
A Volunteered Geographic Information Framework to Enable Bottom-Up Disaster Management Platforms

Abstract
:1. Introduction
2. Previous Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generation 1 | Generation 2 | Generation 3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-i | 1-ii | 1-iii | 2-i | 2-ii | 2-iii | 3-i | 3-ii | ||
| Weiser & Zipf [19] | Mazzetti et al. [20] | Agosto et al. [21] | Okolloh [5] | De Longueville et al. [22] | Zook et al. [6] | Díaz et al. [23] | Schade et al. [24] | ||
| Enabling Infrastructure | Communication Networks and Protocols | HTTP | HTTP | HTTP | HTTP, SMS | HTTP, Social media | HTTP, SMS | HTTP | HTTP, Social media |
| System Architectures 1 | Client-server | SOA | Client-server | Client-server | Client-server | Client-server | SOA | Client-server | |
| Computing Platforms 2 | Local/Cloud | Grid | Grid | Cloud | Local | Local/Cloud | Local/Cloud | Local/Cloud | |
| Standards 3 | W3C, OGC | W3C, OGC | W3C, OGC | W3C | W3C | W3C | W3C, OGC | W3C, OGC | |
| Data Frameworks | Authoritative data | Authoritative data | Authoritative data | VGI | VGI | Authoritative data, VGI | Authoritative data, VGI | Authoritative data, VGI | |
| Function | Discovery and Access 4 | Service-based discovery and access | Service-based access | Service-based access | Ad hoc discovery | Ad hoc discovery | Ad hoc discovery and access | Service-based discovery, access | Service-based discovery, access |
| Quality Control | No | Yes (QoS) | No | Yes (manually) | No | Yes (manually) | No | Yes (spatiotemporal validation) | |
