BROJA-2PID: A Robust Estimator for Bivariate Partial Information Decomposition


Institute of Computer Science, University of Tartu, Ülikooli 17, 51014 Tartu, Estonia
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2018, 20(4), 271; https://doi.org/10.3390/e20040271
Submission received: 22 February 2018
/
Revised: 27 March 2018
/
Accepted: 9 April 2018
/
Published: 11 April 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:Makkeh, Theis, and Vicente found that Cone Programming model is the most robust to compute the Bertschinger et al. partial information decomposition (BROJA PID) measure. We developed a production-quality robust software that computes the BROJA PID measure based on the Cone Programming model. In this paper, we prove the important property of strong duality for the Cone Program and prove an equivalence between the Cone Program and the original Convex problem. Then, we describe in detail our software, explain how to use it, and perform some experiments comparing it to other estimators. Finally, we show that the software can be extended to compute some quantities of a trivaraite PID measure.
1. Introduction
For random variables with finite range, consider the mutual information : the amount of information that the pair contain about X. How can we quantify the contributions of Y and Z, respectively, to ? This question is at the heart of (bivariate) partial information decomposition (PID) [1,2,3,4]. Information theorists agree that there can be: information shared redundantly by Y and Z; information contained uniquely within Y but not within Z; information contained uniquely within Z but not within Y; and information that synergistically results from combining both Y and Z. The quantities are denoted by: ; , ; and , respectively. All four of these quantities add up to ; moreover, the quantity of total information that Y has about X is decomposed into the quantity of unique information that Y has about X and shared information that Y shares with Z about X, and similarly for quantity of total information that Z has about X, thus , and . Hence, if the joint distribution of is known, then there is (at most) one degree of freedom in defining a bivariate PID. In other words, defining the value of one of the information quantities defines a bivariate PID.
Bertschinger et al. [1] have given a definition of a bivariate PID where the synergistic information is defined as follows:
where the maximum extends over all triples of random variables with the same 12,13-marginals as , i.e., for all and for all . It can easily be verified that this amounts to maximizing a concave function over a compact, polyhedral set described by inequalities [5]. Hence, using standard theorems of convex optimization [5,6], BROJA’s bivariate PID can be efficiently approximated to any given precision.
In practice, computing CI has turned out to be quite challenging, owing to the fact that the objective function is not smooth on the boundary of the feasible region, which results in numerical difficulties for state-of-the-art interior point algorithms for solving convex optimization problems. We refer to [5] for a thorough discussion of this phenomenon.
Due to these challenges and the need in the scientific computing community to have a reliable easily usable software for computing the BROJA bivariate PID, we made available on GitHub a Python implementation of our best method for computing the BROJA bivariate PID (https://github.com/Abzinger/BROJA_2PID/). The solver is based on a conic formulation of the problem and thus a Cone Program is used to compute the BROJA bivariate PID. This paper has two contributions. Firstly, we prove the important property of strong duality for the Cone Program and prove an equivalence between the Cone Program and the original Convex problem (1). Secondly, we describe in detail our software and how to use it. Thirdly, we test the software against different instances and then compare the results with the computeUI estimator introduced in [7] and the ibroja estimator from the dit package (https://github.com/dit/dit). Finally, we show how to use the so-called exponential cone to model some quantities of the multivariate PID measure introduced in [8].
This paper is organized as follows. In the remainder of this section, we define some notation we will use throughout, and review the Convex Program for computing the BROJA bivariate PID from [1]. In the next section, we review the math underlying our software to the point which is necessary to understand how it works and how it is used. In Section 3, we walk the reader through an example of how to use the software, and then explain its inner workings and its use in detail. In Section 4, we present some computations on larger problem instances, discuss how the method scales up, and compare it to other methods. In Section 5, we present a modeling, using the exponential cone, of some quantities for a multivariate PID measure. We conclude the paper by discussing our plans for the future development of the code.
Notation and Background
Denote by the range of the random variable X, by the range of Y, and by the range of Z. We identify joint probability density functions with points in ; for example, the joint probability distribution of is a vector in . (We measure information in nats, unless otherwise stated.) We use the following notational convention.
An asterisk stands for “sum over everything that can be plugged in instead of the ∗”, e.g., if ,We do not use the symbol ∗ in any other context.
We define the following notation for the marginal distributions of : With p the joint probability density function of :
These notations allow us to write the Convex Program from [1] in a succinct way. Unraveling the objective function of (1), we find that, given the marginal conditions, it is equal, up to a constant not depending on , to the conditional entropy . Replacing maximizing by minimizing , we find (1) to be equivalent to the following Convex Program:
2. Cone Programming Model for Bivariate PID
In [5], we introduced a model for computing the BROJA bivariate PID based on a so-called “Cone Programming”. Cone Programming is a far reaching generalization of Linear Programming: The usual inequality constraints which occur in Linear Programs can be replaced by so-called “generalized inequalities”—see below for details. Similar to Linear Programs, dedicated software is available for Cone Programs, but each type of generalized inequalities (i.e., each cone) requires its own algorithms. The specific type of generalized inequalities needed for the computation of the BROJA bivariate PID requires solvers for the so-called “Exponential Cone”, of which two we are aware of ECOS [9] and SCS [10].
In the computational results of [5], we found that the Cone Programming approach (based on one of the available solvers) was, while not the fastest, the most robust of all methods for computing the BROJA bivariate PID which we tried, such as projected gradient descent, interior point for general convex programs, geometric programming, etc. The reason for this success is that the interior point method for Cone Programming is an extension of the efficient interior point methods of Linear Programming, see [11] for more details. This is why our software is based on the Exponential Cone Programming model.
In this section, we review the mathematical definitions to the point in which they are necessary to understand our model and the properties of the software based on it.
2.1. Background on Cone Programming
A nonempty closed convex cone is a closed set which is convex, i.e., for any and we have
and is a cone, i.e., for any and we have
for example, is a closed convex cone. Cone Programming is a far-reaching generalization of Linear Programming, which may contain so-called generalized inequalities: For a fixed closed convex cone , the generalized inequality “” denotes for any . Recall the primal-dual pair of Linear Programming. The primal problem is,
over variable , where and . Its dual problem is,
over variables and . There are two properties that the pair (2) and (3) may or may not have, namely, weak and strong duality. The following defines the duality properties.
Definition 1.
Consider a primal-dual pair of the Linear Program (2) and (3). Then, we define the following,
- 1.
- A vector (respectively, ) is said to be a feasible solution of (2) (respectively, (3)) if and (respectively, and ), i.e., none of the constraints in (2) (respectively, (3)) are violated by w (respectively, ).
- 2.
- We say that (2) and (3) satisfy weak duality if for all w and all feasible solutions of (2) and (3), respectively,
- 3.
- If w is a feasible solution of (2) and is a feasible solution of (3), then the duality gap d is
- 4.
- We say that (2) and (3) satisfy strong duality when the feasible solutions w and are optimal in (2) and (3), respectively, if and only if d is zero.
Weak duality always holds for a Linear Program, however strong duality holds for a Linear Program whenever a feasible solution of (2) or (3) exists. These duality properties are used to certify the optimality of w and . The same concept of duality exists for Cone Programming, the primal cone problem is
over variable , where and . The dual cone problem is,
where is the dual cone of . The entries of the vector are called the dual variables for equality constraints, . Those of are the dual variables for generalized inequalities, . The primal-dual pair of Conic Optimization (P) and (D) satisfies weak and strong duality in the same manner as the Linear Programming pair. In the following, we define the interior point of a Cone Program which is a necessary condition for strong duality (see Definition 1) to hold for the Conic Programming pair.
Definition 2.
Consider a primal-dual pair of the Conic Optimization (P) and (D). Then, the primal problem (P) has an interior point if,
- is a feasible solution of (P).
- There exists such that for any , we have whenever
Theorem 1
(Theorem 4.7.1 [12]). Consider a primal-dual pair of the Conic Optimization (P) and (D). Let w and be the feasible solutions of (P) and (D), respectively. Then,
- 1.
- Weak duality always hold for (P) and (D).
- 2.
- If is finite and (P) has an interior point , then strong duality holds for (P) and (D).
If the requirements of Theorem 1 are met for a conic optimization problem, then weak and strong duality can be used as guarantees that the given solution of a Cone Program is optimal.
