
TTool: A Supervised Artificial Intelligence-Assisted Visual Pose Detector for Tool Heads in Augmented Reality Woodworking


Abstract
:1. Introduction
1.1. Context
1.2. Related Works
1.2.1. Tag-Based Tracking
1.2.2. Contour or Edge Approach
1.2.3. Deep Learning Approach
1.2.4. Benchmark Datasets
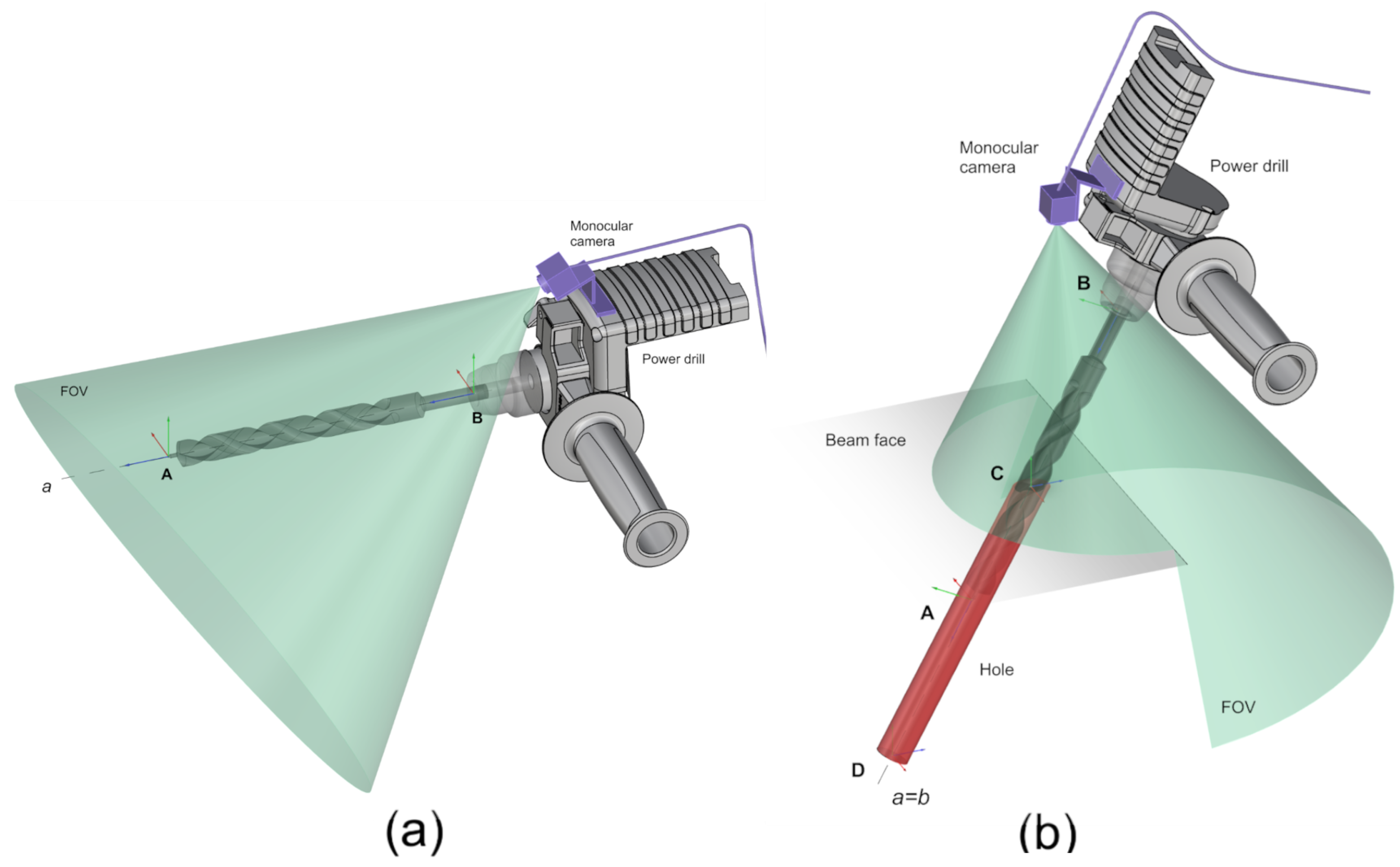
2. Developed Methodology
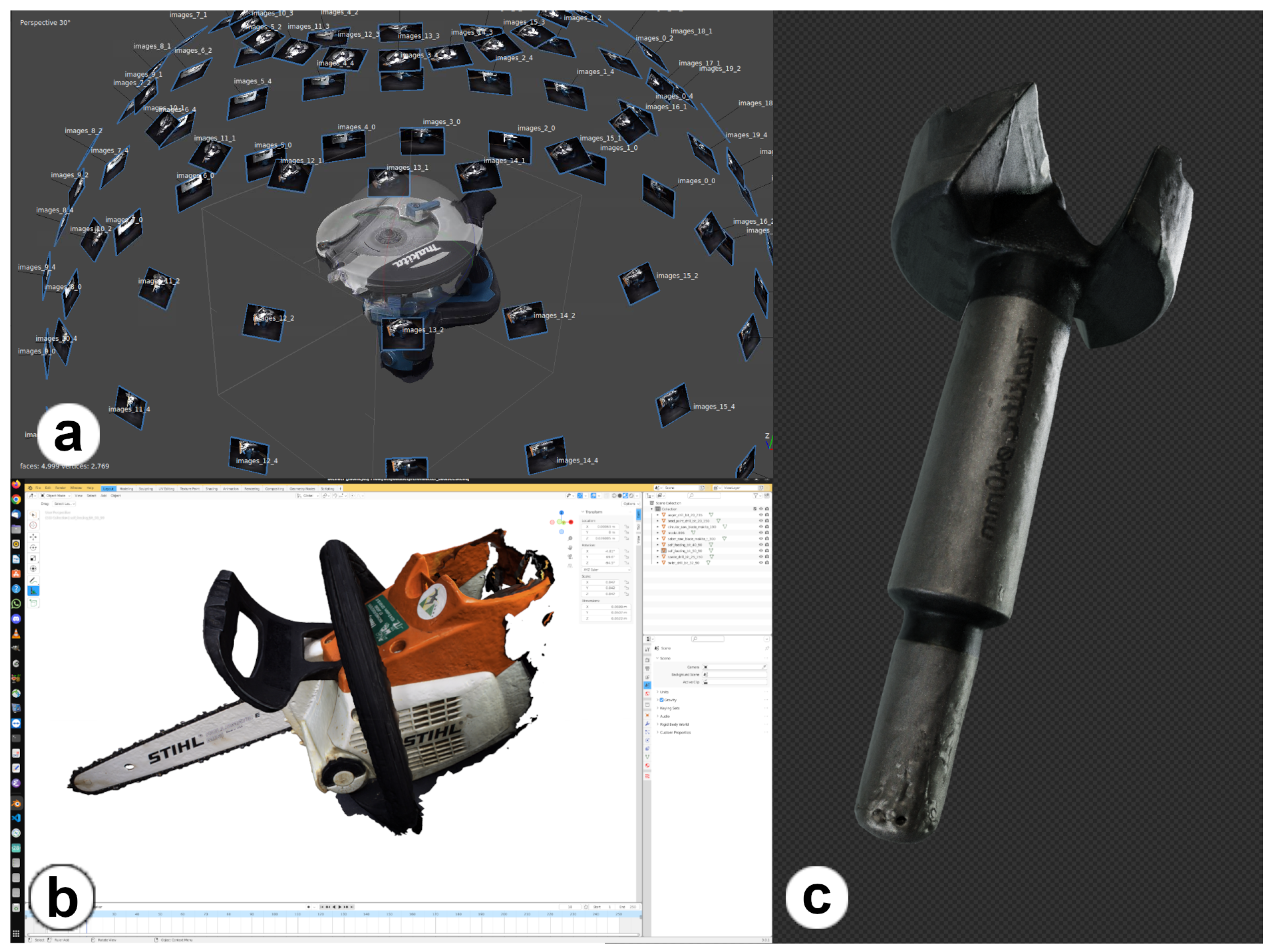
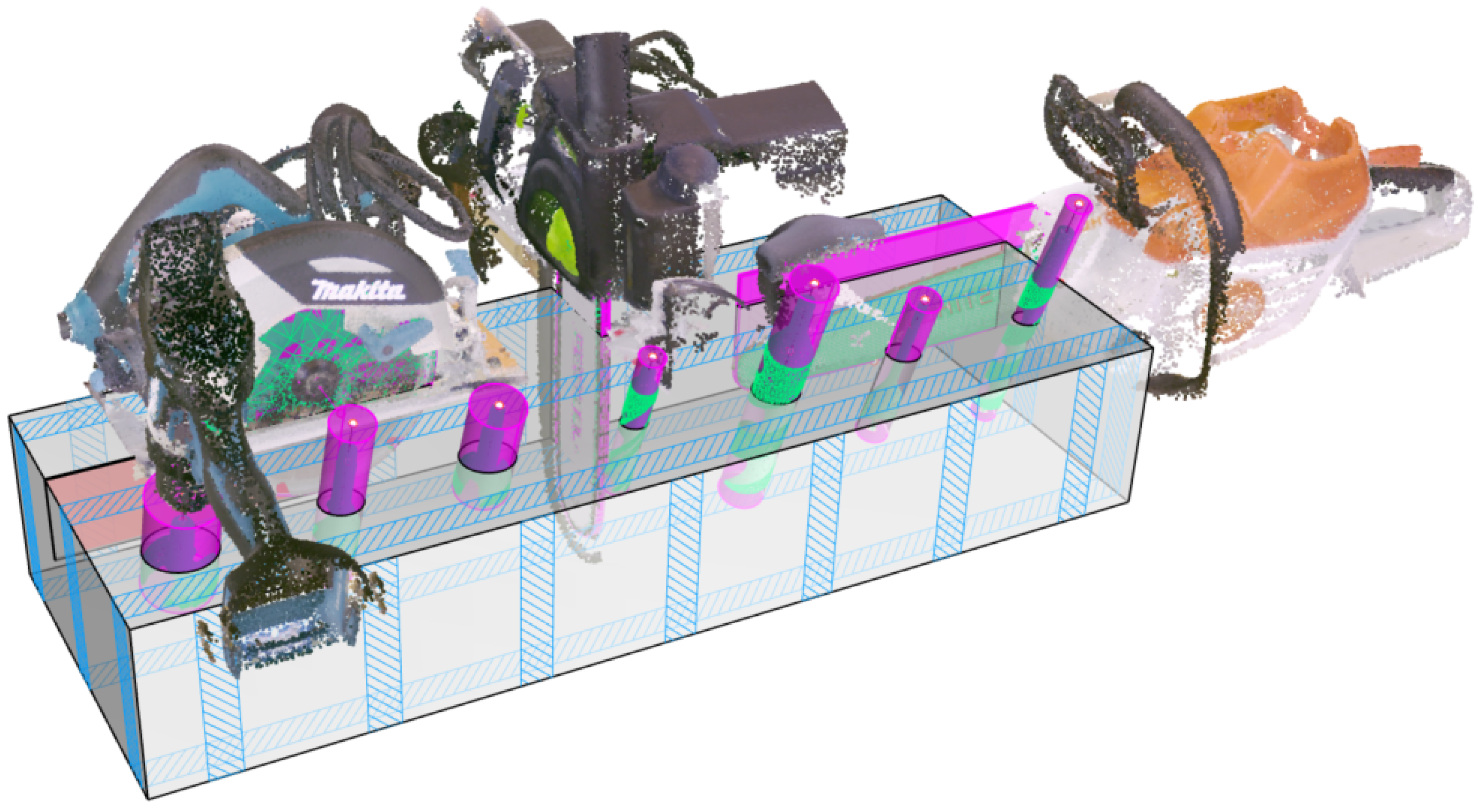
2.1. Dataset Digitization
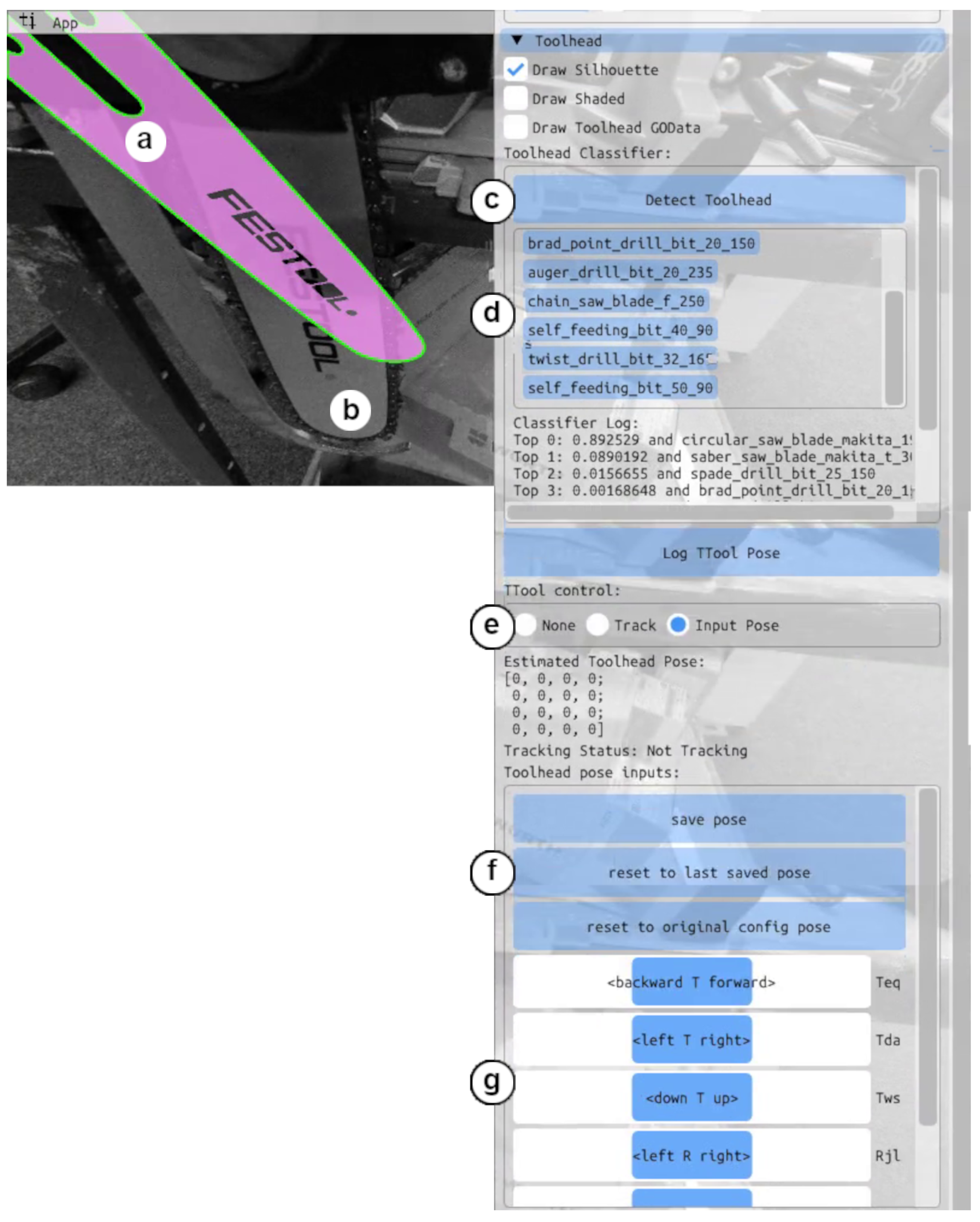
2.2. Typology Detector
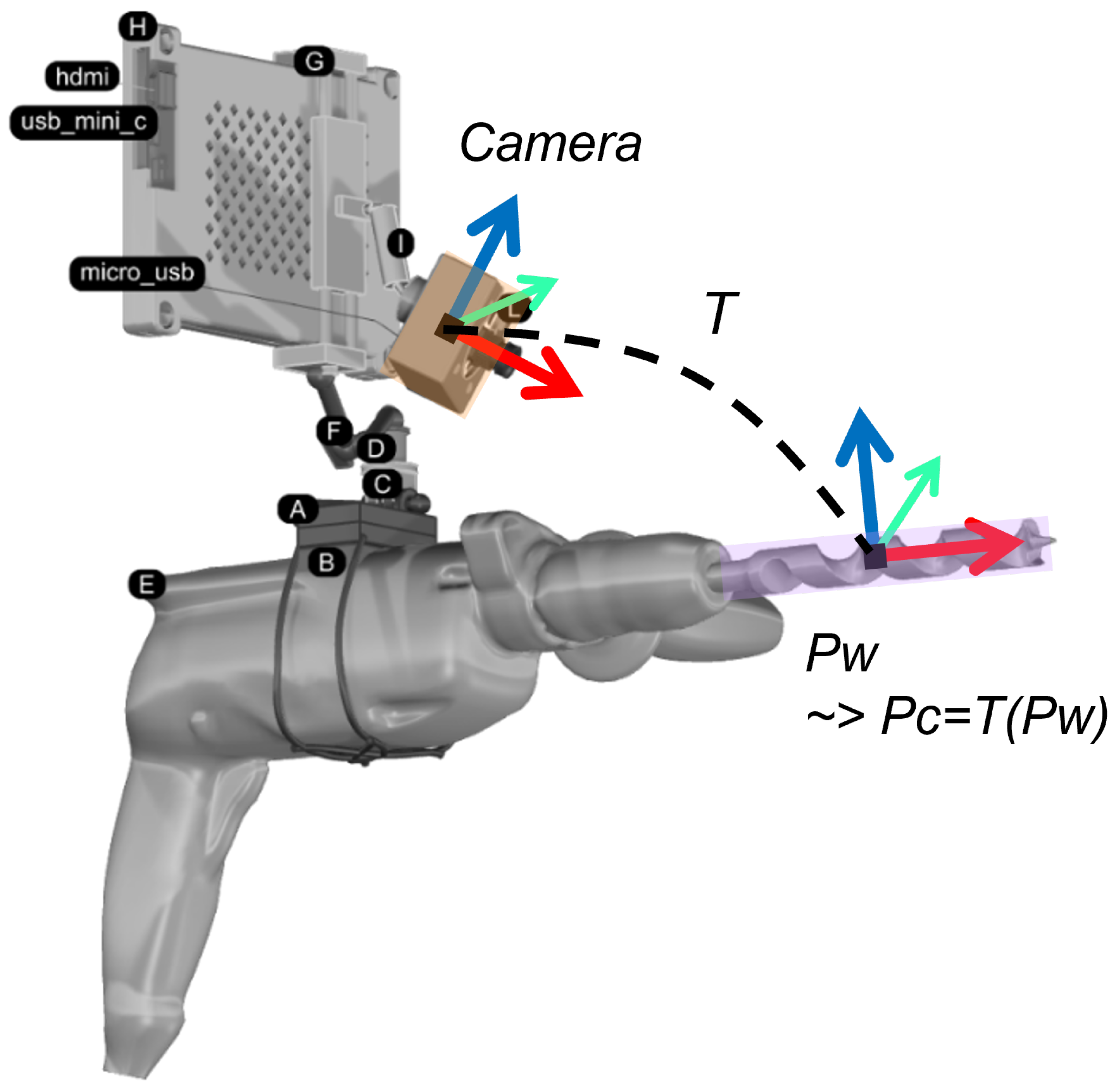
2.3. Global Pose Input
2.4. Supervised Pose Refiner
| Algorithm 1: Pose Update |
 |
3. Experimental Campaign
3.1. Experimental Set-Up
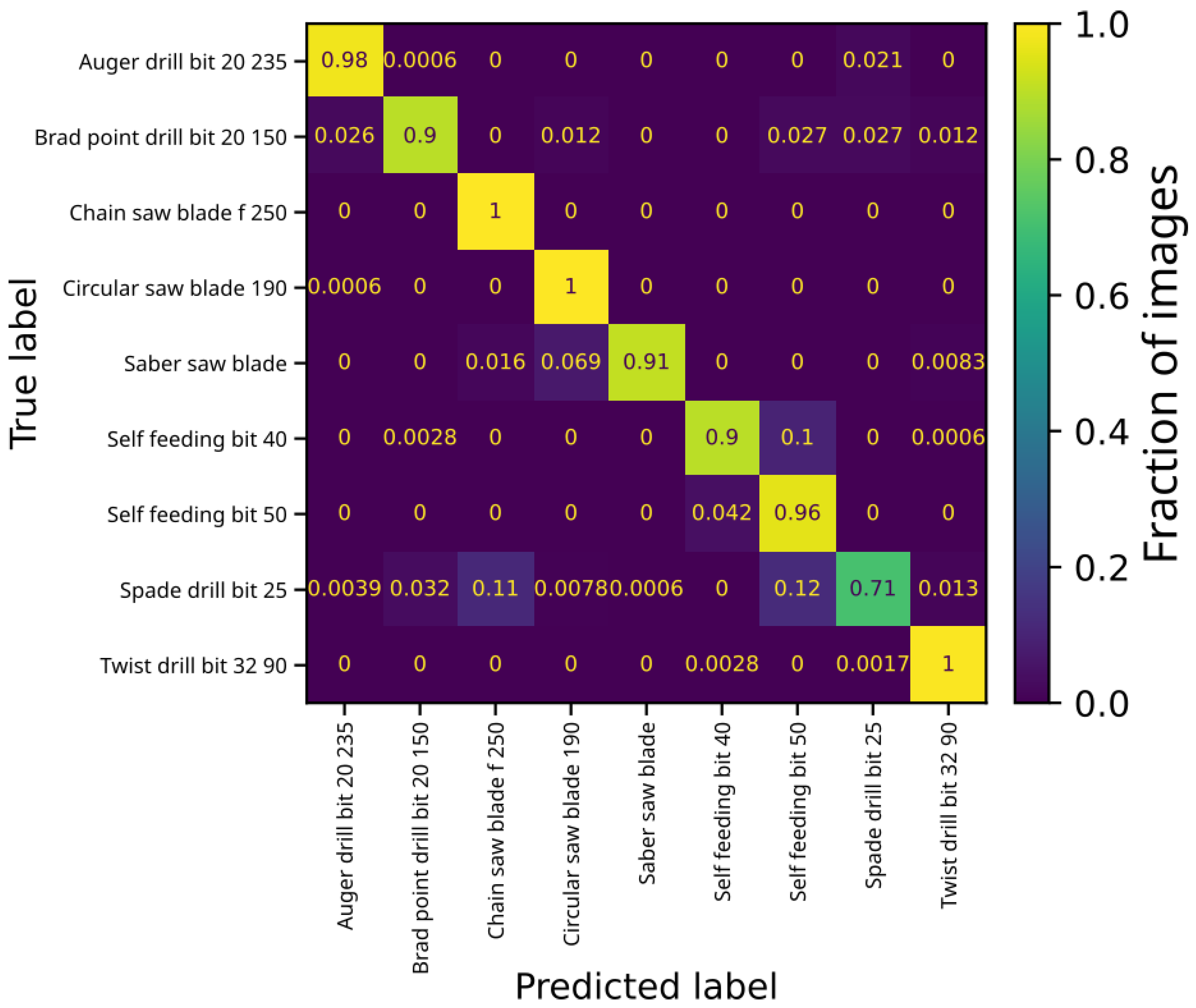
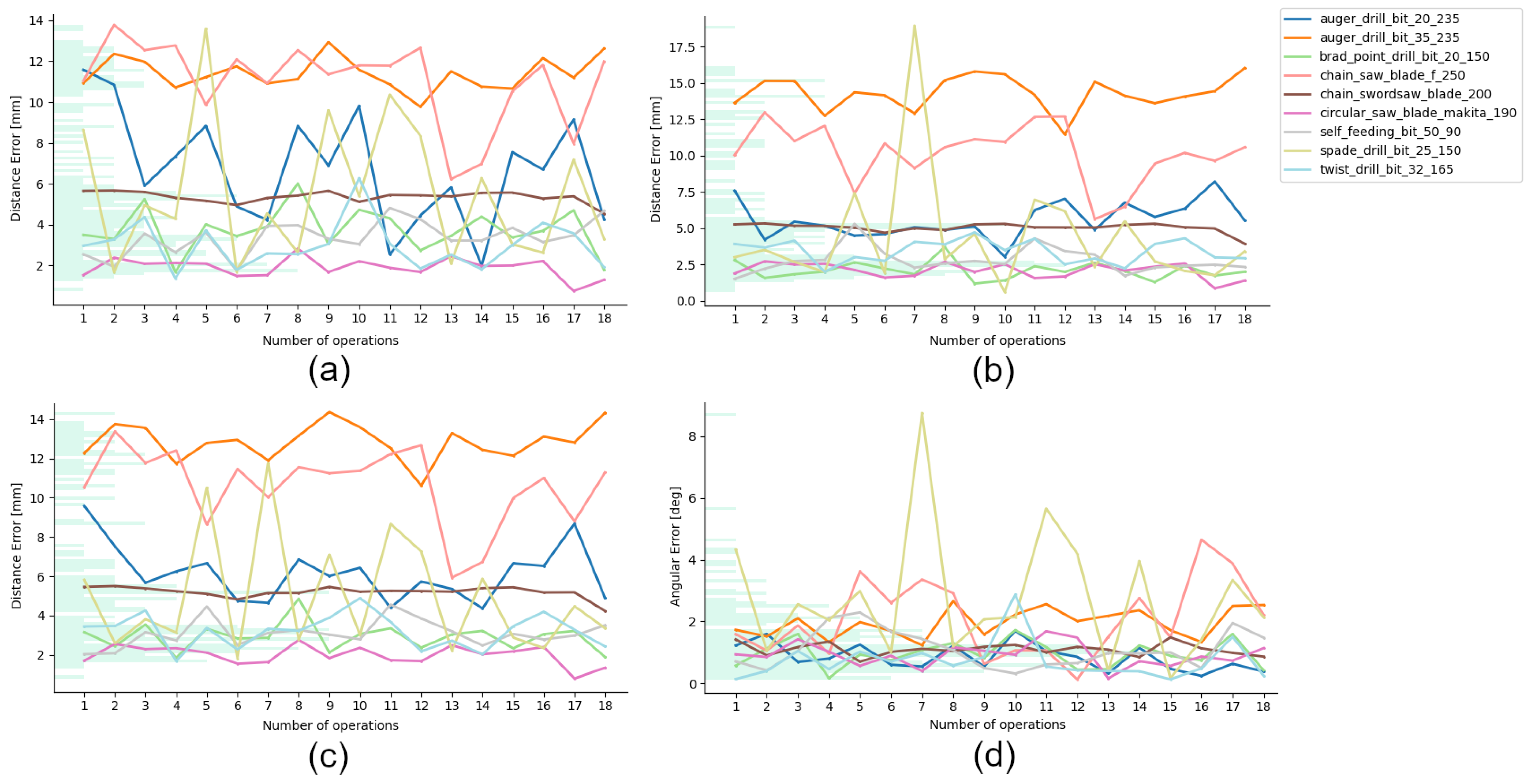
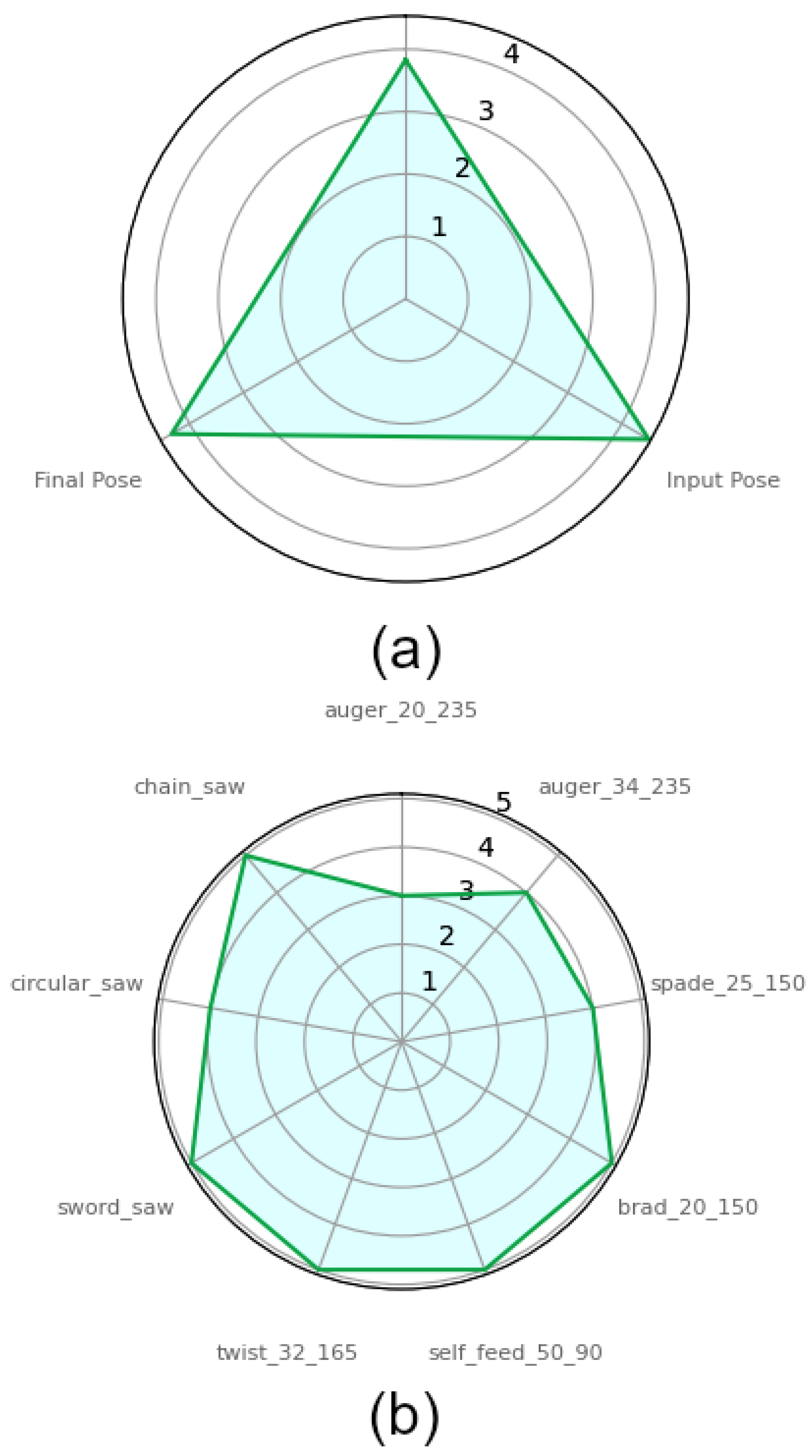
3.2. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TTool | TimberTool |
| AEC | Architecture engineering and Construction |
| AR | Augmented reality |
| 6DoF | Six degrees of freedom |
| HMD | Head-mounted Display |
| GT | Ground truth |
| SfM | Structure from motion |
| PnP | Perspective-n-points |
| RANSAC | Random sample consensus |
| UX | User experience |
| CNC | Computer numerical control manufacturing |
| SLAM | Simultaneous localization and mapping |
References
- Sandy, T.; Giftthaler, M.; Dorfler, K.; Kohler, M.; Buchli, J. Autonomous repositioning and localization of an in situ fabricator. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, Stockholm, Sweden, 16–21 May 2016. [Google Scholar] [CrossRef]