| Dissemination 4 | Service-based dissemination | Service-based dissemination | Service-based dissemination | Ad hoc dissemination | Ad hoc dissemination | Ad hoc dissemination | Service-based dissemination | Service-based dissemination | |
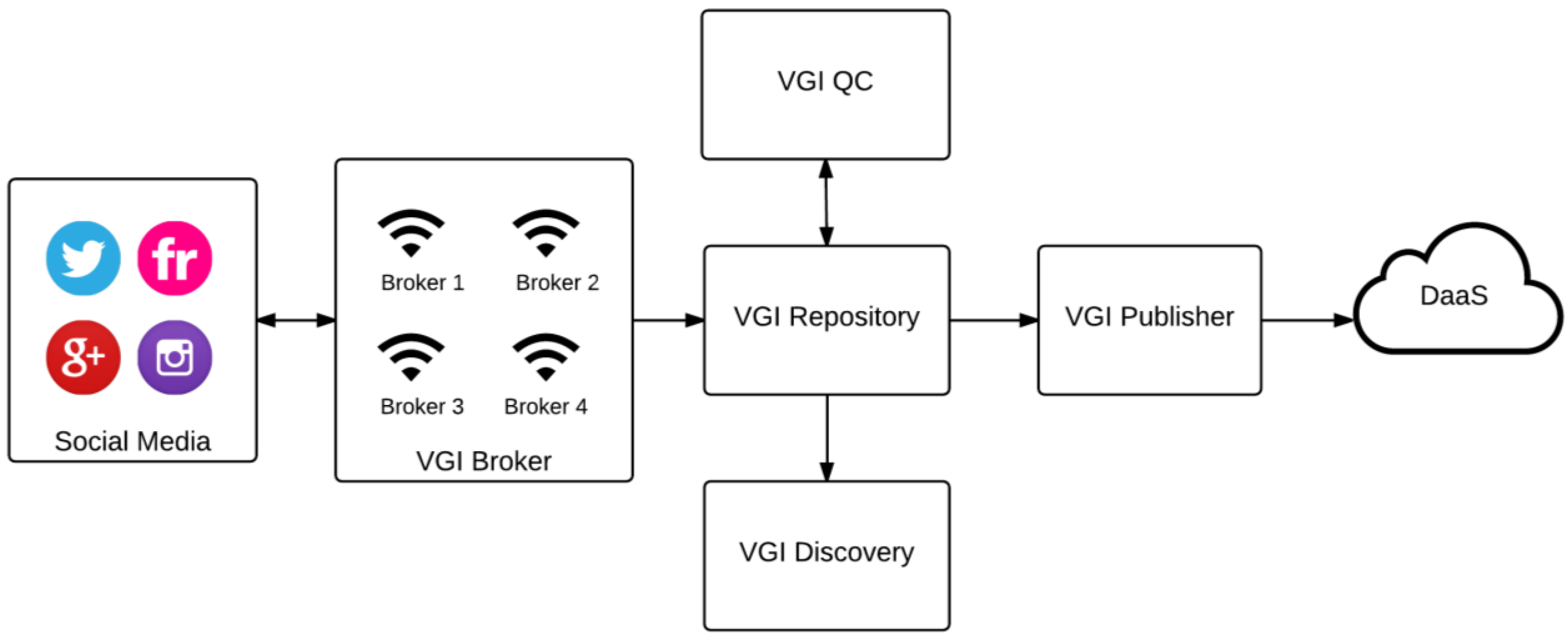
3. The VGI Framework
3.1. Conceptual Design

3.2. Quality Evaluation Metrics
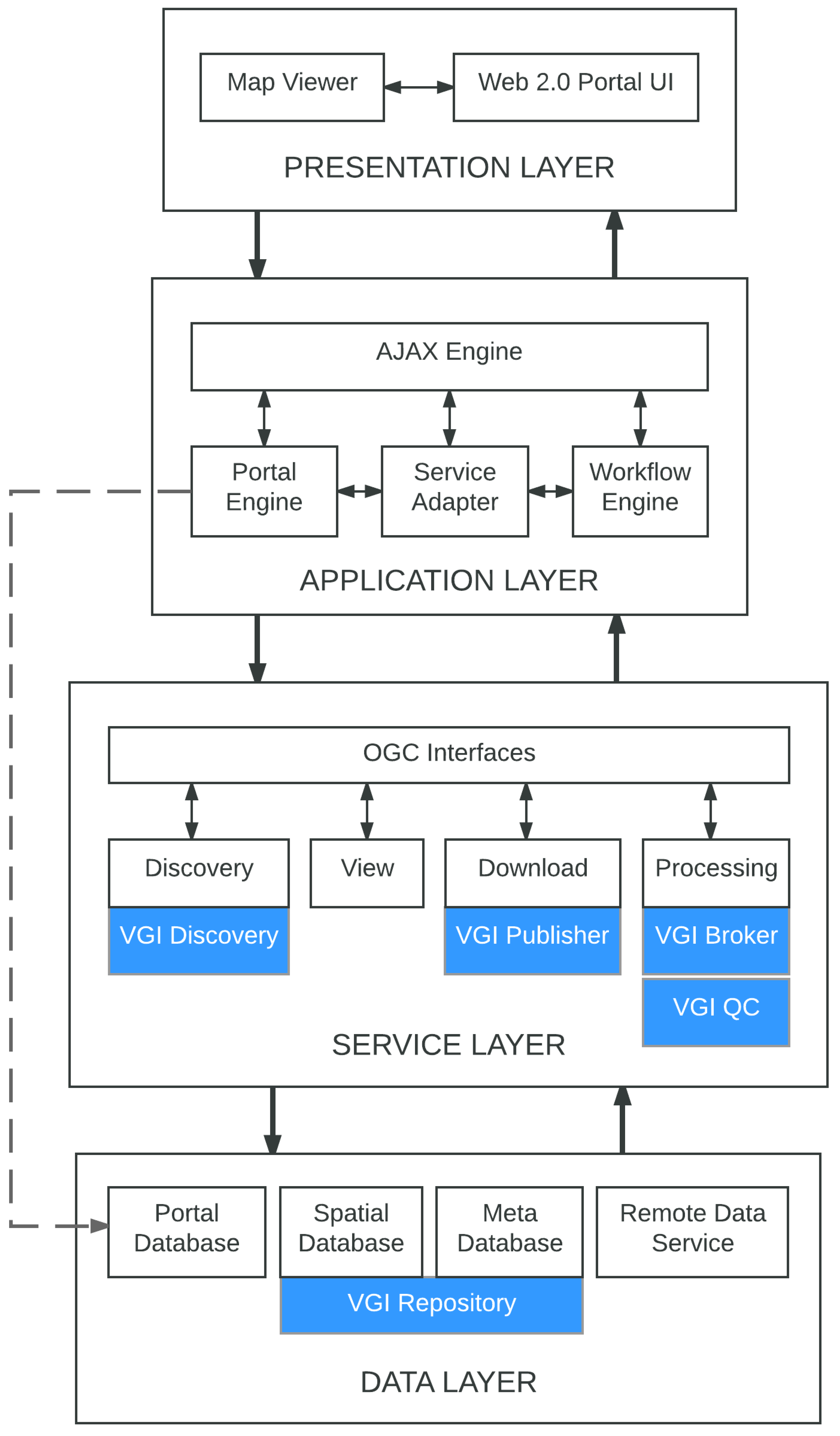
3.3. Technical Architecture

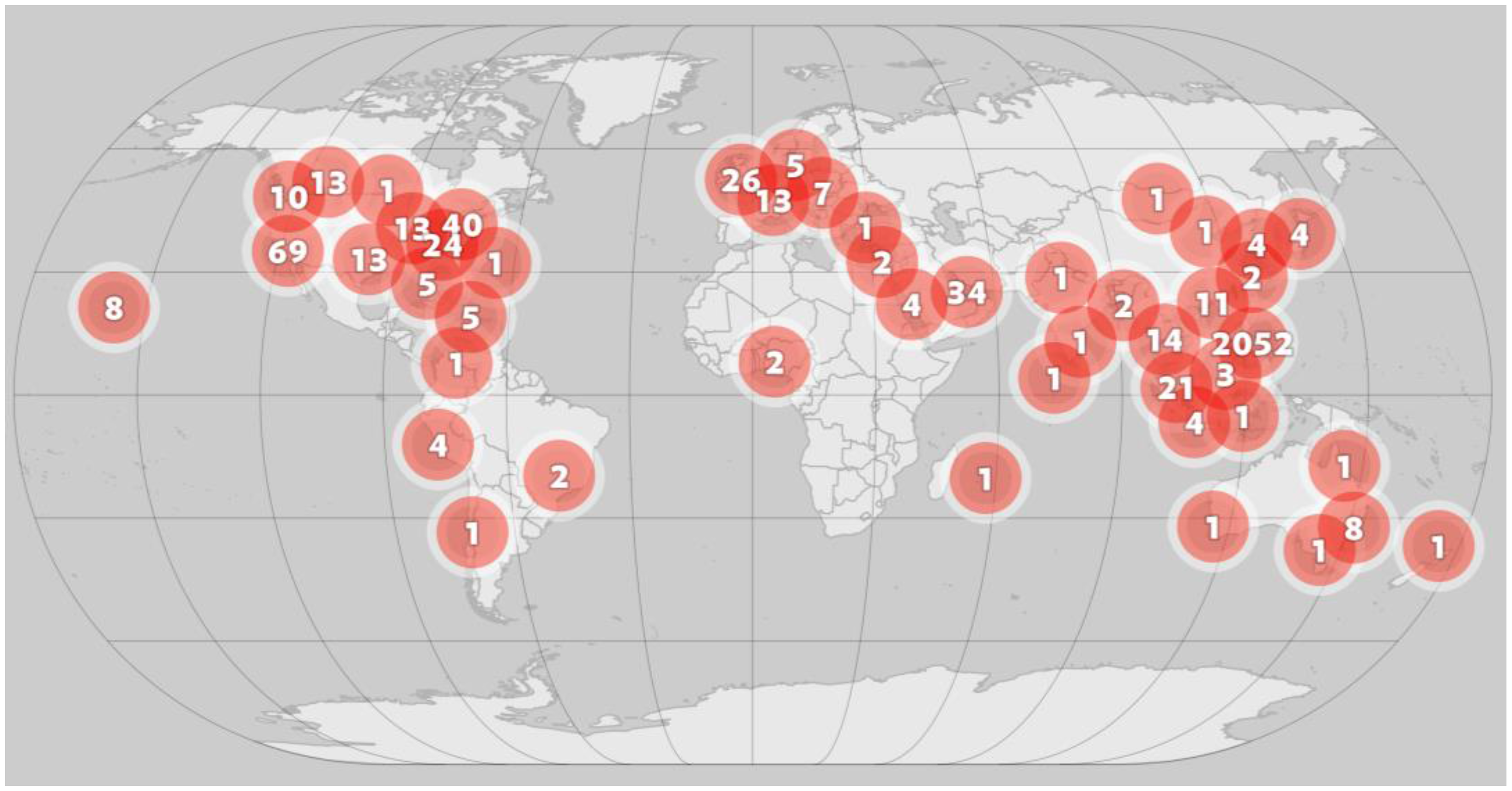
4. The VGI Framework in Action
4.1. Case Study
| Search Parameters (Hashtag/Keyword) | Python API | |
|---|---|---|
| Hashtag: rubyph, hagupit, Keyword: Typhoon Hagupit, Typhoon Ruby | twitter 1.15.0 1 | |
| Flickr | Hashtag: rubyph, hagupit, Keyword: Typhoon Hagupit, Typhoon Ruby | flickrapi 2.0 2 |
| Google Plus | Keyword: Typhoon Ruby, Typhoon Hagupit | googleapiclient 1.3.1 3 |
| Hashtag: typhoonruby, typhoonhagupit | python-instagram 1.3.0 4 |
4.2. Results

| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| PNS | Level 1 | 110,239 | 64 | 935 | 4,165 |
| Level 2 | 8 | 0 | 0 | 35 | |
| Level 3 | 2 | 0 | 0 | 5 | |
| Level 4 | 0 | 2 | 0 | 1,817 | |

| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| TNS | Level 1 | 1,746 | 0 | 65 | 29 |
| Level 2 | 24,041 | 1 | 338 | 1,033 | |
| Level 3 * | 0 | 0 | 0 | 0 | |
| Level 4 | 84,462 | 65 | 532 | 4,960 | |
| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| SSS | Level 1 | 38,967 | 1 | 0 | 5,236 |
| Level 2 | 41,561 | 0 | 0 | 560 | |
