
Fast Quantitative Modelling Method for Infrared Spectrum Gas Logging Based on Adaptive Step Sliding Partial Least Squares

 , ,
, ,
Abstract
:1. Introduction
- Because of the high similarity of the molecular structure of alkane gas, the infrared absorption characteristic peaks are too overlapped to separate in multicomponent gas mixtures;
- Because of the great uncertainties of the composition of the logging gas and the limited number of samples for modelling, fast modelling technology is becoming more and more urgent with the increment of required spectrum range and spectral resolution for analysis of more and more kinds of gases.
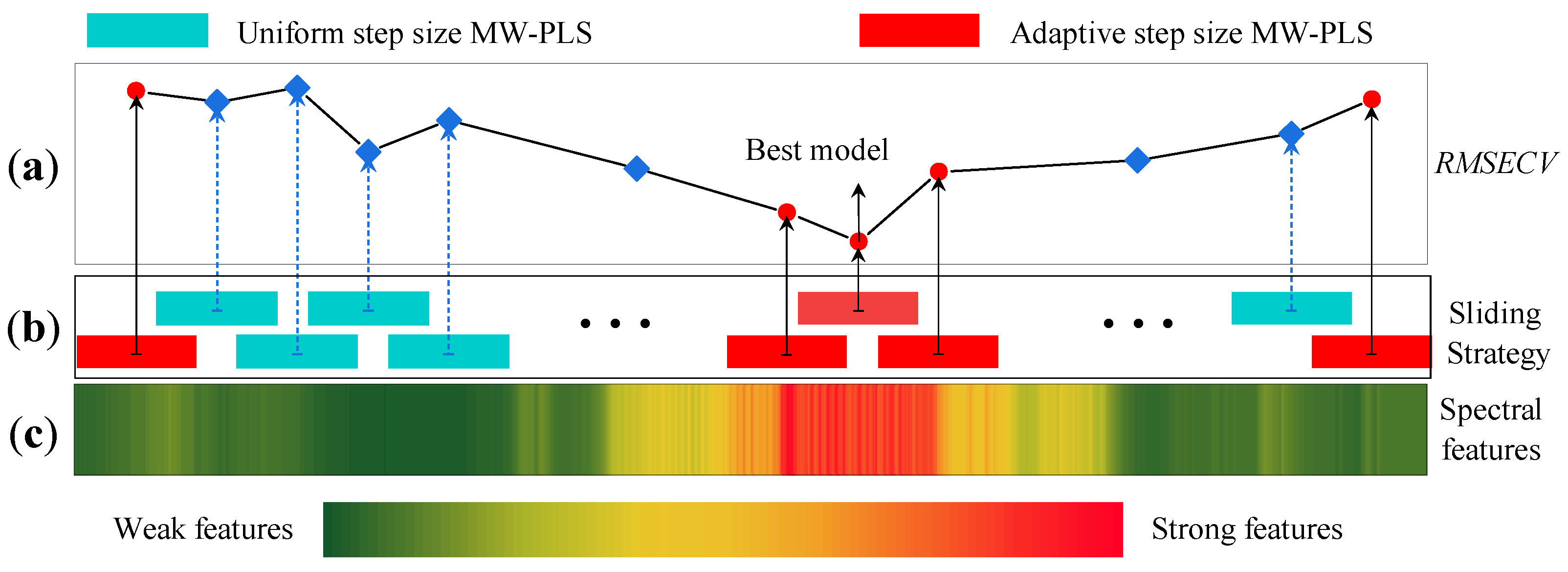
2. Adaptive Step-Sliding Partial Least Squares
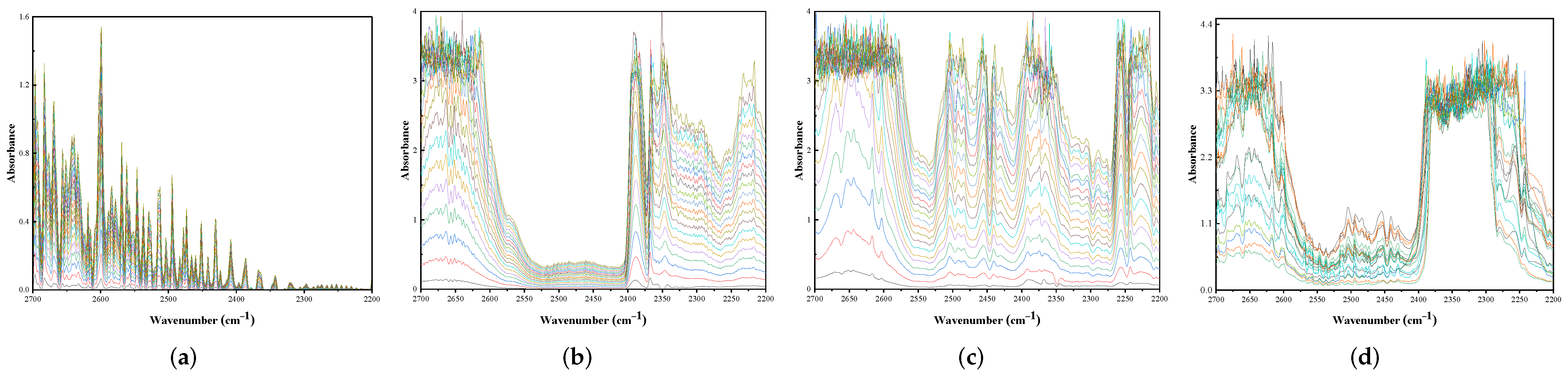
2.1. Infrared Quantitative Analysis Principle
2.2. Partial Least Squares Analysis
2.3. Adaptive Step Sliding
| Algorithm 1: ASS-PLS local modelling algorithm |
 |
3. Experiment and Discussion
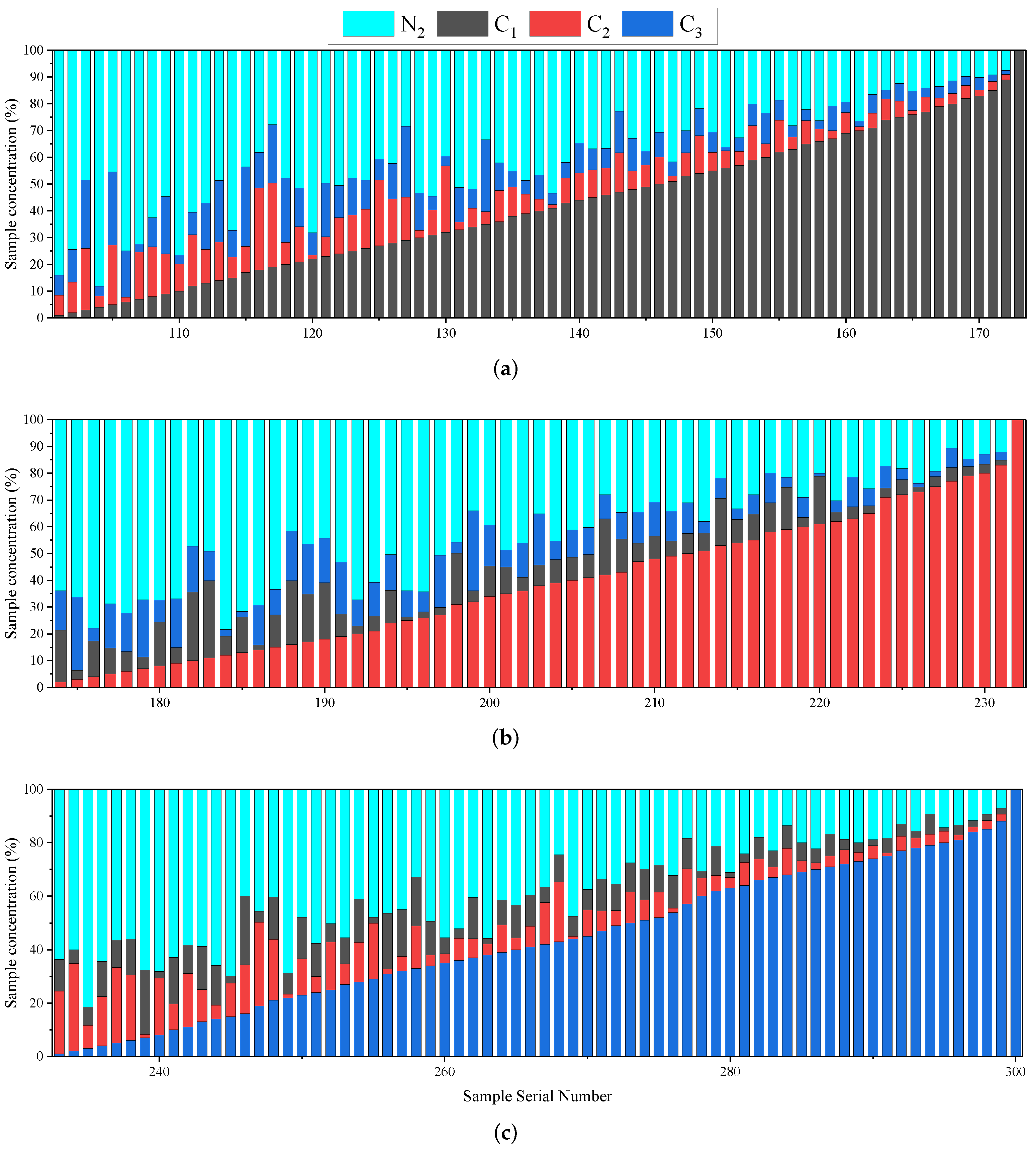
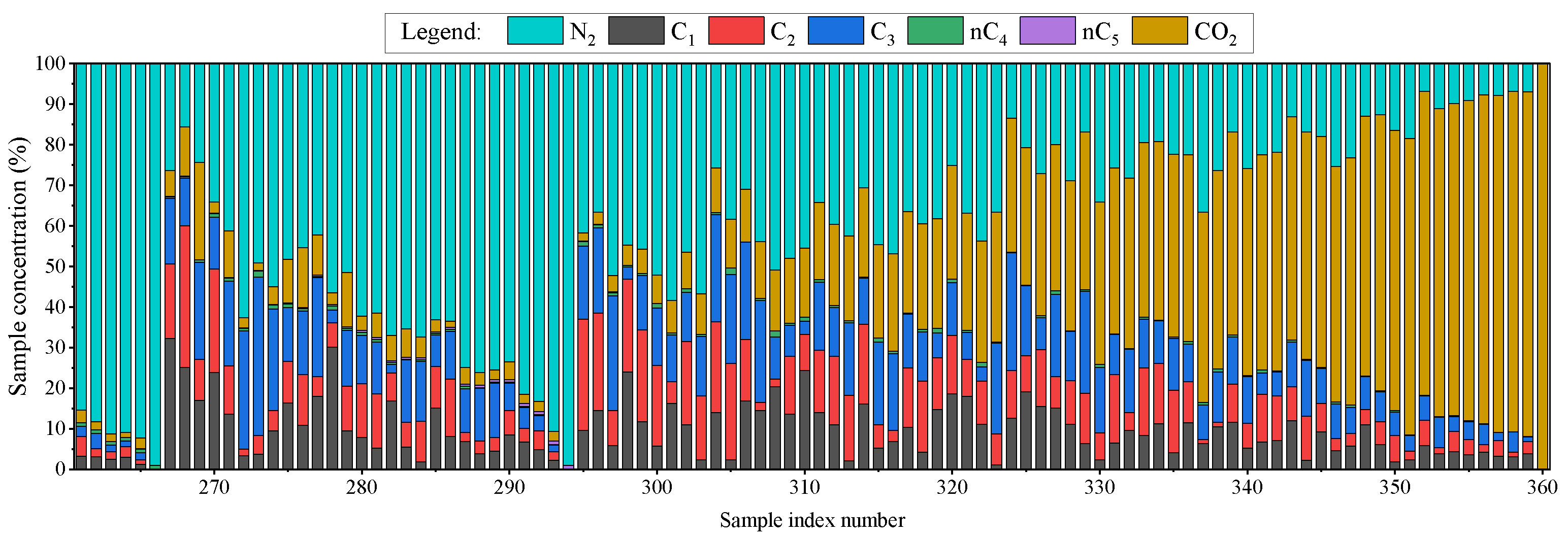
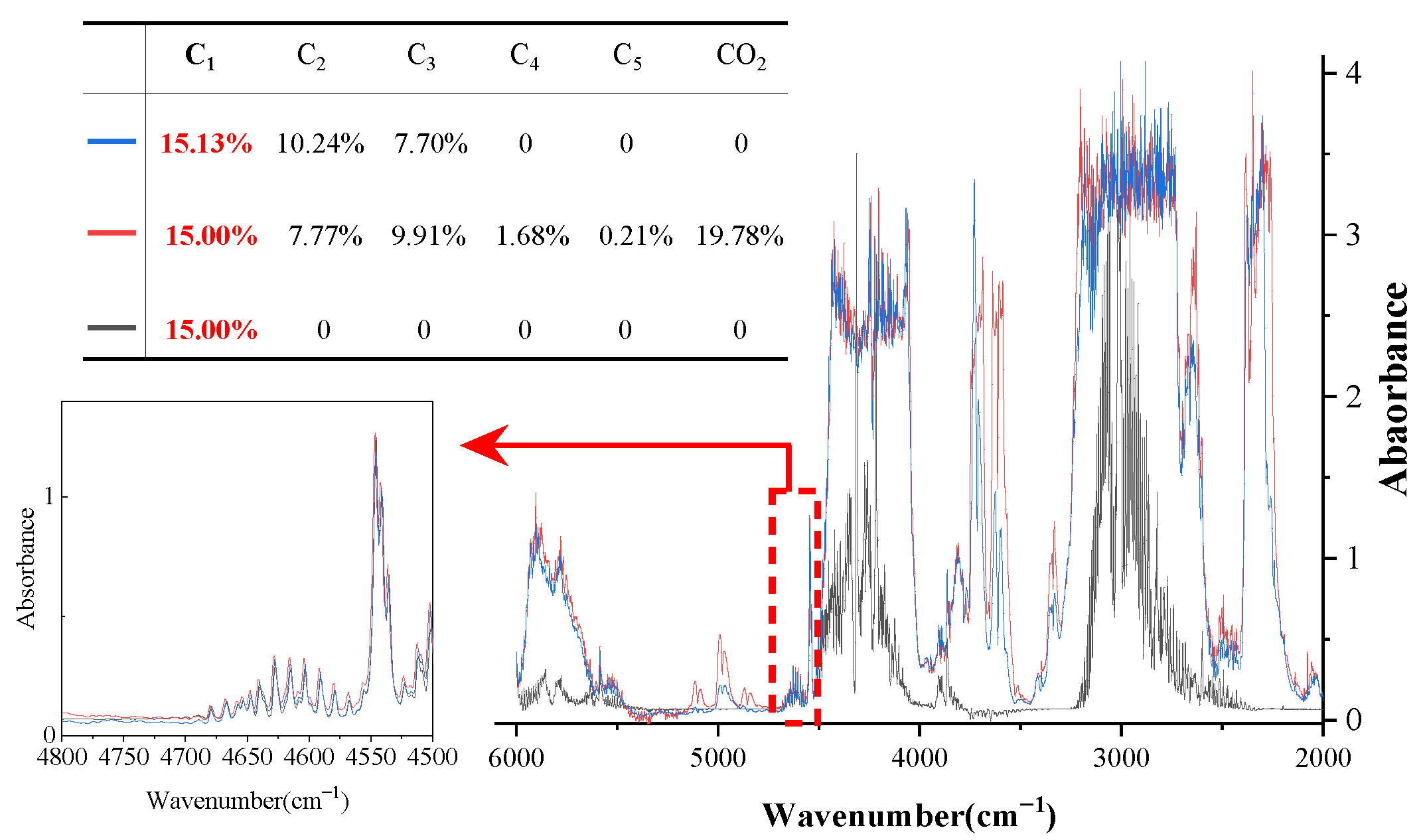
3.1. Experiment Dataset
3.2. Influencing Factors on Local Modelling
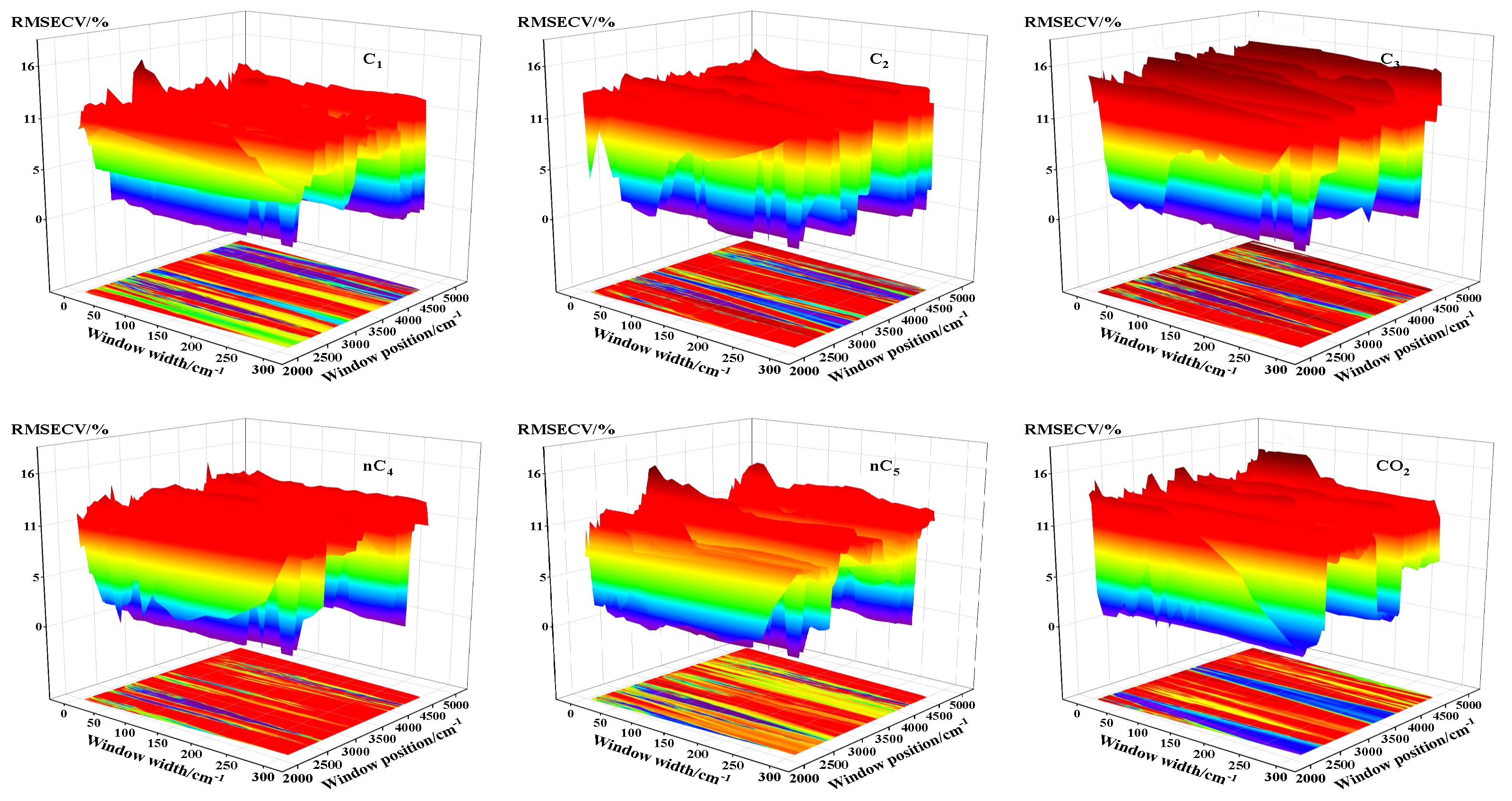
- The RMSECV of different substances are distributed in the range of 0∼16%, and all of them show similar wavelike distribution in the direction of the window position;
- The RMSECV of the same substance shows obvious stripe distribution on the window position;
- The stripe distributions of C∼C are similar, but are obviously different from CO.
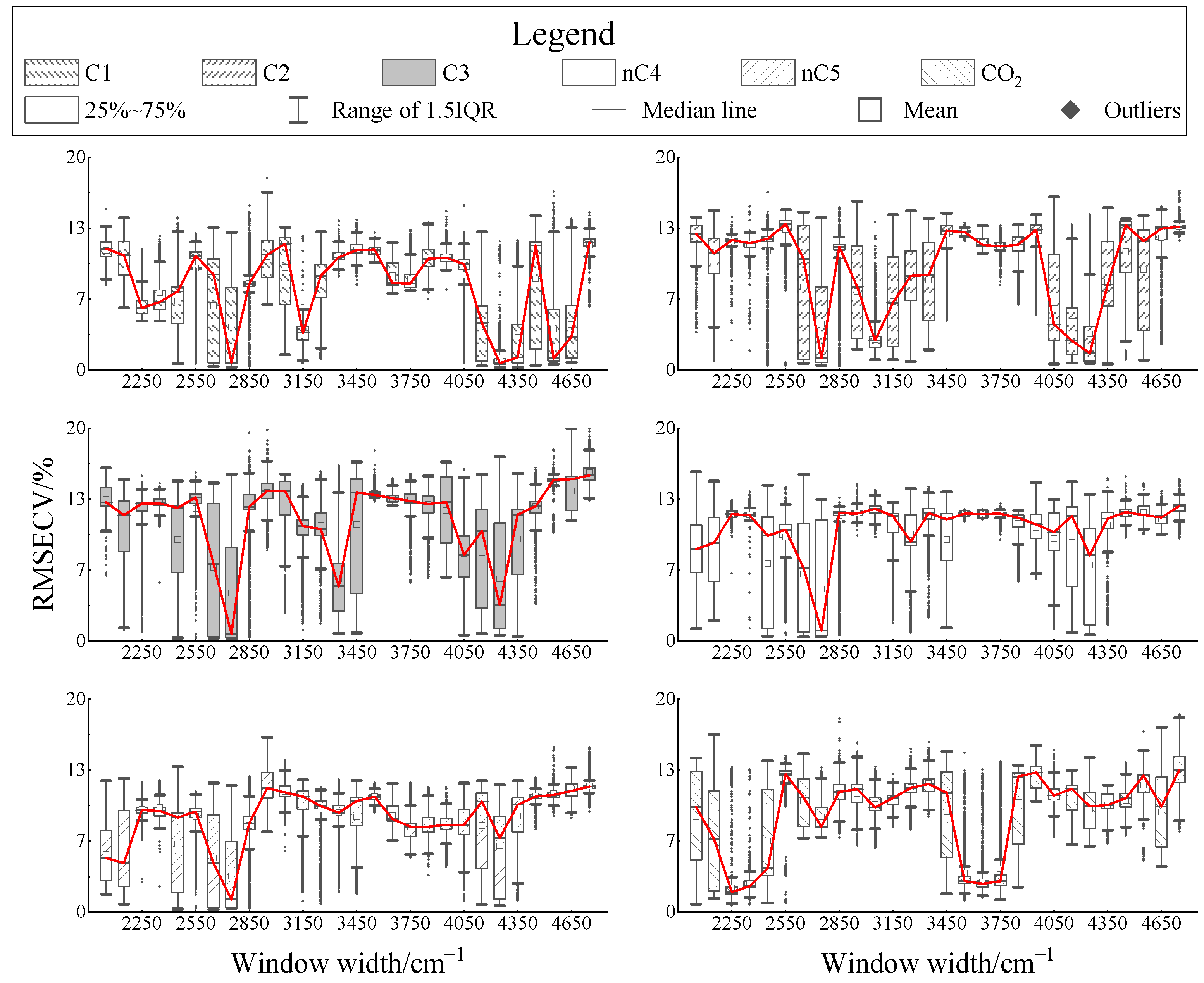
3.2.1. Influence of the Window Position
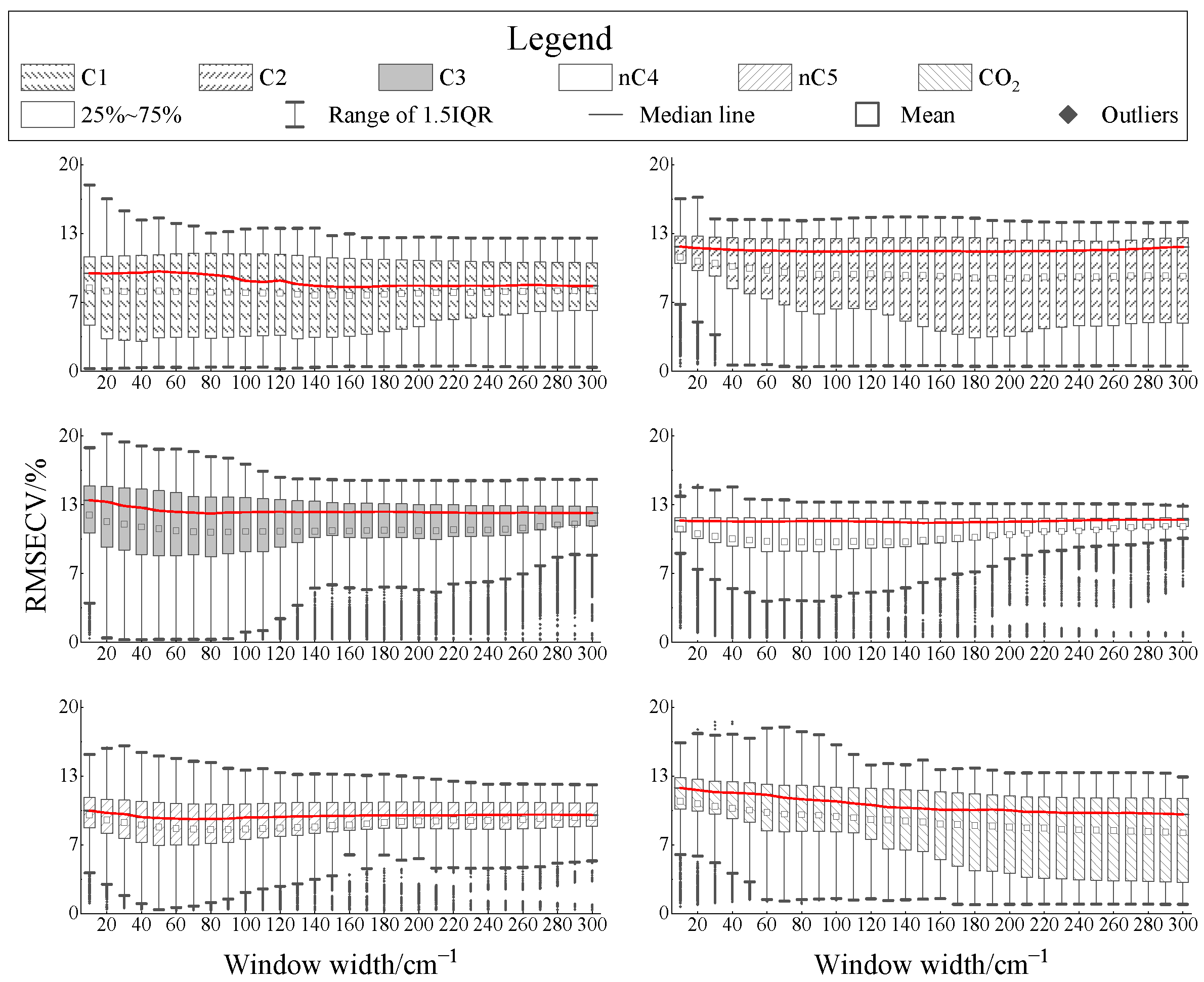
3.2.2. Influence of the Window Width
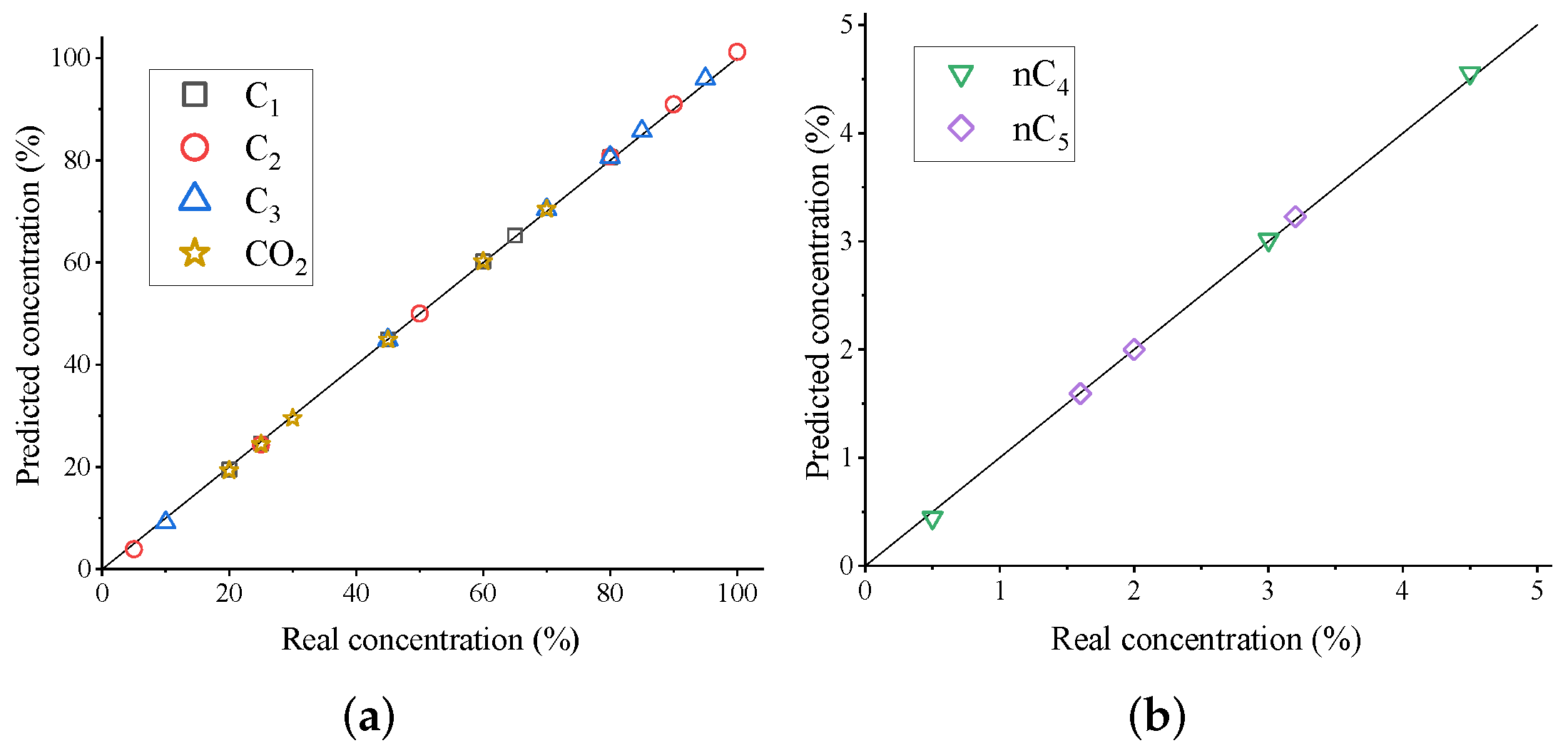
3.3. Quantitative Analysis Results
4. Conclusions
