
Octree Optimized Micrometric Fibrous Microstructure Generation for Domain Reconstruction and Flow Simulation

 , and
, and
Abstract
:1. Introduction
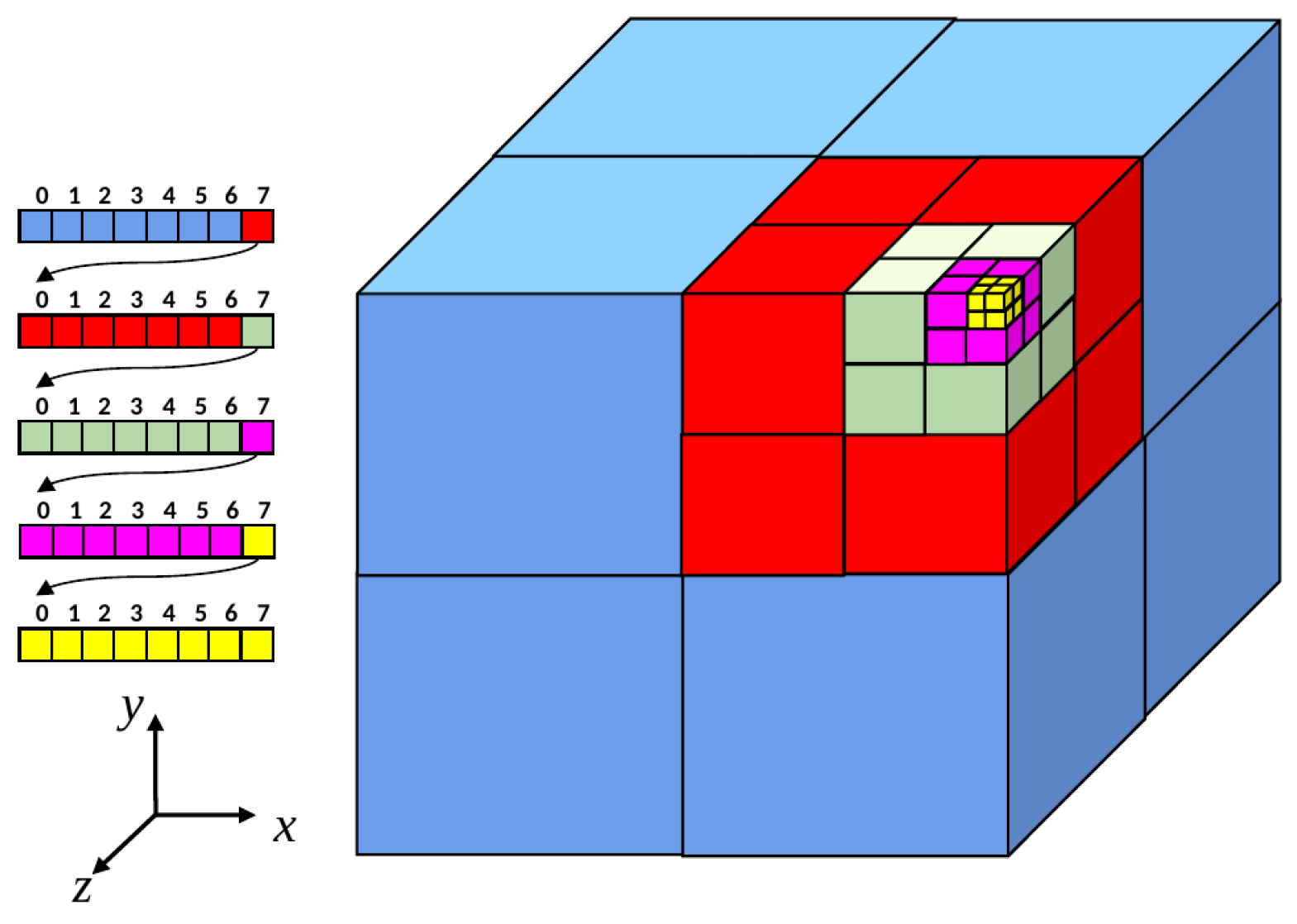
2. Microstructure Generation and Optimization Using Octree
- A new fiber must be always included in the global domain initially built for octree and, if it is not the case, it is necessary to destroy the octree and to reconstruct it;
- The size of a leaf should not exceed the defined maximal size and, if it is not the case, it is necessary to refine the octree.
