Ancient Evolutionary Origin of Intrinsically Disordered Cancer Risk Regions

1
Department of Biochemistry, ELTE Eötvös Loránd University, Pázmány Péter stny 1/c, H-1117 Budapest, Hungary
2
Research Centre for Natural Sciences, Magyar tudósok körútja 2, H-1117 Budapest, Hungary
*
Author to whom correspondence should be addressed.
Biomolecules 2020, 10(8), 1115; https://doi.org/10.3390/biom10081115
Submission received: 21 June 2020
/
Revised: 17 July 2020
/
Accepted: 20 July 2020
/
Published: 28 July 2020
(This article belongs to the Special Issue The Amazing World of IDPs in Human Diseases)
Abstract
:Cancer is a heterogeneous genetic disease that alters the proper functioning of proteins involved in key regulatory processes such as cell cycle, DNA repair, survival, or apoptosis. Mutations often accumulate in hot-spots regions, highlighting critical functional modules within these proteins that need to be altered, amplified, or abolished for tumor formation. Recent evidence suggests that these mutational hotspots can correspond not only to globular domains, but also to intrinsically disordered regions (IDRs), which play a significant role in a subset of cancer types. IDRs have distinct functional properties that originate from their inherent flexibility. Generally, they correspond to more recent evolutionary inventions and show larger sequence variations across species. In this work, we analyzed the evolutionary origin of disordered regions that are specifically targeted in cancer. Surprisingly, the majority of these disordered cancer risk regions showed remarkable conservation with ancient evolutionary origin, stemming from the earliest multicellular animals or even beyond. Nevertheless, we encountered several examples where the mutated region emerged at a later stage compared with the origin of the gene family. We also showed the cancer risk regions become quickly fixated after their emergence, but evolution continues to tinker with their genes with novel regulatory elements introduced even at the level of humans. Our concise analysis provides a much clearer picture of the emergence of key regulatory elements in proteins and highlights the importance of taking into account the modular organisation of proteins for the analyses of evolutionary origin.
1. Introduction
Most human genes are thought to have an extensive and very deep evolutionary history. In line with the thought “Nature is a tinkerer, not an inventor” [1], major human gene families date back to the earliest Eukaryotic evolutionary events, or even beyond. The very oldest layers of human genes encode metabolically, structurally, or otherwise essential proteins that typically go back to unicellular evolutionary stages. Mutations to this core biochemical apparatus can prove disruptive to all aspects of cellular life, and indeed, there are known mutational targets associated with genome stability and cancer. In contrast to these “caretaker” genes, a more novel set of genes have emerged at the transition to a multicellular stage. These “gatekeeper” proteins are involved in cell-to-cell communication, especially in early embryonic development and tissue regeneration. Gatekeeper genes that control cell division are among the best known cancer-associated oncogenes and tumor suppressors [2].
In order to establish the evolutionary origins of cancer genes, Domazet-Loso and Tautz carried out a systematic analysis based on phylostratigraphic tracking [3]. By correlating the evolutionary origin of genes with particular macroevolutionary transitions, they found that a major peak connected to the emergence of cancer genes corresponds to the level where multicellular animals have emerged. However, many cancer genes have a more ancient origin and can be traced back to unicellular organisms. These trends seem to apply to the appearance of disease genes [4] and novel genes in general as well [5]. These studies were based on the evolutionary history of the founder domains. However, new genes can also be generated by duplication either in whole or from part of existing genes, when the duplicate copy of a gene becomes associated with a different phenotype to its paralogous partner. This mechanism can also influence the emergence of disease genes [5].
By taking advantage of the flux of cancer genome data, several new proteins have been identified to play a direct role in driving tumorigenesis during recent years [6]. One of the key signatures of cancer drivers is the presence of mutation hotspot regions, where many different patients might show a similarly recurrent pattern of mutations [7]. These hotspots are typically located within well-folded, structured domains. However, many cancer associated proteins have a complex modular architecture, incorporating not only globular domains, but also intrinsically disordered segments, which can also be sites of cancer mutations. In our recent work, we systematically collected disordered regions that are directly targeted by cancer mutations and analyzed their basic functional and system level properties. [8]. While only a relatively small subset of such disordered cancer drivers was identified, their mutations can be the main driver event in certain cancer types. These disordered regions can function in a variety of ways including post-transcriptional modification sites (PTMs), linear motifs, linkers, and larger sized functional modules typically involved in binding to macromolecular complexes. These disordered cancer drivers have a characteristic functional repertoire and increased interaction potential, and their perturbation can give rise to all ten hallmarks of cancer independently of ordered drivers [8].
In general, owing to the lack of structural constraints, disordered segments show more evolutionary variability [9]. In particular, linear motifs can easily emerge to a previously non-functional region of protein sequence by only a few mutations, or disappear as easily, leaving little trace after millions or billions of years [10]. However, elements fulfilling a critical regulatory function might linger on for a longer time. So far, the evolutionary origin of intrinsically disordered regions that have a critical function proven by a human disease association has not been analyzed.
In the current study, we studied the evolutionary origin of disordered cancer risk regions. For this, we used a dataset of cancer driving proteins in which cancer mutations specifically targeted intrinsically disordered regions [8]. We retrieved phylogeny data from the ENSEMBL Compara database. Using a novel conservation and phylogenetic-based strategy, we determined the evolutionary origin not only at the gene level, but also at the region level. In addition, we also investigated the emergence mechanism of disordered cancer risk regions and how evolutionary constraints, selection, and gene duplications events influenced the fate of these examples. Finally, we presented interesting case studies that demonstrate the ancient evolutionary origin of these examples and the continuing evolution of their genes built around the critical conserved functional module.
2. Materials and Methods
2.1. Dataset
We used a subset of the previously identified disordered cancer risk regions [8]. These regions were identified based on genetic variations collected from the COSMIC database [11] using the method that located specific regions that are enriched in cancer mutations [7]. Disorder status of these regions was verified based on experimental data collected from dedicated databases and from the literature when available, or based on consensus disorder prediction methods [8]. Mapping was not feasible for CDKN2A isoform (Tumor suppressor ARF), because it was not present in the ENSEMBL database we used in our study), hence this protein was excluded from the further analyses. Proteins in which both disordered and ordered cancer regions were identified were filtered out in order to be able to focus clearly on the disordered regions. Regions that were primarily mutated by in-frame insertion and deletion and contained less than 15 missense mutations were also excluded because of our conservation calculation method (see below). Finally, histone proteins were merged, keeping the single entry of HIST1H3B. Ultimately, we obtained a list of 36 disordered cancer risk regions of 32 proteins APC (Adenomatous polyposis coli protein): 1284–1537, ASXL1 (Polycomb group protein ASXL1): 1102–1107, BCL2 (Apoptosis regulator Bcl-2): 2–80, CALR(Calreticulin): 358–384, CARD11 (Caspase recruitment domain-containing protein 11): 111–134; 207–266; 337–436, CBL (E3 ubiquitin-protein ligase CBL): 365–374, CCND3 (G1/S-specific cyclin-D3): 278–290, CD79B (B-cell antigen receptor complex-associated protein beta chain): 191–199, CEBPA (CCAAT/enhancer-binding protein alpha): 293–327, CSF1R (Macrophage colony-stimulating factor 1 receptor): 969–969, CTNNB1 (Catenin beta-1): 32–45, EIF1AX (Eukaryotic translation initiation factor 1A, X-chromosomal): 4–15, EPAS1 (Endothelial PAS domain-containing protein 1): 529–539, ESR1 (Estrogen receptor): 303–303, FOXA1 (Hepatocyte nuclear factor 3-alpha): 248–268, FOXL2 (Forkhead box protein L2): 134–134, FOXO1 (Forkhead box protein O1): 19–26, HIST1H3B (Histone H3.1): 28–28, ID3 (DNA-binding protein inhibitor ID-3): 48–70, MED12 (Mediator of RNA polymerase II transcription subunit 12): 44–44, MLH1 (DNA mismatch repair protein Mlh1): 379–385, MYC (Myc proto-oncogene protein): 57–60, MYCN(N-myc proto-oncogene protein): 44–44, MYOD1(Myoblast determination protein 1): 122–122, NFE2L2 (Nuclear factor erythroid 2-related factor 2): 20–38; 75–82, PAX5 (Paired box protein Pax-5): 75–80, RPS15 (40S ribosomal protein S15): 129–145, SETBP 1 (SET-binding protein): 858–880, SMARCB1 (SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily B member 1): 368–381, SRSF2 (Serine/arginine-rich splicing factor 2): 95–95, USP8 (Ubiquitin carboxyl-terminal hydrolase 8): 713–736, VHL (von Hippel-Lindau disease tumor suppressor): 54–136; 144–193.
2.2. Evolutionary Framework
In this work, we calculated the evolutionary origin of cancer risk regions within our dataset of disordered proteins. Our approach focused on the age of orthologous gene families, instead of focusing on the evolutionary origin of founder domains. Assignment of age of human gene families (origin) was carried out using the ENSEMBL genome browser database. To identify the origin of individual human gene families, we fetched the phylogenies and analysed the evolutionary supertrees built by the pipeline of the ENSEMBL Compara multi-species comparisons project [12,13]. The used release (99) of the project contained 282 reference species including 277 vertebrata, 4 eumetazoa, and 1 opisthokonta (S. cerevisiae) species. Note that, in these phylogenies, the most ancient node can be the ancestor of yeast. The origin of the gene family was identified by taking the taxonomy level of the most ancient node of the phylogenetic supertrees. Taxonomy levels were broken into major nested age categories (mammals, vertebrates, eumetazoa, opisthokonta), similarly to previous studies [14].
To define the evolutionary origin of regions, we built a customized pipeline that included collecting and mapping mutations from COSMIC database to ENSEMBL entries, constructing multiple sequence alignments of protein families, and mapping the cancer regions among orthologs and paralogs. According to the ENSEMBL supertrees, protein sequences of human paralogs (including the cancer gene) and their orthologs were queried from the database using the Rest API function. Then, multiple sequence alignments of the corresponding sequences were created with MAFFT (default settings) [15]. On the basis of the sequence alignments, cancer regions were mapped onto the sequences. In the mapping step, cancer regions were considered as functional units (linear motifs, linkers, disordered domains) and borders of the regions were defined according to this. When the highly mutated regions covered only a single residue, it was extended to cover the known functional linear motif or using its sequence neighbourhood. On this basis, the subset of paralogs, in which the mapped cancer region was found to be conserved, was identified.
