
Fuzzy Markovian Bonus-Malus Systems in Non-Life Insurance



1
Department of Computer Science and Artificial Intelligence, Higher Technical School of Computer and Telecommunication Engineering, University of Granada, Cuesta del Hospicio s/n, 18071 Granada, Spain
2
Department of Mathematics for Economics, Finance and Actuarial Science, Faculty of Economics and Business, University of Barcelona, Avinguda Diagonal 690, 08034 Barcelona, Spain
3
Social and Business Research Laboratory, Campus Bellisens, Rovira i Virgili University, Avinguda de la Universitat 1, 43204 Reus, Spain
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(4), 347; https://doi.org/10.3390/math9040347
Submission received: 24 December 2020
/
Revised: 2 February 2021
/
Accepted: 3 February 2021
/
Published: 9 February 2021
(This article belongs to the Special Issue Fuzzy Sets in Business Management, Finance, and Economics)
Abstract
:Markov chains (MCs) are widely used to model a great deal of financial and actuarial problems. Likewise, they are also used in many other fields ranging from economics, management, agricultural sciences, engineering or informatics to medicine. This paper focuses on the use of MCs for the design of non-life bonus-malus systems (BMSs). It proposes quantifying the uncertainty of transition probabilities in BMSs by using fuzzy numbers (FNs). To do so, Fuzzy MCs (FMCs) as defined by Buckley and Eslami in 2002 are used, thus giving rise to the concept of Fuzzy BMSs (FBMSs). More concretely, we describe in detail the common BMS where the number of claims follows a Poisson distribution under the hypothesis that its characteristic parameter is not a real but a triangular FN (TFN). Moreover, we reflect on how to fit that parameter by using several fuzzy data analysis tools and discuss the goodness of triangular approximates to fuzzy transition probabilities, the fuzzy stationary state, and the fuzzy mean asymptotic premium. The use of FMCs in a BMS allows obtaining not only point estimates of all these variables, but also a structured set of their possible values whose reliability is given by means of a possibility measure. Although our analysis is circumscribed to non-life insurance, all of its findings can easily be extended to any of the abovementioned fields with slight modifications.
1. Introduction
1.1. Motivation
A bonus-malus system (BMS) is a common method for posteriori ratemaking in non-life insurance. It is based on partitioning the insurer’s portfolio into a finite number of classes: bonus and malus classes. A typical case is automobile third-party liability insurance [1]. In a BMS, policyholders do not have a fixed price for their contracts throughout periods (e.g., the mathematical expectation of claims value per period). Their membership into a concrete BMS class is reviewed each period according to the number of claims in the previous one. Claim-free years are rewarded by discounts or bonuses on a base-premium; at-fault accidents are penalized by surcharges called maluses. Some overviews on how BMS are applied in different countries can be found in [2,3,4].
Following [5], in most commercial BMSs, by knowing the insured’s class in the current period and fitting the statistical distribution for the number of claims per period, it is possible to determine the probabilities of the insured’s class in the next period. Therefore, these BMSs are Markovian. For that reason, the academic literature on BMSs uses extensively MCs for their modeling ([1,5,6,7,8,9,10,11]). Therefore, a key question in a BMS is fitting the value of the one-step transition probability matrix. Following [12,13], if full knowledge of the probabilities of this matrix is not available, they have to be estimated somehow with the uncertainty that any estimation procedure involves. Uncertainty may be due to randomness, hazard, vagueness, incomplete information, etc. In our paper, we consider that the claiming process is probabilistic, but the uncertainty about the parameter that governs this random behavior is captured by means of a fuzzy number (FN) and, as a consequence, fuzzy Markov chains (FMCs) will be used.
1.2. Novelties
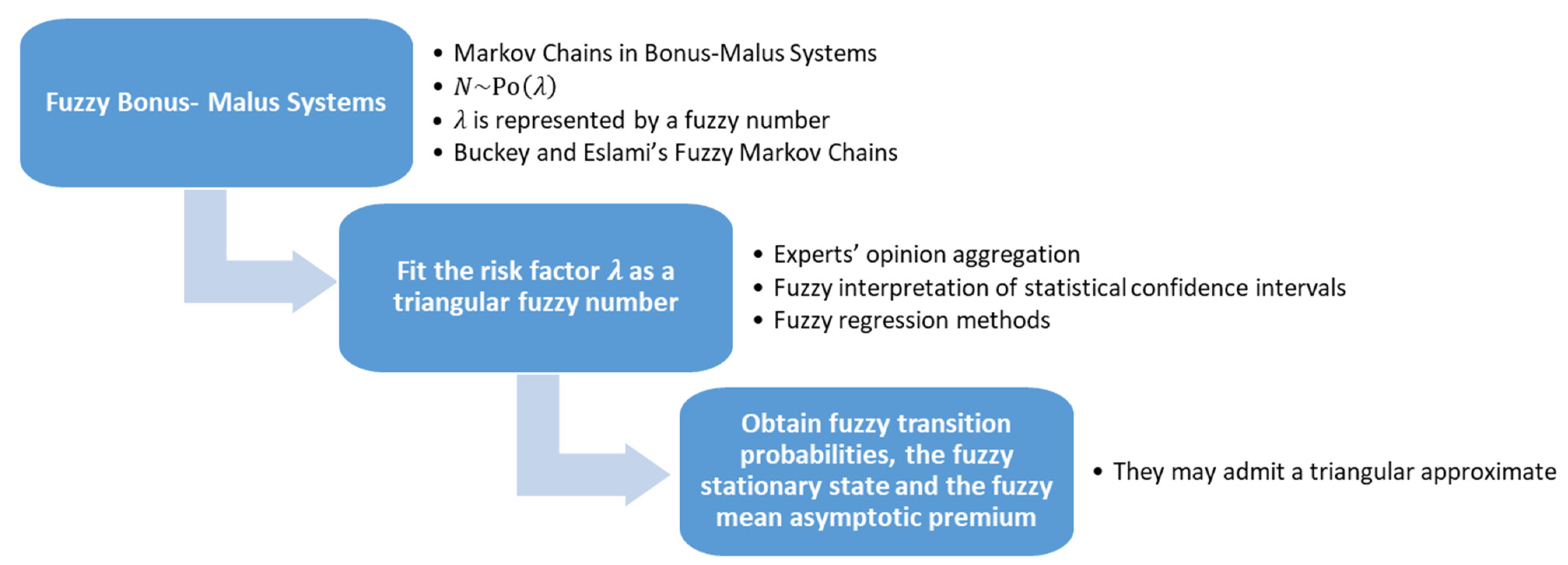
Although other hypotheses can be taken, such as, for example, considering that the number of claims in a period, N, follows a negative binomial distribution ([14]), academic literature on BMSs usually assumes that is a Poisson random variable (RV). So, and the parameter , the claim frequency, is perfectly known and can be interpreted as a risk measure of the policy. However, in a more realistic approach, some authors like [15] use intervals to quantify the uncertainty about the parameter of a distribution function that governs a risk variable. This is also the case within a BMS framework of [11], who model the uncertainty about by means of a modal interval. One extended way to combine randomness and uncertainty of parameters of distribution functions consists in modeling these parameters as FNs. It has been done both for continuous RVs ([16,17,18]), and in the discrete case ([19]). Following this approach, [20,21] and also [15] model risk financial parameters with FNs. In the actuarial field, FNs have been used to capture the uncertainty of insurance pricing variables ([22]) but also to model parameters that quantify risks. In this regard, we can point out [23] in a non-life insurance context, [24] to interpret the parameter that quantifies the dependence in a Farlie-Gumbel-Morgestein copula, and [25,26,27,28] in life insurance pricing. Since any interval can be seen as the -cut of a FN, even in the case of improper intervals ([29]), in this work we consider that is fitted by means of a FN and, more particularly, by a triangular fuzzy number (TFN). So, this paper builds up a framework to model Markovian BMSs that embed the standard case, where the risk parameter is crisp, but also the method developed in [11] that quantifies this parameter as a modal interval. Standard BMSs provide point values for the stationary state and the mean asymptotic premium. Modal BMSs as introduced in [11] allow obtaining these variables as modal intervals whose lower and upper bounds may be understood as pessimistic/optimistic scenarios. Our method generalizes both types of BMSs since it quantifies variables related to BMS as FNs. On the one hand, these FNs can be understood as a set of crisp outcomes with an associated possibility measure. On the other, these FNs can be interpreted as a set of intervals that come from pessimistic/optimistic scenarios and are structured by means of possibility levels. Figure 1 shows a graphical synthesis of the methodological framework developed in this paper.
