
LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models
1
Key Laboratory of Speech Acoustics and Content Understanding, Institute of Acoustic, Chinese Academy of Sciences, No. 21 North 4th Ring Road, Haidian District, Beijing 100190, China
2
University of Chinese Academy of Sciences, Beijing 101408, China
3
Xinjiang Laboratory of Minority Speech and Language Information Processing, Xinjiang Technical Institute of Physics and Chemistry, Chinese Academy of Sciences, 40-1 South Beijing Road Urumqi, Urumqi 830011, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(3), 1587; https://doi.org/10.3390/app13031587
Submission received: 12 December 2022
/
Revised: 29 December 2022
/
Accepted: 3 January 2023
/
Published: 26 January 2023
(This article belongs to the Special Issue Audio, Speech and Language Processing)
Abstract
:Recently end-to-end (E2E) automatic speech recognition (ASR) models have achieved promising performance. However, existing models tend to adopt increasing model sizes and suffer from expensive resource consumption for real-world applications. To compress E2E ASR models and obtain smaller model sizes, we propose a comprehensive compression platform named LWMD (light-weight model designing), which consists of two essential parts: a light-weight architecture search (LWAS) framework and a differentiable structured pruning (DSP) algorithm. On the one hand, the LWAS framework adopts the neural architecture search (NAS) technique to automatically search light-weight architectures for E2E ASR models. By integrating different architecture topologies of existing models together, LWAS designs a topology-fused search space. Furthermore, combined with the E2E ASR training criterion, LWAS develops a resource-aware search algorithm to select light-weight architectures from the search space. On the other hand, given the searched architectures, the DSP algorithm performs structured pruning to reduce parameter numbers further. With a Gumbel re-parameter trick, DSP builds a stronger correlation between the pruning criterion and the model performance than conventional pruning methods. And an attention-similarity loss function is further developed for better performance. On two mandarin datasets, Aishell-1 and HKUST, the compression results are well evaluated and analyzed to demonstrate the effectiveness of the LWMD platform.
1. Introduction
Automatic speech recognition (ASR) transcribes human speech into corresponding transcripts, and it has been widely applied in the real world. After being processed by voice activity detection modules [1,2,3], target speeches will be fed into the ASR systems. Early hybrid ASR systems consist of an acoustic model, a language model and a pronunciation lexicon map, all of which are designed manually and optimized separately. Such hybrid systems result in a cumbersome technique stack and heavily rely on the prior knowledge of the target language, leading to an expensive training cost.
In recent years, end-to-end (E2E) ASR systems have yielded state-of-the-art (SOTA) performance in many ASR tasks, which can integrate the components of hybrid ASR systems into one neural network. And E2E ASR systems have become a more popular alternative to hybrid systems since more simply training pipelines and better performances [4,5,6]. The connectionist temporal classification (CTC) framework [7] and the attention-based encoder-decoder (AED) framework [8] are two popular E2E ASR frameworks in existing works. The CTC framework consists of an acoustic encoder responsible for extracting high-level acoustic representations from the input speeches and a CTC classifier that predicts the output sequence with the CTC criterion. And the AED framework consists of an acoustic encoder and an attention-based decoder that predicts the output sequence in an auto-regressive manner. Based on CTC and AED frameworks, conventional encoders/decoders are usually built by stacking identical blocks, and the multi-headed attention (MHA) based Transformer is the most popular block architecture in existing works [9], which can capture global contextual information effectively with the MHA mechanism. Recently convolution neural network (CNN) also gains increasing attention in building encoders for its advantage in extracting local acoustic information [10].
Even though existing works have achieved promising performance for E2E ASR tasks, most of them tend to adopt large models and ignore resource consumption, which leads to expensive memory and computation costs for real-world applications. There have existed several works that can reduce the resource consumption of neural networks. Refs. [11,12,13] design light-weight architectures on top of Transformer for fewer parameters. Refs. [14,15,16] propose to reduce model parameter numbers with structural pruning based on fixed architectures. Considering the tensor operation is the basic computation in neural networks, several works employ the low-rank decomposition of tensors to reduce the parameter complexity of neural networks [17,18]. And the data low-bit quantization also can reduce model size and computation costs by relieving resource consumption of each parameter, which is widely employ in model compression [19,20,21,22]. Even though these works can indeed reduce model parameter numbers or FLOPs by a certain amount, a non-negligible problem is that most of existing light-weight architectures and structural pruning methods can hardly maintain the same performance with the baseline with a significant parameter reduction.
In order to reduce resource consumption and obtain more light-weight E2E ASR models while maintaining excellent performance, we propose the light-weight model designing (LWMD) platform. LWMD consists of a light-weight architecture searching (LWAS) framework and a differentiable structural pruning (DSP) algorithm. The LWAS framework employs the neural architecture search (NAS) technique to search architectures with small parameter and FLOPs costs, and the DSP framework can further prune searched architectures for fewer resource consumptions. On the one hand, the LWAS framework designs a topology-fused search space to cover many existing human-designed architectures that proved to be effective and develop a resource-aware differentiable search algorithm to select light-weight architectures from the search space based on popular differentiable search algorithms [23,24]. On the other hand, the DSP algorithm proposes a differentiable pruning criterion instead of conventional magnitude-aware criteria to build a stronger correlation between the pruning criterion and the model performance, and an attention-similarity loss function is specially developed for the MHA module of E2E ASR models to get better pruning performance. Moreover, since LWMD only makes modifications to the model architecture, it is orthogonal to some other compression techniques (e.g. quantization) and can be easily combined with them. To summarize, the contributions of this paper can be described as follows:
- LWMD platform. In this paper, we propose the LWMD platform to design light-weight E2E ASR models, which consists of one LWAS framework to search light-weight architectures and one DSP algorithm to prune further searched architectures.
