 Craig M. Hardner1*
Craig M. Hardner1* Mulusew Fikere1†
Mulusew Fikere1† Ksenija Gasic2
Ksenija Gasic2 Cassia da Silva Linge2†
Cassia da Silva Linge2† Margaret Worthington3David Byrne4
Margaret Worthington3David Byrne4 Zena Rawandoozi4
Zena Rawandoozi4 Cameron Peace5
Cameron Peace5- 1Queensland Alliance for Agriculture and Food Innovation, The University of Queensland, Brisbane, QLD, Australia
- 2Department of Plant and Environmental Sciences, Clemson University, Clemson, SC, United States
- 3Faculty Horticulture, University of Arkansas System Division of Agriculture, Fayetteville, AR, United States
- 4College of Agriculture and Life Sciences, Texas A&M University, College Station, TX, United States
- 5Department of Horticulture, Washington State University, Pullman, WA, United States
Genotype-by-environment interaction (G × E) is a common phenomenon influencing genetic improvement in plants, and a good understanding of this phenomenon is important for breeding and cultivar deployment strategies. However, there is little information on G × E in horticultural tree crops, mostly due to evaluation costs, leading to a focus on the development and deployment of locally adapted germplasm. Using sweetness (measured as soluble solids content, SSC) in peach/nectarine assessed at four trials from three US peach-breeding programs as a case study, we evaluated the hypotheses that (i) complex data from multiple breeding programs can be connected using GBLUP models to improve the knowledge of G × E for breeding and deployment and (ii) accounting for a known large-effect quantitative trait locus (QTL) improves the prediction accuracy. Following a structured strategy using univariate and multivariate models containing additive and dominance genomic effects on SSC, a model that included a previously detected QTL and background genomic effects was a significantly better fit than a genome-wide model with completely anonymous markers. Estimates of an individual’s narrow-sense and broad-sense heritability for SSC were high (0.57–0.73 and 0.66–0.80, respectively), with 19–32% of total genomic variance explained by the QTL. Genome-wide dominance effects and QTL effects were stable across environments. Significant G × E was detected for background genome effects, mostly due to the low correlation of these effects across seasons within a particular trial. The expected prediction accuracy, estimated from the linear model, was higher than the realised prediction accuracy estimated by cross-validation, suggesting that these two parameters measure different qualities of the prediction models. While prediction accuracy was improved in some cases by combining data across trials, particularly when phenotypic data for untested individuals were available from other trials, this improvement was not consistent. This study confirms that complex data can be combined into a single analysis using GBLUP methods to improve understanding of G × E and also incorporate known QTL effects. In addition, the study generated baseline information to account for population structure in genomic prediction models in horticultural crop improvement.
Introduction
Genotype-by-environment interaction (G × E) is s common phenomenon in plant breeding (Allard and Bradshaw, 1964). Statistically, G × E may arise due to heterogeneity in variance and/or genetic correlation of less than one across environments (Baker, 1988; Burgueno et al., 2008). The consequence of significant G × E is that elite-performing germplasm in some environments is not necessarily elite in other environments.
Knowledge of G × E is important for designing breeding programs and deploying cultivars (Comstock and Moll, 1963; Cooper and Delacy, 1994; Harshman et al., 2016). If G × E is small, selection strategies will aim to identify germplasm with elite average performance (Hardner et al., 2019b; Kumar et al., 2019). This strategy may also be used where significant G × E is detected but no repeatable factor can be defined to classify and, hence, manage germplasm deployment. In contrast, germplasm may be targeted to specific environments if a repeatable factor explains some, or all, of G × E (Allard and Bradshaw, 1964; Cooper et al., 1996; Basford and Cooper, 1998).
Evaluation of G × E has commonly been undertaken using multi-environment trials (METs) of the connected germplasm (Malosetti et al., 2013). Advanced linear mixed model methods have been applied to combine data from multiple trials with different designs, repeated measures, and unbalanced replication within and across trials (Smith et al., 2005; Hardner et al., 2016, 2019a; Hardner, 2017). Accuracy of prediction in specific environments is commonly improved where data from multiple trials are combined (Hardner, 2017). Historically, the simple univariate genotype’s main effect plus genotype-by-environment interaction model is used to quantify G × E, although this approach is limited as uniform genetic variance and common pairwise correlation among all environments are essentially assumed (Smith et al., 2005). Multivariate models with specific genetic variance, and pairwise correlations, among pairs of environments, may improve the modelling of G × E (Smith et al., 2005; Malosetti et al., 2013). However, these models become complex as the number of environments increases, leading to over-parameterisation and difficulties in obtaining unique solutions for the G × E covariance matrices (Kelly et al., 2007). Solutions to these complex matrices can be obtained using factor-analytic parameterisation to model the major patterns in the covariance matrices with a reduced set of parameter matrices (Smith et al., 2001; Thompson et al., 2003; Kelly et al., 2007; Malosetti et al., 2013; Hardner, 2017).
While horticultural crops are planted around the world, knowledge of patterns of G × E in these crops is generally limited (Hardner et al., 2021). Where multi-environment trials have been used, clonal replication is usually employed to connect trials, but this can be expensive due to the large size of the experimental unit and the cost of assessing these units over several seasons (Peace et al., 2014; Hardner et al., 2021). Without information on the patterns of G × E, many horticultural tree breeding programs tend to have a local focus (e.g., Okie et al., 2008; Iezzoni et al., 2020) due to a lack of confidence in the performance in local target environments of germplasm developed in exotic environments. Local testing may also lead to little replication of the same germplasm among programs. Cost constraints may also mean many programs rely on unadjusted phenotypic observations of un-replicated germplasm to select new parents or advanced elite selections (Okie et al., 2008).
Genomic Best Linear Unbiased Prediction (GBLUP), which is a linear model that incorporates relationship matrices estimated from genome-wide genotypic data (genomic relationship matrices, GRMs), may offer a solution to exploring G × E patterns and improving confidence in the relative performance of exotic germplasm in local environments (Heslot et al., 2013; Hardner et al., 2021; Sneller et al., 2021). Essentially, genome-wide genotypic data enables the tracking of replicated chromosome segments across individuals. Therefore, the GRM models the overall genomic relatedness as well as the linkage disequilibrium between genetic markers and trait loci in a germplasm set (Habier et al., 2007). Commonly, additive genetic effects are modelled (Habier et al., 2007; VanRaden, 2008; Hayes et al., 2009b), but GRMs have been developed to model non-additive variation (Su et al., 2012). As GBLUP is an extension of standard linear mixed models, the flexibility of these mixed models can be exploited (Zhang et al., 2007; VanRaden, 2008; Heslot et al., 2012; Meuwissen et al., 2016).
Peach [Prunus persica (L.) Batsch] is the third-most important temperate fruit crop globally in terms of production and is consumed mainly as fresh fruit (Byrne et al., 2012; NASS USDA, 2017; FAO, 2020). Currently, peach production occurs in a wide range of adaptation zones, ranging from temperate high chill to subtropical and highland tropical low chill environments (Byrne, 2005; Okie et al., 2008; Luedeling, 2012). Although peach breeding programs develop cultivars for their specific adaptation zone, all new peach cultivars require market-specific fruit quality traits to be successful (Okie et al., 2008; Byrne et al., 2012; Cirilli et al., 2016). Peach breeding is undertaken using traditional phenotypic selection, but genotypic information is increasingly being incorporated (Peace, 2017). Genomic resources for peaches are available (Verde et al., 2012, 2013, 2017; Aranzana et al., 2019; Iezzoni et al., 2020), as well as the significant quantitative trait loci (QTLs) for many important quality traits that have been developed into DNA tests and used for selection (Eduardo et al., 2014; Sandefur et al., 2017; Vanderzande et al., 2018; Gasic and Saski, 2019; da Silva Linge et al., 2021; Fleming et al., 2022).
Sweetness is an important attribute supporting consumer demand for peach (Okie et al., 2008; Byrne et al., 2012; Delgado et al., 2013) and is a common selection priority in peach breeding (Byrne et al., 2012; Cirilli et al., 2016; Kelley et al., 2016). Consumer preference for peach fruit depends on the amount of total soluble sugars in ripe fruit (Crisosto et al., 2006; Cirilli et al., 2016). Broad and narrow sense heritability of sweetness measured as soluble solids content (SSC) in peach is reportedly very low (0.01) to moderate (0.47), as is the G × E (Byrne et al., 2012; Cirilli et al., 2016; Rawandoozi et al., 2020; da Silva Linge et al., 2021). Large effect QTLs for SSC and associated genetic markers in peach have been reported (Dirlewanger et al., 1999; Eduardo et al., 2011; Fresnedo-Ramirez et al., 2015; Hernandez Mora et al., 2017; Nunez-Lillo et al., 2019; Rawandoozi et al., 2020) with a large-effect QTL on chromosome 4 that is suggested to have a pleiotropic effect on SSC and ripening date (RD) (Eduardo et al., 2011).
This study evaluated the hypotheses that, by using GBLUP models, complex data from multiple breeding programs can be connected to improve knowledge of G × E for breeding and new cultivar deployment, and accounting for a known large-effect QTL improves the prediction accuracy. Hence, the objectives of this study were to (i) determine the magnitude of G × E for peach fruit sweetness measured as SSC and (ii) determine the improvement in prediction accuracy by accounting for the large-effect sweetness QTL on chromosome 4. The unbalanced dataset was from three US peach breeding programs with four trial locations and 2–3 seasons each with 577 accessions in total and 2–3 each with SNP array genotypic data for 4,473 SNPs.
Materials and methods
Plant material and phenotypic data
A total of 577 accessions (cultivars, breeding parents, progeny) from three breeding programs—Texas A&M University (TAMU) (Rawandoozi et al., 2021), University of Arkansas (UARK) (Worthington and Clark, 2021), and Clemson University (CLEM)—were evaluated for SSC (units: °Brix) for two or three seasons across four trial locations established in several US states (TAMU: Fresno CA, and College Station TX; UARK: Clarksville AR; CLEM: Seneca SC) (Iezzoni et al., 2020; Supplementary Table 1). The preliminary genotypic analysis identified four pairs of accessions with identical SNP-array DNA profiles (three pairs from UARK and one from CLEM), reducing the number of genetically unique individuals to 573 (Table 1).
At Fresno (F), 137 individuals were assessed for SSC in the 2011 and 2012 seasons, while 111 were assessed at College Station (G) in 2012 and 2013, with 104 individuals in common across these two TAMU trial locations (Table 1A). These individuals were in nine biparental F1 peach/nectarine families created from eight low to moderate chill nectarine/peach parents, with family sizes of 8–87 individuals. For the Fresno trial, SSC was assessed with a temperature-compensating refractometer of a composite sample for each individual in a season consisting of a macerated fruit pulp that was centrifuged to collect the juice from five fruit. At College Station, a hand-held refractometer was used to assess juice from individual fruit, and the average of 3–5 five fruits was recorded. Preliminary analysis identified that SSC data obtained from the composite and individual fruit protocols were highly correlated; thus, data were combined.
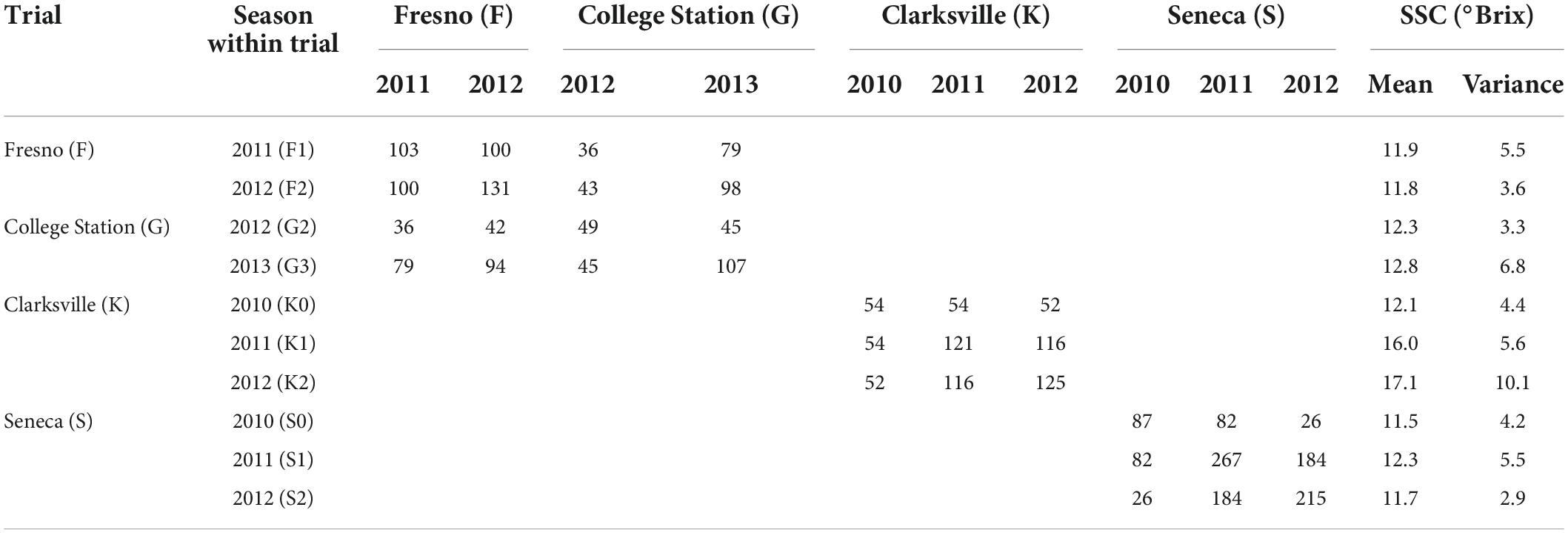
Table 1A. Number of peach/nectarine individuals within and among ten trial-by-season environments assessed for SSC from three breeding programs (Fresno and College Station: Texas A&M University (TAMU) population, Clarksville: University of Arkansas (UARK) population; and Seneca: Clemson University (CLEM) population).