- The infrared characteristic distribution of logging gas has an obvious concentration, and the local modelling strategy of continuous interception can effectively retain the characteristic information and improve the prediction accuracy and stability of the model.
- The accuracy of the local model under the continuous interception strategy is much more sensitive to the modelling position than the interception width.
- The similarity of the alkane molecular structure can lead to a shift in the optimal modelling interval under different mixing types.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ighodalo, E.; Davies, G.; D’Souza, S.A.; Ahmed, A. Increasing Certainty in Formation Evaluation Utilizing Advanced Mud Logging Gas Analysis. In Proceedings of the SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition, Dammam, Saudi Arabia, 25 April 2017. [Google Scholar] [CrossRef]
- Ferroni, G.; Rivolta, F.; Schifano, R. Improved Formation Evaluation While Drilling With a New Heavy Gas Detector. In Proceedings of the Society of Professional Well Log Analysts Annual Logging Symposium, Cartagena, Colombia, 16–20 June 2012. [Google Scholar]
- Zakrevskiy, K.E.; Gazizov, R.K.; Ryzhikov, E.A.; Freydin, K.V. Consistency evaluation technology for automatic well-log correlation using well logging data (Russian). Neft. Khozyaystvo Oil Ind. 2021, 2021, 22–26. [Google Scholar] [CrossRef]
- Kandel, D.; Quagliaroli, R.; Segalini, G.; Barraud, B. Improved Integrated Reservoir Interpretation Using Gas While Drilling Data. SPE Reserv. Eval. Eng. 2001, 4, 489–501. [Google Scholar] [CrossRef]
- Kriel, W.; Spence, A.; Kolodziej, E.; Hoolahan, S. Improved Gas Chromatographic Analysis of Reservoir Gas and Condensate Samples. In Proceedings of the SPE International Conference on Oilfield Chemistry, New Orleans, LA, USA, 2–5 March 1993. [Google Scholar] [CrossRef]
