This section introduces the nature of the electric energy consumption data and provides the basic concepts of time series and feature-based clustering. The data used in this work, the characteristics calculated for the feature-based clustering approach and the basic notions of the clustering algorithms used are all described here.
Electric energy consumption data are usually represented as a time series through a discrete sequence of data points measured at equal time intervals.
In the context of these particular data, each time series represents a sequence of sensor data collected over time. Therefore, the data can be viewed as an energy consumption data matrix EM. EM is a real matrix, where each element represents the electric energy consumption of a feeder (expressed in kWh) as measured by sensor i at the hour t.
3.2. Data Preprocessing
A couple of transformations were applied to the data set to reduce the error in the results. The first step was normalizing the time stamp value. For example, 23:59:59 on a given day was converted to 00:00:00 of the next day. The elimination of negative and zero electric consumption records was applied. Since the collected data did not have a standard timing interval (records were saved every thirty minutes in some periods; in others every hour), the next step was the hourly frequency normalization. All records that did not match an o’clock time were removed from the set. Before the outlier detection and data imputation phase, feeders with less than of records were discarded. After all the preprocessing, 24 records per day from each feeder were expected over four years, i.e., feeders with less than 31.536 records were removed.
The result of these steps is a reduced data set made of 55 feeders distributed in 14 substations with at least of recorded hourly data during said four-year period.
With the reduced data set, outlier detection was performed using the algorithm proposed by Vallis et al. [
30]. This algorithm requires a full data set. Thus, a linear interpolation to fill the gaps was needed before running it.
The Box–Cox transformation [
31] was also used to stabilize the variance in the data, so that they remained stationary and obtained an additive time series as described by Chatfiel [
32] and Hyndman et al. [
33]. This resulted in
as the Box–Cox transformation of
X. Given the time series
, this algorithm implements the Seasonal and Trend decomposition using LOESS (STL) [
34] to obtain the components of seasonality
, trend
and remainder
, such that
. This decomposition method allows the seasonal component to be varied according to the nature of the series; simultaneously, it is robust to the presence of outliers.
After this, the remainder component was recalculated as
, where
is the median of the data considering a non-overlapping moving window of two-week length as described in [
30]. Then, the generalized extreme studentized deviate (ESD) test [
35] was applied over the resulting remainder component using both median and median absolute deviation to detect outliers as described by Vallis et al. [
30].
Finally, the inverse Box–Cox transformation was run. The outliers, as well as the interpolated values that were added at the beginning of this phase, were removed. The outliers quantity per feeder is shown in
Figure 1.
After all outliers and unwanted records were discarded, the historical average data imputation technique [
36] was applied to estimate each missing record
as an average of
representative historical records
, where
. The set
included all historical records where the day of the week (DOW) is the same as the one on the missing record and within selected spans of it. The DOW guaranteed that historical means were calculated over records of the same days of the week and similar seasonal characteristics. The selected DOW span for this analysis was ±6 weeks. The resulting data set contained 1,848,947 records of 55 feeders distributed over 14 substations.
Figure 2 shows the percentage and number of records per feeder.
3.3. Data Sets and Features
In this section, the making of the four data sets used is explained.
The first data set provided the weekly demand registered by the feeders. Calculations considered a Sunday-to-Saturday span, resulting in a time series of 207 records. Sunday was chosen because the time series of the feeders began on that day, on 1 January 2017. Thus, an equitable distribution of the days for each week was obtained from the start. However, some days were dropped, even in the middle of the time series, due to missing data and some weeks yielded data with less than seven days.
The second data set contained the monthly demand, with a time series of 48 records. As on the first data set, some months had fewer data than others due to discarded data. December 2020 was the month with the fewest observations, only 16 days.
The third data set was considered from the work performed by Rasanen et al. [
29]. Seven statistical features were extracted from each of the feeders in a window of size equal to one calendar week
throughout the entire time series, where
weeks. It should be noted that, although
corresponds to one week, it presents different lengths due to missing values in certain weeks.
