Cardiac MRI segmentation of the atria based on UU-NET
 Yi Wang1†
Yi Wang1†  Jing Huang
Jing Huang Yuan-Zhe Li
Yuan-Zhe Li- 1Department of CT/MRI, The Second Affiliated Hospital of Fujian Medical University, Quanzhou, China
- 2Department of Radiology, The First Affiliated Hospital of Zhejiang Chinese Medical University (Zhejiang Provincial Hospital of Traditional Chinese Medicine), Hangzhou, China
- 3Department of Neurology, Jinjiang Municipal Hospital, Quanzhou, China
Background and objective: In today's society, people's work pressure, coupled with irregular diet, lack of exercise and other bad lifestyle, resulting in frequent cardiovascular diseases. Medical imaging has made great progress in modern society, among which the role of MRI in cardiovascular field is self-evident. Based on this research background, how to process cardiac MRI quickly and accurately by computer has been extensively discussed. By comparing and analyzing several traditional image segmentation and deep learning image segmentation, this paper proposes the left and right atria segmentation algorithm of cardiac MRI based on UU-NET network.
Methods: In this paper, an atrial segmentation algorithm for cardiac MRI images in UU-NET network is proposed. Firstly, U-shaped upper and lower sampling modules are constructed by using residual theory, which are used as encoders and decoders of the model. Then, the modules are interconnected to form multiple paths from input to output to increase the information transmission capacity of the model.
Results: The segmentation method based on UU-NET network has achieved good results proposed in this paper, compared with the current mainstream image segmentation algorithm results have been improved to a certain extent. Through the analysis of the experimental results, the image segmentation algorithm based on UU-NET network on the data set, its performance in the verification set and online set is higher than other grid models. The DSC in the verification set is 96.7%, and the DSC in the online set is 96.7%, which is nearly one percentage point higher than the deconvolution neural network model. The hausdorff distance (HD) is 1.2 mm. Compared with other deep learning models, it is significantly improved (about 3 mm error is reduced), and the time is 0.4 min.
Conclusion: The segmentation algorithm based on UU-NET improves the segmentation accuracy obviously compared with other segmentation models. Our technique will be able to help diagnose and treat cardiac complications.
Introduction
Recently, the worldwide prevalence of cardiovascular disease also gradually rise, according to world health organization in 2019 chart “cardiovascular disease risk, according to the world heart vascular disease prevalence in the rising trend, number of cases to exceed 500 million, 17.9 million people die each year from cardiovascular disease, first in all kinds of diseases (1). The public should pay attention to the prevention and treatment of cardiovascular diseases (2). Generally applied in clinical practice, for the diagnosis of cardiovascular disease, doctors usually only by observing the patients with cardiac image two-dimensional image of the fault, and according to the experience of the clinical cases of his past give treatment, the diagnosis for the dependence of subjective experience is bigger, and has led to bigger misjudgment. In addition, in some cases, to save resources and time, methods such as improving mri speed, imaging time, or spatial resolution are often adopted, but in such cases, a large amount of additional data is generated, which greatly reduces the efficiency of doctors to read images (3).
Medical image segmentation is to mark or extract a specific part of a medical image and apply it to other medical tasks. Therefore, the segmentation performance of medical images directly affects the development of other related technologies, such as three-dimensional reconstruction of human organs, registration of human parts, and localization of diseased or necrotic tissues. However, the development of medical image segmentation technology is also limited by many aspects. First, there are many kinds of imaging principles of medical image, and the quality of imaging is greatly affected by acquisition equipment and environment, that is, it is easy to be interfered by various noises. Therefore, it is difficult to generate a universal segmentation technique for all medical images. Secondly, according to the biological characteristics of human beings, the anatomical structure of each organ in human body is extremely complex, and there are significant differences between different ages of the same individual and individuals, which further increases the difficulty of segmentation (4). However, if medical image segmentation can be completed quickly and accurately, it will effectively improve the application of relevant imaging technology in clinical medicine.
The current development of computer field has added a possibility for the development of medical image segmentation. In 2012, artificial intelligence (AI), which focuses on computing power and deep learning, became the core technology of the next era (5). As an important branch of artificial intelligence technology, computer vision is developing very fast. In the 2015 ImageNet image recognition contest (6), computer recognition accuracy surpassed that of humans for the first time. Therefore, if the computer can be used to pre-process medical images to increase the efficiency of doctors or directly diagnose related diseases, it will be beneficial to improve the level of medical treatment.
Magnetic resonance (MRI) is a common heart imaging technique. In the early stage of the development of imaging technology, MRI has a slow imaging speed and is not suitable for the acquisition of cardiac images that require high imaging speed and resolution. However, with the development of medical image imaging technology, cardiac MRI has been able to obtain cardiac motion images by means of time-sharing acquisition in multiple cardiac systolic and diastolic cycles. MRI is the use of hydrogen atoms in the magnetic field in the human body to release energy information sampling technology, unlike conventional CT, MRI without ionizing radiation damage, imaging at the same time to be able to reflect the high contrast between different blood groups, is helpful to obtain clear heart anatomy structure (7). Therefore, MRI is recognized as the gold standard for evaluating cardiac function. Therefore, the image segmentation technology in this paper will be based on MRI imaging.
The left atrium is directly connected with the left ventricle and pulmonary veins. Its basic functions include channel function, contraction function and reserve function. Channel function refers to the early and middle stage of left ventricular diastole, when the left atrium sends blood from the pulmonary vein to the left ventricle. Systolic function refers to the active contraction of left atrial myocardium to provide blood for the left ventricle. Reserve function means that the systole of the left ventricle acts as a vessel for storing blood. In addition, the atrial structure directly maintains human atrial fibrillation (8), and the main reason for the poor clinical performance of atrial fibrillation is the lack of a deeper understanding of the underlying atrial anatomical structure (9). Therefore, understanding the atrial morphology and changes of patients with atrial fibrillation has certain reference value for understanding the clinical treatment of atrial fibrillation.
