
Entropy-Based Discovery of Summary Causal Graphs in Time Series



1
R&D Department, EasyVista, 38000 Grenoble, France
2
Department of Mathematics, Information and Communication Sciences, University of Grenoble Alpes, CNRS, Grenoble INP, LIG, 38000 Grenoble, France
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2022, 24(8), 1156; https://doi.org/10.3390/e24081156
Submission received: 30 June 2022
/
Revised: 5 August 2022
/
Accepted: 14 August 2022
/
Published: 19 August 2022
(This article belongs to the Special Issue Applications of Entropy in Causality Analysis)
Abstract
:This study addresses the problem of learning a summary causal graph on time series with potentially different sampling rates. To do so, we first propose a new causal temporal mutual information measure for time series. We then show how this measure relates to an entropy reduction principle that can be seen as a special case of the probability raising principle. We finally combine these two ingredients in PC-like and FCI-like algorithms to construct the summary causal graph. There algorithm are evaluated on several datasets, which shows both their efficacy and efficiency.
1. Introduction
Time series arise as soon as observations, from sensors or experiments, for example, are collected over time. They are present in various forms in many different domains, such as healthcare (through, e.g., monitoring systems), Industry 4.0 (through, e.g., predictive maintenance and industrial monitoring systems), surveillance systems (from images, acoustic signals, seismic waves, etc.), or energy management (through, e.g., energy consumption data), to name but a few. We are interested in this study in analyzing quantitative discrete-time series to detect the causal relations that exist between them under the assumption of consistency throughout time [1] which states that causal relationships remain constant in direction throughout time. Under this assumption, one can replace the infinite full-time causal graph (Figure 1a) by a window causal graph (Figure 1b) defined as follows:
Definition 1
(Window causal graph [1]). Let be a multivariate discrete-time series and the associated window causal graph for a window of size τ. The set of vertices in that graph consists of the set of components at each time . The edges E of the graph are defined as follows: variables and are connected by a lag-specific directed link in pointing forward in time if and only if causes at time t with a time lag of for and with a time lag of for .
The window causal graph only covers a fixed number of time instants, which are sufficient to understand the dynamics of the system given the largest time gap between causes and effects. This said, it is difficult for an expert to provide or validate a window causal graph because it is difficult to determine which exact time instant is the cause of another. In contrast, there exists another type of causal graph where a node corresponds to a time series, as illustrated in Figure 1c, which usually can be analyzed or validated by an expert easily [2,3,4]. Such graphs are referred to as summary causal graphs [1] and are defined as follows:
Definition 2
(Summary causal graph [1]). Let be a multivariate discrete-time series and the associated summary causal graph. The set of vertices in that graph consists of the set of time series . The edges E of the graph are defined as follows: variables and are connected if and only if there exist some time t and some time lag i such that causes at time t with a time lag of for and with a time lag of for .
Note that a summary causal graph can be deduced from a window causal graph, but the reverse is not true. We focus in this study on the summary causal graph, as it provides a simple and efficient view on the causal relations that exist between time series. In particular, we are interested in inferring a summary causal graph without passing by a window causal graph to avoid unnecessary computations.
An important aspect of real-world time series is that different time series, as they measure different elements, usually have different sampling rates. Despite this, the algorithms that have been developed so far to discover causal structures [5,6,7,8] rely on the idealized assumptions that all time series have the same sampling rates with identical timestamps (assuming identical timestamps in the case of identical sampling rates seems reasonable as one can shift time series so that they coincide in time).
We introduce in this paper a constraint-based strategy to infer a summary causal graph from discrete-time series with continuous values with equal or different sampling rates under the two classical assumptions of causal discovery (causal Markov condition, faithfulness), in addition to acyclicity in summary causal graphs. In summary, our contribution is four-fold:
- First of all, we propose a new causal temporal mutual information measure defined on a window-based representation of time series;
- We then show how this measure relates to an entropy reduction principle, which can be seen as a special case of the probability raising principle;
- We also show how this measure can be used for time series with different sampling rates;
- We finally combine these three ingredients in PC-like and FCI-like algorithms [9] to construct the summary causal graph from time series with equal or different sampling rates.
The remainder of the paper is organized as follows: Section 2 describes the related work. Section 3 introduces the (conditional) mutual information measures we propose for time series and the entropy reduction principle that our method is based on. Section 4 presents two causal discovery algorithms we developed on top of these measures. The causal discovery algorithms we propose are illustrated and evaluated on datasets, including time series with equal and different sampling rates and a real dataset in Section 5. Finally, Section 6 concludes the paper.
2. Related Work
Granger Causality is one of the oldest methods proposed to detect causal relations between time series. However, in its standard form [5], it is known to handle a restricted version of causality that focuses on linear relations and causal priorities, as it assumes that the past of a cause is necessary and sufficient for optimally forecasting its effect. This approach has nevertheless been improved since then in MVGC [10] and has recently been extended to handle nonlinearities through an attention mechanism within convolutional networks [8]. This last extension is referred to as TCDF. Score-based approaches [11] search over the space of possible graphs, trying to maximize a score that reflects how well the graph fits the data. Recently, a new score-based method called Dynotears [12] was presented to infer a window causal graph from time series. In a different line, approaches based on the noise assume that the causal system can be defined by a set of equations that explains each variable by its direct causes and an additional noise. Causal relations are in this case discovered using footprints produced by the causal asymmetry in the data. For time series, the most popular nonlinear algorithm in this family is TiMINo [6], which discovers a causal relationship by looking at independence between the noise and the potential causes. The most popular approaches for inferring causal graphs are certainly constraint-based approaches, based on the PC and FCI algorithms [9], which turn knowledge about (conditional) independencies into causal knowledge assuming the causal Markov condition and faithfulness. Several algorithms, adapted from non-temporal causal graph discovery algorithms, have been proposed in this family for time series, namely oCSE by [13], which is limited to one time lag between causal relations, PCMCI [7], and tsFCI [14]. Our work is thus more closely related to that of [7,14], which use constraint-based strategies to infer a window causal graph. However, we focus here on the summary causal graph, and we introduce a new causal temporal mutual information measure and entropy reduction principle on which we ground our causal discovery algorithms. Constraint-based methods have been also used jointly with other approaches (e.g., with a score-based method [15] and with a noise-based method [16]), but we consider such hybrid methods as beyond the scope of this paper.
At the core of constraint-based approaches lie (in)dependence measures, to detect relevant dependencies, which are based here on an information theoretic approach. Since their introduction [17], information theoretic measures have become very popular due to their non-parametric nature, their robustness against strictly monotonic transformations, which makes them capable of handling nonlinear distortions in the system, and their good behavior in previous studies on causal discovery [18]. However, their application to temporal data raises several problems related to the fact that time series may have different sampling rates, be shifted in time, and have strong internal dependencies. Many studies have attempted to re-formalize mutual information for time series. Reference [19] considered each value of each time series as different random variables and proceeded by whitening the data, such that time-dependent data will be transformed into independent residuals through a parametric model. However, whitening the data can have severe consequences on causal relations. Reference [20] proposed a reformulation of mutual information, called the transfer entropy, which represents the information flow from one state to another and, thus, is asymmetric. Later, Ref. [13] generalized transfer entropy to handle conditioning. However, their approach, called causation entropy, can only handle causal relations with lags equal to 1. Closely related, the directed information [21,22] allows the computation of the mutual information between two instantaneous time series conditioned on the past of a third time series with a lag of 1. One of our goals in this paper is to extend these approaches to handle any lag equal to or greater than 0. Another related approach is the time-delayed mutual information proposed in [23], which aims at addressing the problem of non-uniform sampling rates. The computation of the time-delayed mutual information relates single points from a single time series (shifted in time), but does not consider potentially complex relations between time stamps in different time series, as we do through the use of window-based representations and compatible time lags. The measure we propose is more suited to discovering summary causal graphs as it can consider potentially complex relations between timestamps in different time series through the use of window-based representations and compatible time lags and is more general as it can consider different sampling rates.
3. Information Measures for Causal Discovery in Time Series
We present in this section a new mutual information measure that operates on a window-based representation of time series to assess whether time series are (conditionally) dependent or not. We then show how this measure is related to an entropy reduction principle that is a special case of the probability raising principle [24].
We first assume that all time series are aligned in time, with the same sampling rate, prior to showing how our development can be applied to time series with different sampling rates. Without loss of generality, time instants are assumed to be integers. Lastly, as performed in previous studies [20], we assume that all time series are first-order Markov self-causal (any time instant is caused by its previous instant within the same time series).
3.1. Causal Temporal Mutual Information
Let us consider d univariate time series and their observations . Throughout this section, we will make use of the following Example 1, illustrated in Figure 1, to discuss the notions we introduce.
Example 1.
Let us consider the following two time series defined by, for all t,
with.