At Clarksville (K), 133 accessions (130 unique individuals) were assessed for SSC in 2011, 2012, and 2013, while 302 individuals were assessed at Seneca (S) in the same seasons. No individuals at Clarksville or Seneca were evaluated in any other trial (Table 1A). Accessions at Clarksville consisted of parents and seedlings from six F1 peach families of 10–44 individuals, while accessions from Seneca comprised parents and seedlings of 12 F1 families of 6–22 individuals and three F2 families of 22–66 individuals. The SSC assessment method for Clarksville and Seneca followed the described (Frett et al., 2012; da Silva Linge et al., 2021) protocols. Ten fruits from each individual were harvested from the mid-canopy of each tree when they are slightly firmer than the ripe tree and placed into 0.24-L corrugated trays (FormTex Plastics Corp., Houston, TX, United States). A longitudinal slice was taken from each sample’s five largest fruits and juiced through a hand presser. Two to four drops of juice of the 5-fruit composite sample were measured for SSC using a refractometer (3810 PAL-1 Digital Hand-Held Pocket Refractometer, Atago Inc., Bellevue, WA, United States).
Genotypic data
An initial set of 4,499 curated SNP data were obtained using the 9K peach SNP array (Verde et al., 2012) and published methods of curation (Vanderzande et al., 2019; da Silva Linge et al., 2021). The proportion of missing SNP genotypes per individual was low (0.2–4.5%) as was the proportion of missing genotypes per locus (0.4–2%). Twenty-six SNPs with a minor allele frequency lower than 0.05 were excluded. Genotypic data for a total of 4,473 SNPs were retained for downstream analysis (Supplementary Figure 1), representing an average marker density of 60 kbp per SNP (given a genome size of 265 mb, Yu et al., 2018). Missing alleles were imputed with BEAGLE software version 4.1 (Browning and Browning, 2007; Supplementary methods) to produce a complete sample-by-loci genotype table required by the downstream analyses. Unique QTL joint genotypes present among the accessions were defined for the eight SNPs within the 10,571,103–12,512,099 bp interval on chromosome 4 (Supplementary Figure 1), encompassing the region for the previously detected SSC QTL (Eduardo et al., 2011; da Silva Linge et al., 2021; Table 1B).

Table 1B. Number of defined unique joint genotypes, across a 2-Mb interval encompassing a large-effect QTL for SSC on chromosome 4 of peach, within and common across peach/nectarine germplasms evaluated at the four trials.
Genome-wide genotypic structure of germplasm
Pairwise FST values among the populations from the three breeding programs were estimated to evaluate diversity among germplasm assessed across the three populations evaluated at the four trials. Pearson’s correlation coefficients were estimated to quantify the similarity of SNP allele frequencies for each breeding population with minor allele frequencies estimated across the three populations.
To evaluate the relationship between physical distance and linkage disequilibrium (LD) for the populations, squared correlation LD coefficients (R2) (Hill and Robertson, 1968) were estimated among SNP locus pairs using PLINK software version 9.1 (Purcell et al., 2007) and plotted against physical distance. A second-order, locally weighted scatterplot smoothing function (LOESS) (Esteras et al., 2013) was fitted to describe the decay in LD with physical distance.
Linear models for G × E
Prior to model fitting, phenotypes on the original scale of assessment were scaled by trial-by-season phenotypic standard deviations to reduce the influence of heterogeneity in variance on the presence of G × E (Hill, 1984; Hardner, 2017). Total genomic effects were assumed to be composed of additive and dominance genomic effects with the estimated GRMs, according to VanRaden (2008) and Su et al. (2012), respectively. Where required, GRMs were made positive definite through bending (Jorjani et al., 2003; Nazarian and Gezan, 2016) as implemented in the R package ASRgenomics. An environment was defined with respect to the genomic effect (i.e., additive, dominance, or total) and was considered as a group of trial-by-seasons, among which genomic effects were homogenous (i.e., uniform genomic variance and genomic correlation of one). A full description of the GBLUP models used in this study is detailed in Supplementary methods.
A structured data-modelling strategy was undertaken to identify significant patterns and reduce the complexity of G × E for SSC in peach. In general, a univariate genomic main effect and genomic-by-environment interaction models were initially fitted to test the significance (p < 0.01) of genomic-by-environment interaction. A term for permanent environment effects was also included. Following this, multivariate genomic-by-environment models, where the expression of the phenotype in a specific environment was considered a different trait (following Falconer, 1952; Smith et al., 2001; Hardner et al., 2010), were used to identify significant G × E patterns. Cluster analysis (using Ward’s minimum distance) of the genomic-by-environment covariance matrix from these multivariate models was used to identify possible homogeneous environments (i.e., those that clustered together), and a reduced model (where these environments were constrained to be the same) was fitted and tested for a significant difference to the unconstrained model.
Restricted maximum likelihood (implemented in the R package ASReml v4, Butler et al., 2017) was used to estimate the random parameters of each model. Factor analytic parameterisation (Smith et al., 2001; Thompson et al., 2003) was used to estimate multi-dimensional genomic-by-environment covariance matrices. The significance of fixed effects was tested using the Wald tests (Kenward and Roger, 1997), and the significance of random effects was tested using log-likelihood testing, with appropriate adjustment for testing components at the boundary of the inference space (Stram and Lee, 1994). Akaike Information Criteria (Akaike, 1974) were also used to evaluate parsimony.
Single-trial genome-wide univariate (STGWU) models were fitted independently to data from each trial to test for significant within-trial G × E. GRMs for these analyses were estimated using only the genotypic data for the individuals at each specific trial. For trials where significant genomic-by-environment interaction was detected, single-trial genome-wide multivariate (STGWM) models were fitted to identify significantly unique genomic environments (i.e., combinations of seasons-within-trials, among which phenotypic variances due to genome effects were heterogenous and genomic correlations of these effects were less than 1) and, thereby, the most parsimonious single-trial models.
Multi-trial genome-wide univariate (MTGWU) models were fitted to the multi-trail data by combining the most parsimonious single-trial models to identify significantly unique genomic environments among trials. GRMs for these multi-trial models were estimated from the genome-wide genotypic data from all individuals across all trials. Pearson’s correlation was used to compare the off-diagonal elements of single population GRMs with the same elements in the multi-trial GRM. Where significant G × E was detected in the multi-trial univariate models, multi-trial genome-wide multivariate (MTGWM) models were fitted to identify significant across-trial G × E patterns and parsimonious multi-trial G × E models.
To evaluate the importance of QTL effects and study the interaction of QTL with the environment, genome-wide (additive and dominance) effects were separated into QTL and background effects. Separate GRMs were estimated for the QTL and background genomic effects using only the loci associated with each effect (i.e., the eight SNPs for the QTL GRM and the remaining 4,465 SNPs for the background GRM). A multi-trial QTL + background univariate (MTQBU) model was used to test for the significance of (additive and dominance) QTL-by-environment and background-by-environment interactions. Multi-trial QTL + background multivariate (MTQBM) models were then used to identify significant patterns in G × E and identify parsimonious models.
Genomic architecture of soluble solids content
To evaluate the architecture of genomic effects for SSC, narrow- and broad-sense heritabilities were estimated for each trial-by-genomic environment (Supplementary methods). Phenotypic variation was estimated as the sum of genomic, permanent environment residual variances for the respective trial-by-environment. Genomic correlations among environments were estimated from the respective genomic variances and covariances. A cluster analysis using Ward’s (1963) minimum variance criteria of the Euclidean distance matrix transformation of the genomic effects correlation matrix was undertaken to visualise the genomic correlation among environments. A biplot (Kempton, 1984) of the environments (loadings) and individuals (scores) for the first two dimensions of the principal component reduction of the standardised genomic (additive or total, i.e., sum of additive and dominance effects) values-by-environment matrix was undertaken to visualise the major G × E patterns. Following principal component analysis (PCA), loadings were scaled by their respective variance, and scores were scaled to range from −1 to 1. The predicted performance of individuals in specific environments was obtained by projecting the performance of individuals onto the vectors for the environments for the respective genomic effects. Pearson’s correlation was used to compare the total-genome-effect predictions among models.
Prediction accuracy
Expected prediction accuracy was estimated for additive and dominance genomic effects (genome-wide, QTL, and background) to evaluate the quality of genomic prediction models developed in this study. Three cohorts of individuals were constructed for each unique trial-by-genomic environment combination to evaluate the effect of the availability of phenotypic data on expected prediction accuracy. The first cohort for a specific trial-by-genomic environment included those individuals tested within trial-by-environment (TGE). The second cohort included those within the same trial but tested in a different genomic environment in that trial (Trial tested). The third cohort included individuals tested in another trial (Trial untested). Thus, expected prediction accuracy for the qth genomic effect (additive/dominance by genome-wide/QTL/background) and the zqth genomic environment at the lth trial for the xth cohort (TGE, Trial tested, Trial untested) was estimated as
Realised prediction accuracies of additive and total genomic effects were estimated using five-fold cross-validation as the correlation between predicted genomic values in the validation population with their adjusted phenotypes (prediction ability), divided by the square-root of (narrow or broad-sense) heritability (Legarra et al., 2008; Muranty et al., 2015) estimated from the most parsimonious model. The realised prediction accuracy was also estimated for each trial-by-environment.
Two strategies were used to sample for validation populations. The first was a cross-trial sampling (XTCV), where individuals were sampled across all four trials to construct the validation population. This first strategy simulated performance prediction for new accessions based only on their genome-wide genotypic data. The second strategy was within-trial sampling (WTCV), where individuals were sampled within each trial, simulating performance prediction of accessions untested in a specific trial using their trained performance in other trials.
For each fold, phenotypic observations for the validation population were masked (i.e., set to missing) and the genomic values of the validation population were predicted by fitting the model of interest (including the full GRM containing all individuals in both the reference and validation populations). Adjusted phenotypes for the validation population were estimated by undertaking a full cross-trial model excluding any genomic terms (i.e., only trial, season, permanent environment effect, and residual) and summing the predicted permanent environment effect and the residual for each observational unit.
Results
Genome-wide genotypic structure of germplasm
Twenty-four unique QTL joint genotypes were identified. The majority (19) were identified in the germplasm assessed at Seneca, and only four were identified in the TAMU population evaluated at Fresno and College Station (Table 1B). Less genetic differentiation was detected between the CLEM population and the UARK population (FST = 0.075) than between the TAMU population and either the CLEM (FST = 0.104) or UARK (FST = 0.136) populations. There was a uniform distribution of minor allele frequencies between 0.15 and 0.45 across populations (Supplementary Figure 2). Allele frequencies, estimated using only genotypic data for the CLEM population, were highly correlated (0.85) with allele frequencies estimated across the entire study population (i.e., TAMU, UARK, and CLEM populations combined). The correlation of local allele frequencies across individuals in the UARK population with the entire population was lower (0.67) and lowest for the TAMU population (0.59) (Supplementary Figure 3A). The correlation between the off-diagonals of the population-specific additive GRM with off-diagonals of the GRM estimated using all individuals was higher for the CLEM population (0.98) than the UARK (0.96) or TAMU (0.93) populations (Supplementary Figure 3A).
The average intra-chromosomal LD across the entire peach genome for the entire germplasm set was 0.38. Considerable variability among chromosomes was detected for LD (Supplementary Figure 4). LD decayed sharply with physical distance for the entire population with an average LD of 0.41 at 60 kpb (average marker density) (Figure 1). The distance among markers at 50% of maximum LD was 750 kpb across the entire population.