Manual segmentation of the left atrium by a medical expert does guarantee high accuracy, but it can take a lot of time for the expert to annotate an individual's data. The boring and long-term nature of labeling images will often lead to fluctuations in the state of labeling images and affect the accuracy of labeling, that is, the accuracy level is subjective. The scarcity of medical experts also leads to the lack of widespread application of left atrial segmentation. Therefore, it is necessary to adopt the means of computer field to solve this problem.
However, there are many schemes for ventricular image segmentation based on machine learning, such as deep belief network (DBN) (10), stack autocoding (SAE) (11), deep autoencoder (DAE) (12) and other technologies. However, these researches mainly focus on neuroimage analysis and have little effect on ventricular image segmentation. Using random forest method (13) and constrained Boltzmann machine (14) will lead to high computational complexity and unstable results. Therefore, the above methods have great limitations in the segmentation of ventricular images.
To solve this problem, we design a local image segmentation method based on U-NET. Based on the full convolutional neural network and the combination of deconvolution technology and deconvolution technology, a dual cavity scan image segmentation based on U-NET network is realized. At the same time, in order to avoid excessive model parameters, the number of convolutional filters is appropriately set according to the characteristics of MRI and the needs of the segmentation task. Experimental results show that the segmentation method of U-NET atrial image has better effect compared with several existing classification methods.
Methodology
Region growing
The basic idea of regional growth is that regions to be segmented have the same or similar properties within the region and different properties outside the region (15). The specific implementation steps are as follows:
1. Select a seed pixel for each region to be segmented.
2. All pixels in the field of the region where the seed pixel is located are judged according to certain growth criteria. If there are pixels that meet the growth criteria, all the pixels will be absorbed into the region where the seed pixels are, and the second step will be performed again.
3. When there is no pixel satisfying the growth criterion in the field of a region, the region no longer expands, that is to say, the region has grown.
For the specific segmentation process, please refer to Figure 1, that is, select the growth cycle until the end of all growth.
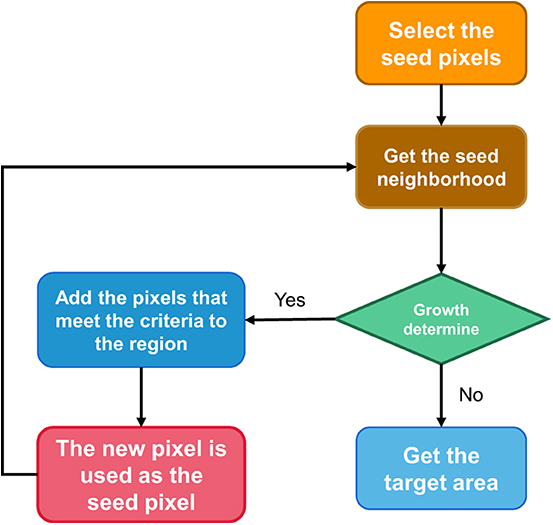
Figure 1. Region growth for image segmentation steps.
It should be pointed out that the growth or similarity standard usually set is related to the characteristics of the image itself, usually, the difference between gray scale and gray scale is within a critical value. This paper uses a threshold of 25.
Threshold segmentation method
Threshold segmentation
Threshold method were the first to be applied to achieve a segmentation method of image segmentation (16), the key technique of the threshold segmentation method is: according to the statistics of the whole image grayscale characteristics, according to the gray level range and the number of the gray value for that one or more of the image threshold value, then one by one traverse each gray value of the image, and each gray level values and threshold values After comparison, classify according to the final comparison results or preset rules, and divide each pixel within different threshold ranges into different categories in order to achieve segmentation. Figure 2 shows the general steps of the threshold segmentation method for image segmentation, among which there are many methods to determine the threshold.
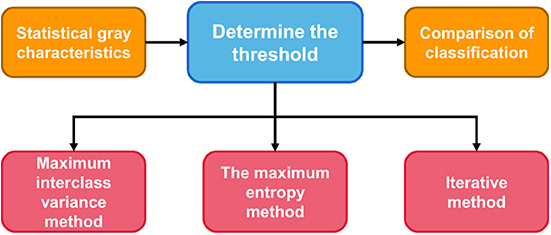
Figure 2. Steps of threshold segmentation method.
The limitations method of threshold
Maximum interclass variance method
The maximum inter-class variance, also known as the algorithm, was proposed by The Japanese scholar Otsu. It is an algorithm for image binary segmentation threshold. The basic idea of threshold determination is that the threshold should be able to maximize the feature difference between the target and the background (17).
Variance is a statistical measure of the uniformity of distribution. Therefore, the segmentation that maximizes the variance between classes means the smallest misclassification probability.
If T is regarded as the segmentation threshold of target and background, the proportion of foreground (target) region to image is denoted as w0, and the average gray level is u0. The proportion of background region to the image is denoted as w1, the average gray level is u1, the total average gray level of the image is U, and the variance of foreground and background image g(T) is as follows:
Since under this method, the image is only treated as foreground and background overlay, there are
Equations (1)–(3) can be obtained simultaneously
To ensure that g(T) is the largest, T is selected as the desired. Notice that this formula w0 is symmetric about w1, so w0 can be set as the partition less than the threshold value, that is, the foreground represents the region s0 occupied by all gray values in the image S less than the threshold value. u0 represents the average gray level of s0 region.
Here, s1 is the same as u1. And then one obtains g(T) as a function of T and then you invert the maximum value of T for g of T.
