
Analysis of the Effects of Lockdown on Staff and Students at Universities in Spain and Colombia Using Natural Language Processing Techniques

 ,
,  , , ,
, , , 

Abstract
:1. Introduction
2. Materials and Methods
2.1. Online Survey
2.2. Study Participants and Procedure
2.3. Labeling
- If the sentences indicated a positive testimony the associated label is positive, i.e., “There are some aspects of home-schooling which I like and value” or “The pandemics have shown us to live better with less money”.
- On the other extreme, if the testimony was clearly negative, the associated label was negative, i.e., “I was not able to progress with my research thesis and I felt anxious”, or “The social relationships are not the same in remote areas, my friendship relationships have deteriorated”.
- The neutral testimonies have received a neutral tag: “In the end, we will all have COVID-19, we will normalize it, and we’ll learn to live with it”, “It’s time to reflect”.
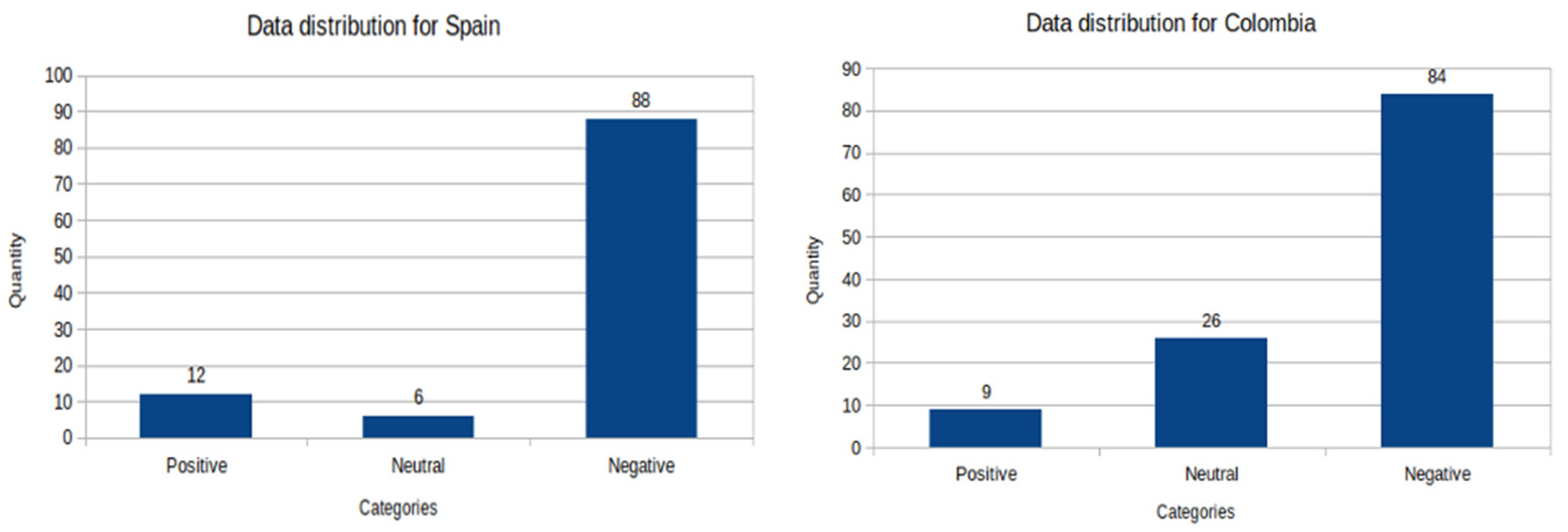
