [Google Scholar] [CrossRef] [Green Version]
- Løkka, A.; Zervos, M. Optimal dividend and issuance of equity policies in the presence of proportional costs. Insur. Math. Econ. 2008, 42, 954–961. [Google Scholar] [CrossRef]
- Avram, F.; Goreac, D.; Renaud, J.F. The Løkka–Zervos Alternative for a Cramér–Lundberg Process with Exponential Jumps. Risks 2019, 7, 120. [Google Scholar] [CrossRef] [Green Version]
- Azcue, P.; Muler, N. Stochastic Optimization in Insurance: A Dynamic Programming Approach; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Li, Y.; Liu, G. Optimal dividend and capital injection strategies in the Cramér-Lundberg risk model. Math. Probl. Eng. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Strini, J.A.; Thonhauser, S. On a dividend problem with random funding. Eur. Actuar. J. 2019, 9, 607–633. [Google Scholar] [CrossRef] [Green Version]
- Xu, R.; Woo, J.K. Optimal dividend and capital injection strategy with a penalty payment at ruin: Restricted dividend payments. Insur. Math. Econ. 2020, 92, 1–16. [Google Scholar] [CrossRef]
- Gajek, L.; Kuciński, L. Complete discounted cash flow valuation. Insur. Math. Econ. 2017, 73, 1–19. [Google Scholar] [CrossRef]
- Avram, F.; Goreac, D.; Adenane, R.; Solon, U., Jr. Optimizing dividends and capital injections limited by bankruptcy, and practical approximations for the Cram∖’er-Lundberg process. arXiv 2021, arXiv:2102.10107. [Google Scholar]
- Avram, F.; Perez-Garmendia, J.L. A Review of First-Passage Theory for the Segerdahl-Tichy Risk Process and Open Problems. Risks 2019, 7, 117. [Google Scholar] [CrossRef] [Green Version]
- Avanzi, B.; Shen, J.; Wong, B. Optimal dividends and capital injections in the dual model with diffusion. ASTIN Bull. J. IAA 2011, 41, 611–644. [Google Scholar] [CrossRef] [Green Version]
- Bayraktar, E.; Kyprianou, A.E.; Yamazaki, K. On optimal dividends in the dual model. ASTIN Bull. J. IAA 2013, 43, 359–372. [Google Scholar] [CrossRef] [Green Version]
- Yin, C.; Wen, Y. Optimal dividend problem with a terminal value for spectrally positive Lévy processes. Insur. Math. Econ. 2013, 53, 769–773. [Google Scholar] [CrossRef] [Green Version]
- Bayraktar, E.; Kyprianou, A.E.; Yamazaki, K. Optimal dividends in the dual model under transaction costs. Insur. Math. Econ. 2014, 54, 133–143. [Google Scholar] [CrossRef] [Green Version]
- Yao, D.; Yang, H.; Wang, R. Optimal risk and dividend control problem with fixed costs and salvage value: Variance premium principle. Econ. Model. 2014, 37, 53–64. [Google Scholar] [CrossRef] [Green Version]
- Yao, D.; Yang, H.; Wang, R. Optimal dividend and reinsurance strategies with financing and liquidation value. ASTIN Bull. J. IAA 2016, 46, 365–399. [Google Scholar] [CrossRef] [Green Version]
- Yao, D.; Wang, R.; Xu, L. Optimal dividend, capital injection and excess-of-loss reinsurance strategies for insurer with a terminal value of the bankruptcy. Sci. Sin. Math. 2017, 47, 969–994. [Google Scholar]