Threshold iteration method
The main idea of threshold iteration method is that the mean sum of two parts A and B after image segmentation basically remains stable (18). In other words, with the iteration, the final convergence value of [mean(A)+mean(B)]/2 is taken as the segmentation threshold. The specific method is as follows:
(1) Select an initial threshold T;
(2) The given image is divided into two groups of images by threshold T, denoted as R1 and R2;
(3) Calculate the mean values of R1 and R2 μ1 and μ2;
(4) Select a new threshold T, and T= (μ1 + μ2) /2;
(5) Repeat steps (2) to (4) until the difference of T for two consecutive times is less than a preset value.
On this basis, in the case that the target region is equal to the background region, the initial threshold T is set as the average gray value of the overall image, so as to accelerate the convergence rate. In the case of large difference between target and background area, the initial threshold T is set as the intermediate value between the maximum gray scale and the minimum gray scale. The default values depend on the image size, grayscale distribution, and calculation time required, but are generally small and accurate. Its construction is shown in Figure 3.
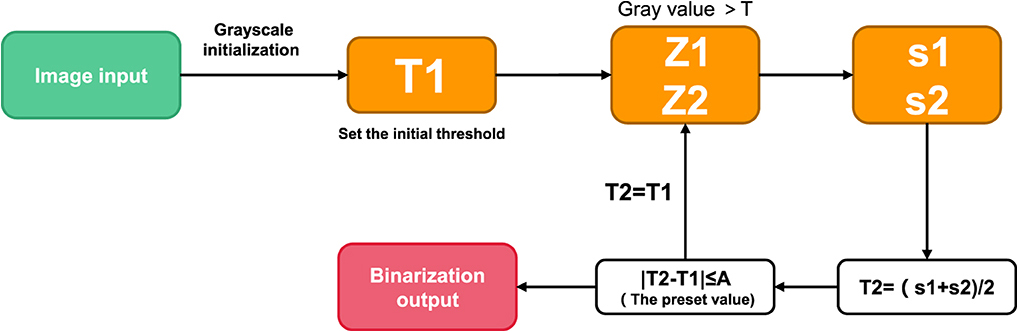
Figure 3. Program flow chart of threshold iteration method.
The maximum entropy method
The principle of image maximum entropy threshold segmentation: make the selected threshold to segment the target area and background area of image gray statistics of the two parts of the maximum information (19).
The area whose gray value is ≤T is S0, and the rest of the image is S1. Let PI represent the probability of gray value being I, and PT represent the sum of gray value probabilities from 0 to T. H (S) represents the information entropy of the region.
By traversing the gray value, T that maximized H(S0)+H(S1) was found.
The difficulty of threshold segmentation
The difficulties of threshold segmentation are as follows: (1) Before image segmentation, the number of regions generated by image segmentation cannot be determined; (2) Determination of threshold value, because the determination of threshold value directly affects the accuracy of segmentation and the correctness of description analysis of the segmented image.
UU-NET network
UU-NET
In 2015, Ronneberger et al. trained the U-NET model based on convolutional neural network with a small number of training samples and won the ISBI Cell Tracking Challenge. The network is called U-NET because it is shaped like the letter “U”. Subsequently, U-NET network obtained excellent segmentation results in medical images of the heart.
The U-NET model consists of a downsampling encoder and an upsampling decoder, as shown in Figure 4. The structure is simple and easy to understand. The contraction process of the model is the down-sampling process. The author extracts features through multiple 3*3 convolution layers and uses the maximum pooling of 2*2 for down-sampling (20). In the expansion process of the model, that is, the upsampling process, the feature graph of the previous stage is firstly upsampled, and then the feature graph of the contraction process is splice and further refined by jumping connection. Finally, the channel number mapping of the feature map is scaled down to the segmented category number through the 1*1 convolution layer. U-net has been widely used in the field of medical image segmentation because of its simple structure, easy transformation and adjustment, and its high ability of obtaining context information and precise positioning.
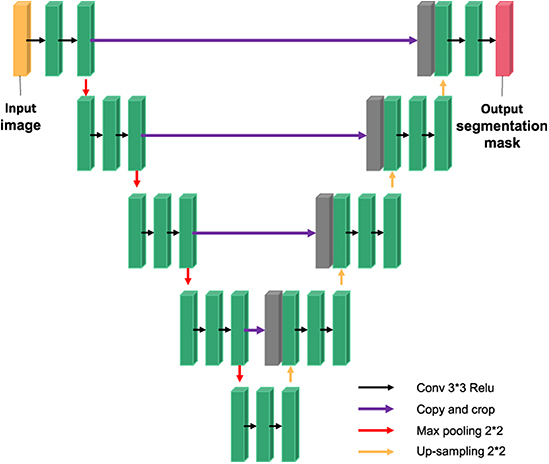
Figure 4. U-NET network model.
Data preprocessing and data amplification
Data standardization
Due to the differences of acquisition equipment and conditions in various research institutions, there are differences in brightness and contrast of cardiac MRI images. The essence of neural networks is to learn by distributing data. If there is a big difference between the training data and the experimental data, the generalization ability of the model will be greatly weakened. To solve this problem, it is often required to normalize the input data.
On this basis, cardiac short-axis MRI was processed to obtain a normalized data with 0 pixel mean, 1. On this basis, a normalization algorithm based on maximum normalization is proposed.
Where xmean represents the average value of the required data, xmax represents the maximum value of the required data, and xmin represents the minimum value of the required data.
Data enhancement
However, due to the high cost of image acquisition, social ethical privacy and high human cost of professionals, many medical image research based on deep learning cannot obtain enough data for training or verification. However, in the case of small samples, there is the problem of over-fitting. The data intensification methods used in this paper include −0.2–0.2 random scale, −5 to +5% random direction shearing, −5 to +5% contrast correction, etc.
UU-NET model structure
Based on the improvement of U-NET model, this paper designs a UU-NET model which is more suitable for medical image segmentation. In this paper, u-shaped upper and lower sampling modules are constructed by using residual theory, which are used as encoders and decoders of the model. Then, the modules are interconnected to form multiple paths from input to output to increase the information transmission capability of the model.