| Level 3 | 29,390 | 17 | 1 | 187 | |
| Level 4 | 331 | 48 | 934 | 39 | |
| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| CRS | Level 1 | 109,545 | 64 | 933 | 4,040 |
| Level 2 | 684 | 0 | 2 | 1,852 | |
| Level 3 | 20 | 2 | 0 | 130 | |
| Level 4 | 0 | 0 | 0 | 0 | |
| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| CS | Level 1 | 108,060 | 64 | 926 | 6,018 |
| Level 2 | 2183 | 0 | 6 | 1 | |
| Level 3 | 6 | 0 | 2 | 2 | |
| Level 4 | 0 | 2 | 1 | 1 | |
| Flickr | Google Plus | ||||
|---|---|---|---|---|---|
| QS | Level 1 | 13,674 | 0 | 0 | 626 |
| Level 2 | 95,566 | 18 | 755 | 3,550 | |
| Level 3 | 1,009 | 46 | 180 | 1,655 | |
| Level 4 | 0 | 2 | 0 | 190 | |
| Level 5 | 0 | 0 | 0 | 0 | |
5. Evaluations and Discussion
5.1. Evaluation of the Technical Framework
- (i)
- The proposed framework follows open geospatial and World Wide Web standards (i.e., OGC and W3C), which facilitate machine-machine and human-machine interactions in an interoperable manner;
- (ii)
- It allows developers to design and build system components (i.e., services) using various technologies and tools (e.g., FOSS or proprietary);
- (iii)
- The architecture supports a service-based development approach, which provides the flexibility necessary to allow changes or customization of the system; and
- (iv)
- It provides a flexible deployment solution where the system components can be easily “plugged into” existing systems, and allows deployment in both local and distributed (e.g., cloud) environments.