One can see in Example 1 that, in order to capture the dependencies between the two time series, one needs to take into account a lag between them, as the true causal relations are not instantaneous. Several studies have recognized the importance of taking into account lags to measure (conditional) dependencies between time series; for example, in [7], a pointwise mutual information between time series with lags was used to assess whether they are dependent or not.
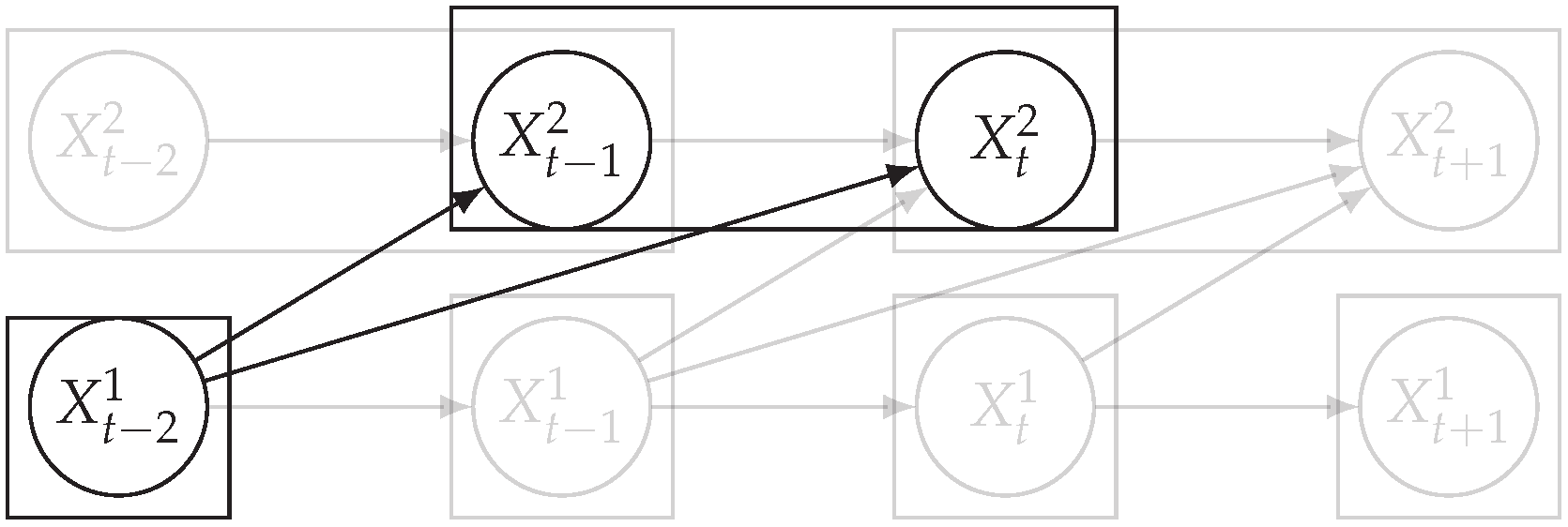
In addition to lags, Example 1 also reveals that a window-based representation may be necessary to fully capture the dependencies between the two time series. Indeed, as and are the effects of the same cause (), it may be convenient to consider them together when assessing whether the time series are dependent or not. For example, defining (overlapping) windows of size two for and one for with a lag of 1 from to , as in Figure 2, allows one to fully represent the causal dependencies between the two time series.
Definition 3.
Letdenote the maximum lag between two time seriesand, and let the maximum window size. The window-based representation, of size, of the time serieswith respect to, which will be denoted, simply amounts to consideringwindows:. The window-based representation, of size, of the time serieswith respect tois defined in the same way. A temporal lag compatible with and relates windows in and with starting time points separated by . We denote by the set of window sizes and compatible temporal lags.
Based on the above elements, we define the causal temporal mutual information between two time series and as the maximum of the standard mutual information over all possible compatible temporal lags and windows , conditioned by the past of the two time series. Indeed, as we are interested in obtaining a summary causal graph, we do not have to consider all the potential dependencies between two time series (which would be necessary for inferring a window causal graph). Using the maximum over all possible associations is a way to summarize all temporal dependencies, which ensures that one does not miss a dependency between the two time series. Furthermore, conditioning on the past allows one to eliminate spurious dependencies in the form of auto-correlation, as in transfer entropy [20]. We follow this idea here and, as in transfer entropy, consider windows of size 1 and a temporal lag of 1 for conditioning on the past, which is in line with the first-order Markov self-causal assumption mentioned above.
Definition 4.
Consider two time series and . We define the causal temporal mutual information between and as:
where I represents the mutual information. In case the maximum can be obtained with different values in , we first set to its largest possible value. We then set to its smallest possible value and, finally, to its smallest possible value. , , and , respectively, correspond to the optimal lag and optimal windows.
In the context we have retained, in which dependencies are constant over time, CTMI satisfies the standard properties of mutual information, namely it is nonnegative, symmetric, and equals 0 iff time series are independent. Thus, two time series and such that are dependent. Setting to its largest possible value allows one to get rid of instants that are not crucial in determining the mutual information between two time series. The choice for the window sizes, even though arbitrary on the choice of treating one window size before the other, is based on the same ground, as the mutual information defined above cannot decrease when one increases the size of the windows. Indeed:
The last inequality is due to the fact that mutual information is positive.
Example 2.
Consider the structure described in Example 1, and assume that . First, we have, for the standard mutual information,
We also have that any has zero mutual information because conditioning on the past of (namely ) is closing all paths from to for all . For , starting by ,
This is similar for . Now, any increase of alone or of and will generate an increase in the mutual information as long as the difference between the last time point of the window of (the cause) and the last time point of the window of is less than or equal to as
because
where (1 is the minimal lag that generates a correlation that cannot be removed by conditioning on the past of and ). For , the optimal window size is equal to 2 as has no other cause than itself; is equal to 2 as causes only (except itself) and . Furthermore, and
3.2. Entropy Reduction Principle
Interestingly, CTMI can be related to a version of the probability raising principle [24], which states that a cause, here a time series, raises the probability of any of its effects, here another time series, even when the past of the two time series is taken into account, meaning that the relation between the two time series is not negligible compared to the internal dependencies of the time series. In this context, the following definition generalizes to window-based representations of time series the standard definition of prima facie causes for discrete variables.
Definition 5
(Prima facie cause for window-based time series).Let and be two time series with window sizes and , and let represent the past of and for any two instants . We say that is a prima facie cause of with delay iff there exist Borel sets , , and such that one has:
We now introduce a slightly different principle based on the causal temporal mutual information, which we refer to as the entropy reduction principle.
Definition 6
(Entropic prima facie cause).Using the same notations as in Definition 5, we say that is an entropic prima facie cause of with delay iff .
Note that considering that the above mutual information is positive is equivalent to considering that the entropy of when conditioned on the past reduces when one further conditions on . One has the following relation between the entropy reduction and the probability raising principles.
Property 1.
With the same notations, if is an entropic prima facie cause of with delay , then is a prima facie cause of with delay . Furthermore, if with , then is an entropic prima facie cause of with delay .
Proof.
