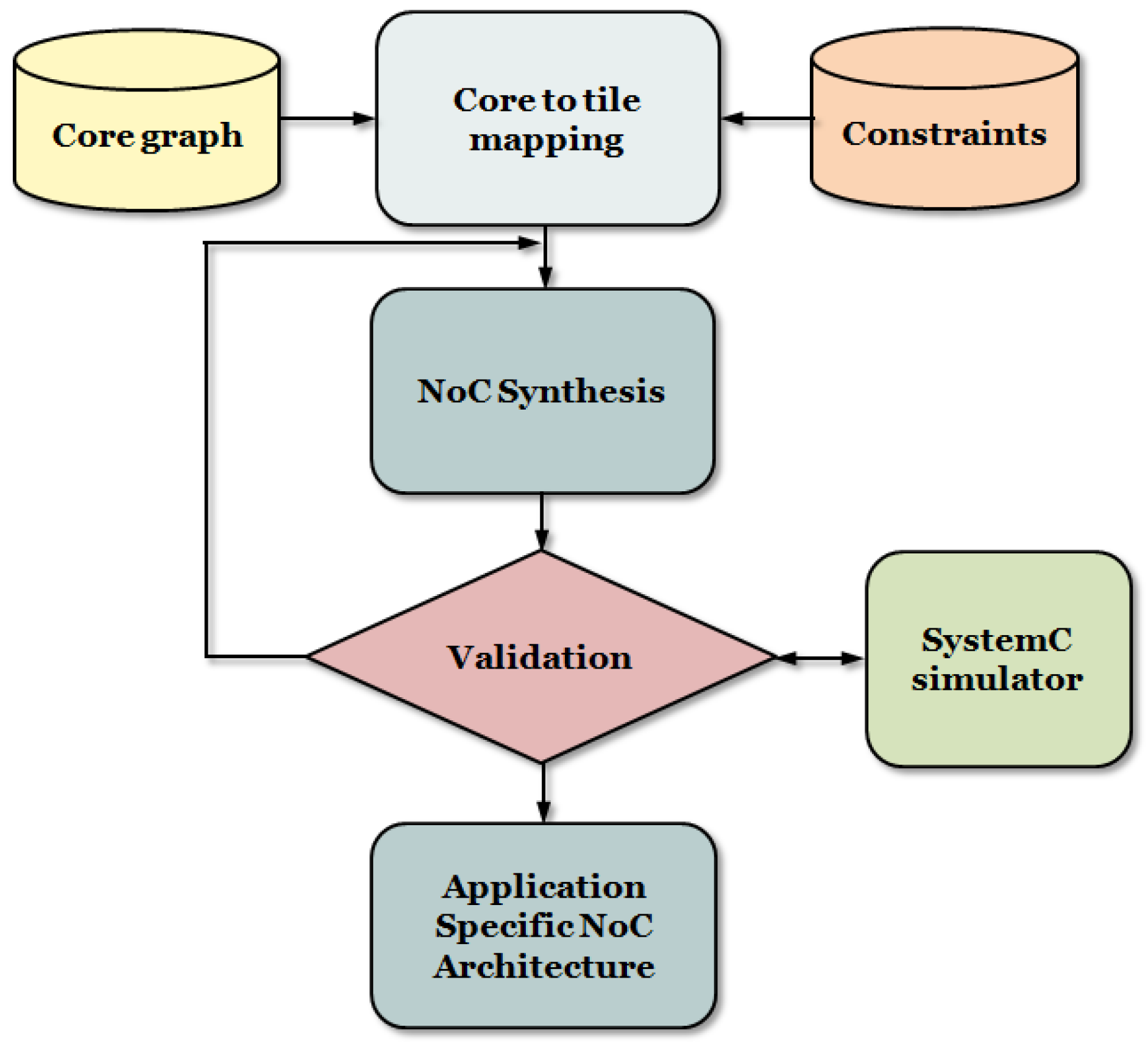
In this subsection, we present details of each of the four NoC synthesis heuristics based on Particle Swarm Optimization (PSO), Ant Colony Optimization (ACO), Simulated Annealing (SA), and Genetic Algorithm (GA) that we utilize to perform hybrid photonic NoC synthesis.
