
Human Activity Recognition for Assisted Living Based on Scene Understanding


Department of Computer Engineering, Faculty of Automatic Control and Computer Engineering, “Gheorghe Asachi” Technical University of Iasi, 700050 Iasi, Romania
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(21), 10743; https://doi.org/10.3390/app122110743
Submission received: 20 September 2022
/
Revised: 18 October 2022
/
Accepted: 21 October 2022
/
Published: 24 October 2022
(This article belongs to the Special Issue Computer Vision-Based Intelligent Systems: Challenges and Approaches)
Abstract
:The growing share of the population over the age of 65 is putting pressure on the social health insurance system, especially on institutions that provide long-term care services for the elderly or to people who suffer from chronic diseases or mental disabilities. This pressure can be reduced through the assisted living of the patients, based on an intelligent system for monitoring vital signs and home automation. In this regard, since 2008, the European Commission has financed the development of medical products and services through the ambient assisted living (AAL) program—Ageing Well in the Digital World. The SmartCare Project, which integrates the proposed Computer Vision solution, follows the European strategy on AAL. This paper presents an indoor human activity recognition (HAR) system based on scene understanding. The system consists of a ZED 2 stereo camera and a NVIDIA Jetson AGX processing unit. The recognition of human activity is carried out in two stages: all humans and objects in the frame are detected using a neural network, then the results are fed to a second network for the detection of interactions between humans and objects. The activity score is determined based on the human–object interaction (HOI) detections.
1. Introduction
Technical solutions for ambient assisted living allow continuous monitoring of vital parameters of the elderly and home automation [1,2]. Such solutions for assisted living are particularly important in the context of an accelerated aging European society: it is estimated that by 2060, one in three Europeans will be over 65 years of age, while the ratio of active people to retired people will decrease from 4:1 currently to 2:1 [3]. Moreover, in the coming years, Europe will face more than 2 million vacancies in the health and social care system.
Monitoring the environmental and physiological parameters of elderly people who suffer from chronic diseases or mental disabilities has become a topic of real interest in recent years. Both the scientific community and industry have proposed various assisted living systems for indoor environments.
At the commercial level, countless assistive devices are available, such as those for administering medications, detecting falls, alarm buttons, monitoring vital parameters, as well as complex solutions for recording and tracking environmental parameters [4]. However, the solutions that integrate multiple such devices in assistance applications for autonomy at home have not yet known a commercial spread at the level of end users. Most of the integrative solutions developed so far are prototypes described in the scientific literature [5,6,7,8,9]. The main barrier to building such solutions is that most of these devices come with proprietary applications, use custom communication protocols and do not expose programming interfaces, which makes them impossible to integrate into third-party applications.
The scientific literature provides many examples of complex and innovative systems for monitoring environmental and physiological parameters. For example, Shao et al. [10] determines the values of physiological parameters (respiratory rate, exhaled air flow, heart rate, pulse) using images from a web camera. Marques and Pitarma [11] describe a system dedicated to environmental monitoring of air temperature, humidity, carbon monoxide and luminosity to assist people inside buildings. For this, a microsensor infrastructure is used for data acquisition, as well as Arduino, ESP8266 and XBee for data processing and transmission using Wi-Fi. The recorded data are evaluated to determine the air quality in the rooms, anticipating technical interventions. A system that analyzes the change of temperature in the environment, as well as physiological indices (temperature, breathing rate, electroencephalogram, electrocardiogram, using Japanese medical equipment from Nihonkohden Co.), is proposed in [12]. With this system, the relationships between ambient temperature, comfort sensations, sleepiness and physiological indicators were determined.
Regarding integrated applications for home assistance using ICT, research efforts have focused on formulating solutions based on the combination of technologies specific to smart home digital platforms, IoT, artificial intelligence and cloud computing. The HABITAT platform [6] incorporates these technologies into everyday household objects: an armchair for monitoring sitting posture, a belt for extracting movement information, a wall panel and mobile phone for user interface. An artificial intelligence component is used for the system to react to various specific events, trigger notifications and receive feedback from the user. However, the radio frequency localization used requires the person to wear a tag, the motion monitoring belt can be uncomfortable and difficult to wear for long periods of time. In addition, the system is not easily scalable, reducing to the implementation of a single usage scenario with specific devices. A significant limitation is the specific character of these integrated systems produced to date—they address limited monitoring and application scenarios.
A very relevant research and development topic is addressing the implementation and interoperability issues encountered in the adoption of life assistance technology. In this sense, possible solutions were formulated for managing the integration of devices and aggregating information from them [7,8]. However, the proposed solutions require significant integration efforts or the involvement of device manufacturers in a common standard alignment process. A relevant effort in this sense is represented by ACTIVAGE [9], a pilot project for intelligent living environments with the main goal of building the first European eco-system. It will have nine implementation locations in seven European countries, reusing and scaling public and private IoT platforms. New interfaces necessary for interoperability are being integrated between these platforms that will implement IoT solutions for active and healthy aging on a large scale. The project will deliver AIOTES (AC-TIVAGE IoT Ecosystem Suite), a set of mechanisms, tools and methodologies for interoperability at different levels between IoT platforms and a free working method for providing their semantic interoperability.