Let us assume that is not a prima facie cause of for the delay . Then, for all Borel sets , , and , one has . This translates, in terms of density functions denoted f, as:
which implies that is greater than , so that is not an entropic prima facie cause of with delay . By contraposition, we conclude the proof of the first statement. The second statement directly derives from the definition of CTMI. □
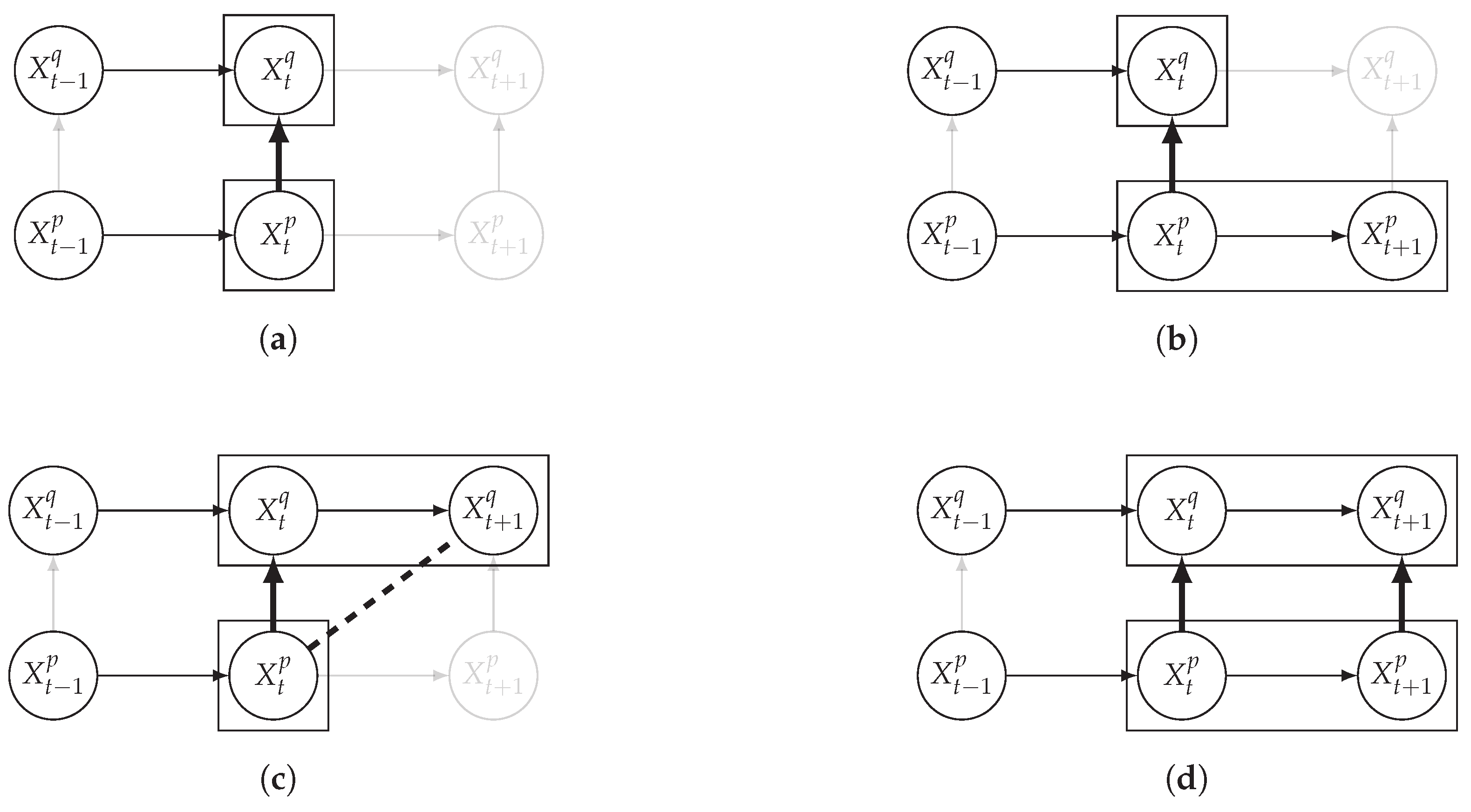
It is also interesting to note that, given two time series and such that causes with , CTMI does not necessarily increase symmetrically with respect to the increase of and . For an illustration on a simple model, see Figure 3. In Figure 3a, the mutual information conditioned on the past between and with is positive since causes instantaneously. In Figure 3b the same mutual information does not increase when increasing only the window size of the cause. However, the mutual information increases when increasing only the window size of the effect, as in Figure 3c, or when increasing simultaneously the window sizes of the effect and the cause, as in Figure 3d.
3.3. Conditional Causal Temporal Mutual Information
We now extend the causal temporal mutual information by conditioning on a set of variables. In a causal discovery setting, conditioning is used to assess whether two dependent time series can be made independent by conditioning on connected time series, i.e., time series that are dependent with at least one of the two times series under consideration. Figure 4 illustrates the case where the dependence between and is due to spurious correlations originating from common causes. Conditioning on these common causes should lead to the conditional independence of the two time series. Of course, the conditional variables cannot succeed simultaneously in time the two time series under consideration. This leads us to the following definition of the conditional causal temporal mutual information.
Definition 7.
The conditional causal temporal mutual information between two time series and such that , conditioned on a set , is given by:
In case the minimum can be obtained with different values, we first set to its largest possible value. We then set to its smallest possible value. and correspond to the optimal conditional lags and window sizes, which minimize, for :
By considering the minimum over compatible lags and window sizes, one guarantees that, if there exist conditioning variables that make the two time series independent, they will be found. Note that the case in which corresponds to , where .
Figure 4 illustrates the above on two different examples. On the left, is correlated to as is a common cause with a lag of 1 for and a lag of 2 for . Conditioning on removes the dependency between and . Note that all time series have here a window of size 1. On the right, and are common causes of and : causes and with a temporal lag of 1, which renders and correlated at the same time point, while causes and with a temporal lag of 1 and 2, respectively, which renders and correlated at lagged time points. The overall correlation between and is captured by considering a window size of 2 in . All other time series have a window size of 1. By conditioning on both and , and become independent, assuming we also condition on the past of and to remove the autocorrelation.
3.4. Estimation and Testing
In practice, the success of the CTMI approach (and in fact, any entropy-based approaches) depends crucially on the reliable estimation of the relevant entropies in question from data. This leads to two practical challenges. The first one is based on the fact that entropies must be estimated from finite-time series data. The second is that to detect independence, we need a statistical test to check if the temporal causation entropy is equal to zero.
Here, we rely on the k-nearest neighbor method [25,26] for the estimation of CTMI. The distance between two windows considered here is the supremum distance, i.e., the maximum of the absolute difference between any two values in the two windows.
In the case of the causal temporal mutual information, we denote by the distance from
to its k-th neighbor, , , and being the numbers of points with a distance strictly smaller than in the subspace
respectively, and the number of observations. The estimate of the causal temporal mutual information is then given by:
where denotes the digamma function.
Similarly, for the estimation of the conditional causal temporal mutual information, we denote by the distance from
to its k-th neighbor, , , and being the numbers of points with a distance strictly smaller than in the subspace
respectively, and the number of observations. The estimate of the conditional causal temporal mutual information is then given by:
where denotes the digamma function.
To detect independencies through CTMI, we rely on the following permutation test:
Definition 8
(Permutation test of CTMI). Given , , and , the p-value associated with the permutation test of CTMI is given by:
where is a permuted version of and follows the local permutation scheme presented in [27].
The advantage of the scheme presented in [27] is that it preserves marginals by drawing as much as possible without replacement and it performs local permutation, which ensures that by permuting , the dependence between and is not destroyed.
Note that Definition 8 is applicable to the causal temporal mutual information (when is empty) and to the conditional causal temporal mutual information.
3.5. Extension to Time Series with Different Sampling Rates
The above development readily applies to time series with different sampling rates, as one can define window-based representations of the two time series, as well as a sequence of joint observations.
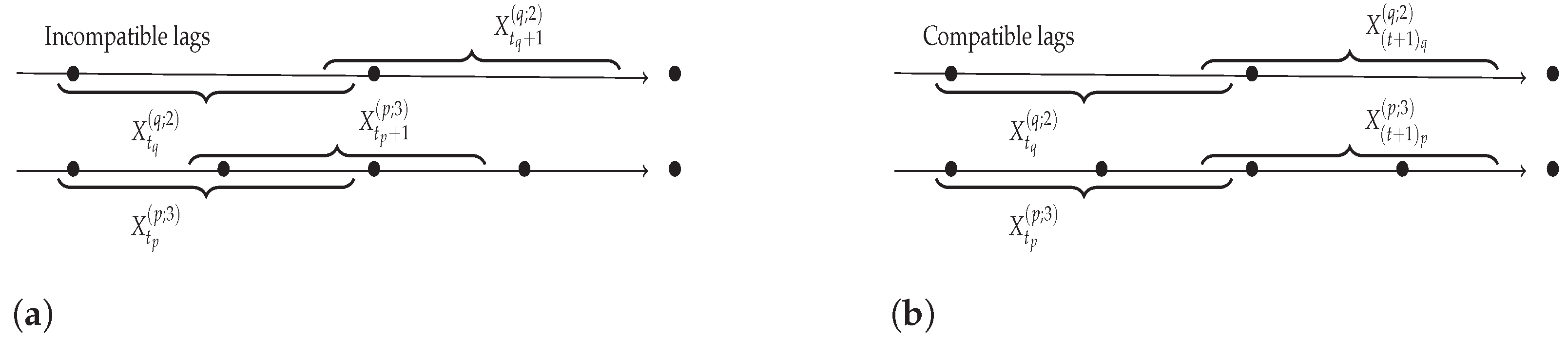
Indeed, as one can note, Definition 3 does not rely on the fact that the time series have the same sampling rates. Figure 5 displays two time series and with different sampling rates, where, while and , the time spanned by each window is the same. The joint sequence of observations, relating pairs of windows from and in the form , should, however, be such that, for all indices i of the sequence, one has: , where represents the starting time of the window X, and is constant over time. This is not the case for the first example, but is true for the second one, which is a relevant sequence of observations.
If the two time series are sufficiently long, there always exists a correct sequence of joint observations. Indeed, if the window sizes and are known, let . Furthermore, let and denote the number of observations per time unit (the time unit corresponds to the largest (integer) time interval according to the sampling rates of the different time series. For example, if a time series has a sampling rate of 10 per second and another a sampling rate of 3 per 10 min, then the time unit is equal to 10 min). Then, , , and are compatible through the set of joint observations S with and such that is the lowest common multiple.