Other more complex forms of FNs, such as generalized FNs (GFNs) or intuitionistic FNs (IFNs), could be considered to quantify uncertain probabilities. Tools like GFNs or IFNs provide a more complete capture of uncertainty than FNs. However, their adjustment has a greater cost than in the case of triangular FNs since they incorporate more parameters and their computational handle may be more expensive as well. Therefore, using TFNs supposes a balance between the simplicity of crisp or modal interval probabilities and more complex representations of uncertain quantities such as GFNs or IFNs.
It should be noted that there are several scientific fields in which MCs are in use. In the field of economics and finance, we can observe applications within Leontief’s input-output model, credit risk measurement, asset price volatility modeling, life insurance, etc. In addition, MCs have shown their usefulness in many other areas: industrial engineering (e.g., queuing theory), computer science (e.g., computer performance evaluation and web search engines), healthcare (e.g., pandemics transmission or evolution of ICU patients), etc. Hence, although our developments are carried out within a non-life insurance context, most of the results can be applied to any problem modeled by means of MCs when the transition probabilities (or the parameters that define them) are not precisely known.
The paper is organized as follows. Section 2 describes briefly how BMSs work. Section 3 shows the basic concepts of FNs and FMCs used throughout the paper. In Section 4, a methodologic approach is proposed to fit a fuzzy BMS (FBMS) when the number of claims within a period, , follows a Poisson distribution with fuzzy parameter . This methodology is applied to the Irish BMS. A sensitivity analysis is conducted in Section 5. Finally, in Section 6, the work ends with a summary of its main contributions and potential extensions.
2. Markovian Bonus-Malus Systems in Non-Life Insurance
A BMS is a usual way to deal with risk aversion and moral hazard in some types of insurance, e.g., automobile third-party liability insurance [1]. BMSs classify insureds in classes in such a way that the percentage of the base-premium to be paid by the th class, , satisfies , . In a BMS, the transition between classes is governed by a set of rules defined over the insured’s number of claims in the current period. To summarize, it can be said that every BMS is determined by three elements (see Table 1):
- The initial class, where new insureds are assigned, .
- The premium scale .
- The transition rules, that is to say, the rules that define the conditions for an insured in one class to be transferred to another class in the next period.
Let us model the insured’s class at time as a discrete stochastic process , being its state space the classes . Furthermore, as it is usually done in the literature (e.g., [10]), we consider that the BMS is a finite MC, i.e., , . An insurer uses a finite Markovian BMS when the following conditions hold [1]:
- There exists a finite number of classes such that each insured stays in one class through each period.
- The premium for each insured depends only on the class where they stay.
- The class for a given period is determined by the class in the preceding period and the number of claims reported in that period.
A finite MC is said to be homogeneous if does not depend on . In this case, transition probabilities , i.e., probabilities of moving from class to class in one-step (period), can be collected in a transition matrix with order . The elements satisfy and = 1.
If denote the probabilities of initially being in state , the probabilities of being in state after periods, are:
where is represented by and are the probabilities of moving from state to state in period. From Equation (1), it follows that:
for some continuous functions , i.e., the elements in are some functions of the elements in .
A homogeneous MC is regular if each state is accessible from any other state, either in one step or more, i.e., there exists such that . One of the features that characterize regular MCs is its stationary distribution, which represents the probability of the chain being at each state after a large number of periods, namely, , where the rows of are identical. So, any regular MC with transition matrix has a stationary distribution, , such that:
The vector can be interpreted as the probability that an insured belongs to class after periods, . That vector does not depend on the insured’s initial class, . So, two main outputs in a BMS are:
- The stationary distribution of , , as defined in Equation (3).
- The mean asymptotic premium, , i.e., the average premium paid by the insured in that stationary distribution, defined as:
The mean asymptotic premium, is a concept of the utmost importance because it has been intensively used to assess the efficiency of a BMS (e.g., [1,6,30,31]).
BMSs consider the number of claims, , as a discrete RV. In our paper, as it is commonplace in actuarial literature, is supposed to follow a Poisson distribution with parameter , ([1,7,8,9,10,11,12]). Therefore:
where stands for a probability measure.
Poisson RVs are often used in actuarial modeling due to their interesting arithmetical properties. Furthermore, the risk parameter can be fitted specifically to each insured taking into account relevant rating factors (e.g., gender, age, and social status) by using a generalised linear model (GLM) ([5,8,32]).
If is modeled with (5), is a function of the risk parameter , in such a way that the BMS probabilities in the one-step transition matrix are:
where and 0 otherwise.
Numerical application 1. Let in Equation (5) for the Irish BMS in Table 2. The transition matrix, , that corresponds to this BMS is:
From (3), and, by considering Equation (4), the mean asymptotic premium is .
In this paper, we will consider that the risk parameter cannot be determined precisely. Uncertainty may be the result of different causes: stochastic variability, inaccuracy, incomplete information, etc. Stochastic variability can be described by using RVs or stochastic processes, but inaccuracy and incomplete information can be captured by means of intervals or FNs. Given that any interval can be interpreted as the -cut of a FN, in this work it is assumed that is a FN.
3. Fuzzy Numbers and Fuzzy Markov Chains
3.1. Fuzzy Numbers
A fuzzy number is a fuzzy set on the referential set that satisfies (i) is normal, (ii) is convex, and (iii) the -cuts of , are closed and bounded (compact) intervals . The lower and upper bounds of the FN are:
FNs can be interpreted as the extension of the concept of a real number.
A triangular fuzzy number represented as , is a FN whose -cuts, are, from Equation (8):
from where, if needed, the membership of could be obtained. The core of is and can be understood as the most reliable value of this TFN. i.e., the possibility of is 1. The support of is . TFNs are used in countless practical applications including actuarial ones [22] because they are easy to handle arithmetically and they are well adapted to the way humans think of uncertain quantities. Moreover, when the information about a variable is vague and imprecise, the parsimony principle leads us to represent that information as simply as possible. The linear shape of TFNs meets that requirement. For instance, the uncertain quantity “approximately ” can be represented in a very natural way as the TFN .
Likewise, let it be a TFN :
Let be a continuous real-valued function of -real variables , . If are not crisp numbers, but FNs with –cuts , , a FN is induced via such that . It is often difficult to obtain a closed expression for the membership function of . However, following [33], the -cuts of , , in the usual case where are not interactive, i.e., the variables that they quantify have an independent behavior, can be obtained as:
where stands for the rectangular domain:
So, the lower (upper) bounds of , (), are the global minimum (maximum) of within the rectangular domain in Equation (13), that is to say:
being , , a vertex of the domain (13) and , , an extreme value of the function within this domain that takes this value at point .
Therefore, if is monotonic, the lower and upper bounds of , and , are in one of the vertexes of (13). Without loss of generality, let us suppose that increases with respect to , , and decreases in the last variables, [34] demonstrates that:
If are interactive, (15) cannot be used to evaluate . However, according to [35], the general formulation to obtain the lower and upper bounds of from Equations (12)–(14) is still valid but now the number of vertexes, , is less than . In [35], the authors study the role of interactive fuzzy variables in decision-making problems and analyze some particular cases. Concretely, when is the mathematical expectation function, is the probability of the th outcome, and it is quantified as a FN, the domain in Equation (13) turns into:
and Equation (14) becomes:
due to the fact that is a linear function.
It is worth noting that the result of evaluating a non-linear with the TFNs is not necessarily a TFN. However, often admits a good triangular approximation through the secant approach. It builds up the shape of the triangular approximate FN to by means of the secant lines that unite the 0-cut and the 1-cut of . Such that is a TFN as:
This approximation, as shown in [36], works pretty well for nonlinear monotonic functions of TFNs such as product, division, power, etc. Likewise, [37,38] show that this approach fits satisfactorily common actuarial and financial calculations with TFN parameters, e.g., the present value of a stream of fuzzy cash-flows. Keeping the triangular shape of the initial data when handling FNs is quite interesting. According to [39], complex shapes of FNs can generate problems with calculations in computer work or interpreting results intuitively. [40] state that a triangular approximate is a kind of defuzzification that is richer than just transforming a FN into a crisp representative value. If defuzzification is carried out too early, a great loss of information occurs, so it is preferable to drag all the fuzzy information in the calculations for as long as possible. The triangular approximation involves a compromise between simplification in computation and interpretation, and not oversimplifying the value of fuzzy parameters. In addition, TFNs have a very intuitive interpretation and, therefore, from the insurance industry point of view, a triangular approximate to actuarial variables and parameters could be very useful in decision-making processes.
