
The Online Processing of Korean Case by Native Korean Speakers and Second Language Learners as Revealed by Eye Movements

 , , and
, , and
Abstract
:1. Introduction
1.1. Characteristics of Korean
- 1 오늘은 소년이 학교에서 점심을 먹었다
- Oneuleun sonyeoni haggyoeseo jeomsimul moegeossta
- Todaytop boynom schoolloc lunchacc ate.
- Today, the boy ate lunch at school.
- 2 어제 의사가 소년에게 책을 주었습니다
- Eoje uisaka sonyeonege chaekul jueosseubnida
- Yesterday doctornom boydat bookacc gave
- Yesterday, the doctor gave a book to the boy
1.2. Characteristics of French
- 3a. Marc voit Jacques.
- Mark sees Jacques.
- 3b. Marie le voit aussi.
- Mary him sees also. Mary also sees him.
- 4a. Jean parle à Jacques
- John talks to Jack.
- 4b. Il lui dit des choses importantes
- He him says important things. He says important things to him.
1.3. Online Processing of Case in Native and Non-Native Speakers
1.4. Auditory Processing of Case
1.5. Written Processing of Case
1.6. Present Study
- 5a. 아이가 어머니를 깨운다.
- aika eomeonilul kkaeunta
- childnom motheracc wake-Pres Ind
- ‘The child wakes the mother’
- 5b. 어머니를 아이가 깨운다.
- Eomeonilul aika kkaeunta
- motheracc childnom wake-Pres Ind
- ‘The child wakes the mother’
- 6a. 환자가 의사에게 이야기한다
- Hwanjaka uisaeykey iyakihanta
- patientnom doctordat say hello to-Pres Ind
- ‘The patient says hello to the doctor’
- 6b. 의사에게 환자가 이야기한다
- Uisaeykey hwanjaka iyakihanta
- doctordat patientnom say hello to-Pres Ind
- ‘The patient says hello to the doctor’
2. Experiment 1
2.1. Methods
2.1.1. Participants
2.1.2. Stimuli
2.1.3. Procedure
2.2. Results
2.2.1. Statistical Analysis
2.2.2. Accuracy
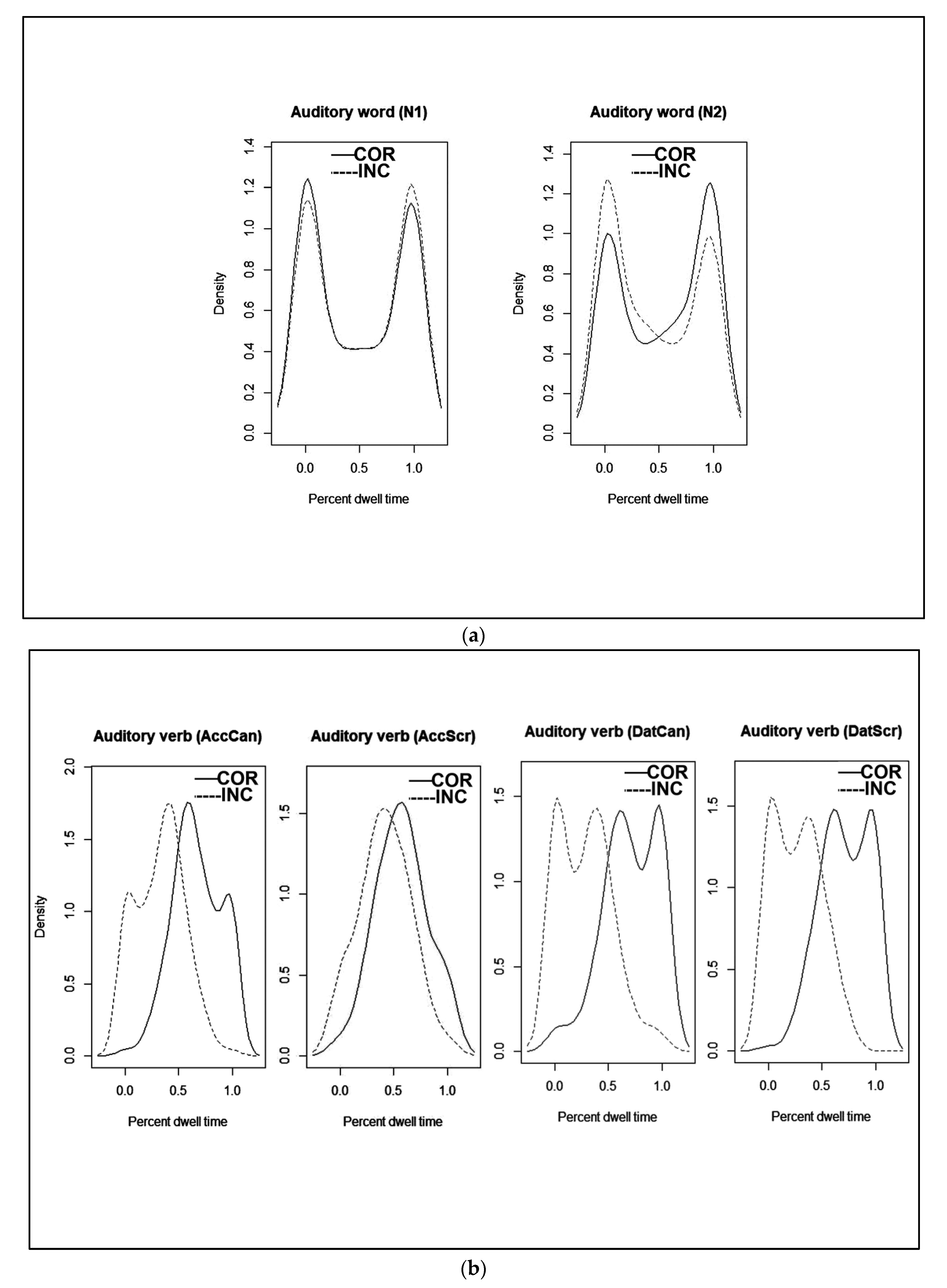
2.2.3. Dwell Times
2.3. Discussion
3. Experiment 2
3.1. Methods
3.1.1. Participants
3.1.2. Stimuli
3.1.3. Procedure
3.2. Results
3.2.1. Statistical Analysis
3.2.2. Accuracy
Reading Times
Accusative Sentences
- First Fixations
- First Pass Dwell Times
- Total Dwell Times
Dative Sentences
- First Fixations
- First Pass Dwell Times
- Total Dwell Times
3.2.3. Regressions
3.3. Discussion
4. General Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hopp, H. Learning (not) to predict: Grammatical gender processing in second language acquisition. Second. Lang. Res. 2016, 32, 277–307. [Google Scholar] [CrossRef]
- Kamide, Y.; Altmann, G.T.M.; Haywood, S.L. The time-course of prediction in incremental sentence processing: Evidence from anticipatory eye movements. J. Mem. Lang. 2003, 49, 133–156. [Google Scholar] [CrossRef]
- Kamide, Y.; Scheepers, C.; Altmann, G.T.M. Integration of syntactic and semantic information in predictive processing: Cross-linguistic evidence from German and English. J. Psycholinguist. Res. 2003, 32, 37–55. [Google Scholar] [CrossRef] [PubMed]
- Hopp, H. Ultimate attainment in L2 inflection: Performance similarities between non-native and native speakers. Lingua 2010, 120, 901–931. [Google Scholar] [CrossRef]
- Hopp, H. Semantics and morphosyntax in predictive L2 sentence processing. Int. Rev. Appl. Linguist. Lang. Teach. 2015, 53, 277–306. [Google Scholar] [CrossRef]