Next, the set of sequences containing regions that showed evolutionary similarity to the mutated regions were identified among the collected orthologs and paralogs. Conservation of the regions among paralogs was evaluated relying on two strategies, by calculating the similarity of mutated positions in the cancer risk regions (see below) and based on HMM profiles. This consideration was taken into account in order to reduce the chance of false conservation interpretation arising from the difficulty of aligning disordered proteins. The HMM profiles were built from conserved cancer regions of vertebrate model organisms using the HMMER (version 3.3) method [16]. The identified region hits were manually checked to minimize the chance of false positives or negatives. Next, we identified the evolutionarily most distant relative in which the cancer region was declared to be conserved. As a result, the origin of the region could differ from the origin of the orthologous gene family, when paralogue sequences that contained the conserved motif had a more ancient origin. Basically, we treated the cancer risk regions as the founder of the family. The taxonomy level of this ortholog was defined as the level in which the cancer region emerged in the common ancestor of this ortholog and H. sapiens.
2.3. Region Conservation
Within the identified cancer risk region, some of the positions could be more heavily mutated and are likely to be more critical for the function of this region. We took this into account when calculating the region conservation. Mutations for each position collected from the COSMIC database were mapped to the corresponding ENSEMBL human entry. On the basis of the sequence alignment corresponding to the cancer risk regions, we identified the positions that were similar to the reference sequence. Two positions were considered similar when the substitution score was non-negative according to the BLOSUM62 substitution matrix. A given cancer region was considered to be conserved between homologs, when the conserved residues carried more than 50% of missense mutations.
2.4. Positive Selection: Selectome and McDonald and Kreitman (MK) Test Results
For each entry in our dataset, we collected information about positive selection using the Selectome database (current version 6) [17]. This database contains collected sites of positive selection detected on a single branch of the phylogeny using the systematic branch-site test of the CODEML algorithm from the PAML [18] phylogenetic package version 4b. The ratio of non-synonymous and synonymous substitutions (ω) can be interpreted as a measurement of selective pressure indicating purifying (ω values < 1), neutral (ω values = 1), or positive (ω values > 1) selection. In our work, positions under positive selection that have a posterior probability higher than 0.9 were extracted from the database and mapped onto our gene set.
However, the branch-site model generally cannot detect species-specific positive selection. Potential cases of human-specific positive selection may be detected effectively by comparing divergence to polymorphism data, as in the McDonald and Kreitman (MK) test. Human-specific positive selection detected by MK test previously calculated [19] was mapped onto our dataset of disordered cancer genes.
3. Results
3.1. Evolutionary Origin of Genes and Regions
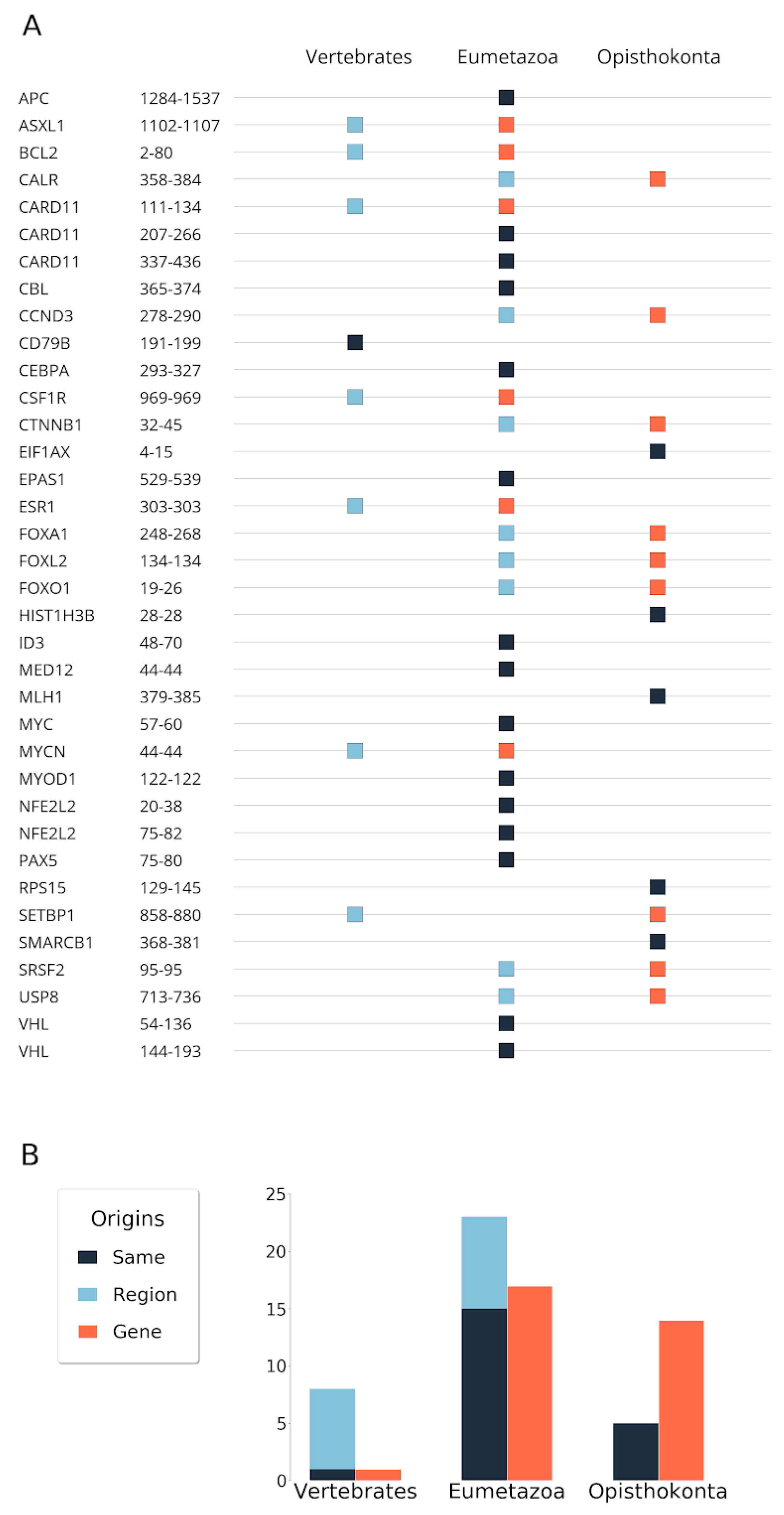
Altogether, we collected 36 cancer risk regions of 32 disordered proteins and investigated the evolutionary origin at the level of genes and regions. The age estimation of disordered cancer genes was obtained using the last common ancestor of descendants using the ENSEMBL supertrees, which includes phylogeny of gene families returning not only individual gene history, but also relationships of ancient paralogs and their history (see Material and Methods). Using this strategy instead of analysing the evolution of individual genes or simply the emergence of the founder domain, we could define the origin of regions more precisely, even the ancient ones, without introducing any bias of overprediction of origins. However, some ambiguity still remained and was manually checked (Supplementary Materials 1). The genes were traced back to opisthokonta (in accordance with the ENSEMBL database) and divided into four major phylostratigraphic groups, which are associated with the emergence of unicellular, multicellular organisms, vertebrates, and mammals.
Previous results identified the level of eumetazoa as the main age for the emergence of cancer associated proteins [3]. We observed a similar trend in the case of disordered cancer proteins. Specifically, we found that 21 disordered cancer proteins, the majority of cases, have emerged at the level of eumetazoa (Figure 1). Fourteen cases were found to be even more ancient and could be traced back to single cell organisms, at least to opisthokonta. The only protein that emerged more recently, at the level of vertebrates, was CD79B, the B-cell antigen receptor complex-associated protein β chain. Its appearance is in agreement with the birth of many immune receptors [20] and is assumed to be driven by the insertion of transposable elements.
In around half of the cases (21), the emergence of the mutated region was the same as the emergence of the protein (Figure 1). Strikingly, these included five cases (EIF1AX, HIST1H3B, MLH1, RPS15, SMARCB1) where not only the gene/protein, but also the region primarily mutated in human cancers were very ancient and could be traced back to unicellular organisms. Fifteen regions with Eumetazoa and one with Vertebrata origin could be traced back to the same level as their corresponding gene. However, in several cases, the emergence of the region was a more recent event compared with the emergence of the gene. Of these, eight regions emerged at the Eumetazoa and seven at the Vertebrate level. In general, there was only one level difference between the emergence of the gene and the region at this resolution. The only exception was SETBP1. In this case, the region itself emerged at the vertebrate level. However, the gene could be traced back to opisthokonta level, although the eumetazoa origin cannot be completely ruled out (see Supplementary Materials 1). Overall, many of the disordered regions were more recent evolutionary inventions compared with the origin of their genes, and date back to the common ancestors of eumetazoans or vertebrates. Nevertheless, the ancestors of all of the regions were already present from the vertebrate level.