3.2. Fuzzy Markov Chains
Fuzzy set literature has provided three approaches to MC under fuzziness, namely FMC. The first one, due to [41], supposes fuzzy probabilities and proposes calculating the matrices , , by applying Zadeh’s extension principle [42]. The second approach, in [43], consists of defining the matrix that governs the transition between states by means of a fuzzy relation. In the third one, [2], like [41], suppose that the probabilities of the one-step transition matrix are FNs. However, Buckley and Eslami’s framework of FMCs uses restricted matrix multiplication to operate with probabilities in such a way that the constraint of being a well-formed probability distribution always holds. That is to say, they take into account the interdependence between the probabilities of a distribution function, similarly to Equations (16) and (17). This paper follows this last approach.
Let us assume that some probabilities in the one-step transition matrix are uncertain and are quantified by means of the FNs , with -cuts . Now we have a fuzzy transition matrix , with . See Equations (10) and (11). Of course, some elements in may be crisp since crisp numbers are a particular case of a FN. FMCs defined by [2] have uncertainty in the transition probabilities but not in the set of outcomes, that is discrete. So, the following constraint on is added: .
To compute the -period transition matrix, , and the fuzzy stationary distribution, , the following process is implemented:
Step 1. For a given , obtain the matrix of intervals .
Step 2. Define the domain of a row of this matrix, , as:
where stands for the cartesian product and .
Step 3. Define the domain of the matrix , for the given , as:
This domain defines a set of matrices that satisfy that each row sums up 1 with a possibility level of at least . So, each matrix , , is a crisp MC.
Step 4. Since in Equation (19) are compact sets, in Equation (20) is also compact. So, any continuous function applied to its elements has a compact image. Then, if Equation (2) is applied, such an image for that is a compact interval. This interval is set as the -cut of the FN , i.e., , which is surely normal [2].
To determine we must find the lower and upper bounds, and by solving:
and
Notice that Equations (21) and (22) can be easily solved in low-dimensional problems. However, in more complex problems it is necessary to use an algorithm (see, e.g., [44]) or a heuristic constrained optimization technique [45].
Finally, by performing Steps 1–4 , the FNs can be obtained.
In regards to the fuzzy stationary state, , its -cuts can be determined from Equation (3) as:
4. Implementing a Markovian Fuzzy Bonus-Malus System Governed by a Fuzzy Poisson Discrete Random Variable
In this Section, we propose an integral methodology to develop a FBMS under the hypothesis that . It embeds the fitting of the risk parameter as a TFN, the obtaining of fuzzy transition matrix and the triangular approximate of the stationary distribution calculated by using Equations (23) and (24), and also the determination of the fuzzy mean asymptotic premium in Equation (4).
Step 1. Fit the risk factor as a TFN.
We point out three different options to estimate this parameter.
Option 1
Given that has an intuitive interpretation since it is the mean number of claims in one period, it may be quantified as a FN based on experts’ opinions. For example, an expert may judge that a concrete type of driver generates approximately one claim every 5 years and so the TFN can be considered. Imprecise or subjective quantitative predictions can often come from a pool of experts, leading to a set of fuzzy quantifications. This set of fuzzy opinions can be aggregated simply by their arithmetic mean or other more sophisticated methods (see [46,47,48] for full details).
Option 2
Papers [49,50] consider a standard statistical confidence interval as the observed -cut of the FN, for some increasing values of , where is an arbitrary value near 0 (it is often chosen to be 0.001, 0.005 or 0.01). In [50] it is suggested that by placing those confidence intervals one on top of the other, a FN close to triangular-shaped is obtained. So, we point out two alternatives to apply that idea:
- (a)
- Given that is the mean value of a Poisson RV, the interval estimates of can be used as the -cuts of . Let us denote as the mean number of claims in a pool of similar contracts, the standard deviation of and the number of policies in the pool. The statistical confidence interval for the mean number of claims is:where stands for the )-percentile of a Student with degrees of freedom and the standard deviation of the sample. So, can be fitted through its -cuts by doing, from Equation (25):
- (b)
- Papers [49,51] propose making fuzzy predictions from statistical linear regression models. In [49] it is stated that a statistical confidence interval of coefficients adjusted with a linear regression may be interpreted as the -cut of a FN for these coefficients. Therefore, let us suppose that a GLM estimate of is determined, as usual, by:being , , the coefficients and the explanatory variables (e.g., age, gender, and driving experience in a car insurance context) that are crisp non-negative observations (in fact, they are usually modeled as dichotomic variables). For the estimate of each coefficient, it is possible to generate a FN whose -cuts, , , are:where is the GLM point estimate of and the standard deviation of that estimate. So, from the fuzzy function , and bearing in mind Equations (15) and (28), the following FN is induced:A similar approach may be developed from the results in [51]. However, in this case, it must be taken into account that their approach to making fuzzy predictions from a statistical regression is built up from the interval predictions of residuals instead of using interval estimates of coefficients. So where is a fuzzy error term induced from the residuals of the conventional regression and, so:
Equations (26), (29) and (30) do not give a TFN. However, can be approximated as a TFN simply by using Equation (18).
Option 3
Fuzzy Regression Methods (FRMs) have been applied in several actuarial issues to fit relevant variables [52] for a comprehensive description of application areas). In this way, [53] fits the term structure of interest rates, [54,55] predicts claim provisions, and [25,28] adjusts the Lee-Carter mortality law.
To fit , the fuzzy extension of the log-Poisson regression by [55] may be used. It combines the conventional Poisson GLM and the minimum fuzziness principle by [56]. In this case, the coefficients in Equation (27) are supposed to be TFNs , . These coefficients are fitted in two stages. At the first stage, the centres are adjusted as in a conventional log-Poisson regression for . At the second stage, the spreads of , and and, consequently, and , , are fitted by solving a quadratic programming problem that minimizes the fuzziness of the system allowing that estimates on the dependent variable contain its observed values.
Once the parameters have been estimated, obtaining is straightforward (see Equation (29)).
Let us remark again that although is a TFN, is not. Nevertheless, can be approximated as a TFN with Equation (18):
Step 2. Obtain the fuzzy transition matrix.
We now suppose that after performing any of the options in Step 1, and the corresponding triangular approximate, the risk parameter is given as the TFN , with α-cuts, .
Fuzzy transitions probabilities come from the fuzzified version of Equation (6):
To obtain the -cuts of by using Equation (15), it is necessary to determine the sign of the first derivative of . Let us show the case of the Irish BMS whose transition matrix is Expression (7), and is either zero, , , or Then:
So, in Equations (33)–(36), , , , and therefore:
Similarly, any other probabilities for different FBMSs could be calculated. Notice that the FNs whose -cuts are Equations (37)–(40) do not have a triangular shape but they admit a triangular approximation by using the secant approach described in Section 3.1. If this is done, we obtain:
Numerical Application 2. Example 3 in [11] (p. 846) considers in Equation (6), and obtains the modal interval version of this crisp transition matrix:
Let us suppose that this interval is the 0-cut of the fuzzy estimate of a triangular in a Poisson FBMS (i.e., ) and , that is to say, . By considering Expression (32) and using Equations (41)–(44), the fuzzy transition matrix, , which corresponds to a FMC, is:
From this matrix, elements different from 0 in the associated matrix are, from Equation (9):
Numerical Application 3. In example 4 of [11] (p. 848), it is considered the risk factor for an Irish BMS. Like in our numerical application above, again, this interval is the 0-cut of the triangular fuzzy estimate for and , i.e., . So, the triangular approximates by Equations (41)–(44) to the probabilities of the transition matrix in Expression (7) and induced by Equation (32) are:
Let us remark that approximates in Equations (41)–(44) produce small errors of the real values by Equations (37)–(40). Table 3 shows that when approximating with Equation (43), the errors incurred on the lower and upper bounds of its -cuts are negligible since they are never over 0.001%. Moreover, notice that we measure the performance of the calculations on a scale of eleven grades of possibility. Following [38], this scale provides sufficient discernment without being excessive since we are using imprecise data and, therefore, more precision is not necessary for a FN representation.
Step 3. Determine the fuzzy stationary distribution function.