Note that this methodology for handling different sampling rates is not unique to our proposal and can be used as soon as lags and windows are defined.
4. Causal Discovery Based on Causal Temporal Mutual Information
We present in this section two new methods for causal discovery in time series based on the causal temporal mutual information introduced above to construct the skeleton of the causal graph. The first method assumes causal sufficiency (there exists no hidden common cause of two observable time series), while the second method is an extension of the first for the case where causal sufficiency is not satisfied. In both methods, the skeleton is oriented on the basis of the entropy reduction principle in addition to classical constraint-based orientation rules (the rules used in the PC algorithm or the rules used in the FCI algorithm). Our methods assume both the causal Markov condition and faithfulness of the data distribution, which are classical assumptions for causal discovery within constraint-based methods in addition to acyclicity in the summary causal graph.
4.1. Without Hidden Common Causes
We present here our main method, which assumes causal sufficiency. We start by describing how we infer the skeleton of the summary graph, then we show how we orient edges using classical PC-rules in addition to rules based on the entropy reduction principle.
4.1.1. Skeleton Construction
We follow the same steps as the ones of the PC algorithm [9], which assumes that all variables are observed. It aims at building causal graphs by orienting a skeleton obtained, from a complete graph, by removing edges connecting independent variables. The summary causal graphs considered are directed acyclic graphs (DAGs) in which self-loops are allowed to represent temporal dependencies within a time series.
Starting with a complete graph that relates all time series, the first step consists of computing CTMI for all pairs of time series and removing edges if the two time series are considered independent. Once this is done, one checks, for the remaining edges, whether the two time series are conditionally independent (the edge is removed) or not (the edge is kept). Starting from a single time series connected to or , the set of conditioning time series is gradually increased until either the edge between and is removed or all time series connected to and have been considered. We will denote by the separation set of and , which corresponds to the smallest set of time series connected to and such that and are conditionally independent given this set. Note that we make use of the same strategy as the one used in PC-stable [28], which consists of sorting time series according to their CTMI scores and, when an independence is detected, removing all other occurrences of the time series. This leads to an order-independent procedure. The following theorem states that the skeleton obtained by the above procedure is the true one.
Theorem 1.
Let be a summary causal graph, and assume that we are given perfect conditional independence information about all pairs of variables in V given subsets . Then, the skeleton previously constructed is the skeleton of .
Proof.
Let us consider two time series and . If they are independent given , then , as otherwise, the conditional mutual information between and would be non-null and the two time series would not be conditionally independent as we are given perfect information. By the causal Markov and faithfulness conditions, there is no edge in this case between and in the corresponding skeleton, as in the true one. Conversely, if for any , then the two time series cannot be dependent conditioned on . Indeed, if this were the case, as we are given perfect conditional information, there would exist a lag and two window sizes and such that with . In this case, the two windows of size centered on time point t in both and contain the windows of sizes and separated by a lag in and as . Thus, would be positive as this quantity cannot be less than , which leads to a contradiction. Finally, as we tested all necessary conditioning sets in the construction of the skeleton, we have the guarantee of removing all unnecessary edges. □
4.1.2. Orientation
Once the skeleton has been constructed, one tries to orient as many edges as possible using the standard PC-rules [9], which yields a completed partially directed acyclic graph (CPDAG).
PC-rule 0
(Origin of causality). In an unshielded triple , if , then is an unshielded collider: .
PC-rule 1
(Propagation of causality). In an unshielded triple , if , then orient the unshielded triple as .
PC-rule 2.
If there exist a direct path from to and an edge between and , then orient .
PC-rule 3.
If there exists an unshielded triple and an unshielded triple , then orient .
As we are using here the standard PC-rules, we have the following theorem, the proof of which directly derives from the results on PC [9].
Theorem 2
(Theorem 5.1 of [9]). Let the distribution of V be faithful to a DAG , and assume that we are given perfect conditional independence information about all pairs of variables in V given subsets . Then, the skeleton constructed previously followed by PC-rules 0, 1, 2, and 3 represents the CPDAG of .
In addition to the PC orientation rules, we introduce two new rules, which are based on the notion of possible spurious correlations and the mutual information we have introduced. The notion of possible spurious correlations captures the fact that two variables may be correlated through relations that do not only correspond to direct causal relations between them. It is formalized as follows:
Definition 9
(Possible spurious correlations). We say that two nodes have possible spurious correlations if there exists a path between them that neither contains the edge nor any collider.
Interestingly, when two connected variables do not have possible spurious correlations, one can conclude about their orientation using CTMI.
Property 2.
Let us assume that we are given perfect conditional independence information about all pairs of variables in V given subsets . Then, every non-oriented edge in the CPDAG obtained by the above procedure corresponds to a prima facie cause and by, causal sufficiency, to a true causal relation between the related time series. Furthermore, the orientation of an unoriented edge between two nodes and that do not have possible spurious correlations is given by the “direction” of the optimal lag in , assuming that the maximal window size is larger than the longest lag between causes and effects.
Proof.
The first part of Property 2 directly derives from Property 1. As we assume that we are given perfect conditional information, the skeleton is the true one from Theorem 1. Thus, if two variables do not have possible spurious correlations, the only correlations observed between them correspond to a causal relation. We now need to prove that the optimal lag can be used to orient edges between any pair of variables and .
Without loss of generality, let us assume that causes , for any time t, via the K time instants with . First, let us consider a window of size 1 in and a window of arbitrary size in with a lag set to . As , there is no cause of in the window . Furthermore, the only observed correlations between and correspond to causal relations. We thus have:
as and all variables in are independent of each other. One the contrary, for the same window size in and a lag set to with , one has:
The first inequality derives from Inequality 2. The second inequality is due to the fact that is a true cause of and the fact that we are given perfect information. Thus, when considering a window of size 1 for , the optimal lag given by CTMI will necessarily go from to , which corresponds to the correct orientation.
We now consider the case where we have a window of arbitrary size in . Let us further consider a window of arbitrary size in with a lag set to . If , there is no causal relations between the elements in and the elements in and the mutual information between these two windows is 0. Otherwise, one can decompose this mutual information as:
as the conditioning on and amounts to conditioning on the instant due to the first-order Markov self-causal assumption.
As there are no causal relations between the elements in and the elements in , the first term on the right-hand side is 0. Using a similar decomposition in order to exclude elements at the end of , which do not cause any element in , one obtains:
Let us now consider the window in of size with a lag set to . Using the same reasoning as before, one obtains:
with:
as the window contains the window . In addition, the first term on the right-hand side of Equation (5) is strictly positive as all the elements in have causal relations in . Thus, the mutual information obtained with the negative lag is better than the one obtained with any positive lag:
meaning that the optimal lag given by CTMI will necessarily go from to , which corresponds to the correct orientation. □
The following orientation rule is a direct application of the above property.
ER-rule 0
(Entropy reduction—). In a pair , such and do not have a possible spurious correlation, if , then orient the edge as: .
Furthermore, we make use of the following rule to orient additional edges when the optimal lag is null based on the fact that CTMI increases asymmetrically with respect to the increase of and (Figure 3). This rule infers the direction of the cause by checking the difference in the window sizes as the window size of the cause cannot be greater than the window size of the effect.
ER-rule 1
(Entropy reduction—). In a pair , such and do not have a possible spurious correlation, if and , then orient the edge as: .
In practice, we also apply the ER-rule 0 before PC-rules, because, experimentally, we found that the ER-rule 0 is more reliable than the PC-rule 0 in detecting lagged unshielded colliders, especially in the case of a low sample size.
We call our method PCTMI; the pseudo-code is available in Algorithm 1. represents all adjacent nodes to in the graph , and is the separation set of and . The output of the algorithm is a CPDAG version of the summary graph such that all lagged relations are oriented, but instantaneous relations are partially oriented.
| Algorithm 1PCTMI. |
| X a d-dimensional time series of length T, the maximum number of lags, a significance threshold Form a complete undirected graph with d nodes n = 0 while there exists such that do for s.t. do for do for all subsets such that and ( or ) for all do append Sort by increasing order of y while is not empty do if and then Compute z the p-value of given by Equation (4) if test then Remove edge from n = n + 1 for each triple in , do apply PC-rule 0 while no more edges can be oriented do for each triple in , do apply PC-rules 1, 2, and 3 for each connected pair in do apply ER-rules 0 and 1 Return |
4.2. Extension to Hidden Common Causes
When unobserved variables are causing a variable of interest, the PC algorithm is no longer appropriate and one needs to resort to the FCI algorithm introduced in [9], which infers a partial ancestral graph (PAG). We extend here the version of this algorithm presented in [29] without the selection bias.