- Sandy, T.; Buchli, J. Object-Based Visual-Inertial Tracking for Additive Fabrication. IEEE Robot. Autom. Lett. 2018, 3, 1370–1377. [Google Scholar] [CrossRef]
- Mitterberger, D.; Dörfler, K.; Sandy, T.; Salveridou, F.; Hutter, M.; Gramazio, F.; Kohler, M. Augmented bricklaying. Constr. Robot. 2020, 4, 151–161. [Google Scholar] [CrossRef]
- Kriechling, P.; Roner, S.; Liebmann, F.; Casari, F.; Fürnstahl, P.; Wieser, K. Augmented reality for base plate component placement in reverse total shoulder arthroplasty: A feasibility study. Arch. Orthop. Trauma Surg. 2020, 141, 1447–1453. [Google Scholar] [CrossRef]
- Cartucho, J.; Wang, C.; Huang, B.; Elson, D.S.; Darzi, A.; Giannarou, S. An enhanced marker pattern that achieves improved accuracy in surgical tool tracking. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2021, 10, 400–408. [Google Scholar] [CrossRef]
- Sin, M.; Cho, J.H.; Lee, H.; Kim, K.; Woo, H.S.; Park, J.M. Development of a Real-Time 6-DOF Motion-Tracking System for Robotic Computer-Assisted Implant Surgery. Sensors 2023, 23, 2450. [Google Scholar] [CrossRef]
- Hein, J.; Cavalcanti, N.; Suter, D.; Zingg, L.; Carrillo, F.; Farshad, M.; Pollefeys, M.; Navab, N.; Fürnstahl, P. Next-generation Surgical Navigation: Multi-view Marker-less 6DoF Pose Estimation of Surgical Instruments. arXiv 2023, arXiv:2305.03535. [Google Scholar] [CrossRef]
- Settimi, A.; Gamerro, J.; Weinand, Y. Augmented-reality-assisted timber drilling with smart retrofitted tools. Autom. Constr. 2022, 139, 104272. [Google Scholar] [CrossRef]