- Breviere, J.; Herzaft, B.; Mueller, N. Gas Chromatography—Mass Spectrometry (Gcms)—A New Wellsite Tool For Continuous C1-C8 Gas Measurement In Drilling Mud—Including Original Gas Extractor And Gas Line Concepts. First Results And Potential. In Proceedings of the Society of Professional Well Log Analysts 43rd Annual Logging Symposium, Oiso, Japan, 2–5 June 2002. [Google Scholar]
- Brumboiu, A.; Hawker, D.; Norquay, D.; Law, D. Advances in Chromatographic Analysis of Hydrocarbon Gases in Drilling Fluids? The Application of Semi-Permeable Membrane Technology to High Speed TCD Gas Chromatography. In Proceedings of the Society of Professional Well Log Analysts 46th Annual Logging Symposium, New Orleans, LA, USA, 22–26 June 2005. [Google Scholar]
- Cramers, C.A.; Janssen, H.G.; van Deursen, M.M.; Leclercq, P.A. High-speed gas chromatography: An overview of various concepts. J. Chromatogr. A 1999, 856, 315–329. [Google Scholar] [CrossRef]
- Agah, M.; Lambertus, G.; Sacks, R.; Wise, K. High-Speed MEMS-Based Gas Chromatography. J. Microelectromech. Syst. 2006, 15, 1371–1378. [Google Scholar] [CrossRef]
- Rowe, M.; Splapikas, T. Jumping Mass Spectrometer. In Proceedings of the SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition, Dammam, Saudi Arabia, 23–26 April 2017. [Google Scholar] [CrossRef]
- Rowe, M.; Muirhead, D. Mud-Gas Extractor and Detector Comparison. In Proceedings of the SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition, Dammam, Saudi Arabia, 23–26 April 2017. [Google Scholar] [CrossRef]
- Sauer, C.; Lorén, A.; Schaefer, A.; Carlsson, P.A. On-Line Composition Analysis of Complex Hydrocarbon Streams by Time-Resolved Fourier Transform Infrared Spectroscopy and Ion–Molecule Reaction Mass Spectrometry. Anal. Chem. 2021, 93, 13187–13195. [Google Scholar] [CrossRef] [PubMed]