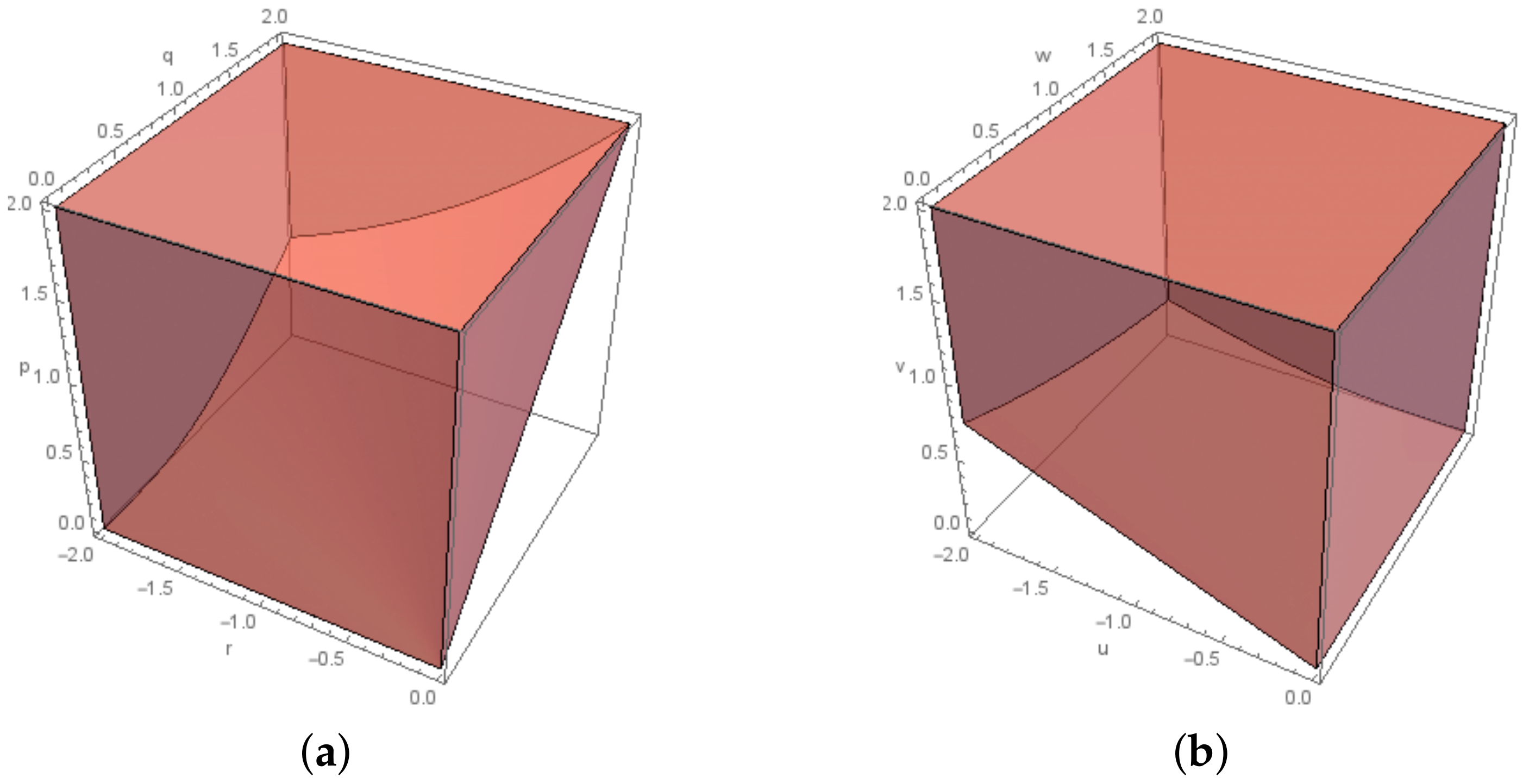
One of the closed convex cones which we use throughout the paper is the exponential cone, , (see Figure 1) defined in [13] as
which is the closure of the set
and its dual cone, (see Figure 1) is
which is the closure of the set
When in (P), the Cone Program is referred to as “Exponential Cone Program”.
2.2. The Exponential Cone Programming Model
The Convex Program (CP) which computes the bivariate partial information decomposition can be formulated as an Exponential Cone Program. Consider the following Exponential Cone Program where the variables are .
The first two constraints are the marginal equations of (CP). The third constraints connects the t-variables with the q-variables which will be denoted as coupling equations. The generalized inequality connects these to the variables forming the objective function.
Proposition 1.
The exponential cone program (EXP) is equivalent to the Convex Program (CP).
Proof.
Let and be the feasible region of (CP) and (EXP), respectively. We define the following
For , we have
and since conditional entropy at vanishes, then the objective function of (CP) evaluated at is equal to that of (EXP) evaluated at . If , then there exists such that and so
☐
The dual problem of (EXP) is
Using the definition of the system consisting of (9a)–(9d) is equivalent to
and so the dual problem of (EXP) can be formulated as
Proposition 2.
Strong duality holds for the primal-dual pair (EXP) and (D-EXP).
Proof.
We assume that Consider the point with such that
is an interior point of (EXP). We refer to [14] for the proof. Hence, by Theorem 1, strong duality holds for the primal-dual pair (EXP) and (D-EXP). ☐
Weak and strong duality in their turn provide a measure for the quality of the returned solution, for more details see Section 3.4.
3. The BROJA_2PID Estimator
We implemented the exponential cone program (EXP) in Python and used a conic optimization solver to get the desired solution. Note that we are aware of only two conic optimization software toolboxes which allow solving Exponential Cone Programs, ECOS and SCS. The current version of Broja_2pid utilizes ECOS to solve the Exponential Cone Program (EXP). ECOS (we use the version from 8 November 2016) is a lightweight numerical software for solving Convex Cone programs [9].
This section describes the Broja_2pid package form the user’s perspective. We briefly explain how to install Broja_2pid. Then, we illustrate the framework of Broja_2pid and its functions. Further, we describe the input, tuning parameters, and output.
3.1. Installation
To install Broja_2pid, you need Python to be installed on your machine. Currently, you need to install ECOS, the Exponential Cone solver. To do that, you most likely pip3 install ecos. If there are troubles installing ECOS, we refer to its Github repository https://github.com/embotech/ecos-python. Finally, you need to gitclone the Github link of Broja_2pid and it is ready to be used.
