Benchmarking a Many-Core Neuromorphic Platform With an MPI-Based DNA Sequence Matching Algorithm

 , , , , and
, , , , and
Abstract
:1. Introduction
- To benchmark the performances of the SpiNNaker board in computing pattern matching tasks by running synchronous data-stream algorithms.
- To explore the potential of the custom shape mesh, implemented on the SpiNNaker board, in a supporting parallel application that adopts a one-to-many communication system.
- To demonstrate how it is easy to port synchronous applications, implemented for the general-purpose computer, on the SpiNNaker board by using our software component that supports MPI for SpiNNaker.
2. Background
2.1. SpiNNaker Architecture
2.2. SpiNNaker Network
2.3. SpiNNaker Software
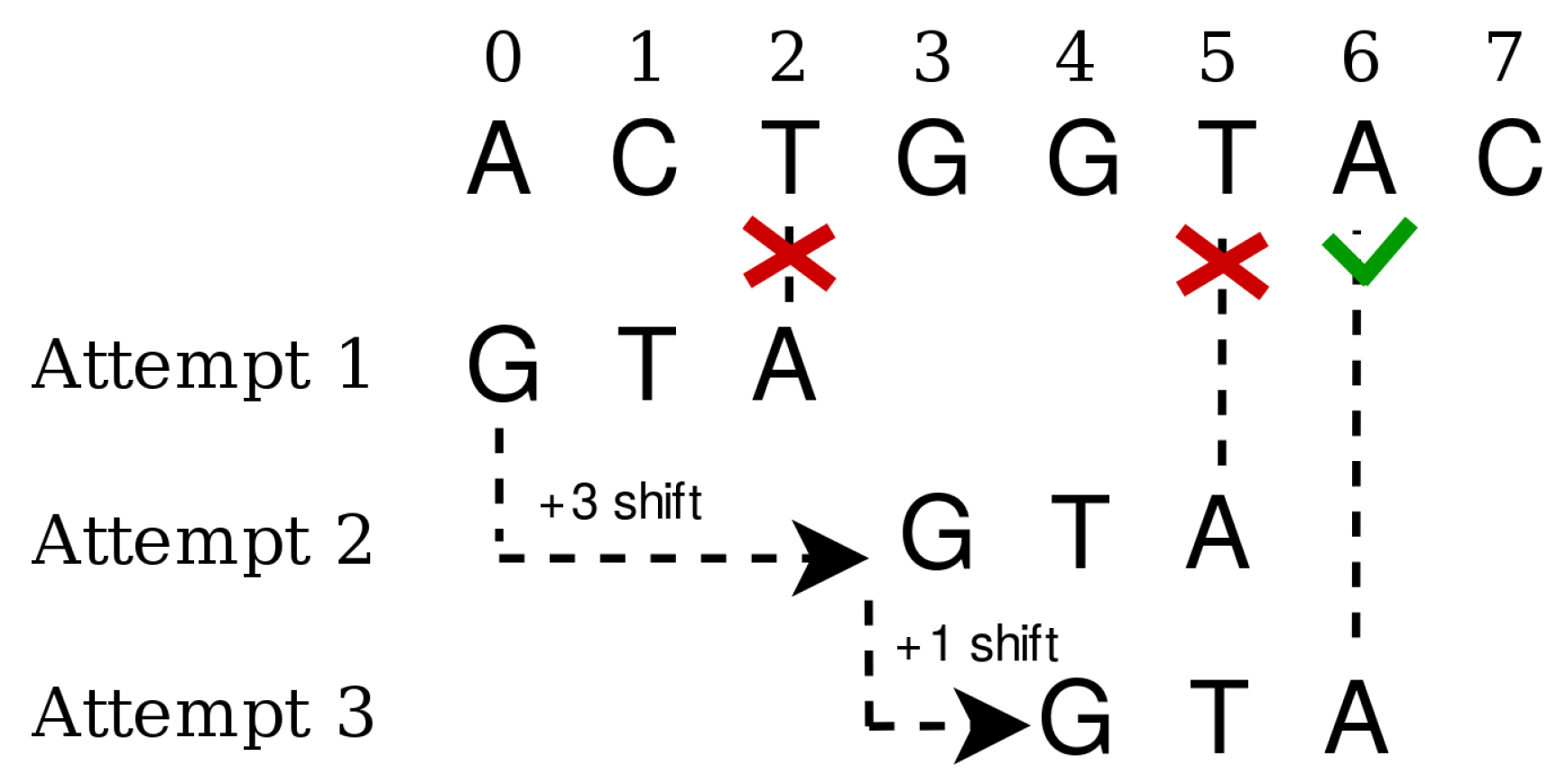
2.4. The DNA Pattern Matching Algorithm
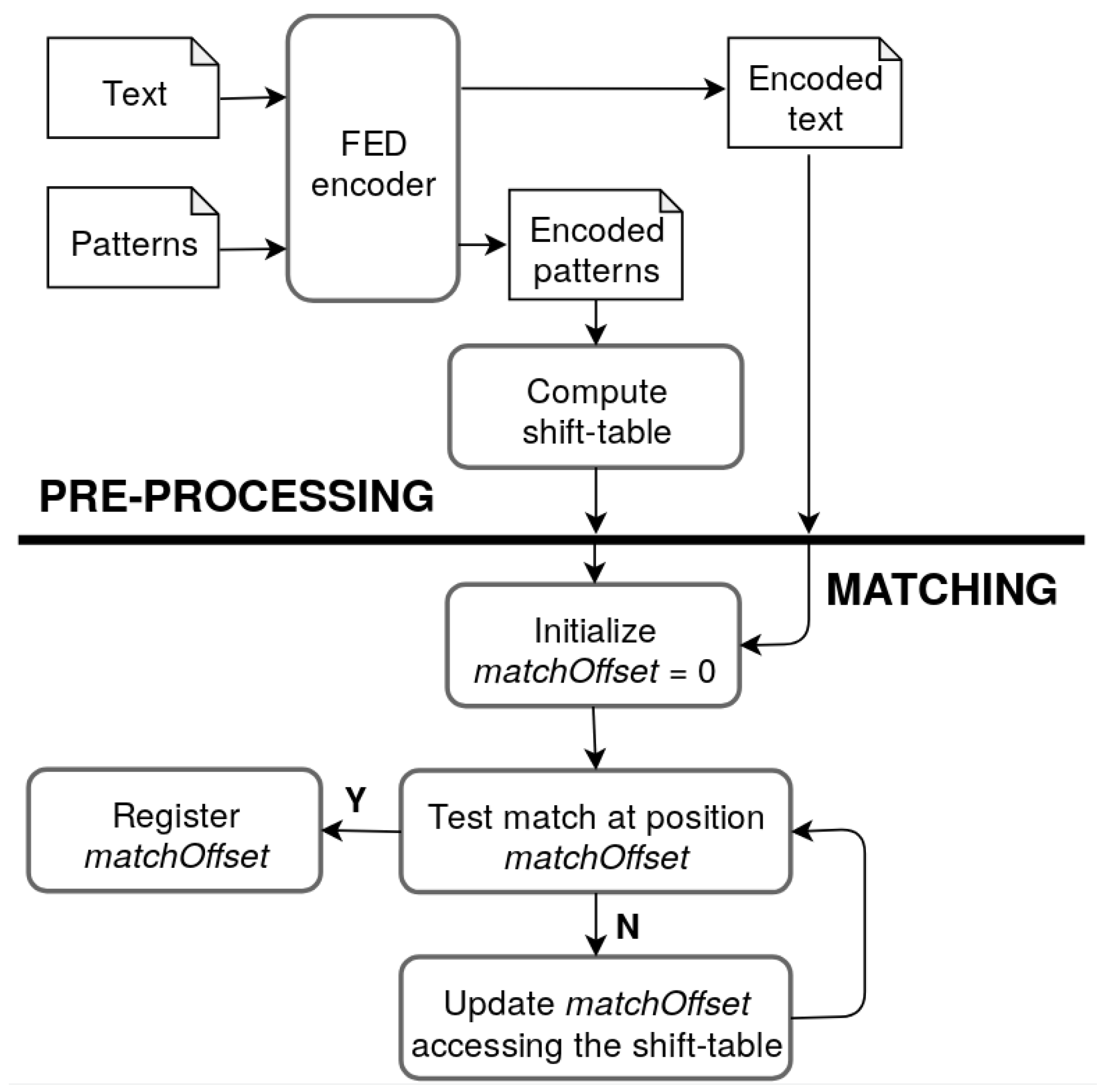
- Pre-processing, where texts and patterns are encoded and a shift table is computed for every pattern to be matched.
- Matching, where the actual search procedure is performed, is implemented as a byte-by-byte comparison between the text and pattern encoded sequences. If every byte of the pattern is sequentially found in the text, then the current position is registered as a match. Otherwise, the shift table is accessed to compute how many positions the pattern is allowed to skip before performing the next check.
