Frequency effects in linear discriminative learning
 Maria Heitmeier
Maria Heitmeier Yu-Ying Chuang
Yu-Ying Chuang Seth D. Axen
Seth D. Axen R. Harald Baayen
R. Harald Baayen- 1Quantitative Linguistics, University of Tübingen, Tübingen, Germany
- 2Cluster of Excellence Machine Learning: New Perspectives for Science, University of Tübingen, Tübingen, Germany
Word frequency is a strong predictor in most lexical processing tasks. Thus, any model of word recognition needs to account for how word frequency effects arise. The Discriminative Lexicon Model (DLM) models lexical processing with mappings between words' forms and their meanings. Comprehension and production are modeled via linear mappings between the two domains. So far, the mappings within the model can either be obtained incrementally via error-driven learning, a computationally expensive process able to capture frequency effects, or in an efficient, but frequency-agnostic solution modeling the theoretical endstate of learning (EL) where all words are learned optimally. In the present study we show how an efficient, yet frequency-informed mapping between form and meaning can be obtained (Frequency-informed learning; FIL). We find that FIL well approximates an incremental solution while being computationally much cheaper. FIL shows a relatively low type- and high token-accuracy, demonstrating that the model is able to process most word tokens encountered by speakers in daily life correctly. We use FIL to model reaction times in the Dutch Lexicon Project by means of a Gaussian Location Scale Model and find that FIL predicts well the S-shaped relationship between frequency and the mean of reaction times but underestimates the variance of reaction times for low frequency words. FIL is also better able to account for priming effects in an auditory lexical decision task in Mandarin Chinese, compared to EL. Finally, we used ordered data from CHILDES to compare mappings obtained with FIL and incremental learning. We show that the mappings are highly correlated, but that with FIL some nuances based on word ordering effects are lost. Our results show how frequency effects in a learning model can be simulated efficiently, and raise questions about how to best account for low-frequency words in cognitive models.
1 Introduction
Word frequency effects are ubiquitous in psycholinguistic research. In fact, word frequency (i.e., the number of times a word occurs in some corpus) is one of the most important predictors in a range of psycholinguistic experimental paradigms (Brysbaert et al., 2011). In the lexical decision task, where participants are asked to decide whether a presented letter string is a word or not, frequency explains by far the most variance in reaction times, compared to other measures such as neighborhood density or word length (e.g. Baayen, 2010; Brysbaert et al., 2011): higher frequency words elicit faster reactions (e.g., Rubenstein et al., 1970; Balota et al., 2004). In word naming, another popular experimental paradigm in psycholinguistics where participants have to read aloud presented words, word frequency is less important, but still has a reliable effect: higher frequency words are named faster (e.g., Balota et al., 2004). Even though the effect of frequency has long been known and studied, to this day new studies are published confirming the effect in ever larger datasets across different languages (e.g., Balota et al., 2004; Ferrand et al., 2010; Keuleers et al., 2010, 2012; Brysbaert et al., 2016). Some studies have also proposed new frequency counts, explaining for example individual differences when it comes to the frequency effect (e.g., Kuperman and Van Dyke, 2013; Brysbaert et al., 2018).
A central challenge for models of word recognition is therefore to explain word frequency effects. This challenge has been met in various different ways by influential models of word recognition. One of the earliest ideas proposed that words are stored in list-like structures ordered by frequency, such that the most frequent words are found earlier than lower frequency words (e.g., Rubenstein et al., 1971). This idea was developed into the “Search Model of Lexical Access” by Forster (1976, 1979). In this model there are “peripheral access files” in which words are stored according to their frequency of occurrence. These files hold “access keys” to where information about each word is stored in a main file. Words in the access files are grouped into bins based on form characteristics. Thus, the model aims to explain both word frequency effects (words are ordered according to their frequency in the peripheral access files) as well as neighborhood effects (words with similar form are stored in the same bin). Later iterations of the model also suggested a hybrid model between serial and parallel search, where each bin is searched serially, but all bins are searched in parallel (Forster, 1994).
The Logogen model (Morton, 1969, 1979a,b) fully doubled down on the idea of a parallel search. A logogen can be seen as a detector for a set of input features. Every time one of its associated input features is encountered, the logogen's counter is increased. If the counter surpasses a threshold, it elicits a response. Each word/morpheme in a speaker's lexicon is assumed to correspond to a logogen. Additionally, there are logogens for lower level visual and auditory input features such as letters or phonemes whose outputs in turn serve as inputs to the word logogens. The Logogen model accounts for frequency effects by assuming that logogens corresponding to words with higher frequency have a lower response threshold than those corresponding to lower frequency words. After a logogen elicits a response, the threshold is lowered, and it takes a long time for the threshold to increase again. This explains trial-to-trial effects because just activated words will be activated faster in subsequent trials, but it also explains the long-term effect of word frequency because words occurring regularly will always have a lower threshold for eliciting a response (Morton, 1969).
The interactive activation model (McClelland and Rumelhart, 1981; Rumelhart and McClelland, 1982) is in many ways a successor of the Logogen model. It proposes three levels of representations: one for letter features, one for letters and one for words. There are excitatory and inhibitory connections from letter features to letters and from letters to words. Additionally, there are excitatory and inhibitory connections from words to letters. Finally, there are both excitatory and inhibitory connections within each representational level (note though that the feature-feature inhibition was set to zero in the original implementation). The interactive activation model was originally proposed to explain the word superiority effect, i.e., the finding that letters are identified faster within a word than within a random letter string (e.g., Reicher, 1969). However, the model also proposes an account of frequency effects: the resting activation level of the word units are set depending on word frequency, such that high frequency words have a higher resting activation than low frequency words. In this way, Jacobs and Grainger (1994) were able to show that the interactive activation model shows the same effect of frequency on reaction times in various lexical decision experiments as human participants.
The interactive activation model was followed by the triangle model (Seidenberg and McClelland, 1989; Harm and Seidenberg, 2004), which consists of distributed representations for orthography, phonology and semantics, each connected via a set of hidden units. In contrast to the interactive activation model, the weights between layers in this network are not set by the modeler but learned using backpropagation (Rumelhart et al., 1986). Thus, the error between the model's prediction and the actual target is reduced each time an input-target pair is encountered. For example, to model reading, the triangle model takes as input a word's orthography and predicts its phonology. Then, the error between the predicted phonology and the correct phonology of the word is computed, and the model's weights are updated such that the next time the same phonology is to be produced from the same orthography, it will be more accurate. The more often a word is presented to the model, the more accurate its predicted phonology becomes. This means that high frequency words will over time produce the lowest prediction error and are thus recognized faster and more accurately. Therefore, word frequency effects arise not as a consequence of manually changing resting activation levels but from the weights within the network changing according to the input distribution.
A final model of word recognition reviewed here is the Bayesian Reader Model (Norris, 2006). This model not only accounts for the frequency effect but also aims to explain why frequency effects should arise in the first place. The model is a simple Bayesian model that integrates a word's prior probability (for which Norris, 2006, uses its frequency) with the incoming evidence. Thus, high frequency words are recognized faster than low frequency ones. According to Norris (2006, 2013) this constitutes an “ideal observer” model, solving the task at hand as optimally as possible. This explains not only why frequency effects should arise in the first place but also why they play out differently in different experiments.
To summarize, these five models offer three broad explanations of frequency effects. Serial search models explain them in terms of list ordering effects; the Logogen, interactive activation and triangle model propose network models where frequency is reflected in units' thresholds/activation levels or in connection weights; and finally, the Bayesian Reader proposes that word frequencies provide lexical priors that contribute to an optimal decision process in word recognition.
Interestingly, reaction times for example in lexical decision are best predicted not by raw word frequencies but by log- or rank-transformed frequencies. Again, the various models account for this in different ways. Since the serial search model incorporates word lists, it directly predicts a rank transformation of word frequencies (see also Murray and Forster, 2004). In the interactive activation model, the resting activation levels of the word units are set according to the words' log frequency (McClelland and Rumelhart, 1989, Chapter 7). In the triangle model, training items are sampled such that they have a probability proportional to log(frequency+2). Note that Seidenberg and McClelland (1989) do this for practical rather than principled reasons, as sampling training items proportionally to full token frequencies would require orders of magnitude more computation to achieve the same coverage (this is a practice adopted also in other work, see for instance Li et al., 2007). Finally, the Bayesian Reader utilizes raw word frequencies.
Comparison of these models highlights a few key questions about how to model the word frequency effect: first, how and why does the frequency effect arise in the first place? Does it arise naturally as a consequence of the input data? And what mechanism does the model provide for how the frequency differences are acquired? Secondly, how does the model keep track of word frequencies? Are there “counters” for each individual word (see also Baayen, 2010)? And finally, how does the model account for the fact that reaction times are best predicted by log- or rank-transformed frequencies rather than raw frequency counts?
We now turn to a more recent model of word comprehension and production, the Discriminative Lexicon Model (DLM; Baayen et al., 2018b, 2019). This model provides a perspective on the mental lexicon in which mappings between numeric representations for form and meaning play a central role. This model conceptualizes comprehension as involving mappings from high-dimensional modality-specific form vectors to high-dimensional representations of meaning. The initial stage of speech production is modeled as involving a mapping in the opposite direction, starting with a high-dimensional semantic vector (known as embeddings in computational linguistics) and targeting a vector specifying which phone combinations drive articulation. The DLM has been successful in modeling a range of different morphological systems (e.g., Chuang et al., 2020, 2022; Denistia and Baayen, 2021; Heitmeier et al., 2021; Nieder et al., 2023) as well as behavioral data such as acoustic durations (Schmitz et al., 2021; Stein and Plag, 2021; Chuang et al., 2022), (primed) lexical decision reaction times (Gahl and Baayen, 2023; Heitmeier et al., 2023b), and data from patients with aphasia (Heitmeier and Baayen, 2020).
The DLM's mappings between form and meaning are implemented by means of matrices. This general matrix-based approach is referred to as linear discriminative learning (LDL). LDL can be implemented in two ways: by means of the matrix algebra underlying multivariate multiple regression (henceforth the “endstate learning”, EL), or by means of incremental regression using the error-driven learning rule of Widrow and Hoff (1960) (henceforth WHL). EL is computationally efficient, WHL is computationally demanding. Conversely, WHL is sensitive to the frequencies with which words are presented for learning, whereas EL is fully type-based (i.e., words' token frequencies do not play a role).
Thus, the DLM proposes that frequency effects arise due to the distribution of the input data: higher frequency words occur more often in the input data, and therefore, the prediction error will be smallest for high frequency words (see Chuang et al., 2021; Heitmeier et al., 2021, for studies utilizing WHL to obtain frequency-informed mapping matrices). Word frequencies are not stored explicitly; rather, they have effects on the weights in the mappings. This account is similar to how frequency effects arise in the triangle model. Similar to the triangle model, the DLM also suffers from computational issues: training on the full frequency distribution with WHL is computationally very demanding.
Recent modeling efforts with the DLM have been limited by the disadvantages of EL and WHL: they either had to opt for EL, which resulted in models that were not informed about word frequencies (e.g., Heitmeier et al., 2023b), or for WHL, which limited the amount of data the models could be trained on (e.g., Chuang et al., 2021; Heitmeier et al., 2021). The present paper aims to solve this problem by introducing a new method for computing the mapping matrices that takes frequency of use into account but is computationally efficient by making use of a numerically efficiently solvable solution: “Frequency-informed learning” (FIL). FIL can be used instead of the already established WHL and EL to compute mapping matrices in the DLM.
In the following we compare the three different methods of estimating mapping matrices in the DLM. We show how the model is able to account for frequency effects using WHL and the newly introduced FIL. We demonstrate that FIL is equivalent to training the model incrementally on full token frequencies and is superior to utilizing log-transformed frequencies. We show how the DLM is able to model reaction times linearly without the need of log- or rank-transformations. Finally, we investigate what role the order in which words are learned plays in word recognition.
This study is structured as follows: we first lay out the basic concepts underlying linear discriminative learning in Section 2. In Section 3, we discuss EL, and subsequently, WHL. Against this background, we proceed with proposing a new method computing non-incremental, yet frequency-informed learning (FIL). We then present three case studies, one using FIL to model visual lexical decision latencies from the Dutch Lexicon Project (Keuleers et al., 2010) (Section 4.1), one where we use FIL to model spoken word recognition in Mandarin (Section 4.2) and a third where we compare WHL and FIL in modeling first word learning with data from CHILDES (Brown, 1973; Demuth et al., 2006) (Section 5). A discussion section brings this study to a close.
2 Linear discriminative learning: basic concepts and notation
In the DLM, word forms are represented as binary vectors that code the presence and absence of overlapping n-grams in the word form (e.g., #a, aa, ap, p# for the Dutch word aap, “monkey”). Form vectors are stored as row vectors in a “cue matrix” C. For an overview of how form vectors can be constructed, see Heitmeier et al. (2021), and for form vectors derived from audio signals, see Shafaei-Bajestan et al. (2023). Semantics are represented as real-valued vectors, following distributional semantics (Landauer et al., 1998), which are stored as row vectors in a semantic matrix S.
To model comprehension, a mapping matrix F transforms the form vectors in C into the semantic vectors in S. Conversely, a production matrix G maps meanings onto forms. The matrices F and G are estimated by solving
where CF and SG refer to the matrix multiplication of C and F and of S and G, respectively. Further information on this operation can be found for instance in Beaumont (1965). Given F and G, we can estimate the predicted semantic vectors
and the predicted form vectors
with the hat on S and C indicating that the predicted matrices are estimates (in the statistical sense) that approximate the gold standard vectors but will usually not be identical to these vectors. It is often convenient to focus on individual words, in which case we have that
To evaluate the accuracy of a comprehension mapping, the predicted semantic row vectors of are correlated with all the corresponding semantic row vectors in the gold standard semantic matrix S. If the predicted semantic vector of a word form is closest to its target vector, it is counted as correct. This accuracy measure is referred to as correlation accuracy in the following, and we will sometimes denote it as accuracy@1.1 More lenient accuracy measures accuracy@k accept model performance as satisfying when s is among the top k nearest target semantic vectors of the predicted semantic vector ŝ. For detailed introductions to the DLM, see Baayen et al. (2018a, 2019) and Heitmeier et al. (2021, 2023a).
3 Three methods for computing mappings in the DLM
This section introduces the two existing methods for computing mappings in the DLM, Endstate Learning (EL) and Widrow-Hoff learning (WHL), and explains their respective disadvantages using a small Dutch dataset from Ernestus and Baayen (2003). Finally, we present Frequency-informed learning (FIL). Since it is much more computationally efficient than WHL, we also demonstrate its usage on a larger dataset from Keuleers et al. (2010). For expositional simplicity, we focus mainly on comprehension. We note, however, that frequency-informed mappings are equally important for modeling production.