A monitoring system designed for a health care environment has the following components: data exchange between devices, data storage, data processing to determine environmental conditions and physiological aspects, data security and confidentiality, as well as data access to them [1,2]. According to Sanchez [13], there are two types of information: unprocessed data from the sensors and context data used to determine behavior patterns or human activity. The context is important because it helps to evaluate environmental conditions and the health of the person monitored. The system must provide a way to represent the environment. Some solutions only have a 2D map [14,15], while others use 3D models [16,17] from which essential information can be extracted (door and window locations, pieces of furniture, gas sources, etc.) and generate positional alerts. In addition to processing sensor data, a monitoring system must integrate communication technologies in order to provide real-time health services that are aligned with the context and the real needs [18]. In an IoT system, nodes containing sensors are used to monitor the user, to collect data which is subsequently sent to a network of nodes.
The pressure put on the health insurance systems by care services for the elderly or people with special needs is increasing. Therefore, an automated system that can assist a person in his environment would be less expensive. Such a system is based on different types of sensors, independent or within a network. L. Malasinghe, N. Ramzan and K. Dahal in [19] review monitoring systems that use different sensors, such as cardiogram sensors for heart rate, sensors for breath measurements, for blood pressure, and for body temperature,. This paper presents a monitoring system for daily activities based on Visual Scene Understanding.
This paper is organized as follows: in Section 2, different approaches for human activity recognition are presented. In Section 3, we will find a short introduction to the SmartCare system, after which we discuss the integration of the HAR module into the project. In this section are also presented the hardware architecture, the monitoring scenarios for various medical conditions and the results on object detection and HOI detection with the selected models. In Section 4, the datasets used for object detection as well as for HOI detection are presented. In Section 5, we shortly present de HAR module architecture, while in Section 6 the design and implementation of the HAR module is presented; a comparison between the tested object detectors in the context of human–object interaction and the use of the HAR results within the SmartCare are also discussed here. Finally, we draw some conclusions in Section 7.
2. Related Work
An approach to recognizing daily activities based on imaging and neural networks is presented by M. Buzzelli, A. Albé and G. Ciocca in [20]. In the first part, the training and testing subsets are defined and the activity groups are decided based on three properties: duration, type and position. Each group is divided into two: by duration of activities, long or short; by type, dangerous or common; and by position, static or mobile. Based on the above classifications, there is a grouping by status, alarming situations and daily activities. The approach has two steps: detect the person using ‘Faster R-CNN’ [21] and then recognize the action by using two neural networks: I3D [22] and DeepHAR [23]. The obtained accuracy is 97% on status activities, 83% on alarming situations and 71% on daily activities.
Another image-based approach is described in [24] and uses depth images and thermal images to maintain confidentiality, as these images do not retain details. The dataset was taken from an elderly person’s home for one month. The defined classes are: the person sleeps, sits on a bed/chair, stands, walks, uses the nightstand and needs assistance from a caretaker. In addition to the six activities, the background was also noted: when the person is not in the room. Having two streams of images, the authors trained two models and decided to merge them into one [25,26]. The deployed models use the ResNet-34 architecture [27], the average accuracy on the six activities and the background is: 94% on thermal images, 93.2% on depth images, 91.8% using early fusion and 95.8% using delayed fusion.
C. Alexandros et al. [28] presents an activity monitoring system using RGB images or data from an RGB-D, which provides 3D information about the objects in the scene. This system can recognize some basic activities: when a person is standing, sitting on a chair/sofa, walking or falling. The system uses RGB images, and the person’s outline is extracted by a background removal algorithm. The system uses a model based on a set of key positions [29] and the most representative body position for each activity class is learned. When the RGB-D sensor data are used, the silhouette of the human body is easier to obtain. The body position is extracted and a generic algorithm is used to select the optimal joints in recognizing activity [30].
In paper [31], the activity monitoring is carried out by means of depth sensors. The images are processed to extract the silhouette and then the human skeleton and its joints. Based on the joints, they compute three features in order to train a hidden Markov model: centroid points, joint distances, and joint magnitude. For each activity, there is a hidden Markov model trained, the obtained results have an accuracy of 84.33%.
V. Vishwakarma, C. Mandal and S. Sural in [32] use a method based on human detection by adaptive background removal and then extract the characteristics by which it will be detected whether a person has fallen. The extracted features are the aspect ratio between the height and the width of the bounding box that fits the person, gradients on X and Y, the fall angle. If the action takes place outside and there are more people, the accuracy is 79%, the sensitivity is 54%, and the specificity is 97%. However, if there is only one person involved, both in outdoor and indoor environments, accuracy, sensitivity, and specificity are 100%.
A different approach in detecting human actions based on videos is presented by Deepmind (Google) in [33,34]. A 700 classes video dataset is used to train the I3D neural network. The model was trained and deployed on a machine with 32 P100 GPUs. The top-1 accuracy on the test set is 57.3%.
A team of researchers from MIT-IBM AI Lab propose a dataset [35,36] of one million short videos for dynamic events which take place over a period of time no longer than three seconds. 339 verbs are associated with over 1000 videos each. Results from three different models are combined resulting in a 31.16% top-1 recognition score.
3. Human Activity Recognition in the SmartCare System
The ICT solution for assisted living proposed in [37] is improving living conditions of the elderly and/or people with chronic disorders through intelligent automation of the environment (home) and monitoring their vital parameters. Home care assistance provides independent living for the categories of people mentioned above. The SmartCare system provides a platform for monitoring, automation, and an alerting protocol in case of life-threatening events. It is a system based on heterogeneous IoT devices which offers access to data services and performs offline analysis using artificial intelligence. The Ambient assisted living system integrates software utilities in order to configure and adapt it to the needs of the beneficiary and make it easily scalable for the designer and the integrator.