We recall the notations needed for FCI: a double arrow indicates the presence of hidden common causes, while the symbol ∘ represents an undetermined mark, and the meta-symbol asterisk * is used as a wildcard, which can denote a tail, an arrow, or a circle. Furthermore, we make use of the notion Possible-Dsep, which is defined as follows:
Definition 10
(Possible-Dsep [9]). is in the Possible-Dsep set of and if and only if is different from and and there is an undirected path U between and such that, for every subpath of U, either is a collider on the subpath or and are adjacent in the PAG.
Lastly, we make use of the following types of paths. A discriminating path between and is a path that includes at least three edges such that each non-endpoint vertex on the path is adjacent to , and is not adjacent to , and every vertex between and is a collider on the path and is a parent of . An uncovered path is a path where every consecutive triple on the path is unshielded. A potentially directed path is a path where the edge between two consecutive vertices is not directed toward the first or against the second.
From the skeleton obtained in Section 4.1.1, unshielded colliders are detected using the FCI-rule 0.
FCI-rule 0
(Origin of causality). For each unshielded triple , if , then orient the unshielded triple as a collider: .
From this, Possible-Dsep sets can be constructed. As elements of Possible-Dsep sets in a PAG play a role similar to the ones of parents in a DAG, additional edges are removed by conditioning on the elements of the Possible-Dsep sets, using the same strategy as the one given in Section 4.1.1. All edges are then unoriented, and the FCI-rule 0 is again applied as some of the edges of the unshielded colliders originally detected may have been removed by the previous step. Then, as in FCI, FCI-rules 1, 2, 3, 4, 8, 9, and 10 are applied.
FCI-rule 1.
In an unshielded triple , if , then orient the unshielded triple as .
FCI-rule 2.
If there exists a triple or a triple with , then orient the pair as .
FCI-rule 3.
If there exists an unshielded triple and an unshielded triple and , then orient the pair as .
FCI-rule 4.
If there exists a discriminating path between and for and , then orient as ; otherwise, orient the triple as .
FCI-rule 8.
If or and , then orient .
FCI-rule 9.
If and U is an uncovered potentially directed path from to such that and are not adjacent, then orient the pair as .
FCI-rule 10.
Suppose , , is an uncovered potentially directed path from to , and is an uncovered potentially directed path from to . Let μ be the vertex adjacent to on (μ could be ) and ω be the vertex adjacent to on (ω could be ). If μ and ω are distinct and are not adjacent, then orient as .
Note that we have not included FCI-rules 5, 6, and 7 from [29], as these rules deal with selection bias, a phenomenon that is not present in the datasets we consider. Including these rules in our framework is nevertheless straightforward.
Finally, as in PCTMI, we orient additional edges using an adapted version of the ER-rules.
LER-rule 0
(Latent entropy reduction—). In a pair , such and do not have a possible spurious correlation, if , then orient the edge as: .
LER-rule 1
(Latent entropy reduction—). In a pair , such and do not have a possible spurious correlation, if and , then orient the edge as: .
The overall process, referred to as FCITMI, is described in Algorithm 2.
| Algorithm 2FCITMI. |
| Require:X a d-dimensional time series of length T, the maximum number of lags, a significance threshold Form a complete undirected graph with d nodes n = 0 while there exists such that do for s.t. do for do for all subsets such that and ( or ) for all do append Sort by increasing order of y while is not empty do if and then Compute z the p-value of given by Equation (4) if test then Remove edge from n = n + 1 for each triple in , do apply FCI-rule 0 using Possible-Dsep sets, remove edges using CTMI Reorient all edges as in for each triple in , do apply FCI-rule 0 while edges can be oriented do for each triple in , apply FCI-rules 1, 2, 3, 4, 8, 9, and 10 for each connected pair in , do apply ER-rules 0 and 1. Return |
5. Experiments
In this section, we evaluate our method experimentally on several datasets. We propose first an extensive analysis on simulated data with equal and different sampling rates, generated from basic causal structures; then, we performed an analysis on real-world datasets. To assess the quality of causal inference, we used the F1-score regarding directed edges in the graph without considering self-loops.
In the following, we first describe the different settings of the methods we compare with and the datasets, and then, we describe the results and provide a complexity analysis.
5.1. Methods and Their Use
We compared our method PCTMI, available at https://github.com/ckassaad/PCTMI (accessed on 29 June 2022),with several methods. From the Granger family, we ran MVGC through the implementation available at http://www.sussex.ac.uk/sackler/mvgc/ (accessed on 29 June 2022) and TCDF through the implementation available at https://github.com/M-Nauta/TCDF (accessed on 29 June 2022). For TCDF, some hyperparameters have to be defined: we use da kernel of size 4, a dilation coefficient 4, one hidden layer, a learning rate of , and 5000 epochs. From the score-based family, we retained Dynotears, which is available at https://github.com/quantumblacklabs/causalnex (accessed on 29 June 2022), the hyperparameters of which were set to their recommended values (the regularization constants ). Among the noise-based approaches, we ran TiMINo, which is available at http://web.math.ku.dk/~peters/code.html (accessed on 29 June 2022). TiMINo uses a test based on the cross-correlation.From the constraint-based family, we ran PCMCI using the mutual information to measure the dependence, both provided in the implementation available at https://github.com/jakobrunge/tigramite (accessed on 29 June 2022).
We compared FCITMI with tsFCI, provided at https://sites.google.com/site/dorisentner/publications/tsfci (accessed on 29 June 2022), where independence or conditional independence is tested, respectively, with tests of zero correlation or zero partial correlation.
For all methods using mutual information, we used the k-nearest neighbor estimator [26], for which we fixed the number of nearest neighbor to . Since the output of those measures are necessarily positive given a finite sample size and a finite numerical precision, we used a significance permutation test introduced in [27]. For all methods, we used , and when performing a statistical test, we used a significance level of .
5.2. Datasets
To illustrate the behavior of the causal inference algorithms, we relied on both artificial and real-world datasets.
5.2.1. Simulated data
In the case of causal sufficiency, we simulated time series with equal and different sampling rates of size 1000 generated from three different causal structures: fork, v structure, and diamond represented in Table 1. In the case of non-causal sufficiency, we considered the 7ts2h structure represented in Table 2.
For each structure, we generated 10 datasets using the following generating process: for all q, , and for all ,
where , are random coefficients chosen uniformly in for all , and f is a nonlinear function chosen at random uniformly among the absolute value, tanh, sine, and cosine.
5.2.2. Real Data
First, we considered the realistic functional magnetic resonance imaging (fMRI) benchmark, which contains blood-oxygen-level dependent (BOLD) datasets [30] for 28 different underlying brain networks. It measures the neural activity of different regions of interest in the brain based on the change of blood flow. There are 50 regions in total, each with its own associated time series. Since not all existing methods can handle 50 time series, datasets with more than 10 time series were excluded. In total, we were left with 26 datasets containing between 5 and 10 brain regions.
Second, we considered time series collected from an IT monitoring system with a one-minute sampling rate provided by EasyVista (https://www.easyvista.com/fr/produits/servicenav, accessed on 29 June 2022). In total, we considered 24 datasets with 1000 timestamps. Each dataset contains three time series: the metric extraction (M.E), which represents the activity of the extraction of the metrics from the messages; the group history insertion (G.H.I), which represents the activity of the insertion of the historical status in the database; and the collector monitoring information (C.M.I), which represents the activity of the updates in a given database. Lags between time series are unknown, as well as the existence of self-causes. According to the domain experts, all these datasets follow a fork structure such that metric extraction is a common cause of the other two time series.
5.3. Numerical Results
5.3.1. Simulated Data
We provide in Table 3 the performance of all methods on simulated data with an equal sampling rate. PCTMI has better results than other methods for the v structure and the fork structure For the diamond structure, PCTMI and PCMCI have the same performance; however, PCTMI has a lower standard deviation. In general, we can say, that constraint-based algorithms perform best.
We also assess the behavior of PCTMI when the time series have different sampling rates in Table 4. We present here results only for PCTMI, because other methods are not applicable to time series with different sampling rates. As one can see, the performance obtained here is close to the ones obtained with equal sampling rates in the case of the v structure, but significantly lower in the case if the fork structure and the diamond. The degradation of the results is not really surprising as one has less data to rely on in a different sampling rate scenario. By comparing the results of PCTMI on time series with different sampling rates with the results of other methods obtained when time series have an equal sampling rate, we can see that PCTMI still performs better than most methods.
In the case of causal non-sufficiency, our proposed algorithm FCITMI outperforms tsFCI, as shown in Table 5.
5.3.2. Real Data
We provide in Table 6 the results on the fMRI benchmark and the IT benchmark for all the methods. In the case of fMRI, VarLiNGAM performs best, followed by Dynotears and, then, by PCTMI and TiMINo. The success of linear methods (VarLiNGAM and Dynotears) on this benchmark might suggest that causal relations in fMRI are linear, especially as this result was not replicated on other datasets considered in this paper. In the case of the IT datasets, TiMINo performs best, followed by PCTMI; however, while investigating the results, we noticed that for datasets, TiMINo returns a fully connected summary graph with arcs oriented from both sides. In both benchmarks, PCTMI clearly outperforms other constraint-based methods.