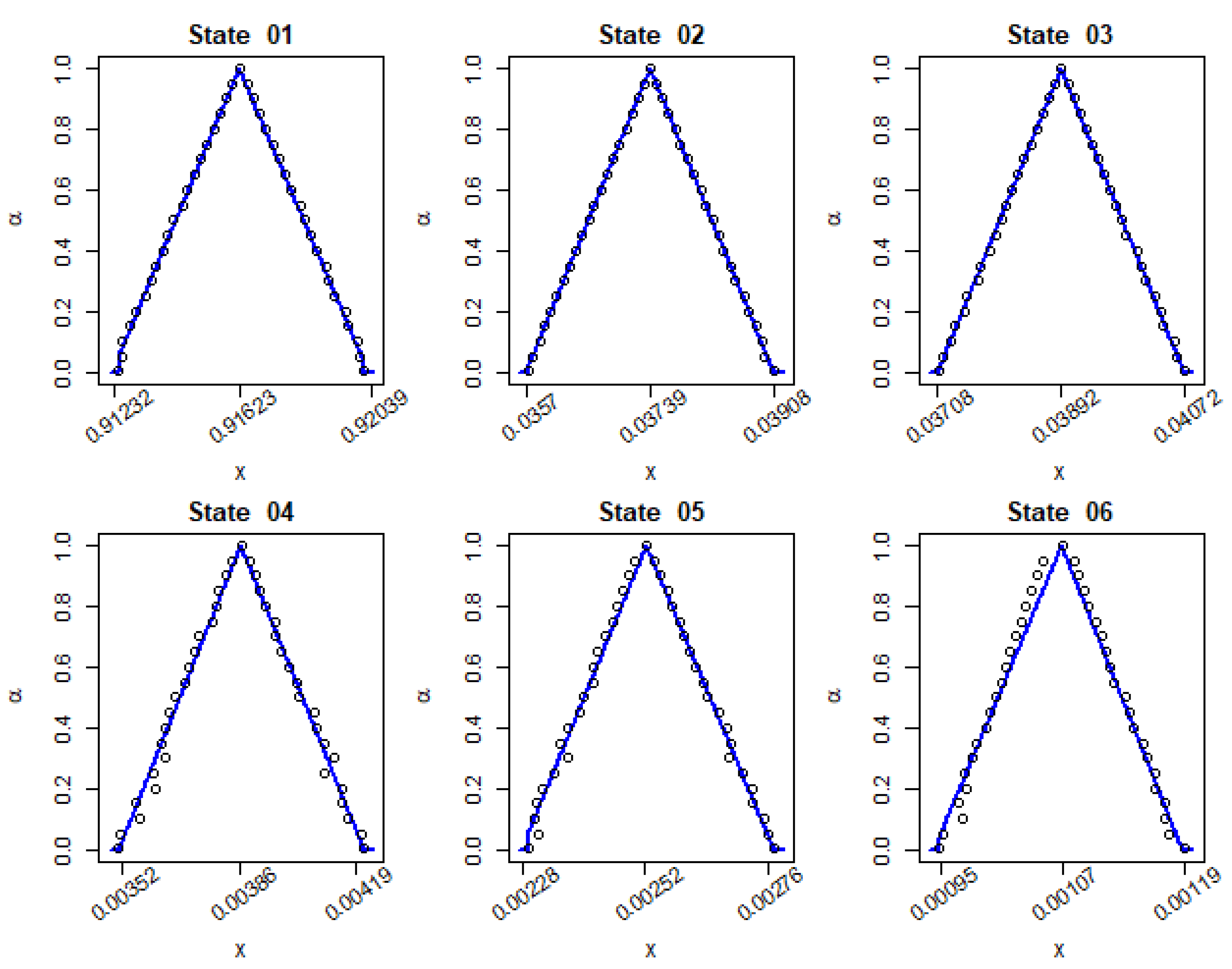
Once the fuzzy transition matrix associated with the FBMS has been obtained, to determine the fuzzy stationary state, Steps 1 to 4 in Section 3.2 should be applied and, therefore, optimization problems in Equations (23) and (24) must be solved. Notice that although the probabilities , , are obtained by solving complex optimization problems, the results of the numerical applications 4 and 5, that have been obtained with the R package FuzzyStatProb by [13] (see Figure 1 and Figure 2) suggest that its triangular approximate by using Equation (18), provides a satisfactory fitting.
Numerical Application 4. Now we compute the fuzzy stationary distribution for the fuzzy transition matrix in numerical application 2. In order to do so, we use the R package FuzzyStatProb described in [13], which is based on the use of Equations (23) and (24). The pseudo-codes and codes used are included in Appendix A and Appendix B, respectively, and the result of in Figure 2.
It should be remarked that the probabilities obtained by [11] (p. 847) are intervals whose values are the -cuts of the probabilities in our FMC.
Numerical Application 5. Let us consider the Irish BMS in numerical application 3. Table 4 shows the supports and cores of the fuzzy stationary state , when considering fuzzy probabilities in Equations (37)–(40). The pseudo-codes and the codes of the R package FuzzyStatProb that have been used to get these results are included in Appendix A and Appendix B, respectively. Figure 3 depicts the graphical representation of , .
The shape of the fuzzy stationary distribution suggests that their triangular approximate must work quite well. Table 5 shows that the relative deviations of the lower and upper bounds of the approximate of , with respect to the respective bounds of are always under 1%. Therefore, the above intuition is confirmed in the case of . We have also observed that this fact also applies to the other stationary probabilities in the numerical application. So, it can be written:
It is worth pointing out that the intervals fitted for the stationary state in [11] (p. 848) are the 0-cuts of , , in the fuzzy version of the Irish BMS.
Two considerations are worth highlighting:
- FBMSs generalize the results of crisp and modal interval BMSs as can be checked by comparing the results of numerical applications 1 and 5. The results of the crisp case are exactly the 1-cut of estimates from FBMSs whereas the estimates obtained by [11] (p. 848) coincide, except in the order of the interval lower and upper bounds in some cases, with the 0-cut of the results by our FBMSs. Likewise, operating by means of -cuts allows obtaining the simulations of intermediate scenarios between that of maximum fuzziness (generated by the 0-cut of ) and that with maximum reliability (that comes from ), as well as their grade of possibility. This information can be extremely useful to the decision-maker since it makes easier the sensitivity analysis for each possible value of Poisson parameter .
- Although a TFN does not produce triangular probabilities and , their triangular approximates work pretty well. We consider this result interesting for two reasons:
- (a)
- The calculations can be done easily with less computational effort. For example, in the two first rows of Table 5, we have performed the calculations on a scale with eleven grades of possibility. So, 20 optimization programs have been solved for a single probability (10 minimizing programs for the lower bounds of -cuts , and other 10 maximizing programs for the respective upper bounds). Likewise, obtaining the 1-cut implies nothing but solving a conventional Markov chain. This computational effort is reduced drastically by using the triangular approximate in Equation (18), which leads us to obtain the results in columns 3 and 4 of Table 5. In this case, it is enough to solve 2 optimization programs (1 minimizing program for the lower bound of the 0-cut and 1 maximizing for the upper one) and also, of course, evaluating a conventional BMS in . The interest in this result is amplified by the fact that the Irish BMS is relatively simple (there are 6 classes) and so it embeds only 36 and 6 probabilities . However, BMSs often have more than 20 classes (e.g., Belgian or German BMSs).
- (b)
- From the perspective of an actuary, a triangular approximate of the fuzzy probabilities can be very useful. A TFN provides an estimate of the most feasible, minimum, and maximum probability that can be interpreted intuitively without any knowledge of fuzzy set theory (FST). Therefore, the triangular approximates presented in this paper could facilitate the use of FBMSs in the insurance industry.
Step 4. Obtain the mean asymptotic premium, .
In order to obtain the asymptotic mean premium, we have to evaluate the fuzzy version of Equation (4), . Bearing in mind Equations (12)–(14), (16) and (17), we first consider the domain:
and then the set . The -cuts of , , are obtained by solving:
which are linear programming problems and so solvable, e.g., with the simplex algorithm. In fact, the problem to solve in this case is the same as that in [35].
A triangular approximate for , can be obtained by using the 0-cut and the 1-cut obtained from Equations (46) and (47) or, alternatively, if these results have not been previously calculated, by considering the TFNs , and solving the following linear problems:
In this latter way, 20 linear problems that come from Expressions (46) and (47) when is performed with a scale of eleven grades of possibility are reduced to 2 linear programs. Moreover:
Numerical Application 6. Let us consider again the Irish BMS in numerical application 3, i.e., . By using the premium level of each class (see Table 2), we obtain the -cuts of the fuzzy mean asymptotic premium, , from Equations (45)–(47). These results are in Table 6, which also show the -cuts of its triangular approximate, , by Equations (48)–(50). From that table, it can be seen that is practically triangular since the errors by in fitting are negligible. Notice that the triangular approximate provides a straightforward generalization of both the point estimate by a crisp BMS, 51.423, as well as the modal interval estimate in [11] (p. 849), [51.344, 51.498].