Therefore, the features used were: mean (
), standard deviation (
), skewness (
), kurtosis (
), maximum Lyapunov exponent (
), energy (
) and periodicity (
). The mean, calculated by Equation (
1), indicates the central value of the analyzed data. In contrast, the standard deviation (Equation (
2)) indicates a measure of the dispersion of the data.
Skewness (Equation (
3)) is a measure that indicates the degree of asymmetry in the distribution of the demand data [
37]. Kurtosis (Equation (
4)) is related to the tails in the distribution. High Kurtosis indicates greater extremity of deviations [
37].
Likewise, chaotic dynamical systems are common natural and artificial phenomena, including energy demand. The measured time series comes from the attractor of an unknown system with a certain ergodicity. In other words, it refers to a set of numerical values towards which the system evolves. This ergodicity contains the attractor information [
38]. The maximum Lyapunov exponent (MLE) is the most used quantity measured on chaotic systems, as it describes the exponential divergence of nearby trajectories. For the case of a time series
, a
-dimensional phase attractor with delay coordinates is considered, i.e., a point on the attractor is represented by
, where
describes the almost arbitrarily considered delay and
the embedding dimension. Then, a initial point
is chosen and the nearest neighbor to it is determined [
39]. The initial separation between these two selected points is represented by the vector
. Therefore, the system diverges approximately at a rate given by
, where
is the maximum Lyapunov exponent and
the sampling period. Hereof,
became more accurate when
. Therefore, it was estimated as the mean rate of separation of the nearest neighbors across the samples. Thus, the MLE was expressed according to Equation (
5).
The energy present was also considered and was obtained using the fast Fourier transform (FFT) [
40]. For this purpose, the resulting Fourier transform sequence was comprised by
. Given this, the energy calculation was performed by adding the squares of the magnitudes of the resultant components; then, it was divided by the length of the sequence (
) to normalize the calculated measurement (Equation (
6)).
Finally, another highly relevant measure to assimilate the behavior of the time series is periodicity. To obtain it, a periodogram was determined to estimate the power spectral density, which also uses the FFT as the basis of the calculation. This function indicates the distribution of the frequencies present in the signal given by the time series. Hereof, the most powerful frequency was selected and converted into an hourly period value via Equation (
7).
where
represents the power spectral density in the frequency domain
and
the period converted to hours, in which the power is higher.
The fourth data set was built in order to capture seasonal and daily effects on the energy demand, as in Haben et al. [
41]. Consequently, each day was divided into five relevant periods that characterized the behavior of daily demand as shown in
Figure 3. It is important to note that these periods were defined considering the Paraguayan electricity demand curve. Therefore, they are different from the proposal presented in [
41]. The intervals of the chosen time periods are detailed in
Table 1.