- van der Veen, A.M.H.; Nieuwenkamp, G.; Zalewska, E.T.; Li, J.; de Krom, I.; Persijn, S.; Meuzelaar, H. Advances in metrology for energy-containing gases and emerging demands. Metrologia 2020, 58, 012001. [Google Scholar] [CrossRef]
- Diller, D.E.; Chang, R.F. Composition of Mixtures of Natural Gas Components Determined by Raman Spectrometry. Appl. Spectrosc. 1980, 34, 411–414. [Google Scholar] [CrossRef]
- Kosacki, I.; Srinivasan, S. Application of Raman Spectroscopy for Hydrocarbon Characterization. In Proceedings of the Nace Corrosion 2017, New Orleans, LA, USA, 26–30 March 2017. [Google Scholar]
- Sharma, R.; Poonacha, S.; Bekal, A.; Vartak, S.; Weling, A.; Tilak, V.; Mitra, C. Raman analyzer for sensitive natural gas composition analysis. Opt. Eng. 2016, 55, 1–8. [Google Scholar] [CrossRef]
- Rathmell, C. Data-Driven Raman Spectroscopy in Oil and Gas: Rapid Online Analysis of Complex Gas Mixtures. Spectrosc. Suppl. 2018, 33, 34–42. [Google Scholar]
- Livanos, G.; Zervakis, M.; Pasadakis, N.; Karelioti, M.; Giakos, G. Deconvolution of petroleum mixtures using mid-FTIR analysis and non-negative matrix factorization. Meas. Sci. Technol. 2016, 27, 114005. [Google Scholar] [CrossRef]
- Sell, J.K.; Jakoby, B. A simple mid-infrared measurement system based on a tunable filter for the analysis of ternary gas mixtures. Meas. Sci. Technol. 2013, 24, 084006. [Google Scholar] [CrossRef]
- Indo, K.; Hsu, K.; Pop, J. Estimation of Fluid Composition From Downhole Optical Spectrometry. SPE J. 2015, 20, 1326–1338. [Google Scholar] [CrossRef]