3. Computational Domain Reconstruction
3.1. Mesh Immersion and Optimization Using the Octree
3.2. Parallel Anisotropic Mesh Adaptation
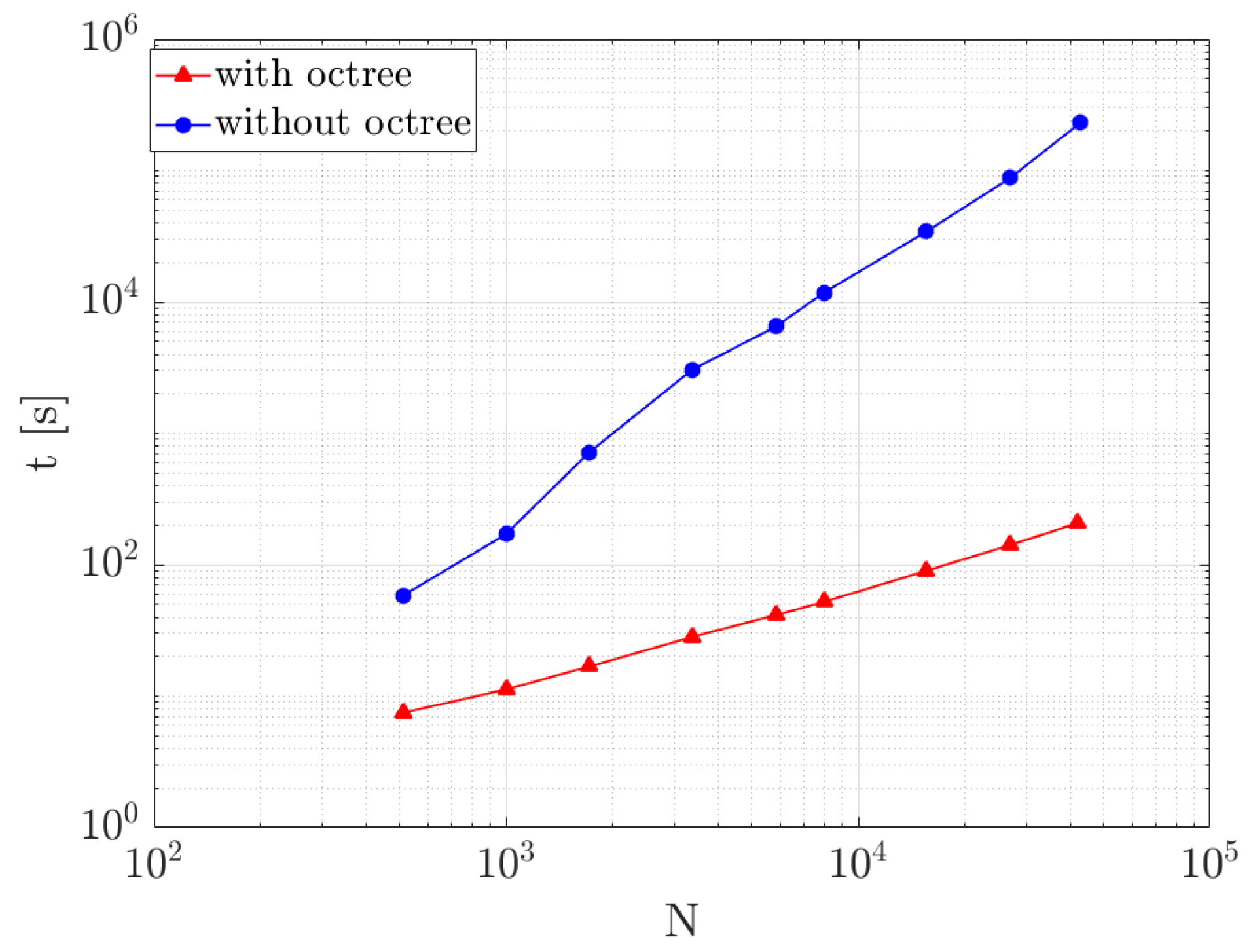
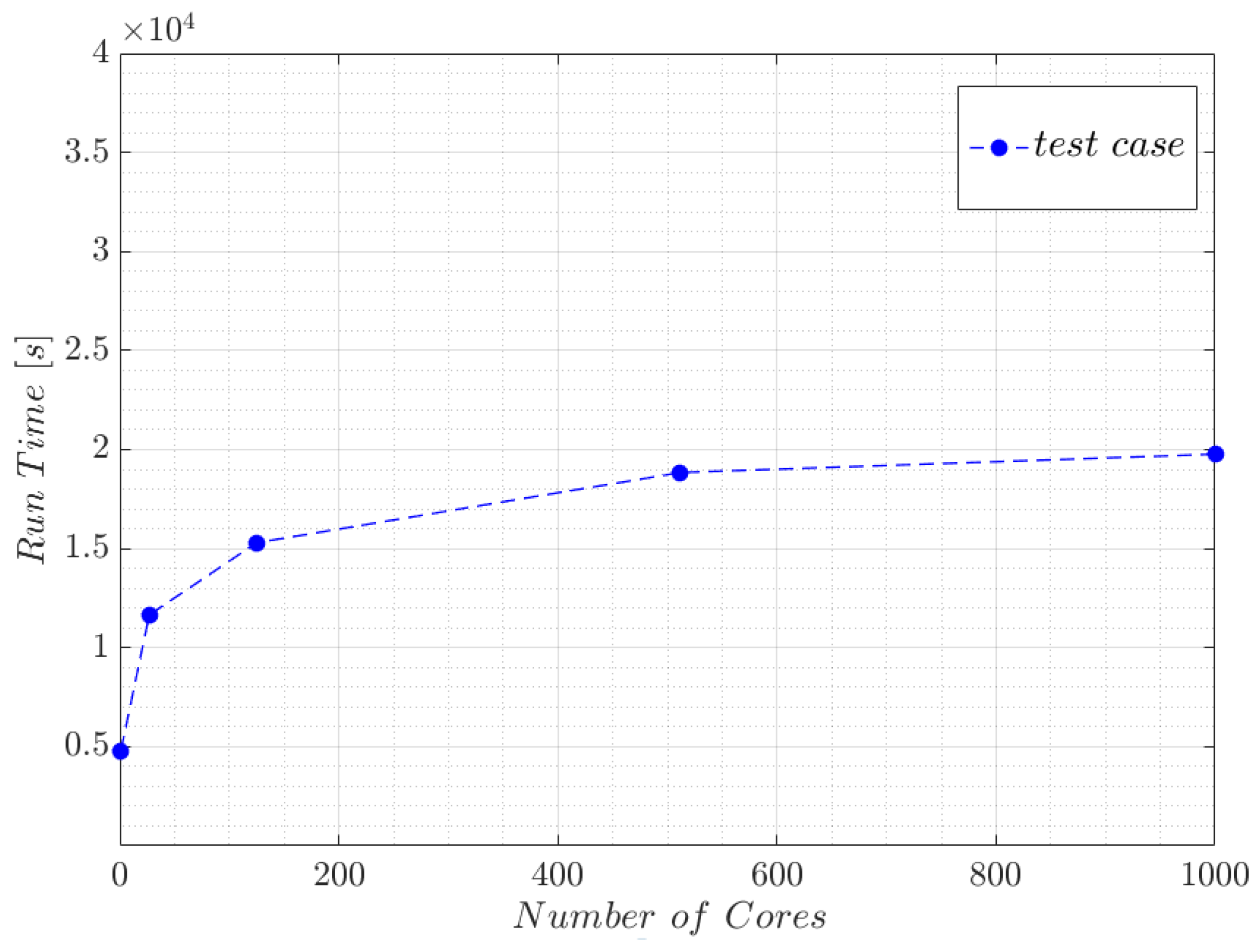
3.3. Weak Scalability Test of the Proposed Reconstruction Approach
4. Flow Simulation Examples: Application to Permeability Computation
4.1. Flow Simulation
4.2. Permeability Computation Procedure
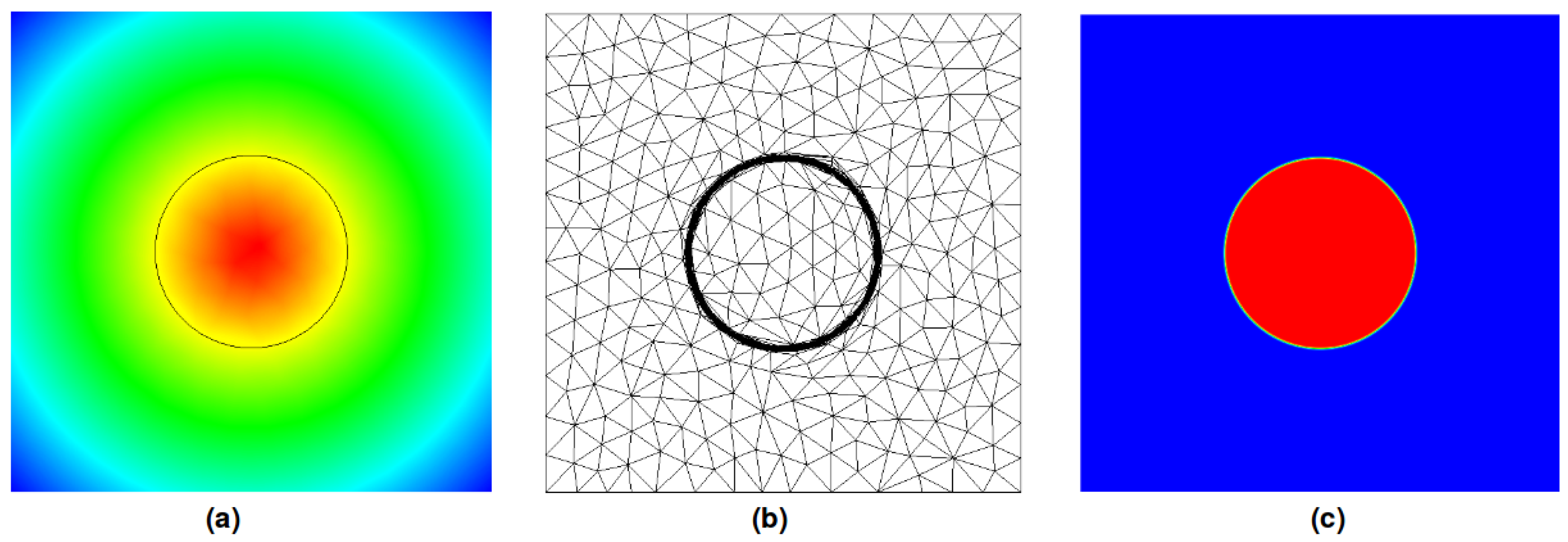
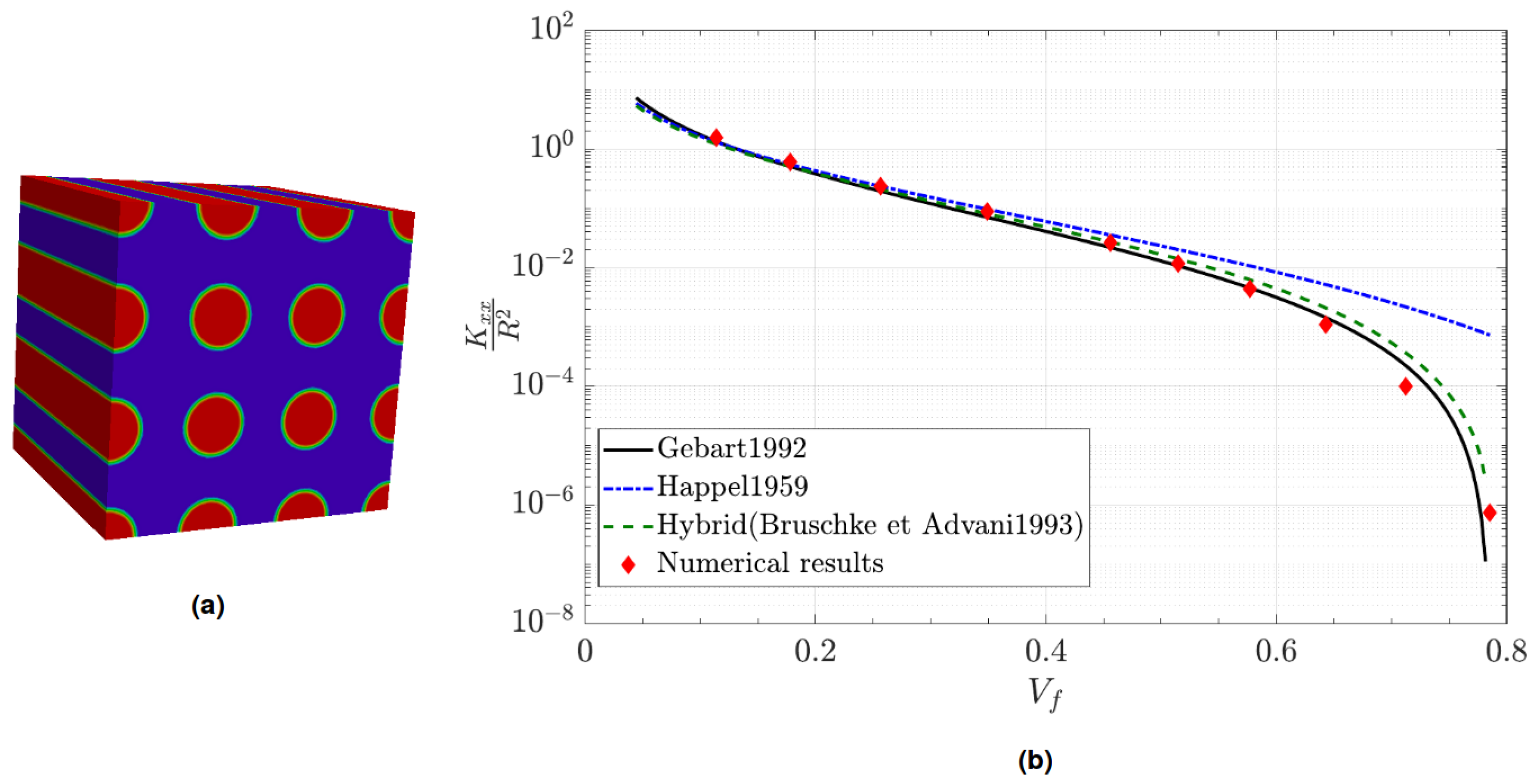
4.3. Permeability Computation Validation
4.4. Application for 10,000 Fibers
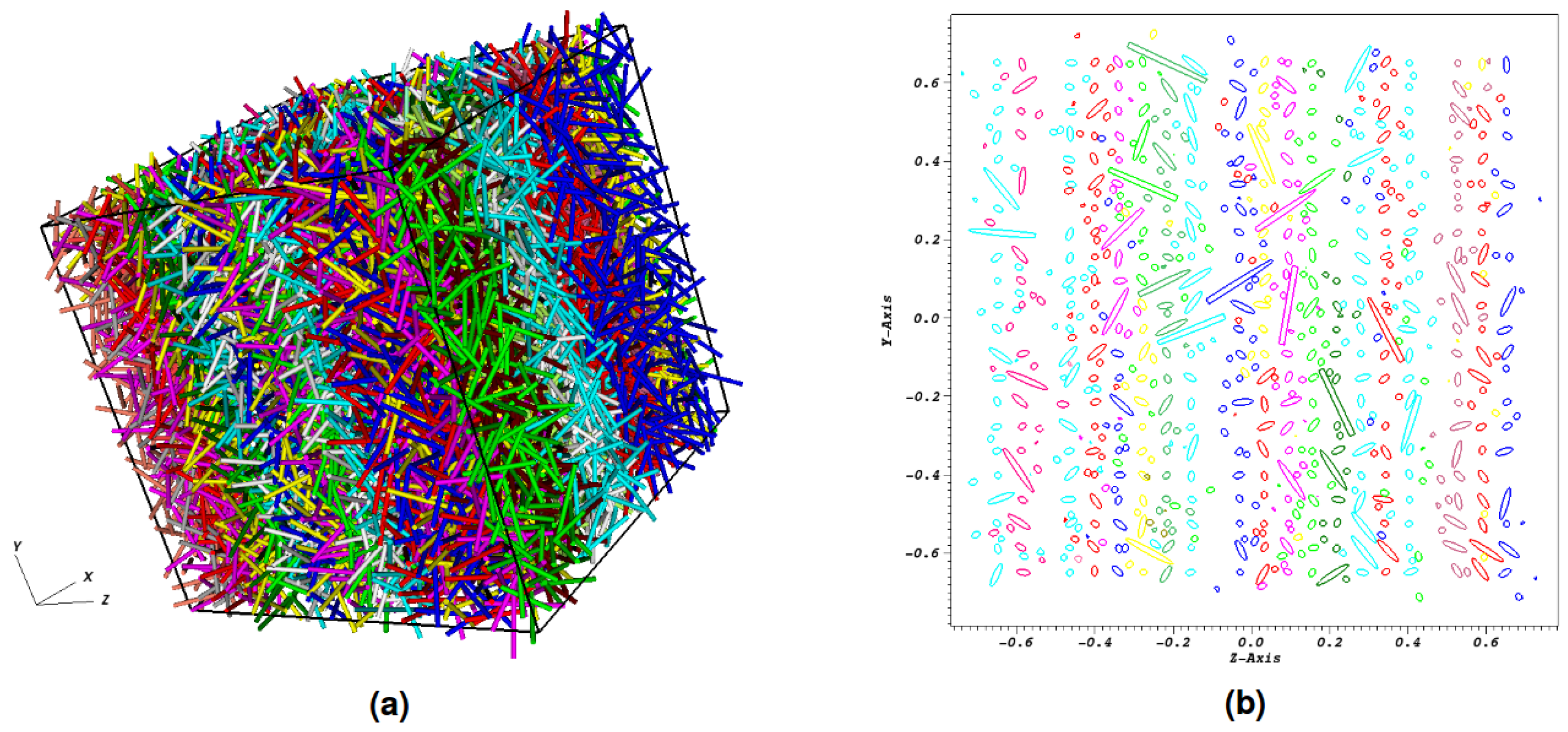
4.4.1. Microstructure Generation
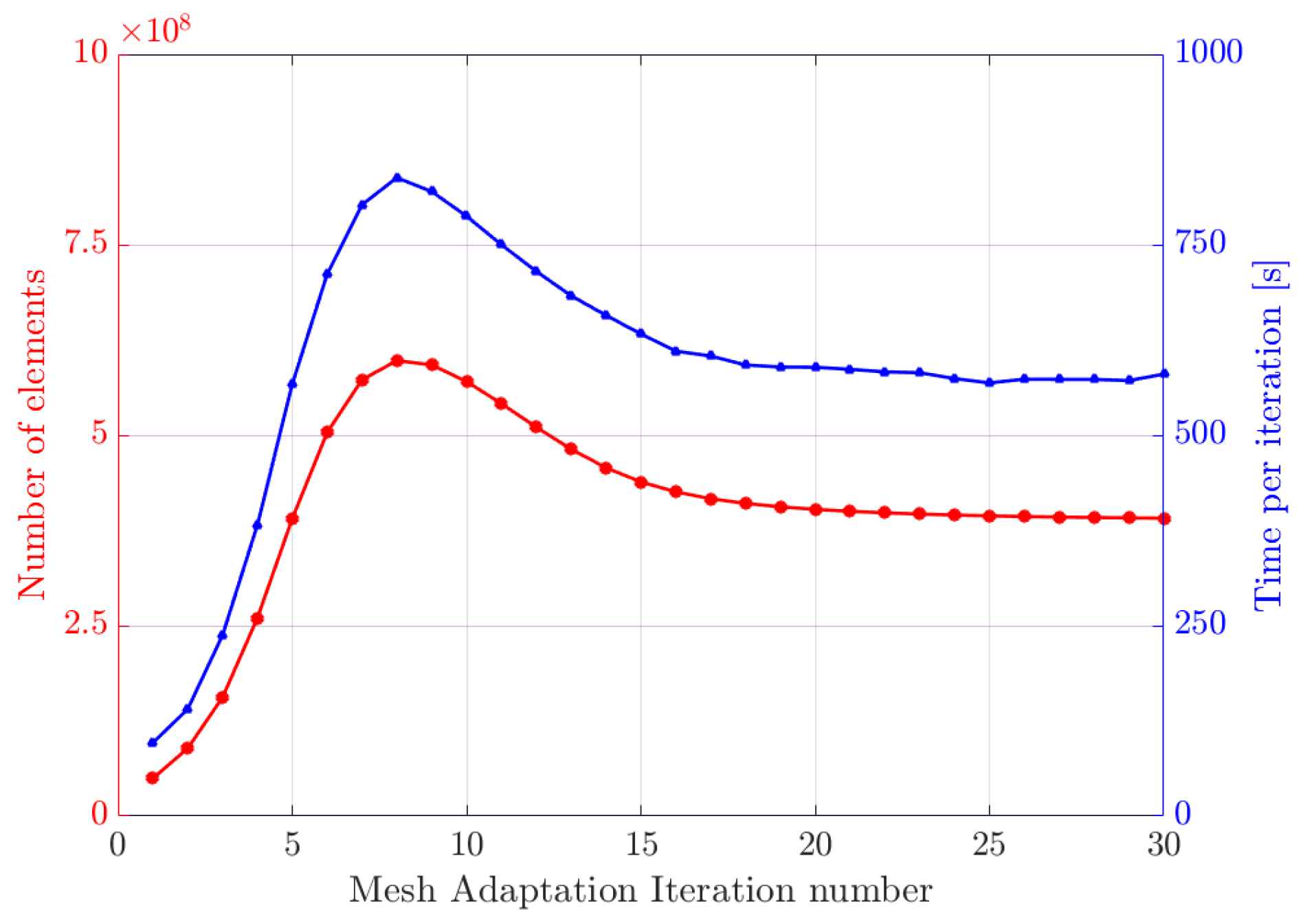
4.4.2. Microstructure Reconstruction with Adaptative Mesh
4.4.3. Flow Resolution and Permeability Tensor Computation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Samet, H. The Design and Analysis of Spatial Data structures Addison-Wesley Series in Computer Science; Addison-Wesley: Reading, MA, USA, 1990. [Google Scholar]