To achieve maximum user satisfaction, the SmartCare project [37] is based on a user-centric design that covers all the needs and preferences of the beneficiary, integrator or system administrator.
As described in [37], the ambient assisted living system consists of three main parts:
- Gateway: Implements the communication and interfaces with the installed telemedicine devices, actuators, as well as with the video monitoring component;
- Expert System: Cloud service that implements the intelligent processing of information from the sensor network and other stand-alone components by defining and following predefined monitoring and alerting rules;
- DeveloperUI: Graphical user interface that facilitates the design of solutions for specific home care applications. The patient’s needs differ from case to case, according to the medical conditions.
In Figure 1, a conceptual architecture of the SmartCare system is presented with the components mentioned above. Among the devices layer it is integrated as well the human activity recognition component using video monitoring, sub-system which communicates with the Gateway.
The purpose of HAR is to identify the patient’s life-threatening events such as falls, fainting or immobility, as well as activities which have to be regularly carried out in order to avoid critical situations, for instance people with diabetes have to serve the meal after a schedule and hydrate continuously. Failure to detect the patient for a longer period of time than a predetermined threshold and the detection of specific activities will generate warnings or notification messages to the caretaker.
The device network is composed of sensors belonging to three main categories: vital parameters (heart rate wristband, glucose meter, blood pressure monitor, body thermometer, pulse oximeter, etc.), home automation (smart switch, smart plug, smart lock, panic button, smart lightbulb, etc.) and physical activity (video monitoring and accelerometer—steps, fall, burned calories). Figure 2 illustrates the human activity recognition module within the bigger SmartCare system.
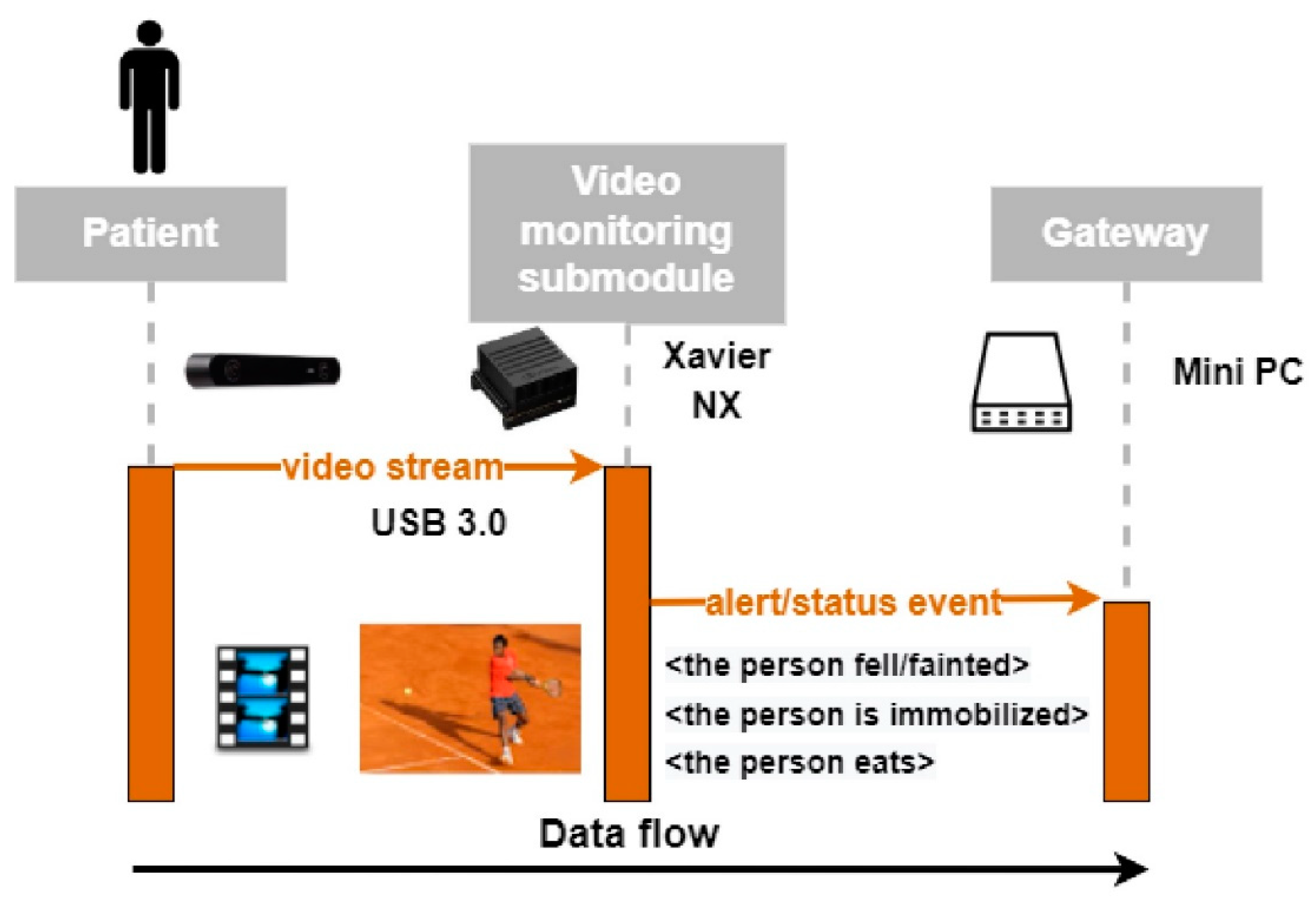
The functional diagram of the system from the perspective of the proposed HAR module is presented in Figure 3: the ZED stereo camera is connected via USB 3.0 to the Jetson unit; the events (activities of interest for the specificity of the monitored person or a life-threatening situation) are sent over MQTT to the Gateway. It is necessary to install the SDK provided in order to make use of all the image post-processing facilities of the ZED sensor. For reasons of modularity but also to relieve the gateway component of the video processing, this task is implemented on a System-on-Chip platform, Nvidia Jetson Xavier AGX. Object detection, human–object interaction detection and activity detection are also performed on Jetson.
3.1. Monitoring Scenarios
In the following three tables are presented the activities that the HAR module is monitoring, according to the specific medical condition of the patient, if any. Table 1 presents the monitoring scenarios for patients with diabetes. For this condition, the focus is on physical activity, the eating schedule and the adequate hydration of the patient. The scenarios for monitoring patients with Alzheimer’s disease are presented in Table 2: due to the condition, the person could do an activity repetitively or might put himself/herself in danger by forgetting various household appliances in operation, such as the oven, the cooker or the tap water. Table 3 summarizes the monitoring scenarios for patients with arthritis for which it is recommended to monitor physical activity and eating habits.
3.2. Object Detection and Human–Object Interaction Detection in HAR
Due to the fact that the HAR system needs to be deployable at the patient’s home on a mobile platform and integrated as a stand-alone sensor, only lightweight models were taken into consideration for SmartCare. Another constraint that must be fulfilled is given by the necessity to detect the interaction of the patient with specific objects of interest (knife, spoon, bottle, oven, chair, etc.); therefore, only solutions based on object detection are suitable. Of all datasets available for human activity recognition used by the solutions presented in Section 2, the ones designed for object detection are the easiest to enhance with new classes. This aspect was also taken into account when the HAR architecture was designed for SmartCare because new classes will be needed in the near future (different type of medicine, wearables such as the insulin pump, fitness wristband, and blood pressure).
Taking into account the limited hardware resources and compatibility restrictions, only the neural networks with a custom architecture for mobile platforms with limited computing power were considered, such as MobileNet v1 and v2 [38,39], Inception [40], or YOLO [41]. The following implementations have been chosen for the four basic architectures:
Jetson Inference [42] is a library written by Nvidia that offers implementations not only for the three neural networks listed above, it provides a wide range of networks for image recognition (ImageNet), object detection (DetectNet), semantic segmentation (SegNet) and pose estimation (PoseNet). The object detection networks are trained on the COCO dataset [44], while the semantic segmentation networks are trained on Cityscapes [45,46], DeepScene [47], Multi-Human [48], Pascal VOC [49] or SUN RGB-D [50].
YOLO v4 and YOLO v4 Tiny [41,43] are not the only open-source network architectures developed by the creators of Darknet [51]. In addition to these, pre-trained models for YOLO v3 [52] or v2 [53] are also available. Just like the Jetson Inference object detector, Darknet uses the COCO dataset.
To understand the context in a scene, we need to recognize how humans interact with objects in the environment. A scene can be further understood by detecting human–object interactions (HOI). Once again, the limited computing power on the used mobile platform restricts us to use the smallest neural network that runs in real time for human–object interaction detection.
In paper [54], the researchers propose a neural network for HOI detection. The model was validated on two public datasets for HOI detection: Verbs in COCO [55] (V-COCO) and Humans Interacting with Common Objects (HICO-DET) [56,57].
We used the V-COCO dataset [55] to evaluate iCAN [54] results for HOI detection. Using the single-thread sequential configuration for the evaluation tests, in Table 4, HOI detection accuracy increases with object detection accuracy. AP is calculated for the Agent (human) and for the Role (object/instrument). Two confidence thresholds were used for the evaluation of HOI detection: 0.5 and 0.2. Gupta Saurabh and Malik Jitendra define in [55] two scenarios for role AP evaluation:
- Scenario 1 (S1): in test cases with missing annotations for role a prediction for agent is correct if the action is correct and the person boxes overlap is >0.5 and the corresponding role is empty. This evaluation scenario is fit for missing roles due to occlusion.
