Regular Article
Information quantity for secondary structure propensities of protein subsequences in the Protein Data Bank
2022 Volume 19 Article ID: e190002

Details
2022 Volume 19 Article ID: e190002
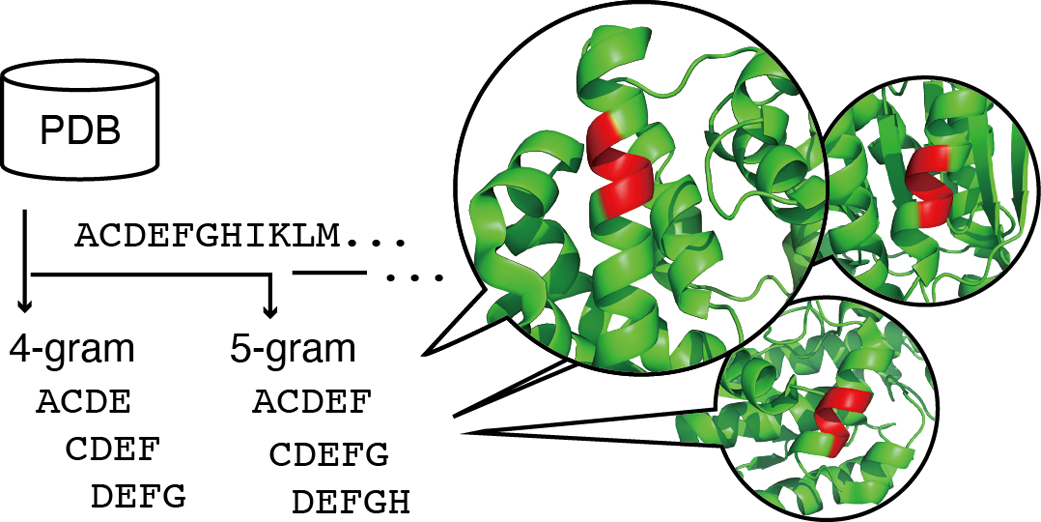
Elucidating the principles of sequence–structure relationships of proteins is a long-standing issue in biology. The nature of a short segment of a protein is determined by both the subsequence of the segment itself and its environment. For example, a type of subsequence, the so-called chameleon sequences, can form different secondary structures depending on its environments. Chameleon sequences are considered to have a weak tendency to form a specific structure. Although many chameleon sequences have been identified, they are only a small part of all possible subsequences in the proteome. The strength of the tendency to take a specific structure for each subsequence has not been fully quantified. In this study, we comprehensively analyzed subsequences consisting of four to nine amino acid residues, or N-gram (4≤N≤9), observed in non-redundant sequences in the Protein Data Bank (PDB). Tendencies to form a specific structure in terms of the secondary structure and accessible surface area are quantified as information quantities for each N-gram. Although the majority of observed subsequences have low information quantity due to lack of samples in the current PDB, thousands of N-grams with strong tendencies, including known structural motifs, were found. In addition, machine learning partially predicted the tendency of unknown N-grams, and thus, this technique helps to extract knowledge from the limited number of samples in the PDB.