
Reconstructing Missing and Anomalous Data Collected from High-Frequency In-Situ Sensors in Fresh Waters

 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Reconstruction Method
2.2. Arikaree River Case Study: Applying the Reconstruction Method
2.3. Simulation Study: Performance Evaluation
2.4. Implementation
3. Results
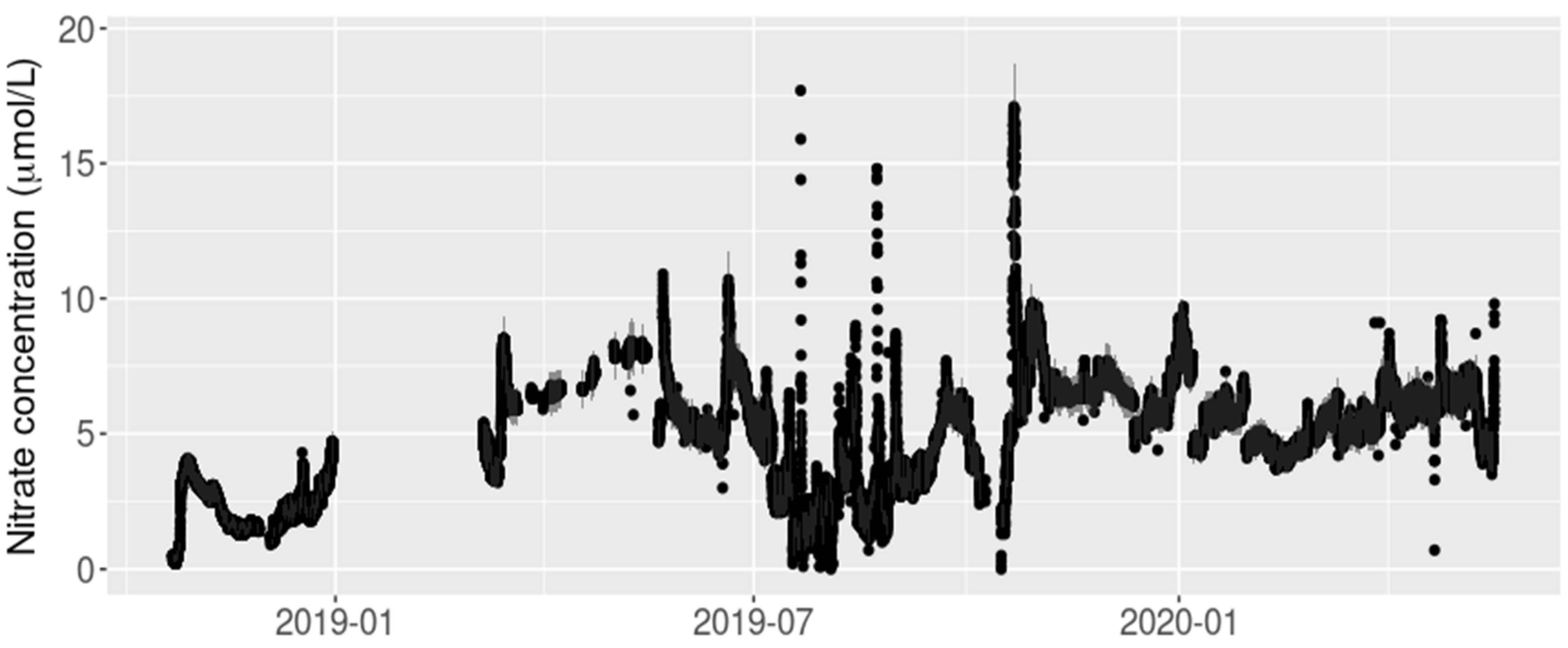
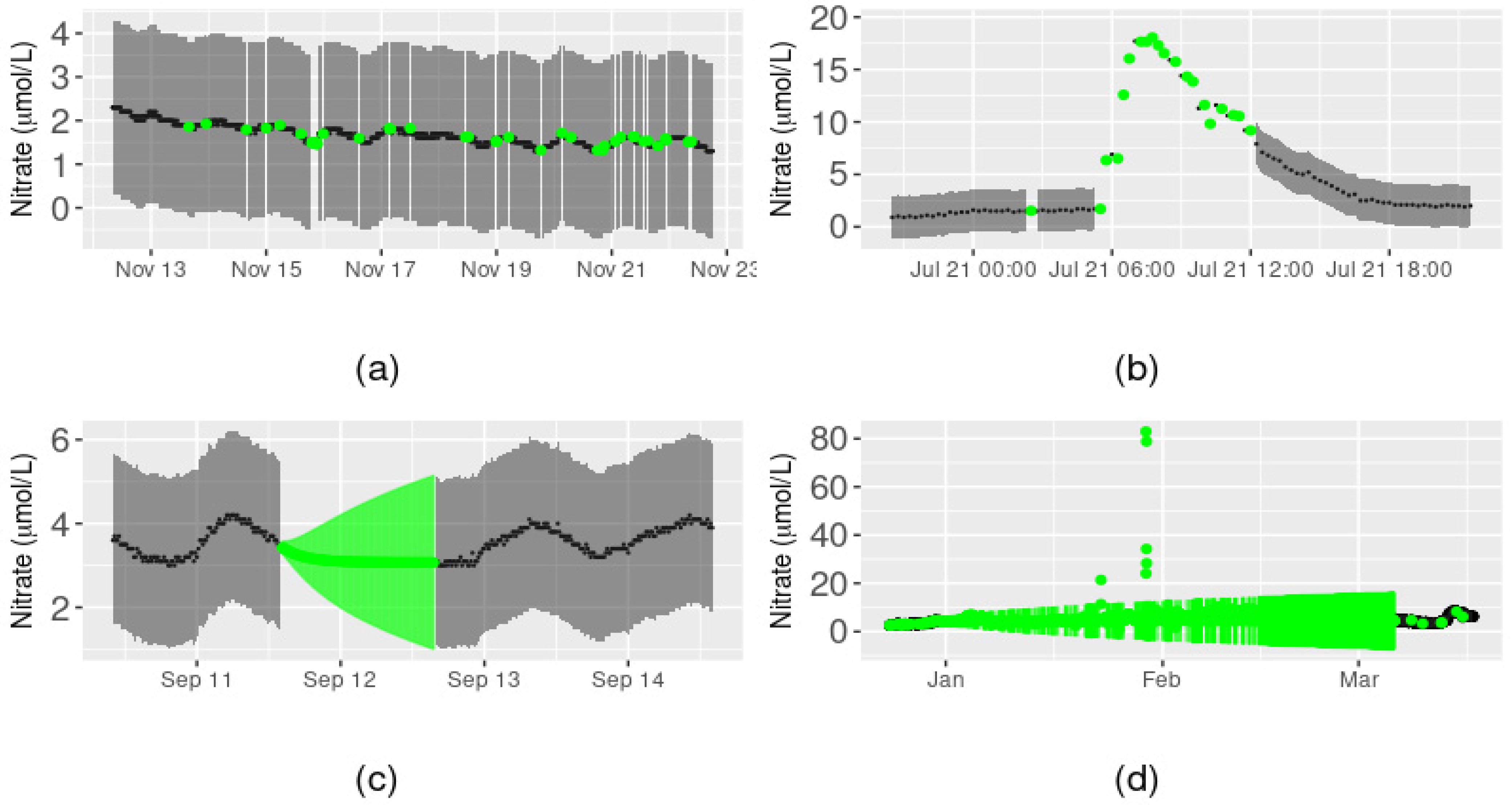
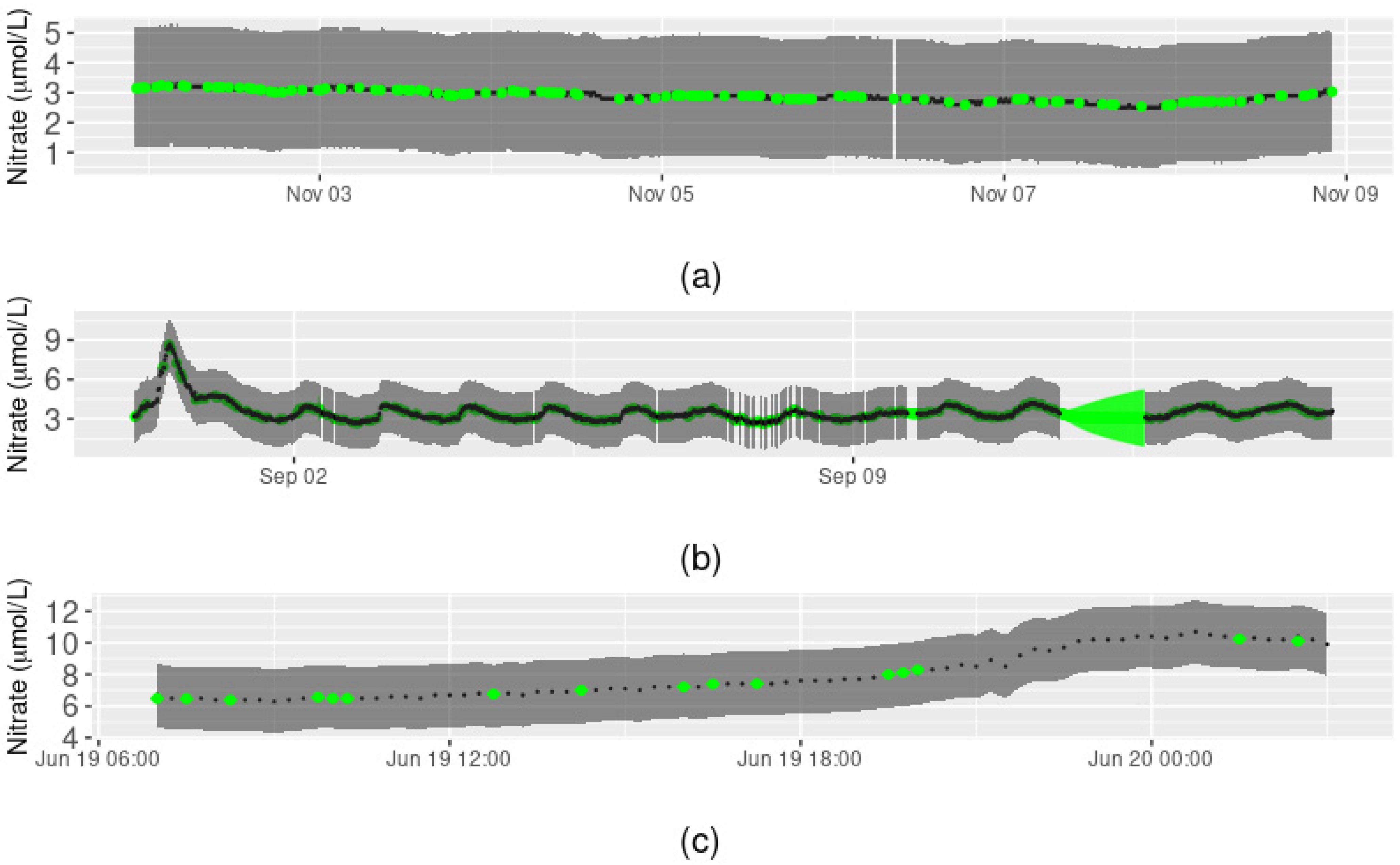
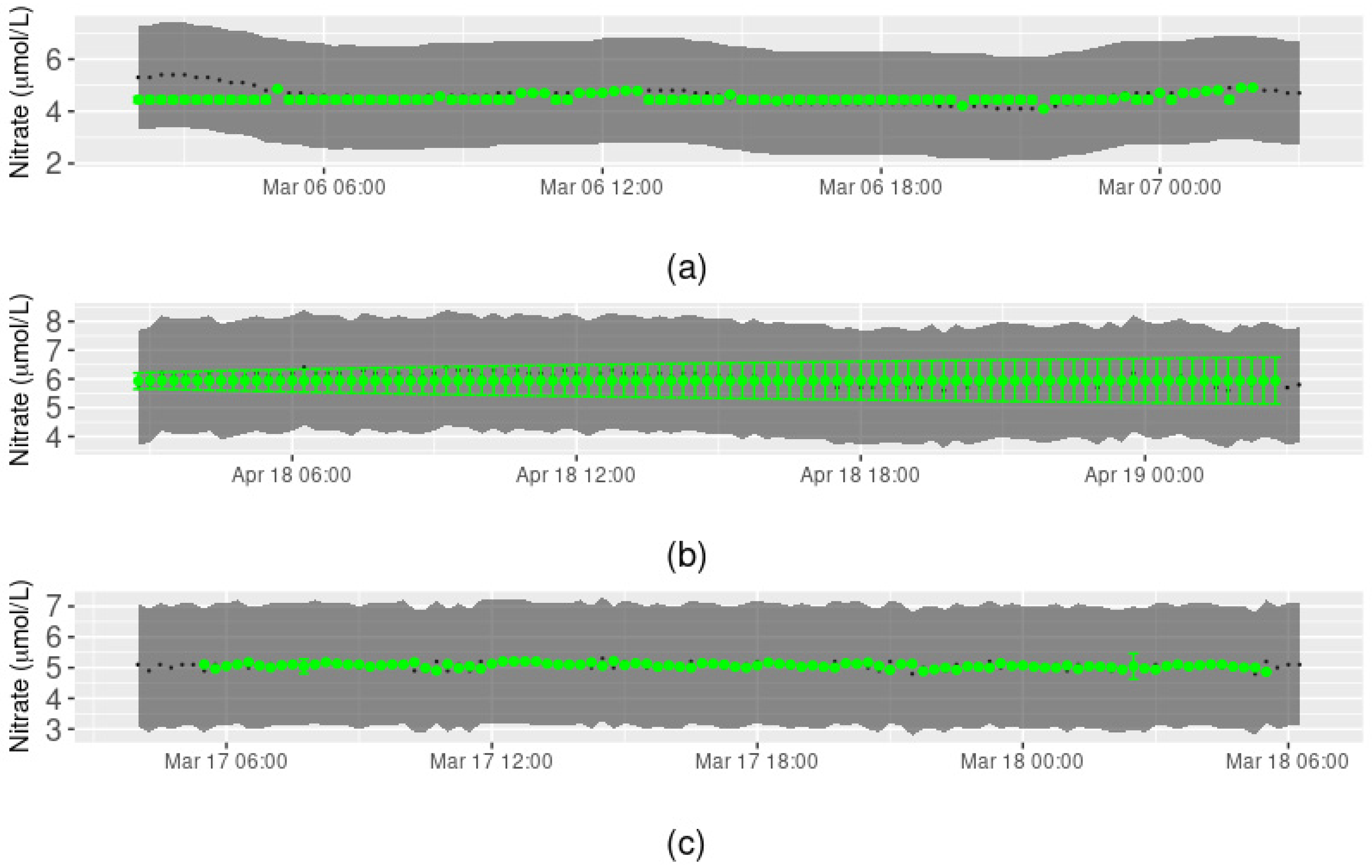
3.1. Arikaree River Case Study
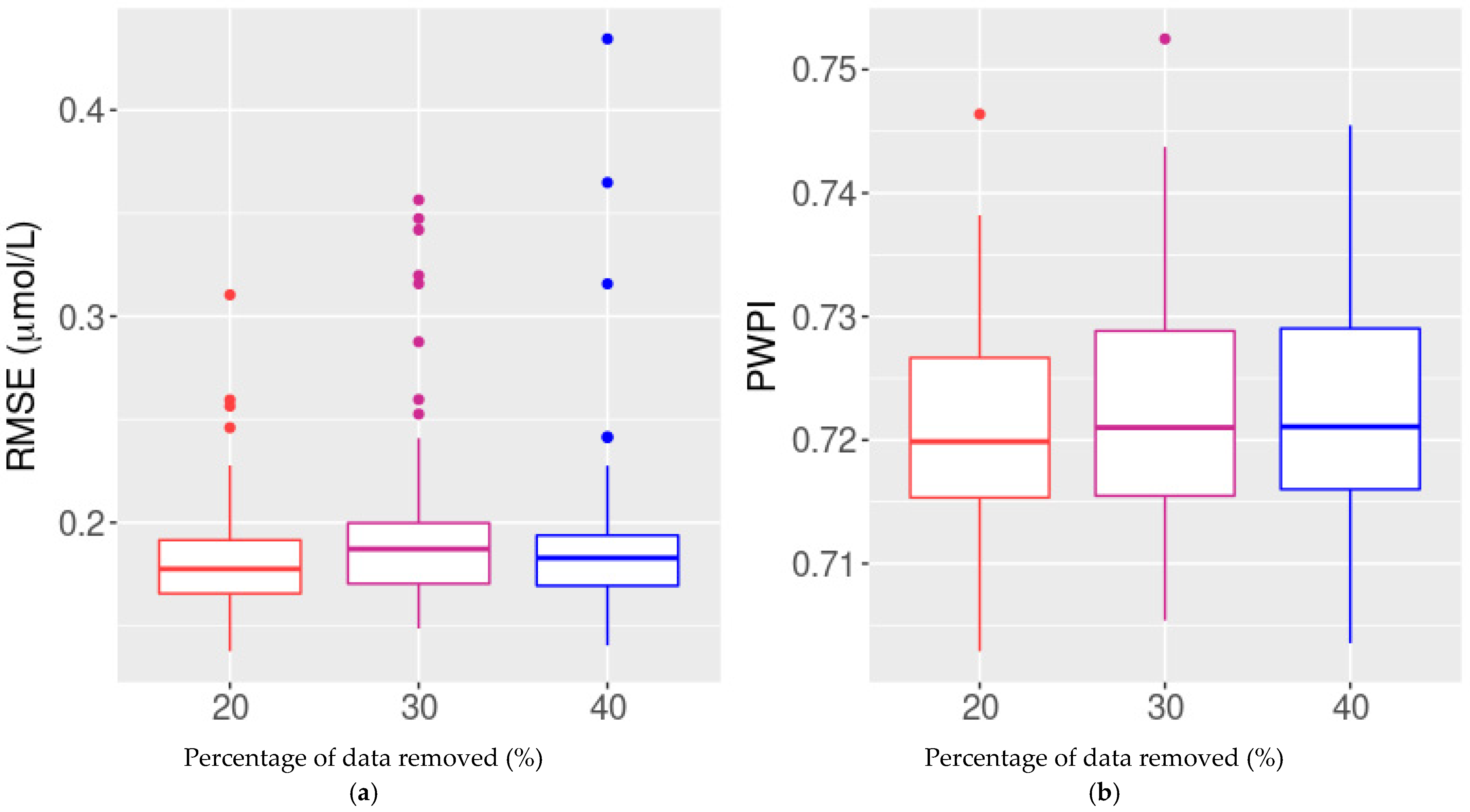
3.2. Simulation Study: Performance Evaluation
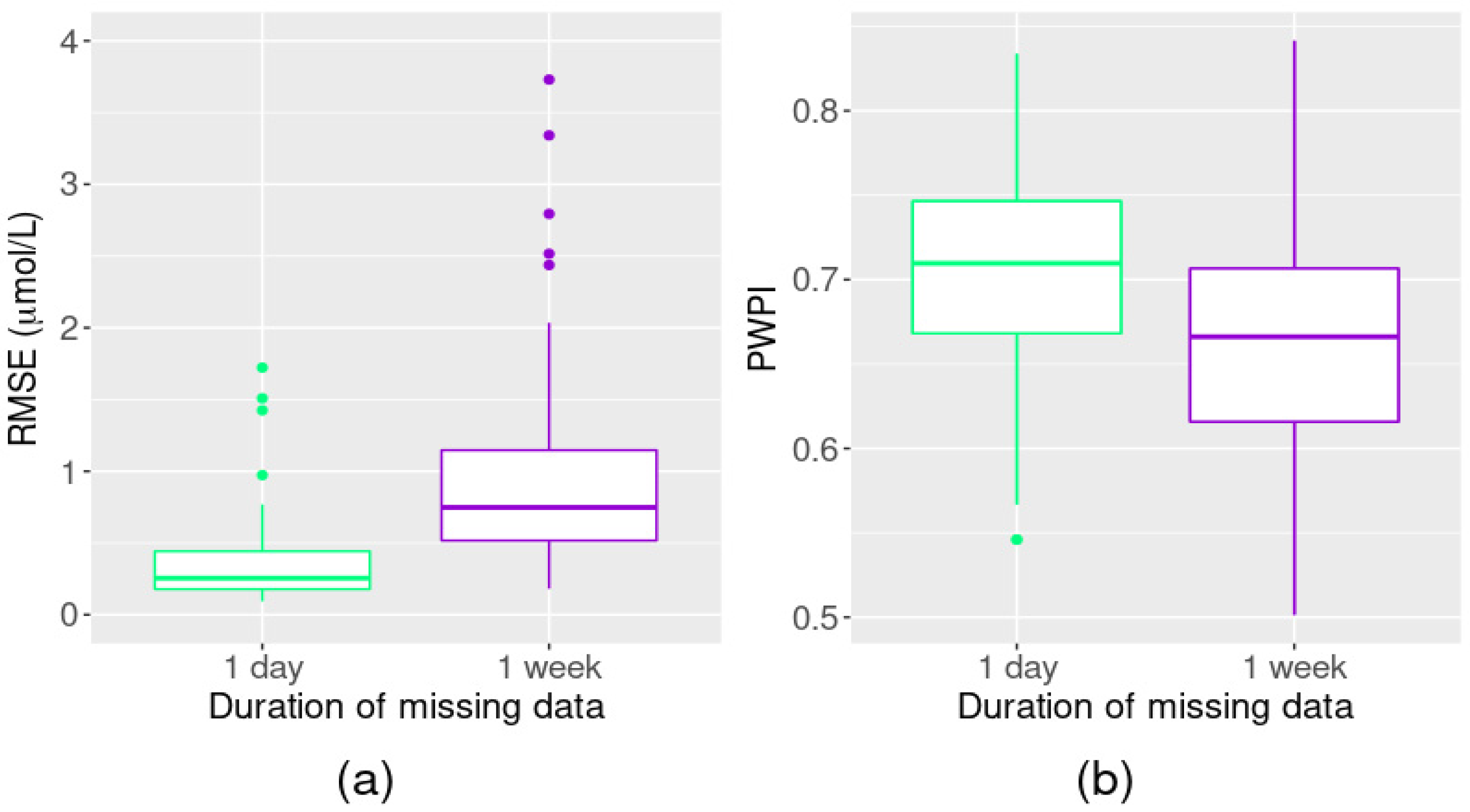
3.2.1. Simulations 1, 2, and 3: Missing Point Data
3.2.2. Simulations 4 and 5: Missing Sequences of Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Water-Quality Variable | Unit | Published Data Resolution | Published Interval (min) | Product Number |
|---|---|---|---|---|---|
| SUNA V2 | Nitrate | µmol/L | 0.1 | 15 | DP1.20033.001 |
| YSI EXO Optical Dissolved Oxygen | Dissolved oxygen | mg/L | 0.01 | 1 | DP1.20288.001 |
| Level TROLL 500 | Water elevation | masl | 0.01 | 5 | DP1.20016.001 |
| YSI EXO Turbidity | Turbidity | FNU | 0.01 | 1 | DP1.20288.001 |
| YSI EXO Conductivity and Temperature | Specific conductance | µS/cm | 0.01 | 1 | DP1.20288.001 |
| Platinum Resistance Thermometer | Water temperature | °C | 0.01 | 1 | DP1.20053.001 |
References
