
A Comparative Study of Natural Language Processing Algorithms Based on Cities Changing Diabetes Vulnerability Data


Abstract
:1. Introduction
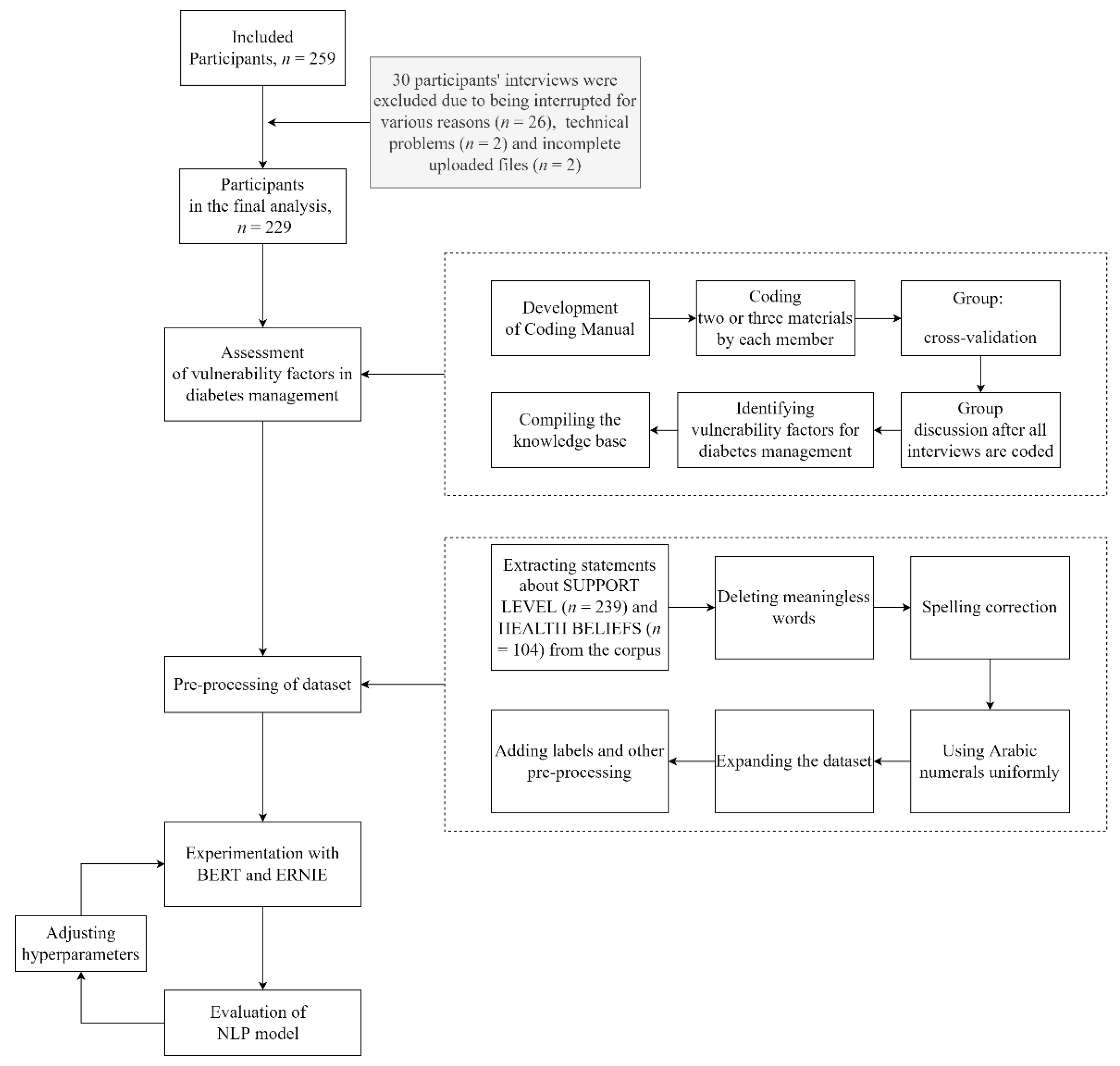
2. Materials and Methods
2.1. Literature Review
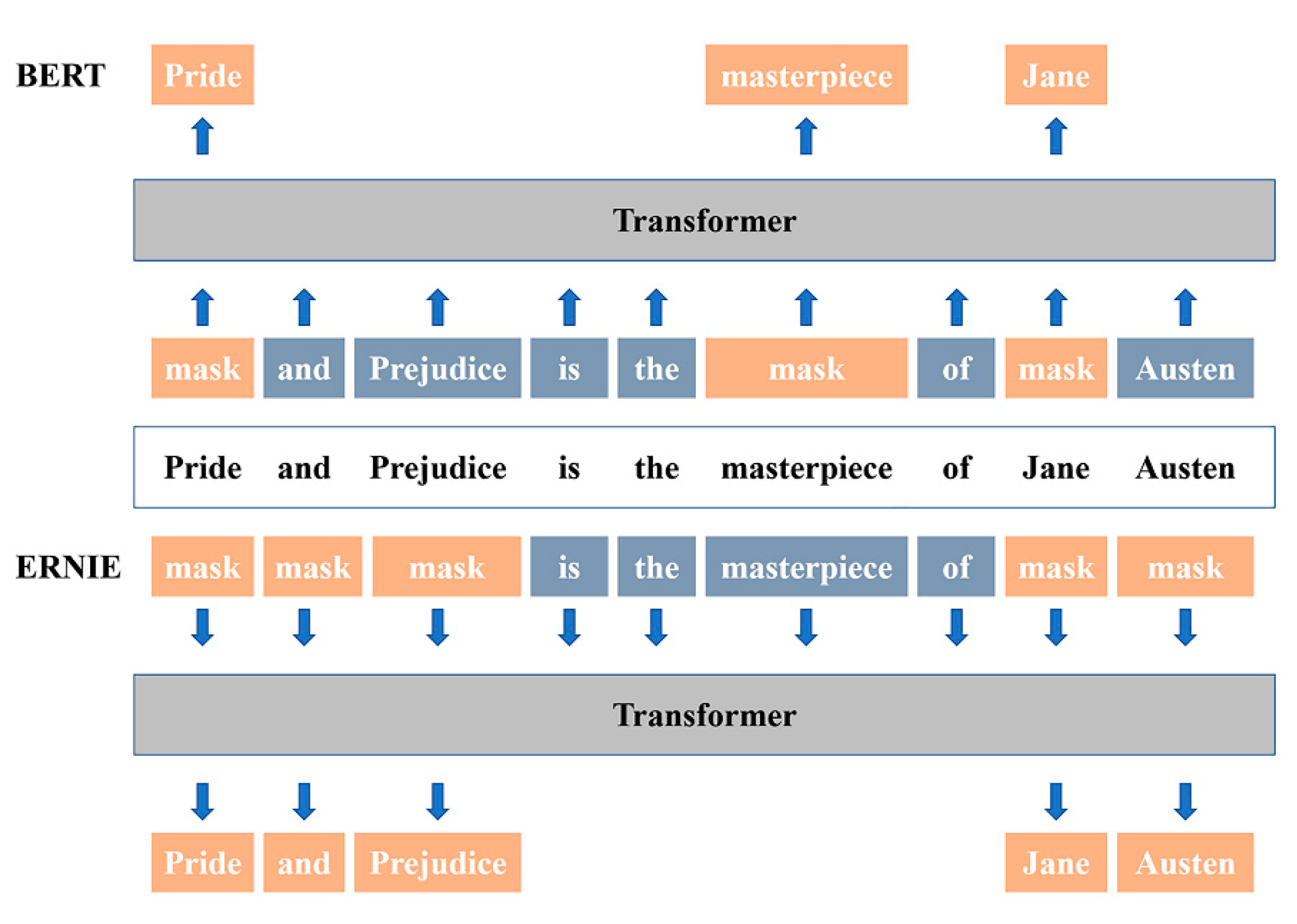
2.2. Bidirectional Encoder Representation from Transformers (BERT)
2.3. Enhanced Language Representation with Informative Entities (ERNIE)
2.4. Data Source
2.5. Pre-Processing of the Dataset
2.6. Experimental Setting
2.7. Model Evaluation
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, H.; Saeedi, P.; Karuranga, S.; Pinkepank, M.; Ogurtsova, K.; Duncan, B.B.; Stein, C.; Basit, A.; Chan, J.C.N.; Mbanya, J.C.; et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res. Clin. Pract. 2022, 183, 109119. [Google Scholar] [CrossRef] [PubMed]
- Heald, A.H.; Stedman, M.; Davies, M.; Livingston, M.; Alshames, R.; Lunt, M.; Rayman, G.; Gadsby, R. Estimating life years lost to diabetes: Outcomes from analysis of National Diabetes Audit and Office of National Statistics data. Cardiovasc. Endocrinol. Metab. 2020, 9, 183–185. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Ji, J.; Wang, Y.; Gu, H.F. Association of the Haze and Diabetes in China. Curr. Diabetes Rev. 2021, 17, 11–20. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Liu, T.; Yuan, X.; Ge, S.; Yang, J.; Li, C.; Sun, W. Factors Influencing Self-Management in Chinese Adults with Type 2 Diabetes: A Systematic Review and Meta-Analysis. Int. J. Environ. Res. Public Health 2015, 12, 11304–11327. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.H.; Yuan, L.; Lou, Q.Q.; Shen, L.; Sun, Z.L.; Zhao, F.; Dai, X.; Huang, J.; Yang, H.Y.; Chinese Diabetes Education Status Survey Study Group. A nationwide survey of diabetes education, self-management and glycemic control in patients with type 2 diabetes in China. Chin. Med. J. 2012, 125, 4175–4180. [Google Scholar]
- Chapman, A.; Yang, H.; Thomas, S.A.; Searle, K.; Browning, C. Barriers and enablers to the delivery of psychological care in the management of patients with type 2 diabetes mellitus in China: A qualitative study using the theoretical domains framework. BMC Health Serv. Res. 2016, 16, 106. [Google Scholar] [CrossRef] [Green Version]