3.2. Position Conservation
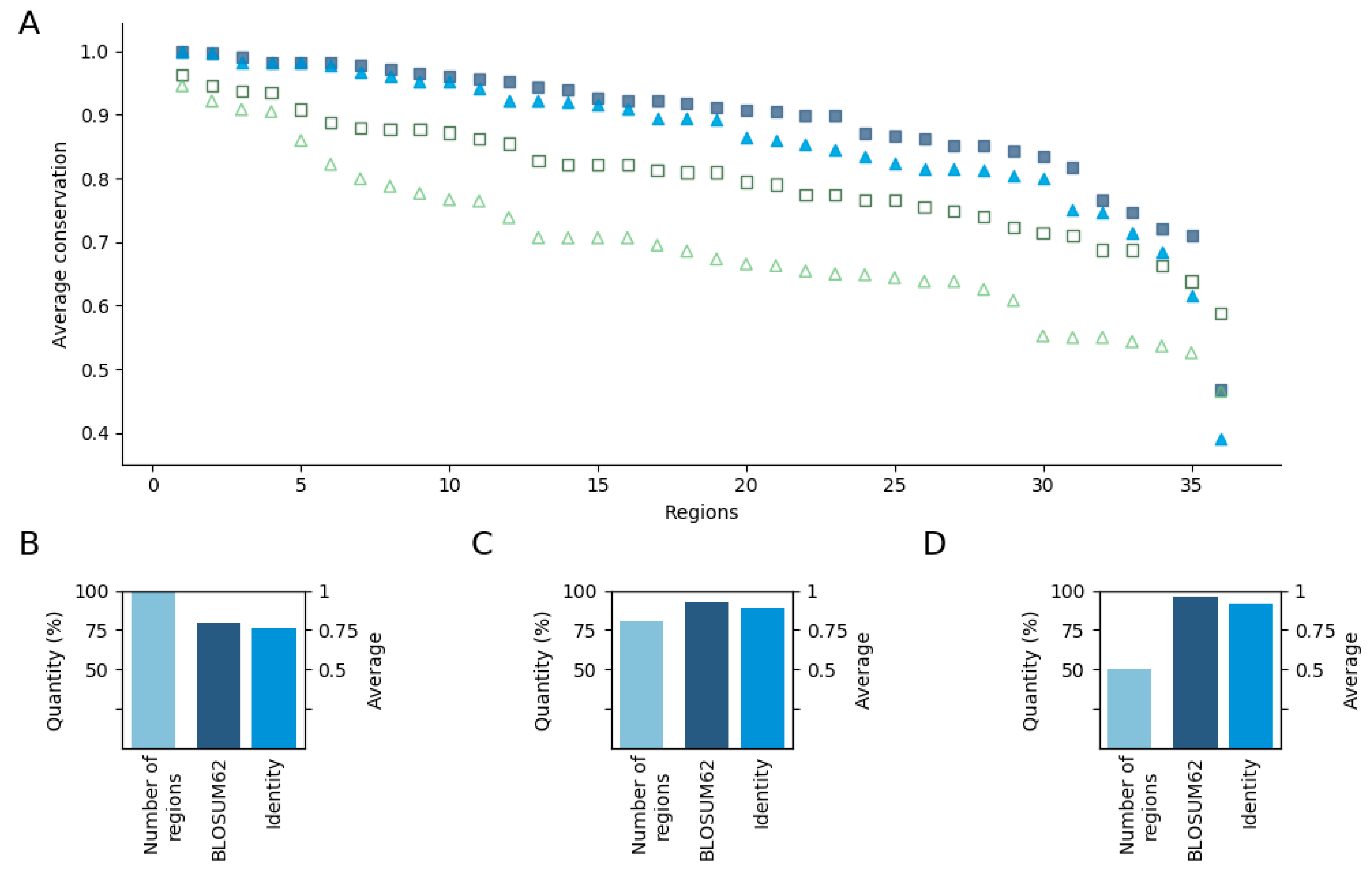
Overall, these results point to the ancient evolutionary origin of disordered regions involved in cancer, not only at the gene level, but also at the region level. To take a closer look, we also calculated the conservation of individual positions within the regions based both in terms of homologous substitutions and identity. The results show that these residues are highly conserved even compared with the conservation of the whole sequence (Figure 2). Here, 86% of the regions have more than 0.8 average conservation value even based on identities (Figure 2A). Among the cases with the four lowest values, the conservation of VHL, CALR, and APC, which all correspond to relatively longer segments, was still relatively high. The only outlier was BCL2. In this case, the mutations are distributed along the N-terminal, encompassing the highly conserved BH4 motif, as well as the linker region between the BH4 and C-terminal part, which is conserved only in mammals (Figure S1).
Next, we investigated how this average value is altered when only the highly mutated positions are considered. We repeated that analysis for positions that had at least 15 and 25 missense mutations, which slightly decreased the number of regions considered. The remaining 28 and 17 regions with positions having at least 15 and 25 mutations had 0.93, 0.89, 0.96, and 0.92 average conservation values based on substitutions and identity, respectively (Figure 2C,D). This reflects a very clear trend with positions with a higher number of cancer mutations showing higher evolutionary conservation.
We also collected sites of potential positive selection mapped onto our genes based on the Selectome database [17], which provides information on likely molecular selection both at the level of the evolutionary branch and the sequence position based on the ratio of non-synonymous and synonymous substitutions (ω). According to these results, positive selection affected only three genes on the human lineage in our dataset, CALR, CTNNB1, and VHL. All of these selections could be mapped onto the vertebrates division with multiple positions (see Material and Methods) (Table 1).
However, these positions showed limited overlap with the mutated regions. In the case of CTNNB1, none of the positions under selection overlapped with the cancer mutated region. In the case of CALR, there was only a single position under selection within the cancer risk region, but it was not directly targeted by cancer mutations. In the case of VHL, six positions were detected with selective pressure and five of them were situated within the significantly mutated region. However, none of them corresponded to a highly mutated residue.
Taking advantage of an earlier analysis [19], we also analyzed if there was any human specific positive selection. As the ω based approach can not be used without uncertainty to identify human-specific positive selection, this work relied on the McDonald and Kreitman (MK) test, which compares the divergence to polymorphism data using closely related species, such as human and chimp. There was only a single entry in our database, ESR1, that showed human specific evolutionary changes (see case studies).
3.3. Contribution of Duplications to the Emergence of Disease Risk Regions
Gene duplications often drive the appearance of a novel function through the process called neofunctionalization. In these cases, after a duplication event, one copy may acquire a novel, beneficial function that becomes preserved by natural selection. Here, we have evaluated whether the emergence of disordered cancer regions corresponds to such neofunctionalization events. For this analysis, we collected paralog sequences and evaluated if there were regions present in these sequences that showed clear evolutionary similarity to the cancer mutated region.
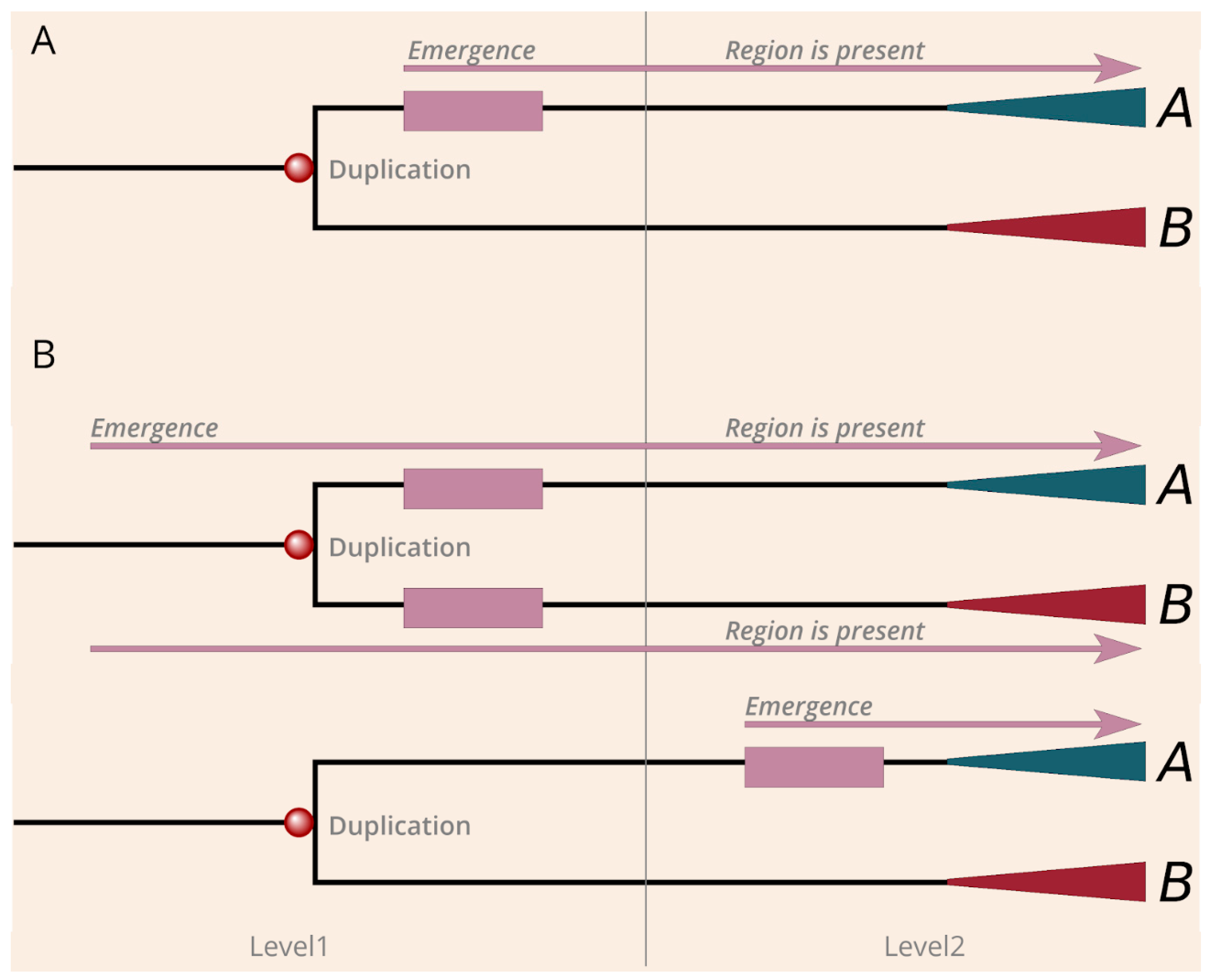
The evolutionary history of many genes is quite complex and can involve multiple duplication events. We focused on the level where the cancer regions emerged and distinguished the following scenarios based on the relationship between the duplication and the presence of the region among the paralogs. The first scenario corresponds to duplication induced neofunctionalization. In this case, an ancient cancer region emerged directly after a given gene duplication and became preserved in only one of the branches that appeared after the duplication (Figure 3A). There are two basic scenarios in which the duplication cannot be directly linked with the emergence of the regions. One possible scenario is when both branches contain the region, which indicates that the region must have emerged before the duplication (Figure 3B). The other possible scenario is when the region emerged at a later evolutionary stage after a duplication, and duplication cannot be directly linked to neofunctionalization (Figure 3B).