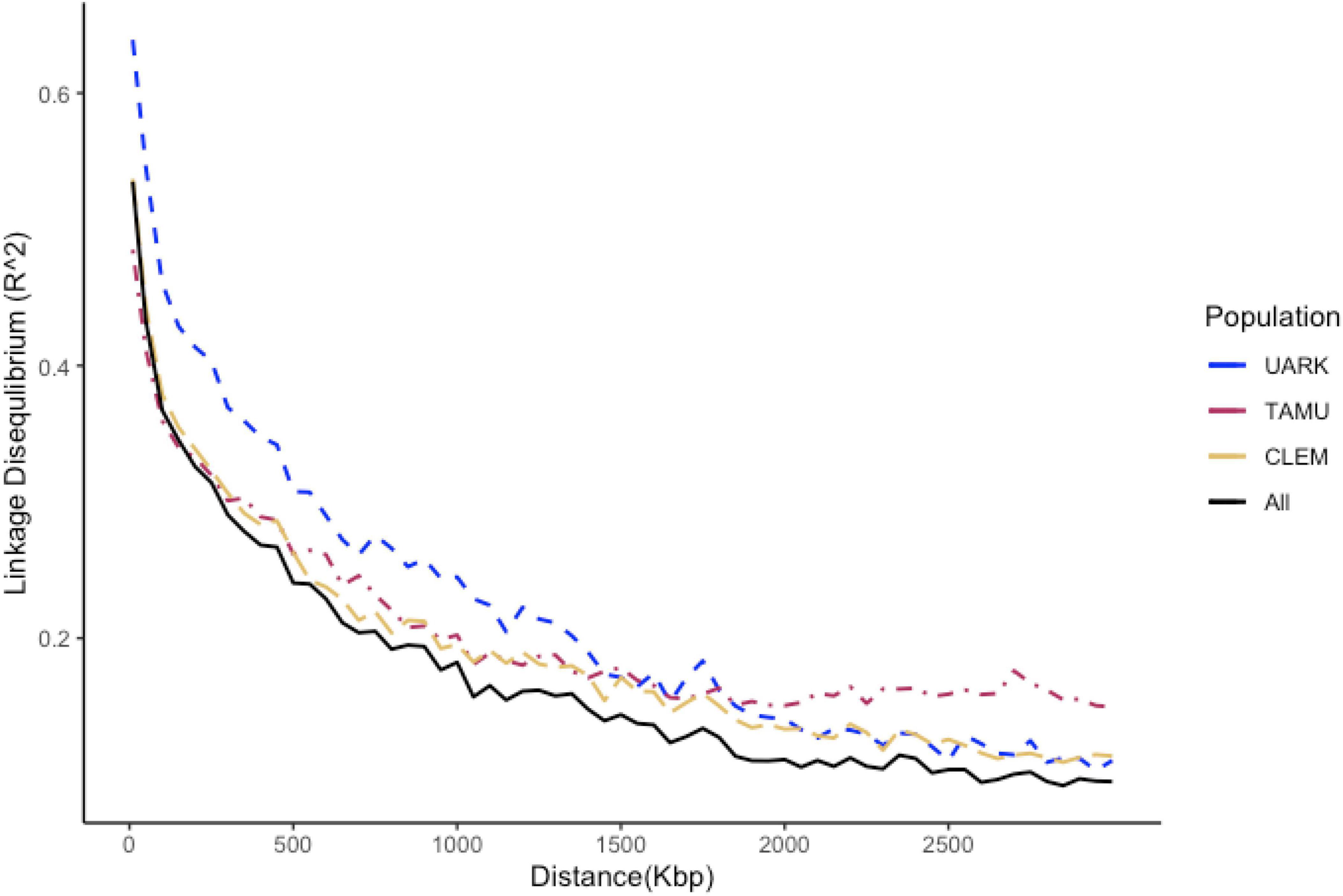
Figure 1. Decay trend of the linkage disequilibrium (LD) coefficient (R2) with a physical distance by the study population of peach/nectarine individuals assessed for SSC (UARK, University of Arkansas population; TAMU, Texas A&M University population; CLEM, Clemson university population; ALL, all populations combined). The vertical line is drawn at 30 kbp and the horizontal line at 0.42; the average LD across the entire set of peach/nectarine.
G × E model fit
The main effect of season was significant for all trials (p < 0.001). No significant effect of the genome-wide dominance effects-by-season interaction on scaled SSC was detected for any of the STGWU models (Supplementary Table 2). The interaction between additive genome-wide effects and season was not significant at Fresno or College Station. The significant interaction between additive genome-wide effects and season at the Clarksville trial was associated with the contrast between the average of additive genomic effects across 2010 and 2011 (K01) against effects in 2012 (K2) (Supplementary Tables 2, 3A,B). The most parsimonious single-trial of a multivariate genome-wide model for accessions at Seneca contained heterogeneous additive genome-wide variances and unique pairwise additive genome-wide correlations for each assessment year (i.e., S0, S1, and S2) (Supplementary Tables 2, 3A,B).
A multi-trial univariate genome-wide model (MTGWU01) was successfully fitted to the full data sets of scaled SSC. Seven environments for additive genome-wide effects were defined for this model, following the results from the single-trial analyses (F, G, K01, K2, S0, S1, and S2). However, no significant dominance genomic-by-environment interaction was detected (MTGWU02, Supplementary Table 4). A multi-trial genome-wide model with a first-order factor analytic structure for the additive genome-wide environments (MTGWM02) was not significantly different from a higher-order model (MTGWM03) for the initial seven additive genome-wide environments. However, there was no significant difference between MTGWM02 and a model where the Clarksville 2010 and 2011 (K01) with Seneca 2012 (S2) were in a single environment (K01S2) (MTGWM07). No other reductions in complexity were identified.
Additive genome-wide by environment and dominance main genome-wide effects were successfully separated into effects associated with the QTL and with the background genome in a multi-trial univariate model (MTQBU01, Supplementary Table 5). However, no significant dominance QTL effects (MTQBU02 cf. MTQBU01), nor additive QTL-by-environment interaction (models MTQBU02 cf. MTQBU04), were detected. The fit of multi-trial multivariate models that attempted to reduce the complexity of the additive background genomic effect-by environment interaction was significantly poorer than the fit of MTQBMB1, which included six additive background genome environments (F, G, K01S2, K2, S0, and S1). As no significant G × E was detected for additive QTL and background dominance genome effects, the six additive genome-wide environments also defined the dimensions of the environments for total genome-wide effects.
Genomic architecture of soluble solids content
Individual narrow-sense heritability for SSC estimated from the most parsimonious multi-trial QTL + background genome multivariate model varied between 0.57 and 0.72 among the seven trial-by-genomic environments (Fresno_F, College Station_G, Clarksville_K01S2, Clarksville_K2, Seneca_S0, Seneca_S1, and Seneca_K02S2) derived from the most parsimonious model (MTQBM91) (Table 2). Estimates of individual broad-sense heritability from the same model ranged from 0.66 to 0.80.
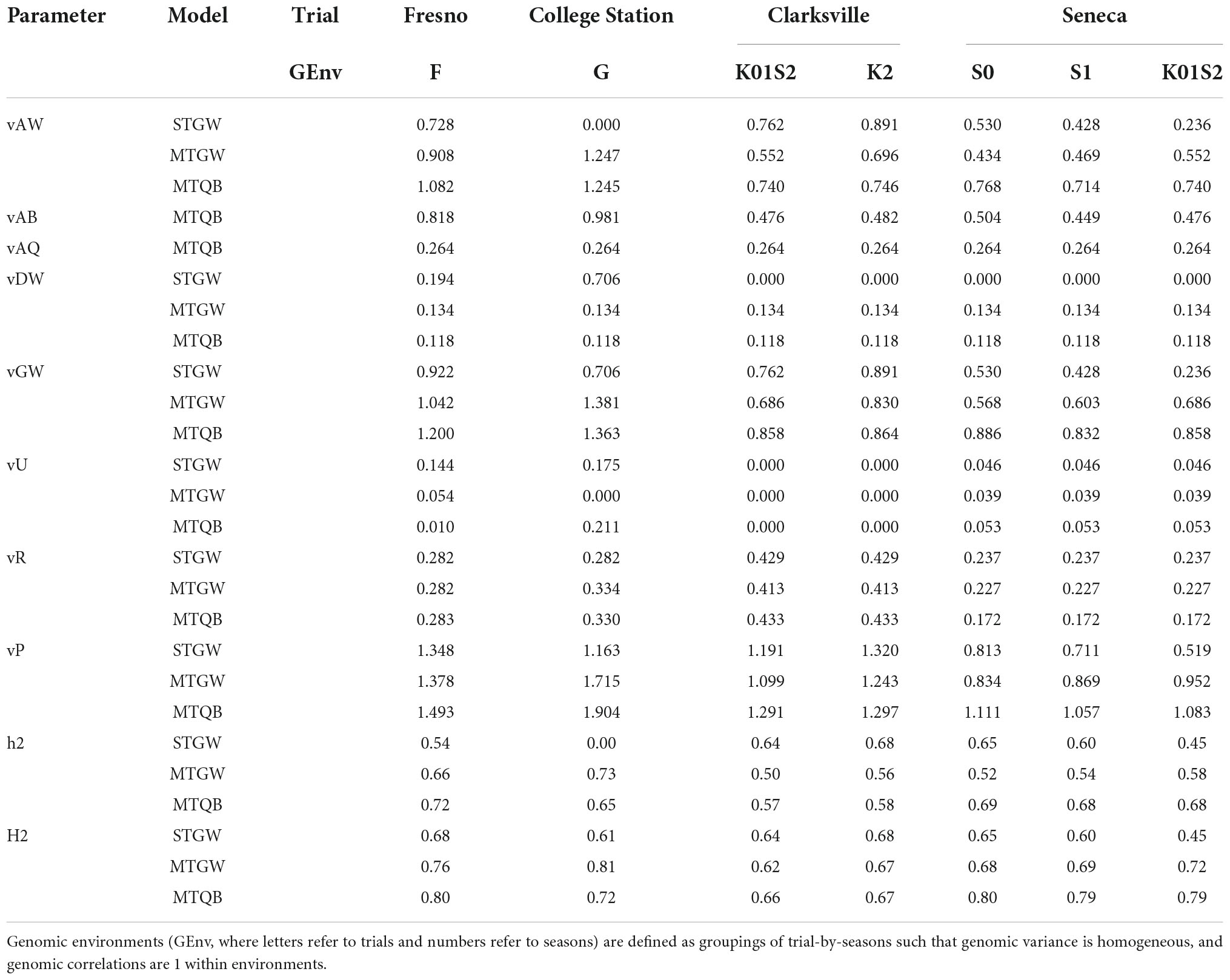
Table 2. Estimated model parameters (vAW, additive whole-genome variance; vAQ, additive QTL variance; vAB, additive background-genome variance; vDW, dominance whole-genome variance; vGW, total whole-genome variance; vU, within trial permanent among tree variance; vR, within trial tree-by-season residual variance; vP, phenotypic variance; h2, narrow sense heritability; H2, broad sense heritability) for most parsimonious single-trial genome-wide (STGW); multi-trial genome-wide (MTGW), or QTL + background (MTQB) multivariate models for SSC assessed on 577 peach/nectarine individuals across 10 trial-by-season environments.
Additive genomic effects were the largest source of genomic variation (Table 2). The proportion of total genomic variance explained by additive effects varied between 86 and 91% for multi-trial QTL + background models and 76 and 90% for the multi-trial genome-wide models. The proportion of total genomic variance explained by additive genomic effects was more variable for the single-trial models as near-zero additive genomic variance was estimated for College Station and near-zero dominance variances were estimated for the Clarksville and Seneca trials. Additive QTL effects were estimated to account for between 21 and 37% of the additive genomic variance, 19–32% of total genomic variation, and 14–25% of phenotypic variation.
Correlations among total genomic effects predicted from single-trial and multi-trial, and genome-wide and QTL + background, multivariate models were higher (>0.87) than correlations among additive genomic effects (Table 3). Reflecting the relatively high correlation in total genomic effects predicted from the alternative multivariate models (0.87), there was little difference in the correlation of total genomic effects predicted from single-trial and multivariate models. On the other hand, correlations among additive genomic effects predicted from the single-trial or multi-trial models were more heterogeneous than for total genomic effects.
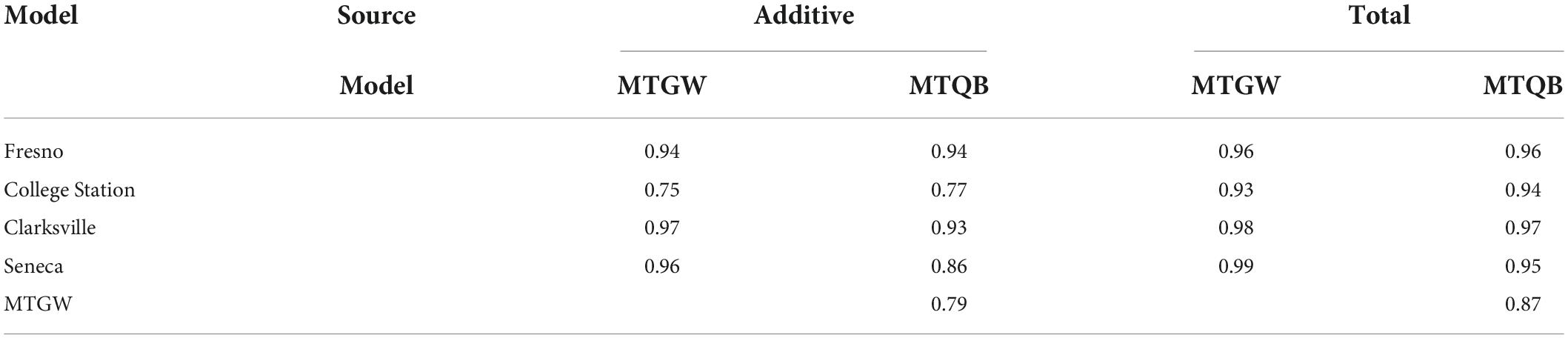
Table 3. Correlation among additive and total genomic effects predicted from single-trial G × E (Fresno, College Station, Clarksville, and Seneca) and multi-trial genome-wide (MTGW) and QTL + background (MTQB) multivariate models for SSC across four peach/nectarine breeding trials.