3.1 Setup
3.1.1 Data
For the present section, we used two datasets:
Small dataset: A subset of 2,646 singular and plural Dutch nouns and verbs (for which frequency was at least 1) taken from a dataset originally extracted from the Dutch CELEX database (Baayen et al., 1995) by Ernestus and Baayen (2003).2 These words have monomorphemic stems ending in an obstruent that is realized as voiceless when word-final but that in syllable onset appears with voicing in some words and without voicing in others. We used 300-dimensional Dutch fasttext embeddings (Grave et al., 2018) to represent semantics.3 Since we were unable to obtain word embeddings for all words in our dataset, this left us with 2,638 word forms (i.e., excluding eight word forms).
Large dataset: We also present results with a larger dataset extracted from the Dutch Lexicon Project (DLP, Keuleers et al., 2010) in later sections. We used all 13,669 words from the DLP for which we were able to obtain fasttext embeddings.
The frequencies of use that we use in this study when working both with the small and the large datasets are taken from CELEX.
3.1.2 Modeling choices
In what follows, we present results with two different form vector setups:
Low-dimensional form vectors: We make use of bi-grams for representing word forms (used in their orthographic representation), resulting in a dimensionality of 360. The use of bigrams is motivated by the choice to minimize the carbon footprint and duration of our simulations, especially when using WHL.
High-dimensional form vectors: For the new, computationally highly efficient frequency-sensitive model that is at the heart of this study, we made use of trigrams. For the small dataset this resulted in a form vector dimensionality of 1,776, and 4,678 for the large dataset.
3.2 Endstate learning
The first implementation of the DLM in the R (R Core Team, 2020) package WpmWithLdl (Baayen et al., 2018b) estimates the “endstate” of learning. This implementation constructs a mapping F between the cue matrix C and the semantic matrix S using the pseudo-inverse by solving the following set of equations:
where I denotes the identity matrix and CT the transpose of C. Details on these equations (known as the normal equations in statistics) can be found in Faraway (2005).
Computing the pseudo-inverse as implemented in WpmWithLdl is expensive and prohibitively so for larger datasets. Fortunately, there now exists a very efficient method implemented in the Julia (Bezanson et al., 2017) package JudiLing4 that makes use of the Cholesky decomposition (Luo, 2021; Heitmeier et al., 2023a). This, together with additional speed-ups due to Julia being in general faster than R and the use of sparse matrices means that JudiLing can handle much larger datasets compared to WpmWithLdl (Luo, 2021).
The endstate learning (EL) results in optimal mapping matrices that reduce the error between the predicted and the target vectors as much as possible, for all word forms. It is optimal in the least-squares sense, and the underlying mathematics are identical to that of multivariate multiple regression. This method is characterized as estimating the “endstate” of learning, because the mappings it estimates can also be approximated by using incremental learning (WHL) applied to an infinite number of passes through one's dataset (assuming that each word occurs a single time in the dataset). With infinite experience, every word has been experienced an equal and infinite amount of times. Any effects of frequency of occurrence in this model are an epiphenomenon of lexical properties such as word length and neighborhood density (Nusbaum, 1985; Baayen, 2001).
Figure 1 illustrates the frequency-free property of EL. It presents the results obtained with an EL model with low-dimensional form vectors for the small dataset introduced in the preceding section, modeling comprehension with the matrix F. The average correlation accuracy for this model is low, at 40.8%; below, we will show how this accuracy can be improved to 83% by increasing the dimensionality of the form vectors.
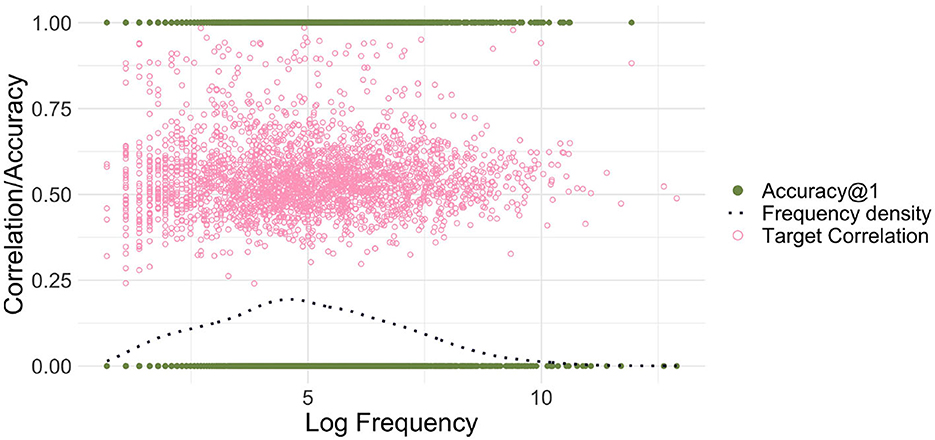
Figure 1. Endstate learning. The green filled dots on the horizontal lines at 0 and 1 represent the correlation accuracies@1 for the individual words (counted as correct if the semantic vector most correlated with the predicted semantic vector is the target), and the light pink circles represent the correlation values of words' predicted semantic vectors with their target vectors. The dark blue dotted line presents the estimated kernel density for log frequency. There is no discernible relationship between Log Frequency and correlation/accuracy for endstate learning.
To illustrate the absence of a relationship between word frequency and correlation accuracy, we used a binomial generalized linear model5 with a logit link function, modeling the probability of correct recognition as a function of log frequency (here and in all later analyses, before log-transformation, a backoff value of 1 was added to word frequencies). Log frequency was not a good predictor of accuracy (p = 0.9772).
In summary, one important advantage of endstate learning is that it is can be computed very quickly: on a MacBook Pro (2017) with a 3.1 GHz Quad-Core Intel Core i7 processor and for the small dataset with low-dimensional form vectors it takes about 20 milliseconds. A second important advantage of this method is that it is frequency-free: it shows what can be learned when frequency of use is not allowed to play a role. In other words, the EL probes the quantitative structure of a dataset, under the assumption that usage can be ignored. Thus, the EL method dovetails well with generative approaches to morphology that deny any role to usage in grammar and work with types only.
However, this is also the achilles heel of the EL method: EL is purely type-based and is blind to the consequences of token frequency for learning. Well-established effects of frequency of use (see, e.g., Baayen et al., 1997; Bybee and Hopper, 2001) are not captured. This is why an alternative way of estimating mappings between form and meaning is implemented in the JudiLing package: incremental learning.
3.3 Incremental learning
Instead of making use of the efficient method estimating the endstate of learning, we can also learn the mappings incrementally using the Widrow-Hoff learning rule (Widrow and Hoff, 1960), a form of error-driven learning closely related to the Rescorla-Wagner learning rule (Rescorla and Wagner, 1972; for a discussion of the Widrow-Hoff learning rule in language research see also Milin et al., 2020). Here, the idea is that each time a word is encountered, a learning event occurs, and the mappings between form and meaning are updated in such a way that next time the same word is encountered (if no unlearning occurs intermittently) the mappings will be more accurate. To be precise, instead of obtaining the mapping matrix F via Equation (1), it is learned gradually via the following equation:
where Ft is the state of the matrix F at learning step t, ct and st are the form and semantic vectors of the wordform encountered at t, and . How fast learning takes place is controlled via the learning rate parameter η. High learning rates lead to fast learning and unlearning, whereas low learning rates result in slower learning and less unlearning.
Incremental learning has the advantage that we can model learning in a frequency-informed way by translating frequencies into learning events. For example, if a word has a frequency of 100, it is presented for learning 100 times. We used the Widrow-Hoff learning rule as implemented in JudiLing to incrementally learn the mapping matrix F. This mapping is now frequency-informed. We experimented with low-dimensional form vectors and three different learning rates: 0.01, 0.001, and 0.0001, modeling words in the small dataset. The average correlation accuracy for the three simulations was 15.5, 14.0, and 10.1%, respectively. As can be seen in the left panel of Figure 2, when learning the mappings incrementally according to their frequency, a clear relationship between frequency and accuracy is obtained for all learning rates: the more frequent a word is, the more accurately it is learned. A binomial GLM indicated a highly significant relationship between frequency and accuracy (p < 0.001 for all learning rates). The lower the learning rate, the steeper the increase in accuracy: accuracy is lower for low-frequency words and higher for high-frequency ones.
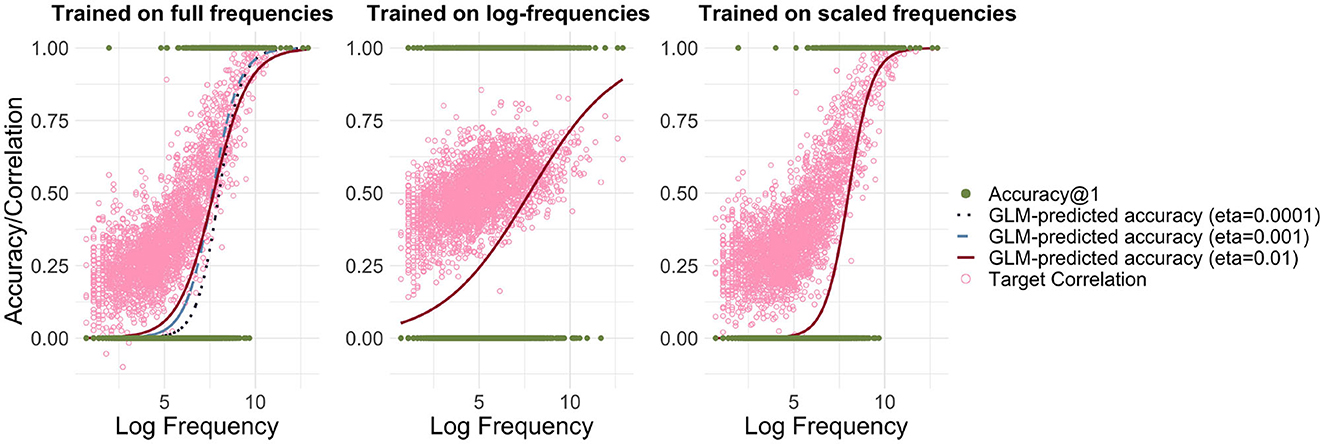
Figure 2. Relationship between accuracy and frequency for incremental learning. Left: Mapping trained using full frequencies. Predicted accuracy is depicted for three different learning rates [η ∈ {0.01, 0.001, 0.0001}], and the light pink circles present target correlations for η = 0.01. Center: Mapping trained using log-transformed frequencies. Right: Mapping trained using frequencies divided by a factor of 100. While there is a strong relationship between log frequency and accuracy/correlation when training on full frequencies and scaled frequencies, this relationship is attenuated when training on log-transformed frequencies.
There are two disadvantages to this approach, one practical, and the other theoretical. The theoretical problem is that for many datasets, there is no intrinsic order in which words are learned. For the present dataset, which is basically a word frequency list, we do not have available any information about the order in which Dutch speakers encounter these words over their lifetime. It is only for intrinsically ordered data, such as child directed speech in corpora such as CHILDES (MacWhinney, 2014), that incremental learning comes into its own (see Section 5). The practical problem is that updates with the Widrow-Hoff learning rule are computationally expensive. For the present dataset, estimating the mapping matrix F took ≈25 minutes on a MacBook Pro (2017) with a 3.1 GHz Quad-Core Intel Core i7 processor, even though the use of bi-grams resulted in a form dimensionality that was already too small to obtain good accuracy. If we would use the better-suited tri-grams (i.e., the high-dimensional form vectors described in Section 3.1.2), the estimated time for computing the mapping matrix F increases strongly even in an optimized language such as Julia.
The computational cost of WHL may be alleviated in (at least) two ways. One option is to transform frequencies by taking logarithms (see, e.g., Seidenberg and McClelland, 1989). The resulting average correlation accuracy is 26.8%. The relationship between frequency and accuracy can be seen in the center panel of Figure 2. While the log transformation does indeed reduce computational costs, it is questionable whether such a transformation is justified and realistic. Low frequency words become proportionally more accurate, while high frequency ones become less so. If WHL with empirical frequencies for time-ordered learning events is taken as a gold standard, then a log-transformation distorts our estimates considerably.
A second option is to simply scale down frequencies by dividing them by a fixed number. By applying a ceiling function to the result, we avoid introducing zero frequencies. Training the model using frequencies divided by 100 speeds up the learning to ≈12 s and does not distort the learning curve (see right panel of Figure 2). The disadvantage of this method is that there are far fewer learning events. As a consequence, words are learned less well. Accordingly, the average correlation accuracy drops to 10.3%.
In summary, it is in principle possible to estimate mapping matrices with incremental learning. This is theoretically highly attractive for data that are intrinsically ordered in learning time (see, e.g., Heitmeier et al., 2023b, for the modeling of within-experiment learning). For unordered data, some random order can be chosen, but for larger datasets, it would be preferable to have a method that is agnostic about order but nevertheless accounts in a principled way for the consequences of experience for discriminative learning.
3.4 Non-incremental, yet frequency-informed mappings
A solution to this conundrum is to construct frequency-informed mappings between form and meaning. Thinking back to incremental learning, learning a word wi with frequency count fi involved learning the mapping from a cue vector ci to the word's meaning si fi times. We could thus construct matrices Cf and Sf reflecting the entire learning history: Cf and Sf are C and S with word forms wi and semantic vectors si repeated according to their frequency count fi. We are looking for the mapping Ff and Gf such that
Formally, let and where each word wi of the m wordforms corresponds to a row in the two matrices with cue vector ci and semantic vector si. Each word form wi has a frequency count fi.
We can create two new matrices Cf and Sf where the cue and semantic vectors of the wordforms are repeated according to their frequency count fi. We want to find the mapping matrix Ff mapping from Cf to Sf. We use the following solution for computing the mapping matrix (see also Baayen et al., 2018a):
with a constant k ∈ ℝ>0. Since k does not change the solution, we can set it such that the algorithm is numerically more stable, for example to so that we have and therefore
Now let P ∈ ℝm×m be a diagonal matrix with pii = pi for i ∈ 1, ..., m. Then we can define and so that and . Then we have
Therefore, the pair has the same mapping matrices as (Cf, Sf).
Practically, this means that we can first weigh C and S with the pertinent frequencies to obtain and . We can then use the solution in Equation (1) (making use of algorithms such as Cholesky decomposition) to obtain frequency-informed mappings between these two matrices.6
In what follows, we sketch the new possibilities enabled by this method, to which we will refer as frequency-informed learning (FIL). A first, practical, advantage of FIL is that it is efficient and fast. A second, theoretical, advantage is that predictions are available for datasets for which no information about the order of learning is available.
3.4.1 Low-dimensional modeling
We first consider modeling studies using the low-dimensional vectors that we used in the preceding sections together with the small dataset. We chose this low dimensionality in order to avoid long computation times for WHL for these exploratory studies.