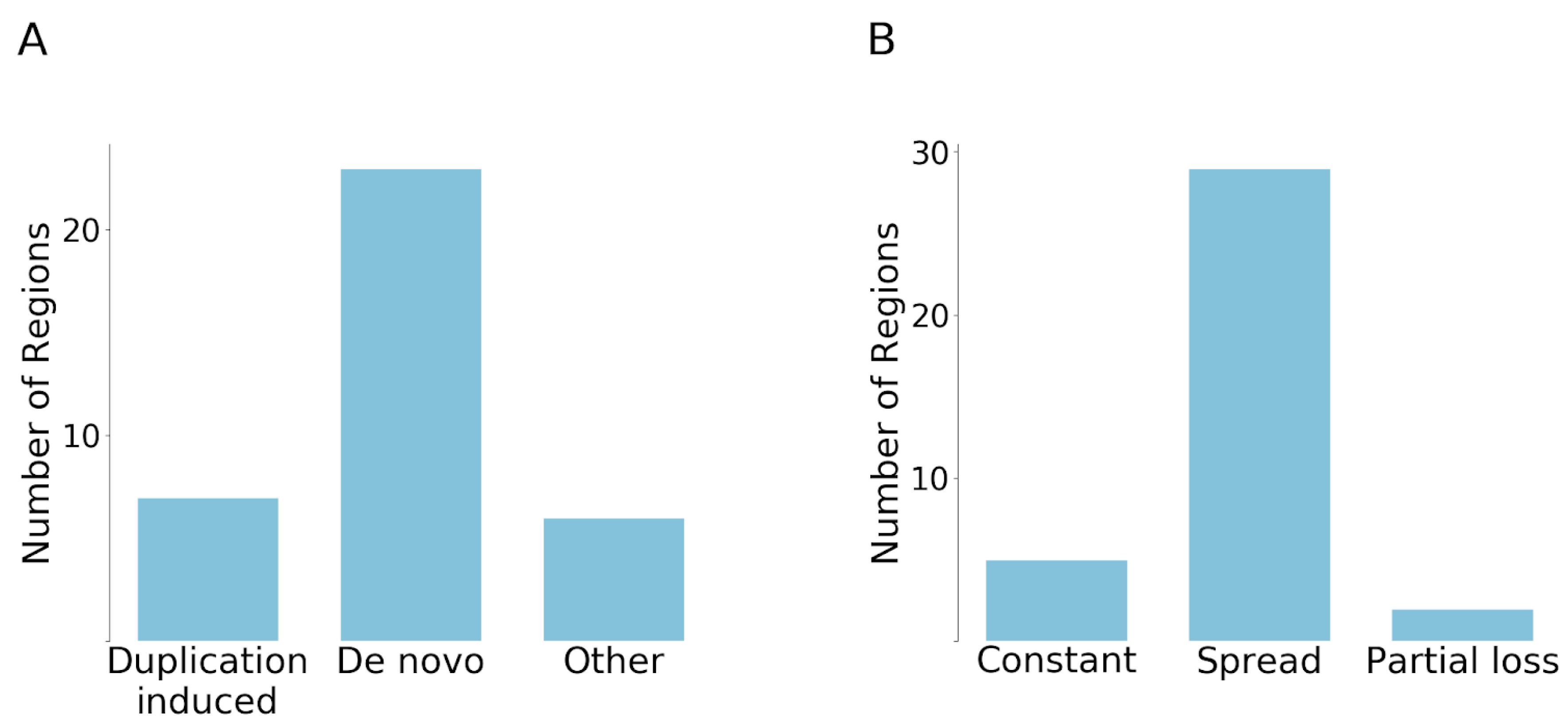
Surprisingly, the duplication induced neofunctionalization was much less common than we expected, with only seven cases showing this behaviour. One example for this scenario is presented by the β-catenin family, where the degron motif [21] based cancer risk region that emerged after duplication is present only on the branch of β-catenin and junctional plakoglobin (JUP). In contrast, we found that 23 regions have evolved by de novo emergence, which seemed to be the dominant mechanisms for the emergence of the analyzed cancer mutated disordered regions (Figure 4A). For example, ID3 underwent multiple duplications, but all paralogs contain the cancer risk region, which indicates that the region emerged prior to the duplication. Another example is ESR1, in which case the paralogs were born at the level of eumetazoa; however, this event is not directly linked to the emergence of the cancer region, which appeared only at the level of the ancient vertebrates. In addition, there were two singletons in our dataset, RPS15 and SMARCB1, which did not have any detectable paralogs. In the cases of ASXL1, CCND3, SETBP1, and the first region of CARD11, the evolutionary scenarios could not be unambiguously established. These six examples formed the “Other” group.
We also analyzed if additional duplication events occurred after the emergence of regions and whether the novel paralogues retained the regions. There are basically three scenarios that can occur: (i) the region is preserved without any further duplications; (ii) the region spreads and becomes preserved in all of the novel duplicates; (iii) partial loss scenario, that is, the region is preserved in some duplicates, but is lost in others. Our results show that the most common evolutionary fate is the second one (Figure 4B). In 29 cases, at least one duplication that inherited the region can be observed after the emergence of the cancer region. In contrast, only five regions were not duplicated. Some ancient cases, such as MLH1 and USP8, are also included among the non-duplicated ones, which means that the reason for the lack of duplications is not the short evolutionary time. The partial loss scenario was observed in only two cases, in the case of VHL and NFE2L2. For instance, in the case of VHL, there was a relatively recent gene duplication at the level of mammals. While the N-terminal segment is present on both paralogs (VHL and VHLL), the C-terminal segment is only present in VHL, but was lost from VHLL. In a similar fashion, NFE2L2 underwent a more recent gene duplication at the level of vertebrates, but the newly emerged paralog did not retain the two linear motifs that are primarily targeted by cancer mutations.
3.4. Case Studies
3.4.1. MLH1
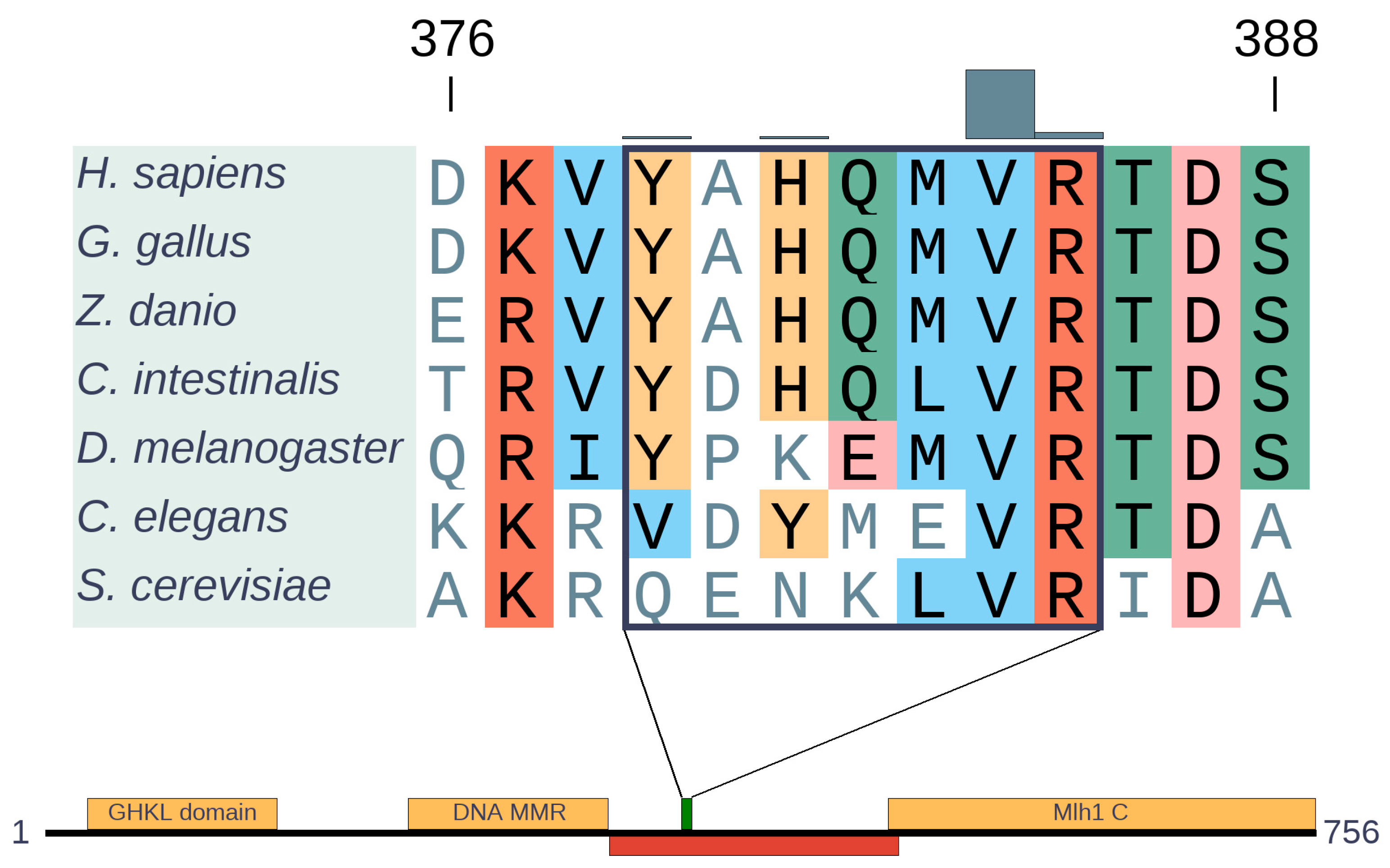
One of the most ancient examples in our dataset corresponds to MLH1 (MutL Homolog 1), an essential protein in DNA mismatch repair (MMR). As one of the classic examples of a caretaker function, mutations of MLH1 can lead to cancer by increasing the rate of single-base substitutions and frameshift mutations [22]. Several positions of MLH1 are mutated in people with Lynch syndrome, also known as hereditary nonpolyposis colorectal cancer (HNPCC). However, according to the COSMIC database of somatic cancer mutations, the most common mutation of MLH1 is V384D. Mutational studies of V384D using yeast assays and in vitro MMR assay did not indicate a strong phenotype, but still showed a limited decrease of MMR activity [23]. However, it was shown that the (mostly germline) V384D variant is clearly associated with increased colorectal cancer susceptibility [24], and it is highly prevalent in HER2-positive luminal B breast cancer [25].