3.2. Computing Bivariate PID
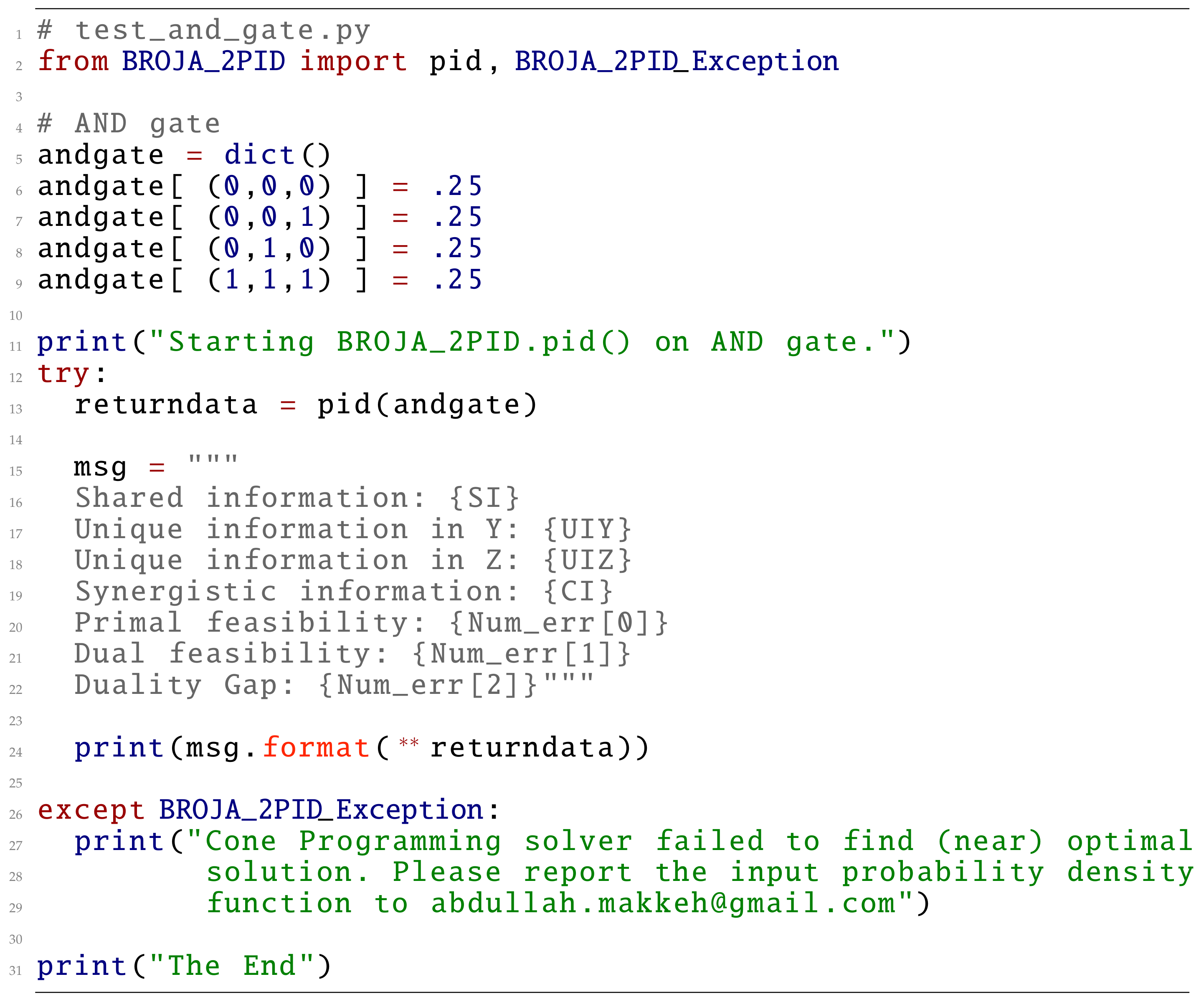
In this subsection, we will explain how Broja_2pid works. In Figure 2, we present a script as an example of using Broja_2pid package to compute the partial information decomposition of the And distribution, where Y and Z are independent and uniformly distributed in .
We will go through the example (Figure 2) to explain how Broja_2pid works. The main function in Broja_2pid package is pid(). It is a wrap up function which is used to compute the partial information decomposition. First, pid() prepares the “ingredients” of (EXP). Then, it calls the Cone Programming solver to find the optimal solution of (EXP). Finally, it receives from the Cone Programming solver the required solution to compute the decomposition.
The “ingredients” of (EXP) are the marginal and coupling equations, generalized inequalities, and the objective function. Thus, pid() needs to compute and store and , the marginal distributions of and . For this, pid() requires a distribution of and Z. In Figure 2, the distribution comes from the And gate where .
Distributions are stored as a Python dictionary data structure in which the random variable is a triplet key and the probability at this point is the value. This provides an associate memory structure where the value of the random variable is a reference to the probability at that point. For example, the triplet occurs with probability and so on for the other triplets. Thus, And distribution is defined as a Python dictionary, andgate=dict() where andgate[ (0,0,0) ]=0.25 is assigning the key “” a value “0.25” and so on.
Note that the user does not need to add the triplets with zero probability to the dictionary since pid() will always discard such triplets. In [5], the authors discussed in details how to handle the triplets with zero probability. The input of pid() is explained in details in the following subsection.
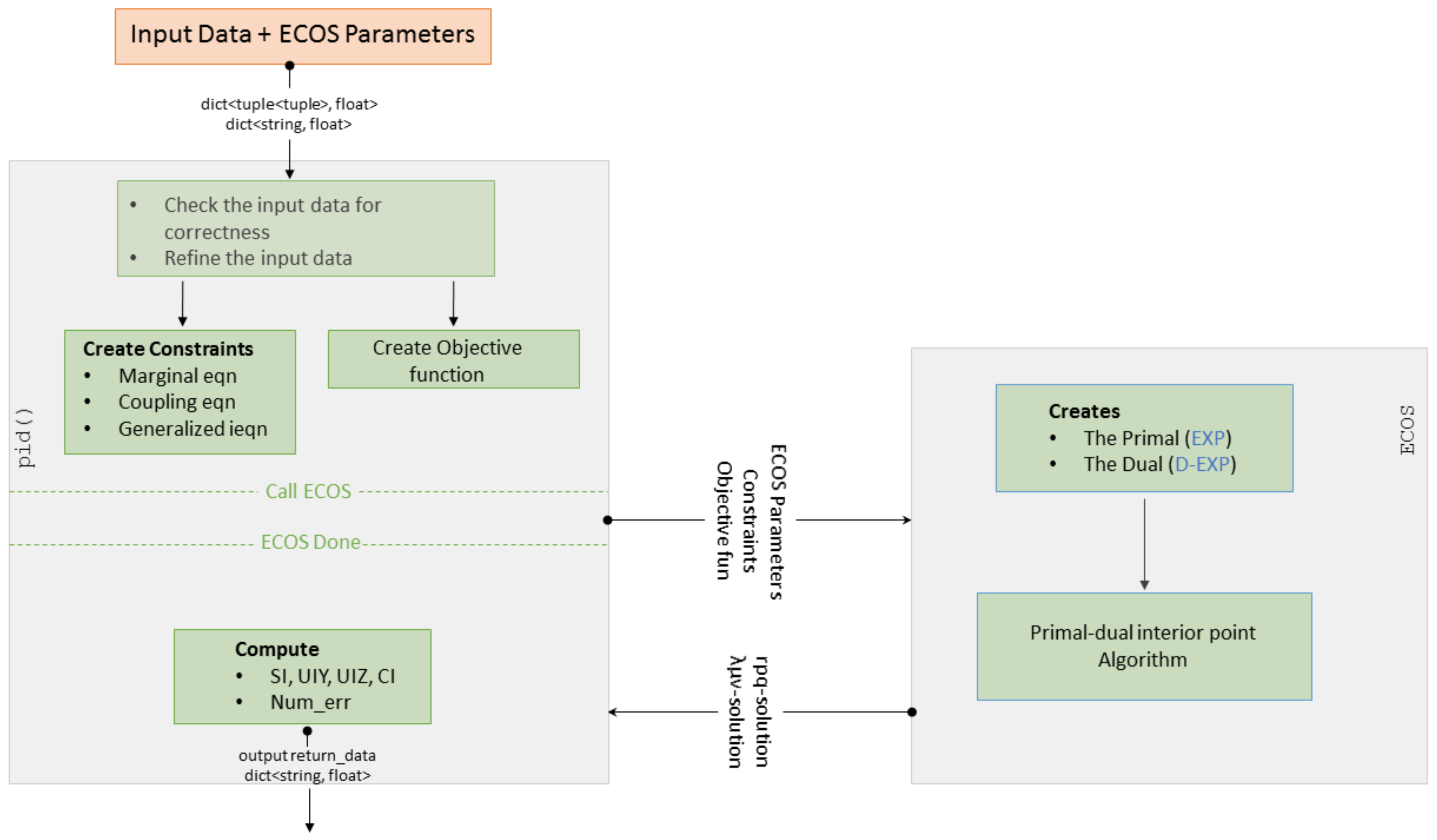
Now, we briefly describe how pid() proceeds to return the promised decomposition. pid() calls the Cone Programming solver and provides it with the “ingredients” of (EXP) as a part of the solver’s input. The solver finds the optimal solution of (EXP) and (D-EXP). When the solver halts, it returns the primal and dual solutions. Using the returned solutions, pid() computes the decomposition based on (1). The full process is explained in Figure 3.
Finally, pid() returns a Python dictionary, returndata containing the partial information decomposition and information about the quality of the Cone Programming solver’s solution. In Section 3.4, we give a detailed explanation on how to compute the quality of the solution and Table 3 contains a description of the keys and values of returndata.
For example, in the returned dictionary returndata for the And gate, returndata[’CI’] contains the quantity of synergistic information and returndata[’Num_err’][0] the maximum primal feasibility violation of (EXP).
Note that conic optimization solver is always supposed to return a solution. Thus, Broja_2pid will raise an exception, BROJA_2PID_Exception, when no solution is returned.
3.3. Input and Parameters
In Broja_2pid package, pid() is the function which the user needs to compute the partial information decomposition. The function pid() takes as input a Python dictionary.
