
Light Field Image Quality Enhancement by a Lightweight Deformable Deep Learning Framework for Intelligent Transportation Systems

 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
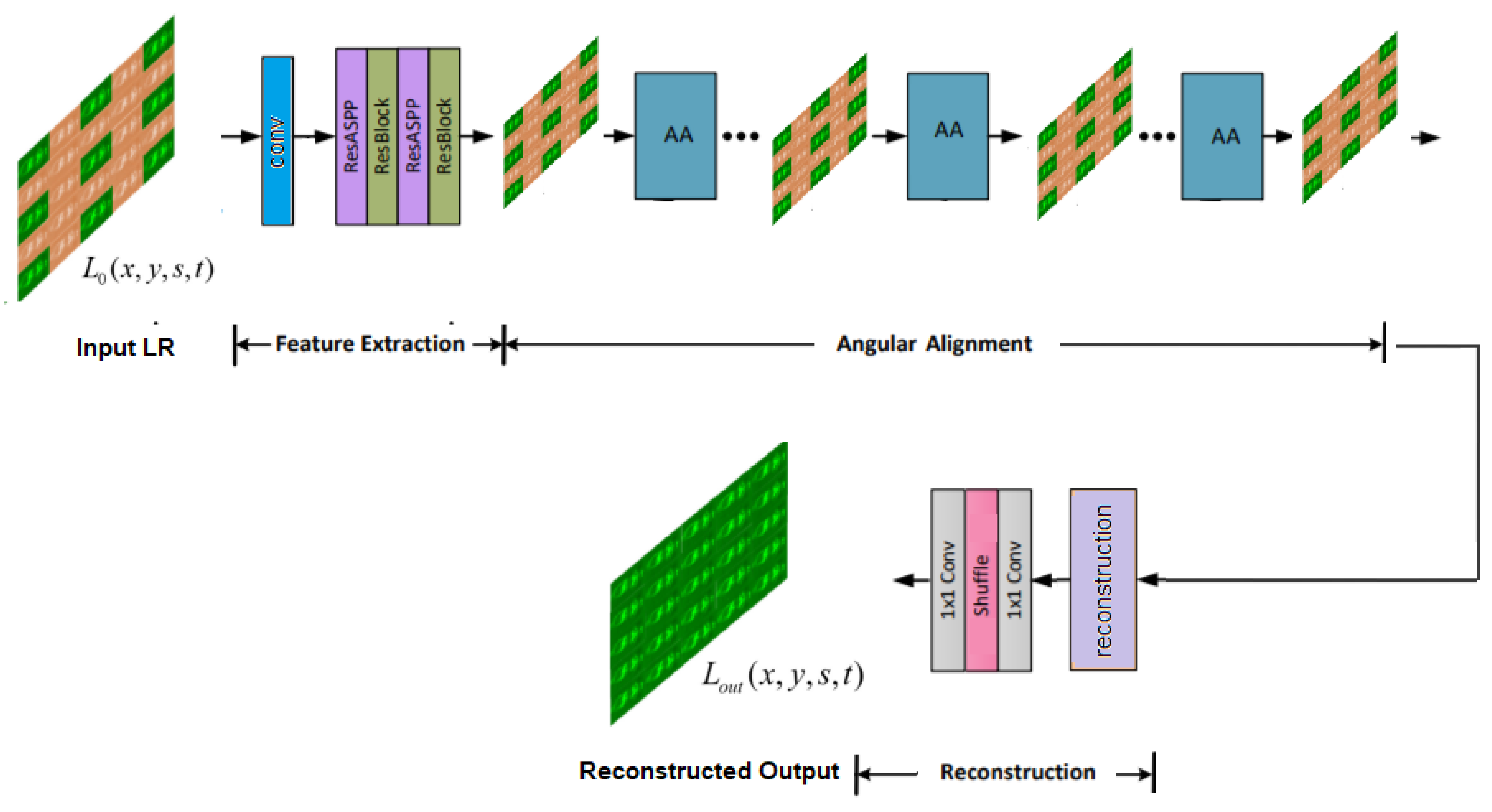
- An improved framework, which considers the feature extraction and angular alignment using the deformable convolution network approach, ruling out the use of applying a loss function.
