Code-Switching in Linguistics: A Position Paper


Theoretical and Applied Linguistics, University of Cambridge, Cambridge CB2 1TN, UK
Languages 2020, 5(2), 22; https://doi.org/10.3390/languages5020022
Submission received: 25 January 2019
/
Revised: 12 August 2019
/
Accepted: 6 December 2019
/
Published: 18 May 2020
(This article belongs to the Special Issue Interdisciplinary Perspectives on Code-Switching)
Abstract
:This paper provides a critical review of the state of the art in code-switching research being conducted in linguistics. Three issues of theoretical and practical importance are explored: (a) code-switching vs. borrowing; (b) grammaticality; and (c) variability vs. uniformity, and I take a position on all three issues. Regarding switching vs. borrowing, I argue that not all lone other-language items are borrowings once more subtle measures of integration are used. I defend the use of empirical data to compare competing theoretical frameworks of grammaticality, and I exemplify quantitative research on variability in code-switching, showing that it also reveals uniformity and the possible influence of community norms. I conclude that more research is needed on a range of bilingual communities in order to determine the relative contribution of individual factors, processing and community norms to the variability and uniformity of code-switching.
1. Introduction
In this paper I will attempt to present, for an interdisciplinary audience, my view of code-switching from linguistics. Linguists themselves do not agree on some of the core issues guiding research in linguistics and therefore I will present these issues from my own perspective while considering some of the counter-arguments to my point of view. I will focus on three particularly divisive issues, the differentiation of code-switching from borrowing, the methods for evaluating competing models of grammaticality in code-switching, and the importance of studying variable as well as uniform patterns in code-switching. Virtually all researchers working on code-switching will need to take a position on these issues, whatever is their disciplinary background.
To begin with concrete examples of what I mean by code-switching, the following examples1 from the Welsh/English and Spanish/English data available on the Bangortalk2 website will help to illustrate.
| 1. | pan | dach | chi | ‘n | defnyddio | wide-angle | lenses |
| when | be.2PL.PRES | PRON.2PLLL | PRT | use.NONFIN | wide-angle | lenses |
‘When you use wide-angle lenses…
| dach | chi | ‘n | emphasize-iodefnyddio | ‘r | foreground | |
| be.2PL.PRES | PRON.2PLL PRO.2PL PRO.2PL | PRTT | emphasize-NONFINNNNNN | DET | foreground |
‘…you emphasize the foreground’ [Fusser17-BEN]
| 2. | el | siempre | me | da | cumplidos | así |
| PRON.3S | always | PRON.1S | give.3S.PRES | compliment.PL | thus |
‘He’s always paying me compliments like that…’
| so | I | said | to defnyddio | him | |
| So | PRON.1S PRO.2PL PRO.2PL | said | to | PRON.3S |
‘…so I said to him…’
| talk | to | me | in | two | more | years | |
| talk | to | PRON.1S | in | two | more | year.PL |
‘…“Talk to me in two more years”’ [Sastre9-VAL]
In Example (1) the speaker is using mainly Welsh, but inserts some English words and phrases (indicated in italics). In Example (2) the speaker starts off in Spanish and then switches to English. The English insertions in Example (1) illustrate what I call intraclausal switching, while Example (2) exemplifies interclausal switching in that a clause entirely in Spanish is followed by a (complex) clause entirely in English.
As outlined above, the three issues to be discussed in this chapter are as follows: code-switching vs. borrowing, grammaticality, and variability and uniformity. While grammaticality and variability are issues of concern to linguists working on any language or languages, the issue of code-switching vs. borrowing is peculiar to those working on bilingual data.
2. Code-Switching vs. Borrowing
Weinreich (1953, p. 11) was one of the first to draw a distinction between code-switching and borrowing. He used the term ‘interference’ to describe a situation where a bilingual is speaking language X but produces an ‘on-the-spot borrowing’ or ‘nonce borrowing’ from language Y (which we refer to here as ‘code-switching’). This is different, he argued, from a situation where a bilingual produces a word from Y which is an established element in language X (which we refer to here as ‘borrowing’).
The issue of distinguishing between switches and borrowing in bilingual speech has been described by Poplack and Meechan (1998, p. 127) as being “at the heart of a fundamental disagreement among researchers about data”, a disagreement which persists even twenty years later. Doubt about the classification of other-language material as either switches or borrowings arises particularly in relation to single words, whereas the longer the stretch of other-language material the easier it generally is to identify that material as a switch. So, with reference to Example (1) we may say without hesitation that the phrase wide-angle lenses is a switch into English, but we might have more doubts about the status of the single words emphasize and foreground. The vocabulary of Welsh includes many well established English borrowings, so one might wonder whether foreground is one of these (although it is not in fact, according to our criteria).
Example 3 below, like example 1, contains a word of English origin, siop, ‘shop’, but in this case we consider it a borrowing rather than a switch. In our work (see e.g., Deuchar et al. 2018) we classify it as a borrowing because it is listed as such in the authoritative Welsh dictionary Geiriadur Prifysgol Cymru3, which also provides evidence of its usage in Welsh from the fourteenth century onwards.
| 3. | a | mae | gynno | Fo | siop | yn | Gaernarfon |
| and.CONJ | be.V.3.S.PRES | with_him | PRON.3SM.3.S | shop | in.PREP | Caernarfon |
‘And he’s got a shop in Caernarfon’ [Fusser16-ANW]
Words like foreground in Example (1) and siop/shop in Example (3) would be described by some investigators as ‘LOLIs’, or ‘lone other language items’ (cf. Poplack and Meechan 1998) on the grounds that they originate in other languages, either in the past history of the recipient language (and are borrowings in the recipient language), or at the time of the speaker’s utterance (and are switches). It is the ‘lone’ or single other-language items which are particularly difficult to classify as either switches or borrowings. Other-language phrases, or chunks of other-language material like wide-angle lenses are easier to classify as switches, partly because the internal syntax of the phrase can give us a clue. In the phrase wide-angle lenses the syntax of a modifier (wide-angle) preceding a head noun (lenses) follows the syntax of English rather than Welsh, in which modifiers generally follow their head nouns. This makes it a clear switch for most researchers. However, it is important to point out here that the internal syntax of a phrase from the other language does not always follow that of the donor language. This is pointed out by Poplack (1988, p. 224) in relation to Example (4) below which comes from her French/English corpus, and in which she points out that building high-rise follows French rather than English syntax:
4. à côté il y en a un autre gros building high-rise. (‘Next-door there’s another big high-rise building’)
This type of example is not further discussed in Poplack’s paper but should arguably be treated as involving two separate switches, building and high-rise which are inserted following the (head-modifier) syntax of the recipient language, French. However, in Poplack’s recent book (Poplack 2018, p. 210) she describes “multiword fragments” from a donor language as “unambiguous code-switches”. As Example (4) illustrates, they are not always unambiguous, and in our Welsh/English data we find several examples of multiword fragments which contain English words but do not follow English syntax. Example (5) below illustrates the point.
| 5. | ges | i | dream | weird | neithiwr | sti |
| get.V.1S.PAST | I.PRON.1S | dream | weird | last_night | you_know |
‘I had a weird dream last night, you know’. [Robert3-BTI]
Returning to the problem of classifying LOLIs as either switches or borrowings, Poplack and Meechan (1998) attempt to propose a foolproof method in their “comparative method” (Poplack and Meechan 1998, p. 130). This involves a quantitative analysis of relevant morphosyntactic patterns in the two contact languages when they are used monolingually or without mixing, and then a comparison of the results with the morphosyntactic patterns in mixed discourse in which a lone item from another ‘donor’ language is being used in a recipient language. If the patterns in which the donor-language item is being used are similar to those used in the recipient language when it is unmixed, they consider the item be linguistically integrated and therefore to be a borrowing rather than a switch. If on the other hand the morphosyntactic patterns are more similar to those of the unmixed donor language, then the lone other-language item is classified as a switch. Poplack and Meechan (1998) and Poplack and Dion (2012) interpret what they find to be frequent integration of LOLIs as indicating that “lone other-language items tend to be borrowed” (Poplack and Dion 2012, p. 296). They consider lone other-language items to be borrowed even if they occur infrequently, and use the term ‘nonce borrowing’ for infrequent other-language items that show morphosyntactic integration into the recipient language.
However, I would argue that Poplack and colleagues do not sufficiently take into account the fact that there are different degrees of morphosyntactic integration, and that an alternative perspective (cf. Myers-Scotton 1993, p. 183) would argue that ‘central’ types of integration like using the word order and inflections of the recipient language may apply to all LOLIs, while more peripheral types of integration may allow us to distinguish switches from borrowings. An example of a peripheral type of integration may be found in the application of the mutation of initial consonants in English verbs used in Welsh/English code-switching (see Stammers and Deuchar 2012; Deuchar and Stammers 2016). The rate of mutation of all verbs (both Welsh and English-origin) was related to their frequency of occurrence in the Siarad corpus (see bangortalk.org.uk) but there was a clear difference between the integration of both Welsh and English-origin verbs found in the Welsh dictionary and English-origin verbs not in the Welsh dictionary. We interpreted this as indicating an important role for ‘listedness’ (see Muysken 2000, p. 71). Thus a (high) rate of mutation, close to that for Welsh verbs, was postulated as indicating a borrowed English-origin verb, whereas a significantly lower rate of mutation was a hallmark of those English-origin verbs not found in the Welsh dictionary. Using mutation as a subtle measure of linguistic integration we could distinguish clearly between borrowings and switches and found the category of ‘nonce borrowing’ to be redundant, given that there were no low frequency LOLIs that were not established borrowings but which had a high degree of this subtle type of integration.
