1. Introduction
Accurate information about forest stands is one of the keys to successful forest management and for efficient wood supply to the forest industry. Modern planning tools, such as the Heureka system [
1], can be applied to support decision making in forestry. These tools rely on accurate information about the stands in the target forest area and have the potential to provide solutions to the spatiotemporal planning problem that go beyond what can be achieved by human intuition [
2].
Traditionally in many countries, stand-level forest information has been collected through recurrent campaigns. That is, every 10–20 years data have been collected in the field from all stands in a forest holding in order to update the information. However, the transfer to digital databases in combination with the increasing flow of low-cost data that are becoming regularly provided through remote sensing motivates a shift towards continuous updating. Several new remote sensing techniques are emerging, and we are entering an unprecedented era of information richness. Modern 3D remote sensing techniques like point clouds from laser scanning [
3] and stereo-view image matching of digital aerial images (denoted “image matching”) [
4] are being rapidly developed and applied. Digital aerial images are regularly acquired in many countries, and it has recently been shown that point clouds from aerial images can be used to estimate canopy heights and correlated variables with good accuracy [
5,
6,
7,
8]. In a similar way, accurate forest height estimates can be obtained frequently from interferometric SAR data [
9,
10] as well as from radargrammetry [
11]. This remote sensing development might imply a paradigm shift regarding how information is collected and compiled for purposes of forest management planning.
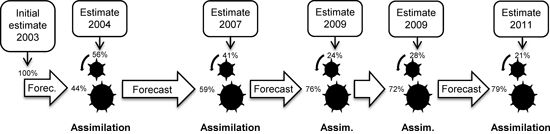
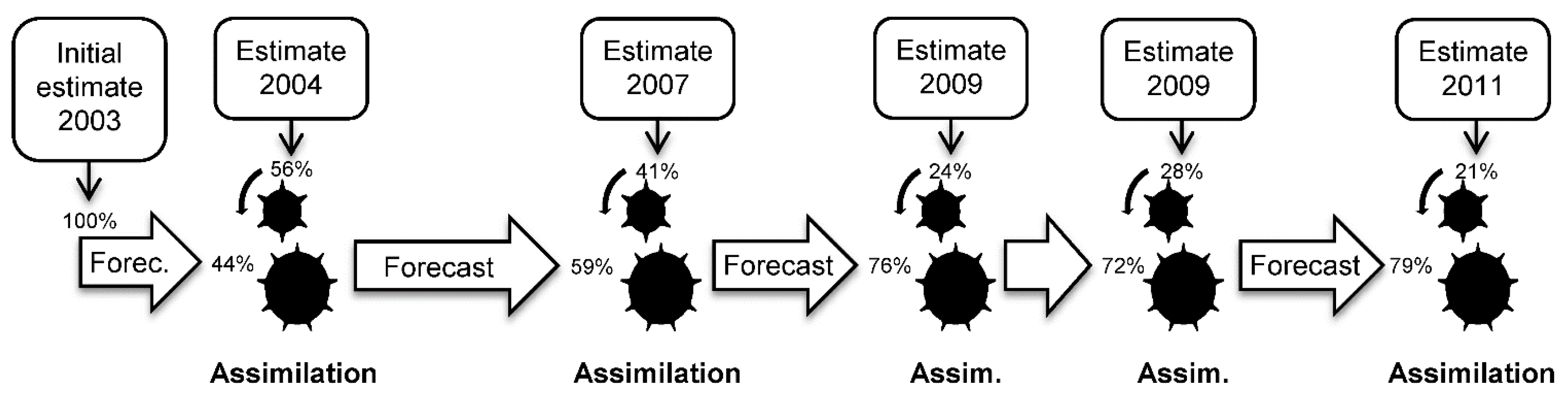
Data assimilation can be used to continuously combine models and new sensor data in an optimal way, offering great potential for making use of new sources of forest information. Existing information about a forest area is forecasted using a model that provides an estimate for the date of the next data acquisition and an estimate of the precision of the forecasted information. Thus, the precision of the forecasted information can be compared with the precision of the new information. In the assimilation step, the two sources of information are combined through weights that are inversely proportional to their uncertainties (
Figure 1). The combined estimate is then forecasted to the time-point of the next data acquisition, and repeated when new data become available.