In the case of the IT datasets, we also provide in Table 7, for each dataset, the inferred summary causal graphs by methods that have an F1-score in Table 6. Here, we can see that in 5 out of 10 datasets, PCTMI was able to infer that M.E is a cause of G.H.I. On the other hand, PCTMI was able to infer that M.E is a cause of C.M.I. in only one dataset. Interestingly, in 9 out 10 datasets, PCTMI did not infer any false positive. As one can expect from Table 6, PCMCI suffers on all datasets; however, one can notice that as PCTMI, PCMCI has a tendency to yield sparse graphs. TiMINo, which has the best F1-score in Table 6, seems to have a very low precision. In 7 out 10 datasets, TiMINo returned a complete bidirected graph. In the other three datasets, TiMINo detects all true causal relations, in addition to one false positive. VarLiNGAM has an even lower precision compared to TiMINo and a lower recall. Finally, MVGC infers most of the time a complete bidirected graph.
5.3.3. Complexity Analysis
Here, we provide a complexity analysis on different constraint-based algorithms including our proposed method.
In the worst case, the complexity of PC in a window causal graph is bounded by , where k represents the maximal degree of any vertex and is the maximum number of lags. Each operation consists of conducting a significance test on a conditional independence measure. Algorithms adapted to time series, as PCMCI [7], rely on time information to reduce the number of tests. PCTMI reduces the number of tests even more since it infers a summary graph. Indeed, PCTMI’s complexity in the worst case is bounded by .
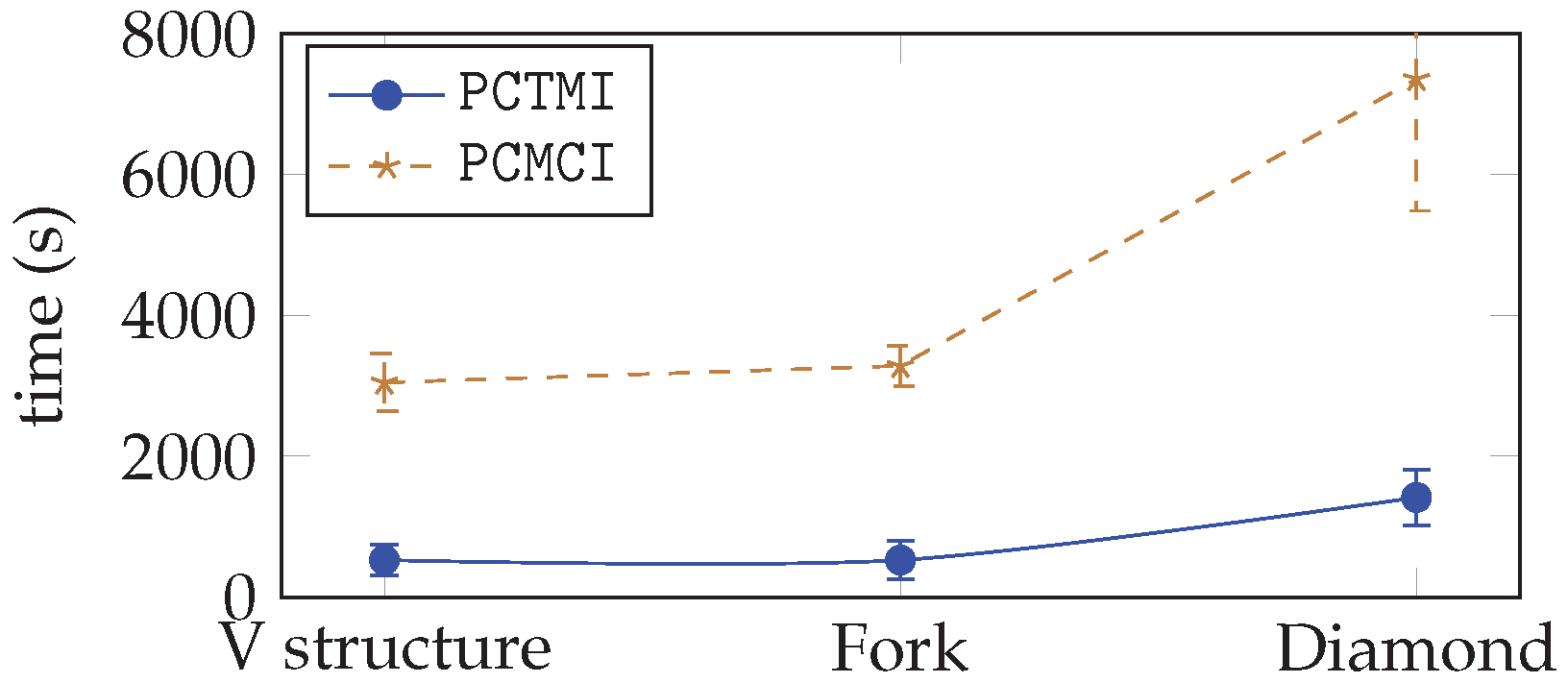
Figure 6 provides an empirical illustration of the difference in the complexity of the two approaches on the three structures (v structure, fork, diamond), sorted according to their number of nodes, their maximal out-degree, and their maximal in-degree. The time is given in seconds. As one can note, PCTMI is always faster than PCMCI, the difference being more important when the structure to be inferred is complex.
5.3.4. Hyperparameters’ Analysis
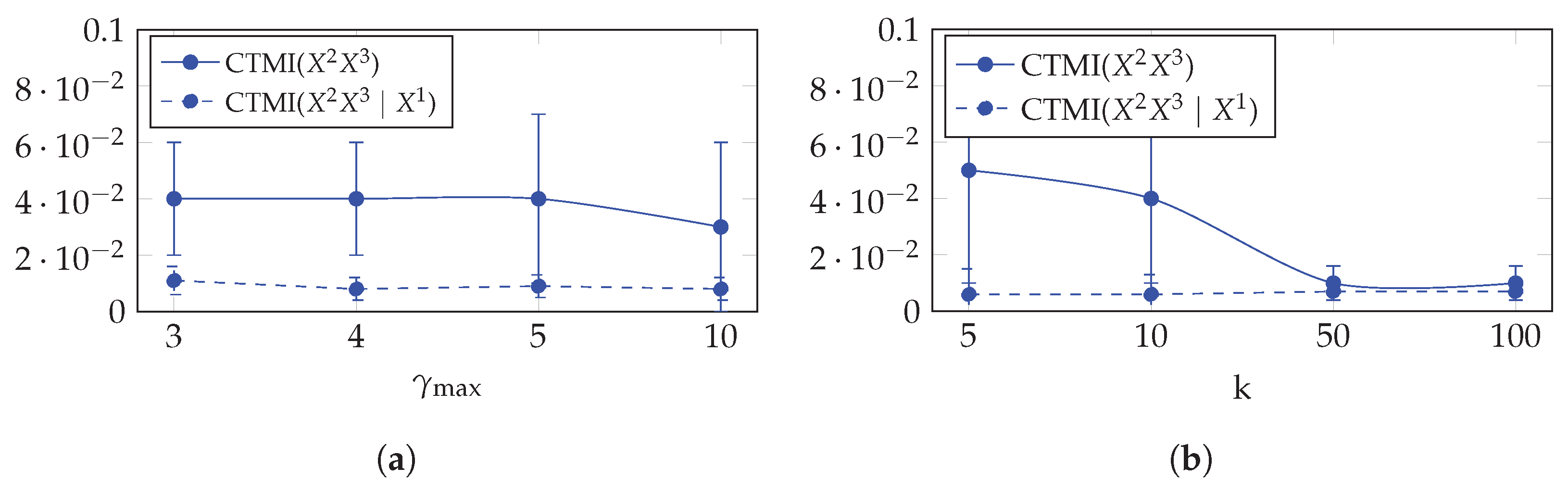
Here, we provide a hyperparameter analysis on CTMI with respect to the maximum lag and the k-nearest neighbor k. Using the same 10 datasets that are compatible with the fork structure in Table 1 and generated as described in Section 5.2.1, we performed two experimentations.
First, we computed the average and the standard deviation of CTMI() and CTMI() over the 10 datasets while varying between 3 and 10. The results given in Figure 7a show that CTMI is robust with respect to in the case of dependency and in the case of conditional independency: the mean of CTMI() remains the same for and slightly decreases for , and the standard deviation remains the same for and slightly increases for . On the other hand, the mean and the standard deviation of CTMI() remain the same for all .
Second, we again computed the average and the standard deviation of CTMI() and CTMI() over the 10 datasets, but now, while varying k between 5 and 100. The results given in Figure 7b show that CTMI is robust with respect to k in the case of conditional independency, but suffers in the case of dependency when k increases: the mean of CTMI() slightly decreases between and , but drastically decreases for .