- Szeliski, R. Rapid octree construction from image sequences. CVGIP Image Underst. 1993, 58, 23–32. [Google Scholar] [CrossRef]
- Laurmaa, V.; Picasso, M.; Steiner, G. An octree-based adaptive semi-Lagrangian VOF approach for simulating the displacement of free surfaces. Comput. Fluids 2016, 131, 190–204. [Google Scholar] [CrossRef] [Green Version]
- Fan, W.; Wang, B.; Paul, J.C.; Sun, J. An octree-based proxy for collision detection in large-scale particle systems. Sci. China Inf. Sci. 2013, 56, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.H.; Ko, S.L. Improvement of cutting simulation using the octree method. Int. J. Adv. Manuf. Technol. 2006, 28, 1152–1160. [Google Scholar] [CrossRef]
- Wang, H.Y.; Liu, S.G. A collision detection algorithm using AABB and octree space division. In Advanced Materials Research; Trans Tech Publications: Zurich, Switzerland, 2014; Volume 989, pp. 2389–2392. [Google Scholar]
- Baehmann, P.L.; Wittchen, S.L.; Shephard, M.S.; Grice, K.R.; Yerry, M.A. Robust, geometrically based, automatic two-dimensional mesh generation. Int. J. Numer. Methods Eng. 1987, 24, 1043–1078. [Google Scholar] [CrossRef]
- Péron, S.; Benoit, C. Automatic off-body overset adaptive Cartesian mesh method based on an octree approach. J. Comput. Phys. 2013, 232, 153–173. [Google Scholar] [CrossRef]
- Zhang, Y.; Bajaj, C.; Sohn, B.S. 3D finite element meshing from imaging data. Comput. Methods Appl. Mech. Eng. 2005, 194, 5083–5106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mezher, R. Modeling and Simulation of Concentrated Suspensions of Short, Rigid and Flexible Fibers. Ph.D. Thesis, Engineering Sciences [physics], Ecole Centrale de Nantes (ECN), Nantes, France, 2015. [Google Scholar]