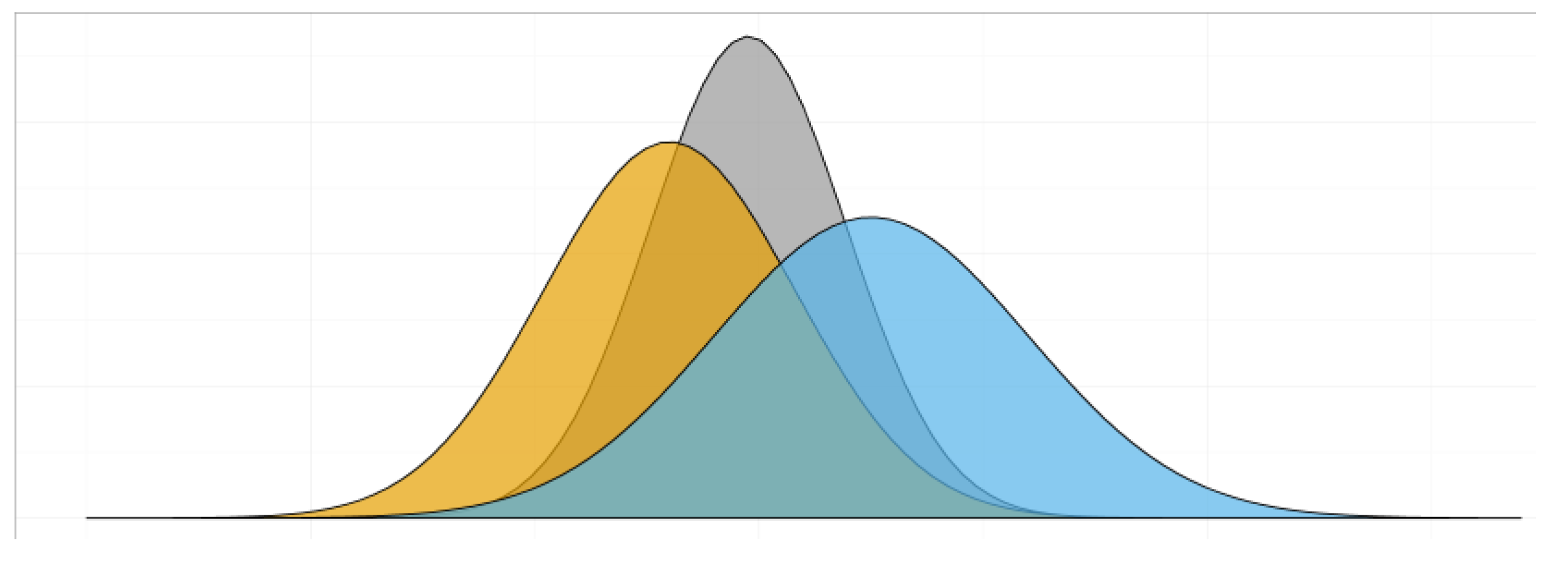
Figure 1.
An illustration of the basic principle of data assimilation applied to a Gaussian model and estimate. The figure shows how the prior forecast (the center of the orange distribution) is updated to the posterior forecast (the center of the grey distribution) when a new estimate (the center of the blue distribution) is taken into account. Notice that the grey distribution is narrower than the orange distribution, indicating that the posterior forecast is more precise (i.e., the estimate has lower variance) than the prior forecast.
Figure 1.
An illustration of the basic principle of data assimilation applied to a Gaussian model and estimate. The figure shows how the prior forecast (the center of the orange distribution) is updated to the posterior forecast (the center of the grey distribution) when a new estimate (the center of the blue distribution) is taken into account. Notice that the grey distribution is narrower than the orange distribution, indicating that the posterior forecast is more precise (i.e., the estimate has lower variance) than the prior forecast.
The success of data assimilation in areas such as meteorology is well documented [
12]. Data assimilation of time series of satellite data has also been used in research studies for calibration of physical models of ecosystem functions [
13]. Such models typically produce estimates of ecosystem variables such as gross primary production, net primary production and ecosystem respiration [
14]. Data assimilation techniques have also been proposed for operational forest inventory [
15,
16,
17,
18], but we are not aware of any previous data assimilation studies where estimates like those usually produced and employed for forest management planning have been made using real data.
However, in order to realize the potential in the context of forest inventory and management, the data assimilation techniques need to be adapted to this field of application. This involves development of new growth models from which not only growth predictions can be made but also the uncertainty of those models can be ascertained. All new estimates from remote sensing or field surveys should be used to adjust the forecasted forest information to the extent motivated by the uncertainties of the new estimates as compared to the uncertainties of the forecasts. Thus, through data assimilation, forest planning would benefit from having up-to-date and accurate information available as input to its different planning processes, from long-term strategic planning to short-term optimization of the value chains linking forests with forest industry.