The Python dictionary represents a probability distribution. This distribution computes the vectors and for the the marginal expressions in (EXP). A key of the Python dictionary is a triplet of which is a possible outcome of the random variables and Z. A value of the key in the Python dictionary is a number which is the probability of and .
The Cone Programming solver has to make sure while seeking the optimal solution of (EXP) that w and are feasible and (ideally) should halt when the duality gap is zero, i.e., w and are optimal. However, w and entries belong to and computers represent real numbers up to floating precision. Thus, the Cone Programming solver considers a solution feasible when none of the constraints are violated, or optimal, duality gap is zero, up to a numerical precision (tolerance). The Cone Programming solver allows the user to modify the feasibility and optimality tolerances along with couple other parameters which are described in Table 1.
To change the default Cone Programming solver parameters, the user should pass them to pid() as a dictionary. For example, in Figure 4, we change the maximum number of iterations which the solver can do. For this, we created a dictionary, parms=dict(). Then, we set a desired value, 1000, for the key ’max_iter’. Finally, we are required to pass parms to pid() as a dictionary, pid(andgate,∗∗parms). Note that, in the defined dictionary parms, the user only needs to define the keys for which the user wants to change the values.
The parameters output determines the printing mode of pid() and is an integer in . This means that it allows the user to control what will be printed on the screen. Table 2 gives a detailed description of the printing mode.
Currently, we only use ECOS to solve the Exponential Cone Program but in the future we will add the SCS solver. Thus, the user should determine which solver to use in the computations. For exmple, setting cone_solver=“ECOS” will utilize ECOS in the computations.
3.4. Returned Data
The function pid() returns a Python dictionary called returndata. Table 3 describes the returned dictionary.
Let and be the lists returned by the Cone Programming solver where and . Note that w is the primal solution and is the dual solution. The dictionary returndata gives the user access to the partial information decomposition, namely, shared, unique, and synergistic information. The partial information decomposition is computed using only the positive values of . The value of the key ’Num_err’ is a triplet such that the primal feasibility violation is returndata[’Num_err’][0], the dual feasibility violation is returndata[’Num_err’][1], and returndata[’Num_err’][2] is the duality gap violation. In the following, we will explain how we compute the violations of primal and dual feasibility in addition to that of duality gap.
The primal feasibility of (EXP) is
We check the violation of which is required by . Since all the non-positive are discarded when computing the decomposition, we check if the marginal equations are violated using only the positive . The coupling equations are ignored since they are just assigning values to the variables. Thus, returndata[’Num_err’][0] (primal feasibility violation) is computed as follows,
The dual feasibility of (D-EXP) is
For dual feasibility violation, we check the non-negativity of (12). Thus, the error returndata[’Num_err’][1] is equal to
When w is the optimal solution of (EXP), we have
The duality gap of (EXP) and (D-EXP) is
where
Since weak duality implies , we are left to check the non-negativity of (13) to inspect the duality gap. Thus, returndata[’Num_err’][2] is given by,
4. Tests
In this section, we test the performance of Broja_2pid on three types of instances. We describe the instances that Broja_2pid is tested against, report the results, and finally compare the performance of other estimators on the same instances. The two estimators that we compare the performance of Broja_2pid to, which produce reasonable results and we are aware of, are computeUI and ibroja. The first two types of instances are used as primitive validation tests. However, the last type of instances is used to evaluate the accuracy and efficiency of Broja_2pid in computing the partial information decomposition. We used a computer server with Intel(R) Core(TM) i7-4790K CPU (4 cores) and 16GB of RAM to compute PID for the instances. All computations of Broja_2pid and computeUI were done using one core, whereas ibroja used multiple cores.
4.1. Paradigmatic Gates
The following set of instances have been studied extensively throughout the literature. The partial information decomposition of the set of instances is known [2]. Despite their simplicity, they acquire desired properties of shared or synergistic quantities.
4.1.1. Data
The first type of instances is based on the “gates” (Rdn, Unq, Xor, And, RdnXor, RdnUnqXor, and XorAnd) described in Table 1 of [1]. Each gate is given as a function which maps a (random) input W to a triple . The inputs are sampled uniformly at random, whereas, in Table 1 of [1], the inputs are independent and identically distributed.
4.1.2. Testing
All the gates are implemented as dictionaries and pid() is called successively with different printing modes to compute them. The latter is coded into the script file at the Github directory Testing/test_gates.py. The values of the partial information decomposition for all the gates distributions (when computed by pid()) were equal to the actual values up to precision error of order and the slowest time of computations is less than a millisecond.
4.1.3. Comparison with Other Estimators
Both estimators, computeUI and ibroja, produced values of the partial information decomposition for all the gate distributions equal to the actual values up to precision error of order but the slowest time of computations is more than ten milliseconds for computeUI and 12 s for ibroja.
4.2. Copy Gate
The Copy gate requires a large number of variables and constraints—see below for details. Thus, we used it to test the memory efficiency of the Broja_2pid estimator. Since its decomposition is known, it also provides to some extent a validation for the correctness of the solution in large systems.
4.2.1. Data
Copy gate is the mapping of chosen uniformly at random to a triplet where . The Copy distribution overall size scales as where . Proposition 18 in [1] shows that the partial information decomposition of Copy gate is
Since Y and Z are independent random variables, then and and .
4.2.2. Testing
The Copy distributions is generated for different sizes of and where and for . Then, pid() is called to compute the partial information decomposition for each pair of . Finally, the returndata dictionary is printed along with the running time of the Broja_2pid estimator and the deviations of returndata[’UIY’] and returndata[’UIZ’] from and , respectively. The latter process is implemented in Testing/test_large_copy.py. The worst deviation was of percentage at most for any
4.2.3. Comparison with Other Estimators
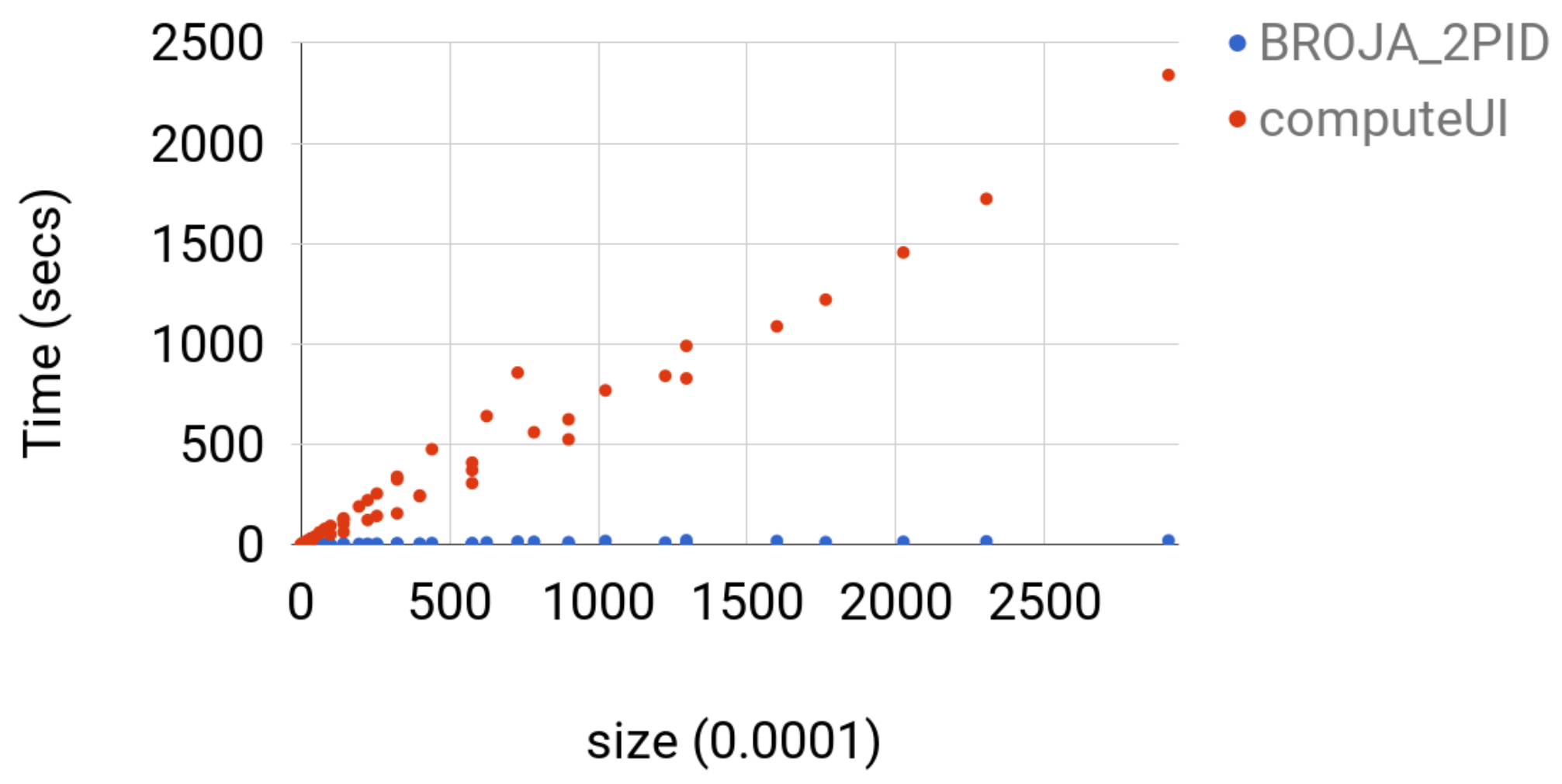
The ibroja estimator failed to give a solution to any instance since the machine was running out of memory. The computeUI estimator could solve instance of size less than or equal to , but, for larger instances, the machine was running out of memory. computeUI was slower than Broja_2pid by at least a factor of 40 and at most factor of 113; see Figure 5 for comparison.