There was a strong pattern in genomic correlations among environments across the various multi-trail G × E models for additive and total genomic effects (Figures 2, 3, Supplementary Table 6, and Supplementary Figures 5A–E); with a main group of environments defined by a large group of environments including all seasons at Fresno, College Station, and Clarksville, and the 2012 season at Seneca, and a looser grouping of genomic effects at Seneca in 2010 and 2011. Total genomic correlations for the most parsimonious QTL + background genomic effects model ranged from 0.66 to 1 within the main group, was 0.54 between 2010 and 2011 at Seneca and ranged between 0.06 and 0.33 among environments in across the two groups (Supplementary Table 6). These patterns were reflected in additive and total genomic correlations estimated with multi-trial genome-wide or QTL + background models (Supplementary Table 6). In general, genomic correlations were lower for additive genome-wide or background genome effects compared to total genomic effects.
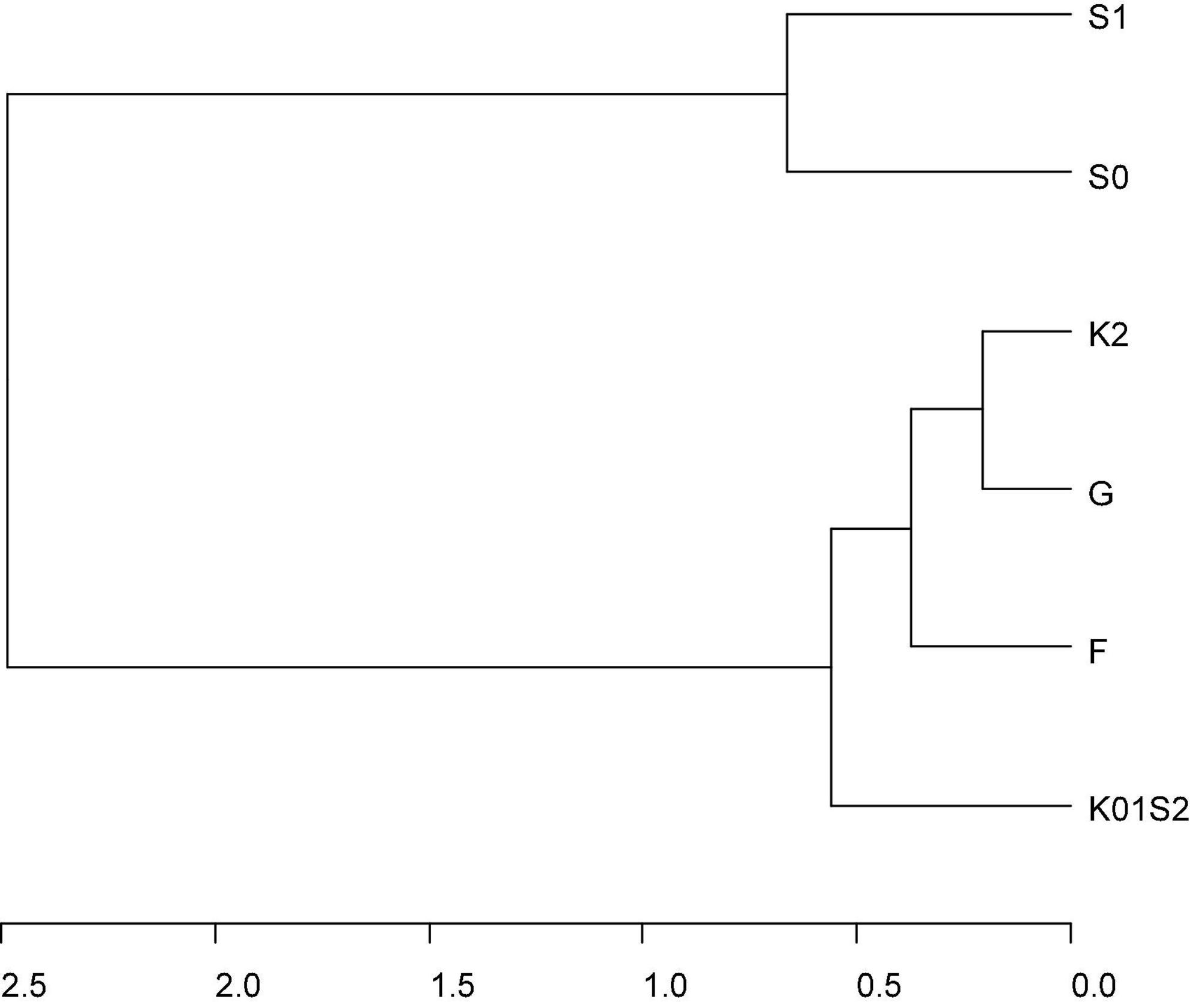
Figure 2. Cluster dendrogram of total genomic correlation matrix across genomic environments (F = Fresno 2011 and 2012, G = College Station 2012 and 2013, K01S2 = Clarksville 2010 and 2011 and Seneca 2012, S0 = Seneca 2010, S1 = Seneca 2011) estimated from the most parsimonious multivariate QTL + background genome model (MTQBM01, Supplementary Table 5) for SSC assessed across four peach/nectarine breeding trials. Genomic environments are defined as groupings of trial-by-seasons such that genomic variance is homogeneous, and genomic correlations are 1 within environments.
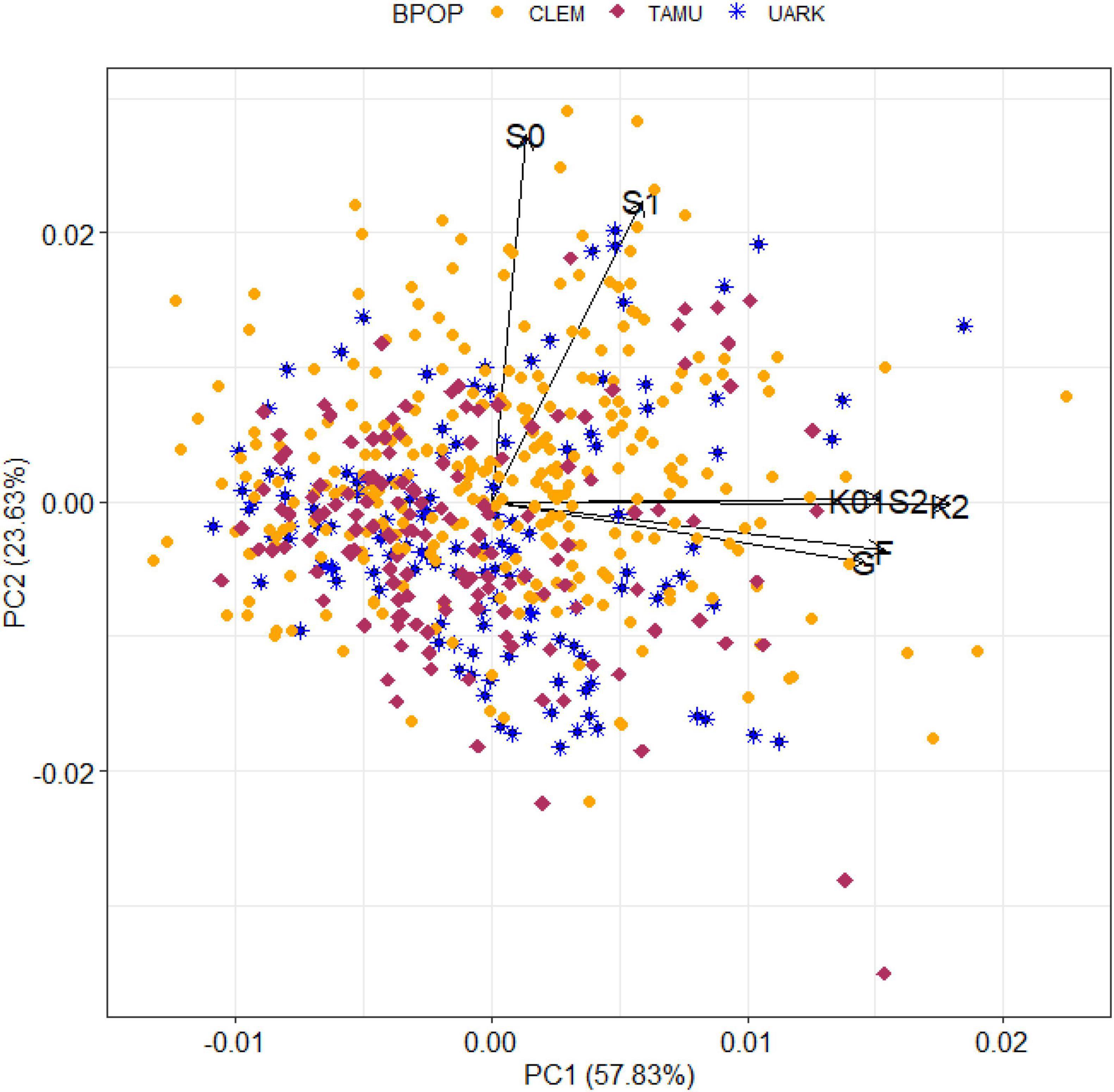
Figure 3. A biplot of the predicted total genomic effect for SSC of peach/nectarine individuals by genomic environment (defined in Figure 2) from the most parsimonious QTL + background genome model (MTQBM01).
The biplot (of standardised environmental loadings and scaled individual scores for the first two principal components of the decomposition of the total genomic-by-environment predicted effects for SSC from the most parsimonious QTL + background model) displayed the differential adaptation of individuals to genomic environments (Figure 3). Elite-performing individuals in each environment could be detected among all three breeding populations. For example, the two individuals with the highest predicted total genomic effect for SSC in the main group of environments (all seasons at Fresno, College Station, and Clarksville, and the 2012 season at Seneca) were from CLEM, while the third highest effect was from UARK and two individuals from TAMU had the eight and ninth highest values for this group of environments. Similarly, the 10 individuals with the highest predicted total genomic effect in the two Seneca environments originated from all three breeding programs. An accession from UARK was predicted to have high SSC in all environments except 2010 at Seneca.
Prediction accuracy
The average expected prediction accuracy of additive genomic effects was higher than for dominance genomic effects (Table 4). In addition, the expected prediction accuracy of the cohort of genotypes tested at the respective trial-by-genomic environment (TGE cohort) was higher than for the cohort of individuals not tested at this trial-by-genomic environment (Trial tested and Trial untested cohorts) for all trial-by-genomic environments.
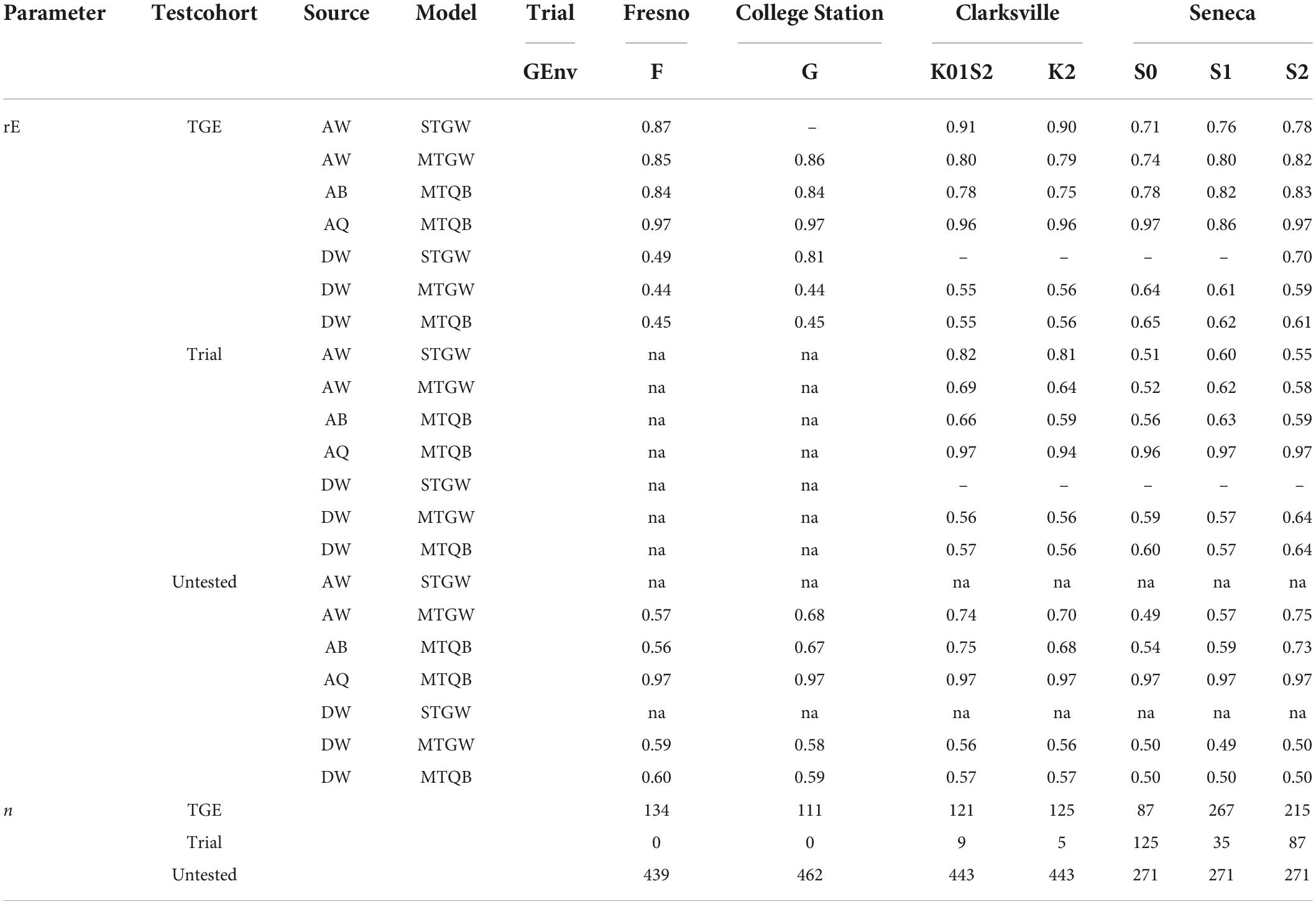
Table 4. Expected peach/nectarine SSC prediction accuracy (rE) of additive (A) and dominance (D) genomic effects for most parsimonious single-trial genome-wide (STGW), multi-trial genome-wide (MTGW), and multi-trial QTL + background genome (MTQB) multivariate models, and the number of individuals (n), by genomic environment (GEnv, for details, see Figure 2), within the trial for three test cohorts (TGE tested, individuals tested in the corresponding genomic environment within a trial; Trial tested, individuals tested in a different genomic environment at the corresponding trial; Trial untested, individuals not tested in the corresponding trial).