5.2.1. Particle Swarm Optimization (PSO)
The Particle Swarm Optimization (PSO) metaheuristic was initially proposed by R. Eberhart and J. Kenned [
16] in 1995. The fundamental idea behind PSO is inspired by the coordinated and collective social behavior of species such as a flock of birds, fish, termites, or even humans. In nature, each individual bird, bee, or fish shares some information with its neighbors and by utilizing shared information collectively, they strive to organize efforts such as developing flying patterns to minimize aerodynamic drag,
etc. Although by itself, a single entity such as a bird or a bee is a simple and unsophisticated creature, collectively as part of a swarm they can perform complex and useful tasks such as building nests, and foraging. Within the PSO framework, an individual entity is called a particle and it shares information with other particles, either in the form of direct or indirect communication to coordinate their problem-solving activities. In recent years, the PSO algorithm has been applied to many combinatorial optimization problems such as optimal placement of wavelength converters in WDM networks [
38] and reconfiguration of field-programmable analog circuits [
39].
To implement the PSO algorithm, particles are placed in the search space of some problem, and each particle evaluates the objective function at its current location to determine its next movement by combining the best (best-fitness) locations in the vicinity. The next iteration takes place after all particles are relocated to the new position. This process is repeated for all particles and eventually for the swarm as a whole. A particle on its own does not have the power to solve the problem; rather the solution evolves as the particles interact and work together, utilizing a social network consisting of bidirectional communication. As the algorithm iterates, particles move towards local as well as global solution optima forming a swarm pattern. For example, when one particle or entity finds a good solution, other particles in the vicinity are likely to be attracted to it. This social interaction feedback eventually causes all particles to move towards a globally optimal solution path. The phenomenon is similar to the social interactions where a leader or a set of leaders emerge from the swarm and followers attempt to follow them. In summary, the key idea in PSO is to mimic the social collective behavior found in nature and utilizing it to solve complex problems.
Figure 3 shows the pseudo-code for our PSO formulation, for the hybrid photonic NoC synthesis problem. The algorithm starts by initializing each particle with the function call InitializeParticles(). This function initializes inertia and learning weights (as discussed later in the section), and initial position and velocity for each parameter from
Table 1. The UpdateParticleSystem() function iterates and updates velocity and positions of the individual particles, using relations (1) and (2) that are presented later in this section. At the end of the evaluation loop, particle positions are updated and they are moved to new positions by calling the UpdatePositionMatrix() function. This process continues for the application, until a dominating (global) solution emerges.
In our adaptation of the PSO algorithm for the hybrid photonic NoC synthesis problem, a particle represents a unique communication request from a source to a destination. A group of particles or solutions are initialized at the beginning of the PSO execution and then the optimal or near optimal solution is constructed using an iterative process. The PSO algorithm selects among various values for the parameters in
Table 1 for each particle. Gradually one dominant solution emerges. This best configuration has a unique value for each of the parameters in
Table 1, and satisfies application-specific latency constraints, while minimizing power.
Within an iteration, a particle tracks the personal best solution (pk), which is the best solution found by the particle k, and the global best solution
(gk), which is the best solution that was found by the entire population. Every particle moves towards the better solutions with some velocity and position. The computation step includes some amount of randomness instead of following an exact profile. This randomness can produce a superior solution, which may result in other particle being attracted towards it. In our implementation of the PSO algorithm, each particle updates its velocity and position based on the following set of equations:
where, the current velocity and position for each particle is defined by v
k and x
k respectively; p
k represents the current best solution based on particle k’s history and g
k defines the current best solution based on the entire population or swarm. The positive inertial weight w is assigned to control how fast or slow each particle can move based on its own weight or inertia, c
1 and c
2 are constant numbers that represent learning weights to control the learning rate of global
vs. local optima,
i.e., the higher the weight, the faster the particles gravitate towards the solution. Instead of just following the current best solution in a linear path, r
1 and r
2 are random numbers from 0 to 1 that change every iteration, adding randomness to the path, thus finding newer and better solutions on the way.
The stability of the PSO algorithm is one of the key concerns during implementation, where position and velocity can diverge instead of achieving convergence. To ensure solution convergence in our implementation, we tune the learning and inertial weights carefully and also implement a velocity limit parameter Vmax, where if the updated velocity exceeds the velocity limit, we saturate the velocity value to Vmax.
5.2.2. Ant Colony Optimization (ACO)
The Ant Colony Optimization (ACO) metaheuristic was proposed by Colorni, Dorigo, and Maniezzo [
17] with the fundamental idea inspired by the behavior of real ants, specifically, the way they organize efforts to collect food. ACO is a probabilistic technique for solving computational problems which can be reduced to finding good paths through graphs. In recent years, this algorithm has been applied to many combinatorial optimization problems such as the asymmetric traveling salesman problem [
31] and the graph coloring problem [
32].