- The LWAS framework. By incorporating different topologies together, LWAS designs one topology-fused search space that can cover many human-designed architectures and develops a resource-aware differentiable search algorithm to select light-weight architectures from the search space.
- The DSP algorithm. With the proposed differentiable pruning criterion, DSP can build a stronger correlation between the pruning criterion and the model performance. An additional attention-similarity loss function is specially developed for MHA modules to get better pruning performance.
- Extensive experiments demonstrate the effectiveness of LWMD in compressing E2E ASR models. More ablation and exploration explain the contributions of the LWAS framework and the DSP algorithm.
2. Related Works
2.1. E2E ASR Models
There exist two popular types of E2E ASR frameworks: CTC and AED. [7] first proposes the CTC framework, which consists of an acoustic encoder and a CTC classifier. The acoustic encoder is responsible for extracting contextual information from the input speeches and generating a high-level acoustic representation to be fed into the CTC classifier, and the CTC classifier is a softmax network that is trained with the CTC criterion. Even though there have been many improvements on top of the CTC framework [25,26], the conditional independent assumption [7] limits the ability of CTC to capture linguistic information, which results in an unsatisfying performance in applications.
The AED framework is originally proposed for sequence-to-sequence modeling [27]. Considering ASR is also a sequence-to-sequence task, [28,29] propose to apply the AED framework in E2E ASR tasks. The AED framework is composed of an acoustic encoder and an attention-based decoder, where the encoder will feed the high-level acoustic representation into the decoder to generate the output sequence in an auto-regressive (AR) manner. Such an AR decoding manner helps to break the conditional independent assumption in CTC and obtain a more promising performance. However, the AED framework needs more parameters and FLOPs meanwhile.
Based on the CTC and LAS framework, there have existed various encoder and decoder architectures in existing works. Early works tend to employ RNN-based architectures for their sequence modeling capabilities [27,30]. More recently, the Transformer network is introduced for E2E ASR [8,9], which adopts the multi-headed attention (MHA) mechanism. The advantage of Transformer is two-fold: The MHA mechanism allows a more direct way to extract global contextual information across the whole sequence, which results in a better performance than RNN. Also, since most operations in Transformer can be calculated in parallel, Transformer provides a faster training and inference speed than RNN. Therefore, the Transformer encoder and decoder have become the most popular choices in E2E ASR.
Existing Transformer encoders or decoders are built by stacking identical blocks, and each block is composed of the MHA module and the FFN module. Considering CNN has a strong advantage in capturing local information, there have been several works that introduce the CNN module into Transformer and achieve promising performance [10,11,12].
2.2. Model Compression
There have been many works that propose to compress E2E ASR models. In general, existing works can be divided as: light-weight architecture design, model parameter pruning, data quantization and some other methods. And methods of different categories are usually orthogonal, which means they can easily be combined with each other.
Light-weight Architecture Design. Light-weight architecture design aims at creating a base light-weight architecture itself from a pool of candidates. LightConv [11] and LiteTransformer [12] design light-weight Transformer variants, [13] propose to search light-weight encoder architectures with the help of NAS automatically.
Model Pruning. Based on the designed architectures, model pruning can further remove redundant parameters of fixed architectures, and unstructured pruning and structured pruning are two major types of pruning. Even though unstructured pruning can effectively reduce model sizes [14,15], it usually results in a negligible improvement in runtime memory or speed due to irregular pruning results. Structured pruning focuses on pruning unimportant structured blocks of weights [16,31], which are friendly to real-world implementations and can indeed improve runtime memory or speed. And the weight magnitude [14] is the most commonly-used pruning criterion in existing methods.
3. The Proposed Method
The proposed compression platform consists of one light-weight architecture search framework named LWAS and one structured pruning algorithm named DSP.
3.1. The LWAS Framework
Inspired by the success of NAS methods, we propose the LWAS framework to design light-weight architectures for E2E ASR models. LWAS first designs a topology-fused search space to provide adequate candidate architectures and then develops a resource-aware search algorithm to select light-weight architectures from the search space. Combined with conventional E2E ASR model training, LWAS employs two stages to design light-weight architectures: a search stage and a retraining stage. In the search stage, LWAS search a proper light-weight architecture, and in the retraining stage, the searched architecture is retrained in the same way as training human-design architectures.
3.1.1. Differentiable Architecture Search
Considering the efficiency superiority, LWAS follows the differentiable NAS methods, where the discrete search space is relaxed into continuous with a weighted summation as shown in
where is the weight of the i-th operation in the operation set O and is the mixed operation.
The weight is generated by one re-parameterization trick and is the corresponding architecture parameter for . And in this paper, LWAS employ the Gumbel-Softmax [24] re-parameterization trick:
where is the Gumbel random variant, is a uniform random variant, and is the temperature of Softmax. After relaxing the search space, the mixed output of candidate architectures and the loss can be obtained, on top of which the gradient descent can be applied to optimize the architecture parameter since the loss is differentiable w.r.t. to . And in this way, light-weight architectures in expectation will be searched by learning .