5. Sensitivity Analysis
In this Section, we evaluate the sensitivity of the errors of the triangular approximates seen in Section 4 with respect to the parameter . The following assumptions are considered:
- The core of may be low (0.04), medium (0.5), or high (0.96).
- The uncertainty of , which can be measured by its spreads, is symmetrical, i.e., left and right spreads are equal. This uncertainty can take two possible values: 0.002 or 0.015.
- We use the Irish BMS in Table 2.
Only results for and are shown. Furthermore, in order to avoid very long calculations, we have performed them on a scale with five grades of possibility. However, it can be verified that for other transition and stationary probabilities, and for a greater scale of grades of possibility, the conclusions to be drawn are practically the same. Table 7 shows that:
- The goodness of triangular approximates is always better than acceptable as can be checked in Table 7. In the worst case, for , and risk parameter , errors are below 5%.
Table 8 shows the mean asymptotic premiums for the cores of considered in Table 7 and the most uncertain scenario (left and right spread equal to 0.015). It can be checked that triangular approximates always reach a practically perfect match to , i.e., errors (as defined for Table 6) are very close to 0.
6. Summary and Further Research
BMSs are often modelled by means of MCs with crisp probabilities. In this paper, it is considered that transition probabilities of Markovian BMSs are not crisp but uncertain. This uncertainty is captured by using a FN, thus giving rise to the concept of FBMSs. FBMSs modeling is based on the concept of FMC by Buckley and Eslami in [12]. As a result, conventional BMSs can be understood as a particular case of our model where transition probabilities are singletons. The model in [11] represents the uncertainty by means of modal intervals. Since its results can be interpreted as the 0-cuts of ours, that model can also be seen as a particular case of our FBMS.
We assume, as it is often done in actuarial literature, that the number of claims in a period is a Poisson RV. Nonetheless, due to uncertainty, its parameter is not a real number but a TFN. So, to implement the model presented in the paper, it is necessary, firstly, to structure available information of the behavior of that RV. From this information, the Poisson parameter can be fitted by means of a TFN. Three alternatives to do so are proposed. Subsequently, by using -cut arithmetic, transition probabilities, the stationary distribution function, and the mean asymptotic premium of the FBMS are obtained by means of their -cuts. The lower and upper bounds of these -cuts can be understood as the result of a sensitivity analysis of the BMS that evaluates two extreme scenarios with possibility . That output can be very useful in actuarial decision-making processes since it provides a set of sensitivity analyses that is structured on the basis of their grade of reliability.
Although the mean number of claims, , is assumed to be a TFN, the outputs from our FBMS do not maintain that shape. However, in the numerical applications developed within the framework of the Irish BMS, we have verified that all the outputs obtained from a triangular are well approximated by a TFN that maintains the support and core of the original FN. This result is quite interesting. On the one hand, other more complex shapes of FNs can produce drawbacks in information modeling, such as problems with calculations in computer implementation. In this regard, we have observed that the number of optimizing problems to be solved in order to obtain transition probabilities, the stationary distribution, and the mean asymptotic premium is reduced drastically. Likewise, TFNs are very attractive from an insurance decision-making perspective since TFNs admit a very intuitive interpretation even without any knowledge of FST. At least, a TFN provides an estimate of the maximum, minimum, and most feasible values of a variable. Therefore, we feel that the triangular approximations introduced in this document would make it easier to use FMCs in the implementation of BMSs by the insurance industry.
Our methodologic approach can be extended, with the necessary adaptations, to other assumptions for the RV number of claims. Likewise, as far as we are concerned, there are several topics that may be the object of further research. Firstly, a wider investigation on how to apply a fuzzy Poisson regression in a BMS context must be carried out. Secondly, a more in-depth evaluation of the goodness of triangular approximations to BMS probabilities and the mean asymptotic premium is needed. In this respect, a wider range for the values of , a greater number of classes in the BMS, and other methods to fit triangular approximates must be tested. Thirdly, it is also needed to extend our model to the case in which fuzzy uncertainty in the BMS does not only appear in the number of claims but also their cost. Moreover, to model , instead of TFNs, other types of FNs, such as GFNs or IFNs, could be considered. We are aware that these tools allow capturing uncertainty with more nuances than FNs. However, their fitting has a greater cost than TFNs since it implies adjusting more parameters. Additionally, implementing computational operations with them is more expensive. This last issue is crucial in our context, especially in complex BMSs like, e.g., the German one. So, we feel that applying FNs suppose a balance between the simplicity of crisp or interval probabilities and more complex representations of uncertain quantities such as GFNs or IFNs. Finally, to evaluate the efficiency of a BMS, it is usually calculated the elasticity of the mean premium (4) with respect to the risk parameter . To do so, numerical simulations for point values of within the reference interval [0,1] are implemented (see, e.g., [2]). The use of fuzzy logic may be of interest in this concern. For example, that reference interval can be granulated into linguistic labels such as “low risk”, “medium risk” and so on, similarly to that proposed by [27] and [57]. Therefore, elasticity evaluations may be made on the basis of linguistic labels instead of point values on [0,1]. Fuzzy linguistic Markov chains, presented by [58], may be the starting point for this.
Author Contributions
All authors have contributed equally to all sections and stages of this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The APC has been funded by the University of Barcelona.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
Authors acknowledge helpful suggestions of anonymous reviewers.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Pseudo-Codes of Numerical Applications 2 and 4
# ----------------------------------
# Numerical Application 2
# ----------------------------------
FuzzyStationaryDistribution()
Plot for
# ----------------------------------
# Numerical Application 4
# ----------------------------------
FuzzyStationaryDistribution()
Plot for
Appendix B. R Codes of Numerical Applications 2 and 4
# ----------------------------------
# Numerical Application 2
# ----------------------------------
library(FuzzyNumbers)
library(FuzzyStatProb)
a = TriangularFuzzyNumber(0.037287, 0.039210, 0.041130)
b = TriangularFuzzyNumber(0.958870, 0.960790, 0.962713)
zero = TriangularFuzzyNumber(0, 0, 0)
allnumbers = list(a = a, b = b, zero = zero)
transitions = matrix(data = c(“a”, “b”, NA, “a”, NA, “b”, “a”, NA, “b”), nrow = 3, byrow = T)
states = c(“01”, “02”, “03”)
rownames(transitions) = states
colnames(transitions) = states
stationary = fuzzyStationaryProb(data = transitions, options = list(regression = “linear”, fuzzynumbers = allnumbers))
m <- matrix(1:3, nrow = 1, ncol = 3, byrow = TRUE)
layout(mat = m, heights = c(0.25, 0.25, 0.25, 0.25))
for (state in states){
cat(“State”, state, “\n”)
fz = stationary$fuzzyStatProb[[state]]
acuts = stationary$acuts[[state]]
print(acuts[acuts$y == 0.001,])
print(acuts[acuts$y == 0.999,])
par(mar = c(4, 4, 2, 1))
plot(fz, col = “blue”, main = paste(“State”, state),
cex.lab = 1.1, lwd = 2, xaxt = "n")
left = supp(fz)[1]
right = supp(fz)[2]
center = core(fz)[1]
at = round(c(left, right, center), digits = 4)
axis(1, at = at, labels = FALSE)
text(x = at, y = par(“usr”)[3] - 0.1,
labels = at, srt = 35, xpd = NA)
points(acuts)
print(“---------------”)
}
# ----------------------------------
# Numerical Application 4
# ----------------------------------
pN0 = TriangularFuzzyNumber(0.958870, 0.960789, 0.962713)
pN1 = TriangularFuzzyNumber(0.036583, 0.038432, 0.040273)
pNgt1 = TriangularFuzzyNumber(0.037287, 0.039211, 0.041130)
pNgt2 = TriangularFuzzyNumber(0.000704, 0.000779, 0.000858)
allnumbers2 = list(pN0 = pN0, pN1 = pN1, pNgt1 = pNgt1, pNgt2 = pNgt2)
transitions2 = matrix(data = c(“pN0”, NA, “pN1”, NA, NA, “pNgt2”, “pN0”, NA, NA, “pN1”, NA, “pNgt2”, NA, “pN0”, NA, NA, “pN1”, “pNgt2”, NA, NA, “pN0”, NA, NA, “pNgt1”, NA, NA, NA, “pN0”, NA, “pNgt1”, NA, NA, NA, NA, “pN0”, “pNgt1”), nrow = 6, byrow = T)
states2 = c(“01”, “02”, “03”, “04”, “05”, “06”)
rownames(transitions2) = states2
colnames(transitions2) = states2
stationary2 = fuzzyStationaryProb(data = transitions2, options = list(regression = “linear”, fuzzynumbers = allnumbers2))
m <- matrix(1:6, nrow = 2, ncol = 3, byrow = TRUE)
layout(mat = m, heights = c(0.25, 0.25, 0.25, 0.25))
for (state in states2){
cat(“State”, state, “\n”)
fz = stationary2$fuzzyStatProb[[state]]
acuts = stationary2$acuts[[state]]
print(acuts[acuts$y == 0.001,])
print(acuts[acuts$y == 0.999,])
par(mar = c(4, 4, 2, 1))
plot(fz, col = “blue”, main = paste(“State”, state),
cex.lab = 1.1, lwd = 2, xaxt = “n”)
left = supp(fz)[1]
right = supp(fz)[2]
center = core(fz)[1]
at = round(c(left, right, center), digits = 5)
axis(1, at = at, labels = FALSE)
text(x = at, y = par(“usr”)[3] - 0.1,
labels = at, srt = 35, xpd = NA)
points(acuts)
print(“---------------”)
}
References
- Lemaire, J. Bonus-Malus Systems in Automobile Insurance; Kluwer Academic Publishers: Norwell, MA, USA, 1995. [Google Scholar]
- Lemaire, J.; Zi, H. A comparative analysis of 30 bonus-malus systems. ASTIN Bull. 1994, 24, 287–309. [Google Scholar] [CrossRef] [Green Version]
- Meyer, U. Third Party Motor Insurance in Europe. Comparative Study of the Economical-Statistical Situation. In Personal Communications; University of Bamberg: Bamberg, Germany, 2000. [Google Scholar]
- Dodu, D. Comparative Analysis of Bonus Malus Systems in Italy and Central and Eastern Europe. 2017. Available online: https://www.milliman.com/en/insight/comparative-analysis-of-bonus-malus-systems-in-italy-and-central-and-eastern-europe (accessed on 7 October 2020).