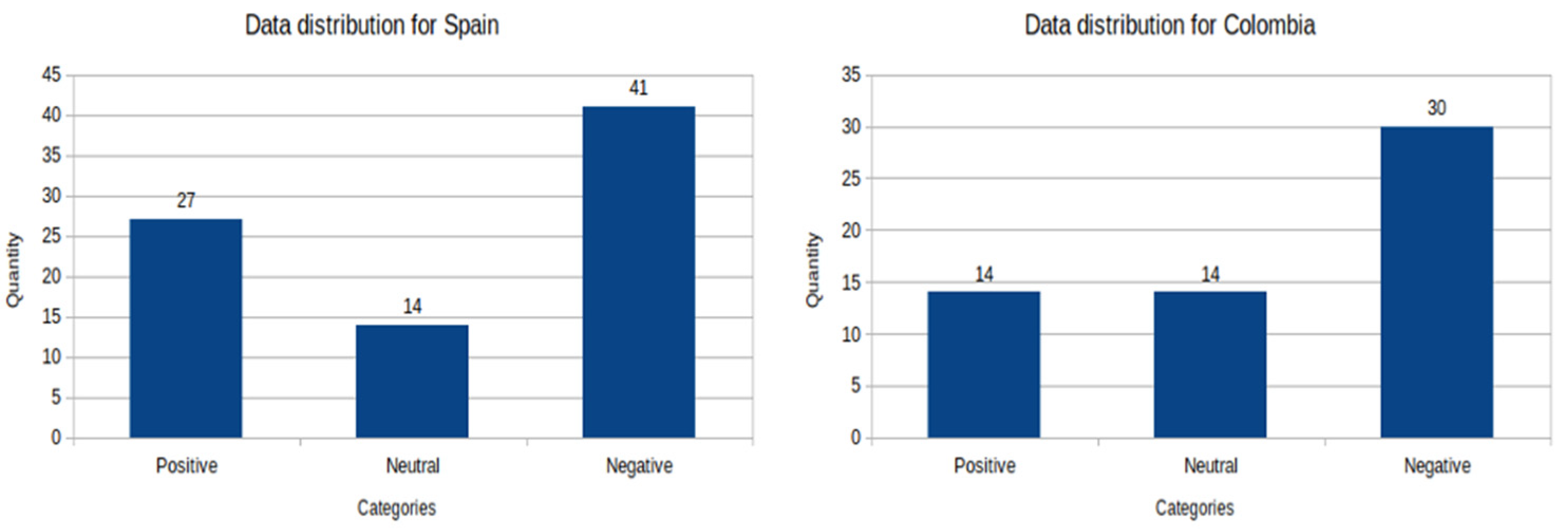
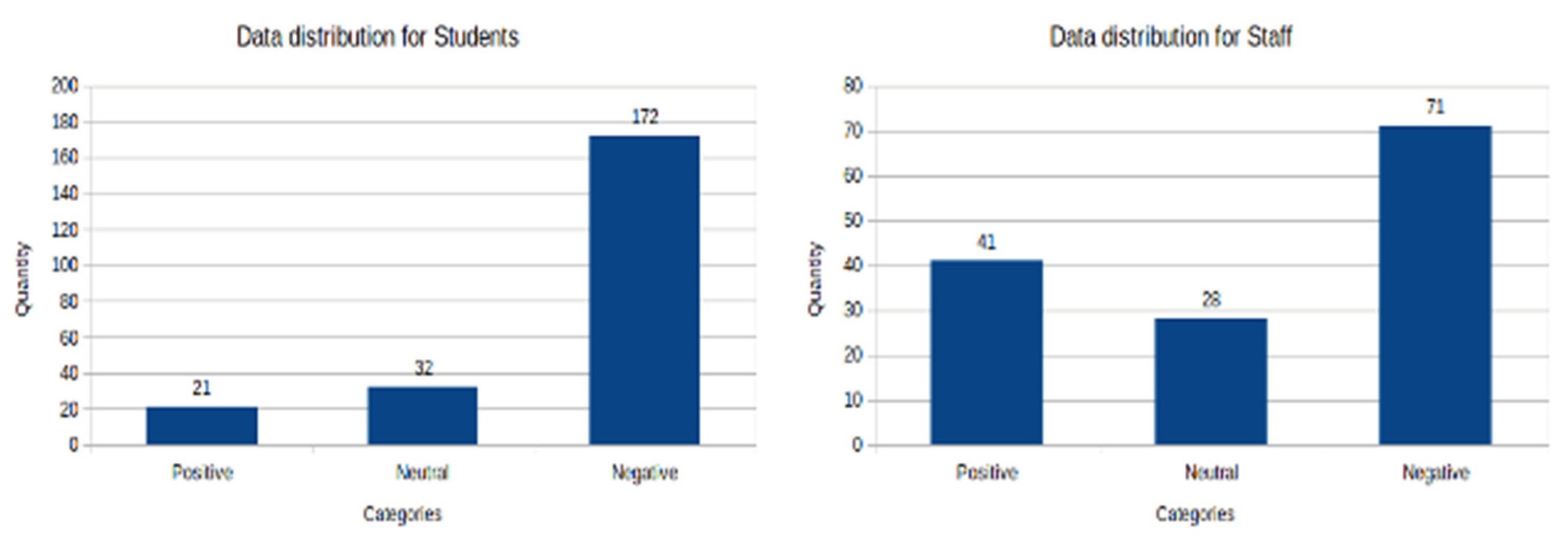
2.3.1. Histograms of Labeled Text by Sentiment Categories
Histograms for Student Group Data
Histograms for the Staff Dataset
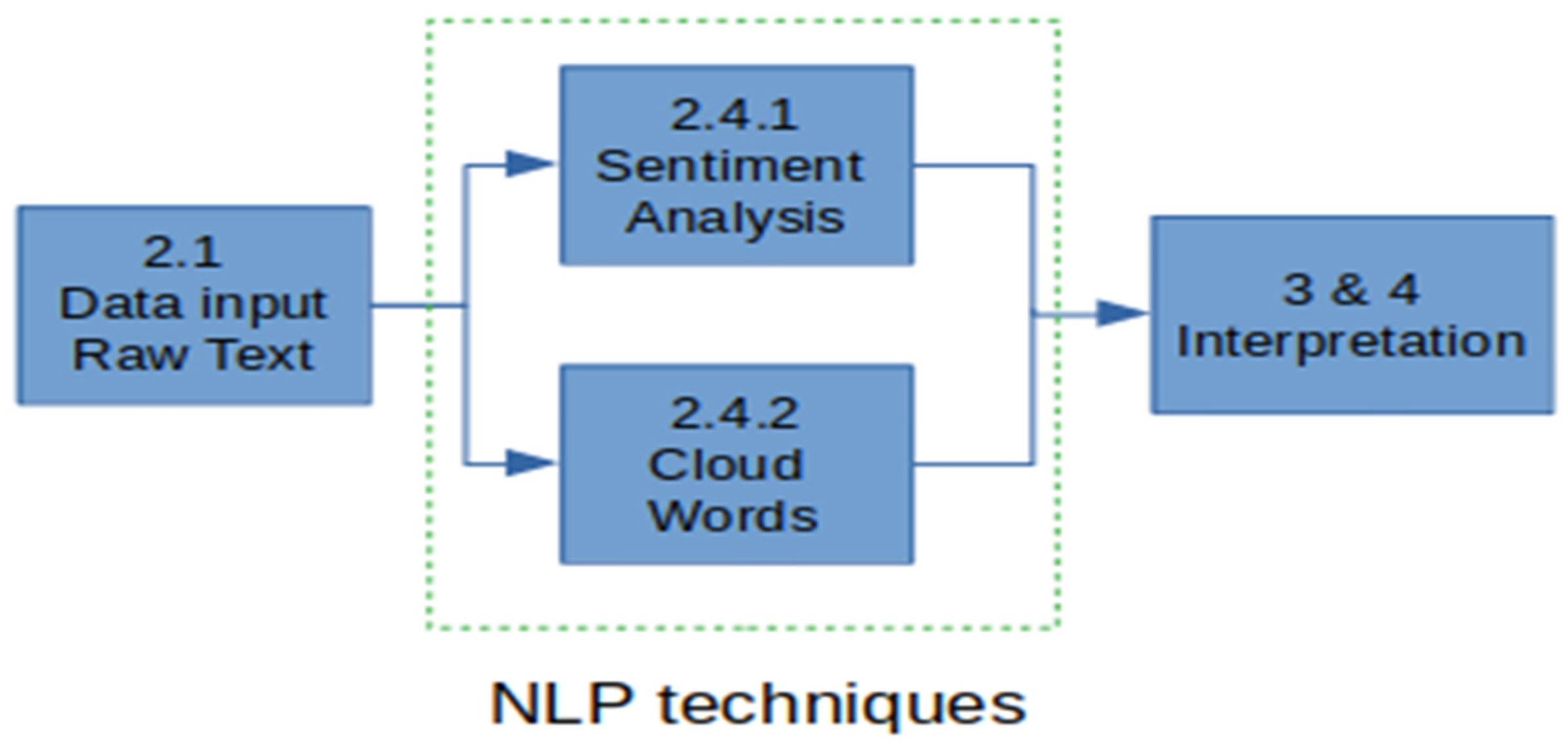
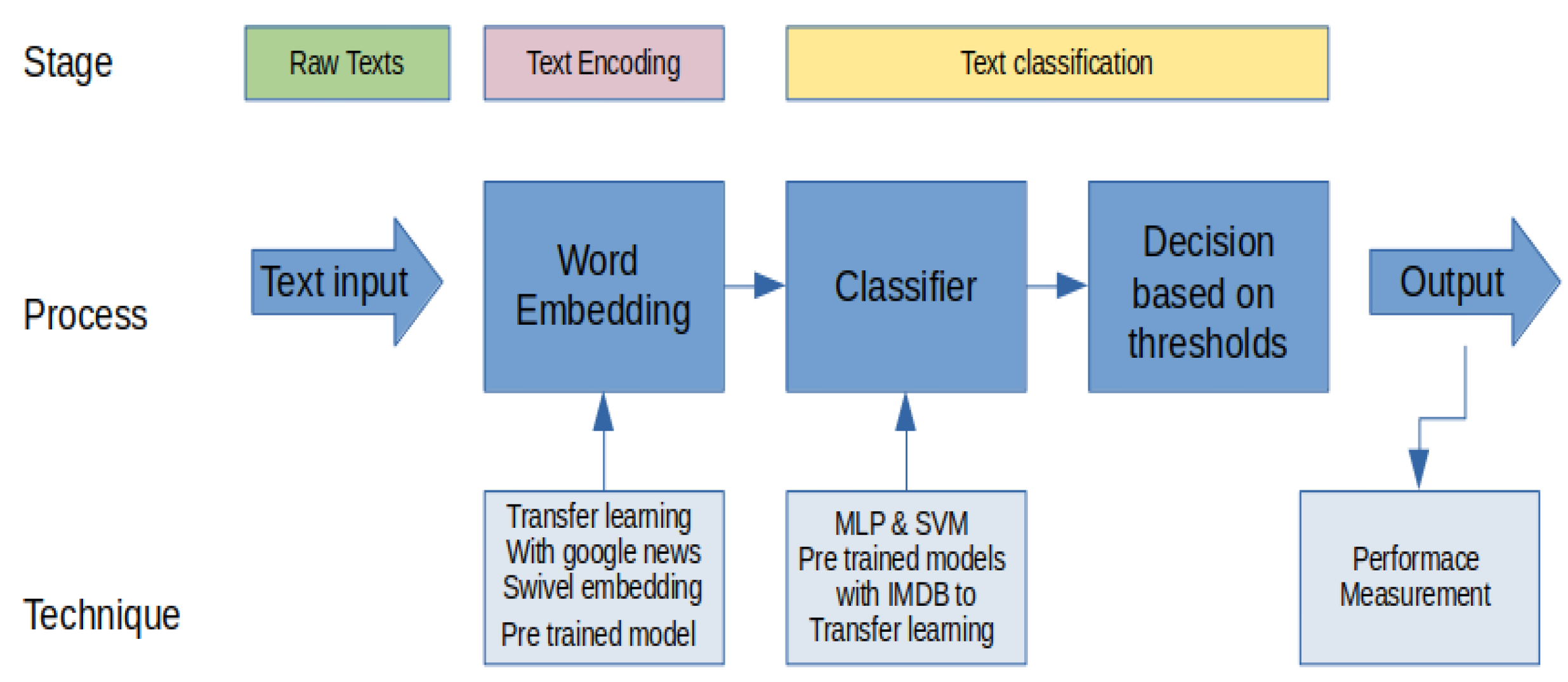
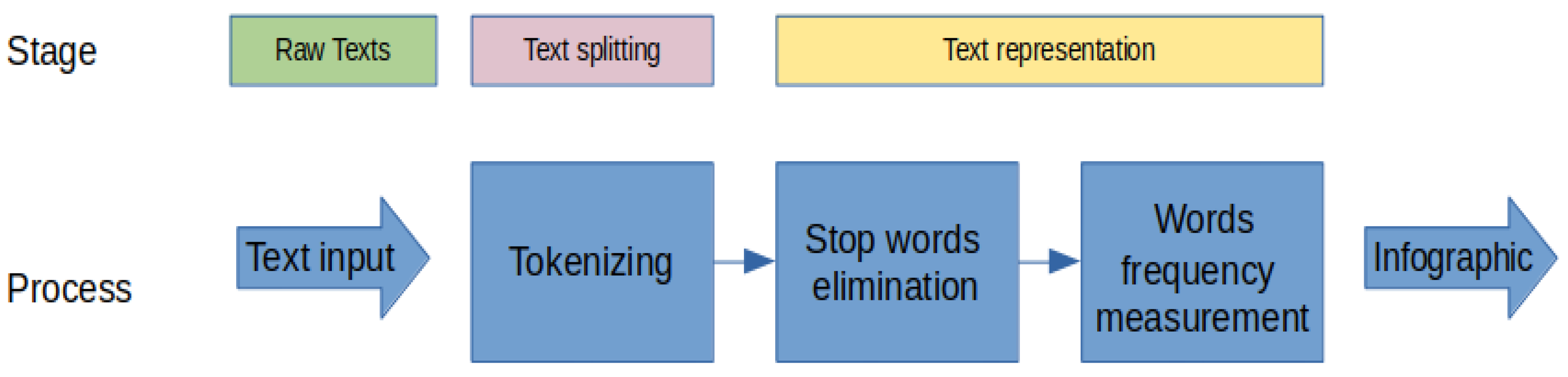
2.4. NLP Techniques
2.4.1. Sentiment Analysis
2.4.1.1. Word Embedding
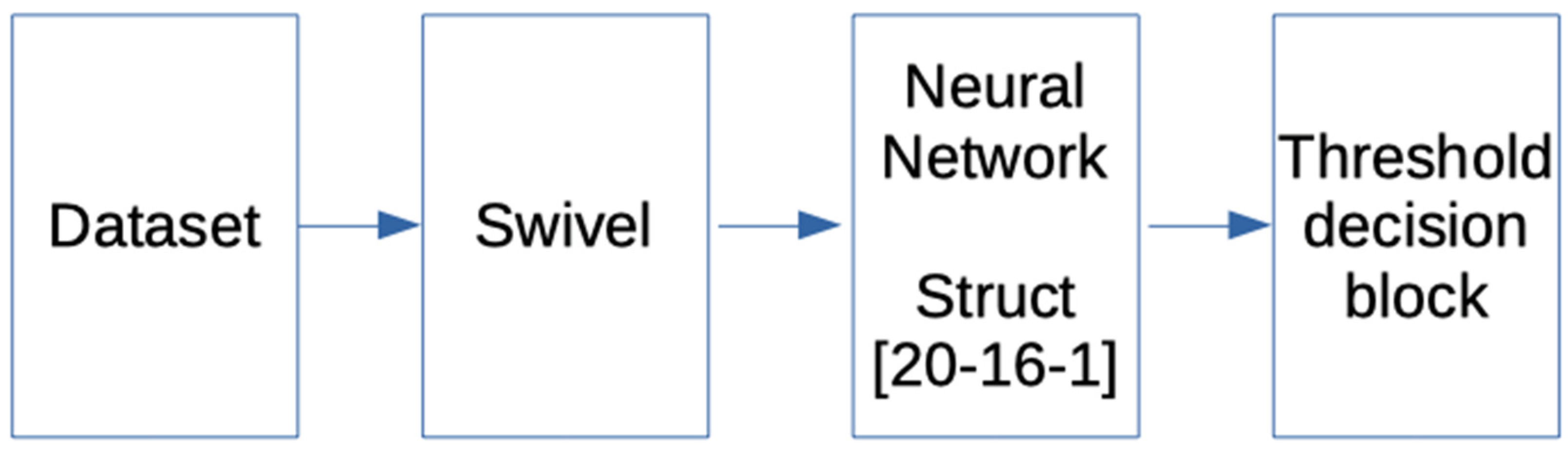
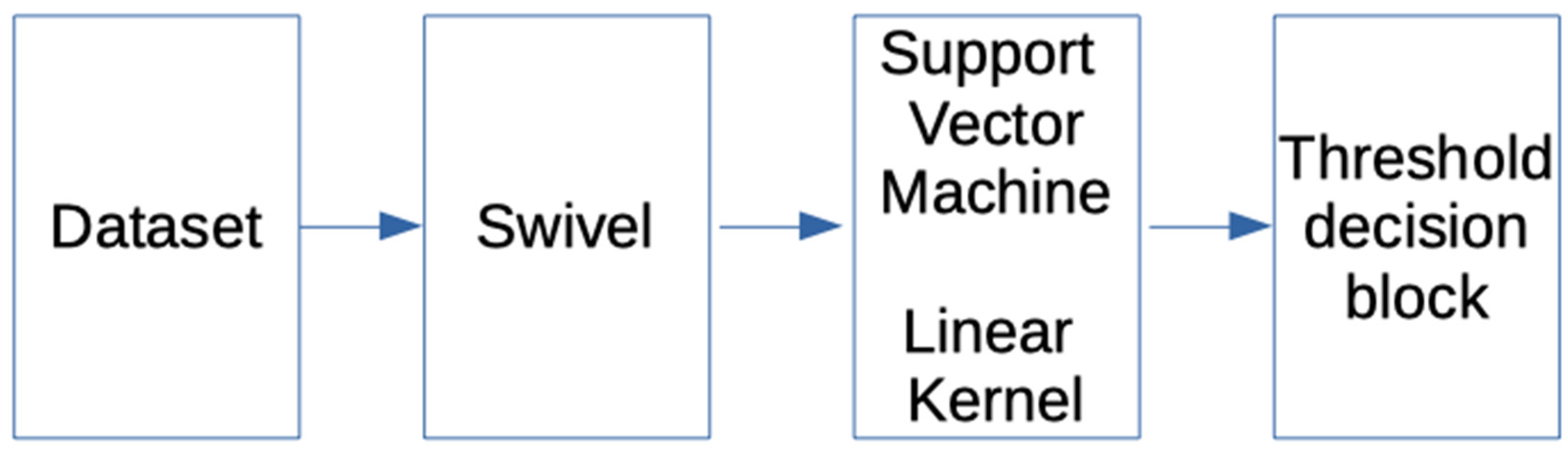
2.4.1.2. Swivel Embedding