3.1.2. The Topology-Fused Search Space
Figure 1 illustrates the search space backbone of LWAS, which also contains an acoustic encoder and an attention-based decoder. By adjusting the encoder output target, the search space can support both the architecture search of the CTC and AED frameworks.
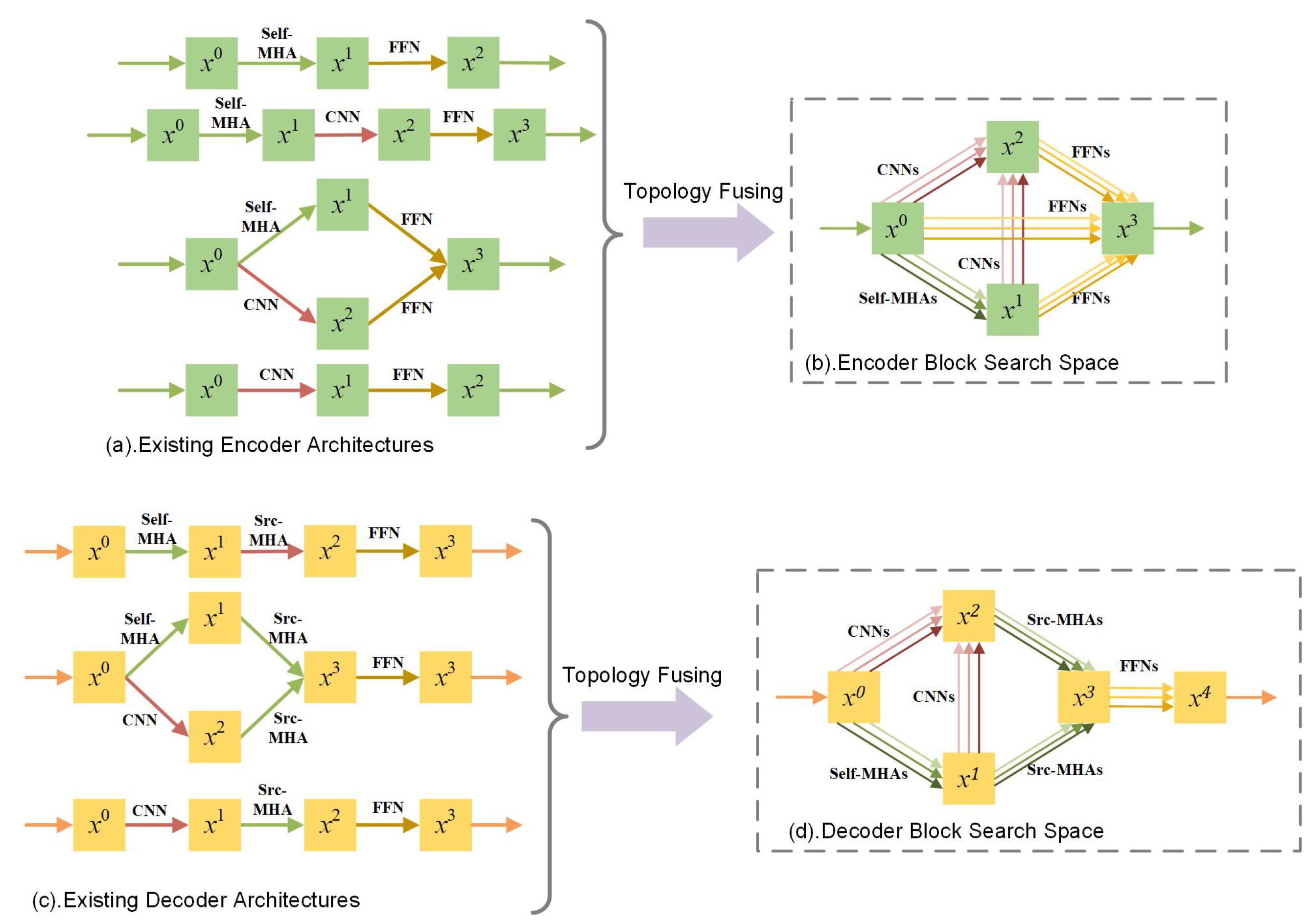
As mentioned above, there have existed several human-designed architectures that have different advantages in performance or resources, as shown in Figure 2a,c. To integrate the advantages of different existing architectures, we propose fusing the topologies of these architectures into the encoder/decoder block search space, i.e., the topology-fused search space, as shown in Figure 2b,d. Drawing on literature methods, we introduce three kinds of edges into the search space, which correspond to MHA, CNN and FFN modules respectively and allow optional topology connections between them. In this way, the architecture topologies of many existing works can be covered in our search space, e.g., in the encoder search space, Transformer , Conformer , LiteTransformer , and LightConv can be obtained. Moreover, apart from these human-designed architectures, more brand-new architecture topologies also can be obtained in the search space. On top of fused topologies, we provide a set of candidate operations for each edge to allow the potential of different operation combinations. The MHA operations own flexible head numbers, e.g., 4, 8, 16, denoted as MHA4, MHA8, and MHA16. A set of CNN operations with diverse kernel sizes are provided, e.g., 7, 15, 31, denoted as CNN7, CNN15, CNN31. The FFN operations have various hidden dimensions, e.g., 512, 1024, 2048, denoted as FFN512, FFN1024, FFN2048.