- Kriechling, P.; Loucas, R.; Loucas, M.; Casari, F.; Fürnstahl, P.; Wieser, K. Augmented reality through head-mounted display for navigation of baseplate component placement in reverse total shoulder arthroplasty: A cadaveric study. Arch. Orthop. Trauma Surg. 2021, 143, 169–175. [Google Scholar] [CrossRef] [PubMed]
- Hasegawa, M.; Naito, Y.; Tone, S.; Sudo, A. Accuracy of augmented reality with computed tomography-based navigation in total hip arthroplasty. J. Orthop. Surg. Res. 2023, 18, 662. [Google Scholar] [CrossRef]
- Wu, P.C.; Wang, R.; Kin, K.; Twigg, C.; Han, S.; Yang, M.H.; Chien, S.Y. DodecaPen: Accurate 6DoF Tracking of a Passive Stylus. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, Quebec City, QC, Canada, 22–25 October 2017. [Google Scholar] [CrossRef]
- Tsukada, S.; Ogawa, H.; Nishino, M.; Kurosaka, K.; Hirasawa, N. Augmented reality-based navigation system applied to tibial bone resection in total knee arthroplasty. J. Exp. Orthop. 2019, 6, 44. [Google Scholar] [CrossRef]
- Tsukada, S.; Ogawa, H.; Kurosaka, K.; Saito, M.; Nishino, M.; Hirasawa, N. Augmented reality-aided unicompartmental knee arthroplasty. J. Exp. Orthop. 2022, 9, 88. [Google Scholar] [CrossRef]
- Zhang, L.; Ye, M.; Chan, P.L.; Yang, G.Z. Real-time surgical tool tracking and pose estimation using a hybrid cylindrical marker. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 921–930. [Google Scholar] [CrossRef]
- Gadwe, A.; Ren, H. Real-Time 6DOF Pose Estimation of Endoscopic Instruments Using Printable Markers. IEEE Sensors J. 2019, 19, 2338–2346. [Google Scholar] [CrossRef]