2.4.1.3. Transfer Learning with English Google News and the IMDB Database
2.4.1.4. Classification Methods: Multilayer Perceptron MLP
2.4.1.5. Classification Methods: SVM Support Vector Machine
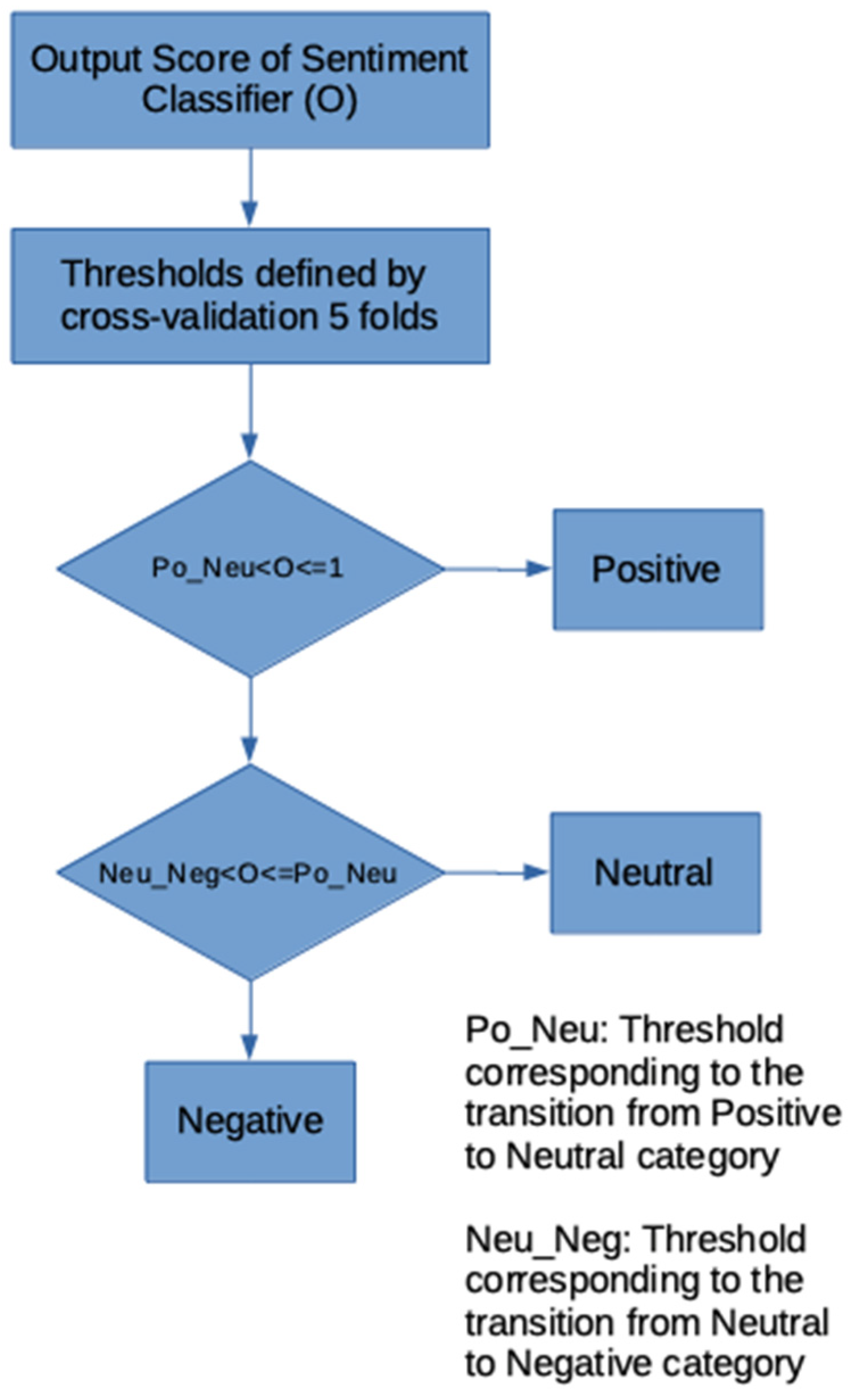
2.4.1.6. Decision Model Based on Interval Comparison
2.4.1.7. Performance Measurement
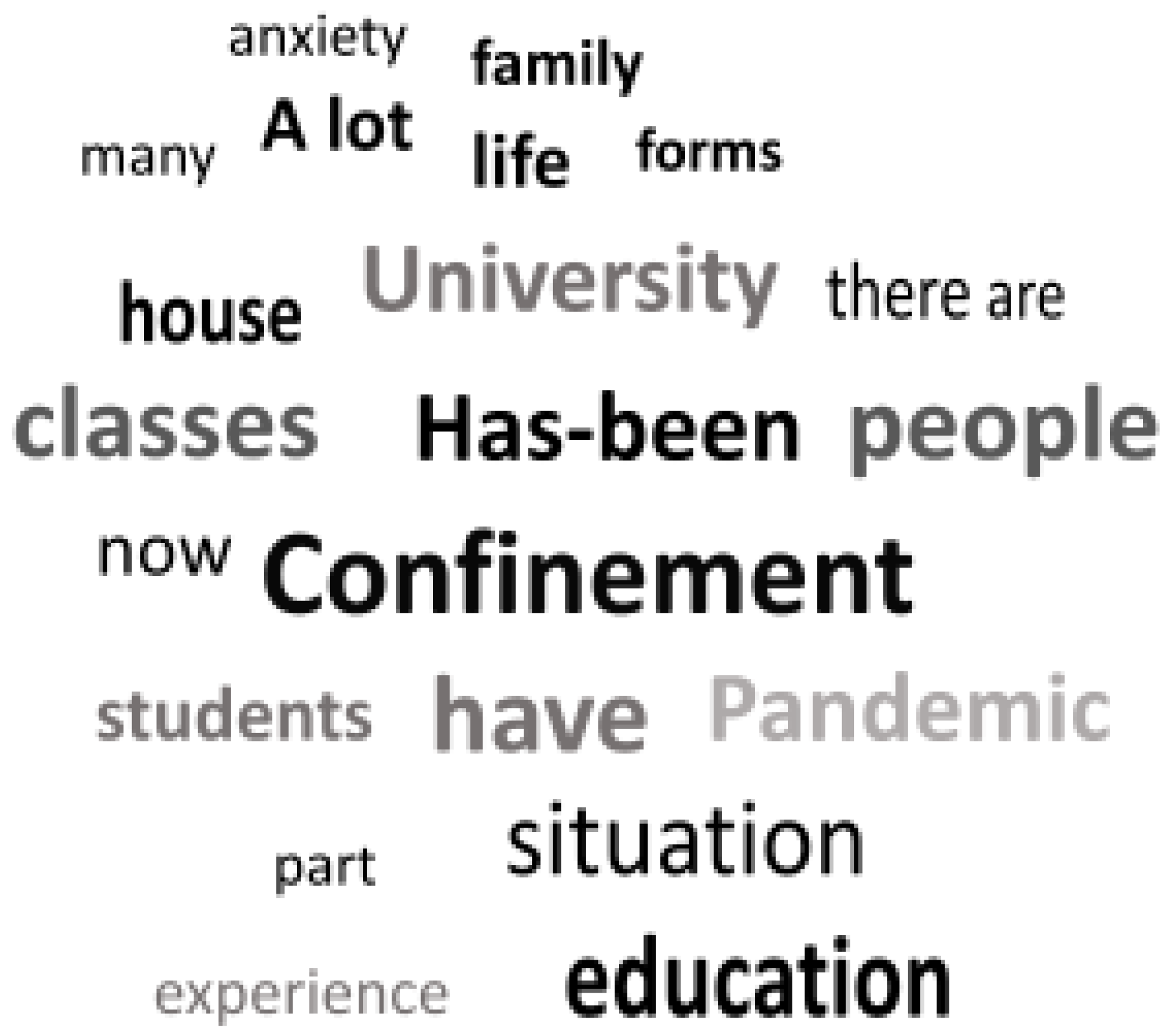
2.4.2. Cloud Words
3. Results
3.1. NLP Techniques
3.1.1. Sentiment Analysis
Decision Thresholds for Each Case
Confusion Matrices for the MLP-Based Classifier Model
Confusion matrices for the SVM-Based Classifier Model
3.1.2. Cloud Words
4. Discussion
4.1. Main Limitations
- The NLP classification model uses an automatic translator to the English language as the original text is in Spanish, and as a result of this errors could occur during the automatic translation of the texts. In the future, a database could be used to apply transfer learning in the Spanish language, in the stage of the codification of the words (embedding) and in the stage of the classification of the texts.