- To reduce the computational complexity for LF SR images, a novel activation function is utilized, which is performed in the proposed CNN model. Thus, a lightweight solution to process LF SR images is obtained.
- The performance assessment of the proposed model is tested using recent databases. Experimental results demonstrated that our proposal reached a high accuracy for image reconstruction, obtaining a better performance in image quality than other similar works.
2. Related Works
2.1. Light Field Representation and Images
2.2. Frameworks Using Deep Learning Algorithms
3. Methodology
3.1. Proposed Framework
3.1.1. Feature Extraction
3.1.2. Angular Alignment
3.1.3. Reconstruction
3.2. Model of the Network
3.3. Details of Implementation of the CNN Model
3.4. Datasets
3.5. Evaluation of the Proposed Method through Comparison with Others’ Methods
4. Experimental Results
4.1. Angular Alignment in the Network Model
4.2. Image Quality Assessment
4.3. Computational Efficiency
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, G.; Masia, B.; Jarabo, A.; Zhang, Y.; Wang, L.; Dai, Q.; Chai, T.; Liu, Y. Light Field Image Processing: An Overview. IEEE J. Sel. Top. Signal Process. 2017, 11, 926–954. [Google Scholar] [CrossRef] [Green Version]
- Park, M.K.; Park, C.S.; Hwang, Y.S.; Kim, E.S.; Choi, D.Y.; Lee, S.S. Virtual-Moving Metalens Array Enabling Light-Field Imaging with Enhanced Resolution. Adv. Opt. Mater. 2020, 8, 2000820. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, G.; Shi, J.; Zhang, H.; Dai, G. Depth-guided view synthesis for light field reconstruction from a single image. Image Vis. Comput. 2020, 95, 103874. [Google Scholar] [CrossRef]
- Haydari, A.; Yilmaz, Y. Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2020, 1–22. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, Y.; Wang, G.; Xu, S. A Deep Learning Model for Transportation Mode Detection Based on Smartphone Sensing Data. IEEE Trans. Intell. Transp. Syst. 2020, 21, 5223–5235. [Google Scholar] [CrossRef]
- Kumar, N.; Rahman, S.S.; Dhakad, N. Fuzzy Inference Enabled Deep Reinforcement Learning-Based Traffic Light Control for Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Barbosa, R.C.; Ayub, M.S.; Rosa, R.L.; Rodríguez, D.Z.; Wuttisittikulkij, L. Lightweight PVIDNet: A priority vehicles detection network model based on deep learning for intelligent traffic lights. Sensors 2020, 20, 6218. [Google Scholar] [CrossRef]
- Veres, M.; Moussa, M. Deep Learning for Intelligent Transportation Systems: A Survey of Emerging Trends. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3152–3168. [Google Scholar] [CrossRef]
- He, P.; Wu, A.; Huang, X.; Scott, J.; Rangarajan, A.; Ranka, S. Truck and Trailer Classification With Deep Learning Based Geometric Features. IEEE Trans. Intell. Transp. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Lasmar, E.L.; de Paula, F.O.; Rosa, R.L.; Abrahão, J.I.; Rodríguez, D.Z. RsRS: Ridesharing Recommendation System Based on Social Networks to Improve the User’s QoE. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4728–4740. [Google Scholar] [CrossRef]
- Huh, J.H.; Seo, K. Artificial Intelligence Shoe Cabinet Using Deep Learning for Smart Home. In Advanced Multimedia and Ubiquitous Engineering; Park, J.J., Loia, V., Choo, K.K.R., Yi, G., Eds.; Springer: Singapore, 2019; pp. 825–834. [Google Scholar]