Residual module
The depth of neural network largely determines image classification and computer vision tasks. Theoretically, the higher the depth of the network, the better its fitting effect. But that's not true. This is because with the increase of network depth, the gradient will gradually weaken, thus affecting the segmentation of the network. In this paper, we use ResNet to delay gradient extinction in network propagation.
The mathematical principle of ResNet is as follows: Assume that the mapping of input X to output Y is H, that is, Y = H(X); After input X passes through multiple nonlinear layers, the result Y satisfies another mapping as F, that is, Y = F(X), where F(X) = H(X) -x between F and H satisfies. Thus, the original mapping H is represented as F(X) + X. In the feedforward neural network, the required mapping H can be realized through the connection mode of “layer hopping,” as shown in Column B in Figures 2, 3. The UU-NET model in this paper uses this residual idea to construct convolution blocks in U-NET as shown in Figure 5. The essence is to replace ordinary convolution modules with residual convolution modules and apply batch regularization rules to model training.
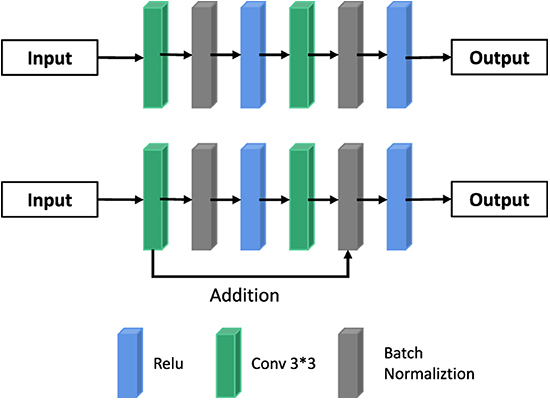
Figure 5. Ordinary convolution block and residual convolution block.
Sampling module
By connecting the intermediate result of the former U-NET decoder to the latter U-NET encoder through Addition, the latter can be supplemented with additional information on the feature graph of each scale. At the same time, this method can construct multiple paths to transmit information, and each path is equivalent to an FCN variant. Therefore, it has the potential to capture more complex features and produce higher accuracy. Similarly, in order to construct multiple paths, this paper constructs two types of U-NET modules, which are respectively used for the outer U-shaped encoder (column A and decoder in Figure 6 and column B in Figure 6 for the design of UU-NET model.
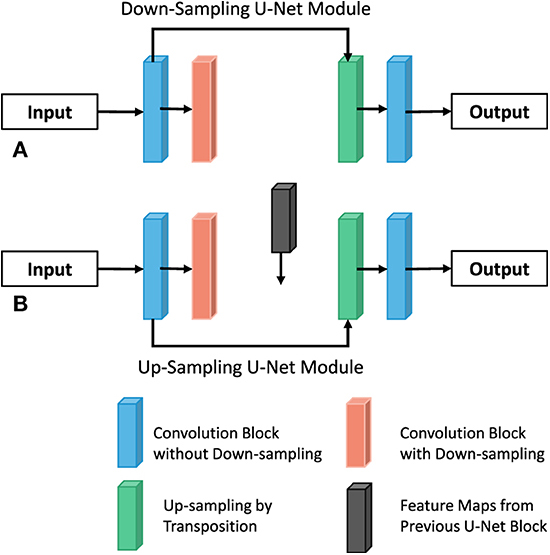
Figure 6. Modules of two UU-NET models. (A) Down-Sampling. (B) Up-Sampling of the U-Net module.
Overall model structure
Through the construction of two types of U-NET modules, referred to as external U encoder module and external U decoder module, the UU-NET model is designed. The “hop layer” in the U-NET module is connected by Concatenation. The smallest feature graph in the outer U encoder module will be the input of the lower outer U encoder module. U decoder module and external U encoder module on the size of the corresponding figure for Addition (Addition) operation, namely “U” encoder module and the intermediate results produced by decoding part of the “U” decoder module coding and some intermediate results, so the latter on the characteristics of various scale chart to get the additional information added, at the same time, Added multiple paths from input to output. Compared with LadderNet, this paper not only uses the residual convolution block to increase the depth of the outer U-shaped structure, but also constructs more information transmission paths through the double-layer structure, that is, more FCN variants are added. As shown in Figure 7, the outer layer of the normal U-Net model is connected by residual convolution blocks, thus forming a double-layer U model. It is equivalent to regard each neural network of U-NET model as a U-NET model.
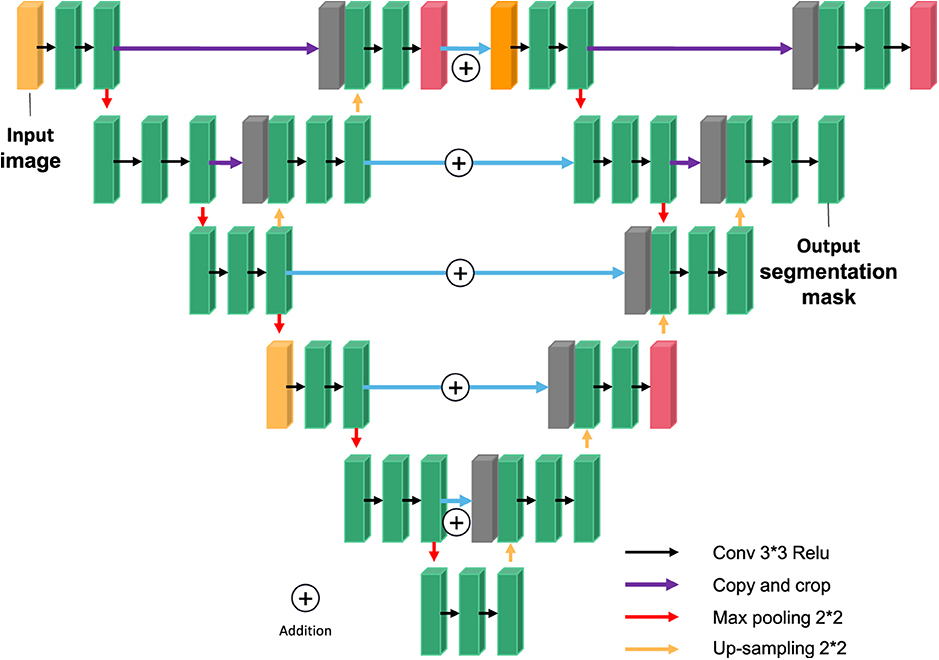
Figure 7. Overall structure of UU-NET network.