- Adu-Manu, K.S.; Tapparello, C.; Heinzelman, W.; Katsriku, F.; Abdulai, J.-D. Water Quality Monitoring Using Wireless Sensor Networks. ACM Trans. Sens. Netw. 2017, 13, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Katsriku, F.A.; Wilson, M.; Yamoah, G.G.; Abdulai, J.-D.; Rahman, B.M.A.; Grattan, K.T.V. Framework for Time Relevant Water Monitoring System; Springer: Singapore, 2015; pp. 3–19. [Google Scholar]
- Jones, A.S.; Horsburgh, J.; Reeder, S.L.; Ramírez, M.; Caraballo, J. A data management and publication workflow for a large-scale, heterogeneous sensor network. Environ. Monit. Assess. 2015, 187, 1–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, J.; Kim, K.T.; Lee, W.H. Recent Advances in Information and Communications Technology (ICT) and Sensor Technology for Monitoring Water Quality. Water 2020, 12, 510. [Google Scholar] [CrossRef] [Green Version]
- Cawley, K.M. NEON Algorithm Theoretical Basis Document (ATBD); Technical Report; National Ecological Observatory Network: Boulder, CO, USA, 2018. [Google Scholar]
- Pellerin, B.A.; Stauffer, B.A.; Young, D.A.; Sullivan, D.J.; Bricker, S.B.; Walbridge, M.R.; Clyde, G.A., Jr.; Shaw, D.M. Emerging tools for continuous nutrient monitoring networks: Sensors advancing science and water resources protection. J. Am. Water Resour. Assoc. 2016, 52, 993–1008. [Google Scholar] [CrossRef]