- Rosa, R.L.; Rodríguez, D.Z.; Bressan, G. SentiMeter-Br: A new social web analysis metric to discover consumers’ sentiment. In Proceedings of the IEEE International Symposium on Consumer Electronics (ISCE), Hsinchu, Taiwan, 3–6 June 2013; pp. 153–154. [Google Scholar] [CrossRef]
- Zinemanas, P.; Rocamora, M.; Miron, M.; Font, F.; Serra, X. An Interpretable Deep Learning Model for Automatic Sound Classification. Electronics 2021, 10, 850. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, G.; Jiang, Y.; Wang, B.; Soleimani, M. Application of Deep Neural Network to the Reconstruction of Two-Phase Material Imaging by Capacitively Coupled Electrical Resistance Tomography. Electronics 2021, 10, 1058. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Guimarães, R.; Rodríguez, D.Z.; Rosa, R.L.; Bressan, G. Recommendation system using sentiment analysis considering the polarity of the adverb. In Proceedings of the IEEE International Symposium on Consumer Electronics (ISCE), Sao Paulo, Brazil, 28–30 September 2016; pp. 71–72. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone Deep Reinforcement Learning: A Review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Wang, X.; Chan, K.C.; Yu, K.; Dong, C.; Loy, C.C. EDVR: Video Restoration with Enhanced Deformable Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1954–1963. [Google Scholar] [CrossRef] [Green Version]
- Militani, D.R.; de Moraes, H.P.; Rosa, R.L.; Wuttisittikulkij, L.; Ramírez, M.A.; Rodríguez, D.Z. Enhanced Routing Algorithm Based on Reinforcement Machine Learning—A Case of VoIP Service. Sensors 2021, 21, 504. [Google Scholar] [CrossRef]
- Kim, H.M.; Kim, M.S.; Lee, G.J.; Yoo, Y.J.; Song, Y.M. Large area fabrication of engineered microlens array with low sag height for light-field imaging. Opt. Express 2019, 27, 4435–4444. [Google Scholar] [CrossRef]
- Perra, C. Assessing the Quality of Experience in Viewing Rendered Decompressed Light Fields. Multimed. Tools Appl. 2018, 77, 21771–21790. [Google Scholar] [CrossRef]
- Kovács, P.T.; Bregović, R.; Boev, A.; Barsi, A.; Gotchev, A. Quantifying Spatial and Angular Resolution of Light-Field 3-D Displays. IEEE J. Sel. Top. Signal Process. 2017, 11, 1213–1222. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Wang, T.C.; Ramamoorthi, R. Learning-Based View Synthesis for Light Field Cameras. ACM Trans. Graph. 2016, 35, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Meng, N.; So, H.K.; Sun, X.; Lam, E. High-dimensional Dense Residual Convolutional Neural Network for Light Field Reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 873–886. [Google Scholar] [CrossRef] [Green Version]
- Affonso, E.T.; Rodríguez, D.Z.; Rosa, R.L.; Andrade, T.; Bressan, G. Voice quality assessment in mobile devices considering different fading models. In Proceedings of the 2016 IEEE International Symposium on Consumer Electronics (ISCE), Sao Paulo, Brazil, 28–30 September 2016; pp. 21–22. [Google Scholar] [CrossRef]
- Rosa, R.L.; Schwartz, G.M.; Ruggiero, W.V.; Rodríguez, D.Z. A Knowledge-Based Recommendation System That Includes Sentiment Analysis and Deep Learning. IEEE Trans. Ind. Inform. 2019, 15, 2124–2135. [Google Scholar] [CrossRef]