- Scenario 2 (S2): in test cases with missing annotations for role, a prediction for agent is correct if the action is correct and the person boxes overlap is >0.5 (the corresponding role is ignored). This evaluation scenario is fit for cases with roles outside the COCO classes.
The more objects are detected in the scene and the higher their confidence factor is, the more HOIs are detected with a higher confidence. Figure 4 shows the activities detected by iCAN using different object detectors.
In order to evaluate the HOI detector we keep track of some of the most relevant actions: to eat, to drink, to sit on, to stand, to hold an object/instrument, to lay on. A comparison of accuracies of the actions mentioned above using the four selected object detectors is presented in Table 5.
4. Used Datasets for Object Detection and HOI Detection
4.1. Common Objects in Context (COCO)
Microsoft developed the COCO dataset [44]. It contains 91 categories of objects and 328,000 images. The majority of the categories have over 5000 annotated objects. The total count of annotated objects is 2,500,000. Although there are other multi-class datasets, such as ImageNet [56], COCO has many more annotated objects in each category. A dataset with fewer classes but more accurate predictions made by the model is preferred over a dataset with more categories but worst predictions. In addition, the COCO dataset contains an average of approximately 8 annotated objects per image, while ImageNet has only 3 or Pascal VOC 2.3 [49]. The used dataset offers annotations for image classification, object detection, and semantic segmentation.
Because a person can interact with different objects, a relevant statistic in choosing the dataset says that only 10% of images contain objects from a single category, while in Pascal VOC approximately 60% of images contain annotations from a single category.
4.2. Verbs in Common Objects in Context (V-COCO)
V-COCO [55] is a dataset that builds on top of COCO for HOI detection. It splits 10,346 images into: 2.533 for training, 2.867 for validation, and 4.946 for testing. In total, there are 16.199 human instances. The dataset considers 26 different action verbs, for a few verbs it includes two types of attributes: instrument and object, resulting in a total number of 29 action classes.
Divided by the existence of an attribute and its type, the verb classes with the associated attributes are as follows:
- <agent, verb>: walk, smile, run, stand;
- <agent, verb, object>: cut, kick, eat, carry, throw, look, read, hold, catch, hit, point;
- <agent, verb, instrument>: surf, ski, ride, talk on the phone, work on computer, sit, jump, lay, drink, eat, hit, snowboard, skateboard.
In the context of the SmartCare project, we split the V-COCO verb classes into three categories: essential, util, and unnecessary, according to Table 6.
V-COCO has, on average, 1.57 people annotated per image that perform actions: over 7000 images with one annotated person, 2000 with two, 800 with three and the rest with four or more people annotated [55]. Figure 5 illustrates situations in which the person performs multiple actions at the same time.
5. Human Activity Recognition Module Architecture
From the HAR system’s point of view, we have a n-Tier architecture: Zed Camera & Nvidia Jetson, Gateway, System Expert. From the point of view of the application that runs on Nvidia Jetson, we have a multi-level architecture. The hardware architecture is presented in Figure 6. The HAR data flow is presented in Figure 7: the video stream is processed on the Jetson platform, after which an alert is sent when activities of interest are recognized.
The ambient images of the patient are acquired by the ZED 2 stereo camera.
At the software level, the application level runs a multi-layer architecture consisting: the image acquisition and preprocessing layer, the logic layer and the communication layer.
- The first layer acquires images and preprocesses them in order to be fed to the logic layer.
- In the logic layer, two neural networks are used: one for human and object detection and another one for human–object interaction detection. Based on the interactions, the activities which are performed by the monitored patient are determined.
- The communication layer prepares the data and transmits it to the server. The communication between the HAR system and the Gateway is carried out over the MQTT protocol. Based on a voting procedure that takes into consideration other sensor results as well, the Gateway decides when notification alerts are sent to the family or the medical doctor.
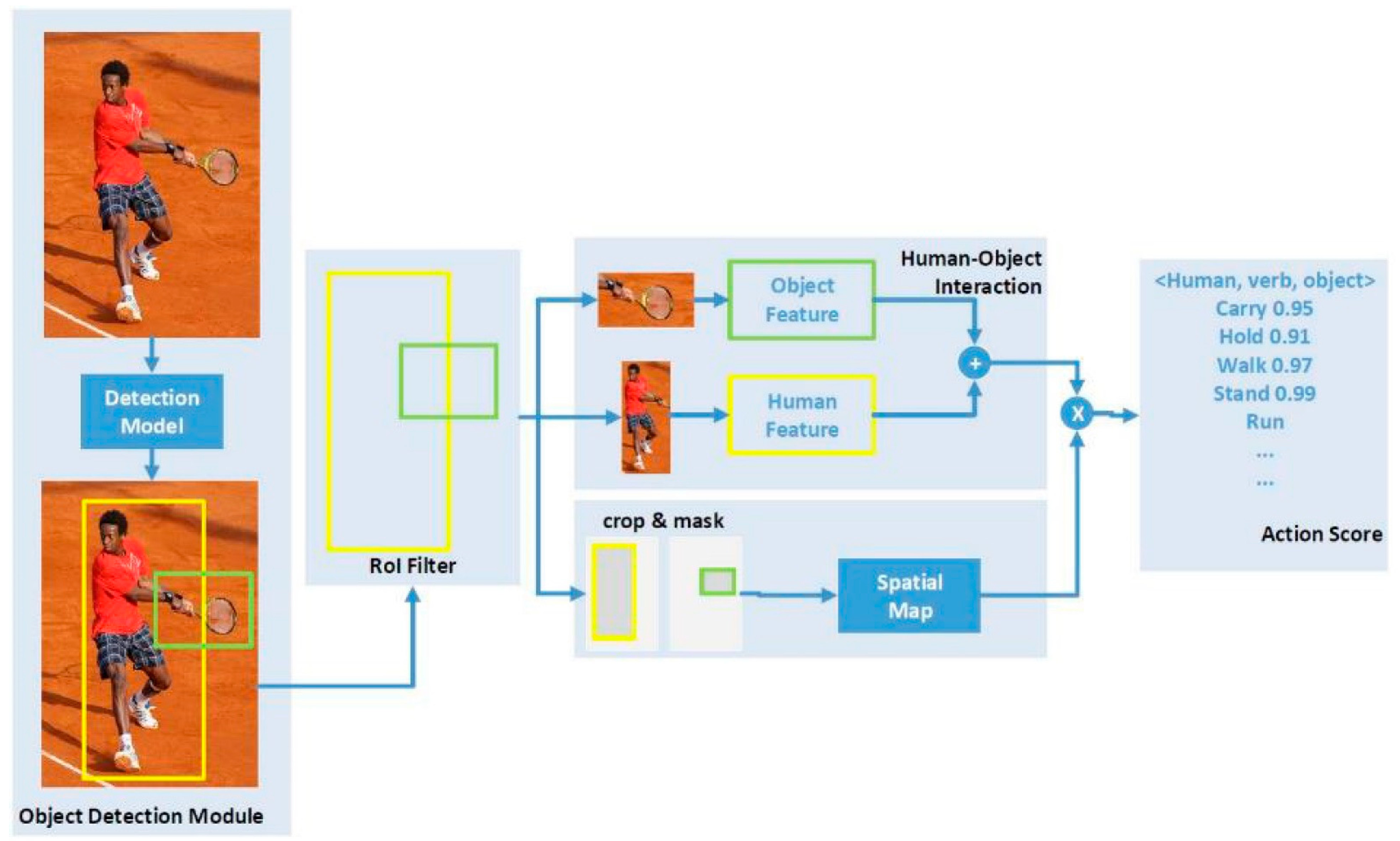
Figure 8 illustrates the proposed pipeline architecture, consisting of two distinct and modular parts: the patient and the environmental objects detection and the detection of the human–object interactions. Based on the interaction between the person and the objects of interest, we can draw conclusions regarding the monitored activities and conditions: falling/fainting, immobility, serving the meal, drinking liquids, etc.
6. Design and Implementation
In this section, we will discuss the following: class diagram, communication between classes, used threads and finally communication with the Gateway-MQTT server.
As presented in the diagram from Figure 9, the application is modular; if needed, different types of cameras or object detectors can be used.
- CameraAcquisition and ZEDAcquisition implement the functionalities of IAcquisition interface: we considered the option of using a generic camera or the ZED camera (default option);
For reasons of optimization, threads are used for independent tasks and the communication between them is carried out using priority queues, as follows:
- AcquisitionAndObjectDetect thread is used for image acquisition and object detection;
- queueImageToHOI stores the object detection results;
- HOIDetector thread reads from queueImageToHOI, performs human–object interaction detection;
- queueHOIToMain stores the detected HOIs;
- MQTTConnection thread initiates the connection with the MQTT agent to which the Gateway is connected.
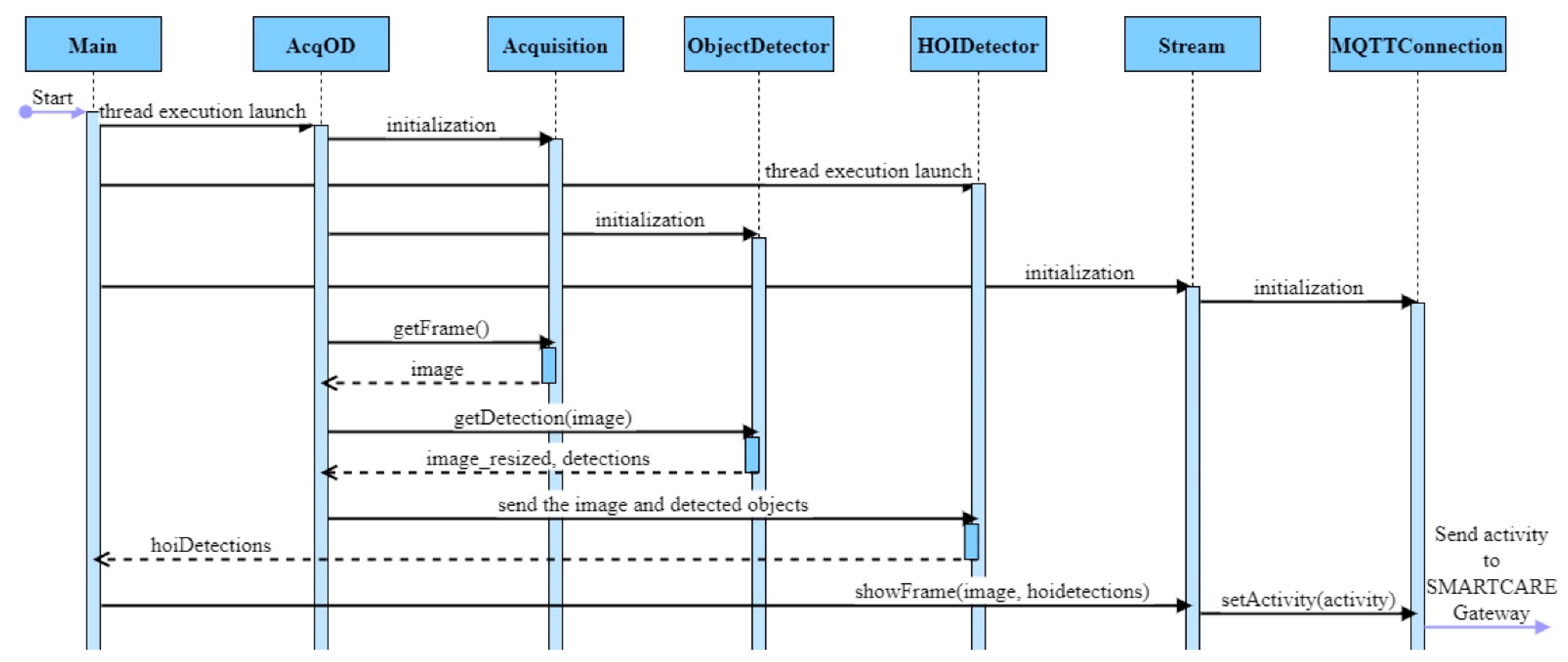
The diagram presented in Figure 10 illustrates the communication between modules and threads for one frame, from acquisition to activity detection.
HOI detector inference time is considerably longer than the time required to detect objects. That is why we decided to test using multiple threads for HOI detections. Figure 11 describes the communication between threads. Priority queues are used for thread communication.
There is only one thread for image acquisition and there are object detection, and multiple threads for HOI detection. ImageToHOI priority queue is used between the AcquisitionAndObjectDetect thread and HOIDetector thread(s), while HOIToMain priority queue is used to return the HOI detections to the MQTTConnection thread which updates the current activity and communicates with the MQTT agent.
6.1. Forwarding Detected Activities to the SmartCare Gateway