Prediction accuracy from single-trial models for the cohort of individuals not tested at the respective trial could not be estimated. In addition, the accuracy of additive effects predicted with the single-trial model at College Station could not be estimated as the estimate of additive genomic variance in this model was near zero (Tables 2, 4). A similar situation occurred for dominance effects at Clarksville and Seneca.
There was little difference in the accuracy of predicted additive genome-wide or additive background genomic effects between multi-trial genome-wide and multi-trial QTL + background genome multivariate models (Table 4). There was also little difference in the expected accuracy of genome-wide dominance effects for either model. However, the expected prediction accuracy of QTL effects was consistently very high for all cohorts in all trial-by-genomic environments.
The difference between the expected accuracy of additive effects predicted from single-trial or multi-trial models was inconsistent among trial-by-genomic environments and cohorts (Table 4). For example, the prediction accuracy of additive genome-wide effects for the cohort of individuals tested within the respective trial-by-genomic environment (TGE, Table 4) was similar for single-trial and multi-trial models, except for the Clarksville trial where expected prediction accuracy was lower for the multi-trial models.
Greater differences were detected in the realised prediction accuracy among environments than among sampling methods or prediction models (Table 5). Prediction accuracy tended to be highest at Seneca, lowest at Clarksville, moderate for Fresno, and variable for College Station. The realised prediction accuracy was slightly higher for within-trial sampling compared to cross-trial sampling, particularly for the multi-trial models, but this was not consistent across models and trial-by-genomic environments. Prediction accuracy of additive effects ranged from 0.17 to 0.63 for single trial models and 0.25 to 0.70 for multi-trial models. The realised prediction accuracy of additive genomic effects was of similar magnitude to that for total genomic effects, except at Clarksville for single-trial models and the S1 and K01S2 genomic environments in the Seneca trial, particularly for single-trial models. Estimates of the realised prediction accuracy of additive genomic effects were higher for QTL + background models compared to single-trial models for most trial-by-genomic environments, except for the K02S1 environment at the Clarksville trial where prediction accuracy appeared lower. Differences in the realised prediction accuracy of additive effects between single-trial and multi-trial genome-wide models, and among all models for total genomic effects, were less consistent.
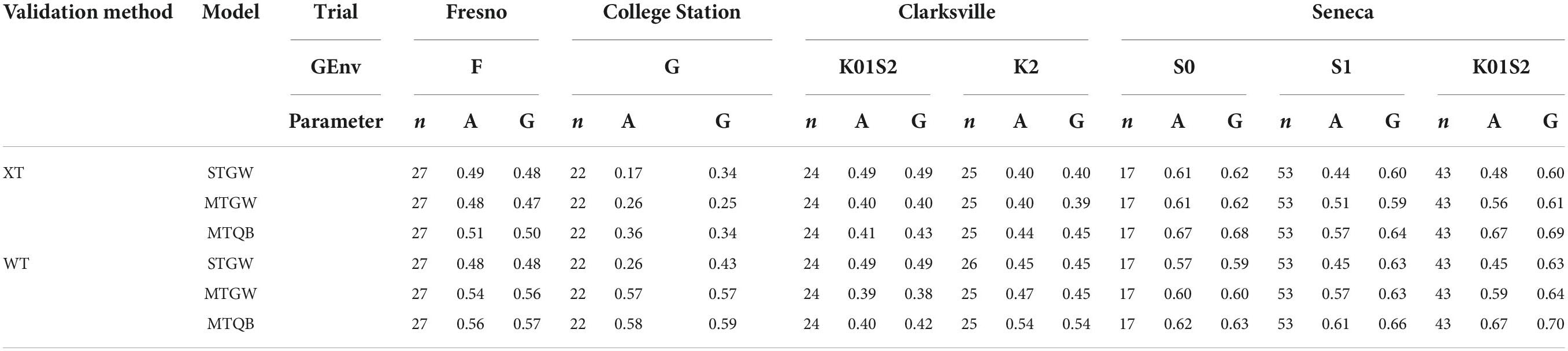
Table 5. Realised peach/nectarine SSC prediction accuracy for additive (A) and total (G) genomic effects, and the number of individuals in the validation population (n), for cross-trial (XT) or within-trial (WT) validation population sampling, predicted for single-trial genome-wide (STGW), multi-trial genome-wide (MTGW) or multi-trial QTL + background genome (MTQB) models by genomic environment (GEnv, for details, see Figure 2) within the trial.
Discussion
Modelling strategy
This study extended and implemented multivariate GBLUP linear mixed models initially developed in cherry (Hardner et al., 2019b) to combine complex phenotypic data for SSC in peach assessed across multiple trials, with limited records of genetic connectedness among trials and unbalanced repeated assessment across seasons, and include dominance effects. Additive and dominance GRMs were successfully employed to connect multi-trial data, even though individuals were not replicated across trials, as the GRMs effectively tracked replicated genome segments across individuals. The linear mixed model framework employed here optimised the use of available data from unbalanced designs by weighting each observation by its correlation with each factor in the model (Henderson, 1963). Simpler models are expected to result in less optimal use of data (Hardner, 2017). Similar to our study, Biscarini et al. (2017) fitted within family repeated measures GBLUP models for peach fruit quality to accommodate non-genomic covariance of observations on the same tree, however, those models are not as general as the multi-family approach presented here.
This study has extended the structured approach for identifying significant parsimonious G × E models developed using pedigree relationship matrices (Hardner, 2017) to incorporate genomic relationship matrices. This approach contrasts with that used in other genomic prediction studies examining relative performance across multiple locations that assumed only a main genomic effect across locations (e.g., Hernandez Mora et al., 2017; da Silva Linge et al., 2021). Scaling observations by the phenotypic variance of each trial-by-season undertaken here to reduce the influence of variance heterogeneity in peach SSC on G × E (sensu Hill, 1984; Hardner, 2017) was not entirely successful as some unconstrained models were a significantly better fit to the data compared to those where highly correlated environments were constrained to be the same. A factor-analytic parameterisation (Smith et al., 2001; Thompson et al., 2003) was successfully implemented in this study to obtain estimates of model parameters for complex genomic-by-environment covariance matrices. The structured approach adopted in this study was preferable to an exhaustive naïve model of background genomic and QTL effects for both additive and dominance genomic effects for each of the 10 trial-by-season combinations, as the exhaustive model would be challenging to solve and interpret.
This study also implemented models to decompose anonymous genome-wide variation into the effect of a previously identified functional QTL and anonymous background genome variation. The higher than expected, and to some degree realised, prediction accuracy estimated here for the QTL + background model compared to a genome-wide anonymous model agrees with other studies (Bernardo, 2014; Bhandari et al., 2019). The inclusion of background effects was expected to have reduced confounding of the QTL effect with correlated unlinked SNPs (Lander and Schork, 1994; Yu et al., 2006; Bink et al., 2014). In addition, by treating the QTL region as random in this study—in contrast to treating it as a fixed effect (e.g., Bernardo, 2014)—over-estimation of QTL effects (e.g., Beavis, 1998) and bias due to dataset unbalance were expected to have been reduced. The successful implementation of a local genomic relationship matrix for the QTL region enabled information from related QTLs to be leveraged to improve accuracy and prediction of the effect of QTL genotypes in environments in which they were untested and therefore into other new environments in the future. Alternatively, QTL regions could have been modelled as haplotypes (Hernandez Mora et al., 2017) and a relationship matrix among the haplotypes incorporated. While the models used here assumed a Gaussian distribution of gene effects so that the flexibility of GBLUP models could be exploited, other models that incorporate a mixture of QTL allelic effect distributions were possible (Meuwissen et al., 2001; Erbe et al., 2012; Bink et al., 2014) but multivariate implementation has been challenging (e.g., Kemper et al., 2018).
Discussion of study results
Estimates of narrow- and broad-sense heritability of sweetness (measured as SSC) reported here (0.6–0.7 and 0.7–0.8, respectively) were considerably higher than those reported in some previous studies (e.g., 0.02–0.33 in Brooks et al., 1993) but comparable to others (0.49—averaged over within family heritability estimates, Biscarini et al., 2017; 0.49, Hernandez Mora et al., 2017; 0.73—using essentially the same populations are these used in this study, da Silva Linge et al., 2021). Heritabilities reported in Rawandoozi et al. (2021) were not comparable here because of differences in approaches for estimating this parameter. The high heritability estimated in our study may be due to the large genetic diversity among parents. As expected (Su et al., 2012), estimates of dominance (and hence estimates of broad-sense heritability) in this study were less precise than estimates of additive genomic variance (and narrow-sense heritability). The higher heritability of the QTL + background model demonstrated the benefit of modelling the underlying genetic architecture of the trait (Meuwissen et al., 2001). Nevertheless, the genomic models employed here may not necessarily explain all variations (Yang et al., 2010). In addition, our results confirmed that the multi-trial estimates of heritability are less variable than the estimates from individual trial data.
While 50–70% of the total genomic variation of SSC in this study was due to the interaction of background genomic effects with the environment, the cluster and biplot results suggested genomic effects were stable across most environments sampled (Fresno, College Station, Clarksville, and 2012 season at Seneca—representing low- to high-chill environments) and that the major source of interaction was due to factors specific to the 2010 and 2011 seasons at the Seneca trial. In agreement with these results, Cantin et al. (2009) also reported that G × E for peach SSC was not significant. While moderate G × E in SSC between the Fresno and College Station environments using the same phenotypic data as this study was reported (Rawandoozi et al., 2021), the genetic models were not comparable. Other multi-trial studies (Biscarini et al., 2017; Hernandez Mora et al., 2017; da Silva Linge et al., 2021) did not directly model G × E. Further research is required to determine the cause of the differential performance of individuals at Seneca in 2010 and 2011. Our results also suggested that QTL and genome-wide dominance effects are expected to be stable across environments similar to those in this study, although the reduced precision in estimating dominance variance (discussed above) may also be a reason for this result.
This study confirmed the significant effect of a QTL on chromosome 4 for SSC in peach. Here, 20–30% of the total genomic variation was explained by the additive effect of the QTL, but significant dominance effects were not detected. Similarly, Eduardo et al. (2011) reported that this region explained 25% of the phenotypic variation in SSC in a single peach family, although only a minor (but significant) effect of this region was reported in other studies (Hernandez Mora et al., 2017; Rawandoozi et al., 2020) or was not detected (Fresnedo-Ramirez et al., 2015; Nunez-Lillo et al., 2019). No significant QTL × E interaction effects were detected, despite this QTL not being the most significant QTL in another study (Rawandoozi et al., 2020) using only the Fresno and College Station data. The absence of a significant QTL × E interaction here may be due to the limited segregation for this QTL in the TAMU population. Nevertheless, as the QTL was treated as random and the QTL segregated in correlated populations, the effect of all QTL genotypes was predicted for all environments, even for those in which they were untested.