- Pitrebois, S.; Denuit, M.; Walhin, J.F. Fitting the Belgian bonus-malus system. Belg. Actuar. Bull. 2003, 3, 58–62. [Google Scholar]
- de Pril, N. The Efficiency of a Bonus-Malus System. ASTIN Bull. 1978, 10, 59–72. [Google Scholar] [CrossRef] [Green Version]
- Bonsdorff, H. On the convergence rate of bonus-malus systems. ASTIN Bull. 1992, 22, 217–223. [Google Scholar] [CrossRef] [Green Version]
- Pitrebois, S.; Denuit, M.; Walhin, J.F. Bonus-malus scales in segmented tariffs: Gilde & Sundt’s work revisited. Aust. Actuar. J. 2004, 10, 107–125. [Google Scholar]
- Niemiec, M. Bonus-Malus Systems as Markov Set-Chains. ASTIN Bull. 2007, 37, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Asmussen, S. Modeling and performance of Bonus-Malus systems: Stationary versus age-correction. Risks 2014, 2, 49–73. [Google Scholar] [CrossRef] [Green Version]
- Adillon, R.; Lambert, J.; Mármol, M. Modal interval probability: Application to Bonus-Malus Systems. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2020, 28, 837–851. [Google Scholar] [CrossRef]
- Buckley, J.J.; Eslami, E. Fuzzy Markov Chains: Uncertain Probabilities. Mathw. Soft Comput. 2002, 9, 33–41. [Google Scholar]
- Villacorta, P.J.; Verdegay, J.L. FuzzyStatProb: An R Package for the Estimation of Fuzzy Stationary Probabilities from a Sequence of Observations of an Unknown Markov Chain. J. Stat. Softw. 2016, 71, 1–27. [Google Scholar] [CrossRef]
- Denuit, M.; Marchal, X.; Pitrebois, S.; Walhin, J.F. Actuarial Modelling of Claims Counts: Risk Classification, Credibility and Bonus-Malus Systems; Wiley: Chichester, UK, 2007. [Google Scholar]
- Vernic, R. On risk measures and capital allocation for distributions depending on parameters with interval or fuzzy uncertainty. Appl. Soft Comput. 2018, 64, 199–215. [Google Scholar] [CrossRef]
- Wierzchoń, S.T. Randomness and Fuzziness in A Linear Programming Problem. In Combining Fuzzy Imprecision with Probabilistic Uncertainty in Decision Making. Lecture Notes in Economics and Mathematical Systems; Kacprzyk, J., Fedrizzi, M., Eds.; Springer: Berlin, Germany, 1988; Volume 310, pp. 227–239. [Google Scholar] [CrossRef]
- Buckley, J.J. Uncertain probabilities III: The continuous case. Soft Comput. 2004, 8, 200–206. [Google Scholar] [CrossRef]
- Buckley, J.J.; Eslami, E. Uncertain probabilities II: The continuous case. Soft Comput. 2004, 8, 193–199. [Google Scholar] [CrossRef]
- Buckley, J.J.; Eslami, E. Uncertain probabilities I: The discrete case. Soft Comput. 2003, 7, 500–505. [Google Scholar] [CrossRef]
- Zmeškal, Z. Value at risk methodology under soft conditions approach (fuzzy-stochastic approach). Eur. J. Oper. Res. 2005, 161, 337–347. [Google Scholar] [CrossRef]
- Moussa, A.M.; Kamdem, J.S.; Terraza, M. Fuzzy value-at-risk and expected shortfall for portfolios with heavy-tailed returns. Econ. Model. 2014, 39, 247–256. [Google Scholar] [CrossRef]
- Shapiro, A.F. Fuzzy logic in insurance. Insur. Math. Econ. 2004, 35, 399–424. [Google Scholar] [CrossRef]
- Huang, T.; Zhao, R.; Tang, W. Risk model with fuzzy random individual claim amount. Eur. J. Oper. Res. 2009, 192, 879–890. [Google Scholar] [CrossRef]
- Kemaloglu, S.A.; Shapiro, A.F.; Tank, F.; Apaydin, A. Using fuzzy logic to interpret dependent risks. Insur. Math. Econ. 2018, 79, 101–106. [Google Scholar] [CrossRef]
- Koissi, M.C.; Shapiro, A.F. Fuzzy formulation of the Lee–Carter model for mortality forecasting. Insur. Math. Econ. 2006, 39, 287–309. [Google Scholar] [CrossRef]
- Shapiro, A.F. Modeling future lifetime as a fuzzy random variable. Insur. Math. Econ. 2013, 53, 864–870. [Google Scholar] [CrossRef]
- Andrés-Sánchez, J.D.; Puchades, L.G.V. Some computational results for the fuzzy random value of life actuarial liabilities. Iran. J. Fuzzy Syst. 2017, 14, 1–25. [Google Scholar] [CrossRef]
- Andrés-Sánchez, J.D.; Puchades, L.G.V. A Fuzzy-Random Extension of the Lee–Carter Mortality Prediction Model. Int. J. Comput. Intell. Syst. 2019, 12, 775–794. [Google Scholar] [CrossRef] [Green Version]
- Jorba, L.; Adillon, R. A Generalization of Trapezoidal Fuzzy Numbers Based on Modal Interval Theory. Symmetry 2017, 9, 198. [Google Scholar] [CrossRef] [Green Version]
- Loimaranta, K. Some Asymptotic Properties of Bonus Systems. ASTIN Bull. 1972, 6, 233–245. [Google Scholar] [CrossRef] [Green Version]
- Heras, A.; Vilar, J.L.; Gil, J.A. Asymptotic Fairness of Bonus-Malus Systems and Optimal Scales of Premiums. Geneva Pap. Risk Insur. Theory 2002, 27, 61–82. [Google Scholar] [CrossRef]
- Kafková, S. Bonus-malus systems in vehicle insurance. Procedia Econ. Financ. 2015, 23, 216–222. [Google Scholar] [CrossRef] [Green Version]
- Dong, W.; Shah, H.C. Vertex method for computing functions of fuzzy variables. Fuzzy Sets Syst. 1987, 24, 65–78. [Google Scholar] [CrossRef]
- Buckley, J.J.; Qu, Y. On using α-cuts to evaluate fuzzy equations. Fuzzy Sets Syst. 1990, 38, 309–312. [Google Scholar] [CrossRef]
- Dong, W.; Wong, F.S. Interactive fuzzy variables and fuzzy decisions. Fuzzy Sets Syst. 1989, 29, 1–19. [Google Scholar] [CrossRef]
- Kaufmann, A. Fuzzy Subsets Applications in O.R. and Management. In Fuzzy Set Theory and Applications; Jones, A., Kaufmann, A., Zimmermann, H.-J., Eds.; Springer: Dordrecht, The Netherlands, 1986; pp. 257–300. [Google Scholar] [CrossRef]
- Heberle, J.; Thomas, A. Combining chain-ladder reserving with fuzzy numbers. Insur. Math. Econ. 2014, 55, 96–104. [Google Scholar] [CrossRef]
- Jiménez, M.; Rivas, J.A. Fuzzy number approximation. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 69–78. [Google Scholar] [CrossRef]
- Grzegorzewski, P.; Pasternak-Winiarska, K. Natural trapezoidal approximations of fuzzy numbers. Fuzzy Sets Syst. 2014, 250, 90–109. [Google Scholar] [CrossRef]
- Grzegorzewski, P.; Mrówka, E. Trapezoidal approximations of fuzzy numbers. Fuzzy Sets Syst. 2005, 153, 115–135. [Google Scholar] [CrossRef]