- Harris, C.; Stennett, C. RAPID—A video rate object tracker. In Proceedings of the British Machine Vision Conference, Oxford, UK, 1 September 1990. [Google Scholar] [CrossRef]
- Drummond, T.; Cipolla, R. Real-time visual tracking of complex structures. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 932–946. [Google Scholar] [CrossRef]
- Wang, B.; Zhong, F.; Qin, X. Robust edge-based 3D object tracking with direction-based pose validation. Multimed. Tools Appl. 2018, 78, 12307–12331. [Google Scholar] [CrossRef]
- Zhong, L.; Lu, M.; Zhang, L. A Direct 3D Object Tracking Method Based on Dynamic Textured Model Rendering and Extended Dense Feature Fields. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2302–2315. [Google Scholar] [CrossRef]
- Huang, H.; Zhong, F.; Sun, Y.; Qin, X. An Occlusion-aware Edge-Based Method for Monocular 3D Object Tracking using Edge Confidence. Comput. Graph. Forum 2020, 39, 399–409. [Google Scholar] [CrossRef]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar] [CrossRef]
- Simpsi, A.; Roggerini, M.; Cannici, M.; Matteucci, M. 6 DoF Pose Regression via Differentiable Rendering. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2022; pp. 645–656. [Google Scholar] [CrossRef]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. Int. J. Comput. Vis. 2019, 128, 657–678. [Google Scholar] [CrossRef]
- Xu, Y.; Lin, K.Y.; Zhang, G.; Wang, X.; Li, H. RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Palazzi, A.; Bergamini, L.; Calderara, S.; Cucchiara, R. End-to-End 6-DoF Object Pose Estimation Through Differentiable Rasterization. In Computer Vision—ECCV 2018 Workshops; Springer: Berlin/Heidelberg, Germany, 2019; pp. 702–715. [Google Scholar] [CrossRef]