4.3. Random Probability Distributions
This is the main set of instances for which we test the efficiency of Broja_2pid estimator. It has three subsets of instance where each one is useful for an aspect of efficiency when the estimator is used against large systems. This set of instances had some hard distributions in the sense that the optimal solution lies on the boundary of feasible region of the problem (1).
4.3.1. Data
The last type of instances are joint distributions of sampled uniformly at random over the probability simplex. We have three different sets of the joint distributions depending on the size of and .
- (a)
- For Set 1, we fix and vary in . Then, for each size of Z, we sample uniformly at random 500 joint distribution of over the probability simplex.
- (b)
- For Set 2, we fix and vary in . Then, for each value of , we sample uniformly at random 500 joint distribution of over the probability simplex.
- (c)
- For Set 3, we fix where . Then, for each s, we sample uniformly at random 500 joint distribution of over the probability simplex.
Note that, in each set, instances are grouped according to the varying value, i.e., and s, respectively.
4.3.2. Testing
The instances were generated using the Python script Testing/test_large_randompdf.py. The latter script takes as command-line arguments and the number of joint distributions of the user wants to sample from the probability simplex. For example, if the user wants to create the instance of Set 1 with , then the corresponding command-line is python3 test_large_randompdf.py 2 2 7 500. The script outputs the returndata along with the running time of Broja_2pid estimator for each distribution and finally it prints the empirical average over all the distributions of and of the running time of Broja_2pid estimator.
In the following, for each of the sets, we look at to validate the solution, the returndata[’Num_err’] triplet to examine the quality of the solution, and the running time to analyze the efficiency of the estimator.
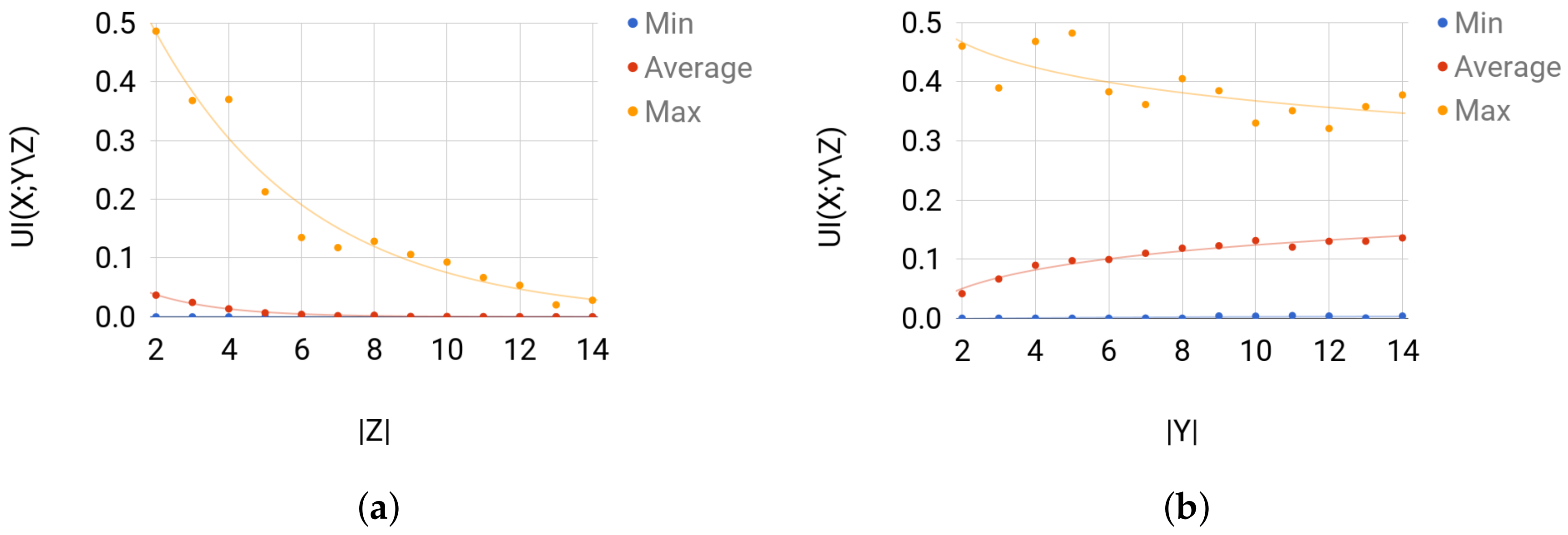
Validation. Sets 1 and 2 are mainly used to validate the solution of Broja_2pid. For Set 1, when is considerably larger than , the amount of unique information that Y has about X is more likely to be small for any sampled joint distribution. Thus, for Set 1, the average is expected to decrease as the size of Z increases. For Set 2, is expected to increase as the size of Y increases, i.e., when is considerably larger than . Broja_2pid shows such behavior of on the instances of Sets 1 and 2 (see Figure 6).