Following the paradigm of NAS, the output of each edge is the weighted sum of all candidates and each node can be calculated based on all its predecessors: . Different from the fixed block number of human-designed architectures, LWAS further makes the block number elastic and determines it based on a block number search module, which is achieved on top of the continuous relaxation of block outputs:
where is the final output of the encoder/decoder, N is the maximum number of the encoder/decoder block, refers to the output of the n-th block. And then, for each block of the encoder and decoder, the block architecture will be derived from the corresponding search space in a block-wise way.
3.1.3. The Resource-Aware Search Algorithm
To take both the effectiveness and resource consumption into consideration, we propose a resource regularization for LWAS. Combined with the training criterion of E2E ASR, the search objective function of NAS-SCAE can be described as:
where refers to the performance-related object, e.g., CTC, or CE, is the resource-related regularization, and is a scaling factor. In this paper, we employ parameter numbers and FLOPs of candidate architectures as , which can be obtained with a table-lookup method.
3.2. The DSP Algorithm
The DSP algorithm is further proposed to prune searched architectures of LWAS. Instead of conventional magnitude-aware criteria (e.g., -Norm, -Norm), we propose to prune model parameters with a differentiable pruning criterion. An attention-similarity loss function is proposed specifically for pruning MHA modules.
3.2.1. The Differentiable Pruning Criterion
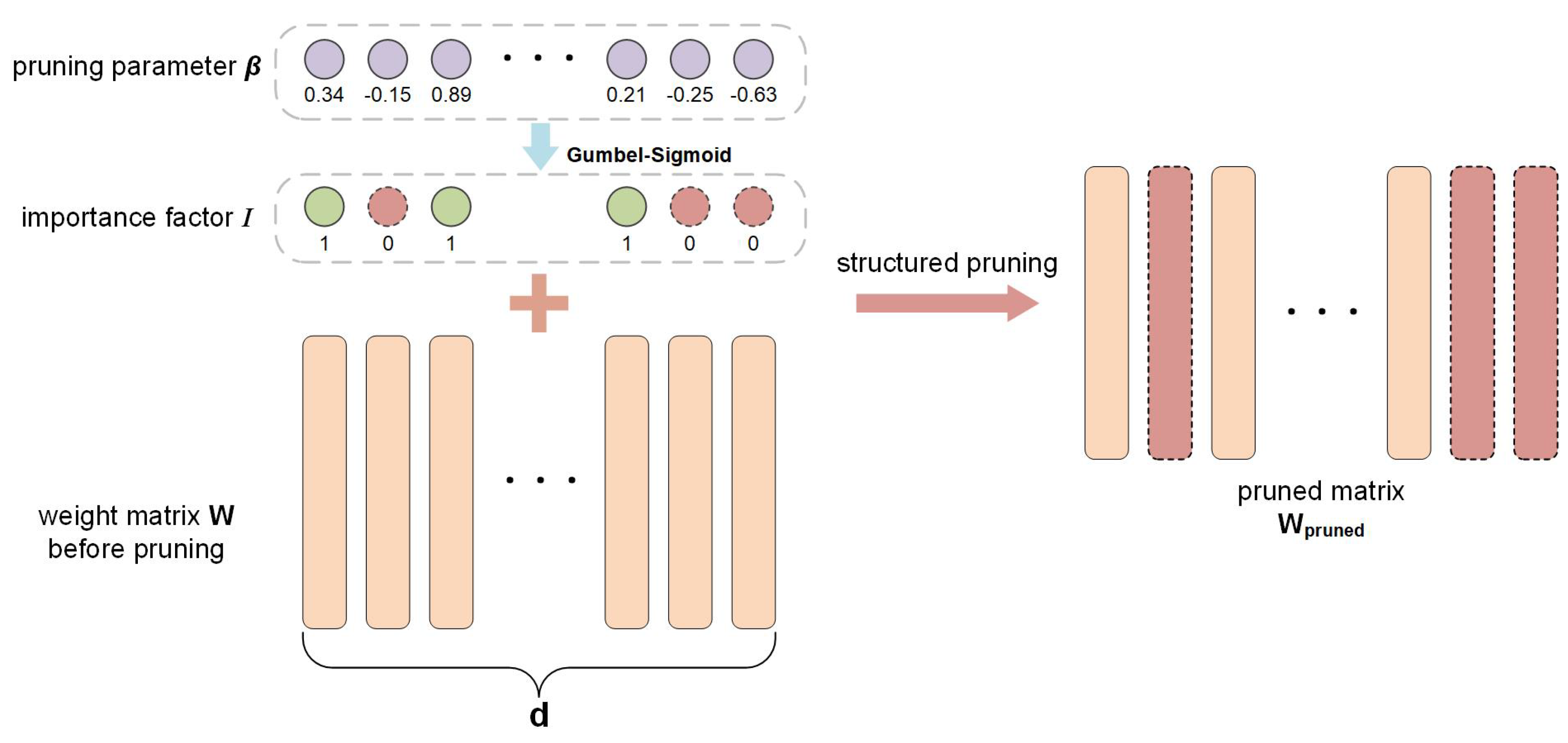
As shown in Figure 3, given a weight matrix , we employ an importance factor to guide the pruning of , where is a one-hot vector, and means the k-th dimension is to be pruned and means the k-th dimension is to be kept:
However, since values of the importance factor is discrete, the gradient can not be calculated directly, which makes it hard to optimize with the back propagation algorithm. Considering the sigmoid activation is a special case of the softmax activation:
we propose a Gumbel-Sigmoid activation on top of the Gumbel-Softmax [24] and relax the importance factor I into soften one-hot with Gumbel-Sigmoid:
where is the corresponding pruning parameter, and are two independent Gumbel random variants, and is a temperature close to zero.