Figure 3 shows the relationship between log-transformed frequency and accuracy predicted by a logistic GLM regressing the correctness of FIL responses on log frequency. Accuracy@k is set to 1 if a word's target semantic vector is among the k target vectors that are most correlated with the predicted semantic vector, and to 0 otherwise.
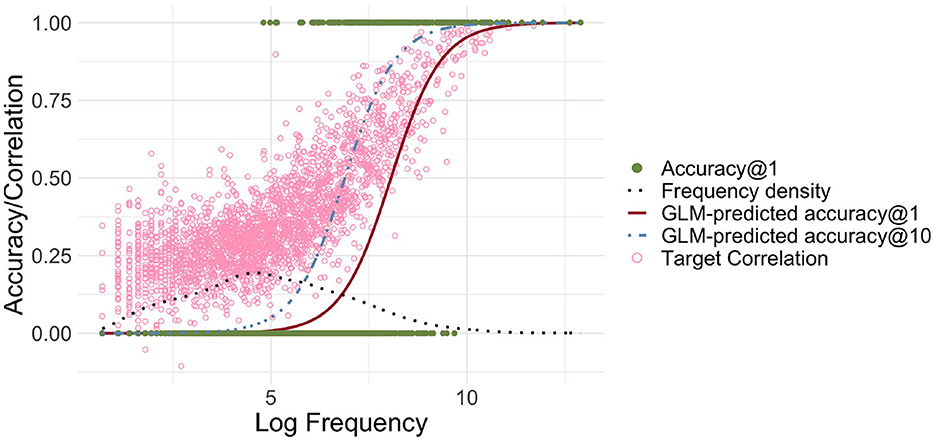
Figure 3. Frequency-informed learning. The red solid line presents the predictions of a GLM when a success is defined as the predicted vector being the closest to its gold standard target vector in terms of correlation (accuracy@1). The light blue dashed line represents predictions of a GLM when a success is defined as the correlation being among the top 10 (accuracy@10). The dark blue dotted line visualizes the estimated density of the log-transformed frequencies. The green filled dots represent the successes and failures for accuracy@1. The light pink circles represent for each word the correlation of the predicted and gold-standard semantic vectors. There is a strong relationship between log frequency and correlation/accuracy, and the GLM-predicted accuracy@10 is shifted to the left, i.e., accuracy@10 rises for lower frequencies.
Correlation and accuracy@1 increase for higher frequency, as required. When comparing accuracies with the frequency distribution depicted in the same plot, we can also see that there is a large number of low frequency words with very low (predicted) accuracy. Although for most words, the correlations are relatively high, the overall accuracy@1 is low, at 9.9%. When we relax our criterion for accuracy, using accuracy@10, counting a predicted vector as correct if the target vector is among the 10 closest semantic vectors, we see that the accuracy starts to rise earlier, but there is still a significant portion of words for which even accuracy@10 is zero.
The relatively large number of words with very low accuracy raises the question of whether accuracy can be improved by using log-transformed frequencies for FIL. Figure 4 clarifies that accuracies increase for lower-frequency words, but decrease somewhat for higher-frequency words. The average accuracy@1 is accordingly higher at 34.6%.
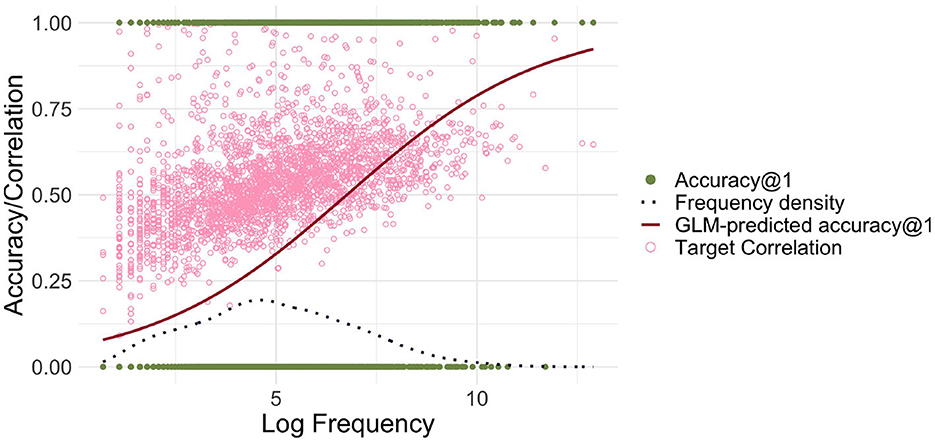
Figure 4. Accuracy@1 as a function of log frequency, using frequency-informed learning with log-transformed frequencies. When FIL is trained with log-transformed frequencies, lower-frequency words are recognized more accurately, but higher-frequency words less accurately.
The upper half of Table 1 provides an overview of the accuracies@1 for different combinations of learning (incremental/frequency-informed) and kind of frequency used (untransformed, scaled, or log-transformed). Here, we observe first of all that endstate learning offers the highest accuracy (40.8%), followed by log-frequency informed learning (34.6%).
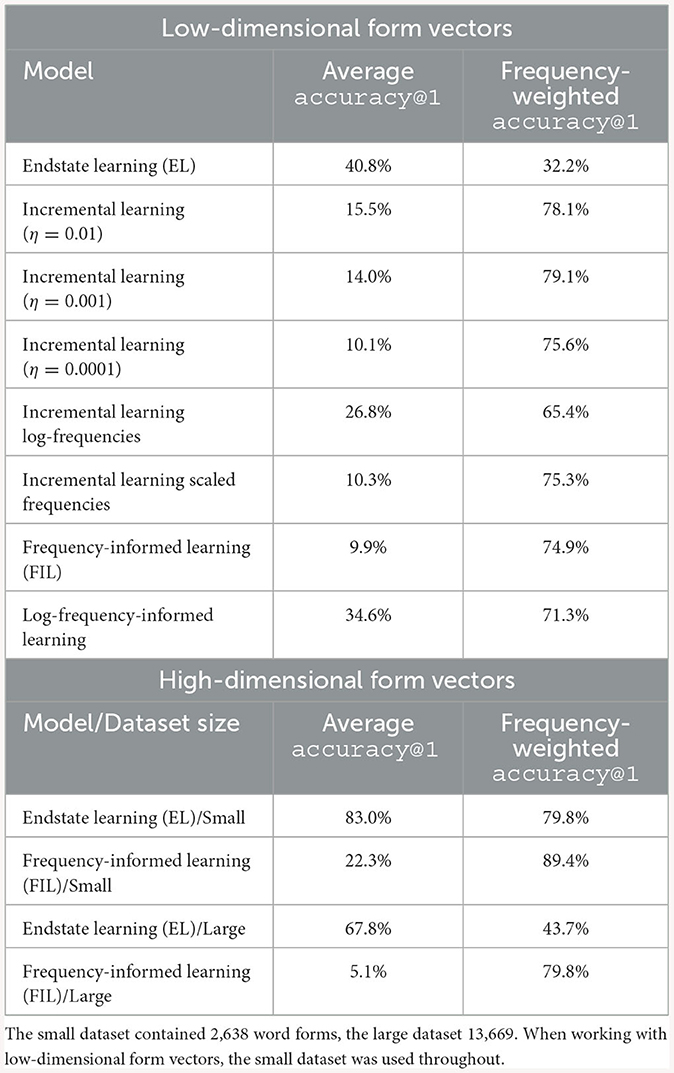
Table 1. Comparison of average and frequency-weighted accuracy@1 (the term “frequency-weighted accuracy” is introduced in Section 3.4.4) across simulation studies.
Figure 5 highlights the differences between the model set-ups, comparing with FIL the effect of a log-transformation (left panel), of scaling (center panel), and of the learning rate (right panel). It is noteworthy that frequency-informed learning with log-transformed frequencies departs the most from both FIL and incremental learning, which suggests that training on log frequency may artifactually increase learning performance.
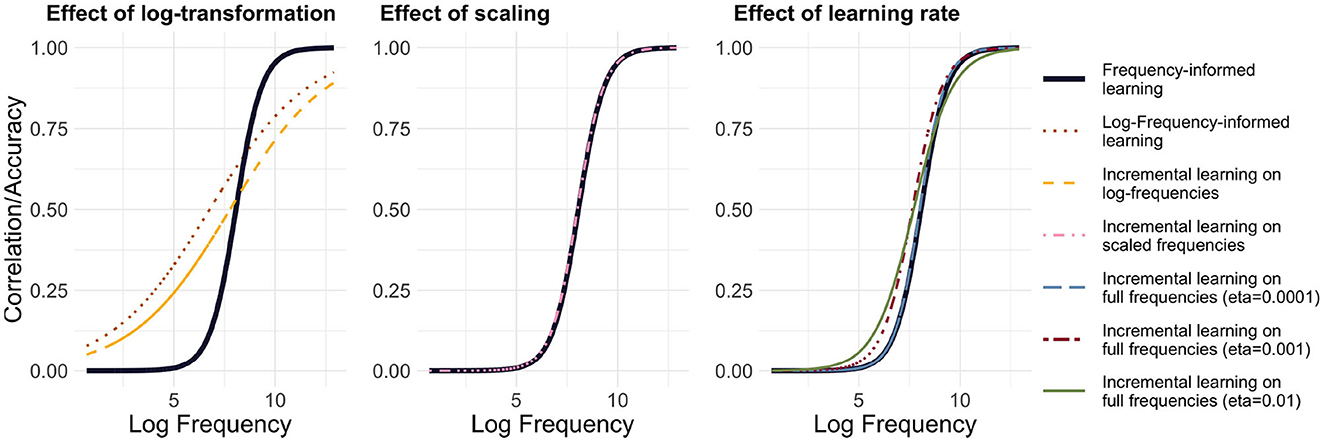
Figure 5. Comparison of methods. GLM-predicted Accuracy@1 with frequency-informed learning is plotted as a black line: The left panel compares methods based on log-frequencies, the center panel compares methods based on scaled frequencies and the right panel compares incremental learning with different learning rates. Incremental learning with scaled frequencies or with a very low learning rate (η = 0.0001) is closest to frequency-informed learning.
Secondly, it can be observed that the incremental learning based on scaled frequencies is closest to frequency-informed learning in terms of average accuracy@1, as well as to incremental learning with the lowest learning rate. This suggests (a) that scaling frequencies has a similar effect as lowering the learning rate in incremental learning and (b) that frequency-informed learning approximates incremental learning for very low learning rates.
3.4.2 High-dimensional modeling
Importantly, the mappings that we used thus far are suboptimal: the dimensionality of the semantic vectors was small and the use of bi-grams for the form vectors often shows underwhelming performance (see Heitmeier et al., 2021, for further discussion of the underlying reasons). While opting for low dimensionality decreased the computational costs for incremental learning immensely and was therefore necessary for comparing methods, we now proceed to investigate the accuracy of frequency-informed learning for larger, more discriminative cue matrices. To this end, we next experimented with the high-dimensional form vectors, still making use of the small dataset.
The model for the endstate of learning now performs much better, at an accuracy@1 of 83% instead of 40.8%. In other words, with infinite experience of just the words in this dataset, and with all token frequencies going to infinity, this is the best our simple multivariate multiple regression approach can achieve (conditional on the way in which we encoded form and meaning).
A model using FIL obtained an average accuracy@1 of 22.3%, which is clearly superior to the 9.9% obtained for the lower-dimensional model. The upper panel of Figure 6 presents the predicted accuracy curves for the high-dimensional FIL model in red (solid line), and the low-dimensional FIL model in blue (dashed line). We see a rise in accuracy for lower frequencies.
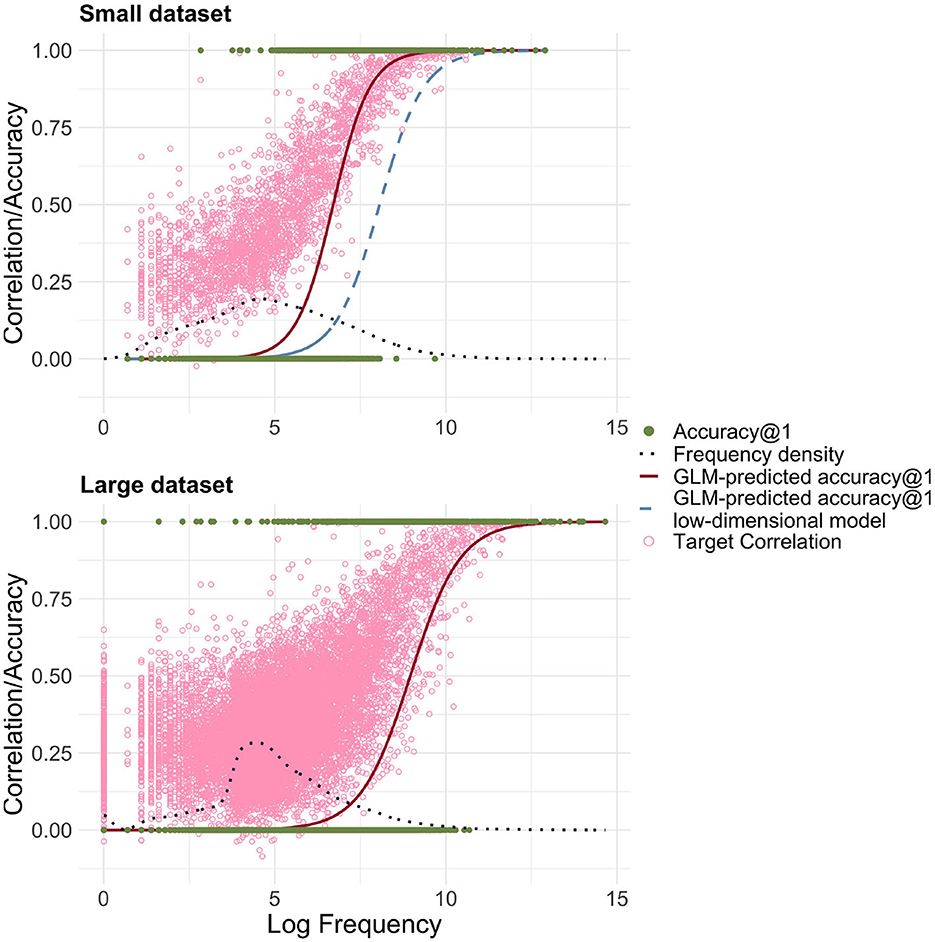
Figure 6. Predicted accuracy@1 as a function of log frequency for high-dimensional representations of form and meaning (red solid line). The light blue dashed line shows the predicted accuracy based on the low-dimensional model, for comparison. The light pink circles represent the target correlations in the high-dimensional model. The small dataset refers to the dataset with 2,638 word forms based on Ernestus and Baayen (2003), the large dataset to the dataset created from the DLP (Brysbaert and New, 2009) including 13,669 word forms. For the small and large datasets, a clear relationship between log frequency and correlation/accuracy is visible.