Deconvolution neural network
Deep deconvolution network is a supervised learning method, which includes training stage and test stage (as shown in Figure 8). Ten times in the training phase, this paper uses the method of cross validation, the magnetic resonance image segmentation and manual real image as the training sample input of neural network, through the forward and reverse transmission, iteratively weight training network model, and with the other five patients image of the sample as the validation sample, for training the model provide supervision and guidance. Finally, a Softmax classifier was trained and Dice loss function was optimized to obtain the classification probability map of the whole image. In the test stage, the test image is input into the trained network model after contrast adjustment processing, and the final test image segmentation result is obtained through a forward propagation calculation.
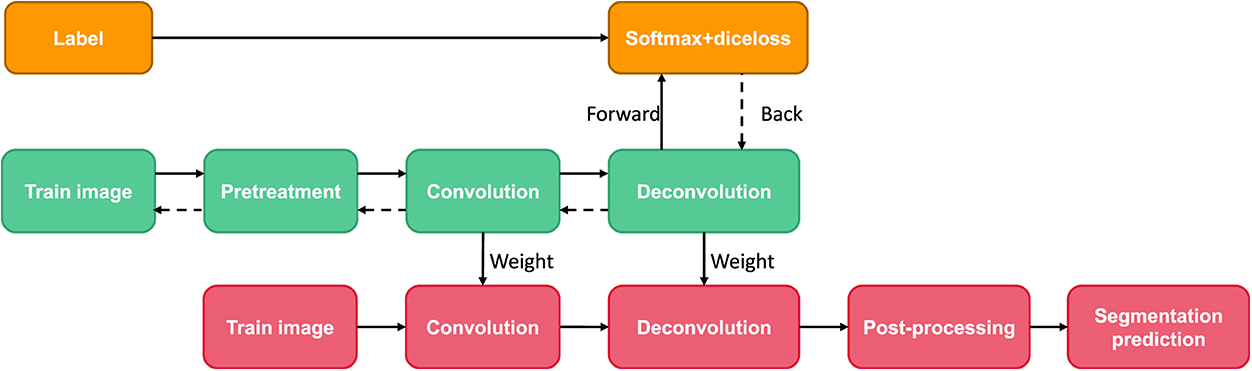
Figure 8. Deconvolution neural network framework used in this paper.
Structure and parameters of deconvolution networks
Figure 9 shows the network architecture referenced here. In order to facilitate network input, all input images are uniformly divided into 3 × 2,244 × 224 pixels. In convolutional networks, we use a similar structure to FCN, and replace all the final connection layers with a convolutional layer. The convolutional network model includes five convolution layers, five maximum layers and two convolution layers. The convolution method is an overlapping method, that is, one or two successive convolution layers are placed behind each convolution layer. In the network, all convolution kernels are small Windows 3 × 3 and 1 step long. In order to keep the size of the feature graph consistent before and after the convolution operation, a numerical value “0” of 1 is added to the edge of the input feature graph. Overlapping convolutional layer can not only improve the depth of the network, learn the parameters of the network, but also effectively prevent over-fitting.
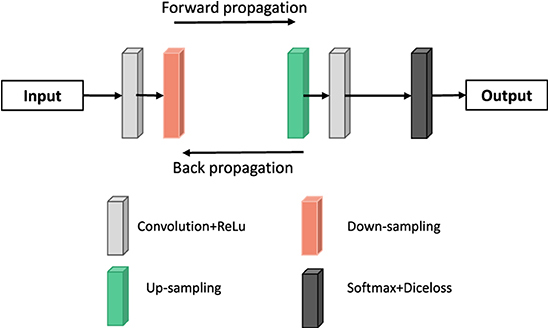
Figure 9. Structure diagram of deconvolution network.
In the deconvolution network part, the mirror structure of the convolutional network is used to reconstruct the input object. Therefore, multilayer deconvolution can also obtain different morphological details like convolutional networks. In the convolutional network model, low-level features can reflect the overall roughness of the target, such as target position and rough shape, while higher-level features have classification characteristics and contain the details of the target.
Dice depletion layer
The image is trained into the network, and then the software mapping layer is used to get the classification map with the same resolution as the initial input, so as to reflect the possibility that each pixel point is the foreground or background. On this basis, the loss function is optimized by using the classification method based on actual tags, so as to obtain the final weight of the convolutional network. In the learning process, due to the strong learning characteristics of the network, the usual loss function tends to fall into local minimization, resulting in the detection of future regions. In order to improve the response curve after classification, a new target loss function D was established by Dice similarity coefficient, which made the predicted response curve and the actual segmentation result have the maximum similarity.
Where, pi and gi represent the value of the ith pixel in the prediction graph and the real segmentation graph, respectively. We take the derivative of this
The partial derivative is used for parameter updating in back propagation. Experimental results show that Dice loss function has better performance than ordinary loss function.