- There is sensitivity of the system to errors in spelling and grammar in the texts written by the users, making it difficult for the NLP model to automatically translate and interpret the feeling of the texts.
- The system is biased by the use of a general-purpose database, such as IMDB, in the application of the transfer learning technique [28], due to the limited number of texts that are used for training from scratch. In the future, researchers may aim to extend the questionnaire to more countries and more users so as to increase the number of texts and thus be able to train a specific model for this application.
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positives Classified as Negatives |
|---|
| Solidaridad |
| Con la pandemia he a prendido a valorar lo que tenemos |
| Negatives Classified as Positives |
|---|
| La mayoría de estudiantes universitarios sufren mucho |
| que den buen descuento de la matrícula |
| La respuesta de los organismos (Gobierno, Universidad…) fue insuficiente con poca información y bastante incertidumbre esto es lo que ha provocado la mayor fuente de estres, ansiedad y malestar. Además de una sensación de indefensión y vulnerabilidad |
| No se ha tenido en cuenta la desigualdad de recuerdos e imposibilidad de muchas familias sin internet a proseguir sus estudios. |
| SOY ESTUDIANTE DE UNIVERSIDAD. EL TRABAJO SE HA MULTIPLICADO POR 3 PORQUE LOS PROFESORES CONSIDERAN QUE “TENEMOS MÁS TIEMPO PORQUE ESTAMOS TODOS EN CASA”. LA ACUMULACIÓN DE TRABAJO ES BOCHORNOSA E INJUSTIFICABLE. |
| La pandemia ha colaborado en que la generación de los milenials tengan muchas dificultades para encontrar estabilidad laboral acorde con sus estudios. |
| Positives Classified as Negatives |
|---|
| Los países tenemos una oportunidad de aprender a mejorar la conciliación familiar, la lucha contra la contaminación ambiental, el teletrabajo y el modo no presencial o mixto en educación, oportunidad para ir bajando el uso de la moneda en papel y bajar el fraude monetario, usar mano de obra nacional en puestos de trabajo de importación de trabajadores extranjeros, mejorar la tasa poblacional en los pueblos y disminuir el descenso de la población rural, aumentar las horas dedicadas al ejercicio. |
| He aprendido a gestionar mejor mi tiempo, mis recursos económicos y mis relaciones con los demás miembros de la familia. No estaba en activo durante el tiempo de confinamiento, lo que me ha ayudado a centrarme en la familia. Considero muy complicado conciliar vida laboral y familiar si tengo que trabajar con mis hijos en casa. |
| Soy personal de administración y servicios de mi universidad. Trabajo desde casa casi igual que antes, usando la línea familiar de ADSL. Trabajar en casa me permite disponer de luz solar, mientras que mi puesto de trabajo se encuentra iluminado artificialmente. Ahora, mi mayor preocupación es poder seguir trabajando desde casa en la modalidad de teletrabajo. No nos permiten traernos los equipos a casa. Creo que el teletrabajo evitaría desplazamientos y contribuiría a la mejora del medio ambiente. |
| El confinanmiento me ha hecho reflexionar sobre lo rápido que iba la vida cotidiana: el trabajo, la vida social...que somos muy vulnerables, que apenas tenemos tiempo para dedicarlo a lo que nos gusta o a nuestros amigos... |
| Esta experiencia me ha hecho pensar que para algunos sectores, el teletrabajo es una opción fiable y beneficiosa para los trabajadores. Creo que tiene que seguir incluso cuando salgamos de esta pandemia. Dar la opción de trabajar desde casa se tiene que contemplar seriamente no solo como medida de preparación para posibles rebrotes sino también una herramienta para mejorar el bienestar de los trabajadores |
| Negatives Classified as Positive |
|---|
| Reduce mucho la calidad de trabajo, es decir, el rendimiento y la concentración. |
References
- UNESCO. Education: From Disruption to Recovery. 2020. Available online: https://en.unesco.org/covid19/educationresponse (accessed on 17 July 2021).