- Mitsugi, S.; Macwhinney, B. The use of case marking for predictive processing in second language Japanese. Biling. Lang. Cogn. 2016, 19, 19–35. [Google Scholar] [CrossRef]
- Clahsen, H.; Felser, C. Grammatical processing in language learners. Appl. Psycholinguist. 2006, 27, 3–42. [Google Scholar] [CrossRef]
- Frenck-Mestre, C.; Kim, S.-K.; Choo, H.; Ghio, A.; Herschensohn, J.; Koh, S. Look and listen! The online processing of Korean case by native and non-native speakers. Lang. Cogn. Neurosci. 2018, 34, 385–404. [Google Scholar] [CrossRef]
- Hopp, H. Syntactic features and reanalysis in near-native processing. Second. Lang. Res. 2006, 22, 369–397. [Google Scholar] [CrossRef]
- Jackson, C.N. Proficiency level and the interaction of lexical and morphosyntactic information during L2 sentence processing. Lang. Learn. 2008, 58, 875–909. [Google Scholar] [CrossRef]
- Jackson, C.N.; Dussias, P.E.; Hristova, A. Using eye-tracking to study the on-line processing of case-marking information among intermediate L2 learners of German. Int. Rev. Appl. Linguist. Lang. Teach. 2012, 50, 101–133. [Google Scholar] [CrossRef]
- Clahsen, H.; Felser, C. Some noteson the shallow structure hypothesis. Stud. Second. Lang. Acquis. 2018, 40, 693–706. [Google Scholar] [CrossRef]
- Havik, E.; Roberts, L.; Van Hout, R.; Schreuder, R.; Haverkort, M. Processing subject-object ambiguities in the L2: A self-paced reading study with German L2 learners of Dutch. Lang. Learn. 2009, 59, 73–112. [Google Scholar] [CrossRef]
- Jackson, C.N.; Bobb, S. The processing and comprehension of wh-questions among L2 German speakers. Appl. Psycholinguist. 2009, 30, 603–636. [Google Scholar] [CrossRef]
- Jackson, C.N.; Dussias, P.E. Cross-linguistic differences and their impact on L2 sentence processing. Biling. Lang. Cogn. 2009, 12, 65–82. [Google Scholar] [CrossRef]
- Duguine, I.; Köpke, B. Procssing strategies used by Basque-French bilingual and Basque monolingual children for the production of the subject-agent in Basque. Linguist. Approaches Biling. 2019, 9, 514–541. [Google Scholar] [CrossRef]
- Janssen, B.; Meir, N. Production, comprehension and repetition of accusative case by monolingual Russian and bilingual Russian-Dutch and Russian-Hebrew children. Biling. Lang. Cogn. 2019, 9, 736–765. [Google Scholar]
- Georg, S.; Michalove, P.A.; Ramer, A.M.; Sidwell, P.J. Telling general linguists about Altaic. J. Linguist. 1998, 35, 65–98. [Google Scholar] [CrossRef]
- Lee, K.-M.; Ramsey, R. A History of the Korean Lang; Cambridge University Press: New York, NY, USA, 2011. [Google Scholar]
- Sohn, H.-M. The Korean Language. Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Finley, S.R. Vowel harmony in Korean and Morpheme correspondence. Harv. Stud. Korean Linguist. 2006, 11, 131–144. [Google Scholar]
- Kim, H. Korean tense consonants as singletons. In Proceedings of the 38th Annual Meeting of the Chicago Linguistics Society, University of Chicago, Chicago, IL, USA, 25–27 April 2002; University of Chicago Press: Chicago, IL, USA, 2002; pp. 329–344. [Google Scholar]