Although by itself, an ant is a simple and unsophisticated creature, collectively a colony of ants can perform useful tasks such as searching for food. Ants achieve stigmergic communication by laying down a chemical substance called pheromone, which can be sensed by other ants. When a pheromone trail laid by an ant that has found food is discovered by other ants, they tend to stop moving randomly and start following this specific trail, returning and reinforcing it if they eventually find food. Over time however, the pheromone trail starts to evaporate, thus reducing its attractive strength. The more time it takes for an ant to travel down the path and back again, the more time the pheromones have to evaporate. A short path, by comparison, gets marched over more frequently, and thus the pheromone density becomes higher on shorter paths than longer ones. Pheromone evaporation is crucial for avoiding the convergence to a locally optimal solution. If there were no evaporation at all, the paths chosen by the first ants would tend to be excessively attractive to the following ones. In that case, the exploration of the solution space would be constrained. The key idea of our ACO based hybrid photonic NoC synthesis algorithm is to mimic this behavior with “simulated ants” walking around a graph representing the problem to solve.
An ant in our formulation can be thought of as a simple computational agent that helps iteratively construct a solution for our synthesis problem. The intermediate solutions are referred to as solution states. At each iteration of the algorithm, an ant k moves probabilistically from a state i to state j. Each of the parameters from
Table 1 has a separate evaporation trail value (τ
ij) that represents the amount of pheromone deposited for a state transition between i and j. The selection probability for a parameter is a function of its attractiveness
, defined by inverse of normalized power consumption for parameter β. Global convergence within the selection process is achieved by increasing attractiveness
for low power dissipation solutions that meets latency constraints.
An empirically-derived pheromone evaporation coefficient (ρ) with a value 1 > (ρ) > 0 is utilized to control the evaporation of a trail over time. Trails are updated usually when all ants have completed their solution, increasing or decreasing the value of trails corresponding to moves that were part of “good” or “bad” solutions, respectively. Δτ
ij represents the change in trail value based on the choices available for a parameter, and the impact they have on the cost function (in our case power dissipation). At the start of simulation, selection probability of each parameter is equal. If power dissipation reduces significantly based on a parameter change for a majority of the communications, then Δτ