6. Discussion and Conclusions
We addressed in this paper the problem of learning a summary causal graph on time series with equal or different sampling rates. To do so, we first proposed a new temporal mutual information measure defined on a window-based representation of time series. We then showed how this measure relates to an entropy reduction principle, which can be seen as a special case of the probability raising principle. We finally combined these two ingredients in PC-like and FCI-like algorithms to construct the summary causal graph. Our method proved to work well with small time complexity in comparison with similar approaches that use mutual information. The main limitations of our methods are that they cannot orient causal relations that are not oriented by the classical PC-rules or FCI-rules and have a possible spurious correlation, and they assume acyclicity in summary causal graphs.
Author Contributions
Conceptualization, C.K.A., E.D. and E.G.; methodology, C.K.A., E.D., and E.G.; software, C.K.A., E.D. and E.G.; validation, C.K.A., E.D. and E.G.; formal analysis, C.K.A., E.D. and E.G.; investigation, C.K.A., E.D. and E.G.; resources, C.K.A., E.D. and E.G.; data curation, C.K.A., E.D. and E.G.; writing—original draft preparation, C.K.A., E.D. and E.G.; writing—review and editing, C.K.A., E.D. and E.G.; visualization, C.K.A., E.D. and E.G.; supervision, C.K.A., E.D. and E.G.; project administration, C.K.A., E.D. and E.G.; funding acquisition, C.K.A., E.D. and E.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly funded by MIAI@Grenoble Alpes Grant Number ANR-19-P3IA-0003.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data presented in this study are publicly available: Simulated data are available at https://dataverse.harvard.edu/dataverse/basic_causal_structures_additive_noise (accessed on 29 June 2022); The original fMRI data are available at https://www.fmrib.ox.ac.uk/datasets/netsim/index.html (accessed on 29 June 2022), and a preprocessed version is available at https://github.com/M-Nauta/TCDF/tree/master/data/fMRI (accessed on 29 June 2022); IT monitoring data are available at https://easyvista2015-my.sharepoint.com/:f:/g/personal/aait-bachir_easyvista_com/ElLiNpfCkO1JgglQcrBPP9IBxBXzaINrM5f0ILz6wbgoEQ?e=OBTsUY (accessed on 29 June 2022).
Acknowledgments
We thank Ali Aït-Bachir and Christophe de Bignicourt from EasyVista for providing us with the IT monitoring data along with their underlying causal graph.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Assaad, C.K.; Devijver, E.; Gaussier, E. Survey and Evaluation of Causal Discovery Methods for Time Series. J. Artif. Intell. Res. 2022, 73, 767–819. [Google Scholar] [CrossRef]
- Wang, P.; Xu, J.; Ma, M.; Lin, W.; Pan, D.; Wang, Y.; Chen, P. CloudRanger: Root Cause Identification for Cloud Native Systems. In Proceedings of the 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid ’18), Washington, DC, USA, 1–4 May 2018; pp. 492–502. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Jiang, H.; Huang, Y.; Wang, J.; Kopru, S.; Xie, T. Groot: An Event-Graph-Based Approach for Root Cause Analysis in Industrial Settings. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE ’21), Melbourne, Australia, 15–19 November 2021; pp. 419–429. [Google Scholar] [CrossRef]
- Zhang, Y.; Guan, Z.; Qian, H.; Xu, L.; Liu, H.; Wen, Q.; Sun, L.; Jiang, J.; Fan, L.; Ke, M. CloudRCA: A Root Cause Analysis Framework for Cloud Computing Platforms. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Association for Computing Machinery, Online, 1–5 November 2021; pp. 4373–4382. [Google Scholar]
- Granger, C. Investigating Causal Relations by Econometric Models and Cross-Spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Peters, J.; Janzing, D.; Schölkopf, B. Causal Inference on Time Series using Restricted Structural Equation Models. In Proceedings of the Advances in Neural Information Processing Systems 26, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 154–162. [Google Scholar]
- Runge, J.; Nowack, P.; Kretschmer, M.; Flaxman, S.; Sejdinovic, D. Detecting and quantifying causal associations in large nonlinear time series datasets. Sci. Adv. 2019, 5, eaau4996. [Google Scholar] [CrossRef] [PubMed]
- Nauta, M.; Bucur, D.; Seifert, C. Causal Discovery with Attention-Based Convolutional Neural Networks. Mach. Learn. Knowl. Extr. 2019, 1, 312–340. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C.; Scheines, R. Causation, Prediction, and Search, 2nd ed.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Granger, C.W.J. Time Series Analysis, Cointegration, and Applications. Am. Econ. Rev. 2004, 94, 421–425. [Google Scholar] [CrossRef]
- Chickering, D.M. Learning Equivalence Classes of Bayesian-Network Structures. J. Mach. Learn. Res. 2002, 2, 445–498. [Google Scholar] [CrossRef]
- Pamfil, R.; Sriwattanaworachai, N.; Desai, S.; Pilgerstorfer, P.; Georgatzis, K.; Beaumont, P.; Aragam, B. DYNOTEARS: Structure Learning from Time-Series Data. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Online, 28 August 2020; Volume 108, pp. 1595–1605. [Google Scholar]
- Sun, J.; Taylor, D.; Bollt, E.M. Causal Network Inference by Optimal Causation Entropy. SIAM J. Appl. Dyn. Syst. 2015, 14, 73–106. [Google Scholar] [CrossRef]
- Entner, D.; Hoyer, P. On Causal Discovery from Time Series Data using FCI. In Proceedings of the 5th European Workshop on Probabilistic Graphical Models, PGM 2010, Helsinki, Filnland, 13–15 September 2010. [Google Scholar]
- Malinsky, D.; Spirtes, P. Causal Structure Learning from Multivariate Time Series in Settings with Unmeasured Confounding. In Proceedings of the 2018 ACM SIGKDD Workshop on Causal Disocvery, London, UK, 20 August 2018; Volume 92, pp. 23–47. [Google Scholar]
- Assaad, C.K.; Devijver, E.; Gaussier, E.; Ait-Bachir, A. A Mixed Noise and Constraint-Based Approach to Causal Inference in Time Series. In Machine Learning and Knowledge Discovery in Databases. Research Track, Proceedings of the Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 453–468. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Affeldt, S.; Isambert, H. Robust Reconstruction of Causal Graphical Models Based on Conditional 2-point and 3-point Information. In Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence (UAI’15); Amsterdam, The Netherlands, 12–16 July 2015, AUAI Press: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Galka, A.; Ozaki, T.; Bayard, J.B.; Yamashita, O. Whitening as a Tool for Estimating Mutual Information in Spatiotemporal Data Sets. J. Stat. Phys. 2006, 124, 1275–1315. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461. [Google Scholar] [CrossRef] [PubMed]
- Marko, H. The Bidirectional Communication Theory—A Generalization of Information Theory. IEEE Trans. Commun. 1973, 21, 1345–1351. [Google Scholar] [CrossRef]
- Massey, J.L. Causality, feedback and directed information. In Proceedings of the International Symposium on Information Theory and Its Applications, Waikiki, HI, USA, 27–30 November 1990. [Google Scholar]
- Albers, D.J.; Hripcsak, G. Estimation of time-delayed mutual information and bias for irregularly and sparsely sampled time-series. Chaos Solitons Fractals 2012, 45, 853–860. [Google Scholar] [CrossRef] [PubMed]
- Suppes, P. A Probabilistic Theory of Causality; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1970. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E Stat. Nonlinear, Soft Matter Phys. 2004, 69 Pt 2, 066138. [Google Scholar] [CrossRef] [PubMed]
- Frenzel, S.; Pompe, B. Partial Mutual Information for Coupling Analysis of Multivariate Time Series. Phys. Rev. Lett. 2007, 99, 204101. [Google Scholar] [CrossRef] [PubMed]
- Runge, J. Conditional independence testing based on a nearest-neighbor estimator of conditional mutual information. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Playa Blanca, Spain, 9 April 2018; Volume 84, pp. 938–947. [Google Scholar]
- Colombo, D.; Maathuis, M.H. Order-Independent Constraint-Based Causal Structure Learning. J. Mach. Learn. Res. 2014, 15, 3921–3962. [Google Scholar]
- Zhang, J. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artif. Intell. 2008, 172, 1873–1896. [Google Scholar] [CrossRef]
- Smith, S.M.; Miller, K.L.; Khorshidi, G.S.; Webster, M.A.; Beckmann, C.F.; Nichols, T.E.; Ramsey, J.; Woolrich, M.W. Network modelling methods for FMRI. NeuroImage 2011, 54, 875–891. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Example of a full-time causal graph (a), a window causal graph (b), and a summary causal graph (c).
Figure 1.
Example of a full-time causal graph (a), a window causal graph (b), and a summary causal graph (c).

Figure 2.