MLH1 is an ancient protein that is present from bacteria to humans. It has a highly conserved domain organization that involves ordered N- and C-terminal domains connected by a disordered linker [26] (Figure 5). This underlines the functional importance not only of the structured domains, but also of the connecting disordered region. In our previous work, we identified the region from 379 to 385 to be significantly mutated [7], which is located within the disordered segment. Recently, it was shown that the linker can regulate both DNA interactions and enzymatic activities of neighboring structured domains [27]. In agreement with the linker function, both the composition and length of this intrinsically disordered region (IDR) are critical for efficient MMR. Overall, most of the linker shows relatively low sequence conservation, however, the identified cancer risk region is highly conserved from across all eukaryotic sequences (Figure 5), in an island-like manner. Although the exact function of this region is not known, the strong evolutionary conservation indicates a highly important function, not yet explored in detail.
3.4.2. VHL
VHL, the Von Hippel-Lindau disease tumor suppressor protein possesses an E3 ligase activity. It plays a key role in cellular oxygen sensing by targeting hypoxia-inducible factors for ubiquitylation and proteasomal degradation. To carry out its function, VHL forms a complex with elongin B, elongin C, and cullin-2 and the RING finger protein RBX1 [28,29]. VHL has an α-domain (also known as the VHL-box, residues 155 to 192) that forms the principal contacts with elongin C, and a larger β-domain (residues 63 to 154) that directly binds the proline hydroxylated substrate, HIF1α. The positions mutated across various types of cancers cover a large part of the protein, including both the α and β domains. While these regions form a well-defined structure in complex with elongin B, elongin C, and cullin-2, they are disordered in isolation and rapidly degraded [30].
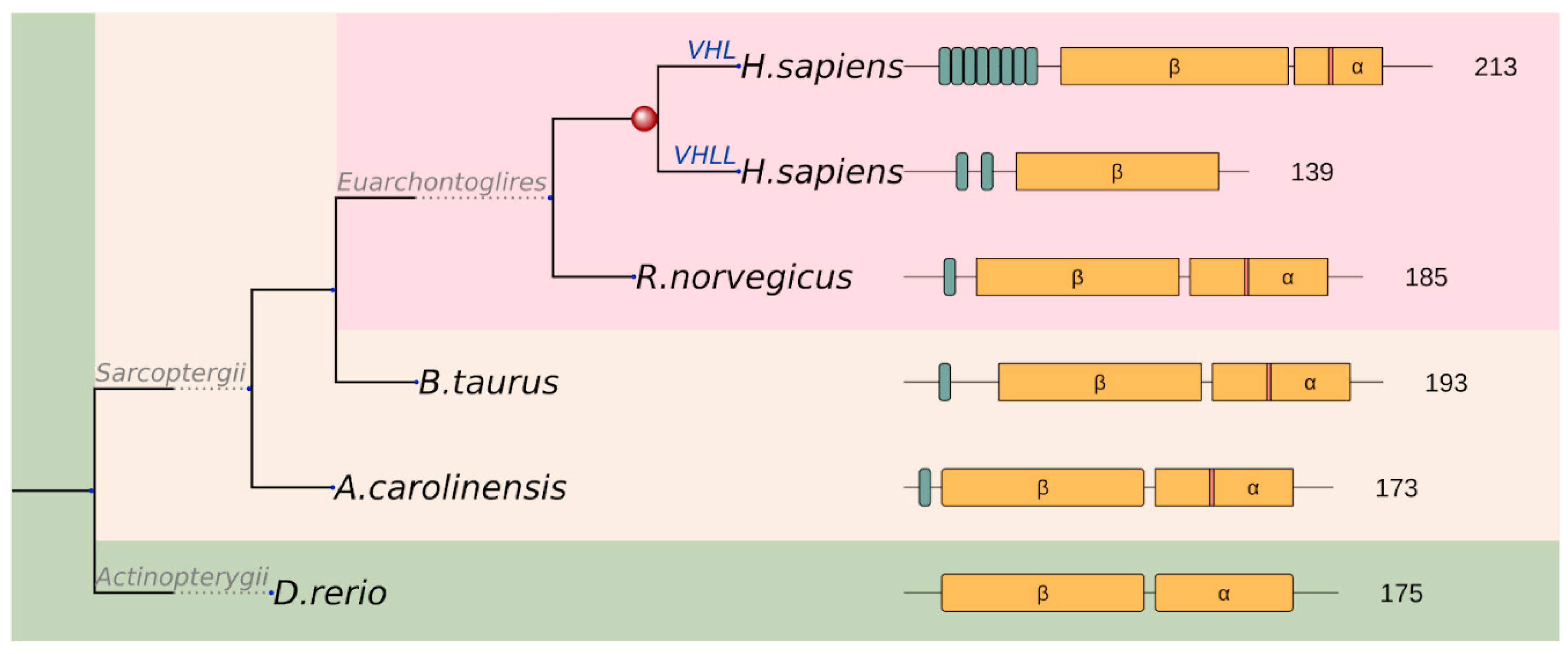
The VHL gene emerged de novo at the level of Eumetazoa together with HIFα and PHD, the other key components of the hypoxia regulatory pathway. However, more recently, the gene underwent various evolutionary events. The VHL gene showed slightly higher evolutionary variations compared with other cancer risk regions (Figure 2). Some positions, including K171, showed signs of positive selection at the level of Sarcopterygii, which might implicate the occurrence of an important evolutionary event. It was shown that the SUMO E3 ligase PIASy interacts with VHL and induces VHL SUMOylation on lysine residue 171 [31]. VHL also undergoes ubiquitination on K171 (and K196), which is blocked by PIASy. In the proposed model of the dynamic regulation of VHL, the interaction of VHL with PIASy results in VHL nuclear localization, SUMOylation, and stability for blocking ubiquitylation of VHL. Meanwhile, PIASy dissociation with VHL or attenuation of VHL SUMOylation facilitates VHL nuclear export, ubiquitylation, and instability. This dynamic process of VHL with reversible modification acts in concert to inhibit HIF1α [32].
A novel acidic repeat region appeared at the N-terminal region of the protein at the level of Sarcopterygii, and this region underwent further repeat expansion in the lineage leading up to humans (Figure 6). These GxEEx repeats are generally thought to confer additional regulation to the long isoform of VHL (translated from the first methionine), with a number of putative (USP7) or experimentally detected (p14ARF) interactors [33]. Although poorly studied, this repetitive region also seems to harbour casein kinase 2 (CK2) phosphorylation as well as proteolytic cleavage sites, regulating VHL half-life (consistent with a deubiquitinase, such as USP7 binding role) [34]. As a result of a recent gene duplication, the human genome even encodes a VHL-like protein (VHLL), which has lost the C-terminal segment including the α domain. Consequently, VHLL cannot nucleate the multiprotein E3 ubiquitin ligase complex. Instead, it was suggested that VHLL functions as a dominant-negative VHL to serve as a protector of HIF1α [35]. This example demonstrates that, while the basic cancer risk region remains largely unchanged during evolution, additional regulatory mechanisms can emerge to further fine-tune the function of the protein.
3.4.3. ESR1
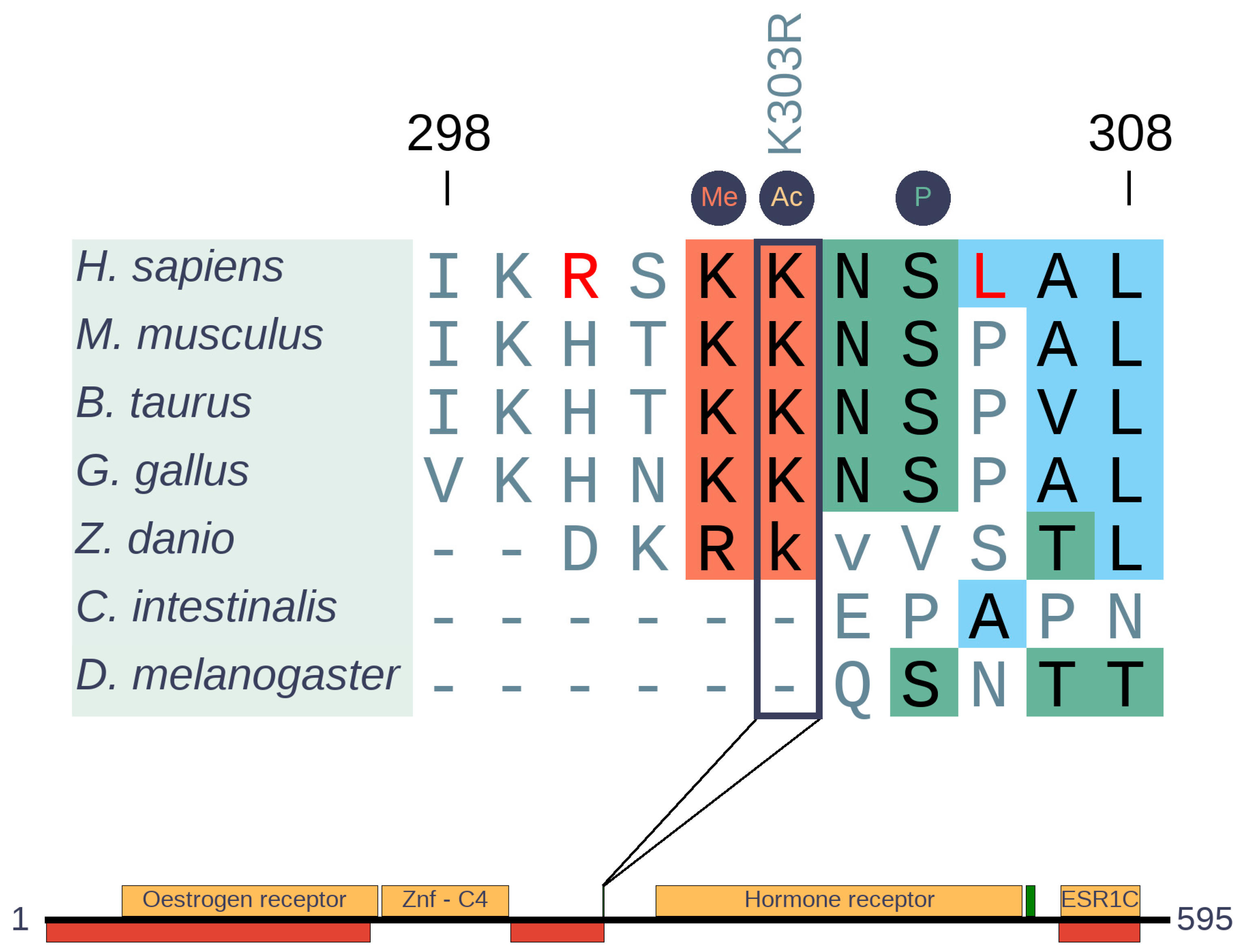
Estrogen receptor 1 (ESR1) is a member of the nuclear hormone receptor family with eumetazoan origin. The most common mutation in both primary and tamoxifen therapy associated samples corresponds to a single mutation (K303R). This single site emerged more recently (Figure 7) and is located in a rather complex switch region adjacent to the ligand-binding domain (Figure S2). The highly mutated K303 of ESR1 (more than 200 K303R missense mutations are seen in COSMIC) is a part of a motif-based molecular switch region involving several mutually exclusive PTMs. At positions 302, 303, and 305, methylation by SET7/9, acetylation by p300, and phosphorylation by PKA or PAK1 were observed in previous studies, respectively [36,37,38,39,40]. Our results show that this region is conserved only in Sarcopterygii, which indicates a relatively young evolutionary origin of the switching mechanism. However, while the methylation and acetylation sites are well conserved, the phosphorylation motif appears to be specific only to H. sapiens. We came to this conclusion because R300 and K302 as well as L306 are required for the protein kinase A (PKA) phosphorylation consensus and the oncogenic mutation K303R is expected to turn this region into an even better PKA substrate [41,42]. Curiously, these residues are not found in any other mammal, supposing species specific adaptive changes.