- Leigh, C.; Alsibai, O.; Hyndman, R.J.; Kandanaarachchi, S.; King, O.C.; McGree, J.M.; Neelamraju, C.; Strauss, J.; Talagala, P.D.; Turner, R.D.; et al. A framework for automated anomaly detection in high frequency water-quality data from in situ sensors. Sci. Total Environ. 2019, 664, 885–898. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodriguez-Perez, J.; Leigh, C.; Liquet, B.; Kermorvant, C.; Peterson, E.; Sous, D.; Mengersen, K. Detecting Technical Anomalies in High-Frequency Water-Quality Data Using Artificial Neural Networks. Environ. Sci. Technol. 2020, 54, 13719–13730. [Google Scholar] [CrossRef]
- Liu, J.; Wang, P.; Jiang, D.; Nan, J.; Zhu, W. An integrated data-driven framework for surface water quality anomaly detection and early warning. J. Clean. Prod. 2020, 251, 119145. [Google Scholar] [CrossRef]
- Shi, B.; Wang, P.; Jiang, J.; Liu, R. Applying high-frequency surrogate measurements and a wavelet-ANN model to provide early warnings of rapid surface water quality anomalies. Sci. Total Environ. 2018, 610–611, 1390–1399. [Google Scholar] [CrossRef]
- Batista, G.; Monard, M.C. An analysis of four missing data treatment methods for supervised learning. Appl. Artif. Intell. 2003, 17, 519–533. [Google Scholar] [CrossRef]
- Dong, Y.; Peng, C.-Y.J. Principled missing data methods for researchers. SpringerPlus 2013, 2, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Hannaford, J.; Buys, G. Trends in seasonal river flow regimes in the UK. J. Hydrol. 2012, 475, 158–174. [Google Scholar] [CrossRef] [Green Version]
- Helsel, D.R.; Hirsch, R.M. Statistical Methods in Water Resources; Elsevier: Amsterdam, The Netherlands, 1992; Volume 49. [Google Scholar]