Evaluation standard
Parameters of the standard
On this basis, DSC and Hausdorff distance (HD) were used to evaluate the two methods quantitatively. DSC algorithm performs similarity analysis in the range of two contour lines. The point set within the range of two contour lines represented by A and B is defined as follows
HD reflects the maximum difference between the two contour point sets and is defined as
Among them
Smaller HD values mean higher segmentation accuracy.
Results
The experimental analysis
A total of 150 patients were enrolled in the Department of CT/MRI at the Second Affiliated Hospital of Fujian Medical University, 8 to 15 groups for each. Each sequence consisted of a 20-frame cardiac cycle, consisting of 15,000 artificially segmented images, 12,000 images as training samples, and 3,000 images as experimental samples. From the initial reading of cardiac MRI data, to the normalization described in the previous, to the normalization and data enhancement of image data, and then, according to the ROI area center and ROI detection results, the image data were divided into 128 × 128 pieces, clustered in the ROI center, namely the left ventricle, and input to the ROI center, namely the left ventricle. Compared with the original cardiac MRI slice with average spatial resolution of 235–263 voxel/slice, the GPU storage capacity was reduced from more than 10 GB to <6 GB by using the same model for training. This method uses ROI to extract 128 × 128 images and reduces unnecessary information while maintaining the left exterior shape.
The segmentation results of region growing image differ greatly when the gray difference threshold is different. When the threshold was small, the whole myocardium could not be separated. When the threshold is large, other surrounding tissues are incorrectly separated. However, the determination of threshold depends on the determination in advance, so it cannot adapt to the changeable conditions of cardiac MR images.
Since other tissues outside the myocardium are similar to the myocardium in gray scale, threshold segmentation method only uses gray level to determine whether pixels belong to segmentation target, without utilizing relevant spatial information. Therefore, tissues near the myocardium with similar gray scale are often segmented together. Threshold method is not effective in ventricular segmentation of cardiac MRI.
The deep learning image segmentation method is relatively ideal, but the deconvolution neural network is sometimes over-sharpened.
Figure 10 shows the manual segmentation and traditional image segmentation methods (region growth, threshold segmentation) and deep learning image segmentation method (UU-NET, deconvolution neural network), where red is right atrium (RA) and blue is left atrium (LA).
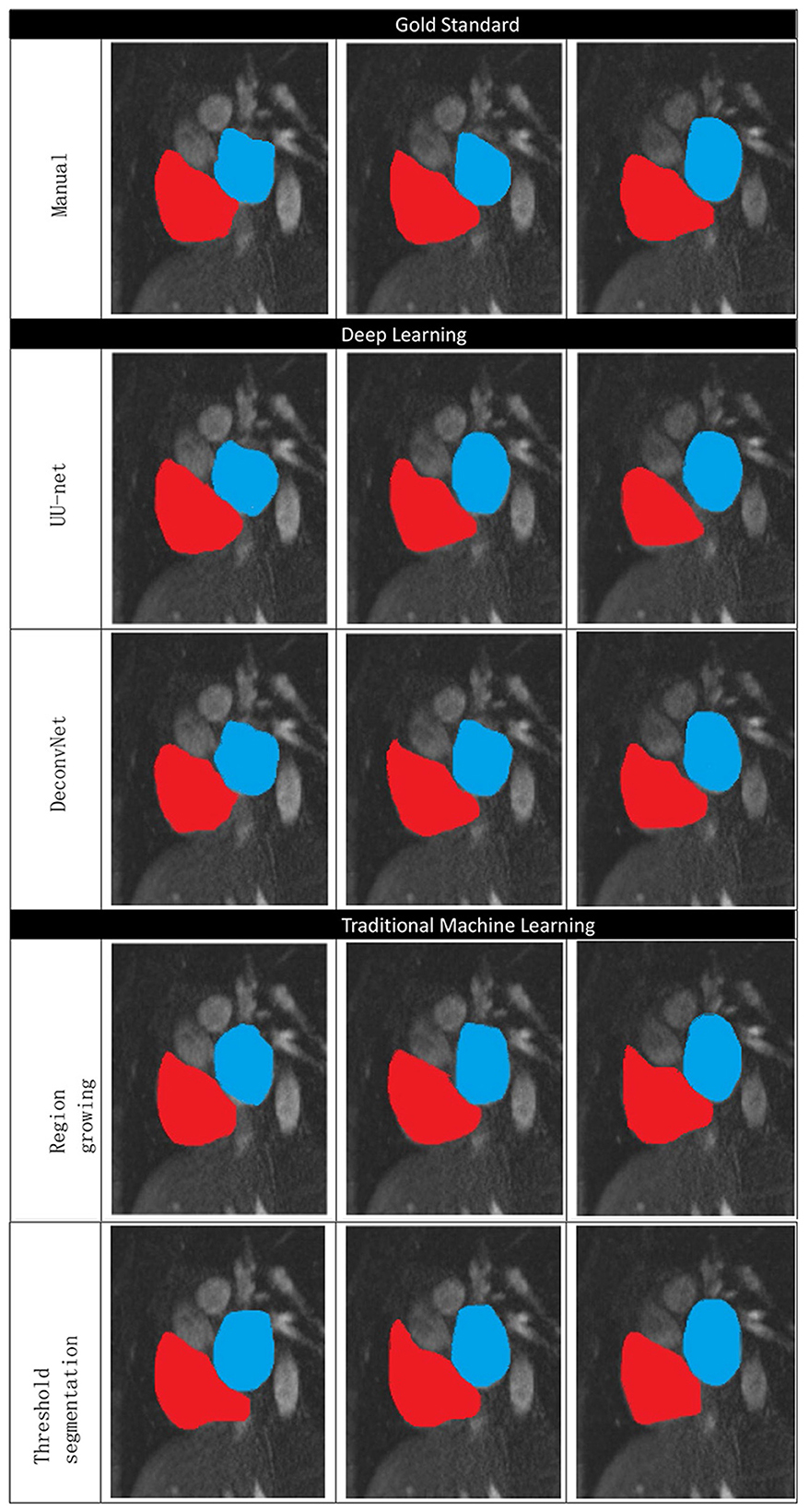
Figure 10. Comparison of traditional methods, deep learning, and manual segmentation in atrial segmentation.