As described in Section 3, the SmartCare Gateway receives information from several devices, one of which is the HAR system. Communication with the Gateway is carried out using the MQTT protocol by publishing messages. We use serialized JSON objects with information about the current activity of the supervised person.
On initialization, the Gateway subscribes to the following topics:
- gateway/register;
- video-monit/1/activity/response-get;
- video-monit/1/activity/response-async-get.
At start-up, the video monitoring system subscribes to:
- gateway/discover;
- video-monit/1/activity/get;
- video-monit/1/activity/async-get.
It must also make itself known to the Gateway by publishing a serialized JSON object containing system data on the gateway/register topic. The video-monit subtopic is the name of the HAR bridge used for the proposed module. The module communication and initialization process can be followed in Figure 11 and Figure 12, both the HAR system and the SmartCare Gateway subscribe to the MQTT Agent for this connection.
Topic description:
- gateway/register and gateway/discover are used for a handshake protocol: bridges from each device in the network (including the HAR system) subscribe to gateway/discover to receive a “get acquainted” message from the server, after which they publish device details to gateway/register to get recognized by the server.
- video-monit/1/activity/get and video-monit/1/activity/response-get: under the video-monit/bridge name we have 1/device enrolled with a resource of type activity/. The Gateway publishes an inquiring operation on the get/subtopic and the video monitoring system responds on the response-get/subtopic with the patient activity details. This message exchange is represented in Figure 13.
- video-monit/1/activity/async-get and video-monit/1/activity/response-async-get: similar with the above get/response-get topics, an asynchronous behavior is triggered by an ‘on’/‘off’ message. An example of asynchronous communication is illustrated in Figure 14.
6.2. Thread Experiments
In this subsection, we present the experimental results of configurations with different numbers of threads. One thread is always needed to run the MQTT client which keeps communication with the Gateway open, but we will focus on the threads used by the other components.
6.2.1. Configuration 1: Single Thread for Acquisition, Object Detection, and Activity Detection
All components except MQTTConnection run on a single thread. The entire processing pipeline runs sequentially: first the image is acquired, then object detection is performed, and finally the HOIs are detected and used to determine the activity performed by the patient. Figure 15 illustrates the single-thread configuration block diagram.
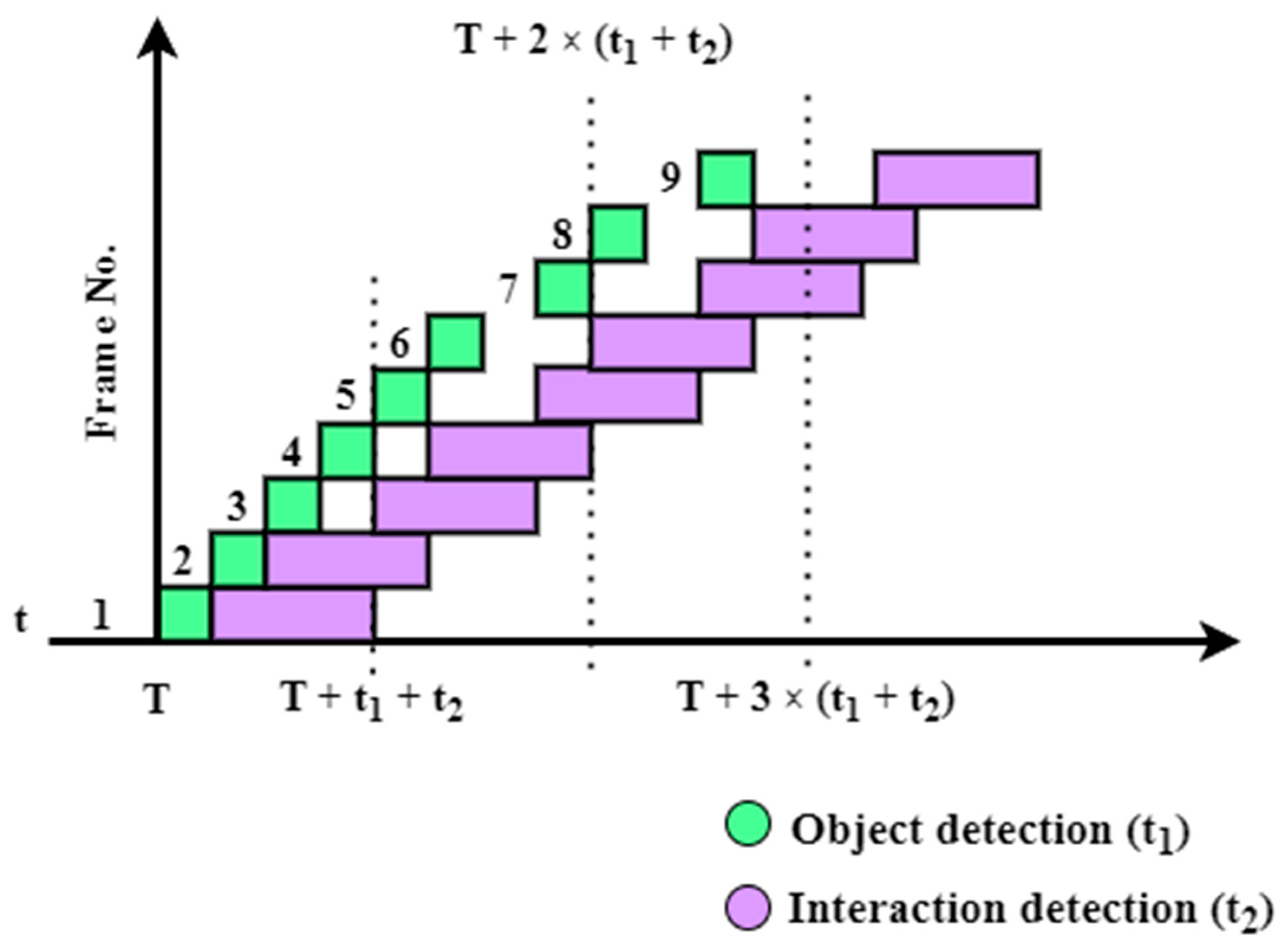
An example of a sequential pipeline timeline is presented in Figure 16: the total processing time is the sum of object detection time and the time needed to detect HOIs. The average frame processing time is t1 + t2; therefore, the result for the third frame is available at T + 3 × (t1 + t2). t1 and t2 are not real measurements; for Figure 16, Figure 17 and Figure 18, they were chosen to ideally exemplify the tested configurations.
6.2.2. Configuration 2: One Thread for Acquisition and Object Detection, Another One for Activity Detection
In this test scenario, we follow the general diagram from Figure 10: one thread is used for image acquisition and object detection, results go through first queue to the HOI detector which writes the output to the second queue in order to be further processed and extract the patient activity.
Figure 17 illustrates the result timeline: In addition to the first iteration, which is always affected by the initialization process and is taken out of the time statistics, each time the HOI detection thread finishes the current frame processing, the queue will feed the object detections for the next frame. The average processing time is, in fact, the inference time for HOI detection (t2), the result for the 3rd frame is available at T + t1 + 3 × t2.
6.2.3. Configuration 3: One Thread for Acquisition and Object Detection, Two Threads for Activity Detection
To the previous scenario we add a second thread for HOI detection: ideally, as exemplified in Figure 18, the run-time for image processing should remain the same even if multiple threads are used. In practice, to run multiple instances of neural networks, there should be multiple GPUs. To satisfy this constraint, multiple logical video cards were created by dividing the physical video memory by the number of threads.
The advantage of using a single thread for acquisition, object detection and HOI detection is that the time elapsed between frame acquisition and activity detection is the shortest of the three configurations, representing mostly the inference time of the two neural networks (Figure 16). In the second and third configurations, the time elapsed between frame acquisition and activity detection is longer, and a delay is added due to unavailable threads for HOI detection (Figure 17 and Figure 18). An advantage of using dedicated threads in the following configuration: one for acquisition and object detection and one/two for HOI detection, is that the FPS is higher.
Table 7 presents a comparison between different scenarios regarding used threads and queue sizes. Increasing the queue size causes a longer time elapsed between frame acquisition and activity result. In order to have the smallest delay, the queue size is set to be equal to the number of threads used for human–object interaction. Ideally, increasing the number of threads should improve FPS, but, because the memory of the video card is split into multiple virtual GPUs, the processing speed decreases considerably, so that the configuration with two threads for HOI detection is actually slower than the configuration that uses only one thread for this process. The fastest configuration in terms of FPS is the second one-two threads: acquisition and object detection, HOI detection.
6.3. Using HAR Results in the SmartCare System
Depending on the monitored patient, the SmartCare system can integrate a wide range of sensors for different aspects, such as
- Vital parameters: heart rate (Fitbit Versa Smartwatch), blood pressure (Omron), blood glucose meter (Contour Plus), etc.
- Home automation: smart dimmer (AD146), smart switch (Fibaro Double Switch 2), valve actuator (Popp Flow Stop 2), smart lock (Danalock V3), waterleak detector (Abus Z-wave SHMW), panic button (Orvibo HS1EB), smart light bulb (Osram Smart A60), ambient temperature, gas sensor, etc.
- Physical activity: steps, fall detection, consumed calories (Fitbit Versa), the video monitoring system.
SmartCare has a predefined set of sensors depending on the health status of the assisted person:
- Alzheimer’s disease: mandatory (smart lock, water tap, flood sensor, panic button), recommendation (switch, ambient temperature), nice to have (smart bulb, vibration sensor, humidity, HAR).
- Diabetic: mandatory (blood pressure, blood sugar), recommendation (oxygen saturation), nice to have (panic button, HAR, ambient temperature, humidity).
- Hypertensive: mandatory (blood pressure, heart rate), recommendation (oxygen saturation), nice to have (panic button, HAR, ambient temperature, humidity).