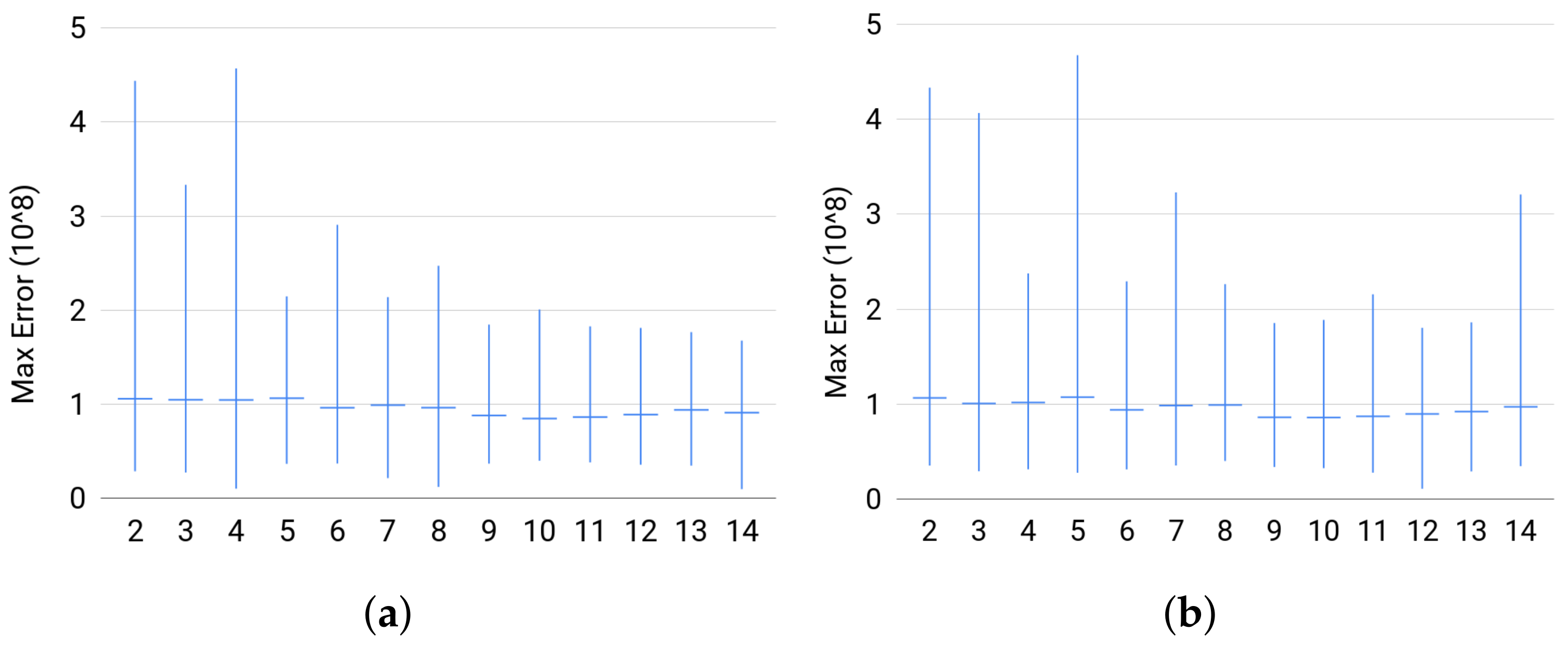
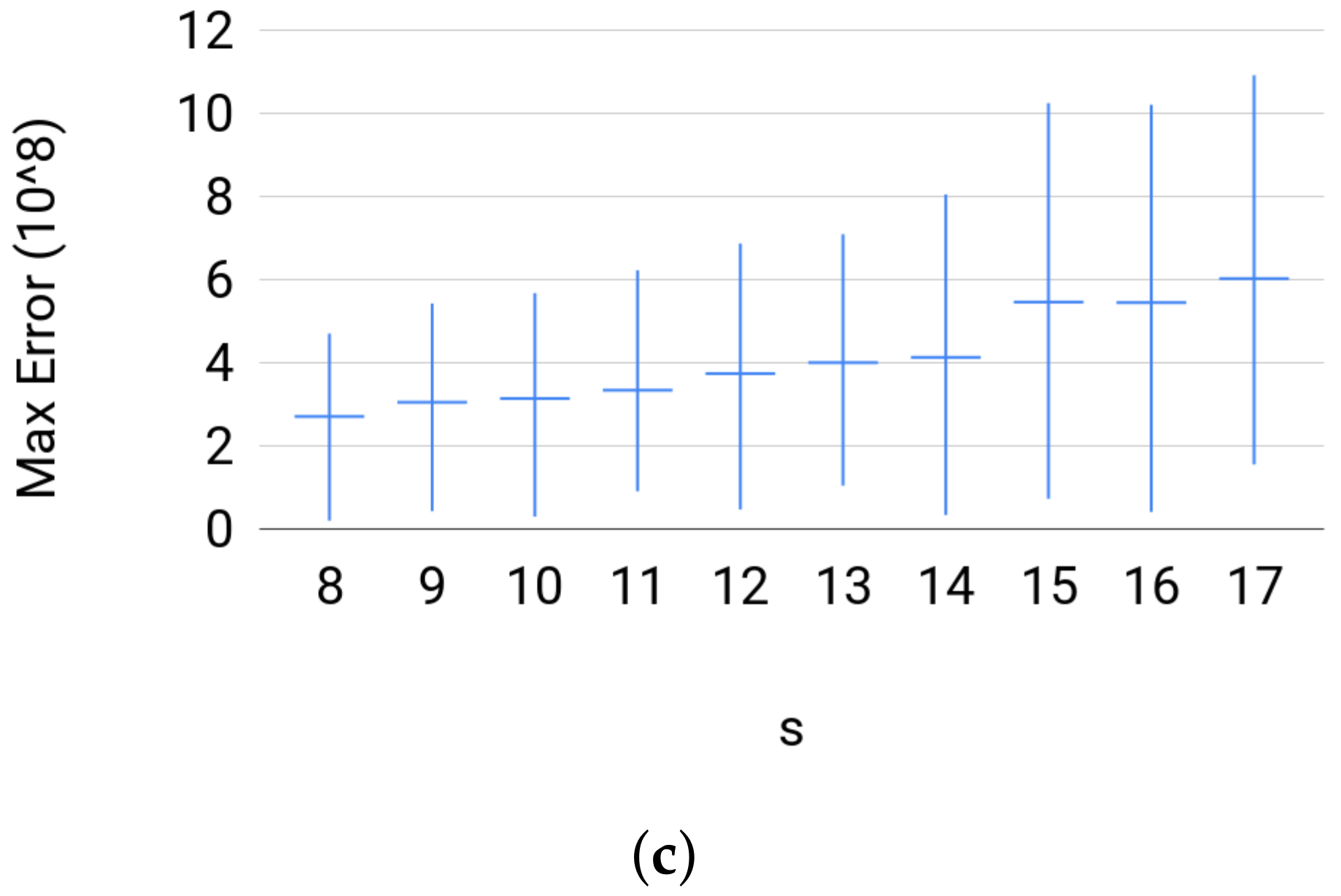
Quality. The estimator did well on most of the instances. The percentage of solved instances to optimality was at least for each size in any set of instances. In Figure 7, we plot the successfully solved instances against the maximum value of the numerical error triplet returndata[’Num_err’]. On the one hand, these plots show that, whenever an instance is solved successfully, the quality of the solution is good. On the other hand, we noticed that the duality gap, returndata[’Num_err’][2], was very large whenever the Cone Programming solver fails to find an optimal solution for an instance, i.e., the primal feasibility or dual feasibility or the duality gap is violated. In addition, even when Broja_2pid fails to solve an instance to optimality, it will return a solution. (Broja_2pidraise an exception if the conic optimization solver fails to return a solution.) Thus, these results reflect the reliability of the solution returned by Broja_2pid.
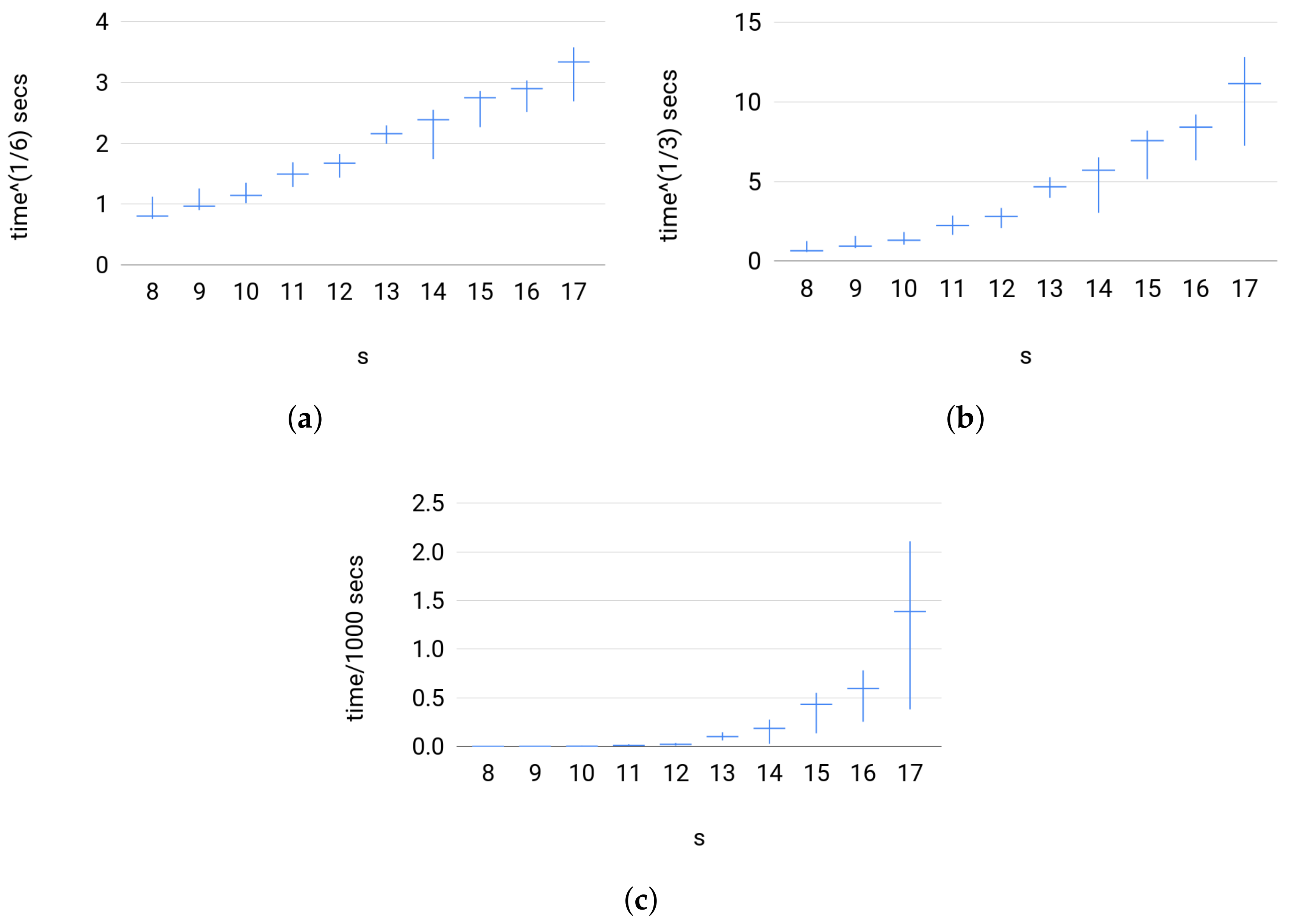
Efficiency. To test the efficiency of Broja_2pid in the sense of running time, we looked at Set 3 because Sets 1 and 2 are small scale systems.Set 3 has a large input size mimicking large scale systems. Testing Set 3 instances also reveals how the estimator empirically scales with the size of input. Figure 8 shows that the running time for Broja_2pid estimator against large instances was below 50 minutes. Furthermore, the estimator has a scaling of , so, on Set 3, it scales as where N is the size of input for the sampled distributions such that .