The experimental results
Table 1 lists the performance of the relevant methods mentioned in this article. As can be seen from the table, deep learning image segmentation algorithm has obvious advantages over traditional methods, while DSC obtained by the algorithm in this paper is slightly higher than deconvolution neural network, which means that the image segmentation completed in this paper is more accurate in atrial coverage. At the same time, it has obvious advantages in HD, which means that the set of contour points in this paper is closer to the standard, that is, the probability of sharpening is lower. At the same time, we should also realize that the processing time of computer-aided calculation is far shorter than that of manual segmentation (15–20 min) by professional doctors, which indicates that the application of deep learning in image segmentation is a general trend.
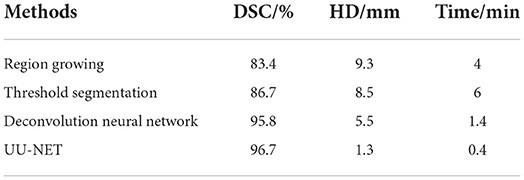
Table 1. Result data of each method on validation set.
Discussion
Segmentation of medical image is an important and difficult problem in clinical diagnosis (21). Accurate segmentation, identification and analysis can be used for qualitative and quantitative analysis of target organs and tissues in clinical practice, improve the accuracy and reliability of diagnosis, and indirectly improve the survival of patients (22). MRI has been widely used in the diagnosis and evaluation of many important diseases including cardiovascular diseases (23). It is widely used. In order to solve the problem of ventricular segmentation in MRI, a new deep deconvolution neural network is used for segmentation, and good results are obtained in the experiment. However, on the basis of in-depth analysis of deep learning technology, existing problems are found and possible directions for further research are proposed:
1. Reliable data sets. First, due to the high cost, there are relatively few relevant data sets that can be used for deep learning modeling. Although common data expansion means can be used to expand, the expansion cannot reflect the sample distribution in the real world, which may have hidden dangers for clinical use. Second, there is no unified standard, because the equipment of different research institutions is not consistent, the data quality, code, scale and so on are not consistent.
2. Expand the application scope. The current application scope of the model in this paper is 2D cardiac MRI, which can be considered for segmentation of other medical images, such as CT, ultrasound and X-ray. Segmentation of medical images of other parts, such as head, neck, chest, etc. The 3D heart model was segmented. In order to better present relevant information to doctors from multiple fields.
3. Improve noise resistance. Because of the particularity of medical image acquisition, shadow and noise are common phenomena. There is still room to improve the noise resistance of the model used in this paper. The subsequent optimization may be carried out by adopting a more suitable preprocessing method and a more accurate loss function.
4. Stereotypes. The types of training sets are also different, which leads to poor generalization performance of the models. Increasing the diversity of data is key to solving this problem. However, one is the lack of credible data in the above data, and the other is that some cases are very rare in the history of human medicine.
Because of the complexity of medical images and gradient fuzzy boundaries, need more high resolution information, after join operations directly from the encoder to the decoder with height on the high-resolution information can provide the division with the fine features, such as gradient, and in view of the left ventricle segmentation data sets have labeled images is small in the segmentation problem such as low precision, learning difficulties, Deep learning in medicine has a long way to go (24–26).
Conclusion
The segmentation task of atrial image is realized by using the latest deep learning technology. In order to achieve pixel-by-pixel segmentation of images, this paper proposes an embedded UU-NET model with dual U structure, which is used to segment the left atrium of MRI data preprocessed by subjective screening, data amplification and image enhancement. Experimental verification shows that this design method improves the segmentation accuracy of left and right atrial in MRI. The experimental results show that the segmentation accuracy of UU-NET model has exceeded that of partial deep learning method. Further improvements will be made under the guidance of experts.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Ethics statement
The studies involving human participants were reviewed and approved by the Second Affiliated Hospital of Fujian Medical University. The patients/participants provided their written informed consent to participate in this study.
Author contributions
Study design: YW and S-TL. Data interpretation: JH and Q-QL. Manuscript production and takes responsibility for the integrity of the data analysis: YW and Y-ZL. All authors contributed to the article and approved the submitted version.