Two common approaches to data assimilation are Kalman filtering [
19] and Bayesian methods [
20]. Kalman filters assume that the errors of the forecasts and the new measurements based on sensor data are normally distributed whereas Bayesian methods can handle any distribution of errors. In the basic setting, the Kalman filter assumes linear forecasting models, so that the variance of forecasted variables can be calculated without approximation. However, several further developments of the Kalman filter are available as well, such as the extended Kalman filter which uses a Taylor approximation to linearize non-linear prediction models. Bayesian methods assume the true state to be a random variable and predict entire joint probability distributions of the variables of interest.
In a previous simulation study made by our research group [
15], several challenges for applying data assimilation to forest information were identified. These included non-linear growth models, temporal correlation of errors from growth models, poorly known uncertainty of estimates, spatiotemporally correlated inventory errors, and the need in some cases to handle discrete data, such as individual trees within description units. Thus, any future system for data assimilation in forestry would need to be developed through a series of research studies where the different challenges are addressed.
The objective of the present study was to present our first empirical results of the application of data assimilation to forest stand data. In our previous study [
15], the results were based on theoretical assumptions and the article provided case examples of the potential benefits of applying data assimilation. In the present study, we applied the data assimilation technique to empirical estimates based on point clouds from image matching from six time-points obtained over an eight year period (2003–2011) calibrated with forest estimates from circular field plots. Estimates were compiled for three variables: stem volume (V), basal area (BA) and Lorey’s mean height (H
L). Data assimilation using the extended Kalman filter was compared to two methods used in practice for estimation of forest variables: (i) estimates of the target variables using point clouds from image matching from the most recent time-point (denoted “most recent estimate”) and (ii) forecasting the stand development with growth models from the initial state estimate (denoted “forecast”).
3. Results and Discussion
The initial state (2003) was estimated from point clouds obtained from image matching. The validation was made with field data for the 40 m radius validation plots reflecting the state in 2011.
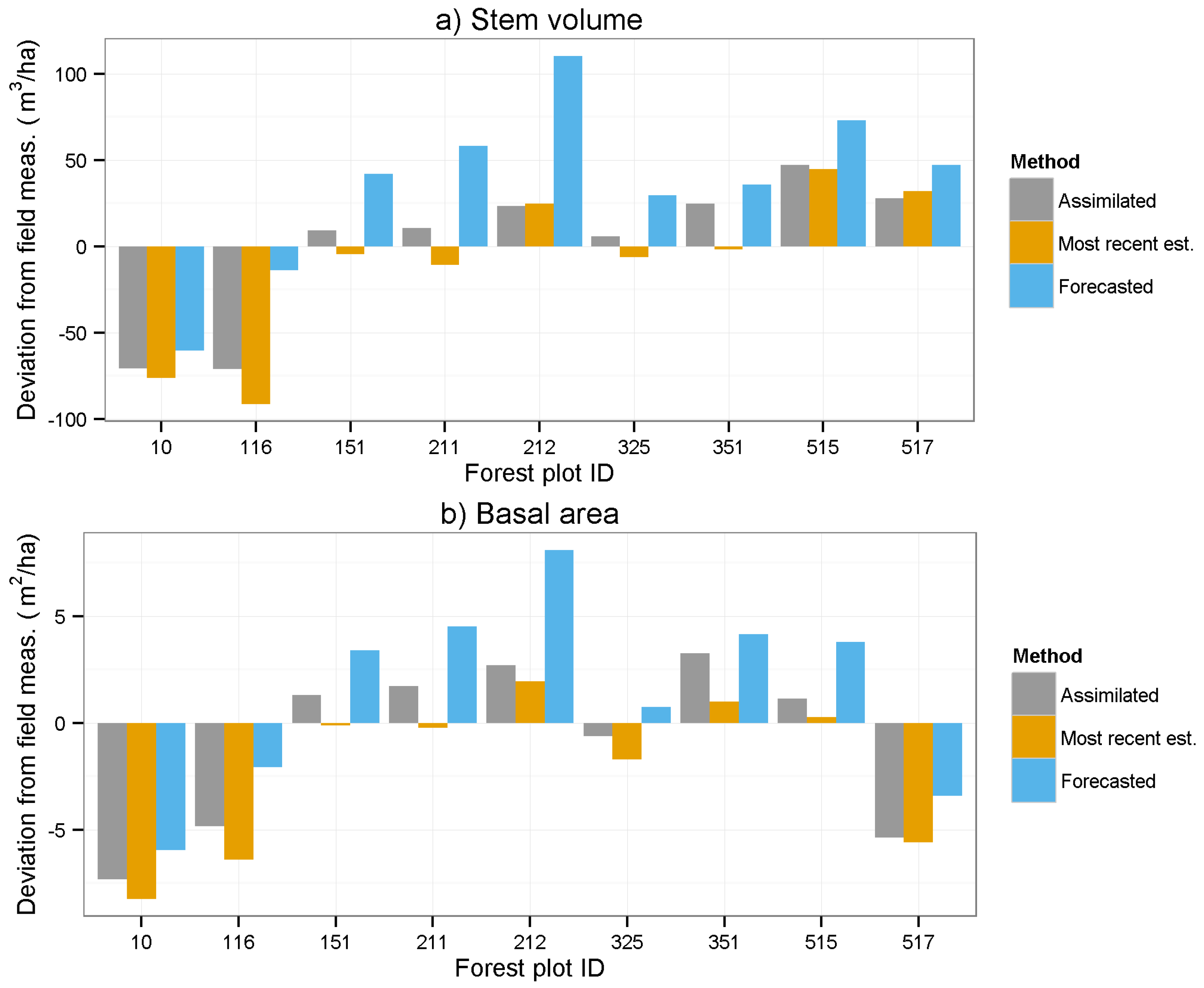
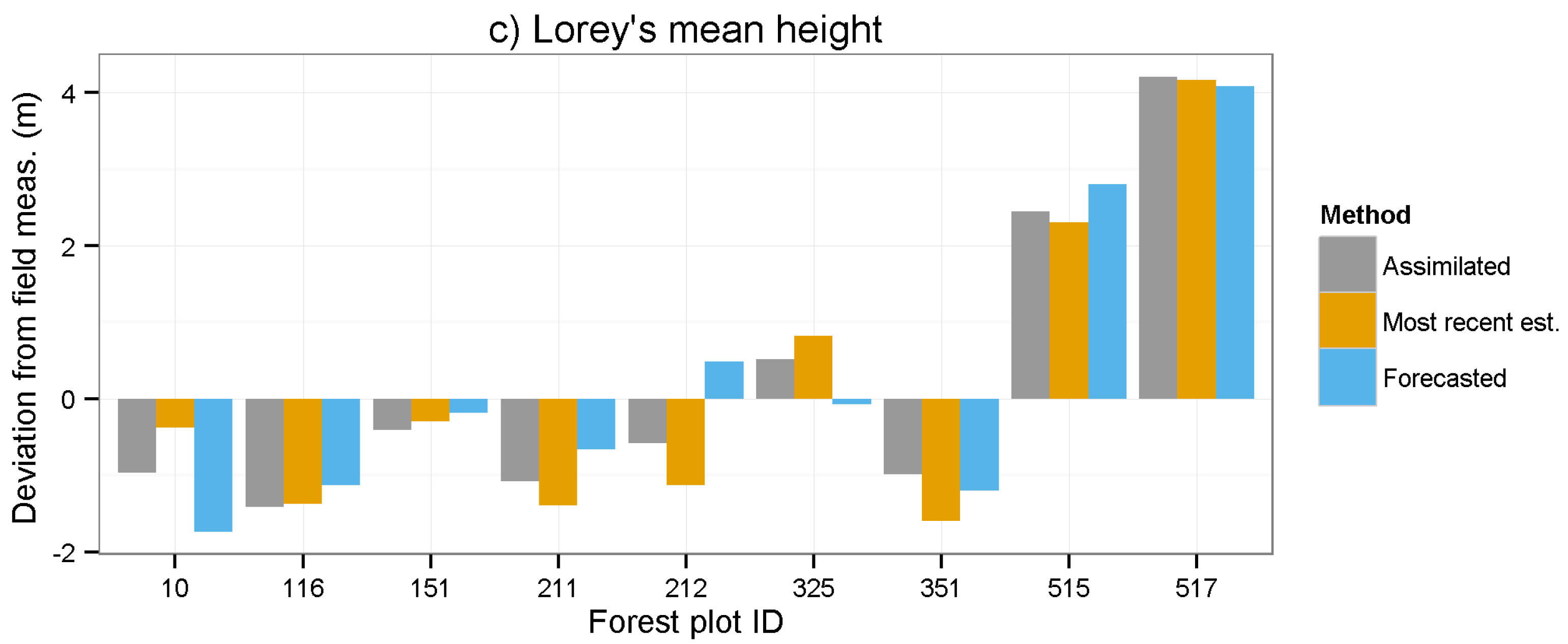
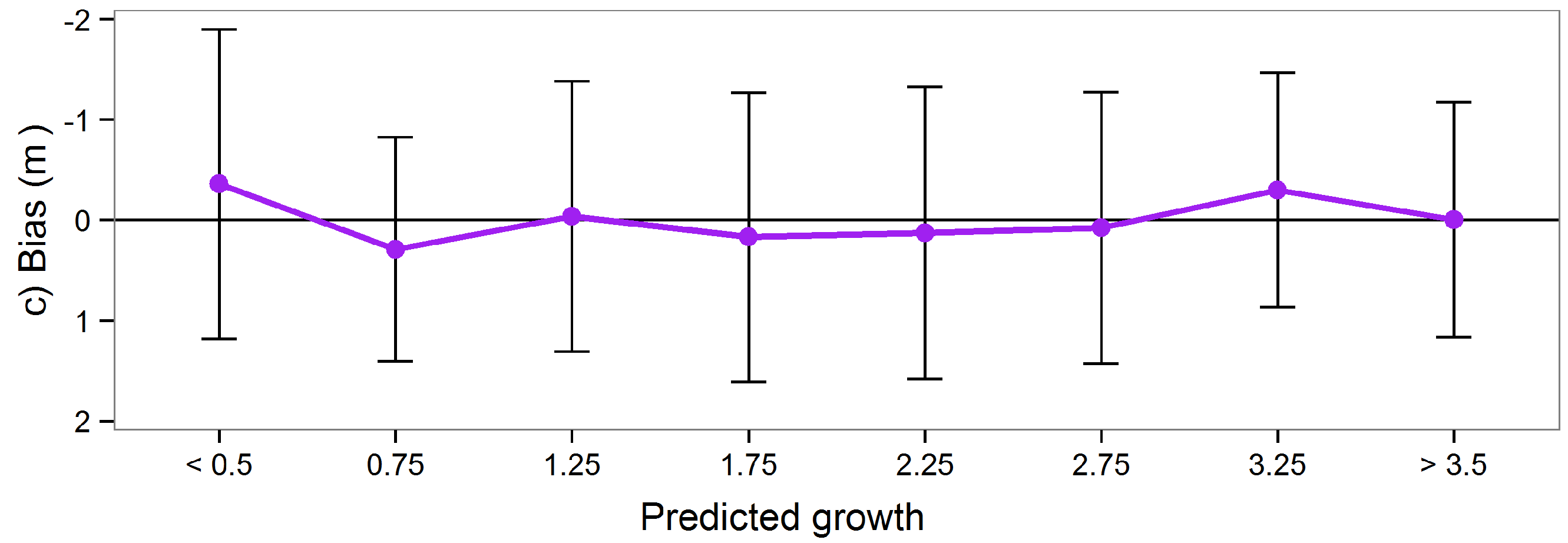
Figure 5 shows the deviation from the field measured value for each of the three methods (
i.e., assimilation, most recent estimate, forecasting) for the nine validation plots.
Table 4 shows the
of the deviation from the field measurements and
Table 5 shows the corresponding mean deviation (
). A positive
means that the plot value is on average overestimated. It can be seen that the
are smaller using data assimilation compared to forecasting the value from the first (initial state) remote sensing prediction. The full strength of data assimilation will probably first be seen when data from multiple sources are combined. For example, if data are first acquired using airborne laser scanning (ALS) and later acquired with a technique that has lower accuracy, we will be able to update the high accuracy acquisition from the ALS with new data. In a similar way, the data assimilation framework can be used for maintaining information from earlier high quality measurements, for example from field visits, and combining it, rather than replacing it, with new information from remote sensing.
Figure 5.
Deviation at year 2011 between field measurement and estimates of (a) stem volume; (b) basal area, and (c) Lorey’s mean height using different methods. A positive value means that the plot has an overestimated value.
Figure 5.
Deviation at year 2011 between field measurement and estimates of (a) stem volume; (b) basal area, and (c) Lorey’s mean height using different methods. A positive value means that the plot has an overestimated value.
Table 4.
Root mean squared error (RMSE) of the deviation from the field measurement 2011 for the nine assimilated plots. In parentheses is relative RMSE.
Table 4.