With such a relaxation, I becomes soften one-hot, and the gradient descent can be directly applied to optimize I since the loss function is differentiable to . In other words, the structured pruning is equivalent to learning the pruning parameter . Compared with conventional magnitude-aware criterion, a stronger correlation between our pruning criterion and model performance can be built. And we adopt a bi-level optimization manner to optimize [23]. An additional sparse loss is employed to evaluate the sparsity of the pruned matrix during the bi-level optimization, and it can be calculated by counting the remaining parameter size of W after pruning.
3.2.2. The Attention-Similarity Loss Function
Based on the differentiable pruning criterion, we can directly prune model parameters with the back propagation algorithm by calculating the gradient according to the loss function. Considering the MHA module is an important module in searched architectures that is responsible for extracting global information, we further develop an attention-similarity loss function for MHA modules.
Given Q, K, V as the inputs, each head of the MHA module will calculate an attention weight based on Q and K, and apply the attention weight on V to get a weighted sum as the output. Therefore, the attention weight directly influences the ability to extract global information, and it can be employed to evaluate the quality of the MHA head. In general, a smaller attention weight difference from the well-trained attention head indicates a closer performance of the pruned MHA head. On top of this point, we propose to calculate the attention-similarity loss function as follows:
where refers to the cosine similarity function. refers to the well-trained attention weight and, refers to the pruned attention weight.
When pruning CNN and FFN modules, DSP adopts the standard loss function (e.g., CTC or CE). When pruning MHA modules, DSP will replace the standard loss function with the proposed attention-similarity loss function . In this way, a more accurate gradient can be calculated to optimize .
4. Experiments
4.1. Dataset and Model Implementation
Dataset. In this work, we evaluate the LWMD platform on two widely-used Mandarin datasets: Aishell-1, HKUST and the performance is evaluated by character error rate (CER). We extract acoustic features using 80-dimensional Mel-filterbanks with a 25 ms window and a 10 ms shift and 3-dimensional pitch features are added to the extracted features. We randomly select 5% from the training set as the architecture search evaluation set and the differentiable pruning set.
Baselines. We employ the most commonly-used Transformer and Conformer models as basic baselines. Additionally, LiteTransformer and LightConv are employed as lightweight baselines. It should be noted that Conformer and Transformer only differ in the encoder architectures, while their decoder all follow the Transformer decoder architecture. Further, we employ a random search baseline to compare with LWAS by randomly sampling 5 candidate architectures based on the proposed search space.
Implementation and Testing Details. All the experiments are conducted based on a widely-used E2E ASR toolkit ESPnet [35]. Following the finetuned configuration of ESPnet developers, we set the attention dimension as 256 and the FFN hidden dimension as 2048 with the encoder block number as 12 and the decoder block number as 6 for the Transformer and Conformer baselines. For the LiteTransformer and LightConv encoder, we halve the attention dimension into 128 and the FFN hidden dimension into 1024 with the encoder block number as 18 and the decoder block number as 9. For LWAS, we set and in Figure 1 with the attention dimension as 256. All the CNN modules follow the same settings in [10].
4.2. Performance Comparisons
To demonstrate the effectiveness of LWMD, we conduct experiments under CTC and AED frameworks, and Table 1 and Table 2 provide experiment results. For the AED framework, we set the beam size as 5 for the beam search and find FLOPs of AED frameworks are obviously larger than CTC frameworks.
Among the human-designed baselines, Conformer obtains the best performance, which demonstrates the effectiveness of combing the CNN module with the MHA module. Even though LiteTransformer and LightConv can obtain fewer parameters and FLOPs, there existed obvious performance drops compared with Conformer, which indicates they are not the best light-weight architecture choices for E2E ASR.
Different from human-designed baselines, LWMD result in a better performance-speed trade-off. Compared with the best human-designed baseline, the searched architectures by LWAS can obtain much smaller parameter numbers and FLOPs with comparable performance both on CTC and AED frameworks. Compared with the random search results that adopt the same search space as LWAS, the performance gain of LWAS owns to our search algorithm. To be specific, the LWAS framework can obtain at least 1.77×, 1.79× parameter reduction and 2.18×, 2.49× FLOPs reduction under CTC and AED frameworks, respectively, which demonstrates the effectiveness of LWAS in searching light-weight architectures. Moreover, by incorporating LWAS with DSP, the complete LWMD platform can further reduce parameters and FLOPs of searched architecture by around 20% with a negligible performance drop. To sum up, these comparisons illustrate the promising ability of LWMD as a comprehensive E2E ASR model compression platform.