- Bhojani, U.; Mishra, A.; Amruthavalli, S.; Devadasan, N.; Kolsteren, P.; De Henauw, S.; Criel, B. Constraints faced by urban poor in managing diabetes care: Patients’ perspectives from South India. Glob. Health Action 2013, 6, 22258. [Google Scholar] [CrossRef] [Green Version]
- Inzucchi, S.E.; Bergenstal, R.M.; Buse, J.B.; Diamant, M.; Ferrannini, E.; Nauck, M.; Peters, A.L.; Tsapas, A.; Wender, R.; Matthews, D.R. Management of hyperglycemia in type 2 diabetes, 2015: A patient-centered approach: Update to a position statement of the American Diabetes Association and the European Association for the Study of Diabetes. Diabetes Care 2015, 38, 140–149. [Google Scholar] [CrossRef] [Green Version]
- Rawlings, G.H.; Brown, I.; Stone, B.; Reuber, M. Written accounts of living with epilepsy: A thematic analysis. Epilepsy Behav. 2017, 72, 63–70. [Google Scholar] [CrossRef]
- Yamada, M.; Saito, Y.; Imaoka, H.; Saiko, M.; Yamada, S.; Kondo, H.; Takamaru, H.; Sakamoto, T.; Sese, J.; Kuchiba, A.; et al. Development of a real-time endoscopic image diagnosis support system using deep learning technology in colonoscopy. Sci. Rep. 2019, 9, 14465. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Beard, E.J.; Sivaraman, G.; Vazquez-Mayagoitia, A.; Vishwanath, V.; Cole, J.M. Comparative dataset of experimental and computational attributes of UV/vis absorption spectra. Sci. Data 2019, 6, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Turchin, A.; Florez Builes, L.F. Using Natural Language Processing to Measure and Improve Quality of Diabetes Care: A Systematic Review. J. Diabetes Sci. Technol. 2021, 15, 553–560. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Wang, Y.; Hao, S.; Shin, A.Y.; Jin, B.; Ngo, A.D.; Jackson-Browne, M.S.; Feller, D.J.; Fu, T.; Zhang, K.; et al. Web-based Real-Time Case Finding for the Population Health Management of Patients With Diabetes Mellitus: A Prospective Validation of the Natural Language Processing-Based Algorithm With Statewide Electronic Medical Records. JMIR Med. Inform. 2016, 4, e37. [Google Scholar] [CrossRef]
- Upadhyaya, S.G.; Murphree, D.H., Jr.; Ngufor, C.G.; Knight, A.M.; Cronk, D.J.; Cima, R.R.; Curry, T.B.; Pathak, J.; Carter, R.E.; Kor, D.J. Automated Diabetes Case Identification Using Electronic Health Record Data at a Tertiary Care Facility. Mayo Clin. Proc. Innov. Qual. Outcomes 2017, 1, 100–110. [Google Scholar] [CrossRef] [Green Version]