- Muller, A.E.; Hafstad, E.V.; Himmels, J.P.W.; Smedslund, G.; Flottorp, S.; Stensland, S.Ø.; Stroobants, S.; Van De Velde, S.; Vist, G.E. The mental health impact of the COVID-19 pandemic on healthcare workers, and interventions to help them: A rapid systematic review. Psychiatry Res. 2020, 293, 113441. [Google Scholar] [CrossRef] [PubMed]
- Thome, J.; Deloyer, J.; Coogan, A.N.; Bailey-Rodriguez, D.; Silva, O.A.B.D.C.E.; Faltraco, F.; Grima, C.; Gudjonsson, S.O.; Hanon, C.; Hollý, M.; et al. The impact of the early phase of the COVID-19 pandemic on mental-health services in Europe. World J. Biol. Psychiatry 2021, 22, 516–525. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, T.; Haroon, H.; Baig, M.; Hui, J. Coronavirus disease 2019 (COVID-19) pandemic and economic impact. Pak. J. Med. Sci. 2020, 36, S73. [Google Scholar] [CrossRef] [PubMed]
- Aristovnik, A.; Keržič, D.; Ravšelj, D.; Tomaževič, N.; Umek, L. Impacts of the COVID-19 pandemic on life of higher education students: A global perspective. Sustainability 2020, 12, 8438. [Google Scholar] [CrossRef]
- Aucejo, E.M.; French, J.; Araya, M.P.U.; Zafar, B. The impact of COVID-19 on student experiences and expectations: Evidence from a survey. NBER Work. Pap. 2020, 191, 27392. [Google Scholar]
- Katz, R.; Jung, J.; Callorda, F. El Estado de la Digitalización de América Latina Frente a la Pandemia del COVID-19; Socioteca: Caracas, Venezuela, 2020. [Google Scholar]
- Valle-Cruz, D.; Fernandez-Cortez, V.; López-Chau, A.; Sandoval-Almazán, R. Does twitter affect stock market decisions? Financial sentiment analysis during pandemics: A comparative study of the h1n1 and the COVID-19 periods. Cogn. Comput. 2021, 14, 372–387. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef]
- Jang, H.; Rempel, E.; Roth, D.; Carenini, G.; Janjua, N.Z. Tracking COVID-19 Discourse on Twitter in North America: Topic Modeling and Aspect-based Sentiment Analysis. J. Med. Internet Res. 2021, 23, e25431. [Google Scholar] [CrossRef]
- Alamoodi, A.; Zaidan, B.; Zaidan, A.; Albahri, O.; Mohammed, K.; Malik, R.; Almahdi, E.; Chyad, M.; Tareq, Z.; Hameed, H.; et al. Sentiment analysis and its applications in fighting COVID-19 and infectious diseases: A systematic review. Expert Syst. Appl. 2021, 167, 114155. [Google Scholar] [CrossRef]
- Sasangohar, F.; Dhala, A.; Zheng, F.; Ahmadi, N.; Kash, B.; Masud, F. Use of telecritical care for family visitation to ICU during the COVID-19 pandemic: An interview study and sentiment analysis. BMJ Qual. Saf. 2021, 30, 715–721. [Google Scholar] [CrossRef]
- Ali, N.M.; El Hamid, M.M.A.; Youssif, A. Sentiment analysis for movies reviews dataset using deep learning models. Int. J. Data Min. Knowl. Manag. Process IJDKP 2019, 9, 19–27. [Google Scholar]
- Sanu, J.; Xu, M.; Jiang, H.; Liu, Q. Word embeddings based on fixed-size ordinally forgetting encoding. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 26 September 2017; pp. 310–315. [Google Scholar]
- Iacobacci, I.; Pilehvar, M.T.; Navigli, R. Sensembed: Learning sense embeddings for word and relational similarity. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 14 July 2015; pp. 95–105. [Google Scholar]
- Gunawan, D.; Sembiring, C.A.; Budiman, M.A. The implementation of cosine similarity to calculate text relevance between two documents. J. Phys. Conf. Ser. 2018, 978, 012120. [Google Scholar] [CrossRef] [Green Version]
- Lopez, M.M.; Kalita, J. Deep Learning applied to NLP. arXiv 2017, arXiv:1703.03091. [Google Scholar]
- Islam, A.; Inkpen, D. Semantic text similarity using corpus-based word similarity and string similarity. ACM Trans. Knowl. Discov. Data TKDD 2008, 2, 1–25. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 15 October 2014; pp. 1532–1543. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef] [Green Version]
- Shazeer, N.; Doherty, R.; Evans, C.; Waterson, C. Swivel: Improving embeddings by noticing what’s missing. arXiv 2016, arXiv:1602.02215. [Google Scholar]
- Mimno, D.; Thompson, L. The strange geometry of skip-gram with negative sampling. In Proceedings of the Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 12 September 2017. [Google Scholar]
- Faruqui, M.; Tsvetkov, Y.; Rastogi, P.; Dyer, C. Problems with evaluation of word embeddings using word similarity tasks. arXiv 2016, arXiv:1605.02276. [Google Scholar]
- Mowery, D.; South, B.R.; Kvist, M.; Dalianis, H.; Velupillai, S. Recent advances in clinical natural language processing in support of semantic analysis. Yearb. Med. Inform. 2015, 24, 183–193. [Google Scholar] [CrossRef] [Green Version]
- Qiang, J.; Chen, P.; Wang, T.; Wu, X. Topic modeling over short texts by incorporating word embeddings. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Cham, Switzerland, 23 April 2017; pp. 363–374. [Google Scholar]
- Acosta, M.; Castillo-Sánchez, G.; Garcia-Zapirain, B.; Díez, I.D.L.T.; Franco-Martín, M. Sentiment Analysis Techniques Applied to Raw-Text Data from a Csq-8 Questionnaire about Mindfulness in Times of COVID-19 to Improve Strategy Generation. Int. J. Environ. Res. Public Health 2021, 18, 6408. [Google Scholar] [CrossRef]
- De Lucia Castillo, F.; Brito, J.O.; Santos, C.A. Animated words clouds to view and extract knowledge from textual information. In Proceedings of the 22nd Brazilian Symposium on Multimedia and the Web, Teresina, Brazil, 8–11 November 2016; pp. 127–134. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 15 June 2019; pp. 2790–2799. [Google Scholar]
- Solomou, I.; Constantinidou, F. Prevalence and predictors of anxiety and depression symptoms during the COVID-19 pandemic and compliance with precautionary measures: Age and sex matter. Int. J. Environ. Res. Public Health 2020, 17, 4924. [Google Scholar] [CrossRef]
- Fernandes, N. Forbes Colombia. Education Changes the World. Or Maybe Not. 2021. Available online: https://forbes.co/2020/06/11/actualidad/la-educacion-cambia-el-mundo-o-tal-vez-no/ (accessed on 22 February 2021).
- Ministry of Information and Communication Technologies. Minister Constaín Explains Measures Adopted to Confront Pandemic through ICTs. 2020. Available online: https://mintic.gov.co/portal/inicio/Sala-de-Prensa/Noticias/135664:Ministra-Constain-explica-medidas-adoptadas-para-enfrentar-pandemia-desde-las-TIC (accessed on 22 February 2021).
- Prada, N.; Raúl, G.S.; Audin, A.; Hernándezm, S.; César, A. Depressive Effects of Compulsory Preventive Isolation Associated with the COVID-19 Pandemic on Teachers and Students of a Public University in Colombia; Psicogente: Cúcuta, Colombia, 2021; Volume 24. [Google Scholar]
- Cárdenas, S.; Jorge, H.; Orjuela, G.; Alejandra, M.; Juan, M. Publications Detail BULLETIN 3: Higher Education in Times of Coronavirus|Colombian Association of Universities. 2020. Available online: Ascun.org.co (accessed on 22 February 2021).