- Park, K.; Mousavian, A.; Xiang, Y.; Fox, D. LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation, 2019. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Bukschat, Y.; Vetter, M. EfficientPose: An efficient, accurate and scalable end-to-end 6D multi object pose estimation approach. arXiv 2020, arXiv:2011.04307. [Google Scholar] [CrossRef]
- Wang, G.; Manhardt, F.; Tombari, F.; Ji, X. GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Di, Y.; Manhardt, F.; Wang, G.; Ji, X.; Navab, N.; Tombari, F. SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Peng, S.; Zhou, X.; Liu, Y.; Lin, H.; Huang, Q.; Bao, H. PVNet: Pixel-Wise Voting Network for 6DoF Object Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3212–3223. [Google Scholar] [CrossRef] [PubMed]
- Zakharov, S.; Shugurov, I.; Ilic, S. DPOD: 6D Pose Object Detector and Refiner. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Chen, B.; Chin, T.J.; Klimavicius, M. Occlusion-Robust Object Pose Estimation with Holistic Representation. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar] [CrossRef]
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects. arXiv 2018, arXiv:1809.10790. [Google Scholar] [CrossRef]
- Tjaden, H.; Schwanecke, U.; Schomer, E.; Cremers, D. A Region-Based Gauss-Newton Approach to Real-Time Monocular Multiple Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1797–1812. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, B.; Zhu, S.; Cao, X.; Zhong, F.; Chen, W.; Li, T.; Gu, J.; Qin, X. BCOT: A Markerless High-Precision 3D Object Tracking Benchmark. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Wu, P.C.; Lee, Y.Y.; Tseng, H.Y.; Ho, H.I.; Yang, M.H.; Chien, S.Y. [POSTER] A Benchmark Dataset for 6DoF Object Pose Tracking. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR-Adjunct), Nantes, France, 9–13 October 2017. [Google Scholar] [CrossRef]
- De Roovere, P.; Moonen, S.; Michiels, N.; Wyffels, F. Dataset of Industrial Metal Objects. arXiv 2022, arXiv:2208.04052. [Google Scholar] [CrossRef]
- Settimi, A.; Naravich; Gamerro, J.; Weinand, Y. TTool-dataset, Version v36; CERN: Genewa, Switzerland, 2023. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the CVPR09, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef]
- Aymanns, F.; Zholmagambetova, N.; Settimi, A. ibois-epfl/TTool-ai: V1.0.1: First TTool-AI Release; CERN: Genewa, Switzerland, 2024. [Google Scholar] [CrossRef]
- Settimi, A.; Naravich, C.; Nazgul, Z. Software of TTool: A Supervised AI-Assisted Visual Pose Detector for AR Wood-Working; CERN: Genewa, Switzerland, 2024. [Google Scholar] [CrossRef]
- Danielsson, O.; Syberfeldt, A.; Brewster, R.; Wang, L. Assessing Instructions in Augmented Reality for Human-robot Collaborative Assembly by Using Demonstrators. Procedia CIRP 2017, 63, 89–94. [Google Scholar] [CrossRef]
- Aromaa, S.; Frangakis, N.; Tedone, D.; Viitaniemi, J.; Aaltonen, I. Digital Human Models in Human Factors and Ergonomics Evaluation of Gesture Interfaces. Proc. Acm. Hum. Interact. 2018, 2, 1–14. [Google Scholar] [CrossRef]