ij increases which causes the resulting selection probability to also increase. The selection for each parameter is performed using the following rules:
which is the trail update relation, with Δτ
ij given by:
for all
m ants. The probability
of moving from state
i to
j for the
kth ant is given as:
This probability depends on the attractiveness of the move computed based on increasing a tunable weight for an ant for which power is lower and latency is within the constraints, and the trail level τij of the move, indicating how proficient it has been in the past to make that particular move. α ≥ 0 is a parameter to control the influence of τij, and β ≤ 1 controls the influence of ηij.
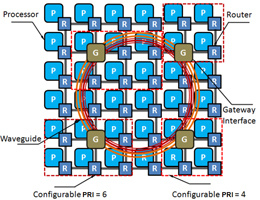
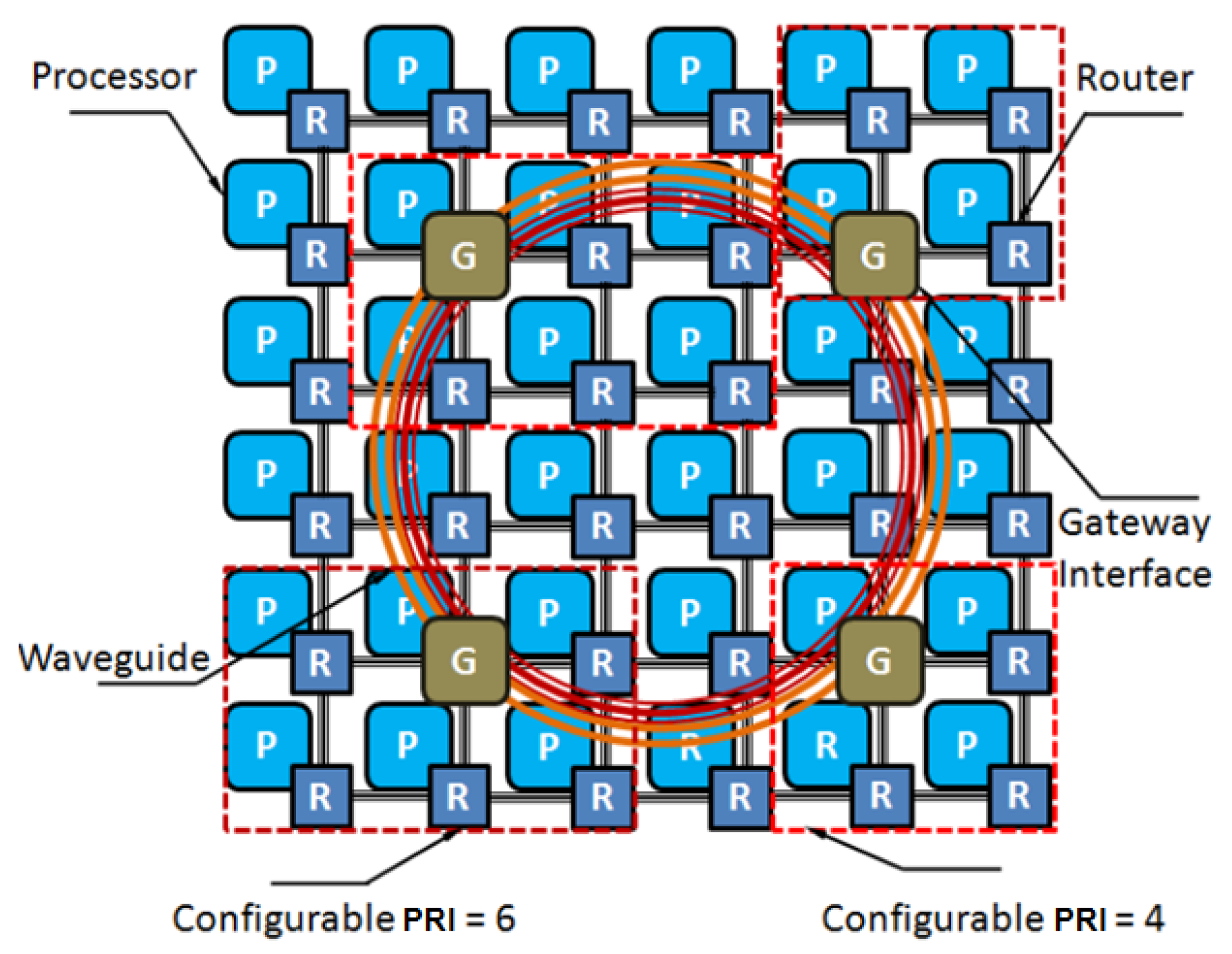
Figure 4 shows the pseudo-code for our ACO formulation to solve the hybrid photonic NoC synthesis problem. The algorithm starts by calling InitializeAntSystem() to initialize the ant system, with each ant representing a unique communication trace between a pair of cores. The function also sets up equal selection probability for every parameter. The function UpdateAntSystem() updates the probabilities of the individual ants, using Relations (3), (4), and (5). If the source core lies within a PRI region, the flow (ant) is directed towards the nearest gateway interface. The state transition parameter selection probability
is applied to select serialization degree, clock frequency, flit width, and PRI data threshold. Once a flit reaches the uplink, number of waveguides and WDM density are selected for the next state. The same process is repeated for the destination gateway interface and destination core. As ants reach the destination, trail values are updated based on Equations (4) and (5), improving selection probability of parameters that lead to lower power dissipation. At the end of the evaluation loop, the trail and pheromone updates are performed by calling UpdateTrailMatrix(). This process continues until a dominant solution emerges.
5.2.3. Simulated Annealing (SA)
Simulated Annealing (SA) algorithms [
14,
41,
42] generate solutions to optimization problems using techniques inspired by annealing in solids. SA algorithms simulate the cooling of a metal in the heat bath known as annealing where the structural properties depend on the cooling rate. When a metal is hot and in liquid state, if cooled in a controlled fashion, large and consistent grains can be formed. On the other hand, grains may contain imperfections if the liquid is quenched or cooled rapidly. The key idea in SA algorithms is that by slowly lowering the temperature, globally optimal solutions can be approached asymptotically. SA allows hill climbing (
i.e., moves with inferior quality) to be taken within the initial part of the iteration process to escape local minima.