Although Poplack and colleagues do not appear to have recognised a distinction between more central and more peripheral morphosyntactic integration, they do recognise the potential role of phonological integration in identifying borrowings versus switches, though Poplack’s latest (2018, p. 185) verdict is that it does not play a role. In her early work (e.g., Poplack 1980) she suggested that a clear case of borrowing would involve phonological, morphological and syntactic integration, but extensive research led her to argue that “In many bilingual communities, phonological integration of loanwords is highly variable…disqualifying phonology as a (foolproof) criterion” Poplack (2000, p. 221). This conclusion became widely accepted by code-switching researchers as shown by Bullock’s (2009) statement that “The failure of all borrowings to be consistently adapted to the phonology of the source language led to the abandonment of phonological integration as a necessary property of loan words” (Bullock 2009, p. 166). One reason for the widespread acceptance of this conclusion was the recognition that bilingual speakers may have a higher degree of proficiency in one of their languages than the other, and that, especially where they have acquired one language later than the other, the second language may have characteristics of ‘non-native’ pronunciation. In other words, some bilingual speakers will be more able to integrate LOLIs phonetically than others. Poplack (2018) argues that despite the copious evidence provided by Poplack et al. (1988) regarding the high degree of phonetic variability in other-language items, no one factor (even proficiency) has been found to account for the variability. This leads her to suggest that “phonetic and morphosyntactic integration can proceed independently” (Poplack 2018, p. 185) and that “Phonetic integration of borrowed material should not simply be assumed; it must be established first on a speaker-by-speaker basis, and then community by community”.
This challenge is taken up by Bessett (2017a, 2017b), who sets out to determine whether phonological and morphosyntactic integration are correlated in the speech of Spanish-English bilinguals in Southern Arizona. He analysed the speech of 24 residents of Southern Arizona in either Tucson or Nogales, whose families came from the Mexican state of Sonora on the other side of the border between the USA and Mexico. All participants except one had been born in the USA or arrived before the age of ten, and were highly proficient in both Spanish and English. In choosing these participants Bessett was thus able to control for the variable of proficiency and to assume that speakers were able to use native-like pronunciation of both Spanish and English words if they chose to do so. Bessett investigated the morphological and phonetic integration of lone English nouns (‘LOLNs’) surrounded by Spanish in the speech of his participants. In coding English LOLNs for morphological integration, Bessett noted whether each noun had a determiner or was bare, since the distribution of nouns with and without determiners contrasts in English and Spanish. He found that while established English noun borrowings in Spanish were morphosyntactically integrated in Spanish according to the Spanish norms for determiner presence vs. absence, this was not always the case for English noun insertions that were not established borrowings. In particular, English generic nouns that were not established borrowings were likely to be inserted without any determiner, following the pattern characteristic of that in English but not Spanish, where generic nouns appear with determiners. This is an excellent example of using a ‘peripheral’ kind of morphosyntactic integration in order to study the borrowing vs. code-switching status of LOLIs. He also coded the same LOLNs for ‘English phonology’ vs. ‘Spanish phonology’, having established that his judgments agreed both with those of 19 monolingual English participants and with an acoustic analysis using PRAAT. LOLNS with English-like morphology (based on determiner presence vs. absence) and/or phonology were considered to be morphosyntactically and/or phonologically integrated into Spanish, the recipient language. His results showed a correlation between the two types of integration, leading him to suggest that phonological integration may be relevant in distinguishing borrowings from switches. This research thus represents an innovative lifting of the ban on considering the phonological integration of LOLIs and should be pursued further in relation to more data in a range of different corpora.
3. Grammaticality
The notion of grammaticality is usually understood to refer to the rule-governed nature of language. Crystal (2008, p. 219) defines the term as referring to “the conformity of a sentence (or part of a sentence) to the rules defined by a specific grammar of a language”. This definition makes clear the general assumption that the rules of grammar are language-specific, and does not deal with the question of what happens if you combine material from two languages in the same sentence or clause. In code-switching between clauses of the kind illustrated in Example (2) above, this is not so much of an issue because it can be assumed that the grammar of Spanish applies to the first clause el siempre me da cumplidos así (‘He always gives me compliments like this’) while the grammar of English applies to the next sentence so I said to him ‘Talk to me in two more years’. But in the case of intraclausal code-switching as in Example (1) we can reasonably ask whether we should evaluate grammaticality either in terms of Welsh or English grammar, or neither. Despite the fact that Labov (1971, p. 457) described the intraclausal code-switching of a New York Puerto Rican Spanish/English bilingual as “the irregular mixture of two distinct systems”, stating that no one had yet been able to identify any systematic rules or constraints, constraints were indeed being postulated by the end of the 1970s. Pfaff (1979) produced one of the first such studies, in which she argued that the “mixture of Spanish and English, whether in isolated loan words or in code-switching of clauses and sentences, while socially motivated, is subject to clear linguistic constraints” (Pfaff 1979, p. 291). She based her conclusions on the analysis of a corpus of Spanish/English conversational data from about 200 speakers of various ages and social backgrounds. The scope of her coverage is impressive for those early days, and she provides plenty of examples to illustrate her proposed constraints. She concludes that “It is unnecessary to posit the existence of a third grammar to account for the utterances in which the languages are mixed; rather, the grammars of Spanish and English are meshed according to a number of constraints” (Pfaff 1979, p. 314). She summarises the structural constraints as favouring “Surface structures common to both languages”, illustrating this with evidence showing combination of Spanish auxiliaries and English participles, contrasted with the apparently prohibited mixing of adjectives and nouns within NPs where the surface order of adjectives in relation to nouns in Spanish and English is different. This observation is echoed in Poplack’s ‘Equivalence constraint’, according to which “Code switches will tend to occur at points in discourse were juxtaposition of L1 and L2 elements does not violate a syntactic rule of either language” (Poplack 1980, p. 586). This generalization is expressed in the more modern notion of a tendency towards ‘congruence’ (cf. Deuchar 2005; Sebba 2009) although current theories are now more able to account for the counter-examples to the equivalence constraint which subsequent investigators discovered. Nartey (1982), for example, reports on code-switching between English and Adãŋme, a Western Kwa language spoken in Ghana. Nominal constructions in these two languages provide a good example of non-equivalence of word order, in that whereas the normal English order is Det + Adj + N, in Adãŋme it is the reverse: N + Adj + Det. Nevertheless, Nartey’s data include insertions of an English adjective between an Adãŋme noun and an Adãŋme determiner, as in Figure 1 below, and of English noun and adjectives inserted in otherwise Adãŋme sentences in both Adãŋme order (see Figure 2) and English order (see Figure 3).
In addition to the equivalence constraint, Poplack (1980) also proposed the free morpheme constraint, according to which “Codes may be switched after any constituent in discourse provided that constituent is not a bound morpheme” (Poplack 1980, pp. 585–86). This is illustrated by the oft-cited example *eat-iendo ‘eating’, representing the free English morpheme eat, followed by the bound Spanish morpheme -iendo indicating a present participle. However, she adds the caveat that this kind of combination may be allowed if one of the morphemes has been phonologically integrated into the language of the other. Nartey (1982) is doubtful about the applicability of this caveat, and finds evidence in his data against the constraint. He even reports an example (see Figure 4 below) which is exactly parallel to eat-iendo in that it involves the inflection of the English verb help with an Adãŋme tense marker:
It is worth noting at this point that Poplack’s original constraints referred to switch points rather than to the nature of material switched, whereas in the earlier sections of this paper we referred to insertions of other-language material as switches. Researchers do not always make clear which definition they are using, but recent research suggests that referring to switch points alone is not sufficiently explanatory. As we shall show below, reference to the morphosyntax of the entire clause is necessary.
Given the counter-examples to Poplack’s constraints, Poplack (2001) argues that the notion of constraints on code-switching should be replaced by that of general principles. One of these principles, I would suggest, is that of asymmetry between the contribution of the two languages in code-switching. Joshi (1982) was one of the earliest code-switching researchers to provide evidence of an asymmetry between open and closed class items in code-switching, using Marathi/English data. Labelling the two languages of a bilingual the ‘matrix’ vs. the ‘embedded’ language, he argued that the matrix language is the source in bilingual speech of both open and closed class (e.g., determiners, prepositions, tense-marked verbs) items, whereas the embedded language can only supply open class items (e.g., nouns, adjectives). We illustrate this asymmetry from our own Welsh/English data in Example (6):
| 6. | mae | Americans | yn | mwy | commercial. |
| be.3S.PRES | Americans | PRT | more | commercial |
“Americans are more commercial.” [Fusser27-Lis]
In this example an English noun Americans and the English adjective commercial have been inserted into an otherwise Welsh clause. Both of these English words belong to open class categories. However, the finite verb mae4 comes from the matrix language, Welsh, as one would expect from a closed class word. In order to demonstrate that we have not identified Welsh as the matrix language purely on the basis of the closed class item mae, we can point out that the word order of the clause follows that of Welsh (a VSO language) rather than English (SVO) in that the verb appears first.