- Affonso, E.T.; Nunes, R.D.; Rosa, R.L.; Pivaro, G.F.; Rodríguez, D.Z. Speech Quality Assessment in Wireless VoIP Communication Using Deep Belief Network. IEEE Access 2018, 6, 77022–77032. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An Efficient Building Extraction Method from High Spatial Resolution Remote Sensing Images Based on Improved Mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Efros, A.A.; Ramamoorthi, R. Depth Estimation with Occlusion Modeling Using Light-Field Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2170–2181. [Google Scholar] [CrossRef] [PubMed]
- Fei, L.; Hou, G.; Sun, Z.; Tan, T. High Quality Depth Map Estimation of Object Surface from Light Field Images. Neurocomputing 2017, 252, 3–16. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J. Reconstruction of compressively sampled light field by using tensor dictionaries. Multimed. Tools Appl. 2020, 79, 20449–20460. [Google Scholar] [CrossRef]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 740–756. [Google Scholar]
- Wu, G.; Zhao, M.; Wang, L.; Dai, Q.; Chai, T.; Liu, Y. Light Field Reconstruction Using Deep Convolutional Network on EPI. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1638–1646. [Google Scholar]
- Wu, G.; Liu, Y.; Fang, L.; Dai, Q.; Chai, T. Light Field Reconstruction Using Convolutional Network on EPI and Extended Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1681–1694. [Google Scholar] [CrossRef] [PubMed]
- Xiaoping, L.; Zhenjun, T.; Zhenjun, T.; Xiaolan, X.; Xianquan, Z. Robust and fast image hashing with two-dimensional PCA. Multimed. Syst. 2020, 1, 4435–4444. [Google Scholar] [CrossRef]
- Veerasamy, B.; Annadurai, S. Video compression using hybrid hexagon search and teaching–learning-based optimization technique for 3D reconstruction. Multimed. Syst. 2020, 1, 1–15. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, Q.; Cheng, S. Multilevel active registration for kinect human body scans: From low quality to high quality. Multimed. Syst. 2018, 24, 257–270. [Google Scholar] [CrossRef] [Green Version]
- Shah, N.M.H.; Junaid, M.; Faseeh, N.M.; Shin, D.R. A Multi-blocked Image Classifier for Deep Learning. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 583–594. [Google Scholar] [CrossRef]
- Tong, C.; Liang, B.; Su, Q.; Yu, M.; Hu, J.; Bashir, A.K.; Zheng, Z. Pulmonary Nodule Classification Based on Heterogeneous Features Learning. IEEE J. Sel. Areas Commun. 2020, 39, 574–581. [Google Scholar] [CrossRef]
- Ashraf, R.; Afzal, S.; Rehman, A.U.; Gul, S.; Baber, J.; Bakhtyar, M.; Mehmood, I.; Song, O.Y.; Maqsood, M. Region-of-Interest Based Transfer Learning Assisted Framework for Skin Cancer Detection. IEEE Access 2020, 8, 147858–147871. [Google Scholar] [CrossRef]
- Saadi, M.; Ahmad, T.; Kamran Saleem, M.; Wuttisittikulkij, L. Visible light communication–an architectural perspective on the applications and data rate improvement strategies. Trans. Emerg. Telecommun. Technol. 2019, 30, e3436. [Google Scholar] [CrossRef]
- Fu, L.; Ren, C.; He, X.; Wu, X.; Wang, Z. Single Remote Sensing Image Super-Resolution with an Adaptive Joint Constraint Model. Sensors 2020, 20, 1276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farrugia, R.A.; Galea, C.; Guillemot, C. Super Resolution of Light Field Images Using Linear Subspace Projection of Patch-Volumes. IEEE J. Sel. Top. Signal Process. 2017, 11, 1058–1071. [Google Scholar] [CrossRef] [Green Version]