- Piazza, R.; Vieira, A.; Sacorague, L.A.; Jones, C.; Dai, B.; Pearl, M.; Aguiar, H. Real-Time Downhole MID-IR Measurement of Carbon Dioxide Content. In Proceedings of the Society of Professional Well Log Analysts 60th Annual Logging Symposium, The Woodlands, TX, USA, 15–19 June 2019. [Google Scholar] [CrossRef]
- Ren, Q.; Chen, C.; Wang, Y.; Li, C.; Wang, Y. A Prototype of ppbv-Level Midinfrared CO2 Sensor for Potential Application in Deep-Sea Natural Gas Hydrate Exploration. IEEE Trans. Instrum. Meas. 2020, 69, 7200–7208. [Google Scholar] [CrossRef]
- Moro, M.K.; dos Santos, F.D.; Folli, G.S.; Romão, W.; Filgueiras, P.R. A review of chemometrics models to predict crude oil properties from nuclear magnetic resonance and infrared spectroscopy. Fuel 2021, 303, 121283. [Google Scholar] [CrossRef]
- Kamboj, U.; Kaushal, N.; Jabeen, S. Near Infrared Spectroscopy as an efficient tool for the Qualitative and Quantitative Determination of Sugar Adulteration in Milk. J. Phys. Conf. Ser. 2020, 1531, 012024. [Google Scholar] [CrossRef]
- Gao, Q.; Wang, M.; Guo, Y.; Zhao, X.; He, D. Comparative Analysis of Non-Destructive Prediction Model of Soluble Solids Content for Malus micromalus Makino Based on Near-Infrared Spectroscopy. IEEE Access 2019, 7, 128064–128075. [Google Scholar] [CrossRef]
- Sun, J.; Yang, W.; Feng, M.; Liu, Q.; Kubar, M.S. An efficient variable selection method based on random frog for the multivariate calibration of NIR spectra. RSC Adv. 2020, 10, 16245–16253. [Google Scholar] [CrossRef] [Green Version]
- Galvão, R.K.H.; Araújo, M.C.U.; Fragoso, W.D.; Silva, E.C.; José, G.E.; Soares, S.F.C.; Paiva, H.M. A variable elimination method to improve the parsimony of MLR models using the successive projections algorithm. Chemom. Intell. Lab. Syst. 2008, 92, 83–91. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, J.; Zhu, J.; Liang, S. An Accurate Noninvasive Blood Glucose Measurement System Using Portable Near-Infrared Spectrometer and Transfer Learning Framework. IEEE Sens. J. 2021, 21, 3506–3519. [Google Scholar] [CrossRef]