Joshi’s (1982) distinction between the matrix and the embedded language in code-switching is built upon by Myers-Scotton (2002) in her Matrix Language Frame (MLF) model. The asymmetry mentioned above is captured in her ‘Asymmetry Principle’ which she describes as being reflected in bilingual speech in “the morphosyntactic dominance of one variety in the frame” of a clause (Myers-Scotton 2002, p. 9). The language which provides the morphosyntactic frame of the clause is referred to as the ‘matrix language’. The other language is the ‘embedded language’, and material in this language constitutes the switches away from the matrix language. Whereas there is no restriction on the grammatical categories of constituents from the matrix language, only certain broadly ‘open class’ items can be drawn from the embedded language. An exception to this restriction is where a ‘chunk’ of embedded language items appear together.
In identifying the matrix language in our data (see bangortalk.org.uk) we draw on Myers-Scotton’s “System Morpheme Principle and the Morpheme Order Principle (Myers-Scotton 2002, p. 59)” as described and exemplified by Deuchar et al. (2018, pp. 115–18). As explained in more detail by Deuchar et al. 2018, the matrix language of a clause can by identified by the language of a particular kind of ‘system morpheme’, e.g., an inflection on a finite verb which agrees with the subject of the verb. In addition, it can also be identified by the order of the words or morphemes in the clause. This can be illustrated by Example (7) below from our Welsh/English data:
| 7. | oedd | ‘na | fath | â | ryw | alley yna | bach | Yna |
| be.3S.IMP | there | kind | with | some | alley | little | There |
‘There was kind of a little alley there.’ [Davies6-Hec]
As shown by the gloss of the first word oedd, which is the finite verb, the verb is marked as third person singular, which agrees with the third person subject ryw alley bach (‘Some little alley’). The fact that the agreement is expressed by a Welsh morpheme is an indicator that the matrix language of the clause is Welsh. This is then confirmed by looking at the word order, as the verb comes first as in Welsh (a VSO language), and the adjective bach (‘little’) follows the noun as in Welsh (in contrast to adjective-noun order as in English). Thus according to both the System Morpheme Principle and the Morpheme Order Principle, the matrix language of the clause in Example (7) is Welsh.
Myers-Scotton’s (2002) Matrix Language Frame model (MLF) is arguably the most influential model of code-switching, and works well in accounting for data from many language pairs (see e.g., Blokzijl et al. 2017a, Carter et al. 2011, Deuchar et al. 2018, Ihemere 2016, Khan and Khalid 2018). Before deciding to use it in our analysis, however, we evaluated four alternative models according to whether or not they (1) were designed to deal with production data; (2) could analyse individual clauses; and (3) applied to both monolingual and bilingual data. The MLF was the only model evaluated which satisfied all criteria (see Carter et al. 2011, p. 157) and was chosen by us for our analysis. A quantitative implementation of it, coding all clauses as either bilingual or monolingual and identifying the matrix language of each clauses, allowed Deuchar et al. (2018) to arrive at a characterization of the Siarad corpus as shown in Figure 5.
Despite its usefulness for our research, the MLF model is not without its critics. One of the most carefully argued critiques is by Auer and Muhamedova (2005), who argue that the distinction between the matrix and the embedded languages is not always absolute. Auer and Muhamedova (2005) use sixteenth century data from Martin Luther’s dinner table conversations to show how Latin insertions in Early New High German did not always follow the morphosyntax of the German of that period. For example, they find that some Latin nouns following German prepositions are marked with the case that would be expected in Latin, and not the expected German case. So in the prepositional phrase vom praecaeptore ‘from the teacher’, the German preposition vom has the dative marking of the contracted definite article dem (<von dem), but the Latin noun praecaeptore is marked for the ablative case (as would be expected after the Latin preposition de) rather than for the dative (praecaeptori). They argue that an analogous kind of ‘mixture’ of the grammar of the two languages also occurs in modern Kazakh/Russian code-switching data, where both languages have rich morphological systems which are nevertheless different. For example, the use of a subordinating conjunction in Russian may be followed by Kazakh material which is not entirely grammatical either in Kazakh or Russian. Their conclusion is that “a neat separation between matrix and embedded language is impossible” (Auer and Muhamedova 2005, p. 52). In fact, their examples show that a matrix language can usually be identified, but that there is sometimes ‘leakage’, such that constructions of the matrix language sometimes influence those of the embedded language and vice versa. Overall, though, they consider the MLF model to be “basically correct” (Auer and Muhamedova 2005, p. 36).
Indeed, this latter view gains traction as a result of a study by Fricke and Kootstra (2016). They report from their analysis of the Bangor Miami data that “a strong and reliable association was found between the matrix language of a given codeswitched utterance (indexed by the language of its finite verb) and the matrix language of the utterance that immediately preceded it”. In other words, they consider that using a particular matrix language in one utterance will increase the likelihood of the same matrix language being used in the next utterance. They suggest that this result “supports the psycholinguistic validity of the MLF model” (Fricke and Kootstra 2016, p. 185).
Even one of the most longstanding and ardent critics of the MLF (see e.g., MacSwan 2005) states that “Myers-Scotton’s (1993) Matrix Language Frame (MLF) model has had a very strong influence on the field of CS” (MacSwan 2014, p. 14). However, he considers it to be part of a ‘constraint-based’ approach, whereas he favours a lexicalist, ‘constraint-free’ approach which “will not tolerate any grammatical device that makes explicit reference to (code)switching or language(s)” (MacSwan 2014, p. 18). I should make clear at this point that I consider the distinction that MacSwan draws between between ‘constraint-free’ and ‘constraint-based’ approaches to be entirely artificial, and to depend on a specific definition of ‘constraint’. As stated at the outset of this section, the notion of grammaticality depends on the notion of constraints (or rules) in a general sense, so all theories of the grammar of code-switching will contain some kind of constraints. An example from MacSwan’s work is what he refers to as the “ban on CS in pronominal subjects” (MacSwan 2014, p. 23), which he illustrates by pointing out that a Spanish subject with an English verb is acceptable if the subject is a noun, but not if it is a pronoun. His proposal (see Van Gelderen and MacSwan 2008) for accounting for this “ban” does not use the word “constraint” but proposes that pronouns and lexical DPs (Determiner Phrases) use “different checking strategies” (Van Gelderen and MacSwan 2008, p. 765) An alternative proposal for similar facts is put forward by Jake (1994) in terms of a distinction between “content” and “system” morphemes. Both proposals are thus dealing with a recognized ‘constraint’ which is apparent in code-switching, but they are using different theoretical models to account for the data.
MacSwan’s lexicalist position on code-switching involves no statement of language-specific co-occurrence relations between distinct grammatical categories in the clause or CP (Complementiser Phrase), but relies on feature checking between related members of constituents. This approach is illustrated in the work of Moro Quintanilla (2014), who considers how a Minimalist approach accounts for code-switching within a DP, from a Spanish determiner to an English noun. An example of this is provided by her in Example (8) below, in which there is a switch from the Spanish determiner Los (‘the’ plural) to the English noun employers.
(8) Los employers toman la persona.
‘The employers take the person’ (Moro Quintanilla 2014, p. 219).
Moro Quintanilla assumes that in both Spanish and English there is a functional head, the determiner, which selects as its complement a projection of the noun. She argues that the determiner in Spanish contains gender and number features, whereas the determiner in English only contains number features. For a DP with a Spanish determiner to be well-formed, the gender and number features of the determiner must be ‘checked’ to identify matching or agreeing features on the noun and are then deleted. She argues that because the English determiner lacks gender, it is deficient in its agreement features and cannot therefore ‘check’ the full set of features on a following Spanish noun. This, she argues, would cause the derivation to crash. Thus the combination of a Spanish determiner with an English noun (e.g., los employers) is deemed to be grammatical whereas an English determiner followed by a Spanish noun (e.g., the empleadores) would be deemed ungrammatical. However, Grimstad et al. (2018) argue that standard assumptions regarding feature checking would lead to the opposite result to that claimed by Moro Quintanilla, allowing mixed DPs like the empleadores but not los employers. While aligning themselves with a Minimalist approach they reject lexicalism as illustrated in Moro Quintanilla’s analysis, and propose instead an ‘exoskeletal’ alternative based on the model Distributed Morphology, which favours the generation of the syntactic frame first and then the insertion of lexical items. They show how an exoskeletal approach, illustrated with Norwegian/English data, can allow for the generation of mixed DPs with both Norwegian and English determiners. If applied to Spanish/English, this would account for the finding by Herring et al. (2010) that mixed DPs consisting of an English determiner and a Spanish noun do occur as well as the reverse pattern.
Grimstad et al.’s (2018) view of the determiner in mixed DPs as part of the abstract syntactic structure into which nouns are inserted is highly compatible with the approach of Myers-Scotton’s MLF, where determiners are a kind of system morpheme while nouns are content morphemes. Both approaches find support in the finding by Herring et al. (2010) that there is a strong tendency in code-switched clauses for the determiner to match the language of the inflected verb. This suggests that a lexicalist approach of the kind outlined above will be too limited in its scope and that attention is needed to co-occurrence restrictions applying at the clause level in whatever approach is taken.