Root mean squared error (RMSE) of the deviation from the field measurement 2011 for the nine assimilated plots. In parentheses is relative RMSE.
| Target Variable | Assimilated | Most Recent Estimate | Forecasted |
|---|
| V | 40.1 (13.5%) | 44.7 (15.0%) | 58.5 (19.7%) |
| BA | 3.80 (12.0%) | 4.05 (12.8%) | 4.49 (14.2%) |
| HL | 1.81 (9.3%) | 1.86 (9.6%) | 1.86 (9.5%) |
Table 5.
Mean deviation () from the field measurement 2011 for the nine assimilated plots. A positive means that the value is on average overestimated compared to the field measurements. In parentheses is relative .
Table 5.
Mean deviation () from the field measurement 2011 for the nine assimilated plots. A positive means that the value is on average overestimated compared to the field measurements. In parentheses is relative .
| Target Variable | Assimilated | Most Recent Estimate | Forecasted |
|---|
| V | 0.73 (0.3%) | −10.0 (−3.4%) | 35.7 (12.0%) |
| BA | −0.89 (−2.8%) | −2.12 (−6.7%) | 1.47 (4.7%) |
| HL | 0.19 (1.0%) | 0.12 (0.6%) | 0.27 (1.4%) |
The results of the validation shows that the accuracy of estimates are similar to other studies of image matching based forest inventory [
5,
6].
Table 4 and
Table 5 show that the assimilated values on average for all stands and variables are better than the most recent estimates, as well as the forecasted estimates. The only exception is that the mean deviation of Lorey’s mean height is lower when using only the most recent estimate. This might be explained by the fact that the photogrammetric point cloud contains particularly accurate information about tree height, and then the gain by data assimilation to reduce noise is less [
15]. It is also evident from
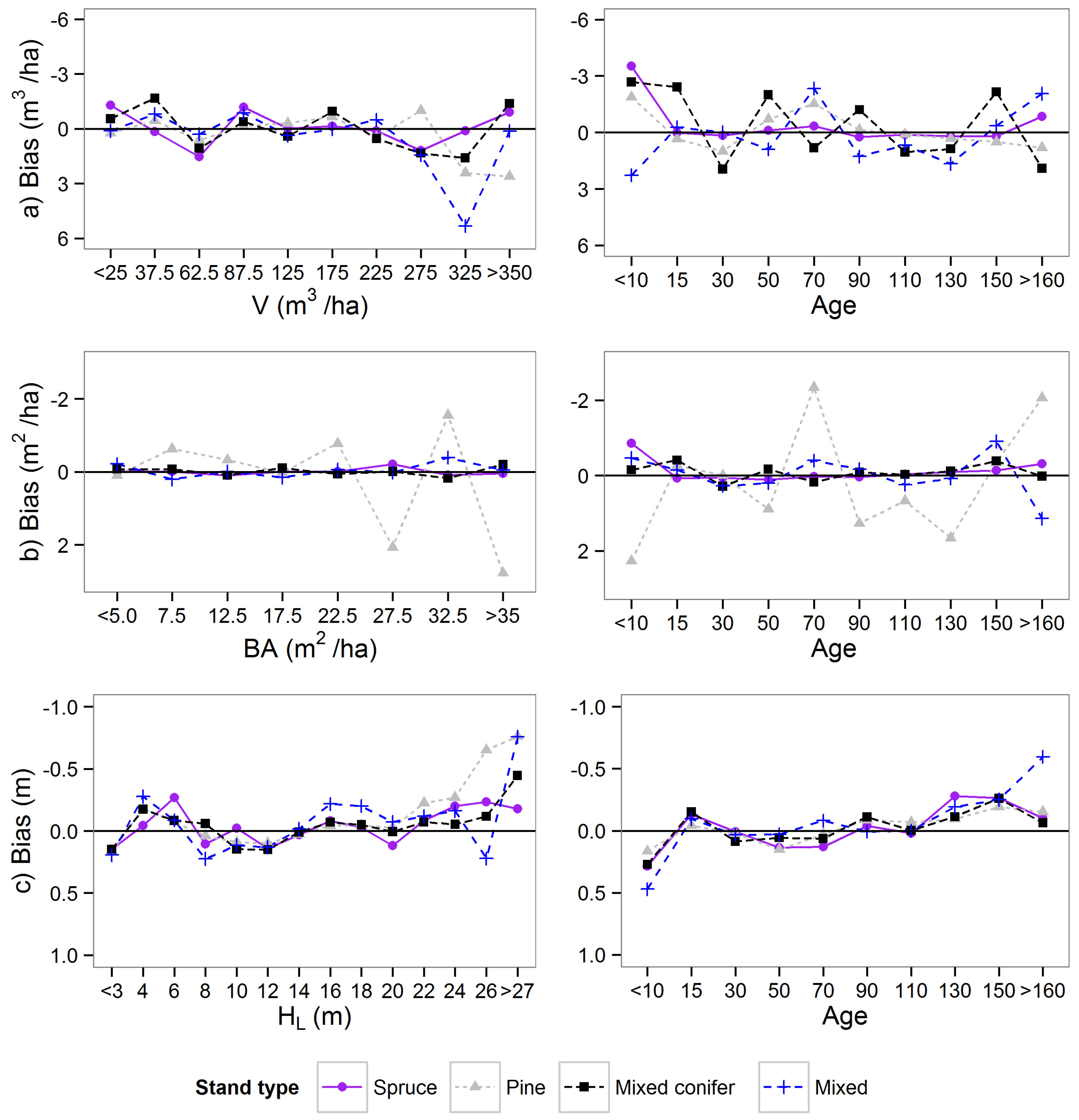
Figure 5 that two of the mixed stands (515 and 517) had comparatively large over estimates of the canopy height. This might be because broadleaved trees have more leaves and branches in the upper part of the canopy than cone-shaped spruces. Thus, developing separate regression models for different tree species groups might improve the results in future studies.