- Wang, J.; Lu, S.; Wang, S.H.; Zhang, Y.D. A review on extreme learning machine. Multimed. Tools Appl. 2021. [Google Scholar] [CrossRef]
- Jiang, H.; Liu, G.; Mei, C.; Yu, S.; Xiao, X.; Ding, Y. Measurement of process variables in solid-state fermentation of wheat straw using FT-NIR spectroscopy and synergy interval PLS algorithm. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2012, 97, 277–283. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Du, W.; Lang, Z.Q.; Wang, K.; Long, J. A Novel Integrated Approach to Characterization of Petroleum Naphtha Properties From Near-Infrared Spectroscopy. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Ouyang, T.; Wang, C.; Yu, Z.; Stach, R.; Mizaikoff, B.; Huang, G.B.; Wang, Q.J. NOx Measurements in Vehicle Exhaust Using Advanced Deep ELM Networks. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Liu, L.; Yan, L.; Xie, Y.; Xia, G. Content measurement of textile mixture by near infrared spectroscopy based on BP neural network. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, CISP 2010, Yantai, China, 16–18 October 2010; Volume 7, pp. 3354–3358. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhang, W.B.; Xu, Y.Y.; Zhang, G.J. Comparative study of partial least squares and neural network models of near-infrared spectroscopy for aging condition assessment of insulating paper. Meas. Sci. Technol. 2020, 31, 045501. [Google Scholar] [CrossRef]
- Kumar, K. Competitive adaptive reweighted sampling assisted partial least square analysis of excitation-emission matrix fluorescence spectroscopic data sets of certain polycyclic aromatic hydrocarbons. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 244, 118874. [Google Scholar] [CrossRef]