| Framework Characteristics | Business Goals |
|---|---|
| OGC- and W3C-compatible service interfaces and data encodings | Interoperability Integrability Flexibility Ease-of-use |
| Service-based development approach | Portability Integrability Ease-of-installation Flexibility Ease-of–repair Scalability Functionality |
| FOSS development strategy | Portability Flexibility Ease-of-repair Functionality |
5.2. Evaluation of Quality Control Metrics
| Tweet | Total QS | PNS | TNS | SSS | CRS | CS |
|---|---|---|---|---|---|---|
| Trust in the Lord always!! Pray for our country! Philippines! Typhoon #hagupit! http://t.co/bm3w1eR7FN | 2.753 | 0.503 | 1 | 0.75 | 0.5 | 0 |
| Typhoon #Hagupit Kills 21 In The Philippines @IanWoodsSky reports from south of Manila http://t.co/ARrJlw5LNA | 2.619 | 0.118 | 1 | 0.75 | 0.5 | 0.25 |
| An evacuated family in #Borongan, waits as #Philippines prepares for typhoon #RubyPH #Hagupit @UNDPPH @UNDPasiapac http://t.co/PjB0aWyRnn | 2.594 | 0.084 | 1 | 0.75 | 0.5 | 0.26 |
| Philippines Braces For Typhoon #Hagupit: http://t.co/zWpIp2wU07 http://t.co/zlT74zmv8x | 2.585 | 0.084 | 1 | 0.75 | 0.5 | 0.251 |
| As Typhoon #Hagupit nears, millions in the #Philippines are preparing for wind speeds of up to 286 km/h and 4 metre storm surges. | 2.585 | 0.084 | 1 | 0.75 | 0.5 | 0.251 |
| Text | Attachment title | Total QS | PNS | TNS | SSS | CRS | CS |
|---|---|---|---|---|---|---|---|
| Bed weather... me, still in bed literally!!! So apparently according to the latest updates about typhoon… | Bed weather... me, still in bed literally!!! So apparently according to the latest updates about typhoon…, the expected 4th landfall is around 8 pm tonight. | 2.556 | 0 | 1 | 1 | 0 | 0.556 |
| www.Suspicious0bservers.org www.ObservatoryProject.com TODAY''s LINKS: Unzicker: http://www.euroscientist.com… | Big Earthquake, Magnetic Storm | S0 News December 7, 2014 | 2.55 | 0 | 1 | 1 | 0 | 0.55 |
| Manila - NO CLASSES TOMORROW...The picture below showed some situation in some provinces that been … | Manila - NO CLASSES TOMORROW… The picture below showed some situation in some provinces that been hit by the typhoon Hagupit. The typhoon Ruby with it''s international name Hagupit is expected to hit Manila tonight until tomorrow morning.. Please continue to pray for my country. THANK YOU! | 2.368 | 0 | 1 | 1 | 0 | 0.368 |
| Super Typhoon Hagupit/Ruby from Space #Typhoon #Philippines #RubyPH | Super Typhoon Hagupit/Ruby from Space #Typhoon #Philippines #RubyPH | 2.344 | 0 | 1 | 1 | 0 | 0.344 |
| PAGASA: Typhoon 'Ruby' has slightly weakened as it continues to threaten the Samar provinces while maintaining... | Typhoon Ruby (Hagupit): December 6, 2014 Update | 2.317 | 0 | 1 | 1 | 0 | 0.317 |
| Caption | Photo | Total QS | PNS | TNS | SSS | CRS | CS |
|---|---|---|---|---|---|---|---|
| Calm before the Storm |  | 3.968 | 1 | 1 | 1 | 0.75 | 0.218 |
| Pre Ruby |  | 3.957 | 1 | 1 | 1 | 0.75 | 0.207 |
| Typhoon Hagupit |  | 3 | 0 | 1 | 1 | 0 | 1 |
| Super Typhoon Hagupit |  | 2.266 | 0 | 0.5 | 1 | 0 | 0.766 |
| Week 46/52: I will trust in the shelter of your wings |  | 2.24 | 0 | 1 | 1 | 0 | 0.24 |
| Caption | Photo | Total QS | PNS | TNS | SSS | CRS | CS |
|---|---|---|---|---|---|---|---|
| Typhoon ruby is coming in now. The wind is building and it’s quite rainy. There are a few Poole on the street, mostly looking around but the majority have taken shelter. #Philippines #tacloban #typhoonruby #hagupit #cnn |  | 3.523 | 1 | 1 | 1 | 0.5 | 0.023 |
| #RUBYPH Latest satellite image of Typhoon Ruby (Super Typhoon Hagupit as it makes it way to the Philippines. 19 days before Christmas we will be hit by a devastating typhoon #SuperTyphoonHagupit #TyphoonRuby #PAGASA #Philippines #PrayForPhilippines |  | 3.503 | 1 | 1 | 1 | 0.5 | 0.003 |
| Welcoming new members for Miracles Do Happen! Yep, that’s right! MDH Philippines is back to serve. Excited to donate and participate in charity work? Stay tune for more updates as we are going to help people affected by the typhoon #Ruby add us on Facebook and learn how you can be a miracle to others. #mdhphilippines #miraclesdohappen #beamiracle #typhoonruby #hagupit #volunteer |  | 3.502 | 1 | 1 | 1 | 0.5 | 0.002 |
| My lovely neighbours always smile even if it's rains, even if their houses are flood... #lovethem #locals #typhoonhagupit #tocute #neighbors #girls #kids #bacolod #filipinas #philippines #pilipinas #rain #hagupit #ruby |  | 3.501 | 1 | 1 | 0.75 | 0.75 | 0.001 |
| Just over a year ago, our C.O.O. snapped this photo while visiting a small mountain town in Northern Cebu as part of a relief team in the days after Super Typhoon Haiyan ravaged the Philippines...sadly, these same children just had to brave Super Typhoon Hagupit The Just Picked CoCoWater team are sending all our love to the people of the Philippines and asking for you to help in any way you can #Philippines #TyphoonHagupit #BeStrong #Love |  | 3.501 | 1 | 1 | 0.75 | 0.75 | 0.001 |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix

References
- Mansourian, A.; Rajabifard, A.; Valadan Zoej, M.J.; Williamson, I. Using SDI and web-based system to facilitate disaster management. Comput. Geosci. 2006, 32, 303–315. [Google Scholar] [CrossRef]
- Zlatanova, S.; Fabbri, A.G. Geo-ICT for risk and disaster management. In Geospatial Technology and the Role of Location in Science; Scholten, P.H.J., van de Velde, D.R., van Manen, N., Eds.; Springer: Amsterdam, The Netherlands, 2009; pp. 239–266. [Google Scholar]
- Schulz, A.; Paulheim, H. Mashups for the emergency management domain. In Semantic Mashups; Endres-Niggemeyer, B., Ed.; Springer: Berlin, Germany, 2013; pp. 237–260. [Google Scholar]
- Li, D.; Zeng, L.; Chen, N.; Shan, J.; Liu, L.; Fan, Y.; Li, W. A framework design for the Chinese National Disaster Reduction System of Systems (CNDRSS). Int. J. Digit. Earth 2014, 7, 68–87. [Google Scholar] [CrossRef]
- Okolloh, O. Ushahidi, or “testimony”: Web 2.0 tools for crowdsourcing crisis information. Particip. Learn. Action 2009, 59, 65–70. [Google Scholar]
- Zook, M.; Graham, M.; Shelton, T.; Gorman, S. Volunteered geographic information and crowdsourcing disaster relief: A case study of the Haitian Earthquake. World Med. Health Policy 2010, 2, 7–33. [Google Scholar] [CrossRef]
- Spinsanti, L.; Ostermann, F. Automated geographic context analysis for volunteered information. Appl. Geogr. 2013, 43, 36–44. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Duc, K.N.; Vu, T.-T.; Ban, Y. Ushahidi and Sahana Eden open-source platforms to assist disaster relief: Geospatial components and capabilities. In Geoinformation for Informed Decisions; Lecture Notes in Geoinformation and Cartography; Rahman, A.A., Boguslawski, P., Anton, F., Said, M.N., Omar, K.M., Eds.; Springer: Amsterdam, The Netherlands, 2014; pp. 163–174. [Google Scholar]
- Díaz, L.; Granell, C.; Huerta, J.; Gould, M. Web 2.0 Broker: A standards-based service for spatio-temporal search of crowd-sourced information. Appl. Geogr. 2012, 35, 448–459. [Google Scholar] [CrossRef]
- Roche, S.; Propeck-Zimmermann, E.; Mericskay, B. GeoWeb and crisis management: Issues and perspectives of volunteered geographic information. GeoJournal 2013, 78, 21–40. [Google Scholar] [CrossRef]
- Jaeger, P.T.; Shneiderman, B.; Fleischmann, K.R.; Preece, J.; Qu, Y.; Fei Wu, P. Community response grids: E-government, social networks, and effective emergency management. Telecommun. Policy 2007, 31, 592–604. [Google Scholar] [CrossRef]
- Huang, C.-M.; Chan, E.; Hyder, A.A. Web 2.0 and internet social networking: A new tool for disaster management?—Lessons from Taiwan. BMC Med. Inf. Decis. Mak. 2010. [Google Scholar] [CrossRef]
- Global Spatial Data Infrastructure Association. Spatial Data Infrastructure Cookbook; Global Spatial Data Infrastructure Association: Orono, ME, USA, 2009. [Google Scholar]
- Granell, C.; Gould, M.; Manso, Á.M.; Bernabé, Á.B. Spatial data infrastructures. In Handbook of Research on Geoinformatics; Karimi, H.A., Ed.; Hershey: New York, NY, USA, 2009; pp. 36–41. [Google Scholar]
- Annoni, A.; Bernard, L.; Douglas, J.; Greenwood, J.; Laiz, I.; Lloyd, M.; Sabeur, Z.; Sassen, A.-M.; Serrano, J.-J.; Usländer, T. Orchestra: Developing a unified open architecture for risk management applications. In Geo-Information for Disaster Management; van Oosterom, P.D.P., Zlatanova, D.S., Fendel, E.M., Eds.; Springer: Berlin, Germany, 2005; pp. 1–17. [Google Scholar]
- Molina, M.; Bayarri, S. A multinational SDI-based system to facilitate disaster risk management in the Andean Community. Comput. Geosci. 2011, 37, 1501–1510. [Google Scholar] [CrossRef] [Green Version]
- Giuliani, G.; Peduzzi, P. The PREVIEW Global Risk Data Platform: A geoportal to serve and share global data on risk to natural hazards. Nat. Hazards Earth Syst. Sci. 2011, 11, 53–66. [Google Scholar] [CrossRef]
- Weiser, A.; Zipf, A. Web service orchestration of OGC web services for disaster management. In Geomatics Solutions for Disaster Management; Li, A.P.J., Zlatanova, A.P.S., Fabbri, P.A.G., Eds.; Springer: Berlin, Germany, 2007; pp. 239–254. [Google Scholar]
- Mazzetti, P.; Nativi, S.; Angelini, V.; Verlato, M.; Fiorucci, P. A grid platform for the European civil protection e-infrastructure: The forest fires use scenario. Earth Sci. Inform. 2009, 2, 53–62. [Google Scholar] [CrossRef]
- Agosto, E.; Dalmasso, S.; Pasquali, P.; Terzo, O. Ithaca worldwide flood alert system: The web framework. Appl. Geomat. 2011, 3, 83–89. [Google Scholar] [CrossRef]
- De Longueville, B.; Smith, R.S.; Luraschi, G. “OMG, from Here, I Can See the Flames!”: A Use Case of Mining Location Based Social Networks to Acquire Spatio-temporal Data on Forest Fires. In Proceedings of the 2009 International Workshop on Location Based Social Networks, Seattle, WA, USA, 4–6 November 2009.