3.4.3 Increasing the dataset size
Having established the relationship between EL, WHL and FIL, we can also investigate how EL and FIL fare when the modeled dataset is significantly larger. To this end we used the large dataset introduced above. We found that accuracies in general were clearly lower: For EL, the accuracy@1 was 67.8% and for FIL it was 5.1%. Qualitatively, the differences between EL and FIL are therefore similar (see also Figure 6), but our simple linear mappings clearly perform less well with very large datasets, especially when taking into account frequency.
3.4.4 Frequency-weighted accuracy
A final question is whether the way we have been evaluating accuracy so far is reasonable. In the average accuracy@1 each word's accuracy contributes the same, that is, we have effectively calculated accuracy across all word types in our corpus. However, from a usage-based perspective, comprehending high frequency words is much more important than comprehending low frequency words —this is why, for instance, second language learners are generally taught the most frequent words of a language first. In a usage-based analysis of our model we should therefore be calculating accuracy across word tokens instead. Practically this means that if we go through a corpus of written English, instead of counting how many unique words our model is able to comprehend, we count how many of all of the encountered word tokens are understood correctly.7
Following this line of argumentation we also provide frequency-weighted accuracies in Table 1. For instance, the word with the highest frequency in the Dutch Lexicon Project (large dataset) is de (eng. the). Since this word accounts for 7% of all word tokens in the Dutch Lexicon Project (calculated by summing up the frequencies of all word types), it also contributes 7% to our frequency-weighted accuracy measure. There are also 349 words with a frequency of 0 in CELEX (2.6% of all word types) which accordingly do not contribute to the frequency-weighted accuracy at all. We find that with this method, the results flip in comparison with average accuracy@1: Generally, FIL and WHL based on untransformed frequencies perform the best, followed by methods based on log-transformed frequencies, while EL clearly performs the worst. For example, for the high-dimensional simulations on the large dataset, EL has a frequency-weighted accuracy@1 of 43.7%, while FIL achieves 79.8%. This means that EL understands less than half of the word tokens it encounters in a corpus, while FIL comprehends about eight out of 10 word tokens.
Whether type or token accuracy should be used to evaluate a model depends on the type of analysis conducted by the modeler. For a usage-based perspective as we haven taken here, a token-based measure is more appropriate. For other types of analysis, a type-based measure may be more suited. For instance, in the case of morphologically more complex languages such as Estonian or Russian, the modeler may well be interested in how well the model is able to understand and produce even low-frequency inflected forms of well-known lemmas. A token-based accuracy measure is not helpful in such cases.
To summarize, FIL provides an efficient way of estimating mappings between frequency-informed representations of form and meaning. FIL does not reach the average accuracy across types of EL, but, importantly, unlike for EL, accuracy varies systematically with frequency in a way similar to how human accuracy is expected to vary with frequency. Moreover, FIL clearly outperforms EL when accuracy is calculated across tokens rather than types. The question addressed in the next section is whether FIL indeed provides predictions that match well with a particular behavioral measure: reaction times in a visual and an auditory lexical decision task.
4 FIL-based modeling of reaction times
4.1 Visual word recognition in Dutch
In order to assess the possibilities offered by FIL-based modeling (using untransformed frequencies and the high-dimensional form and meaning vectors) for predicting behavioral measures of lexical processing, we return to the large dataset of reaction times to Dutch words described in Section 3.1.1 (13,669 words represented as trigrams with a form dimensionality of 4,678, and semantics represented using 300-dimensional fasttext vectors).
Figure 7 presents the partial effects according to three Gaussian Location-Scale GAMs fitted to the response latencies in the Dutch Lexicon Project. Response latencies were inverse transformed (−1,000/RT) in order to avoid marked non-normality in the residuals (effects for the untransformed RTs are very similar in shape, but confidence intervals are not reliable due to the marked departure from normality of the residuals). The left-hand panels present the partial effects for the mean (in blue), the right panels the partial effects for the variance [in green, on the log(σ − 0.01) scale; for further information on how partial effects are calculated in GAMs see Wood, 2017]. The upper panels pertain to a GAM predicting RT from log frequency (AIC −16,384.8; a backoff value of 1 was again added before log-transformation of word frequencies). Mean and variance decrease non-linearly with increasing frequency. The smooth for the mean shows the kind of non-linearity that is typically observed for reaction time data (see, e.g., Baayen, 2005; Miwa and Baayen, 2021): the effect of log frequency levels off strongly for high-frequency words and to a lesser extent also for low-frequency words. The partial effect of the variance is less wiggly and decreases as frequency increases. This decrease in variability for increasing frequency has at least two possible sources. First, high-frequency words are known to all speakers, whereas low-frequency words tend to be specialized and known to smaller subsets of speakers. Second, more practice, as in the case of high-frequency words, typically affords reduced variability (see, e.g., Tomaschek et al., 2018).
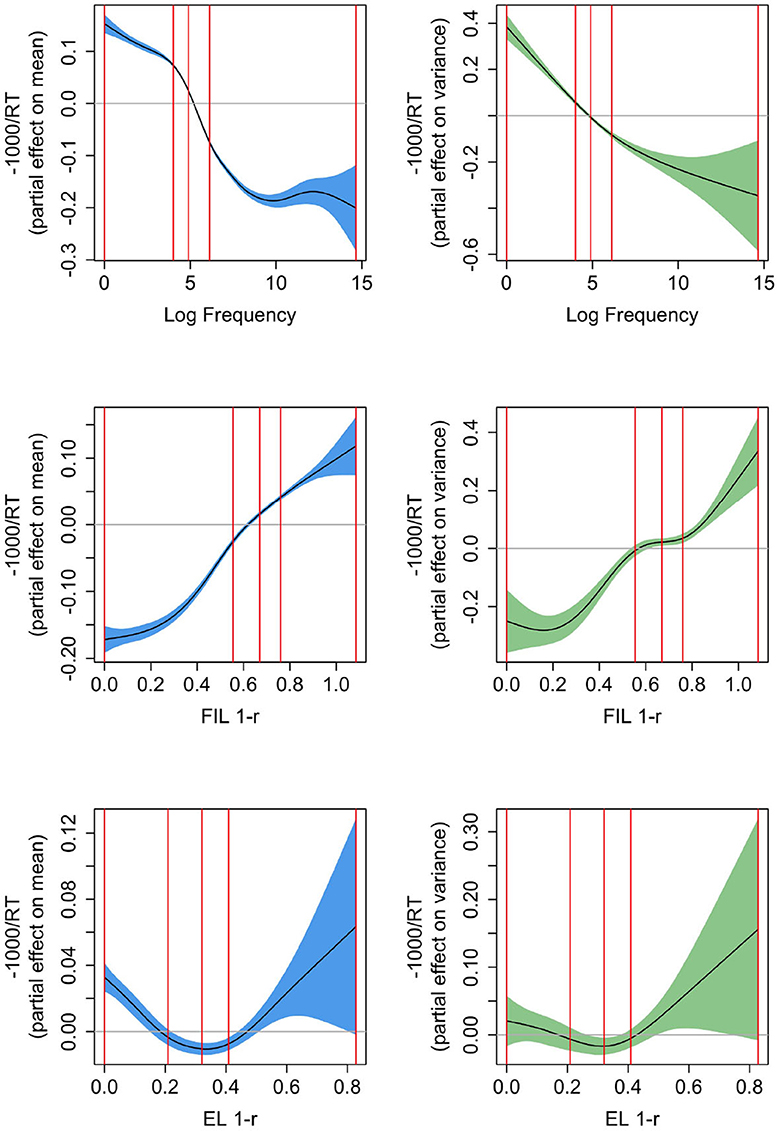
Figure 7. Partial effects for mean (left, confidence intervals in blue) and variance [right, confidence intervals in green, the y-axis is on the log(σ − 0.01) scale], for Gaussian Location-Scale GAMs predicting reaction times from log frequency (upper panels), from 1 − r based on FIL (center panels), and from 1 − r based on EL (bottom panels). The vertical red lines represent the 0, 25, 50, 75, and 100% percentiles. FIL 1-r is a solid predictor for mean and variance in RTs.
A model-based measure that we expected to correlate with reaction time is the proximity of a word's predicted semantic vector to its corresponding gold standard vector (i.e., the target correlation). The more similar the two vectors are, the better a word's meaning is reconstructed from its form. In other words, the more effective a word form is in approximating its meaning, the more word-like it is and the faster a lexicality decision can be executed. We used the correlation r of and s as a measure of semantic proximity. Since for large r, lexical decision times are expected to be short, whereas for small r long decision times are more likely, we took 1 − r as a measure that we expect to enter into a positive correlation with RT. This measure, when based on FIL, has a density that is roughly symmetrical, and that does not require further transformations to avoid adverse affects of outliers.
The panels in the middle row present the partial effect of 1 − r as predictor of RT using FIL (AIC −12,900.75), and the bottom panels present the corresponding partial effects using EL (AIC −10,896.19). The GAM with the FIL-based predictor clearly provides the superior fit to the observed response latencies. The effect of 1 − r on the mean is fairly linear for FIL but U-shaped for EL. A strong effect on the variance is present for FIL, but absent for EL. Effects are opposite to those of frequency, as expected, as 1 − r is constructed to be positively correlated with RT. The absence of a highly significant effect on the variance in RT for EL (p = 0.0356) is perhaps unsurprising given that EL learns the mapping from form to meaning to perfection (within the constraints of a linear mapping and the type distributions of forms and meanings), and hence little predictivity for human processing variance is to be expected. The question of why 1 − r has a U-shaped effect on RT for EL will be addressed below.
In summary, FIL generates a predictor (1 − r) that is better aligned with observed RTs. However, log frequency provides a better fit (AIC −16,384.8). Here, it should be kept in mind that word frequency is correlated with many other lexical properties (Baayen, 2010), including word length and number of senses. Longer, typically less frequent, words require more fixations, and hence are expected to have longer reaction times. The greater number of senses for higher-frequency words are not directly reflected in the embeddings, which typically consist of a single embedding per unique word form, rendering the mapping less precise. As a consequence, there is necessarily imprecision in measures derived from our learning models. Furthermore, 1 − r is only one of the many learning-based measures that predict lexical decision times, see Heitmeier et al. (2023b) for detailed discussion.
What we have not considered thus far is how 1 − r is affected by frequency when learning is based on FIL and on EL, and how the effect of frequency on these measures compares to the effect of frequency on reaction times. Figure 8 presents the partial effects of Gaussian Location-Scale GAMs for FIL (upper panels) and EL (lower panels). The leftmost panels present effects for the mean, and the center panels effects for the variance. For FIL, the highest-frequency words are learned to perfection, and hence the variance in 1 − r is extremely small. To highlight the variance function for most of the datapoints, the upper right panel restricts the y-axis to a smaller range. For all points in the interquartile range of frequency, the variance increases with frequency.
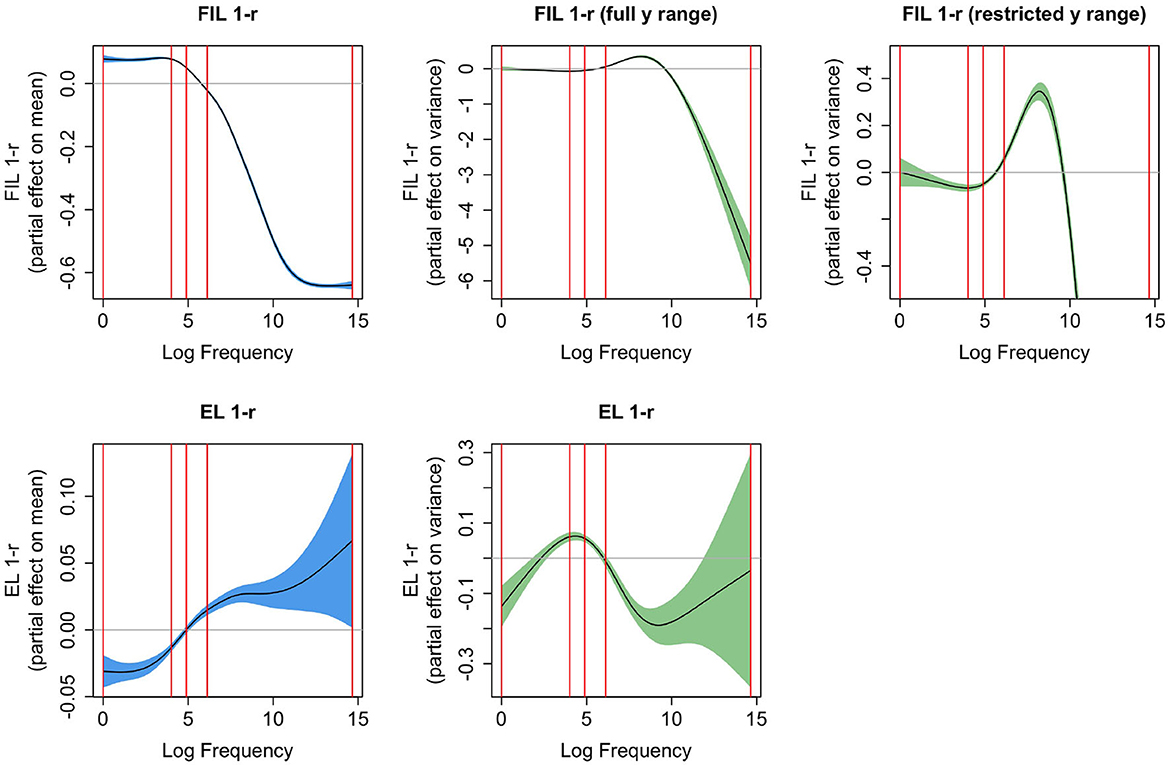
Figure 8. Partial effects for mean (left, confidence intervals in blue) and variance [center and right, confidence intervals in green, the y-axis is on the log(σ − 0.01) scale], for Gaussian Location-Scale GAMs predicting 1 − r from log frequency for FIL (upper panels), and for EL (bottom panels). The panel in the upper right zooms in on the partial effect of variance shown to its left. The vertical red lines represent the quartiles of log frequency. FIL 1-r shows a similar S-shaped curve as a function of frequency as observed for reaction times, but does not have a similar effect as frequency on the variance in the reaction times.
Comparing the partial effects for the means, FIL presents a curve that is similar to the partial effect of log frequency on reaction time (see Figure 7, upper left panel), whereas the curve for EL is an increasing function of frequency, rather than a decreasing function. The reason for this is straightforward: higher-frequency words share more segments and substrings with other words than lower frequency words, they are shorter, and tend to have more form neighbors (Nusbaum, 1985; Baayen, 2001). As a consequence, they provide less information for the mapping from form to meaning, resulting in less accurate predicted semantic vectors, and hence higher values of 1 − r. This disadvantage of being shorter and easier to pronounce is overcome in FIL. FIL, and also incremental learning, provide higher frequency words with more learning opportunities compared to lower-frequency words.