- Slater, L.; Villarini, G. On the impact of gaps on trend detection in extreme streamflow time series. Int. J. Clim. 2017, 37, 3976–3983. [Google Scholar] [CrossRef] [Green Version]
- Hirsch, R.M. An evaluation of some record reconstruction techniques. Water Resour. Res. 1979, 15, 1781–1790. [Google Scholar] [CrossRef]
- Wallis, J.R.; Lettenmaier, D.P.; Wood, E. A daily hydroclimatological data set for the continental United States. Water Resour. Res. 1991, 27, 1657–1663. [Google Scholar] [CrossRef]
- Raman, H.; Mohan, S.; Padalinathan, P. Models for extending streamflow data: A case study. Hydrol. Sci. J. 1995, 40, 381–393. [Google Scholar] [CrossRef]
- Woodhouse, C.A.; Gray, S.T.; Meko, D.M. Updated streamflow reconstructions for the Upper Colorado River Basin. Water Resour. Res. 2006, 42, W05415. [Google Scholar] [CrossRef]
- Amisigo, B.A.; Van De Giesen, N.C. Using a spatio-temporal dynamic state-space model with the EM algorithm to patch gaps in daily riverflow series. Hydrol. Earth Syst. Sci. 2005, 9, 209–224. [Google Scholar] [CrossRef] [Green Version]
- Khalil, M.; Panu, U.; Lennox, W. Groups and neural networks based streamflow data infilling procedures. J. Hydrol. 2001, 241, 153–176. [Google Scholar] [CrossRef]
- Elshorbagy, A.; Simonovic, S.; Panu, U. Estimation of missing streamflow data using principles of chaos theory. J. Hydrol. 2002, 255, 123–133. [Google Scholar] [CrossRef]
- Coulibaly, P.; Baldwin, C.K. Nonstationary hydrological time series forecasting using nonlinear dynamic methods. J. Hydrol. 2005, 307, 164–174. [Google Scholar] [CrossRef]