Comparison of substitutions and polymorphic sites is a powerful approach to identify specific changes in a pair of closely related species, like H. sapiens and chimpanzee. Relying on this approach, 198 of 9785 analyzed genes were identified to show human-specific changes including ESR1 [19]. In ESR1, there are three more changes besides R300 and K306 (L44, Q502, S559) between H. sapiens and chimp that are also thought to be adaptive substitutions according to the MK test. Phosphorylation of S559 was experimentally identified, suggesting this residue is also a H. sapiens specific PTM [43,44], but there is no specific data in the literature about the biological function of L44 and Q502. Yet, we know that phosphorylation of S305 allows the increase of estrogen sensitivity by external stimuli other than steroids, and permits ESR1 activity even when the canonical estrogen effect is completely blocked by tamoxifen [40,42]. In mice, ESR1 activity is essential for the estrogen effect and normal estrous episodes [45,46]. Although we lack information, we theorize that this human-specific signaling crosstalk might somehow be connected to the continuous menstrual cycle of H. sapiens (quite unusual among mammals), or some other human-specific reproductive adaptation.
4. Discussion
In our study, we aimed to estimate the evolutionary origin of disordered regions that are specifically targeted in cancer. Intrinsically disordered protein regions play essential roles in a wide-range of biological processes and can function as linear motifs, linkers, or other intrinsically disordered domain-sized segments [47]. They are integral parts of many cancer associated proteins and, in a smaller number of cases, they can also be the direct targets of cancer driving mutations. In general, IDRs are believed to be of more recent evolutionary origin, and exhibit higher rates of evolutionary variations compared with that of folded globular domains [9]. However, this is not what we see in the case of disordered cancer genes. Instead, we observed that cancer-targeted disordered regions are extremely conserved with deep evolutionary origins, which underlines their critical function. The two main ages for emergence of disordered cancer genes can be linked to unicellular organisms and the emergence of multicellularity, in agreement with the result of phylostratigraphic tracking of cancer genes in general [3].
One of the most unexpected findings of our study is the examples of disordered cancer genes that can be traced back to unicellular organisms. Mechanistically, the group of cancer genes that emerged in unicellular organisms were suggested to play a caretaker role and contribute to tumorigenesis by increasing mutation rates and genome instability. In contrast, cancer genes that emerged at the level of multicellularity were suggested to typically have a gatekeeper function and promote tumour progression directly by changing cell differentiation, growth, and death rates [48]. MLH1 is one of the best characterized examples of a gene with a caretaker function [49]. It is involved in mismatch repair (MMR) of DNA bases that have been misincorporated during DNA replication. Thus, disruptive mutations of MLH1 greatly increase the rate of point mutations in genes and underline various inherited forms of cancer. However, the most commonly seen alterations in patients are located in the flexible internal linker. Mutational studies indicate that this highly conserved segment might not be directly involved in MMR, but likely has an important, currently uncharacterized function. The other ancient examples are also involved in basic cellular processes, however, they are associated with a broader set of functions. HIST1H3B, SMARCB1, and SETBP1 are involved in epigenetic regulation and their mutations can alter gene expression patterns [50,51]. Mutations of EIF1AX and RPS15 are likely to perturb translation events [52,53]. However, SRSF2, which is responsible for orchestrating splicing events, can also have a global influence on cellular states [54]. Therefore, the caretaker function is also a subject of evolution and some of its components emerged as a result of more recent evolutionary events.
A clear novelty of our approach is to focus at the origin of sub-gene elements; that is, regulatory regions, modules, and domains, instead of full genes. The genes can be built around founder genes that have an extremely ancient origin, but their biological function and regulation can change fundamentally during subsequent evolution. In several cases, the origin of the cancer mutated region was substantially more recent than the origin of the gene. Nevertheless, after their emergence, disordered cancer regions were fixated rapidly and showed little variations afterwards. However, their evolution at the gene level was not set in stone and there are several indications that this process continues indefinitely. In several cases, the cancer genes underwent gene duplications, further regulatory regions were added, or fine-tuned by changing some of the less critical positions. We highlighted a fascinating case when such an event occurred when our species, H. sapiens, separated from its primate relatives.
In general, the rate of gene duplications is very high (0.01 per gene per million years) over evolution, which provides the source of emergence of evolutionary novelties [55]. According to the general view, paralogs go through a brief period of relaxed selection directly after duplications—this time ensures the acquisition of novelties—and subsequently experience strong purifying selection, preserving the newly developed function. However, our results showed that only a few disordered cancer regions have emerged in a duplication induced manner and the vast majority of disordered cancer regions emerged de novo, independent of duplications. The evolution of disordered regions is better described by the ex-nihilo motif theory, which is based on the rapid disappearance and emergence of linear motifs by the change of only a few residues within a given disordered protein segment [10]. This evolutionary phenomenon is commonly observed in the case of linear motifs, for example, in the case of NFE2L2. This protein carries a pair of crucial linear motifs that have emerged in the ancient eumetazoa, but are not preserved in the most recent duplicates. In an evolutionary biology aspect, our results suggest that the evolution of functional novelties in the case of disordered region mediated functions requires a more complex model.
Exploring the evolutionary origin of cancer genes is an important step to understand how this disease can emerge. This knowledge can also have important implications of how their regulatory networks are disrupted during tumorigenesis and can be incorporated into developing improved treatment options [56]. In this work, we focused on a subset of cancer genes that belong to the class of intrinsic disordered proteins, which rely on their inherent flexibility to carry out their important functions. While the selected examples represent only a small subset of cancer genes, they are highly relevant for several specific cancer types [8]. In general, disordered proteins are evolutionarily more variable compared with globular proteins, however, the disordered cancer risk regions showed remarkable conservation with ancient evolutionary origin, highlighting their importance in core biological processes. Nevertheless, we found several examples where the region specifically targeted by cancer mutations emerged at a later stage compared with the origin of the gene family. Our results highlight the importance of taking into account the complex modular architecture of cancer genes in order to get a more complete understanding of their evolutionary origin.
Supplementary Materials
The following are available online at https://www.mdpi.com/2218-273X/10/8/1115/s1, Figure S1: Sequence alignment of BCL2 cancer region. Figure S2: Schematic representation of the evolutionary scenario and functional units of the ESR1 and ESR2 proteins. Supplementary Materials 1: Evolutionary origins of selected cases.