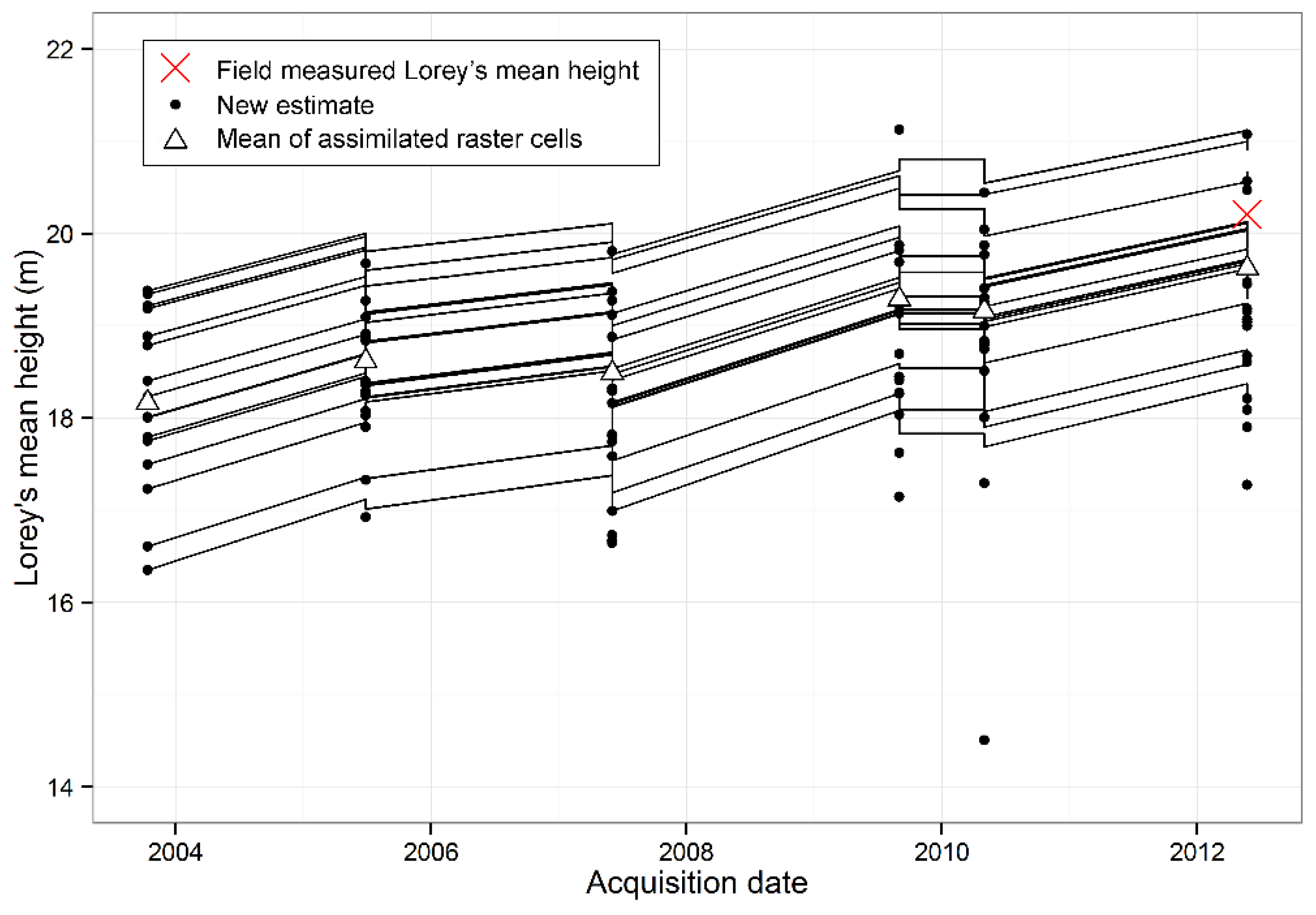
Figure 6 shows the growth of validation plot 212. Each line represents one raster cell within the 40 m radius validation plot. The black dots represent remote sensing based estimates. In the fifth acquisition (2 May 2010), there is one clear outlier at 14.5 m, but the assimilation remained stable despite this. The result of the last assimilation (the rightmost triangle) should be compared with the field measured value (the red cross). It should also be noticed that the acquisition dates are shown on the x-axis, but it is the growth season that determines the growth prediction, and, therefore, the slope is different between the acquisitions.