- Topaz, M.; Murga, L.; Grossman, C.; Daliyot, D.; Jacobson, S.; Rozendorn, N.; Zimlichman, E.; Furie, N. Identifying Diabetes in Clinical Notes in Hebrew: A Novel Text Classification Approach Based on Word Embedding. Stud. Health Technol. Inform. 2019, 264, 393–397. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Cambridge, MA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Chen, N.; Su, X.; Liu, T.; Hao, Q.; Wei, M. A benchmark dataset and case study for Chinese medical question intent classification. BMC Med. Inform. Decis. Mak. 2020, 20, 125. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Grave, E.; Sklar, E.; Elhadad, N. Longitudinal analysis of discussion topics in an online breast cancer community using convolutional neural networks. J. Biomed. Inform. 2017, 69, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. arXiv 2016, arXiv:1605.05101v1. [Google Scholar]
- Chowdhury, S.; Dong, X.; Qian, L.; Li, X.; Guan, Y.; Yang, J.; Yu, Q. A multitask bi-directional RNN model for named entity recognition on Chinese electronic medical records. BMC Bioinform. 2018, 19, 499. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Kim, Y.M.; Lee, T.H. Korean clinical entity recognition from diagnosis text using BERT. BMC Med. Inform. Decis. Mak. 2020, 20, 242. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Jin, Z.; Mao, C.; Zhang, Y.; Luo, Y. Traditional Chinese medicine clinical records classification with BERT and domain specific corpora. J. Am. Med. Inform. Assoc. 2019, 26, 1632–1636. [Google Scholar] [CrossRef] [PubMed]
- Zong, H.; Yang, J.; Zhang, Z.; Li, Z.; Zhang, X. Semantic categorization of Chinese eligibility criteria in clinical trials using machine learning methods. BMC Med. Inform. Decis. Mak. 2021, 21, 128. [Google Scholar] [CrossRef]
- Guo, S.; Wang, Q. Application of Knowledge Distillation Based on Transfer Learning of ERNIE Model in Intelligent Dialogue Intention Recognition. Sensors 2022, 22, 1270. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. ERNIE: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Li, Z.; Ren, J. Fine-tuning ERNIE for chest abnormal imaging signs extraction. J. Biomed. Inform. 2020, 108, 103492. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Kelley, D.R. Cross-species regulatory sequence activity prediction. Plos. Comput. Biol. 2020, 16, e1008050. [Google Scholar] [CrossRef]