Author Contributions
Conceptualization, M.P., A.Z. and Z.D.; Data curation, M.P.; Formal analysis, M.P.; Funding acquisition, Z.D.; Investigation, M.P., A.Z. and Z.D.; Methodology, M.P.; Supervision, Z.D.; Visualization, M.P.; Writing—original draft, M.P., A.Z. and Z.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the “FIEK” grant from the National Research, Development, and Innovation Office (FIEK16-1-2016-0005) and the ELTE Thematic Excellence Programme (ED-18-1-2019-003) supported by the Hungarian Ministry for Innovation and Technology.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jacob, F. Evolution and tinkering. Science 1977, 196, 1161–1166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kinzler, K.W.; Vogelstein, B. Cancer-susceptibility genes. Gatekeepers and caretakers. Nature 1997, 386, 761–763. [Google Scholar] [CrossRef] [PubMed]
- Domazet-Lošo, T.; Tautz, D. Phylostratigraphic tracking of cancer genes suggests a link to the emergence of multicellularity in metazoa. BMC Biol. 2010, 8, 66. [Google Scholar] [CrossRef] [Green Version]
- Domazet-Loso, T.; Tautz, D. An ancient evolutionary origin of genes associated with human genetic diseases. Mol. Biol. Evol. 2008, 25, 2699–2707. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dickerson, J.E.; Robertson, D.L. On the origins of mendelian disease genes in man: The impact of gene duplication. Mol. Biol. Evol. 2012, 29, 2284. [Google Scholar] [CrossRef] [Green Version]
- Bailey, M.H.; Tokheim, C.; Porta-Pardo, E.; Sengupta, S.; Bertrand, D.; Weerasinghe, A.; Colaprico, A.; Wendl, M.C.; Kim, J.; Reardon, B.; et al. Comprehensive characterization of cancer driver genes and mutations. Cell 2018, 173, 371–385.e18. [Google Scholar] [CrossRef] [Green Version]
- Mészáros, B.; Zeke, A.; Reményi, A.; Simon, I.; Dosztányi, Z. Systematic analysis of somatic mutations driving cancer: Uncovering functional protein regions in disease development. Biol. Direct 2016, 11, 23. [Google Scholar] [CrossRef] [Green Version]
- Mészáros, B.; Hajdu-Soltész, B.; Zeke, A.; Dosztányi, Z. Intrinsically disordered protein mutations can drive cancer and their targeted interference extends therapeutic options. Bioinform. bioRxiv 2020, 2443. [Google Scholar] [CrossRef]
- Brown, C.J.; Johnson, A.K.; Dunker, A.K.; Daughdrill, G.W. Evolution and disorder. Curr. Opin. Struct. Biol. 2011, 21, 441–446. [Google Scholar] [CrossRef]
- Davey, N.E.; Cyert, M.S.; Moses, A.M. Short linear motifs—Ex nihilo evolution of protein regulation. Cell Commun. Signal. 2015, 13, 43. [Google Scholar] [CrossRef] [Green Version]
- Sondka, Z.; Bamford, S.; Cole, C.G.; Ward, S.A.; Dunham, I.; Forbes, S.A. The COSMIC cancer gene census: Describing genetic dysfunction across all human cancers. Nat. Rev. Cancer 2018, 18, 696–705. [Google Scholar] [CrossRef] [PubMed]
- Flicek, P.; Amode, M.R.; Barrell, D.; Beal, K.; Brent, S.; Carvalho-Silva, D.; Clapham, P.; Coates, G.; Fairley, S.; Fitzgerald, S.; et al. Ensembl 2012. Nucleic Acids Res. 2011, 40, D84–D90. [Google Scholar] [CrossRef] [Green Version]
- Herrero, J.; Muffato, M.; Beal, K.; Fitzgerald, S.; Gordon, L.; Pignatelli, M.; Vilella, A.J.; Searle, S.M.J.; Amode, R.; Brent, S.; et al. Ensembl comparative genomics resources. Database 2016, 2016, bav096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liebeskind, B.J.; McWhite, C.D.; Marcotte, E.M. Towards consensus gene ages. Genome Biol. Evol. 2016, 8, 1812–1823. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Standley, D.M. MAFFT multiple sequence alignment software version 7: Improvements in performance and usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [Green Version]
- Eddy, S.R. Accelerated Profile HMM Searches. PLoS Comput. Biol. 2011, 7, e1002195. [Google Scholar] [CrossRef] [Green Version]
- Moretti, S.; Laurenczy, B.; Gharib, W.; Castella, B.; Kuzniar, A.; Schabauer, H.; Studer, R.A.; Valle, M.; Salamin, N.; Stockinger, H.; et al. Selectome update: Quality control and computational improvements to a database of positive selection. Nucleic Acids Res. 2013, 42, D917–D921. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z. PAML 4: Phylogenetic Analysis by Maximum Likelihood. Mol. Biol. Evol. 2007, 24, 1586–1591. [Google Scholar] [CrossRef] [Green Version]
- Gayà-Vidal, M.; Alba, M.M. Uncovering adaptive evolution in the human lineage. BMC Genom. 2014, 15, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Berg, T.K.V.D.; Yoder, J.A.; Litman, G. On the origins of adaptive immunity: Innate immune receptors join the tale. Trends Immunol. 2004, 25, 11–16. [Google Scholar] [CrossRef]
- Wu, G.; Xu, G.; Schulman, B.A.; Jeffrey, P.D.; Harper, J.W.; Pavletich, N.P. Structure of a beta-TrCP1-Skp1-beta-catenin complex: Destruction motif binding and lysine specificity of the SCF(beta-TrCP1) ubiquitin ligase. Mol. Cell 2003, 11, 1445–1456. [Google Scholar] [CrossRef]
- Shcherbakova, P.V.; Kunkel, T.A. Mutator Phenotypes conferred by MLH1 Overexpression and by Heterozygosity for mlh1 Mutations. Mol. Cell. Biol. 1999, 19, 3177–3183. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takahashi, M.; Shimodaira, H.; Andreutti-Zaugg, C.; Iggo, R.; Kolodner, R.D.; Ishioka, C. Functional analysis of human MLH1 variants using yeast and in vitro mismatch repair Assays. Cancer Res. 2007, 67, 4595–4604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akagi; Ohsawa, T.; Sahara, T.; Muramatsu, S.; Nishimura, Y.; Yathuoka, T.; Tanaka, Y.; Yamaguchi, K.; Ishida, H. Colorectal cancer susceptibility associated with the hMLH1 V384D variant. Mol. Med. Rep. 2009, 2, 887–891. [Google Scholar] [CrossRef]
- Lee, S.E.; Lee, H.S.; Kim, K.-Y.; Park, J.-H.; Roh, H.; Park, H.Y.; Kim, W.S. High prevalence of the MLH1 V384D germline mutation in patients with HER2-positive luminal B breast cancer. Sci. Rep. 2019, 9, 10966. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gueneau, E.; Dhérin, C.; Legrand, P.; Tellier-Lebègue, C.; Gilquin, B.; Bonnesoeur, P.; Londino, F.; Quemener, C.; Le Du, M.-H.; A Márquez, J.; et al. Structure of the MutLα C-terminal domain reveals how Mlh1 contributes to Pms1 endonuclease site. Nat. Struct. Mol. Biol. 2013, 20, 461–468. [Google Scholar] [CrossRef]
- Kim, Y.; Furman, C.M.; Manhart, C.M.; Alani, E.; Finkelstein, I.J. Intrinsically disordered regions regulate both catalytic and non-catalytic activities of the MutLα mismatch repair complex. Nucleic Acids Res. 2018, 47, 1823–1835. [Google Scholar] [CrossRef] [Green Version]
- Kamura, T.; Maenaka, K.; Kotoshiba, S.; Matsumoto, M.; Kohda, D.; Conaway, R.C.; Conaway, J.W.; Nakayama, K.I. VHL-box and SOCS-box domains determine binding specificity for Cul2-Rbx1 and Cul5-Rbx2 modules of ubiquitin ligases. Genes Dev. 2004, 18, 3055–3065. [Google Scholar] [CrossRef] [Green Version]
- Cardote, T.A.; Gadd, M.S.; Ciulli, A. Crystal structure of the Cul2-Rbx1-EloBC-VHL Ubiquitin Ligase complex. Structure 2017, 25, 901–911.e3. [Google Scholar] [CrossRef] [Green Version]
- Sutovsky, H.; Gazit, E. The von Hippel-Lindau tumor suppressor protein is a molten globule under native conditions. J. Biol. Chem. 2004, 279, 17190–17196. [Google Scholar] [CrossRef] [Green Version]
- Cai, Q.; Verma, S.C.; Kumar, P.; Ma, M.; Robertson, E.S. Hypoxia Inactivates the VHL tumor suppressor through PIASy-Mediated SUMO modification. PLoS ONE 2010, 5, e9720. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Q.; Robertson, E.S. Ubiquitin/SUMO modification regulates VHL protein stability and nucleocytoplasmic localization. PLoS ONE 2010, 5, e12636. [Google Scholar] [CrossRef] [PubMed]
- Minervini, G.; Mazzotta, G.; Masiero, A.; Sartori, E.; Corrà, S.; Potenza, E.; Costa, R.; Tosatto, S.C.E. Isoform-specific interactions of the von Hippel-Lindau tumor suppressor protein. Sci. Rep. 2015, 5, 12605. [Google Scholar] [CrossRef] [PubMed]
- German, P.; Bai, S.; Liu, X.-D.; Sun, M.; Zhou, L.; Kalra, S.; Zhang, X.; Minelli, R.; Scott, K.L.; Mills, G.B.; et al. Phosphorylation-dependent cleavage regulates von Hippel Lindau proteostasis and function. Oncogene 2016, 35, 4973–4980. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, H.; Gervais, M.L.; Li, W.; DeCaprio, J.A.; Challis, J.R.G.; Ohh, M. Molecular cloning and characterization of the von Hippel-Lindau-like protein. Mol. Cancer Res. 2004, 2, 43–52. [Google Scholar]
- Dhayalan, A.; Kudithipudi, S.; Rathert, P.; Jeltsch, A. Specificity analysis-based identification of new methylation targets of the SET7/9 protein lysine methyltransferase. Chem. Biol. 2011, 18, 111–120. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Fu, M.; Angeletti, R.H.; Siconolfi-Baez, L.; Reutens, A.T.; Albanese, C.; Lisanti, M.P.; Katzenellenbogen, B.S.; Kato, S.; Hopp, T.; et al. Direct Acetylation of the Estrogen receptor α hinge region by p300 regulates transactivation and hormone sensitivity. J. Biol. Chem. 2001, 276, 18375–18383. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.-A.; Mazumdar, A.; Vadlamudi, R.K.; Kumar, R. P21-activated kinase-1 phosphorylates and transactivates estrogen receptor-α and promotes hyperplasia in mammary epithelium. EMBO J. 2002, 21, 5437–5447. [Google Scholar] [CrossRef]
- Michalides, R.; Griekspoor, A.; Balkenende, A.; Verwoerd, D.; Janssen, L.; Jalink, K.; Floore, A.; Velds, A.; vant Veer, L.; Neefjes, J. Tamoxifen resistance by a conformational arrest of the estrogen receptor α after PKA activation in breast cancer. Cancer Cell 2004, 5, 597–605. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Zhang, M.; Pestell, R.; Curran, E.M.; Welshons, W.V.; Fuqua, S.A.W. Phosphorylation of estrogen receptor α blocks its Acetylation and regulates estrogen sensitivity. Cancer Res. 2004, 64, 9199–9208. [Google Scholar] [CrossRef] [Green Version]
- Rust, H.L.; Thompson, P.R. Kinase consensus sequences: A breeding ground for crosstalk. ACS Chem. Biol. 2011, 6, 881–892. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Leeuw, R.; Flach, K.; Toaldo, C.B.; Alexi, X.; Canisius, S.; Neefjes, J.; Michalides, R.; Zwart, W. PKA phosphorylation redirects ERα to promoters of a unique gene set to induce tamoxifen resistance. Oncogene 2012, 32, 3543–3551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Atsriku, C.; Britton, D.J.; Held, J.M.; Schilling, B.; Scott, G.K.; Gibson, B.W.; Benz, C.C.; Baldwin, M.A. Systematic mapping of posttranslational modifications in human estrogen receptor-α with emphasis on novel phosphorylation sites. Mol. Cell. Proteom. 2008, 8, 467–480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, C.C.; Basu, A.; El-Gharbawy, A.; Carrier, L.; Smith, C.L.; Rowan, B.G. Identification of four novel phosphorylation sites in estrogen receptor α: Impact on receptor-dependent gene expression and phosphorylation by protein kinase CK2. BMC Biochem. 2009, 10, 36. [Google Scholar] [CrossRef] [Green Version]