- Rossi, M.; Frossard, P. Geometry-Consistent Light Field Super-Resolution via Graph-Based Regularization. IEEE Trans. Image Process. 2018, 27, 4207–4218. [Google Scholar] [CrossRef] [Green Version]
- Ghassab, V.K.; Bouguila, N. Light Field Super-Resolution Using Edge-Preserved Graph-Based Regularization. IEEE Trans. Multimed. 2020, 22, 1447–1457. [Google Scholar] [CrossRef]
- Alain, M.; Smolic, A. Light Field Super-Resolution via LFBM5D Sparse Coding. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2501–2505. [Google Scholar]
- Yuan, Y.; Cao, Z.; Su, L. Light-Field Image Superresolution Using a Combined Deep CNN Based on EPI. IEEE Signal Process. Lett. 2018, 25, 1359–1363. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, Y.; Sheng, H. Residual Networks for Light Field Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, Y.; Liu, F.; Zhang, K.; Hou, G.; Sun, Z.; Tan, T. LFNet: A Novel Bidirectional Recurrent Convolutional Neural Network for Light-Field Image Super-Resolution. IEEE Trans. Image Process. 2018, 27, 4274–4286. [Google Scholar] [CrossRef]
- Yeung, H.W.F.; Hou, J.; Chen, X.; Chen, J.; Chen, Z.; Chung, Y.Y. Light Field Spatial Super-Resolution Using Deep Efficient Spatial-Angular Separable Convolution. IEEE Trans. Image Process. 2019, 28, 2319–2330. [Google Scholar] [CrossRef]
- Saadi, M.; Saeed, Z.; Ahmad, T.; Saleem, M.K.; Wuttisittikulkij, L. Visible light-based indoor localization using k-means clustering and linear regression. Trans. Emerg. Telecommun. Technol. 2019, 30, e3480. [Google Scholar] [CrossRef]
- Qiao, F.; Wu, J.; Li, J.; Bashir, A.K.; Mumtaz, S.; Tariq, U. Trustworthy edge storage orchestration in intelligent transportation systems using reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 1–14. [Google Scholar] [CrossRef]
- Ji, B.; Chen, Z.; Mumtaz, S.; Liu, J.; Zhang, Y.; Zhu, J.; Li, C. SWIPT Enabled Intelligent Transportation Systems with Advanced Sensing Fusion. IEEE Sens. J. 2020, 1. [Google Scholar] [CrossRef]
- Noomwongs, N.; Bajpai, A.; Phutthaburee, P.; Wongpiya, L.; Skulthai, A.; Maung, T.Z.B.; Myint, Y.M.; Ullah, I.; Wuttisittikulkij, L.; Saadi, M. Design and Testing of Autonomous Steering System Implemented on a Toyota Ha: mo. In Proceedings of the 2020 International Conference on Electronics, Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Du, G.; Wang, Z.; Gao, B.; Mumtaz, S.; Abualnaja, K.M.; Du, C. A Convolution Bidirectional Long Short-Term Memory Neural Network for Driver Emotion Recognition. IEEE Trans. Intell. Transp. Syst. 2020, 1–9. [Google Scholar] [CrossRef]
- Khan, M.Z.; Harous, S.; Hassan, S.U.; Khan, M.U.G.; Iqbal, R.; Mumtaz, S. Deep unified model for face recognition based on convolution neural network and edge computing. IEEE Access 2019, 7, 72622–72633. [Google Scholar] [CrossRef]
- Lin, Z.; Shum, H.Y. A Geometric Analysis of Light Field Rendering. Int. J. Comput. Vis. 2004, 58, 121–138. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.; Dai, F.; Lv, J.; Ma, Y.; Zhang, Y. Panoramic Light Field From Hand-Held Video and Its Sampling for Real-Time Rendering. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1011–1021. [Google Scholar] [CrossRef]
- Suzuki, T.; Takahashi, K.; Fujii, T. Disparity estimation from light fields using sheared EPI analysis. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1444–1448. [Google Scholar]