The U-shaped curve of 1 − r using EL as predictor of reaction time (see the lower left panel of Figure 7) can now be understood. For EL, median 1 − r is 0.32, which is where the curve reaches its minimum. As we move to the left of the median, word frequency goes down, and as a consequence, salient segments and segment combinations (cf. English qaid, “tribal chieftain”, which has the highly infrequent bigram qa) are more common. These salient segments and n-grams allow these words to map precisely onto their meanings, much more so than is warranted by their very low frequencies of use. Although EL provides estimates of 1 − r that are low, EL underestimates the difficulty of learning these words in actual usage. As a consequence, actual reaction times are higher than expected given the computed 1 − r. Conversely, when we move from the median to the right, we see the expected slowing due to being further away from the semantic target. Apparently, the greater form similarity and denser form neighborhoods that characterize higher-frequency words results in estimates of 1 − r that are reasonably aligned with reaction times, albeit by far not as well as when FIL is used to estimate 1 − r.
We have seen that the variance in RTs goes down as word frequency is increased, which we attributed to higher frequency words being known and used by more speakers than is the case for lower-frequency words, and the general reduction in variability that comes with increased practice. These kinds of factors are not taken into account in the current FIL mapping. It is therefore interesting to see that without these factors, FIL suggests that, at least for the interquartile range of frequency, the variance increases with frequency. But why this might be so is unclear to us.
Considered jointly, these results provide good evidence that FIL adequately integrates frequency into linear discriminative learning, outperforming endstate learning by a wide margin, both qualitatively and quantitatively.
4.2 Spoken word recognition in Mandarin
Mandarin, as a tone language, alters pitch patterns to distinguish word meanings. There are four lexical tones in Mandarin: high level, rising, dipping, and falling, which will, for convenience, henceforth be referred to as T1, T2, T3, and T4, respectively. Take the syllable ma for example. It could mean “mother,” “hemp,” “horse,” or “scorn,” depending on which lexical tone it is associated with.
The role that tone plays in Mandarin word recognition has been widely discussed. Specifically, researchers are interested in whether native listeners exploit tonal information similarly as they do for segmental information. In other words, will a mismatch in tone (e.g., ma3 and ma1) reduce the activation of a given word, to the same extent as a mismatch in segments (e.g., ba1 and ma1)? Lee (2007) addresses this issue with an auditory priming experiment. In his study, four priming conditions were designed, as shown in Table 2. Among them, ST is an identity priming condition, and UR is a control priming condition. The experimentally critical conditions are S and T, where only either syllable or tone is shared between primes and targets. If tonal information is as important as segmental information in Mandarin, then the degree of priming should be similar for both conditions. On the contrary, differences should be observed if the two sources of information are treated differently by native listeners.
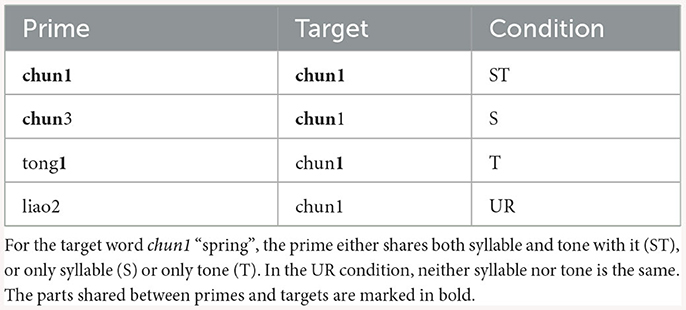
Table 2. The design of priming conditions for Experiments 1 and 2 of Lee (2007).
It was found that reaction times to the target words are shortest in the ST condition, hence most priming, as expected. Interestingly, mere tone sharing or syllable sharing is not sufficient to induce a reliable priming effect: the T condition does not differ significantly from the UR condition, whereas the S condition differs from UR only in item analysis, but not in subject analysis. But importantly, there is still a significant difference between the S and T conditions, where syllable sharing induces faster responses than tone sharing. In other words, more priming is found for syllable sharing than tone sharing. It is noteworthy that this pattern of results holds regardless of whether a long (250 ms, experiment 1) or short (50 ms, experiment 2) inter-stimulus interval is adopted in the experiment.
To model this priming experiment, we made use of the Chinese Lexical Database (Sun et al., 2018). In total 48,274 one- to four-character Mandarin words were selected, which include all the stimuli of the experiment, and for which fasttext word embeddings (Grave et al., 2018) are available. For cue representations, following Chuang et al. (2021), we created segmental and suprasegmental (tonal) cues separately. Thus, for a bisyllabic word such as wen4ti2 “question”, the segmental cues will be triphones of #we, wen, ent, nti, ti#, and there will also be tritone cues of #42 and 42#. The separation of segmental and suprasegmental information, however, does not do justice to the fact that segments do have influence on tonal realizations and vice versa (e.g., Howie, 1974; Ho, 1976; Xu and Wang, 2001; Fon and Hsu, 2007). We therefore also made cues out of tone-segment combinations. To operationalize this, we marked tones on vowels, so that vowels with different tones are treated as separate phones. For the word wen4ti2, we then have additional tone-segment triphone cues of #we4, we4n, e4nt, nti2, ti2#. This resulted in an overall form vector dimensionality of 47,791.
We ran two LDL models, one with EL and the other with FIL. With EL, comprehension accuracy is at 83.71%. The accuracy is substantially worse with FIL; accuracy@1 is 8.98%. As discussed previously, this is largely due to the low accuracy for especially low frequency words. After taking token frequency into account, the frequency-weighted accuracy is at 86.89%.
To model the RTs of the auditory priming experiment of Lee (2007), we calculated the correlation between the predicted semantic vector of the prime word (ŝprime) and the gold standard semantic vector of the target word (starget), and again took 1 − r to predict RTs (see Baayen and Smolka, 2020, for the same implementation to simulate RTs for visual priming experiments). Results of simulated RTs with EL and FIL are presented in Figure 9. For EL (left panel), the simulated RTs of the ST condition is the shortest, unsurprisingly. For both the S and T conditions, the simulated RTs are similar to those of the UR condition, indicative of no priming. Tukey's HSD test reported no significant difference for any pairwise comparison among the S, T, and UR conditions. Although the general pattern of results is in line with the behavioral data, we however missed the crucial difference between the S and T conditions.
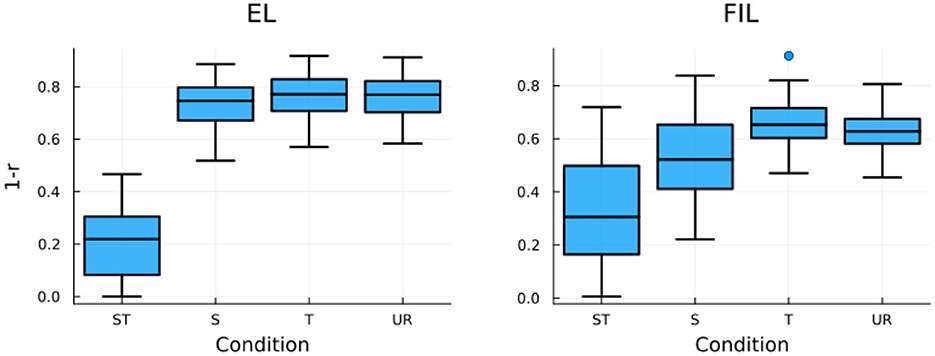
Figure 9. Boxplots of LDL simulated RTs for the four priming conditions in Lee (2007) with EL (left) and FIL (right). FIL correctly predicts the experimental results of Lee (2007).
A different picture emerges with the FIL modeling. As shown in the right panel of Figure 9, not only does the ST condition induce faster responses than the other three conditions, but the simulated RTs of the S condition are also significantly shorter than those of the T condition (p < 0.0001, according to a Tukey's HSD test), as was found in the behavioral data. We note that when compared to the UR condition, the S condition induces significantly shorter simulated RTs, but not the T condition. This pattern of results also to a large extent replicates the empirical findings of Lee (2007), as the S-UR difference is significant in item analysis but not in subject analysis. As both the S-T and S-UR differences are absent in EL modeling, we conclude that FIL provides an estimate that better approximates the actual auditory comprehension of native Mandarin listeners.
5 But what about order?
Arguably, there is a piece of information missing when using FIL: order information. If a word is highly frequent early in a learning history and never occurs later, would it be forgotten by a WHL model but learned fairly well by a FIL model? To investigate how much of a problem this loss of order is in real-world longitudinal data, we used data of “Sarah” in the CHILDES Brown corpus (Brown, 1973) and of “Lily” in the PhonBank English Providence corpus (Demuth et al., 2006). To access all child-directed speech, we utilized the childesr package (Sanchez et al., 2019) to extract the data of all utterances not made by the target children themselves, resulting in 189,772 and 373,606 tokens, respectively.8 Of these, we kept all tokens for which pronunciations were available in CELEX (Baayen et al., 1995) and for which we could obtain word embeddings in 300-dimensional Wikipedia2Vec word embeddings (Yamada et al., 2020). This resulted in 162,443 learning events (3,865 unique word tokens) for Sarah and 326,518 learning events (7,433 unique words tokens) for Lily. The cue matrix was created based on bigrams of CELEX DISC notation symbols, so for example, thing was represented as #T, TI, IN, N#, in order to model auditory comprehension (thus, the form vector dimensionality was 943 and 1,087 for Sarah and Lily, respectively). We then trained the comprehension matrix F incrementally, evaluating after every 5,000 learning events the correlation of the predicted semantics of all word tokens with their target semantics, as well as keeping track of the frequency of each word token within the last 5,000 learning events. To gauge the effect of different learning rates we ran this simulation for η ∈ {0.1, 0.01, 0.001, 0.0001}.
In order to investigate the consequences of neglecting order during learning, we also trained a model with the same form and semantic matrix but using the FIL method. The FIL method results in a correlation accuracy of 12.9% for Sarah and 8.1% for Lily. For WHL the correlation accuracies vary across learning rates (Table 3), with accuracy decreasing for lower learning rates. FIL correlation accuracies are somewhat better than WHL accuracies for η = 0.001 and somewhat worse than for η = 0.01. Target correlations obtained with FIL and WHL are in general remarkably similar, correlated the highest for learning rates of 0.001 and 0.01 for “Lily” and “Sarah”, respectively. This can also be observed visually in Figure 10: WHL and FIL target correlations are the least similar for η = 0.1 and η = 0.0001. Interestingly, for higher learning rates, low WHL correlations tend to be higher in FIL and vice versa, whereas for lower learning rates an advantage of FIL over WHL is more visible for higher accuracies, while low accuracies in WHL tend to be even lower in FIL.
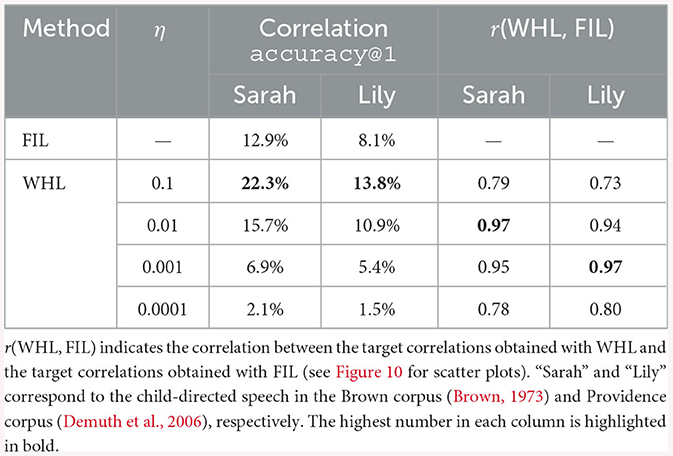
Table 3. Correlation accuracies@1 for FIL and WHL with different learning rates (η).
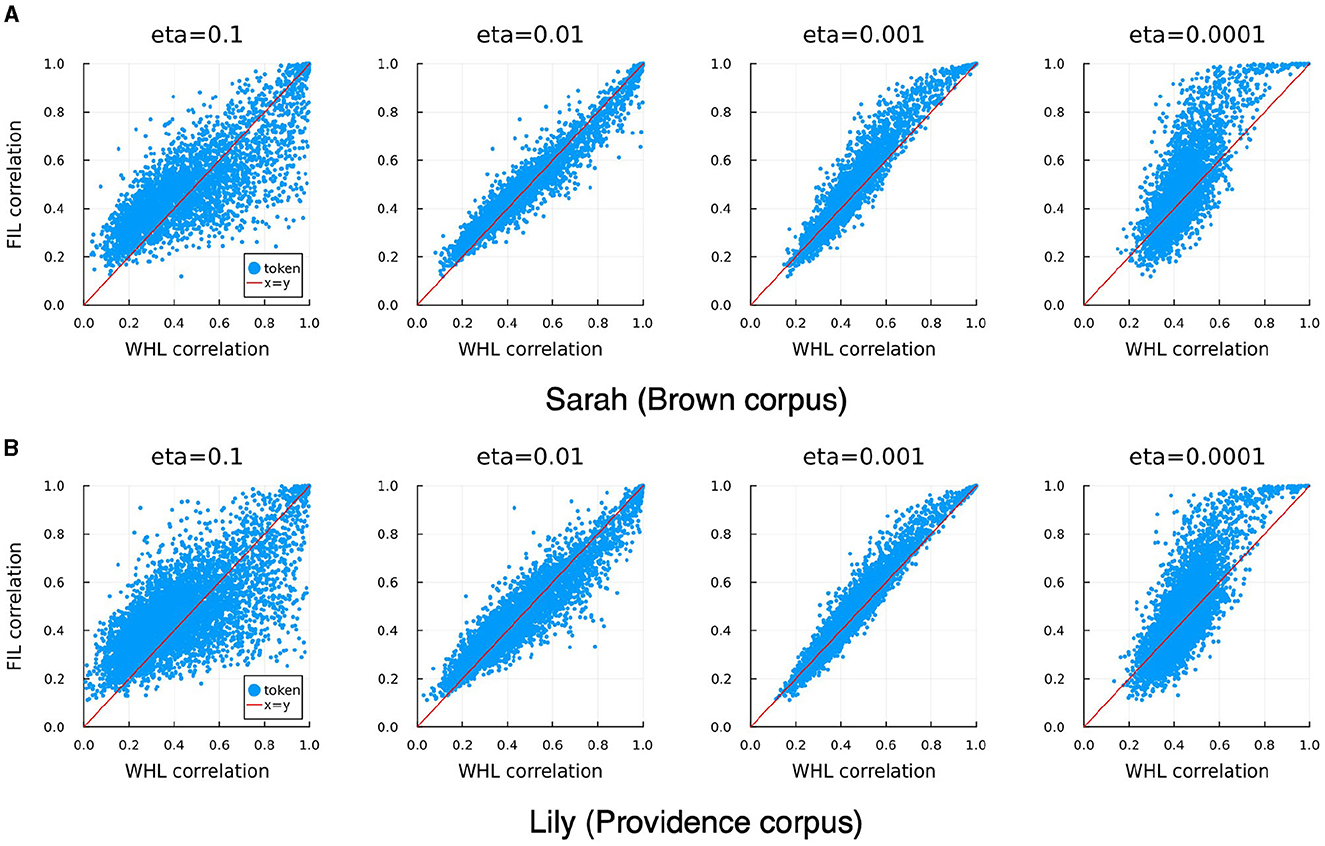
Figure 10. Correlation of WHL learned predicted semantics with their targets against correlations of FIL learned predicted semantics with their targets (blue dots), for different learning rates, and for Sarah (A) and Lily (B). The diagonal red lines denote the x = y line. WHL target correlations and FIL target correlations are highly correlated, with the tightest relationship visible for η = 0.01 for Sarah and η = 0.001 for Lily (see also Table 3).