- Pidanziak, C.J.; Witty, S.M. Framing Korean Complex–Coda Resolution with Optimality Theory. Suvrem. Lingvist. 2011, 37, 87–103. [Google Scholar]
- Pae, H.K. Is Korean a syllabic alphabet or an alphabetic syllabary? Writ. Syst. Res. 2011, 3, 103–115. [Google Scholar] [CrossRef]
- Bai, J.; Shi, J.; Jiang, Y.; He, S.; Weng, X. Chinese and Korean characters engage the same visual word form area in proficient early Chinese-Korean bilinguals. PLoS ONE 2011, 6, e22765. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.Y.; Liu, L.; Cao, F. How does first language (L1) influence second language (L2) reading in the brain? Evidence from Korean-English and Chinese-English bilinguals. Brain Lang. 2017, 171, 1–13. [Google Scholar] [CrossRef]
- Yoon, H.W.; Cho, K.-D.; Chung, J.-Y.; Park, H.W. Neural mechanisms of Korean word reading: A functional magnetic resonance imaging study. Neurosci. Lett. 2005, 373, 206–211. [Google Scholar] [CrossRef] [PubMed]
- Frenck-Mestre, C.; Osterhout, L.; McLaughlin, J.; Foucart, A. The effect of phonological realization of inflectional morphology on verbal agreement in French: Evidence from ERPs. Acta Psychol. 2008, 128, 528–536. [Google Scholar] [CrossRef]
- Jaffré, J.-P.; Fayol, M. Orthography and literacy in French. In Handbook of Orthography and Literacy; Joshi, R.M., Aaron, P.G., Eds.; Lawrence Erlbaum: New York, NY, USA, 2006; pp. 81–104. [Google Scholar]
- Largy, P.; Fayol, M. Oral crues improve subject-verb agreement in written French. Int. J. Psychol. 2001, 36, 121–132. [Google Scholar] [CrossRef]
- Dumay, N.; Frauenfelder, U.H.; Content, A. The Role of the Syllable in Lexical Segmentation in French: Word-Spotting Data. Brain Lang. 2002, 81, 144–161. [Google Scholar] [CrossRef]
- Carrasco, H.; Frenck-Mestre, C. Phonological and orthographic cues enhance the processing of inflectional morphology. ERP evidence from L1 and L2 French. Front. Psychol. 2014, 5, 888. [Google Scholar]
- Frenck-Mestre, C.; Carrasco-Ortiz, H.; McLaughlin, J.; Osterhout, L.; Foucart, A. Linguistic input factors in native and L2 processing of inflectional morphology: Evidence from ERPs. Lang. Interact. Acquis. 2010, 1, 206–228. [Google Scholar] [CrossRef]
- Takahashi, S.; Hulsey, S. Wholesale Late Merger: Beyond the A/Ā Distinction. Linguist. Inq. 2009, 40, 387–426. [Google Scholar] [CrossRef]
- Hopp, H. The Syntax–Discourse Interface in Near-Native L2 Acquisition: Off-Line and on-line performance. Biling. Lang. Cogn. 2009, 12, 463–483. [Google Scholar] [CrossRef]
- Jackson, K.H. The Effect of Information Structure on Korean Scrambling. Ph.D. Thesis, University of Hawaii at Manoa, Honolulu, HI, USA, 2008. [Google Scholar]
- Kim, J.-B.; Choi, I. The Korean Case System: A Unified, Constraint-based Approach. Second. Lang. Res. 2004, 40, 885–921. [Google Scholar]