- Suprun, V. Problem of destruction and resolvent of a terminating process with independent increments. Ukr. Math. J. 1976, 28, 39–51. [Google Scholar] [CrossRef]
- Bertoin, J. Lévy Processes; Cambridge University Press: Cambridge, UK, 1998; Volume 121. [Google Scholar]
- Avram, F.; Kyprianou, A.; Pistorius, M. Exit problems for spectrally negative Lévy processes and applications to (Canadized) Russian options. Ann. Appl. Probab. 2004, 14, 215–238. [Google Scholar] [CrossRef]
- Kyprianou, A. Fluctuations of Lévy Processes with Applications: Introductory Lectures; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Kuznetsov, A.; Kyprianou, A.E.; Rivero, V. The theory of scale functions for spectrally negative Lévy processes. In Lévy Matters II; Springer: Berlin/Heidelberg, Germany, 2013; pp. 97–186. [Google Scholar]
- Avram, F.; Palmowski, Z.; Pistorius, M.R. On Gerber–Shiu functions and optimal dividend distribution for a Lévy risk process in the presence of a penalty function. Ann. Appl. Probab. 2015, 25, 1868–1935. [Google Scholar] [CrossRef]
- Loeffen, R.L.; Renaud, J.F.; Zhou, X. Occupation times of intervals until first passage times for spectrally negative Lévy processes. Stoch. Process. Their Appl. 2014, 124, 1408–1435. [Google Scholar] [CrossRef] [Green Version]
- Loeffen, R. On obtaining simple identities for overshoots of spectrally negative L∖’evy processes. arXiv 2014, arXiv:1410.5341. [Google Scholar]
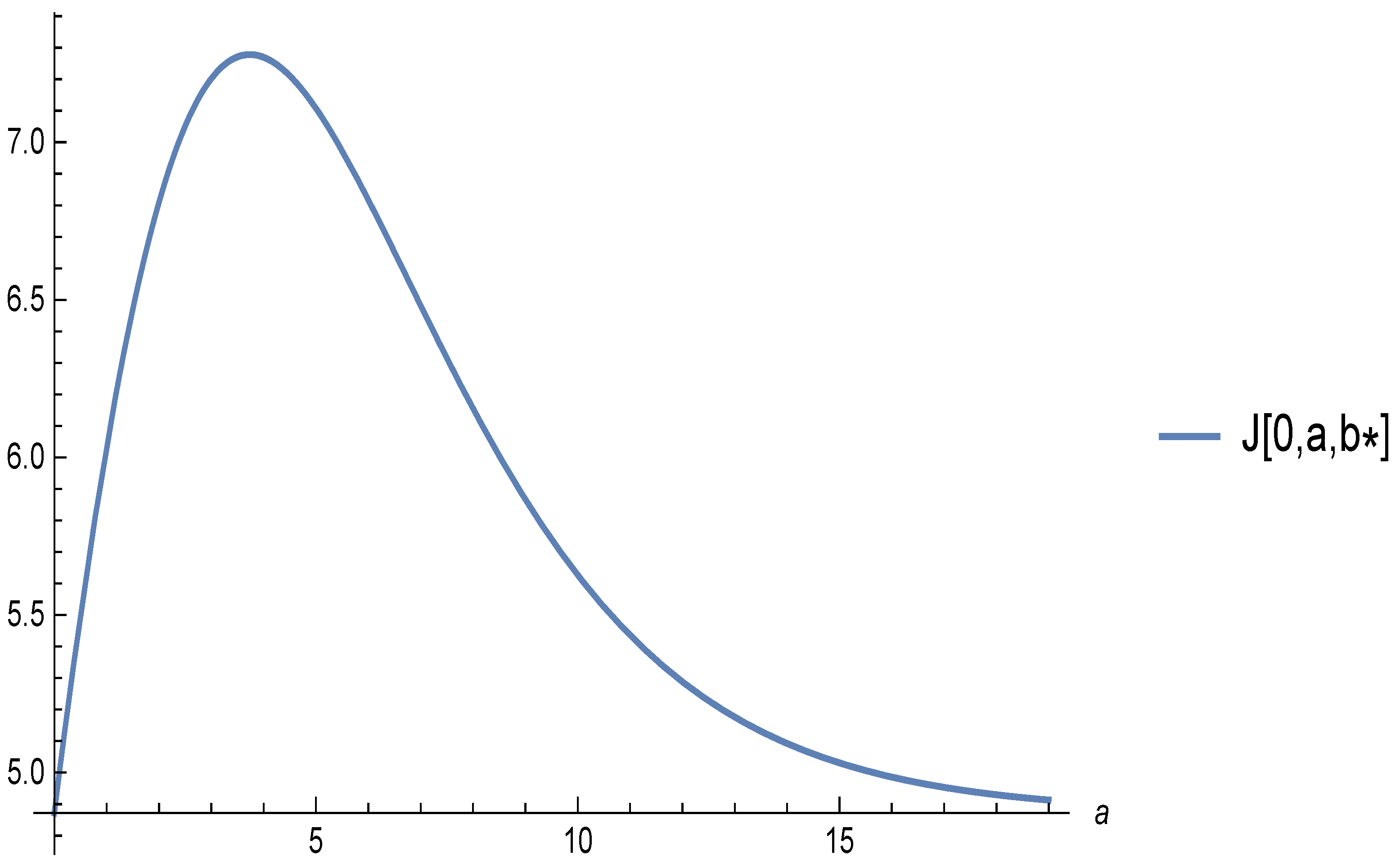
Figure 1.
Value function as a function of a, with fixed to the optimal de Finetti barrier, and chosen so that is also the optimal Shreve, Lehoczky and Gaver barrier. The parameters are . The optimal a for fixed is and the value is . Even so, the guess is below the optimum obtained for : and leading to .
Figure 1.
Value function as a function of a, with fixed to the optimal de Finetti barrier, and chosen so that is also the optimal Shreve, Lehoczky and Gaver barrier. The parameters are . The optimal a for fixed is and the value is . Even so, the guess is below the optimum obtained for : and leading to .

Figure 2.
Impact of claim average on equity expensiveness.

Figure 3.
Impact of inflation on equity expensiveness.

Figure 4.
The optimal surface as function of equity k for λ = q = μ = 1 and p = 5.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Avram, F.; Goreac, D.; Li, J.; Wu, X. Equity Cost Induced Dichotomy for Optimal Dividends with Capital Injections in the Cramér-Lundberg Model. Mathematics 2021, 9, 931. https://doi.org/10.3390/math9090931
AMA Style
Avram F, Goreac D, Li J, Wu X. Equity Cost Induced Dichotomy for Optimal Dividends with Capital Injections in the Cramér-Lundberg Model. Mathematics. 2021; 9(9):931. https://doi.org/10.3390/math9090931
Chicago/Turabian StyleAvram, Florin, Dan Goreac, Juan Li, and Xiaochi Wu. 2021. "Equity Cost Induced Dichotomy for Optimal Dividends with Capital Injections in the Cramér-Lundberg Model" Mathematics 9, no. 9: 931. https://doi.org/10.3390/math9090931
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.