- Díaz, L.; Granell, C.; Gould, M.; Huerta, J. Managing user-generated information in geospatial cyberinfrastructures. Future Gener. Comput. Syst. 2011, 27, 304–314. [Google Scholar] [CrossRef]
- Schade, S.; Díaz, L.; Ostermann, F.; Spinsanti, L.; Luraschi, G.; Cox, S.; Nuñez, M.; De Longueville, B. Citizen-based sensing of crisis events: sensor web enablement for volunteered geographic information. Appl. Geomat. 2013, 5, 3–18. [Google Scholar] [CrossRef]
- Poorazizi, M.E.; Steiniger, S.; Hunter, A.J.S. A service-oriented architecture to enable participatory planning: an e-planning platform. Int. J. Geogr. Inf. Sci. 2015, 1–30. [Google Scholar] [CrossRef]
- Foster, I.; Zhao, Y.; Raicu, I.; Lu, S. Cloud computing and grid computing 360-degree compared. In Proceedings of the 2008 Grid Computing Environments Workshop, Austin, TX, USA, 16 November 2008; pp. 1–10.
- Bejar, R.; Latre, M.A.; Nogueras-Iso, J.; Muro-Medrano, P.R.; Zarazaga-Soria, F.J. An architectural style for spatial data infrastructures. Int. J. Geogr. Inf. Sci. 2009, 23, 271–294. [Google Scholar] [CrossRef]
- Bugs, G.; Granell, C.; Fonts, O.; Huerta, J.; Painho, M. An assessment of public participation GIS and Web 2.0 technologies in urban planning practice in Canela, Brazil. Cities 2010, 27, 172–181. [Google Scholar] [CrossRef]
- De Longueville, B.; Annoni, A.; Schade, S.; Ostlaender, N.; Whitmore, C. Digital Earth’s nervous system for crisis events: Real-time sensor web enablement of volunteered geographic information. Int. J. Digit. Earth 2010, 3, 242–259. [Google Scholar] [CrossRef]
- McCall, M. Can Participatory GIS Strengthen Local-Level Planning? Suggestions for Better Practice; Universiti Teknologi Malaysia: Johor, Malaysia, 2004. [Google Scholar]
- Li, L.; Goodchild, M.F. The role of social networks in emergency management: A research agenda. Int. J. Inf. Syst. Crisis Response Manag. 2010, 2, 48–58. [Google Scholar] [CrossRef]
- Mooney, P.; Corcoran, P. Has OpenStreetMap a role in digital earth applications? Int. J. Digit. Earth 2014, 7, 534–553. [Google Scholar] [CrossRef]
- Budhathoki, N.R.; Bruce, B.; Nedovic-Budic, Z. Reconceptualizing the role of the user of spatial data infrastructure. GeoJournal 2008, 72, 149–160. [Google Scholar] [CrossRef]
- Genovese, E.; Roche, S. Potential of VGI as a resource for SDIs in the North/South context. Geomatica 2010, 64, 439–450. [Google Scholar]
- Olson, J.A. Data as a service: Are we in the clouds? J. Map Geogr. Libr. 2009, 6, 76–78. [Google Scholar] [CrossRef]
- Wei-dong, C.; Qing-zhan, Z. Research of GIS services mode based on SaaS. In Proceedings of the 2nd International Conference on Information Science and Engineering (ICISE), Hangzhou, China, 4–6 December 2010; pp. 6812–6814.
- Castronova, A.M.; Goodall, J.L.; Elag, M.M. Models as web services using the Open Geospatial Consortium (OGC) Web Processing Service (WPS) standard. Environ. Model. Softw. 2013, 41, 72–83. [Google Scholar] [CrossRef]
- Sahin, K.; Gumusay, M.U. Service oriented architecture (SOA) based web services for geographic information systems. In Proceedings of the XXIst ISPRS International Archives of Photogrammetry, Remote Sensing, and Spatial Information Science, Beijing, China, 3–11 July 2008.
- Granell, C.; Díaz, L.; Gould, M. Service-oriented applications for environmental models: Reusable geospatial services. Environ. Model. Softw. 2010, 25, 182–198. [Google Scholar] [CrossRef]
- Haesen, R.; Snoeck, M.; Lemahieu, W.; Poelmans, S. On the definition of service granularity and its architectural impact. In Advanced Information Systems Engineering; Lecture Notes in Computer Science; Bellahsène, Z., Léonard, M., Eds.; Springer: Berlin, Germany, 2008; Volume 5074, pp. 375–389. [Google Scholar]
- Friis-Christensen, A.; Lucchi, R.; Lutz, M.; Ostländer, N. Service chaining architectures for applications implementing distributed geographic information processing. Int. J. Geogr. Inf. Sci. 2009, 23, 561–580. [Google Scholar] [CrossRef]
- Arcaini, P.; Bordogna, G.; Sterlacchini, S. Flexible Querying of Volunteered Geographic Information for Risk Management; Atlantis Press: Paris, France, 2013. [Google Scholar]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual Web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Mandl, T. Implementation and evaluation of a quality-based search engine. In Proceedings of the Seventeenth Conference on Hypertext and Hypermedia (HYPERTEXT’06), Odense, Denmark, 22–25 August 2006.
- Poser, K.; Dransch, D. Volunteered geographic information for disaster management with application to rapid flood damage estimation. Geomatica 2010, 64, 89–98. [Google Scholar]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Fu, Q.; Neis, P. Quality assessment for building footprints data on OpenStreetMap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Bishr, M.; Mantelas, L. A trust and reputation model for filtering and classifying knowledge about urban growth. GeoJournal 2008, 72, 229–237. [Google Scholar] [CrossRef]
- Bishr, M.; Kuhn, W. Trust and reputation models for quality assessment of human sensor observations. In Spatial Information Theory; Lecture Notes in Computer Science; Tenbrink, T., Stell, J., Galton, A., Wood, Z., Eds.; Springer: Amsterdam, The Netherlands, 2013; pp. 53–73. [Google Scholar]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Bodnar, T.; Salathé, M. Validating models for disease detection using Twitter. In Proceedings of the 22Nd International Conference on World Wide Web Companion (WWW’13 Companion), Rio de Janeiro, Brazil, 13–17 May 2013.