Why do we need windows and lags? An illustration with two time series where causes in two steps (circles correspond to observed points and rectangles to windows). The arrows in black are discussed in the text.
Figure 2.
Why do we need windows and lags? An illustration with two time series where causes in two steps (circles correspond to observed points and rectangles to windows). The arrows in black are discussed in the text.

Figure 3.
Illustration of the asymmetric increase of CTMI with the increase of the window sizes. The mutual information conditioned on the past in (a) is . It increases when increasing only the window size of the effect, as in (c), i.e, , or when increasing simultaneously the window sizes of the effect and the cause, as in (d), i.e, . However, it does not increase when increasing only the window size of the cause, as in (b), i.e, . Dashed lines are for correlations that are not causations, and bold arrows correspond to causal relations between the window representations of time series.
Figure 3.
Illustration of the asymmetric increase of CTMI with the increase of the window sizes. The mutual information conditioned on the past in (a) is . It increases when increasing only the window size of the effect, as in (c), i.e, , or when increasing simultaneously the window sizes of the effect and the cause, as in (d), i.e, . However, it does not increase when increasing only the window size of the cause, as in (b), i.e, . Dashed lines are for correlations that are not causations, and bold arrows correspond to causal relations between the window representations of time series.

Figure 4.
Example of conditional independence between dependent time series. In (a) the conditioning set contains one time series in addition to the past of and . In (b) the conditioning set contains one time series and in addition to the past of and . Dashed lines are for correlations that are not causations, and bold arrows correspond to conditioning variables.
Figure 4.
Example of conditional independence between dependent time series. In (a) the conditioning set contains one time series in addition to the past of and . In (b) the conditioning set contains one time series and in addition to the past of and . Dashed lines are for correlations that are not causations, and bold arrows correspond to conditioning variables.

Figure 5.
Illustration for constructing sequences of windows for two time series with different sampling rates. In (a) the construction represents incompatible lags and in (b) the construction represents compatible lags.
Figure 5.
Illustration for constructing sequences of windows for two time series with different sampling rates. In (a) the construction represents incompatible lags and in (b) the construction represents compatible lags.

Figure 6.
Time computation for PCTMI and PCMCI.

Figure 7.
CTMI with respect to the maximum lag in (a) and the k-nearest neighbor k in (b) for dependent time series ( and in the fork structure in Table 1) and conditionally independent time series ( and conditioned on in the fork structure in Table 1).


{kind=link}
{kind=link}
{kind=link}
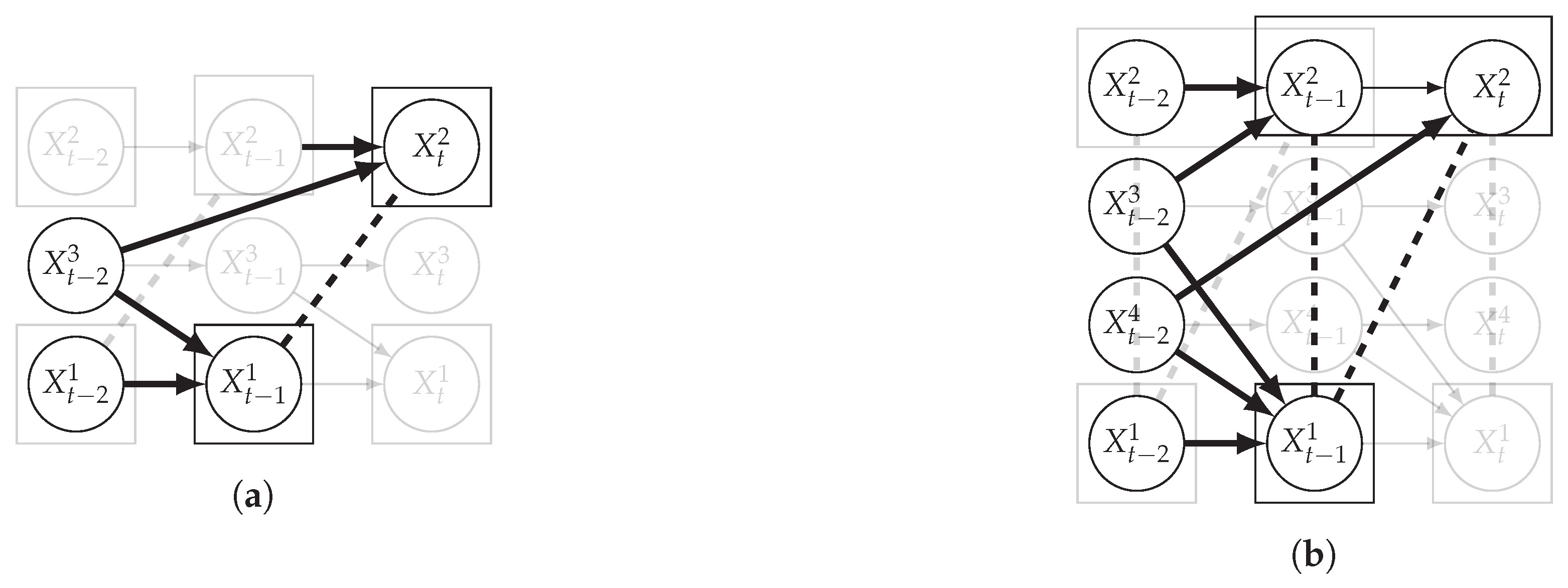{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Structures of simulated data without hidden common causes. means that A causes B.
| V-Structure | Fork | Diamond |
|---|---|---|
 |  |  |
Table 2.
Structures of simulated data with hidden common causes. means that A causes B and represents the existence of a hidden common cause between A and B.
Table 2.
Structures of simulated data with hidden common causes. means that A causes B and represents the existence of a hidden common cause between A and B.
| 7ts2h |
|---|
 |
Table 3.
Results for simulated datasets with an equal sampling rate. We report the mean and the standard deviation of the F1-score. The best results are in bold.
Table 3.
Results for simulated datasets with an equal sampling rate. We report the mean and the standard deviation of the F1-score. The best results are in bold.
| PCTMI | PCMCI | TiMINo | VarLiNGAM | Dynotears | TCDF | MVGC | |
|---|---|---|---|---|---|---|---|
| V structure | |||||||
| Fork | |||||||
| Diamond |
Table 4.
Results for simulated datasets with different sampling rates. We report the mean and the standard deviation of the F1-score.
Table 4.
Results for simulated datasets with different sampling rates. We report the mean and the standard deviation of the F1-score.
| PCTMI | |
|---|---|
| V structure | |
| Fork | |
| Diamond |
Table 5.
Results for simulated datasets with an equal sampling rate and with hidden common causes. We report the mean and the standard deviation of the F1-score.
Table 5.
Results for simulated datasets with an equal sampling rate and with hidden common causes. We report the mean and the standard deviation of the F1-score.
| FCITMI | tsFCI | |
|---|---|---|
| 7ts2h |
Table 6.
Results for real datasets. We report the mean and the standard deviation of the F1-score. The best results are in bold.
Table 6.
Results for real datasets. We report the mean and the standard deviation of the F1-score. The best results are in bold.
| PCTMI | PCMCI | TiMINo | VarLiNGAM | Dynotears | TCDF | MVGC | |
|---|---|---|---|---|---|---|---|
| fMRI | |||||||
| IT |
Table 7.
Summary causal graphs inferred by different methods using 10 different monitoring IT datasets. means that A causes B and means that A causes B and B causes A.
Table 7.
Summary causal graphs inferred by different methods using 10 different monitoring IT datasets. means that A causes B and means that A causes B and B causes A.
| PCTMI | PCMCI | TiMINo | VarLiNGAM | MVGC | |
|---|---|---|---|---|---|
| Dataset 1 |  |  |  |  |  |
| Dataset 2 |  |  |  |  |  |
| Dataset 3 |  |  |  |  |  |
| Dataset 4 |  |  |  |  |  |
| Dataset 5 |  |  |  |  |  |
| Dataset 6 |  |  |  |  |  |
| Dataset 7 |  |  |  |  |  |
| Dataset 8 |  |  |  |  |  |
| Dataset 9 |  |  |  |  |  |
| Dataset 10 |  |  |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Assaad, C.K.; Devijver, E.; Gaussier, E. Entropy-Based Discovery of Summary Causal Graphs in Time Series. Entropy 2022, 24, 1156. https://doi.org/10.3390/e24081156
AMA Style
Assaad CK, Devijver E, Gaussier E. Entropy-Based Discovery of Summary Causal Graphs in Time Series. Entropy. 2022; 24(8):1156. https://doi.org/10.3390/e24081156
Chicago/Turabian StyleAssaad, Charles K., Emilie Devijver, and Eric Gaussier. 2022. "Entropy-Based Discovery of Summary Causal Graphs in Time Series" Entropy 24, no. 8: 1156. https://doi.org/10.3390/e24081156
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.