Given that grammaticality as defined above is concerned with the rule-governed nature of language, in our case code-switching between languages, we can compare competing models of code-switching in terms of the extent to which they make accurate predictions about which code-switched constructions are grammatical and which are not. The results of this kind of comparison are reported in papers such as Parafita Couto et al. (2015) and Eppler et al. (2017). Parafita Couto et al. (2015) used the Siarad data (see bangortalk.org.uk) in their evaluation of competing theoretical accounts of the relative position of noun and adjective in Welsh/English bilingual speech. Switches between Welsh nouns and English adjectives or between English nouns and Welsh adjectives may be considered ‘conflict sites’ (cf. Poplack and Meechan 1998, p. 132) in that word order contrasts in the two languages, with adjectives occurring before nouns in English and (normally) after nouns in Welsh. The question for code-switching researchers is which order is grammatical when code-switching occurs between a noun and its attributive adjective. Parafita Couto et al. (2015) noted that the MLF and Minimalism make contrasting predictions as to the grammatical order, and they set out to test these predictions empirically. The MLF predicts that word order will follow that of the matrix language of the clause, whereas one Minimalist approach pursued by Cantone and MacSwan (2009) in relation to Italian-German code-switching suggested that the language of the adjective should determine the relative word order of adjective and noun. In order to adjudicate between the two approaches Parafita Couto et al. first drew on naturally occurring mixed constructions found in Siarad. 137 examples of mixed constructions containing an adjective and a noun were extracted from the data. All of these constructions occurred in clauses where the morphosyntactic frame or matrix language was Welsh. In about two-thirds of the data the noun was English and the adjective was Welsh, whereas in the remainder of the data the noun was Welsh and the adjective English. Then, in a semi-experimental ‘Director-Matcher task’ (cf. Gullberg et al. 2009), a further 238 mixed nominal constructions were elicited. All mixed nominal constructions turned out to occur in clauses with a Welsh matrix language and the most common combination, as in the Siarad corpus, was an English noun with a Welsh adjective, with a less common combination again being Welsh noun and English adjective. The results showed overwhelming support for the word order following that of Welsh grammar, in line with the Welsh matrix language and with the predictions of the MLF. Whereas the instances of an English noun followed by a Welsh adjective were also in line with the predictions of the Minimalist approach, this was not the case for the instances of a Welsh noun followed by an English adjective, leading to the conclusion that the MLF could account for more of the data accurately.
MacSwan (2014, p. 25) argues that “it is not meaningful or informative to make empirical comparison between theories formulated within a constraint-free approach and those formulated within a constraint-based approach”. As an example of the work he disapproves of, he refers to Herring et al., outlined above. However, as explained above I reject the division between the two types of theory he is outlining, and argue that all theories should be subject to empirical testing. Indeed he agrees in admitting that counter-evidence would stimulate Minimalist researchers to “adjust the analysis to newly discovered data”, as indeed he points out is done by researchers using the MLF model. Lohndal (2019) points out that the use of empirical data by generativists dates from the beginning of work on comparative syntax in the 1980s, and suggests that work on multilingualism has adopted the same approach. Indeed, generative linguists including MacSwan and also López (Forthcoming) do indeed use some actual data from corpora as evidence for their approach, although they also use grammaticality judgments as evidence of intuitions about grammatical vs. ungrammatical code-switching.
López (Forthcoming), argues that bilinguals have an ‘integrated I-language’ (cf. Chomsky 1995) rather than two linguistic systems. López illustrates his arguments with data from code-switching although he does not recognise that bilinguals switch between two separate systems. This is a fairly radical approach in current research on bilingualism, although the grammatical machinery used for his analyses, that of Distributed Morphology, is also used by others (e.g., Grimstad et al. mentioned above) who continue to recognise code-switching as a concept.
In reviewing structural approaches to code-switching, Toribio (2017) shows that we cannot rely entirely on formal or grammatical approaches in accounting for the phenomena that occur (cf. also Poplack 2001). Toribio points out that such approaches fail to account for “how bilinguals innovate forms not found in the participating languages and why patterns of code-switching vary for speakers of the same language pairing” (Toribio 2017, p. 217). For example, Vergara Wilson and Dumont (2015, p. 448) report on the use of a bilingual compound verb construction in the New Mexico Spanish-English bilingual corpus. This construction is illustrated in Example (9) and makes use of the Spanish verb hacer ‘do’ in combination with an English bare verb.
| 9. | yo | hacía | draw | mejor |
| I | did | draw | better |
‘I drew better’ (Vergara Wilson and Dumont 2015, p. 448).
However, Toribio points out that this construction is not used to the same extent in all Spanish/English bilingual communities, and suggests that there is variation in its use both within and between communities. This takes us to the theme of the next section, variability and uniformity in code-switching.
4. Variability and Uniformity
Variation in code-switching patterns has been approached using a range of quantitative approaches, some focusing on its description per se and others attempting to account for the variability (or its absence) either in terms of structural or psycholinguistic factors, or to link specific aspects of variation to extra- or intra-linguistic factors. As we shall show, the search for patterns of variability will also reveal where there is uniformity.
A descriptive approach is illustrated by the work described above on the quantitative distribution of the matrix language in the Siarad corpus, and depicted in Figure 5. The overwhelming prominence of the Welsh language in bilingual as well as monolingual clauses provides evidence for considerable uniformity in the patterns of code-switching used by the Welsh/English bilingual community. This degree of uniformity is not necessarily found in other communities, however, as we can see if we compare Figure 5 above to Figure 6 below, showing the distribution of the matrix language in a sample of data from the Spanish/English bilingual community in Miami. Blokzijl et al. (2017b) took the clauses containing DPs that had been extracted in the study by Blokzijl et al. (2017a), and calculated the distribution of English vs. Spanish as a matrix language in monolingual and bilingual clauses. We found that although English occurred slightly more frequently as a matrix language than Spanish in the sample taken as a whole, and also in monolingual (single language) clauses, Spanish occurred as a matrix language almost twice as often as English in the bilingual clauses looked at separately. This distribution of the matrix language in monolingual vs. bilingual clauses is very different from that found in the Welsh/English data. We propose that the striking differences between the distribution of the matrix language in the two bilingual communities can be at least partially accounted for by community norms, a topic which needs further exploration in the study of code-switching (but see Poplack 1988, Aaron 2015).
The data portrayed in Figure 6 were initially analysed by Blokzijl et al. (2017a) in a quantitative study of the use of determiners in mixed DPs in Spanish/English code-switching. The aim was to address the question of why previous investigators (e.g., Moro Quintanilla 2014, as outlined above, as well as Liceras et al. 2008) have assumed a preference in Spanish/English code-switching for mixed DPs consisting of Spanish rather than English determiners, so that e.g., la house (‘the house’), with a Spanish determiner and an English noun, is preferred over the casa (‘the house’). As outlined above Grimstad et al. (2018) have argued for an ‘exoskeletal’ model which would allow both combinations, but a quantitative study of corpus data was needed in order to establish the facts before trying to explain them. Blokzijl et al. (2017a) therefore extracted a total of 8586 mixed and unmixed DPs from the Bangor Miami corpus and 3506 DPs from a smaller corpus of Nicaraguan English-based creole and Spanish. All the DPs analysed appeared in clauses with finite verbs, which allowed us to code the matrix language of each clause containing a mixed or unmixed DP. The reason for including unmixed as well as mixed DPs in the analysis was to uphold what Labov called the ‘Principle of Accountability’, which is summarized by Tagliamonte (2012, p. 10) as requiring “that all the relevant forms in the subsystem of grammar that you have targeted for investigation, not simply the variant of interest, are included in the analysis”. The results showed that 98% of the DPs contained a determiner from the same language as the matrix language. English determiners with Spanish nouns did occur, although less frequently than Spanish determiners with English nouns, but always in clauses with an English matrix language. Overall there were more clauses with an English matrix language, but a smaller proportion of mixed English DPs with English matrix language than mixed Spanish DPs with Spanish matrix language. In other words, when speakers are mainly speaking Spanish they are more likely to switch to English after the determiner than they are likely to switch in this position when speaking English. This may be more likely to be due to the prestige of English than to grammatical factors, but we may speculate that a community norm has been established that allows switching from Spanish to English while not favouring the reverse, from English to Spanish. Blokzijl et al. also looked at the mixed and unmixed DPs in a smaller corpus of Nicaraguan English-based creole and Spanish, finding that out of 3506 instances, 99.7% matched the matrix language. Furthermore, in the case of the mixed DPs, the language of the finite verb was always Nicaraguan Creole English and not Spanish. These findings, taken together, suggest that the language of determiners in code-switching is much more related to the speaker’s choice of morphosyntactic frame, including the language of the finite verb, than to the grammatical features of the determiner. The main contribution of this study is to show that the source of the variability in the language of the determiner is not the grammar of the source language, but the matrix language of the clause. There is a high degree of uniformity in the language of the determiner once the matrix language is taken into account, and the variability which then needs accounting for is instead the variability that we find here in the choice of the matrix language.