- Obese: mandatory (blood pressure, blood sugar), recommendation (heart rate), nice to have (HAR, ambient temperature).
- etc.
Due to the possibility of a life-threatening event, a rule engine implemented on the Gateway uses information from all connected devices and systems and defines the rules according to the particularities of the monitored person. The WHO and the EU have standardized the use of such rules for the assisted living applications. Accordingly, we define three alert classes: notification (patient), alert (patient, caregiver) and emergency (caregiver, initiate help procedure). Some examples of rules are:
- If the light intensity is below 300 lux (which is the recommended value for an adult’s bedroom), the light is turned on (the dimmer is at a value greater than 0) and the patient is detected (HAR), then the light intensity value is increased step by step up to 300 lux.
- If the patient is using the sink (HAR) and a leak is detected, then the electricity is turned off (smart switch, smart plug), the tap is closed and the caregiver is alerted.
- If the patient serves the meal (HAR) and the blood sugar is above the upper limit for diabetes, then the patient and the caregiver are alerted.
The implementation of the HAR system is available at https://github.com/MihaiCHG/VideoMonitoring, accessed on 20 October 2022.
7. Conclusions
In order to reduce the cost of health services provided to an increasingly inactive population, especially the elderly and people with chronic diseases or mental disabilities, the European Union has focused on digital strategies such as e-health and telemedicine. Through programs such as Ageing Well in the Digital World, the EU is financing the development of medical products aiming to maintain the same level of quality in health care services and create a better quality of life for the elderly. An EU pilot project for intelligent living environments worth mentioning is ACTIVAGE. The SmartCare Project follows the European AAL directives being designed to improve living conditions, especially regarding life independence, according to the context of specific needs that people with disabilities may have.
The SmartCare platform in which the human activity recognition system is included has a ‘connect and use’ architecture that does not require settings to be made. It is designed as a modular platform to which devices can be added or removed in the simplest way possible without affecting the functionality.
To detect activities, this HAR system uses two convolutional neural networks. The first network detects objects in images, including people, while the second one detects human–object interactions based on objects and people received from the previous network. Because the system must run in real time, these networks must have as little processing time as possible. Yolo V4 was chosen from the neural networks for object detection presented in this paper, and iCAN was chosen for the detection of interactions. Based on the detected actions, the monitored activities are detected.
Activities are sent to the gateway via MQTT. The system subscribes to topics that it listens to when it needs to submit activities, and then publishes them on paired topics.
The lab results presented in this paper demonstrate that such a system can be integrated in the SmartCare platform in order to provide information about the activity of the monitored patient, to confirm or deny events detected by other sensors connected to the platform (e.g., IMU). The activity of the person will not be established on the basis of the information received from a single sensor/module, but by merging the information received from other devices.
Future work includes dataset expansion with annotation for specific object classes such as different types of medicine, other objects often found in the patient’s environment (home or medical center)—wheelchair, walking crutches, rolling crutches, different types of prostheses or specific wearable technology which also has integration with the SmartCare platform—insulin pump, fitness wristband, blood pressure monitor, panic button, smart switch and smart plug, etc. The object detection model can easily be retrained with an enhanced dataset. The HOI verbs and possible interactions will also be tailored according to the newly added objects.
The recent COVID-19 pandemic has led us to include within SmartCare a stand-alone module in order to monitor the distance and physical interaction between people: patient and patient, patient and caregiver, and patient and medical staff. Future work also implies adapting the HAR output so that the system is compliant with this feature as well.
Author Contributions
Conceptualization, S.-D.A., M.-C.H., R.-G.L. and V.-I.M.; methodology, S.-D.A., M.-C.H., R.-G.L. and V.-I.M.; software, S.-D.A. and M.-C.H.; validation, S.-D.A., M.-C.H., R.-G.L. and V.-I.M.; formal analysis, S.-D.A. and R.-G.L.; investigation, S.-D.A.; resources, S.-D.A.; data curation, S.-D.A. and M.-C.H.; writing—original draft preparation, S.-D.A. and M.-C.H.; writing—review and editing, S.-D.A., M.-C.H. and R.-G.L.; visualization, S.-D.A. and M.-C.H.; supervision, R.-G.L. and V.-I.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Romanian National Authority for Scientific Research (UEFISCDI), Project PN-III-P2-2.1-PTE-2019-0756/2020 Integrative platform for assistance solutions for home autonomy (SMARTCARE).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mshali, H.; Lemlouma, T.; Moloney, M.; Magoni, D. A Survey on Health Monitoring Systems for Health Smart Homes. Int. J. Ind. Ergon. 2018, 66, 26–56. [Google Scholar] [CrossRef] [Green Version]
- Dang, L.M.; Piran, M.J.; Han, D.; Min, K.; Moon, H. A Survey on Internet of Things and Cloud Computing for Healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef] [Green Version]
- European Commission. The 2015 Ageing Report: Economic and Budgetary Projections for the 28 EU Member States (2013–2060); Publications Office of the European Union: Luxembourg, 2015.
- Vayyar. Smart Home-Vayyar. Available online: https://vayyar.com/smart-home (accessed on 20 October 2022).
- Ahmed, A.; Adewale, A.L.; James, A.; Mikail, O.O.; Umar, B.U.; Samuel, E. Human Vital Physiological Parameters Monitoring: A Wireless Body Area Technology Based Internet of Things. J. Teknol. Dan Sist. Komput. 2018, 6, 13039. [Google Scholar] [CrossRef] [Green Version]
- Borelli, E.; Paolini, G.; Antoniazzi, F.; Barbiroli, M.; Benassi, F.; Chesani, F.; Chiari, L.; Fantini, M.; Fuschini, F.; Galassi, A.; et al. HABITAT: An IoT Solution for Independent Elderly. Sensors 2019, 19, 1258. [Google Scholar] [CrossRef] [Green Version]
- Cubo, J.; Nieto, A.; Pimentel, E. A Cloud-Based Internet of Things Platform for Ambient Assisted Living. Sensors 2014, 14, 14070–14105. [Google Scholar] [CrossRef] [Green Version]
- CareStore Project. Available online: https://cordis.europa.eu/project/rcn/105930/factsheet/en (accessed on 20 October 2022).
- ACTIVAGE Project. Available online: https://cordis.europa.eu/project/rcn/206513/factsheet/en (accessed on 20 October 2022).
- Shao, D.; Yang, Y.; Liu, C.; Tsow, F.; Yu, H.; Tao, N. Non-contact Monitoring Breathing Pattern, Exhalation Flow Rate and Pulse Transit Time. IEEE Trans. Biomed. Eng. 2014, 61, 2760–2767. [Google Scholar] [CrossRef]