- Stewart, C.E.; Kan, C.F.K.; Stewart, B.R.; Sanicola, H.W., 3rd; Jung, J.P.; Sulaiman, O.A.R.; Wang, D. Machine intelligence for nerve conduit design and production. J. Biol. Eng. 2020, 14, 25. [Google Scholar] [CrossRef] [PubMed]
- Bootle, S.; Skovlund, S.E.; Editorial Group of the 5th DAWN International Summit. Proceedings of the 5th International DAWN Summit 2014: Acting together to make person-centred diabetes care a reality. Diabetes Res. Clin. Pract. 2015, 109, 6–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Janjic, P.; Petrovski, K.; Dolgoski, B.; Smiley, J.; Zdravkovski, P.; Pavlovski, G.; Jakjovski, Z.; Davceva, N.; Poposka, V.; Stankov, A.; et al. Measurement-oriented deep-learning workflow for improved segmentation of myelin and axons in high-resolution images of human cerebral white matter. J. Neurosci. Methods 2019, 326, 108373. [Google Scholar] [CrossRef] [PubMed]
- Zeng, K.; Pan, Z.; Xu, Y.; Qu, Y. An Ensemble Learning Strategy for Eligibility Criteria Text Classification for Clinical Trial Recruitment: Algorithm Development and Validation. JMIR Med. Inform. 2020, 8, e17832. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Lu, S.; Lu, C. Exploring and Monitoring the Reasons for Hesitation with COVID-19 Vaccine Based on Social-Platform Text and Classification Algorithms. Healthcare 2021, 9, 1353. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Case Filter | Definition |
|---|---|
| High BMI | BMI > 28 kg/m2 |
| High blood glucose levels | FBG > 6.1 mmol/L, 2 h PBG > 7.8 mmol/L |
| Duration if diabetes/comorbidities | Have co-morbidities |
| Health insurance | No worker basic insurance, urban basic insurance or commercial health insurance |
| Employment status | Unemployment |
| Below poverty level | For urban residents, the per capita income is less than 705 Yuan, for rural residents, the per capita income is less than 540 Yuan |
| Body size and physical characteristics | Waistline: male ≥ 90 cm, female ≥ 85 cm |
| Distance between home and work | ≥16 km |
| Education background | Primary and illiteracy |
| Physical activity level | Low (civil service, no exercise, etc.) |
| Themes | Factors |
|---|---|
| Financial constraints | Low income |