- Ahn, H.; Herschensohn, J. Anglophone acquisition of case particles in L2 Korean. In Proceedings of the 12th Generative Approaches to Second Language Acquisition, University of Florida, Gainesville, FL, USA, 26–28 April 2013; Amaro, J.C., Judy, T., Pascual y Cabo, D., Eds.; Cascadilla Proceedings Project: Somerville, MA, USA, 2013; pp. 1–10. [Google Scholar]
- Chung, E.S.; Lee, E.-K. Morpho-syntactic processing of Korean case-marking and case drop. Linguist. Res. 2017, 34, 191–204. [Google Scholar]
- Lee, H.; Choi, H. Focus types and subject-object asymmetry in Korean case ellipsis: A new look at focus effects. In Proceedings of the 24th Pacific Asia Conference on Language, Information and Computation, Tohoku University, Sendai, Japan, 4–7 November 2010; Otoguro, R., Ishikawa, K., Umemoto, H., Yoshimoto, K., Harada, Y., Eds.; pp. 213–222. [Google Scholar]
- Lee, S.-H.; Song, J.-Y. Annotating Particle Realization and Ellipsis in Korean. In Proceedings of the 6th Linguistic Annotation Workshop, Jeju, Korea, 12–13 July 2012; pp. 175–183. [Google Scholar]
- Ahn, H.-D.; Cho, S. Subject-Object Asymmetries of Morphological Case Realization. Korean Soc. Lang. Inf. 2007, 11, 53–76. [Google Scholar] [CrossRef]
- Aissen, J. Differential Object Marking: Iconicity vs. economy. Nat. Lang. Linguist. Theory 2003, 21, 435–483. [Google Scholar] [CrossRef]
- Kwon, S.-N.; Zribi-Hertz, A. Differential function marking, cases, and information structure: Evidence from Korean. Language 2008, 84, 258–299. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, H.L.; Gordon, P.C. Linguistic complexity and information structure in Korean: Evidence from eye-tracking during reading. Cognition 2007, 104, 495–534. [Google Scholar] [CrossRef]
- Lee, I. A Principles-and Parameters Approach to the Acquisition of IP in Korean. Ph.D. Thesis, University of Essex, Colchester, UK, 1999. [Google Scholar]
- Kim, K.; O’Grady, W.; Schwartz, B.D. Case in Heritage Korean. Linguist. Approaches Biling. 2018, 8, 252–282. [Google Scholar] [CrossRef]
- Cho, S.-Y.; Choe, J.-J. Nominal Markers and Word Order in Korean. In Proceedings of the 15th Pacific Asia Conference on Language, Information and Computation, Hong Kong, China, 1–3 February 2001; T’sou, B.K., Kwong, O.O.Y., Lai, T.B.Y., Eds.; pp. 247–257. [Google Scholar]
- Ko, H. Scrambling in Korean Syntax. In Oxford Research Encyclopedia of Linguistics; Aronoff, M., Ed.; Oxford University Press: New York, NY, USA, 2018. [Google Scholar]
- Lee, E. Types of Scrambling in Korean Syntax. Ph.D. Thesis, University of North Carolina at Chapel Hill, Chapel Hill, NC, USA, 2007. [Google Scholar]
- Choi, H.-Y. Optimizing Structure in Context: Scrambling and Information Structure. Ph.D. Thesis, Stanford Unversity, Stanford, CA, USA, 1996. [Google Scholar]
- Imamura, S.; Sato, Y.; Koizumi, M. The Processing Cost of Scrambling and Topicalization in Japanese. Front. Psychol. 2016, 7, 531. [Google Scholar] [CrossRef]
- Koizumi, M.; Tamaoka, K. Psycholinguistic evidence for the VP-internal subject position in Japanese. Linguist. Inq. 2010, 41, 663–680. [Google Scholar] [CrossRef]