- Marques, G.; Pitarma, R. An Indoor Monitoring System for Ambient Assisted Living Based on Internet of Things Architecture. Int. J. Environ. Res. Public Health 2016, 13, 1152. [Google Scholar] [CrossRef] [Green Version]
- Gwak, J.; Shino, M.; Ueda, K.; Kamata, M. An Investigation of the Effects of Changes in the Indoor Ambient Temperature on Arousal Level, Thermal Comfort, and Physiological Indices. Appl. Sci. 2019, 9, 899. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, L.; Lanza, J.; Olsen, R.; Bauer, M.; Girod-Genet, M. A Generic Context Management Framework for Personal Networking Environments. In Proceedings of the 2006 Third Annual International Conference on Mobile and Ubiquitous Systems: Networking & Services, San Jose, CA, USA, 17–21 July 2006; pp. 1–8. [Google Scholar] [CrossRef]
- Höllerer, T.; Hallaway, D.; Tinna, N.; Feiner, S. Steps Toward Accommodating Variable Position Tracking Accuracy in a Mobile Augmented Reality System. In Proceedings of the 2nd International Workshop on Artificial Intelligence in Mobile Systems (AIMS’01), Seattle, WA, USA, 4 August 2001. [Google Scholar]
- Tsetsos, V.; Anagnostopoulos, C.; Kikiras, P.; Hadjiefthymiades, S. Semantically enriched navigation for indoor environments. Int. J. Web Grid Serv. 2006, 2, 453–478. [Google Scholar] [CrossRef]
- Chen, L.; Tee, B.K.; Chortos, A.; Schwartz, G.; Tse, V.; Lipomi, D.J.; Wang, H.-S.P.; McConnell, M.V.; Bao, Z. Continuous wireless pressure monitoring and mapping with ultra-small passive sensors for health monitoring and critical care. Nat. Commun. 2014, 5, 5028. [Google Scholar] [CrossRef] [Green Version]
- Lyardet, F.; Grimmer, J.; Mühlhäuser, M. CoINS: Context Sensitive Indoor Navigation System. In Proceedings of the Eigth IEEE International Symposium on Multimedia, San Diego, CA, USA, 11–13 December 2006. [Google Scholar] [CrossRef]
- Mshali, H.H. Context-Aware e-Health Services in Smart Spaces. Ph.D. Thesis, Université de Bordeaux, Bordeaux, France, 2017. [Google Scholar]
- Malasinghe, L.P.; Ramzan, N.; Dahal, K. Remote patient monitoring: A comprehensive study. J. Ambient Intell. Human Comput. 2019, 10, 57–76. [Google Scholar] [CrossRef] [Green Version]
- Buzzelli, M.; Albé, A.; Ciocca, G. A Vision-Based System for Monitoring Elderly People at Home. Appl. Sci. 2020, 10, 374. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is Faster R-CNN Doing Well for Pedestrian Detection? In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Hsieh, J.-T.; Balachandar, N.; Yeung, S.; Pusiol, G.; Luxenberg, J.; Li, G.; Li, L.-J.; Downing, N.; Milstein, A.; et al. Computer Vision-Based Descriptive Analytics of Seniors’ Daily Activities for Long-Term Health Monitoring. Mach. Learn. Healthc. 2018, 2, 1–18. [Google Scholar]
- Karen, S.; Andrew, Z. Two-Stream Convolutional Networks for Action Recognition in Videos. Adv. Neural Inf. Process. Syst. 2014, 568–576. [Google Scholar] [CrossRef]
- Lee, R.Y.; Carlisle, A.J. Detection of falls using accelerometers and mobile phone technology. Age Ageing 2011, 40, 690–696. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-López, J.R.; Ferrández-Pastor, F.J.; Nieto-Hidalgo, M.; Flórez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef] [Green Version]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. An Efficient Approach for Multi-view Human Action Recognition Based on Bag-of-Key-Poses. In Human Behavior Understanding; HBU 2012; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-López, J.R.; Climent-Pérez, P.; Flórez-Revuelta, F. Evolutionary joint selection to improve human action recognition with RGB-D devices. Expert Syst. Appl. 2014, 41, 786–794. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Jalal, A.; Mahmood, M. Vision-Based Human Activity Recognition System Using Depth Silhouettes: A Smart Home System for Monitoring the Residents. J. Electr. Eng. Technol. 2019, 14, 2567–2573. [Google Scholar] [CrossRef]
- Vishwakarma, V.; Mandal, C.; Sural, S. Automatic Detection of Human Fall in Video. In Proceedings of the Pattern Recognition and Machine Intelligence, Kolkata, India, 18–22 December 2007. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A Short Note on the Kinetics-700 Human Action Dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar] [CrossRef]
- Smaira, L.; Carreira, J.; Noland, E.; Clancy, E.; Wu, A.; Zisserman, A. A Short Note on the Kinetics-700-2020 Human Action Dataset. arXiv 2020, arXiv:2010.10864. [Google Scholar] [CrossRef]
- Monfort, M.; Pan, B.; Ramakrishnan, K.; Andonian, A.; McNamara, B.A.; Lascelles, A.; Fan, Q.; Gutfreund, D.; Feris, R.; Oliva, A. Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Monfort, M.; Jin, S.; Liu, A.; Harwath, D.; Feris, R.; Glass, J.; Oliva, A. Spoken Moments: Learning Joint Audio-Visual Representations From Video Descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14871–14881. [Google Scholar] [CrossRef]
- Achirei, S.; Zvorișteanu, O.; Alexandrescu, A.; Botezatu, N.; Stan, A.; Rotariu, C.; Lupu, R.; Caraiman, S. SMARTCARE: On the Design of an IoT Based Solution for Assisted Living. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Jetson-Inference. Available online: https://github.com/dusty-nv/jetson-inference (accessed on 20 October 2022).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Scharwächter, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision. 2015. Available online: https://www.cityscapes-dataset.com/wordpress/wp-content/papercite-data/pdf/cordts2015cvprw.pdf (accessed on 20 October 2022).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Valada, A.; Oliveira, G.; Brox, T.; Burgard, W. Deep Multispectral Semantic Scene Understanding of Forested Environments Using Multimodal Fusion. In 2016 International Symposium on Experimental Robotics. ISER 2016. Springer Proceedings in Advanced Robotics; Springer: Cham, Switzerland, 2017; pp. 465–477. [Google Scholar] [CrossRef]
- Zhao, J.; Li, J.; Cheng, Y.; Sim, T.; Yan, S.; Feng, J. Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 792–800. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar] [CrossRef]
- YOLO v4 and YOLO v4 Tiny Implementation by Darknet. Available online: https://github.com/pjreddie/darknet (accessed on 20 October 2022).
- Joseph, R.; Farhadi, A. Yolov3: An Incremental Improvement. 2018. Available online: https://doi.org/10.48550/arXiv.1804.02767 (accessed on 20 October 2022).
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Chen, G.; Zou, Y.; Huang, J. iCAN: Instance-centric attention network for human-object interaction detection. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar] [CrossRef]
- Gupta, S.; Malik, J. Visual Semantic Role Labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar] [CrossRef]
- Chao, Y.; Liu, Y.; Liu, X.; Zeng, H.; Deng, J. Learning to Detect Human-Object Interactions. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar] [CrossRef]
- Chao, Y.; Wang, Z.; He, Y.; Wang, J.; Deng, J. HICO: A Benchmark for Recognizing Human-Object Interactions in Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
Figure 1.
Conceptual architecture of the SmartCare system [37].
Figure 1.
Conceptual architecture of the SmartCare system [37].