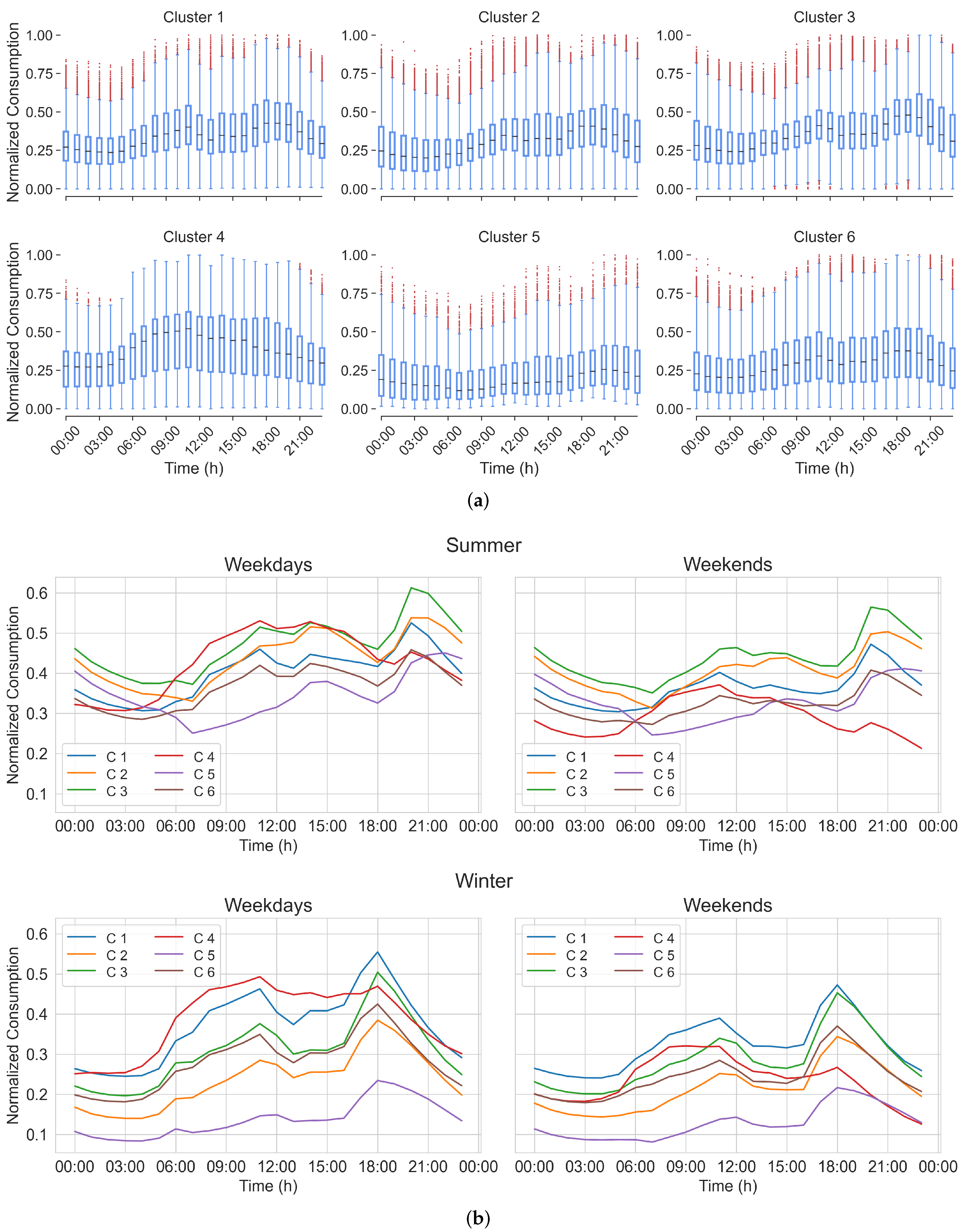
The features to be used were defined, taking into consideration such periods. For a specific feeder and each period over the entire time series, was represented as the mean electricity demand with corresponding to its standard deviation. Meanwhile, was considered as the mean daily demand over the complete time series. In each period, the mean demands corresponding to the summer and winter seasons, and , respectively, were also computed. Similarly, the mean demands on weekdays and weekends were considered in each period of the entire time series. They were noted as and , respectively. As a result, the following eight features were extracted:
Features from 1 to 5: The relative average power in each time period over the entire time series given by
Feature 6: Mean relative standard deviation over the entire time series given by
Feature 7: A seasonal score given by
Feature 8: A weekend vs. weekday difference score given by
It is important to mention that, for each data set obtained, the values of the preprocessed time series were scaled within a
range for each feeder, through the transformation
, since, otherwise, the clustering process would have been carried out as a function of the mean daily demand [
42]. Finally, the conformed data sets are represented in
Figure 4.