The range of the realised prediction accuracy achieved in this study under the most parsimonious multi-trial QTL + background genome models (0.36–0.68) is considered (Hickey et al., 2014) relatively low. Biscarini et al. (2017) reported the realised prediction ability of 0.65–0.78 for peach SSC from fitting GBLUP models within individual full-sib families. This may be a consequence of trait architecture, prediction model, population size and structure, marker density, and validation strategy, as reviewed in other studies (reviewed Isidro et al., 2015; Crossa et al., 2017; Lebedev et al., 2020). However, higher marker density for these peach populations may not greatly increase prediction accuracy. This is because the LD of 0.41 at 60 kpb (average marker density) reported here is greater than an LD of 0.15 among adjacent markers suggested by Calus and Veerkamp (2007) as the minimum to capture all genetic variation in their study. Prediction accuracy in here may have been underestimated as the heritability estimates, used to adjust the correlation of the predicted genomic and phenotypic values, might be upwardly biased (as discussed above).
The difference between expected and realised prediction accuracies reported here indicated that these parameters assessed different characteristics of the genomic prediction models. The relatively high (0.75–0.97) expected prediction accuracy estimated in this study for additive, dominance, and QTL effects for individuals in the environments in which they were tested suggested that genetic effects are well-predicted, given the assumed genetic model is true. This assumption is similar to that made for the estimation of expected prediction accuracy in pedigree-based models which are based on laws of inheritance (Mrode, 2005). In contrast, the lower realised prediction accuracies reported in this study suggested that the assumption of a common GBLUP model of QTL and background effects across populations may not be the best model for prediction of untested individuals based only on genome-wide genotypic data. Similar to our results, Hayes et al. (2009a) reported expected prediction accuracy is lower than realised prediction accuracy for GBLUP models trained with multi-breed animal data. However, Hayes et al. (2009a) reported no difference between the two measures of prediction accuracy for models trained and applied within the same breed of animal in contrast to our results where differences were apparent even for single-trial models.
The higher expected, and in some cases realised, prediction accuracy, observed in this study demonstrated the value of using multi-trial models compared to single-trial models. Predictions from single-trial models only included those individuals tested at a particular trial; hence, the expected accuracy would be zero for untested individuals not included in the single-trial genomic relationship. In contrast, multi-trial models such as that developed here support the prediction of all individuals in all environments through genomic correlations among trials (Burgueno et al., 2012). The benefit of leveraging data from individuals in correlated trials was demonstrated by the higher expected prediction accuracy for individuals tested within a particular environment compared to predictions for individuals not tested in that environment. The higher realised prediction accuracy at Fresno and College Station (where individuals were replicated across trials) for multi-trial models compared to single-trial models for within-trial sampling for cross-validation (where individuals were replicated across trials) further demonstrates the benefit of correlated performance data. However, in agreement with previous studies (Burgueno et al., 2012; Krause et al., 2020), there was little enhancement in the realised prediction accuracy from multi-trial models where no phenotypic data were available (i.e., cross-trial sampling for the validation population).
This study highlighted the influence of population structure on estimates of the realised prediction accuracy. The major drivers of genomic prediction are short-range ancestral LD, co-segregation of linkage blocks within families, and general genome relationships, particularly among parents (Habier et al., 2013; Hickey et al., 2014). This study found evidence for divergent genetic structure among the breeding populations (FST values > 0.1, differences in LD among populations, and reduced correlation of within-population allele frequencies with overall allele frequencies). This structure was expected as the TAMU germplasm is focused on low-chill production while the focus of UARK and CLEM germplasm is on high-chill environments (Okie et al., 2008). In addition, the CLEM population was an admixture of alleles found in either the TAMU or UARK populations (da Silva Linge et al., 2021). However, estimates of th realised prediction accuracy in this study are unlikely to be upwardly biased by spurious correlations between unlinked markers and QTLs induced by historical selection history (sensu Yu et al., 2006; Toosi et al., 2010; Guo et al., 2014) as the breeding population was confounded with trial, and prediction accuracy was estimated for each trial-by-genomic environment. However, studies (Windhausen et al., 2012; Hickey et al., 2014; Werner et al., 2020) demonstrated that the realised prediction accuracy is driven by parental genetic values for training populations with strong family structures, such as in this and other horticultural tree crop studies (Kumar et al., 2012; O’Connor et al., 2021). While not undertaken here, training models within families (e.g., Biscarini et al., 2017) might avoid bias arising from strong family structure (Hickey et al., 2014; Werner et al., 2020), but such training might be expensive with little utility due to poor prediction accuracy in unrelated families (Riedelsheimer et al., 2013; Schopp et al., 2017). Training in a diverse unstructured population with high-density markers (e.g., Lorenz and Smith, 2015; Roth et al., 2020) is likely to better capture short-range ancestral LD between markers and functional QTLs.
The lack of consistent improvement in the realised prediction accuracy between single-trial and multi-trial models observed here might be explained by confounding testing location with population structure. The GRM for the single-trial models was estimated using only the local-germplasm genotypic data in contrast to the multi-trial GRM. However, allele frequencies differed between the single and combined populations. Thus, the single-trial models might have more accurately reflected the correlation between genomic effects of an individual and its phenotype compared to the multi-trial GRMs. In addition, the linkage phase between the marker and large-effect QTL alleles might be opposite across populations, hence reducing the correlation between marker and phenotype across a structured population. In contrast to our study, it is expected that the realised prediction accuracy would be improved if there was less differentiation among trials such as if some individual are replicated across trials (e.g., Hardner et al., 2019b). Prediction accuracy might also be improved if prediction models that explicitly account for population structure (Janss et al., 2012; Guo et al., 2014; Wientjes et al., 2017) are employed.
Implications of study results
This study confirmed the hypothesis that the GBLUP models can be used to combine phenotypic data from multiple trials to support the genetic improvement of horticultural tree crops. In general, genomic models used in this study identified and dissected significant patterns in G × E for the deployment of elite germplasm, predicted additive and total genomic values for the selection of elite germplasm, and predicted genomic performance of untested germplasm in new environments. However, this study also identified population structure as a challenge for the use of genomic prediction models to combine data from different breeding programs.
Assuming the trials included in this study were representative of local production environments, the high genomic correlation of additive QTL background and dominance genomic effects among most environments observed here suggests attention to genotype-environmental matching for this trait is not required. However, other traits might influence the genomic expression of SSC in particular environments. For example, germplasm adapted to fruit production in high-chill environments similar to Clarksville, Fresno, and Seneca might not produce any fruit in low-chill environments, such as College Station, although introgression, particularly guided by genomic prediction, could support the development of locally adapted germplasm from exotic germplasm elite for particular traits (e.g., Kumar et al., 2020). A clearer understanding of the factors causing the poor genomic correlation of performance in 2010 and 2011 at Seneca with the other environments would improve confidence in deployment strategies.
The predictions of additive and total genomic values for individuals tested in this study could be used to select elite parents to produce new breeding populations (e.g., Kumar et al., 2020) and to select candidate cultivars for advanced testing and possible deployment in commercial orchards. The trials included in this study were similar to many others in horticultural tree crop improvement where only the phenotype of a single replicate of an individual is available to infer its genetic value. Given that heritability is the square of prediction accuracy, the expected prediction accuracy of individuals tested in a particular environment (TGE cohort in Table 4) is higher than the accuracy of the phenotypic section (estimated as the square root of heritability from the QTL + background model following Falconer, 1989). However, the advantage of genomic predictions over own phenotype is expected to be greater for traits with lower heritability compared to high-heritability traits such as SSC as information from genomic correlated individuals can be used to improve the performance of un-replicated individuals (Burgueno et al., 2012).
The relatively low estimates of the realised prediction accuracies for SSC in peach reported here suggested that the response to genomic selection for this trait may not be large (Hickey et al., 2014). However, these estimates may be low due to inflated individual heritability estimates. In addition, due to the family structure, our estimates of the realised prediction accuracy may more reflect the accuracy of predicting the breeding value of the parents used in this study rather than for genomic selection of individuals within families (sensu Hickey et al., 2014). On the contrary, our results, and those of others (Burgueno et al., 2012), suggest that genomic prediction would reduce experimental costs through unbalanced testing of individuals across environments (Krause et al., 2020) because prediction accuracy is higher for individuals tested in exotic environments but untested locally compared to individuals without any performance data.
Similar to the approaches undertaken here, Hardner et al. (2021) and others (Heslot et al., 2012; Hickey et al., 2014; Sneller et al., 2021) proposed using GBLUP models to connect data from breeding programs on a global scale to leverage additional value (i.e., improved prediction accuracy and increased selection intensity) from multiple available datasets. While our results confirm that there are benefits to improved understanding of patterns in G × E, prediction of untested germplasm into new environments, and increased prediction accuracy, the population structure needs to be better accounted to optimise this approach. This accounting could be through the use of less-structured germplasm that is more genetically related across testing locations and with denser genotyping than in the present study and/or statistical methods that account for population structure.
Data availability statement
The data presented in this study are deposited in GDR data repository (https://www.rosaceae.org/publication_datasets) with accession number: tfGDR1062. The R-script for the analyses using these data has been deposited at GitHub (https://github.com/MulusewFikere/PeachGS), including the RData for the estimation of prediciton accuracy.
Author contributions
CH performed the conceptualisation, data analysis, and preparation of the manuscript. MF contributed to data analysis and preparation of figures. KG performed the data collection, interpretation of results, manuscript review, and funding acquisition. CS wrote and reviewed the manuscript. MW performed the interpretation of results, wrote and reviewed the manuscript. DB performed the interpretation of results, manuscript review, and funding acquisition. ZR performed the data collection and wrote and reviewed the manuscript. CP performed the conceptualisation, interpretation of results, and wrote and reviewed the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was funded in part by USDA’s National Institute of Food and Agriculture (NIFA) Specialty Crop Research Initiative Projects, “RosBREED: Enabling marker-assisted breeding in Rosaceae” (2009-51181-05858), “RosBREED: Combining disease resistance and horticultural quality in new rosaceous cultivars” (2014-51181-22378), and the NIFA Hatch project 1014919, Crop Improvement and Sustainable Production Systems (WSU reference 00011).
Acknowledgments
The authors would like to thank Terrence Frett, Ralph Burrell, and Musser Fruit Research Farm staff at Clemson University; Natalie Anderson, Pamela Hornby, Tim Hartman, and Silvia Carpendo at Texas A&M University; and John Clark and Paul Sandefur at the University of Arkansas and Arkansas System Division of Agriculture Fruit Research Station staff for their help with orchard maintenance and phenotypic data acquisition.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2022.960449/full#supplementary-material
References
Allard, R. W., and Bradshaw, A. D. (1964). Implications of genotype-environment interaction in applied plant breeding. Crop Sci. 4, 503–508. doi: 10.1016/j.tplants.2014.01.001
Aranzana, M. J., Decroocq, V., Dirlewanger, E., Eduardo, I., Gao, Z. S., Gasic, K., et al. (2019). Prunus genetics and applications after de novo genome sequencing: Achievements and prospects. Hortic. Res. 6:58. doi: 10.1038/s41438-019-0140-8
Baker, R. J. (1988). Tests for crossover genotype-environment interactions. Can. J. Plant Sci. 68, 405–410. doi: 10.3389/fpls.2021.656158
Basford, K. E., and Cooper, M. (1998). Genotype x environment interactions and some considerations of their implications for wheat breeding in Australia. Aust. J. Agric. Res. 49, 153–174.
Beavis, W. D. (1998). “QTL analyses: Power, precision, and accuracy,” in Molecular dissection of complex traits, ed. A. H. Paterson (Boca Raton, FL: CRC Press), 145–162.
Bernardo, R. (2014). Genomewide selection when major genes are known. Crop Sci. 54, 68–75. doi: 10.2135/cropsci2013.05.0315
Bhandari, A., Bartholome, J., Cao-Hamadoun, T. V., Kumari, N., Frouin, J., Kumar, A., et al. (2019). Selection of trait-specific markers and multi environment models improve genomic predictive ability in rice. PLoS One 14:e0208871. doi: 10.1371/journal.pone.0208871
Bink, M., Jansen, J., Madduri, M., Voorrips, R. E., Durel, C. E., Kouassi, A. B., et al. (2014). Bayesian QTL analyses using pedigreed families of an outcrossing species, with application to fruit firmness in apple. Theor. Appl. Genet. 127, 1073–1090. doi: 10.1007/s00122-014-2281-3
Biscarini, F., Nazzicari, N., Bink, M., Arus, P., Aranzana, M. J., Verde, I., et al. (2017). Genome-enabled predictions for fruit weight and quality from repeated records in European peach progenies. BMC Genomics 18:432. doi: 10.1186/s12864-017-3781-8
Brooks, S. J., Moore, J. N., and Murphy, J. B. (1993). Quantitative and qualitative changes in sugar content of peach genotypes Prunus persica (L) Batsch. J. Am. Soc. Hortic. Sci. 118, 97–100. doi: 10.21273/jashs.118.1.97
Browning, S. R., and Browning, B. L. (2007). Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. Am. J. Hum. Gen. 81, 1084–1097. doi: 10.1086/521987
Burgueno, J., Crossa, J., Cornelius, P. L., and Yang, R. C. (2008). Using factor analytic models for joining environments and genotypes without crossover genotype x environment interaction. Crop Sci. 48, 1291–1305. doi: 10.2135/cropsci2007.11.0632
Burgueno, J., de los Campos, G., Weigel, K., and Crossa, J. (2012). Genomic prediction of breeding values when modeling genotype x environment interaction using pedigree and dense molecular markers. Crop Sci. 52, 707–719. doi: 10.2135/cropsci2011.06.0299
Butler, D. G., Cullis, B. R., Gilmour, A. R., Gogel, B. G., and Thompson, R. (2017). ASReml-R reference manual version 4. Hemel Hempstead: VSN International Ltd.