3. Materials and Methods
3.1. Implementation of DNA Sequence Matching with MPI
3.2. Adaptation of FED with MPI for SpiNNaker
4. Results and Discussion
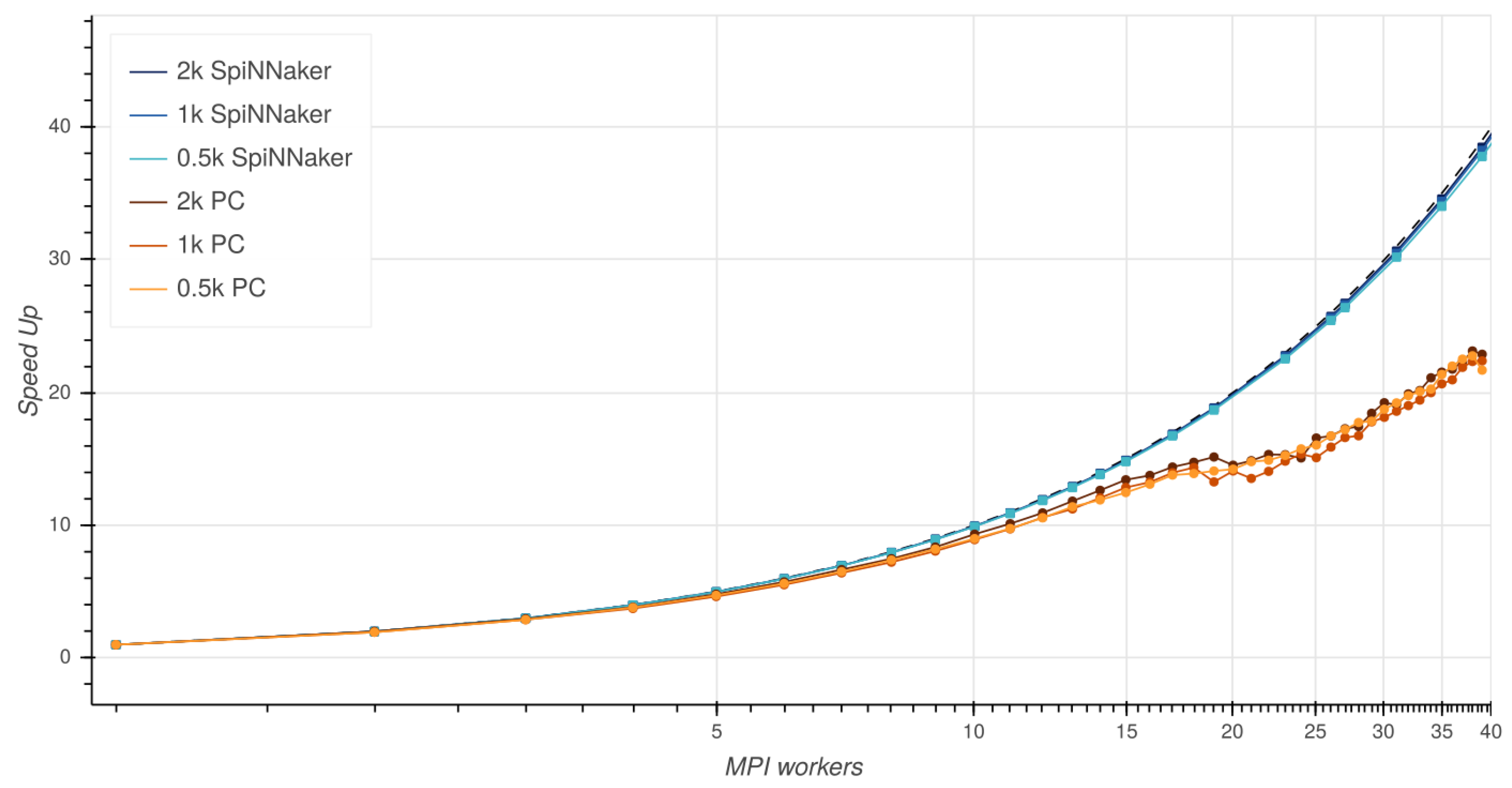
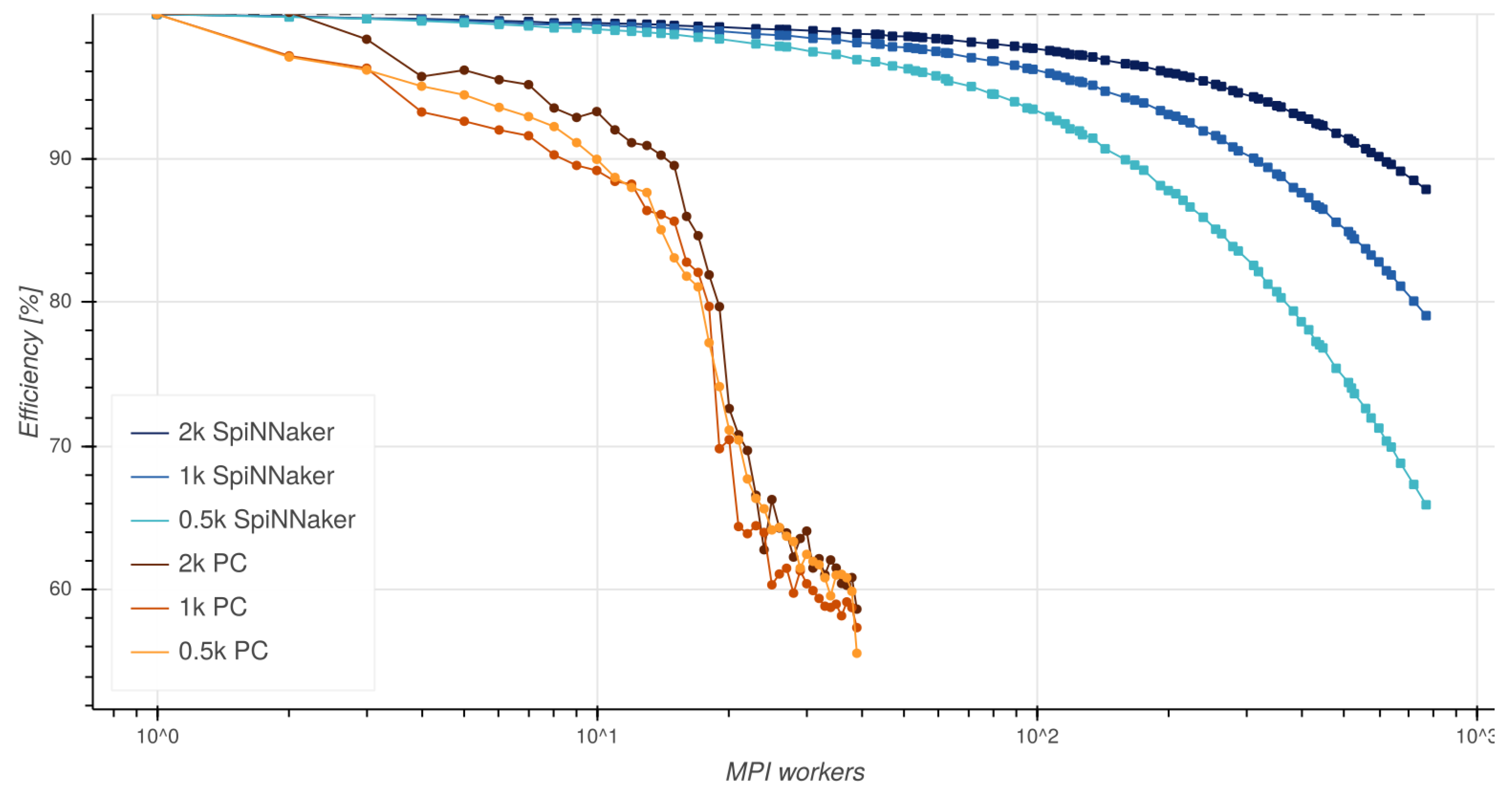
4.1. Performance of MPI on SpiNNaker
4.2. Evaluation of Boyer-Moore MPI Implementation Running on SpiNNaker
- Strong-scaling [28] keeps the size of the problem fixed and evaluates the application runtime when multiple processes are used. This strategy is suitable for CPU-bounded problems.