- Koizumi, M.; Tamaoka, K. Cognitive processing of Japanese sentences with ditransitive verbs. J. Linguist. Soc. Jpn. 2004, 125, 173–190. [Google Scholar]
- Mitsugi, S.; MacWhinney, B. Second language processing in Japanese scrambled sentences. In Research in Second Language Processing and Parsing; VanPatten, B., Jegerski, J., Eds.; John Benjamins: Philadelphia, PA, USA, 2010; Volume 53, pp. 159–175. [Google Scholar]
- Miyamoto, E.T.; Takahashi, S. Filler-Gap Dependencies in the Processing of Scrambling in Japanese. Lang. Linguist. 2004, 5, 153–166. [Google Scholar]
- Shibata, H.; Suzuki, M.; Kim, J.; Gyoba, J.; Koizumi, M. Reading Times and Priming Effects in Japanese Scrambled Sentences. Tohoku Psychol. Folia 2005, 63, 84–94. [Google Scholar]
- Yamashita, H. The effects of word-order and case marking information on the processing of Japanese. J. Psycholinguist. Res. 1997, 26, 163–188. [Google Scholar] [CrossRef]
- Ahn, H. Second Language Acquisition of Korean Case by Learners with Different First Languages. Ph.D. Thesis, University of Washington, Washington, DC, USA, 2015. [Google Scholar]
- Bates, D.; Mächler, M.; Boler, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef]
- Goldschneider, J.M.; DeKeyser, R.M. Explaining the “natural order of L2 morpheme acquisition” in English: A meta-analysis of multiple determinants. Lang. Learn. 2001, 51, 1–50. [Google Scholar] [CrossRef]
- Miyamoto, E.T.; Takahashi, S. Sources of difficulty in the processing of scrambling in Japanese. In Sentence Processing in East Asian Languages; Nakayama, M., Ed.; CSLI: Stanford, CA, USA, 2002; pp. 167–188. [Google Scholar]
- Clifton, C.; Ferreira, F.; Henderson, J.M.; Inhoff, A.W.; Liversedge, S.P.; Reichle, E.D.; Schotter, E.R. Eye movements in reading and information processing: Keith Rayner’s 40 year legacy. J. Mem. Lang. 2016, 86, 1–19. [Google Scholar] [CrossRef]
- Kim, Y.-S.; Radach, R.; Vorstius, C. Eye movements and parafoveal processing during reading in Korean. Read. Writ. 2012, 25, 1053–1078. [Google Scholar] [CrossRef]
- Wang, A.; Yeon, J.; Zhou, W.; Shu, H.; Yan, M. Cross-language parafoveal semantic processing: Evidence from Korean-Chinese bilinguals. Psychon. Bull. Rev. 2016, 23, 285–290. [Google Scholar] [CrossRef]
- Hohenstein, S.; Kliegl, R. Semantic preview benefit during reading. J. Exp. Psychol. Learn. Mem. Cogn. 2014, 40, 166–190. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Koh, S. The perceptual span during reading Korean sentences. Korean Open Access J. 2009, 20, 573–601. [Google Scholar]
- Rayner, K. Eye movements in reading and information processing. Psychol. Bull. 1978, 85, 618–660. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. The effect of case marking information on Korean sentence processing. Lang. Cogn. Processes 1999, 14, 687–714. [Google Scholar] [CrossRef]
- Koh, S. The Resolution of the Dative NP Ambiguity in Korean. J. Psycholinguist. Res. 1997, 26, 265–273. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Experiment 1 | Experiment 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Accusative | Dative | Accusative | Dative | |||||