4.3. Ablation Study
4.3.1. The Proposed Search Space
In Table 3, we conduct ablation studies with reduced search spaces on Aishell-1 by fixing block numbers or the operation on certain edges. We observe obvious performance drops after fixing the MHA or CNN operations, which indicates the necessity of diverse candidate operations for the MHA and CNN modules in maintaining performance. Even though there is no performance drop after fixing the block number or fixing the FFN operations, the resource consumption becomes larger than the complete search space since the FFN module and the block number play an important role in adjusting model sizes. Taking all results into consideration, we can see it is essential for LWAS to search light-weight architectures with diverse operation combinations and elastic block number selection, which demonstrates the contribution of the designed search space.
4.3.2. The DSP Algorithm
To explore the effectiveness of the DSP algorithm, we conducted more ablation studies as shown in Table 4. Besides the result without any pruning, we further provide experiment results with three different pruning algorithms. Random pruning refers to pruning parameters randomly, structured -pruning and structured -pruning refer to pruning parameters according to the -norm or -norm magnitude. Among these pruning methods, the worst performance of random pruning indicates the necessity of a proper pruning algorithm. Even though -pruning and structured -pruning can achieve the same compression ratio with the DSP algorithm, the performance gap demonstrates that the DSP algorithm is a better choice. Further, we compare the results of DSP with/without the attention-similarity loss and observe that the attention-similarity Loss indeed can help to maintain the performance of pruned models. And in Figure 4, we can find the attention-similarity loss results in a more close attention weight with the weight before pruning.
4.4. Low-Bit Quantization
Since LWAS and DSP both focus on designing model architectures, it is orthogonal to the general acceleration techniques, e.g., low-bit quantization. We further employ quantization methods to reduce model sizes without removing parameters. As shown in Table 5, we introduce additional quantization methods into the LWMD platform. With an acceptable performance loss, LWMD can achieve 4.27× parameter reduction with the float16 precision and 8.55× parameter reduction with the int8 precision. In this way, an extreme compression result can be achieved by the LWMD platform.
5. Conclusions
In this paper, we propose a comprehensive platform named LWMD to compress E2E ASR models and save resource consumption for real-world applications. LWMD first propose an LWAS framework to search light-weight architectures for E2E ASR models and then develop a DSP structured pruning algorithm to remove redundant parameters in searched architectures further. Extensive experiments on Aishell-1 and HKUST demonstrate the effectiveness of LWMD in model compression. By combing the LWAS framework and the DSP algorithm, parameter sizes and FLOPs of E2E ASR systems can be reduced significantly without any performance drops. Moreover, we observe that LWMD is friendly to low-bit quantization methods, which can further reduce model sizes. A slight flaw of the proposed platform is that it cannot integrate all kinds of model compression methods together. Therefore, on top of LWMD, we plan to explore more orthogonal model compression methods for future work. Combining tensor decomposition or knowledge distillation with our existing differentiable methods illustrates a promising point.
Author Contributions
Conceptualization, P.Z. and Y.Y.; Methodology, Y.L. and T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the National Key Research and Development Program of China (No.2020AAA0108002) and the Goal-Oriented Project Independently Deployed by Institute of Acoustics, Chinese Academy of Sciences (MBDX202106).
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated during the current study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Korkmaz, Y.; Boyacı, A. Unsupervised and supervised VAD systems using combination of time and frequency domain features. Biomed. Signal Process. Control 2020, 61, 102044. [Google Scholar] [CrossRef]
- Korkmaz, Y.; Boyacı, A. milVAD: A bag-level MNIST modelling of voice activity detection using deep multiple instance learning. Biomed. Signal Process. Control 2022, 74, 103520. [Google Scholar] [CrossRef]
- Korkmaz, Y.; Boyacı, A. Hybrid voice activity detection system based on LSTM and auditory speech features. Biomed. Signal Process. Control 2023, 80, 104408. [Google Scholar] [CrossRef]
- Hori, T.; Watanabe, S.; Hershey, J.R. Joint CTC/attention decoding for end-to-end speech recognition. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 518–529. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; PMLR: New York, NY, USA, 2016; pp. 173–182. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Miao, H.; Cheng, G.; Zhang, P.; Yan, Y. Online hybrid CTC/attention end-to-end automatic speech recognition architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1452–1465. [Google Scholar] [CrossRef]
- Cheng, G.; Miao, H.; Yang, R.; Deng, K.; Yan, Y. ETEH: Unified Attention-Based End-to-End ASR and KWS Architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1360–1373. [Google Scholar] [CrossRef]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay less attention with lightweight and dynamic convolutions. arXiv 2019, arXiv:1901.10430. [Google Scholar]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite transformer with long-short range attention. arXiv 2020, arXiv:2004.11886. [Google Scholar]
- Liu, Y.; Li, T.; Zhang, P.; Yan, Y. NAS-SCAE: Searching Compact Attention-based Encoders For End-to-end Automatic Speech Recognition. Proc. Interspeech 2022, 2022, 1011–1015. [Google Scholar]
- Gordon, M.A.; Duh, K.; Andrews, N. Compressing bert: Studying the effects of weight pruning on transfer learning. arXiv 2020, arXiv:2002.08307. [Google Scholar]
- Mao, Y.; Wang, Y.; Wu, C.; Zhang, C.; Wang, Y.; Yang, Y.; Zhang, Q.; Tong, Y.; Bai, J. Ladabert: Lightweight adaptation of bert through hybrid model compression. arXiv 2020, arXiv:2004.04124. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are sixteen heads really better than one? Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/hash/2c601ad9d2ff9bc8b282670cdd54f69f-Abstract.html (accessed on 11 December 2022).