- Weak-scaling [29] is used to test the scalability of memory-bounded problems, as it keeps constant the ratio between the problem size and the number of working processes used.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SpiNNaker | Spiking Neural Network Architecture |
| Dynap-SEL | Dynamic Asynchronous Processor Scalable and Learning |
| BrainScaleS | Brain-inspired multiscale computation in neuromorphic hybrid systems |
| FED | Fast string matching method for Encoded DNA sequences |
References
- Mead, C. Neuromorphic electronic systems. Proc. IEEE 1990, 78, 1629–1636. [Google Scholar] [CrossRef]
- Boahen, K.A. Point-to-point connectivity between neuromorphic chips using address events. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 2000, 47, 416–434. [Google Scholar] [CrossRef]
- Furber, S. To build a brain. IEEE Spectr. 2012, 49, 44–49. [Google Scholar] [CrossRef]
- Liu, C.; Bellec, G.; Vogginger, B.; Kappel, D.; Partzsch, J.; Neumärker, F.; Höppner, S.; Maass, W.; Furber, S.B.; Legenstein, R.; et al. Memory-efficient deep learning on a SpiNNaker 2 prototype. Front. Neurosci. 2018, 12, 840. [Google Scholar] [CrossRef]
- Blin, L.; Awan, A.J.; Heinis, T. Using Neuromorphic Hardware for the Scalable Execution of Massively Parallel, Communication-Intensive Algorithms. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018; pp. 89–94. [Google Scholar] [CrossRef]
- Sugiarto, I.; Liu, G.; Davidson, S.; Plana, L.A.; Furber, S.B. High performance computing on spinnaker neuromorphic platform: A case study for energy efficient image processing. In Proceedings of the 2016 IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Barchi, F.; Urgese, G.; Macii, E.; Acquaviva, A. An Efficient MPI Implementation for Multi-Core Neuromorphic Platforms. In Proceedings of the 2017 New Generation of CAS (NGCAS), Genova, Genoa, 6–9 September 2017; pp. 273–276. [Google Scholar] [CrossRef]
- Furber, S. Large-scale neuromorphic computing systems. J. Neural Eng. 2016, 13, 051001. [Google Scholar] [CrossRef]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A survey of neuromorphic computing and neural networks in hardware. arXiv 2017, arXiv:1705.06963. [Google Scholar]
- Young, A.R.; Dean, M.E.; Plank, J.S.; Rose, G.S. A Review of Spiking Neuromorphic Hardware Communication Systems. IEEE Access 2019. [Google Scholar] [CrossRef]
- Schemmel, J.; Grübl, A.; Hartmann, S.; Kononov, A.; Mayr, C.; Meier, K.; Millner, S.; Partzsch, J.; Schiefer, S.; Scholze, S.; et al. Live demonstration: A scaled-down version of the brainscales wafer-scale neuromorphic system. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems, Seoul, Korea, 20–23 May 2012; p. 702. [Google Scholar] [CrossRef]
- Moradi, S.; Qiao, N.; Stefanini, F.; Indiveri, G. A scalable multicore architecture with heterogeneous memory structures for dynamic neuromorphic asynchronous processors (dynaps). IEEE Trans. Biomed. Circuits Syst. 2017, 12, 106–122. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L. The spinnaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Furber, S.; Lester, D.; Plana, L.; Garside, J.; Painkras, E.; Temple, S.; Brown, A. Overview of the SpiNNaker System Architecture. Comput. IEEE Trans. 2013, 62, 2454–2467. [Google Scholar] [CrossRef]
- Brown, A.D.; Furber, S.B.; Reeve, J.S.; Garside, J.D.; Dugan, K.J.; Plana, L.A.; Temple, S. SpiNNaker— Programming model. IEEE Trans. Comput. 2015, 64, 1769–1782. [Google Scholar] [CrossRef]
- Urgese, G.; Barchi, F.; Macii, E. Top-down profiling of application specific many-core neuromorphic platforms. In Proceedings of the 2015 IEEE 9th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, Turin, Italy, 23–25 September 2015; pp. 127–134. [Google Scholar] [CrossRef]
- Urgese, G.; Barchi, F.; Macii, E.; Acquaviva, A. Optimizing network traffic for spiking neural network simulations on densely interconnected many-core neuromorphic platforms. IEEE Trans. Emerg. Top. Comput. 2018, 6, 317–329. [Google Scholar] [CrossRef]