Byrne, D. H. (2005). Trends in stone fruit cultivar development. HortTechnology 15, 494–500. doi: 10.21273/HORTTECH.15.3.0494
Byrne, D. H., Raseira, M. C., Perez, S., Bassi, D., Piagnani, M. C., Moreno, M. C., et al. (2012). “Peach breeding,” in Handbook of plant breeding: Fruit breeding, eds M. Badenes and D. H. Byrne (Philadelphia, PA: Springer), 505–570.
Calus, M. P. L., and Veerkamp, R. F. (2007). Accuracy of breeding values when using and ignoring the polygenic effect in genomic breeding value estimation with a marker density of one SNP per cM. J. Anim. Breed. Genet. 124, 362–368. doi: 10.1111/j.1439-0388.2007.00691.x
Cantin, C. M., Gogorcena, Y., and Moreno, M. A. (2009). Analysis of phenotypic variation of sugar profile in different peach and nectarine Prunus persica (L.) Batsch breeding progenies. J. Sci. Food Agric. 89, 1909–1917. doi: 10.1002/jsfa.3672
Cirilli, M., Bassi, D., and Ciacciulli, A. (2016). Sugars in peach fruit: A breeding perspective. Hortic. Res. 3:15067. doi: 10.1038/hortres.2015.67
Comstock, R. E., and Moll, R. H. (1963). “Genotype-environment interactions,” in Statistical genetics and plant breeding. Publication 982, eds W. D. Hanson and H. F. Robinson (Washington, DC: National Academy of Sciences-National Research Council), 164–1986.
Cooper, M., Brennan, P. S., and Sheppard, J. A. (1996). “A strategy for yield improvement of wheat which accommodates large genotype by environment interactions,” in Plant adaptation and crop improvement, eds M. Cooper and G. L. Hammer (Wallingford: CABI Publishing), 487–512.
Cooper, M., and Delacy, I. H. (1994). Relationships among analytical methods used to study genotypic variation and genotype-by-environment interaction in plant-breeding multi-environment experiments. Theor. Appl. Genet. 88, 561–572. doi: 10.1007/BF01240919
Crisosto, C. H., Crisosto, G. M., Echeverria, G., and Puy, J. (2006). Segregation of peach and nectarine (Prunus persica (L.) Batsch) cultivars according to their organoleptic characteristics. Postharvest Biol. Technol. 39, 10–18. doi: 10.1016/j.postharvbio.2005.09.007
Crossa, J., Perez-Rodriguez, P., Cuevas, J., Montesinos-Lopez, O., Jarquin, D., de los Campos, G., et al. (2017). Genomic selection in plant breeding: Methods, models, and perspectives. Trends Plant Sci. 22, 961–975. doi: 10.1016/j.tplants.2017.08.011
da Silva Linge, C. D., Cai, L. C., Fu, W. F., Clark, J., Worthington, M., Rawandoozi, Z., et al. (2021). Multi-locus genome-wide association studies reveal fruit quality hotspots in peach genome. Front. Plant Sci. 12:644799. doi: 10.3389/fpls.2021.644799
Delgado, C., Crisosto, G. M., Heymann, H., and Crisosto, C. H. (2013). Determining the primary drivers of liking to predict consumers’ acceptance of fresh nectarines and peaches. J. Food Sci. 78, S605–S614. doi: 10.1111/1750-3841.12063
Dirlewanger, E., Moing, A., Rothan, C., Svanella, L., Pronier, V., Guye, A., et al. (1999). Mapping QTLs controlling fruit quality in peach (Prunus persica (L.) Batsch). Theor. Appl. Genet. 98, 18–31. doi: 10.1007/s001220051035
Eduardo, I., Lopez-Girona, E., Batlle, I., Reig, G., Iglesias, I., Howad, W., et al. (2014). Development of diagnostic markers for selection of the subacid trait in peach. Tree Genet. Genomes 10, 1695–1709. doi: 10.1007/s11295-014-0789-y
Eduardo, I., Pacheco, I., Chietera, G., Bassi, D., Pozzi, C., Vecchietti, A., et al. (2011). QTL analysis of fruit quality traits in two peach intraspecific populations and importance of maturity date pleiotropic effect. Tree Genet. Genomes 7, 323–335. doi: 10.1007/s11295-010-0334-6
Erbe, M., Hayes, B. J., Matukumalli, L. K., Goswami, S., Bowman, P. J., Reich, C. M., et al. (2012). Improving accuracy of genomic predictions within and between dairy cattle breeds with imputed high-density single nucleotide polymorphism panels. J. Diary Sci. 95, 4114–4129. doi: 10.3168/jds.2011-5019
Esteras, C., Formisano, G., Roig, C., Diaz, A., Blanca, J., Garcia-Mas, J., et al. (2013). SNP genotyping in melons: Genetic variation, population structure, and linkage disequilibrium. Theor. Appl. Genet. 126, 1285–1303. doi: 10.1007/s00122-013-2053-5
FAO (2020). FAOSTAT: The statistics division of the food and agriculture Organization of the United Nations. Rome: Food and agriculture Organization of the United Nations (FAO).
Fleming, M. B., Miller, T., Fu, W., Li, Z., Gasic, K., and Saski, C. (2022). Ppe.XapF: High throughput KASP assays to identify fruit response to Xanthomonas arboricola pv. pruni (Xap) in peach. PLoS One 17:e0264543. doi: 10.1371/journal.pone.0264543
Fresnedo-Ramirez, J., Bink, M., van de Weg, E., Famula, T. R., Crisosto, C. H., Frett, T. J., et al. (2015). QTL mapping of pomological traits in peach and related species breeding germplasm. Mol. Breed. 35:166. doi: 10.1007/s11032-015-0357-7
Frett, T. J., Gasic, K., Clark, J. R., Byrne, D., Gradziel, T., and Crisosto, C. (2012). Standardized phenotyping for fruit quality in peach Prunus persica (L.) Batsch. J. Am. Pomo Soc. 66, 214–219.
Gasic, K., and Saski, C. (2019). “Advances in fruit genetics,” in Achieving sustainable cultivation of temperate zone tree fruits and berries. Volume 1: Physiology, genetics and cultivation, ed. G. A. Lang (Cambridge: Burleigh Dodds Science Publishing Limited), 135–162.
Guo, Z. G., Tucker, D. M., Basten, C. J., Gandhi, H., Ersoz, E., Guo, B. H., et al. (2014). The impact of population structure on genomic prediction in stratified populations. Theor. Appl. Genet. 127, 749–762.
Habier, D., Fernando, R. L., and Dekkers, J. C. M. (2007). The impact of genetic relationship information on genome-assisted breeding values. Genetics 177, 2389–2397. doi: 10.1534/genetics.107.081190
Habier, D., Fernando, R. L., and Garrick, D. J. (2013). Genomic BLUP decoded: A look into the black box of genomic prediction. Genetics 194, 597–607. doi: 10.1534/genetics.113.152207
Hardner, C. (2017). Exploring opportunities for reducing complexity of genotype-by-environment interaction models. Euphytica 213:248. doi: 10.1007/s10681-017-2023-0
Hardner, C., Hayes, B. J., Kumar, S., Vanderzande, S., Cai, L., Piaskowsi, J., et al. (2019b). Prediction of genetic value for sweet cherry fruit maturity across environments using a 6K SNP array. Hortic. Res. 6:6. doi: 10.1038/s41438-018-0081-7
Hardner, C., Costa e Silva, J., Williams, E., Meyers, N., and McConchie, C. (2019a). Breeding new cultivars for the Australian macadamia industry. Hortscience 54, 621–628. doi: 10.21273/hortsci13286-18
Hardner, C., Kumar, S., Main, D., and Peace, C. (2021). Global genomic prediction in horticultural crops: Promises, progress, challenges and outlook. Front. Agric. Sci. Eng. 8, 353–355. doi: 10.15302/j-fase-2021387
Hardner, C. M., Dieters, M., Dale, G., DeLacy, I., and Basford, K. E. (2010). Patterns of genotype-by-environment interaction in diameter at breast height at age 3 for eucalypt hybrid clones grown for reafforestation of lands affected by salinity. Tree Genet. Genomes 6, 833–851.
Hardner, C. M., Evans, K., Brien, C., Bliss, F., and Peace, C. (2016). Genetic architecture of apple fruit quality traits following storage and implications for genetic improvement. Tree Genet. Genomes 12:20. doi: 10.1007/s11295-016-0977-z
Harshman, J. M., Evans, K. M., and Hardner, C. M. (2016). Cost and accuracy of advanced breeding trial designs in apple. Hortic. Res. 3:16008. doi: 10.1038/hortres.2016.8
Hayes, B. J., Visscher, P. M., and Goddard, M. E. (2009b). Increased accuracy of artificial selection by using the realized relationship matrix. Genet. Res. 91, 47–60. doi: 10.1017/s0016672308009981
Hayes, B. J., Bowman, P. J., Chamberlain, A. C., Verbyla, K., and Goddard, M. E. (2009a). Accuracy of genomic breeding values in multi-breed dairy cattle populations. Genet. Sel. Evol. 41:51. doi: 10.1186/1297-9686-41-51
Henderson, C. R. (1963). “Selection index and expected genetic advance,” in Statistical genetics and plant breeding, eds W. D. Hanson and H. F. Robinson (Washington, DC: National Academy of Sciences–National Research Council), 141–163.
Hernandez Mora, J. R., Micheletti, D., Bink, M., Van de Weg, E., Cantin, C., Nazzicari, N., et al. (2017). Integrated QTL detection for key breeding traits in multiple peach progenies. BMC Genomics 18:404. doi: 10.1186/s12864-017-3783-6
Heslot, N., Jannink, J. L., and Sorrells, M. E. (2013). Using genomic prediction to characterize environments and optimize prediction accuracy in applied breeding data. Crop Sci. 53, 921–933. doi: 10.2135/cropsci2012.07.0420
Heslot, N., Yang, H. P., Sorrells, M. E., and Jannink, J. L. (2012). Genomic selection in plant breeding: A comparison of models. Crop Sci. 52, 146–160. doi: 10.2135/cropsci2011.06.0297
Hickey, J. M., Dreisigacker, S., Crossa, J., Hearne, S., Babu, R., Prasanna, B. M., et al. (2014). Evaluation of genomic selection training population designs and genotyping strategies in plant breeding programs using simulation. Crop Sci. 54, 1476–1488. doi: 10.2135/cropsci2013.03.0195
Hill, W. G., and Robertson, A. (1968). Linkage disequilibrium in finite populations. Theor. Appl. Genet. 38, 226–231. doi: 10.1007/bf01245622
Iezzoni, A. F., McFerson, J., Luby, J., Gasic, K., Whitaker, V., Bassil, N., et al. (2020). RosBREED: Bridging the chasm between discovery and application to enable DNA-informed breeding in rosaceous crops. Hortic. Res. 7:177. doi: 10.1038/s41438-020-00398-7
Isidro, J., Jannink, J. L., Akdemir, D., Poland, J., Heslot, N., and Sorrells, M. E. (2015). Training set optimization under population structure in genomic selection. Theor. Appl. Genet. 128, 145–158. doi: 10.1007/s00122-014-2418-4
Janss, L., de los Campos, G., Sheehan, N., and Sorensen, D. (2012). Inferences from genomic models in stratified populations. Genetics 192, 693–704. doi: 10.1534/genetics.112.141143
Jorjani, H., Klei, L., and Emanuelson, U. (2003). A simple method for weighted bending of genetic (co)variance matrices. J. Diary Sci. 86, 677–679. doi: 10.3168/jds.S0022-0302(03)73646-7
Kelley, K. M., Primrose, R., Crassweller, R., Hayes, J. E., and Marini, R. (2016). Consumer peach preferences and purchasing behaviour: A mixed methods study. J. Sci. Food Agric. 96, 2451–2461. doi: 10.1002/jsfa.7365
Kelly, A. M., Smith, A. B., Eccleston, J. A., and Cullis, B. R. (2007). The accuracy of varietal selection using factor analytic models for multi-environment plant breeding trials. Crop Sci. 47, 1063–1070.
Kemper, K. E., Bowman, P. J., Hayes, B. J., Visscher, P. M., and Goddard, M. E. (2018). A multi-trait Bayesian method for mapping QTL and genomic prediction. Genet. Sel. Evol. 50:10. doi: 10.1186/s12711-018-0377-y
Kempton, R. A. (1984). The use of biplots in interpreting variety by environment interactions. J. Agric. Sci. 103, 123–135.