- Kildal, J.; Martín, M.; Ipiña, I.; Maurtua, I. Empowering assembly workers with cognitive disabilities by working with collaborative robots: A study to capture design requirements. Procedia CIRP 2019, 81, 797–802. [Google Scholar] [CrossRef]
- Gutierrez, L.E.; Betts, M.M.; Wightman, P.; Salazar, A.; Jabba, D.; Nieto, W. Characterization of Quality Attributes to Evaluate the User Experience in Augmented Reality. IEEE Access 2022, 10, 112639–112656. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development ofNASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. In Human Mental Workload; Elsevier: Amsterdam, The Netherlands, 1988; pp. 139–183. [Google Scholar] [CrossRef]
- Benligiray, B.; Topal, C.; Akinlar, C. STag: A stable fiducial marker system. Image Vis. Comput. 2019, 89, 158–169. [Google Scholar] [CrossRef]
- Bergamasco, F.; Albarelli, A.; Rodola, E.; Torsello, A. RUNE-Tag: A high accuracy fiducial marker with strong occlusion resilience. In Proceedings of the CVPR, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar] [CrossRef]
- Bergamasco, F.; Albarelli, A.; Cosmo, L.; Rodola, E.; Torsello, A. An Accurate and Robust Artificial Marker Based on Cyclic Codes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2359–2373. [Google Scholar] [CrossRef]
- Kalaitzakis, M.; Cain, B.; Carroll, S.; Ambrosi, A.; Whitehead, C.; Vitzilaios, N. Fiducial Markers for Pose Estimation. J. Intell. Robot. Syst. 2021, 101, 71. [Google Scholar] [CrossRef]
- Cornut, O. Dear ImGui: A Bloat-Free Graphical User Interface Library for C++. 2023. Available online: https://github.com/ocornut/imgui (accessed on 2 February 2023).