- Rowley, A.G.D.; Brenninkmeijer, C.; Davidson, S.; Fellows, D.; Gait, A.; Lester, D.; Plana, L.A.; Rhodes, O.; Stokes, A.; Furber, S.B. SpiNNTools: The execution engine for the SpiNNaker platform. Front. Neurosci. 2019, 13, 231. [Google Scholar] [CrossRef] [PubMed]
- Rhodes, O.; Bogdan, P.A.; Brenninkmeijer, C.; Davidson, S.; Fellows, D.; Gait, A.; Lester, D.R.; Mikaitis, M.; Plana, L.A.; Rowley, A.G.; et al. sPyNNaker: A Software Package for Running PyNN Simulations on SpiNNaker. Front. Neurosci. 2018, 12. [Google Scholar] [CrossRef] [PubMed]
- Barchi, F.; Urgese, G.; Siino, A.; Di Cataldo, S.; Macii, E.; Acquaviva, A. Flexible on-line reconfiguration of multi-core neuromorphic platforms. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Soni, K.K.; Vyas, R.; Sinhal, A. Importance of String Matching in Real World Problems. Int. J. Eng. Comput. Sci. 2014, 3, 6371–6375. [Google Scholar]
- Boyer, R.S.; Moore, J.S. A fast string searching algorithm. Commun. ACM 1977, 20, 762–772. [Google Scholar] [CrossRef]
- Horspool, R.N. Practical fast searching in strings. Softw. Pract. Exp. 1980, 10, 501–506. [Google Scholar] [CrossRef]
- Reinert, K.; Dadi, T.H.; Ehrhardt, M.; Hauswedell, H.; Mehringer, S.; Rahn, R.; Kim, J.; Pockrandt, C.; Winkler, J.; Siragusa, E.; et al. The SeqAn C++ template library for efficient sequence analysis: A resource for programmers. J. Biotechnol. 2017, 261, 157–168. [Google Scholar] [CrossRef]
- Kim, J.W.; Kim, E.; Park, K. Fast Matching Method for DNA Sequences. In Combinatorics, Algorithms, Probabilistic and Experimental Methodologies; Chen, B., Paterson, M., Zhang, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 271–281. [Google Scholar]
- Xue, Q.; Xie, J.; Shu, J.; Zhang, H.; Dai, D.; Wu, X.; Zhang, W. A parallel algorithm for DNA sequences alignment based on MPI. In Proceedings of the 2014 International Conference on Information Science, Electronics and Electrical Engineering, Sapporo, Japan, 26–28 April 2014; Volume 2, pp. 786–789. [Google Scholar]
- Amdahl, G.M. Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities. In Proceedings of the AFIPS ’67 Spring Joint Computer Conference, Atlantic, NJ, USA, 18–20 April 1967; pp. 483–485. [Google Scholar]
- Gustafson, J.L. Reevaluating Amdahl’s Law. Commun. ACM 1988, 31, 532–533. [Google Scholar] [CrossRef]
- Intel Xeon Processor Scalable Family, Datasheet, Volume One: Electrical. 2018. Available online: https://www.intel.com/content/www/us/en/processors/xeon/scalable/xeon-scalable-datasheet-vol-1.html (accessed on 1 November 2019).
- Painkras, E.; Plana, L.A.; Garside, J.; Temple, S.; Galluppi, F.; Patterson, C.; Lester, D.R.; Brown, A.D.; Furber, S.B. SpiNNaker: A 1-W 18-Core System-on-Chip for Massively-Parallel Neural Network Simulation. IEEE J. Solid-State Circuits 2013, 48, 1943–1953. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cores | Time (ms) | Memory Usage |
|---|---|---|
| 2 | 4.0 | 0.128 |
| 192 | 18.0 | 0.165 |
| 384 | 20.0 | 0.204 |
| 576 | 21.0 | 0.242 |
| 768 | 22.79 | 0.280 |
| Data Size | Time (ms) |
|---|---|
| 1 kB | 2.07 |
| 2 kB | 4.12 |
| 4 kB | 8.24 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urgese, G.; Barchi, F.; Parisi, E.; Forno, E.; Acquaviva, A.; Macii, E. Benchmarking a Many-Core Neuromorphic Platform With an MPI-Based DNA Sequence Matching Algorithm. Electronics 2019, 8, 1342. https://doi.org/10.3390/electronics8111342
Urgese G, Barchi F, Parisi E, Forno E, Acquaviva A, Macii E. Benchmarking a Many-Core Neuromorphic Platform With an MPI-Based DNA Sequence Matching Algorithm. Electronics. 2019; 8(11):1342. https://doi.org/10.3390/electronics8111342
Chicago/Turabian StyleUrgese, Gianvito, Francesco Barchi, Emanuele Parisi, Evelina Forno, Andrea Acquaviva, and Enrico Macii. 2019. "Benchmarking a Many-Core Neuromorphic Platform With an MPI-Based DNA Sequence Matching Algorithm" Electronics 8, no. 11: 1342. https://doi.org/10.3390/electronics8111342