- Aissa, N. Simulation Haute Performance des Suspensions de Fibres Courtes Pour les Procédés de Fabrication de Composites. Ph.D. Thesis, Mécanique des Fluides [physics.class-ph], École Centrale de Nantes, Nantes, France, 2021. [Google Scholar]
- Coupez, T.; Hachem, E. Solution of high-Reynolds incompressible flow with stabilized finite element and adaptive anisotropic meshing. Comput. Methods Appl. Mech. Eng. 2013, 267, 65–85. [Google Scholar] [CrossRef]
- Coupez, T. Metric construction by length distribution tensor and edge based error for anisotropic adaptive meshing. J. Comput. Phys. 2011, 230, 2391–2405. [Google Scholar] [CrossRef]
- Zhao, J.X.; Coupez, T.; Decencière, E.; Jeulin, D.; Cárdenas-Peña, D.; Silva, L. Direct multiphase mesh generation from 3D images using anisotropic mesh adaptation and a redistancing equation. Comput. Methods Appl. Mech. Eng. 2016, 309, 288–306. [Google Scholar] [CrossRef] [Green Version]
- Digonnet, H.; Coupez, T.; Laure, P.; Silva, L. Massively parallel anisotropic mesh adaptation. Int. J. High Perform. Comput. Appl. 2019, 33, 3–24. [Google Scholar] [CrossRef]
- Silva, L.; Coupez, T.; Digonnet, H. Massively parallel mesh adaptation and linear system solution for multiphase flows. Int. J. Comput. Fluid Dyn. 2016, 30, 431–436. [Google Scholar] [CrossRef]
- Beaume, G. Modélisation et Simulation Numérique de l’Écoulement d’un Fluide Complexe. Ph.D. Thesis, Mécanique [physics.med-ph], École Nationale Supérieure des Mines de Paris, Paris, France, 2008. [Google Scholar]
- Gebart, B. Permeability of unidirectional reinforcements for RTM. J. Compos. Mater. 1992, 26, 1100–1133. [Google Scholar] [CrossRef]
- Happel, J. Viscous flow relative to arrays of cylinders. AIChE J. 1959, 5, 174–177. [Google Scholar] [CrossRef]
- Bruschke, M.; Advani, S. Flow of generalized Newtonian fluids across a periodic array of cylinders. J. Rheol. 1993, 37, 479–498. [Google Scholar] [CrossRef]