- Harvey, C.L.; Dixon, H.; Hannaford, J. An appraisal of the performance of data-infilling methods for application to daily mean river flow records in the UK. Hydrol. Res. 2012, 43, 618–636. [Google Scholar] [CrossRef] [Green Version]
- Tencaliec, P.; Favre, A.-C.; Prieur, C.; Mathevet, T. Reconstruction of missing daily streamflow data using dynamic regression models. Water Resour. Res. 2015, 51, 9447–9463. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Zheng, F. Missing Data Reconstruction Using Adaptively Updated Dictionary in Wireless Sensor Networks. In Proceedings of the 7th International Conference on Computer Engineering and Networks—PoS(CENet2017), Sissa Medialab, Shanghai, China, 22–23 July 2017; Volume 299, p. 40. [Google Scholar]
- Pan, L.; Li, J. A multiple-regression-model-based missing values imputation algorithm in wireless sensor network. J. Comput. Res. Dev. 2009, 46, 2101. [Google Scholar]
- Wu, H.; Xian, J.; Wang, J.; Khandge, S.; Mohapatra, P. Missing data recovery using reconstruction in ocean wireless sensor networks. Comput. Commun. 2018, 132, 1–9. [Google Scholar] [CrossRef]
- Lee, C.-M.; Ko, C.-N. Time series prediction using RBF neural networks with a nonlinear time-varying evolution PSO algorithm. Neurocomputing 2009, 73, 449–460. [Google Scholar] [CrossRef]
- Jeong, S.; Ferguson, M.; Hou, R.; Lynch, J.P.; Sohn, H.; Law, K.H. Sensor data reconstruction using bidirectional recurrent neural network with application to bridge monitoring. Adv. Eng. Inform. 2019, 42, 100991. [Google Scholar] [CrossRef]