- Settimi, A. TTool: Evaluation Raw Data and Results, Version v1.0.0; CERN: Genewa, Switzerland, 2024. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool Name (-) | Number of Operations (-) | Mean Rotation Error * (°) | Mean Position Error ** (mm) |
|---|---|---|---|
| Drill auger ⌀20 | 18 | 0.85 ± 0.42 | 6.17 ± 1.38 |
| Drill spade ⌀25 | 18 | 2.74 ± 2.04 | 4.97 ± 2.91 |
| Drill auger ⌀35 | 18 | 1.96 ± 0.45 | 12.85 ± 0.91 |
| Drill brad point ⌀20 | 18 | 0.95 ± 0.43 | 2.92 ± 0.69 |
| Drill twist ⌀32 | 18 | 0.73 ± 0.62 | 3.21 ± 0.83 |
| Drill self-feeding ⌀50 | 18 | 1.09 ± 0.59 | 3.09 ± 0.67 |
| Circular sawblade | 18 | 0.92 ± 0.37 | 1.99 ± 0.48 |
| Sword sawblade | 18 | 1.1 ± 0.2 | 5.2 ± 0.28 |
| Chain sawblade | 18 | 2.08 ± 1.21 | 10.61 ± 1.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Settimi, A.; Chutisilp, N.; Aymanns, F.; Gamerro, J.; Weinand, Y. TTool: A Supervised Artificial Intelligence-Assisted Visual Pose Detector for Tool Heads in Augmented Reality Woodworking. Appl. Sci. 2024, 14, 3011. https://doi.org/10.3390/app14073011
Settimi A, Chutisilp N, Aymanns F, Gamerro J, Weinand Y. TTool: A Supervised Artificial Intelligence-Assisted Visual Pose Detector for Tool Heads in Augmented Reality Woodworking. Applied Sciences. 2024; 14(7):3011. https://doi.org/10.3390/app14073011
Chicago/Turabian StyleSettimi, Andrea, Naravich Chutisilp, Florian Aymanns, Julien Gamerro, and Yves Weinand. 2024. "TTool: A Supervised Artificial Intelligence-Assisted Visual Pose Detector for Tool Heads in Augmented Reality Woodworking" Applied Sciences 14, no. 7: 3011. https://doi.org/10.3390/app14073011