One of the most influential and highly respected examples of work on the varying patterns of code-switching to be found in different bilingual communities is that by Muysken (2000) who identifies code-switching patterns as belonging to three main types, ‘insertion’, ‘alternation’ and ‘congruent lexicalization’. These three patterns can be identified according to diagnostic features with overlapping distributions for each type. Muysken suggested that one type may be more predominant in some bilingual communities than others, and this idea was tested quantitatively in a study by Deuchar et al. (2007) using data from Welsh/English, Tsou/Mandarin Chinese and Taiwanese/Mandarin Chinese bilingual communities. The results suggested that two of the communities showed a predominantly insertional pattern, but all communities also showed evidence of a secondary pattern. For example, the Welsh/English data showed a primary insertion pattern but a secondary pattern indicating congruent lexicalisation.
Another, prominent approach to variation in code-switching makes use of the Labovian variationist method (cf. Labov 1972), which is a prime method used in sociolinguistics. It was used for the first time in code-switching research in Poplack’s seminal (1980) article on Spanish/English code-switching by the Puerto Rican community in New York City. The variationist method assumes, with Labov, that language is inherently variable (cf. Weinreich et al. 1968), but tries to identify the ways in which this variability patterns, using quantitative analysis and taking account of both linguistic and social factors. Poplack’s quantitative analysis of the Puerto Rican data showed, for example, that the most frequently switched constituent was the sentence, while within sentences she found single nouns to be most switched. Regarding the importance of social factors, she also used a pioneering (for those times) method of multivariate analysis named VARBRUL 2, which showed that four extralinguistic factors contributed to the occurrence of intraclausal code-switching: speaker sex, age of L2 acquisition, language dominance and workplace. While the age of the speaker is an important extralinguistic variable in many studies of monolingual speech because of what it indicates about ongoing language change (see e.g., Bailey 2002), age of acquisition is an additional important variable in studies of bilinguals. This is because whereas the age of acquisition of the language of a monolingual is usually from birth onwards, bilingual acquisition can either involve simultaneous acquisition of the two languages from birth or acquisition from birth of one language while the other language is learned later. Poplack (1980) found that speakers who had been born in the USA or who had arrived there in early childhood did more code-switching than those who arrived in adulthood, arguably because the latter group acquired English later and were less ‘balanced’ in their proficiency in their two languages.
Nortier (1990), in a study of code-switching between Dutch and Moroccan Arabic, found, along similar lines, that speakers with a high degree of proficiency in the two languages produced a relatively large quantity of intraclausal code-switching compared to those who were less proficient. The results of this study find a parallel in our own variationist study (Deuchar et al. 2016) of the factors influencing quantity of code-switching by Welsh/English speakers. The analysis using Rbrul showed that one of the most important factors was the pattern of bilingual acquisition, such that that speakers who had acquired both Welsh and English from birth produced significantly more intraclausal code-switching than speakers who had acquired one language from birth and the other later. The details of the results are reproduced in Table 1, which is based on Table 8.4 in Deuchar et al. (2016, p. 229) and Table 6.3 in Deuchar et al. (2018, p. 102).
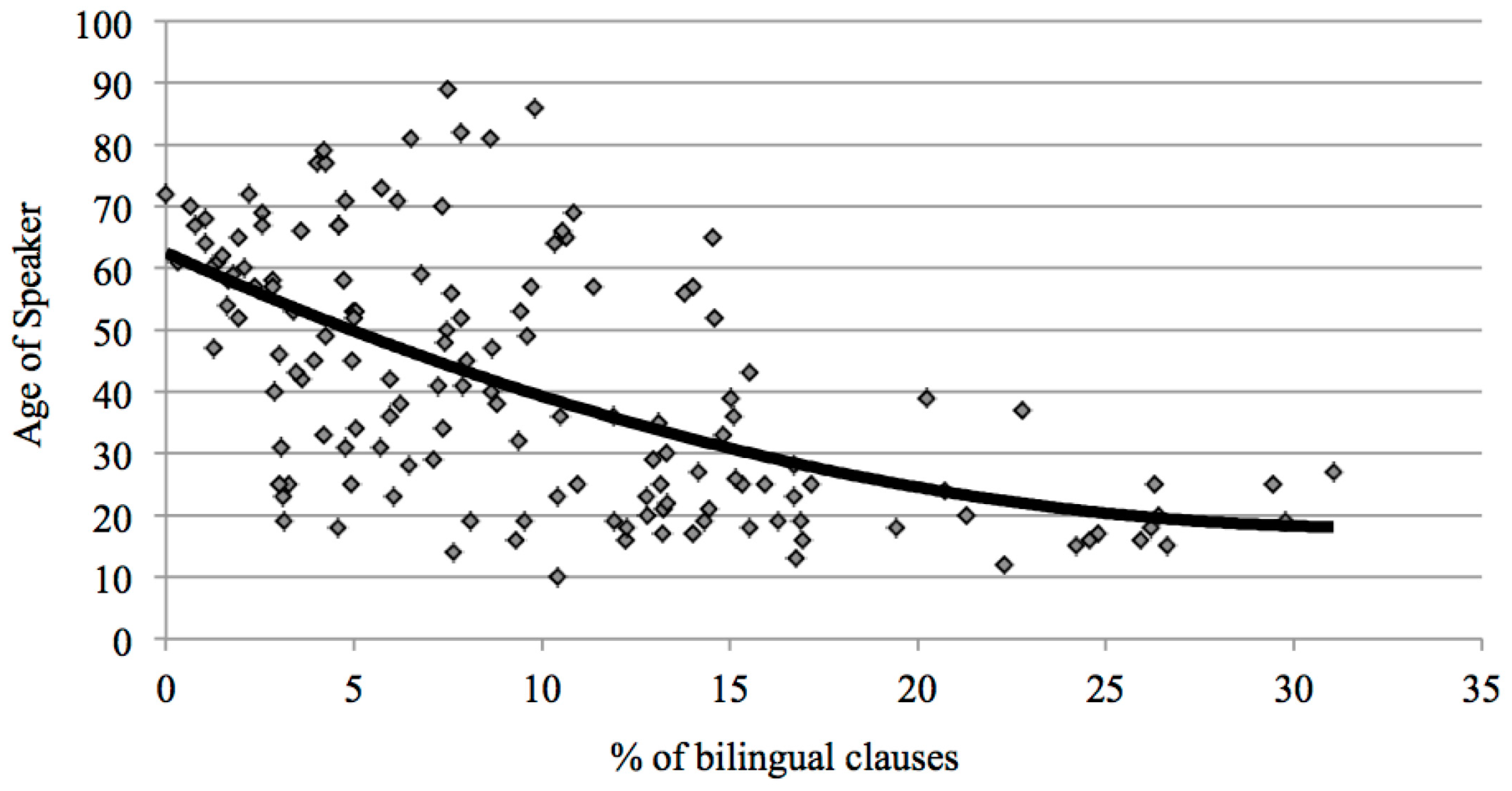
Our results as summarized in Table 1 are similar to Nortier’s in that we may assume that the earlier both languages are acquired, the higher is the proficiency in both (see discussion in Deuchar et al. 2016, pp. 233–34). Linguistic factors were also taken into account in our study in that we looked to see whether the patterns for single-word insertions were the same as multiword insertions, and we found that they were, since the percentages of in the data from each speaker were positively correlated (see Deuchar et al. 2016, p. 232). An additional (negative) correlation was found between the age of speakers and the quantity of code-switching, so that the older the speaker, the less they tended to code-switch. This pattern is shown in Figure 7, which is based on Figure 8.2 of Deuchar et al. (2016, p. 229).
Deuchar et al. interpret the pattern shown in Figure 7 as suggesting that language use norms are in the process of changing, and that young people’s greater propensity to code-switch indicates that code-switching is becoming more common and acceptable, at least in informal contexts.
In the study by Deuchar et al. (2016) we did not find that the linguistic factors examined (single vs. multiword insertions) made a difference to the results, but linguistic factors do seem to be operating in a preliminary study of the choice of the matrix language in the Spanish/English data analysed by Blokzijl et al. (2017b). As outlined above, the apparent variability in the choice of the language of the determiner was in fact linked to the variable choice of the matrix language. A preliminary analysis of the data using Rbrul indicated that the type of clause (i.e., monolingual vs. bilingual) appeared to be the most important predictor of the matrix language, while extralinguistic variables (like age or gender) seemed not to be so important. As shown in Figure 6 above, we had found that although English occurred slightly more frequently as a matrix language than Spanish in the sample taken as a whole, and also in monolingual (single language) clauses, Spanish occurred as a matrix language almost twice as often as English in the bilingual clauses looked at separately. This difference in the distribution of the matrix language in monolingual vs. bilingual clauses was significant.