| Unemployment | |
| No medical insurance/Low reimbursement ratio | |
| Significant family expenditure | |
| Severity of disease | Appear symptoms, complications, comorbidities Poor disease control |
| Health literacy | Low literacy |
| Health beliefs | Perceived diabetes indifferently |
| Acquire health knowledge passively | |
| Distrust of primary health services | |
| Medical environment | Needs not met by medical services |
| Life restriction | Limited daily life behaviors |
| Occupational restriction | |
| Lifestyle change | Adherence to the traditional or unhealthy diet |
| Lack of exercise | |
| Low-quality sleep | |
| Time poverty | Healthcare seeking behaviors were limited by work/taking care of family issues |
| Mental condition | Appearance of negative emotions towards diabetes treatment or life |
| Support Level | Lack of community support |
| Lack of support from friends and family | |
| Lack of social support | |
| Social integration | Low degree of social integration |
| Faith in suffering alone | |
| Experience of transitions | Diet transformation |
| Dwelling Environment/Place of residence transformation |
| Hyperparameters | Value |
|---|---|
| Hidden Size | 768 |
| Learning Rate | 5 × 10−5 |
| Pad Size | 16 |
| Require Improvement | 1000 |
| Epoch | 100 |
| Batch Size | 32 |
| Splitting Ratio | Class | Training Set | Validation Set | Testing Set |
|---|---|---|---|---|
| 8:1:1 | HEALTH BELIEFS | 316 (30.41%) | 43 (32.82%) | 41 (31.78%) |
| SUPPORT LEVEL | 723 (79.54%) | 88 (67.18%) | 88 (68.22%) | |
| 7:2:1 | HEALTH BELIEFS | 282 (31.02%) | 78 (30.12%) | 40 (30.53%) |
| SUPPORT LEVEL | 627 (68.98%) | 181 (69.88%) | 91 (69.47%) | |
| 6:3:1 | HEALTH BELIEFS | 240 (30.81%) | 112 (28.79%) | 48 (36.64%) |
| SUPPORT LEVEL | 539 (69.19%) | 277 (71.21%) | 83 (63.36%) |
| Name | Batch Size | Splitting Ratio | Test Acc (%) | Completion Time |
|---|---|---|---|---|
| BERT | 32 | 8:1:1 | 96.12 | 0:07:38 |
| 7:2:1 | 96.95 | 0:07:46 | ||
| 6:3:1 | 96.18 | 0:09:27 | ||
| 64 | 8:1:1 | 97.67 | 0:09:29 | |
| 7:2:1 | 96.18 | 0:09:43 | ||
| 6:3:1 | 97.71 | 0:10:24 | ||
| ERNIE | 32 | 8:1:1 | 97.67 | 0:35:36 |
| 7:2:1 | 97.71 | 0:48:31 | ||
| 6:3:1 | 96.95 | 1:29:05 | ||
| 64 | 8:1:1 | 97.67 | 0:12:36 | |
| 7:2:1 | 96.18 | 0:10:16 | ||
| 6:3:1 | 95.42 | 0:08:45 |