Acknowledgments
The deep learning based segmentation model in this research is generated using the Deep Red AI Toolbox (http://www.deepredsys.com).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Knaul FM, Farmer PE, Krakauer EL, De Lima L, Bhadelia A, Kwete XJ, et al. Alleviating the access abyss in palliative care and pain relief-an imperative of universal health coverage: the Lancet Commission report. Lancet (2018) 391:1391–454. doi: 10.1016/S0140-6736(17)32513-8
2. Galarza-Delgado DA, Colunga-Pedraza IJ, Azpiri-Lopez JR, Guajardo-Jauregui N, Rodriguez-Romero AB, et al. Statin indication according to the 2019 World Health Organization cardiovascular disease risk charts and carotid ultrasound in Mexican mestizo rheumatoid arthritis patients. Adv Rheumatol. (2022) 62:6. doi: 10.1186/s42358-022-00235-6
3. Karimi D, Salcudean SE. Reducing the hausdorff distance in medical image segmentation with convolutional neural networks. IEEE Trans Med Imaging. (2020) 39:499–513. doi: 10.1109/TMI.2019.2930068
4. Audebert N, Boulch A, Le Saux B, Lefèvre S. Distance transform regression for spatially-aware deep semantic segmentation. Comp Vision Image Understand. (2019) 39:499–513. doi: 10.1016/j.cviu.2019.102809
5. Morid MA, Borjali A, Del Fiol G, A. scoping review of transfer learning research on medical image analysis using ImageNet. Comput Biol Med. (2021) 128:104115. doi: 10.1016/j.compbiomed.2020.104115
6. Zhou T, Ruan S, Canu S, A. review: deep learning for medical image segmentation using multi-modality fusion. Array. (2019) 3:100004. doi: 10.1016/j.array.2019.100004
7. Wijesurendra RS, Casadei B. Heart (British Cardiac Society) Mechanisms of atrial fibrillation. Heart. (2019) 105:1860–7. doi: 10.1136/heartjnl-2018-314267
8. Delgado V, Di Biase L, Leung M, Romero J, Tops LF, Casadei B, et al. Structure and function of the left atrium and left atrial appendage: AF and stroke implications. J Am Coll Cardiol. (2017) 70:3157–72. doi: 10.1016/j.jacc.2017.10.063
9. Dangi S, Linte CA, Yaniv Z, A. distance map regularized CNN for cardiac cine MR image segmentation. Med Phys. (2019) 46:5637–51. doi: 10.1002/mp.13853
10. Bansal A, Pandey MK, Yamada S. Zr-DBN labeled cardiopoietic stem cells proficient for heart failure. Nucl Med Biol. (2020) 90:23–30. doi: 10.1016/j.nucmedbio.2020.09.001
11. Li J, Li X, He D, Qu Y, A. novel method for early gear pitting fault diagnosis using stacked SAE and GBRBM. Sensors. (2019) 19:758. doi: 10.3390/s19040758
12. Larrazabal AJ, Martinez C, Glocker B, Ferrante E. Post-DAE: Anatomically plausible segmentation via post-processing with denoising autoencoders. IEEE Trans Med Imaging. (2020) 39:3813–20. doi: 10.1109/TMI.2020.3005297
13. Yang L, Wu H, Jin X, Zheng P, Hu S, Xu X, et al. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci Rep. (2020) 10:5245. doi: 10.1038/s41598-020-62133-5
14. Wu J, Mazur TR, Ruan S, Lian C, Daniel N, Lashmett H, et al. A deep Boltzmann machine-driven level set method for heart motion tracking using cine MRI images. Med Image Anal. (2018) 47:68–80. doi: 10.1016/j.media.2018.03.015
15. Biratu ES, Schwenker F, Debelee TG, Kebede SR, Negera WG, Molla HT. Enhanced region growing for brain tumor MR image segmentation. J Imaging. (2021) 7:22. doi: 10.3390/jimaging7020022
16. Tamal M. Intensity threshold based solid tumour segmentation method for positron emission tomography (PET) images: a review. Heliyon. (2020) 6:e05267. doi: 10.1016/j.heliyon.2020.e05267
17. Liu X, Yin G, Shao J, Wang X. Learning to predict layout-to-image conditional convolutions for semantic image synthesis. Adv Neu Inform Process Sys. (2019) 5:32.
18. Han S, Carass A, He Y, Prince JL. NeuroImage Automatic cerebellum anatomical parcellation using U-Net with locally constrained optimization. Neuroimage. (2020) 218:116819. doi: 10.1016/j.neuroimage.2020.116819
19. Isola P, Zhu JY, Zhou TH, et al. Proceedings of the IEEE conference on computer vision and pattern recognition. Image-to-Image Translat Cond Adv Networks. (2017) 5:632. doi: 10.1109/CVPR.2017.632
20. Ding H, Jiang X, Liu AQ. Boundary-aware feature propagation for scene segmentation. in Proceedings of the IEEE/CVF International Conference on Computer Vision. (2019) (p. 6819–6829). doi: 10.1109/ICCV.2019.00692
21. Zhao M, Wei Y, Lu Y, Wong KK. A novel U-Net approach to segment the cardiac chamber in magnetic resonance images with ghost artifacts. Comput Methods Programs Biomed. (2020) 196:105623. doi: 10.1016/j.cmpb.2020.105623
22. Zhu X, Wei Y, Lu Y, Zhao M, Yang K, Wu S, et al. Comparative analysis of active contour and convolutional neural network in rapid left-ventricle volume quantification using echocardiographic imaging. Comp Meth Program Biomed. (2020) 199:105914. doi: 10.1016/j.cmpb.2020.105914
23. Zhao M, Wei Y, Wong KK. A generative adversarial network technique for high-quality super-resolution reconstruction of cardiac magnetic resonance images. Magn Reson Imaging. (2022) 85:153–60. doi: 10.1016/j.mri.2021.10.033
24. Gunderman R. Deep questioning and deep learning. Acad Radiol. (2012) 19:489–90. doi: 10.1016/j.acra.2011.12.018
25. Lindner T, Debus H, Fiehler J. Virtual non-contrast enhanced magnetic resonance imaging (VNC-MRI). Magn Reson Imaging. (2021) 81:67–74. doi: 10.1016/j.mri.2021.06.004
Keywords: cardiac MRI, deep deconvolution neural network, UU-NET, image segmentation, edge detection segmentation, threshold segmentation
Citation: Wang Y, Li S-T, Huang J, Lai Q-Q, Guo Y-F, Huang Y-H and Li Y-Z (2022) Cardiac MRI segmentation of the atria based on UU-NET. Front. Cardiovasc. Med. 9:1011916. doi: 10.3389/fcvm.2022.1011916
Received: 04 August 2022; Accepted: 04 November 2022;
Published: 24 November 2022.
Edited by:
Ruizheng Shi, Xiangya Hospital, Central South University, ChinaReviewed by:
Yu Lu, Shenzhen Technology University, ChinaBijiao Ding, Huaqiao University Affiliated Strait Hospital, China
Copyright © 2022 Wang, Li, Huang, Lai, Guo, Huang and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuan-Zhe Li, ctmr@fjmu.edu.cn; Yin-Hui Huang, 251045413@qq.com
†These authors have contributed equally to this work