| CAN | SCR | CAN | SCR | CAN | SCR | CAN | SCR | |
| Koreans | 98(16) | 98(14) | 94(24) | 95(22) | 98(16) | 86(35) | 99(11) | 93(36) |
| L2 learners | 87(33) | 29(46) | 77(42) | 63(48) | 75(43) | 54(46) | 87(33) | 75(44) |
| L2 Learners | Koreans | |||||
|---|---|---|---|---|---|---|
| Correct Trials | ||||||
| Accusative | N1 | N2 | VB | N1 | N2 | VB |
| Canonical | ||||||
| COR | 50.6(43) | 55.2(42) | 66.9(22) | 51.4(43) | 58.2(42) | 72.5(31) |
| INC | 49.2(43) | 44.7(42) | 33.0(22) | 48.5(43) | 40.9(42) | 27.5(31) |
| Scrambled | ||||||
| COR | 42.1(45) | 57.7(44) | 57.5(24) | 53.8(43) | 59.7(44) | 73.7(28) |
| INC | 56.7(45) | 41.3(44) | 41.6(24) | 46.2(43) | 40.1(44) | 26.3(28) |
| Dative | ||||||
| Canonical | ||||||
| COR | 50.6(44) | 52.3(40) | 70.9(25) | 49.6(40) | 57.6(36) | 69.5(32) |
| INC | 49.3(44) | 47.7(40) | 28.9(25) | 50.4(40) | 42.4(36) | 28.2(31) |
| Scrambled | ||||||
| COR | 44.4(41) | 53.4(40) | 72.1(22) | 41.9(40) | 57.4(38) | 74.9(29) |
| INC | 55.6(41) | 44.9(40) | 27.2(22) | 57.7(41) | 42.5(38) | 22.0(25) |
| All Trials | ||||||
| Accusative | N1 | N2 | VB | N1 | N2 | VB |
| Canonical | ||||||
| COR | 52.3(43) | 53.8(42) | 62.9(25) | 50.8(43) | 58.2(42) | 71.5(32) |
| INC | 47.9(43) | 46.2(42) | 37.0(25) | 48.5(43) | 41.0(42) | 27.8(31) |
| Scrambled | ||||||
| COR | 45.9(44) | 50.7(44) | 43.9(23) | 53.4(43) | 59.9(44) | 72.7(28) |
| INC | 53.6(44) | 48.8(44) | 55.6(23) | 46.6(43) | 40.0(44) | 26.9(28) |
| Dative | ||||||
| Canonical | ||||||
| COR | 51.9(44) | 54.4(39) | 62.6(28) | 48.6(41) | 56.3(36) | 70.6(31) |
| INC | 47.8(44) | 45.6(39) | 37.1(28) | 51.4(41) | 43.7(36) | 29.4(31) |
| Scrambled | ||||||
| COR | 48.2(41) | 50.2(40) | 59.4(28) | 42.2(41) | 56.9(38) | 74.8(28) |
| INC | 51.8(41) | 48.9(40) | 40.1(27) | 57.4(41) | 43.1(38) | 25.2(28) |
| L2 Learners | Koreans | |||||||
|---|---|---|---|---|---|---|---|---|
| Accusatives: Correct Trials | ||||||||
| Canonical | N1 | N2 | VB | N1 | N2 | VB | ||
| First fixation | 282(128) | 267(101) | 329(166) | 258(99) | 238(127) | 176(102) | ||
| First pass gaze | 731(338) | 573(313) | 575(317) | 364(150) | 360(220) | 220(129) | ||
| Total | 1339(653) | 1241(596) | 824(534) | 601(247) | 597(285) | 298(228) | ||
| Scrambled | ||||||||
| First fixation | 275(104) | 278(119) | 305(115) | 264(81) | 242(127) | 164(82) | ||
| First pass gaze | 741(348) | 617(314) | 546(320) | 362(146) | 416(265) | 210(132) | ||
| Total | 1573(701) | 1571(625) | 987(520) | 634(266) | 604(219) | 293(266) | ||
| Accusatives: All Trials | ||||||||
| Canonical | N1 | N2 | VB | N1 | N2 | VB | ||
| First fixation | 286(127) | 273(109) | 336(158) | 256(98) | 236(125) | 175(101) | ||
| First pass gaze | 749(340) | 598(321) | 617(340) | 368(152) | 365(220) | 221(129) | ||
| Total | 1360(665) | 1303(606) | 903(573) | 601(247) | 597(285) | 298(228) | ||
| Scrambled | ||||||||
| First fixation | 267(103) | 284(121) | 321(134) | 262(77) | 243(123) | 160(79) | ||