- Alain, M.; Smolic, A. Light field denoising by sparse 5D transform domain collaborative filtering. In Proceedings of the 2017 IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Ha, I.Y.; Wilms, M.; Heinrich, M. Semantically Guided Large Deformation Estimation with Deep Networks. Sensors 2020, 20, 1392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Lu, Z.; Yeung, H.; Qu, Q.; Chung, Y.; Chen, X.; Chen, Z. Improved image classification with 4D light-field and interleaved convolutional neural network. Multimed. Tools Appl. 2019, 78, 29211–29227. [Google Scholar] [CrossRef]
- Mendonça, R.V.; Teodoro, A.A.M.; Rosa, R.L.; Saadi, M.; Melgarejo, D.C.; Nardelli, P.H.J.; Rodríguez, D.Z. Intrusion Detection System Based on Fast Hierarchical Deep Convolutional Neural Network. IEEE Access 2021, 9, 61024–61034. [Google Scholar] [CrossRef]
- Terra Vieira, S.; Lopes Rosa, R.; Zegarra Rodríguez, D.; Arjona Ramírez, M.; Saadi, M.; Wuttisittikulkij, L. Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning. Sensors 2021, 21, 1880. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network; Springer: Cham, Switzerland, 2016; Volume 9906, pp. 391–407. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar] [CrossRef] [Green Version]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A Magnification-Arbitrary Network for Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1575–1584. [Google Scholar]
- Yoon, Y.; Jeon, H.; Yoo, D.; Lee, J.; Kweon, I.S. Light-Field Image Super-Resolution Using Convolutional Neural Network. IEEE Signal Process. Lett. 2017, 24, 848–852. [Google Scholar] [CrossRef]
- Tian, Y.; Zeng, H.; Hou, J.; Chen, J.; Ma, K. Light Field Image Quality Assessment via the Light Field Coherence. IEEE Trans. Image Process. 2020, 29, 7945–7956. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-Angular Interaction for Light Field Image Super-Resolution. arXiv 2020, arXiv:1912.07849. [Google Scholar]
- Jin, J.; Hou, J.; Chen, J.; Kwong, S. Light Field Spatial Super-Resolution via Deep Combinatorial Geometry Embedding and Structural Consistency Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xiang, X.; Tian, Y.; Zhang, Y.; Fu, Y.; Allebach, J.P.; Xu, C. Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Le Pendu, M.; Jiang, X.; Guillemot, C. Light Field Inpainting Propagation via Low Rank Matrix Completion. IEEE Trans. Image Process. 2018, 27, 1981–1993. [Google Scholar] [CrossRef] [Green Version]
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A Dataset and Evaluation Methodology for Depth Estimation on 4D Light Fields. In Proceedings of the Computer Vision—ACCV 2016, Taipei, Taiwan, 20–24 November 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 19–34. [Google Scholar]
- Rerabek, M.; Ebrahimi, T. New Light Field Image Dataset. In Proceedings of the 8th International Workshop on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Wanner, S.; Meister, S.; Goldluecke, B. Datasets and Benchmarks for Densely Sampled 4D Light Fields. In Proceedings of the 18th International Workshop on Vision, Modeling and Visualization (VMV 2013), Lugano, Switzerland, 11–13 September 2013; pp. 225–226. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin, Germany, 2018; Volume 11211, pp. 294–310. [Google Scholar] [CrossRef] [Green Version]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Test | Type | Scenes | AngRes | SpaRes (Mpx) | GT Depth |