- Huang, G.; He, J.; Zhang, X.; Feng, M.; Tan, Y.; Lv, C.; Huang, H.; Jin, Z. Applications of Lambert-Beer law in the preparation and performance evaluation of graphene modified asphalt. Constr. Build. Mater. 2021, 273, 121582. [Google Scholar] [CrossRef]
- Silalahi, D.D.; Midi, H.; Arasan, J.; Mustafa, M.S.; Caliman, J.P. Kernel partial diagnostic robust potential to handle high-dimensional and irregular data space on near infrared spectral data. Heliyon 2020, 6, e03176. [Google Scholar] [CrossRef]
- Jiang, W.; Lu, C.; Zhang, Y.; Ju, W.; Wang, J.; Hong, F.; Wang, T.; Ou, C. Moving-Window-Improved Monte Carlo Uninformative Variable Elimination Combining Successive Projections Algorithm for Near-Infrared Spectroscopy (NIRS). J. Spectrosc. 2020, 6, 3590301. [Google Scholar] [CrossRef]
- Kazansky, V.B.; Subbotina, I.R.; Jentoft, F.C.; Schlögl, R. Intensities of C-H IR Stretching Bands of Ethane and Propane Adsorbed by Zeolites as a New Spectral Criterion of Their Chemical Activation via Polarization Resulting from Stretching of Chemical Bonds. J. Phys. Chem. B 2006, 110, 17468–17477. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Substance | Standard Gas Concentration | Concentration Gradient | Sample Index Number |
|---|---|---|---|
| C | 99.999% | 5% | 1∼20 |
| C | 21∼40 | ||
| C | 41∼60 | ||
| CO | 61∼80 | ||
| nC | 4.999% | 0.5% | 81∼90 |
| nC | 3.999% | 0.4% | 91∼100 |
| Substance | Dataset | RMSE (%) | ||||
|---|---|---|---|---|---|---|
| F-PLS | CARS-PLS | SPA-PLS | MW-PLS | ASS-PLS | ||
| C | A 1 | 3.8690 | 0.8772 | 1.0151 | 0.4902 | 0.3586 |
| B 2 | 7.5254 | 3.3254 | 1.3851 | 1.1743 | 1.1628 | |
| C 3 | 10.7304 | 3.8698 | 1.8750 | 1.9742 | 1.5020 | |