While variationist studies have tended to focus on the role of internal (linguistic) and external (extralinguistic or social) factors in influencing variation in speech, recent studies have shown that the immediately preceding discourse may play a role in code-switching patterns. In the study mentioned above by Fricke and Kootstra (2016), they considered the relation they found between the choice of the matrix language in juxtaposed clauses to be an example of structural priming, or “speakers’ tendency to re-use the syntactic structure of recently processed sentences” (Fricke and Kootstra 2016, p. 181). Their main finding was that “When all variables were taken into account, the ML of the immediately preceding utterance was a significant predictor of the ML of the target utterance…consistent with structural priming of the ML” (Fricke and Kootstra 2016, p. 191). Their results show that despite the apparent matrix language priming effect, the proportion of code-switched utterances with Spanish ML following utterances with English ML (0.4) is higher than the proportion of code-switched utterances with English ML following utterances with Spanish ML (0.2). They had already noted (Fricke and Kootstra 2016, p. 191) that of the 1208 code-switched utterances in their data, 62% (744) had a Spanish ML, observing that “the proportion of English vs. Spanish ML codeswitches may be somewhat surprising given the predominance of default-English conversations in the corpus”. This frequency of 62% is almost identical to our own of 63%, as represented in Figure 6 above. We suggest that this greater tendency to switch in clauses where Spanish is the ML may be accounted for more in terms of community norms than by priming even though priming may determine the choice of ML in both monolingual and bilingual clauses in the first place. In other words, priming effects will influence the choice of English or Spanish ML (depending on the ML in the previous discourse), but switching will then be more facilitated within clauses with Spanish ML (and relatively inhibited within clauses with English ML) as a result of community norms. This might be an example of community norms contributing to ‘top-down’ processes while these work (as Fricke and Kootstra suggest) in conjunction with ‘bottom-up’ processes like priming. The influence of community norms no doubt help account also for the fact that, in these data at least, code-switched utterances occur far less commonly than monolingual utterances.
In most studies of variation in code-switching conducted so far, aspects of code-switching (e.g., quantity, choice of matrix language) have been treated as the dependent variable. However, Torres Cacoullos and Travis (2018) describe a study in which code-switching is one of the independent variables influencing the choice of a null or overt subject pronoun (the dependent variable) in the speech of Spanish/English bilinguals in New Mexico. In their analysis of bilingual Spanish, they extracted all tokens of Spanish finite verbs with pronominal and unexpressed human first and third person singular subjects. They found that while co-referential pronouns in both Spanish and English had a priming effect on the occurrence of overt subject pronouns with the Spanish finite verbs extracted, the presence of English in the same or preceding clause did not have an effect. However, code-switching (to English) was found to have an effect on the opportunities for priming to occur by changing relevant features of the immediately preceding discourse. In particular, English insertions in the preceding discourse increased the occurrence of overt subject primes (since null subjects are less common in English than Spanish) and overt subject primes made it more likely that subsequent Spanish subjects would also be overt. However, the language of the overt subject prime made a difference in that the effect of an overt Spanish prime was stronger than that of an overt English subject prime (see Torres Cacoullos and Travis 2018, p. 193).
In our review of the studies outlined above we have demonstrated that in studying how code-switching patterns can vary both within and between bilingual communities, we can also discover where variation is missing and where instead we can find uniformity. Future research should help us discover the relative role of external and internal factors as well as community norms in accounting for these patterns.
5. Conclusions and Implications for Future Research
In this paper I have focused on three issues that arise in linguistic approaches to code-switching: (1) the distinction between borrowing and code-switching; (2) grammaticality; and (3) variability vs. uniformity.
I have argued that a distinction between borrowing and code-switching can be drawn, but that it should not rely on all types of linguistic integration, since the evidence suggests that other-language items tend to follow the word order and inflections of the recipient language. Instead, the focus should be on peripheral types of integration, such as the example of mutation in Welsh. It may be a challenge to identify peripheral integration in other languages, but Bessett’s work has shown an innovative way (outlined above) of coding the presence vs. absence of Spanish determiners before English nouns according to whether they represented an English or a Spanish pattern. Where they manifested a Spanish pattern, he concluded they were morphosyntactically integrated into Spanish. Since Bessett also found a correlation between morphosyntactic and phonological integration, it would be interesting to see if future studies can replicate his results in both the same and other language pairs, thus helping us to finally conclude how useful it is to study phonological integration.
Regarding grammaticality, I have reviewed alternative approaches and have argued that their relative value can and should be assessed by the extent to which they make accurate empirical predictions. These predictions should be tested on corpora which are fully open to all investigators. At the moment relatively few corpus-based studies of code-switching make their corpora fully accessible, which hampers the assessment of the validity of results. Corpus-studies should also be complemented by those using experimental and neuroscientific methods (see Van Hell et al. (2015) for a review) but these should always maximise their ecological validity by using corpora as well. Parafita Couto et al. (2015) outlined above, is a good example of this. In reviewing the empirical validity of alternative models of code-switching I have argued that lexicalist models (such as that described by MacSwan 2014) fail a test of full empirical validity since they do not sufficiently take into account co-occurrence restrictions within the clause, an approach which is central to Myers-Scotton’s MLF theory.
Finally, I have reviewed a range of approaches to investigating variability and uniformity in code-switching. I have suggested that future research should help us discover the relative role of external and internal factors as well as community norms in accounting for these patterns. Labov (1972) was trying to persuade researchers to move away from the traditional focus on shared norms as invariant and to recognize the variability of language. However, it could be argued that the revolutionary power of his variationist model has led us to pay insufficient attention to what is nevertheless invariant, or relatively invariant. It is to be hoped that future research will yield a more comprehensive model which will identify uniformity more explicitly, and will be able to relate this to the development and acquisition of community norms in both code-switching and other areas of linguistic research.
Funding
The data available at bangortalk.org.uk were collected with funding from the AHRC and ESRC of the UK.
Acknowledgments
The author is grateful to Draško Kašćelan for his role in the editorship of this paper and the special issue to which it is being submitted, and also to the anonymous reviewers of this paper.
Conflicts of Interest
The author declares no conflict of interest.
References
- Aaron, Jessi Elana. 2015. Lone English-origin nouns in Spanish: The precedence of community norms. International Journal of Bilingualism 19: 459–80. [Google Scholar] [CrossRef]
- Auer, Peter, and Raihan Muhamedova. 2005. ’Embedded language’ and ‘matrix language’ in insertional language mixing: Some problematic cases. Rivista Di Linguistica 17: 35–54. [Google Scholar]
- Bailey, Guy. 2002. Real and apparent time. In Handbook of Language Variation and Change. Edited by Jack K. Chambers, Peter Trudgill and Natalie Schilling-Estes. Oxford: Blackwell, pp. 232–48. [Google Scholar]
- Bessett, Ryan Matthew. 2017a. Exploring the phonological integration of lone other-language items in the Spanish of southern Arizona. University of Pennsylvania Working Papers in Linguistics 23: 31–39. [Google Scholar]
- Bessett, Ryan Matthew. 2017b. The Integration of Lone English Nouns into Bilingual Sonoran Spanish. Tucson: The University of Arizona. [Google Scholar]
- Blokzijl, Jeffrey, Margaret Deuchar, and M. Carmen Parafita Couto. 2017a. Determiner asymmetry in mixed nominal constructions: The role of grammatical factors in data from Miami and Nicaragua. Languages 2: 20. [Google Scholar] [CrossRef] [Green Version]
- Blokzijl, Jeffrey, Margaret Deuchar, Kevin Donnelly, El Mauder, and M. Carmen Parafita Couto. 2017b. How can determiner asymmetry in mixed nominal constructions inform linguistic theory? Paper presented at the Meeting of Societas Linguistica Europaea, Zurich, Switzerland, September 10–13. [Google Scholar]
- Borsley, Robert D., Maggie Tallerman, and David Willis. 2007. The Syntax of Welsh. Cambridge: Cambridge University Press. [Google Scholar]
- Bullock, Barbara E. 2009. Phonetic reflexes of code-switching. In The Cambridge Handbook of Linguistic Code-Switching. Edited by Barbara E. Bullock and Almeida Jacqueline Toribio. Cambridge: Cambridge University Press, pp. 163–81. ISBN 978-0-521-87591-2. [Google Scholar]
- Cantone, Katja F., and Jeff MacSwan. 2009. The syntax of DP-internal codeswitching. In Multidisciplinary Approaches to Codeswitching. Edited by Ludmila Isurin, Donald Winford and Kees de Bot. Amsterdam: John Benjamins, pp. 243–78. [Google Scholar] [CrossRef]
- Carter, Diana, Margaret Deuchar, Peredur Davies, and M. Carmen Parafita Couto. 2011. A systematic comparison of factors affecting the choice of matrix language in three bilingual communities. Journal of Language Contact 4: 1–31. [Google Scholar] [CrossRef] [Green Version]
- Chomsky, Noam. 1995. The Minimalist Program. Cambridge: MIT Press. [Google Scholar]