- Kleyle, R.M.; de Korvin, A. Constructing one-step and limiting fuzzy transition probabilities for finite Markov chains. J. Intell. Fuzzy Syst. 1998, 6, 223–235. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Avrachenkov, K.E.; Sánchez, E. Fuzzy Markov Chains: Specificities and Properties. In Proceedings of the 8th IPMU’2000 Conference, Madrid, Spain, 3–7 July 2000; pp. 1851–1856. [Google Scholar]
- Li, G.; Xiu, B. Fuzzy Markov Chains Based on the Fuzzy Transition Probability. In Proceedings of the 26th Chinese Control and Decision Conference, Changsha, China, 31 May–2 June 2014; pp. 4351–4356. [Google Scholar] [CrossRef]
- Buckley, J.J. Fuzzy Probabilities: New Approach and Applications, Volume 115 of Studies in Fuzziness and Soft Computing, 2nd ed.; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- Bardossy, A.; Duckstein, L.; Bogardi, I. Combination of fuzzy numbers representing expert opinions. Fuzzy Sets Syst. 1993, 57, 173–181. [Google Scholar] [CrossRef]
- Hsu, H.M.; Chen, C.T. Aggregation of fuzzy opinions under group decision making. Fuzzy Sets Syst. 1996, 79, 279–285. [Google Scholar] [CrossRef]
- Tsabadze, T. A method for aggregation of trapezoidal fuzzy estimates under group decision-making. Fuzzy Sets Syst. 2015, 266, 114–130. [Google Scholar] [CrossRef]
- Buckley, J.J. Fuzzy statistics: Regression and prediction. Soft Comput. 2005, 9, 769–775. [Google Scholar] [CrossRef]
- Sfiris, D.S.; Papadopoulos, B.K. Non-asymptotic fuzzy estimators based on confidence intervals. Inf. Sci. 2014, 279, 446–459. [Google Scholar] [CrossRef]
- Al-Kandari, M.; Adjenughwure, K.; Papadopoulos, K. A Fuzzy-Statistical Tolerance Interval from Residuals of Crisp Linear Regression Models. Mathematics 2020, 8, 1422. [Google Scholar] [CrossRef]
- Andrés-Sánchez, J.D. Fuzzy Regression Analysis: An Actuarial Perspective. In Fuzzy Statistical Decision-Making. Studies in Fuzziness and Soft Computing; Kahraman, C., Kabak, Ö., Eds.; Springer: Cham, Switzerland, 2016; Volume 343, pp. 175–201. [Google Scholar] [CrossRef]
- Shapiro, A.F. Fuzzy Regression and the Term Structure of Interest Rates Revisited. In Proceedings of the 14th International AFIR Colloquium, Boston, MA, USA, 8–9 November 2004; pp. 29–45. [Google Scholar]
- Apaydin, A.; Baser, F. Hybrid fuzzy least-squares regression analysis in claims reserving with geometric separation method. Insur. Math. Econ. 2010, 47, 113–122. [Google Scholar] [CrossRef]
- Woundjiagué, A.; Bidima, M.L.D.M.; Mwangi, R.W. An Estimation of a Hybrid Log-Poisson Regression Using a Quadratic Optimization Program for Optimal Loss Reserving in Insurance. Adv. Syst. 2019, 2019, 1393946. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nii, M. Fuzzy regression using asymmetric fuzzy coefficients and fuzzified neural networks. Fuzzy Sets Syst. 2001, 119, 273–290. [Google Scholar] [CrossRef]
- Andrés-Sánchez, J.D.; Puchades, L.G.V.; Zhang, A. Incorporating fuzzy information in pricing substandard annuities. Comput. Ind. Eng. 2020, 145, 106475. [Google Scholar] [CrossRef]
- Villacorta, P.J.; Verdegay, J.L.; Pelta, D. Towards Fuzzy Linguistic Markov Chains. In Proceedings of the 8th Conference of the European Society for Fuzzy Logic and Technology (EUSFLAT-13), Milan, Italy, 11–13 September 2013. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Graphical representation of our fuzzy bonus-malus systems (FBMS) model.

Figure 2.
Results of Numerical Application 2. Source: Own elaboration.

Figure 3.
Results of the Irish BMS when —graphical representation. Source: Own elaboration.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Elements of a bonus-malus system (BMS).
| Class | Premium Level | Class after Claims | |||
|---|---|---|---|---|---|
| … | |||||
 | |||||
| 1 | |||||
Source: Own elaboration based on [10].
Table 2.
Irish bonus-malus system.
| Class | Premium Level | Class after Claims | ||
|---|---|---|---|---|
| 6 | 100 | 5 | 6 | 6 |
| 5 | 90 | 4 | 6 | 6 |
| 4 | 80 | 3 | 6 | 6 |
| 3 | 70 | 2 | 5 | 6 |
| 2 | 60 | 1 | 4 | 6 |
| 1 | 50 | 1 | 3 | 6 |
Source: [10].
Table 3.
-cuts of , it’s triangular approximate, and errors.
| Error * | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.03921 | 0.03921 | 0.03921 | 0.03921 | 0.000% | 0.000% |
| 0.9 | 0.03902 | 0.03940 | 0.03902 | 0.03940 | 0.000% | 0.000% |
| 0.8 | 0.03883 | 0.03959 | 0.03883 | 0.03959 | 0.001% | 0.001% |
| 0.7 | 0.03863 | 0.03979 | 0.03863 | 0.03979 | 0.001% | 0.001% |
| 0.6 | 0.03844 | 0.03998 | 0.03844 | 0.03998 | 0.001% | 0.001% |
| 0.5 | 0.03825 | 0.04017 | 0.03825 | 0.04017 | 0.001% | 0.001% |
| 0.4 | 0.03806 | 0.04036 | 0.03806 | 0.04036 | 0.001% | 0.001% |
| 0.3 | 0.03786 | 0.04055 | 0.03786 | 0.04055 | 0.001% | 0.001% |
| 0.2 | 0.03767 | 0.04075 | 0.03767 | 0.04075 | 0.001% | 0.001% |
| 0.1 | 0.03748 | 0.04094 | 0.03748 | 0.04094 | 0.000% | 0.000% |
| 0 | 0.03729 | 0.04113 | 0.03729 | 0.04113 | 0.000% | 0.000% |
Source: Own elaboration. * and .
Table 4.
Results of the Irish BMS when —supports and cores.
| Stationary Probabilities | ||
|---|---|---|
| 0.916232 | ||
| 0.037394 | ||
| 0.038921 | ||
| 0.003861 | ||
| 0.002523 | ||
| 0.001069 |
Source: Own elaboration.
Table 5.
-cuts of , it’s triangular approximate, , and errors.
| Error * | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.00386 | 0.00386 | 0.00386 | 0.00386 | 0.000% | 0.000% |
| 0.9 | 0.00381 | 0.00390 | 0.00383 | 0.00389 | 0.345% | 0.188% |
| 0.8 | 0.00379 | 0.00393 | 0.00379 | 0.00393 | 0.092% | 0.082% |
| 0.7 | 0.00375 | 0.00398 | 0.00376 | 0.00396 | 0.368% | 0.405% |
| 0.6 | 0.00371 | 0.00400 | 0.00372 | 0.00399 | 0.442% | 0.145% |
| 0.5 | 0.00368 | 0.00403 | 0.00369 | 0.00402 | 0.289% | 0.194% |
| 0.4 | 0.00364 | 0.00408 | 0.00366 | 0.00406 | 0.324% | 0.474% |
| 0.3 | 0.00360 | 0.00411 | 0.00362 | 0.00409 | 0.537% | 0.484% |
| 0.2 | 0.00356 | 0.00413 | 0.00359 | 0.00412 | 0.655% | 0.272% |
| 0.1 | 0.00354 | 0.00418 | 0.00355 | 0.00415 | 0.406% | 0.550% |
| 0 | 0.00352 | 0.00419 | 0.00352 | 0.00419 | 0.000% | 0.000% |
Source: Own elaboration. * and .