Striking a balance between WHL accuracy and correlation between WHL and FIL accuracies, we now focus on η = 0.01. As can be seen in Figure 10 there are a few outliers where either FIL clearly outperforms WHL or vice versa. For the former case, the most apparent cases for Sarah are no, mummy, cold, later, michael, and told. Except no which suffers due to its homophone know, all show a relatively higher frequency at the beginning of the learning trajectory compared to the end (see upper panel of Figure 11). Moreover, they tend to have overlapping di-phones: for example, told has overlap with old with which they are confused in the WHL model. Lily's data shows a similar pattern. WHL therefore unlearns when two conditions apply: a word occurs very infrequently in the later stages of the learning sequence and it has overlaps with cues in other words. WHL has an advantage over FIL when words have a higher frequency later in the sequence: for Sarah's data this is the case for idea, old, mister, giraffe, and alligator (see lower panel of Figure 11).
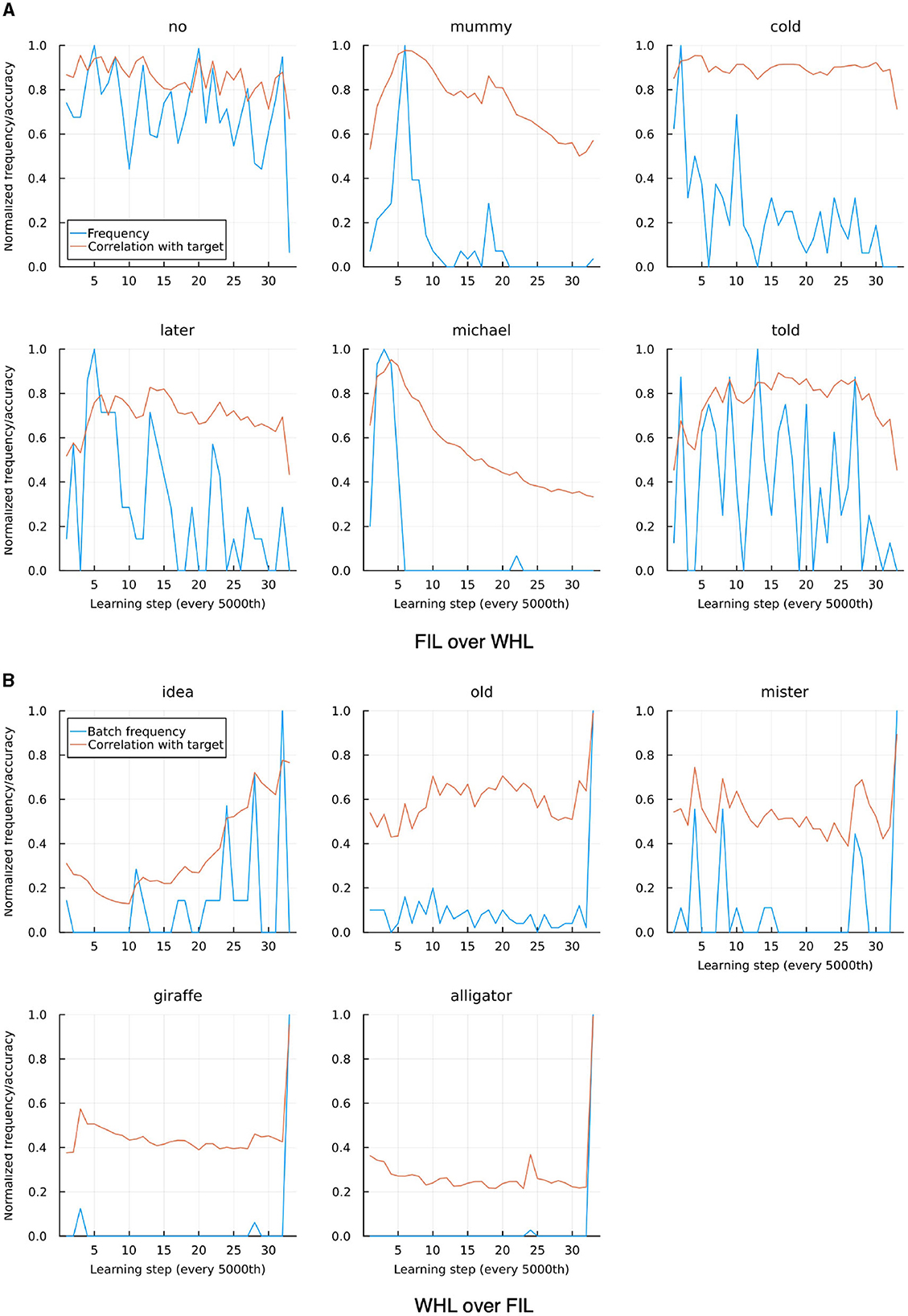
Figure 11. Individual tokens where FIL and WHL correlations to target differ clearly, taken from “Sarah”, trained with WHL and η = 0.01. (A) Shows cases where FIL outperforms WHL, (B) where WHL outperforms FIL. Frequencies are normalized by their maximal frequency inside a learning batch of 5,000 learning events. In (A), frequency tends to decrease over time. Thus, the item is learned well in the beginning, and the correlation with target goes down over time. In (B) the opposite is the case.
To confirm this qualitative analysis quantitatively, we computed the mean, mode, skewness and kurtosis of the frequency distribution across time for each word. We then used these as predictors in individual (due to collinearity) Generalized Additive Models (GAMs; Wood, 2011) to predict the difference in target correlation in WHL and FIL for η = 0.01, i.e., predicting whether WHL or FIL perform better depending on the frequency distribution of a word across time (details on method in Supplementary material). We found that the higher the mean and mode, and the more negative the skew of the frequency distribution (all indicating that frequencies are higher at later timesteps; compare e.g., “giraffe” and “alligator” in Figure 11 for examples of high mean and mode and low skewness, with “mummy” and “michael” in Figure 11 for examples of low mean and mode and high skewness), the better WHL performed than FIL. To illustrate, we show the effect of the mean on performance in the upper row of Figure 12. Additionally, when kurtosis was entered (differentiated by whether skewness was positive or negative), an interesting effect emerged: for negative skewness values (high frequency at later time steps), more positive kurtosis (peakier distribution) yielded an advantage of WHL, while a peakier distribution of positive skewness values led to an advantage of FIL (see bottom row of Figure 12). All these results confirmed our qualitative analysis above.
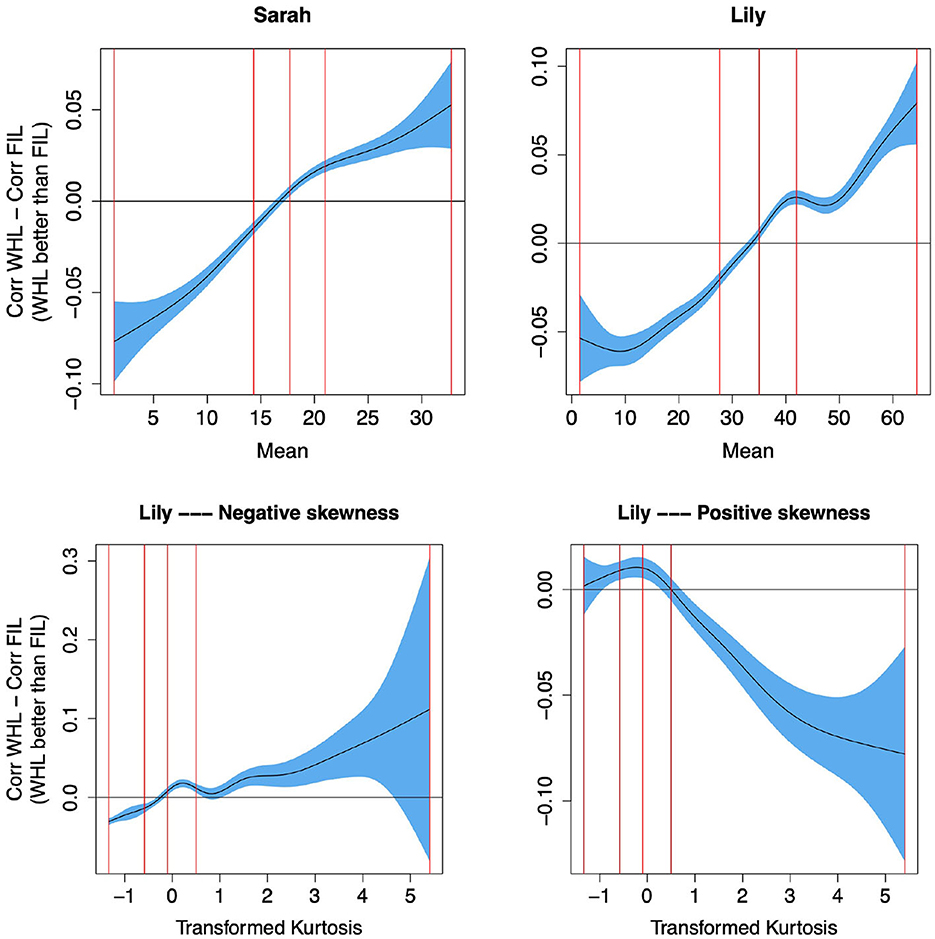
Figure 12. Predicting the difference between target correlations in WHL and in FIL from frequency distribution of words across time. The y-axes show partial effects. Top row: The higher the mean (i.e., higher frequencies at later time steps, see “giraffe” and “alligator” in the lower row of Figure 11 for examples of words with a high mean), the better WHL performs than FIL. The vertical red lines represent the 0, 25, 50, 75, and 100% percentiles. Bottom row: For negative skew (higher frequencies at later time steps), the peakier the distribution (higher kurtosis), the larger the advantage of WHL over FIL, and vice versa for positive skew. Kurtosis was transformed to reduce outlier effects, details in Supplementary material. WHL outperforms FIL for words with higher frequencies at later learning steps.
To summarize, some interesting phenomena related to order information get lost when using FIL. For higher learning rates, WHL overall yields higher accuracies, possibly because it is sensitive to the burstiness of frequency during the course of learning. On the other hand, for words that are equally distributed across learning events, the predictions of WHL and FIL are very similar, and the two methods thus result in highly similar correlations with their respective target semantics (see also Milin et al., 2020).
6 Discussion
We have introduced a new way for estimating mappings between form and meaning in the Discriminative Lexicon Model (DLM; Baayen et al., 2018a, 2019) that takes frequency of use into account, Frequency-Informed Learning (FIL), complementing incremental learning with the learning rule of Widrow-Hoff (WHL) and endstate learning using multivariate multiple regression (EL). Each of these methods has advantages as well as disadvantages.
6.1 Three methods for computing mappings in the DLM
WHL enables trial to trial learning and hence is, in principle, an excellent choice for datasets with learning events that are ordered in time. Examples of such datasets are child-directed speech in the CHILDES database ordered by the age of the addressee and the time-series of reaction times in mega-experiments (Heitmeier et al., 2023b). The disadvantage of WHL is that it is computationally demanding, and prohibitively so for large datasets.
FIL offers a computationally lean way of taking frequency of use into account, but it is insensitive to the order of learning events. It is therefore an excellent choice for datasets with learning events that are unordered, which is typically the case for data compiled from corpora or databases. For large datasets with temporally ordered learning events, FIL can be applied to a sequence of datasets with increasing sample sizes to probe how learning develops over time. How exactly such sequential modeling compares with WHL is a topic for further research.
Models using EL are not computationally demanding, but they are also not sensitive to the frequencies with which learning events occur. For usage-based approaches to language (see, e.g., Bybee, 2010), this is a serious drawback. Nevertheless, EL has an important advantage of its own: it provides a window on what can be learned in principle, with infinite experience. In other words, EL is a good analytical tool for any datasets for which a type-based analysis is appropriate or insightful. For instance, if one's interest is in how well Dutch final devoicing can be mastered on the basis of subliminal learning only, the EL model informs us that a comprehension accuracy of 83% can be reached (see also Heitmeier et al., 2023a). When measures are gleaned from an EL model and used as predictors for aspects of lexical processing, it will typically be necessary to include a measure of frequency of use as a covariate.
With FIL, however, we have an analytical instrument that integrates experience into mappings between form and meaning. It obviates the practical necessity, when using WHL, of scaling frequencies down, nor is a log-transform of usage required. The latter is particularly undesirable as it artifactually boosts performance for low-frequency words while degrading performance for high-frequency words.
An open question when it comes to comparing the three methods is whether measures of the models' accuracy should be type-based, i.e., all words contribute equally to the overall accuracy measure, or whether it should be token-based. Previous models have usually been evaluated based on type-accuracy, but a high token-accuracy in word recognition might be of more practical use in every day life than a high type- but low token-accuracy, where a model is able to recognize many low frequency words but struggles with many of the high frequency words with which speakers are constantly confronted. In this context, it is worth keeping in mind the forgetting curve of Ebbinghaus (1885) and recent advanced methods for repeating words at exactly the right moment in time to optimize fact learning, including vocabulary learning (van der Velde et al., 2022). From this literature, it is crystal clear that words encountered only once, which in corpora typically constitute roughly 50% of word types, cannot be learned with a single exposure. Whereas EL does not capture effects of frequency, FIL clarifies that once we start taking frequency into account, it is practice that makes perfect.