| First pass gaze | 753(335) | 617(311) | 550(311) | 363(147) | 420(269) | 203(127) | ||
| Total | 1525(681) | 1458(620) | 930(510) | 628(245) | 590(226) | 275(250) | ||
| Datives: Correct Trials | ||||||||
| Canonical | N1 | N2 | N3 | VB | N1 | N2 | N3 | VB |
| First fixation | 274(127) | 287(126) | 327(143) | 345(160) | 258(91) | 225(106) | 213(87) | 195(87) |
| First pass gaze | 762(402) | 770(451) | 697(320) | 669(339) | 371(147) | 383(208) | 250(87) | 211(85) |
| Total | 1412(698 | 1438(685) | 1001(515) | 923(511) | 577(213) | 585(237) | 365(211) | 270(187) |
| Scrambled | ||||||||
| First fixation | 248(89) | 274(121) | 316(123) | 320(135) | 256(72) | 216(88) | 218(89) | 180(93) |
| First pass gaze | 938(473) | 614(320) | 655(306) | 703(372) | 428(154) | 294(135) | 250(102) | 200(91) |
| Total | 1775(890) | 1454(653) | 1113(574) | 970(568) | 734(257) | 581(258) | 381(225) | 297(233) |
| Datives: All Trials | ||||||||
| Canonical | N1 | N2 | N3 | VB | N1 | N2 | N3 | VB |
| First fixation | 275(124) | 284(120) | 337(151) | 343(156) | 257(91) | 225(106) | 213(87) | 195(87) |
| First pass gaze | 802(409) | 797(450) | 697(311) | 682(350) | 369(148) | 382(207) | 250(87) | 211(85) |
| Total | 1467(694) | 1478(681) | 1052(547) | 939(537) | 573(215) | 583(237) | 365(211) | 270(187) |
| Scrambled | ||||||||
| First fixation | 250(110) | 272(118) | 320(141) | 329(142) | 257(70) | 212(87) | 216(88) | 178(92) |
| First pass gaze | 943(463) | 629(325) | 668(319) | 727(390) | 425(152) | 296(137) | 251(102) | 198(91) |
| Total | 1748(856) | 1414(632) | 1112(551) | 9990(581 | 728(254) | 576(260) | 381(220) | 291(231) |
| First Fixations | First Pass Dwell Times | Total Reading Times | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accusatives | |||||||||
| Fixed effects | Estimate | SE | t | Estimate | SE | t | Estimate | SE | t |
| Koreans + Learners (Intercept) | 262.93 | 7.01 | 37.50 ** | 546.49 | 33.88 | 16.13 * | 1031.65 | 43.95 | 23.48 * |
| GROUP.sum1 | 12.06 | 6.62 | 1.82 | 138.76 | 33.25 | 4.17 * | 406.58 | 42.89 | 9.48 * |
| ORDER.sum1 | −1.72 | 4.48 | −0.38 | −9.58 | 8.49 | −1.13 | −61.81 | 16.93 | −3.65 * |
| ROI.sum1 | 6.81 | 3.78 | 1.80 | 40.52 | 7.52 | 5.39 * | 22.00 | 14.46 | 1.52 |
| ORDER.sum1:ROI.sum1 | 1.53 | 3.74 | 0.41 | 8.39 | 7.39 | 1.14 | 6.66 | 14.25 | 0.47 |
| GROUP.sum1:ROI.sum1 | −3.93 | 3.78 | −1.04 | 28.62 | 7.52 | 3.81 * | −1.16 | 14.46 | −0.08 |
| GROUP.sum1:ORDER.sum1 | 1.79 | 3.84 | 0.47 | 5.67 | 8.32 | 0.68 | −50.59 | 14.61 | −3.46 * |
| GROUP.sum1:ORDER.sum1:ROI.sum1 | 2.80 | 3.74 | 0.75 | −0.57 | 7.40 | −0.08 | 17.48 | 14.25 | 1.23 |
| Koreans (Intercept) | NA | NA | NA | 408.93 | 34.45 | 11.87* | −19.05 | 14.77 | −1.29 |
| ORDER.sum1 | NA | NA | NA | −23.73 | 13.99 | −1.70 | 21.81 | 13.46 | 1.62 |
| ROI.sum1 | NA | NA | NA | 12.68 | 8.14 | 1.56 | 5.05 | 13.03 | 0.39 |
| ORDER.sum1:ROI.sum1 | NA | NA | NA | 4.11 | 7.96 | 0.52 | −19.05 | 14.77 | −1.29 |
| Learners (Intercept) | NA | NA | NA | 687.12 | 57.53 | 11.94 * | 1439.00 | 88.60 | 16.24 * |