- Crystal, David. 2008. A Dictionary of Linguistics and Phonetics, 6th ed. Oxford: Blackwell Publishing, ISBN1 9781405152969. ISBN2 9781444302776. [Google Scholar] [CrossRef]
- Deuchar, Margaret. 2005. Congruence and code-switching in Welsh. Bilingualism: Language and Cognition 8: 255–69. [Google Scholar] [CrossRef]
- Deuchar, Margaret, Pieter Muysken, and Sung-Lan Wang. 2007. Structured variation in codeswitching: Towards an empirically based typology of bilingual speech patterns. International Journal of Bilingual Education and Bilingualism 10: 298–340. [Google Scholar] [CrossRef]
- Deuchar, Margaret, and Jonathan R. Stammers. 2016. English-origin verbs in Welsh: Adjudicating between two theoretical approaches. Languages 1: 7. [Google Scholar] [CrossRef] [Green Version]
- Deuchar, Margaret, Kevin Donnelly, and Caroline Piercy. 2016. ‘Mae pobl monolingual yn minority’: Factors favouring the production of code-switching by Welsh/English speakers. In Sociolinguistics in Wales. Edited by Mercedes Durham and Jonathan Morris. London: Palgrave Macmillan, pp. 209–39. [Google Scholar]
- Deuchar, Margaret, Peredur Webb-Davies, and Kevin Donnelly. 2018. Building and Using the Siarad Corpus: Bilingual Conversations in Welsh and English. Amsterdam: John Benjamins Publishing Company, ISBN1 9789027200112. ISBN2 9789027264589. [Google Scholar]
- Eppler, Eva Duran, Adrian Luescher, and Margaret Deuchar. 2017. Evaluating the predictions of three syntactic frameworks for mixed determiner-noun constructions. Corpus Linguistics and Linguistic Theory 13: 27–63. [Google Scholar] [CrossRef]
- Fricke, Melinda, and Kootstra Gerrit J. 2016. Primed codeswitching in spontaneous bilingual dialogue. Journal of Memory and Language 91: 181–201. [Google Scholar] [CrossRef]
- Grimstad, Maren Berg, Brita Ramsevik Riksem, Terje Lohndal, and Tor A. Åfarli. 2018. Lexicalist vs. exoskeletal approaches to language mixing. The Linguistic Review 35: 187–218. [Google Scholar] [CrossRef]
- Gullberg, Marianne, Peter Indefrey, and Pieter Muysken. 2009. Research techniques for the study of code-switching. In The Cambridge Handbook of Linguistic Code-Switching. Edited by Barbara E. Bullock and Almeida Jacqueline Toribio. Cambridge: Cambridge University Press, pp. 21–39. [Google Scholar]
- Herring, John R., Margaret Deuchar, M. Carmen Parafita Couto, and Monica Moro Quintanilla. 2010. Evaluating predictions about codeswitched determiner-noun sequences using Spanish/English and Welsh/English data. International Journal of Bilingual Education and Bilingualism 13: 553–73. [Google Scholar] [CrossRef]
- Ihemere, Kelechukwu. 2016. In support of the Matrix Language Frame Model: Evidence from Igbo-English intrasentential code-switching. Language Matters: Studies in the Languages of Africa 47: 105–27. [Google Scholar] [CrossRef] [Green Version]
- Jake, Janice L. 1994. Intrasentential code switching and pronouns: On the categorial status of functional elements. Linguistics 32: 271–98. [Google Scholar] [CrossRef]
- Joshi, Aravind K. 1982. Processing of sentences with intra-sentential code-switching. Paper presented at the 9th Conference on Computational Linguistics, Prague, Czechoslovakia, July 5–10; vol. 1, pp. 145–50. [Google Scholar]
- Khan, Arshad Ali, and Amina Khalid. 2018. Pashto-English codeswitching: Testing the morphosyntactic constraints of the MLF model. Lingua 201: 78–91. [Google Scholar] [CrossRef]
- Labov, Williams. 1971. The notion of ‘system’ in creole studies. In Pidginization and Creolization of Languages. Edited by Dell Hymes. Cambridge: Cambridge University Press, pp. 447–72. [Google Scholar]
- Labov, Williams. 1972. Sociolinguistic Patterns. Philadelphia: University of Pennsylvania Press. [Google Scholar]
- Liceras, Juana M., Raquel Fernández Fuertes, Susana Perales, Rocío Pérez-Tattam, and Kenton Todd Spradlin. 2008. Gender and gender agreement in bilingual native and non-native grammars: A view from child and adult functional-lexical mixings. Lingua 118: 581–618. [Google Scholar] [CrossRef]
- Lohndal, Terje. 2019. Multilingualism as the new comparative syntax. In Mapping Linguistic Data: Essays in Honour of Liliane Haegeman. Edited by Metin Bağrıaçık, Anne Breitbarth and Karen De Clercq. Ghent: Ghent University, pp. 171–78. Available online: https://www.haegeman.ugent.be/wp-content/uploads/2019/06/Lohndal.pdf (accessed on 17 March 2020).
- López, Luis. Forthcoming. Bilingual Grammar: Toward an Integrated Model. Cambridge: Cambridge University Press.
- MacSwan, Jeff. 2005. Codeswitching and generative grammar: A critique of the MLF model and some remarks on “modified minimalism”. Bilingualism: Language and Cognition 8: 1–22. [Google Scholar] [CrossRef] [Green Version]
- MacSwan, Jeff, ed. 2014. Programs and proposals in codeswitching research. In Grammatical Theory and Bilingual Codeswitching. Cambridge: MIT Press, pp. 1–33. [Google Scholar]
- Moro Quintanilla, Monica. 2014. The semantic interpretation and syntactic distribution of determiner phrases in Spanish/English codeswitching. In Grammatical Theory and Bilingual Codeswitching. Edited by Jeff MacSwan. Cambridge: MIT Press, pp. 213–26. [Google Scholar]
- Muysken, Pieter. 2000. Bilingual Speech. Cambridge: Cambridge University Press. [Google Scholar]
- Myers-Scotton, Carol. 1993. Duelling Languages: Grammatical Structure in Codeswitching, 1st ed. Oxford: Clarendon Press. [Google Scholar]
- Myers-Scotton, Carol. 2002. Contact Linguistics: Bilingual Encounters and Grammatical Outcomes. Oxford: Oxford University Press. [Google Scholar]
- Nartey, Jonas N. A. 1982. Code-switching, interference or faddism? Language use among educated Ghanians. Anthropological Linguistics 24: 183–92. [Google Scholar]
- Nortier, Jacomine. 1990. Dutch-Moroccan Arabic Code Switching. Dordrecht: Foris. [Google Scholar]
- Parafita Couto, M. Carmen, Margaret Deuchar, and Marika Fusser. 2015. How do Welsh/English bilinguals deal with conflict? Adjective-noun resolution. In Code-Switching between Structural and Sociolinguistic Perspectives. Edited by Gerard Stell and Kofi Yakpo. Berlin: De Gruyter, pp. 65–84. [Google Scholar]
- Pfaff, Carol W. 1979. Constraints on language mixing: Intrasentential code-switching and borrowing in Spanish/English. Language 55: 291–318. [Google Scholar] [CrossRef]
- Poplack, Shana. 1980. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of code-switching. Linguistics 18: 581–618. [Google Scholar] [CrossRef] [Green Version]
- Poplack, Shana. 1988. Contrasting patterns of code-switching in two communities. In Codeswitching: Anthropological and Sociolinguistic Perspectives. Edited by Monica Heller. Berlin, New York and Amsterdam: Mouton de Gruyter, pp. 215–44. ISBN 0-899-25412-8. [Google Scholar]
- Poplack, Shana. 2000. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of code-switching. In The Bilingualism Reader. Edited by Li Wei. London and New York: Routledge, pp. 221–56. [Google Scholar]
- Poplack, Shana. 2001. Code-switching (Linguistic). In International Encyclopedia of the Social and Behavioral Sciences. Edited by Smelser Niel and Baltes Paul. Amsterdam: Elsevier Science Ltd, pp. 2062–65. [Google Scholar]
- Poplack, Shana. 2018. Borrowing: Loanwords in the Speech Community and in the Grammar. New York: Oxford University Press. [Google Scholar]
- Poplack, Shana, and Nathalie Dion. 2012. Myths and facts about loanword development. Language Variation and Change 24: 279–315. [Google Scholar] [CrossRef] [Green Version]
- Poplack, Shana, and Marjory Meechan. 1998. How languages fit together in code-mixing. International Journal of Bilingualism 2: 127–38. [Google Scholar] [CrossRef]
- Poplack, Shana, David Sankoff, and Miller Christopher. 1988. The social correlates and linguistic processes of lexical borrowing and assimilation. Linguistics 26: 47–104. [Google Scholar] [CrossRef] [Green Version]
- Sebba, Mark. 2009. On the notions of congruence and convergence in code-switching. In The Cambridge Handbook of Linguistic Code-Switching. Edited by Barbara E. Bullock and Almeida Jacqueline Toribio. Cambridge: Cambridge University Press, pp. 40–47. ISBN 978-0-521-87591-2. [Google Scholar]
- Stammers, Jonathan, and Margaret Deuchar. 2012. Testing the nonce borrowing hypothesis: Counter-evidence from English-origin verbs in Welsh. Bilingualism: Language and Cognition 15: 630–43. [Google Scholar] [CrossRef]
- Tagliamonte, Sali. 2012. Variationist Sociolinguistics: Change, Observation, Interpretation. Malden: Wiley-Blackwell. [Google Scholar]
- Toribio, Almeida Jacqueline. 2017. Structural approaches to code-switching: Research then and now. In Romance Languages and Linguistic Theory 12: Selected Papers from the 45th Linguistic Symposium on Romance Languages (LSRL), Campinas, Brazil. Edited by Ruth E. V. López, Juanito Ornelas de Avelar and Sonia M. L. Cyrino. Amsterdam: John Benjamins Publishing Company, pp. 213–33. [Google Scholar] [CrossRef]
- Torres Cacoullos, Rena, and Catherine E. Travis. 2018. Bilingualism in the Community: Code-Switching and Grammars in Contact. Cambridge: Cambridge University Press. [Google Scholar]
- Van Gelderen, Elly, and Jeff MacSwan. 2008. Interface conditions and code-switching: Pronouns, lexical DPs, and checking theory. Lingua 118: 765–76. [Google Scholar] [CrossRef] [Green Version]
- Van Hell, Janet G., Kaitlyn A. Litcofsky, and Caitlin Y. Ting. Sentential code-switching: Cognitive and neural approaches. 2015, In The Cambridge Handbook of Bilingual Processing. Schwieter, John W., ed. Cambridge: Cambridge University Press, pp. 459–82. [Google Scholar]
- Vergara Wilson, Damián, and Jenny Dumont. 2015. The emergent grammar of bilinguals: The Spanish verb hacer ‘do’ with a bare English infinitive. International Journal of Bilingualism 19: 444–58. [Google Scholar] [CrossRef]
- Weinreich, Uriel. 1953. Languages in Contact: Findings and Problems. New York: Linguistic Circle. [Google Scholar]
- Weinreich, Uriel, William Labov, and Marvin I. Herzog. 1968. Empirical foundations for a theory of language change. In Directions for Historical Linguistics. Edited by Winfred P. Lehmann and Yakov Malkiel. Austin: University of Texas Press, pp. 97–195. [Google Scholar]
| 1 | In the data examples, italics are used for English words and normal font for words for other languages. Glosses are as follows: 1 = 1st person, 2 = 2nd person, 3 = 3rd person, DET = determiner, IMP = imperfect, NONFIN = nonfinite, PL = plural, PRES = present tense, PRON = pronoun, PRT = particle. |
| 2 | |
| 3 | |
| 4 | The Welsh verb is in singular form since this is the default when the subject (Americans) is non-pronominal (see Borsley et al. 2007, p. 34). |
| 5 | |
| 6 | Deuchar et al. (2018, p. 102) include a guide to the interpretation of this table for those more familiar with earlier versions of multivariate analysis used in sociolinguistics. |
Figure 1.