|---|---|---|---|---|---|---|---|
| EPFL a [82] | 70 | 10 | real (lytro) | 119 | 14 × 14 | 0.034 | no |
| HCInew b [81] | 20 | 4 | synthetic | 24 | 9 × 9 | 0.026 | yes |
| HCIold c [83] | 10 | 2 | synthetic | 12 | 9 × 9 | 0.070 | yes |
| INRIA d [80] | 35 | 5 | real (lytro) | 57 | 14 × 14 | 0.027 | no |
| Method | EPFL | HCInew | HCIold | INRIA |
|---|---|---|---|---|
| EDSR [74] | 33.01 | 35.29 | 42.01 | 34.33 |
| RCAN [84] | 34.22 | 35.02 | 42.14 | 35.12 |
| SAN [85] | 33.11 | 35.39 | 42.41 | 34.43 |
| LFNet [49] | 32.09 | 34.01 | 40.17 | 33.02 |
| LFSSR [50] | 35.19 | 37.23 | 44.11 | 37.37 |
| resLF [48] | 33.49 | 36.11 | 43.19 | 34.33 |
| LF-ATO [76] | 34.10 | 38.03 | 44.29 | 36.21 |
| LF-InterNet [75] | 34.36 | 38.09 | 45.33 | 36.37 |
| Proposed model with Leaky ReLU | 34.41 | 38.22 | 45.49 | 37.51 |
| Proposed model with SR | 35.83 | 39.91 | 46.89 | 38.59 |
| Method | EPFL | HCInew | HCIold | INRIA |
|---|---|---|---|---|
| EDSR [74] | 0.943 | 0.940 | 0.960 | 0.942 |
| RCAN [84] | 0.945 | 0.942 | 0.962 | 0.948 |
| SAN [85] | 0.947 | 0.942 | 0.963 | 0.948 |
| LFNet [49] | 0.940 | 0.936 | 0.964 | 0.940 |
| LFSSR [50] | 0.951 | 0.949 | 0.963 | 0.951 |
| resLF [48] | 0.943 | 0.944 | 0.960 | 0.952 |
| LF-ATO [76] | 0.950 | 0.952 | 0.961 | 0.964 |
| LF-InterNet [75] | 0.950 | 0.950 | 0.964 | 0.964 |
| Proposed model with Leaky ReLU | 0.953 | 0.956 | 0.964 | 0.966 |
| Proposed model with SR | 0.985 | 0.988 | 0.997 | 0.997 |
| Method | #Params. | FLOPs (G) |
|---|---|---|
| EDSR [74] | 14.18 M | 15.33 × 25 |
| RCAN [84] | 14.39 M | 15.71 × 25 |
| SAN [85] | 14.56 M | 16.05 × 25 |
| LFNet [49] | 5.83 M | 36.18 |
| LFSSR [50] | 6.23 M | 36.87 |
| resLF [48] | 6.29 M | 36.96 |
| LF-ATO [76] | 1.39 M | 569.33 |
| LF-InterNet [75] | 4.58 M | 46.18 |
| Proposed model | 3.17 M | 43.41 |
| Method | Training (h) | Execution (h) |
|---|---|---|
| EDSR [74] | 8.2 | 0.9 |
| RCAN [84] | 8.3 | 0.9 |
| SAN [85] | 9.1 | 1.1 |
| LFNet [49] | 9.8 | 1.3 |
| LFSSR [50] | 9.7 | 1.3 |
| resLF [48] | 8.9 | 1.1 |
| LF-ATO [76] | 8.4 | 1.0 |
| LF-InterNet [75] | 8.3 | 0.9 |
| Proposed model with Leaky ReLU | 7.2 | 0.7 |
| Proposed model with SR | 5.1 | 0.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ribeiro, D.A.; Silva, J.C.; Lopes Rosa, R.; Saadi, M.; Mumtaz, S.; Wuttisittikulkij, L.; Zegarra Rodríguez, D.; Al Otaibi, S. Light Field Image Quality Enhancement by a Lightweight Deformable Deep Learning Framework for Intelligent Transportation Systems. Electronics 2021, 10, 1136. https://doi.org/10.3390/electronics10101136
Ribeiro DA, Silva JC, Lopes Rosa R, Saadi M, Mumtaz S, Wuttisittikulkij L, Zegarra Rodríguez D, Al Otaibi S. Light Field Image Quality Enhancement by a Lightweight Deformable Deep Learning Framework for Intelligent Transportation Systems. Electronics. 2021; 10(10):1136. https://doi.org/10.3390/electronics10101136
Chicago/Turabian StyleRibeiro, David Augusto, Juan Casavílca Silva, Renata Lopes Rosa, Muhammad Saadi, Shahid Mumtaz, Lunchakorn Wuttisittikulkij, Demóstenes Zegarra Rodríguez, and Sattam Al Otaibi. 2021. "Light Field Image Quality Enhancement by a Lightweight Deformable Deep Learning Framework for Intelligent Transportation Systems" Electronics 10, no. 10: 1136. https://doi.org/10.3390/electronics10101136