- Xue, J.; Li, J.; Yu, D.; Seltzer, M.; Gong, Y. Singular value decomposition based low-footprint speaker adaptation and personalization for deep neural network. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6359–6363. [Google Scholar]
- Dudziak, L.; Abdelfattah, M.S.; Vipperla, R.; Laskaridis, S.; Lane, N.D. Shrinkml: End-to-end asr model compression using reinforcement learning. arXiv 2019, arXiv:1907.03540. [Google Scholar]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8bert: Quantized 8bit bert. In Proceedings of the 2019 Fifth IEEE Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; pp. 36–39. [Google Scholar]
- Zadeh, A.H.; Edo, I.; Awad, O.M.; Moshovos, A. Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 811–824. [Google Scholar]
- Bondarenko, Y.; Nagel, M.; Blankevoort, T. Understanding and overcoming the challenges of efficient transformer quantization. arXiv 2021, arXiv:2109.12948. [Google Scholar]
- Bhandare, A.; Sripathi, V.; Karkada, D.; Menon, V.; Choi, S.; Datta, K.; Saletore, V. Efficient 8-bit quantization of transformer neural machine language translation model. arXiv 2019, arXiv:1906.00532. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. arXiv 2018, arXiv:1812.09926. [Google Scholar]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Xue, J.; Zheng, T.; Han, J. Convolutional Grid Long Short-Term Memory Recurrent Neural Network for Automatic Speech Recognition. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 12–15 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 718–726. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Xue, J.; Zheng, T.; Han, J. Exploring attention mechanisms based on summary information for end-to-end automatic speech recognition. Neurocomputing 2021, 465, 514–524. [Google Scholar] [CrossRef]
- Billa, J. Improving LSTM-CTC based ASR performance in domains with limited training data. arXiv 2017, arXiv:1707.00722. [Google Scholar]
- Hou, L.; Huang, Z.; Shang, L.; Jiang, X.; Chen, X.; Liu, Q. Dynabert: Dynamic bert with adaptive width and depth. Adv. Neural Inf. Process. Syst. 2020, 33, 9782–9793. [Google Scholar]
- Tian, S.; Deng, K.; Li, Z.; Ye, L.; Cheng, G.; Li, T.; Yan, Y. Knowledge Distillation For CTC-based Speech Recognition Via Consistent Acoustic Representation Learning. Proc. Interspeech 2022, 2022, 2633–2637. [Google Scholar]
- Winata, G.I.; Cahyawijaya, S.; Lin, Z.; Liu, Z.; Fung, P. Lightweight and efficient end-to-end speech recognition using low-rank transformer. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6144–6148. [Google Scholar]
- Sun, X.; Gao, Z.F.; Lu, Z.Y.; Li, J.; Yan, Y. A model compression method with matrix product operators for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2837–2847. [Google Scholar] [CrossRef]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Ochiai, T. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar]
Figure 1.
The backbone of our proposed search space. The encoder output can be fed into the CTC classifier or the decoder, and in this way, the search space can support the architecture search of the CTC and AED frameworks meanwhile.
Figure 1.
The backbone of our proposed search space. The encoder output can be fed into the CTC classifier or the decoder, and in this way, the search space can support the architecture search of the CTC and AED frameworks meanwhile.

Figure 2.
(a) is four human-designed encoder architectures. (b) is our topology-fused encoder search space. (c) is three human-designed decoder architectures. (d) is our topology-fused decoder search space.
Figure 2.
(a) is four human-designed encoder architectures. (b) is our topology-fused encoder search space. (c) is three human-designed decoder architectures. (d) is our topology-fused decoder search space.

Figure 3.
The differentiable structured pruning criterion. With a Gumbel-Sigmoid activation, DSP employs a soften one-hot vector to guide the pruning. 1 corresponds to remained parameters and 0 corresponds to removed parameters.
Figure 3.
The differentiable structured pruning criterion. With a Gumbel-Sigmoid activation, DSP employs a soften one-hot vector to guide the pruning. 1 corresponds to remained parameters and 0 corresponds to removed parameters.

Figure 4.
Visualized attention weights. (a) is the original attention weight without any pruning, (b) is the attention weight pruned with the attention-similarity loss, and (c) is the attention weight pruned without the attention-similarity loss.
Figure 4.
Visualized attention weights. (a) is the original attention weight without any pruning, (b) is the attention weight pruned with the attention-similarity loss, and (c) is the attention weight pruned without the attention-similarity loss.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Experiment results under the CTC framework. FLOPs refer the averages of processing one-second speech. The best results on each framework are in boldface.
Table 1.
Experiment results under the CTC framework. FLOPs refer the averages of processing one-second speech. The best results on each framework are in boldface.
| Aishell-1 | HKUST | |||||||
|---|---|---|---|---|---|---|---|---|
| #Params (M) | FLOPs (G) | Dev CER | Test CER | #Params (M) | FLOPs (G) | Dev CER | Test CER | |
| Transformer | 18.3 | 0.83 | 5.6 | 6.2 | 18.3 | 0.83 | 22.1 | 22.8 |
| Conformer | 20.9 | 0.96 | 5.4 | 5.9 | 20.9 | 0.96 | 21.6 | 22.2 |
| LiteTransformer | 14.1 | 0.60 | 5.9 | 6.5 | 14.1 | 0.60 | 22.8 | 23.3 |
| LightConv | 11.0 | 0.52 | 6.1 | 6.8 | 11.0 | 0.52 | 23.0 | 23.9 |
| Random Search | 12.4 | 0.56 | 5.7 | 6.4 | 11.9 | 0.54 | 22.5 | 23.2 |
| LWAS | 11.4 | 0.51 | 5.4 | 5.9 | 11.8 | 0.54 | 21.4 | 22.2 |
| LWMD (LWAS + DSP) | 8.5 | 0.39 | 5.4 | 5.9 | 9.4 | 0.44 | 21.5 | 22.4 |
Table 2.