- Advani, S.G.; Tucker, C.L., III. The use of tensors to describe and predict fiber orientation in short fiber composites. J. Rheol. 1987, 31, 751–784. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Signification |
|---|---|
| x | Point of computational mesh |
| Shape immersed represented by elements | |
| Closest element of the set representing from x | |
| Closest octree leaf from x | |
| Maximal theoretical distance from x to | |
| Circle/sphere of center x and radius | |
| Signed distance from x to |
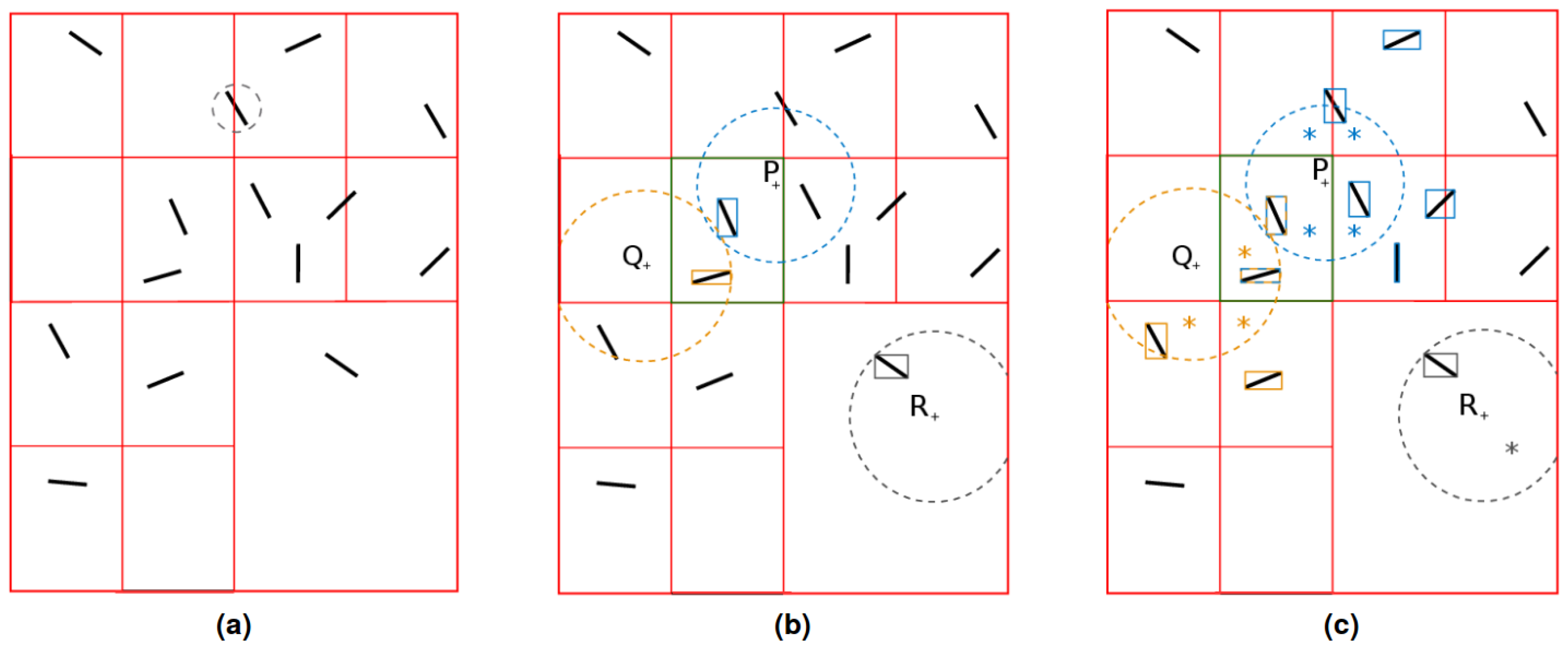
| Distances to Fiber/Points | P | Q | R | Total |
|---|---|---|---|---|
| no octree | 14 | 14 | 14 | 42 |
| octree | 3 | 3 | 1 | 7 |
| Number of Fibers | Domain Edge Size | Number of Cores | Total Mesh Nodes | |
|---|---|---|---|---|
| test 1 | 8 | 0.178 | 1 | 172,245 |
| test 2 | 216 | 0.534 | 27 | 728,895 |
| test 3 | 1000 | 0.890 | 125 | 37,153,365 |
| test 4 | 4096 | 1.425 | 512 | 160,374,769 |
| test 5 | 8000 | 1.781 | 1000 | 317,813,266 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aissa, N.; Douteau, L.; Abisset-Chavanne, E.; Digonnet, H.; Laure, P.; Silva, L. Octree Optimized Micrometric Fibrous Microstructure Generation for Domain Reconstruction and Flow Simulation. Entropy 2021, 23, 1156. https://doi.org/10.3390/e23091156
Aissa N, Douteau L, Abisset-Chavanne E, Digonnet H, Laure P, Silva L. Octree Optimized Micrometric Fibrous Microstructure Generation for Domain Reconstruction and Flow Simulation. Entropy. 2021; 23(9):1156. https://doi.org/10.3390/e23091156
Chicago/Turabian StyleAissa, Nesrine, Louis Douteau, Emmanuelle Abisset-Chavanne, Hugues Digonnet, Patrice Laure, and Luisa Silva. 2021. "Octree Optimized Micrometric Fibrous Microstructure Generation for Domain Reconstruction and Flow Simulation" Entropy 23, no. 9: 1156. https://doi.org/10.3390/e23091156