3.4. Distance Measurements
The work aims to find similarities in feeder consumption. Thus, it was essential to determine appropriate distance measures. Since one of the strategies was based on feature extraction, the use of Euclidean distance was reasonable. However, when considering the strategy based on patterns present in the consumption time series, the distance measure based on dynamic time warping (DTW) proved to be a better choice [
43], although the Euclidean distance showed some promising results that should be considered for experimentation [
7].
Therefore, for the time series approach, the definition of the Euclidean distance is such that, given two time series
and
of lengths
N, is represented as
In the case of feature extraction, x and y correspond to the arrangement of the considered features.
On the other hand, the DTW algorithm presents an efficient method that minimizes shifting and distortion effects. It includes a transformation that allows similar shapes with different phases between time series to be detected [
44]. Given the time series
and
of lengths
N, a cost matrix is created with objects that correspond to the all pairwise distance between the
x and
y components, such that
M:
for
. From here, the optimal warping path
is determined, where
represents the pair of indices of the selected components in the matrix
M. The value of L corresponding to the length of
is such that
. For the determination of
wp, there are three conditions to be followed. The first one corresponds to the boundary condition, in which
and
; thus, it is ensured that such a path starts at the beginning of both series and closes at the end. The second refers to the monotonicity condition, where it is fulfilled that
and
, in order to preserve the time-ordering of points. The third condition is known as the step size condition, whose criterion limits the warping path of the long jumps while aligning the series. This last condition is formulated as
. Then,
is composed in such a way that the cost function
is minimized. Finally, the DTW distance is expressed as
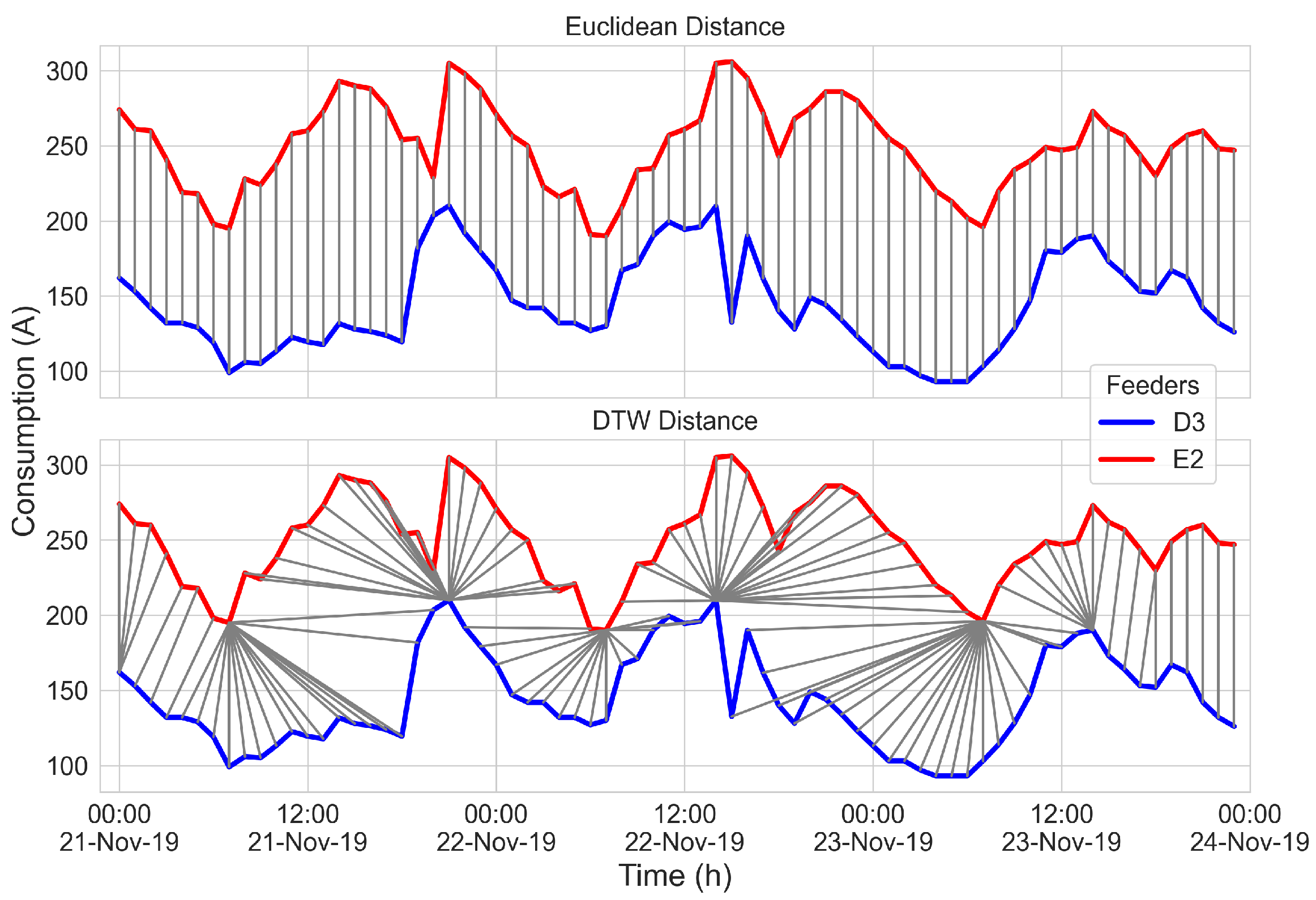
Figure 5 shows the difference between the components considered for the calculation of the distance between the D3 and E2 feeders, both Euclidean and DTW. The latter shows that the pairs of components considered were not necessarily located in the same temporal location.
3.6. Cluster Validity Indices
Since the task of grouping objects that share similar characteristics belongs to the area of unsupervised methods, it is challenging, at first, to select the number of sets to be considered. For this purpose, several clustering validation indices provide a quantitative criterion about the number of clusters formed. In this work, the Silhouette, Davies–Bouldin and Calinski–Harabasz validation indices were considered. They have shown promising results in comparative studies [