An SA algorithm involves the evolution of an individual solution over a number of iterations, with a fitness value used for evaluating solution quality whose determination is problem dependent. Based on the law of thermodynamics, at temperature
t the probability of an increase in energy of magnitude
δE is given by:
where
k is the Boltzmann’s constant. This equation is directly applied to SA by dropping the Boltzmann constant which was only introduced into the equation to cope with different materials. The probability of accepting a state in SA is:
where
r is a random number between 0 and 1,
c defines the change in evaluation function output,
t defines current temperature which is decremented at every iteration by a regression algorithm involving a linear method
t(k+1) = α.t(k), where
α < 1 (our chosen value for
α is presented in the Experimental Setup section (
Section 6.1)). At each iteration, values for individual parameters (from
Table 1) are selected randomly for the current solution and the probability of accepting the solution is determined by Equation (7). A high enough starting temperature (T
0) is selected to allow movement through the entire search space. As the algorithm progresses, the temperature is cooled down to confine solutions, allowing better solutions to be accepted until the final temperature is reached. As SAs are heuristics, the solution found is not always guaranteed to be optimal. However in practice, SA has been used successfully to generate high quality solutions in several problem domains.
Figure 5 shows the pseudo-code of our SA formulation for the hybrid photonic NoC synthesis problem. Our SA implementation begins by calling GenerateInitialSolution() to generate an initial solution, where parameters from
Table 1 in the solution are populated with randomly chosen valid values. Subsequently, four key parameters for annealing are initialized by calling ScheduleCoolingRate(): (i) Starting temperature; (ii) Temperature decrement; (iii) Final temperature, and
(iv) Iterations at each temperature. We tuned the starting temperature to be hot enough to allow our hybrid photonic NoC synthesis parameters to traverse farther along in the solution space. Without this consideration, the final solution would be very close to the starting SA solution. Based on the number of iterations for which the algorithm will be running, the temperature needs to be decremented such that it will eventually arrive at the stopping criterion. We also need to allow enough iterations at each temperature such that the system stabilizes at that temperature. We evaluated a method first suggested in [
43] that proposes implementing one iteration at each temperature by decreasing the temperature very slowly. The formula we used was
t(k+1) =
t(k)/(1 +
βt(k+1)) where β is a suitably small value as defined in [
43]. However the approach did not yield any benefits in terms of improvement in results. The fitness value is updated by calling ComputeFitnessValue(), and the process continues until temperature decays below a certain threshold or a predefined number of iterations have passed. The fitness value we use in our SA algorithm is a weighted combination of average packet latency and communication power dissipation.
5.2.4. Genetic Algorithm (GA)
Genetic algorithms (GAs) [
15] generate solutions to optimization problems using techniques inspired by natural evolution, such as inheritance, mutation, selection, and crossover. A GA involves the evolution of a population of individuals over a number of generations. Each individual of the population is assigned a fitness value whose determination is problem dependent. At each generation, individuals are selected for reproduction based on their fitness value. Such individuals are crossed to generate new individuals, and the new individuals are mutated with some probability.
Figure 6 shows the pseudo-code of the GA formulation for our hybrid photonic NoC synthesis problem. Our GA implementation begins with the generation of an initial population by calling GenerateInitialPopulation(). Each individual element of this population consists of a chromosome with constituent parameters as defined in
Table 1. Thus, each chromosome in the population represents a unique solution to our hybrid photonic NoC synthesis problem. Based on empirical analysis, we set our GA population size to 2000, composed of chromosomes with parameter values set according to a uniform random distribution. The fitness value assigned to each chromosome consists of a weighted combination of average packet latency and communication power dissipation. The fitness is evaluated analytically based on the communication requirements of the application for which the hybrid NoC is being synthesized. Each application can have a unique set of communication patterns (represented by edges in the core graph), and thus the same architectural optimization (e.g., changing PRI size) can impact the latency and power dissipation of different applications differently.
Similar to a roulette wheel, a probability based selection process was implemented for choosing chromosomes from the population to perform crossover and mutation on. Crossover was applied to randomly paired parameters of selected chromosome pairs by exchanging genetic information via swapping bits within the parent’s chromosome (by calling Crossover()). We also implemented multipoint crossovers where multiple parts of chromosome strings replaced each other. Then mutation was performed by calling Mutation(), where one parameter was changed within allowable limits (as defined in
Table 1). Mutations and crossovers produced the chromosomes for the next generation, and the process continues iteratively till a termination criteria is met.
As GA is a stochastic search algorithm, it is difficult to formally specify convergence criteria based on optimality. The results are expected to get better with every generation, however sometimes the fitness of a population, calculated by calling ComputeFitnessValue(), may remain unchanged for a number of generations before any superior chromosomes can be created. The general practice is to terminate the GA after a predefined number of generations and then to evaluate the quality of the results within the population against the expected optimal, where expected optimal is obtained using extended GA runs or iterations.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}