Insertion of English adjective between Adãŋme noun and Adãŋme determiner (from Nartey 1982, p. 187, example 4).
Figure 1.
Insertion of English adjective between Adãŋme noun and Adãŋme determiner (from Nartey 1982, p. 187, example 4).

Figure 2.
Insertion of English noun and adjective in Adãŋme order (from Nartey 1982, p. 187, example 5).
Figure 2.
Insertion of English noun and adjective in Adãŋme order (from Nartey 1982, p. 187, example 5).

Figure 3.
Insertion of English noun and adjective in English order (from Nartey 1982, p. 187, example 6).
Figure 3.
Insertion of English noun and adjective in English order (from Nartey 1982, p. 187, example 6).

Figure 4.
Evidence against the free morpheme constraint (from Nartey 1982, p. 185, example 3).
Figure 4.
Evidence against the free morpheme constraint (from Nartey 1982, p. 185, example 3).

Figure 5.
Quantitative distribution of matrix language in Siarad corpus.

Figure 6.
Quantitative distribution of matrix language in data from Miami Spanish/English community5.
Figure 6.
Quantitative distribution of matrix language in data from Miami Spanish/English community5.

Figure 7.
Percentage of bilingual clauses by speaker age.


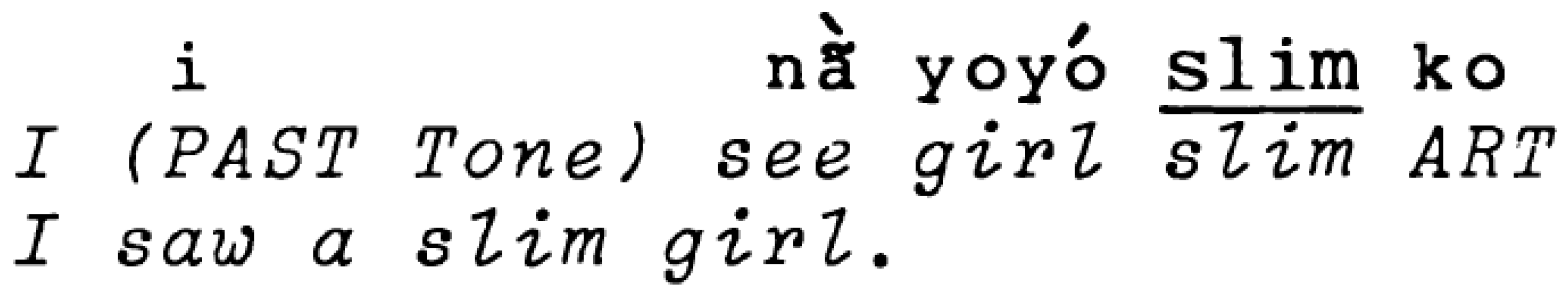{kind=link}
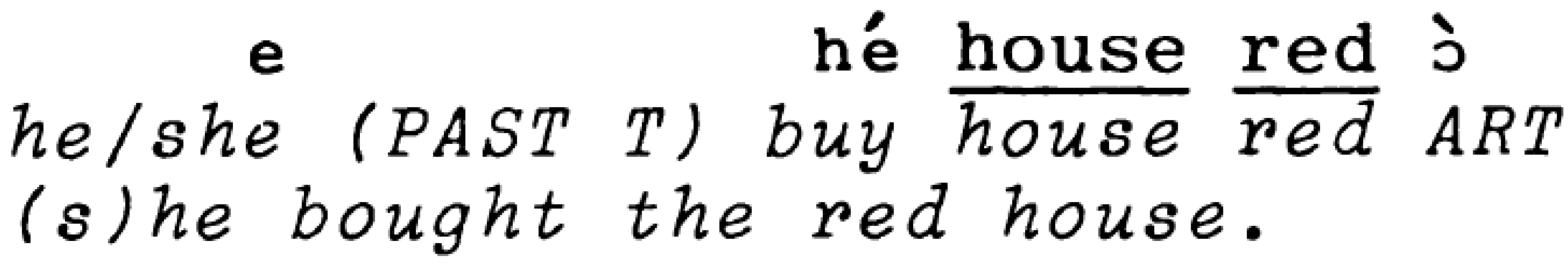{kind=link}
{kind=link}
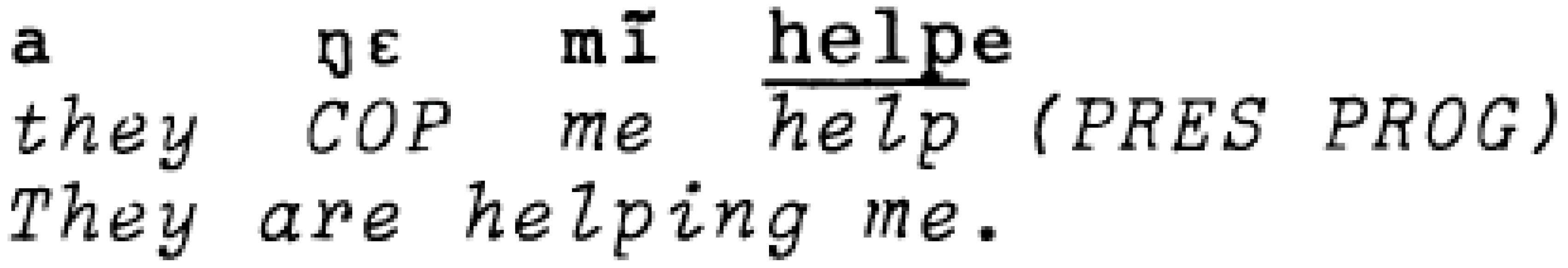{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
6 Mixed effects logistic regression predicting bilingual clauses with speaker as a random effect.
Table 1.
6 Mixed effects logistic regression predicting bilingual clauses with speaker as a random effect.
| Pattern of Bilingual Acquisition | Number of Clauses | % of Bilingual Clauses | Centred Factor Weight | Log-Odds |
|---|---|---|---|---|
| Both Welsh and English from birth | 15,572 | 14.7 | 0.6 | 0.407 |
| L2 by age four | 19,006 | 10.3 | 0.487 | −0.053 |
| L2 at primary school | 26,501 | 7.8 | 0.478 | −0.087 |
| L2 at secondary school | 3710 | 6.6 | 0.485 | −0.059 |
| L2 in adulthood | 2726 | 5.6 | 0.448 | −0.209 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Deuchar, M. Code-Switching in Linguistics: A Position Paper. Languages 2020, 5, 22. https://doi.org/10.3390/languages5020022
AMA Style
Deuchar M. Code-Switching in Linguistics: A Position Paper. Languages. 2020; 5(2):22. https://doi.org/10.3390/languages5020022
Chicago/Turabian StyleDeuchar, Margaret. 2020. "Code-Switching in Linguistics: A Position Paper" Languages 5, no. 2: 22. https://doi.org/10.3390/languages5020022