| Name | Batch Size | Splitting Ratio | Class | Precision | Recall | F1 | Macro-F1 |
|---|---|---|---|---|---|---|---|
| BERT | 32 | 8:1:1 | HEALTH BELIEFS | 0.9663 | 0.9773 | 0.9718 | 0.9551 |
| SUPPORT LEVEL | 0.9500 | 0.9268 | 0.9383 | ||||
| 7:2:1 | HEALTH BELIEFS | 0.9677 | 0.9890 | 0.9783 | 0.9635 | ||
| SUPPORT LEVEL | 0.9737 | 0.9250 | 0.9487 | ||||
| 6:3:1 | HEALTH BELIEFS | 0.9432 | 1.0000 | 0.9708 | 0.9580 | ||
| SUPPORT LEVEL | 1.0000 | 0.8958 | 0.9451 | ||||
| 64 | 8:1:1 | HEALTH BELIEFS | 0.9885 | 0.9773 | 0.9829 | 0.9734 | |
| SUPPORT LEVEL | 0.9524 | 0.9756 | 0.9639 | ||||
| 7:2:1 | HEALTH BELIEFS | 0.9886 | 0.9560 | 0.9721 | 0.9560 | ||
| SUPPORT LEVEL | 0.9070 | 0.9750 | 0.9398 | ||||
| 6:3:1 | HEALTH BELIEFS | 0.9762 | 0.9880 | 0.9820 | 0.9752 | ||
| SUPPORT LEVEL | 0.9787 | 0.9583 | 0.9684 | ||||
| ERNIE | 32 | 8:1:1 | HEALTH BELIEFS | 0.9885 | 0.9773 | 0.9829 | 0.9734 |
| SUPPORT LEVEL | 0.9524 | 0.9756 | 0.9639 | ||||
| 7:2:1 | HEALTH BELIEFS | 0.9783 | 0.9890 | 0.9836 | 0.9728 | ||
| SUPPORT LEVEL | 0.9744 | 0.9500 | 0.9620 | ||||
| 6:3:1 | HEALTH BELIEFS | 0.9759 | 0.9759 | 0.9759 | 0.9671 | ||
| SUPPORT LEVEL | 0.9583 | 0.9583 | 0.9583 | ||||
| 64 | 8:1:1 | HEALTH BELIEFS | 0.9885 | 0.9773 | 0.9829 | 0.9734 | |
| SUPPORT LEVEL | 0.9524 | 0.9756 | 0.9639 | ||||
| 7:2:1 | HEALTH BELIEFS | 0.9574 | 0.9890 | 0.9730 | 0.9541 | ||
| SUPPORT LEVEL | 0.9730 | 0.9000 | 0.9351 | ||||
| 6:3:1 | HEALTH BELIEFS | 0.9529 | 0.9759 | 0.9643 | 0.9503 | ||
| SUPPORT LEVEL | 0.9565 | 0.9167 | 0.9362 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Song, F.; Qiao, Q.; Liu, Y.; Chen, J.; Ma, J. A Comparative Study of Natural Language Processing Algorithms Based on Cities Changing Diabetes Vulnerability Data. Healthcare 2022, 10, 1119. https://doi.org/10.3390/healthcare10061119
Wang S, Song F, Qiao Q, Liu Y, Chen J, Ma J. A Comparative Study of Natural Language Processing Algorithms Based on Cities Changing Diabetes Vulnerability Data. Healthcare. 2022; 10(6):1119. https://doi.org/10.3390/healthcare10061119
Chicago/Turabian StyleWang, Siting, Fuman Song, Qinqun Qiao, Yuanyuan Liu, Jiageng Chen, and Jun Ma. 2022. "A Comparative Study of Natural Language Processing Algorithms Based on Cities Changing Diabetes Vulnerability Data" Healthcare 10, no. 6: 1119. https://doi.org/10.3390/healthcare10061119