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.-H.; Liu, B. Predicting flu trends using Twitter data. In Proceedings of the 2011 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Shanghai, China, 10–15 April 2011.
- Ostermann, F.O.; Spinsanti, L. A conceptual workflow for automatically assessing the quality of volunteered geographic information for crisis management. In Proceedings of AGILE 2011 Conference, Utrecht, Netherlands, 7–13 August 2011.
- Web Map Service. Available online: portal.opengeospatial.org/files/?artifact_id=5316 (accessed on 1 February 2014).
- Web Feature Service Implementation Specification. Available online: https://portal.opengeospatial.org/files/?artifact_id=8339 (accessed on 16 July 2014).
- Evans, J.D. Web Coverage Service (WCS). Available online: portal.opengeospatial.org/files/?artifact_id=3837 (accessed on 3 April 2014).
- Botts, M.; Percivall, G.; Reed, C.; Davidson, J. OGC® sensor web enablement: Overview and high level architecture. In GeoSensor Networks; Nittel, S., Labrinidis, A., Stefanidis, A., Eds.; Springer: Berlin, Germany, 2008; Volume 4540, pp. 175–190. [Google Scholar]
- Bröring, A.; Jirka, S.; Rieke, M.; Pross, B. OGC® Testbed-10 CCI VGI Engineering Report 2014; Open Geospatial Consortium: New York, NY, USA.
- Elwood, S. Volunteered geographic information: Future research directions motivated by critical, participatory, and feminist GIS. GeoJournal 2008, 72, 173–183. [Google Scholar] [CrossRef]
- Cornford, D.; Williams, M.; Bastin, L. Uncertainty enabled Sensor Observation Services; EGU General Assembly: Vienna, Austria, 2010; Volume 12, p. 9082. [Google Scholar]
- Devaraju, A.; Kunkel, R.; Sorg, J.; Bogena, H.; Vereecken, H. Enabling quality control of sensor web observations. In Proceedings of the 3rd International Conference on Sensor Networks (SENSORNETS 2014), Lisboa, Portugal, 7–9 January 2014.
- Williams, M.; Cornford, D.; Bastin, L.; Pebesma, E. Uncertainty Markup Language (UnCertML). Available online: https://portal.opengeospatial.org/files/?artifact_id=33234. (accessed on 20 May 2015).
- Barbacci, M.R.; Ellison, R.J.; Lattanze, A.J.; Stafford, J.A.; Weinstock, C.B.; Wood, W.G. Quality Attribute Workshops (QAWs); Software Engineering Institute, Carnegie Mellon University: Pittsburgh, Pennsylvania, 2003. [Google Scholar]
- Kazman, R.; Bass, L. Categorizing Business Goals for Software Architectures; Software Engineering Institute, Carnegie Mellon University: Pittsburgh, Pennsylvania, 2005. [Google Scholar]
- Kazman, R.; Gagliardi, M.; Wood, W. Scaling up software architecture analysis. J. Syst. Softw. 2012, 85, 1511–1519. [Google Scholar] [CrossRef]
- Spinsanti, L.; Ostermann, F. Validation and relevance assessment of volunteered geographic information in the case of forest fires. In Proceedings of 2nd International Workshop on Validation of Geo-Information Products for Crisis Management, Ispra, Italy, 11–13 October 2010.
- Bimonte, S.; Boucelma, O.; Machabert, O.; Sellami, S. A new Spatial OLAP approach for the analysis of Volunteered Geographic Information. Comput. Environ. Urban Syst. 2014, 48, 111–123. [Google Scholar] [CrossRef]
- Meek, S.; Jackson, M.J.; Leibovici, D.G. A Flexible Framework for Assessing the Quality of Crowdsourced Data; AGILE Digital Editions: Castellón, Spain, 2014. [Google Scholar]
- Nebert, D.; Whiteside, A.; Vretanos, P. OpenGIS® Catalogue Services Specification. Available online: portal.opengeospatial.org/files/?artifact_id=20555 (accessed on 21 February 2014).
- Maso, J.; Pomakis, K.; Julia, N. OpenGIS® Web Map Tile Service Implementation Standard. Available online: http://www.opengeospatial.org/standards/wmts (accessed on 1 June 2014).
- Schut, P. OpenGIS Web Processing Service. Available online: portal.opengeospatial.org/files/?artifact_id=28772&version=2 (accessed on 10 August 2014).
- Na, A.; Priest, M. Sensor Observation Service. Available online: http://portal.opengeospatial.org/files/?artifact_id=12846 (accessed on 2 July 2014).
- Observations and Measurements—XML Implementation. Available online: http://portal.opengeospatial.org/files/?artifact_id=41510 (accessed on 11 September 2014).
- Gonçalves, P. OGC® OpenSearch Geo and Time Extensions. Available online: https://portal.opengeospatial.org/files/?artifact_id=56866 (accessed on 26 April 2014).
- Ellis, R.; Gray, M. Thousands Evacuate as Typhoon Hagupit Lashes Philippines. Available online: http://www.cnn.com/2014/12/06/world/asia/philippines-typhoon-hagupit-ruby/index.html (accessed on 9 February 2015).
- Rice, D. Super Typhoon Hagupit takes aim on the Philippines. Available online: http://www.usatoday.com/story/weather/2014/12/03/super-typhoon-hagupit-philippines/19849821/ (accessed on 9 February 2015).