- Camargo, J.A.; Alonso, A.; Salamanca, A. Nitrate toxicity to aquatic animals: A review with new data for freshwater invertebrates. Chemosphere 2005, 58, 1255–1267. [Google Scholar] [CrossRef]
- Boesch, D.; Boynton, W.R.; Crowder, L.B.; Diaz, R.J.; Howarth, R.W.; Mee, L.D.; Nixon, S.W.; Rabalais, N.N.; Rosenberg, R.; Sanders, J.G.; et al. Nutrient Enrichment Drives Gulf of Mexico Hypoxia. Eos 2009, 90, 117–118. [Google Scholar] [CrossRef]
- Bricker, S.; Longstaff, B.; Dennison, W.; Jones, A.; Boicourt, K.; Wicks, C.; Woerner, J. Effects of nutrient enrichment in the nation’s estuaries: A decade of change. Harmful Algae 2008, 8, 21–32. [Google Scholar] [CrossRef]
- Camargo, J.; Ward, J. Nitrate (NO3-N) toxicity to aquatic life: A proposal of safe concentrations for two species of nearctic freshwater invertebrates. Chemosphere 1995, 31, 3211–3216. [Google Scholar] [CrossRef]
- Davidson, J.; Good, C.; Williams, C.; Summerfelt, S.T. Evaluating the chronic effects of nitrate on the health and performance of post-smolt Atlantic salmon Salmo salar in freshwater recirculation aquaculture systems. Aquac. Eng. 2017, 79, 1–8. [Google Scholar] [CrossRef]
- Moore, A.; Bringolf, R.B. Effects of nitrate on freshwater mussel glochidia attachment and metamorphosis success to the juvenile stage. Environ. Pollut. 2018, 242, 807–813. [Google Scholar] [CrossRef]