4.3.3. Comparison with Other Estimators
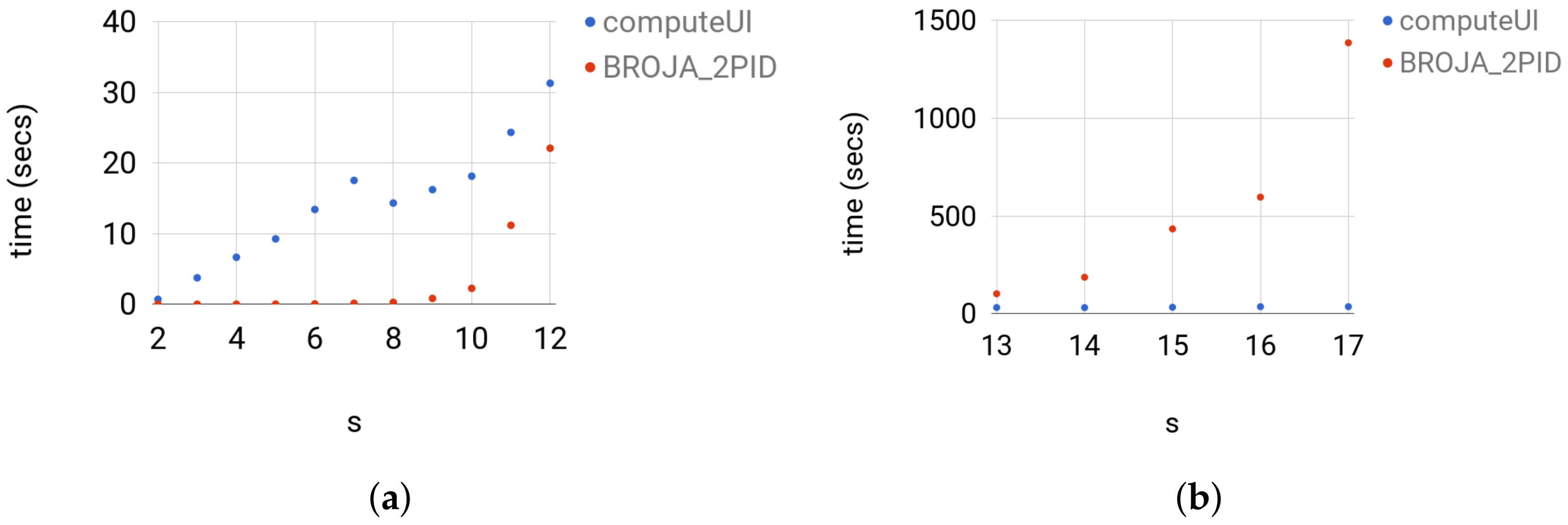
We compare the Broja_2pid estimator with the computeUI estimator and ibroja against the instance of the same type of Set 3 for .
ComputeUI: We ran computeUI with the default parameters, which are the -far from optimality , maximum outer iterations 1000, and maximum inner iteration 1000, for more details, see [7]. The estimator computeUI was slower than Broja_2pid on the instances of sizes and faster on the larger instances. For , computeUI was slower than Broja_2pid by at least a factor of 1.4 and at most factor of 1330; see Figure 9 for the actual running times. For , computeUI was faster than Broja_2pid by at least a factor of 3.2 and at most factor of 39; see Figure 9 for the actual running times. The comparison shows that computeUI scales better than Broja_2pid on large instances, whereas on the regime , which is needed in practice, Broja_2pid scales better than computeUI.
Even though the optimality criterion of computeUI is , the solution of Broja_2pid was closer to the optima with a magnitude of more than that of computeUI which concludes that Broja_2pid produces more enhanced solutions than those of computeUI. The test is implemented in Testing/test_from_file_broja_2pid_computeUI.py where the distributions in the folder randompdfs/ are the inputs.
Ibroja: The estimator ibroja is slower on any instances than Broja_2pid. For ibroja was slower than Broja_2pid by at least a factor of 206 and at most factor of 6626. Note that the factor was increasing as increases. We did not compute the instances of sizes since ibroja started taking immensely long time to obtain the solutions for these instances.
The solution of Broja_2pid was closer to the optima with a magnitude of for instances with more than that of ibroja. Note that the results of this comparisons aligns with the claims imposed in [5] that first order methods are not suitable to tackle this problem. The test is implemented in Testing/test_from_file_dit.py where the distributions in the folder randompdfs/ are the inputs.
5. Cone Programming Model for Multivariate PID
Chicharro [8] introduced a multivariate PID measure using the so-called tree-base decompositions. The measure is similar to the bivariate BROJA PID measure yet it is not an extension of the BROJA PID measure. In this section, we show how to model some of the trivariate PID quantities using the exponential cone. Thus, with some modification, the Broja_2pid can be extended to compute some of the trivariate PID quantities. Note that, due to time constraint, we could not check whether the other trivariate PID quantities can be also fitted into the exponential cone.
Let be random variables with finite range, where S is the target and are the sources. Chicharro [8] defined the quantity of synergistic information that the sources hold about the target S as:
where the maximum extends over the triples of random variables with the same 12,13,14-marginals as , i.e., for all , for all , and for all . The objective function of (14), given the marginal conditions, is equal, up to a constant not depending on , to the conditional entropy . Thus, we find that (14) is equivalent to the following Convex Program:
Hence, the following Exponential Cone Program where the variables are :
Proposition 3.
The exponential cone program in (16) is equivalent to the Convex Program (15).
Proof.
The proof follows in the same manner to that of Proposition 1. ☐
The dual problem of (16) can be formulated as
Proposition 4.
Strong duality holds for the primal-dual pair (16) and (17).
Proof.
The proof follows in the same manner to that of Proposition 2. ☐
Chicharro [8] defined the quantity of unique information that the sources X hold about the target S as:
where both minimums extend over the triples of random variables with the same 12,13,14-marginals as , i.e., for all , for all , and for all . Analogously, he defines the unique information and . Computing consists of solving two optimization problems. The first problem in (18) can be formulated as (15) and the second problem can be formulated as follows:
Hence, the following Exponential Cone Program where the variables are :
Similarly, we can prove the equivalence of (20) and (19) and that strong duality holds for (20) and its dual.