Table 6.
-cuts of it’s triangular approximate and its errors.
| Error * | ||||||
|---|---|---|---|---|---|---|
| 1 | 51.423 | 51.423 | 51.423 | 51.423 | 0.000% | 0.000% |
| 0.9 | 51.415 | 51.430 | 51.415 | 51.430 | 0.000% | 0.000% |
| 0.8 | 51.407 | 51.438 | 51.407 | 51.438 | 0.000% | 0.000% |
| 0.7 | 51.399 | 51.445 | 51.399 | 51.445 | 0.000% | 0.000% |
| 0.6 | 51.391 | 51.453 | 51.391 | 51.453 | 0.000% | 0.000% |
| 0.5 | 51.383 | 51.460 | 51.383 | 51.460 | 0.000% | 0.000% |
| 0.4 | 51.375 | 51.468 | 51.375 | 51.468 | 0.000% | 0.000% |
| 0.3 | 51.367 | 51.475 | 51.367 | 51.475 | 0.000% | 0.000% |
| 0.2 | 51.359 | 51.483 | 51.359 | 51.483 | 0.000% | 0.000% |
| 0.1 | 51.352 | 51.491 | 51.352 | 51.491 | 0.000% | 0.000% |
| 0 | 51.344 | 51.498 | 51.344 | 51.498 | 0.000% | 0.000% |
Source: Own elaboration. * and .
Table 7.
-cuts of and , their triangular approximate and errors for different parameters .
| Error | Error | |||||||
| 1 | 0.03921 | 0.03921 | 0.000% | 0.000% | 0.00386 | 0.00386 | 0.000% | 0.000% |
| 0.75 | 0.03873 | 0.03969 | 0.001% | 0.001% | 0.00376 | 0.00395 | 0.044% | 0.041% |
| 0.5 | 0.03825 | 0.04017 | 0.001% | 0.001% | 0.00367 | 0.00405 | 0.060% | 0.054% |
| 0.25 | 0.03777 | 0.04065 | 0.001% | 0.001% | 0.00358 | 0.00415 | 0.046% | 0.039% |
| 0 | 0.03729 | 0.04113 | 0.000% | 0.000% | 0.00352 | 0.00419 | 0.000% | 0.000% |
| Error | Error | |||||||
| 1 | 0.03921 | 0.03921 | 0.000% | 0.000% | 0.00386 | 0.00386 | 0.000% | 0.000% |
| 0.75 | 0.03560 | 0.04281 | 0.057% | 0.047% | 0.00318 | 0.00460 | 2.985% | 1.955% |
| 0.5 | 0.03198 | 0.04639 | 0.085% | 0.058% | 0.00257 | 0.00540 | 4.958% | 2.208% |
| 0.25 | 0.02834 | 0.04996 | 0.072% | 0.040% | 0.00202 | 0.00626 | 4.757% | 1.420% |
| 0 | 0.02469 | 0.05351 | 0.000% | 0.000% | 0.00153 | 0.00717 | 0.000% | 0.000% |
| Error | Error | |||||||
| 1 | 0.39347 | 0.39347 | 0.000% | 0.000% | 0.15618 | 0.15618 | 0.000% | 0.000% |
| 0.75 | 0.39317 | 0.39377 | 0.000% | 0.000% | 0.15617 | 0.15618 | 0.000% | 0.000% |
| 0.5 | 0.39286 | 0.39408 | 0.000% | 0.000% | 0.15617 | 0.15618 | 0.001% | 0.001% |
| 0.25 | 0.39256 | 0.39438 | 0.000% | 0.000% | 0.15617 | 0.15618 | 0.000% | 0.000% |
| 0 | 0.39226 | 0.39468 | 0.000% | 0.000% | 0.15617 | 0.15618 | 0.000% | 0.000% |
| ) | ||||||||
| Error | Error | |||||||
| 1 | 0.39347 | 0.39347 | 0.000% | 0.000% | 0.15618 | 0.15618 | 0.000% | 0.000% |
| 0.75 | 0.39119 | 0.39574 | 0.003% | 0.003% | 0.15615 | 0.15618 | 0.024% | 0.023% |
| 0.5 | 0.38890 | 0.39800 | 0.004% | 0.004% | 0.15611 | 0.15620 | 0.032% | 0.030% |
| 0.25 | 0.38661 | 0.40025 | 0.003% | 0.003% | 0.15604 | 0.15623 | 0.024% | 0.022% |
| 0 | 0.38430 | 0.40250 | 0.000% | 0.000% | 0.15596 | 0.15625 | 0.000% | 0.000% |
| Error | Error | |||||||
| 1 | 0.61711 | 0.61711 | 0.000% | 0.000% | 0.09850 | 0.09850 | 0.000% | 0.000% |
| 0.75 | 0.61692 | 0.61730 | 0.000% | 0.000% | 0.09842 | 0.09857 | 0.000% | 0.000% |
| 0.5 | 0.61672 | 0.61749 | 0.000% | 0.000% | 0.09835 | 0.09864 | 0.000% | 0.000% |
| 0.25 | 0.61653 | 0.61768 | 0.000% | 0.000% | 0.09827 | 0.09872 | 0.000% | 0.000% |
| 0 | 0.61634 | 0.61787 | 0.000% | 0.000% | 0.09820 | 0.09879 | 0.000% | 0.000% |
| Error | Error | |||||||
| 1 | 0.61711 | 0.61711 | 0.000% | 0.000% | 0.09850 | 0.09850 | 0.000% | 0.000% |
| 0.75 | 0.61567 | 0.61854 | 0.001% | 0.001% | 0.09794 | 0.09905 | 0.003% | 0.003% |
| 0.5 | 0.61422 | 0.61997 | 0.002% | 0.002% | 0.09738 | 0.09962 | 0.004% | 0.003% |
| 0.25 | 0.61278 | 0.62139 | 0.001% | 0.001% | 0.09683 | 0.10018 | 0.003% | 0.003% |
| 0 | 0.61132 | 0.62281 | 0.000% | 0.000% | 0.09628 | 0.10074 | 0.000% | 0.000% |
Source: Own Elaboration.
Table 8.
-cuts of , it’s triangular approximate and errors for different parameters .
| Error | Error | Error | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 51.422 | 51.422 | 0.000% | 0.000% | 81.396 | 81.396 | 0.000% | 0.000% | 93.246 | 93.246 | 0.000% | 0.000% |
| 0.75 | 51.270 | 51.579 | 0.012% | 0.012% | 81.215 | 81.574 | 0.004% | 0.004% | 93.200 | 93.292 | 0.001% | 0.001% |
| 0.5 | 51.121 | 51.739 | 0.016% | 0.016% | 81.033 | 81.751 | 0.005% | 0.005% | 93.153 | 93.338 | 0.001% | 0.001% |
| 0.25 | 50.977 | 51.904 | 0.012% | 0.012% | 80.848 | 81.925 | 0.004% | 0.004% | 93.106 | 93.383 | 0.001% | 0.001% |
| 0 | 50.836 | 52.073 | 0.000% | 0.000% | 80.662 | 82.098 | 0.000% | 0.000% | 93.058 | 93.427 | 0.000% | 0.000% |
Source: Own Elaboration.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Villacorta, P.J.; González-Vila Puchades, L.; de Andrés-Sánchez, J. Fuzzy Markovian Bonus-Malus Systems in Non-Life Insurance. Mathematics 2021, 9, 347. https://doi.org/10.3390/math9040347
AMA Style
Villacorta PJ, González-Vila Puchades L, de Andrés-Sánchez J. Fuzzy Markovian Bonus-Malus Systems in Non-Life Insurance. Mathematics. 2021; 9(4):347. https://doi.org/10.3390/math9040347
Chicago/Turabian StyleVillacorta, Pablo J., Laura González-Vila Puchades, and Jorge de Andrés-Sánchez. 2021. "Fuzzy Markovian Bonus-Malus Systems in Non-Life Insurance" Mathematics 9, no. 4: 347. https://doi.org/10.3390/math9040347
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.