- Walker, V.R.; Korach, K. Estrogen receptor knockout mice as a model for endocrine research. ILAR J. 2004, 45, 455–461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porteous, R.; Herbison, A.E. Genetic deletion of Esr1 in the mouse preoptic area disrupts the LH surge and estrous cyclicity. Endocrinology 2019, 160, 1821–1829. [Google Scholar] [CrossRef]
- Van Der Lee, R.; Buljan, M.; Lang, B.; Weatheritt, R.J.; Daughdrill, G.W.; Dunker, A.K.; Fuxreiter, M.; Gough, J.; Gsponer, J.; Jones, D.T.; et al. Classification of intrinsically disordered regions and proteins. Chem. Rev. 2014, 114, 6589–6631. [Google Scholar] [CrossRef] [PubMed]
- Lengauer, C.; Kinzler, K.W.; Vogelstein, B. Genetic instabilities in human cancers. Nature 1998, 396, 643–649. [Google Scholar] [CrossRef]
- Ellison, A.R.; Lofing, J.; Bitter, G.A. Human MutL homolog (MLH1) function in DNA mismatch repair: A prospective screen for missense mutations in the ATPase domain. Nucleic Acids Res. 2004, 32, 5321–5338. [Google Scholar] [CrossRef] [Green Version]
- Duchatel, R.J.; Jackson, E.R.; Alvaro, F.; Nixon, B.; Hondermarck, H.; Dun, M.D. Signal transduction in diffuse intrinsic Pontine Glioma. Proteomics 2019, 19, e1800479. [Google Scholar] [CrossRef] [Green Version]
- Piazza, R.; Magistroni, V.; Redaelli, S.; Mauri, M.; Massimino, L.; Sessa, A.; Peronaci, M.; Lalowski, M.M.; Soliymani, R.; Mezzatesta, C.; et al. SETBP1 induces transcription of a network of development genes by acting as an epigenetic hub. Nat. Commun. 2018, 9, 2192. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martin-Marcos, P.; Zhou, F.; Karunasiri, C.; Zhang, F.; Dong, J.; Nanda, J.; Kulkarni, S.D.; Sen, N.D.; Tamame, M.; Zeschnigk, M.; et al. eIF1A residues implicated in cancer stabilize translation preinitiation complexes and favor suboptimal initiation sites in yeast. eLife 2017, 6, e31250. [Google Scholar] [CrossRef] [PubMed]
- Bretones, G.; Álvarez, M.G.; Arango, J.R.; Rodríguez, D.; Nadeu, F.; Prado, M.A.; Valdés-Mas, R.; Puente, D.A.; Paulo, J.A.; Delgado, J.; et al. Altered patterns of global protein synthesis and translational fidelity in RPS15-mutated chronic lymphocytic leukemia. Blood 2018, 132, 2375–2388. [Google Scholar] [CrossRef] [Green Version]
- Masaki, S.; Ikeda, S.; Hata, A.; Shiozawa, Y.; Kon, A.; Ogawa, S.; Suzuki, K.; Hakuno, F.; Takahashi, S.-I.; Kataoka, N. Myelodysplastic syndrome-associated SRSF2 mutations cause splicing changes by altering binding motif sequences. Front. Genet. 2019, 10, 338. [Google Scholar] [CrossRef] [PubMed]
- Assis, R.; Bachtrog, D. Rapid divergence and diversification of mammalian duplicate gene functions. BMC Evol. Biol. 2015, 15, 138. [Google Scholar] [CrossRef] [Green Version]
- Trigos, A.S.; Pearson, R.B.; Papenfuss, A.T.; Goode, D. How the evolution of multicellularity set the stage for cancer. Br. J. Cancer 2018, 118, 145–152. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Conservation-based evolutionary origin of disordered cancer regions and genes. (A) The orange and sky blue squares represent the origin of genes and regions, respectively. Gunmetal squares indicate the same evolutionary origin at both region and gene levels. (B) Summary barchart of origins in the three gene-age categories.
Figure 1.
Conservation-based evolutionary origin of disordered cancer regions and genes. (A) The orange and sky blue squares represent the origin of genes and regions, respectively. Gunmetal squares indicate the same evolutionary origin at both region and gene levels. (B) Summary barchart of origins in the three gene-age categories.

Figure 2.
Representation of average conservation values. (A) Sorted conservation values for each region having positions with at least one mutation and for the whole protein. Squares (dark blue—region, green—whole sequence) and triangles (light blue—regions, green—full sequence) represent BLOSUM62 and identity based conservation values, respectively. The outlier at the very end of the sequence corresponds to the region of BCL2. (B–D) The number of regions and average conservation value of regions having positions with at least 1, 15, and 25 mutations, respectively. The conservation values are based on BLOSUM62 and identity, and the number of regions are colored by dark, medium, and sky blue, respectively.
Figure 2.
Representation of average conservation values. (A) Sorted conservation values for each region having positions with at least one mutation and for the whole protein. Squares (dark blue—region, green—whole sequence) and triangles (light blue—regions, green—full sequence) represent BLOSUM62 and identity based conservation values, respectively. The outlier at the very end of the sequence corresponds to the region of BCL2. (B–D) The number of regions and average conservation value of regions having positions with at least 1, 15, and 25 mutations, respectively. The conservation values are based on BLOSUM62 and identity, and the number of regions are colored by dark, medium, and sky blue, respectively.

Figure 3.
The mechanisms of emergence of regions by neofunctionalization and de novo. (A) Demonstration of the model of duplication induced (neofunctionalization) cancer region emergence. (B) Depiction of the two sub-scenarios of the de novo region emergence. Mallow boxes and arrows explain the evolution of the region. Red and green triangles symbolize the further evolution of paralogs after gene duplications.
Figure 3.
The mechanisms of emergence of regions by neofunctionalization and de novo. (A) Demonstration of the model of duplication induced (neofunctionalization) cancer region emergence. (B) Depiction of the two sub-scenarios of the de novo region emergence. Mallow boxes and arrows explain the evolution of the region. Red and green triangles symbolize the further evolution of paralogs after gene duplications.

Figure 4.
Categorization of emergence scenarios and evolutionary fates of cancer regions. (A) The number of regions that have emerged by duplication or de novo. Six regions were not categorized (Other). (B) Classification of cancer regions in terms of their evolutionary fate after emergence.
Figure 4.
Categorization of emergence scenarios and evolutionary fates of cancer regions. (A) The number of regions that have emerged by duplication or de novo. Six regions were not categorized (Other). (B) Classification of cancer regions in terms of their evolutionary fate after emergence.

Figure 5.
Alignment of MLH1 orthologs generated with MAFFT [15] and domain structure of human MLH1. The segment of the alignment represents the cancer region (highlighted by a rectangle) with the missense mutation distribution depicted by gray bars. Domains are depicted by yellow, disordered regions by red boxes, while the green box indicates the cancer risk region.
Figure 5.
Alignment of MLH1 orthologs generated with MAFFT [15] and domain structure of human MLH1. The segment of the alignment represents the cancer region (highlighted by a rectangle) with the missense mutation distribution depicted by gray bars. Domains are depicted by yellow, disordered regions by red boxes, while the green box indicates the cancer risk region.

Figure 6.
Schematic representation of the evolutionary scenario of the VHL family and the functional units of the members. Repeat units in varying numbers and the α and β core domains are depicted by green and yellow boxes, respectively. Red stripe in the α domain of human VHL indicates K171 identified to emerge by positive selection on the Sarcopterygii branch (mapped K171 to other Sarcopterygii are also indicated by red stripes).
Figure 6.
Schematic representation of the evolutionary scenario of the VHL family and the functional units of the members. Repeat units in varying numbers and the α and β core domains are depicted by green and yellow boxes, respectively. Red stripe in the α domain of human VHL indicates K171 identified to emerge by positive selection on the Sarcopterygii branch (mapped K171 to other Sarcopterygii are also indicated by red stripes).

Figure 7.
Insertion-free sequence alignment of estrogen receptor 1 (ESR1) orthologs and domain structure of human ESR1. The alignment generated with MAFFT [15] represents the cancer region with sites of post-translational modifications. Borders of non-depicted insertion of zebrafish are indicated by lower case letters. The highly mutated position (K303R) is highlighted by a rectangle. PTM sites are indicated by circles above the alignment. H. sapiens specific changes are colored in red. Domains are depicted in yellow, disordered regions are depicted by red boxes, while the green boxes indicate the cancer risk regions.
Figure 7.
Insertion-free sequence alignment of estrogen receptor 1 (ESR1) orthologs and domain structure of human ESR1. The alignment generated with MAFFT [15] represents the cancer region with sites of post-translational modifications. Borders of non-depicted insertion of zebrafish are indicated by lower case letters. The highly mutated position (K303R) is highlighted by a rectangle. PTM sites are indicated by circles above the alignment. H. sapiens specific changes are colored in red. Domains are depicted in yellow, disordered regions are depicted by red boxes, while the green boxes indicate the cancer risk regions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Positive selection within disordered cancer genes. Positions within cancer risk regions are colored blue. The numbers in brackets are the posterior probability of positive selection for each position.
Table 1.
Positive selection within disordered cancer genes. Positions within cancer risk regions are colored blue. The numbers in brackets are the posterior probability of positive selection for each position.
| Gene | Positions under Positive Selection Referring to the Human Protein Sequence |
|---|---|
| CALR | 83(0.971), 155(0.971), 177(0.990), 267(0.995), 307(0.994), 336(0.991), 360(0.999) |
| CTNNB1 | 121(0.999), 206(0.993), 250(0.998), 287(0.991), 411(0.998), 433(0.993), 525(0.997), 552(0.998), 556(0.916) |
| VHL | 127(0.957), 132(0.942), 141(0.923), 171(0.947), 183(0.963), 185(0.920) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pajkos, M.; Zeke, A.; Dosztányi, Z. Ancient Evolutionary Origin of Intrinsically Disordered Cancer Risk Regions. Biomolecules 2020, 10, 1115. https://doi.org/10.3390/biom10081115
AMA Style
Pajkos M, Zeke A, Dosztányi Z. Ancient Evolutionary Origin of Intrinsically Disordered Cancer Risk Regions. Biomolecules. 2020; 10(8):1115. https://doi.org/10.3390/biom10081115
Chicago/Turabian StylePajkos, Mátyás, András Zeke, and Zsuzsanna Dosztányi. 2020. "Ancient Evolutionary Origin of Intrinsically Disordered Cancer Risk Regions" Biomolecules 10, no. 8: 1115. https://doi.org/10.3390/biom10081115
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.