- Miranda, V.; Margoth, A.; Pantoja, V.M.B.; Valdivieso, Á.S.B. Percepción de estudiantes universitarios colombianos sobre el efecto del confinamiento por el coronavirus, y su rendimiento académico. Rev. Espac. 2020, 41, 269–281. [Google Scholar]
- Osipenko. The LockedDown Survey. Available online: https://www.healthbit.com/the-lockeddown/ (accessed on 28 May 2021).










| Country | Students | Staff |
|---|---|---|
| Spain | 106 | 82 |
| Colombia | 119 | 58 |
| Subtotal | 225 | 140 |
| Total | 365 | |
| Model | Dataset | Positive Max | Mean Positive to Neutral Threshold | Mean Neutral to Negative Threshold | Negative Min |
|---|---|---|---|---|---|
| MLP | Students | 1 | 0.49 | 0.22 | −1 |
| MLP | Staff | 1 | 0.52 | 0.38 | −1 |
| SVM | Students | 1 | 0.41 | 0.24 | −1 |
| SVM | Staff | 1 | 0.42 | 0.26 | −1 |
| Metrics | MLP Students | MLP Staff | SVM Students | SVM Staff |
|---|---|---|---|---|
| Weighted Accuracy | 92.49% | 92.59% | 88.42% | 82.55% |
| Weighted Precision | 88.89% | 88.57% | 83.11% | 72.86% |
| Weighted Recall | 88.64% | 88.47% | 82.86% | 71.77% |
| Weighted F1 Score | 88.74% | 88.29% | 82.88% | 71.75% |
| Accuracy | 88.88% | 88.57% | 83.11% | 72.85% |
| Class | Real | |||
|---|---|---|---|---|
| Negative | 165 | 8 | 2 | |
| Neutral | 1 | 22 | 6 | |
| Positive | 6 | 2 | 13 | |
| Predicted | Class | Negative | Neutral | Positive |
| Positives Classified as Negatives |
|---|
| Solidarity |
| With the pandemic, I have come to appreciate what we have |
| Negatives Classified as Positives |
|---|
| Most college students suffer greatly |
| that give a good tuition discount |
| The response of the organizations (Government, University...) was insufficient, with little information and a great deal of uncertainty, which is what has caused the greatest source of stress, anxiety and discomfort. In addition to a feeling of helplessness and vulnerability. |
| The inequality of memories and the impossibility of many families without internet to continue their studies has not been taken into account. |
| I am a university student. the workload has been multiplied by 3 because the professors consider that ‘‘we have more time because we are all at home’’. the accumulation of work is embarrassing and unjustifiable. |
| The pandemic has contributed to the fact that the millennial generation is having a very difficult time finding job stability in line with their studies. |
| Class | Real | |||
|---|---|---|---|---|
| Negative | 70 | 3 | 5 | |
| Neutral | 0 | 22 | 4 | |
| Positive | 1 | 3 | 32 | |
| Predicted | Class | Negative | Neutral | Positive |
| Positives Classified as Negatives |
|---|
| Countries have the opportunity to learn how to improve family reconciliation, the fight against environmental pollution, teleworking and non-face-to-face or mixed modality in education, the opportunity to decrease the use of paper money and reduce monetary fraud, use national labor in jobs imported by foreign workers, improve the population rate in villages and reduce the decline in rural population, increase the hours dedicated to exercise, etc. |
| I have learned to better manage my time, my financial resources and my relationships with other family members. I was not working during the confinement time, which has helped me to focus on the family. I find it very difficult to reconcile work and family life if I have to work with my children at home. |
| I am an administration and services staff at my university. I work from home almost as before, using the family ADSL line. Working at home allows me to have sunlight, while my workstation is artificially illuminated. Now, my biggest concern is to be able to continue working from home in telecommuting mode. We are not allowed to bring our equipment home. I believe that teleworking would avoid commuting and contribute to the improvement of the environment. |
| The confinement has made me reflect on how fast everyday life was going: work, social life... that we are very vulnerable, that we hardly have time to dedicate to what we like or to our friends... |
| This experience has made me think that for some sectors, telework is a reliable and beneficial option for workers. I think it has to continue even when we come out of this pandemic. Giving the option to work from home has to be seriously contemplated not only as a preparedness measure for possible resurgences but also as a tool to improve the well-being of the workers. |
| Negatives Classified as Positives |
|---|
| It greatly reduces the quality of work, i.e., performance and concentration. |
| Class | Real | |||
|---|---|---|---|---|
| Negative | 160 | 11 | 3 | |
| Neutral | 8 | 18 | 9 | |
| Positive | 4 | 3 | 9 | |
| Predicted | Class | Negative | Neutral | Positive |
| Class | Real | |||
|---|---|---|---|---|
| Negative | 66 | 5 | 11 | |
| Neutral | 3 | 15 | 9 | |
| Positive | 2 | 8 | 21 | |
| Predicted | Class | Negative | Neutral | Positive |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jojoa, M.; Garcia-Zapirain, B.; Gonzalez, M.J.; Perez-Villa, B.; Urizar, E.; Ponce, S.; Tobar-Blandon, M.F. Analysis of the Effects of Lockdown on Staff and Students at Universities in Spain and Colombia Using Natural Language Processing Techniques. Int. J. Environ. Res. Public Health 2022, 19, 5705. https://doi.org/10.3390/ijerph19095705
Jojoa M, Garcia-Zapirain B, Gonzalez MJ, Perez-Villa B, Urizar E, Ponce S, Tobar-Blandon MF. Analysis of the Effects of Lockdown on Staff and Students at Universities in Spain and Colombia Using Natural Language Processing Techniques. International Journal of Environmental Research and Public Health. 2022; 19(9):5705. https://doi.org/10.3390/ijerph19095705
Chicago/Turabian StyleJojoa, Mario, Begonya Garcia-Zapirain, Marino J. Gonzalez, Bernardo Perez-Villa, Elena Urizar, Sara Ponce, and Maria Fernanda Tobar-Blandon. 2022. "Analysis of the Effects of Lockdown on Staff and Students at Universities in Spain and Colombia Using Natural Language Processing Techniques" International Journal of Environmental Research and Public Health 19, no. 9: 5705. https://doi.org/10.3390/ijerph19095705