6. Outlook
We are aware of one other Cone Programming solver with support for the Exponential Cone, SCS [10]. We are currently working on adding the functionality to our software. When that is completed, giving the parameter cone_solver=“SCS” to the function pid() will make our software use the SCS-based model instead of the ECOS-based one. (The models themselves are in fact different: SCS requires us to start from the dual exponential cone program (D-EXP).) SCS employs parallelized first-order methods which can be run on GPUs, so we expect a considerable speedup for large-scale problem instances.
We may note that other information theoretical functions can also be fitted into the exponential cone. Thus, with some modification, the model can be used to solve other problems.
Thanks
The authors would like to thank Patricia Wollstadt and Michael Wibral for their feedback on pre-production versions of our software. In addition, we thank Daniel Chicharro for fruitful discussions and pointing us to applications of our approach to estimate multivariate formulations of PID.
Acknowledgments
This research was supported by the Estonian Research Council, ETAG (Eesti Teadusagentuur), through PUT Exploratory Grant #620. R.V. also thanks the financial support from ETAG through the personal research grant PUT1476. We also gratefully acknowledge funding by the European Regional Development Fund through the Estonian Center of Excellence in in IT, EXCITE.
Author Contributions
A.M. and D.O.T. conceived and designed the experiments; A.M. performed the experiments; A.M. and D.O.T. analyzed the data; R.V. contributed reagents/materials/analysis tools; and A.M. wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception; Springer: Berlin, Germany, 2014; pp. 159–190. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Makkeh, A.; Theis, D.O.; Vicente, R. Bivariate Partial Information Decomposition: The Optimization Perspective. Entropy 2017, 19, 530. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Banerjee, P.K.; Rauh, J.; Montúfar, G. Computing the Unique Information. arXiv, 2017; arXiv:1709.07487. [Google Scholar]
- Chicharro, D. Quantifying multivariate redundancy with maximum entropy decompositions of mutual information. arXiv, 2017; arXiv:1708.03845. [Google Scholar]
- Domahidi, A.; Chu, E.; Boyd, S. ECOS: An SOCP solver for embedded systems. In Proceedings of the European Control Conference (ECC), Zurich, Switzerland, 17–19 July 2013; pp. 3071–3076. [Google Scholar]
- O’Donoghue, B.; Chu, E.; Parikh, N.; Boyd, S. SCS: Splitting Conic Solver, Version 1.2.7, 2016. Available online: https://github.com/cvxgrp/scs (accessed on 26 November 2017).
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming; Springer: Berlin, Germany, 1984; Volume 2. [Google Scholar]
- Gärtner, B.; Matousek, J. Approximation Algorithms and Semidefinite Programming; Springer: Berlin, Germany, 2012. [Google Scholar]
- Chares, R. Cones and Interior-Point Algorithms for Structured Convex Optimization Involving Powers Andexponentials. Ph.D. Thesis, UCL-Université Catholique de Louvain, Louvain-la-Neuve, Belgium, 2009. [Google Scholar]
- Makkeh, A. Applications of Optimization in Some Complex Systems. Ph.D. Thesis, University of Tartu, Tartu, Estonia, 2018. forthcoming. [Google Scholar]
Figure 1.
The cone and its dual: (a) for and ; and (b) for and .

Figure 2.
Computing the partial information decomposition of the And gate using Broja_2pid.

Figure 3.
Broja_2pid workflow: (Left) the flow in pid(); and (Right) the flow in ECOS. The arrows with oval tail indicate passing of data, whereas the ones with line tail indicate time flow.
Figure 3.
Broja_2pid workflow: (Left) the flow in pid(); and (Right) the flow in ECOS. The arrows with oval tail indicate passing of data, whereas the ones with line tail indicate time flow.

Figure 4.
Tuning parameters.

Figure 5.
For each and , the time for estimator computeUI and Broja_2pid for computing BROJA PID for the Copy gate with and is shown. The instances were arranged in increasing order with respect to the value of .
Figure 5.
For each and , the time for estimator computeUI and Broja_2pid for computing BROJA PID for the Copy gate with and is shown. The instances were arranged in increasing order with respect to the value of .

Figure 6.
For each group of instances in Sets 1 and 2: (a) of Set 1; and (b) of Set 2 show the instance with the largest , the average value of for the instances, and the instance with the smallest .
Figure 6.
For each group of instances in Sets 1 and 2: (a) of Set 1; and (b) of Set 2 show the instance with the largest , the average value of for the instances, and the instance with the smallest .

Figure 7.
For each group of instances in Sets 1, 2, and 3: (a) maximum numerical error of Set 1; (b) maximum numerical error of Set 2; and (c) maximum numerical error of Set 3 show the instance with the largest ϵ, the average value of ϵ for the instances, and the instance with the smallest ϵ; where ϵ is the maximum numerical error.
Figure 7.
For each group of instances in Sets 1, 2, and 3: (a) maximum numerical error of Set 1; (b) maximum numerical error of Set 2; and (c) maximum numerical error of Set 3 show the instance with the largest ϵ, the average value of ϵ for the instances, and the instance with the smallest ϵ; where ϵ is the maximum numerical error.


Figure 8.
For each group of instances in Set 3: (a) versus s; (b) versus s; and (c) versus s show the slowest instance, the average value of running times, and the fastest instance; where the running time of Broja_2pid, t (secs), is scaled to and , respectively.
Figure 8.
For each group of instances in Set 3: (a) versus s; (b) versus s; and (c) versus s show the slowest instance, the average value of running times, and the fastest instance; where the running time of Broja_2pid, t (secs), is scaled to and , respectively.

Figure 9.
For each group of instances in Set 3: (a) t versus ; and (b) t versus show the running times of computeUI and Broja_2pid; where the running time t is in seconds.
Figure 9.
For each group of instances in Set 3: (a) t versus ; and (b) t versus show the running times of computeUI and Broja_2pid; where the running time t is in seconds.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters (tolerances) of ECOS. The parameter reltol is not recommended to be set higher. For more explanation, see https://github.com/embotech/ecos.
Table 1.
Parameters (tolerances) of ECOS. The parameter reltol is not recommended to be set higher. For more explanation, see https://github.com/embotech/ecos.
| Parameter | Description | Recommended Value |
|---|---|---|
| feastol | primal/dual feasibility tolerance | |
| abstol | absolute tolerance on duality gap | |
| reltol | relative tolerance on duality gap | |
| feastol_inacc | primal/dual infeasibility relaxed tolerance | |
| abstol_inacc | absolute relaxed tolerance on duality gap | |
| reltol_inacc | relaxed relative duality gap | |
| max_iter | maximum number of iterations that “ECOS” does | 100 |
Table 2.
Description of the printing mode in pid().
| Output | Description |
|---|---|
| 0 (default) | pid() prints its output (python dictionary, see Section 3.4). |
| 1 | In addition to output=0, pid() prints a flags when it starts preparing (EXP). |
| 2 | and another flag when it calls the conic optimization solver. |
| In addition to output=1, pid() prints the conic optimization solver’s output. | |
| (The conic optimization solver usually prints out the problem statistics and the status of optimization.) |
Table 3.
Description of returndata, the Python dictionary returned by pid().
| Key | Value |
|---|---|
| ’SI’ | Shared information, . |
| (All information quantities are returned in bits.) | |
| ’UIY’ | Unique information of Y, . |
| ’UIZ’ | Unique information of Z, . |
| ’CI’ | Synergistic information, . |
| ’Num_err’ | information about the quality of the solution. |
| ’Solver’ | name of the solver used to optimize (CP). |
| (In this version, we only use ECOS, but other solvers might be added in the future.) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Makkeh, A.; Theis, D.O.; Vicente, R. BROJA-2PID: A Robust Estimator for Bivariate Partial Information Decomposition. Entropy 2018, 20, 271. https://doi.org/10.3390/e20040271
AMA Style
Makkeh A, Theis DO, Vicente R. BROJA-2PID: A Robust Estimator for Bivariate Partial Information Decomposition. Entropy. 2018; 20(4):271. https://doi.org/10.3390/e20040271
Chicago/Turabian StyleMakkeh, Abdullah, Dirk Oliver Theis, and Raul Vicente. 2018. "BROJA-2PID: A Robust Estimator for Bivariate Partial Information Decomposition" Entropy 20, no. 4: 271. https://doi.org/10.3390/e20040271
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.