53] and also provide enough information to select the most optimal configuration.
The Silhouette index describes a measure of quality based on how similar an object is to those belonging to the same cluster (cohesion) in contrast to how dissimilar it is from those belonging to the nearest cluster (separation) [
54]. This index is normalized within a
range, where high values indicate a good conformation of the objects based on their similarities concerning the distinctions of the other clusters. In this case, the average of the Silhouette index scores for each component of a given cluster was considered. Since
represents the average distance of an
i-th sample for the others in the same cluster and
represents the average distance of the same sample with respect to those in the nearest cluster, the Silhouette index for a sample is represented by
Therefore, the average score of the Silhouette index is given by
where
N corresponds to the total amount of samples.
The Davies–Bouldin validation index represents the average similarity between clusters [
55]. In this case, the cohesion estimation is based on the average distance
between the centroid of a considered cluster
i and the objects that conform it. The separation is represented by the distance
between the centroids of the cluster
i and another cluster
j. Thus,
is maximized, where
represents the cohesion estimation for cluster
j. Therefore, the Davies–Bouldin index is represented by the expression
where
K indicates the number of clusters. The lowest score that can be obtained for this index is 0; values close to it indicate better clustering.
Finally, the Calinski–Harabasz validation index measures the ratio of the sum of the between-cluster dispersion and within-cluster dispersion for all clusters [
56]. In this sense, dispersion is defined as the sum of the squared distances. Therefore, when considering a set of objects
of size
, which have been clustered in one of the
K clusters, it is necessary to determine both the between-cluster dispersion matrix
B and the within-cluster dispersion matrix
W, expressed as
where
indicates the set of objects belonging to cluster
i,
the center of cluster
i,
the center of
and
the number of objects in cluster
i. Once this is carried out, the traces
and
corresponding to the matrices
B and
W, respectively, are considered. With them, the Calinski–Harabasz index is defined as
High scores indicate well separated and dense clusters, which is expected when the clustering algorithm is correctly applied.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}