| C | A | 3.6831 | 1.4582 | 1.3080 | 0.7736 | 0.5228 |
| B | 7.2151 | 1.6526 | 1.8951 | 0.9414 | 1.4882 | |
| C | 10.7826 | 1.2329 | 2.1340 | 1.6683 | 1.3673 | |
| C | A | 5.0227 | 1.5765 | 1.6862 | 0.5816 | 0.7659 |
| B | 8.7754 | 1.7951 | 2.2651 | 1.1151 | 1.2864 | |
| C | 12.2141 | 2.3778 | 3.9925 | 1.6114 | 1.5182 | |
| nC | A | 7.2256 | 0.7946 | 1.2773 | 0.2026 | 0.1930 |
| C | 11.6557 | 6.4614 | 5.5224 | 1.7623 | 1.4150 | |
| nC | A | 5.8746 | 0.2965 | 0.1137 | 0.1584 | 0.1874 |
| C | 9.6520 | 4.1198 | 5.6541 | 1.4386 | 1.5524 | |
| CO | A | 4.2137 | 0.2237 | 0.0963 | 0.1236 | 0.1731 |
| C | 4.9388 | 0.7007 | 0.6676 | 0.3152 | 0.2897 | |
| Model ( = 0.05) | Wavenumber Variables | Analysis Time (s) | Modelling Time (s) |
|---|---|---|---|
| F-PLS | 3882 | 0.0208 | 41.2200 |
| CARS-PLS | 56 | 0.0056 | 32.6267 |
| SPA-PLS | 27 | 0.0033 | 27.2036 |
| ASS-PLS | 100 | 0.0047 | 32.7247 |
| MW-PLS | 100 | 0.0043 | 11,443.6870 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Pang, W.; Liang, H.; Chen, G.; Duan, H.; Jiang, C. Fast Quantitative Modelling Method for Infrared Spectrum Gas Logging Based on Adaptive Step Sliding Partial Least Squares. Energies 2022, 15, 1325. https://doi.org/10.3390/en15041325
Li Z, Pang W, Liang H, Chen G, Duan H, Jiang C. Fast Quantitative Modelling Method for Infrared Spectrum Gas Logging Based on Adaptive Step Sliding Partial Least Squares. Energies. 2022; 15(4):1325. https://doi.org/10.3390/en15041325
Chicago/Turabian StyleLi, Zhongbing, Wei Pang, Haibo Liang, Guihui Chen, Hongming Duan, and Chuandong Jiang. 2022. "Fast Quantitative Modelling Method for Infrared Spectrum Gas Logging Based on Adaptive Step Sliding Partial Least Squares" Energies 15, no. 4: 1325. https://doi.org/10.3390/en15041325