| ORDER.sum1 | NA | NA | NA | −2.68 | 14.74 | −0.18 | −108.91 | 35.75 | −3.05 * |
| ROI.sum1 | NA | NA | NA | 68.98 | 13.29 | 5.19* | 20.95 | 28.64 | 0.731 |
| ORDER.sum1:ROI.sum1 | NA | NA | NA | 7.64 | 13.29 | 0.5 | 24.24 | 28.64 | 0.846 |
| Datives Fixed Effects | |||||||||
| Koreans + Learners (Intercept) | 255.35 | 5.84 | 43.70 * | 585.36 | 38.28 | 15.22 * | 1088.01 | 65.30 | 16.66 * |
| GROUP.sum1 | 16.09 | 5.51 | 2.92 * | 206.33 | 36.70 | 5.62 * | 453.39 | 64.47 | 7.03 * |
| ORDER.sum1 | 7.29 | 4.10 | 1.78 | 2.52 | 8.44 | 0.30 | −67.43 | 16.36 | −4.12 * |
| ROI.sum1 | 4.55 | 3.21 | 1.42 | 59.41 | 7.85 | 7.56 * | 61.74 | 13.00 | 4.75 * |
| ORDER.sum1:ROI.sum1 | 0.81 | 3.20 | 0.25 | 58.58 | 7.80 | −7.51 * | −62.59 | 12.92 | −4.84 * |
| GROUP.sum1:ROI.sum1 | −14.16 | 3.21 | −4.41 * | 20.70 | 7.85 | 2.63 * | 15.62 | 13.00 | 1.20 |
| GROUP.sum1:ORDER.sum1 | 3.93 | 3.61 | 1.09 | −5.38 | 7.96 | −0.68 | −25.51 | 15.19 | −1.68 |
| GROUP.sum1:ORDER.sum1:ROI.sum1 | 2.32 | 3.20 | 0.72 | −25.19 | 07.80 | −3.23 * | −25.37 | 12.92 | −1.96 * |
| Koreans (Intercept) | 238.92 | 7.59 | 31.49 * | 380.17 | 19.57 | 19.43 * | 634.60 | 31.52 | 20.13 * |
| ORDER.sum1 | 2.77 | 3.97 | 0.70 | 10.87 | 8.60 | 1.26 | −41.38 | 9.92 | −4.17 * |
| ROI.sum1 | 18.72 | 3.82 | 4.89 * | 38.81 | 6.63 | 5.86 * | 45.52 | 9.36 | 4.86 * |
| ORDER.sum1:ROI.sum1 | −1.77 | 3.79 | 0.47 | −31.78 | 6.55 | −4.85 * | −37.36 | 9.25 | −4.04 * |
| Learners (Intercept) | 270.73 | 9.19 | 29.46 | 789.97 | 73.98 | 10.67 * | 1541.27 | 126.68 | 12.17 * |
| ORDER.sum1 | 11.91 | 7.67 | 1.55 | −2.79 | 19.20 | 0.14 | −89.78 | 33.08 | −2.71 * |
| ROI.sum1 | −9.64 | 5.22 | 1.85 | 80.11 | 14.30 | 5.60 | 77.44 | 24.79 | 3.12 * |
| ORDER.sum1:ROI.sum1 | 3.07 | 5.22 | 0.59 | −83.65 | 14.30 | −5.85 | −88.04 | 24.79 | −3.55 * |
| Accusative | Dative | |||||||
|---|---|---|---|---|---|---|---|---|
| Canonical | Scrambled | Canonical | Scrambled | |||||
| N1 | N2 | N1 | N2 | N1 | N2 | N1 | N2 | |
| Koreans | 82(39) | 19(39) | 80(40) | 15(36) | 84(37) | 32(47) | 81(39) | 37(49) |
| Learners | 85(36) | 41(49) | 93(26) | 48(50) | 87(33) | 37(48) | 91(28) | 46(50) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frenck-Mestre, C.; Choo, H.; Zappa, A.; Herschensohn, J.; Kim, S.-K.; Ghio, A.; Koh, S. The Online Processing of Korean Case by Native Korean Speakers and Second Language Learners as Revealed by Eye Movements. Brain Sci. 2022, 12, 1230. https://doi.org/10.3390/brainsci12091230
Frenck-Mestre C, Choo H, Zappa A, Herschensohn J, Kim S-K, Ghio A, Koh S. The Online Processing of Korean Case by Native Korean Speakers and Second Language Learners as Revealed by Eye Movements. Brain Sciences. 2022; 12(9):1230. https://doi.org/10.3390/brainsci12091230
Chicago/Turabian StyleFrenck-Mestre, Cheryl, Hyeree Choo, Ana Zappa, Julia Herschensohn, Seung-Kyung Kim, Alain Ghio, and Sungryung Koh. 2022. "The Online Processing of Korean Case by Native Korean Speakers and Second Language Learners as Revealed by Eye Movements" Brain Sciences 12, no. 9: 1230. https://doi.org/10.3390/brainsci12091230