Kenward, M. G., and Roger, J. H. (1997). Small sample inference for fixed effects from restricted maximum likelihood. Biometrics 53, 983–997. doi: 10.2307/2533558
Krause, M. D., Dias, K. O. D., dos Santos, J. P. R., de Oliveira, A. A., Guimaraes, L. J. M., Pastina, M. M., et al. (2020). Boosting predictive ability of tropical maize hybrids via genotype-by-environment interaction under multivariate GBLUP models. Crop Sci. 60, 3049–3065. doi: 10.1002/csc2.20253
Kumar, S., Chagne, D., Bink, M., Volz, R. K., Whitworth, C., and Carlisle, C. (2012). Genomic selection for fruit quality traits in apple (Malus x domestica Borkh.). PLoS One 7:e36674. doi: 10.1371/journal.pone.0036674
Kumar, S., Hilario, E., Deng, C. C. H., and Molloy, C. (2020). Turbocharging introgression breeding of perennial fruit crops: A case study on apple. Hortic. Res. 7:47. doi: 10.1038/s41438-020-0270-z
Kumar, S., Kirk, C., Deng, C. H., Shirtliff, A., Wiedow, C., Qin, M. F., et al. (2019). Marker-trait associations and genomic predictions of interspecific pear (Pyrus) fruit characteristics. Sci. Rep. 9:9072. doi: 10.1038/s41598-019-45618-w
Lander, E. S., and Schork, N. J. (1994). Genetic dissection of complex traits. Science 265, 2037–2048. doi: 10.1126/science.8091226
Lebedev, V. G., Lebedeva, T. N., Chernodubov, A. I., and Shestibratov, K. A. (2020). Genomic selection for forest tree improvement: Methods, achievements and perspectives. Forests 11:1190. doi: 10.3390/f11111190
Legarra, A., Robert-Granie, C., Manfredi, E., and Elsen, J. M. (2008). Performance of genomic selection in mice. Genetics 180, 611–618. doi: 10.1534/genetics.108.088575
Lorenz, A. J., and Smith, K. P. (2015). Adding genetically distant individuals to training populations reduces genomic prediction accuracy in barley. Crop Sci. 55, 2657–2667. doi: 10.2135/cropsci2014.12.0827
Luedeling, E. (2012). Climate change impacts on winter chill for temperate fruit and nut production: a review. Sci. Horticult. 144, 218–229. doi: 10.1016/j.scienta.2012.07.011
Malosetti, M., Ribaut, J. M., and van Eeuwijk, F. A. (2013). The statistical analysis of multi-environment data: Modeling genotype-by-environment interaction and its genetic basis. Front. Physiol. 4:44. doi: 10.3389/fphys.2013.00044
Meuwissen, T., Hayes, B., and Goddard, M. (2016). Genomic selection: A paradigm shift in animal breeding. Anim. Front. 6, 6–14. doi: 10.2527/af.2016-0002
Meuwissen, T. H., Hayes, B. J., and Goddard, M. E. (2001). Prediction of total genetic value using genome-wide dense marker maps. Genetics 157, 1819–1829.
Mrode, R. A. (2005). Linear models for the prediction of animal breeding values. Wallingford: CABI Publishing.
Muranty, H., Troggio, M., Ben Sadok, I., Al Rifai, M., Auwerkerken, A., Banchi, E., et al. (2015). Accuracy and responses of genomic selection on key traits in apple breeding. Hortic. Res. 2:15060. doi: 10.1038/hortres.2015.60
NASS USDA (2017). National agricultural statistics service–quick stats. USDA NASS. Available online at: https://data.nal.usda.gov/dataset/nass-quick-stats (accessed January 26, 2022).
Nazarian, A., and Gezan, S. A. (2016). GenoMatrix: a software package for pedigree-based and genomic prediction analyses on complex traits. J. Hered. 107, 372–379. doi: 10.1093/jhered/esw020
Nunez-Lillo, G., Balladares, C., Pavez, C., Urra, C., Sanhueza, D., Vendramin, E., et al. (2019). High-density genetic map and QTL analysis of soluble solid content, maturity date, and mealiness in peach using genotyping by sequencing. Sci. Hortic. 257:108734. doi: 10.1016/j.scienta.2019.108734
O’Connor, K. M., Hayes, B., Hardner, C. M., Alam, M., Henry, R. J., and Topp, B. L. (2021). Genomic selection and genetic gain for nut yield in an Australian macadamia breeding population. BMC Genomics 22:370. doi: 10.1186/s12864-021-07694-z
Okie, W. R., Bacon, T., and Bassi, D. (2008). “Fresh market cultivar development,” in The peach: Botany, production and uses, eds D. R. Layne and D. Bassi (Wallingford: CAB International), 139–174.
Peace, C. P. (2017). DNA-informed breeding of rosaceous crops: Promises, progress and prospects. Hortic. Res. 4:17006. doi: 10.1038/hortres.2017.6
Peace, C. P., Luby, J. J., van de Weg, W. E., Bink, M. C. A. M., and Iezzoni, A. F. (2014). A strategy for developing representative germplasm sets for systematic QTL validation, demonstrated for apple, peach, and sweet cherry. Tree Genet. Genomes 10, 1679–1694. doi: 10.1007/s11295-014-0788-z
Purcell, S., Neale, B., Todd-Brown, K., Thomas, L., Ferreira, M. A. R., Bender, D., et al. (2007). PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Gen. 81, 559–575. doi: 10.1086/519795
Rawandoozi, Z., Hartmann, T., Byrne, D., and Carpenedo, S. (2021). Heritability, correlation, and genotype by environment interaction of phenological and fruit quality traits in peach. J. Am. Soc. Hortic. Sci. 146, 56–67. doi: 10.21273/jashs04990-20
Rawandoozi, Z. J., Hartmann, T. P., Carpenedo, S., Gasic, K., Linge, C. D., Cai, L. C., et al. (2020). Identification and characterization of QTLs for fruit quality traits in peach through a multi-family approach. BMC Genomics 21:522. doi: 10.1186/s12864-020-06927-x
Riedelsheimer, C., Endelman, J. B., Stange, M., Sorrells, M. E., Jannink, J. L., and Melchinger, A. E. (2013). Genomic predictability of interconnected biparental maize populations. Genetics 194, 493–503. doi: 10.1534/genetics.113.150227
Roth, M., Muranty, H., Di Guardo, M., Guerra, W., Patocchi, A., and Costa, F. (2020). Genomic prediction of fruit texture and training population optimization towards the application of genomic selection in apple. Hortic. Res. 7:148. doi: 10.1038/s41438-020-00370-5
Sandefur, P., Frett, T., Clark, J., Gasic, K., and Peace, C. (2017). A DNA test for routine prediction in breeding of peach blush, Ppe-R-f-SSR. Mol. Breed. 37:15. doi: 10.1007/s11032-016-0615-3
Schopp, P., Muller, D., Wientjes, Y. C. J., and Melchinger, A. E. (2017). Genomic prediction within and across biparental families: Means and variances of prediction accuracy and usefulness of deterministic equations. G3 7, 3571–3586. doi: 10.1534/g3.117.300076
Smith, A., Cullis, B., and Thompson, R. (2001). Analyzing variety by environment data using multiplicative mixed models and adjustments for spatial field trend. Biometrics 57, 1138–1147. doi: 10.1111/j.0006-341x.2001.01138.x
Smith, A. B., Cullis, B. R., and Thompson, R. (2005). The analysis of crop cultivar breeding and evaluation trials: An overview of current mixed model approaches. J. Agric. Sci. 143, 449–462. doi: 10.1017/s0021859605005587
Sneller, C., Ignacio, C., Ward, B., Rutkoski, J., and Mohammadi, M. (2021). Using genomic selection to leverage resources among breeding programs: Consortium-based breeding. Agronomy 11:1555. doi: 10.3390/agronomy11081555
Stram, D. O., and Lee, J. W. (1994). Variance-components testing in the longitudinal mixed effects model. Biometrics 50, 1171–1177.
Su, G. S., Christensen, O. F., Ostersen, T., Henryon, M., and Lund, M. S. (2012). Estimating additive and non-additive genetic variances and predicting genetic merits using genome-wide dense single nucleotide polymorphism markers. PLoS One 7:e45293. doi: 10.1371/journal.pone.0045293
Thompson, R., Cullis, B., Smith, A., and Gilmour, A. (2003). A sparse implementation of the average information algorithm for factor analytic and reduced rank variance models. Aust. N. Z. J. Stat. 45, 445–459.
Toosi, A., Fernando, R. L., and Dekkers, J. C. M. (2010). Genomic selection in admixed and crossbred populations. J. Anim. Sci. 88, 32–46. doi: 10.2527/jas.2009-1975
Vanderzande, S., Howard, N. P., Cai, L. C., Linge, C. D., Antanaviciute, L., Bink, M., et al. (2019). High-quality, genome-wide SNP genotypic data for pedigreed germplasm of the diploid outbreeding species apple, peach, and sweet cherry through a common workflow. PLoS One 14:e0210928. doi: 10.1371/journal.pone.0210928
Vanderzande, S., Piaskowski, J. L., Luo, F., Edge Garza, D. A., Klipfel, J., Schaller, A., et al. (2018). Crossing the finish line: How to develop diagnostic DNA tests as breeding tools after QTL discovery. J. Hortic. 5, 1–6. doi: 10.4172/2376-0354.1000228
VanRaden, P. M. (2008). Efficient methods to compute genomic predictions. J. Diary Sci. 91, 4414–4423. doi: 10.3168/jds.2007-0980
Verde, I., Abbott, A. G., Scalabrin, S., Jung, S., Shu, S. Q., Marroni, F., et al. (2013). The high-quality draft genome of peach (Prunus persica) identifies unique patterns of genetic diversity, domestication and genome evolution. Nat. Genet. 45, 487–494. doi: 10.1038/ng.2586
Verde, I., Bassil, N., Scalabrin, S., Gilmore, B., Lawley, C. T., Gasic, K., et al. (2012). Development and evaluation of a 9K SNP array for peach by internationally coordinated SNP detection and validation in breeding germplasm. PLoS One 7:e35668. doi: 10.1371/journal.pone.0035668
Verde, I., Jenkins, J., Dondini, L., Micali, S., Pagliarani, G., Vendramin, E., et al. (2017). The Peach v2.0 release: High-resolution linkage mapping and deep resequencing improve chromosome-scale assembly and contiguity. BMC Genomics 18:225. doi: 10.1186/s12864-017-3606-9
Ward, J. H. Jr. (1963). Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 58, 236–244. doi: 10.2307/2282967
Werner, C. R., Gaynor, R. C., Gorjanc, G., Hickey, J. M., Kox, T., Abbadi, A., et al. (2020). How population structure impacts genomic selection accuracy in cross-validation: Implications for practical breeding. Front. Plant Sci. 11:592977. doi: 10.3389/fpls.2020.592977
Wientjes, Y. C. J., Bijma, P., Vandenplas, J., and Calus, M. P. L. (2017). Multi-population genomic relationships for estimating current genetic variances within and genetic correlations between populations. Genetics 207, 503–515. doi: 10.1534/genetics.117.300152
Windhausen, V. S., Atlin, G. N., Hickey, J. M., Crossa, J., Jannink, J. L., Sorrells, M. E., et al. (2012). Effectiveness of genomic prediction of maize hybrid performance in different breeding populations and environments. G3 2, 1427–1436. doi: 10.1534/g3.112.003699
Worthington, M., and Clark, J. R. (2021). Peach breeding at the University of Arkansas. Acta. Hortic. 1304, 21–28. doi: 10.17660/ActaHortic.2021.1304.3
Yang, J. A., Benyamin, B., McEvoy, B. P., Gordon, S., Henders, A. K., Nyholt, D. R., et al. (2010). Common SNPs explain a large proportion of the heritability for human height. Nat. Genet. 42, 565–569. doi: 10.1038/ng.608
Yu, J. M., Pressoir, G., Briggs, W. H., Bi, I. V., Yamasaki, M., Doebley, J. F., et al. (2006). A unified mixed-model method for association mapping that accounts for multiple levels of relatedness. Nat. Genet. 38, 203–208. doi: 10.1038/ng1702
Yu, Y., Fu, J., Xu, Y. G., Zhang, J. W., Ren, F., Zhao, H. W., et al. (2018). Genome re-sequencing reveals the evolutionary history of peach fruit edibility. Nat. Commun. 9:5404. doi: 10.1038/s41467-018-07744-3
Keywords: global genomic prediction, multivariate, G × E, mixed models, parsimony, factor-analytic
Citation: Hardner CM, Fikere M, Gasic K, da Silva Linge C, Worthington M, Byrne D, Rawandoozi Z and Peace C (2022) Multi-environment genomic prediction for soluble solids content in peach (Prunus persica). Front. Plant Sci. 13:960449. doi: 10.3389/fpls.2022.960449
Received: 03 June 2022; Accepted: 01 August 2022;
Published: 06 October 2022.
Edited by:
Diego Rubiales, Institute for Sustainable Agriculture (CSIC), SpainReviewed by:
Ke Cao, Zhengzhou Fruit Research Institute (CAAS), ChinaJonathan Fresnedo Ramirez, The Ohio State University, United States
Copyright © 2022 Hardner, Fikere, Gasic, da Silva Linge, Worthington, Byrne, Rawandoozi and Peace. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Craig M. Hardner, craig.hardner@uq.edu.au
†Present addresses: Mulusew Fikere, Institute for Molecular Bioscience, The University of Queensland, Brisbane, QLD, Australia; Cassia da Silva Linge, Department of Agriculture and Environmental Sciences, University of Milan, Milan, Italy