- Leigh, C.; Burford, M.A.; Connolly, R.M.; Olley, J.M.; Saeck, E.; Sheldon, F.; Smart, J.C.; Bunn, S.E. Science to Support Management of Receiving Waters in an Event-Driven Ecosystem: From Land to River to Sea. Water 2013, 5, 780–797. [Google Scholar] [CrossRef] [Green Version]
- O’Brien, K.R.; Weber, T.R.; Leigh, C.; Burford, M. Sediment and nutrient budgets are inherently dynamic: Evidence from a long-term study of two subtropical reservoirs. Hydrol. Earth Syst. Sci. 2016, 20, 4881–4894. [Google Scholar] [CrossRef] [Green Version]
- Fisher, S.G.; Grimm, N.B.; Martí, E.; Holmes, R.M.; Jones, J.J.B. Material Spiraling in Stream Corridors: A Telescoping Ecosystem Model. Ecosystems 1998, 1, 19–34. [Google Scholar] [CrossRef]
- Wood, S.N. Generalized Additive Models: An Introduction with R; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Sakamoto, Y.; Ishiguro, M.; Kitagawa, G. Akaike Information Criterion Statistics; D. Reidel: Dordrecht, The Netherlands, 1986. [Google Scholar] [CrossRef]
- Box, G.E.P.; Pierce, D.A. Distribution of Residual Autocorrelations in Autoregressive-Integrated Moving Average Time Series Models. J. Am. Stat. Assoc. 1970, 65, 1509–1526. [Google Scholar] [CrossRef]
- Vance, J.; Nance, B.; Monahan, D.; Mahal, M.; Cavileer, M. NEON Preventive Maintenance Procedure: AIS Surface Water Quality Multisonde. NEON.DOC.001569 Revision: B, Technical Report, National Ecological Observatory Network 2019. Available online: http://data.neonscience.org/documents (accessed on 4 December 2021).