6.2 The relationship between word frequency and lexical decision reaction times
A surprising property of FIL is that the correlation r of the predicted semantic vector with its gold standard target semantic vector emerges as a key to understanding two findings in lexical decision tasks. We found that FIL is crucial for modeling a stronger priming effect of segmental information compared to tone information in an auditory lexical decision task in Mandarin Chinese. For unprimed lexical decisions as available in the Dutch Lexicon Project, reasoning that greater correlation should afford shorter decision times, we used 1 − r as an approximation of simulated decision times. We found that 1 − r based on FIL provided much improved prediction accuracy compared to 1 − r based on EL. Moreover, FIL also provides insights into the non-linear nature of the word frequency effect in the lexical decision task. We showed that the mirror-sigmoid relation between empirical decision times and log frequency emerging from a GAM analysis also characterizes the functional relation between “simulated decision times” 1 − r and log frequency. This suggests that FIL successfully filters usage through discriminative learning to obtain estimates of how well the meanings of words are understood.
This finding fits in well with a recent debate that was re-sparked by Murray and Forster (2004) arguing that rank-transformed frequencies account for lexical decision reaction times better than log-transformed ones and that, therefore, serial-search models should not be discounted as models of word recognition.9 Recently, Kapatsinski (2022) showed that log frequencies transformed by the logistic function (a function frequently used in deep learning models) predict reaction times in the same way as a rank-transformation, implying that the linear relationship between rank frequency and reaction times is not necessarily evidence in favor of the serial search model. Since the DLM is not a classification model, we do not make use of the logistic function but use correlation to compute how close a word's predicted meaning is to its true meaning. The estimated functional relation between − 1,000/RT and 1 − r estimated with FIL is close to linear [see Figure 7, panel (2,1)], and a very similar partial effect emerges when the untransformed RTs are regressed on 1 − r. Thus, a linear relationship between a FIL-based predictor, 1 − r (or equivalently, r) and reaction times falls out directly of the DLM, without requiring further transformations. This provides further evidence in favor of theories suggesting that frequency effects arise due to the distributional properties of words' forms and meanings during learning. 10
A question that we leave to future research is whether measures derived from FIL mappings will obviate the need to include frequency of use as a covariate, reduce the variable importance of this predictor, or complement it. One possible complication here is that while frequency-informed mappings make the DLM predictions more realistic, they naturally also create a confound with word frequency, which needs to be teased apart from other (e.g., semantic) effects captured by the DLM (see Gahl and Baayen, 2023, for further discussion). Furthermore, in the present study we did not take into account (any measure of) a word's context (e.g., Adelman and Brown, 2008; Hollis, 2020). Gahl and Baayen (2023) explore an additional measure of frequency which is informed by a word's context by measuring how strongly a word predicts itself in any utterances it occurs in. This measure outperforms frequency for predicting acoustic durations of English homophones, and it also outperforms frequency as a predictor of visual lexical decision latencies. This measure may complement the measures from the DLM.
What complicates such comparisons is that frequencies based on corpora typically concern lexical use in a language community, whereas individual speakers have very different experiences with lower-frequency words, depending on their interests, professions, education, and reading/speaking habits (e.g., Kuperman and Van Dyke, 2013; Baayen et al., 2016). For instance, about 5% of the Dutch words in the present dataset are unknown to the fourth author. These are low-frequency words that the EL gets correct in 30 out of 35 cases. By contrast, the FIL gets only two out of these 35 cases correct. In a similar vein, Diependaele et al. (2012) showed that in the DLP, when reacting twice to the same lowest-frequency word stimuli in the DLP participants only agree in about 50% of cases, bringing their accuracy to chance level.
The inter- and intra-variability of subjects' word knowledge might also be a reason why FIL underestimates the variance of reaction times in the Dutch Lexicon Project for low-frequency words. Naturally, FIL, being based on “community” frequencies, is not able to account for this effect. Our results, however, highlight the importance of modeling not only the mean but also the variance of reaction times, as it might provide a further window into speakers' word recognition process and differentiating between different models attempting to account for the observed behavioral data. To our knowledge, previous models of word recognition have not attempted to account for both the mean and variance of reaction times (but see Ratcliff et al., 2004, for a model attempting to also predict the distribution of reaction times).
When evaluating the accuracy of a FIL model, having the closest proximity to the semantic vector of the target word is probably too stringent a criterion. Especially for lower-frequency words, having a rank among the top k (for low k) nearest neighbors may be a more reasonable criterion. The reason is that for lower frequency words, knowledge of what words may mean is only approximate. For instance, although the names of gemstones such as jasper, ruby, tourmaline, and beryl will be known to many readers, picking out the ruby from four reddish pieces of rock requires more precise knowledge than is available to the authors. Especially for lexical decision making, being “close enough” may be good enough for a yes-response (see Heitmeier et al., 2023b, for detailed discussion of lexical decision making).
An additional complication is that low-frequency words often have multiple, equally rare, meanings (by contrast, for high-frequency words, one often finds that of a set of possible meanings, one is dominant). By way of example, the low-frequency Dutch word bras in our dataset can denote “uncooked but peeled rice,” “junk,” and “a specific set of ropes used on sailing ships.” This may provide further explanation of why the correlation measure (1 − r) underestimates the variance in decision latencies for lower-frequency words as compared to higher-frequency words.
6.3 Computational modeling of word frequency effects
Our findings are particularly enlightening when comparing them to accounts of word frequency effects in previous models of word recognition. To answer the three key questions regarding the word frequency effects identified in the introduction, in the DLM, frequency effects arise as a consequence of the input distribution it is trained on. Similarly to other network models, the effect of word frequency is stored in the model's mapping weights. The DLM is an extremely simple computational model involving only linear mappings, which can be efficiently numerically computed. As demonstrated, the resulting mappings are very similar to those obtained by training the model incrementally on unordered data (as is done in all deep learning models utilizing backpropagation, such as the triangle model, Seidenberg and McClelland, 1989). As such, it enables the modeler to answer many questions related to the word frequency effect, such as that of individual differences, in a computationally lean way. Finally, we demonstrate that the DLM is able to account for the non-linear relationship between frequency and reaction times in lexical decision without requiring to use a log-transformation (cf. McClelland and Rumelhart, 1981; Rumelhart and McClelland, 1982; Seidenberg and McClelland, 1989). Moreover, the DLM can not only account for frequency effects but also enables investigation of the influence of words' more finegrained characteristics on reaction times. Crucially, these are not independent. The DLM's predicted reaction times also depend on words' form and meaning properties, not only their frequency distribution.
Therefore, it is important to note that the DLM's performance also depends on many modeling choices, such as the chosen form granularity, semantic vectors etc. Ideal modeling choices can often vary across languages—for instance, while for English, Dutch and German, trigrams are often the unit of choice (Heitmeier et al., 2021, 2023b), previous work has found that for Vietnamese, bigrams are preferable (Pham and Baayen, 2015), while for Maltese, Kinyarwanda and Korean, form representations based on syllables perform well (Nieder et al., 2023; van de Vijver et al., 2023, Chuang et al., 2022; an in-depth discussion of the various considerations when modeling a language with the DLM can be found in Heitmeier et al., 2021). While the present study is limited to Dutch, Mandarin and English, future work should further verify the efficacy of FIL on morphologically more diverse languages.
To put the present results in a broader perspective, consider the characterization given by Breiman (2001) of machine learning on the one hand and statistics on the other hand. They argue that machine learning aims at obtaining accurate predictions. How these predictions are obtained and why a technique works is not of interest. By contrast, statistics aims to formulate a model that could have generated the data. Within this characterization—which may be too extreme (e.g., Shmueli, 2010)—FIL is much closer to statistical modeling than to machine learning, and it is surprising to us how much can be achieved simply with a form of weighted multivariate multiple regression. We hope that FIL will prove to be a useful tool not only for modeling data with “community” frequencies but also for exploring, by means of simulation, what the consequences are of individual differences in usage for lexical processing.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/supplementary material.
Author contributions
SA contributed the mathematical derivations of the method. MH, Y-YC, and RB conducted the reported simulations and analyses and wrote the first draft of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy—EXC number 2064/1—Project Number 390727645 and by the European Research Council, project WIDE-742545.
Acknowledgments
The authors thank members of the Quantitative Linguistics group for helpful feedback and discussions and Yu-Hsiang Tseng for helpful comments on an earlier version of this manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^As only 2.7% of the words in our Dutch dataset are homographs, for simplicity we use “strict evaluation” throughout this study, i.e., we do not take homographs into account while evaluating accuracy (further information on the various methods to evaluate accuracy in Heitmeier et al., 2021).
2. ^Data, code and statistical models presented in this study are available at https://osf.io/h2szj/.
3. ^https://fasttext.cc/docs/en/crawl-vectors.html#models
4. ^https://github.com/MegamindHenry/JudiLing.jl
5. ^https://github.com/JuliaStats/GLM.jl
6. ^Note that while we here work with a learning rule for continuous vectors, FIL is also applicable to mappings between discrete vectors, as in Rescorla-Wagner learning (Rescorla, 1967) which is used in Naive Discriminative Learning (NDL, Baayen et al., 2011): instead of having to impose some random order on the learning events, the expected value irrespective of order can be estimated using FIL.
7. ^As pointed out by a reviewer, this accuracy metric puts a lot of emphasis on high frequency closed class words which are often considered stopwords in computational linguistics [examples in English are the, of, and, at, by, of ,...; see for instance the English stopword list in NLTK (Bird, 2006)]. However, stopwords have to be learned just as other words, so excluding them a-priori seems unprincipled. We also do not see a plausible cognitive mechanism that would filter out stopwords but not other high frequency open class words. Another issue is that what are considered stopwords in English or Dutch, are often incorporated inside word forms in other languages (e.g., what is expressed with prepositions in English is expressed with case inflection in Finnish). Excluding stopwords for English but including case inflections in Finnish would make modeling incomparable and incompatible across languages.
8. ^We ordered the data by age, followed by utterance id, followed by the token sequence within the utterance. Unfortunately, this part of childesr is not very well documented, so though sampling suggests that this corresponds to the original order of the data, we cannot be absolutely sure. However, the overall ordering by age should ensure that our results are valid even if some of the utterances might be in the wrong order.
9. ^However, note that the variance of word frequencies is similar in magnitude to the frequency itself (under the assumption that word frequencies are Poisson-distributed). By moving from frequencies to ranks, differences in frequency that seem large but that will vary substantially across samples are reduced to much smaller differences in ranks. In the light of these considerations, the excellent predictivity of rank for reaction times is due to distributional properties of the language in combination with sampling error, rather than due to serial searches in frequency ordered mental word lists.
10. ^See Norris (2006) for a similar argument in the context of a Bayesian approach to the role of word frequency in lexical processing.
References
Adelman, J. S., and Brown, G. D. (2008). Modeling lexical decision: the form of frequency and diversity effects. Psychol. Rev. 115, 214. doi: 10.1037/0033-295X.115.1.214
Baayen, R. H. (2005). “Data mining at the intersection of psychology and linguistics,” in Twenty-First Century Psycholinguistics: Four Cornerstones, ed A. Cutler (Hillsdale, NJ: Erlbaum), 69–83.
Baayen, R. H. (2010). Demythologizing the word frequency effect: a discriminative learning perspective. Ment. Lex. 5, 436–461. doi: 10.1075/ml.5.3.10baa
Baayen, R. H., Chuang, Y.-Y., and Heitmeier, M. (2018b). WpmWithLdl: Implementation of Word and Paradigm Morphology With Linear Discriminative Learning. R package Version 1.2.20.
Baayen, R. H., Chuang, Y.-Y., and Blevins, J. P. (2018a). Inflectional morphology with linear mappings. Ment. Lex. 13, 230–268. doi: 10.1075/ml.18010.baa
Baayen, R. H., Chuang, Y.-Y., Shafaei-Bajestan, E., and Blevins, J. (2019). The discriminative lexicon: a unified computational model for the lexicon and lexical processing in comprehension and production grounded not in (de) composition but in linear discriminative learning. Complexity 2019, 4895891. doi: 10.1155/2019/4895891
Baayen, R. H., Dijkstra, T., and Schreuder, R. (1997). Singulars and plurals in Dutch: evidence for a parallel dual route model. J. Mem. Lang. 36, 94–117. doi: 10.1006/jmla.1997.2509
Baayen, R. H., Milin, P., and Ramscar, M. (2016). Frequency in lexical processing. Aphasiology 30, 1174–1220. doi: 10.1080/02687038.2016.1147767
Baayen, R. H., Milin, P., Urević, D. F., Hendrix, P., and Marelli, M. (2011). An amorphous model for morphological processing in visual comprehension based on naive discriminative learning. Psychol. Rev. 118, 438. doi: 10.1037/a0023851
Baayen, R. H., Piepenbrock, R., and Gulikers, L. (1995). The CELEX Lexical Database [cd rom]. Philadelphia, PA: Linguistic Data Consortium, University of Pennsylvania.
Baayen, R. H., and Smolka, E. (2020). Modeling morphological priming in german with naive discriminative learning. Front. Commun. 5, 17. doi: 10.3389/fcomm.2020.00017
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H., and Yap, M. J. (2004). Visual word recognition of single-syllable words. J. Exp. Psychol. Gen. 133, 283. doi: 10.1037/0096-3445.133.2.283
Balota, D. A., Yap, M. J., Hutchison, K. A., Cortese, M. J., Kessler, B., Loftis, B., et al. (2007). The english lexicon project. Behav. Res. Methods 39, 445–459. doi: 10.3758/BF03193014
Bezanson, J., Edelman, A., Karpinski, S., and Shah, V. B. (2017). Julia: a fresh approach to numerical computing. SIAM Rev. 59, 65–98. doi: 10.1137/141000671
Bird, S. (2006). “NLTK: the natural language toolkit,” in Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions (Philadelphia, PA), 69–72.
Breiman, L. (2001). Statistical modeling: the two cultures (with comments and a rejoinder by the author). Stat. Sci. 16, 199–231. doi: 10.1214/ss/1009213726
Brysbaert, M., Buchmeier, M., Conrad, M., Jacobs, A. M., Bölte, J., and Böhl, A. (2011). The word frequency effect: a review of recent developments and implications for the choice of frequency estimates in German. Exp. Psychol. 58, 412–424. doi: 10.1027/1618-3169/a000123
Brysbaert, M., Mandera, P., and Keuleers, E. (2018). The word frequency effect in word processing: an updated review. Curr. Dir. Psychol. Sci. 27, 45–50. doi: 10.1177/0963721417727521
Brysbaert, M., and New, B. (2009). Moving beyond kučera and francis: a critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for american english. Behav. Res. Methods 41, 977–990. doi: 10.3758/BRM.41.4.977
Brysbaert, M., Stevens, M., Mandera, P., and Keuleers, E. (2016). The impact of word prevalence on lexical decision times: evidence from the dutch lexicon project 2. J. Exp. Psychol. 42, 441. doi: 10.1037/xhp0000159
Bybee, J. L., and Hopper, P. J. (2001). Frequency and the Emergence of Linguistic Structure, Vol. 45. Amsterdam: John Benjamins Publishing.