- Typhoon Hagupit 2014. Available online: http://en.wikipedia.org/w/index.php?title=Typhoon_Hagupit_(2014)&oldid=644324125 (accessed on 27 January 2015).
- Pama, A. SitRep No. 27 re Effects of Typhoon “Ruby” (Hagupit); National Disaster Risk Reduction and Management Council: Quezon City, Philippines, 2014; p. 42. [Google Scholar]
- Official Gazette. Tropical Cyclone Warning: Tropical Storm Ruby; National Printing Office: Quezon City, Philippines, 2014.
- Murugesan, S.; Deshpande, Y.; Hansen, S.; Ginige, A. Web engineering: A new discipline for development of web-based systems. In Web Engineering; Murugesan, S., Deshpande, Y., Eds.; Springer: Berlin, 2001; pp. 3–13. [Google Scholar]
- Currion, P.; Silva, C. de; van de Walle, B. Open source software for disaster management. Commun. ACM 2007, 50, 61–65. [Google Scholar] [CrossRef]
- Steiniger, S.; Hunter, A.J.S. The 2012 free and open source GIS software map—A guide to facilitate research, development and adoption. Comput. Environ. Urban Syst. 2013, 39, 136–150. [Google Scholar] [CrossRef]
- Devillers, R.; Jeansoulin, R. Spatial data quality: Concepts. In Fundamentals of Spatial Data Quality; Devillers, R., Jeansoulin, R., Eds.; ISTE: New Delhi, India, 2006; pp. 31–42. [Google Scholar]
- Guptill, S.C.; Morrison, J.L. Elements of Spatial Data Quality; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Van Oort, P. Spatial Data Quality: From Description to Application; Wageningen Universiteit: Wageningen, The Netherlands, 2006. [Google Scholar]
- Shi, W.; Fisher, P.; Goodchild, M.F. Spatial Data Quality; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar]
- Haklay, M. Volunteered geographic information, quality assurance. Int. Encycl. Geogr. People Earth Environ. Technol. 2015, in press. [Google Scholar]
- Crooks, A.; Croitoru, A.; Stefanidis, A.; Radzikowski, J. #Earthquake: Twitter as a distributed sensor system. Trans. GIS 2013, 17, 124–147. [Google Scholar]
- Purves, R.; Jones, C. Geographic information retrieval. SIGSPATIAL Spec. 2011, 3, 2–4. [Google Scholar] [CrossRef]
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitanyi, P.M.B. The similarity metric. IEEE Trans. Inf. Theory 2004, 50, 3250–3264. [Google Scholar] [CrossRef]
- Chan, C.K.; Vasardani, M.; Winter, S. Leveraging Twitter to detect event names associated with a place. J. Spat. Sci. 2014, 59, 137–155. [Google Scholar] [CrossRef]
- Olteanu, A.; Castillo, C.; Diaz, F.; Vieweg, S. CrisisLex: A lexicon for collecting and filtering microblogged communications in crises. In Proceedings of the 8th International AAAI Conference on Weblogs and Social Media, Ann Arbor, ML, USA, 1–4 June 2014.
- Steiniger, S.; Hunter, A.J.S. A scaled line-based kernel density estimator for the retrieval of utilization distributions and home ranges from GPS movement tracks. Ecol. Inform. 2013, 13, 1–8. [Google Scholar] [CrossRef]
- Moe, W.W.; Schweidel, D.A. Online product opinions: Incidence, evaluation, and evolution. Mark. Sci. 2012, 31, 372–386. [Google Scholar] [CrossRef]
- Romero, D.M.; Meeder, B.; Kleinberg, J. Differences in the mechanics of information diffusion across topics: Idioms, political hashtags, and complex contagion on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011.
- Guo, D.; Chen, C. Detecting non-personal and spam users on geo-tagged Twitter network. Trans. GIS 2014, 18, 370–384. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Laituri, M.; Kodrich, K. On line disaster response community: People as sensors of high magnitude disasters using internet GIS. Sensors 2008, 8, 3037–3055. [Google Scholar] [CrossRef]
- Shankar, K. Wind, water, and Wi-Fi: New trends in community informatics and disaster management. Inf. Soc. 2008, 24, 116–120. [Google Scholar] [CrossRef]
- Rak, A.; Coleman, D.; Nichols, S. Legal liability concerns surrounding volunteered geographic information applicable to Canada. In Spatially Enabling Government, Industry and Citizens: Research and Dev elopment Perspectives; Rajabifard, A., Coleman, D., Eds.; GSD I Association Press: Needham, MA, USA, 2012; pp. 25–142. [Google Scholar]
- Ho, S.; Rajabifard, A. Learning from the crowd: The role of volunteered geographic information in realising a spatially enabled society. In Proceedings of GSDI 12 World Conference: Realising Spatially Enabled Societies, Singapore, 19–22 October 2010.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poorazizi, M.E.; Hunter, A.J.S.; Steiniger, S. A Volunteered Geographic Information Framework to Enable Bottom-Up Disaster Management Platforms. ISPRS Int. J. Geo-Inf. 2015, 4, 1389-1422. https://doi.org/10.3390/ijgi4031389
Poorazizi ME, Hunter AJS, Steiniger S. A Volunteered Geographic Information Framework to Enable Bottom-Up Disaster Management Platforms. ISPRS International Journal of Geo-Information. 2015; 4(3):1389-1422. https://doi.org/10.3390/ijgi4031389
Chicago/Turabian StylePoorazizi, Mohammad Ebrahim, Andrew J.S. Hunter, and Stefan Steiniger. 2015. "A Volunteered Geographic Information Framework to Enable Bottom-Up Disaster Management Platforms" ISPRS International Journal of Geo-Information 4, no. 3: 1389-1422. https://doi.org/10.3390/ijgi4031389