- Willingham, R.; Cavileer, M.; Csavina, J.; Monahan, D. NEON Preventive Maintenance Procedure: Submersible Ultraviolet Nitrate analyzer. NEON.DOC.002716 Revision: B, Technical Report, National Ecological Observatory Network 2019. Available online: http://data.neonscience.org/documents (accessed on 4 December 2021).
- Cawley, K.M. NEON Aquatic Sampling Strategy, Technical Report, National Ecological Observatory Network 2016. Available online: http://data.neonscience.org/documents (accessed on 4 December 2021).
- NEON, Nitrate in Surface Water (DP1.20033.001) (2021). Available online: https://data.neonscience.org/data-products/DP1.20033.001/RELEASE-2021 (accessed on 4 December 2021). [CrossRef]
- NEON, Water Quality (DP1.20288.001) (2021). Available online: https://data.neonscience.org/data-products/DP1.20288.001/RELEASE-2021 (accessed on 4 December 2021). [CrossRef]
- NEON, Temperature (PRT) in Surface Water (DP1.20053.001) (2021). Available online: https://data.neonscience.org/data-products/DP1.20053.001/RELEASE-2021 (accessed on 4 December 2021). [CrossRef]
- NEON, Elevation of Surface Water (DP1.20016.001) (2021). Available online: https://data.neonscience.org/data-products/DP1.20016.001/RELEASE-2021 (accessed on 4 December 2021). [CrossRef]
- Leigh, C.; Kandanaarachchi, S.; McGree, J.M.; Hyndman, R.J.; Alsibai, O.; Mengersen, K.; Peterson, E.E. Predicting sediment and nutrient concentrations from high-frequency water-quality data. PLoS ONE 2019, 14, e0215503. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. Ser. B 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Ratnasingham, S.; Hebert, P.D. BOLD: The Barcode of Life Data System (http://www.barcodinglife.org). Mol. Ecol. Notes 2007, 7, 355–364. [Google Scholar] [CrossRef] [Green Version]
- Fox, J.; Weisberg, S.D.; Adler, D.; Bates, D.; Baud-Bovy, G.; Ellison, S. Package ‘car’; R Foundation for Statistical Computing: Vienna, Austria, 2012. [Google Scholar]
- Hastie, T. Gam: Generalized Additive Models, R Package Version 1.20. 2020. Available online: https://CRAN.R-project.org/package=gam (accessed on 4 December 2021).
- Wickham, H.; Chang, W. Ggplot2: An Implementation of the Grammar of Graphics. R Package Version 0.7. Available online: http://CRAN.R-project.org/package=ggplot2 (accessed on 10 September 2021).
- Taylor, J.; Street, S.; Sturtevant, C. NEON Algorithm Theoretical Basis Document (ATBD): QA/QC Plausibility Testing. NEON.DOC.011081 Revision: C, Technical Report, National Ecological Observatory Network 2020. Available online: https://data.neonscience.org/api/v0/documents/NEON.DOC.011081vC (accessed on 4 December 2021).
- Langhammer, J.; Česák, J. Applicability of a Nu-Support Vector Regression Model for the Completion of Missing Data in Hydrological Time Series. Water 2016, 8, 560. [Google Scholar] [CrossRef] [Green Version]
- Jones, T.L.; Jones, A.S. Horsburgh, toward automating post processing of aquatic sensor data. Earth Archiv. Prepr. 2021. [Google Scholar] [CrossRef]
- Kermorvant, B.; Liquet, G.; Litt, K.; Mengersen, E.E.; Peterson, R.; Hyndman, J.B.; Jones, C., Jr. Understanding links between water-quality variables and nitrate concentration in freshwater streams using high-frequency sensor data. arXiv 2021, arXiv:2106.01719. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kermorvant, C.; Liquet, B.; Litt, G.; Jones, J.B.; Mengersen, K.; Peterson, E.E.; Hyndman, R.J.; Leigh, C. Reconstructing Missing and Anomalous Data Collected from High-Frequency In-Situ Sensors in Fresh Waters. Int. J. Environ. Res. Public Health 2021, 18, 12803. https://doi.org/10.3390/ijerph182312803
Kermorvant C, Liquet B, Litt G, Jones JB, Mengersen K, Peterson EE, Hyndman RJ, Leigh C. Reconstructing Missing and Anomalous Data Collected from High-Frequency In-Situ Sensors in Fresh Waters. International Journal of Environmental Research and Public Health. 2021; 18(23):12803. https://doi.org/10.3390/ijerph182312803
Chicago/Turabian StyleKermorvant, Claire, Benoit Liquet, Guy Litt, Jeremy B. Jones, Kerrie Mengersen, Erin E. Peterson, Rob J. Hyndman, and Catherine Leigh. 2021. "Reconstructing Missing and Anomalous Data Collected from High-Frequency In-Situ Sensors in Fresh Waters" International Journal of Environmental Research and Public Health 18, no. 23: 12803. https://doi.org/10.3390/ijerph182312803