Chuang, Y.-Y., Bell, M. J., Banke, I., and Baayen, R. H. (2021). Bilingual and multilingual mental lexicon: a modeling study with linear discriminative learning. Lang. Learn. 71, 219–292. doi: 10.1111/lang.12435
Chuang, Y.-Y., Kang, M., Luo, X., and Baayen, R. H. (2022). “Vector space morphology with linear discriminative learning,” in Linguistic Morphology in the Mind and Brain, ed D. Crepaldi (Abingdon, VA: Routledge).
Chuang, Y.-Y., Lõo, K., Blevins, J. P., and Baayen, R. H. (2020). “Estonian case inflection made simple a case study in word and paradigm morphology with linear discriminative learning,” in Complex Words: Advances in Morphology, Chapter 7, eds L. Körtvélyessy, and P. Štekauer (Cambridge: Cambridge University Press), 119–114.
Demuth, K., Culbertson, J., and Alter, J. (2006). Word-minimality, epenthesis and coda licensing in the early acquisition of english. Lang. Speech 49, 137–173. doi: 10.1177/00238309060490020201
Denistia, K., and Baayen, R. H. (2021). The Morphology of Indonesian: Data and Quantitative Modeling. The Routledge Handbook of Asian Linguistics. Abingdon, VA: Routledge.
Diependaele, K., Brysbaert, M., and Neri, P. (2012). How noisy is lexical decision? Front. Psychol. 3, 348. doi: 10.3389/fpsyg.2012.00348
Ernestus, M. T. C., and Baayen, R. H. (2003). Predicting the unpredictable: Interpreting neutralized segments in dutch. Language 79, 5–38. doi: 10.1353/lan.2003.0076
Ferrand, L., New, B., Brysbaert, M., Keuleers, E., Bonin, P., Méot, A., et al. (2010). The french lexicon project: Lexical decision data for 38,840 french words and 38,840 pseudowords. Behav. Res. Methods 42, 488–496. doi: 10.3758/BRM.42.2.488
Fon, J., and Hsu, H.-J. (2007). “Positional and phonotactic effects on the realization of dipping tones in Taiwan Mandarin,” in Phonology and Phonetics, Tones and Tunes: Vol. 2. Experimental Studies in Word and Sentence Prosody, eds C. Gussenhoven, and T. Riad (Berlin: Mouton de Gruyter), 239–269.
Forster, K. (1976). “Accessing the mental lexicon,” in New Approaches to Language Mechanisms, eds F. Wales, and E. Walker (Amsterdam: North Holland Publ. Co.), 257–286.
Forster, K. I. (1979). “Levels of processing and the structure of the language processor,” in Sentence Processing: Psycholinguistic Essays Presented to Merrill Garrett, eds W. E. Cooper and E. Walker (Hillsdale, NJ: Erlbaum).
Forster, K. I. (1994). Computational modeling and elementary process analysis in visual word recognition. J. Exp. Psychol. 20, 1292. doi: 10.1037/0096-1523.20.6.1292
Gahl, S., and Baayen, R. H. (2023). Time and Thyme Again: Connecting Spoken Word Duration to Models of the Mental Lexicon. Under Revision for Language.
Grave, É., Bojanowski, P., Gupta, P., Joulin, A., and Mikolov, T. (2018). “Learning word vectors for 157 languages,” in Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) (Miyazaki).
Harm, M. W., and Seidenberg, M. S. (2004). Computing the meanings of words in reading: cooperative division of labor between visual and phonological processes. Psychol. Rev. 111, 662. doi: 10.1037/0033-295X.111.3.662
Heitmeier, M., and Baayen, R. H. (2020). Simulating phonological and semantic impairment of English tense inflection with linear discriminative learning. Ment. Lex. 15, 385–421. doi: 10.1075/ml.20003.hei
Heitmeier, M., Chuang, Y.-Y., and Baayen, R. H. (2021). Modeling morphology with linear discriminative learning: considerations and design choices. Front. Psychol. 12, 720713. doi: 10.3389/fpsyg.2021.720713
Heitmeier, M., Chuang, Y.-Y., and Baayen, H. (2023a). Linear Discriminative Learning: Theory and implementation in the julia package JudiLing. Tübingen: University of Tübingen.
Heitmeier, M., Chuang, Y.-Y., and Baayen, R. H. (2023b). How trial-to-trial learning shapes mappings in the mental lexicon: Modelling lexical decision with linear discriminative learning. Cogn. Psychol. 146, 101598. doi: 10.1016/j.cogpsych.2023.101598
Ho, A. T. (1976). The acoustic variation of Mandarin tones. Phonetica 33, 353–367. doi: 10.1159/000259792
Hollis, G. (2020). Delineating linguistic contexts, and the validity of context diversity as a measure of a word's contextual variability. J. Mem. Lang. 114, 104146. doi: 10.1016/j.jml.2020.104146
Howie, J. M. (1974). On the domain of tone in mandarin. Phonetica 30, 129–148. doi: 10.1159/000259484
Jacobs, A. M., and Grainger, J. (1994). Models of visual word recognition: sampling the state of the art. J. Exp. Psychol. 20, 1311. doi: 10.1037/0096-1523.20.6.1311
Kapatsinski, V. (2022). “The logistic perceptron accounts for rank frequency effects in lexical processing,” in Proceedings of the Second International Conference on Error-Driven Learning in Language (EDLL 2022), eds J. Nixon, F. Tomaschek, and R. H. Baayen (Tübingen), 16–17.
Keuleers, E., Diependaele, K., and Brysbaert, M. (2010). Practice effects in large-scale visual word recognition studies: a lexical decision study on 14,000 dutch mono-and disyllabic words and nonwords. Front. Psychol. 1, 174. doi: 10.3389/fpsyg.2010.00174
Keuleers, E., Lacey, P., Rastle, K., and Brysbaert, M. (2012). The british lexicon project: Lexical decision data for 28,730 monosyllabic and disyllabic english words. Behav. Res. Methods 44, 287–304. doi: 10.3758/s13428-011-0118-4
Kuperman, V., and Van Dyke, J. A. (2013). Reassessing word frequency as a determinant of word recognition for skilled and unskilled readers. J. Exp. Psychol. 39, 802. doi: 10.1037/a0030859
Landauer, T., Foltz, P., and Laham, D. (1998). Introduction to latent semantic analysis. Discour Proc. 25, 259–284. doi: 10.1080/01638539809545028
Lee, C.-Y. (2007). Does horse activate mother? Processing lexical tone in form priming. Lang. Speech 50, 101–123. doi: 10.1177/00238309070500010501
Li, P., Zhao, X., and Mac Whinney, B. (2007). Dynamic self-organization and early lexical development in children. Cogn. Sci. 31, 581–612. doi: 10.1080/15326900701399905
Luo, X. (2021). JudiLing: An Implementation for Linear Discriminative Learning in JudiLing (unpublished Master's thesis), Tübingen, Germany.
MacWhinney, B. (2014). The CHILDES Project: Tools for Analyzing Talk, Volume II: The Database. Hove: Psychology Press.
McClelland, J. L., and Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychol. Rev. 88, 375. doi: 10.1037/0033-295X.88.5.375
McClelland, J. L., and Rumelhart, D. E. (1989). Explorations in Parallel Distributed Processing: A Handbook of Models, progRams, and Exercises. Cambridge, MA: MIT Press.
Milin, P., Madabushi, H. T., Croucher, M., and Divjak, D. (2020). Keeping it simple: implementation and performance of the proto-principle of adaptation and learning in the language sciences. arXiv doi: 10.48550/arXiv.2003.03813
Miwa, K., and Baayen, H. (2021). Nonlinearities in bilingual visual word recognition: an introduction to generalized additive modeling. Biling. Lang. Cogn. 24, 825–832. doi: 10.1017/S1366728921000079
Morton, J. (1969). Interaction of information in word recognition. Psychol. Rev. 76, 165. doi: 10.1037/h0027366
Morton, J. (1979a). Facilitation in word recognition: experiments causing change in the logogen model. Process. Visible Lang. 13, 259–268. doi: 10.1007/978-1-4684-0994-9_15
Murray, W. S., and Forster, K. I. (2004). Serial mechanisms in lexical access: the rank hypothesis. Psychol. Rev. 111, 721. doi: 10.1037/0033-295X.111.3.721
Nieder, J., Chuang, Y., van de Vijver, R., and Baayen, H. (2023). A discriminative lexicon approach to word comprehension, production, and processing: maltese plurals. Language 99, 242–274. doi: 10.1353/lan.2023.a900087
Norris, D. (2006). The bayesian reader: explaining word recognition as an optimal bayesian decision process. Psychol. Rev. 113, 327. doi: 10.1037/0033-295X.113.2.327
Norris, D. (2013). Models of visual word recognition. Trends Cogn. Sci. 17, 517–524. doi: 10.1016/j.tics.2013.08.003
Nusbaum, H. C. (1985). A Stochastic Account of the Relationship Between Lexical Density and Word Frequency. Technical report, Indiana University. Research on Speech Perception, Progress Report #11.
Pham, H., and Baayen, H. (2015). Vietnamese compounds show an anti-frequency effect in visual lexical decision. Lang. Cogn. Neurosci. 30, 1077–1095. doi: 10.1080/23273798.2015.1054844
R Core Team (2020). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Ratcliff, R., Gomez, P., and McKoon, G. (2004). A diffusion model account of the lexical decision task. Psychol. Rev. 111, 159. doi: 10.1037/0033-295X.111.1.159
Reicher, G. M. (1969). Perceptual recognition as a function of meaningfulness of stimulus material. J. Exp. Psychol. 81, 275. doi: 10.1037/h0027768
Rescorla, R. A. (1967). Pavlovian conditioning and its proper control procedures. Psychol. Rev. 74, 71. doi: 10.1037/h0024109
Rescorla, R. A., and Wagner, A. R. (1972). Classical Conditioning II: Current Research and Theory, Chapter A Theory of Pavlovian Conitioning: Variations in the Effectiveness of Reinforcement and Nonreinforcement. New York, NY: Appleton-Century-Crofts, 64–99.
Rubenstein, H., Garfield, L., and Millikan, J. A. (1970). Homographic entries in the internal lexicon. J. Verb. Learn. Verb. Behav. 9, 487–494. doi: 10.1016/S0022-5371(70)80091-3
Rubenstein, H., Lewis, S. S., and Rubenstein, M. A. (1971). Homographic entries in the internal lexicon: effects of systematicity and relative frequency of meanings. J. Verb. Learn. Verb. Behav. 10, 57–62. doi: 10.1016/S0022-5371(71)80094-4
Rumelhart, D., Hinton, G., and Williams, R. (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi: 10.1038/323533a0
Rumelhart, D. E., and McClelland, J. L. (1982). An interactive activation model of context effects in letter perception: II. the contextual enhancement effect and some tests and extensions of the model. Psychol. Rev. 89, 60. doi: 10.1037/0033-295X.89.1.60
Sanchez, A., Meylan, S. C., Braginsky, M., MacDonald, K. E., Yurovsky, D., and Frank, M. C. (2019). childes-db: a flexible and reproducible interface to the child language data exchange system. Behav. Res. Methods 51, 1928–1941. doi: 10.3758/s13428-018-1176-7
Schmitz, D., Plag, I., Baer-Henney, D., and Stein, S. D. (2021). Durational differences of word-final/s/emerge from the lexicon: modelling morpho-phonetic effects in pseudowords with linear discriminative learning. Front. Psychol. 12, 2983. doi: 10.3389/fpsyg.2021.680889
Seidenberg, M., and McClelland, J. (1989). A distributed, developmental model of word recognition and naming. Psychol. Rev. 96, 523. doi: 10.1037/0033-295X.96.4.523
Shafaei-Bajestan, E., Moradipour-Tari, M., Uhrig, P., and Baayen, R. H. (2023). LDL-AURIS: a computational model, grounded in error-driven learning, for the comprehension of single spoken words. Lang. Cognit. Neurosci. 38, 509–536. doi: 10.1080/23273798.2021.1954207
Stein, S. D., and Plag, I. (2021). Morpho-phonetic effects in speech production: modeling the acoustic duration of english derived words with linear discriminative learning. Front. Psychol. 12, 678712. doi: 10.3389/fpsyg.2021.678712
Sun, C. C., Hendrix, P., Ma, J., and Baayen, R. H. (2018). Chinese lexical database (cld) a large-scale lexical database for simplified mandarin chinese. Behav. Res. Methods 50, 2606–2629. doi: 10.3758/s13428-018-1038-3
Tomaschek, F., Tucker, B., and Baayen, R. H. (2018). Practice makes perfect: the consequences of lexical proficiency for articulation. Linguist. Vanguard 4, 1–13. doi: 10.1515/lingvan-2017-0018
van de Vijver, R., Uwambayinema, E., and Chuang, Y. (2023). Comprehension and production of Kinyarwanda Verbs in the Discriminative Lexicon. Linguistics. doi: 10.1515/ling-2021-0164
van der Velde, M., Sense, F., Borst, J. P., van Maanen, L., and Van Rijn, H. (2022). Capturing dynamic performance in a cognitive model: estimating act-r memory parameters with the linear ballistic accumulator. Top. Cogn. Sci. 14, 889–903. doi: 10.1111/tops.12614
Widrow, B., and Hoff, M. (1960). Adaptive Switching Circuits. 1960 WESCON Convention Record Part IV.
Wood, S. N. (2011). Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. B 73, 3–36. doi: 10.1111/j.1467-9868.2010.00749.x
Xu, Y., and Wang, Q. E. (2001). Pitch targets and their realization: evidence from Mandarin Chinese. Speech Commun. 33, 319–337. doi: 10.1016/S0167-6393(00)00063-7
Yamada, I., Asai, A., Sakuma, J., Shindo, H., Takeda, H., Takefuji, Y., et al. (2020). “Wikipedia2Vec: an efficient toolkit for learning and visualizing the embeddings of words and entities from Wikipedia,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 23-30. Association for Computational Linguistics.
Keywords: linear discriminative learning, word frequency, incremental learning, weighted regression, lexical decision, mental lexicon, distributional semantics
Citation: Heitmeier M, Chuang Y-Y, Axen SD and Baayen RH (2024) Frequency effects in linear discriminative learning. Front. Hum. Neurosci. 17:1242720. doi: 10.3389/fnhum.2023.1242720
Received: 19 June 2023; Accepted: 14 December 2023;
Published: 08 January 2024.
Edited by:
Michael Zock, Centre National de la Recherche Scientifique (CNRS), FranceReviewed by:
James P. Blevins, George Mason University, United StatesXiaowei Zhao, Emmanuel College, United States
Copyright © 2024 Heitmeier, Chuang, Axen and Baayen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Maria Heitmeier, maria.heitmeier@uni-tuebingen.de