Figure 2.
The human activity recognition module integrated in the SmartCare system.

Figure 3.
HAR system diagram.

Figure 4.
(a) Input frame; (b) HOI detections using YOLO V4 tiny; (c) HOI detections using SSD-MobleNet V2; (d) HOI detections using YOLO V4.
Figure 4.
(a) Input frame; (b) HOI detections using YOLO V4 tiny; (c) HOI detections using SSD-MobleNet V2; (d) HOI detections using YOLO V4.

Figure 5.
Examples of annotations in the dataset with a human doing multiple actions at the same time: (a) person lying on the bed and working on a computer and (b) person sitting on a chair, eating a sandwich and working on a computer [55].
Figure 5.
Examples of annotations in the dataset with a human doing multiple actions at the same time: (a) person lying on the bed and working on a computer and (b) person sitting on a chair, eating a sandwich and working on a computer [55].

Figure 6.
Hardware and software architecture.

Figure 7.
HAR module communication diagram.

Figure 8.
Human–object interaction pipeline architecture.

Figure 9.
Class diagram.

Figure 10.
Communication using priority queues.

Figure 11.
Communication diagram.

Figure 12.
Initialization sequence for the connection between the HAR module and the SmartCare Gateway.
Figure 12.
Initialization sequence for the connection between the HAR module and the SmartCare Gateway.

Figure 13.
Synchronous communication between the HAR module and the SmartCare system.

Figure 14.
Asynchronous communication between the HAR module and the SmartCare system.

Figure 15.
Sequential configuration: single thread for acquisition, object detection and activity detection.
Figure 15.
Sequential configuration: single thread for acquisition, object detection and activity detection.

Figure 16.
Sequential configuration.

Figure 17.
Configuration using two threads.

Figure 18.
Configuration using three threads.

Figure 19.
Activity detection result.

Figure 20.
MQTT message sent to the SmartCare Gateway.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Monitoring scenarios for diabetes.
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient is active | Person, chair, couch, bed | To run, to sit, to lay | <human, sits on, chair> <human, lays on, bed> |
| The patient serves the meal (after a diet recommended by the doctor) | Person, dining table, pizza, banana, apple, sandwich, orange, broccoli, carrot, hot dog, donut, cake, fork, knife, spoon, bowl, plate, oven, microwave, toaster, fridge, chair | To eat, to hold, to cut, to catch, to sit, to carry | <human, eats, sandwich> <human, eats, broccoli> <human, sits on, chair> <human, holds, fork> <human, eats, pizza> |
| The patient drinks liquids | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, drinks from, cup> <human, holds, bottle> <human, drinks from, wine glass> |
Table 2.
Monitoring scenarios for Alzheimer’s disease.
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient serves the meal (too often due to the condition, eats too much) | Person, food (different types of food: pizza, banana, apple, sandwich, hot fog, etc.), dining table, fork, knife, spoon, bowl, oven, toaster, fridge, microwave | To eat, to sit, to hold, to cut, to carry | <human, eats, donut> <human, carry, fork> <human, holds, bowl> <human, cuts with, knife> <human, holds, spoon> |
| The patient drinks liquids (too often) | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, drinks from, cup> <human, holds, bottle> |
| The patient opens the tap (and may forget it opened) | Person, sink | To stand, to hold, to point | <human, stands, -> <human, points at, sink> |
| The patient opens the gas while cooking (and may forget it opened) | Person, oven, bowl | To hold, to carry, to point | <human, holds, bowl> <human, points at, oven> <human, carry, bowl> |
Table 3.
Monitoring scenarios for arthritis.
| Monitored Activity | Object Classes | Verbs | Resulted Triplets <Human, Verb, Object> |
|---|---|---|---|
| The patient is active | Person, chair, couch, bed | To run, to sit, to lay | <human, runs, -> <human, lays on, bed> |
| The patient serves the meal (after a diet recommended by the doctor) | Person, dining table, pizza, banana, apple, sandwich, orange, broccoli, carrot, hot fog, donut, cake, fork, knife, spoon, bowl, plate, oven, microwave, toaster, fridge, chair | To eat, to hold, to cut, to catch, to sit, to carry | <human, holds, spoon> <human, holds, bowl> <human, sits at, dining table> <human, eats, apple> <human, eats, cake> |
| The patient drinks liquids | Person, wine glass, bottle, cup | To drink, to hold, to carry | <human, holds, bottle> <human, carry, cup> <human, drinks from, wine glass> |
Table 4.
HOI detection evaluation for agent and role.
| Object Detector | Average Agent AP | Average Role AP [S1] | Average Role AP [S2] | Average Agent AP | Average Role AP [S1] | Average Role AP [S2] |
|---|---|---|---|---|---|---|
| Threshold = 0.2 | Threshold = 0.5 | |||||
| SSD-Mobilenet-v2 [39,42] | 25.78% | 11.75% | 12.99% | 26.43% | 13.43% | 14.80% |
| YOLO v4 tiny [41,43] | 26.62% | 13.41% | 15.09% | 26.79% | 14.92% | 16.70% |
| SSD-Inception-v2 [40,42] | 29.80% | 14.26% | 15.94% | 30.02% | 14.78% | 17.56% |
| YOLO v4 [41,43] | 56.68% | 37.77% | 43.20% | 57.05% | 40.07% | 45.72% |
Table 5.
HOI detection evaluation for the most relevant actions.
| Detected Activity | SSD—Mobilenet—v2 | YOLO v4 Tiny | SSD—Inception—v2 | YOLO v4 |
|---|---|---|---|---|
| To eat | 4.24% | 7.06% | 4.14% | 32.11% |
| To drink | 0.75% | 5.76% | 2.13% | 25.69% |
| To lay on | 9.09% | 0.32% | 13.43% | 10.68% |
| To sit on | 17.17% | 7.91% | 22.59% | 34% |
| To stand | 48.88% | 53.27% | 54.35% | 78.51% |
| To hold an object/instrument | 7.85% | 9.48% | 9.03% | 34.78% |
Table 6.
V-COCO categories in SmartCare.
| Category | Verbs with Associated Attribute Type |
|---|---|
| Essential verbs for SmartCare | walk, eat_object, sit_instrument, lay_instrument, drink_instrument, eat_instrument, hold_object, stand |
| Util verbs for SmartCare | cut_instrument, cut_object, talk_on_phone_instrument, work_on_computer_instrument, carry_object, smile, look_object, point_instrument, read_object, run, jump_instrument |
| Unnecessary verbs for SmartCare | surf_instrument, ski_instrument, ride_instrument, kick_object, hit_instrument, hit_object, snowboard_instrument, skateboard_instrument, catch_object |
Table 7.
HOI detection thread experiments.
| Acquisition and OD Threads | HOI Threads | Queue Size | FPS |
|---|---|---|---|
| 0 | 0 | 0 | 2.17 |
| 1 | 1 | 1 | 2.43 |
| 1 | 2 | 2 | 2.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Achirei, S.-D.; Heghea, M.-C.; Lupu, R.-G.; Manta, V.-I. Human Activity Recognition for Assisted Living Based on Scene Understanding. Appl. Sci. 2022, 12, 10743. https://doi.org/10.3390/app122110743
AMA Style
Achirei S-D, Heghea M-C, Lupu R-G, Manta V-I. Human Activity Recognition for Assisted Living Based on Scene Understanding. Applied Sciences. 2022; 12(21):10743. https://doi.org/10.3390/app122110743
Chicago/Turabian StyleAchirei, Stefan-Daniel, Mihail-Cristian Heghea, Robert-Gabriel Lupu, and Vasile-Ion Manta. 2022. "Human Activity Recognition for Assisted Living Based on Scene Understanding" Applied Sciences 12, no. 21: 10743. https://doi.org/10.3390/app122110743
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.