Experiment results under the AED framework. FLOPs refer the averages of processing one-second speech. The best results on each framework are in boldface.
Table 2.
Experiment results under the AED framework. FLOPs refer the averages of processing one-second speech. The best results on each framework are in boldface.
| Aishell-1 | HKUST | |||||||
|---|---|---|---|---|---|---|---|---|
| #Params (M) | FLOPs (G) | Dev CER | Test CER | #Params (M) | FLOPs (G) | Dev CER | Test CER | |
| Transformer | 29.9 | 6.96 | 5.0 | 5.4 | 29.9 | 7.14 | 20.3 | 20.8 |
| Conformer | 32.5 | 7.09 | 4.7 | 5.2 | 32.5 | 7.27 | 19.8 | 20.4 |
| LiteTransformer | 25.0 | 5.72 | 5.2 | 5.7 | 25.0 | 5.87 | 20.7 | 21.3 |
| LightConv | 20.8 | 5.61 | 5.4 | 6.0 | 20.8 | 5.76 | 21.0 | 21.9 |
| Random Search | 19.6 | 3.75 | 5.1 | 5.6 | 19.5 | 4.50 | 21.2 | 22.3 |
| LWAS | 17.7 | 2.81 | 4.7 | 5.2 | 18.1 | 2.90 | 20.0 | 20.4 |
| LWMD (LWAS + DSP) | 13.2 | 2.13 | 4.7 | 5.2 | 14.5 | 2.41 | 20.0 | 20.5 |
Table 3.
Ablation Studies of the search space on Aishell-1. The complete search space is compared with reduced search spaces.
Table 3.
Ablation Studies of the search space on Aishell-1. The complete search space is compared with reduced search spaces.
| Search Space | #Params (M) | FLOPs (G) | Dev CER | Test CER |
|---|---|---|---|---|
| Conformer Baseline | 32.5 | 7.09 | 4.7 | 5.2 |
| Fix MHA as MHA4 | 18.2 | 2.94 | 5.1 | 5.6 |
| Fix CNN as CNN15 | 17.9 | 2.84 | 5.2 | 5.6 |
| Fix FFN as FFN2048 | 23.4 | 4.22 | 4.7 | 5.2 |
| Fix Block Number | 22.3 | 3.95 | 4.7 | 5.2 |
| Complete Search Space | 17.7 | 2.81 | 4.7 | 5.2 |
Table 4.
The ablation studies of pruning algorithms on Aishell-1. For random pruning, structured -pruning and structured -pruning, we manually set the pruning ratio to ensure they have close pruning ratios for a fair comparison.
Table 4.
The ablation studies of pruning algorithms on Aishell-1. For random pruning, structured -pruning and structured -pruning, we manually set the pruning ratio to ensure they have close pruning ratios for a fair comparison.
| Pruning Methods | #Params (M) | FLOPs (G) | Dev CER | Test CER |
|---|---|---|---|---|
| w/o pruning | 17.7 | 2.81 | 4.7 | 5.2 |
| random pruning | 13.2 | 2.13 | 5.2 | 5.8 |
| structured -pruning | 13.2 | 2.13 | 5.0 | 5.6 |
| structured -pruning | 13.2 | 2.15 | 5.0 | 5.5 |
| DSP w/o Attention-similarity Loss | 13.2 | 2.13 | 4.8 | 5.4 |
| DSP with Attention-similarity Loss (Default) | 13.2 | 2.13 | 4.7 | 5.2 |
Table 5.
Exploration results of low bit quantization on the LWMD platform. We try to introduce the float16 precision and the int8 precision into LWMD.
Table 5.
Exploration results of low bit quantization on the LWMD platform. We try to introduce the float16 precision and the int8 precision into LWMD.
| Pruning Methods | #Params (M) | Dev CER | Test CER |
|---|---|---|---|
| Conformer Baseline | 32.5 | 4.7 | 5.2 |
| LWMD (float32) | 13.2 | 4.7 | 5.2 |
| LWMD + float16 | 7.6 | 4.9 | 5.3 |
| LWMD + int8 | 3.8 | 5.2 | 5.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, Y.; Li, T.; Zhang, P.; Yan, Y. LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models. Appl. Sci. 2023, 13, 1587. https://doi.org/10.3390/app13031587
AMA Style
Liu Y, Li T, Zhang P, Yan Y. LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models. Applied Sciences. 2023; 13(3):1587. https://doi.org/10.3390/app13031587
Chicago/Turabian StyleLiu, Yukun, Ta Li, Pengyuan Zhang, and Yonghong Yan. 2023. "LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models" Applied Sciences 13, no. 3: 1587. https://doi.org/10.3390/app13031587
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.