Figure 6.
Data assimilation of Lorey’s mean height on validation plot 212. The black dots are the estimates from remote sensing where each dot represents one 18 m × 18 m raster cell within the validation plot. The triangles are the mean value of the assimilation for each time-point. The red cross is the field measured Lorey’s mean height for the same growth season (2011) as the last acquisition. The black lines are the current estimate for each raster cell. Note that the lines jump either up or down depending on the outcome of the assimilation at each acquisition time-point.
Figure 6.
Data assimilation of Lorey’s mean height on validation plot 212. The black dots are the estimates from remote sensing where each dot represents one 18 m × 18 m raster cell within the validation plot. The triangles are the mean value of the assimilation for each time-point. The red cross is the field measured Lorey’s mean height for the same growth season (2011) as the last acquisition. The black lines are the current estimate for each raster cell. Note that the lines jump either up or down depending on the outcome of the assimilation at each acquisition time-point.
In this study, the data are all from the same remote sensing method,
i.e., point clouds from image matching of aerial images. Therefore, it is likely that the estimation errors are correlated, which would imply that too much weight is being put on the forecasted information as compared to the new information. This could explain why data assimilation did not perform much better than using information from the most recent estimate (
Table 4). Methods to compensate for this will be developed in future studies but requires non-standard filters for the data assimilation. During the course of the study, a test was made where smaller weights were consistently given to the forecasted values in the assimilation step as compared to the weights assigned by the Kalman filter. This led to improved assimilation results, which indicates that the issue of correlated errors needs to be more carefully addressed in future studies.
In a future version of the data assimilation application, the models for prediction of the stand attributes ought to be evaluated in a simultaneous setting to handle cross-correlated errors across models. However, in the present study, we analyzed the different growth characteristics separately over a short time period using simple growth models where the non-static predictors (V, BA, HL) were not used as predictor variables across the growth models to reduce cross-correlation effects in the forecasts.
The first images were from growth season 2003 and the last from 2011. Thus, the assimilation period is rather short (eight years) considering the time perspective in Nordic forestry where the rotation period is typically 80–100 years. In an operational case, we would have a model that is continuously updated when new data become available and probably spans over much longer time periods than eight years. The starting point for the assimilation is an estimate based on the first aerial images. The short time period might give fairly good growth predictions; however, since the initial state itself is an estimate, it is difficult to evaluate how the forecasts perform.
In this study, the assimilation was conducted on 18 m × 18 m raster cells. Further research is needed to investigate at what level the assimilation should be performed. An alternative could be to assimilate directly at stand level. However, the modeling units for the growth forecasts and the estimates based on remotely sensed data need to correspond, and it must be possible to acquire high quality field reference data for purposes of modeling. These issues point towards raster based approaches to data assimilation being more straightforward than stand based approaches. However, procedures need to be developed where the precision of aggregated raster elements can be estimated.
We are entering an era with a frequent flow of data from different sources and of different types. An example of this is the potential availability of several optical and radar satellite images per year, point clouds from digital photogrammetry with a few years’ time interval, and laser scanning data with five to ten years’ time interval. In addition, there will also be different types of field reference data, for example, from field plots, harvesters and ground based laser scanners. The data assimilation technique offers a potential method for utilizing all of these data sources, even if some of these sources would not be sufficient for use in operational forest planning when used alone. The combination of these different data sources will be the subject of further studies.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








